國立臺灣大學文學院圖書資訊學系 碩士論文
Department of Library and Information Science College of Liberal Arts
National Taiwan University Master Thesis
以網絡書櫃資料建構讀者閱讀偏好多樣性之指標研究 The Estimation of aNobii User Reading Diversity
Using Book Co-ownership Network
柯逸凌 Yi-Ling Ke
指導教授:唐牧群 博士 Advisor: Muh-Chyun Tang, Ph.D.
中華民國 102 年 8 月
August, 2013
本論文獲國立公共資訊圖書館博(碩)士論文研究獎助
謝辭
論文的完成,象徵碩士班學習的休止符,感覺就像是自己設計的房子完工,
很有成就感而且心中充滿感激。
感謝唐牧群老師在研究中給予的幫助,您在我研究過程中熱心的指導與協助,
讓我能夠放手去做屬於自己的研究,而您時常迸發的靈感也讓我的研究變得 更精采可期,謝謝您。
感謝論文計畫書與學士論文口試委員林頌堅老師與吳怡瑾老師,你們給予的 建議讓我的研究得以與實際應用接軌。
感謝國立台灣大學圖書資訊學系全體教授長達八年的指導,你們在各個領域 帶給我的啟發與教導帶領我到達現在。
感謝我的研究室同學謝宜瑾與董采維,謝謝你們在每個過程中的熱心幫助。
感謝參與這個研究的 aNobii 讀者們,謝謝你們提供豐富的資料,讓我有機會 做這樣有趣的研究。
感謝在研究過程中協助我的每一個人,台大電機所的唐立宇同學,台大資工 所的彭維謙同學與台大資訊系的曹穎欣同學,謝謝你們在研究所需程式與資 料運算上的實質幫助。
感謝我的男朋友聞浩凱,謝謝你在各種安全與危險的時刻,不論是生活或課 業,一切因為有你而順利圓滿。
最後要感謝我的父母,感謝你們在學生生涯的照顧與包容,讓我能無後顧之 憂的快樂學習。
柯逸凌 2013.08.16
摘要
網路愛書人社群 aNobii 的興起,提供了讀者閱讀活動記錄的資料,讓我 們得以研究讀者的閱讀偏好,並因此提升系統的書籍推薦表現。過去研究
(Ross, 1999; Tang et al., 2012)藉由了解讀者的閱讀偏好結構,分析讀者的 閱讀活動。其中,閱讀偏好結構包含偏好發展、閱讀偏好多樣性與閱讀涉入 性。閱讀偏好多樣性在過去研究中顯示,對推薦書籍策略有影響,相較於其 他兩個閱讀偏好結構的面向,相較容易量化,因此本研究選擇閱讀偏好多樣 性為目標,希望藉由網路書櫃資料的建置,找出能呈現讀者閱讀偏好多樣性 的指標。
閱讀偏好多樣性的計算,我們抽樣 50 個網路書櫃,並建立書籍的共現網 絡,計算書籍間的相似性。接著,在 5 種相似性計算下,選擇 3 種分群方式,
針對抽樣的書櫃做分群,分群數量則作為讀者的閱讀偏好多樣性,分群數量 愈多,閱讀偏好愈多樣,反之亦然。由於過去研究顯示作者為重要的選書因 素(Mikkonen & Vakkari, 2012; Tang et al., 2012),我們同時建立作者共現網 絡,選擇書目計量學中計算研究跨領域多樣性的指標,以作者在個別書櫃中 的種類與其所占比例做為計算多樣性的依據。此外,利用作者共現網絡計算 作者間的相似性,將作者相似性加入多樣性指標的計算。為檢定個別書櫃分 群數量與作者多樣性指標是否能呈現讀者的閱讀偏好,研究針對 50 個抽樣書 櫃的擁有者進行問卷訪談,訪談結果則做為評量閱讀偏好多樣性的標竿。
研究結果顯示,Interminus 相似性測量的分群結果與讀者自評多樣性呈 顯著正相關,而作者多樣性指標結果則皆無顯著相關。Interminus 相似性測 量可大幅去除書籍僅被一個書櫃所擁有,而造成書籍相似性被扭曲的結果,
而其餘 4 種相似性測量之個別書櫃分群結果,除與使用者自評多樣性皆無顯 著相關,反之卻與個別書櫃之書籍總數呈高度正相關。綜上述,一般認為讀
者閱讀偏好多樣性與閱讀書籍總數有關,然而,本研究閱讀偏好多樣性結果 顯示,單從書籍總數無法判別讀者閱讀偏好多樣性,應進一步考量其閱讀書 籍的相似性,才能準確地呈現讀者的閱讀偏好多樣性。
關鍵字:閱讀偏好多樣性、社會網絡分析、書籍共現網絡、作者共現網絡
Abstract
Usage data available through social media provides a great many opportunities to capture users’ preference. Using books saved in users’ online bookshelves, the study set out to explore social network analytical methods to capture the diversity of a reader’s reading interests. “Reading diversity” denotes how widely scattered one’s reading interests are. Drawing from data from aNobii, a social networking site for booklovers, users’ reading diversity was defined by the number of components created by the book co-ownership network of the books in their bookshelves. A total of 50 user’s bookshelf data were collected, resulting in a total of 21,199 distinctive books. They were also asked to fill out a questionnaire designed to elicit three dimensions of their preference: “reading diversity”, “preference insight” and “involvement.”
Networks of the books were created where each node represented a book and the strength of their linkages were determined by five co-ownership based similarity measures: cosine, correlation coefficient, “normalized interaction”, and
“intersection-minus-1.” The thresholds for the dichotomization of the five respective similarity measures were then determined by a level above which where the greatest percentage of the disappearance of the edges, which were then applied to the individual bookshelves so the number of the components in each bookshelf could be determined. Correlation analyses were then performed between the user’s self-assessed reading diversity and the number of the components in her/his bookshelf. One of the proposed similar measures,
“intersection-minus-1” produced a clustering result that was significantly correlated with users’ self-assessed diversity. Furthermore, multiple repression
analysis showed the proposed measure was able to provide explanatory power over and above mere counting the number of books in the bookshelf.
Keywords: Reading Preference Diversity, Social Network Analysis, Book Co-ownership Network, Author Co-ownership Network
目 次
摘要 ... I
ABSTRACT ... III
目 次 ... V 表 次 ... VI 圖 次 ... VII第一章 緒論 ... 1
第一節 研究動機 ... 1
第二節 研究目的與問題 ... 4
第三節 名詞解釋 ... 5
第二章 文獻分析 ... 7
第一節 社會媒體與休閒閱讀 ... 9
第二節 推薦策略與偏好結構 ... 15
第三節 以網路分析法探討閱讀多樣性 ... 21
第三章 研究方法與步驟 ... 32
第一節 研究方法與架構 ... 32
第二節 研究實施 ... 36
第三節 研究範圍與限制 ... 48
第四章 結果與討論 ... 49
第一節 研究結果 ... 49
第二節 綜合討論 ... 66
第五章 結論與建議 ... 70
第一節 結論 ... 70
第二節 建議 ... 71
第三節 進一步研究之建議 ... 72
表 次
表 1 推薦策略 (Senecal & Nantel, 2004) ... 16
表 2 使用者偏好發展程度分組 ... 19
表 3 顧客偏好發展與推薦策略(Kwon et al., 2009) ... 20
