以主題模式進行多樣且相關的線上課程推薦
62
0
0
全文
(2)
(3) 致謝 在研究生生涯中,得到很多人的幫助,讓我能夠完成這一階段的任務,需要感謝 這些人。本論文能完成,首先要感謝 指導教授蕭文峰教授的指導,謝謝教授從我大 學到研究所的這段時間中給我的教導和幫助。在我論文看不懂的部分,會細心的解說, 在我程式遇到瓶頸的時候,會耐心的解決,在我遇到問題,更是熱心幫助我解決問題, 也在論文上給予我許多的建議,讓我在研究所學到學術,還學到技術和態度等不少的 收穫。謝謝教授每月也會撥專案計畫的款給我們,陪著我們到中山大學參與討論,讓 我能夠順利完成本篇論文。 接著要感謝每個月陪我們一起參與討論的中山大學教授 張德民教授,在每次的 討論都給予我許多寶貴的意見,提供我許多的想法,讓我學到能夠從更多角度去思考 問題的本質。感謝本論文的口試委員 陳耀宗教授,願意在百忙之中,特地來屏東幫 我口試,在口試給我很多的意見,並在口試之後,再給予論文上的建議。 研究所的這段時間,感謝家人的支持與鼓勵,讓我能夠完成本論文。還要感謝同 班的同學,建銘、庭葦、程文、書瑜、郁涵和雅清,有大家的彼此打氣,讓我再研究 所的這段時間能夠開心渡過,特別是庭葦,謝謝你總是幫助我解決問題,遇到問題也 能與你一起討論,還能有你一起陪同參與研討會、口試和討論,讓我的研究所過的很 開心。 最後要謝謝平常給我幫助的資管助教,謝謝您從大學和研究所對我的照顧,每次 遇到問題,總是耐心幫我解決問題,以及資管系上的各位老師們,謝謝您們在我求學 路上,教導我以及給予我的建議。. 陳登裕 于. 謹誌. 國立屏東大學資訊管理系 中華民國一○四年七月. I.
(4) 摘要 傳統的推薦系統僅只由內容的相似性或由相似興趣的群體的偏好來進行推薦,很 難為目標使用者推薦多樣且相關的內容。本論文整理過去一些推薦系統的評估定義。 提議藉由分析所有課程單元的文字稿,並建立主題模式(Latent Dirichlet Allocation; LDA)以獲取文字稿之主題機率分佈,使推薦更多樣性。新課程單元則透過與其他課 程單元進行主題相似性分群,透過項目為基礎的主題模型將多樣且相關的課程藉此推 薦給他/她。由電影、笑話、課程資料集的實驗結果顯示,與使用者為基礎的主題模 型和傳統的協同過濾比較,雖然在一般常用的評估上表現普通,但在總體多樣性上的 效果都有明顯比較好,而且主題分析的推薦都有較高的多樣性,結果也發現推薦站在 項目為基礎的角度會比使用者為基礎的還要好,這代表項目為基礎的主題模型可有效 達到多樣且相關內容的推薦。. 關鍵字:主題模式、多樣性、課程推薦. II.
(5) Abstract Traditional recommender systems make recommendations based solely on content similarities or preferences from similar groups. It is therefore difficult to recommend users diversified but related items. In this study we proposed to use Latent Dirichlet Allocation (LDA) to overcome this shortage. LDA can help obtain the topic distribution of the input transcripts from online course units. New course units are then compared with the topic distributions of the existent courses to check their degree of diverseness and relatedness. We then can recommend diversified but related course units to learners. The results from three experiments show that (1) comparing with traditional CF our proposed approach can achieve a better aggregate diversity; (2) item-based LDA is better than user-based LDA in recommending diverse and related items; (3) our method can be applied to different rating metrics.. Keywords: Topic Modeling, Diversity, Course Recommendation. III.
(6) 目錄 1. 緒論 ............................................................................................................ 1 1.1.. 研究目的 ...................................................................................... 2. 2. 文獻探討 .................................................................................................... 3 2.1.. 大規模開放線上課程 .................................................................. 4. 2.2.. 內容為基礎的推薦系統 .............................................................. 4. 2.3.. 協同式的推薦系統 ...................................................................... 5. 2.4.. 主題模型 ...................................................................................... 5. 2.5.. 推薦多樣性 .................................................................................. 6. 2.6.. 一般推薦的衡量 .......................................................................... 8. 2.7.. 多樣性的衡量 .............................................................................. 9 2.7.1.. 覆蓋率 ................................................................................... 9. 2.7.2.. 新穎性 ................................................................................... 9. 2.7.3.. 偶然性 ................................................................................. 10. 2.7.4.. 驚奇性 ................................................................................. 10. 3. 研究方法 .................................................................................................. 11 3.1.. 主題模型之協同過濾推薦系統 ................................................ 15. 3.2.. 使用者為基礎的推薦系統 ........................................................ 16. 3.3.. 項目為基礎的推薦系統 ............................................................ 16 IV.
(7) 3.4.. 衡量多樣性 ................................................................................ 17. 3.5.. 一般的衡量 ................................................................................ 18. 4. 實驗結果 .................................................................................................. 20 4.1.. 資料集說明 ................................................................................ 21. 4.2.. 實驗一 LDA 對多樣性推薦的效果 ......................................... 22. 4.3.. 實驗二 項目為基礎的對使用者為基礎的效果 ...................... 33. 4.4.. 實驗三 課程資料集的多樣性反應結果 .................................. 42. 5. 結論 .......................................................................................................... 46 5.1.. 研究貢獻 .................................................................................... 47. 5.2.. 未來研究方向 ............................................................................ 47. V.
(8) 圖目錄 圖 1. LDA 系統架構...................................................................................... 12 圖 2. 主題產生流程 ...................................................................................... 15 圖 3. MovieLens 精確度曲線圖.................................................................... 24 圖 4. MovieLens 召回率曲線圖.................................................................... 26 圖 5. MovieLens F1 值曲線圖 ...................................................................... 28 圖 6. MovieLens MAP 直條圖 ...................................................................... 29 圖 7. MovieLens MAE 直條圖 ...................................................................... 30 圖 8. MovieLens 總體多樣性的比例曲線圖 ............................................... 33 圖 9. 笑話精確度曲線圖 .............................................................................. 35 圖 10. 笑話召回率曲線圖 ............................................................................ 37 圖 11.笑話 F1 曲線圖 .................................................................................... 38 圖 12. 笑話 MAP 直條圖 ............................................................................. 39 圖 13. 笑話 MAE 直條圖 ............................................................................. 40 圖 14. 笑話總體多樣性曲線圖 .................................................................... 42 圖 15. 線上課程精確度曲線圖 .................................................................... 43 圖 16.線上課程召回率曲線圖 ...................................................................... 44 圖 17. 線上課程 F1 值曲線圖...................................................................... 45. VI.
(9) 表目錄 表 2. 精確度、召回率例子 .......................................................................... 18 表 3. MAP 例子 ............................................................................................. 19 表 4. MAE 例子 ............................................................................................. 20 表 5. MovieLens 項目為基礎的精確度 ....................................................... 22 表 6. MovieLens 使用者為基礎的精確度 ................................................... 23 表 7. MovieLens LDA(ItoI)推薦的精確度 ................................................... 23 表 8. MovieLens LDA(UtoU)推薦的精確度................................................ 23 表 9. MovieLens 項目為基礎的召回率 ....................................................... 24 表 10. MovieLens 使用者為基礎的召回率 ................................................. 25 表 11. MovieLens LDA(ItoI)推薦的召回率 ................................................. 25 表 12. MovieLens LDA(UtoU)推薦的召回率.............................................. 25 表 13. MovieLens 項目為基礎的 F1 ............................................................ 26 表 14. MovieLens 使用者為基礎的 F1 ........................................................ 27 表 15. MovieLens LDA(ItoI)的 F1................................................................ 27 表 16. MovieLens LDA(UtoU)的 F1 ............................................................ 27 表 17. MovieLens MAP ................................................................................. 28 表 18. MovieLens MAE ................................................................................. 29 表 19. MovieLens 總體多樣性...................................................................... 30 VII.
(10) 表 20. MovieLens 總體多樣性百分比 ........................................................ 31 表 21.笑話項目為基礎的精確度 .................................................................. 33 表 22.笑話使用者為基礎的精確度 .............................................................. 34 表 23. 笑話 LDA(ItoI)推薦的精確度 .......................................................... 34 表 24. 笑話 LDA(UtoU)推薦的精確度 ....................................................... 34 表 25. 笑話項目為基礎的召回率 ................................................................ 35 表 26. 笑話使用者為基礎的召回率 ............................................................ 35 表 27. 笑話 LDA(ItoI)推薦的召回率 .......................................................... 36 表 28. 笑話 LDA(UtoU)推薦的召回率 ....................................................... 36 表 29. 笑話項目為基礎的 F1....................................................................... 37 表 30. 笑話使用者為基礎的 F1................................................................... 37 表 31. 笑話 LDA(ItoI)推薦的 F1 ................................................................. 38 表 32. 笑話 LDA(UtoU)推薦的 F1 .............................................................. 38 表 33. 笑話 MAP .......................................................................................... 39 表 34.笑話 MAE ............................................................................................ 40 表 35.笑話總體多樣性 .................................................................................. 41 表 36. 線上課程精確度 ................................................................................ 43 表 37. 線上課程召回率 ................................................................................ 43 表 38. 線上課程 F1 值.................................................................................. 44 VIII.
(11) 表 39. 線上課程 MAE、MAP ..................................................................... 45 表 40. 線上課程總體多樣性 ........................................................................ 46. IX.
(12) 1. 緒論 過去傳統的教學課程受到環境空間的限制,沒辦法讓想聽課的學生 無限制的參與,受到人數、地區等的限制。因此發展了遠距教學,但這 還是沒辦法讓更多非在校的學生參與,後來出現大規模開放線上課程, 可在國內就能參與國外名師的課程,讓知識無國界的交流。但線上課程 的課程數量越來越龐大,學習者再選擇的時候需花許多時間搜尋,因此 我們想要建立一個線上課程的推薦,讓學習者不需要花太多時間在選擇 課程上,學習者可以很容易的發現符合他興趣的課程,降低使用者的搜 尋成本,學習者就可以很快找到自己想要的課程。 一般的推薦只能推薦熱門及相似學習者之前參與的課程給學習者, 但較冷門的課程不一定就對學習者沒有幫助,以及學習者偶而也會想要 一些不一樣的課程,而這些課程也要與學習者要有些關係,否則入門門 檻太高的課程,會讓學習者會感到挫折。如果只是符合學習者興趣這樣 單調的推薦系統,是不能滿足求知慾強烈的學習者,他們可能想要學習 其他領域的知識,但一般的推薦卻沒辦法帶給他們其他領域的推薦,因 此,我們在推薦系統中,加入多樣性的因素,讓學習者可以獲得更多樣 的推薦,學習到更廣泛的知識。對於這些課程來說,一般的推薦常常會 導致熱門的課程更加普遍,而冷門的課程,因為推薦策略導致曝光率低, 參與的學習者較少,但不代表這些冷門的課程對學習者沒有任何幫助, 1.
