行政院國家科學委員會專題研究計畫 期中進度報告
營造廠商財務信用評等模式最佳化之研究(2/3)
計畫類別: 個別型計畫
計畫編號: NSC91-2211-E-011-032-
執行期間: 91 年 08 月 01 日至 92 年 07 月 31 日 執行單位: 國立臺灣科技大學營建工程系
計畫主持人: 王慶煌
計畫參與人員: 李威憲.洪瑞辰
報告類型: 精簡報告
處理方式: 本計畫可公開查詢
中 華 民 國 92 年 6 月 11 日
行政院國家科學委員會專題研究計畫成果報告
營造廠商財務信用評等模式最佳化之研究(2/3) The Optimal Model of Financial Cr edit Rating for
Constr uction Contr actor s 計畫編號:NSC 90-2211-E-011-053 執行期限:91 年 8 月 1 日至 92 年 7 月 31 日 主持人:王慶煌教授 國立台灣科技大學營建工程系
一、摘要
本研究第一期計畫導入信用評等之觀念,並結合 SOM(Self-Organizing Map) 及 BP(Back-Propagation)兩種類神經網路之特性,用以建構一個財務信用評等模 式,用來評估營造廠商之財務狀況。第一期研究成果已發表於中國土木水利工程 學刊(第十五卷第一期 pp. 199-209)。本期(二)計畫主要在發展一學習係數互 動模式,用以改善 BPNN 之學習績效,提升推論值正確率;同時,配合案例之應 用計算,來驗證本模式推論結果之可靠度及改善程度。
關鍵詞:信用評等,類神經網路,學習係數,互動模式
Abstr act
The first stage of this study conducts a credit rating concept and combines the advantages of neural networks of SOM and BP, so as to build a model of financial credit rating for construction contractors. All the achievement and results of the stage have been published on the
Journal of the Chinese Institute of Civil and Hydraulic Engineering (Vol. 15, No. 1, pp. 199-209). Thereafter, the second stage of this study
focuses on improving the learning performance and the inference accuracy of BPNN.In accordance with this purpose, a new interactive learning-rate calculation model is developed. Finally, a case study is performed to prove the model’s reliability and improvement.
Keywor ds: credit rating, neural network, learning rate, interactive model
二、緣由與目的
台灣近年來由於經濟快速成長,許多重大公共工程也隨之發包、興建,而且 工程規模亦日益龐大。在這種市場趨勢下,使得營造業必需要面對更多之財務挑 戰及擁有更多的企業融資途徑,如此方能增加公司財務調度之彈性,並能適當地 處理施工期間龐大且複雜之現金流量。但由於台灣之營造廠商大部份仍屬於傳統 企業型態,一般而言均較缺乏財務管理之能力。在承攬工程後,常因財務問題而 產生逾期、解約,甚至宣布公司倒閉等問題,不但延誤工期,而且對業主帶來鉅 大之損失與難以估計的困擾。
本研究第一期計畫有鑑於營造廠商之財務狀況常為公共工程執行成敗之重 要關鍵因素之一,因此第一期計畫已建立一個適用於台灣營造廠商之財務信用評 等模式,能有效地篩選出財務信用狀況良好之投標廠商。
