國立交通大學
電控工程研究所
碩士論文
一近似的費雪線性鑑別分析於分群的應用
An Approximate Fisher Linear Discriminant Analysis for
Clustering
研 究 生:楊承綱
指導教授:周志成 博士
一近似的費雪線性鑑別分析於分群的應用
An Approximate Fisher Linear Discriminant Analysis for
Clustering
研 究 生:楊承綱 Student:Cheng-Gang Yang 指導教授:周志成 Advisor:Chi-Cheng Jou 國 立 交 通 大 學 電控工程研究所 碩 士 論 文 A ThesisSubmitted to Department of Electrical and Control Engineering College of Electrical Engineering
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master
in
Electrical and Control Engineering June 2011
Hsinchu, Taiwan, Republic of China
一近似的費雪線性鑑別分析於分群的應用
學生:楊承綱 指導教授:周志成 國立交通大學電控工程研究所 摘 要 在大量資料取得越來越容易的時代,資料分群顯得更為重要。分群的困難處 在於每一筆資料都有多種統計數據,稱為特徵,我們如何選擇特徵或其組合尤其 影響分群結果。主成份分析是一種常見的特徵提取方法,然而提取最大變異成分 未必對分類或分群有最好的效果。本論文針對特徵提取進行改善,我們結合在分 類應用上具有優秀特徵提取功能的費雪線性鑑別分析,與傳統的 K-平均分群法(K-means) 成 一 個 近 似 費 雪 線 性 鑑 別 分 析 演 算 法 (approximate Fisher linear
discriminant, AFD)。先令 K-平均分群後的結果作為已知類別,再利用費雪線性鑑 別分析尋找最佳特徵,之後又使用此特徵重新分群再作費雪分析,又得到新分群 結果的最佳特徵,如此反覆直到收斂。本論文選用兩種含有三個類別的資料 Iris 和 Wine 進行實驗,並根據真實類別比對分群結果的準確率。實驗結果發現,變異 最大的成份雖保有原始資料最多的訊息,但並非都對分群有幫助,透過 AFD 演算 法提取關鍵的特徵再進行分群,證實比主成份分析來的優秀,在相同的特徵數下 能有較好的分群結果。
ii
An Approximate Fisher Linear Discriminant Analysis
for Clustering
Student:Cheng-Gang Yang Advisor:Dr. Chi-Cheng Jou
Department of Electrical and Control Engineering
National Chiao Tung University
ABSTRACT
In the era we get the large amounts of data more and more easily, the data
clustering becomes more and more important. The difficulty of clustering is that every
case has many statistics which call features, how we choose these features or their
combination will effect the clustering result extremely. Principal component analysis
(PCA) is one of the common feature extraction methods, but extracting the components
of maximum variance is uncertain best for both classification and clustering. This thesis
focuses on improving the feature extraction, we combine Fisher linear discriminant
(FLD) which can extract the features excellently for classification and the traditional
K-means clustering to an approximate Fisher linear discriminant (AFD) algorithm. Let
the K-means clustering result is the known class, then use FLD to find the best features,
after that, use these features to cluster and then do FLD again, we also get the best
features for this new clustering result. Repeat above process until convergence. This
thesis chooses two kinds of the data, Iris and Wine, that have three classes to do
find that even though the components of maximum variance can contain the most
information of the original data, but it is not useful for clustering. Extracting the key
features by AFD algorithm to cluster is better than PCA, and in the same number of
iv
誌謝
碩士畢業了,首先要感謝我的父母,從小一路栽培我至今,也因為他們的支 持與鼓勵,讓我在學業上能無後顧之憂的全力以赴。 研究所兩年生活中,最要特別感謝的便是我的指導教授周志成老師。周老師 的平行思考往往讓我有仰之彌高的感覺,對我思考模式有大的啟發,在我研究陷 入死胡同時,老師都能指引一條明路讓我走,除此之外,老師也很健談,讓每周 固定的討論時間不會無聊,能順利的完成碩士論文,要謝謝老師。 此外,也十分感謝實驗室的夥伴們,能在研究之餘一同休閒,讓研究所生活 增添不少樂趣,學業上也得之於夥伴們的互相幫忙,讓我課業問題能得以解決。 最後,謝謝口試委員對論文的建議以及提點,讓我可以知道改進的方向,也 讓這份論文能更加完善。目錄
口試委員會審定書 ... # 中文摘要………..i 英文摘要………..ii 誌謝 ...iv 目錄 ... v 圖目錄 ... vii 表目錄 ...ix 第一章 序論... 1 1.1 前言 ... 1 1.2 研究動機與目的 ... 2 1.3 論文架構 ... 5 第二章 分群演算法及特徵提取 ... 6 2.1 分割式分群法 ... 6 2.1.1 K-means 演算法 ... 6 2.1.2 K-medoids 演算法 ... 7 2.1.3 模糊 C-means 演算法 ... 8 2.2 階層式分群法 ... 9 2.3 主成份分析 ... 11 2.4 費雪線性鑑別 ... 14vi 3.1 AFD 演算法 ... 17 3.2 方法探討 ... 20 第四章 實驗結果... 26 4.1 Iris 實驗結果 ... 26 4.2 Wine 實驗結果 ... 35 4.3 軸數與分群數 ... 37 4.4 結果比較 ... 43 第五章 結論... 45 參考文獻 ... 47
圖目錄
