國 立 交 通 大 學
電子工程學系電子研究所
博 士 論 文
適用於功率受限視訊編碼系統之運動估測演算法
與積體電路架構設計
Algorithm and Architecture Design of Motion
Estimation for Power Constrained Video Coding
Systems
研 究 生 :王 士 豪
指導教授 :蔣 迪 豪
適用於功率受限視訊編碼系統之運動估測演算法與積體
電路架構設計
Algorithm and Architecture Design of Motion Estimation
for Power Constrained Video Coding System
研 究 生:王 士 豪 Student:Shih-Hao Wang
指導教授:蔣 迪 豪 博士 Advisor:Dr. Tihao Chiang
國 立 交 通 大 學
電 子 工 程 學 系 電 子 研 究 所
博 士 論 文
A Dissertation
Submitted to Department of Electronics Engineering & Institute of Electronics College of Electrical and Computer Engineering
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy in
Electronics Engineering September 2007
Hsinchu, Taiwan, Republic of China
推 薦 函
主旨:推薦電子工程學系博士班學生王士豪,舉行博士班學位口試。
說明:本人所指導之博士班學生王士豪,業已通過資格考試,並完成本校電子工程學系 電子研究所博士班規定之學科課程及論文研究訓練。王君主要從事視訊編、解碼 演算法與積體電路架構設計之研究工作,其論文「適用於功率受限視訊編碼系統 之運動估測演算法與積體電路架構設計」(Algorithm and Architecture Design of Motion Estimation for Power Constrained Video Coding System)主要包含兩項應用 於功率受限編碼系統上的運動估測技術。其中第一項技術『低功率、低頻寬需求 之 二 元 化 運 動 估 測 』 (Low power and bandwidth efficient binary motion estimation) ,利用二元化的影像作為運動估測準則,並提出其最佳化的硬體架構 設計,此技術可達到低於 1 mW 的功率消耗需求,並節省 I/O 頻寬存取需求達 54.3%以上。第二項技術為『具功率感知之功率可調適性之疊代二元化運動估測』 (Power adaptive motion estimation using iterative binary searches),此技術為一套新 穎的疊代二元化運動估測,基於第一項二元化搜尋技術,發展出可自我感知、自 我調節之功率可調適運動估測。相較於其他可調適運動估測技術,所提出的方法 具有較佳的功率可調適能力、低頻寬需求,與較佳的功率-失真(Power-Distortion) 特性曲線。這兩項技術業已發表或投稿於著名國際期刊及會議論文。其中,第二 項技術並完成晶片中心(CIC)的晶片下線與測試。 王君在視訊編、解碼演算法與架構設計之研究工作並有多項貢獻與論文發 表。在 H.264/AVC 解碼器系統設計方面,其提出一套最佳化的 H.264/AVC 解碼 器參考軟體,架構於以 ARM RISC 為核心的硬體平台上,實現軟、硬體共設計 之 QCIF 即時解碼器系統設計。此方面的研究,在 Google 學術搜尋,兩篇論文 被引用共 21 次。在視訊轉碼器設計方面,其提出一套『低複雜度碼率-失真最佳 化之多層位元流技術』,應用於異質轉碼(heterogeneous transcoding)系統上,可達 到 1.4-8.6 dB PSNR 改善。在數位浮水印技術方面,王君提出一個新的數位浮水 印嵌入技術,作為數位影像版權的保護。此方法的貢獻在於利用統計性的能量差 異法,在面對各種不同的幾何與非幾何攻擊時,仍能有效維持其統計上能量差 異,以保存所嵌入的數位浮水印,且不需要原始影像作為解出數位浮水印的憑 據。此部分研究,刊登於著名期刊 IEEE Trans. Image Processing,並於 Google 學術搜尋,被引用達 21 次。王君另於 2001-2003 期間,積極參與 MPEG 國際標 準會議的參照軟體(Optimized MPEG-4 Simple Profile reference software)撰寫與維 護工作,提出多項 MPEG 貢獻文件,並獲 MPEG 會議的書面表揚。
總體而言,王君論文有相當之學術貢獻與重要性,且其積極而深入的參與國 際標準會議之參照軟體撰寫,使其貢獻成為標準的一部份,兼具實用之價值。以 下詳列其所發表之論文(依代表性排序):
期刊論文
1. S.-H. Wang, W.-H. Peng, Y.-W. He, G.-Y. Lin, C.-Y. Lin, S.-C. Chang, C.-N. Wang, and
T. Chiang, “A software-hardware co-implementation of MPEG-4 advanced video coding decoder with block level pipelining,” Journal of VLSI Signal Processing Systems, vol. 41, no. 1, pp. 93-110, Jan. 2005. [Google Citation: 7]
2. S.-H. Wang, W.-L. Chen, and Tihao Chiang, “An efficient FGS to MPEG-1/2/4 single
layer transcoder with R-D optimized multi-layer streaming technique for video quality improvement,” Journal of the Chinese Institute of Engineers, vol. 31, 2008. (to be
appeared)
3. S.-C. Chang, W.-H. Peng, S.-H. Wang, and T. Chiang, “A Platform based Bus-interleaved Architecture for Deblocking Filter in H.264/MPEG-4 AVC,” IEEE
Trans. Consumer Electronics, vol. 51, no. 1, pp. 249-255, Feb. 2005.
4. S.-H. Wang, and Y.-P. Lin, “Wavelet tree quantization for copyright protection
watermarking,” IEEE Trans. Image Processing, vol. 13, no. 2, pp. 154-165, Feb. 2004.
[Google Citation: 21]
審查中國際期刊
1. S.-H. Wang, and T. Chiang, “A power adaptive motion estimation IP core design using
iterative binary search,” IEEE Trans. Circuits and Systems for Video Technology, 2006. 2. S.-H. Wang, S. -H. Tai, and T. Chiang, “A low power and bandwidth efficient motion
estimation IP core design using binary search,” IEEE Trans. Circuits and Systems for
Video Technology, 2006.
國際會議論文
1. S.-H. Wang, W.-L. Tao, W.-H. Peng, C.-N. Wang, and T. Chiang, “Platform based
design of all binary motion estimation (ABME) with bus interleaved architecture,” Proc.
IEEE International Symposium on VLSI Technology, System and Applications, Hsinchu,
April 2005.
2. S.-H. Wang, C.-N. Wang, and T. Chiang, “A complexity aware variable-bit-depth
motion estimation,” Proc. IEEE International Conference on Consumer Electronics, Las Vegas, Jan. 2005.
3. S.-C. Chang, W.-H. Peng, S.-H. Wang, and T. Chiang, “A platform-based de-blocking filter design with bus interleaved architecture for H.264,” Proc. IEEE International
Conference on Consumer Electronics, Las Vegas, Jan. 2005. [Google Citation: 17]
4. S.-H. Wang, W.-H. Peng, Y. He, G.-Y. Lin, C.-Y. Lin, S.-C. Chang, C.-N. Wang, and T.
Chiang, “A Platform Based MPEG-4 Advanced Video Coding Decoder with Block Level Pipelining,” Proc. IEEE ICICS-PCM, Singapore, Nov. 2003.
5. S.-H. Wang, and Y.-P. Lin, “Blind watermarking using wavelet tree quantization,” Proc. IEEE International Conference on Multimedia and Expo, Lausanne, August, 2002.
MPEG 視訊標準會議文件
1. S.-H. Wang, C.-N. Wang, Yi-Shin Tung, T. Chiang, and H. Sun, “ISO/IEC JTC1/SC
29/WG 11 M9951: AHG report on editorial convergence of MPEG-4 reference software,” Oct. 2003.
2. S.-H. Wang, C.-N. Wang, Y.-S. Tung, T. Chiang, and H. Sun, “ISO/IEC JTC1/SC
29/WG 11 M9632: AHG report on editorial convergence of MPEG-4 reference software,” July 2003.
3. S.-H. Wang, C.-N. Wang, Y.-S. Tung, T. Chiang, and H. Sun, “ISO/IEC JTC1/SC
29/WG 11 M9355: AHG report on editorial convergence of MPEG-4 reference software,” March 2003.
4. S.-H. Wang, C.-N. Wang, G.-Y. Lin, T. Chiang, and H. Sun, “ISO/IEC JTC1/SC 29/WG
11 M9073: AHG report on editorial convergence of MPEG-4 reference software,” Dec. 2002.
5. S.-H. Wang, C.-N. Wang, T. Chiang, and H. Sun, “ISO/IEC JTC1/SC 29/WG 11 M8886:
Proposed text of proposed draft technical reports of ISO/IEC PDTR 14496-7 for optimized simple profile reference software, ” Oct. 2002.
6. S.-H. Wang, C.-N. Wang, T. Chiang, and H. Sun, “ISO/IEC JTC1/SC 29/WG 11 M8884:
AHG report on editorial convergence of MPEG-4 reference software,” Oct. 2002. 7. S.-H. Wang, C.-N. Wang, Tihao Chiang, and H.F. Sun, “ISO/IEC JTC1/SC 29/WG 11
M8603: AHG report on editorial convergence of MPEG-4 reference software,” July 2002.