第二期計畫係針對 BPNN 之輸出推論值正確率,提出學習係數互動模式,
可以提昇 BPNN 之處理效率及效能,使營造廠商之財務信用評等模式更加完備。
三、結果與討論
本研究第二期計畫係建立一學習係數互動模式,並結合批次學習與即時學習 之優點,發展新的案例投入方式。本方式可以獲得學習績效之最佳權重組合,作 為調整各維學習係數基準,同時也可兼具批次學習可過濾系統噪音與即時學習可 包含背景環境資料之優點。最後,經由案例計算結果之相互比較,證明本期計畫 所提出之方法的合理性。
3-1 模式建構之概念
BPNN 為 MFNN (Multilayer Feedforward Neural Network)網路結構之一種學 習法,應用廣泛。傳統之 BPNN 之學習係數為固定值,此種以線性搜尋最佳解 之方法,因多維權重空間內之各維間尺度相對於輸出誤差比例不一致,及決定權 重調整方向等問題,常導致偽局部最小化(False Local Minima,FLM)。此外,
結點連結權重學習方法也是影響推論值正確率之主因。因此,本研究發展一學習 係數互動模式,以提升訓練正確率。
3-2 學習係數互動模式之說明
本研究提出之學習係數互動模式,其計算過程如下所示:
(1)將一定數量訓練案例投入 BPNN 模式,經學習過程訓練後,得到相對應之多 組權重組合,其中訓練績效最佳(即 E 值最小)訓練案例之結點 i 與結點 j 間 權重空間特性長度組合,作為後續學習過程中調整學習係數之基準 W
ij
。 (2)以學習係數調整準則方程式計算學習係數。準則方程式如下所示:η
ijk
=Wijk
/wijk
(ave)w
ijk
(ave):第 k 次計算學習係數過程中(於本研究即為一樣本區塊)所有樣本 權重空間之特性長度平均值。k:調整權重次數
(3)將學習係數進行爾後學習過程之權重調整,權重調整機制如下:
w
ij
(k+1)→wij
(k)-ηij
(k)gs
g
s
:樣本之錯誤方程式斜率。(4)由新的學習績效良好之權重組合,取代原有之學習係數調整方程式基準權 重,並計算下一階段之學習係數,循環至收斂為止。
3-3 Batch-Online 學習模式之說明
為避免 BPNN 在訓練過程中陷入局部最小化,本研究提出 Batch-online 學習 模式,以作為學習係數互動模式更新頻率之控制機制,該學習模式係利用區塊資 料批次學習模式以強調該樣本區塊背景資料特性;並應用即時學習模式將各區塊 資料整合為訓練資料,再由整體訓練資料中獲得新的學習係數。藉此將區塊背景 環境資訊之特性差異,交叉投入於新學習過程中的適度擾動,以達到本研究提升 BPNN 推論值正確率之目的。
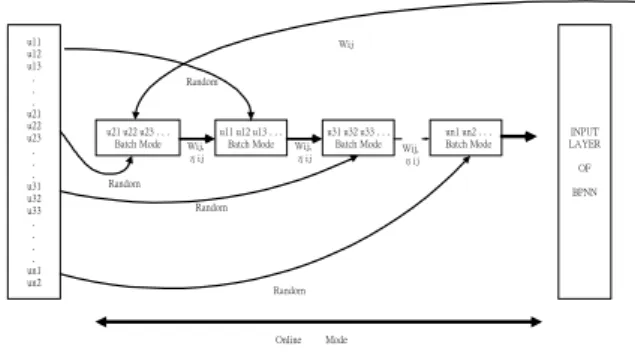
Batch-online 學習模式首先針對問題之訓練樣本資料特性,將訓練案例分割 成 n 個不同區塊(Block)條件,於同一區塊內,所有訓練案例均以隨機方式投入 BPNN 模式,以批次學習模式調整權重,並配合批次計算以推論式方法計算該群 組之學習係數。然後,以隨機方式排程各時間點訓練案例區塊之序列,投入 BPNN 中,而前一區塊批次訓練所得之權重組合即為本區塊之訓練初始權重。因此,就 整體學習過程之資訊傳遞而言,本研究之學習過程中,訓練案例投入方式於各區 塊內為批次學習模式,而區塊間以即時學習模式連結,並同時計算即時模式學習 係數,以作為下一學習循環之初始值,整個過程詳圖 1。
3-4 案例驗證
本研究之案例以臺灣地區某通過 ISO9000 認證之營造廠之 14 家專業協力廠 商,在 34 個不同連續時間點所構成之案例(22 個訓練案例 12 個測試案例)。
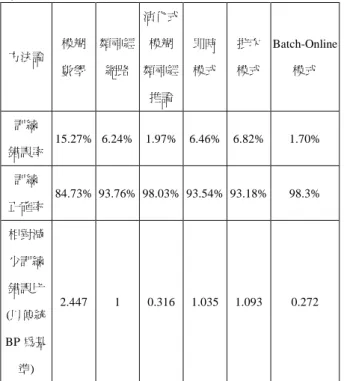
本研究以傳統 BPNN 之批次學習模式、即時學習模式及本研究提出之 Batch-online 學習模式,同時應用於上述之案例,並將計算結果彙整為圖 2 及表 1 到表 4。圖 2 為三種學習模式之學習曲線,表 1 為三種學習模式之訓練錯誤率