表 4 研究論文詞語高頻分析網絡分析閾值使用之結構特性(林頌堅, 2010) ... 28
表 5 selected measures of diversity (Rafols & Meyer, 2010) ... 30
表 6 資料收集與研究結果比較架構 ... 35
表 7 偏好結構問卷之平均數與標準差 ... 37
表 8 抽樣書櫃統計資料 ... 49
表 9 Jaccard 最適閾值 ... 50
表 10 Inter 最適閾值 ... 51
表 11 Interminus 最適閾值 ... 53
表 12 Cosine 最適閾值 ... 55
表 13 Correlation 最適閾值 ... 56
表 14 Region 分群敘述性統計 ... 59
表 15 Region 分群相關性分析 ... 59
表 16 Block 分群敘述性統計 ... 60
表 17 Block 分群相關性分析 ... 60
表 18 Girvan-Newman 最佳分群最小值分群數敘述性統計 ... 62
表 19 Girvan-Newman 最佳分群最小值 Q 值敘述性統計 ... 62
表 20 Girvan-Newman 分群最小值相關性分析 ... 63
表 21 Girvan-Newman 最佳分群最大值分群數敘述性統計 ... 63
表 22 Girvan-Newman 最佳分群最大值 Q 值敘述性統計 ... 64
表 23 Girvan-Newman 分群最大值相關性分析 ... 64
圖 次
圖 1 本研究之研究架構 ... 21
圖 2 Schematic representation of the attributes of diversity, based on (Andrew Stirling, 1998),p. 41) ... 29
圖 3 aNobii 讓使用者建議該書分類之畫面 ... 34
圖 4 擷取抽樣書櫃中每一本書籍的所有書櫃擁有者,以「Whoops!!大債時 代」一書為例,這本書有 1195 個書櫃擁有者將其加入書櫃 ... 39
圖 5 book-owner 矩陣 ... 39
圖 6 Region 分群演算法 ... 42
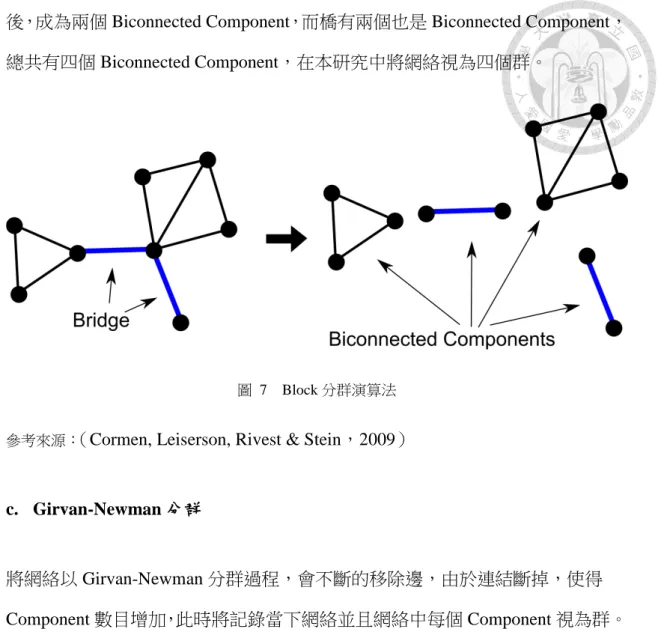
圖 7 Block 分群演算法 ... 43
圖 8 Girvan-Newman 分群演算法 ... 44
圖 9 Jaccard 最適閾值 ... 51
圖 10 Inter 最適閾值 ... 52
圖 11 Interminus 最適閾值 ... 54
圖 12 Cosine 最適閾值 ... 56
圖 13 Correlation 最適閾值 ... 57
第一章 緒論
第一節 研究動機
網路社群的盛行讓有類似興趣或嗜好的人們得以在其中進行交流或是進一 步成立社團,以愛書人網路社群為例,國內有 aNobii、iReading 等,國外則有 Library Thing。這些社團可讓讀者記錄其擁有的書籍、評分或發表書評等,透過 瀏覽閱讀偏好類似的其他讀者書櫃,或藉由社群網友推薦類似的書籍,愛書人可 以從自身的閱讀出發尋找延伸閱讀的目標。網路讀者社群創造了愛書人資訊偶遇 的機會,讀者可藉由社團中書與書、人與人、人與書之間的連結作為導覽
(navigation)途徑進行延伸閱讀。網路社群內讀者閱讀活動的紀錄連結可做為 了解閱讀活動的重要線索,並進一步成為閱讀推薦的重要參考資料。然而過去關 於書籍推薦相關研究,多以改善系統預測準確度為目標做改進(Bell & Koren, 2007; Bennett & Lanning, 2007),較少關注使用者間的互動情形以及使用者偏好結 構對系統效能的影響,而在許多電子商務網站推薦系統相關研究指出(Kwon, Cho,
& Park, 2009; Simonson, 2005),使用者的偏好結構與推薦策略之間有交互關係。
過去閱讀偏好結構研究關注的面向有偏好發展程度(Simonson, 2005)、偏好 異質性與閱讀涉入程度(Tang, Ting, & Sie, 2012)。其中,偏好發展程度為消費者 對自己於某類型產品的了解與偏好的穩定程度(Franke, Keinz, & Steger, 2009;
Kwon et al., 2009; Simonson, 2005),如果應用於閱讀,所指則為讀者是否已清楚 發展出自己偏好的閱讀類型,或是並未發展出特定偏好、不清楚自己喜歡閱讀的 是什麼;除了自我了解與穩定度之外,本研究提出閱讀多樣性作為偏好結構的另 一面向,多樣性指讀者偏好閱讀類型的多寡,讀者是否執著固定於少數閱讀文類,
亦或不限於某一類作品或作者。我們認為閱讀偏好的多元或單一性可能影響書籍 的推薦策略。閱讀偏好單一的讀者,由於其閱讀集中於固定文體、追隨固定作者,
若給予新奇性較高的書籍,讀者的接受程度可能不高;而之若為閱讀偏好較多元
的讀者,通常較願意嘗試新事物,因此非顯而易見(non-obviousness)符合其閱 讀偏好的書籍推薦可能更吸引該類讀者。
然而,過去關於使用者閱讀偏好結構之研究僅使用問卷調查作為研究方法 (Tang et al., 2012),若欲對休閒閱讀讀者之閱讀偏好結構多樣性進行一般性之調 查,因讀者數目過多,實不適合採用使用者調查研究。回顧使用者偏好之研究,
以音樂、電影為主題之研究,新近大量利用社會網絡分析,從使用者資料分析使 用者的興趣偏好(Bell & Koren, 2007; Bennett & Lanning, 2007; Buldú, Cano, Koppenberger, Almendral, & Boccaletti, 2007; Tang et al., 2012)。本研究嘗試以社會 網絡分析方法探索讀者偏好結構多樣性的指標。因考慮閱讀偏好結構的眾多面向 中如涉入性、閱讀發展程度,多樣性為最容易被量化測量之指標,亦可能對閱讀 推薦策略選擇有影響,因此本研究於閱讀偏好結構上,將以閱讀偏好多樣性為分 析目標。
若欲分析讀者偏好結構之多樣性,需要藉由在資訊豐富的平台上收集資料,
並於其中探索適合作為分析讀者閱讀偏好結構多樣性之指標。aNobii 為結合科技 性與社會性的個人書櫃管理平台,不但記錄了個別讀者的藏書,也記錄了人與人、
人與書之間的關聯,且使用者眾,是目前最多華人使用的閱讀分享社會網絡。讀 者可以在 aNobii 中建立自己的閱讀清單,並且能夠撰寫評論、給予閱畢書籍評 分,更能進一步藉以網路書櫃作為媒介與其他讀者互動(如傳送訊息)、分享資 訊(如邀請參加閱讀社團)。此外,在選書的過程中,讀者亦能參考資訊線索如 書評、評分、系統推薦輔助其選書決策。於現今之資訊環境中,讀者之閱讀偏好 結構多樣性為讀者選書之關鍵,若欲進行客觀、量化之閱讀偏好一般性研究,需 大量收集讀者的閱讀記錄,因此本研究選擇 aNobii 作為探索閱讀偏好多樣性之 研究場域。
本研究於 aNobii 利用網絡分析法中使用節點與連線的方式蒐集資料,本研 究將網路書櫃的書籍作為網絡中的節點(node),書籍之間共同出現在同樣的書 櫃作為連結(edge)的依據,共同出現的次數則做為連結的權重(weighted),以 連結的強度作為書籍間的相似性(similarity)。接著,對個別書櫃利用 UCINet 之 Region、Block 與 Girvan Newman 進行個別書櫃的分群,最後以個別書櫃中的 集群種類與數量作為書櫃多樣性(diversity)的判斷依據,以個別書櫃內集群數 量做為判別多樣性之依據。
除使用網絡分析方法測量多樣性之外,亦可使用書目計量學分析方式。書目 計量學中常使用多種多樣性指標如 Simpson’s Diversity、Gini 與 Shannon’s Entropy 測量學術跨領域的情形(Rafols & Meyer, 2010);於閱讀偏好相關研究中,尚未存 在普遍採用於測量多樣性之指標。書目計量學中藉由分析引用文獻之多樣性,測 量期刊文章或作者研究跨領域的情形。而論文作者引用其他多篇不同領域論文與 讀者閱讀多本不同類型書籍,兩種情形於形式上相似,因此有可供參考之處,故 本研究嘗試類比書目計量學之多樣性至閱讀偏好中,採用書目計量學之多樣性指 標作為測量閱讀偏好多樣性之依據。
綜言之,本研究欲從網路書櫃中書籍的分配、書籍網絡的集中與分群情形,
並採用上述兩種方法,探討讀者的閱讀偏好多樣性,期未來能夠對書籍推薦與相 關個人化服務有所助益。
第二節 研究目的與問題
本研究欲從讀者的網路書櫃出發,目的為利用網絡分析法與書目計量學多樣性指 標分析呈現讀者的閱讀偏好多樣性。
一、本研究欲分析書籍間的關聯性,利用共現矩陣進行相似性測量(similarity measurement)後之相似性矩陣(proximity matrix)分析書籍間的關聯性,並進 一步利用網絡分析法針對個別書櫃進行分群。接著,利用個別書櫃內分群數量作 為判斷多樣性之依據,呈現不同書櫃(代表讀者偏好結構)多樣性。根據以上目 的,本研究的研究問題如下:
(一)進行相似性測量之共現矩陣,呈現讀者閱讀偏好多樣性之最適閾值為何?
(二)選擇閾值後,經由分群之結果,是否能呈現讀者閱讀偏好多樣性?
二、學術文獻分類中常使用主題詞與作者作為分類的依據,在休閒閱讀的範疇內 重要的分類方式則為作者。由個別書櫃作品集中於特定作者的程度判別多樣性,
藉此呈現不同讀者偏好結構多樣性。
此外,過去判別多樣性僅以不同種類作為判別多樣性之依據,由於不同種類間亦 有較相似與較相異種類的差別(degree of difference),因此本研究嘗試加入種類 相似性(disparity of similarity),即以作者與作者間的相似程度,探索加入種類 相似性之後的多樣性指標是否更能準確測量讀者閱讀偏好結構多樣性。
(一)作者作為多樣性分析依據,Simpson’s Diversity、Gini、Shannon’s Entropy 三種多樣性指標是否能呈現讀者的閱讀偏好結構多樣性?
(二)Stirling’s Revised Diversity 加入作者共現矩陣作為作者(類別)間距離作 為多樣性指標,所得結果是否更接近讀者自我評量之多樣性指標?