圖 1-1 分類(左)與分群(右)的差異 ... 1 圖 1-2 分群流程 ... 2 圖 1-3 示範變數無用的情形 ... 4 圖 2-1 (a)K-means 的中心 (b)K-medoids 的中心,箭頭所指處 ... 7 圖 2-2 四種分群樹狀圖 ... 10 圖 2-3 兩個主成份方向 PC1 和 PC2... 13 圖 2-4 FLD 範例 ... 14 圖 3-1 演算流程 ... 19 圖 3-2 側影值示意圖 ... 22 圖 3-3 AFD 向量收斂過程 ... 23 圖 3-4 兩類人造資料 ... 24 圖 3-5 各軸分群結果 ... 24 圖 4-1 Iris 資料散佈圖矩陣 ... 26 圖 4-2 各原始變數直方圖 ... 28 圖 4-3 向量收斂過程圖 ... 29 圖 4-4 Iris 資料 AFD 散佈圖矩陣 ... 31 圖 4-5 Iris 資料 PCA 散佈圖矩陣 ... 31 圖 4-6 Iris AFD 第一鑑別向量收斂過程 ... 33 圖 4-7 三類別在 AFD 四軸上的直方圖 ... 34viii 圖 4-9 Wine 資料 PCA 散佈圖矩陣 ... 36 圖 4-10 Wine 資料各鑑別向量的 FCI 值與準確率... 37 圖 4-11 Iris 資料 FCI 值和側影值 VS 準確率 ... 38 圖 4-12 Wine 資料 FCI 值和側影值 VS 準確率 ... 39 圖 4-13 AFD 軸數 VS 準確率 ... 40 圖 4-14 Iris 單一軸與多軸的準確率 ... 40 圖 4-15 Wine 單一軸與多軸的準確率 ... 41 圖 4-16 分群數 VS 側影值 ... 42 圖 4-17 Iris 分兩群 ... 42
表目錄
表 3-1 各軸 FCI ... 25 表 4-1 各變數與類別變數的互信息 ... 27 表 4-2 原始變數的分群準確率 ... 28 表 4-3 AFD 和 PCA 各軸向量 ... 30 表 4-4 各軸 FCI 值 ... 30 表 4-5 各軸分群準確率 ... 30 表 4-6 PCA 因素負荷矩陣 ... 32 表 4-7 AFD 因素負荷矩陣 ... 32 表 4-8 組內變異和組間變異 ... 34 表 4-9 ... 34 表 4-10 Wine 各軸的 FCI 值和準確率 ... 36 表 4-11 Iris 資料總結果 ... 43 表 4-12 Wine 資料總結果 ... 43 表 4-13 側影值改善情形 ... 441
第一章
序論
1.1
前言
在機器學習 (machine learning)領域上,大致可以分為兩類: 1. 監督式學習 (supervised learning):現有資料含有明確的訊息,這些資料稱為訓 練資料 (training data),把每一筆資料當作輸入變數,皆對應一個輸出變數,這 個輸出變數可以是連續變數或是離散變數,若為連續變數,則訓練資料可以用 來建立迴歸模型,當某一筆測試資料輸入時,可以用此模型來預測輸出;若是 離散變數,代表是類別訊息,可以用訓練資料建立分類模型,並預測測試資料 所屬的類別。 2. 非監督式學習 (unsupervised learning);與監督式學習相反,現有的資料皆不帶 任何明確訊息,每一筆資料當作輸入,沒有對應的輸出,無法建立任何模型。 分類 (Classification)是根據資料已知的離散類別變數來建立分類模型,屬於監督式 學習的應用。分群 (Clustering)則是在全部皆為未標記 (unlabeled)的資料上進行集 群分析,屬於非監督式學習,如下圖: -10 0 10 20 -20 0 20 40 X Y 原 始 資 料(標 記) -10 0 10 20 -20 0 20 40 X Y 原 始 資 料(未 標 記) 圖 1-1 分類(左)與分群(右)的差異 上圖左,當問綠色的點是屬於紅色還是藍色那類,這是屬於分類問題;相反的,上圖右若問裡面應該有幾群資料,又該怎麼劃分,這就屬於分群問題。而為什麼 要進行分群呢?透過分群,我們可以量化資料,還能找出圖形的結構,並且把資 料宇集合分成數個子集合,子集合內的資料有較相似的屬性,因此在各群內可以 用較少的資料代表此群全體資料,借此可以減少計算量。 分群過程可分為下圖幾個步驟: 前處理 特徵提取 計算相似度 進行分群 圖 1-2 分群流程 前處理包括過濾離群值 (outlier)以及刪除或補足遺漏值 (Missing),目的是為了增 加資料的有效性。進行分群時,是以相似度為依據,期望各組之內的相似度越大, 而組與組之間的相似度越小,相似度的計算則可以依需求制定,如歐式距離
(Euclidean distance)以及馬式距離 (Mahalanobis distance)等。歐式距離則是一種常
用的相似度計算方式。分群可以針對變數或是資料,變數分群可以探討變數之間 的相關性,本論文則是針對資料進行分群。分群被廣泛應用於資料探勘、圖形分 類、文件檢索、生物資訊,以及影像分割等。分群演算法可粗略分為兩種: 1. 階層式 (hierarchical) 2. 分割式 (partitioning) 其中,階層式包含聚合法、分裂法兩種方式。常見的聚合法有單一連結聚合法、 全部連結聚合法、平均連結聚合法,華德法等。分割式則有 K-means 演算法和 fuzzy C-means 演算法,其中尤以 K-means 演算法為最常見的方法。
1.2
研究動機與目的
從分群流程圖 1-2 中,可以發現能改變分群結果的步驟為:特徵提取、計算3 相似度,以及進行分群的部分。要有意義的改變相似度的計算方式必須先觀察資 料 散 佈 的 情 形 , 如 馬 氏 距 離 的 計 算 是 依 據 各 變 數 間 的 共 變 矩 陣 (covariance matrix),然而這樣的改變未必對分群是有幫助的,因此改變相似度的方式多半應 用在分類模型。而分群流程的最後一個步驟─進行分群,主要改善的方向在於討 論合理的分群數目,這方面也已經有許多的分群指標可以用來判斷合理的分群數 目,待後面章節我們會介紹。剩下特徵提取的部分,作特徵提取的原因在於原始 變數中往往有許多對分群無用甚至有害的訊息,例如兩個相關性很強的變數x 和1 2 x ,當x 的值很大時,1 x 值也會很大,如此一來在計算兩點距離時會因為2 1 2 1 1 x x 很大, 1 2 2 2 x x 也跟著很大(註:上標代表不同筆數,下標代表不同變數),兩點距 離就變很遠,那麼變數x 和1 x 就可能成為分群的重要依據,或者發生下圖情形時,2 X 軸顯然會對分群較無幫助。
-10 0 10 20 -10 0 10 20 X Y -20 -10 0 10 20 0 10 20 30 X軸 直 方 圖 -10 0 10 20 30 0 10 20 30 Y軸 直 方 圖 圖 1-3 示範變數無用的情形
對於變數存有相關性的問題,傳統的主成份分析 (Principal Component Analysis,
PCA)可將原始變數透過線性轉換,轉成一組彼此無相關性的變數,即便如此,仍 然未解決無用變數的問題,因此本論文便針對特徵提取作出改善。改善的目標即 為挑選出對分群有幫助的特徵,方法如下: 1. 使用投影的方法。由於焦點放在統計資料的分群上,不同於人造資料或圖形式 的資料,自然的統計資料其群聚邊界多半為線性,且使用線性的投影方法也較 為容易。 2. 投影軸必須對於不同群集有良好的鑑別能力。如此一來投影上去的資料,才能 明顯的觀察出各群聚邊界,也期望能藉此更容易判斷出該分成幾群。 基 於 以 上兩 點 , 若 在監 督 式 學習 上 , 就是費 雪 線 性鑑 別 分 析 (Fisher Linear
5 Discriminant Analysis, FLD),但是 FLD 無法應用在分群上,我們無法從未標記資 料上找出這個投影軸。現在假設在未標記資料上可以找出這一個分群結果較佳的 投影軸,反過來說,在這個軸上進行分群就會有較佳的結果,所以期望能應用這 種監督式學習的方法在分群上,產生一個新的學習方法,可以用來提取特徵,並 且預期會有較好的分群結果。
