第 2 章 相關文獻探討
自動摘要不是一種新興觀念,在 1950 年代至 1960 年代學者們就已開始在這方面 的研究。因為當時尚無較大的文字語料集,在自然語言處理上也無較為成熟的統 計模型,再加上電腦的計算能力及記憶體的容量也有所限制,因此當時的研究重 點在於精簡的流程處理,著重於下列技術 [Luhn 1959;Edmundson 1969] :
z 文字所在的位置:位於重要段落的字句佔有較高的權重,如第一段或者 位於標題如『簡介、目的、結論』的段落,被視為重要
z 語彙的隱含:字句中包含重要字詞,如『重要的、艱難的』等主題句 z 位置:每一段落的第一句和最後一句被視為重要
雖然上述的方法有效,然而它們非常依賴於特別的寫作格式與風格。例如利 用第一段形成摘要,僅在新聞及新聞雜誌類型的文件中適用。是以本研究試圖能 發展對不同文件類型皆能通用的自動摘要模型,並不專注於特定文件的寫作方式 與風格;換言之,本論文希望所探討的摘要模型,能經過一些處理(訓練)進而 能自動獲得這方面的資訊,如構成摘要的重要語彙。
在回顧自動摘要模型上,可以發現其技術裡的許多重要觀念來自於資訊檢索
(Information Retrieval, IR),此外資訊檢索上許多成功的檢索模型,也被驗證 同樣適用於自動摘要上,如向量空間模型、潛藏式語意分析模型等 [Gong and Liu 2001; 葉鎮源 2002; 何遠 2003; 黃建霖 2004; Hirohata et al. 2005] 。
資訊檢索處理的問題是如何依使用者的問句(Query)從大量的文件中找出 相關(即符合使用者需求)的文件;而自動摘要常常假定使用者的需求為 『看 看文件中的最重要的部分是什麼?』 來找出與文件最相關的字句。資訊檢索與自 動摘要的比較,可由圖 2. 1 所示。
以下小節介紹幾個自動摘要中常用且來源於資訊檢索的觀念。
圖 2. 1 資訊檢索與自動摘要比較圖
2.1 向量空間模型(Vector Space Model, VSM)
在資訊檢索(Information Retrieval, IR)領域中,向量空間模型是個典型的檢索 模型 [Baeza-Yates et al. 1999]。其將每一篇文件d 與問句 qj 視為一 T-維的向量(T 是索引特徵的總數):
j 1, 2, ,
dJJG=(w j, , w j ..., )wT j
(2. 1)
1, 2, ,
( q, , q ..., )T q qG = w w w
(2. 2)
向量的權重w 代表索引特徵 i 在文件i j, d 的權重,其計算常使用 詞頻-反文件頻j
(Term Frequency-Inverse Document Frequency, TF-IDF)乘積來表示。詞頻統計 其出現的頻率來決定其重要性,越常出現愈重要,其值經由正規化算出;反文件 頻用以決定一索引特徵是否具有鑑別力,如一索引特徵在每一篇文件都存在(如 中文:的、了),則應降低其權重,上述討論可由以下數學式來表示:
,
, ,
,
max log
i j
i j i j i
h j i
h
freq N w tf idf
freq n
= ∗ = ∗ (2. 3)
,
i j j
i
freq i d
N
n i
其中
: 索引特徵 在文件 中出現的次數 : 文件集總數
: 索引特徵 在文件集中出現的文件數
自動摘要
1. Doc i 2. Doc j
資訊檢索
相關的文件或字句
最後每一篇文件d 與問句 q 經由估測兩向量的餘弦(Cosine)值來決定其相關性: j
, ,
1
2 2
, ,
1 1
( , )
T
i j i q
j i
j T T
j
i j i q
i i
w w d q
sim d q
d q
w w
=
= =
⋅ ×
= =
× ×
∑
∑ ∑
JJK K
JJK K (2. 4)
近年來有學者應用向量空間模型於自動摘要上,其拿整篇文件做問句
(Query)去檢索文件中的每一字句,得到一相關度排名(句排名),並依摘要比 例將字句摘錄出來形成摘要 [何遠 2003]。
2.2 相關評估(Relevance Measure, RM)
