Chapter Four Results and Discussion
This chapter presents the results of the present study with respect to the research questions about the acquisition order of hui zenme and zenme hui, the agency effects, genericity effects, task effects, other patterns produced, and age effects. Section 4.1 examines our subjects’ performance on manner questions hui zenme and causal questions zenme hui. Section 4.2 presents the influence of agency and Section 4.3 discusses the effect of genericity on the acquisition of zenme questions. Section 4.4 compares the results of the two tasks (PI Task and QA Task), followed by Section 4.5, which analyzes the error patterns of the subjects’ responses in the production Task.
Finally, a brief summary of this chapter is given in Section 4.6.
4.1 Acquisition Order of Hui Zenme and Zenme Hui
This section mainly addresses our first research question—to find out which wh-question, hui zenme and zenme hui, is acquired earlier. In the present study, the structure hui proceeding zenme denotes ‘how’ questions and zenme proceeding hui denotes ‘why’ questions. The results of these two structures will be presented first, followed by the discussion about the subjects’ use of hui zenme and zenme hui. Table 4-1 illustrates the overall results of the subjects’ performances.
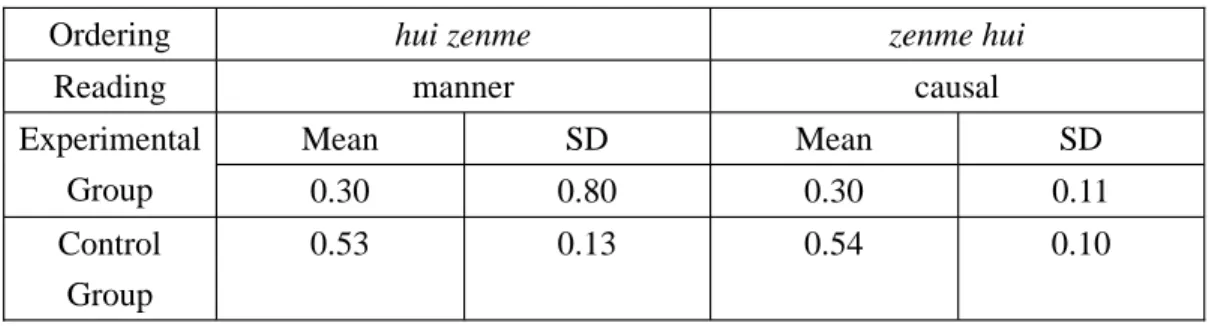
Table 4-1. Subjects’ Correct Performance on the Two Tasks1
Ordering hui zenme zenme hui
Reading manner causal
Mean SD Mean SD
Experimental
Group 0.30 0.80 0.30 0.11
Control Group
0.53 0.13 0.54 0.10
As shown in Table 4-1, the mean score of both hui zenme ‘how’ and zenme hui
‘why’ questions for the experimental group was 0.30. The subjects performed
similarly on both types of the questions. In other words, at the early stage of language acquisition, our preschoolers did not show a significant difference in their use of zenme in its related meaning (p= .633). This result was also found in the control group.
The means scores of the native controls are 0.53 for hui zenme and 0.54 for zenme hui respectively (p= .786). Compared with the experimental group, the native controls performed significantly better to these two questions (p= .000, p= .000).
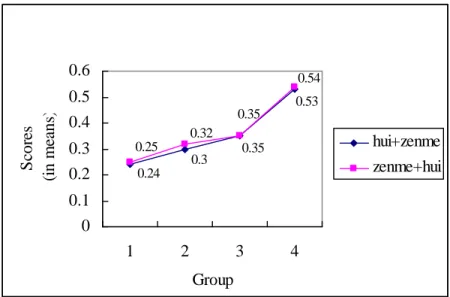
As shown in Figure 4-1, even though the subjects did not perform significantly differently in their use of hui zenme and zenme hui, they always performed slightly better in the use of zenme hui than in the use of hui zenme. In addition, a developmental progress was found in the subjects’ use of these two structures. The older groups, as far as their overall performance is concerned, performed better than the younger groups. In terms of hui zenme, the average score of correct responses for Group 4 (0.53) was higher that for Group 3 (0.35), and Group 3 higher than Group 2 (0.32), and Group 2 higher than Group 1 (0.25). With regard to zenme hui, the rising
1 Indeed, there are some other patterns that can be adapted to ask how and why questions, but our major focus of the present study is on the two structure hui zenme and zenme hui and the questions they denote, (i.e., how and why). Therefore, the points were given only when the exact wording was produced in the QA Task, and this brought about the low mean scores of our control group, in which other patterns of asking manner and causal questions were found. As for these patterns that also denote how and why questions, they will be discussed in section 4.5.
curve (Group 4 > Group 3> Group 2> Group 1) was found.
0.53
0.35 0.3
0.24
0.54 0.35
0.32 0.25
0 0.1 0.2 0.3 0.4 0.5 0.6
1 2 3 4
Group Scores (in means)
hui+zenme zenme+hui
Figure 4-1. Developmental Tendency of Hui Zenme and Zenme Hui
To see if different age groups performed significantly differently, One-way ANOVA was applied. It was shown that among the experimental group no significance was found in the use of zenme hui, but there existed a significance difference between each age group of the experimental group and the control group.
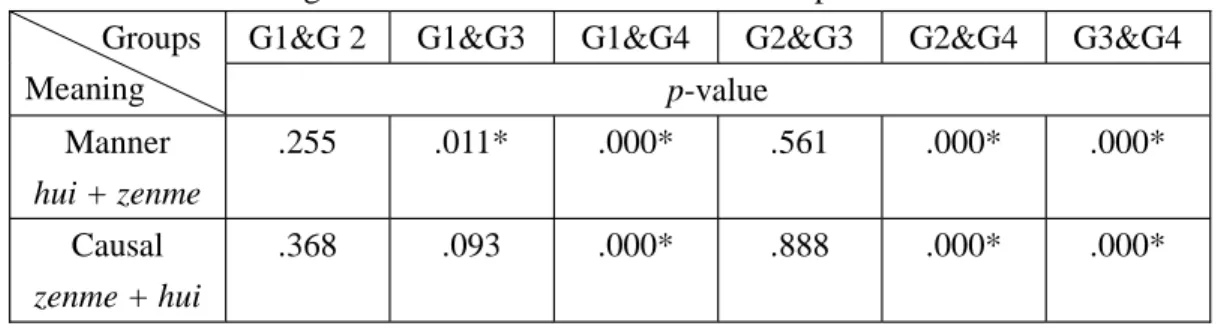
On the other hand, it was found in Table 4-2 that there was a significant difference between Group 1 and Group 3 (p=. 011) in the use of hui zenme, but the difference in performance between Group 1 and Group 2 (p= .255), and Group 2 and Group 3 (p= .561) did not reach a statistical significance. To sum up, experimental group did not perform significantly differently when responding to zenme hui meaning ‘why’;
however, when responding to hui zenme, Group 3 significantly outperformed Group 1 and no significant difference was found between Group 1 and Group 2, and neither was there between Group 2 and Group 3.