1.3
論文架構
第一章序論為問題描述,簡短說明作本研究的動機與目的以及研究的方向; 第二章介紹特徵提取的方法以及分群的演算方法;第三章為本文所提出的方法並 接著探討,之後在第四章使用含有真實類別的統計資料做實驗;第五章為結論。第二章
分群演算法及特徵提取
當資料的變數多且數據量大時,將不易運用這些資料,若能經由數學變換找 出具有代表性的特徵,保留少數重要訊息,不但後續的應用能更為正確,也能減 少系統運算量,這便是特徵提取的目的。 如同之前所提,分群方法已存在許多知名且常用的方法,本章節將介紹其中 幾種,並在之後的章節用這些方法進行實驗。2.1
分割式分群法
2.1.1 K-means 演算法
K-means 演算法是 J. B. MacQueen 於 1967 提出的演算法[1]。以k為輸入參 數,欲把 n 筆資料分為k群,以使其各群內具有較高的相似度,而各群與各群之間 的相似度較低。相似度的計算是根據群中資料點的平均值來進行。其目的在於最 小化誤差平方總合: 2 1 i k i i X C E X m
(2.1) X 為任一筆資料,m 為第i i個群集的中心,k為群集數目。 其演算法步驟如下: 輸入:全部的資料以及分群數目k 1. 隨機選取k筆資料作為初始k個群集中心。 2. 計算每一筆資料到各個中心之間的距離,並指派此筆資料給距離最近的群集, 此時會形成一個群集邊界,產生了群集的成員集合。 3. 根據邊界內的每一筆資料重新計算出該群集的中心,並取代上一次的中心。7 4. 重複步驟 2 和步驟 3,直到群集成員不再變動為止。
2.1.2 K-medoids 演算法
由於離群值對中心點位置有極大的影響,中心點的位置又會影響群集的邊 界,因此 K-means 演算法對離群值是敏感的,為了改善這種敏感性,誕生了 K-medoids 演算法[2],其過程類似 K-means 演算法,差別在於後者直接以群集平 均值當作中心,前者則是以最靠近此平均值的真實資料點作為中心。其演算過程 如下: 輸入:全部的資料以及分群數目k 1. 隨機選取k筆資料當作起始中心。 2. 計算每一筆資料到各個中心之間的距離,並指派此筆資料給距離最近的群集 3. 各群隨機選取任一不為中心點的資料計算其成本,即以此筆資料當作中心,計 算其誤差平方和,若成本小於原先的中心,便以此筆資料當作新的中心點。 4. 重複步驟 2 和步驟 3,一直執行到群集成員不再變動為止。 以下圖作為範例說明 K-means 和 K-medoids 的差異。最左邊的點(-200,0)是離群值, 右邊三個點(10,10),(5,0),(8,-10)是對分群有幫助的資料樣本。 圖 2-1 (a)K-means 的中心 (b)K-medoids 的中心,箭頭所指處從圖 2-1 可看出 K-means 的中心受到左邊的離群值影響,而 K-medoids 的中心是 從真正存在的資料上選取,因此與真正有用的右邊三個點的中心更為相近。這就 是 K-medoids 較能抵抗離群值的原因,但其缺點是計算量比 K-means 來的多。若 總共有 n 筆資料,K-means 的複雜度為O n( ),而 K-medoids 為 2 ( ) O n ,因此較適合 在資料筆數少的情況。
2.1.3 模糊 C-means 演算法
最早由 Dunn 於 1973 年首先提出[3],並在經 Bezdek 改善[4]。其目的是透過 模糊邏輯的概念,希望能進一步提升分群的效果。與 K-means 相似,差別在於任 何一筆資料,可以用 0 到 1 的數字表示屬於某一群集的程度,而不像 K-means 只 有屬於和不屬於兩種選擇。假設U為一個 c n 的矩陣,其中 n 為資料樣本數目,c 為欲分的群數,則uij代表第 j 筆資料屬於第 i 群的程度,而每一行總和為 1,即 1 1 c ij i u
(2.2) 在此條件下欲最小化目標函數 2 1 1 c n m ij j i i j J u X C
(2.3) m 為大於 1 的權重指數, Xj為第 j 筆資料,C 為第i i群中心,代入拉格朗日 (Lagrangian )條件方程可得 1 1 n m ij j j i n m ij j u X c u
(2.4) 所以其演算過程如下 1. 初始化矩陣U。9 2. 透過式(2.4)計算各群集中心。 3. 更新U, 2 1 1 1 ij m c j i k j k u X C X C
4. 透過式(2.3)計算J,若與前次差距 (t 1) ( )t J J ,則停止,否則重複步驟 2 到 步驟 4。 最後,分群結果依據矩陣U,將第 j 筆資料指派給arg max ij i u 。2.2
階層式分群法
階層式分群法會產生一樹狀結構,由樹狀結構可看出其分群結果,分為兩種: 1. 聚合式:由樹狀底部開始,一開始每個資料點都自成一個群集,並逐一將相似 度較大的兩個合併,慢慢往上生成頂部。 2. 分裂式:由樹狀頂部開始,一開始全部資料都是同一個群集,逐一將相似度小 的分離,慢慢往下生成底部。 聚合法為較常用的方法,以下介紹聚合法中較常使用的距離度量方式。 單一連結法 (single linkage): 群集X 與群集Y之間的距離定義為兩群之中最接近兩點的距離: , ( , ) min ( , ) x X y Y D X Y d x y (2.5) 全部連結法 (complete linkage): 群集X 與群集Y之間的距離定義為兩群之中最遠兩點的距離: , ( , ) max ( , ) x X y Y D X Y d x y (2.6) 平均連結法 (average linkage):群集X 與群集Y之間的距離定義為兩群之間各點到各點的距離平均: , ( , ) ( , ) x X y Y d x y D X Y X Y
(2.7) 華德法 (Ward's method): 群集 X 與群集Y 間的距離定義為在將兩群合併後,各點到合併後中心的距離平方 和 2 ( , ) v X Y D X Y v m
(2.8) m 為合併後的中心。 下圖為針對圖 1-3 的兩類人造資料分別使用四種連結方法的樹狀圖。 11226 211 9 31420242819172523222127 713 630102915 5 416 818 1 1.5 2 2.5 3 single 2729211719 5 91411 112 6 315 2 7 41013182228162320 824263025 5 10 15 20 complete 2627172119 212 7 31314 410 911 515 1 6 816182920222523282430 2 4 6 8 average 2728222423 112 8131725161920 2 7 4 610 32126 514 91115182930 20 40 60 ward 圖 2-2 四種分群樹狀圖 我們可以發現,單一連結法出現極不對稱的結果,因為每次合併都只考慮最近的11 距離。對某個點來說,距離它最近的點有越大的機會在越多點的群內,因此大的 群會越來越大,所以這四種連結方法以此為最少人使用。平均連結以及完整連結 則是比較容易出現群數較多的情形,因為群內的點一旦變多時,外部的點與此群 的距離就會越來越大,要併入的機會也越來越小。華德法則是四種方法裡較佳的 方法。
2.3
主成份分析
主成份分析由 Pearson 於 1901 年提出,並在 1933 年經由 Hotelling 加以發展。 在統計學上,主成份分析是一種維度簡化的技術。它是將原始變數經過線性變換 後得到一組新的變數,而這組新的變數其變數與變數之間並沒有相關性,彼此是 正交的。並且,原始數據投影上去後,第一個坐標軸擁有最大的變異量,稱為第 一主成份,第二個坐標軸擁有第二大變異量,稱為第二主成份,以此類推。相較 於其他基底,主成份分析可以提取對資料全體變異量有最大貢獻的特徵。 原理敘述如下: 為方便起見,假設 N 筆資料資料已先經過中心化 (centered),為 1 2 3 , , , , N x x x x , 維度為p,現有一組正交且單位長的基底V { ,v v v1 2, 3, ,vp},即 1 0 T i j i j i j v v (2.9) 原始空間中的資料皆可以表示為此基底的線性組合 1