彙整,表 2 為三種學習模式在不同學習循環數下之訓練錯誤率變動量,表 3 為 Batch-online 學習模式之權重-學習係數變動關係。此外,本研究以所提出之 Batch-online 學習模式和 Batch 學習模式、Online 學習模式、模糊數學、類神經 網路及演化式模糊類神經推論模式等方法論進行比較,以驗證本研究所發展之方 法論對於預測非線性問題分析使用 MFNN 架構時可有效地提升訓練績效,結果 詳表 4。
四、計畫成果自評
本研究第二期計畫旨在進行 BPNN 處理效能及效率之改善,用來提升營造 廠商財務信用評等模式之運作效能,以期能達到模式之最佳化。第二期計畫可獲 致以下結論:
(1)本研究中 Batch-Online 模式之錯誤率較傳統類神經網路減少約 72.8%,明顯地 跳脫局部最小化。主要原因為 Batch-Online 模式中之學習係數調整不同於傳統 BPNN 之固定學習係數方式,以階段最佳學習績效為權重基準,進行學習係數 及權重之疊代更換,減少學習錯誤嚐試機會,並有跳脫局部最小化之能量;而 且各結點間連結權重均為各自獨立學習係數,因此本模式可以於極短學習循環 數內(本研究約為 30 次左右)找到最佳學習績效之權重組合。
2.學習曲線之穩定性(即曲線擺盪程度)方面,批次學習優於 Batch-Online 學習,
Batch-Online 學習優於即時學習。因即時學習較易受噪音之影響造成錯誤率變 動,而批次學習較不受影響。Batch-Online 學習之結構係結合上述兩者,因此 有介於兩者間之錯誤率變動表現。
3.本研究為驗證 Batch-online 模式之訓練收斂速度績效,將學習曲線中起始訓練 錯誤率到穩定階段之訓練錯誤率變化量除以所需學習循環數,得到訓練錯誤率 曲線斜率如表 4,由表 4 中得知,Batch-Online 學習法均較傳統 BPNN 學習法 花費較少學習循環次數,便能達到錯誤率穩定狀態。上述現象係起始權重為影 響學習績效之主因之一,而 Batch-Online 學習法中下一學習循環起始權重以 前一學習循環中學習績效最佳之權重組合為計算基準,其精神類似基因演算法 之優生觀念,每次學習循環之權重調整幅度遠大於傳統 BPNN,且其調整方向 指向正確方向,因此能很快產生出最佳學習績效之權重組合。
4.本研究於文獻探討中得知 Newton’s Method 為提昇學習正確率成效最佳之方法 論,然而,其計算二階導數矩陣時所需之記憶空間較傳統 BPNN 呈二次級數 擴張,如傳統 BPNN 需 S(N)容量記憶體,而 Newton’s Method 需 S(N2)容量記 憶體 (N:權重數)。以本研究為例,Batch-Online 學習模式之 BPNN 需 S(52)記 憶體空間,而 Newton’s Method 需 S(2710)記憶體空間,此可證明本研究 Batch-Online 學習模式可在維持訓練績效之前提下,大量降低計算成本。
5.傳統 BPNN 之學習係數係固定值,因此其權重調整為逐步漸進之方式。為避免 訓練錯誤率跌入區域最小值,因此調整幅度採用微小值,進而造成學習收斂速
度隨之緩慢。本研究之 Batch-online 學習模式之權重與學習係數係以階段最佳 訓練績效之權重組合為調整基準,因此學習係數與相關調整權重變化幅度較 大,並可獲得快速之學習收斂,詳表 3。
綜合上述之成果,顯示本研究發展介於批次與即時方式間之新的案例投入方 式、針對各種權重得個別推論調整權重學習係數法,無論在學習錯誤率、學習收 斂速度、學習曲線穩定度均有明顯改善成果。 本研究成果將投稿於 Journal of
Computing in Civil Engineering, ASCE.
五、參考文獻
[1] Si-Zhao Qin, Comparison of Four Neural Net Learning Methods for Dynamic System Identification, IEEE Transactions on Neural Networks, vol. 3, no. 1, 1992, pp.122-130.
