國 立 交 通 大 學
電信工程研究所
碩 士 論 文
使用韻律信息之中文自發性語音辨認
A Prosody-Assisted Mandarin
Spontaneous Speech Recognition
研究生:黃仰駿
指導教授:陳信宏 博士
使用韻律信息之中文自發性語音辨認
A Prosody-Assisted Mandarin
Spontaneous Speech Recognition
研 究 生:黃仰駿 Student:Yang-Chun Huang
指導教授 :陳信宏 博士 Advisor:Dr. Sin-Horng Chen
國 立 交 通 大 學 電 信 工 程 學 系
碩 士 論 文
A Thesis
Submitted to Institute of Communication Engineering College of Electrical and Computer Engineering
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master of Science in Communication Engineering
August 2014
Hsinchu, Taiwan, Republic of China
I
使用韻律信息之中文自發性語音辨認
研 究 生:黃仰駿 指導教授:陳信宏
博士
國立交通大學電信工程研究所碩士班
中文摘要
近年來朗讀式語音辨識已有相當不錯的效能,但自發性語音辨認卻因為語速較快、 語法不規則、語流不流暢等原因仍舊困難,本論文探討中文自發性語音辨認,研究重點 在語言模型的建立及加入韻律信息的辨認過程。在語言模型建立上,考慮語者說話猶豫 時所使用的感嘆詞及無意義的慣用插語,並利用語言模型調適來解決文字語料不足及文 法語流特性和朗讀語音不同的問題,以建立一套自發性語言模型;在辨認過程上,使用 兩階段辨認來加入韻律信息協助辨認,首先在第一階段辨認使用傳統聲學模型及 bigram 語言模型產生一個 word lattice,接著在第二階段辨認先擴展語言模型為 factored 語言模 型,再加入韻律邊界停頓資訊與音節韻律狀態資訊,經過重新評分後得到一條最佳路徑, 並同時解碼出相關資訊。使用中研院 MCDC 語料作實驗,獲得詞、字及音節的辨識率 分別為 58.29%、64.94%及 68.89%,較傳統只使用第一階段辨認的作法絕對辨認率改善 了 4.43%、4.6%及 3.06%。經辨認結果分析發現,對於正常語流而言,加入韻律信息能 夠改善搶詞及聲調辨認錯誤;但對於不正常語流來說,改善的效能非常有限。II
A Prosody-Assisted Mandarin
Spontaneous-Speech Recognition
Student:Yang-Chun Huang Advisor:Dr. Sin-Horng Chen
Institute of Communication Engineering
National Chiao Tung University
Abstract
In recent years, the Mandarin read-speech recognition technology is quite mature. However, it is still difficult for spontaneous speech recognition due to high speaking rate and the existence of disfluent speech events. This thesis discusses Mandarin spontaneous speech recognition, focusing on language model establishment and the process of prosody-assisted recognition. In the language model establishment, two particular words of particle and marker are added to the vocabulary to model the disfluency phenomena of spontaneous speech. Besides, language model adaptation is employed to solve the problem of the insufficiency of texts of spontaneous speech. In recognition, a two-stage recognition process to incorporate prosodic information is adopted. In the first stage, an acoustic model and a bigram language model is used to generate a word lattice. Then, in the second stage the word lattice is firstly extended to replace the bigram LM with a factorized LM. Then, break-related models and prosodic state-related models of a hierarchical prosodic model are sequentially added to rescore all searching paths in order to find the best recognized word sequence. Experimental results on the Academia Sinica MCDC corpus showed that word, character and base-syllable accuracy rates of 58.29%, 64.94% and 68.89% were achieved. They were better than the results of the baseline system by 4.43%, 4.6% and 3.06%, respectively. By error analysis we find that prosodic information is useful in resolving word segmentation ambiguity and tone pattern confusion for fluent speech part, while it is less effective for disfluent part.
III
致謝
終於要畢業了,在這兩年的日子裡,吃了不知道幾餐的ㄆㄨㄣ,咪了不知道幾次。 首先感謝陳信宏老師,在百忙之中還是經常關心我的研究進度;感謝王逸如老師,給了 我許多研究上的方法與建議,也許我不是個適合做研究的研究生,但是從中還是學到了 許多;也感謝許多學長的幫助,讓我在研究上能夠順利許多。 感謝 707 實驗室裡的每個人,很會推導公式的實驗室ㄧ哥王柏(?)、關於小熊的茂隆 (沒吧大哥)、提供 FHM 配咖啡的仲毛、從大學就一起打拼的阿璋、和我一起做辨識的 小鋒、美麗翹秘書 Jean,還有每位有潛力的學弟妹,因為有你們每個人,我的實驗室生 活變得更多采多姿。謝謝交大電研所有給力的隊友,也要謝謝每個給予我鼓勵的朋友們, 很開心有你們大家。 最後我要感謝我的父母和女朋友,多少次掙扎著想要放棄,如果沒有你們的支持, 我想不會有今天的成果。以此論文獻給所有幫助過我的人,謝謝你們!IV
目錄
中文摘要 ... I Abstract ... II 致謝 ... III 目錄 ... IV 表目錄 ... VII 圖目錄 ... IX 第一章 緒論 ... 1 1.1 研究動機 ... 1 1.2 研究方向 ... 2 1.3 文獻回顧 ... 3 1.4 章節概要 ... 4 第二章 漢語口語對話語料庫介紹 ... 5 2.1 語料庫介紹 ... 5 2.1.1 音檔格式說明 ... 5 2.1.2 語料標記格式說明 ... 6 2.2 自發性語音之特性 ... 8 2.2.1 感嘆詞 (particle) ... 8 2.2.2 語助詞 (marker) ... 8 2.2.3 無法或難以辨識的語音 ... 8 2.2.4 非語音聲 (Non-Speech sounds) ... 9 2.2.5 語流中斷 ... 9 2.2.6 非流暢現象 (disfluency) ... 9 2.3 自發性語音現象分析 ... 10V 2.3.1 Particle 和 Marker 於句中位置分析 ... 10 2.3.2 自發性語音特有現象 ... 11 2.4 MCDC 語料庫初步統計 ... 13 2.5 語料庫之後處理 ... 13 2.5.1 斷詞與相關統計 ... 14 2.5.2 切除音檔頭尾過長的靜音 ... 14 2.5.3 修正音節切割位置 ... 14 第三章 辨識模型介紹 ... 16 3.1 聲學模型 ... 16 3.2 語言模型 ... 17 3.2.1 朗讀式語言模型之建立 ... 18 3.2.2 語言模型之調適 ... 20 3.2.3 語言模型效能分析 ... 21 3.2.4 辨識率與詞涵蓋率比較 ... 22 3.3 韻律模型 ... 24 3.3.1 中文語音韻律階層式架構 ... 24 3.3.2 階層式韻律模型設計 ... 26 第四章 語音辨認系統架構 ... 33 4.1 加入韻律訊息於 two-stage 語音辨認系統 ... 33