p n n i i i z x v (2.10) ( ) n n T i i z x v (2.11) 1 2 3 , [ , , , , N T] 1, 2, , i i i p z Xv X x x x x (2.12)主成份分析的目的是要在 , zi i1, 2, ,p之中找出擁有最大變異量的變數z。 樣本變異數 2 1 1 var( ) ( ) 1 N n n z z N
z ,因為中心化,所以 1 0 N n n
x ,將式(2.10)代 入, 1 1 1 1 1 0 0 p p N N N n n n i i i i n n i i n z z
x
v
v ,又因為v 彼此獨立,故可得 i 1 0 0 , for 1, 2, N n i i n z z i p
,因此 2 1 1 1 var( ) ( ) 1 1 N n T n z N N
z z z,式(2.12) 代入可得 1 var( ) 1 T T T N z v X Xv v Cv (2.13) 1 1 T N C X X,為樣本共變異數矩陣(sample covariance matrix)。欲在條件v vT 1下
最大化式(2.13),可代入拉格朗日條件方程: ( , ) T ( T 1) L v v Cv v v (2.14) 將式(2.14)偏微分 2 2 L v Cv v (2.15) 1 T L v v (2.16) 令式(2.15)及式(2.16)等於 0 可得 Cv v (2.17) v 即為C的最大特徵值所對應的單位長特徵向量,稱為第一主成份向量,而擁有最 大變異量的 z ,即 X 投影在 v 的座標,稱為第一主成份得點 (score)。第二主成份 向量即為C的第二大特徵值所對應的單位長特徵向量,以此類推。 主成份分析性質如下:
13 1. 將式(2.17)代入式(2.13)重新整理可得 var( )z v CvT vTvv vT ,換句話說,變異量第i大的變數z ,其變異i 量就是樣本共變異數矩陣第i大的特徵值i。 2. z ziT j (Xvi) (T Xvj)v X XvTi T j v X XviT( T j)(N1)2v vTi j 0 , for i j,可看 出變數與變數之間並沒有相關性,彼此正交。 3. 若變數x的度量尺度不同,可以先將其標準化,此時共變異數矩陣C等於相關 係數矩陣R,所有變數z 的變異量總和等於維度數i p 1 1 1 var var( ) ( ) ( ) ( ) ( ) p p T T i i i i p tr tr tr tr tr p
z
z D V RV RVV R 圖 2-3 兩個主成份方向 PC1 和 PC2 變異量 2 2 1 1 1 var( ) ( ) ( ) 1 N N n n n n z z N
z 與能量成正比,因此比較大的主成份有較大 的能量,當我們捨棄較小的主成份時,形同捨棄了較小的能量,而較小的能量通 常是由雜訊所造成,所以主成份分析不但能有效降低維度,同時能保留真正的訊號,移除雜訊的影響,可謂一舉兩得。
2.4
費雪線性鑑別
在給定一主成份分析的基底之後,資料投影在此空間前後的差距會最小,然 而費雪線性鑑別並不是如此,資料在投影之後群集能有明顯的區別,以利於分類。 如下圖:L 線便是 FLD 找出的方向。 圖 2-4 FLD 範例 原理敘述如下: FLD 是希望能找出一個軸,能將兩群標記資料投影上去之後,同一群內資料能越 近越好,而兩群彼此之間能越遠越好。令這個軸為 a ,兩群原始資料的平均分別為 1 2 1 2 1 2 1 1 , n n
x C x C m x m x ,投影上去之後的平均值為 1 2 1 1 2 2 1 2 1 1 , T T T T m m n n
x C x C a x a m a x a m (2.18) 定義度量群與群之間分散程度的方式為 2 1 2 (m m ) (2.19) 各群內分散的程度為15 2 2 ( ) i T i i S m
x C a x (2.20) 根據 FLD 所期望的結果,可以最大化下式: 2 1 2 2 2 1 2 ( ) ( ) m m J S S a (2.21) 稱為費雪準則 (Fisher criterion)。將式(2.18)代入式(2.19)重新整理 2 2 1 2 1 2 1 2 1 2 1 2 1 2 ( ) ( ) ( )( ) ( )( ) T T T T T T T T T B m m a m a m a m a m m a m a a m m m m a a S a (2.22)其中S 稱為組間共變異矩陣 (between-class covariance matrix)。式(2.18)和式(2.20)B
代入式(2.21)的分母 1 2 1 2 1 2 2 2 2 2 1 2 1 2 1 1 2 2 1 1 2 2 ( ) ( ) ( )( ) ( )( ) ( )( ) ( )( ) T T T T T T T T T T T T T T W S S m m
x C x C x C x C x C x C a x a x a x a m x a m a a x a m x a m a a x m x m x m x m a a S a (2.23)其中S 稱為組內共變異矩陣 (within-class covariance matrix)。 W
將式(2.22)和式(2.23)代入式(2.21)可得 ( ) T B T W J a a S a a S a (2.24) 2 1 ( ) ( ) ( ) 0 ( ) ( ) ( ) T T W B B W T W T T W B B W B W W B J c c a S a S a a S a S a a a a S a a S a S a a S a S a S a S a S S a a (2.25)
最後可以得到 a 就是 1 W B S S 的最大特徵值對應到的特徵向量,注意到式(2.25)整理一 下可得 1 1 1 1 2 1 2 1 2 ( )( )T ( ) W B W W a S S a S m m m m a S m m (2.26) 所以我們無須解特徵值問題。 以 上 是 兩 類 別 一 個 軸 的 問 題 , 現 在 將 問 題 延 伸 到 c 類 別 p 個 軸 : 1 2 [ , , , p] A a a a 。修改 1 ( )( ) i c T W i i i
x C S x m x m (2.27) 1 ( )( ) c T B i i i i n
S m m m m (2.28) m為全部資料平均,m 為第i i 類資料平均,n 為第i i 類資料數目, c 為類別數目。 欲讓同一類別內散佈情形越靠近,不同類別間散佈越分開,可最大化費雪準則: det( ) ( ) det( ) T B T W J A A S A A S A (2.29) 或者 ( ) ( ) ( ) T B T W tr J tr A S A A A S A (2.30) 取行列式值 (determinant)或是跡 (trace)都是量化散步矩陣的方式。 解之可得 1 W B c S S A A (2.31) A即為 1 W B S S 的特徵向量。與主成份向量不同的是,解出來並非是正交基底。17
第三章
研究方法
有鑑於費雪線性鑑別對於分類應用有良好的特徵提取能力,唯其無法用在未
標記資料上。因此若是能找出最佳分群結果的關鍵特徵,並用此特徵進行分群,
預期能有良好的分群結果。以下稱本論文所提出的方法為近似的費雪線性鑑別分
析 (approximate Fisher linear discriminant, AFD),簡稱 AFD。
先令前次分群的結果當作已知的類別來作 FLD 找出最佳特徵,再用此特徵進 行分群,此次新分群的結果再作一次 FLD 又可得到新的最佳特徵,如此反覆的用 分群結果更新特徵,便是 AFD 演算法的架構。
3.1
AFD 演算法