(13) 課程如果可以有效分配推薦給學習者,這樣就能推廣更多知識,讓更多 課程更普及。 本論文採用主題模型(Topic Model)產生課程主題,再透過主題分群, 最後推薦使用者多樣的推薦。因為有主題的相似度在,因此還是保留有 相關的項目給使用者,利用主題模型讓項目的主要主題相關,但其他部 分卻是使用者還沒碰觸的,例如:商業英文的主要主題是英文,我們可以 推薦同樣具有英文主題的旅遊英文、新聞英文等。如此一來可讓推薦更 有多樣性。 1.1. 研究目的 過去的推薦系統要求推薦的精確度,推薦項目有多少是使用者喜歡 的項目,精確度越高越能代表推薦系統的表現越好。現在的推薦系統已 經出現其他的評估標準,一些研究認為其他像是覆蓋率(Coverage)、驚奇 性(Surprise)、偶然性(Serendipity)、新穎性(Novelty)、多樣性(Diversity) 等…這些指標都是為了讓推薦系統的表現更符合人性,使用者也許會想 嘗試更多不同的項目、尋求會讓他/她驚奇的項目、讓他/她發現新的項目 可以帶給他/她更廣泛的視野。 為了方便理解,我們整理本研究目的歸納為以下三個 (1) 過去多樣性的方法,推薦其他相似度較低的項目給使用者,相似 度越低,越能提供更廣泛的項目。但我們希望能不降低相似度的 2.
(14) 方式去看多樣性。本論文欲瞭解主題模型是否能比傳統的推薦方 法更能在有限的正確性損失條件下,提供多樣性的推薦。 (2) 協同過濾的推薦系統主要有兩種觀點,一種是站在使用者的角度 去做推薦,另一種則是站在項目的角度去做推薦,本論文希望比 較主題模式套用於項目為基礎及套用於使用者為基礎的推薦何 者可得到較佳的績效。 (3) 本論文亦將透過三個不同的資料集來瞭解所提方法的穩健性。 本研究目的最重要的就是產生多樣性,透過 LDA 主題模型,產生比 傳統還要更多樣的推薦,但卻不是降低相關的推薦。實驗結果顯示 LDA 的主題模型能帶給使用者更多樣的推薦,雖然精確度、召回率…這些一 般評估沒辦法太突出,但還是能帶給使用者有傳統推薦的精確度,且有 著更多樣的推薦。 2. 文獻探討 本論文我們主要焦點是在大規模開放線上課程上推薦多樣性的問題, 因此這裡會先介紹大規模開放線上課程,然後是常見的內容為基礎的推 薦方法和協同過濾的方法,以及現有的主題模型,再探討一些目前有的 多樣性研究和多樣性的衡量,最後探討目前一般推薦的衡量和其他推薦 的衡量。. 3.
(15) 2.1. 大規模開放線上課程 大規模開放線上課程(Massive Open Online Course; MOOC)是一種線 上的課程,可讓大眾透過網路開放參與。許多 MOOC 提供互動的論壇, 輔助教授、學生等之間的互動。對於 MOOC 沒有明確的定義,但他有一 些特徵:第一是開放共享,參與者不必是在校的學生,讓大家共享,且大 多數是免費的,第二可擴張性,在傳統課程中,是一群學生對應一位老 師,但 MOOC 的設計,是針對不特定的學生,且規模可能非常龐大。 MOOC 起源於教育資源運動和學習連接主義的思潮。例如,Coursera1、 Udacity2、edX3、Share Course4等。 2.2. 內容為基礎的推薦系統 推薦系統的目的是推薦使用者他們可能有興趣的項目,而內容為基礎 (Content-Based)的推薦系統就是要推薦相似於他們感興趣的項目。它是根 據使用者過去喜歡的項目,系統會推薦類似使用者過去選擇過的項目給 使用者(Lops et al. 2011)。內容為基礎的推薦系統需要建立一組使用者的 特徵檔案,用來表示使用者過去評分或選擇過的項目,因此項目的內容 是相當重要的。但這種策略會遇到一些狀況,當新項目加進來,內容是 從來沒見過的關鍵字,所以這項產品自然會與其他產品相似度低,而無. 1 2 3 4. https://zh-tw.coursera.org/ https://www.udacity.com/ https://www.edx.org/ http://www.sharecourse.net/sharecourse/ 4.
(16) 法被推薦。 2.3. 協同式的推薦系統 協同過濾(Collaborative Filtering)是利用相同喜好,或者是相同經驗的 群體,來推薦使用者感興趣的項目,換句話說,就是以大眾的喜好做基 礎,推理其他人可能會喜歡什麼項目。協同過濾需要一組使用者對項目 的評分集,然後根據擁有該項目的使用者,來預測使用者的評分(Candillier et al. 2007)。協同過濾通常分為三種,第一是使用者為基礎(User-based), 根據相似性的方法,找到與使用者喜好相鄰的使用者,但隨著使用者數 量增加,計算的時間也會增加;但通常我們無法獲得太多使用者喜歡的項 目資訊,資料訊息太少,因此另一個方法是從項目的角度來看,因為項 目被使用者選擇的訊息,比使用者選擇項目的訊息還來的充足,所以更 能推斷正確的項目給使用者。第二是項目為基礎(Item-Based),這方法 有一個基本的假設是使用者有興趣的項目,必定相似於使用者先前給予 高評分的項目,根據相似性的方法,找到使用者先前評高分的相似性高 的項目。第三是模型為基礎(Model-Based),是先利用過去的資料建立 一個模型,再利用模型預測評分(Candillier et al. 2007)。 2.4. 主題模型 LDA(Latent Dirichlet allocation)是由 Blei et al. (2003)提出。是一種非 監督式的機率生成模型,訓練時不需要手動標記訓練集,就可將文件集 5.
(17) 中每篇文件的主題按照機率分布的形式產生。LDA 優點就是能夠從文件 集中,得到潛在的語意訊息。過去有很多將 LDA 加入推薦系統的研究, 混合推薦系統已經有加 LDA 潛在主題模型加入的例子,利用潛在主題分 佈基於項目為基礎的協同過濾的演算法,來提高推薦系統的整體性能 (Chang & Hsiao 2013)。Chen (2012)的研究將 LDA 找出文件潛在主題分布, 再結合協同過濾並與結合內容式過濾的做比較,都有優於傳統的協同過 濾,我們也採用他提出的語意為基礎的協同過濾(SBCF)。用基於 LDA 潛 在因素模型去模擬根據個人排名上使用者興趣的變化,能夠更了解使用 者、項目之間和使用者興趣,並推薦更準確的排名,還因為考慮使用者 興趣和興趣的變化,更能減輕過度專業化和冷啟動的問題(Liu et al. 2012)。 Wilson et al. (2014)提出一種 LDA 結合使用者為基礎的協同過濾的推薦, 利用使用者的潛在主題相似性,雖然計算使用者之間的相似性,但他們 使用組合相似的衡量包含評分,這方法降低稀疏性的問題,因為他做了 使用者之間的相似度的計算。 2.5. 推薦多樣性 推薦系統之前的研究,衡量推薦的品質都是用推薦的正確性來看,在 傳統內容為基礎的推薦策略注重在找出最相似的項目,但這樣的推薦會 造成多樣性低,使用者難以發現潛在的興趣,導致推薦集中在使用者的 喜好內,而限制未來推薦的範圍(Bradley & Smyth 2001),而協同過濾的 6.
(18) 策略在找最多人喜好的項目,這樣的結果反而只會讓已經熱門的項目更 加普及化(Fleder & Hosanagar 2009)。 現在一些研究認為多樣性(Diversity)可以解決這樣的問題,推薦系統 需要提供更多樣性的推薦,因為多樣性可以推薦更多樣的項目,這些項 目之間具有異質性,因此代表有更多替代的選擇(Adomavicius & Kwon 2012; Bradley & Smyth 2001; Castells et al. 2011; de Máster 2012; Fleder & Hosanagar 2009; McSherry 2002; Smyth & McClave 2001; Ziegler et al. 2005)。這些研究結果發現增加多樣性,造成的正確性降低,這樣的結果 反而增加使用者的滿意度。多樣性可分為個體多樣性(Individual Diversity) 與總體多樣性(Aggregate Diversity),個體多樣性是指在使用者推薦清單中, 每對項目之間的差異,總體多樣性是指所有使用者中,與其他人推薦的 項目不同。但最近的研究較多用總體多樣性,個體多樣性高並不代表總 體多樣性也高,例如:推薦系統推薦給使用者的項目中,每個項目之間具 有差異性,這表示個體多樣性高,但如果推薦系統推薦給每個使用者都 是相同差異性的清單,這表示推薦具有個體多樣性高,但總體多樣性低。 因為總體多樣性的優點在於提供廣泛的項目,而不只注重在熱門的項目 (Adomavicius & Kwon 2012; Zheng & Ip 2012)。 我們定義多樣性是相對於某項目或某群之中的相異程度,越多樣化的 推薦,代表越多替代的選擇,越低多樣化的推薦,代表推薦的項目之間 太相似。站在使用者角度來看,多樣性可帶給使用者們更多的選擇項目, 7.
(19) 而不是一組相似的項目清單,因為太相似的項目,使用者可能認為選擇 任何項目都差異不大。但站在推薦系統的角度,推薦的項目不僅在暢銷 熱門的那些,能將更多樣的項目讓使用者看見,增加商品的曝光率,提 高使用者對於推薦系統的滿意度。站在銷售的角度,為了達到長尾的效 應,不能只注重暢銷商品,銷售量小但種類多的冷門品商總量的總收益 是超過暢銷商品的,根據帕雷托法則(Pareto Principle),企業的 80%收益 主要是由 20%的商品所獲得的,因此也需要注重冷門的商品,多樣性的 推薦目的就是將更多樣的商品銷售出去,不僅只是集中在暢銷商品,這 將可能替企業帶來更多價值收益。 2.6. 一般推薦的衡量 推薦系統的衡量,一般常見的就是精確度(Precision)的衡量,精確度 是一組推薦的項目中,有多少推薦的項目是使用者真正喜歡的,高精確 度表示系統能夠準確預測到使用者的喜好。另一個常見的衡量是召回率 (Recall),召回率是所有使用者真正會喜歡的項目中,有多少項目被推薦 給使用者。如果單看其中一個,對於推薦系統的品質衡量會有問題,因 為高精確度並不代表高召回率,例如推薦系統將所有項目都推薦給使用 者,那根據召回率,系統的表現是好的,但根據精確度,系統的表現很 差,但如果只推薦一個正確的給使用者,那反而精確度的表現很好,但 召回率的表現是差的。所以還會用 F 值來一起看精確度、召回率的指標。 8.