Gong 提出使用相關評估的方法來產生摘要 [Gong and Liu 2001],其方法主要以 向量空間模型為基礎,試圖找出文件中不同主題的重要字句為標的,其步驟如下:
1. 將文件 D 斷句,D ={S1, , S2 ..Si.., SN},這些字句S 用來組成候選 i
句 S
2. 對於每一字句S 產生詞頻(Term-Frequency, TF)向量i SJJKi
,以及對於 整篇文件 D 的詞頻向量 DJK
3. 對於S 中每一字句S ,估測i SJJKi 與 DJK
之間的相關分數(餘弦分數)
4. 選取最大相關分數的字句S ,並將其置於摘要中 k
5. 將S 自 S 中移除,並將k S 中所含的字詞自文件 D 中移除;並重新計 k 算向量 DJK
6. 如摘要的字句達到摘要比例的量則終止運算,否則回到步驟 3 執行 本方法在步驟 4 中,選取文件中最大的相關分數的字句,代表其含有文件的 主要意涵。為了使相關分數所選取到的摘要可覆蓋整篇文件的主要主題,是以在 步驟 5 去除第 k 句中所含的字詞,讓接下來所選取的字句與第 k 句具有最小重 覆,此傾向於所摘要的字句間具有最小的重覆。
2.3 潛藏語意分析(Latent Semantic Analysis, LSA)
潛藏語意分析 [G. Furnas et al. 1988; Bellegarda 2000] 是基於線性代數方法為核 心的模型,包括了奇異值分解(Singular Value Decomposition, SVD)與維度約化
(Dimension Reduction)兩個處理過程。LSA 的應用非常廣泛,諸如同義詞建構、
判斷字詞與字句間的關係、跨語言語言模型調適(Language Model Adaptation)
[KIM et al. 2004]、與自動摘要 [Gong and Liu 2001; 葉鎮源 2002] 等。
2.3.1 索引與字句矩陣
在 進 行 奇 異 值 分 解 之 前 , 要 將 文 件 轉 換 成 索引 -字 句 矩 陣 (Term-Sentence Matrix)。假設一篇文件中不同的索引字或詞有 M 個,此外文件可斷句成 N 句。
所以 索引-字句矩陣 A 的維度是M×N,矩陣中每個元素w 的值,可使用ij 對數-熵(Log-Entropy)來計算 [Bellegarda 2000; Giles et al. 2003] :
ij ij i
w = × (2. l g 5)
l 代表索引 i 在字句 j 的對數權重,ij g 代表索引 i 的熵權重: i
( )
log 1
ij ij
l = + f (2. 6)
i 1 i
g = − (2. ε 7)
其中
:
fij 索引 在字句 中出現的次數 i j
1
: ij
ij N
ij j
p i j f
f
∑=
索引 在字句 中的機率值 =
εi:索引 i 在字句中的正規化熵值
1
1 log
log
N
ij ij
j
p p
N =
= − ∑ ,即 0≤ ≤ 。εi 1 εi越
接近 0 代表索引 i 在越少的字句中出現,越具有鑑別力 N :字句數
圖 2. 2 奇異值分解圖示
使用 Log-Entropy 權重的方式在大部份潛藏語意分析為基礎的實驗中皆有 不錯的效果 [Berry and Browne, 1999; Bellegarda 2000]。
2.3.2 奇異值分解(Singular Value Decomposition, SVD)
建立好索引-字句矩陣之後,便可進行奇異值分解:
A U= ∑VT (2. 8)
其中∑ 是 R R× 維的對角奇異值矩陣,U是 M R× 維的左奇異向量(Left Singular Vector)矩陣,V 是T R N× 維的右奇異向量(Right Singular Vector)矩陣,奇異 值分解如圖 2. 2 所示。
經過奇異值分解後,索引和字句都被投影到新的空間,稱為潛藏語意空間
(LSA Space),此空間的維度是 R 維, R 小於M 與N。換句話說,奇異值分解 透過降維的方式,將在高維度(M 與N)內互不相關的索引與字句,投影到低 維度的同一空間內,如此即可於潛藏語意空間估測其相關性。