第三節 名詞解釋 一、休閒閱讀
與一般常見資訊行為不同,閱讀的動機非起源於完成任務。讀者帶著自發性的閱 讀渴求,依據情緒、情境、想獲得的閱讀經驗等尋找閱讀材料,進行閱讀行為。
二、社群媒體
社會媒體(Social Media)是人們能夠分享與交流意見、心得、見解、想法與觀 點的平台。與過去傳統媒體不同處為社會媒體是大眾可參與發聲的媒體,對於媒 體內容擁有更多選擇與編輯的權力,並能自行集結成閱聽社群。
三、網絡分析
於此本研究所指為社會網絡分析(Social Network Analysis)。社會網絡分析利用 網路理論(network theory)來分析社會關係(social relations),常把關聯(relation)
利用節點(node)和連線(tie)來分析。它是一種跨領域研究,結合多種概念如 圖論、理論模擬、認知分析等了解不同的網絡特性。本研究嘗試用社會網絡分析 的概念來分析 aNobii 使用者的書櫃。
四、偏好結構
由消費者行為領域的研究延伸而來的使用者變項,泛指人們於某類型產品之個人 偏好特質,涵括個人偏好特質的各種不同層面。過去研究之閱讀偏好結構包括偏 好異質性、偏好發展程度、產品涉入程度等三種面向。於本研究中僅採用偏好異 質性(homogeneity)之概念,但與書目計量學中之多樣性指標結合,稱為多樣
性(diversity)描述閱讀偏好結構中的多樣性程度。
五、多樣性
多樣性是書目計量學中分析研究跨領域常用指標,用以測量學術研究跨領域的程 度。於本研究中,多樣性(diversity)可由三個性質來考慮:種類(variety)、平 衡(balance)與差距(disparity)。種類是指不同類別(distinctive categories)的 數量,平衡為類別的分布或是平均程度,差距是指類別與類別中的差別。
第二章 文獻分析
與任務導向的搜尋行為不同,休閒閱讀讀者所追尋的是閱讀過程中能獲得的 經驗,而非特定主題的知識。因此,讀者所處的環境或個人情緒等主觀因素可能 導致閱讀經驗與選書因素的改變,故休閒閱讀讀者的資訊行為,和取用與學習某 領域知識或解決特定問題等任務導向的資訊行為有相當大的差異。在過去休閒閱 讀讀者的資訊環境,讀者常從自己的信賴來源如朋友處找到感興趣的書籍。另外 也有其他管道,譬如讀者可在圖書館的 OPAC 查找瀏覽、或藉由瀏覽網路書店找 到感興趣的書籍。而隨著社會媒體的興起,也有愈來愈多的讀者透過這個管道獲 得新書的訊息,除提供更豐富的尋書管道,使用者在社會媒體上的活動資料,也 成為分析使用者偏好的一個重要來源。現在的社會媒體就像是富含資訊的資訊生 態系統,網際網路打破了距離的藩籬,數位化儲存的資料記錄了使用者的各種活 動歷程,對資料進行適當分析後將可探勘出使用者的使用情形並提供多種應用,
例如若能改善資訊系統的表現將能讓使用者能更容易互動或進行資訊交換,或是 在了解使用者偏好後使用適當的策略進行推薦或行銷等。讀者可加入閱讀社群或 在社群中藉由朋友(的書櫃)遇見喜愛的書籍,或在社群網站中書籍之間的關連 找到「你可能感興趣的書」。讀者本身可能希望搜尋的過程能輕鬆方便,而圖書 館員、書籍出版與銷售者,尤其是電子商務網站為了提供更好的服務與銷售,皆 希望能在了解讀者在資訊環境的尋書過程後進行自動化分析而成為推薦系統,因 此本研究希望能探索非干擾式的資料分析方法了解讀者的偏好結構,讓休閒閱讀 的尋書推薦能夠更符合需要。
而讀者喜歡推薦書籍與否與其閱讀偏好與偏好結構有關,(Franke et al., 2009;
Kari & Hartel, 2007; Kwon et al., 2009)其中偏好結構包含偏好穩定度或自我察覺 度等因素影響(Simonson, 2005; 謝宜瑾, 2012)。近來於行銷研究的文獻中也有學 者發現偏好結構對於個人化推薦工具效能的影響(Kwon et al., 2009)。本研究欲透
過休閒閱讀讀者常用的社會媒體觀察休閒閱讀的讀者閱讀偏好結構,研究結果期 能在未來的休閒閱讀推薦系統發展上,對不同的閱讀偏好與偏好結構使用適當的 策略,推薦使用者可能感興趣的書籍。基於上述目標,首先必須尋找合宜的社會 媒體並選用適當的方法來進行分析。本研究選擇了網路書櫃服務 aNobii.com 作 為分析讀者偏好的場域。關於讀者的偏好結構分析,本研究將採取兩種嘗試,第 一是社會網絡分析,利用書櫃內書籍共現矩陣(co-occurrence matrix)建立書籍 間連結,並使用正規化(Normalize)共現原始資料(raw)形成正規化後之共現 矩陣(normalized co-occurrence matrix)與多種分析網絡結構(structure)之相似 性測量(similarity measure)形成之相似性矩陣(proximity matrix),建立書籍連 結的強弱關係,並根據關係將其分群(clustering)呈現該讀者之偏好結構。其二 是使用書目計量學指標分析作者的多樣性,並利用作者相似矩陣考慮作者間的相 似性以探究個別書櫃內的作品多元程度。最後本研究將上述兩結果和使用者自我 評估(user self-assessment)的閱讀偏好多樣性做驗證,期望能找出最適之偏好 結構分析方法,方能在未來使用非干擾式(non-intrusive)之資料收集分析使用 者之休閒閱讀偏好結構,並對休閒閱讀推薦系統之推薦策略選擇、個人化推薦有 所助益。以下就研究主題相關之社會媒體與休閒閱讀、推薦系統偏好結構與網絡 分析法分析閱讀多樣性三面向分述。
第一節 社會媒體與休閒閱讀 一、休閒閱讀
傳統上,圖書資訊領域資訊行為的研究多著重於使用者解決特定問題
(problem-solving)、執行特定任務(task)的資訊尋求與資訊利用,其中更以協 助學術、教育環境中的資訊使用者為主。然而在讀者進行休閒閱讀活動的情境下,
並無任務導向的檢索目標。(Xu, 2007)將非問題導向的資訊檢索與過去問題導向 的研究做比較,研究目標為了解使用者在非問題導向的情境下,其資訊檢索的相 關判斷是否有所不同。研究結果發現,使用者在非問題導向的情境下確實著重不 同的相關判斷標準。此種非以完成特定任務為目標之資訊行為(Kari & Hartel, 2007; Ross, 1999),在圖資領域也較少被討論。休閒閱讀與一般常見資訊行為不 同,在休閒閱讀的過程中,讀者並非尋找某本明確的書籍,有時候只是一個單純 的閱讀慾望,或欲獲得特定閱讀經驗等難以清楚描述的動機,驅使讀者產生閱讀 需求。由於休閒閱讀需求起源目的性較薄弱,更由於休閒性的資訊需求應考慮使 用者偏好及作品內容,讀者常需要結合多種不同的相關判斷方式作為選書標準 (Pejtersen & Austin, 1983),如主題、背景架構、作者目標、可及性等,此種資訊 行為與任務導向的資訊行為有相當大的差異。
(Lancaster, 1998)提及休閒閱讀:「相較於一般在書目資料庫中使用主題搜尋 以尋找期刊文章類的資訊,讀者在搜尋休閒作品時的判斷標準會更為個人化,也 更為主觀而難以預測。」因此圖書館欲提供良好休閒作品的主題檢索有困難,也 讓休閒閱讀讀者在尋找讀物時更倚靠非正式管道與人際網絡取得資訊(林珊如, 2001)。(Hopper, 2005)在青少年的休閒閱讀研究中指出朋友間口耳相傳對於青少 年休閒讀物的選擇是一重要因素,而(Ross, 1999) 也指出讀者通常仰賴其他資訊 來源如朋友或評論來幫助他們發現和決定閱讀目標。此外,愛書人不僅會進行大
量的閱讀,亦會支持助長與拓展他人的閱讀經驗。因此提出閱讀是社會活動的觀 點:我們會影響朋友的閱讀;而朋友的閱讀也會影響我們。於 aNobii 的長期研 究結果更為社會網絡在閱讀上的社群面向提供了實證。(Aiello, Barrat, Cattuto, Ruffo, & Schifanella, 2010)此外,其中更發現,隨著書櫃間連結間的增加,書櫃 之間的相似性也會增加。而使用者在與其他使用者互動的過程之中,能夠找到新 的閱讀材料、參與新的閱讀社團,而這些活動更造成讀者閱讀檔案的變化,可能 使得這些人的閱讀檔案更接近,而書櫃間的相似性會提高(Ross, 1999)。
(Ross, 1999)針對休閒閱讀的質性研究中整理了下列五點休閒閱讀讀者選書 時著重的因素 1. 當下欲獲得之閱讀經驗 2.取得新書資訊之管道 3.書籍本身要 素 4. 書籍提供讀者可能獲得之閱讀經驗的線索 5.書籍取得成本。綜合以上五點,
休閒閱讀讀者重視的是在閱讀過程中能獲得的經驗,而非得到特定主題或問題的 相關資訊。因此讀者當下所處的環境或個人情緒等因素可能不僅導致選書因素的 改變,亦可能改變閱讀經驗。故作品本身的內容主題與其能帶給讀者的閱讀經驗 並非絕對相關。因此面對讀者從事著重閱讀經驗的休閒閱讀而非對特定主題尋求 資訊與知識時,要連結作品內容資訊與讀者閱讀後可能得到的感受顯得較為困難。
(Tang et al., 2012)指出儘管閱讀通常被視為一項單獨存在的活動,而事實上它通 常發生在社會關係網絡上,且現在可以透過社會媒體網絡連結大量拓展。因此下 段將就人際網絡與資訊交換發生的重要場域—社會媒體進行回顧分析。