(20) 平均絕對誤差(Mean Absolute Error; MAE)是經常出現的指標,經常用來計 算兩者之間的距離,可用來衡量預測資料與真實資料之間的差距。 2.7. 多樣性的衡量 推薦的衡量除了正確率與上面提到的多樣性之外,還有一些其他的衡 量指標,這邊將介紹覆蓋率、新穎性、偶然性和驚奇性,這些指標在近 幾年都有被提到,目的都是為了提高推薦的品質,讓使用者更滿意。 2.7.1. 覆蓋率 覆蓋率(Coverage)也是很多推薦系統常用的指標(Ge et al. 2010; Herlocker et al. 2004),覆蓋率有兩種,系統能夠產生的項目百分比,通常 指的是預測覆蓋率(Prediction Coverage),另一種是有用的項目,有效地推 薦給使用者的百分比,被稱為目錄覆蓋率(Catalogue Coverage)。高覆蓋率 的推薦系統可以帶給使用者較高的價值,因為使用者可以選擇的範圍會 更廣泛,而低覆蓋率的推薦系統,會帶給使用者較低的價值,因為使用 者在選擇範圍內受到限制,這也代表許多有用的項目在推薦系統中,沒 有有效地被推薦。 2.7.2. 新穎性 新穎性(Novelty)的定義是使用者先前從未看過的,與多樣性的差異是 一組具有多樣性的項目,彼此之間不相同,那每個項目對於其他的項目 來說就是新穎的,一直提高新穎性,最後容易產生整體多樣性(Castells et 9.
(21) al. 2011)。Adamopoulos 與 Tuzhilin(2011)認為與意外發現(Unexpectedness) 相似,都必頇要是使用者從未知道的項目,且新穎性不考慮使用者對於 推薦的評分。 2.7.3. 偶然性 偶然性(Serendipity)是系統能夠在推薦清單中,出現不平常和驚奇的 推薦,偶然性可改善傳統推薦,單純透過使用者的偏好的乏味,能提供 有趣的推薦清單(Ge et al. 2010),例如在廣告單上看到你不曾看過的商品, 而這些商品是貼近你生活方式,你會喜歡它的。Iaquinta et al. (2008)認為 偶然性是主觀的,很難去概念化,因為這是運氣的概念,例如你去逛街, 你只是想要隨便看看,但突然會發現一個新的商品,是你有興趣的,但 你沒想到你會發現它的這種感覺。偶然性是能夠幫助使用者發現令人驚 奇有趣的項目,這個項目是使用者平常不會去發現到的(Herlocker et al. 2004)。我們認為偶然性是使用者期待之外的項目,這些項目也是使用者 會喜歡的,但使用者從來不知道這個項目。 2.7.4. 驚奇性 驚奇性(Surprise)的目的是讓使用者發現意想不到的新穎性項目 (Zheng & Ip 2012),也有的認為驚奇性是能夠讓使用者擴展視野,推薦的 項目與使用者的興趣接近,但對於使用者來說是一個尚未發現的新領域 (Onuma et al. 2009)。驚奇性存在開放性的問題,每位使用者都有著不同 10.
(22) 的個性,對於驚奇性的感受也不同,也就是取決於主觀看法,例如保守 使用者與喜愛冒險的使用者,驚奇性的推薦就有差別,對保守就能驚奇 的項目,愛冒險的使用者可能就無法滿足。我們認為新穎性是推薦新穎 的項目,而項目應該要是使用者喜歡的,這樣才會對使用者感到驚奇, 而且驚奇性也包含了新穎性。 3. 研究方法 為了推薦多樣性的課程給學習者,我們使用三組實驗,分別為電影 資料集、笑話資料集、課程資料集,來觀察使用者為基礎的主題模型、 項目為基礎的主題模型、使用者為基礎推薦和項目為基礎的推薦之間的 表現。使用評估方法為精確度、召回率、F1 值、MAE、MAP 和總體多 樣性來比較四種方法之間的差異。 本研究主題模型的系統架構如圖 1,除了需要使用者的評分資料, 還需要所有項目內容,因此本研究的原始資料需要包含每個項目的內容 和使用者給項目的評分。而這些項目內容中,若有沒有內容的項目,本 研究會先把這幾筆去除,並整理每位使用者選過的項目。在這些項目內 容中,有許多無代表性的字,例如:his、her、is、are、of…所以要先去除 這些停用字,然後再用 LDA 對所有的項目找出主題字詞分布,結合使用 者看過的項目內容,就能獲得到該使用者的主題分布,若是結合項目內 容,就能得到該項目的主題分布,再利用這些主題分布,對未評分的項 11.
(23) 目計算出預測評分,在降冪排序,將前 N 名的項目推薦給該使用者。. 原始資料 (項目內容、使用 者對項目評分). 計算未評分 項目. 過濾沒內容 的項目. 過濾完的項目. 去除停用字. 項目預測評分. 主題分布. 評分排序. LDA找出主 題. 前N名推薦項目. 整理過的項 目內容. 圖 1. LDA 系統架構 主題分布的產生在項目為基礎的 LDA 和使用者為基礎的 LDA 都是 相同的,是透過所有項目 LDA 獲得的主題分布 T,即. ⃗ ⃗ ⃗. ⃗ ,. 為主題分布中第 k 個主題,而每個主題中又有代表該主題的字,即 t⃗. 𝑤. 𝑤. 𝑤. 𝑤. 𝑛. ,𝑤 𝑛 為 k 個主題中第 n 個字。. 以項目為基礎的 LDA,項目的主題分布是結合所有項目 LDA 獲得的 主題分布結果所獲得,因為所有項目 LDA 後的結果只有主題字詞的分布, 不管是使用者的主題分布或是項目的主題分布都要再另外推導。其步驟 12.
(24) 如下: (1) 將項目 i 的內容去對應 k 主題中的字,記錄擊中次數 c,除上項目 i 的總字數 s,會得到項目 i 在第 k 個主題中的第 n 個字的權重,即 𝑝𝑖. 𝑛. 𝑐𝑤𝑘1 /𝑠𝑖,例如:項目 1 在主題 0 中 tells 出現過 3 次,但項目共. 有 150 個字,所以 tells 的值為 3/150=0.02 (Chen 2011)。 (2) 將主題 k 中所有字得到的值加總起來,會得到項目 i 中 k 主題的值, 即. 𝑝𝑖. 𝑖. 𝑝𝑖. 𝑝𝑖. 𝑝𝑖. 𝑛 ,所以會得到該項目. i 的每個. 主題 v 的值。因此,我們就會得到每個項目的主題分布 𝑖 ,即 𝑖. 𝑖. 𝑖. 𝑖. 𝑖. 。之後再透過餘弦相似度計算出項目之間的. 相似度,然後利用這些相似度來計算未看過的項目的預測分數。 以使用者為基礎的 LDA,使用者的主題分布也是結合所有項目 LDA 獲得的主題分布 T 所獲得的。每個使用者 u 的主題分布是由該使用者看 過的項目主題分布結合,成為該使用者的主題分布。(Wilson et al. 2014) (1) 為了得到使用者看過的每個項目的主題分布向量,需要先計算項目 i 的內容對應主題中的字,記錄擊中次數 c,除上項目 i 的總字數 s,會 得到項目 i 在第 k 個主題中的第 n 個字的權重,即𝑝𝑖 得到該項目 i 在第 k 個主題之下的值, 𝑖 也能得到該項目 i 的主題分布向量,. 𝑖. 𝑝𝑖. (𝑝𝑖 𝑖. 𝑖. 𝑖. 不代表是該使用者對該項目 i 的主題的分布向量。 13. 𝑐𝑤𝑘1 /𝑠𝑖,能. 𝑛. 𝑝𝑖. 𝑝𝑖 𝑖. 𝑛). ,但這並. 。.
(25) (2) 所以我們需要將剛得到的主題分布乘上評分標準化,才能成為使用者 對該項目的主題分布向量。評分標準化我們是計算該使用者 u 對該項 目 i 的評分 用者的. 𝑖為. 𝑖 ,除上該使用者. 3,但. u 對所有評分項目的總分. ,例如:使. 為 24,那該主題分布向量的每個𝑤𝑛 就乘上 1/8。. 該項目的第 k 個主題分布向量為t. ∗ (𝑝𝑖. 𝑖. 𝑝𝑖. 𝑝𝑖. 𝑝𝑖. 𝑛 ),. 因此得到該使用者 u 對評分過的項目 i 的主題分布向量。 (3) 該使用者 u 的第 k 個主題. ,是由 n 個評分過的項目的主題分布向. 量的加總,. 𝑛. ,將每個使用者評分過的項. 目的主題分布向量加總起來,最後會得到該使用者 u 的主題分布向量 𝑇 ,𝑇. 。透過以上方法,得到每位使用. 者的主題分布向量,再透過餘弦相似度計算使用者主題分布向量之間 的相似度,來預測項目的評分。. 14.
(26) 主題字詞 分布. 項目內容. 項目的預測評 分. 預測評分 計算項目主 題分布 項目間的相似 度. 餘弦相似度 計算項目相 似度. 主題分布. 圖 2. 主題產生流程 3.1. 主題模型之協同過濾推薦系統 主題模型是將所有項目,透過 LDA 找出所有項目的主題分布,利用 這主題分布可以推導出每個項目的主題向量或每個使用者的主題向量, 項目為基礎的主題模型是利用主題模型得到的項目主題向量,用以下的 餘弦相似度公式,將項目 i 的主題分布 與項目 j 的主題分布 ,計算相 似度,然後依據該使用者曾經看過的項目喜好,利用項目為基礎的協同 過濾的方法來推薦。 𝑠𝑖𝑚(𝑇𝑖 𝑇 ). ⃗⃗⃗ 𝑇 ⃗⃗⃗) 𝑐𝑜𝑠(𝑇 15. ⃗⃗⃗ ⃗⃗⃗ 𝑇 ∙𝑇 ⃗⃗⃗‖‖𝑇 ⃗⃗⃗‖ ‖𝑇.
(27) 使用者為基礎的主題模型是利用主題模型得到的使用者主題向量,使 用以下的餘弦相似度來計算,該使用者 u 的主題分布 u 與鄰近使用者 g 的主題分布 g 的相似度,依據鄰近使用者對該項目的偏好,利用使用者 為基礎的協同過濾方法來推薦。 ⃗⃗⃗⃗⃗ 𝑇 ⃗⃗⃗⃗ cos(𝑇 𝑔). sim(𝑇 𝑇𝑔 ). ⃗⃗⃗⃗⃗ ∙ ⃗⃗⃗⃗ 𝑇 𝑇𝑔 ⃗⃗⃗⃗⃗‖‖𝑇 ⃗⃗⃗⃗ ‖𝑇 𝑔‖. 3.2. 使用者為基礎的推薦系統 使用者為基礎的推薦,目的是找到與該使用者相似的使用者,也就是 興趣相同的使用者,因此首先要計算該使用者與所有其他使用者喜歡的 項目清單之間的相似度,例如 Pearson 方法來獲得。然後計算與該使用者 相似的使用者對於預測項目的評分,如以下公式。透過上述得到的預測 結果,產生推薦清單給該使用者。 𝑃𝑎 𝑖. ∑𝑦∈𝑃 𝑅𝑦 𝑖 − ̅̅̅̅ 𝑅𝑦 𝑤𝑎 𝑦 ∑𝑦∈𝑃|𝑤𝑎 𝑦 |. 公式中,𝑃𝑎 𝑖 為使用者 a 對於項目 i 的預測評分,𝑅𝑦 𝑖 為鄰近使用者群 ̅̅̅̅ P 中的使用者 y,對於項目 i 的評分,𝑅 𝑦 為使用者 y 的平均評分,𝑤𝑎 𝑦 為 使用者 a 對使用者 y 的相似度。 3.3. 項目為基礎的推薦系統 項目為基礎的推薦,是找到使用者評分過的項目相似預測評分高的項 目。因此首先要計算預測項目與使用者評分的項目之間的相似度,然後 16.