Table 4-2. Significances Difference Between Groups on the Two Tasks G1&G 2 G1&G3 G1&G4 G2&G3 G2&G4 G3&G4 Groups
Meaning p-value
Manner hui + zenme
.255 .011* .000* .561 .000* .000*
Causal zenme + hui
.368 .093 .000* .888 .000* .000*
Some previous studies have showed different results of the acquisition of how and why questions2. The results of Bloom et al. (1982), Miao (1985), Okubo (1967), Savic (1975) and Wode (1974) showed that how questions are earlier than why questions, and the results of Cairns & Hsu (1978), Clancy (1989), Ingram (1972), Ernip-Tripp (1970), and Tyack & Ingram (1977) showed why questions are acquired earlier than how questions. However, there was no significance between our subjects’
performance on hui zenme (i.e., how) and zenme hui (i.e., why) (p= .633), and no significant difference was found within each age group. It seems not easy for us to tell which one was acquired earlier. However, if we take a closer look at the performance of each age group, we will see that most of our subjects gained higher scores on why questions than on how questions except the eldest group (G1:
0.25>0.24; G2: 0.32>0.30; G3; 0.35=0.35), indicating that that zenme hui questions (i.e., why questions) are easier than hui zenme questions (i.e., how questions).
Another piece of evidence lies in the difference between the subjects’
performance on hui zenme and zenme hui questions among the three age groups. The children in our experimental group performed similarly (G1 & G2: p= .368; G1 &G3:
p= .093; G2 & G3 p= .888) on zenme hui (i.e., why questions) but our four-year-old subjects and six-year-old subjects performed significantly differently in response to hui zenme (i.e., how questions) (p= .011). In other words, zenme hui questions (why
2 These results were summarized in Table 4-2 on p.329 in Clancy (1989).
questions) are easier and less challenging than hui zenme questions (how questions).
This result is consistent with some previous findings which showed that why were acquired before how questions. For example, in the comprehension task of Tyack &
Ingram’s (1977) study on 100 children aged from three-year-old to five-year-old, within each age group the scores of correct responses to why questions were higher than those to how questions. In their production task, the percentage of why questions was also higher than that of how questions. It was found that the mean scores of why questions were higher than how questions in each group in Cairns and Hsu (1978). As they explained, children’s ability to deal with the concept of causality develops fairly early and that ‘how seems like a mixed bag conceptually (p. 486).’ The difficulty of forming how questions may lie in the variety of the answers to how questions. There are at least three interpretations of manner zenme, i.e., in what way, with what method, and in what style, and thus at least three answers can be produced3. Therefore, it is reasonable that children have poorer abilities in dealing with how questions.
However, the present study contradicts Miao’s (1985) study on the acquisition order of zenme and weisheme questions in Mandarin Chinese. In her study on children’s comprehension of wh-questions, weisehme questions were acquired later
than zenme questions, which was contrary to other research on wh-questions conducted in English Ervin-Tripp (1970) Tyack & Ingram (1977), and Cairns & Hsu (1978). This difference may result from the different contents presented to the subjects, as explained by Miao. In her study, the questions asked were about ‘riding bikes,’ ‘washing clothes,’and ‘eating breakfast,’ while in the present study, different
3 Since the main focus of the present study is on the acquisition order of hui zenme and zenme hui, the subjects’ responses to the three interpretations of zenme were not discussed. That is why only method and style interpretations were examined. Therefore, anyone who is interested in the other interpretation can conduct a further experiment. In spite of that, based on the data collected, it was found that our subjects performed significantly better on the method interpretation than the style interpretations (p= .000). Besides, the three age groups gained significantly higher scores on the method interpretation than the style interpretation (G1: p= .001, G2: p= .000, G3: p= .001).
contents were presented (hitting a person, moving books, seeing a person, liking a person, paint falling off, stone/wood floating.)
In spite of the different voices about whether how questions or why questions emerge earlier, the developmental tendency of these two questions was found (Cairns
& Hsu 1978, Clancy 1989, Ingram 1972, Ervin-Tripp 1970, Miao 1985) This is also true in the present study. The percentage of the correct responses to both manner questions hui zenme and causal questions zenme hui increased as the subjects got older, indicating a different time period of the development for manner questions and causal questions. Let’s look at zenme hui first. The result that no significant difference among the experimental group showed that our children might pick up causal questions with zenme hui earlier than the age range adapted in the present study. This assumption is confirmed by other studies. In Miao’s (1985) study, the 4-year-old subjects had significant better ability in responding to weisheme questions than the 3-year-old subjects. In Cairns and Hsu’s (1978) study on the wh-questions in English, a great deal of correct responses to why questions was found between the subjects aged from 3;0 to 3;6 (mean = 1.7) and those aged from 3;6-4;0 (mean =3.3). Based on the results of the present study and Miao and Cairns & Hsu, it can be inferred that children may acquire why questions before they reach the age of four.
Interestingly, in Miao’s study, a statistical difference was found between the four-year-olds and five-year-olds (p < .01). However, this was not applied in the present study and Cairns & Hsu (1978)4. Although there was an inconsistence between the children’s development of why questions in the previous research, and the present study, it has been found that why questions are still not fully acquired by the
4 In Cairns & Hsu’s results, the p-values between the age groups were not shown; only the mean scores of correct answers by each group were provided. The full score was 6.0. The mean scores of correct answer to why questions of each age group were as following: 1.7 for the subjects of 3;0-3;6, 3.3 for the subjects of 3;6-4;0, 3.5 for the subjects of 4;0-4;6, 4.0 for the subjects of 4;6-5;0, and 4.5 for the subjects of 5;0-5;6.
six-year-olds. A statistical significance (p= .000) was found between our eldest subjects and the native controls; the six-year-old subjects in Miao’s study only reached 79% of weisehme questions correctly; the eldest subjects only gained 4.5 points in Cairns and Hsu (1978). These results indicate that children still can’t deal with why questions when they reach the age of six, either with the genuine causal wh-word weisheme or its alternative expression zenme hui.