8. S.-H. Wang, Y.-C. Lin, C.-N. Wang, T. Chiang, and H. Sun, “ISO/IEC JTC1/SC 29/WG
11 M8408: AHG report on editorial convergence of MPEG-4 reference software,” May 2002.
9. S.-H. Wang, C.-N. Wang, T. Chiang, and H. Sun, “ISO/IEC JTC1/SC 29/WG 11 M8041:
AHG report on editorial convergence of MPEG-4 reference software,” March 2002.
專利
1. M.-Y. Huang, T.-L. Su, S.-H. Wang, C.-N. Wang and T. Chiang, “MPEG-4 streaming system with adaptive error concealment,” 美國專利,專利號 20060104366.
審查中專利
1. S.-H. Wang, L. Kohn, and T. Chiang, “Mode decision using approximate 1/2 pel
interpolation,” 美國專利. (Filed on Nov. 23, 2005)
適用於功率受限視訊編碼系統之運動估測演算法與積體電路
架構設計
研究生: 王士豪 指導教授: 蔣迪豪 博士
國立交通大學
電子工程學系暨電子研究所
摘要
受限於可攜式行動設備之有限的電池容量,功率受限之視訊編碼系統設計逐漸受 到了重視,在此之中,以低功率和功率可調適設計為最熱門的研究主題,本論文 將以此兩主題為研究中心,以二元化搜尋技術為中心,逐步發展出兩項適用於低 功率與功率可調適視訊編碼系統之運動估測技術,這兩項技術皆包含了演算法與 積體電路架構設計。 本論文第一部份為提出一個具低功率與低頻寬需求之低功率全二元化搜尋之 運動估測(Low Power-All Binary Motion Estimation, LP-ABME)積體電路設計。低功 率與低頻寬需求為應用於行動視訊編碼應用上的兩大重要設計因素。為達到低功 率與低頻寬需求,本技術架構於一個全二元化的運動估測(ABME)演算法上,藉由 使用二元化的影像來完成運動估測,並將二元化的搜尋技術實現於金字塔式搜尋 架構(pyramid search)下,以大量地降低了運動估測運算複雜度,且二元化的影像也 降低了在 I/O 頻寬上的存取需求。為達成全二元化的運動估測(ABME)於積體電路 實現,我們提出了一個基於原二元化的運動估測(ABME)之新的低功率全二元化搜 尋之運動估測(LP-ABME)演算法與硬體架構設計。此設計具有四項重要的特色: (1)基於 MB 管狀設計的前處理器設計,(2)高硬體運算效率的二元化搜尋架構,(3)平行化的 8x8 與 16x16 搜尋架構,(4)可平行處理雙向預測搜尋架構。第一項技術 降低了對 I/O 存取頻寬上的需求,另三項則降地了運算複雜度與運算功率消耗。此 積體電路架構設計在 I/O 存取頻寬、效能、與功率消耗上表現出很好的效能。功率 消耗方面,執行 IPPPP CIF 30fps ,功率消耗為 763 微瓦(uW),IPBPB CIF 30fps 則為 896 微瓦。I/O 存取頻寬方面,則可節省 54.3 至 67.1%.
本論文第二部份為提出一個具功率感知能力的功率可調適疊代二元化搜尋 (Power Adaptive Iterative Binary Search, PA-IBS)技術,目的在改善: (1)功率可調適 能力,(2)高硬體閒置,與(3)功率-失真(Power-Distortion)效能。舊有功率可調適運 動估測設計,使用了硬體遮罩的方式實現功率可調適性,卻也延伸出許多問題, 如:多餘的 I/O 存取頻寬浪費,多餘的記憶體頻寬浪費,與高硬體閒置等問題,導 致功率可調適能力降低,與不好的功率-失真效能。為解決這些問題,本論文延伸 了二元化搜尋技術的應用,發展出一套具功率可調適能力的演算法與積體電路架 構。此演算法稱之為功率可調適疊代二元化搜尋(PA-IBS),其包含了: (1)疊代二元 化搜尋技術,與(2)內容感知之疊代迴圈控制器。疊代二元化搜尋技術使用了最多 八個迴圈的二元化搜尋,藉由疊代迴圈的應用,達到不同層次的預測品質與運算 複雜度。內容感知之疊代迴圈控制器,則藉由運動向量(motion vector)來偵測視訊 影像的運動複雜層度,以調整疊代迴圈數,並達到利用最少的迴圈達到最佳的預 測品質與運算複雜度。積體電路設計方面,則使用頻率延展(frequency scaling)技 術,將疊代迴圈數與功率消耗作一連結,藉由調整疊代迴圈數,來控制功率消耗 與功率可調適能力,並解決高硬體閒置問題。實驗結果證明,相較於既有的功率 可調適設計,PA-IBS 可改善功率可調適能力達 19-125%,I/O 存取頻寬需求最高則 可降低 87.5%,同時具有較佳的功率-失真曲線。
總結,本論文提出兩個適用於低功率與功率可調適視訊編碼系統之運動估測 技術。第一個技術達成了低於 1 毫瓦(mW)的功率消耗,和高於 50%的 I/O 存取頻 寬節省。第二個技術則改善了現有功率可調適設計在功率可調適能力、高硬體閒 置,與不好的功率-失真(Power-Distortion)效能等方面的問題。在功率受限視訊編 碼系統上面的應用,提供了顯著的改善與更大的應用空間。
Algorithm and Architecture Design of Motion Estimation for
Power Constrained Video Coding Systems
Student: Shih-Hao Wang Advisor: Dr. Tihao Chiang
Department of Electronics Engineering & Institute of Electronics
National Chiao Tung University
Abstract
The design of power constrained video coding systems has drawn attentions in mobile devices or portable terminals due to the limited battery energy. Among the power constrained video coding applications, low power and power adaptive designs are two of the most attractive design topics. Inside the video coding system, motion estimation (ME) takes most of computation powers, and becomes the design bottleneck of the low power and power adaptive video coding systems. This thesis contains 2 major parts to address the design issues of low power and power adaptive motion estimation.
The first part is to propose a new Low Power-All Binary Motion Estimation (LP-AMBE) hardware design for motion estimation to achieve low power and bus bandwidth efficiency. Low power and high bus bandwidth efficiency are the two key issues for portable video applications. To address such issues, we first study an efficient algorithm called all binary motion estimation (ABME), and analyze its architecture issues in operational flow and bus access. Then, we propose an hardware architecture for ABME with four new features (1) macroblock level pre-processing (2) efficient binary pyramid search structure (3) parallel processing of 8x8 and 16x16 block searches (4) parallel processing of bi-directional search. Such architecture leads to a superior performance in bus access, speed and power. The experiments show that the power
consumption is as low as 763uW for IPPPP CIF 30fps and 896uW for IPBPB CIF 30fps. The bus bandwidth savings are 54.3% for P-frame search and 67.1% for B-frame search.
The second part is to propose a new Power Adaptive Iterative Binary Search (PA-IBS) design for motion estimation to improve the power adaptation performance. In the prior power adaptive ME designs that use the hardware masking approach, there exist design overheads such as redundant bus access, unnecessary on-chip memory access, and poor hardware utilization that lead to poor power adaptation performance. Our proposed power adaptive solution addresses these issues with a new ME algorithm called Iterative Binary Search (IBS) and the associated hardware architecture called PA-IBS. The IBS uses eight binary searches where each search can be either an independent search or one of the eight joint searches. Hence, redundant bus and on-chip memory access are eliminated. A Content Adaptive Mechanism (CAM) is used to dynamically select the number of iterations on a macroblock basis. The PA-IBS uses the frequency scaling technique to provide a link between the number of iterations and the power consumption level. Therefore, it reduces hardware idling and enhances hardware utilization. Experiments show that the PA-IBS delivers lower peak power consumption, better power adaptation performance and lower bus bandwidth requirement as compared to the prior hardware masking based designs such as sub-sampling or least significant bits truncation methods. As compared to those approaches, the power adaptation performance is improved up to 19-125% and bus bandwidth is saved up to 87.5%.
In conclusion, we have presented two algorithm and architecture designs of motion estimation for different power constrained video coding applications, and showed the advantages in low power consumption and bus bandwidth requirements as compared to
prior works. The proposed power adaptive design is also shown to have better power adaptation ability and better power-distortion performance. Moreover, the proposed low power and power adaptive ME designs can be applied to upcoming Scalable Video Coding (SVC) standard for further complexity and power reduction.