二、社會媒體
社會媒體(Social Media)是人們能夠分享與交流意見、心得、見解、想法 與觀點的平台。現今主流社會媒體主要是基於網路或移動科技將溝通方式轉變為 組織、個人或社群之間的互動對話。而社會媒體的發展,讓大量實體的社會活動 可在社會媒體上實現,也創造了新的傳播工具及方法。一般而言,由於具有無遠 弗屆的特性,社會媒體讓社會交流活動的進行變得更便利、豐富。因此社會媒體
可讓社會媒體上的資訊傳達變得容易,也更不受時間地點的限制。而現今社會媒 體通常可夾帶多媒體資訊,使得資訊的傳達方式變得更豐富多變。社會媒體與傳 統媒體的差異在於傳播結構、近用能力與專業要求,傳統的媒體-如電視與廣播,
組織結構為中央集權;媒體的內容走向由業主掌握,目標通常為大量宣傳或生產 銷售;而通常接受較高的專業要求。社群媒體則通常扁平無階層或較少階層,依 照使用的需求而定;社群媒體通常免費或低價供社會大眾使用,如眾多網路部落 格可免費申請;而社群媒體的內容發佈者通常不需專職,只需貢獻社群有需要的 內容即可。其中社群媒體的重要轉捩點在 Web 2.0 觀念的興起,使用者可以上傳 自己的數位內容與其他人分享。在 Web 2.0 後的社會媒體上,資訊發佈者與資訊 接收者之間的角色可以隨時轉換,更多人可以參與社會媒體上資訊的發佈,讓社 會媒體逐漸成為人與人之間重要而獨特的互動方式,社會媒體已成為資訊行為與 交流的重要場域。
透過網際網路與社會網絡,人際關係的發展更可以不受地理空間的限制。如 (Preece, 2001) 對網路社群的定義即為「在虛擬空間從事資訊交換、相互學習、
相互支援或找尋同伴的一群人,無論其規模大小為何,而此社群可能為當地、國 內或是國際性。因此在打破距離的限制後,透過網路上的社會媒體,不但可以聯 絡因距離而分開的朋友,也可能認識實體生活圈外的同好。如(Armstrong & Hagel Iii, 1996) 從成員組成的參與需求做區分網路社群的類型中的興趣社群(interest community),(Armstrong & Hagel Iii, 1996)定義興趣社群為對某一主題有共同興 趣或專長的人為討論該興趣或專長,而聚集起來之群體。如網路上喜好閱讀者可 能會瀏覽閱讀相關討論區並在討論區發表,或是透過社會媒體記錄與分享他們擁 有或閱讀的書籍,網路書櫃服務即是此例。透過網路書櫃的分享,網路書櫃的使 用者可能有不同選書與閱讀行為(丁培涵, 2011)。
從之前對於休閒閱讀的討論可以得知,休閒作品分類囿於讀者需求的多層面 複雜本質而有其困難之處(Pejtersen & Austin, 1983),而書籍在排架上亦只能依照
最能反應讀者需求的小說文類主題(Genre)作為分類系統,但分類標準依據亦 難以界定(Pejtersen & Austin, 1983),由於傳統的主題式資訊檢索在面對休閒性資 訊需求時所能達到的效能不高,相對於主題檢索人際網絡往往成為讀者取得閱讀 資訊來源的管道。(Dourish & Chalmers, 1994)提出了社會導覽(Social Navigation)
的概念。社會導覽是指物品與物品間關連參考的資訊蒐集的導覽(瀏覽過程)是 透過社會媒體社群中的成員行為而達成的。(Dieberger, Dourish, Höök, Resnick, &
Wexelblat, 2000)擴大社會導覽的解釋,讓透過社群成員中的相互協助而來的導覽
(瀏覽過程)亦是屬於社會導覽的範疇。如利用 Del.ici.ous 分享網路書籤即是 一種對於網站的廣義社會導覽。而(Svensson, Höök, Laaksolahti, & Waern, 2001) 則進一步區分直接社會導覽與非直接社會導覽。直接社會導覽需包含資訊需求者 與提供者的對話。非直接社會導覽則是資訊需求者從提供者留下的訊息或線索先 幫助使用者。不僅社會導覽在社會媒體中變得益加受歡迎,社會導覽配合社會媒 體更發展出了社會過濾(social filtering)的導覽行為。社會過濾並不主要關注使 用者喜歡什麼,而是去關注該使用者的朋友喜歡什麼。因此過去電子商務網站從 使用者的決定(選擇)推斷其偏好,發展成可透過使用者的朋友或相似偏好者一 起分析其偏好。
三、網路書櫃服務與 aNobii
網路書櫃服務是社會媒體應用在書籍及閱讀的一個實例,使用者不僅可以在 網路上記錄他擁有的書籍,亦可發表書評或對書籍評分,更可能透過找尋相似的 書櫃認識新的朋友或是找到感興趣的休閒閱讀圖書,這是傳統實體互動較難達到 的互動方式,因此為本研究非常適合的場域。而目前網路上較知名的網路書櫃服 務有 aNobii、BookArmy、douban(豆瓣)、LibraryThings 與 Selfari 等。
在網路書櫃服務中,本研究選擇了 aNobii 作為分析的資料來源,aNobii 為 創立於香港的網路書櫃服務,但因網路無遠弗屆,主要使用群來自義大利、台灣、
西班牙和香港(Aiello et al., 2010)。aNobii.com 為台灣讀者使用率最高的網路書櫃,
在 (李書萍, 2012)的研究中將目前台灣常見的網路書籍管理與書評發表平台做調 查,該調查中使用網路書籍管理(網路書櫃)中的使用者使用 aNobii 的比率約 佔 83%,由此可見 aNobii 在台灣網路書櫃的代表性,會有如此高佔有率的原因 是因其中文支援度佳、且書目資料更新快又豐富,幾乎不需自行輸入資料,也 aNobii 不僅提供的藏書登錄管理系統,亦有評分與書評撰寫的功能,可在同一網 站下完成多項書及相關紀錄與筆記功能,因此廣受愛書人歡迎。
aNobii.com 的內容主要由個人檔案(profile)、我的書櫃(book collection)
與聯絡人(relations)3 種元素所組成,個人檔案可讓使用者選擇性的揭露性別、
年齡、地點等個人資訊;我的書櫃為主要網路書櫃服務部分,使用者可以利用 ISBN 大量匯入個人書籍,管理個人閱讀進度、評分並利用標籤分類,並可整理 發表個人閱讀心得等。聯絡人可設定朋友與鄰居書櫃,鄰居書櫃是指非朋友但關 注的書櫃。個人書櫃為此平台之服務核心,使用者將欲閱讀、正在閱讀或已閱畢 之書籍加入其網路書櫃,使用者在書櫃中點選某一書籍除可瀏覽書籍基本資料外,
亦可看到有哪些書櫃擁有此書;而點選他人書櫃,可以看到該使用者擁有的書籍,
亦可知道該書櫃與自己書櫃的「品味相似度」,品味相似度為 aNobii 提供兩書櫃 是否相似之指標,但其計算方式為統計兩書櫃中共同擁有書籍的數量,然而此種 方法過於簡單,未考慮書櫃數量大小差異等基礎因素,僅能作讀者參考基礎,未 能準確真實描述書櫃間的相似程度。除了相似書櫃之外,使用者在進入首頁時讀 者也可以看到朋友或其他 aNobii 使用者目前新加入的書籍或書評,讀者或可從 其中挑選其可能會喜歡的書籍作為休閒閱讀目標。因此目前 aNobii 使用者的尋 書流程是以書櫃為基礎,可能是看到其他使用者的新活動,或是瀏覽朋友或鄰居 書櫃,亦或是從自己的書籍中看到其他同時擁有此書的陌生人,進入上述對象的 書櫃後,瀏覽該書櫃可能感興趣的書籍。
四、小結
休閒閱讀的讀物尋找過程並非回答特定問題或滿足特定目的,而是受讀者心 中的情境、人際網路及信賴來源等影響,因此較難用目錄服務如圖書館線上公用 目錄(OPAC, Open Public Access Catalog)或是網路關鍵字搜尋找到喜好的休閒 閱讀讀物,而往往仰賴朋友或同好的推薦;網際網路環境下發展的社會媒體,讓 社會媒體有了無遠弗屆、多媒體、互動等特性。因此過去休閒閱讀尋書資料來源 將不受實體生活環境中時間地點的限制,可以結交不同地區朋友或得知不同國家 的專家意見。社會媒體應用在書籍及閱讀的一個實例即為網路書櫃服務,使用者 在自己書櫃中瀏覽書籍基本資料、查閱擁有此書的書櫃;在他人書櫃查看該使用 者擁有的書籍,讀者可透過以上方式尋找休閒閱讀目標讀物。因休閒閱讀與讀者 偏好息息相關,而從朋友或他人書櫃中挑選可能喜好的書籍,廣義來說亦是一種 推薦。綜言之,社會媒體對愛書人的影響可分為兩個面向:取用面與決策面。取 用面方面愛書人藉由社會媒體獲得了直接(從朋友書櫃)與間接(藉由社會式過 濾)的方式取得閱讀的材料;決策方面則受到社會媒體中資訊如書評的影響,兩 面向關連複雜多樣,於下節回顧。
第二節 推薦策略與偏好結構 一、推薦策略
在生活中許多時候我們必須在欠缺足夠資訊或經驗下做出決策,此時往往會 倚賴其他人的推薦,而推薦有許多種形式—可能是親朋好友的經驗與口碑,亦可 能是報紙或名人的評論。書店中銷售排行榜或是新上架書籍陳列平台是熱門商品 推薦及新奇商品推薦,詢問愛看書或電影的親朋好友最近是否有好看的新書或電 影,或是針對特定的研究領域請教該領域的老師或教授列出書單則是專家推薦。
「熱門商品推薦」或「專家推薦」為某一種推薦策略(Recommendation Strategy),
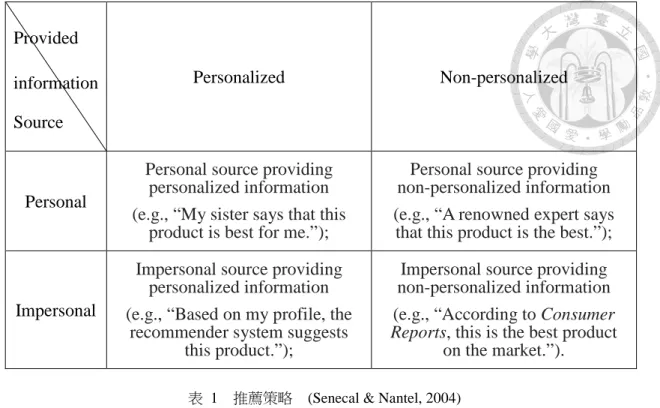