先介紹步驟,之後再解釋各個步驟的含意。 其步驟如下: 1. 資料先做主成份分析,找出其第一主成份。 很直覺的,這麼作的目的是為了讓收斂的速度變快。 2. 使用各筆資料的第一主成份做 K-means 演算法分群。 注意到 K-means 演算法會受到起始中心的影響,因此我們根據 Barakbah 和 Kiyoki [5]提出的方法改善初始值造成的局部最佳化。 3. 根據 K-means 分群的結果,依式(2.31)算出 FLD 第一鑑別向量 4. 將資料投影到步驟 3 找出的向量之後,其投影得點即為最佳特徵,用此特徵重 新做 K-means 分群 5. 重複步驟 3 到步驟 4,直到收斂為止。 此時,我們已經找出第一個有最佳特徵的向量,但由於太少的特徵往往會失去許多重要的資訊,因此欲找齊全部p個向量。根據 Duchene 及 Leclercq 所提出的方 法能改善傳統費雪方法[6],其法是找出一組正交的向量,有別於傳統不一定正交, 其實驗結果也較為出色,故之後也選擇找出正交的鑑別向量,方法如下: 假設第一次找出的單位長鑑別向量為a ,欲找出與其正交的向量1 a ,在與2 a 垂直1 的空間中找即可,因此對a 做奇異值分解可以得到由左奇異向量組成的矩陣,即1 1 1 T a a 的特徵向量組成的矩陣U 1 1 , diag( , 1 2, ,p) T a a U = UV V (3.1) 由於 1 1T a a 的秩為 1,根據線性代數定理,將會有p1個特徵值是 0,即 1 1 1 1 0 0 0 , 2,3, , since 0 i i i i p T T a a u u a u a (3.2) 又, 1 1 1 1 1 1 1
=trace( ) trace( ) trace(1) 1 1
p i i
T T a a a a ,即 1 1 1 1 1 1 1 1 1 1 1 , if 1 c T a a u u a u a u a u (3.3) 由式(3.2)和式(3.3)可知U即為自己和與自己垂直的一組正交基底所組成。當算出第 一個鑑別向量a 時,可以找出這組1 p1個的基底,再將原始空間的資料全部投影 上去,並在這空間中找出第二個鑑別向量,重複此方法直到找出所有正交的鑑別 向量為止。 全部演算流程如下頁圖:19 原始資料 設定 求出第一主 成分 K-means分 群 依分群結果 算出FLD鑑 別向量ui 是否收斂 i u 否 是 原始資料投影至 1 2 , [ , , , i] U U u u u 否 是 輸出U 1 i ? i p 1 i i 資料投 影上去 圖 3-1 演算流程
找出正交基底在已標記資料的分類應用上不但具有較好的實驗結果,在未標記資 料上,這種做法還可以避免第二個以後的鑑別向量被第一個鑑別向量影響,因為 之後找出來的鑑別向量可能全部都以很小的夾角圍繞在第一鑑別向量上,如此一 來便失去找多個特徵軸的意義。
3.2
方法探討
由式(2.1)的目標函數E和式(2.27),
1 1 1 2 1 2 1 ( ) ( )( ) ( )( ) ( ) ( ) i i i i i c T W i i i c T i i i c T i i i c i i c i i trace trace trace trace trace E
x C x C x C x C x C S x m x m x m x m x m x m x m x m (3.4)可以得到 K-means 演算法的目標就是 min trace S( W)。再由主成份分析的原理可得 知,其目的是要找出單位向量 a
arg max T arg maxtrace( T T )
a a Ca a a S a (3.5)
其中總共變異矩陣 (total covariance matrix)ST (N 1) C SBS W
21
( )
( ) ( )
arg max arg max
( ) ( ) ( ) ( ) arg max 1 ( ) ( ) arg max ( ) T T T W B T T T T W W W T T T W T T T W trace trace trace
trace trace trace
trace trace trace trace b b b b b S b b S b b S b b S b b S b b S b b S b b S b b S b b S b (3.6) 結合式(3.4)、式(3.5),和式(3.6),如下 PCA FLD = ( ) ( ) T T T W trace trace b S b b S b K-means 當向量b讓分母最小,分子最大時,就是最大的鑑別向量,但由於S 未知,所以W 初始時就先讓分子最大,也就是式(3.5)的主成份分析找出 a ,之後再作 K-means 分群讓分母最小,即式(3.4),如此一來,收斂的速度會最快。 找 出 近 似 的 鑑 別 向 量 後 , 我 們 可 以 由 向 量 元 素 的 大 小 看 出 原 始 變 數 1 2 [ p] X x x x 中哪些是對分群有幫助的,若找出的向量為u u u1 2 upT,那 麼新的變數即為zXuu1 1x u2x2 upxp,兩點距離為: 2 2 1 1 1 2 2 2 (zmzk) u x( mxk)u x( mxk) u xp( mp xkp) ,假設u 很大,表示原始變i 數x 對區別群集有很大的貢獻,在判斷距離上給予i x 很高的權重。 i 最後一個問題:在非監督式學習的前提下,該如何證明 AFD 找出來的軸是比 較好的呢?找出來的軸既然是用來分群,就依分群的結果來決定軸的優劣。甚麼 樣的分群才是好的分群結果,這向來沒有一定的對與錯,也因此有許多指標可以 用來評分,只要指標定義的方式符合分群的想法,也就是組間相似度小,組內相 似度大即可,因此使用費雪準則當做我們的指標,以下簡稱為 FCI。常用的指標還
有側影值 (Silhouette value)和 DBI 指數 (Davies-Bouldin index,DBI)。側影值定義 如 下 : 令 ( , )i d x A 為x 到 A 群 所 有 點 的 平 均 距 離 , 則 ( )i a i d( , ) , xi A xiA, ( ) min ( , ) , i i B b i d x B x B, ( ) 1 ( ) ( ) ( ) ( ) 0 ( ) ( ) ( ) 1 ( ) ( ) ( ) a i a i b i b i S i a i b i b i a i b i a i (3.7) 即 ( ) ( ) ( ) , -1 ( ) 1 max{ ( ) , ( )} b i a i S i S i a i b i 圖 3-2 側影值示意圖 最後分群結果的側影值計算為:先分別算出每一群所有點的側影值平均,有幾群 便有幾個數值,再算出這些數值的平均,即 1 1 1 ( ) ( ) i k i i x C SC k S x k C
(3.8)23 以下用範例來說明 AFD 演算法收斂的過程:先用高斯分布隨機產生兩包資料,分 別為紅色(o)和藍色(+),再假裝我們都不知道類別訊息來進行分群。 圖 3-3 AFD 向量收斂過程 第一次找出來的方向其實就是 PCA 的第一主軸,跟最後收斂出來的方向幾乎要垂 直,代表在此例子中 AFD 跟 PCA 幾乎選擇了完全相反的特徵。由圖上原本的兩 類別來看,AFD 所找出的方向的確比 PCA 更適合拿來分群。 會產生這樣正確的收斂過程,是因為每次找出方向後,資料投影上去作分群都會 有更接近原本真實類別的分群結果,如此不斷的先分群再修正方向直到收斂。 現在就再以人造資料來觀察選出的軸其 FCI 值與分群結果之間的關係:
-10 0 10 20 -15 -10 -5 0 5 10 15 20 X Y 原 始 資 料(標 記) -10 0 10 20 -15 -10 -5 0 5 10 15 20 X Y 原 始 資 料(未 標 記) 圖 3-4 兩類人造資料 -10 0 10 20 -20 0 20 natural 1st -10 0 10 20 -20 0 20 AFD 1st -10 0 10 20 -20 0 20 PCA 1st -10 0 10 20 -20 0 20 natural 2nd -10 0 10 20 -20 0 20 AFD 2nd -10 0 10 20 -20 0 20 PCA 2nd 圖 3-5 各軸分群結果