Let us turn to manner questions. In the present study, a significant difference was found only between the 4-year-olds and 6-year-olds (p= .011). This suggests that age five should be a period for the preschoolers to develop manner questions. Our 6-year-olds also showed a significant difference from the controls in response to manner questions, indicating that the development of manner questions continues after the age of six. However, in Miao’s study, 42 % of correct responses to zenme questions was found in the group of 3-year-olds, the percentage of correct reposes even reached 77% in the group of 4-year-olds and 80 % in the group of 5-year-olds.
These results show that zenme questions actually acquire quite earlier, and thus differs from the results of the present study. These differences may be attributed to the task adapted. Miao only checked the subjects’ comprehension by asking questions and counting the correct responses, while in the present study a production task as well as a comprehension task was conducted. The fact that our subjects gained low scores in the production task results in their scores of hui zenme questions not as high as that of Miao’s.
To sum up, the present study showed that zenme hui (why questions) was acquired earlier than hui zenme (how questions). However, because the difference between these two questions within each group has not yet reached the significant level, further studies are still needed.
4.2 Agency Effects
We hypothesized that the agency can influence the acquisition of zenme questions. From the mean score shown in Table 4-3, it can be seen that our preschoolers gained a higher score in responding to zenme questions with an agent subject (mean = 0.32) than those with a non-agent subject (mean = 0.28) and a statistical difference was achieved (p= .001). That is to say, our young children showed a preference between zenme questions with an agent subject and a nonagent subject. The same result was obtained in the control group. The mean score for zenme questions with an agent subject was 0.54 and the mean score for questions with an nonagent subject was 0.53, but no significant difference was found (p= .300).
However, the experimental group and control group performed significantly differently on zenme with questions (non)agent subjects (p= .000). When we compared the mean scores within each group, it was found that G1 showed a significant difference (p= .048), while G2 and G3 failed to show such significance (G2: .395; G3: .150) in agency. This result indicates that our younger children were more sensitive to the agency effect than the other two groups.
Table 4-3. Subjects’ Performance on Zenme Questions Regarding agency
Agent Non-Agent
Properties
Group Mean SD Mean SD
Experimental 0.32 0.08 0.28 0.09
Control 0.54 0.12 0.53 0.12
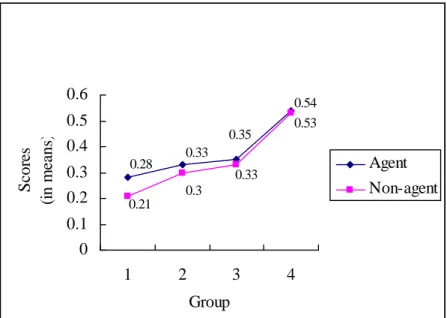
As shown in Figure 4-2, the score of zenme questions with an agent subject was always higher than that of its counterpart. Besides, a developmental progress was found regarding the agency. We can see that the elder subjects earned higher scores than the younger ones. The score of correct reposes to zenme questions with an agent
subject for Group 3 (0.35) was higher than that for Group 2 (0.33) and Group 1 (0.28).
The score of correct responses to zenme questions with a nonagent subject for Group 3 (0.33) was higher than that for Group 2 (0.30) and Group 1 (0.21).
0.54 0.35
0.33 0.28
0.53
0.33 0.3
0.21
0 0.1 0.2 0.3 0.4 0.5 0.6
1 2 3 4
Group Scores (in means)
Agent Non-agent
Figure 4-2. Developmental Curve of the Subjects' Acquisition of Manner and Causal Questions with (non)Agent Subjects
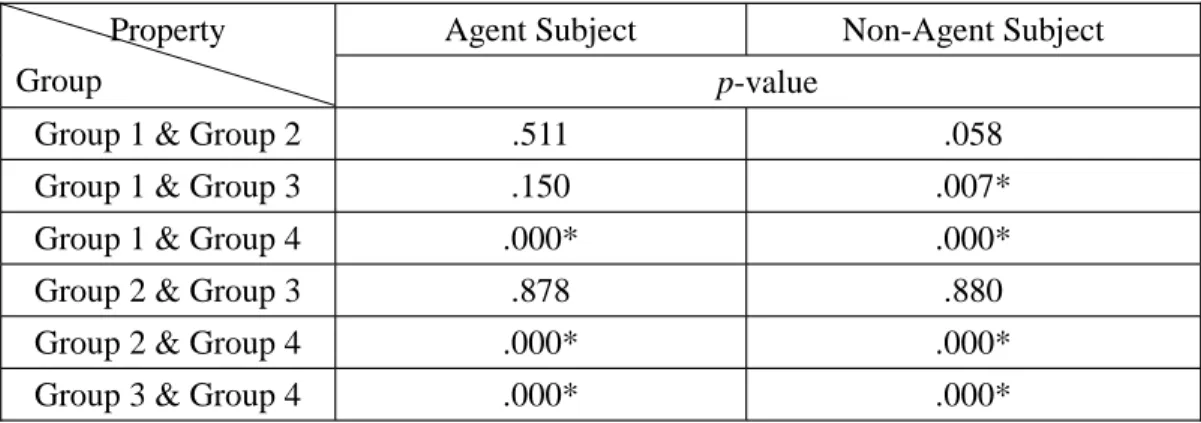
Moreover, as shown in Table 4-4, if we compare the results among the three age groups, we can see that the difference between G1 and G3 reached a significant level (p = .007) when they were responding to questions with a nonagent subject. However, no statistical significances were found between G1 and G3 (p = .511), and between G2 and G3 (p = .150). Besides, no significant differences were found in the subjects’
responses to questions with an agent subject.
Table 4-4. Subjects’ Performance on Zenme Questions Concerning Agentivity Between Groups
Agent Subject Non-Agent Subject
Property
Group p-value
Group 1 & Group 2 .511 .058
Group 1 & Group 3 .150 .007*
Group 1 & Group 4 .000* .000*
Group 2 & Group 3 .878 .880
Group 2 & Group 4 .000* .000*
Group 3 & Group 4 .000* .000*
To sum up, the experimental group showed a significant difference in their performance on questions with agent and nonagent subjects. Within each age group, G1 responded significantly differently on agentivity, but G2 and G3 didn’t. The between-group showed that G1 and G3 showed significant difference in response to questions with a nonagent subject, but G1 and G2 and G2 and G3 didn’t. As for questions with an agent subject, the difference did not reach the significant level among all the groups.