4.1.1 Joint Syntax Model 之架構與建立 ... 34
4.1.2 參數正規化 ... 36
4.1.3 The Second Stage 之實作 ... 37
4.2 鑑別式模型組合 ... 41
第五章 實驗結果與分析 ... 45
5.1 加入韻律信息之辨認率 ... 45
VI 5.1.2 標點符號(PM)辨認率算法 ... 47 5.2 辨認結果分析與比較 ... 47 5.2.1 錯誤分析 ... 48 5.2.2 辨認結果之改善 ... 49 第六章 結論與未來展望 ... 51 6.1 結論 ... 51 6.2 未來展望 ... 51 參考文獻 ... 52 附錄一:詞類分類表 ... 54
VII
表目錄
表 2.1:MCDC 語料庫對話主題與語者對照表 ... 6 表 2.2 : 文字轉寫範例 ... 7 表 3.1:訓練語料統計 ... 16 表 3.2:測試語料統計 ... 16 表 3.3:參數抽取基本設定 ... 17 表 3.4:HMM 模型之設定 ... 17 表 3.5:感嘆詞在兩語料庫中所佔比例 ... 19 表 3.6:常用詞在兩語料庫中所佔比例 ... 19 表 3.7:語言模型混淆度評估 ... 22 表 3.8:加入語言模型之辨識率 ... 22 表 3.9:口語對話常用詞之辨識率 ... 23 表 3.10:詞涵蓋率比較 ... 23 表 3.11:韻律結構之停頓標記 ... 25表 3.12:syllable-like unit 與 particular unit 分類表 ... 26
表 3.13:韻律標記、聲學參數以及語言參數之數學符號 ... 27
表 4.1:factored POS model 的 perplexity ... 35
表 4.2:factored PM model 的 perplexity ... 36
表 5.1:詞(word)辨認率 ... 45 表 5.2:字元(character)辨認率 ... 45 表 5.3:音節(syllable)辨認率 ... 46 表 5.4:詞性(POS)辨認率 ... 46 表 5.5:標點符號(PM)辨認率 ... 46 表 5.6:各語者之平均音節長度與詞辨識率 ... 48
VIII
表 5.7:搶詞狀況的改善 ... 49 表 5.8:音節合併辨認的改善 ... 49 表 5.9:聲調的修正 ... 50
IX
圖目錄
圖 1.1:訓練與辨識系統架構圖 ... 2 圖 2.1:標籤式的語言格式 ... 7 圖 2.2:語料庫中每個 Sub-turn 之音節數分佈圖 ... 13 圖 3.1:語言模型訓練流程 ... 18 圖 3.2:詞語修補示意圖 ... 20 圖 3.3:中文語音韻律之階層式架構 ... 24 圖 3.4:本研究所使用的中文自發性語音韻律階層式架構 ... 25 圖 4.1:以 two-stage 方式之韻律輔助中文語音辨認系統流程圖 ... 33圖 4.2:factored POS model 的 back-off 路徑 ... 34
圖 4.3:factored PM model 的 back-off 路徑 ... 35
圖 4.4:辨認器第二級三階段實作流程圖 ... 38
1
第一章 緒論
1.1 研究動機
當語音辨認(Automatic Speech Recognition, ASR)系統已有相當程度的技術,對於朗 讀式語音辨認效能相當好時,人們開始研究更接近日常生活的自發性語音辨認,而在外 國的研究方面,自發性語音也有一定的辨識率,但中文自發性語音辨識系統卻仍然沒有 很好的效能,辨認率與朗讀式(Read Speech)有一段差距,造成這樣的原因主要是自發性 語音說話速度(speaking rate)較快、語者在說話時未經大腦良好的規劃,使得語音型態發 生改變、說話聲音大小不定、語流不流暢、語料不足等。 上述的原因可能造成自發性語音發生一些特殊的語音現象,像是語速較快時,語者 為了要節省發音時所需的力氣,造成發音變異(pronunciation variation)或是音節合併 (syllable contraction)現象,對於人腦也許可以辨識出來,但是對於機器辨識上卻是一大 挑戰;另外,因為說話時未經大腦良好規劃,語者常出現遲疑(hesitation)、詞語修補(repair) 、重複(repetition)…等現象,都會造成語流不順暢(disfluency);而在文法結構上,常會 產生不具意義的感嘆詞(particle)、語者慣用的語助詞(marker),以上這些特殊現象都會造 成辨認上的困難,如果我們能有效解決這些自發性語音特殊現象對語音辨認造成的問題, 相信自發性語音辨識效能會有大幅的提升。
在辨認系統上,聲學模型(Acoustic Model, AM)因為發音變異和音節合併這些現象必 須做修正;語言模型(Language Model, LM)方面,因為難有大量的自發性文字語料,所 以必須利用調適(adaptation)來得到適合的語言模型;而韻律模型方面,也必須考慮特殊 單元和語流不流暢而需重新設計。傳統上的語音辨識系統是由聲學模型加入語言模型做 辨識,本研究希望藉由韻律模型的加入來提升辨識率。
2
1.2 研究方向
在本論文中,希望先建立一套傳統的自發性語音辨識系統,並試著利用韻律模型的 協助來提升辨識效能,辨認系統架構如圖 1.1 所示。首先,聲學模型是基於隱藏式馬可 夫 模 型 (Hidden Markov Model, HMM) 訓 練 出 Context-Dependent 的 三 連 音 素 模 型 (tri-phone model);在語言模型方面,先利用大量文字資料訓練出朗讀式語音之語言模型, 再利用語言模型 MAP 調適法中的 Model Interpolation 來將背景語言模型調適成合乎自發 性語音之語言模型;另外,韻律模型是針對自發性語音特性進行設計。辨識過程是採用 兩個階段辨識,在第一階段首先利用聲學模型加入語言模型進行辨識來產生一個 word lattice,第二階段辨識則是在 word lattice 上加入韻律模型分數,再將此三種模型機率分 數做權重結合重新計算分數,以決定出最有可能的辨識結果。 圖 1.1:訓練與辨識系統架構圖 Read Speech Language Model Read Speech Text Corpora LM Adaptation Spontaneous Speech Corpora PLM training HMM training Prosody Model Acoustic Model Language Model rescoring Recognition Results Spontaneous Speech Language Model
3
1.3 文獻回顧
在自發性語音中,因為常發生許多特殊現象,使得聲學模型難以有效建立,像是發 音變異導致聲學模型混淆而辨識效能下降,這個問題可以從辨認字典(lexicon)中加入可 能之發音變異【1】,或是改進底層之聲學模型來解決,文獻【2】中利用決策樹(decision tree)的方式來決定額外訓練的發音變異聲學模型,接著使用 state tying 以及 mixture tying 來得到較好的聲學模型。而自發性語音中語者因為重複或是遲疑現象造成不流暢語流, 【3】提出偵測重複現象的相關研究,考慮單一重複和多重重複,並將這些重複單元加 入辨識字典中,對於偵測重複現象有不錯的效果;Zgank 等人【4】則將 filled pause 加 入聲學模型中,並且利用 Interpolation 調適朗讀式語料與自發性語料來訓練語言模型, 自發性語音文字語料量少一直是語言模型難以有效建立的原因,口語對話因為回答對方 或是猶豫時常有無意義的 particle 的產生,【5】考慮 filler prediction model,預估這些 particle 產生的位置;Ng and Ostendorf【6】則是利用從網路上收集文字資料,再與朗讀 式語言模型作調適結合;【7】研究中也利用 MAP 及 Class-based Deleted Interpolation Smoothing 方法調適出適合自發性語音的語言模型。
在韻律模型幫助辨認之研究方面,【8】用 event-based 的方式增加語音辨認效能,利 用韻律參數建立一個偵測事件的模型,例如:類語句邊界(sentence-like unit)或詞語修補 中斷點,並利用事件及詞的序列一起建立語言模型,對辨認結果所產生之詞格(word lattice)重新計算分數;【9】則是利用韻律和語言結構之間的關係建立一套韻律相關之語 言模型(prosody-dependent language model),並且利用韻律邊界資訊來建立韻律相關之聲 學模型(prosody-dependent acoustic model)【10】。
4
1.4 章節概要
本論文共分為六章,各章節內容分配如下: 第一章 緒論:說明研究動機及研究方向。 第二章 漢語口語對話語料庫介紹:介紹本研究實驗所使用之自發性語音語料庫、自發 性語音之特性及現象分析、初步統計以及後處理。 第三章 辨識模型介紹:說明本研究所使用之聲學模型、語言模型、韻律模型之建立及 調適。 第四章 語音辨識系統架構:說明加入韻律訊息於 two-stage 語音辨認系統之架構及實 作、鑑別式模型組合。 第五章 實驗結果與分析:韻律訊息加入辨認後之實驗結果及分析。 第六章 結論與未來展望。5
第二章 漢語口語對話語料庫介紹
2.1 語料庫介紹
本研究使用中央研究院語言學研究所提供一個完整的自發性語音語料庫-現代漢 語口語對話語料庫(Mandarin Conversational Dialogue Corpus,MCDC)作為研究素材。