25 FCI 1st 2nd 自然基底 1.791 2.635 AFD 4.176 1.775 PCA 2.143 1.842 表 3-1 各軸 FCI 由表可斷定 AFD 的第一個軸,以及自然基底的 Y 軸,有較好的分群結果,我們從 圖上來看可以發現,確實在這兩個軸上的分群較能接近資料原本的分類情形。
第四章
實驗結果
本論文使用著名的 Iris 和 Wine 資料來做實驗。Iris 最初是由安德森從加拿大
加斯帕半島上的鳶尾屬花朵中提取的數據,後來由費雪作為判別分析的一個例 子,運用到統計學中。Iris 是由四個變數,150 筆資料所形成的三種類別,每類各 50 筆,變數分別為花萼和花瓣的長度以及寬度;Wine 是由十三個變數,178 筆資 料,所形成的三種類別葡萄酒,每類分別有 59、71,和 48 筆資料,其變數都是化 學成分如酒精,蘋果酸,…等。這兩種資料都有已知的三種類別,所以可以拿他 來比對分群的結果。
4.1
Iris 實驗結果
下圖為 Iris 資料的四個變數交互散佈圖矩陣。 0 1 2 2 4 6 2 3 4 6 8 0 1 2 2 4 6 2 3 4 6 827 首先,可以由變數與類別之間的互信息 (mutual information)了解彼此之間的相關 性,互信息的含意為兩個變數之間能互相解釋的程度,其定義如下: ( ; ) ( ) ( ) ( ) ( ) I X Y H Y H Y X H X H X Y (4.1) 其中 ( ) ( ) log ( , ) ( ) ( , ) log ( ) x x y H X p x p x y H X Y p x y p x y
(4.2) ( ) H X 為X 的熵 (entropy),代表了X 的混亂程度,H X Y 就代表了當已知( ) Y 以 後,X 剩下的混亂程度。在算出互信息之後,將其正規化,使其較具參考價值, 即
( ; )
min ( ), (Y) I X Y H X H (4.3) 由上式可以算出下表: 變數 X1 X2 X3 X4 正規化的互信息 0.475 0.278 0.852 0.940 表 4-1 各變數與類別變數的互信息 從表上可看出變數x 和3 x 比較能解釋三種類別,直接從圖 4-1 上也可看出這兩個4 變數對於分辨三種花,有明顯的區別。而x 則完全看不出與三種類別之間的關聯2 性,對分群顯然是較無用的變數。單獨使用各變數來觀察分群的準確率。下圖為 三類別之於各變數的直方圖2 4 6 8 10 0 5 10 15 X1 1 2 3 4 5 0 5 10 15 20 X2 0 2 4 6 8 0 5 10 15 X3 -1 0 1 2 3 0 10 20 30 X4 圖 4-2 各原始變數直方圖 X1 X2 X3 X4 準確率(%) 72.00 51.33 89.33 96.00 表 4-2 原始變數的分群準確率 可以發現,互信息越大,其準確率也越高。這是理所當然的,因為互信息越大代 表就是造成三類別差異的主要原因。 現在用 AFD 演算法嘗試找出近似的費雪鑑別向量,其向量收斂過程如下圖:每張 圖代表每個向量的各個元素收斂的過程。
29 1 2 3 4 5 -1 -0.5 0 0.5 1 收 斂 次 數 此向量各元素值 1st向 量 u 1 u 2 u3 u 4 1 2 3 4 5 6 7 -1 -0.5 0 0.5 1 收 斂 次 數 此向量各元素值 2nd向 量 u1 u 2 u 3 u4 1 2 3 4 5 6 7 -0.5 0 0.5 1 收 斂 次 數 此向量各元素值 3rd向 量 u 1 u 2 u 3 u 4 1 2 -0.5 0 0.5 1 收 斂 次 數 此向量各元素值 4th向 量 u1 u 2 u 3 u4 圖 4-3 向量收斂過程圖
可以看出四個向量幾乎在第二次收斂時便很接近最後結果,也證實使用主成份分 析當作起始軸收斂會較快的事實。第二個鑑別向量在第六次收斂時發生變號,但 其實不影響結果。第四個鑑別向量,理所當然一次就會被決定,因為它必須與前 三個鑑別向量正交。找出的鑑別向量是否真的對分群有比較好的效果,來看看跟 主成份分析的比較,以及各軸的 FCI 值。 AFD 1st 2nd 3rd 4th 0.222 -0.103 0.969 -0.032 0.407 -0.029 -0.067 0.911 -0.589 0.716 0.221 0.302 -0.662 -0.690 0.088 0.280 PCA 1st 2nd 3rd 4th 0.361 0.657 0.582 -0.315 -0.085 0.730 -0.598 0.320 0.857 -0.173 -0.076 0.480 0.358 -0.075 -0.546 -0.754 表 4-3 AFD 和 PCA 各軸向量 FCI 1st 2nd 3rd 4th AFD 33.804 15.434 7.591 5.788 PCA 15.628 3.666 4.306 4.212 表 4-4 各軸 FCI 值 準確率(%) 1st 2nd 3rd 4th AFD 98.67 80.67 80.67 71.33 PCA 91.33 42.67 52.00 43.33
31
AFD 各軸鑑別能力皆比 PCA 高出許多。比對可以發現,較大的 FCI 值對應著較高
準確率,再次證明根據 FCI 值來斷定軸的優劣是可行的。接著,我們畫散佈圖觀 察群聚分佈的情形: 4 6 4 6 8 0 1 2 -2 0 2 4 6 4 6 8 0 1 2 -2 0 2 圖 4-4 Iris 資料 AFD 散佈圖矩陣 -0.5 0 0.5 0 0.5 1 4 5 6 2 4 6 8 -0.5 0 0.5 0 0.5 1 4 5 6 2 4 6 8 圖 4-5 Iris 資料 PCA 散佈圖矩陣
從上面兩張圖可以看到在第一軸上 AFD 的群聚都比 PCA 來的緊密,並且在第二
軸以後(框起來的部分),PCA 完全分不出群聚,AFD 還能清楚的分出來。主成份
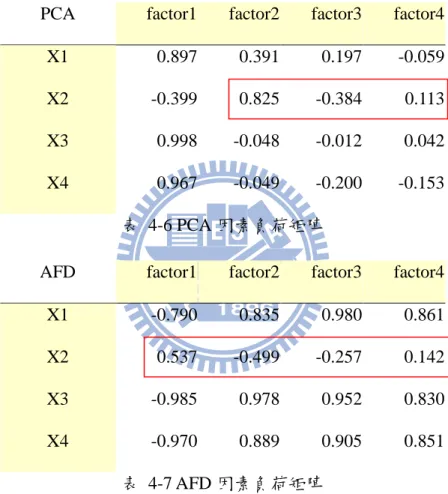
分析在各軸上的分群準確率都不及我們所找出的鑑別向量,可由因素負荷(factor
loading)來解釋。因素負荷定義為兩變數之間的相關性,即 fXY corr X Y( , )。因素 負荷的絕對值大小代表了因素解釋變數的能力。
PCA factor1 factor2 factor3 factor4
X1 0.897 0.391 0.197 -0.059
X2 -0.399 0.825 -0.384 0.113
X3 0.998 -0.048 -0.012 0.042
X4 0.967 -0.049 -0.200 -0.153
表 4-6 PCA 因素負荷矩陣
AFD factor1 factor2 factor3 factor4
X1 -0.790 0.835 0.980 0.861 X2 0.537 -0.499 -0.257 0.142 X3 -0.985 0.978 0.952 0.830 X4 -0.970 0.889 0.905 0.851 表 4-7 AFD 因素負荷矩陣 由於主成份分析在第二主成份以後,解釋變數x 和3 x 的能力很少,然而由表 4-14 知道變數x 和3 x 對分群才有明顯的幫助,因此主成份分析在這些軸上的分群效果4 並不理想。然而 AFD 在四個軸上對x 和3 x 都有很強的解釋能力,也因此每一個軸4 都有不錯的分群準確率。觀察到在四個鑑別向量上,x 的因素負荷都是最小,然2 而 PCA 第二軸對x 的因素負荷很大,準確率又非常的低,因此可以推測變數2 x 不2