(28) 計算使用者對於預測項目的評分,透過計算與預測項目相似的項目評分 總和來獲得,如以下公式。透過上述結果得到預測結果,產生推薦清單 給使用者。 𝑃𝑎 𝑖. ∑𝑛∈𝑁𝑎. 𝑎 𝑛 𝑤𝑖 𝑛. ∑𝑛∈𝑁𝑎 |𝑤𝑖 𝑛 |. 公式中,𝑃𝑎 𝑖 為使用者 a 對於項目 i 的預測評分,. 𝑎 𝑛 為使用者. a 對於. 使用者評分過的項目𝑁𝑎 中的項目 n 的評分,𝑤𝑖 𝑛 為項目 i 對於項目 n 的相 似度。 3.4. 衡量多樣性 推薦的多樣性逐漸增加,代表著相似度逐漸下降,多樣性的衡量又可 分為個體多樣性和總體多樣性,衡量個體多樣性,是根據以下相似度的 公式,課程清單表示 C={𝐶 , 𝐶 , 𝐶 ,..., 𝐶𝑛 },n 表示推薦前 N 名的數量,Q 表示為目標查詢的課程,從這公式得到推薦清單與 Q 之間的相似度。 ∑𝑛𝑖= 𝑆𝑖𝑚 𝐶𝑖 𝑄 𝑛. 𝑆𝑖𝑚𝑖𝑙𝑎 𝑖 𝑦 𝐶 𝑄. 個體多樣性的衡量可以根據以上公式來獲得,為了提高多樣性,務必 要犧牲相似度,這公式可以得到推薦清單內的多樣性程度。 𝐼𝐷𝑖 𝑒 𝑠𝑖 𝑦 𝐶. 𝑛 ∑𝑛− 𝑖= ∑ =𝑖+ 1 − 𝑆𝑖𝑚(𝐶𝑖 𝐶 ) 𝑛 𝑛−1 2. 衡量總體多樣性,我們可以用以下公式來獲得,U 是所有使用者, 𝐿𝑁 𝑢 是代表使用者 u 的推薦清單,當使用者們的差異越大,總體多樣性 17.
(29) 也會越大,相對的當使用者們差異越小,總體多樣性也會越小。 𝐴𝐷𝑖 𝑒 𝑠𝑖 𝑦. |⋃ 𝐿𝑁 𝑢 | ∈𝑈. 3.5. 一般的衡量 本研究除了進行多樣性的比較,還會利用一般的一些評估方法來做 比較,探究在多樣性的結果之下,其他評估方法的表現如何。我採用一 些評估傳統推薦系統的方法,像是精確度、召回率、F1、MAE、MAP 的 測量。 精確度是指推薦清單中,正確被推薦的項目數。例如,推薦前 5 名 的項目,正確擊中的有 3 個,如表 1,所以精確度就是 3/5。雖然可以知 道推薦清單有多少是使用者喜歡的,但卻不能知道使用者真正喜歡的有 多少被推薦出來,因此,這需要再考慮召回率。 表 1. 精確度、召回率例子 Ranking. 1. 正確. ◎. 𝑃 𝑒𝑐𝑖𝑠𝑖𝑜𝑛. 2. 3. 4. ◎. 5 ◎. { 𝑒𝑙𝑒 𝑎𝑛 𝑖 𝑒𝑚} ∩ {𝑇𝑜𝑝𝑁} {𝑇𝑜𝑝𝑁}. 召回率是指使用者真正喜歡的項目,有多少項目真正被推薦出去。 例如,目前有 6 個項目是使用者真正會喜歡的,而範例只推薦 3 個項目 18.
(30) 給使用者,所以召回率就是 3/6。但召回率會有一個問題,當我們推薦前 N 名的清單,N 逐漸增加,那召回率也會逐漸增加,因此會再考慮 F1 值。 𝑅𝑒𝑐𝑎𝑙𝑙. { 𝑒𝑙𝑒 𝑎𝑛 𝑖 𝑒𝑚} ∩ {𝑇𝑜𝑝𝑁} { 𝑒𝑙𝑒 𝑎𝑛 𝑖 𝑒𝑚}. 精確度和召回率的綜合指標,使用 F1,因為通常推薦清單越大,精 確度就會越小,而召回率會越大,但是當推薦清單越小,精確度就會越 大,召回率會愈小,因此我們需要 F1 來計算。 𝐹1. 2 ∗ 𝑃 𝑒𝑐𝑖𝑠𝑖𝑜𝑛 ∗ 𝑅𝑒𝑐𝑎𝑙𝑙 𝑃 𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑅𝑒𝑐𝑎𝑙𝑙. MAP(Mean Average Precision)是由 AP 延伸,AP 是計算單次查詢的 結果。 例如: 目前有 6 個項目是使用者真正會喜歡的,推薦兩次前 5 名 的排名,如表 2,AP 的計算就是將正確的精確度相加,除上個數, AP#1=(1.0+0.67+0.6)/3=0.76。而 MAP 是計算所有查詢的結果取平均。例 如:目前有兩個排名,第一個有 6 個正確答案,第二個有 5 個正確答案, AP#1=(1.0+0.67+0.6)/3=0.76,AP#2=(1.0+0.4)/2=0.7, MAP=(0.76+0.7)/2=0.73。 表 2. MAP 例子 Ranking#1. 1. 2. 3. 4. 正確. ◎. Recall. 0.17. 0.17. 0.33. 0.33. 0.5. Precision. 1.0. 0.5. 0.67. 0.5. 0.6. Ranking#2. 1. 2. 3. 4. 5. ◎. 19. 5 ◎.
(31) 正確. ◎. ◎. Recall. 0.2. 0.2. 0.2. 0.2. 0.4. Precision. 1.0. 0.5. 0.33. 0.25. 0.4. MAE(Mean Absolute Error)是用來看預測值和實際值之間的差距,結 果越小表示誤差越小,代表越好。MAE 公式中𝑓𝑖 表示預測值,在這也就 是預測評分,𝑦𝑖 表示實際值,n 是項目數。例如:目前推薦前三名,如表 3, 前三名的 MAE=(0.4+0.7+1.2)/3,MAE=0.77。 ∑𝑛𝑖= |𝑓𝑖 − 𝑦𝑖 | 𝑛. 𝑀𝐴𝐸. 表 3. MAE 例子 Ranking#2. 1. 2. 3. 預測評分. 3.4. 3.7. 2.8. 實際評分. 3. 3. 4. 4. 實驗結果 為了證明主題模型能夠推薦多樣性的課程給學習者,我們用三組實 驗來觀察主題模型是否能帶給學習者多樣性的推薦,第一組實驗我們使 用 MovieLens 的電影資料集,第二組實驗我們使用了線上笑話資料集, 第三組實驗我們 MITx 和 HarvardX 的課程資料集。透過 Mahout 提供的 內容為基礎的推薦和協同為基礎的推薦,與項目為基礎的主題模型、使 用者為基礎的主題模型的推薦比較,使用評估多樣性和精確度與召回率 20.
(32) 的方法比較四者之間的差異。內容為基礎的推薦方法的資料集需要學習 者過去曾參與學習的資料,而協同過濾的推薦方法需要學習者對於參與 過的課程進行評分,主題模型需要所有項目的內容摘要來找出主題。 本研究共有三次實驗,MovieLens 資料集用 80%當訓練集,20%當測 試集,5 等分交叉驗證實驗,笑話資料集用 80%當訓練集,20%當測試集, 5 等分交叉驗證實驗,課程資料集分成 90%當訓練集和 10%當測試集。 在項目為基礎的 LDA(ItoI)、使用者為基礎的 LDA(UtoU),與另外兩個傳 統的協同過濾模型,分別為使用者為基礎(UB)和項目為基礎(IB),在相同 資料集中的訓練結果,觀察精確度、召回率、F1、MAP、MAE 和總體多 樣性。 4.1. 資料集說明 電影資料集是 MovieLens 提供的資料集,共有 100,000 筆資料,943 位使用者與 1682 部電影,評分介於 1 至 5 之間的整數。笑話資料集是 Jester 提供的資料集,共有 900,615 筆資料,12,491 位使用者與 100 則笑話,每 位使用者至少評分過 36 則笑話以上,評分介於-10 至 10 之間的實數。課 程資料集是 2012 年秋季到 2013 年春季 MITx 和 HarvardX 在 edX 平台的 課程學習資料,共有 641,139 筆資料、13 門課程、476,532 位使用者,包 含課程 ID、使用者 ID 以及一些使用者的學習紀錄。我們只採用選課超過 4 門以上的資料,過濾後共有 116,234 筆資料,12,491 位使用者,再將學 21.
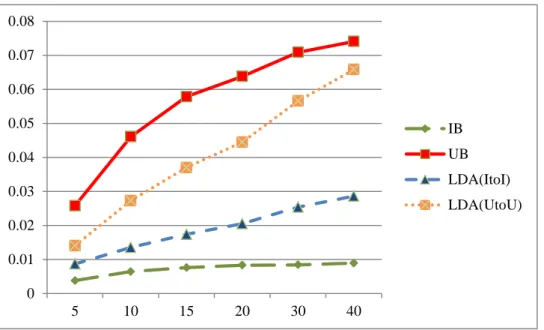
(33) 習者的參與程度作為評分使用者喜好的程度,評分介於 0 至 10 之間的實 數。 4.2. 實驗一 LDA 對多樣性推薦的效果 本實驗是透過電影資料集來觀察結果,觀察 LDA 是否比傳統協同過 濾還要更有多樣性。精確度的評估,本研究取前 5、10、15、20、30、40 名的推薦清單來看,若採用太高的推薦清單,可能不符合實際情況,因 為可能沒有人想看太多的推薦項目清單。從精確度的結果顯示 UB 高於 IB,雖然不符合我們直覺,但過去實驗也有這樣的情況,推測可能是 UB 資料量足夠去分析使用者的喜好,且我們訓練集是 80%,這可能已經足 以代表使用者的喜好,每個使用者平均都有 100 部以上的資料,因此推 薦才會比項目為基礎的高。而我們的 LDA 模型,UtoU 比 ItoI 的模型還 要高,ItoI 介於 IB 與 UB 之間,推測因為我們 LDA 是採用 IB 當基礎, 但因為加入主題做推斷,才會高於 IB,但還是不夠高於資料充足的 UB, 因此低於 UB。初期,UtoU 模型的表現的高於 UB,後期表現 UB 高於 UtoU。 表 4. MovieLens 項目為基礎的精確度 Precision. Precision. Precision. Precision. Precision. Precision. @5. @10. @15. @20. @30. @40. D1. 0.0048656 0.0061254 0.0064928 0.0067623 0.0065445 0.0067188. D2. 0.0043367 0.0068376 0.0060815 0.0064449 0.0070361 0.0067823 22.