[2] Simon Haykin, Neural Networks : A Comprehensive Foundation, Prentice Hall, 1999.
[3] Mahmoud H. Alrefaei, Simulated Annealing Algorithm with Constant Temperature for Discrete Stochastic Optimization, Management Science, vol.45, No.5, 1999, pp.748-764.
[4] Robert A. Jacobs, Increased Rates of Convergence Through Learning Rate Adaptation, Neural Networks, vol.1, 1988, pp.295-307.
[5] E. Barnard, A comparative study of optimization techniques for backpropagation, Neurocomputing, vol.6, 1994, pp.19-30.
[6] Roberto Battiti, First and Second-Order Methods for Learning: Between Steepest Descent and Newton’s Method, Neural Computation, vol.4, 1992, pp.141-166.
[7] Chia-Yiu Maa, A Two-Phase Optimization Neural Network, IEEE Transactions on Neural Networks, vol. 3, no. 6, 1992, pp.1003-1009.
[8] Harris Drucker, Improving Generalization Performance Using Double Backpropagation, IEEE Transactions on Neural Networks, vol. 3, no. 6, 1992, pp.991-997.
[9] Timothy L. Ruchti, Estimation of Artificial Neural Network Parameters for Nonlinear System Identification, Proceedings of the Conference on Decision and Control, 1992, pp.2728-2733.
[10] Gian Paolo Drago, Sandoro Ridella, Statistically Controlled Activation Weight Initiallzation, IEEE Transactions on Neural Networks, vol. 3, no. 4, 1992, pp.627-631.
[11] Mingsheng Zhao, Speeding up the training process of the MFNN by optimizing the hidden layers’
outputs, Neurocomputing, vol.11, 1996,pp.89-100.
[12] D.Rumelhart, Parallel Distributed Processing., Cambridge, MA,1974.
[13] Lodewyk F.A. Wessels, Avoid False Local Minima by Proper Initialization of Connections, IEEE Transactions on Neural Networks, vol. 3, no.6, 1992, pp.899-905.
[14] Marwan Jabri, Weight Perturbation:An Optimal Architecture and Learning Technique for Analog VLSI Feedforward and Recurrent Multilayer Networks, IEEE Transactions on Neural Networks, vol. 3, no.1, 1992, pp.154-157.
[15] Etienne Barnard, Optimization for Training Neural Nets, IEEE Transactions on Neural Networks,
vol. 3, no.2, 1992, pp.232-240.
[16] Min-Yuan Cheng and Amos Chien-Ho Ko, An Intelligent Inference Model Using Neuro-Fuzzy-Genetic Method, Computing in Civil Engineering, ASCE (Accepted).
[17] David Miller, A Global Optimization Technique for Statistical Classifier Design, IEEE Transactions on Signal Processing, vol. 44, no. 12, 1996.
[18] Claas de Groot, Plain backpropagation and advanced optimization algorithms: A comparative study, Neurocomputing, vol.6, 1994,pp.153-161.
u11 u12 u13 . . . u21 u22 u23 . . . u31 u32 u33 . . . . un1 un2
u21 u22 u23 . . . Batch Mode
u11 u12 u13 . . . Batch Mode
u31 u32 u33 . . . Batch Mode
un1 un2 . . . Batch Mode
INPUT LAYER OF BPNN Random
Random Random
Random
Online Mode Wij,
ηij Wij,
ηij Wij,
ηij Wij
圖 1 Batch-Online 學習模式資料傳遞示意圖
OUTPUT LAYER
OF BPNN
Wij(1) Wij(2) Wij(3) Wij(4) . . . . . Wij(k)
INTPUT LAYER OF BPNN
OUTPUT LAYER
OF BPNN HIDDEN
LAYER OF BPNN
ONLINE LEARNING STAGE BATCH LEARNING STAGE
Wij(t-1),ηij(opt(E)) Online Mode
ηij(opt(E))
圖 1 Batch-Online 學習模式資料傳遞示意圖(續)
學習曲線比較圖(當期)
0 0.02 0.04 0.06 0.08 0.1
1 200 400 600 800 1000 1200 1400 1600 1800 2000
學習循環數(次)
錯誤百分比(%) online
batch batch-online