現代漢語口語對話語料庫是由中央研究院語言學研究所曾淑娟博士等人 2000~2002 年間所錄製,語者是由台北市民隨機抽樣,並依據 16~25 歲、26~35 歲以及 36~45 歲三 大年齡層,選取 60 位語者(37 位女性、23 位男性),共錄製 30 段對話,但其中有轉寫的 僅有 8 段對話,因此拿 8 段對話當作語料,其中有 16 位語者(9 位女性、7 位男性)兩兩 互相交談,總長度 496 分鐘。
2.1.1 音檔格式說明
MCDC 音檔錄製使用 Audio Technica ATM 33a 手持式麥克風,以取樣頻率 44.1kHz 將兩位語者的聲音分錄於左右聲道,再利用軟體 Cool Edit Pro,將它們分割成小的雙聲 道音檔,依長度約三分鐘找到一個清楚可辨的停頓切開,其簡介如表 2.1 所示。在本研 究中將每組對話語料之左右聲道抽取,並轉換為兩個單聲道之音檔,分別為對話中兩位 語者之語料,並且將其取樣頻率下降至 16kHz,再利用每一段落相對應之開始及結束時 間作切割,經由以上處理後產生 7,085 個音段(turn),扣除一些只有非正常語音以及一些 聲音過小之音檔後剩下 5,900 個音段(turn)將作為本研究所使用之語料。
6 表 2.1:MCDC 語料庫對話主題與語者對照表 對話序號 長度 (分鐘) 發音人 聲道 (L/R) 語者編 號 對話主題 mcdc-01 61 MISC-08-male-25 R 01R 工作、休閒活動、經 濟、開車 MISC-07-female-29 L 01L mcdc-02 63 MISC-10-male-35 R 02R 休閒活動、經濟、工 作、性別、政治 MISC-09-female-37 L 02L mcdc-03 61 MISC-12-female-17 R 03R 家庭、學校、購物、 生涯規劃、明星 MISC-11-female-16 L 03L mcdc-05 63 MISC-15-male-40 L 05L 工作、家庭、社會階 級、保險、歷史、省 籍情結、名人 MISC-16-female-46 R 05R mcdc-09 66 MISC-23-female-30 R 09R 工作、旅行、生活態 度、環保、健康 MISC-24-female-35 L 09L mcdc-10 54 MISC-26-male-23 R 10R 電影、政治、軍隊、 捷運、學校、經濟 MISC-25-male-35 L 10L mcdc-25 55 MISC-57-male-43 L 25L 交通、工作、小孩、 旅行、電腦、管理 MISC-58-female-45 R 25R mcdc-26 46 MISC-60-male-24 R 26R 工作、求職、家庭、 車禍、休閒活動、學 英文、婚姻、軍隊 MISC-59-female-37 L 26L
2.1.2 語料標記格式說明
本研究的 MCDC 文字語料標記是使用中央研究院語言學研究所釋出之版本,所採 用的標注格式是ㄧ種標籤式的語言格式,有點類似於 XML 語法,標記段落上大致以對 話中語者轉換處為一個段落 (Sub-turn) 作轉寫,轉寫內容包括:對應之音檔名稱、語者 代號、段落的開始及結束時間、語音之文字轉寫以及其發音相對之漢語拼音,文字以及 漢語拼音的轉寫包括語言及非語言部分,非語言部分主要是標記非人類產生聲音以及人 類所產生但不是語音的聲音,例如:咳嗽聲、笑聲、呼吸聲等。如圖 2.1 及表 2.2 所示, 為一個段落之文字轉寫範例及說明。7 checkfile recordplace recorddate speechtypei speechtypeii language samplingrate recordtype segment Transcription voicefile speaker start end translator chinese english comment 圖 2.1:標籤式的語言格式 表 2.2 : 文字轉寫範例 <segment> (段落開始) <voicefile>D:\MCDC\stereo_01\mcdc-01-01.wav (音檔名稱) <speaker>MISC-07-female-29 (發音人) <start>020976 (音檔開始時間) <end>025360 (音檔結束時間) <translator>Fen (文字轉寫者) <chinese> (中文轉寫內容)
O 我在一家公關公司上班 (unrecognizable non-speech sound) </chinese>
<english> (漢語拼音轉寫內容)
O wo3 zai4 yi4 jia1 gong1 guan1 gong1 si1 shang4 ban1 (unrecognizable non-speech sound) </english>
<comment> (註解標示)
</comment>
8
2.2 自發性語音之特性
自發性語音與朗讀式語音最大的不同在於自發性語音不是經過事先設計好的,所以 說話時常常會伴隨著因大腦思考或情緒變化而產生一些無法預期的聲音或發生在語言 學中較詞層次(word level)更為上層之行為,因而導致發音的完整性、文法結構、語速快 慢,都與朗讀式語音有很大的差異。基於上述各種情況,致使自發性語音產生許多特有 的現象,以下我們將針對 MCDC 語料庫中常出現的特性作介紹。2.2.1 感嘆詞 (particle)
不具標準語意的感嘆詞,其語用成份居多如回應或同意。語流中出現的感嘆詞可以 分成下列四類: (1). 有相對應國字的感嘆詞,例如:A(啊)、AI(哎/唉)、BA(吧)、LA(啦)、MA(嗎、嘛)、 O(喔/噢/哦)、E(呃)、NO(喏)、WA(哇)、YA(呀)、YOU(呦) (2). 無相對應國字的感嘆詞,例如:EI、HEN (3). 源於台語的感嘆詞,例如:HAN、HEIN、HO (4). 其他的感嘆詞(Fillers),例如:MHM、MHMHM2.2.2 語助詞 (marker)
說話者本身在語流中慣用的插入語,這些習慣插語有其基本詞彙意義。但在語流中 習慣插語已不保有其原有的完整語意,而較具語用功能。例如,作用於口語中說話者意 欲保有其說話權且又需緩衝時間去思索組織其想說的句子,此時習慣插語 NA 便常被 使用。語流中常出現的語助詞包括有:NE(那)、NA(那)、ZHE(這)、GE(個)、SHEN(什)、 ME(麼)。2.2.3 無法或難以辨識的語音
無法或難以辨識的語音主要可分為:9
(1). 無法辨識的語音(unrecognizable speech sound):標記員確定此為人類所發出之語音 但無法辨認是何字何意何音 (2). 不確定字/音(uncertain): i. 可猜測出大概的語音內容,但無法百分之百確定 ii. 無法根據語意猜測出對應字詞,但可清楚記錄出其發音
2.2.4 非語音聲 (Non-Speech sounds)
在口語對話語料庫中常常會有一些非語音的聲音出現,非語言部分可分為人類所產 生之副語言現象(para-linguistic)或非語言現象(non-linguistic)。 一般的非語音聲確定是由人所發出來的即稱為副語言現象,例如:笑聲、咳嗽聲、吞口 水聲等等;而非語音且確定不是由人所發出來的則稱為非語言現象,例如:背景的雨聲、 敲擊到麥克風聲等等。2.2.5 語流中斷
在本研究中關注之語流中斷主要有沉默(silence)、停頓(pause)或短停頓(short break), 為語者在語流中因話題銜接不上或自身所產生之沉默。2.2.6 非流暢現象 (disfluency)
不流暢的語音為自發性語音中一個重要特性,在本研究中關注之詞語修補主要有重 覆(repetition)、詞語更正(repair)、部分重覆(restart)以及更正插語(editing term),重覆是指 完整地重覆詞語一次以上;詞語更正為說話者覺得說出的話不適當,立即更正說話內容; 而部分重覆則是說話者重新說出這個句子且重覆詞語的片段,與完整的詞語重覆不同。 更正插語是出現在被更正詞語與更正詞語之間,或是出現在完整重覆或部分重覆中,兩 個重覆詞語之間。本研究定義詞語修補中斷點(IP)為被更正詞語與更正後詞語間之停頓 點,或完整重覆或部分重覆中的兩個重覆詞語間之停頓點,本研究在文字轉寫中將詞語 修補中斷點標記成「*」。以下為幾種非流暢現象範例:10 重覆範例: 昨天卡卡表現的(普通)*(普通) 詞語更正範例: 今晚世足賽是(烏拉圭)*[EN](巴拉圭)對日本 部份重覆範例: (今)*(今天)晚上是冠軍賽
2.3 自發性語音現象分析
2.3.1 Particle 和 Marker 於句中位置分析
marker
大部分出現在句首或句中 GE ME NA NE SHEN ZHE 國字 個 麼 那 那 什 這 注音 ㄍㄜ ㄇㄛ ㄋㄚ ㄋㄜ ㄕㄜ ㄓㄜ Tone 5 5 4 4 2 4 EX: [那] 賴 先 生 呢 ? 我 就 說 [那] 你 們 真 的 會 去 嗎 ? 不 是 [那 個 什 麼] 大 稻 埕 啊 !particle
只出現在句尾 BA LA MA NA NE YA 國字 吧 吧 啦 啦 嗎 嘛 哪 呢 呀 注音 ㄅㄚ ㄅㄚ ㄌㄚ ㄌㄚ ㄇㄚ ㄇㄚ ㄋㄚ ㄋㄜ ㄧㄚ Tone 5 1 5 1 1 5 1 1 5 EX: 應 該 這 種 比 較 能 夠 讓 大 家 接 受 [吧] ! 只單獨出現E EI HAN HEIN HEN YA AI
國字 呃 無相對應國字 源於台語 源於台語 無相對應國字 ya 唉
注音 ㄜ ㄟ ㄏㄚ ㄏㄟ ㄏㄣ ㄧㄚ ㄞ
Tone 5 2 2 3 3 4 1
11 出現在句尾 or 單獨出現 A EI HO NO O WA YOU 國字 啊 無相對應國字 源於台語 源於台語 喏 哦 喔 哇 呦 注音 ㄚ ㄟ ㄏㄡ ㄏㄡ ㄋㄨㄛ ㄛ ㄛ ㄨㄚ ㄧㄡ Tone 1 1 4 3 4 2 1 5 1 EX: 句尾:我們每個司機都會知道[哇]! 單獨:那我一看,[哇]!好吧!