誌 謝
從博士班入學到現在拿到學位,回想這幾年的點點滴滴,彷彿又回到這些記憶的 時光隧道‧一開始為了從事多媒體視訊方面的研究,轉換了研究領域,在蔣教授 的指導與俊能學長的帶領下,開始了我的博士班研究。接著,進入了 commlab 這個大家庭,認識了很多厲害的學長姐、學弟妹,大家一起作研究、討論功課、 游泳、烤肉、參加電子週的比賽..等等。還有那超強的 commlab 影音資料庫,提 供了在無數研究作不下去的夜晚時,有打發時間的娛樂。在文孝學長的幫助下, 慢慢走向了作 IC design 這個領域。在那無數的週末,跟自己帶的碩士班學弟們, 討論如何作研究,同時也學習了自己帶 project 的經驗。 能完成博士學位,首先必須要感謝蔣迪豪教授。從收我進 group 開始,蔣老師就 提供了我無數的機會去擴展自己的研究領域與國際視野,同時也提供了我無數的 學習機會與成長。從參加國際會議、到園區公司去作計畫結案報告、自己帶學弟 作計畫等等,這些都會是很寶貴的經驗。而在學校的研究之外,工作的選擇上也 給我許多建議。非常謝謝蔣老師這幾年來在各方面的幫助及鼓勵。 其次,我要謝謝 commlab 的各位成員們,特別是俊能與文孝兩位學長。俊能學長 從我進入蔣老師 group 開始,不論是在做研究或者參與計畫,都給了我很多的幫 忙與建議。從完全不懂什麼是 MPEG 到可以在上面發展演算法、作研究,俊能學 長給了我最大的幫助。在博士班後期,開始從事 IC design 這個領域,文孝學長 則是從帶領我們作 H.264/AVC 解碼器計畫開始,給了我很多的意見與想法,提醒 我很多忽略的細節。此外,項群、俊毅、鑑明、志鴻、以及所有 commlab 學長姐、 同學們,大家在學業上的討論、生活上的幫忙,都給了我對 commlab 最好的回憶。 另外,我也要謝謝我的口試委員: 交大電子系的杭學鳴教授、任建葳教授、王聖 智教授、交大電信系的張文鐘教授、清大資工系的張隆紋教授、電機系的黃仲陵 教授、中央電機系蔡宗漢教授。感謝您們在百忙之中能抽空給予我指導,也因你 們的寶貴建議使得論文能更加完備。 最後,我要感謝我的家人,包括了我們父母親以及未婚妻秋女英。感謝你們在這 幾年來的照顧、協助與包容。 謹以此論文獻給所有愛我與我所愛的人。 王士豪 2007/10/01Contents
Table of Contents . . . 1 List of Figures . . . 4 List of Tables . . . 7 1 Introduction 1 1.1 Motivations . . . 11.1.1 Importance of Low Power Designs . . . 2
1.1.2 Importance of Power Adaptive Designs . . . 6
1.2 Power Constrained Motion Estimation Designs . . . 7
1.2.1 Low Power Motion Estimation . . . 8
1.2.2 Power Adaptive Motion Estimation . . . 11
1.3 Organization and Contribution . . . 14
2 Review of Power Constrained Motion Estimation Designs 16 2.1 Block Motion Estimation . . . 16
2.1.1 Block Matching Criterion . . . 16
2.1.2 Design Metrics Evaluation . . . 17
2.1.3 Motion Estimation Hardware Design . . . 22
2.1.4 Memory Hierarchy . . . 23
2.2 Low Power Motion Estimation Designs . . . 27
2.2.1 Low Power by Fast ME Algorithms . . . 28
2.2.2 Low Power by Simplified Block Matching Criteria . . . 29
2.2.3 Low Power by Efficient Hardware Architecture . . . 30
2.3 Power Adaptive Motion Estimation Designs . . . 31
2.3.1 Power Adaptive by Fast Algorithms . . . 31
2.3.2 Power Adaptive by Pixel Number for Block Matching . . . 38
2.3.3 Power Adaptive by Pixel Bit Precision . . . 39
2.3.4 Summary of Power Adaptive Design Schemes . . . 40
3 Bi-directional Binary Motion Estimation (BBME) 41 3.1 Introduction . . . 41
2 Contents
3.2 Problem Statement . . . 44
3.2.1 Review of ABME Algorithm . . . 44
A. Frame Level of Pre-processing . . . 44
B. Three Levels of Binary Pyramid Search . . . 45
3.2.2 Design Issues of ABME Algorithm . . . 46
A. Pre-processing for Binary Images Generation . . . 48
B. Sequential LV2 Binary Pyramid Search Structure . . . 49
C. Support of B-frame and 8x8 Block Search . . . 50
3.3 BBME Algorithm . . . 50
3.3.1 Macroblock Pre-processing Unit (MBPPU) . . . 53
3.3.2 Efficient LV2 Search . . . 54
3.3.3 Parallel Processing of 8 × 8 and 16 × 16 Block Searches . . . 54
3.4 Hardware Architecture . . . 58
3.4.1 System Architecture . . . 58
3.4.2 Macroblock Pre-processing Unit (MBPPU) . . . 61
3.4.3 Three Levels of Binary Search . . . 62
3.5 Experimental Results and Analysis . . . 62
3.5.1 Rate-Distortion (R-D) Performance Evaluation . . . 62
3.5.2 Hardware Design Performance . . . 66
3.5.3 Bus Bandwidth Analysis . . . 77
3.5.4 Comparison of ABME and BBME . . . 81
3.6 Summary . . . 85
4 Power Adaptive Iterative Binary Search (PA-IBS) 86 4.1 Introduction . . . 86
4.2 Power Adaptation Performance . . . 89
4.3 Power Adaptive Iterative Binary Search (PA-IBS) Algorithm . . . 91
4.3.1 BInary Image Preprocessor (BIP) . . . 92
4.3.2 Iterative Binary Search (IBS) . . . 92
4.3.3 Content Adaptive Mechanism (CAM) . . . 95
4.4 Hardware Design Issues . . . 96
4.4.1 Power Adaptation . . . 96
4.4.2 SOD Accumulation . . . 97
4.4.3 Binary Image Preprocessor . . . 99
4.5 PA-IBS Hardware Architecture . . . 102
4.5.1 System Architecture . . . 102
4.5.2 8×1 Line Search . . . 103
4.5.3 Pipelined Buffers . . . 104
4.6 Experimental Results and Analysis . . . 107
4.6.1 Evaluation of Algorithmic Performance . . . 107
A. R-D Performance for PA-IBS without CAM . . . 107
Contents 3
4.6.2 Evaluation of Hardware Performance . . . 109
A. Chip Specification . . . 109
B. Evaluation on Bus Bandwidth . . . 113
C. Evaluation on Power Adaptation Performance . . . 114
D. Evaluation on Peak Power Consumption . . . 114
E. Evaluation on Power-Distortion Performance . . . 115
4.7 Summary . . . 122
5 Conclusions and Future Work 126 5.1 Conclusions . . . 126
5.2 Future Work . . . 128
List of Figures
1.1 Power consumption of encoder modules [7]. . . 4 1.2 Estimated ME power consumption for different video resolutions. . . 5 1.3 I/O bandwidth for different video resolutions. . . 5 1.4 Battery discharging curve [13]. . . 7 1.5 Lifetime improvement by power adaptive designs. . . 8 1.6 Block diagram of portable multimedia player based on TI DaVinci platform
[14]. . . 9 1.7 Power management IC for DaVinci technology based portable electronics
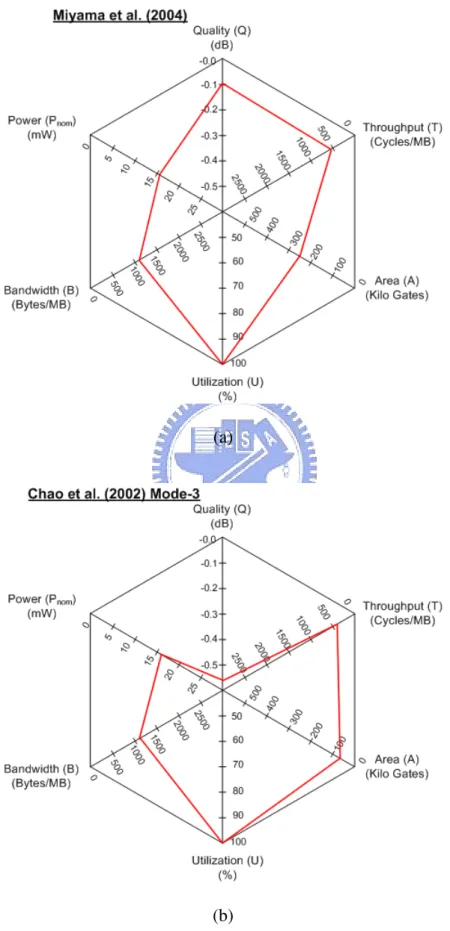
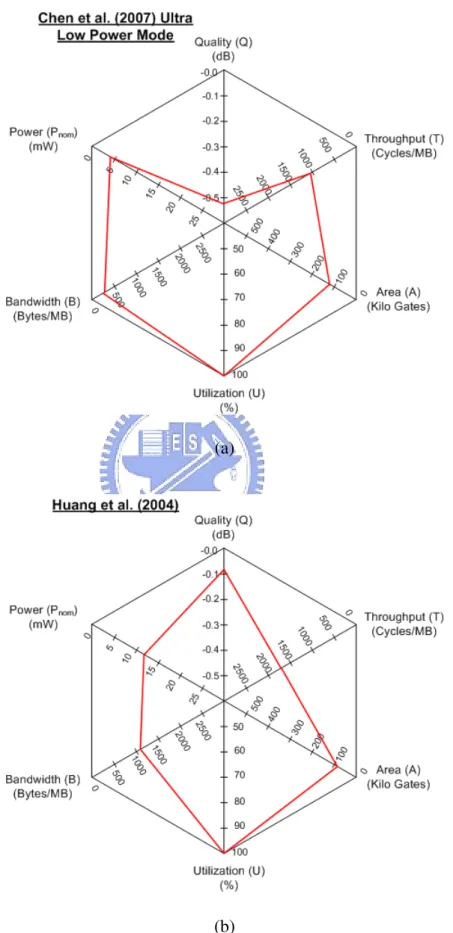
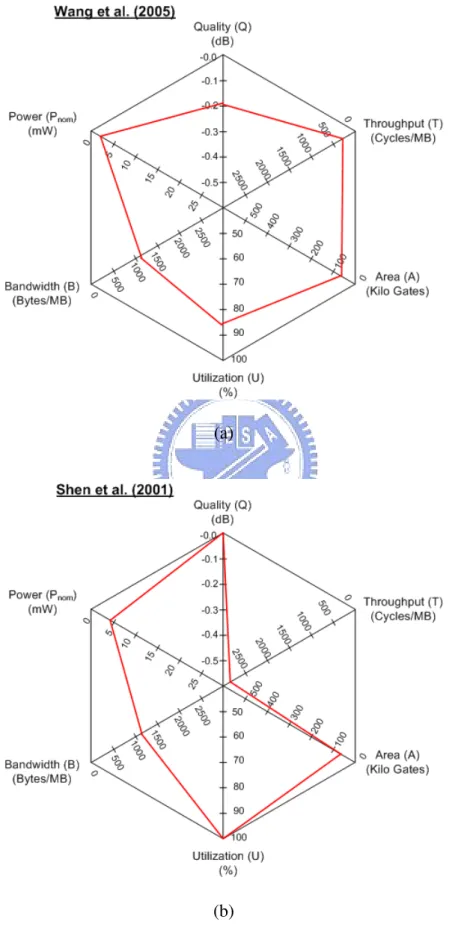
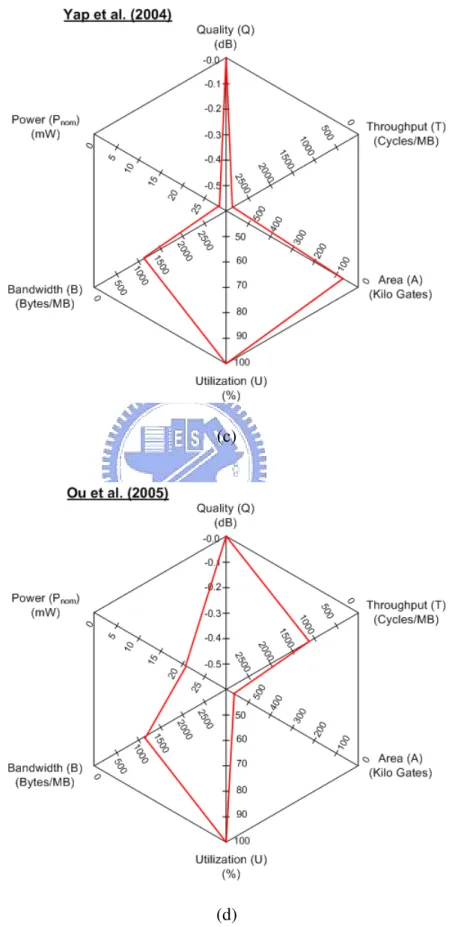
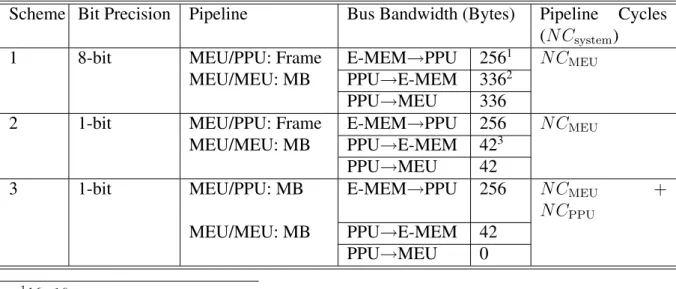
[15]. . . 9 2.1 Block motion estimation. . . 18 2.2 Video encoder hardware architecture with ME module. . . 23 2.3 Motion estimation hardware architecture. . . 24 2.4 Search window data reuse. (a)Level C (b)Level D. . . 26 2.5 Hexagonal plot of 6 design metrics for different ME hardware architectures
evaluation. (a) Miyama’s work [36] (b) Chao’s work [30]. . . 34 2.6 Hexagonal plot of 6 design metrics for different ME hardware architectures
evaluation. (a) Chen’s work [26] (b) Huang’s work [37]. . . 35 2.7 Hexagonal plot of 6 design metrics for different ME hardware architectures
evaluation. (a) Wang’s work [35] (b) Shen’s work [39]. . . 36 2.8 Hexagonal plot of 6 design metrics for different ME hardware architectures
evaluation. (a) Yap’s work [40] (b) Ou’s work [67]. . . 37 3.1 Motion predictors for LV2 search. . . 47 3.2 Functional block diagram of a generic video encoder by adopting ABME
algorithm. . . 51 3.3 The processing flow of pre-processing module in ABME algorithm. . . 51 3.4 The processing procedure for ABME and BBME flow. (a) ABME flow