即是為何推薦某一商品的依據或方法。推薦即是整合並轉換各種資料來源,使用 不同推薦策略將資料變成可供使用者參考之資訊。傳統之推薦是銷售人員藉由詢 問顧客需求,根據其需求給予顧客適當的建議。而推薦系統則是利用程式處理資 料,從資料中嘗試分析使用者的偏好結構,進而瞭解使用者個人對產品偏好後根 據推薦策略進行推薦。因採用程式處理資料,可同時處理大量的使用者需求。在 網路購物平台中,基本的推薦策略如銷售排行等可以方便且即時的透過銷售程式 統計,亦不需要額外的成本,因此幾乎所有的電子商務網站都有如銷售排行等基 本的推薦策略。而隨著社會媒體與電子商務的發展,使用者的購物歷程與個人基 本資料(如年齡、性別、居住區域等)能夠以數位化的形式儲存,根據這些歷程 與個人資料,可以利用電腦分析計算後可採用更複雜或個人化的推薦策略來進行 對不同消費者的推薦。(Senecal & Nantel, 2004)將推薦資訊來源區分個人資料與 非個人資料,亦將推薦策略分為個人化與非個人化,形成四種不同面向,如下表。
Provided information Source
Personalized Non-personalized
Personal
Personal source providing personalized information (e.g., “My sister says that this
product is best for me.”);
Personal source providing non-personalized information (e.g., “A renowned expert says
that this product is the best.”);
Impersonal
Impersonal source providing personalized information (e.g., “Based on my profile, the
recommender system suggests this product.”);
Impersonal source providing non-personalized information (e.g., “According to Consumer Reports, this is the best product
on the market.”).
表 1 推薦策略 (Senecal & Nantel, 2004)
(Simonson, 2005)指出若銷售者能進行適切的客製化推薦、推薦能貼近使用 者的個人偏好,將能大幅增進銷售者與顧客的關係,發揮潛在的顧客價值,這也 是各網站紛紛進行推薦策略研究的原因。此一現象也從各大購物網站,包括以書 籍 銷 售 出 發 的 亞 馬 遜 書 店 ( Amazon.com ) 與 線 上 影 片 出 租 的 奈 飛 公 司
(Netflix.com)都紛紛引入推薦系統並投入推薦系統的研究可見一斑。
而現今推薦系統常使用的個人化推薦策略大致上可區分為內容式推薦
(content-based)與協同過濾(collaborative filtering)。內容式推薦分析使用紀錄,
比對使用者曾經使用之產品或服務推薦具相似性的商品,將使用者的使用的單一 產品記錄視為偏好的象徵;協同過濾則是使用全部群體的資料集合,將使用者所 使用的所有產品紀錄作為偏好的代表,從群體中找出相似的使用者集合,並對集 合中使用者普遍擁有但推薦目標使用者未擁有的商品進行推薦。此種從使用者群 中找出行為相似的使用者進行推薦,又稱作社會式過濾法。
過去休閒閱讀選書行為相關文獻,閱讀偏好是重要的選書影響因素,在產品 涉入較少、閱讀經驗較不豐富的讀者,可能因對類型、作者或資訊來源較不了解
或確定,較難做出選書抉擇;而經驗豐富的讀者則有更高的閱讀動機,想要興趣 的閱讀目標,因此也更常認為推薦系統是有價值的(Ross, 1999; Tang et al., 2012)。
一般而言,對於推薦系統皆採用下列假設(Peppers, Rogers, & Rogers, 1999):經由 使用者給予的外顯或內隱式回饋,系統可以建立使用者之個人偏好,故獲取使用 者偏好的效果與效率可決定推薦系統的能力。
因此,讀者在網路書櫃如 aNobii 找尋休閒作品時,若推薦系統與策略能參 考使用者個別偏好結構與群體資料,推薦符合使用者需求的書籍,能在讀者尋找、
判斷閱讀材料時產生助益。因此下小節將回顧關於偏好結構之文獻。
二、偏好結構
無論是要推薦消費者購買商品,或是廠商要設計產品或行銷,都需要知道消 費者喜歡什麼,因此消費者的偏好結構是一項被廣泛研究的主題。在讀者從事休 閒閱讀時亦同,讀者會根據他本身的閱讀偏好結構挑選喜歡或是可能喜歡的書籍 來閱讀。有學者指出進行休閒閱讀與推薦相關的研究,可能必須關注消費者或讀 者的偏好結構。在早期經濟學界對偏好結構的研究中通常假設使用者的偏好為固 定不變的,並且使用者知道其偏好為何。推薦系統或銷售人員是逐漸了解該使用 者已發展的固定偏好,而使用者會了解其偏好,且無偏好的發展過程,此種為穩 定性偏好,(Simonson, 2005)認為人們面對熟悉、簡單、較直接經驗的狀況時通 常有穩定的偏好;。這種情形與人們對經驗的存取有關,若是熟悉的情境,人們 傾向依賴經驗法則進行判斷,不會仔細評估。
然而研究指出,使用者對自己的偏好或需求不一定清楚明確,在早期資訊系 統中常需要中介者的角色(例如:圖書館員的參考服務)來輔助使用者釐清自己 的需求並將其轉換至資訊系統中查詢(Taylor, 1962)。此外偏好或需求亦會受到環 境或決策過程影響,如(Bettman, Luce, & Payne, 1998)認為偏好並非固定不變的狀
態,而是會經由刺激產收,或受到任務類型、時間各種因素的影響。消費者行為 領域也對此做出研究,產品的選擇或偏好往往是與當下目標、環境與情境、個人 特質與自我認知等等因素交互影響下的結果。因此,同一使用者在不同的環境與 情境,或是不同使用者在相同的情境與環境下,其偏好與選擇皆會有不同。隨著 對產品的了解或使用者對自己的了解增加,可能會做出不同的決定,因此產生了 偏好建構: 消費者的偏好是發展而來,而非過去所認為總是固定且清楚的。
(Bettman et al., 1998; Haubl & Murray, 2003; Kramer, 2007)以休閒閱讀領域為例,
此一假設亦非常適用,讀者並非帶著明確的閱讀需求,而往往在接觸某類型作品 後才找到該類型中自己最喜歡的作家或書籍,且在實際閱讀前其實並不確定該作 家或某本書是否會讓他著迷。在休閒閱讀的情境下,商品(書籍)的價值是基於 主觀的判斷,在使用者尚未親自使用、經驗性之前,都無法了解商品的價值,此 種商品稱為經驗性商品。經驗性商品能滿足情緒感官經驗(Holbrook & Hirschman, 1982),但無法用明確屬性和因素做比較。文化事業相關活動或商品為偏向經驗 性商品,在使用商品之前,使用者較無法確認對此商品的評價。書籍亦是一種經 驗性商品,每個人對書籍的價值看法有所不同,在尚未閱讀前也無法確認自己是 否喜歡一本書。此種面對不確定性高之經驗性商品的歷程,由於難以藉由客觀條 件或主觀判斷確認商品是否符合需求,傾向尋求他人的評價。
(Simonson, 2005)針對上述偏好變動的現象進行觀察並提出了偏好發展的理 論。此理論挑戰過去偏好既存且不變的假設,亦即消費者可以判斷何種商品最能 符合其需求。當消費者面臨了商品或是推薦商品時,往往因為受到主觀與情境因 素影響其決策反應與結果:偏好發展程度、與銷售人員的信任關係、商品的展示 形式等。針對偏好建構與偏好發展(preference development),(Simonson, 2005) 將消費者依據偏好固定程度(stability)與自我認知程度(self-consciousness)兩 面向分成四個區塊(見下表)。偏好固定程度意指消費者擁有固定的偏好的程度,
偏好發展愈完整偏好愈穩定。而偏好自我認知程度則是消費者清楚了解自身偏好 的程度,包含了解偏好穩定的程度。若消費者偏好不穩定且缺乏偏好自我認知,
雖看似因自我偏好不穩定而難以進行推薦,事實上卻因為此一類型消費者欠缺偏 好自我認知,加上不穩定的偏好,反而是四種類型消費者中,最易接受推薦系統 的一般推薦,亦可能受到影響而認知推薦系統所做的推薦符合其偏好,而感到滿 足。下表為(Simonson, 2005)提出之使用者偏好發展程度分組:
偏好穩定 偏好自我認知
不穩定 穩定
模糊 組一 組三
清楚 組二 組四
表 2 使用者偏好發展程度分組
在(Simonson, 2005)提出此一偏好結構概念後,之後有許多研究依此概念試 圖將此概念做實際驗證與應用。(Franke et al., 2009)針對偏好結構與客製化商品 之效果進行研究。除了偏好自我認知程度外,(Franke et al., 2009)等加入了偏好 表達能力與產品涉入程度兩因素之影響,綜合上述所有條件比較大眾化商品與客 製化商品對消費者達成的滿意程度與願意購買金額(WTP, Willing To Pay)的影 響。綜上所述,客製化產品推薦對於擁有下列特質的消費者最能發揮其效益: 1.