2.3.3 潛藏語意分析摘要模型
Gong 提出應用潛藏語意分析於摘要模型上 [Gong and Liu 2001],其方法如下:
1. 將文件 D 斷句,D = {S1, , S2 ..Si.., SN},這些字句S 用來組成候選 S i
,設 k=1
2. 由 D 建立 索引 字句矩陣 A ×
3. 對 A 進行奇異值分解,在右奇異向量(Right Singular Vector)矩陣 V t中,
圖 2. 3 潛藏語意分析摘要模型示意圖
每一字句S 可由 V i t中的行向量[v vi1, i2,...,viR]T表示 4. 在 V t中選取第 k 個右奇異向量(列向量)
5. 由上述向量中,選取含有最大索引值所對應的字句,將其加入摘要中 6. 如 k 達到摘要比例的量則終止運算,否則將 k 加 1,並執行步驟 4 此方法假設,每一奇異值分別代表一概念或主題。是以奇異值所對應到的列 向量(V t 中某一列),用以描述各字句所能表達的概念或主題。因奇異值矩陣∑ 是經由遞減排序,是以第 k 個所選取的列向量,代表第 k 名重要的概念或主題,
而其含有最大索引值所對應的字句就代表第 k 名重要的字句;且每一右奇異向量 是相互獨立,是以所選取的字句間具有最小的重覆,如圖 2. 3 所示。
A 代表原索引-字句矩陣,∑ 是 R R× 維的對角奇異值矩陣、U 是 M R× 維代 表索引在此語意空間的表示法、V 是T R N× 維代表字句在此語意空間的表示法。
如在V 的第 1 個右奇異向量(列向量)T ,以第 2 個索引值為最大,是以將其所對 應原始文件 D 中的第 2 句加入摘要;同理,第 2 個右奇異向量,加入第 N 句。
2.4 馬可夫模型(Markov Model)
隱藏式馬可夫模型是由馬可夫模型演變而來,根據 [Rabiner et al. 1989] 馬可夫 在右奇異向量(列向量)中選取含有最大索引值所對應的字句
模型之相關定義,如下所示:
定理 1:若隨機過程(Stochastic Process){St, 0t ≥ }中,第 t +1 的時間狀態 只和第 t 的時間狀態有關,並與之前的時間狀態無關:
{ t 1 t 1| 0 0, 1 1,..., t t} { t 1 t 1| t t}
p S+ =s+ S =s S =s S =s = p S+ =s+ S =s (2. 9) 則稱這個隨機過程為一階馬可夫鏈(First Order Markov Chain),此乃馬可夫
模型中最簡單的模型。
一階馬可夫鏈在 N 個狀態下,可用三個元素來表示(S A, ,∏)
z S 表示所有狀態的集合,S ={s1, , s2 ..., sN},其中 N 為狀態的個數 z A=( )aij 代表狀態轉移機率矩陣,aij = p S{ t+1=sj |St =si} , 1≤i j, ≤N
表示從狀態 i 跳到狀態 j 的機率,且必須滿足
1
0, 1
N
ij ij
j
a a
=
≥ ∑ =
z Π =( )πi 代表狀態初始的機率向量πi = p S( 1 =si) , 1≤ ≤i N 表示在 t=1 時,狀態為 i 的機率,且需滿足∑πi =1的條件
若馬可夫鏈中每一時間的可能狀態均來自一有限集合S ={s1, , s2 ..., sN},則稱 之為有限狀態馬可夫鏈(Finite State Markov Chain)。
定理 2:若隨機過程{St, 0t≥ }的轉移機率a 不隨時間改變,也就是說滿足性質:ij
{ t 1 j | t i} { 2 j| 1 i} ij
p S+ =s S =s = p S =s S =s = (2. a 10) 則稱為穩定型之有限狀態馬可夫鏈(Stationary Finite State Markov Chain)。
滿足上述定理 1 與定理 2 的隨機過程即可稱之為馬可夫鏈或具有馬可夫之性質。
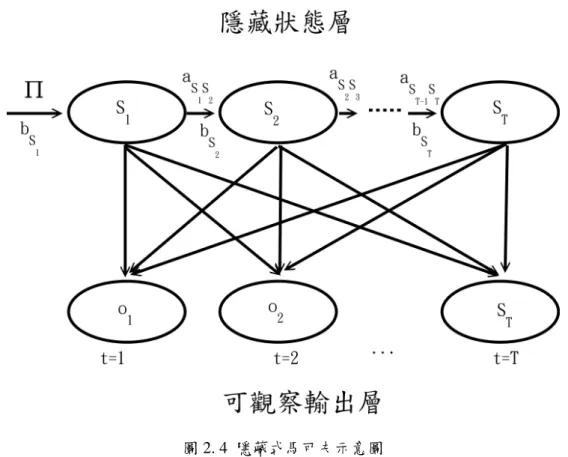
2.5 隱藏式馬可夫模型(Hidden Markov Model, HMM)
隱藏式馬可夫模型最早是由 Baum 和 Petrie 在 1966 年所發展出來 [Baum et al.