[41] (b) BBME flow. . . 52 3.5 The pre-processing flow in macroblock pre-processing unit. (a) K=30 (b)
K=18. (The shadow area is padding pixels) . . . 56
List of Figures 5 3.6 The LV2 processing flow. (a) original LV2 flow in ABME (b) new LV2
flow in BBME. The number represents the processing order. . . 57 3.7 System architecture for the BBME design. . . 63 3.8 Architecture of macroblock based pre-processing unit. . . 64 3.9 Shared processing unit for three levels of binary pyramid searches. . . 65 3.10 R-D curves for full search (FS), ABME [?], and BBME designs with
Fore-man sequence. (a) IPPP (M=1) (b) IBPBP (M=2). . . 68 3.11 R-D curves for full search (FS), ABME [?], and BBME designs with
Mo-bile sequence. (a) IPPP (M=1) (b) IBPBP (M=2). . . 69 3.12 Visual quality comparison for full search and BBME with Foreman 32th
frame. (Left: 34.73dB for full search, Right: 34.39dB for BBME.) . . . 70 3.13 Visual quality comparison for full search and BBME with Foreman 99th
frame. (Left: 34.74dB for full search, Right: 34.36dB for BBME.) . . . 70 3.14 Visual quality comparison for full search and BBME with Foreman 148th
frame. (Left: 34.99dB for full search, Right: 34.63dB for BBME.) . . . 71 3.15 Hexagonal plot of 6 design metrics for different ME hardware architectures
evaluation. (a) Miyama’s work [36] (b) Chao’s work [30]. . . 73 3.16 Hexagonal plot of 6 design metrics for different ME hardware architectures
evaluation. (a) Chen’s work [26] (b) Huang’s work [37]. . . 74 3.17 Hexagonal plot of 6 design metrics for the propose BBME design. . . 75 3.18 Hexagonal plot of 6 design metrics for different ME hardware architectures
evaluation. (a) Yap’s work [40] (b) Ou’s work [67]. . . 76 3.19 Pipeline timing of data movement and motion search. . . 82 4.1 Power adaptation curves for prior arts [56, 57, 58]. . . 91 4.2 Functional block diagram of a generic video encoder with power
adaptive-iterative binary search (PA-IBS). . . 94 4.3 Processing procedure of the power adaptive-iterative binary search
(PA-IBS) algorithm. . . 94 4.4 Partitioned 8×8 regions for z-th binary search window under search range
of ±16. . . 99 4.5 Block diagram of PA-IBS architecture. . . 105 4.6 Architecture of line based search engine. . . 106 4.7 Output data timing from line based search engine to the pipelined buffers
for φ iterations of binary searches. . . 106 4.8 Temporal distribution of the target number of iterations (φ) for the PA-IBS
algorithm. (a) Foreman with 300 fames (b) Flower&Garden with 250 frames.109 4.9 Temporal distribution of PSNR and coding bits for the PA-IBS algorithm
with and without the CAM on Foreman sequence. . . 110 4.10 Chip photo. . . 115 4.11 Comparison of bus bandwidth for the PA-IBS and conventional power
6 List of Figures
4.12 Comparison of the power adaptation performance for the PA-IBS and prior power adaptive designs. . . 117 4.13 Hexagonal plot of 6 design metrics for different ME hardware architectures
evaluation. (a) Yap’s work [40] (b) Ou’s work [67]. . . 120 4.14 Hexagonal plot of 6 design metrics for different ME hardware architectures
evaluation. (a) PA-IBS (CAR=1/8) (b) Chen’s work [26]. . . 121 4.15 Power-Distortion curves for power adaptive designs. . . 123
List of Tables
1.1 Analysis on the power consumption for the state-of-the-art video encoder chip designs. . . 3 1.2 Data access bandwidth in one macroblock (MB) for full search. (SR=search
range). . . 4 1.3 I/O access bandwidth for different image resolutions. . . 4 2.1 Required memory size and data reuse ratio for data reuse schemes of Level
C and Level D. . . 27 2.2 Evaluation of low power designs using design metrics. . . 28 2.3 Evaluation of design metrics for low power designs (Group 1 and 2). . . 32 2.4 Evaluation of design metrics for low power designs (Group 3). . . 33 2.5 Summary of three groups of complexity adaptive ME works. . . 40 3.1 Evaluation of the pre-processing unit design schemes for pyramid based
search. . . 49 3.2 Comparison of different K values for macroblock based pre-processing unit. 53 3.3 Evaluation of the ABME and BBME flow for block 8×8 and 16×16 searches
in LV3. . . 55 3.4 Comparison for serial and parallel architecture. . . 61 3.5 R-D performance for full search (FS), ABME algorithm (ABME)[35] and
the BBME algorithm at the bitrate of 256 kilo bps (N=300). . . 66 3.6 R-D performance for full search (FS), ABME algorithm [35] and the BBME
algorithm at the bitrate of 512 kilo bps (N=300). . . 67 3.7 R-D performance for full search (FS), ABME algorithm [35] and the BBME
algorithm at the bitrate of 1024 kilo bps (N=300). . . 67 3.8 Gate count and execution cycles for each module of our design. . . 72 3.9 Summary of cycles of data movement for P-frame and B-frame searches. . . 77 3.10 Performance comparison with state-of-the-art designs. . . 78 3.11 Design metrics evaluation for the state-of-the-art low power designs. . . 79 3.12 Design metrics evaluation for the state-of-the-art low power designs. . . 80
8 List of Tables
3.13 Bus bandwidth analysis for conventional 8-bit ME scheme and the pro-posed design (Search range = [-16, +15]). . . 83 3.14 Comparison of prior ABME design [35] and the proposed BBME design. . 84 4.1 A summary of power adaptive motion estimation designs. . . 88 4.2 Filters used to generate binary images. . . 95 4.3 Analysis of hardware requirement for four region sizes. . . 100 4.4 Memory index for the partitioned regions in search range of ±16 (z =
iter-ation index from 0 to 7). Each word is 64 bits. . . 100 4.5 Evaluation of the pre-processing unit design schemes for PA-IBS. . . 101 4.6 R-D performance for three power adaptive algorithms as compared to full
search (LSB = LSB truncation, SUB = sub-sampling, IBS = iterative binary search). . . 111 4.7 Complexity reduction for PA-IBS algorithm with CAM as compared to
PA-IBS without CAM. . . 112 4.8 Chip design specification of PA-IBS. . . 116 4.9 Comparison of the power adaptive designs. . . 117 4.10 Comparison of H.264/AVC ME hardware designs. . . 118 4.11 Evaluation of design metrics for low power designs (Group 3). . . 119 4.12 Power-Distortion performance for power adaptive designs. . . 124