33 但對分群沒有幫助,甚至會讓結果變得更糟。 接著看收斂過程是否如預期般慢慢將群與群之間分隔開來,以 AFD 第一鑑別 向量為例。由於主成份分析在第一個軸上的鑑別能力不差,因此我們改由隨機產 生的方向當做起始方向,也可看看收斂的穩定性如何。 5 10 15 0 5 10 15 1-th -10 -8 -6 -4 -2 0 5 10 15 2-th -10 -8 -6 -4 -2 0 5 10 15 3-th -10 -8 -6 -4 -2 0 5 10 15 4-th 0 2 4 6 8 0 10 20 5-th -2 0 2 4 0 5 10 15 6-th -4 -2 0 2 4 0 5 10 15 7-th 圖 4-6 Iris AFD 第一鑑別向量收斂過程 由圖可以看出在收斂過程,群聚漸漸明顯。不但群與群之間越分越開,群內散佈 也越來越緊密。如下表:
with-class
variance class1 class2 class3 SUM Between-class
1-th 0.670 0.992 0.866 2.529 2.075 2-th 0.437 0.677 0.593 1.707 2.765 3-th 0.393 0.662 0.577 1.631 3.811 4-th 0.285 0.675 0.594 1.554 9.704 5-th 0.181 0.547 0.487 1.215 16.204 6-th 0.198 0.303 0.275 0.775 31.386 7-th 0.224 0.278 0.264 0.765 32.104 表 4-8 組內變異和組間變異 下圖為 Iris 資料在 AFD 四軸上的直方圖 -4 -2 0 2 4 0 5 10 15 1st -1 0 1 2 3 0 5 10 15 2nd 2 4 6 8 10 0 5 10 15 3rd 2 4 6 8 0 5 10 15 20 4th 圖 4-7 三類別在 AFD 四軸上的直方圖 AFD 第一向量 FLD 第一向量 PCA 第一向量 0.222 0.209 0.361 0.407 0.386 -0.085 -0.589 -0.554 0.857 -0.662 -0.707 0.358 表 4-9
35 AFD 演算法所求出的第一鑑別向量與真實 FLD 的第一鑑別向量,其夾角為 1 cos ( a b )3.6 a b ,而 PCA 第一向量與 FLD 第一向量夾角為46.8。雖然在高維空 間已經看不出向量夾角的幾何意義,但投影到兩個夾角很小向量,其座標可以確 定是很接近的。
4.2
Wine 實驗結果
Wine 資料有 13 維,取前四個 AFD 和 PCA 向量來畫散佈圖矩陣
-1 0 1 -2 0 2 -2 0 2 -2 0 2 -1 0 1 -2 0 2 -2 0 2 -2 0 2 圖 4-8 Wine 資料 AFD 散佈圖矩陣
-2 0 2 4 -5 0 5 -4 -2 0 2 -4 -2 0 2 4 -2 0 2 4 -5 0 5 -4 -2 0 2 -4 -2 0 2 4 圖 4-9 Wine 資料 PCA 散佈圖矩陣 上面兩圖搭配各軸比較如下表: 準確率(%) 1st 2nd 3rd 4th AFD 83.10 70.80 66.90 46.60 PCA 80.30 66.90 39.30 37.10 FCI 1st 2nd 3rd 4th AFD 10.927 8.85 8.875 6.082 PCA 8.774 7.228 2.722 2.821 表 4-10 Wine 各軸的 FCI 值和準確率
AFD 找出來的各軸準確率都比對應的 PCA 各軸來的好。可以發現到 AFD 第三鑑
別向量的 FCI 值雖大,卻沒有相應的準確率。先來看看鑑別向量大小(註:鑑別向
37 0 2 4 6 8 10 12 14 0 10 20 F C I 鑑 別 向 量 大 小 0 2 4 6 8 10 12 140 0.5 1 a c c u ra c y FCI accuracy 圖 4-10 Wine 資料各鑑別向量的 FCI 值與準確率 我們發現越大(越前面找出的)的鑑別向量,並不一定有較大的 FCI 值,也不一定有 較高的準確率。顯然,指標並不是完美的,然其大致上的趨勢還是足以採信。
4.3
軸數與分群數
上述實驗都是使用準確率做最後判斷的依據,那麼在未標記資料上該如何斷 定分群的優劣呢?這有幾個必須討論的方向:1. 資料該分成幾群 2. 要用多少個軸 來分群 3. 分群數與軸數都決定了以後,該怎麼挑選軸。 先看第三個問題,決定了軸數以後我們便選擇前幾大的鑑別向量,在之前的 實驗已經看過 FCI 值,越大(越先找出)的鑑別向量通常有越大的 FCI 值,越大的FCI 值通常有越高的準確率,Iris 的實驗結果也證實具有可信度,下圖為 FCI 值與
向量來比較。 0 10 20 30 40 0.4 0.5 0.6 0.7 0.8 0.9 1 FCI a c c u ra c y 0 0.2 0.4 0.6 0.8 0.4 0.5 0.6 0.7 0.8 0.9 1 Silhouette value a c c u ra c y 圖 4-11 Iris 資料 FCI 值和側影值 VS 準確率 隨機挑選的軸在側影值的大小上可以逼近甚至超過第一鑑別向量,然而在 FCI 值 的大小上卻很難逼近,這代表如果 AFD 演算法找出來的軸其 FCI 值較其他軸來的 大許多,那麼就是找到了最佳分群結果的鑑別向量。可以發現,Iris 資料的 FCI 值 或側影值對於預測準確率是相當不錯的,然而我們在 Wine 的實驗發現越大的 FCI 值,卻不見得有越高的準確率,這是因為在 Wine 資料上,指標的趨勢不像 Iris 資 料那麼明顯。隨機產生 200 個軸的指標對準確率作圖
39 0 5 10 15 0.4 0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 FCI a c c u ra c y 0 0.2 0.4 0.6 0.8 0.4 0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 Silhouette value a c c u ra c y 圖 4-12 Wine 資料 FCI 值和側影值 VS 準確率 如上圖,指標的大小無法精確的反應出 Wine 資料分群的準確率,猜測這是由於 Wine 資料原始的分類模型較為複雜,不易在線性轉換的空間用分群去近似。可以 看到圈起來的地方有不尋常的情形,這是由於 K-means 分群產生極不平衡的群集 大小所造成。 第二個問題,要使用幾個軸分群呢?來看看使用軸數與準確率的關係
1 2 3 4 0.88 0.9 0.92 0.94 0.96 0.98 1 軸 數 a c c u ra c y Iris 0 5 10 15 0.8 0.85 0.9 0.95 1 Wine 軸 數 a c c u ra c y 圖 4-13 AFD 軸數 VS 準確率 圖上顯示越多的軸不見得有越高的準確率,因此選擇適當的軸數便顯得重要,我 們從單一各軸的 FCI 值觀察: 1 2 3 4 0 10 20 30 40 軸 的 順 序 F C I 值 Iris單 一 軸 AFD PCA 1 2 3 4 0.4 0.6 0.8 1 軸 的 順 序 準確率 Iris單 一 軸 AFD PCA 1 2 3 4 0.85 0.9 0.95 1 軸 的 數 目 準確率 Iris多 軸 AFD PCA 圖 4-14 Iris 單一軸與多軸的準確率
41
從左上的圖可以看到不論是 AFD 或是 PCA 在第二軸以後,FCI 值有很大的落差,
因此可以研判,在 Irsi 資料中,第二軸以後便已經對分群無用了,從右上的圖可以 證實第二軸以後的單一軸分群準確率的確大幅下降,因此 Irsi 資料就使用一個軸分 群即可。最下邊的圖顯示只使用一軸的準確率的確是最高的。 1 2 3 4 5 6 7 8 910111213 0 5 10 15 軸 的 順 序 F C I 值 Wine單 一 軸 AFD PCA 1 2 3 4 5 6 7 8 9 10111213 0.2 0.4 0.6 0.8 1 軸 的 順 序 準確率 Wine單 一 軸 AFD PCA 1 2 3 4 5 6 7 8 9 10 11 12 13 0.8 0.85 0.9 0.95 1 軸 的 數 目 準確率 Wine多 軸 AFD PCA 圖 4-15 Wine 單一軸與多軸的準確率