As noticed by Givon (1984), there is a semantic hierarchy for the subject position:
agent > recipient/benefactive > theme/patient> instrument > location. In the present study, a significant difference was found between the questions with agent and nonagent subjects (p= .001). The overall performances of our children followed the prediction of the hierarchy. A close look at the performance within each group showed there was semantic tendency. Within G1, the subjects showed their preference (p= .048) for the questions with an agent subject over those with an nonagent subject.
In spite of the fact that no statistical significance was found within G2 (0.33>0.30) and G3 (0.35 > 0.33), the higher scores gained in the questions with an agent subject indicated that our children preferred an agent subject with zenme questions. That is to say, questions with an agent subject were easier to acquire and less challenging.
Therefore, Givon’s hierarchy still holds and it can be used to account for the results of the present study. Actually, in addition to the present study, the results of some studies on the acquisition of passive sentences also fit the hierarchy well (Angiolillo &
Goldin-Meadow 1982, Bever 1970, Bridges 1984, Dewert 1979, Slobin 1982).
Therefore, it is plausible to consider the agentivity as a universal factor when it comes to first language acquisition. As shown in the results, as the age increases, the degree of the influence of the agentivity decreases. The influence of agentivity is strong enough so that our youngest children performed significantly differently (p= .048).
However, such significant difference did not appear in the older groups (G2: p= .395;
G3: p= 150). On the other side of the same coin, it was not surprising to find that the three groups did responded similarly to questions with an agent subject and that the only statistical difference was found in the performances between G1 and G3 (p= .007). To put it differently, our younger children encounter more difficulty handling questions with a nonagent subject. To sum up, the younger children are, the more likely they are influenced by the agentivity of the subject when using and comprehending zenme questions.
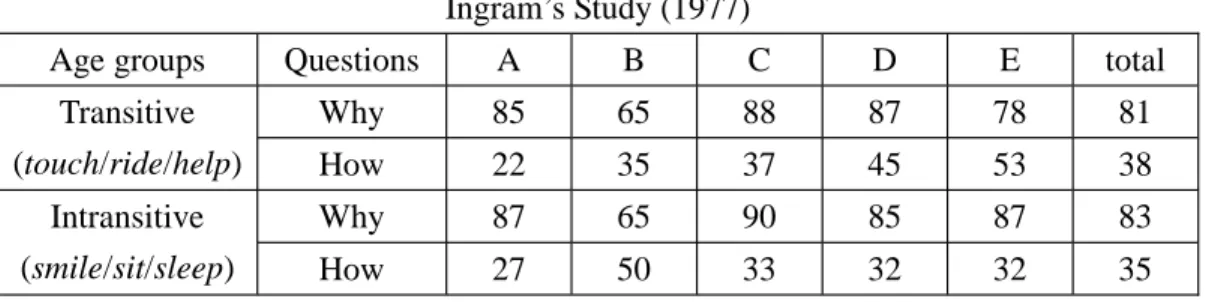
This agency effect can also be found in Tyack and Ingram’s (1977) study on wh-questions in English. In Tyack & Ingram’s study (1977), 100 children were divided into five groups: A 3;0-3;5, B 3;6-3;11, C 4;0-4;5, D 4;6-4;11, E 5;0-5;5. They were tested in a comprehension task on six wh-words by using three transitive verbs (touch, ride, help) and three intransitive verbs (smile, sit, sleep). According to Kreidler’s (1998) classification5 of semantic roles adapted in the present study, the subjects of the verbs in the former group are agents, while the subjects of the verbs in the latter subjects are nonagents. Their results are shown in Table 4-5:
5 See the Footnote on p.25.
Table 4-5. The Percent of Correct Responses to Why and How Questions in Tyack and Ingram’s Study (1977)
Age groups Questions A B C D E total
Why 85 65 88 87 78 81
Transitive
(touch/ride/help) How 22 35 37 45 53 38
Why 87 65 90 85 87 83
Intransitive
(smile/sit/sleep) How 27 50 33 32 32 35
Overall speaking, it can be found that even though there seems no significant difference between transitive and intransitives verbs, the overall percentage of correct responses of transitive verbs is slightly higher than that of intransitive verbs. This finding is consistent with our results. In responding to causal questions, the agency effect was not obvious across the five age groups; in responding to manner questions, the percentage of correct responses to the questions with transitive verbs got higher as the children’s age increased while the percent of correct responses with intransitive verbs did not increases with age.
In accordance with the study just mentioned, our study also showed the agency preference. Group 1 to Group 3 in the present study encountered less difficulty in the questions with an agent subject than those with a non-agent subject. As Robertson &
Suci (1980) pointed out, agents are more attention catching for little children and are better ‘pegs’ for word learning than the latter. According to Slobin (1981), the notions first marked grammatically by young children are those that are more salient. In other words, sentences with an agent subject are easier for young children to acquire.
Therefore, it seems plausible for us to account for the lower mean score of zenme questions with a non-agent subject than those with an agent subject.
4.3 Genericity Effects
In this section, the genericity effects on the acquisition of zenme questions will be
discussed. As shown in Table 4-6, our children in the present study gained higher scores on the questions in the non-generic conditions (mean = 0.32) than those in generic conditions (mean = 0.28), and a significant difference was found (p= .006) .
Table 4-6. Subjects’ Performance on Zenme Questions Regarding Genericity
Generic Non-Generic
Condition
Group Mean SD Mean SD
Experimental 0.28 0.07 0.32 0.10
Control 0.53 0.12 0.55 0.12
The results found in the experimental group were similar to those obtained in the control group. The native controls also gained higher scores on the zenme questions in the nongeneric conditions (mean = 0.55) than one those in generic conditions (mean = 0.53), and no significance was found (p= .497). In addition, the control group performed significantly better than the experimental group on both conditions (p= .000). In response to (non)genericty, only G1 reached a significant difference (p= .010), but G2 and G3 did not (p= .083, p= .086).
0.22
0.29 0.32
0.53 0.26
0.34 0.36
0.55
0 0.1 0.2 0.3 0.4 0.5 0.6
1 2 3 4
Group Scores (in means)
Generic Non-gen
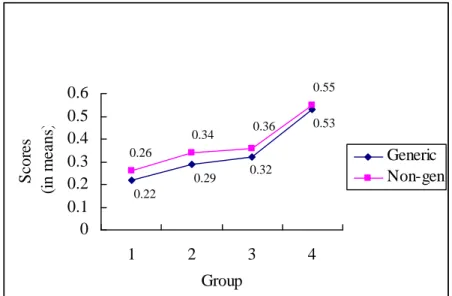
Figure 4-3. Developmental Curve of the Subjects' Acquisition of Zenme Questions in (non)Generic Conditions
Let us look at the subjects’ performances across the three age groups. It was found that the subjects showed a developmental sequence in responding to genericity.