Chapter 1
Introduction
1.1 Motivations
With the rapid development of communication techniques and the popularity of mobile devices, vendors are providing more and more content services for end users. These con-tent services include Digital TeleVision (DTV), Multimedia Messaging Services (MMS), mobile TV programs, MP4 movie/MP3 music playing, and video recording applications on Digital Still Camera (DSC), etc. Among these applications, video encoding/decoding applications are boosting the demands since the mobile devices are more powerful now than ever before to process heavier duty tasks such as video recording and compression. However, these devices are still powered by batteries and the battery power is still limited. Hence, developing the video coding application under power constraints to have efficient power usage for longer battery life is becoming important.
2 Chapter 1: Introduction
1.1.1 Importance of Low Power Designs
The video coding applications for mobile devices draw attentions in designing the video coding system in a more power efficient way. The most popular applications are to design a video coding system by minimizing its power for longer battery life. This design approach for power minimization is referred to as low power designs[34, 35, 36, 37, 38, 39, 40]. When the power consumption is reduced, the battery life can be lifted.
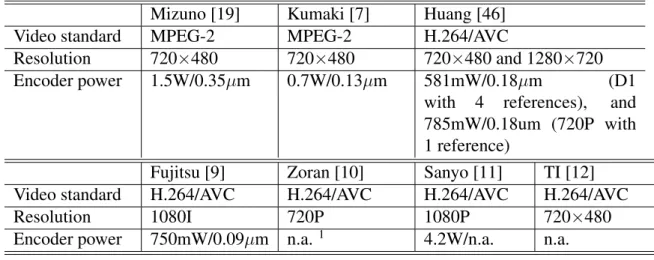
We survey the MPEG-related encoder chip designs in the academic or industrial areas [19, 7, 8, 9, 10, 11, 12] and summarize their design information in Table 1.1. The power consumption for the encoder chips is in the range of 600 milli-Watt (mW) to 4.2 Watt(W). Inside the encoder, the power consumption for the ME module will also increase to 1 2 W when the video resolutions increase to HDTV 720P (1280×720) or 1080I (1920× 1080). This shows the importance of low power ME designs, especially for the high resolutions of video coding applications.
Kumaki et al. [7] further analyze the power consumption of each module in their en-coder chip design. The power consumption for motion estimation (ME), DCT/Q/IQ/IDCT, VLC, video in/out, SDRAM interface, and clock distribution are 39, 15, 5, 3, 8, and 22%, respectively, in which ME and the DRAM access take around 50% of the total encoder power (i.e. 750mW for D1 720x480 30fps under 0.35µm process). Fig. 1.1 shows the distribution of power consumption for each of the modules in [7]. After scaling it image resolution from D1 (720×480) to CIF, the power consumption for the ME is around 15 mW.
When image resolution and search range become larger, the power consumption for the ME becomes unacceptable. Fig. 1.2 plots the estimated power consumption of ME for
Chapter 1: Introduction 3 Table 1.1: Analysis on the power consumption for the state-of-the-art video encoder chip designs.
Mizuno [19] Kumaki [7] Huang [46]
Video standard MPEG-2 MPEG-2 H.264/AVC
Resolution 720×480 720×480 720×480 and 1280×720
Encoder power 1.5W/0.35µm 0.7W/0.13µm 581mW/0.18µm (D1 with 4 references), and 785mW/0.18um (720P with 1 reference)
Fujitsu [9] Zoran [10] Sanyo [11] TI [12] Video standard H.264/AVC H.264/AVC H.264/AVC H.264/AVC
Resolution 1080I 720P 1080P 720×480
Encoder power 750mW/0.09µm n.a.1 4.2W/n.a. n.a.
1not available
different search ranges and image resolutions. From this Figure, when image resolution increases from CIF to HDTV 1080I60, the power consumption will increase from 15 mW to 19.6 W, which is a huge power consumption.
When image resolution and search range become larger, the I/O bandwidth also in-creases very quickly. Table 1.2 analyzes the I/O access bandwidth in one macroblock. Table 1.3 lists the I/O bandwidth for different search range and image resolution, and the I/O bandwidth is plotted in Fig. 1.3. From this Figure, when image resolution increases from CIF to HDTV 1080I60, the I/O bandwidth will increase from 13.2 mega bytes/sec to 642.5 mega bytes/sec. The huge I/O bandwidth cause more power consumption and become another ME design issue.
The issues of high power consumption and high I/O bandwidth shows the motivations for the low power ME designs.
4 Chapter 1: Introduction
Table 1.2: Data access bandwidth in one macroblock (MB) for full search. (SR=search range).
Scheme In/out data Full search
P-frame current block 16×16
reference block 16 × (16 + (SR + 2) × 2) Motion vectors 4 (bytes/MV) × 5 (MVs) Total (bytes/MB) 596+32×SR
B-frame current block 16×16
reference block (16 × (16 + (SR + 2) × 2)) × 2 Motion vectors 4 (bytes/MV) × 5 (MVs)
Total (bytes/MB) 936+64×SR
Table 1.3: I/O access bandwidth for different image resolutions. I/O bandwidth (Mbytes/s) CIF 30fps, SR=±16 CIF 30fps, SR=±32 D1 30fps, SR=±32 HDTV 720P 30fps, SR=±32 HDTV 1080I 60fps, SR=±64 Full search 13.2 19.3 65.6 175.0 642.5
Chapter 1: Introduction 5
Figure 1.2: Estimated ME power consumption for different video resolutions.
6 Chapter 1: Introduction
1.1.2 Importance of Power Adaptive Designs
Another approach for power constrained video applications is to design with config-urable power modes for different demands from low power to high quality applications. Such a design approach is referred to as power adaptive designs [45, 46, 47] or power
aware designs [59, 5, 56]. The power adaptive designs can adapt the configuration to a
suitable battery status manually or automatically considering the video content variations, and the power and video quality tradeoff [5]. That means the power adaptive designs have wider application range to adapt the power consumption and video coding quality to dif-ferent application scenarios.
Fig. 1.4 shows the discharging curve of the 700 mAh AA NiCad battery [13]. Similar discharging curves can be observed for different types of batteries [13]. With the constant loading, the power discharging curve is shown in Fig. 1.5. Under this power discharging curve, a low power design will stop at T1since the remaining power is under its operational
power. However, a power adaptive design can adapt to the real battery power status by adjusting its power consumption to extend its lifetime to T2with ∆T lifetime improvement.