清楚了解自我偏好 2.能清楚表達自我偏好 3.對於產品涉入程度(involvement)
高。此一研究清楚地指出了使用者偏好結構與其特質確實對推薦系統與客製化商 品帶來的效益有顯著的影響。(Kwon et al., 2009)則嘗試對不同組的使用者使用不 同推薦系統策略,針對前述(Simonson, 2005)四組偏好固定程度與偏好自我認知 了解程度組合分別採用不同推薦策略,使用之策略包括上節所述協同式過濾、內 容式推薦、高分推薦與專家推薦,交互比較評估不同策略在不同偏好結構狀態下
的表現。研究結果發現不同推薦策略在不同偏好狀態下效果確實不同,不同偏好 狀態可能分別適合不同的策略,證實使用不同偏好結構使用不同策略有助於改善 推薦系統表現,亦即偏好結構屬性與推薦策略有交互作用,確認了個人的偏好狀 態與推薦策略成效有關。
Preference Stability Unstable
H1:Non-personalized recommendation
Stable H2:Personalized recommendation
Insight into preference
Poor
H3:User-collaborative recommendation
Segment 1 H5:Average opinion (non-personalized and
user collaborative)
Segment 3
H7:Neighborhood-based CF(personalized and
user collaborative) Good
H4:Knowledge or expertise based recommendation
Segment 2 H6:Expert opinion (non-personalized and
expertise-based)
Segment 4 H8:Content-based filtering (personalized
and attribute-based)
表 3 顧客偏好發展與推薦策略(Kwon et al., 2009)
綜言之,使用者偏好可依不同觀點分析,本身亦由多種特質構成,又包含多 個面向,因此在不同研究中的定義亦有不同。在過去社會媒體蓬勃發展前,在休 閒閱讀之情境下,使用者僅能透過倚賴相同偏好朋友的推薦或推專家的書評等找 尋與自己閱讀偏好結構類似之書籍;而透過新興社會媒體-如本研究之研究場域 aNobii 網路書櫃服務,使用者除能在此平台管理其閱讀歷程,亦能在此瀏覽不同 書櫃,在書櫃間尋找符合閱讀品味之書籍,並能與品味相投之使用者分享閱讀經 驗。因此本研究將以偏好發展觀點出發(Simonson, 2005),期能藉由休閒閱讀社 會媒體 aNobii 產生之休閒閱讀歷程記錄,觀察使用者的閱讀偏好結構,進一步 對休閒閱讀推薦系統之策略選擇與個人化推薦有所助益。本研究嘗試用社會網絡 分析方法來分析 aNobii 使用者社群的書櫃,而相關方法內容將於下節詳述。
第三節 以網路分析法探討閱讀多樣性
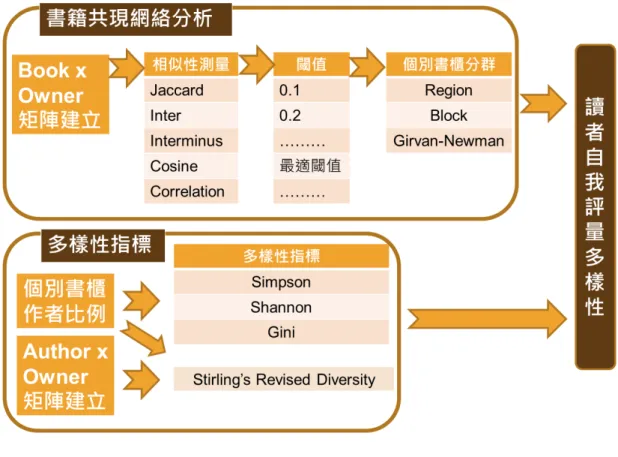
本研究以社會網絡分析方法作為資料收集之方法,藉由建立書籍於抽樣書櫃 中共現之情形建立共現矩陣呈現讀者閱讀偏好結構。由於讀者之閱讀偏好多樣性 與推薦策略有交互關係(Kwon et al., 2009; Simonson, 2005),本研究以呈現讀者閱 讀偏好之多樣性為研究目標,而判別多樣性前必須定義在閱讀偏好(讀者個人書 櫃)中的種類為何,因此首先必須計算書籍間的相似性,方能依此分析閱讀偏好 之多樣性。多樣性的概念早於書目計量學中跨領域研究即發展成熟,並發展出多 樣性指標(Rafols & Meyer, 2010);而近年來社會網絡分析方法則是分析關聯常用 且熱門的方法(Buldú et al., 2007; 林頌堅, 2010)。本研究利用社會網絡分析方法 與多樣性指標,探索呈現讀者閱讀偏好多樣性的方法,下述文獻分析之架構如圖 所示。
圖 1 本研究之研究架構
一、社會網絡分析與共現矩陣
社會網絡分析是一種跨領域研究,將數學與資訊工程領域上網路理論
(network theory)應用在分析社會網路上的資料。通常將資料視為節點(node),
而資料間的關係則用連結節點的邊(edge)來表示,邊的連結又可分為有方向性 有向圖或無連結方向性的無向圖。除方向外,邊亦可能有權重(weighted),來 表示連結關係的強度,若邊包含權重,則稱為 Weighted Graph,若無權重則為 Binominal Graph,Binominal Graph 亦可視為 Weighted Graph 的一種特例。建立 網路後可用多種圖形理論指標如 Cardinality、Centrality 等研究圖形連結關係。或 是將圖型資料已適當資料結構儲存並做進一步計算。如(Buldú et al., 2007)的音樂 品味(music taste)研究。其以 The art of the Mix Project 的資料作為研究平台,
從社會網絡的變化分析使用者的音樂品味。該研究蒐集 1998 年 1 月 22 日至 2005 年 6 月 4 日之間使用者播放清單中的歌曲,藉由分析共同出現在同一播放清單的 歌曲探討音樂品味網路特性,該研究假設出現在同一歌單中的歌曲可能屬於同一 種音樂品味(music taste),即使歌曲們可能分屬於不同的音樂類型(music genres),
因此,常常出現在同一播放清單之 A 曲與 B 曲,若使用者將 A 曲加入播放清單,
則 B 曲很有可能也是使用者喜愛的歌曲。故當兩首歌同時出現在一個播放清單,
以歌曲作為節點就產生連結,而兩首歌同時被收在同一播放清單的次數代表兩個 歌曲(節點)的關聯強度。此外,(Buldú et al., 2007)亦於研究中採用歌曲加入播 放清單的時間(input time),藉此觀察音樂網路特色參數(characteristic parameter)
在時間演進下如何變化。研究結果發現 92%的歌曲會被包含在連結形成的巨大組 件(giant component)中,亦即只有 8%的歌曲與其他歌曲幾乎無連結,而熱門 歌曲常常是中介歌曲(bridge songs),中介歌曲連結兩個獨立的播放清單網絡,
可利用中介歌曲連結的播放清單進行撥放清單(歌曲)的推薦。
在書目計量學中,Small & Sweeney (1985)利用共同引用(co-citation)並分
群(clustering)來分析領域論文的引用(citation)做了整理與回顧,此一概念逐 漸擴展到多種共同出現的情形,如文字共現(co-word)、連結共現(co-link),
因此類似概念現今用共現(co-occurrence)來包含之。共現網絡(co-occurrence network)則是將統計目標物共同出現於同一集合的情形製成圖形網路,通常以 目標物為節點而共同出現情形次數為 Weighted Edge,如(林頌堅, 2010)利用共現 網路計算圖書與資訊學刊論文的高頻詞語抽取與分析,將詞語視為節點,而將詞 語共同出現在論文的次數為連結強度。共現矩陣(co-occurrence matrix)為一常 用於共現網路的資料儲存與表示方式,每一節點視為一個欄(Column),而與其 他節點或性質的連結情形使用該欄的不同列(Row)表示。若為 Binominal Graph,
則連結與否常用 0 與 1 代表,若為 Weighted Graph,則用不同數值代表連結強度。
如(Leydesdorff & Vaughan, 2006)將共現矩陣的使用進行了分析,文中提到在過往 研究中如(H. Small & Sweeney, 1985)關注的是共同引用(co-citation),是將共同 引用的發生視為該資料的性質(attribute),此時可使用正規化方法如 Jaccard Index 直接加以分析比較,此種方式關注兩筆資料性質的相似度,著重資料在區域間的 表現。而在社會網絡分析的脈絡下,共同引用的資料可作為相似性之依據,因此 資料可透過與其他資料間的連結關係比較相似度,著重兩資料在全體網絡間的相 互關係,因此會將資料的所有連結關係透過常用的相似度計算如餘弦相似度