1966],其植基於統計的機率模型,並於近十幾年來逐漸被廣泛應用,概因其擁
有豐富的數學架構及基礎能夠成功地解決所欲處理的問題。
目前,除了被廣泛應用在語音辨識(Speech Recognition)[Rabiner et al.
1989] 、自然語言 [Thede et al. 1999] 處理,甚至被應用於影像處理(Image Processing)之分析 [Aas et al. 1999] 與網路通訊 [Salamatian et al. 2001] 上。
根據 [Rabiner et al. 1989]對離散型隱藏式馬可夫模型之定義為:它是一個雙 層隨機程序,包含了隱藏的狀態層和可觀察的輸出層;隱藏層無法直接觀察,但 可從另一能產生輸出序列之輸出層觀察得出。
隱藏式馬可夫模型在 N 個狀態下,可用四個元素來表示(S, , ,Π A B)
(一) 符號的表示意義如下:
z S 表示所有狀態的集合,S={s1, , s2 ..., sN},其中 N 為狀態的個數 z V ={v1, , v2 ..., vM}代表可觀察輸出的集合,其中 M 為所有可能輸出符
號的數目
z O={o1, , o2 .. .., ot oT}表示可觀察的輸出序列,o 代表在時間 t 下,對t 於任一狀態所有可能產生的觀察輸出符號,且需滿足ot∈ V
(二) 模型的參數為:
z Π =( )πi 代表狀態初始的機率向量πi = p S( 1 =si) , 1≤ ≤ 表示在 t=1 i N 時,狀態為 i 的機率,且需滿足
1
1
N i i
π
=
∑
= 的條件z A=( )aij 代表狀態轉移機率矩陣,aij = p S{ t+1=sj |St =si} , 1≤i j, ≤N
表示從狀態 i 跳到狀態 j 的機率,且必須滿足
1
0, 1
N
ij ij
j
a a
=
≥ ∑ =
z B={b kj( )} 代 表 可 觀 察 輸 出 矩 陣 b kj( )= p o{ t =vk |St =sj}
, 1≤ ≤j N , 1≤ ≤k M ,表示在狀態為 j 時,νk的發生機率,且滿足
( )
1
1
K j k
b k
=
∑
=圖 2. 4 隱藏式馬可夫示意圖
當適當地決定Π 、A 和 B 時,隱藏式馬可夫模型的產生過程、運作方式如下:
1. 根據起始狀態機率分佈Π 決定S 1 2. 設定 t=1。
3. 由 ( )
St
b k 的機率分佈產生o t
4. 由狀態轉移機率矩陣
1
S St t
a + 的機率分佈決定St+1
5. 設定 t=t+1,當 t<T 時回到步驟 3,否則結束程式。
上述的步驟,可由圖 2. 4 所示。
2.6 統計式語言模型(Statistical Language Model, SLM)
以統計式語言模型(Statistical Language Model, SLM),來觀察字詞間可能相接的 情形,已被廣泛於語音辨識器上 [Rosenfeld 2000; Siivola et al. 2001],給定一長 度為 n 之詞串 W,W =w w1, , 2 ..., wn,要估測 W 的機率,P( )W ,可以利用連鎖
律(Chain Rule)將其分解:
( ) ( ) ( )
( ) ( ) ( )
( )
( )
∏
∏
=
= −
=
=
=
=
n
i
i i n
i
i i
n n
h w P
w w w P
w w w w P w w P w P
w w w P w P W P
1 1
1 1
2 1 3
1 2 1
1 2
1
| ,...,
|
,
| ,...,
|
| ,...,
(2. 11)
其中 hi是詞 wi的歷史詞串(history),hi =w1,...,wi−1。
假設| V 為詞典大小,則式(2.11)中| P(wi |hi)的w 與歷史詞串i h 之參數量為i
|V ,此為一極其龐大的計算量而無法估測,勢必要做簡化。是以 N-連語言模型|i 廣泛的被使用來處理這個問題,N 連語言模型是帶入N−1階馬可夫模型假設,
即假設詞 wi的出現只與其前面N−1個詞有關聯,而與N−1個詞以前的詞沒有關 聯,所以式(2.11)可以改寫成:
( ) ( ) ( 1 1)
1 1
| | ,...,
n n
i i i i N i
i i
P W P w h P w w− + w−
= =
=
∏
=∏
(2. 12)如三連語言模型(Tri-gram Language Model)可表示成
( )
∏