The lifetime improvement show the motivations for the power adaptive ME designs. Fig. 1.6 shows how an power adaptive design works on a battery operated multime-dia system. This system is built on TO DaVinci platform. For power adaptive applica-tions, this system builds an power management mechanism to control the power consump-tion of LCD, DSP/CPU, and I/O peripherals by detecting the battery status. As shown in Fig. 1.7, the power management mechanism uses 3 step-down converters to adjust the volt-age of DSP/CPU, memory and I/O peripherals for 32 levels of power consumptions (i.e. 0.8V 1.6V, step=0.025V). The power control signal is via I2S communication protocol. The
Chapter 1: Introduction 7
Figure 1.4: Battery discharging curve [13].
power adaptive ME can dynamically adjust its power consumption according to the control signal.
1.2 Power Constrained Motion Estimation Designs
The power constrained motion estimation design has two major applications: (1)low power design, and (2)power adaptive design. Low power design is to minimize the power consumption for ME with acceptable quality loss. On the other hand, the power adaptive design is to achieve a good power and video quality tradeoff to provide best quality under the same power consumption or minimal power consumption under fixed video quality. In this thesis, we will discuss the design challenges and our solutions.
8 Chapter 1: Introduction
Figure 1.5: Lifetime improvement by power adaptive designs.
1.2.1 Low Power Motion Estimation
Motion estimation (ME) is the most computationally expensive module in multimedia compression standards such as MPEG-1/2/4 and H.26x. For portable video applications, low power and efficient bus access are two major design goals [42]. The huge power consumption from ME needs to be reduced to extend battery life. The ME is also a data intensive module. It moves huge data for pattern matching to find the best predicted block with minimal distortion for motion compensation. The amount of data movement increases proportionally to the square of search range, and becomes the performance bottleneck for System-on-Chip (SoC) designs due to the limited available bus bandwidth. Hence, an efficient data movement scheme via bus is another key design issue for portable video applications.
Chapter 1: Introduction 9
Figure 1.6: Block diagram of portable multimedia player based on TI DaVinci platform [14].
10 Chapter 1: Introduction
To investigate low power ME designs, most of them are developed based on fast search algorithms [34, 35, 36, 37, 38] or low cost full search architectures [39, 40]. These fast al-gorithms include three-step search (TSS) [38], gradient descent search (GDS) [36], global elimination search [37], binary search [34, 35], etc. For low power or low cost full search architectures, one-dimensional (1-D) systolic array is the most widely used architecture [33]. Among these designs, binary search [34, 35] has both advantages of low computa-tional complexity and low bus bandwidth requirement. The reason is it reduces the pixel precision from eight bits to one bit for block matching. Such a search strategy can also be viewed as a kind of feature matching with binary images. Therefore, in this paper, we de-velop our low power and bandwidth efficient ME design based on a binary pyramid search algorithm called All Binary Motion Estimation (ABME) [41].
Although ABME [41] is a low complexity and bandwidth efficient algorithm, it is not well optimized for VLSI implementation. We face the hardware design challenges in (1) image pre-processing to form the binary image (2) low power and bus bandwidth efficient architecture for binary pyramid search (3) support of bi-directional (or called B-frame) and 8x8 block searches. We solve these design issues in the proposed hardware architecture. Firstly, we propose a new pre-processing flow for binary image generation at the mac-roblock (MB) level instead of the original frame level. The binary image generation and binary motion search are integrated as an MB level pipelining to simplify redundant bus access. Secondly, we re-examine the data flow in the three levels of binary pyramid search structure, and modify the algorithm to remove the data dependency and inefficient opera-tions for the second level of search. Finally, we address the design issues in B-frame search scheme and optimize the hardware architecture to enhance the processing throughput.
Chapter 1: Introduction 11 The contributions of this work include:
• Modified ABME algorithm (referred to as BBME) for efficient VLSI
implementa-tion. The BBME algorithm is developed based on a low complexity ABME algo-rithm [41]. We modify the ABME in the binary image generation and search method for efficient VLSI implementation. The power consumption for video encoding with CIF 30 fps and search range of [-16, +15] only needs less than 1 mW.
• MB level pipelining architecture for efficient bus access. We propose a new
pre-processing flow for binary image generation at MB level as opposed to frame level. The new processing flow integrates both binary image generation and binary motion search using MB level pipelining to avoid repeated bus access. The bus bandwidth saving can achieve up to 67.1%.
• Bi-direction binary search architecture. We design our hardware to be able to handle
B-frame search in parallel. It reuses the same current search data to save on-chip memory access and power. Thanks to the simple binary image matching, the gate counts have increased twice but not as much as the conventional 8-bit designs.
1.2.2 Power Adaptive Motion Estimation
The power adaptive designs have become an important feature especially for portable video applications [59]. Unlike the low power designs that aim for minimized power con-sumption, the power adaptive design targets on the efficient allocation of power resources with equal video quality and longer battery life. In multimedia compression systems such as MPEG-1/2/4 and H.26x, the motion estimation (ME) that dominates the power
con-12 Chapter 1: Introduction
sumption of the video encoder plays a key role in the power adaptive design. We will present a power adaptive ME design to improve power allocation and power efficiency.
In the power adaptive or complexity adaptive ME algorithms and designs [56, 57, 58, 47, 48, 49, 50, 45], we can roughly categorize them into two types according to their imple-mentation methods. The first type is to achieve power adaptation by integration of multiple search strategies. This type adopts 2 to 3 search strategies such as three-step search, dia-mond search or full search to deliver different levels of search complexity. For example, the authors in [47] proposed a three-mode complexity adaptive method by using three-step search and enhanced four-step search for low power applications, and full search for high quality applications. Although this type of method can provide large scale of complexity differences, the coding quality for low power modes usually has significant quality loss.
The second type is to achieve power adaptation by simplified matching criterion. The simplified criterion include bit-depths truncation, pixel decimation, etc. By keeping differ-ent bit-depths or decimated pixel resolutions for block matching, the design can achieve different levels of computational complexity and power consumption. For example, the au-thors in [57, 58, 49] adopt the least-significant-bit truncation method to design their power adaptive ME. Pixel bit-depth of 1 or 2 is served for low power mode, and bit-depth of 8 is served for high quality mode. This type can provide the significant power reduction by dynamically adjusting the bit-depths, but it still suffers from significant quality loss in low power mode.
For both of the above 2 methods, they have the same problems of significant quality loss in low power modes. The bit-depth truncation method also has the issues in limited pixel bit-depths and bit-plane dependency. Limited pixel bit-depths cause the difficulty for
Chapter 1: Introduction 13 fine-granularity of power adaptation. Bit-plane dependency causes the inefficiency for data access and processing. To address these issues, a new power adaptive ME algorithm and hardware architecture called Power Adaptive-Iterative Binary Search (PA-IBS) is proposed with four key features:
To address such issues, a new power adaptive ME design called Power Adaptive-Iterative Binary Search (PA-IBS) is proposed with two features:
• Frequency decomposed bit-planes design: PA-IBS algorithm adopts the frequency
decomposition method for bit-planes design. The new bit-plane design method gen-erates directional and gradient image features in binary format, and can provide better rate-distortion performance as compared to using pixel bit-planes.
• Finer granularity of power adaptation: The number of frequency decomposed
bit-planes is not limited to pixel bit-depths. This allows finer granularity of power adap-tation for smooth power and video quality adjustment.
• Independent bit-plane processing: The frequency decomposed bit-planes can be
in-dividually stored in the memories and independently processed. Therefore, we can avoid unnecessary memory access and data processing to those unrelated bit-planes.
• Frequency scaling based hardware architecture: The independent bit-plane
process-ing provides the advantage to design the hardware for processprocess-ing sprocess-ingle bit-plane instead of all bit-planes. To full use this hardware design for single bit-plane process-ing, the frequency scaling technique scales the working frequency with the number of bit-planes to be processed. Such hardware architecture reduces the overheads to design the hardware for the worst case of all bit-planes, and enhances the hardware
14 Chapter 1: Introduction
utilization and power adaptation performance.
1.3 Organization and Contribution
In chapter 2, we review the principle of motion estimation and the block matching criteria. Toward ME hardware design, we present the design metrics for evaluation of dif-ferent ME works. The memory hierarchy architecture is also analyzed. Then, we survey low power and power adaptive ME designs, and categorize them into three major groups according to their implementation methods. The frequently cited ME works are also eval-uated according to the design metrics, and used as the reference works for our low power and power adaptive binary motion search algorithm and architecture designs.
In chapter 3, a new Low Power ME algorithm and architecture design called Bi-directional Binary Motion Estimation (BMBE) is proposed to achieve low power and bus bandwidth efficiency. Low power and high bus bandwidth efficiency are the two key issues for portable video applications. To address such issues, we first study an efficient algorithm called all binary motion estimation (ABME), and analyze its architecture issues in opera-tional flow and bus access. Then, we propose an hardware architecture called BBME with four new features (1) macroblock level pre-processing (2) efficient binary pyramid search structure (3) parallel processing of 8x8 and 16x16 block searches (4) parallel processing of bi-directional search. Such architecture leads to a superior performance in bus access, throughput and power.