Filler
填補詞 (Fillers),本身不具任何語意,也不具句法功能,通常是說話者正在思考接 下來所要講的句子時,用來填補對話空白,也可以使說話者保留說話權。 MHM MHMHM 國字 Fillers Fillers 注音 ㄣ ㄣㄣ Tone2.3.2 自發性語音特有現象
特殊單元
難以辨認的語音
uncertain 6333 有標記 tone 的資訊,但 syllable type 有些 不在 411 base-syllables 中 unrecognizable speech sound 226
Code-Switch
English 135 Japan 15 MinNan 28312
特殊現象
syllable contraction
EX: 對呀repeat
EX: 斜坡,沒有斜坡,沒有斜坡。 EX: 那棟大樓蠻大。我,我,我(340)記得應該叫國王與我吧! 重覆中斷點 重覆中斷點13
更正插語
EX: 忠孝東路那個統, {@呼吸聲}MHM!統領購物中心的背後。2.4 MCDC 語料庫初步統計
音檔處理後將每段對話切割成若干 Sub-turn,統計語料庫中所有 Sub-turn 之音 節數分佈如圖 2.2 所示。其中音節個數大於 100 的 Sub-turn 有 325 個。 圖 2.2:語料庫中每個 Sub-turn 之音節數分佈圖2.5 語料庫之後處理
由於中央研究院語言學研究所釋出之 release 版本中並無標記某些聲學現象及語言 資訊,但這些資訊在語音處理中相當重要,因此在本節介紹本研究將對語料庫聲學以及 語言學資訊的處理方法。另外,針對文字語料庫標注錯誤的部分進行更正。 2 0 4 10 16 14 57 222 411 1654 3522 Sub -t ur n 個數 Unit個數區間Sub-turn中Unit個數分佈
14
2.5.1 斷詞與相關統計
由於中研院提供的文字轉寫並沒有斷詞和詞性(Part of Speech, POS)的相關標記,因 此本研究先利用國立交通大學語音處理實驗室之斷詞器對 MCDC 之文字轉寫進行斷詞 及標詞性,詞性標記以中研院的 46 類詞性為標準(參見附錄一)。值得注意的是,MCDC 的文字轉寫中包含了許多音節間(如:笑聲、呼吸聲)或是特殊現象的標記,為了不受這 些標記的影響,斷詞時會先移除這些標記等斷完後再加回,另外對於感嘆詞和語助詞的 部分,會先將其轉成相對應國字再放入斷詞器,以避免其被視為外來語(Foreign word, FW)。
2.5.2 切除音檔頭尾過長的靜音
中研院提供的語料庫,雖然是使用雙聲道的方式將交談的兩語者的聲音用左右聲道 分開錄製,但交談的過程中,麥克風仍舊會收錄到另一位語者的聲音。如果另一位語者 的聲音與原聲道的語者出現重疊的話,會進一步形成 cross talk 的現象。此外在中研院 提供的 MCDC 文字轉寫中有標註每一語段(Sub-Turn)的開始與結束時間,但某些語段所 標註的開始與結束時間預留了過長的靜音(silence),並且這些在語段頭尾預留的靜音往 往不屬於純靜音,而含有從另一位語者收錄過來的聲音。由於這些聲音在文字轉寫上是 標為靜音,但實際辨認時仍舊能夠辨認出另一位語者的說話內容,進而導致嚴重的插入 型錯誤(insertion error)。由於這些現象並不是我們研究的主要內容,因此針對這些頭尾 過長的靜音,我們利用切割位置找出頭尾長度大於 500 毫秒且能量大於平均值的靜音予 以切除。2.5.3 修正音節切割位置
要訓練出好的聲學模型及韻律模型首先要有良好的音節切割位置,但目前中研院提 供的 MCDC 語料並不包括音節切割資訊。為了得到較準確的切割資訊,本研究首先使 用【11】建立之自發性語音聲學模型,利用 HTK【12】以強迫對齊的方式對每一個音15 檔作音節之切割,得到每一個音節的音節長度以及停頓時長,接著檢查一些較明顯音節 切割錯誤的位置,以人工的方式進行修正。較明顯音節切割錯誤的情況如下: 1. 詞內邊界(intra-word)中出現超過 0.1 秒的停頓。 2. 容易出現極端音節長度的切割位置,如:音節合併現象、拖長音現象。 3. 停頓時長區間內的能量高於平均值的停頓 4. 發生不流暢現象的音節切割位置
16
第三章 辨識模型介紹
第三章介紹語音辨認所使用的模型,3.1 節為聲學模型介紹,本研究使用【14】訓 練之自發性語音聲學模型,它是基於隱藏式馬可夫模型(Hidden Markov Model, HMM), 而所使用的工具為英國劍橋大學開發的 HTK (HMM Tool Kit) 【12】軟體;3.2 節為語 言模型介紹,首先會利用 SRILM toolkit【13】訓練出朗讀式語言模型,再利用調適方法 訓練出適合自發性語音的語言模型;3.3 節介紹本研究所使用【14】所設計的韻律模型, 考慮自發性語音的特殊現象,希望藉由此模型對自發性語音辨認有所幫助。
3.1 聲學模型
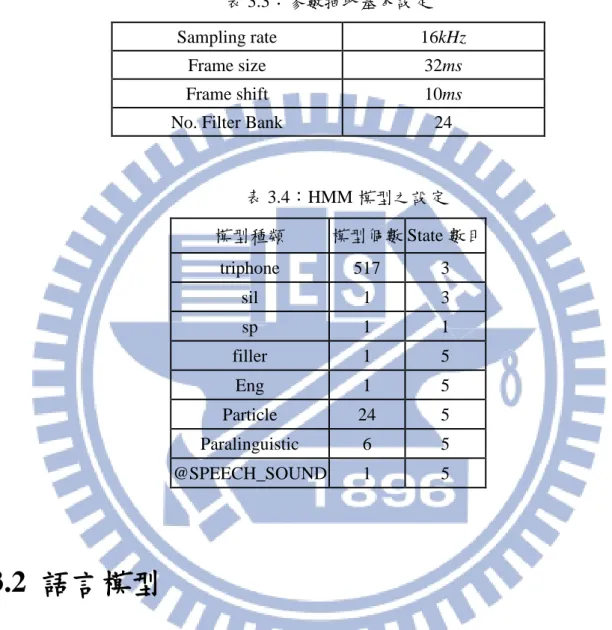
本研究是使用【14】所訓練的聲學模型,其採用多語者辨識方式,也就是訓練和測 試語料皆有相同的語者,但是句子不同,由 MCDC 內 16 名語者中,選取每位語者約 9/10 的語句做訓練語料,如表 3.1,其餘的 1/10 做為測試語料如表 3.2。 表 3.1:訓練語料統計 正常語音 難以辨認的語音 語助詞和感嘆詞 Code-Switch 非語音 字數 105,800 6,857 10,198 494 5,053 比例 82.40% 5.34% 7.94% 0.38% 3.94% 總字數 128,402 (89.99%) 音檔數 5,750 時間長度 7.967 (hours) 語者數 16 表 3.2:測試語料統計 正常語音 難以辨認的語音 語助詞和感嘆詞 Code-Switch 非語音 字數 12,048 750 756 72 652 比例 84.38% 5.25% 5.29% 0.50% 4.57% 總字數 14,278 (10.01%) 音檔數 150 時間長度 59.79 (minutes) 語者數 1617 表 3.3 為訓練時相關參數抽取的基本設定,所使用的聲學模型為音節內 context-dependent 的三連音素模型 (tri-phone model),表 3.4 為各個 HMM 模型之設定 表 3.3:參數抽取基本設定 Sampling rate 16kHz Frame size 32ms Frame shift 10ms
No. Filter Bank 24
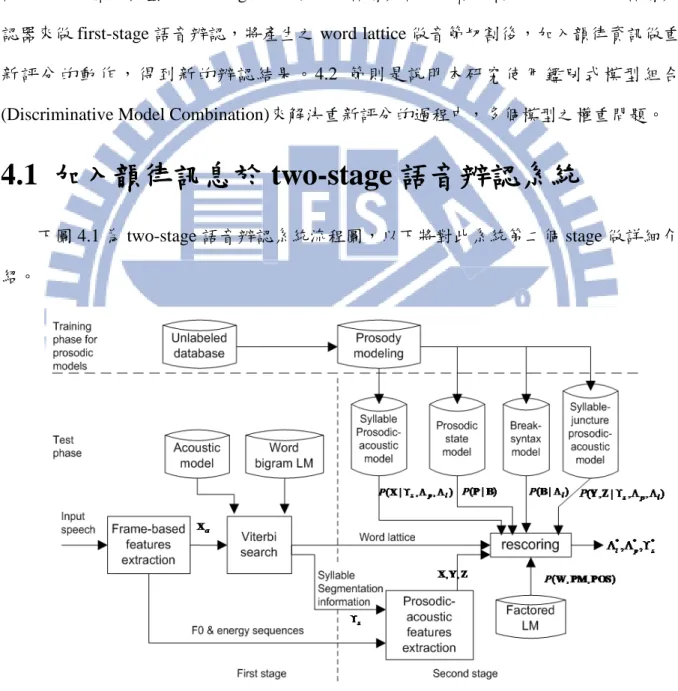
表 3.4:HMM 模型之設定 模型種類 模型個數 State 數目 triphone 517 3 sil 1 3 sp 1 1 filler 1 5 Eng 1 5 Particle 24 5 Paralinguistic 6 5 @SPEECH_SOUND 1 5
3.2 語言模型
由於所有語言都有其獨特的文法規則,因此我們可針對此規則性來求得一個機率模 型,一般稱此為語言模型(Language Model, LM)。在語音辨認時,除了聲學模型外,若 能加入語言模型的參考,通常能大幅提升辨識系統的效能。本節中首先介紹朗讀式語言 模型的建立,接著介紹本研究所使用的語言模型調適方法,最後介紹語言模型之效能分 析及涵蓋率與辨識率比較。18
3.2.1 朗讀式語言模型之建立
文字語料庫簡介
用於訓練朗讀式語言模型的文字資料庫共有以下來源: 1.) 光華雜誌(Sinorama):內容為一般雜誌的文章,蒐集的資料年代範圍介於 1976 年到 2000 年之間。 2.) NTCIR:為一個建立資訊檢索系統的標竿測試集,其內容由數種不同學科領域文章 構成。 3.) 中研院平衡語料庫(Sinica):它是一套由中研院收集,內容包含多種主題,以語言分 析研究為目的的資料庫。4.) Chinese Gigaword:由 Linguistic Data Consortium (LDC)整合發行,內容包含台灣中 央社、北京新華社等國際新聞。 5.) 維基百科語料(Wiki) :維基百科為領域廣泛且資訊較為新,可以使語言模型更加多 元,資料庫增加。 總詞數為 4.4 億,文章篇數為 8771 篇。 文字語料庫 文本前處理 建立辨識辭典 N-gram training 圖 3.1:語言模型訓練流程 上圖 3.1 為語言模型訓練流程,我們有了文字語料庫後,需先對語料庫的文章進行 前處理,其中大致上分為 CRF 斷詞、文字正規化…等等,將文章中會影響辨識效能的 內容移除或修改,在文本前處理後,再經由選詞將常出現、較重要的詞收錄在辭典內以 便訓練出語言模型,本研究是利用蘇仲銘【15】論文中王逸如博士所提出的選詞方法, 依據詞頻與出現文章篇數評估一個詞彙在文章中分布的均勻程度,共選入了 60,000 個詞 彙,而六萬詞詞典在 MCDC 文字語料 99179 個詞中只出現 5177 個詞,可以看出口語對
19 話中的使用的詞不多,且都不艱深。表 3.5 及表 3.6 為感嘆詞及口語常用詞在朗讀式語 料和 MCDC 語料中所佔的比例,由此可見兩語料用詞上的差異。 表 3.5:感嘆詞在兩語料庫中所佔比例 朗讀式語料 MCDC 語料 啊 0.0029% 1.98% 喔 0.0007% 1.26% 啦 0.0016% 0.37% 嘛 0.0009% 0.28% 吧 0.0042% 0.21% 表 3.6:常用詞在兩語料庫中所佔比例 朗讀式語料 MCDC 語料 然後 0.01% 0.72% 因為 0.074% 0.65% 所以 0.034% 0.47% 可是 0.008% 0.45% 其實 0.013% 0.42% 本研究訓練語言模型使用的軟體為 SRILM【13】,並利用退化平滑法(back off)及使 用 Good-Turing discounting 建立而成一個 tri-gram 語言模型,其數學式如(3.1)式所示。