(34) D3. 0.0043590 0.0064234 0.0077295 0.0086242 0.0086685 0.0087621. D4. 0.002853. D5. 0.0023468 0.0045124 0.0068716 0.0071577 0.0067766 0.0072034. 0.005806. 0.007554. 0.008197. 0.007975. 0.008168. 表 5. MovieLens 使用者為基礎的精確度 Precision. Precision. Precision. Precision. Precision. Precision. @5. @10. @15. @20. @30. @40. D1. 0.0215109 0.0426791 0.0479082 0.0566769 0.0672173 0.0729679. D2. 0.0271046 0.0433919 0.0530754 0.0567625 0.0633915 0.0721953. D3. 0.0249037 0.0427835 0.0535613 0.0560679 0.0631871 0.0702053. D4. 0.0249027 0.0385139 0.0482735 0.0542472 0.0642095 0.0740969. D5. 0.0248366 0.0411559 0.0537394 0.0582592. 0.070506. 0.0768925. 表 6. MovieLens LDA(ItoI)推薦的精確度 Precision. Precision. Precision. Precision. Precision. Precision. @5. @10. @15. @20. @30. @40. D1. 0.0413943. 0.0363834. 0.0368918. 0.0366013. 0.0371823. 0.0369826. D2. 0.0272588 0.0274119 0.0276672 0.0270291 0.0277693 0.0279096. D3. 0.0253165 0.0224396 0.0210203 0.0214614 0.0223245 0.0225546. D4. 0.0242687 0.0217768 0.0215240 0.0210726 0.0207656 0.0206392. D5. 0.0198489 0.0200647 0.0199928 0.0204423 0.0202445 0.0203614. 表 7. MovieLens LDA(UtoU)推薦的精確度 Precision. Precision. Precision. Precision. Precision. Precision. @5. @10. @15. @20. @30. @40. D1. 0.0479303. 0.0686275. 0.0742193. 0.0750545. 0.0792302. 0.0856754. D2. 0.0410413. 0.0447167. 0.0508423. 0.0529096. 0.0563042. 0.0573507. 23.
(35) D3. 0.0400460. 0.0375144. 0.0418872. 0.0417721. 0.0447678. 0.0449942. D4. 0.0342362. 0.0416035. 0.0414590. 0.0420910. 0.0420368. 0.0436891. D5. 0.0699029. 0.0638619. 0.0587558. 0.0569579. 0.0537217. 0.0517530. 0.08 0.07 0.06 0.05. IB. 0.04. UB LDA(ItoI). 0.03. LDA(UtoU) 0.02 0.01 0 5. 10. 15. 20. 30. 40. 圖 3. MovieLens 精確度曲線圖 召回率與精確度一樣,採用前 40 名之內的項目來比較,結果可明顯 看出同樣 UB 的表現最好,然後是 UtoU,但在推薦前 40 名,UtoU 超越 了 UB,UtoU 又比 ItoI 表現還好,ItoI 比 IB 還好。但還是需要進一步用 F1 值做比較。 表 8. MovieLens 項目為基礎的召回率 Recall. Recall. Recall. Recall. Recall. Recall. @5. @10. @15. @20. @30. @40. D1. 0.0049296. 0.0069834. 0.0075313. 0.0083815. 0.0087301. 0.0095385. D2. 0.0045706. 0.008768. 0.0077643. 0.0080443. 0.0084956. 0.0094798. D3. 0.0044231. 0.0079348. 0.0095681. 0.0115147. 0.0115819. 0.0127585. D4. 0.0028534. 0.0064644. 0.0088278. 0.0101765. 0.0115327. 0.0125843. 24.
(36) D5. 0.0023468. 0.0051021. 0.0082078. 0.0091331. 0.0087556. 0.0106367. 表 9. MovieLens 使用者為基礎的召回率 Recall. Recall. Recall. Recall. Recall. Recall. @5. @10. @15. @20. @30. @40. D1. 0.0235809. 0.0518705. 0.0607752. 0.0694924. 0.0691863. 0.0768188. D2. 0.0291029. 0.0548456. 0.0706544. 0.0743244. 0.0735285. 0.0750135. D3. 0.0263889. 0.0530396. 0.0675121. 0.0735923. 0.074417. 0.075112. D4. 0.0287938. 0.0474186. 0.0643145. 0.0733028. 0.0777394. 0.0786133. D5. 0.0272925. 0.0502149. 0.0685407. 0.0766733. 0.0791461. 0.0800799. 表 10. MovieLens LDA(ItoI)推薦的召回率 Recall. Recall. Recall. Recall. Recall. Recall. @5. @10. @15. @20. @30. @40. D1. 0.0050830. 0.0091441. 0.0138483. 0.0175078. 0.0247247. 0.0318698. D2. 0.0047807. 0.0087184. 0.0123485. 0.0157128. 0.0246624. 0.0311606. D3. 0.0059475. 0.0094362. 0.0125795. 0.0176329. 0.0271655. 0.0361482. D4. 0.0067286. 0.0117804. 0.0162395. 0.0202223. 0.0288664. 0.0365058. D5. 0.0036294. 0.0078500. 0.0127081. 0.0177453. 0.0252088. 0.0332032. 表 11. MovieLens LDA(UtoU)推薦的召回率 Recall. Recall. Recall. Recall. Recall. Recall. @5. @10. @15. @20. @30. @40. D1. 0.00757666 0.01764107 0.02820503 0.03939645 0.06202193 0.08719900. D2. 0.00651073 0.0140442. D3. 0.00598187 0.01330972 0.02462777 0.03357555 0.05512003 0.07207425. D4. 0.00659387 0.01899758 0.02753396 0.03665522 0.05337494 0.07547299. 0.02175671 0.02943431 0.04857055 0.06640372. 25.
(37) D5. 0.01490537 0.03052337 0.04296883 0.05586497 0.08130104 0.10975349 0.09 0.08 0.07 0.06 IB 0.05. UB. 0.04. LDA(ItoI). 0.03. LDA(UtoU). 0.02 0.01. 0 5. 10. 15. 20. 30. 40. 圖 4. MovieLens 召回率曲線圖 精確度和召回率都明顯的可以看出 UB 表現比 ItoI 和 IB 還要好,雖 然可以看出 UB 表現好,但與 UtoU 的比較卻不明顯,我們沒辦法明顯看 出 UB 和 UtoU 之間的表現,因此我們用 F1 值來看之間的比較,結果可 以看到,UB 比 UtoU 表現還好,UtoU 又比 ItoI 表現還好,最差的是 IB, 可以得知,IB 加入 LDA 的判斷是有幫助推薦更精確,而 UB 加入 LDA, 卻沒有比 UB 還好,還是需要改進。 表 12. MovieLens 項目為基礎的 F1 F@5. F@10. F@15. F@20. F@30. F@40. D1. 0.004897 0.006526 0.006974 0.007485 0.007481 0.007884. D2. 0.004451 0.007683 0.006821 0.007156 0.007697 0.007907. D3. 0.004391 0.0071. D4. 0.002853 0.006118 0.008141 0.00908 0.009429 0.009906. 0.008551 0.009862 0.009916 0.010389. 26.
(38) D5. 0.002347 0.004789 0.00748 0.008026 0.00764 0.00859 表 13. MovieLens 使用者為基礎的 F1 F@5. F@10. F@15. F@20. F@30. F@40. D1. 0.022498 0.046828 0.05358 0.062434 0.071698 0.071027. D2. 0.028068 0.048451 0.060616 0.064367 0.068715 0.072856. D3. 0.025625 0.047363 0.059733 0.063646 0.068344 0.072576. D4. 0.026707 0.042505 0.055151 0.062352 0.070685 0.075874. D5. 0.026007 0.045236 0.060244 0.06621 0.074989 0.078003 表 14. MovieLens LDA(ItoI)的 F1 F@5. F@10. F@15. F@20. F@30. F@40. D1. 0.009054 0.014615 0.020137 0.023686 0.029700 0.034236. D2. 0.008135 0.013229 0.017076 0.019873 0.026124 0.029446. D3. 0.009632 0.013286 0.015740 0.019360 0.024508 0.027777. D4. 0.010536 0.015290 0.018512 0.020639 0.024155 0.026370. D5. 0.006137 0.011285 0.015539 0.018999 0.022456 0.025243 表 15. MovieLens LDA(UtoU)的 F1 F@5. F@10. F@15. F@20. F@30. F@40. D1. 0.013085 0.028067 0.040876 0.051671 0.069578 0.086430. D2. 0.011239 0.021375 0.030473 0.037826 0.052152 0.061546. D3. 0.010409 0.019648 0.031018 0.037228 0.049407 0.055402. D4. 0.011058 0.026084 0.033091 0.039185 0.047032 0.055342. D5. 0.024571 0.041305 0.049637 0.056406 0.064695 0.070339. 27.
(39) 0.08 0.07 0.06 0.05. IB. 0.04. UB. LDA(ItoI). 0.03. LDA(UtoU) 0.02 0.01 0 5. 10. 15. 20. 30. 40. 圖 5. MovieLens F1 值曲線圖 除了精確度的比較之外,本研究還用 MAP 來比較,MAP 採用前 30 名項目的推薦,從 MAP 來看,UtoU 比 UB 還要高,UB 比 ItoI 高,ItoI 又比 IB 高,在 MAP 更能明顯的看出 ItoI 的表現高於 IB,但還是低於 UB 和 UtoU,原因可能是因為那些資料量已經足以讓 UB 表現更好,但對於 IB 為基礎的 ItoI、IB 表現卻沒 UB 的好。 表 16. MovieLens MAP D1. D2. D3. D4. D5. LDA(ItoI) 0.0844410 0.0644361 0.0569237 0.0587382 0.0548747 LDA(UtoU) 0.1182769 0.0879251 0.0825632 0.0827545 0.1195362. IB. 0.0272069 0.0207243 0.0138117. UB. 0.1127509. 0.0197844 0.0178410. 0.0873072 0.0752828 0.0609625 0.0616515. 28.
(40) 0.14 0.12 0.1 LDA(ItoI). 0.08. LDA(UtoU) 0.06. IB UB. 0.04 0.02 0 D1. D2. D3. D4. D5. 圖 6. MovieLens MAP 直條圖 本研究還用 MAE 來評估預測出的評分資料與真實評分資料之間的 差距,越高表示越差,越低表示越好。由結果來看,IB 的表現明顯最差, UtoU 的表現略勝 ItoI、UB,ItoI 與 UB 差距不大,這表示 LDA 能有將預 測值接近實際值的能力,雖然前面精確度不比 UB 好,但 MAE 卻能與 UB 相差不大,甚至還要更好。 表 17. MovieLens MAE D1. D2. D3. D4. D5. LDA(ItoI) 0.8706732 0.8940149 0.8595345 0.8256173 0.8747597 LDA(UtoU) 0.7339188 0.8773448 0.8540431 0.8578271 0.8842681. IB. 1.563654. 1.601066. 1.59236. 1.457079. 1.69387. UB. 0.857766. 0.864566. 0.876269. 0.849942. 0.881234. 29.