(cosine similarity)或關聯性係數(correlation)做比較。
本研究將應用共現矩陣計算書籍在全體 aNobii 書櫃中共同被擁有的次數。
並同時透過上述區域間與整體的概念進行計算,將在下一小節回顧。
二、結構等同與數值距離(Structural
Equivalence and Distance Measurement)
若兩書籍在全體書櫃中共現次數較高,則兩書可能較常被同一讀者選擇,若 讀者具固定偏好,則兩本書應屬相似,但「相似」為一模糊之概念,在日常生活 中會形容兩本書「很像」,即是相似的概念,但「很像」,可能是閱讀感受,由題 材、敘事風格、段落或劇情安排等種種性質構成。多本書若依主觀判斷來界定相 互相似性關係,則每個人意見可能均不同。因此首先需要將性質以數值記錄後,
以結構分析的方式,使用不同計算方式計算出數值距離(Distance Measurement)
來表現出相似性,再從多種相似性測量方式中選出較適合者。至於如何了解測量 方式的適合,則會使用相似性測量結果加以分群並以使用者的自我認知加以驗 證。
相似情形可從區域間結構(local structure) 與書籍間整體結構(global structure)兩方面觀察。共現矩陣表示了書籍間的共現情形,書櫃的主人可能有 某一種的偏好,因此同時放入了 A、B 兩本書籍,造成了 A、B 共現情形發生,
若 A、B 共現情形發生次數多,則兩本書可能因皆符合某偏好的同一需求所以形 成所有該偏好的讀者都同時擁有此兩本書,因此此兩本書可能較相似。此特性是 觀察單一書櫃情形再累計總數,亦即注重區域間結構(local Structure)。但此一 方式,,須注意書籍的受歡迎程度可能影響到書籍間相似性的計算。任意兩本受 歡迎的書籍,可能因為同時都是暢銷書,即使分別屬於差異極大的類別,仍可能 因為共同出現的次數大,而造成書籍相似性計算結果偏高。
因此在考慮相似度的數值計算時,需觀察了解計算中必要涉入但造成扭曲的 因素與造成之影響,在計算結束前將結果做校正,此一過程為正規化(normalize)。 本研究將使用三種不同的正規化方式。方法一為 Jaccard Index 為統計學中常用於
比較兩集合相似度的方式,不直接使用共現數值,而是採用共現除以書籍總數和,
亦即𝐴𝐴∩𝐵𝐵
𝐴𝐴∪𝐵𝐵, A、B 為任意兩本書,A∩B 為書籍 A 與書籍 B 之共現次數,𝐴𝐴 ∪ 𝐵𝐵為
書籍 A 在所有書櫃中總數加上書籍 B 在所有書櫃中總數扣掉共現部分,進而避 免 A、B 書籍受歡迎程度的差異造成相似性的扭曲。方法二採用共現次數除以 兩本書籍中被持有次數較少者,亦即 𝐴𝐴∩𝐵𝐵
𝑀𝑀𝑀𝑀𝑀𝑀(𝐴𝐴,𝐵𝐵),A∩B 為書籍 A 與書籍 B 之共現次
數,Min(A,B)為書籍 A 與書籍 B 之整體書櫃出現次數(被持有數)較小者,亦 是避免 A、B 書籍受歡迎程度差異造成相似性的扭曲,但方法一著重兩本書全 部出現的書櫃範圍與相互共現次數間的比率,方法二較注重較少被持有的書籍與 共現次數間的比率,林頌堅(2010) 計算詞語間共現比重公式亦採用此一方式,
但此方法有一問題為當兩本書 A、B 偶然在全部書櫃中共現一次時,A∩B 與 Min(A,B)均為 1,造成相似計算結果為本方法之結果的極大值 1,兩本書為相互 最相似的書籍之一,但共現僅一次,代表兩本書都符合某一偏好的情形並不多,
因此兩本書最相似之結果並不合理。因此本研究嘗試改良此一方法,將於第三章 研究方法中討論。
另一觀點關注書籍在書櫃中相互關係的的整體結構(global structure),透過 結構分析為在圖型中的節點與其他節點的關係尋找相同(equivalence)的結構
(structure)或樣式(pattern),並以相同的結構與樣式為分析的基礎。結構性相 同著重的概念為:定義兩標的物之間的關係並非觀察兩標的物之特徵值,而是觀 察兩標的物在整體觀察母體中的結構相似性,亦即某個體於整體結構中的位置,
亦可說是透過該個體與其他個體的關係定義該個體在群體中的角色。若以人與人 之間的相似性舉例,觀察兩個人是否相似並非觀察兩人的背景、興趣等是否相似,
而是觀察兩人在社交圈的聯集中(或是結構類似的社交圈子集中),在社交圈中 所處的位置是否相似。常用在尋找圖型中相同社會角色(social role)中。常用 的相同定義有 structure equivalence、automorphic equivalence、regular equivalence。
Structure equivalence 需為一節點關係上完全等同其他節點,在位置順序上必須可 以相互取代。automorphic equivalence 則是一群(set)擁有相同連結(ties)的節 點被區域結構包圍(local structure),亦即此兩群節點是平行結構。Regularly equivalent 是兩節點擁有相同的連結(ties),而同一群中的節點亦是 regularly equivalent。(Hanneman & Riddle, 2005)上述之分析方式可用來尋找不同書櫃的巨 大元件(giant component)中具有相同(equivalence)性質的節點(書籍)的特 性。
而針對多種數值性質形成的組合,有多種常用相似性計算方式。首先最常見 者為 Cosine Similarity,(Spertus, Sahami, & Buyukkokten, 2005)及比較了多種相似 性測量方式來分析 Orkut Social Network 內社群與使用者間相似性作為推薦社群 之依據,而以 Cosine Similarity 的方式最好。Cosine Similarity 為將多種性質數值 排列成一向量(vector)。每一性質為一維度,而一個具有 N 個性質的性質組合 將是一組 N 維向量。Cosine Similarity 的計算方式即為計算兩向量在此 N 維向量 空間的角度差異。著重的是差異的累積大小,但避免在計算 Euler Distance 時須 考慮正負數值,以及會易受到過大離群值影響的問題。
Similarity(A, B) = cos 𝜃𝜃 = 𝐴𝐴⃑ ∙ 𝐵𝐵�⃑
��𝐴𝐴⃑�� ��𝐵𝐵�⃑�� = ∑𝑀𝑀 𝐴𝐴⃑𝑀𝑀× 𝐵𝐵�⃑𝑀𝑀 𝑀𝑀=1
�∑ (𝐴𝐴⃑𝑀𝑀𝑀𝑀=1 𝑀𝑀)2× �∑ (𝐵𝐵�⃑𝑀𝑀𝑀𝑀=1 𝑀𝑀)2
其中𝐴𝐴, 𝐵𝐵為行向量,且兩者維度須相同,n 為兩向量之維度。Similarity(A,B) 即為向量 A 與向量 B 之相似度。(Spertus et al., 2005)比較不同的相似性指標在分 析 Orkut 社會網絡的使用者社群相似性時的表現,就以 Cosine Similarity 為最佳。
另一常見之計算方式即為計算兩組數值間的相關性(Correlation),其計算方 式等同於離散數值(discrete)的相關性係數計算。著重於兩數值組在變動時共 同變化情形的大小。在計算兩兩相似性後,可以得知所有節點之間的根據數值距 離計算結果得知的距離關係。此一距離關係可供偏好結構分析用。
Correlation(A, B) =𝑐𝑐𝑐𝑐𝑐𝑐(𝐴𝐴, 𝐵𝐵)
𝜎𝜎𝐴𝐴𝜎𝜎𝐵𝐵 =𝐸𝐸[(𝐴𝐴 − 𝜇𝜇𝐴𝐴)(𝐵𝐵 − 𝜇𝜇𝐵𝐵)]
𝜎𝜎𝐴𝐴𝜎𝜎𝐵𝐵
在評估相關性公式的計算效果時,(Klavans & Boyack, 2006),提出了幾個可 以觀察的面向:準確率(Accuracy)、包含率(Coverage)、規模可變性(Scalability)
與強固性(Robustness)。準確率是指在一固定的相似性閾值或取固定數量的結果 時,有多少結果是正確結果。而包含率則是同樣在一固定的相似性閾值或取固定 數量的結果時,包含了正確結果的多少比率。上述兩概念相近於資訊檢索