若定義訓練語料中詞串出現的次數門檻𝑘,則可將詞串分為出現次數高於門檻值、出現 次數低於門檻值及從未出現三種。則參數可表示為下式: P(𝑤𝑖|𝑤𝑖−𝑛+2, … , 𝑤𝑖−1) = ⎩ ⎪ ⎨ ⎪ ⎧𝛼(𝑤𝑖−𝑛+1⋯ 𝑤𝑖−1)𝑃(𝑤𝑖|𝑤𝑖−𝑛+2⋯ 𝑤𝑖−1) , 𝐶𝐶𝐶𝐶𝐶(𝑤𝑖−𝑛+1, … , 𝑤𝑖) = 0 𝑑𝛼∙𝐶𝐶𝐶𝑛𝐶(𝑤𝐶𝐶𝐶𝑛𝐶(𝑤𝑖−𝑛+1,…,𝑤𝑖) 𝑖−𝑛+1,…,𝑤𝑖−1) ,1 ≤ 𝐶𝐶𝐶𝐶𝐶(𝑤𝑖−𝑛+1, … , 𝑤𝑖) ≤ 𝑘 𝐶𝐶𝐶𝑛𝐶(𝑤𝑖−𝑛+1,…,𝑤𝑖) 𝐶𝐶𝐶𝑛𝐶(𝑤𝑖−𝑛+1,…,𝑤𝑖−1) , 𝐶𝐶𝐶𝐶𝐶(𝑤𝑖−𝑛+1, … , 𝑤𝑖) > 𝑘 (3.1)
訓練出來的朗讀式語言模型其 perplexity 為 66.501,OOV rate 為 2.87%,對 MCDC 測試語料 perplexity 為 733.719,OOV rate 為 2.91%。
20 以下本研究將利用此朗讀式語言模型與自發性語言模型的進行調適。
3.2.2 語言模型之調適
在進行語言模型調適之前,必須先訓練出自發性語言模型,其中我們把 MCDC 中 的感嘆詞替換回朗讀式語料也有的感嘆詞,例如:LA→啦、BA→吧,並根據 2.2 章自 發性語音的特性,加入 particle 和 marker 兩詞於詞典中: particle:語者說話猶豫或回應對方時所發出的,其在語法上屬於較獨立的。 (如:MHM、E、EI) marker:語者的習慣插語,已不保有其原來的語意 (如:NA-GE、ZHE-GE、SHEN-ME) 語者在說話時不像朗讀式語音那麼順暢,常會有這兩類詞插入句子中,下圖 3.2 為語者 詞語修補(repair)示意圖: 圖 3.2:詞語修補示意圖 在語言模型調適中,MAP(maximum a posteriori)調適法【16】是最普遍的方法,其 主要概念是改變已知的模型參數分布使其與觀察資料的參數分布相符合,其數學式(3.2) 如下:𝑋
𝑀𝑀𝑀= arg max
𝑥𝑃(𝑋|𝑊) = arg max
𝑥𝑃(𝑊|𝑋)𝑃(𝑋)
(3.2)𝑋:已知的參數模型分布(model parameter distribution) 𝑊:有限的觀察資料(observation) 𝑃(𝑊|𝑋):觀察資料𝑊的概似度(likelihood) marker 統 particle 統領 購物 中心 NA-GE ZHE-GE SHEN-ME E EI
21
根據 MAP 調適法又可分為 count merging 和 model interpolation 兩種做法,本研究是使 用 model interpolation 進行調適,其是將 out-of-domain model 與 in-domain model 進行內 插,來得到我們要的語言模型,其數學式(3.3)如下:
𝑃′(𝑤
𝑖|𝑤𝑖−𝑛+1, … 𝑤𝑖−1) = 𝜆𝑃𝑏𝑏𝑏𝑏(𝑤𝑖|𝑤𝑖−𝑛+1, … , 𝑤𝑖−1)
+(1 − 𝜆)𝑃𝑏𝑎𝑏𝑎𝐶(𝑤𝑖|𝑤𝑖−𝑛+1, … , 𝑤𝑖−1) (3.3)
𝑃𝑏𝑏𝑏𝑏: probability for word sequence 𝑤𝑖 of the baseline language model
𝑃𝑏𝑎𝑏𝑎𝐶: probability for word sequence 𝑤𝑖 of the adaptation language model
𝜆: linear interpolation coefficient, 0 ≤ 𝜆 ≤ 1
權重𝜆也是根據 SRILM 上的估計方法,使用 EM algorithm,最大化調適模型與測試 語料的概似度(likelihood),經過迭代(iterative)7 次得到𝜆 = 0.690221。
3.2.3 語言模型效能分析
評估語言模型通常是以計算其混淆度(perplexity, PPL)來判斷。混淆度是根據消息理 論(information theory)而得,如下式: 𝐻 = −𝑚1log 𝑃(𝑊 = 𝑤1, 𝑤2, … , 𝑤𝑚) (3.4) 上式為一個詞串𝑊 = 𝑤1, 𝑤2, … , 𝑤𝑚,對於每個新詞提供的平均資訊量(entropy),經過適 當的化簡而得。而混淆度可直接使用(3.4)式進一步定義為: 𝑃𝑃𝑃 = exp (𝐻) (3.5) 若𝑃(𝑊 = 𝑤1, 𝑤2, … , 𝑤𝑚) = ∏ 𝑃(𝑤𝑚𝑖=1 𝑖|𝑤1, 𝑤2, … , 𝑤𝑖−1)則可發現混淆度就是 𝑃(𝑤𝑖|𝑤1, 𝑤2, … , 𝑤𝑖−1)的幾何平均數的倒數。因此混淆度可以解讀為語言模型估測一個歷 史詞串後面,平均可能的可接詞數;混淆度越高,表示一個歷史詞串後接的詞有較多選22 擇,辨認時就越難找到確切的答案;反之,則較易找到正確答案。利用(3.5)式來評估調 適後的語言模型效能,如表 3.7 所示。 表 3.7:語言模型混淆度評估 語言模型 混淆度(PPL) Read-Speech_tg-LM 733.719 Adapted_tg-LM 280.741
3.2.4 辨識率與詞涵蓋率比較
利用聲學模型對語音辨識將產生音節辨認資訊,若加入語言模型,辨識單元可由音 節變為詞,同詞產生 word lattice,但為了與聲學模型比較,我們亦會將詞轉為字元及音 節做比較。表 3.8 為本研究調適語言模型後之辨識率。其中 Free-gram-syllable-LM 即為 3.1 節聲學模型之辨認實驗,只有音節辨認率;加入 Read-Speech_tg-LM 之後的實驗開 始有字元及詞的辨識率,在此值得注意的是,由於 MCDC 的測試語料中的辨識單元含 有「particle」及「marker」,但是 Read-Speech_tg-LM 中並無這兩類的機率,為了比較公 平性,在此只計算「一般詞」的辨識率。 表 3.8:加入語言模型之辨識率case Acc Word Character Syllable
Free-gram-syllable-LM 48.10% Read-Speech_tg-LM 38.86% 47.42% 57.20% Adapted_tg-LM 53.44% 60.34% 65.83% 觀察表 3.8 可注意到在加入 Read-Speech_tg-LM 後音節辨識率上升了 9.1%,此乃因 為有了文法的資訊,確實可以幫助中文辨識,但是 Read-Speech_tg-LM 中並沒有「particle」 及「marker」之機率,會造成許多刪除型錯誤,另外,訓練語料類型也完全屬於朗讀式 語料,在用詞與文法上皆有所不同;而經過調適後 Adapted_tg-LM 辨識率有了大幅改善, 其中「particle」及「marker」辨識率分別為 51.03%及 30.56%,加入這兩類詞後能夠有 效減少刪除型和取代型錯誤。
23 此外,在口語對話中有許多口語常用詞,這些詞以連接詞與副詞居多,下表列出一 些口語常用詞的辨識率,由表 3.9 可以看出用 MAP 方法調適後更能有效的辨認出來。 而表中「然後」、「因為」及「所以」的辨識率較其他詞低,觀察後發現,這些詞常被說 話者當作句首的常用插入詞,通常會出現音節合併的現象,造成聲學模型較難建立,這 也是自發性語音較難處理的問題。 表 3.9:口語對話常用詞之辨識率 詞(數量) 模型 就是(132) 我們(88) 然後(115) 因為(71) 沒有(48) 所以(51) Read-Speech_tg-LM 55.30% 75.00% 46.96% 43.66% 60.42% 43.14% Adapted_tg-LM 74.24% 80.68% 64.35% 53.52% 72.91% 52.94% 接著,為了未來要加入韻律模型幫助改善辨識率,所以我們先將產生的 word lattice 與辨認標準答案做 Optimal Search 得到詞的涵蓋率(coverage rate),來判斷韻律模型加入 後可以改進的程度。
詞涵蓋率Accuracy的計算方式為(3.6)式
Accuracy =
𝑀𝑏𝐶𝑀ℎ+𝑆𝐶𝑏+𝐷𝑏𝐷𝑀𝑏𝐶𝑀ℎ−𝐼𝑛𝑏 (3.6)而表 3.10 為朗讀式模型與調適後之語言模型的詞涵蓋率比較 表 3.10:詞涵蓋率比較
case word coverage rate Read-Speech_tg-LM 74.89%
Adapted_tg-LM 82.42%
表示調適後 Adapted_tg-LM 所產生的 lattice 較接近我們的正確答案,由詞辨識率 53.44% 和詞涵蓋率 82.42%可以看出,加入其他資訊來幫助辨識還有大幅的提升空間,期望加 入韻律訊息來尋找 lattice 上之最佳路徑,以改善辨識率。
24
3.3 韻律模型
人類在說話時會有抑揚頓挫、高低起伏的表現,這些韻律訊息主要表現在語速 (speaking rate)、停頓時長(pause duration)、因高軌跡(pitch contour)、音量大小(energy level) 等因素上,而在自發性語音上,語者可能因為猶豫、遲疑造成音節拉長等特殊現象,本 研究使用吳聲鋒論文【14】中所訓練的自發性語音韻律模型,其設計考慮了這些特殊單 元於模型中。本節首先介紹中文語音韻律階層式架構,接著則介紹階層式韻律模型之設 計。
3.3.1 中文語音韻律階層式架構
根據語言學家研究發現【17】,語音的韻律結構會呈現出階層式的架構,以五階層 為中文語音韻律的架構,如下圖 3.3 所示: PG BG BG PPh PPh PPh PW PW PW PWSYL SYL B1/B0 SYL SYL SYL