在 Wine 資料中,可以看到 PCA 的 FCI 值在第二軸和第三軸之間有極大落差,代
表對 PCA 來說,取前兩軸就夠了,而 AFD 的特徵提取能力較 PCA 好,AFD 理所
當然不會比 PCA 還需要更多的軸,因此 PCA 取兩軸 AFD 也是取兩軸就夠了。
最後,分群的數目就使用側影值來決定,透過式(3.8),可以算出每次分群的側
影值,取發生最大側影值時的分群數,arg max ( )
2 3 4 5 6 7 8 9 10 0.4 0.6 0.8 1 Ir is 側影值 分 群 數 2 3 4 5 6 7 8 9 100.2 0.3 0.4 0.5 W in e 側影值 Iris Wine 圖 4-16 分群數 VS 側影值 Wine 資料透過側影值的判斷與真實類別數目一致,然而 Iris 側影值判斷為兩群, 事實上根據下圖,誤判為兩群確實有其道理。 1 2 3 4 5 6 7 0 0.5 1 1.5 2 2.5 Iris data X3 X4
43
4.4
結果比較
根據上一節決定了軸的數目之後,Iris 資料使用一個軸,Wine 資料使用兩個
軸。最後用第二章所提到的分群演算法及特徵提取法,進行實驗比較:
準確率(%) Kmeans Kmedois fuzzy C-means Ward
自然基底 89.33 92.67 89.33 89.33
AFD 98.67 98.67 98.67 96.67
PCA 91.33 91.33 91.33 90.00
FCI Kmeans Kmedois fuzzy C-means Ward
自然基底 7.641 7.191 7.622 7.593
AFD 33.804 33.804 33.804 33.245
PCA 15.628 15.628 15.628 15.394
表 4-11 Iris 資料總結果
準確率(%) Kmeans Kmedois fuzzy C-means Ward
自然基底 96.63 89.33 96.63 92.70
AFD 97.19 97.19 96.63 95.51
PCA 97.19 94.94 97.19 96.63
FCI Kmeans Kmedois fuzzy C-means Ward
自然基底 0.811 0.762 0.811 0.773
AFD 3.903 3.903 3.895 3.793
PCA 3.935 3.928 3.937 3.898
表 4-12 Wine 資料總結果
致上比 PCA 來的好,分群效果皆能有效的提升,並且 FCI 值在判斷分群準確率也 有一定的可信度。雖然在 Wine 資料我們由各種實驗圖可以看出,不論是 FCI 指標 還是側影值指標,都無法非常有效的反應準確率,對此也只能猜測 Wine 資料的分 散情形不是那麼的理想。 透過 AFD,也較能分辨出該分成三群: 側影值(SC) 分兩群 分三群 差距 百分比(%) 自然基底 0.865 0.739 0.126 14.57 AFD 第一軸 0.951 0.887 0.064 6.73 表 4-13 側影值改善情形 可以看出,側影值的差距縮小,代表在 AFD 第一軸上,三群群聚的情形比自然基 底中來的明顯,對於分成三群變得更有說服力了。
45
第五章
結論
主成份分析是一個很好的維度化簡方法,在同樣的維度上,能保有全部資料 最多的訊息,在迴歸應用上是個很好的特徵提取方法,然而對分群而言,資料全 部的訊息不見得是有幫助的,往往有許多對分群無用的變數,真正有幫助的是每 一群之間差異最大的訊息,因此本論文所提出的是一個訓練特徵的想法,我們應 用費雪線性鑑別分析提取並訓練特徵,透過不斷修正向量的方向,漸漸的給予原 始空間中重要變數較高的權重係數,這意味著不同方向的距離不再是一視同仁, 改變了距離量測的方式。實驗結果發現 AFD 演算法確實對分群準確率有幫助,能 找出對分群效果最佳的特徵。 透過特徵提取保留有用的少數特徵,也能減少分群系統的負荷,由於進行分 群最為耗時的步驟就是在於計算相似度,若維度很大,計算量將會很重,維度簡 化後的資料,將能減少大量的相似度計算時間。 本論文訴求的重點以及貢獻便在於針對分群給出有別於 PCA 的另一組正交基 底,並且能用最少的特徵保留大部分對分群有用的訊息,而且此正交基底各軸分 群的能力都較 PCA 來的好。用 AFD 找出基底後,並非用越多的軸就會有越好的 分群結果,這是因為少數的軸往往已經包含有用的全部訊息,剩下的軸含有過多 的雜訊,使用越多,越會干擾分群的結果。實際應用在 Wine 資料實驗中,我們發 現 FCI 指標無法很正確的反應出準確率,研判造成 Wine 資料發生不如預期情況的 原因如下:Wine 資料散佈情形不如 Iris 來的理想,或者說群距的邊界不是理想的 直線,這個原因導致了指標在這包資料上面的可信度下降。針對這點,我們期望 在未來改善分群的目標便在於:嘗試找出非線性的邊界。關於這個問題,近年來已有非常熱門的核化法 (kernel method),可以將資料轉換到另一個高維空間中,而
在此空間中,群聚邊界是線性的,至於要怎麼應用改善,便是未來的目標。若未
47
參考文獻
[1] J. B. MacQueen, "Some Methods for classification and Analysis of Multivariate
Observations," Proceedings of 5-th Berkeley Symposium on Mathematical
Statistics and Probability, Berkeley, University of California, pp. 1:281-297, 1967.
[2] L. Kaufman and P. J. Rousseeuw, Finding Groups in Data: an Introduction to
Cluster Analysis: John Wiley & Sons, 1990.
[3] J. C. Dunn, "A Fuzzy Relative of the ISODATA Process and Its Use in Detecting
Compact Well-Separated Clusters," Journal of Cybernetics, pp. 3:32-57, 1973.
[4] J. C. Bezdek, Pattern Recognition with Fuzzy Objective Function Algoritms. New
York: Plenum Press, 1981.
[5] A. R. Barakbah and Y. Kiyoki, "A pillar algorithm for K-means optimization by
distance maximization for initial centroid designation," presented at the IEEE,
2009.
[6] J. Duchene and S. Leclercq, "An Optimal Transformation for Discriminant and
Principal Component Analysis," transactions on pattern analysis and machine
intelligence, vol. 10, pp. 978-983, 1988.
[7] J. Han and M. Kamber, Data mining, first ed.: Morgan Kaufmann, 2003.
[8] 張智星. 資料群聚與樣式辨認.
[9] T. Hastie, et al., The elements of statistical learning: data mining, inference, and