(41) 1.8. 1.6 1.4 1.2 LDA(ItoI). 1. LDA(UtoU). 0.8. IB. 0.6. UB. 0.4 0.2 0 D1. D2. D3. D4. D5. 圖 7. MovieLens MAE 直條圖 本研究的模型在精確度和召回率上,UB 的表現比 IB 還要好,而我 們的兩個模型雖然比 UB 的來的低,但從 MAE 來看卻能看出 LDA 還是 有好的表現,這表示我們的模型還是能跟傳統的一樣,推薦使用者喜歡 的。但我們也要考慮到推薦的多樣性,是否能夠將推薦清單變成多樣的 結果,因此我們用總體多樣性來比較,表 18 是在不同 N 之下得到的總 體多樣性結果。. 表 18. MovieLens 總體多樣性 TOP. 5. 10. 15. 20. 25. 30. D1. LDA(ItoI). 571. 863. 1071. 1190. 1355. 1465. D1. LDA(UtoU). 432. 576. 681. 748. 832. 880. D1. ITEM. 324. 464. 617. 748. 876. 988. D1. USER. 378. 512. 591. 653. 692. 722. 30.
(42) D2. LDA(ItoI). 589. 888. 1072. 1190. 1368. 1473. D2. LDA(UtoU). 229. 317. 388. 453. 546. 623. D2. ITEM. 283. 464. 612. 755. 892. 1028. D2. USER. 352. 471. 577. 629. 679. 705. D3. LDA(ItoI). 574. 875. 1061. 1206. 1369. 1474. D3. LDA(UtoU). 190. 295. 371. 418. 506. 578. D3. ITEM. 332. 476. 593. 728. 858. 967. D3. USER. 378. 489. 568. 626. 668. 703. D4. LDA(ItoI). 563. 896. 1069. 1198. 1368. 1480. D4. LDA(UtoU). 157. 226. 266. 310. 387. 446. D4. ITEM. 332. 516. 648. 790. 936. 1049. D4. USER. 344. 469. 553. 614. 653. 695. D5. LDA(ItoI). 550. 874. 1051. 1190. 1380. 1492. D5. LDA(UtoU). 154. 206. 258. 296. 356. 407. D5. ITEM. 285. 453. 609. 747. 876. 994. D5. USER. 360. 490. 561. 619. 673. 713. SUM. LDA(ItoI). 2847. 4396. 5324. 5974. 6840. 7384. SUM LDA(UtoU). 1162. 1620. 1964. 2225. 2627. 2934. SUM. ITEM. 1556. 2373. 3079. 3768. 4438. 5026. SUM. USER. 1812. 2431. 2850. 3141. 3365. 3538. 表 19. MovieLens 總體多樣性百分比 5. 10. 15. 20. 25. 30. 33.85% 52.27%. 63.31%. 71.03%. 81.33%. 87.80%. 13.82%. 23.35%. 26.46%. 31.24%. 34.89%. LDA (ItoI) LDA. 19.26%. 31.
(43) (UtoU). IB. 18.50% 28.22%. 36.61%. 44.80%. 52.77%. 59.76%. UB. 21.55% 28.91%. 33.89%. 37.35%. 40.01%. 42.07%. 由表 19 可看出,這些數值是所有推薦的項目占所有項目的比例。我 們的 LDA 模型能提供比傳統模型還要多樣的項目,在前 10 名的時候已 經能提供 50%以上的項目給使用者,讓使用者能接觸到高達 5 成的項目, 而傳統的推薦沒辦法從所有項目中,表現較好的 IB 也要前 25 名的推薦, 才能有一半的項目被推薦,增加推薦清單項目雖然可以增加推薦多樣性, 但使用者通常沒有辦法有耐心看完那麼多項的推薦項目。值得注意的是, UtoU 在總體多樣性並沒有很好的表現,這可能是因為它採用的是使用者 為基礎,容易產生其他人也選過或是喜歡的項目,讓推薦的範圍集中在 熱門的項目,而導致總體多樣性過低。而 ItoI 因為是由項目的相似度去 做推薦,比較不需考慮其他使用者的喜好,推薦範圍就能比使用者為基 礎的還要廣泛,而有多樣性的推薦。 100.00% 90.00% 80.00%. 70.00% 60.00%. IB. 50.00%. UB. 40.00%. LDA(ItoI). 30.00%. LDA(UtoU). 20.00% 10.00%. 0.00% 5. 10. 15. 20. 30. 32. 40.
(44) 圖 8. MovieLens 總體多樣性的比例曲線圖 由圖 8 更能清楚看到我們的 ItoI 模型提供的多樣性,遠超過傳統的 推薦系統,傳統的推薦,IB 的推薦多樣性在前 10 名之後,就逐漸超越 UB,雖然 UB 在 F1、MAP、MAE 的表現都比 ItoI 和 IB 還要好,但從多 樣性的角度來看,卻沒有辦法推薦太多樣的項目。在推薦清單逐漸增加 之後,傳統的推薦方法都有明顯增加推薦比例,但還是遠不及我們提出 的模型。而 UtoU 卻沒有太好的表現,這可能表示如果我們想要有多樣的 推薦,應該要站在使用者個人的角度,而不是全部使用者的角度。 4.3. 實驗二 項目為基礎的對使用者為基礎的效果 本實驗利用笑話資料集來觀察結果,觀察站在項目為基礎的和站在 使用者為基礎上的多樣性表現如何。在這資料集中共有 12,491 位使用者, 100 篇笑話。我們分別去看前 5、10、15、20 名的精確度結果,從結果可 以看到,在笑話資料集中,LDA 的 ItoI 和 UtoU 精確度表現沒 IB 和 UB 好,IB 在前 5 名表現較好,隨著推薦名次增加,UB 表現比 IB 還要高。 LDA 如電影資料集一樣,UtoU 比 ItoI 還要高,這資料集中,每個使用者 都至少評分過三分之一以上的笑話,使用者評分過的資料夠多,資訊較 充足。 表 20.笑話項目為基礎的精確度 Precision@5. Precision@10 Precision@15 Precision@20 33.
(45) D1. 0.6128102. 0.5599840. 0.5281986. 0.4902042. D2. 0.6048839. 0.5589031. 0.5278303. 0.4888911. D3. 0.6179343. 0.5649079. 0.5307873. 0.4914532. D4. 0.6169736. 0.5627462. 0.5293888. 0.4908046. D5. 0.6121227. 0.5619825. 0.5280273. 0.4899311. 表 21.笑話使用者為基礎的精確度 Precision@5. Precision@10 Precision@15 Precision@20. D1. 0.5906645. 0.5670296. 0.5373525. 0.496093. D2. 0.5887269. 0.5669335. 0.5374326. 0.495776. D3. 0.5969415. 0.5698959. 0.5392047. 0.497454. D4. 0.5831705. 0.5643555. 0.5372244. 0.496813. D5. 0.5982064. 0.5719192. 0.5401286. 0.497978. 表 22. 笑話 LDA(ItoI)推薦的精確度 Precision@5. Precision@10 Precision@15 Precision@20. D1. 0.4594075. 0.4679904. 0.4689512. 0.4514412. D2. 0.4600961. 0.4679664. 0.4690686. 0.4511289. D3. 0.4602402. 0.4693515. 0.4695276. 0.4512730. D4. 0.4600641. 0.4684788. 0.4690419. 0.4516133. D5. 0.4587237. 0.4669229. 0.4678944. 0.4505965. 表 23. 笑話 LDA(UtoU)推薦的精確度 Precision@5. Precision@10 Precision@15 Precision@20. D1. 0.5002562. 0.5070296. 0.5012757. 0.4763731. D2. 0.5102002. 0.5187267. 0.5100347. 0.4832426. D3. 0.5031705. 0.5131946. 0.5068001. 0.4817774. 34.
(46) D4. 0.5086149. 0.5169496. 0.5089298. 0.4823979. D5. 0.5046841. 0.5162623. 0.5094937. 0.4833774. 0.65. 0.6. IB. 0.55. UB LDA(ItoI). 0.5. LDA(UtoU) 0.45. 0.4 5. 10. 15. 20. 圖 9. 笑話精確度曲線圖 在召回率的結果,跟精確度一致,UB 表現最好,UB 高於 IB,IB 高 於兩個 LDA 的方法,UtoU 的表現高於 ItoI。 表 24. 笑話項目為基礎的召回率 Recall@5. Recall@10. Recall@15. Recall@20. D1. 0.2114911. 0.3763796. 0.5228572. 0.6393376. D2. 0.2074992. 0.3747995. 0.5213915. 0.6359279. D3. 0.2134066. 0.3802723. 0.5263114. 0.6417474. D4. 0.2123283. 0.3777041. 0.5232284. 0.6391561. D5. 0.2112705. 0.3780657. 0.5231506. 0.6397358. 表 25. 笑話使用者為基礎的召回率. D1. Recall@5. Recall@10. Recall@15. Recall@20. 0.2091866. 0.3898274. 0.54064533. 0.6542353. 35.
(47) D2. 0.2077440. 0.3897698. 0.54087827. 0.6534141. D3. 0.2109866. 0.3917426. 0.54296163. 0.6570626. D4. 0.2055694. 0.3876446. 0.54071923. 0.6556622. D5. 0.2122289. 0.3941255. 0.54492716. 0.6587338. 表 26. 笑話 LDA(ItoI)推薦的召回率 Recall@5. Recall@10. Recall@15. Recall@20. D1. 0.140952. 0.2895880. 0.4364985. 0.56062334. D2. 0.141504. 0.2898224. 0.4367012. 0.56051444. D3. 0.141583. 0.2914199. 0.4380210. 0.56170779. D4. 0.141265. 0.2900938. 0.4366409. 0.56129657. D5. 0.14102. 0.289703. 0.436552. 0.5616280. 表 27. 笑話 LDA(UtoU)推薦的召回率 Recall@5. Recall@10. Recall@15. Recall@20. D1. 0.1655623. 0.3350339. 0.4930599. 0.6197125. D2. 0.1684698. 0.3436916. 0.5029300. 0.6301096. D3. 0.1647258. 0.3381425. 0.4981600. 0.6276978. D4. 0.1681239. 0.3426322. 0.5016536. 0.6294036. D5. 0.165877. 0.341834. 0.502552. 0.631034. 36.
(48) 0.7 0.6 0.5. IB UB. 0.4. LDA(ItoI) 0.3. LDA(UtoU). 0.2 0.1 5. 10. 15. 20. 圖 10. 笑話召回率曲線圖 從精確度和召回率觀察,可預想到 F1 值,UB 高於 IB,IB 高於 UtoU, UtoU 高於 ItoI。 表 28. 笑話項目為基礎的 F1 F@5. F@10. F@15. F@20. D1. 0.314458. 0.450181. 0.525514. 0.554926. D2. 0.308999. 0.448701. 0.524591. 0.552799. D3. 0.31725. 0.454556. 0.52854. 0.556634. D4. 0.315931. 0.452021. 0.526291. 0.555242. D5. 0.314123. 0.452033. 0.525578. 0.554901. 表 29. 笑話使用者為基礎的 F1 F@5. F@10. F@15. F@20. D1. 0.308955. 0.46202. 0.538994. 0.564294. D2. 0.307116. 0.461948. 0.53915. 0.563783. D3. 0.311777. 0.464317. 0.541077. 0.566226. D4. 0.303984. 0.459599. 0.538966. 0.56529. 37.