In chapter 4, a new Power Adaptive Iterative Binary Search (PA-IBS) design for mo-tion estimamo-tion is proposed to improve the power adaptamo-tion performance. In the prior power adaptive ME designs that use the hardware masking approach, there exist design
Chapter 1: Introduction 15 overheads such as redundant bus access, unnecessary on-chip memory access, and poor hardware utilization that lead to poor power adaptation performance. Our proposed power adaptive solution addresses these issues with a new ME algorithm called Iterative Binary Search (IBS) and the associated hardware architecture called PA-IBS. The IBS integrates a new frequency decomposed bit-plane design method to improve the rate-distortion curve and provide the flexibility for finer granularity of power adaptation. The IBS also exe-cutes the multiple bit-plane searches in an either individual or accumulated manner, thus redundant bus and on-chip memory access are eliminated. A Content Adaptive Mechanism (CAM) is used to dynamically select the number of iterations on a macroblock basis. The PA-IBS uses the frequency scaling technique to provide a link between the number of itera-tions and the power consumption level. Therefore, it reduces hardware idling and enhances hardware utilization.
Chapter 2
Review of Power Constrained Motion
Estimation Designs
2.1 Block Motion Estimation
2.1.1 Block Matching Criterion
Motion estimation is to remove the temporal redundancy between neighboring frames for efficient video coding. For practical applications, a whole frame is partitioned into small blocks for motion compensated prediction. This block based method needs less data for one point of block matching, and thus is widely used in video compression standards such as MPEG-1/2/4 and H.26x.
Fig. 2.1 shows the block motion estimation flow to find the best matched block from previous frame. The current frame IC is firstly partitioned into several L × L blocks. The
motion estimation is done by checking all the candidate blocks in the search window of the 16
Chapter 2: Review of Power Constrained Motion Estimation Designs 17 reference frame IR, and the best matched block is found with minimal matching distortion.
The distance from the current block to the best matched block is the Motion Vector (MV). The commonly used distortion metrics are Sum of Absolute Difference (SAD) or Sum of Square Difference (SSD). The SAD which is denoted as
SAD = L−1X y=0 L−1X x=0 |IC(x, y) − IR(x + x0, y + y0)| (2.1)
is to calculate the difference in absolute values for each pixel data between current block
IC(x, y) and candidate blocks IR(x + x0, y + y0) in the search window. The SSD which is
denoted as SSD = L−1X y=0 L−1X x=0 (IC(x, y) − IR(x + x0, y + y0))2 (2.2)
is to calculate the difference in squared values for each pixel data. The SSD can provide better prediction results but with higher computational complexity. The SAD which can also provide good prediction results with minor computational complexity is widely used in video coding.
2.1.2 Design Metrics Evaluation
For evaluation of ME designs, there are several important design metrics under consid-eration. For ME algorithm development, the design metrics for evaluation are: (1) number of operations, (2) quality of the algorithm in terms of PSNR, (3) memory access bandwidth [33]. However, to evaluate an ME hardware architecture, there are 6 major design metrics for consideration as follows [33].
• Quality (Q): The quality metric is to evaluate the motion search performance
18 Chapter 2: Review of Power Constrained Motion Estimation Designs
Chapter 2: Review of Power Constrained Motion Estimation Designs 19 the computation complexity by search candidates reduction or matching criterion simplification, etc. However, it suffers quality loss due to the complexity reduction for poor search performance. The quality loss is usually measured by Peak Signal Noise Ratio (PSNR) denoted as
P SNR = 10 · log10 2552 NhP m=1 NvP n=1 ³ IC(m, n) −IbC(m, n) ´ / (Nh· Nv) (2.3)
where IC is the current frame,IbC(m, n) is the reconstructed image of current frame,
Nh and Nv are the frame width and height. Thus, to have a fair comparison of
different ME algorithms or hardware architectures, the quality metric (Q) is defined as the PSNR difference between FS and FME denoted as
Quality Metric (Q) = P SNRFME− P SNRFS (dB). (2.4)
To apply this metric for fair design evaluations in later sections, the PSNR is mea-sured under search range of [-16, +15].
• Throughput (T): The throughput metric is to measure the processing speed of the
hardware architecture to see if it can meet the real-time requirement. To quantify the processing speed, the throughput metric is defined as the required number of cycles for one macroblock (MB) of block matching denoted as
Throughput Metric (T) = NCMB(cycles) (2.5)
, where NCMB represents the required cycles for one MB of block matching.
Al-though the throughput is application dependent, and there is no need to over-design the hardware, the throughput metric is still an important parameter to measure the
20 Chapter 2: Review of Power Constrained Motion Estimation Designs
hardware design performance. The more cycles the design takes to meet the real-time requirement, the slower the processing speed. If the processing speed is too slow, the applications are limited to those devices target on processing low resolution of video sequences. To apply this metric for fair design evaluations in later sections, the throughput is measured in the number of clock cycles under search range of [-16, +15].
• Silicon area (A): The chip size is determined by the hardware silicon area and the
VLSI technology. That means the chip size is not available until the chip is really designed. However, we can have a more efficient way to estimate the silicon area on the architectural level by measuring the equivalent gate counts for ME designs. The gate counts includes the number of logic gates for memories and design logics denoted as
Area Metric (A) = AMemory+ ALogic. (2.6)
, where AMemory is the silicon area for memory including Synchronous Random
Ac-cess Memory (SARM) and/or register files, and ALogic is the silicon area for all the
ME hardware logics except memories. In this thesis, we will use gate counts as the silicon area for the evaluation of the ME designs.
• Hardware Utilization (U): Hardware utilization or hardware efficiency [33] is to
evaluate the hardware utilization ratio in percentage by calculating the active cycles and idle cycles in designs. This metric can also be used to evaluate the design over-heads. The higher the utilization ratio, the lower the overheads in the ME hardware designs. That means a design is a highly efficient design if its hardware utilization ratio is high.
Chapter 2: Review of Power Constrained Motion Estimation Designs 21
Utilization Metric (U) = NCMB(Active)
NCMB(Active) + NCMB(Idle)
= NCMB(Active) NCMB
(%). (2.7)
• I/O Bandwidth (B): The I/O bandwidth is to evaluate the amount of data
transmis-sion between off-chip memories and ME processing core. Since most of the ME designs put frame buffers in off-chip memories, the access to the off-chip memories is unavoidable. Thus, the I/O bandwidth will directly affect the design throughput and hardware utilization ratio. If the bandwidth requirement is high, the ME design will take longer cycles in waiting data before the motion search begins. This will lead to poor throughput and poor hardware utilization since there are many hardware idle cycles existed. In this thesis, the metric for I/O bandwidth evaluation is defined as the number of read cycles and write cycles from off-chip memories denoted as
Bandwidth Metric (BI/O) = NCread+ NCwrite(bytes) (2.8)
, where NCread and NCwrite are read and write cycles respectively. The unit is the
number of bytes required for the bus access under the search range of [-16, +15].
• Power consumption (P): Power consumption is the most critical issue in ME
de-signs, and power constrained designs have wider applications in mobile or portable devices. To evaluate ME designs, the power consumption metric is defined as the total power consumption for memory and hardware logics and is denoted as
Power Consumption Metric (P) = PMemory+ PLogic(mW). (2.9)
, where PMemoryis the power consumption for memory, and PLogicis the power
22 Chapter 2: Review of Power Constrained Motion Estimation Designs
using this power consumption metric with the unit of milli-watt (mW). To provide a fair comparison basis, we use the normalized power consumption [26] by mapping the original power consumption to the equivalent power consumption for 0.18 µm denoted as
NormalizedPower Consumption Metric (Pnom) = P ×
0.182
Process2 ×
1.82
Voltage2.
(2.10)
2.1.3 Motion Estimation Hardware Design
Under the consideration of the design metrics in Section 2.1.2, we are able implement the block ME algorithm in Section 2.1.1 as an effective low power or power adaptive ME hardware designs. Fig. 2.2 shows the functional blocks of a generic video encoder hardware architecture with the ME module. The encoder architecture contains a RISC CPU to con-trol the data and command flow, External Memory Interface (EMI) to access current and reference frames which are put in external memories, dedicated co-processors including ME module for processing acceleration.
Fig. 2.3 has detail views to the architecture of the ME module. This ME architecture contains several local memories to store current and reference search window data, a ME core for motion search, a control unit for data and search flow control, and the decision unit to determine the final motion vectors. Firstly, The current and reference data for motion search are received via memory interface (MEM IF) and then stored in local memories (LM CUR and LM REF). After the data are ready in local memories, the controller sends commands to get data from local memories, and sends commands to ME core starts the motion search. The block matching results are sent to decision engine for final motion
Chapter 2: Review of Power Constrained Motion Estimation Designs 23
Figure 2.2: Video encoder hardware architecture with ME module.
vector determination.
2.1.4 Memory Hierarchy
In the ME hardware design, memory hierarchy is equally important as designing the motion estimation core. The motion estimation core determines the overall design through-put (T). However, the memory hierarchy architecture is related to the I/O bandwidth (BI/O),
24 Chapter 2: Review of Power Constrained Motion Estimation Designs
Chapter 2: Review of Power Constrained Motion Estimation Designs 25 (U).