As shown in Figure 4-3, with regard to zenme questions in generic conditions, the subjects performed consistently better (G1: mean = 0.22; G2: mean = 0.29; G3: mean
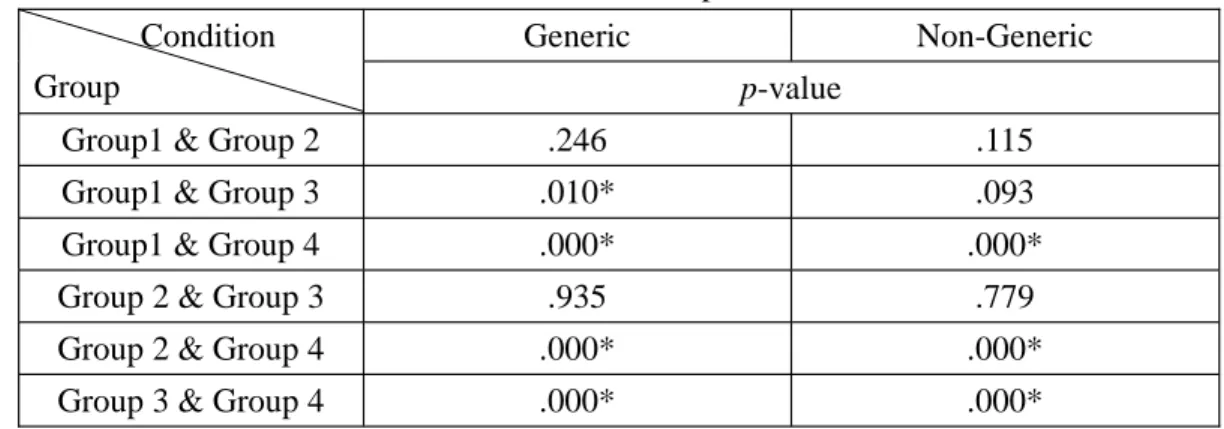
= 0.32) as age increased. On the other hand, with respect to questions in nongeneric conditions, there was an increase in mean scores between G1 and G2 (from 0.26 to 0.35), but a slowdown between G2 and G3 (from 0.34 to 0.36). The mean scores of questions in generic conditions between groups shown in Table 4-7 showed that G1 and G3 performed significantly differently (p= .010), but that G1 and G2 did not show significance (p = .246), and that G2 and G3 (p = .935) did not, either (G1&G2:
p= .115; G1&G3: p= .093; G2&G3: p= 779).
Table 4-7. Subjects’ Performance on Zenme Questions Concerning Genericity Between Groups
Generic Non-Generic
Condition
Group p-value
Group1 & Group 2 .246 .115
Group1 & Group 3 .010* .093
Group1 & Group 4 .000* .000*
Group 2 & Group 3 .935 .779
Group 2 & Group 4 .000* .000*
Group 3 & Group 4 .000* .000*
If we further look into the hui zenme and zenme hui questions, we can find that subjects better performed in responding to the questions in nongeneric conditions than in generic conditions. As shown in Table 4-8, our subjects gained higher scores (0.35) in hui zenme questions in nongeneric conditions than in generic conditions (0.25), and the difference reached a significant level (p= .000). Similar results were also obtained in response to zenme hui questions (CNG: 0.31 > CG 0.29), but no significance was found (p= .614).
Table 4-8. Subjects’ Performance on Hui Zenme and Zenme Hui Questions Regarding Genericity
Structure hui zenme zenme hui
Generic Nongeneric Generic Nongeneric
Condition
Groups Mean SD Mean SD Mean SD Mean SD
Experimental 0.25 0.11 0.35 0.11 0.29 0.12 0.31 0.17
Control 0.51 0.14 0.54 0.08 0.54 0.12 0.54 0.10
Moreover, within each group, the scores of manner and casual questions in nongeneric conditions were higher than those questions in generic conditions, as shown in Figures 4-4 and 4-5. For manner questions, the subjects’ performances on genericity and nongnericity were significantly different within Group 2 (p= .043) and
Group 3 (p= .004), but not within Group 1 (p= .120); however, for causal questions, no significance was found (Group 1: p=. 594; Group 2: p= .892; Group 3: p= .502).
0.51
0.29 0.25
0.21
0.54 0.41
0.36 0.28
0 0.1 0.2 0.3 0.4 0.5 0.6
1 2 3 4
Group
Scores in mean
mannerquestionsin genericconditions mannerquestionsin nongenericconditions
Figure 4-4. Subjects’ Mean Scores of Manner Questions in Generic and Nongeneric Conditions
0.54
0.33 0.32
0.23
0.54 0.36
0.32 0.25
0 0.1 0.2 0.3 0.4 0.5 0.6
1 2 3 4
Group
Scores in mean
causalquestionsin genericconditions causalquestionsin nongenericconditions
Figure 4-5. Subjects’ Mean Scores of Causal Questions in Generic and Nongeneric Conditions
To sum up the results presented so far, the zenme questions in nongeneric
conditions were generally in favor over generic conditions. Within each age group, only Group 1 showed a significant difference in responding zenme questions in generic conditions and in nongeneric conditions, while others did not. The between-group comparison showed that Group 1 and Group 3 were significantly different in responding to zenme questions in generic conditions. As for zenme questions in nongeneric conditions, no significant difference was found. The subjects’
performances on hui zenme (how questions) and zenme hui (why questions) showed the tendency that nongeneric conditions were preferred over nongeneric conditions only in hui zenme questions, but not in zenme hui questions.
Based on the present results, we may conclude that our subjects showed a difference in genericity. The experimental group tended to use and comprehend zenme questions in nongeneric conditions and gained higher scores (mean = 0.32) than they did when they responded to zenme questions in generic conditions (mean = 0.28), and the difference was significant (p= .006). If we examine the performances within each group, the genericity effect was found influential. The subjects earned higher scores in the non-generic zenme questions than generic ones within the three age groups except the eldest group. This is probably due to their life experience. In the present study:
four generic scenarios were used, the roses pricking people, the alarm clock awaking people, the stone floating on the river, and the color falling off. For the youngest children, they might not have the opportunity to be pricked by roses, be waken by the alarm clock, see the stone float on the river, or see the color fall off from the wall.
However, it is very likely for them to receive the non-generic scenarios, hitting another person, moving things, liking people, seeing people in their daily life, and thus they could better understand the questions containing these events, and thus performed better on these events. Therefore, it is not surprising to see a significant difference between the subjects’ on zenme questions in generic and nongeneric
conditions (p = .006).