(49) D5. 0.313305. 0.466662. 0.542517. 0.567185. 表 30. 笑話 LDA(ItoI)推薦的 F1 F@5. F@10. F@15. F@20. D1. 0.215719. 0.357783. 0.452143. 0.500143. D2. 0.216441. 0.357955. 0.452307. 0.499908. D3. 0.216549. 0.359578. 0.453227. 0.500471. D4. 0.216158. 0.358312. 0.452262. 0.500516. D5. 0.215723. 0.357558. 0.45168. 0.500023. 表 31. 笑話 LDA(UtoU)推薦的 F1 F@5. F@10. F@15. F@20. D1. 0.248787. 0.403466. 0.497134. 0.53867. D2. 0.253299. 0.413447. 0.506457. 0.546989. D3. 0.248198. 0.407671. 0.502443. 0.545142. D4. 0.252713. 0.412116. 0.505266. 0.546182. D5. 0.249688. 0.41132. 0.505999. 0.547424. 0.6 0.55 0.5. 0.45. IB. 0.4. UB LDA(ItoI). 0.35. LDA(UtoU) 0.3 0.25 0.2 5. 10. 15. 20. 圖 11.笑話 F1 曲線圖 38.
(50) MAP 是採用前 20 名的推薦來計算,從 MAP 觀察還是可以看到 IB 明顯比 UB 高,而 LDA 產生的結果卻比傳統的還要低,LDA 中, UtoU 的表現高於 ItoI。這樣的結果都與精確度、召回率、F1 值得結 果一致。 表 32. 笑話 MAP D1. D2. D3. D4. D5. LDA(ItoI) 0.5320279 0.5330144 0.5307532 0.5324665 0.5314526 LDA(UtoU) 0.5657582 0.5745836 0.5680120 0.5725505 0.5696942. IB. 0.6602898 0.6550814 0.6636971 0.6628546 0.6596477. UB. 0.6403895 0.6382121 0.6448112. 0.6357534 0.6448700. 0.7 0.65 0.6 0.55 0.5 0.45 0.4 0.35 0.3 0.25 0.2 0.15 0.1 0.05 0. LDA(ItoI) LDA(UtoU) IB UB. D1. D2. D3. D4. D5. 圖 12. 笑話 MAP 直條圖 在 MAE 來看,IB 最低,表示他與實際值差距最小,然後是 UB,LDA 的結果也與之前的一樣,UtoU 的表現高於 ItoI。會造成這些結果,可能 是笑話資料集的笑話內容,通常只是一句話,而電影資料集的內容,通 39.
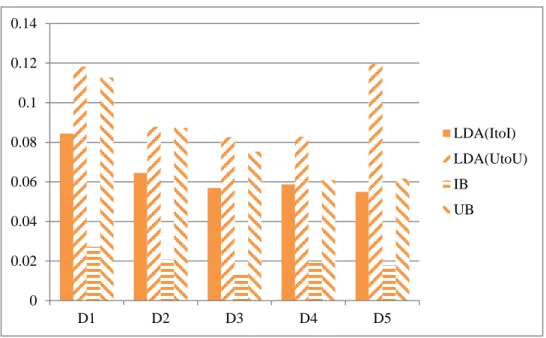
(51) 常有上百個字,造成笑話資料集中,LDA 不易找出代表性的主題,讓 LDA 的精確度指標表現較差。 表 33.笑話 MAE D1. D2. D3. D4. D5. LDA(ItoI) 3.7013937 3.6866539 3.6731705 3.6790537 3.6797041 LDA(UtoU) 3.5791988 3.6155919 3.6165012 3.6239372 3.6212145. IB. 3.4253802 3.4306668 3.4122404 3.4107188 3.4166427. UB. 3.4364722 3.4418345 3.4270232 3.4231444 3.4293635. 3.75 3.7 3.65 3.6 LDA(ItoI). 3.55. LDA(UtoU). 3.5. IB. 3.45. UB. 3.4 3.35 3.3. 3.25 D1. D2. D3. D4. D5. 圖 13. 笑話 MAE 直條圖 笑話資料集的總體多樣性是隨機抽取 30 位使用者,採用前 5、10、 15、20 名的推薦去計算,重複做 1000 次的隨機抽取後平均,笑話項目共 100 則。雖然從上面的評估,都顯示 LDA 的兩種方法造成的結果沒有比 傳統的好,但是在總體多樣性中,LDA 的表現反而有高於傳統的推薦。 從總體多樣性的結果看到,ItoI 的表現最好,雖然在前 5 名的時候 IB 表 40.
(52) 現高於 ItoI,但隨著推薦增加,ItoI 的表現快速增加。在笑話資料集中, UtoU 表現得比 UB 好,我們可以從這結果看到,加入 LDA 的推薦,會 增加多樣性,而 IB 為基礎的在多樣性的表現會高於 UB 帶來的結果。因 此我們認為若要增加多樣性,應該要從 IB 的角度去推薦,才能帶來多樣 性的結果。 表 34.笑話總體多樣性 TOP. 5. 10. 15. 20. D1. LDA(ItoI). 59.073. 86.492. 95.771. 98.527. D1. LDA(UtoU). 55.588. 75.734. 89.469. 96.419. D1. ITEM. 60.827. 83.409. 94.033. 97.935. D1. USER. 50.593. 72.451. 87.459. 95.25. D2. LDA(ItoI). 58.881. 86.123. 95.84. 98.556. D2. LDA(UtoU). 56.975. 77.368. 89.987. 96.609. D2. ITEM. 60.765. 83.673. 94.102. 97.962. D2. USER. 50.362. 72.237. 87.506. 95.202. D3. LDA(ItoI). 58.982. 86.3. 95.996. 98.547. 77.325. 90.084. 96.725. D3. LDA(UtoU) 56.817. D3. ITEM. 61.514. 84.109. 94.191. 97.948. D3. USER. 51.538. 72.819. 87.637. 95.45. D4. LDA(ItoI). 58.872. 86.263. 95.85. 98.617. LDA(UtoU) 57.038. 77.25. 89.799. 96.656. D4 D4. ITEM. 61.553. 84.227. 94.174. 98.029. D4. USER. 50.732. 72.445. 87.408. 95.343. 41.
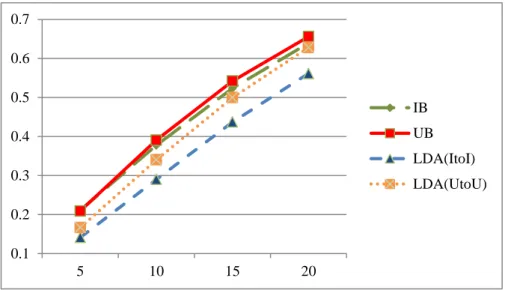
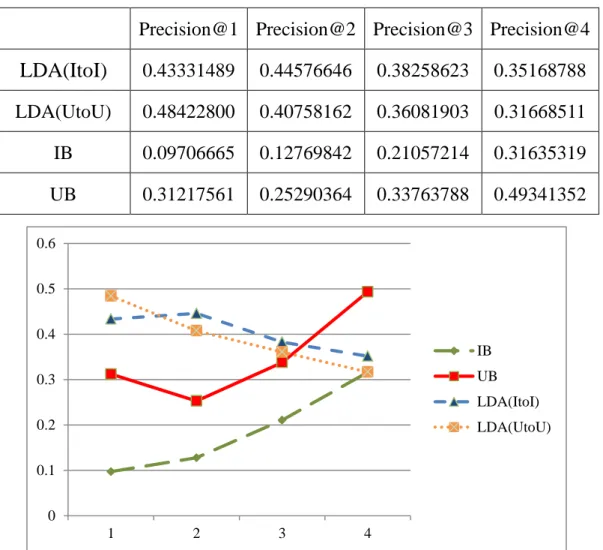
(53) D5 D5. LDA(ItoI). 58.826. 86.224. 95.73. 98.599. LDA(UtoU) 56.598. 76.874. 89.838. 96.576. D5. ITEM. 61.102. 83.796. 93.94. 97.957. D5. USER. 51.201. 72.645. 87.278. 95.417. SUM. LDA(ItoI) 294.634 431.402 479.187 492.846. SUM LDA(UtoU) 283.016 384.551 449.177 482.985 SUM. ITEM. 305.761 419.214 470.44 489.831. SUM. USER. 254.426 362.597 437.288 476.662. 100.00% 95.00% 90.00%. 85.00% 80.00%. IB. 75.00%. UB. 70.00%. LDA(ItoI). 65.00%. LDA(UtoU). 60.00% 55.00%. 50.00% 5. 10. 15. 20. 圖 14. 笑話總體多樣性曲線圖 4.4. 實驗三 課程資料集的多樣性反應結果 本實驗是線上課程資料集的觀察結果,觀察多樣性在線上課程上的 表現是否也能推薦多樣的項目。線上課程的資料集在精確度上的表現如 表 35,這資料集只有 13 門課程,所以我們取前 N 名從 1 到 4,從結果 來看,IB 的表現比 UB 還差,而 UtoU 和 ItoI 的表現最好。UB 比 IB 表 現還好可能是因為我們取的資料都是選擇課程大於 4 以上,因此使用者 42.
(54) 選擇課程的資訊較充足,表現比 UB 還好,而 UtoU 和 ItoI 可能因為又考 慮了課程主題,所以表現比 UB 和 IB 還要好。 表 35. 線上課程精確度 Precision@1 Precision@2 Precision@3 Precision@4. LDA(ItoI). 0.43331489. 0.44576646. 0.38258623. 0.35168788. LDA(UtoU). 0.48422800. 0.40758162. 0.36081903. 0.31668511. IB. 0.09706665. 0.12769842. 0.21057214. 0.31635319. UB. 0.31217561. 0.25290364. 0.33763788. 0.49341352. 0.6 0.5 0.4 IB UB. 0.3. LDA(ItoI) 0.2. LDA(UtoU). 0.1 0 1. 2. 3. 4. 圖 15. 線上課程精確度曲線圖 從召回率的角度看三種推薦的表現,IB 雖然一開始表現不好,但隨 著推薦清單增加,而越來越好,但在前 1、2 名的推薦,都是 UB 比 ItoI 和 UtoU 好,而 UtoU 和 ItoI 比 IB 好。 表 36. 線上課程召回率 Recall@1. Recall @2 43. Recall @3. Recall @4.
(55) LDA(ItoI). 0.14443830. 0.27172108. 0.36081903. 0.42224681. LDA(UtoU). 0.16140933. 0.29717764. 0.38258623. 0.46891717. IB. 0.09672368. 0.21582000. 0.48694030. 0.84691745. UB. 0.23183169. 0.39442595. 0.58644279. 0.66248694. 0.9 0.8 0.7. 0.6 IB 0.5. UB. 0.4. LDA(ItoI). 0.3. LDA(UtoU). 0.2 0.1 0 1. 2. 3. 4. 圖 16.線上課程召回率曲線圖 精確度和召回率上,不能明顯看出哪個比較好,但能看出 IB 在線上 課程的表現是不好的,所以我們從 F1 值觀察可以看到,如表 37,ItoI 和 UtoU 表現相差不多,IB 如預期的在前 3 名都是最差的,而 UB 的表現 會越來越好。 表 37. 線上課程 F1 值 F@1. F @2. F @3. F @4. LDA(ItoI). 0.216657. 0.337634. 0.371384. 0.383751. LDA(UtoU). 0.242114. 0.343732. 0.371384. 0.378052. IB. 0.096895. 0.160456. 0.294005. 0.460641. 44.