B2 B3 B4 B5 B5 PPh PW SYL 圖 3.3:中文語音韻律之階層式架構
圖中最底層為音節層次(syllable layer, SYL),中文特性為一個音節一個字,故最底 層的韻律單元為音節;向上發展依序為韻律詞層次(prosodic word layer, PW),由雙音節 或多音節所構成的詞組,此詞組通常在語法和語意上有緊密的關係;韻律短語層次 (prosodic phrase layer, PPh),由一個或多個韻律詞組成,結尾通常會帶有不明顯但可察覺
25
之停頓;呼吸組層次(breath group, BG),代表一個有音高及音常明顯變化的段落;最上 層則為韻律組句(prosodic phrase group),由連續的呼吸組構成。這整體架構統稱「階層 是多短語韻律句群(Hierarchical Prosodic Phrase Grouping,HPG)」架構【18】。
本研究所使用的韻律架構以 HPG 為基礎對其做修改,如圖 3.4 的四層韻律結構: BG/PG PPh PW PW SYL/Par B3 B2 B1/B0 PW PPh SYL/Par B3 B3 B1/B0 SYL/Par SYL/Par SYL/Par B2 B4 B4 B4 B4 B4 B4 B4 B4 圖 3.4:本研究所使用的中文自發性語音韻律階層式架構 其中主要由七種韻律邊界停頓(break type) B={B0, B1, B2-1, B2-2, B2-3, B3, B4}來標記四 種韻律單元:音節(SYL)、韻律詞(PW)、韻律短語(PPh)、呼吸組/韻律句組(BG/PG),其 對應關係如下表 3.11 所示。 表 3.11:韻律結構之停頓標記 韻律結構 停頓標記 意義 韻律群(PG)或呼吸群(BG) B4 長停頓且含有明顯的基頻跳躍 韻律短句(PPh) B3 長停頓 韻律詞(PW) B2-1 相鄰兩音節具有明顯的基頻跳躍 B2-2 短停頓 B2-3 前一音節發生音節拉長
音節(SYL) B1 音節邊界相鄰兩音節是普通連接(normal coupling) B0 音節邊界相鄰兩音節是音節合併(syllable contraction)
另外,在自發性語音中會發生一些特殊現象造成語流不順暢,為了避免這些特殊現 象影響其他正常語流之統計特性,我們依其特性分成兩類做為模型設計的依據:一類是 可以融入流暢語流的 syllable-like unit;而另一類則歸類成屬於特殊韻律現象的 particular unit(共可分成 26 種類別),分類方法如下表 3.12 所示:
26
表 3.12:syllable-like unit 與 particular unit 分類表
類別 分類方法 syllable-like unit base syllable 有相對應國字的 uncertain Particular unit particle (MHM、E、EI、HAN、HEIN) marker (NA-GE、ZHE-GE、SHEN-ME) unrecognized speech sound
Code-switch
3.3.2 階層式韻律模型設計
在本節所介紹之韻律模型主要是幫助語音辨認,自發性語音在韻律上的較不規則使 得辨認上的困難,希望利用此模型來幫助搶詞等狀況的改善,本研究是根據【19】使用 韻律訊息幫助語音辨認:給定聲學參數Λ = X Xa { a, p}的條件下,找出最佳的語言參數序列 { , , } lΛ = W POS PM 、韻律標記Λ = B Pp { , }及 acoustic segmentation ϒs,如下式(3.7):
, , , , , , arg max ( , , , , , | , ) arg max ( , , , , , , , ) l p s l p s l p s s a p s a p P P Λ Λ ϒ Λ Λ ϒ ∗ ∗ ∗ Λ Λ ϒ = ϒ = ϒ W POS PM B P X X W POS PM B P X X (3.7) 其中
{ }
1 M w = W 是代表詞序列; { 1 } M pos = POS 是詞所對應到的詞性序列;至於PM={pm1M}是 代表標點符號序列;M 代表詞的全部數量;B={B1N}則是韻律停頓標記序列,包含七種 韻律停頓標記 Bn∈{B0, B1, B2-1, B2-2, B2-3, B3, B4};P={ , , }p q r 則代表音節韻律狀態序 列,它包含音節音高軌跡p={p1N}、音節長度 1 {qN} = q 及音節能量強度r={r1N};N 代表音 節的全部數量;Xa代表一個 frame-based 頻譜參數序列(如:MFCCs 及它們的一階和二 階 derivatives);Xp ={ , , }X Y Z 則是一個韻律聲學參數序列,其中 X 代表音節參數,包含 了音節音高軌跡(sp)、音節能量強度(se)及音節長度(sd);Y 代表音節邊界參數,包含了 音節間的停頓長度(pd)及音節間的能量低點(ed);Z 代表音節間的 differential 參數,包含 了正規化的音節內基頻差(pj)及經正規化過的音節長度拉長因子(dl)。在下表 3.13 中將 對所有在(3.7)式中有包含到的韻律標記、聲學參數及語言參數做一個統整。27
表 3.13:韻律標記、聲學參數以及語言參數之數學符號
T: prosodic tag
B: break type ={B0, B1, B2-1, B2-2, B2-3, B3, B4}
PS: prosodic state
p: pitch prosodic state q: duration prosodic state r: energy prosodic state
A: prosodic feature
X: syllable prosodic feature
sp: syllable pitch contour sd: syllable duration se: syllable energy level Y: inter-syllabic prosodic
feature
pd: pause duration ed: energy-dip level Z: differential prosodic
features
pj: normalized pitch jump
dl: normalized duration lengthening factor
L: linguistic feature
l: reduced linguistic feature set t: syllable tone sequence s: base-syllable type f: final type 以下根據(3.7)式提出下列五種假設,以方便韻律模型的設計: 假設一:頻譜參數序列 Xa 只會相依於詞序列 W。 假設二:韻律聲學參數序列 Xp 會相依於韻律標記序列Λp及語言參數序列Λl。 假設三:音節韻律聲學參數序列 X 與音節邊界韻律參數序列 Y 及音節間的 differential參數序列 Z 相互獨立。 假設四:韻律停頓標記序列 B 相依於鄰近相關的語言參數序列 Λl。 假設五:音節韻律狀態序列 P 相依於鄰近的韻律停頓標記 B。 經由以上五種假設後,(3.7)式將會簡化成以下形式:
{
}
, , , , arg max ( , | ) ( , , ) ( | ) ( | ) ( | , , ) ( , | , , ) l p s l p s a s l s p l s p l P P P P P P Λ Λ ϒ ∗ ∗ ∗ Λ Λ ϒ ≈ ϒ ⋅ Λ ϒ Λ Λ ϒ Λ Λ X W W POS PM B P B X Y Z (3.8)其中P(Xa,ϒs |W) 代表聲學模型(AM);P W POS PM( , , )則是 joint syntax model,它描述了
W、POS 及 PM 之間的關係,這部分在後面 4.1.1 節中會做更詳細的介紹;P( |B Λl)是代
28 B 的模式,P P B( | )稱為韻律狀態轉移模型,用來描述韻律狀態 P 的變化是如何受到韻律 停頓 B 的影響;P( |Xϒ Λ Λs, p, l)稱為音節韻律模型,用來說明音節韻律參數受到 B、P、L 的影響而產生的變化;P( , |Y Zϒ Λ Λs, p, l)則為停頓聲學模型,用來說明在各個不同的韻律 邊界停頓和語言參數之下,音節內的聲學特性。以下我們將對【14】所設計的這四種韻 律模型作進一步的介紹。
停頓語法模型
我們可以將停頓語法模型 P( |B Λl) 近似成以下式: 1 1 ( | ) ( | ) N l n n n P P B L − = Λ ≈∏
B (3.9) 其中P B( n|Ln)是描述音節韻律停頓與相關的語言參數之間關係的模型,可經由分類樹與 決策樹(CART)演算法堆導出來。停頓聲學模型
我們將停頓聲學模型進一步化簡,可以得到五個子模型,如下式:{
}
, , , , , , , , 1 2 , , , , , , 1 2 2 , , , , , , , , ( , | , , ) ( , , , | , , ) ( ; , ) ( ; , ) ( ; , ) ( ; , ) n l n n l n n l n n l n n l n n l n n l n n l n s p l s p l N n B B n ed B ed B n n pj B pj B n dl B dl B P P g pd N ed N pj N dlα
β