The between-group also showed that the 4-year-olds performed significantly worse than 6-year-old subjects (p= .010). Based on this result, it can be inferred that children prefer zenme questions in nongeneric conditions before age six. This is probably because nongeneric events usually happen at the time of speaking, and thus are easier for them to capture. Therefore, it is possible the three age groups did not perform significantly differently. On the contrary, generic events are usually about natural laws or habits, which are more abstract and thus more difficult. As pointed out by Piaget (cited in Papalia & Olds 1992), children aged from around 2 to 5 are at the pre-operation stage, in which their learning is closely related to their experience. That is why generic events were more difficult for our young children. After some years of learning and life experience, that is to say, children may have learned about natural laws, and thus become more familiar with them. To put it differently, their familiarity with the world betters their abilities to deal with zenme questions in generic conditions, as suggested by some studies that familiarity influences L1 acquisition and L2 learning (German & Newman 2004, Lee 2007, Liben & Posnansky 1997, Marinellie & Chan 2006, Nippold & Taylor 2002, Schmidt-Rinehart 1994 ).
Overall speaking, zenme questions in nongeneric conditions were favored.
However, when we examined hui zenme and zenme hui, this tendency was found only in the manner reading of zenme questions (p= .000), but not in the causal reading (p= .614). The incompatibility between the manner reading of zenme questions and genericity might result from children’s difficulty in accepting manner questions with inanimate subjects since the inanimate subjects are likely to occur in conditions involving natural laws without volition or will is involved. However, as far as manner questions are concerned, they usually involve subjects’ will or volition about how they carry out an action. Therefore, the incompatibility arises. When young children
grow older, the incompatibility starts to fade out, as suggested by the results of the present study in which the mean scores got higher as the subjects’ age increased (G1:
0.21; G2: 0.25; G3: 0.29). On the other hand, casual questions involves no volition or will of the subjects. This type of questions only asks about the cause of events; thus it does not present as much difficulty as manner questions do to young children, as seen in Figure 4-4, where our subjects performed similarly either in generic or nongeneric conditions.
4.4 Methodology Effects
As mentioned in Chapter Three, two tasks were designed (i.e., PI and QA Tasks) to avoid the bias caused by a single experiment and, more importantly, to see if our subjects would perform differently on different tasks. The former task enables us to test children’s competence of some language aspects they do not show in their production while the latter task helps us to see a better picture of children’s linguistic representations than PI Task (McDaniel et al. 1996).
In Table 4-9, it was found that overall speaking, the experimental group performed significantly (p= .000) better in the comprehension task (mean= 0.57) than in the production task (0.02).
Table 4-9. Subjects’ Overall Performance on Zenme Questions in PI and QA Tasks Task PI Task (comprehension) QA Task (production)
Group Mean SD Mean SD
Experimental 0.57 0.13 0.02 0.17
Control 0.96 0.03 0.11 0.23
The same findings were obtained in the control group. The comparison between PI Task and QA Task with each group showed that the scores of PI Task were always
significantly higher than those of the QA Task as shown in Figure 4-6:
0.48
0.56
0.69
0.96
0.11 0.01
0.06 0.007
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2
1 2 3 4
Group
Scores in Mean
PITask QA Task
Figure 4-6. Mean Scores of Zenme Questions in PI and QA Tasks
If we look further into the subjects’ performance on hui zenme and zenme hui in the two tasks, we can see that our subjects gained much higher scores in the PI Task than in the QA Task. In their response to hui zenme, the mean score of the PI Task was 0.59 and that of the QA Task was 0.01; for zenme hui, the mean score of the PI task was 0.56, and that of the QA Task 0.05 (p= .000, p= .000, respectively), as shown in Table 4-10:
Table 4-10. Subjects’ Correct Responses to the Two Tasks
Ordering hui + zenme zenme + hui
Task PI QA PI QA
Mean SD Mean SD Mean SD Mean SD
Experimental
Group 0.59 0.15 0.01 0.04 0.56 0.19 0.05 0.14
Control Group
0.96 0.05 0.10 0.26 0.97 0.05 0.11 0.22
Likewise, a significant difference between the tasks was found within each age
group in the subjects’ response to hui zenme and zenme hui, as shown in Figures 4-9 and 4-10:
0.48
0.6
0.68
0.96
0 0.01 0.02
0.1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
1 2 3 4
Group
Scores (in means)
PI Task QA Task
Figure 4-7. Subjects’ Scores of Manner Questions in the PI and the QA Tasks
0.48 0.52
0.69
0.97
0.01
0.11
0.007
0.11
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
1 2 3 4
Group
Scores (in means)
PI Task QA Task
Figure 4-8. Subjects’ Scores of Causal Questions in the PI and the QA Tasks
In Figures 4-7 and 4-8, like what we have seen in our discussion in the previous sections, a developmental sequence was also obtained in both tasks when the subjects
responded to hui zenme and zenme hui questions. Interestingly enough, in response to zenme hui in QA Task, there was a drop in G3.
In the present study, a significant difference was found in the PI and the QA Tasks. Our subjects, as shown in Figures 4-9 and 4-10, performed significantly much better in the comprehension task (PI Task) than in the production task (QA Task.) This result supports the generally-accepted model that comprehension precedes production (Gerken & Shady, 1996), and corresponds to the previous studies on different language aspects (Bates et al. 1988, Benedict 1979, Goldin-meadow, Seligman, &
Gelman 1976, Mills, Coffey, & Neville 1993, Oviatt 1980).
Tyack & Ingram (1977) tested on children’s comprehension and production of six wh-questions. In the comprehension task, the experimenter described a picture, and then asked children wh-questions based on the picture describe; as for the production part, parents record children’s questions in their daily life. Compared with the other wh-questions, how-questions (2.1%) and why-questions (6.9%) occurred less frequently than such wh-questions as what-questions (14.5%) and where-questions (11.8%) in children’s production. In the comprehension task, the percentages of correct responses to why-questions (81 % with transitive verbs, and 83% with intransitive verbs) were not necessary lower than those of what-questions (57 % with object what and 35 % with subject what) and where-questions (67% with transitive verbs and 94 with intransitive verbs). In line with Tyack and Ingram, our study found that even though the scores of the QA Task was extremely low in each age group, the subjects still could differentiate hui zenme from zenme hui. In other words, the comprehension task was valid in testing their sensitivity to the aspect of language which they did not produce in their speech, and thus lend support to the assumption that comprehension is prior to production in language development.