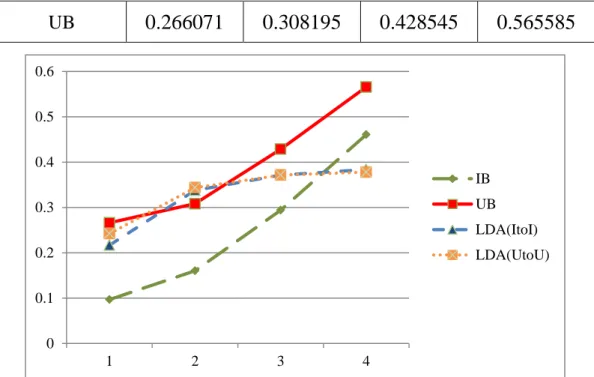
(56) 0.266071. UB. 0.308195. 0.428545. 0.565585. 0.6 0.5 0.4 IB UB. 0.3. LDA(ItoI) 0.2. LDA(UtoU). 0.1. 0 1. 2. 3. 4. 圖 17. 線上課程 F1 值曲線圖 從 MAE 中,表現最好的是 UtoU,然後是 IB,接著是 ItoI,表現最 差的是 UB,但這裡 IB 的表現就比 UB 還要來的好,預測誤差比較小, 從 MAP 中可以觀察到,ItoI 和 UtoU 的表現差距不大,都是表現得很好,且 都表現得比 IB 和 UB 還好。 表 38. 線上課程 MAE、MAP MAE. MAP. LDA(ItoI). 0.72530021 0.61277132. LDA(UtoU). 0.52362584 0.61181824. IB. 0.61294850 0.43326451. UB. 0.76343425 0.43196980. 從 F1 值、MAE 和 MAP 的表現,我們可以看出 UtoU 和 ItoI 的表現 大多位居中間,這代表我們的模型雖然不是最好,但也是有一定的推薦 45.
(57) 水準,然後我們從多樣性的角度來看。我們採用隨機抽 10 個使用者,看 這 10 個使用者的總體多樣性,重複 1000 次抽取,然後取前 1、2 名來看, 因為取 3 名,出來的數字會太接近全部課程數 13,因此不列作考慮。 表 39. 線上課程總體多樣性 1. 2. LDA(ItoI). 9.661. 11.317. LDA(UtoU). 6.856. 8.184. IB. 7.281. 10.884. UB. 4.655. 7.392. 我們可以看到這結果和前面電影資料集的結果一致,ItoI 在總體多樣 性的表現一樣比傳統的還要來的好,而傳統的 IB 會比 UB 還要好,但 UtoU 表現比 UB 還好,這可以證明我們的 LDA 模型是可以提供多樣性的推 薦。 5. 結論 線上課程的發展,帶來更多更快速的知識交流,雖然已經有一些線 上課程的推薦,但在大多數的推薦中,都只在意課程相似於學習者過去 參與的課程,但這對學習者或課程來說,隱含著許多的缺點。我們為了 解決這些的缺點,讓推薦的結果更有多樣性來讓學習者更滿意、因選擇 多而學習的領域更多樣,許多研究也證實多樣性地推薦確實可以讓使用 者更滿意,且課程也不會有太多冷門而不被推薦的情況。雖然項目為基 46.
(58) 礎的推薦目前精確度不高,但在多樣性的部分卻都高於使用者為基礎, 這表示,我們若是需要有多樣性的推薦,應該站在項目的角度,站在使 用者的角度只會讓大多數人選過的項目熱門。 5.1. 研究貢獻 本論文希望由主題模型的方法,找到課程相似的主題,再把相似的 主題做推薦,並產生多樣性的方法,這可讓推薦的項目不會過於侷限在 使用者興趣範圍內,但還是有相關性。透過三組實驗,將項目為基礎的 主題模型與使用者為基礎、項目為基礎的協同過濾和使用者為基礎的主 題模型相互比較,發現項目為基礎的主題模型能夠比傳統的推薦還要更 能產生多樣性,且更能比使用者為基礎的還要有更好的多樣性表現。也 發現推薦站在項目的角度,會比使用者的角度還更有多樣性。 5.2. 未來研究方向 目前的研究採用項目為基礎的主題模型來做推薦,一般評估推薦的 結果表現介於使用者為基礎和項目為基礎之間,但多樣性的角度來看, 我們的主題模型已經能產生多樣的推薦。過去一些論文提到提高多樣性, 必會犧牲精確度,如何在這兩者之間取得平衡,但我們發現,推薦是能 有多樣性又可能同時有精確度的,但前提是項目的內容要夠豐富能夠代 表項目。我們未來可將主題模式加以修改,讓系統能同時擁有這兩項指 標。 47.
(59) 資料集能夠蒐集更多的內容來增加主題模型的精確度,還能看不同 訓練比例之下,多樣性的表現。課程資料集在本研究因太少課程,不太 容易看出多樣性的比較,因此未來可以增加更多的課程,並把課程內容 字幕加入作參考,讓多樣性的表現更明顯。. 參考文獻 Adamopoulos, P., & Tuzhilin, A. (2011, October). On unexpectedness in recommender systems: Or how to expect the unexpected. In Workshop on Novelty and Diversity in Recommender Systems (DiveRS 2011), at the 5th ACM International Conference on Recommender Systems (RecSys' 11) (pp. 11-18). Chicago, Illinois, USA: ACM. Adomavicius, G., & Kwon, Y. (2012). Improving aggregate recommendation diversity using ranking-based techniques. Knowledge and Data Engineering, IEEE Transactions on, 24(5), 896-911. Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. the Journal of machine Learning research, 3, 993-1022. Bradley, K., & Smyth, B. (2001). Improving recommendation diversity. In Proceedings of the Twelfth Irish Conference on Artificial Intelligence and Cognitive Science, Maynooth, Ireland (pp. 85-94). Candillier, L., Meyer, F., & Boullé, M. (2007). Comparing state-of-the-art collaborative filtering systems. In Machine Learning and Data Mining in Pattern Recognition (pp. 548-562). Springer Berlin Heidelberg. Castells, P., Vargas, S., & Wang, J. (2011). Novelty and diversity metrics for recommender systems: choice, discovery and relevance. Retrieved from 48.
(60) http://ir.ii.uam.es/rim3/publications/ddr11.pdf Chang, T. M., & Hsiao, W. F. (2013). LDA-based Personalized Document Recommendation. In PACIS. Retrieved from http://aisel.aisnet.org/cgi/viewcontent.cgi?article=1012&context=pacis20 13 Chen, E. (2011) Introduction to Latent Dirichlet Allocation. Retrieved from http://blog.echen.me/2011/08/22/introduction-to-latent-dirichlet-allocatio n/ Chen, L. Z. (2012). Personalized Document Recommendation by Latent Dirichlet Allocation. Retrieved from http://etd.lib.nsysu.edu.tw/ETD-db/ETD-search/getfile?URN=etd-08131 12-201905&filename=etd-0813112-201905.pdf de Máster, T. F. (2012). Novelty and Diversity Enhancement and Evaluation in Recommender Systems. Retrieved from http://nlp.uned.es/ma2vicmr/docs/tfm-vargas-sandoval.pdf Fleder, D., & Hosanagar, K. (2009). Blockbuster culture's next rise or fall: The impact of recommender systems on sales diversity. Management science, 55(5), 697-712. Ge, M., Delgado-Battenfeld, C., & Jannach, D. (2010, September). Beyond accuracy: evaluating recommender systems by coverage and serendipity. In Proceedings of the fourth ACM conference on Recommender systems (pp. 257-260). ACM. Herlocker, J. L., Konstan, J. A., Terveen, L. G., & Riedl, J. T. (2004). Evaluating collaborative filtering recommender systems. ACM Transactions on Information Systems (TOIS), 22(1), 5-53. Iaquinta, L., De Gemmis, M., Lops, P., Semeraro, G., Filannino, M., & 49.
(61) Molino, P. (2008, September). Introducing serendipity in a content-based recommender system. In Hybrid Intelligent Systems, 2008. HIS'08. Eighth International Conference on (pp. 168-173). IEEE. Lops, P., De Gemmis, M., & Semeraro, G. (2011). Content-based recommender systems: State of the art and trends. In Recommender systems handbook (pp. 73-105). Springer US. McSherry, D. (2002). Diversity-conscious retrieval. In Advances in Case-Based Reasoning (pp. 219-233). Springer Berlin Heidelberg. Onuma, K., Tong, H., & Faloutsos, C. (2009, June). TANGENT: a novel,'Surprise me', recommendation algorithm. In Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 657-666). ACM. Liu, Q., Chen, E., Xiong, H., Ding, C. H., & Chen, J. (2012). Enhancing collaborative filtering by user interest expansion via personalized ranking. Systems, Man, and Cybernetics, Part B: Cybernetics, IEEE Transactions on, 42(1), 218-233. Smyth, B., & McClave, P. (2001). Similarity vs. diversity. In Case-Based Reasoning Research and Development (pp. 347-361). Springer Berlin Heidelberg. Wilson, J., Chaudhury, S., & Lall, B. (2014, August). Improving Collaborative Filtering based Recommenders using Topic Modelling. In Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT)-Volume 01 (pp. 340-346). IEEE Computer Society. Zheng, Q., & Ip, H. H. (2012, December). Customizable Surprising Recommendation Based on the Tradeoff between Genre Difference and 50.
(62) Genre Similarity. In Web Intelligence and Intelligent Agent Technology (WI-IAT), 2012 IEEE/WIC/ACM International Conferences on (Vol. 1, pp. 702-709). IEEE. Ziegler, C. N., McNee, S. M., Konstan, J. A., & Lausen, G. (2005, May). Improving recommendation lists through topic diversification. In Proceedings of the 14th international conference on World Wide Web (pp. 22-32). ACM.. 51.
(63)
數據

+3
Outline
相關文件
可以看出和 critical-damped 和 over-damped case 因為阻泥太強,都連 原點都回不去。但 over-damped 的圖線在 critical-damped 之上,i.e.,over- damped
當然,儘管根據以往的經驗,某個問題的解決看似比較容易,但通常事先不會知道困難
多樣而複雜的曲調反而會主客不分,妨礙身心收攝,以此觀點則既有的梵唄曲調已夠用,但 當梵唄變成公開的表演,甚至演出成為一種常態,則傳統的模式顯然不足以滿足舞台可以轉
熟悉財務比率的計算和表達 : 毛利率, 淨利率,資本運用回報率,營運
說明 闡明目的或原因/弄清事物之間的關係/說出原因和/或方式
從視覺藝術學習發展出來的相關 技能與能力,可以應用於日常生 活與工作上 (藝術為表現世界的知
3.・評賞和比較江啟明和賀普納 (Charles D. Hoeppner) 寫生
說明 闡明目的或原因/弄清事物之間的關係/說出原因和/或方式