(Information Retrieval)的準確率(Precision)與召回率(Recall)。提升準確率 與提升包含率有相互取捨之關係(trade-off),若閾值取越高或數量取越少,只取 前幾名則準確率可能很高,但包含率可能很少;反之,若取大量資料或降低閾值,
則包含率可能提高但準確率可能會下降。規模可變性是指公式是否能同時套用在 少 量 與 大 量 的 資 料 中 。 強 固 性 指 的 是 面 對 經 過 不 同 程 度 的 維 度 降 低 轉 換
(Dimension Reduction)後是否能維持結果的一致。
三、閾值(Threshold)選擇與分群(Clustering)
在建立相似性關係後,若以書即為節點,書籍間的相似性為連結之距離或權 重,可利用書籍間之相似性關係建立一圖型。此圖型可展現書籍間的相互關係,
並可以此為基礎將書籍進行分群(clustering),在(Henry Small, 2009)即是使用分 群方式將多個領域的論文建立連結關係。因建立之連結圖形往往複雜且相互連結,
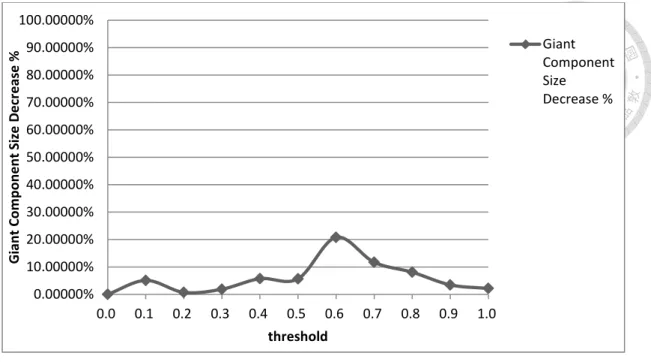
難以分析,為了能進行分群,避免過多不相關資料影響分群結果與速度,需要訂 定一閾值(Threshold)作為輔助。(Henry Small, 2009)即是利用一適當閾值,論 文間相似性在此閾值之下視為無連結,在此之上為具有連結。而其中相互連結的 論文會形成數個連結子圖(connected sub-graph),並將其中最大者稱為巨大元件
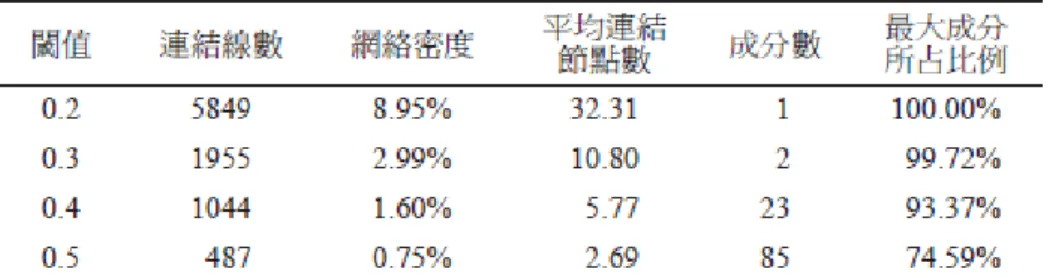
(giant component),前述閾值即決定於巨大元件尺寸的急遽改變點,若某一閾 值之下會讓巨大元件急遽擴張或尺寸改變速度增加,此閾值即為適當閾值。(林
頌堅, 2010)在論文詞語高頻分析的研究中,亦使用閾值來保留重要的連結關係並 移除不必要的干擾部分,而該研究採用的閾值選擇考慮條件有連結線數、網絡密 度、平均連結線點數、成分數與最大成分所佔比例。
表 4 研究論文詞語高頻分析網絡分析閾值使用之結構特性(林頌堅, 2010)
針對單一書櫃中書籍進行分群需利用閾值。本研究預計採用 UCINet 軟體針 對個別書櫃進行階層式分群(Hierarchical Clustering),(Hanneman & Riddle, 2005) 說明可使用此種方式進行社會網絡分析。階層式分群是將最相似之群集兩兩合併,
不斷重複此一過程,直至所有群集合併成唯一群集。可透過檢視合併的歷程了解 群集的結構關係,或是在合併過程中需選擇適當停止點以了解群集的分布情形。
在考慮群集間相似時可能有不同計算方式,如 UCINet 有四種相似距離定義,包 括 Single Link、Complete Link、WTD Average 與 Simple Average。Single Average 為兩群集間之最短距離為群集間距離,Complete Link 為兩群集集合中最大距離 為群集距離,WTD Average 為群集點平均距離除以群集尺寸,而 Simple Average 則直接使用群集平均距離。
四、多樣性分析
目前休閒閱讀書籍並無客觀且廣泛的區分書籍種類方式,主題標目(subject heading)與書籍寫作風格不一定有關,一般圖書分類法休閒閱讀的書籍又可能 大量被分在同一類,如武俠小說類就包含的大量的不同作者與類型風格,讀者往
往不會接受全部分類中的書籍。根據(謝宜瑾, 2012),休閒閱讀讀者最常利用作 者來尋書,因此利用作者區分書籍種類可能是合理的嘗試。而書櫃書書籍的瀏覽 列表與論文文獻中的引用文獻有些許類似之處,因此除社會網絡分析外,本研究 將應用書目計量學中的多樣性指標(citations)來測量個別書櫃的多樣性,對於 單一書櫃或可用多樣性(diversity)指標針對其組成做分析。多樣性是書目計量 學針對跨領域主題常用的分析方式,論文的主題通常屬於某一領域,但引用可能 來自不同領域的資料,因此發展多樣性指標計算該論文跨領域的程度。而一讀者 書櫃的書櫃亦可能包含不同書籍種類,因此可嘗試用以分析休閒閱讀之多樣性。
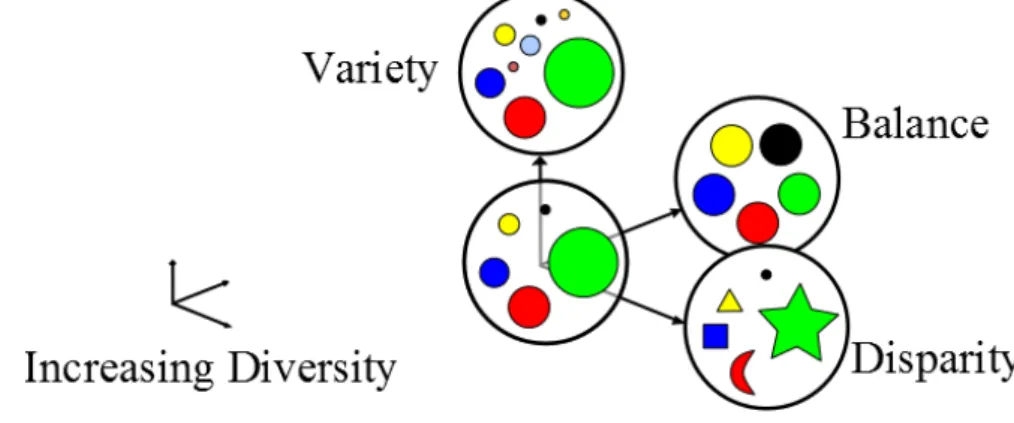
根據前述分析,書籍種類在本研究中將以不同作者視為不同種類的方式作為多樣 性分析中研究領域的對應。多樣性(diversity)可由三個性質來考慮:種類(variety)、 平衡(balance)與差距(disparity)。種類是指不同類別(distinctive categories)
的數量,愈多不同種類領域多樣性愈高。平衡是指類別的分布或是平均程度,若 種類大小分布不均,則領域則主要由種類數量最大的領域為代表,多樣性較低;
若種類大小分布平均,則代表同時且平均地具備多種領域的特質,多樣性較高。
差距是指類別與類別中的差別。若種類間差別大,譬如以大學系所做為領域種類 依據,同樣是文學院的系所,與電資學院語文學院的系所,由於不同學院所學差 距較同學院大,後者的種類差別較大。(Purvis & Hector, 2000; Andrew Stirling,
1998; Andy Stirling, 2007)因此,以上三個性質的增加皆會增加其多樣性。
圖 2 Schematic representation of the attributes of diversity, based on (Andrew Stirling, 1998),p. 41)
(Rafols & Meyer, 2010)展示了常見的多樣性衡量指數,如 Simpson’s 或 Simpson’s 同時衡量了 variety 和 balance,但無法去衡量類別中的相似度或是距離,
因此他提到(Andy Stirling, 2007)提出了更一般化的多樣性指標,本研究可以利用 此一計算方式計算單一書櫃中作者的多樣性。常見之衡量多樣性之指標另有吉尼 係數(Gini)與熵(Entropy)。吉尼係數是義大利統計學家 Corrado Gini 所設計 來計算數值散布程度(Statistical dispersion)的指標,吉尼係數通常被用來衡量 統計數值分布不均的狀況,在社會學與經濟學皆有應用,最常見的應用為計算國 家國民所得不均的情形。熵在資訊系統中為衡量系統資訊量的指標,若一系統包 含大量資訊—如讀者閱讀的興趣廣泛含多種類型,則系統之資訊量就高。
本研究將以 Simpson’s Diversity、Stirling’s Revised diversity、Gini 與 Shannon’s Shannon’s Entropy 並評估該書櫃的多樣性,並比較上述指標的差異。例如不同讀 者可能具有不同的偏好多樣性(Preference diversity),偏好多樣性是使用者偏好 的廣泛程度,或說使用者的偏好是分散或是集中。偏好同質性與偏好穩定度都反 應了使用者興趣的可能改變程度,但重要的不同之處在於使用者可能擁有廣泛而 穩定的興趣,亦可能使用者有狹窄但不穩定的興趣。而在本研究中係指讀者閱讀 類型的多元程度,閱讀偏好同質性高代表偏好特定書籍;閱讀偏好同質性低則代 表閱讀的類型較廣泛。
表 5 selected measures of diversity (Rafols & Meyer, 2010)
五、小結
據前述有關偏好結構之文獻回顧一節,可得知休閒閱讀使用者應有其休閒閱讀偏 好結構,而偏好結構皆有其特性如多元或單一、穩定或不穩定。若個別書櫃可代 表使用者之閱讀偏好結構,那麼就可以假設在整體 aNobii 網路書櫃中共現模式
(pattern)相同之書籍應具有較高相似性。建立書籍與書櫃擁有者間的非對稱矩 陣(Asymmetric matrix),進行相似性計算,在取用適當閾值後,可從相似關係 圖型中取得巨大組件,可以巨大組件為代表,基於等同(equivalence)的概念針 對全體書櫃與個別書櫃的書籍結構作為分析,並將多樣性計算結果與讀者自我認 知鄉比較,可探究在社會媒體中讀者偏好與社會推薦發展的可能。