In addition to supporting the assumption that comprehension precedes
production, our subjects’ better performance on the PI Task can be attributed to the fact that there are still other ways to ask manner questions and causal questions in Mandarin Chinese besides hui zenme and zenme hui. For the former, our subjects adapted other wh-words such as sheme as in Laohu ni yao yong sheme fonfa da Xiaoxiung (Tiger, in what way will you use to hit Bear?) or use other words such as yao ‘want’ and xiong ‘think instead of hui.’ For the latter, wh-word for causal questions weisheme was most frequently used. This might be due to the pragmatic factor that lies in the use of zenme hui. As pointed out by Tang (1978), zenme with causal meaning involves speakers’ emotions, like surprise. In our QA Task, the subjects were required to ask questions for the Rabbit, and the questions were not related to them. Therefore, it is reasonable for them to choose weisheme over zenme hui even though the scenario was appropriate.
Besides, the frequency of zenme hui and weisheme may also account for the lower scores for zenme hui. We did a frequency search in the spoken domain for zenme hui and weisheme in the Academia Sinica Balanced Corpus of Modern Chinese6. There are totally 17 tokens for zenme hui found while 115 tokens for weisheme. Based on the frequency, we can infer that weisheme occurs much more frequently than zenme hui. If we take a look at the result of the control group, we can see that zenme hui was seldom uttered. That is to say, it is highly likely that children actually receive insufficient input for zenme hui, and thus they do not produce zenme hui in their speech. This can also be supported by their performance on the QA Task.
The frequency of input has been linked to the acquisition of wh-questions (Clancy 1989, Rowland, Pine & Theakston 2003).
6 Academia Sinica Balanced Corpus of Modern Chinese is developed and maintained by the Institute of Information Science and the CKIP group in Academia Sinica. The corpus contains five million words, and the texts are collected from different areas, such as philosophy, natural science, social, science, arts, general/leisure and literature.
On the whole, it was found that there was a significant difference between the comprehension task (PI Task) and production task (QA Task) (p= .000). Our subjects aged from four to six had better abilities in comprehension than in production of hui zenme and zenme hui because there are other alternatives for manner and causal questions. Meanwhile, our subjects’ use of weisheme over zenme hui was due to the frequency and emotional dis-involvement from the questions they were required to ask causal questions.
4.5 Other Patterns Found in Response to the QA Task
This section is aimed to answer our fourth research questions, attempting to investigate what are the general patterns of our subjects’ production regarding zenme
questions. In the QA Task, there were 11 types of patterns found other than our target questions hui zenme and zenme hui. As shown in Table 4-11, Type A, B and C are non-interrogatives, while the rest are interrogatives. Type A refers to no elicitation, Type B refers to the repetition of the whole or part of the leading sentences, and Type C is the responses the subjects provided as answers to the questions. Types D, E, F, and G are related to causal questions, and Types H, I, and J are about manner questions. The last one is Type K, which contains wrong responses for the designed scenarios.
Table 4-11. Other Patterns Found in the QA Task
Type Example
A No elicitation --
B Repetition Tuzi xiang zhidao naochung chaoxingren de fangfa ->Naochung hui chaoxing ren(G1S11)
C Key words Nouns: Shitou zai he li zenme hui piao->shui(G1S13) Verbs: Laohu hui zenme da Xiaoxiong->yong jiaoG1S10) D Weisheme + modal+ verb weisheme yao qu : Xiaoxiong ni weisheme yaoqu kan
Laohu(G2S2)
E Weisheme + verb Laohu weisheme da Xiongxiong(G2S9)
F Shi sheme yuanyin Laohu ban yizi shi yinwei sheme yuanyin ne (G2S15)
G Zenme + V Meigui ni zenme ci ren (G2S3)
H Zenme+ V Naozhong zenme chaoxing ren (G1S11)
I V+ zenme Shi zenme: Meiguihua ni shi zenme cishang bie de dongwu de(G3S15)
yao zenme: Xiaoxiong ni yao zenme xihuan Laohu (G4S4)
J modal + verb + sheme + noun yong sheme fongfa/ dongxi
Laohu ni hui yong sheme fangfa da Xiaoxiong (G3G15) 1. Zenme modal for manner
Xiaoxiong hui zenme ban shitou
-> Xiaoxiong zenme hui ban shitou (G2S10) 2. Weisheme for manner
Meigui hua hui zenme cishang ren -> Meiguihua ni weisheme cishang ren (G2S9)
3. Yes-no question : Xiaoxiong ni xihuan laohu ma? (G1S8) K Wrong responses
4. Other wh-questions
Laohu zenme hui ban zhuozi->Laohu ni yao qu nali(G1S15)
Overall speaking, there were 685 responses produced excluding our target patterns found in the experimental group and 226 responses found in the control group. The frequency and rate of each type are presented in Table 4-12:
Table 4-12. Frequency and Rate of Other Patterns Produced in the QA Task
Type Experimental Group Control Group
A No elicitation 114 (15.34%) 0
B Repetition 90 (12.11%) 0
C Key words 96 (12.92%) 0
D Weisheme + modal+ verb 113 (15.20%) 83 (36.73%)
E Weisheme + verb 53 (7.13%) 27 (11.95%)
F Shi sheme yuanyin 10 (1.35%) 0 (0%)
G Zenme + V 16 (2.15%) 2 (0.89%)
H Zenme+ V 9 (1.21%) 10 (4.42%)
I V+ zenme 12 (1.62%) 92 (40.71%)
J Modal + verb + sheme + noun 32 (4.31%) 12 (5.31%)
K Wrong responses 198 (26.65%) 0
Total 743 226
As shown in Table 4-12, Type K (26.65%) was the most frequently produced, and Type A (15.34%) was the second, followed by Type D (15.20%), Type C (12.92%), Type B (12.11%), Type E (7.13%), Type J (4.31%), Type G (2.15%), Type I (1.62%) and Type H (1.21%). With regard to the meaning of the questions, it was found that causal questions (25.83%) (i.e., Types D, E, F, G) were more frequently produced than manner questions (7.14%) (i.e., Type H, I, J). Among the four types for casual questions, the rate of Type D (15.20%) was twice higher than that of Type E (7.13%). This was the same in the control group. The native controls adapted Type D most frequently (36.73%) to form causal questions, which was three times higher than their second favorite type, Type C (11.95%). As for the three types for manner questions, Type J (4.31%) accounted for the most percentage and was almost three times as high as three the second favorite, Type I (1.62%). However, in the control group, Type I (40.70%) was the most adapted patterns for manner questions instead of Type J (5%).