( )= − −
= n
i
i i
i w w
w P W
P
1
1 2,
| (2. 13)
要 估 測 式 (2.13) 中 的 P(wi |wi−2,wi−1)可 使 用 最 大 相 似 度 估 測 法 ( Maximum Likelihood Estimation, MLE)得到:
( ) ( )
( 2 2 1 1)
1
2 ,
, , ,
|
−
−
−
− −
− =
i i
i i i i
i
i C w w
w w w w C
w w
P (2. 14)
( i 2, i 1, i) ( i 2, i 1)
C w− w− w 與 C w− w− , 分 別 為 w ,i-2 wi−1,wi 同 時 出 現 的 次 數 與
i-2 1
w ,wi− 同時出現的次數
2.7 主題混合模型(Topical Mixture Model, TMM)
主題混合模型最早由 [Chen et al. 2004b; Chen 2005] 所提出並使用於語音文件 檢索上。在傳統資訊檢索上,給定一使用者查詢 Query Q=q q q q1 2.. ..n N,一文件
D 可根據其機率 (i p D Q ,得到相關程度的排名,經貝式定理可表示為: i| ) ( | ) ( )
( | )
( )
i i
i
p Q D p D p D Q
= p Q (2. 15)
( | i)
p Q D 是文件D 產生查詢i Q 的機率, (p D 是文件i) D 相關的事前機率,i p Q 是( ) 查詢 Q 的事前機率(Prior Probability)。對於所有文件來說 ( )p Q 是相同的且不影 響文件的排名,是以可省略。於外,估計 (p D 的機率仍然未知,是以可進一步i) 簡化假設 ( )p D 是均勻分佈(Uniform Distribution)i ,也就是對於所有的文件是相 同的 [Miller et al. 1999]。如此便可藉由 ( |p Q D 來近似i) p D Q 。 ( i| )
另一方面,假設查詢Q = q q1 2..qn..qN 中,每個查詢項的發生互為獨立事 件,因此估測 ( |p Q D 可視為查詢 Q 中每一查詢項i) q 於文件n D 機率分佈的連乘i 積,數學式如下:
1
( | ) ( | )
N
i n i
n
p Q D p q D
=
=
∏
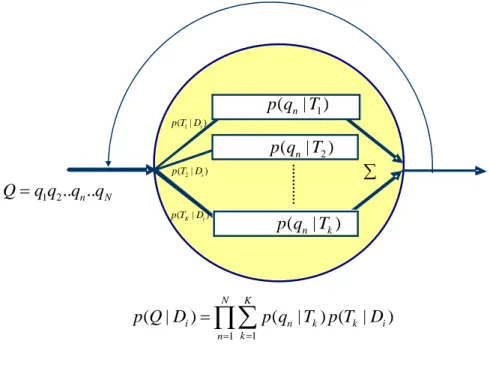
(2. 16)在此研究中,每一篇文件D 可被詮釋為混合模型(Mixture Model)i ,模型中 定義 K 個潛藏主題,各由一個主題單連語言模型(Topical Unigram)所表示,且 每一潛藏主題在各文件都有不同的權重。換句話說,每一篇文件可以產生許多主 題,每個主題都有相對應的單連語言模型,因此查詢 Q 與每一文件D 的相關程i 度,可進一步改寫為:
1 1
( | ) ( | ) ( | )
N K
i n k k i
k n
p Q D p q T p T D
=
=
=
∏ ∑
(2. 17)( n| k)
p q T 指特定潛藏主題T 產生查詢項k q 的機率,n p T( k|D 是潛藏主題i) T 在文k 件D 的權重,且須滿足i
1
( | ) 1
K
k i
k
p T D
=
∑
= 的限制。總結來說,主題混合模型的主 題單連語言模型, (p q T ,是經由整個文件集訓練而來,且每一潛藏主題n| k) T 在k 各文件D 都有其所屬的權重,i p T( k |D ,如圖i) 2. 5 所示。在主題混合模型中,不同於逐字比對(Literal Term Matching),如向量空間 模型,是以查詢 Q 中每一查詢項q 在文件n D 出現的次數做計算,在主題混合模i 型中是以q 發生在主題n T 與文件k D 產生主題i T 的機率來表示。是以即使查詢項k 並未出現在文件D 中,經由主題混合模型還是可以給予i p Q D 較高的值,而( | i) 達到概念比對的目的。
圖 2. 5 主題混合模型示意圖
2.7.1 主題混合模型訓練
在訓練時,K-means 演算法 [Ball and Hall 1967; Duda and Hart 1973] 被用來事先 切割整個文件集為 K 個潛藏主題。因此,對於每一潛藏主題,其初始的主題單 連語言模型可用主題所包含的文件來估測;而其在每一文件D 的權重,可由與i 中心C 的鄰近程度來估計,如下所示: k
1
( , ) ( | )