µ
s
µ
s
µ
s
− Λ Λ Λ Λ = Λ Λ Λ Λ ϒ Λ Λ ≈ ϒ Λ Λ ≈ ⋅∏
Y Z pd ed pj dl (3.10)其中 pause duration ( pdn) 為第 n 個音節跟隨的接合點停頓長度,以 Gamma distribution
來模擬;energy dip (edn) 為第 n 個接合點的能量下降程度,以 normal distribution 模擬; pitch jump (pjn) 為跨越第 n 個接合點的正規化基頻差,其定義為(3.11)式,以 normal distribution 模擬;normalized duration lengthening (dln) 則為正規化的音節長度拉長因子,
其定義為(3.12)式,同樣以 normal distribution 模擬。 1 1 ( (1) (1)) ( (1) (1)) n n n n t n t pj = sp + −β + − sp −β (3.11)
29 (3.11)式中,spn(1)為第 n 個音節音高軌跡的第一維度; (1) n t β 為第 n 個音節聲調影響因 素的第一維度。 1 1 1 ( ) ( ) n n n n n n t s n t s dl sd
γ
γ
sdγ
γ
− − − = − − − − − (3.12) (3.12)式中,sdn為第 n 個音節長度;γ
tn為第 n 個音節長度影響因素。 在實作過程中,P(pd ed pj dl, , , |ϒ Λ Λs, p, l)是經由分類數與決策樹(CART)推導出來,其 節點的分類標準是依據 maximum likelihood gain,而 CART 演算法主要是利用一個已經 設計好的問題集,依據不同的韻律邊界停頓同時將所有音節的pdn、edn、pjn和dln做好 分類。韻律狀態模型
韻律狀態模型P P B( | )可以進一步分解成三個子模型,如下所示: 1 1 1 1 1 1 1 1 1 2 ( | ) ( | ) ( | ) ( | ) ( ) ( ) ( ) ( | , ) ( | , ) ( | , ) N n n n n n n n n n n P P P P P p P q P r P p p − B − P q q − B − P r r− B − = = ≈ ⋅∏
P B p B q B r B (3.13) 其中 P p( n|pn−1,Bn−1)、P q( n|qn−1,Bn−1)及P r(n|rn−1,Bn−1)分別表示三種不同韻律狀態,在給定 音節邊界停頓Bn−1的情況下,從第 n-1 個音節的韻律狀態到第 n 個音節韻律狀態的轉移 機率。音節韻律模型
音節韻律模型P( |Xϒ Λ Λs, p, l)可以進一步分解成三個子模型,如下所示: 1 1 1 1 ( | , , ) ( | , , , ) ( | , , , , ) ( | , , , , ) ( | , , ) ( | , , ) ( | , , ) s p l s s s N n n n n n n n n n n n n n n n P P P P P sp p B− t −+ P sd q s t P se r f t = ϒ Λ Λ ≈ ϒ ϒ ϒ ≈∏
X sp B p t sd B q t s se B r t f (3.14) 分別為音節軌跡、音節長度、音節能量,這三個子模型可以拆解成各個影響因子(affecting factor)之貢獻,以下分別介紹這三個子模型:30 Syllable pitch contour model
1 1 1 1 ( | , , ) ( | , , ) N n n n n n n n p P sp p B− t−+ = ≈
∏
sp B p t (3.15) 其中 1, 1 , _ _ _, if th syllable is syllable-like unit for 1 , if th syllable is particular unit
n n n n n n n n r f b n t p B tp B tp sp n pr r n pr pr p pr sp n n N n − − + + + + + = ≤ ≤ + + + sp β β β β μ sp sp β β μ
為第n個音節之 syllable log-F0 contour,是由四維正交化係數
[
a0 a1 a2 a3]
T以向 量的方式表示;Bnn-1=(Bn−1,Bn);tnn-1+1=(tn−1, ,t tn n+1);μsp及μpr_sp分別為 syllable-like unit 及particular unit 的總體平均值(global mean),僅第一維為非零值;sprn及
_
pr r n
sp 為 n 屬於
syllable-like unit 或 particular unit 的sp 正規化 (normalization)n 後的基頻殘餘值(residual);
x
β 則為某一影響因子x之影響型態(Affecting Pattern, AP),各種 AP 說明如下:
Syllable-like unit 的 APs
n
t
β 為 目 前 音 節 聲 調 tn∈{lexical tone 1~5} 的 APs ; βpn 為 目 前 音 節 韻 律 狀 態
{prosody state 1~16}
n
p ∈ 的 APs,其中韻律狀態的影響只限制對目前音節的 LogF0 level,故
將β 的四維正交係數,僅第一維設為非零值;pn 1, 1 n n f B− tp− β 及 , n n b B tp β 分別是第 n-1 個和第 n+1
個音節所貢獻的前後連音效應(forward and backward coarticulations) APs,其中
tp
n−1是tone pair 1 ( ' 1, )
n
n n n
t − = t − t ,t'n−1∈{lexical tone 1~5 for (n-1)th syllable is syllable-like unit;
otherwise is particular unit};
tp
n 是 tone pair 1 ( , ' 1)n
n n n
t + = t t + ,t'n+1∈{lexical tone 1~5 for (n+1)th syllable is syllable-like unit; otherwise is particular unit}。此外,針對 utterance boundary 再另外給定兩個特殊的 break type B 和b B 來表示所有 utterance 的起頭和結束e
31 位置(i.e. B B0= 和b BN= ),以及兩個代表開頭和結尾連音效應的特殊 APs Be 1 0 0 , , b f f B t = B tp β β 和 , , e N N N b b B t = B tp β β 。
Particular unit 的 APs
n
pr
β 為各種 particular unit prn∈{particular unit type 1~26}的 APs;βpr_pn為 particular unit
的目前音節韻律狀態pr p_ n∈{prosody state 1~4}的 APs。
Syllable duration model
1 ( | , , , , ) ( | , , ) N s n n n n n P P sd q s t = ϒ ≈
∏
sd B q t s (3.16) 其中 _ _ _, if th syllable is syllable-like unit
for 1 , if th syllable is particular unit
n n n n n r n t s q sd n pr r n pr pr q pr sd sd n sd n N sd n γ γ γ µ γ γ µ + + + + = ≤ ≤ + + +
為第n個音節之音節長度,其中
µ
sd及µ
pr_sd分別為 syllable-like unit 及 particular unit 的總體平均值(global mean); r n
sd 及 pr_r n
sd 為 n 屬於 syllable-like unit 或 particular unit 的sdn
正規化後的殘餘值;γx則為某一影響因子x之影響型態(Affecting Pattern, AP),各種 AP 說明如下:
Syllable-like unit 的 APs
n
t
γ 為 目 前 的 音 節 聲 調 tn∈{lexical tone 1~5} 對 sdn 的 APs ; γsn 為 基 本 音 節 類 型
{base syllable type 1~82}
n
s ∈ 對sdn的 APs;γqn為目前韻律狀態qn∈{prosody state 1~16}對
n
sd 的 APs
Particular unit 的 APs
n
pr
γ 為各種 particular unitprn∈{particular unit type 1~26}的 APs;γpr_qn 為 particular unit
32 Syllable energy model
1 ( | , , , , ) ( | , , ) N s n n n n n P P se r f t = ϒ ≈
∏
se B r t f (3.17) 其中 _ _ _, if th syllable is syllable-like unit
for 1 , if th syllable is particular unit