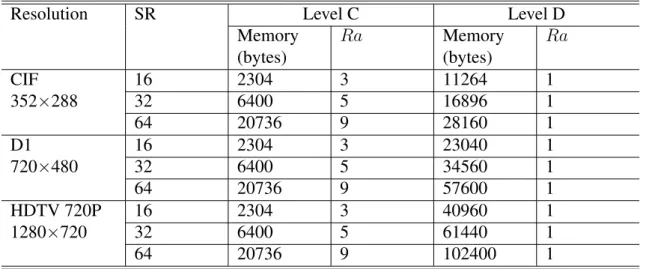
The memory hierarchy in ME hardware design is related to the data reuse of the search window [42, 16, 17]. The data reuse approaches can be roughly categorized into 4 levels (Level A to D) according to the reuse percentage from low to high [16]. In the 4 levels, the most commonly used approaches are Level C and Level D. They are depicted as below.
• Level C: The Level C approach is to buffer the search window data in the same MB
row as the current MB. As shown in Fig. 2.4(a), suppose current block size is L and the search range is [-SR, +(SR-1)], the data reuse ratio is Ra = L×(L+(SR·2))L×L = 1 + (SR·2)L . The required memory buffer size is S = (L + (SR · 2))2.
• Level D: The Level D approach is to buffer the whole MB row data in the same
MB row as the current MB. As shown in Fig. 2.4(b), suppose the image width is
Nh, the data reuse ratio is Ra =
³
L×L L×L
´
= 1. The required memory buffer size is
S = (L + SR) × Nh.
Table 2.1 summarizes the required memory size and data reuse ratio under different search range and frame resolution for Level C and Level D schemes. Level D has better data reuse ratio, but requires larger memory buffers as compared to Level C. Level C is more com-monly used in the application with larger frame sizes such as High-Definition Television (HDTV) to avoid huge memory requirements with median data reuse ratio.
In the following sections, we will survey the prior low power ME works in Section 2.2 and power adaptive ME works in Section 2.3. Then, these works are evaluated according to the design metrics depicted in Section 2.1.2.
26 Chapter 2: Review of Power Constrained Motion Estimation Designs
(a)
(b)
Chapter 2: Review of Power Constrained Motion Estimation Designs 27 Table 2.1: Required memory size and data reuse ratio for data reuse schemes of Level C and Level D.
Resolution SR Level C Level D
Memory (bytes) Ra Memory (bytes) Ra CIF 16 2304 3 11264 1 352×288 32 6400 5 16896 1 64 20736 9 28160 1 D1 16 2304 3 23040 1 720×480 32 6400 5 34560 1 64 20736 9 57600 1 HDTV 720P 16 2304 3 40960 1 1280×720 32 6400 5 61440 1 64 20736 9 102400 1
2.2 Low Power Motion Estimation Designs
The low power ME designs from 1995 to 2007 are surveyed and categorized into 3 groups according to their design approaches. The first group is to achieve low power by fast ME algorithms [19, 36, 37, 38, 42, 20, 21, 26]. This group of designs apply fast ME algorithms such as three-step search (TSS), hierarchical search, etc. which reduce the search candidates for computational power reduction. The second group is to achieve low power by simplified block matching criterion [34, 35, 49, 52]. The commonly used block matching criterion is SAD (eqn. 2.1) or SSD (eqn. 2.2). Although they can provide good R-D performance, it takes lots of computational power. For power reduction, the approaches such as using Most Significant Bits (MSB) only for block matching, or pel-subsampling which takes partial pixel data in that block for block matching, etc. are able to reduce computational power of the block matching operations for power saving. The third group of designs is to archive low power by efficient hardware architectures [18, 39, 40, 22, 23, 24, 25, 26, 17, 27, 29]. For example, the one-dimensional (1-D) systolic array for
28 Chapter 2: Review of Power Constrained Motion Estimation Designs
Table 2.2: Evaluation of low power designs using design metrics.
Groups Q T A U B P
Reduced candidates X O - - - O
Simplified Matching Criteria X O - - - O
Efficient Architectures - O - - - O
O: improved X: degraded -: case dependent
full search or an efficient memory hierarchy architecture can effectively reduce the power consumption. Table 2.2 shows the influences to the design metrics in Section 2.1.2 by using these three design approaches for low power hardware designs.
In the following, we will introduce the frequently cited low power design works, and summarize their design metrics evaluation in Table 2.3 and Table 2.4. These works are also used as the reference to the proposed BBME design in later chapters.
2.2.1 Low Power by Fast ME Algorithms
Miyama et al. [36] proposed a sub-mW motion estimation processor core by developing a Gradient Descent Search (GDS) algorithm with the optimized hardware architecture for mobile applications. The GDS algorithm is to reduce the required computational complex-ity and hardware operational cycles for ME. The Single Instruction Multiple Data (SIMD) data path is to reduce the required clock frequency by maximizing the parallel processing ability. The three-port SRAM acts as the data cache to reduce the power consumption. These features make this hardware core to be able to run QCIF 15fps at 0.85 MHz with 0.4 mW power consumption. The hexagon plot is shown in Fig. 2.5(a).
Chapter 2: Review of Power Constrained Motion Estimation Designs 29 Successive Elimination Algorithm (SEA) and Diamond Dearch (DS). The irregular flow between the two fast algorithms are solved to achieve different applications for high quality and low power. This design has 3 modes including: (1) SEA without early cut, (2) SEA with early cut (at cycle 4208 to meet CIF 30fps at 50MHz), (3) DS without early cut. Running on the third mode, the power consumption is 223.6 mW for CIF 30 fps with 50MHz clock frequency. The hexagon plot is shown in Fig. 2.5(b).
Chen et al. [26] proposed a an optimal low power IME engine with a parallel hardware architecture supporting fast algorithms and efficient data reuse (DR) called content adaptive parallel-VBS 4SS. This design has 3 modes to achieve different video quality and power consumption. These 3 modes are: (1)high quality mode, (2)low power mode, and (3) ultra low power mode. The first mode is with 2 reference frame and multiple iterations to achieve high quality. The second mode is with 1 reference frame and multiple iterations to achieve minor quality loss and low power consumption. The third mode is with one reference and single iteration to achieve ultra low power consumption. Running on the third mode, the power consumption is 2.13 mW for CIF 30 fps with 13.5 MHz clock frequency. The hexagon plot is shown in Fig. 2.6(a).
2.2.2 Low Power by Simplified Block Matching Criteria
Huang et al. [37] proposed a new block matching algorithm called Global Elimination Algorithm (GEA) and its optimized architecture to achieve the low power design. The GEA is developed from Successive Elimination Algorithm (SEA), but saves more SAD compu-tations by calculating sub-sampled pixel data for early terminations. The early termination can save more unnecessary power consumption for SAD computations. This hardware
de-30 Chapter 2: Review of Power Constrained Motion Estimation Designs
sign can achieve more than CIF 30 fps at 25 MHz with 189 mW power consumption. The hexagon plot is shown in Fig. 2.6(b).
Wang et al. [35] proposed a low power ME design by implementing All Binary Motion Estimation (ABME) algorithm and proposing an optimized hardware architecture for the binary bitplane of block matching. The images for search are firstly formatted as binary bitplane, and the block matching criterion is modified to use the binary data for pattern matching. The pattern matching using binary data can greatly reduce the computational complexity, thus the power consumption is saved. The power consumption for CIF 30fps is 2.2mW. The hexagon plot is shown in Fig. 2.7(a).
2.2.3 Low Power by Efficient Hardware Architecture
Shen et al. [39] proposed a low-power full-search block matching (FSBM) motion-estimation design for H.263+. To minimize power consumption, techniques such as gated-clock and dual-supply voltages are used. This design runs CIF 36fps at 60 MHz, and the power consumption is 423.8 mW. The hexagon plot is shown in Fig. 2.7(b).
Chen et al. [66] proposed an parallel-SAD tree with a shared reference buffer for H.264 integer motion estimation (IME). To solve the huge memory bandwidth required by H.264 IME, an efficient memory architecture is proposed to save 99.9% off-chip memory band-width and 99.22% on-chip memory bandband-width. This design can run 720P 30fps solution at 108 MHz with 330.2k gate count and 208k bits on-chip memory.
Yap et al. [40] proposed a new 1-D VLSI architecture for H.264 IME. The SAD com-putation is performed by reusing the results of smaller sub-block comcom-putations to save the computations and power. They are combined with a shuffling mechanism within each
![Figure 1.6: Block diagram of portable multimedia player based on TI DaVinci platform [14].](https://thumb-ap.123doks.com/thumbv2/9libinfo/8742707.204460/35.892.173.799.199.670/figure-block-diagram-portable-multimedia-player-davinci-platform.webp)
![Figure 3.4: The processing procedure for ABME and BBME flow. (a) ABME flow [41] (b) BBME flow.](https://thumb-ap.123doks.com/thumbv2/9libinfo/8742707.204460/78.892.205.666.343.813/figure-processing-procedure-abme-bbme-flow-abme-bbme.webp)