( , )
i k
k i K
i r
r
R D C p T D
R D C
=
=
∑
JJG JJG
JJG JJG (2. 18)
其中R D C(JJG JJGi, k)
代表利用餘弦估測文件D 與中心i C 的距離,如下所示: k
( i, k) i k
i k
R D C D C
D C
= ⋅
× JJG JJG JJG JJG
JJG JJG (2. 19)
2.7.1.1 主題混合模型訓練—監督式
更進一步來說,主題單連語言模型與其在各文件的權重,可使用期望值最大化
(Expectation-Maximization, EM)演算法來優化此二者的機率分佈 [Dempster et al. 1977]。給定一訓練集,如每一查詢 Q 均有與其相關文件的資訊,則主題混合
∑
1 2.. ..n N Q=q q q q
( n| 1) p q T
( n| 2) p q T
( n | k) p q T
(2| i) p T D
(K| i) p T D
(1| i) p T D
1 1
( | ) ( | ) ( | )
N K
i n k k i
k n
p Q D p q T p T D
=
=
=
∏ ∑
模型可迭代更新,利用下面三個公式:
l to Q
to Q
[ ] [ ]
[ ] [ ]
( , ) ( | , ) ( | )
( , ) ( | , )
Q i R
Q i R s
n k n i
Q TrainSet D Doc
n k
s k s i
Q TrainSet D Doc q Q
n q Q p T q D p q T
n q Q p T q D
∈ ∈
∈ ∈ ∈
=
∑ ∑
∑ ∑ ∑
(2. 20)l i to Q
i to Q
[ ]
. D [ ]
[ ]
. D [ ]
( , ) ( | , ) ( | )
Q s
R
Q R
s k s i
Q TrainSet q Q
st Doc
k i
Q TrainSet
st Doc
n q Q p T q D p T D
Q
∈ ∈
∈
∈
∈
=
∑ ∑
∑
(2. 21)
1
( | ) ( | ) ( | , )
( | ) ( | )
k i n k
k n i K
l i n l
l
p T D p q T p T q D
p T D p q T
=
=
∑
(2. 22)其中,⎡⎣TrainSet⎤⎦Q是查詢範例的訓練集合,⎡⎣Doc⎤⎦Rto Q是與特定查詢範例 Q 相關的文件
集合, ( , )n q Q 是每一查詢項n q 出現在查詢範例n Q 的次數,Q 是查詢範例 Q 的長
度,Q∈[TrainSet] Q st. Di∈[Doc]Rto Q表示查詢範例 Q 滿足D 在文件集中是與其相關的條i
件, (p Tk|q D 是在查詢項n, i) q 與文件n D 出現的條件下潛藏主題i T 發生的機率。 k 2.7.1.2 主題混合模型訓練—非監督式
如果訓練資料集,沒有與使用者查詢 Q 相關文件的資訊,則可將每一文件D 視i 為與自已相關,用以訓練主題混合模型,經由簡單的更改式(2.20)-(2.22) 得到:
l [ ]
[ ]
( , ) ( | , ) ( | )
( , ) ( | , )
i
i s i
n i k n i
D D
n k
s i k s i
D D q D
n q D p T q D p q T
n q D p T q D
∈
∈ ∈
= ∑
∑ ∑ (2. 23)
l
( , ) ( | , ) ( | ) s i
s i k s i
q D
k i
i
n q D p T q D p T D
D
= ∑∈
(2. 24)
[D]代表整個文件集,Di 是文件D 的長度, (i n q D 是查詢項n, i) q 出現在文件n D 的i 次數, (p Tk |q D 是在查詢項n, i) q 與文件n D 出現的條件下潛藏主題i T 發生的機k 率。


![圖 2. 3 潛藏語意分析摘要模型示意圖 每一字句 S 可由 V i t 中的行向量 [ v vi 1 , i 2 ,..., v iR ] T 表示 4. 在 V t 中選取第 k 個右奇異向量(列向量) 5](https://thumb-ap.123doks.com/thumbv2/9libinfo/7087828.25742/6.892.138.778.116.433/潛藏語意分析摘要模型示意每一字句可由中的行向T表示中選取第.webp)