n n n n n r n t f r se n pr r n pr pr r pr se se n se n N se n α α α µ α α µ + + + + = ≤ ≤ + + +
為第n個音節之音節能量,其中
µ
se及µ
pr_se分別為 syllable-like unit 及 particular unit 的總體平均值(global mean); r n
se 及 pr_r n
se 為 n 屬於 syllable-like unit 或 particular unit 的se 正n
規化後的殘餘值;αx則為某一影響因子x之影響型態(Affecting Pattern, AP),各種 AP 說明如下:
Syllable-like unit 的 APs
n
t
α 目前音節聲調tn∈{lexical tone 1~5}對sen的 APs;
α
fn 為聲母類型 fn∈{final type 1~40}對sen的 APs;αrn 為目前韻律狀態rn∈{prosody state 1~16}對sen的 APs
Particular unit 的 APs
n
pr
α 為各種 particular unitprn∈{particular unit type 1~26}的 APs;αpr r_n 為 particular unit
33
第四章 語音辨認系統架構
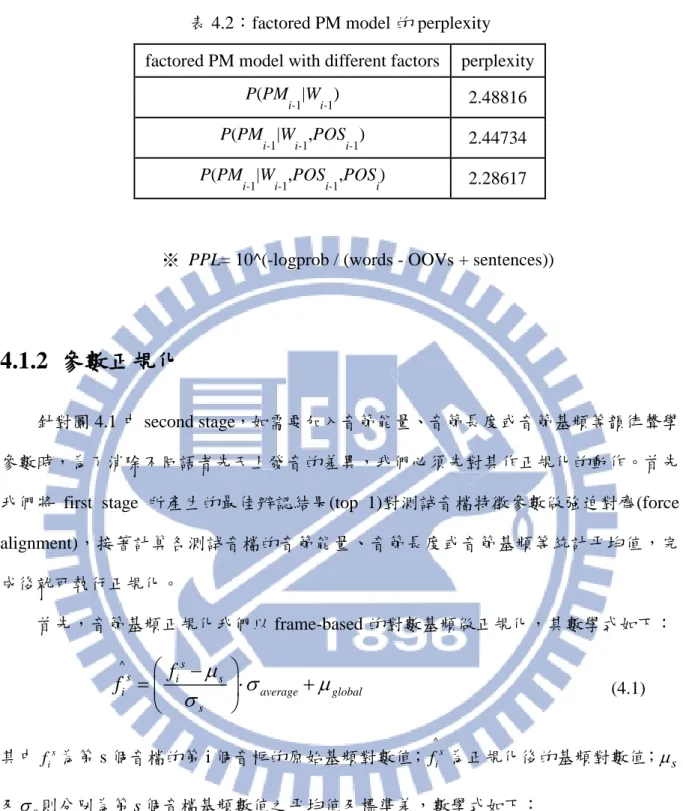
在本章節中,我們利用劉銘傑【19】論文中使用階層式語音韻律模型於中文語音辨 認系統,本研究則用在自發性語音上,希望藉由韻律資訊來改善辨識率。在 4.1 節中會 說明如何將韻律模型以 two-stage 的方式加入語音辨認中,首先利用 HMM-based 語音辨 認器來做 first-stage 語音辨認,將產生之 word lattice 做音節切割後,加入韻律資訊做重 新評分的動作 ,得到 新的辨認結果 。4.2 節則是說明本研究使用鑑別式模型組合 (Discriminative Model Combination)來解決重新評分的過程中,多個模型之權重問題。
4.1 加入韻律訊息於 two-stage 語音辨認系統
下圖 4.1 為 two-stage 語音辨認系統流程圖,以下將對此系統第二個 stage 做詳細介 紹。
34
4.1.1 Joint Syntax Model 之架構與建立
由 3.3 小節可以發現到,韻律模型的建立需要給定語言參數資訊,其中包含詞性(POS) 以及標點符號(PM)這兩種語言參數資訊,本研究所使用的 joint syntax model 包含一個 trigram LM、一個 factored POS model 與一個 factored PM model,在這裡我們是使用 FLM approach【20】建構 factored POS model 和 factored PM model,並使用 SRILM toolkit 及 利用 Witten-Bell smoothing 的方式來訓練模型,其中 FLM approach 的最主要的概念是利 用其他相關資訊(factor)的輔助來預估目標,所以這裡將充分利用語言知識來提升預估 POS 或 PM 的準確性。
當使用多種語言資訊做預估時難免會面臨到資料量不足的問題,因此會採取退化 (back-off)的架構,factored POS model 與 factored PM model 的退化路徑如下:
P(POSi|Wi,POSi-1,POSi-2)
P(POSi|Wi) P(POSi|Wi,POSi-1)
圖 4.2:factored POS model 的 back-off 路徑
如上圖 4.2 所示 factored POS model 的 back-off 路徑,在最上層的情況,期望以前兩個 POS 與目前的詞來預估,若此機率的組合沒有出現,則丟棄最遠的 POS,若仍是沒有出 現,就退化到最下層的狀態,此時就一定有機率。
35
P(PMi-1|POSi,POSi-1,Wi-1)
P(PMi-1|POSi-1,Wi-1)
P(PMi-1|Wi-1)
P(PMi-1)
圖 4.3:factored PM model 的 back-off 路徑
factored PM model 亦是如此,如上圖 4.3 所示,我們使用了前一個詞、POS 以及現在的 POS 來預估中間的 PM 機率為何,若是沒此機率,則丟掉現在的 POS,若再沒有機率, 接著丟掉前一個 POS,最後退化到最下層的狀態,此時就一定有機率。
另外,在 3.2.2 節中我們依其特性加入了兩類詞「particle」與「marker」,而以數量 上來看,MCDC 的資料量太少,必須經過調適後才能更符合我們要的模型,所以考慮像 調適 Word tri-gram LM 的方法,使用 model interpolation 來調適 Factored POS model 與 Factored PM model。
在訓練 factored POS model 時分成 48 類詞姓,另外加上 particle 與 marker 兩類,共 50 類詞姓;factored PM model 則依據標點符號的性質分成:逗號(COM)、頓號(DOT)、 無標點符號(NONE)、句點或驚嘆號等具有句子結束意義的標點符號(OTH),共 4 類。
兩種 factored model 訓練完成後,其 perplexity 效能評估於表 4.1 及表 4.2,觀察 perplexity 的下降,可以看出每加入一個 factor 都有助於預估 POS 或 PM。
表 4.1:factored POS model 的 perplexity factored POS model with different factors perplexity
P(POS
i |Wi) 2.24832
P(POS
i |Wi ,POSi-1) 2.06332
P(POS
36
表 4.2:factored PM model 的 perplexity factored PM model with different factors perplexity
P(PM
i-1|Wi-1) 2.48816
P(PM
i-1|Wi-1,POSi-1) 2.44734
P(PM
i-1|Wi-1,POSi-1,POSi) 2.28617
※ PPL= 10^(-logprob / (words - OOVs + sentences))
4.1.2 參數正規化
針對圖 4.1 中 second stage,如需要加入音節能量、音節長度或音節基頻等韻律聲學 參數時,為了消除不同語者先天上發音的差異,我們必須先對其作正規化的動作。首先 我們將 first stage 所產生的最佳辨認結果(top 1)對測試音檔特徵參數做強迫對齊(force alignment),接著計算各測試音檔的音節能量、音節長度或音節基頻等統計平均值,完 成後就可執行正規化。 首先,音節基頻正規化我們以 frame-based 的對數基頻做正規化,其數學式如下: ^ s s i s i average global s
f
f
µ
s
µ
s
−
=
⋅
+
(4.1) 其中 s i f 為第 s 個音檔的第 i 個音框的原始基頻對數值; ^ s i f 為正規化後的基頻對數值;µs 及ss則分別為第s個音檔基頻數值之平均值及標準差,數學式如下: ( ) 1( )
I s s i i sf
I s
µ
=
∑
= (4.2) ( ) 2 1(
)
( )
I s s i s i sf
I s
µ
s
=−
=
∑
(4.3)37 在(4.2)式及(4.3)式中I s( )為第s個音檔基頻之總音框數,而µglobal及saverage分別為訓練 韻律模型時所統計出的結果,代表所有語者基頻之總體平均及平均標準差。 而音節能量、音節長度的正規化方法也與基頻正規化類似,只是以 syllable-based 做正規化,對音節能量而言,(4.1)式中的µs、ss、µglobal及saverage分別改為代表第s個 音檔音節能量之平均值、標準差、訓練韻律模型時統計之所有語者能量之總體平均及平 均標準差;對音節長度而言,(4.1)式中的µs、ss、µglobal及saverage則分別改為代表第s 個音檔音節長度之平均值、標準差、訓練韻律模型時統計之所有語者音節長度之總體平 均及平均標準差。
4.1.3 The Second Stage 之實作
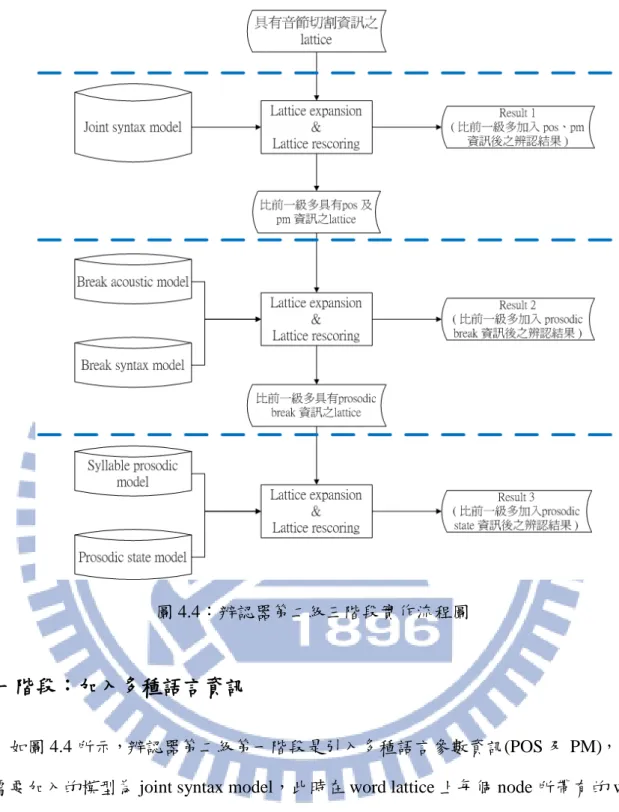
在第二個 stage 開始之後,需要加入許多韻律資訊來幫助辨認,為了瞭解每個模型 對於辨識系統的影響力,本研究根據【19】將針對 second stage 再細分成三個階段,逐 次加入模型資訊並觀察實驗結果,其詳細流程圖如下:
38
圖 4.4:辨認器第二級三階段實作流程圖
第一階段:加入多種語言資訊
如圖 4.4 所示,辨認器第二級第一階段是引入多種語言參數資訊(POS 及 PM),在這 裡需要加入的模型為 joint syntax model,此時在 word lattice 上每個 node 所帶有的 word 資訊會根據 factored POS model 與 factored PM model 找出相對應的詞性與標點符號做展 開動作。
在 lattice 展開之後,我們將每個模型的分數乘上其權重後加起來,所以每一個 arc 上會累積 AM、LM、POS 及 PM 的分數,再做重新評分來得到一條最佳路徑作為辨識 答案,並解碼出相關的語言資訊。