If we take a closer look at the responses given by each group, we can see that
Type K was still one of the patterns most frequently produced (16.67% in G1, 30.54%
in G2, and 32.94% in Group 3), generally followed by Types A , B, C and D. However, in Group 3, Type D was the second favorite pattern while Types A, B, and C decreased tremendously, as shown in Table 4-13:
Table 4-13. Frequency and Rate of Other Patterns Produced in the QA Task of Each Age group
Type G1 G2 G3
A No elicitation 87 (34.52%) 24 (10.04%) 3 (1.19%)
B Repetition 43 (17.06%) 29 (12.13%) 18 (7.14%)
C Key words 41 (16.27%) 46 (19.25%) 9 (3.57%)
D weisheme + modal+ verb 20 (7.94%) 25 (10.46%) 68 (26.98%)
E weisheme + verb 9 (3.57%) 13 (5.44%) 31 (12.30%)
F Shi sheme yuanyin 0 (0%) 2 (0.84%) 8 (3.17%)
G Zenme + V 2 (0.79%) 11 (4.60%) 3 (1.19%)
H zenme+ V 5 (1.98%) 2 (0.84%) 2 (0.79%)
I V+ zenme 1 (0.40%) 4 (1.67%) 7 (2.78%)
J modal + verb + sheme + noun 2 (0.79%) 10 (4.18%) 20 (7.93%)
K Wrong responses 42 (16.67%) 73 (30.54%) 83 (32.94%)
Total 252 239 252
Now let us examine the subjects’ responses to manner and causal scenarios separately within each group. Generally speaking, Types A, B and C occurred in the manner scenarios as much as they did in the causal scenarios, and they appeared less as the age increased; however, it was found that Type K occurred most frequently in manner scenarios (G1: 24.6% > 8.73%, G2: 53.97% > 4.42%, G3: 64.80% > 1.57%), as shown in Table 4-14:
Table 4-14. Subjects’ Responses to Manner and Causal Scenarios in the QA Task
G1 G2 G3
Type
Manner Causal Manner Causal Manner Causal
A No elicitation 47
(37.30%) 40 (31.75%)
10 (7.94%)
14 (12.39%)
2 (1.60%)
1 (0.79%) B Repetition 18
(14.29%) 25 (19.84%)
11 (8.73%)
18 (15.93%)
8 (6.402%)
10 (7.87%)
C Key words 22
(17.46%) 19 (15.08%)
21 (16.67%)
25 (22.12%)
5 (4.00%)
4 (3.15%)
K Wrong
responses
31 (24.60%)
11 (8.73%)
68 (53.97%)
5 (4.42%)
81 (64.80%)
2 (1.57%)
Total 126 95 126 62 113 17
To sum up, it was found that Type K, the wrong responses, was the most frequently produced type. By looking at the responses to the manner and causal scenarios, it was found that the wrong responses mostly occurred in response to the manner scenarios, and that weisheme was the most frequently used (133 tokens out of 180). In addition, overall speaking, patterns for casual questions were more frequently produced than those for manner questions. Among the types for causal questions, Type D (weisheme + modal+ verb) was more frequently adapted by the experimental group. As for the manner questions, the experimental group produced more Type J questions, but the controls used more Type I questions.
According to the results presented above, we can see that forming manner and causal questions with hui zenme and zenme hui is actually quite challenging for our children. Hence, they adapted different kinds of strategies to respond to the task. They provided no responses, repeated the sentences, or even gave answers to the questions they were expected to form. These responses accounted for about 40 % of the total responses we got. In addition, more than one-fourth of wrong responses to the
scenarios were found. About 33 % of the total responses were manner and causal and manner questions formed with other wh-words instead of zenme. As their age increased, the rate of non-question types (i.e., no elicitation, repetition and key words) decreased, while the questions type increased. This result may be attributed to the development of children’s linguistic capacity (Wootten et al. 1979). When children grow older, they have better ability to form questions concerning ‘how,’ ‘why’ and
‘when,’ and thus the rate of the non-interrogatives decreases.
If we look at manner and causal questions produced in the present study, we can see that casual questions (25.83%) were more easily produced than manner questions (7.14%). Furthermore, more wrong responses were produced to manner scenarios than to causal scenarios. The result that causal questions were more easily made was also obtained in Erreich (1984). Even though her focus was on the subject-auxiliary inversion, her results showed that casual questions are easier to produce than manner questions. She designed a task to elicit different wh-questions in English from 18 children (aged from 2;5 to 3;0) to see if there was any subject-auxiliary inversion. The results showed that her subjects could produce 66 tokens of why questions out of 563 wh-questions and only 18 tokens of how questions. Therefore, casual questions occupied 11% and manner questions 3 %. Even though Erreich did not discuss the order of wh-questions, her results lent its support for the claim that causal questions are easier than manner questions, which is in line with our findings here.
If we further examine causal and manner questions our children produced, we can see that they preferred to use other wh-words rather than hui zenme and zenme hui when producing casual and manner questions. 116 tokens of causal questions with weisheme were produced, but only 18 zenme hui were found in the experimental group’s responses. As for the manner questions, yong sheme noun was in favor, and it occurred 52 times, while hui zenme only occurred 7 times. The control group’s
preference of using other wh-words was also found. For causal questions, weisheme questions were produced 110 times by them while zenme hui 16 times; for the manner questions, the pattern Verb + zenme was used 92 times while hui zenme 14 times. In other words, the alternatives adapted by our subjects were actually much more frequent than our target structures hui zenme and zenme hui. For casual questions, weisheme questions were frequently used by the experimental group and by the control group. In addition, weisheme questions always occupied a large proportion among the three age groups, indicating that weisheme questions appeared earlier than the other two types: (Shi sheme yuanyin and zenme + verb). These results show that weisheme may be the unmarked form for causal questions compared with zenme hui since form acquired earlier is usually unmarked (Jakobson 1968). As for manner questions, we found two different dominant patterns: yong sheme noun in the experimental group and verb + zenme in the control group. Our children seemed to consider the sheme + noun (tool) easier because the meaning of this pattern would be more transparent than that of the wh-word zenme. As they got elder, they turned to the use of verb+ zenme.
Let us turn to the most frequently produced pattern, Type K: Wrong Responses.
If we examine the subjects’ responses to the manner and causal scenarios separately, we can see that Type K occupied a large proportion of the responses across the three age groups in manner scenarios (G1: 24.60%, G2:53.97%, G3: 64.80%), and the most frequently produced type was casual questions formed with weisheme in the subjects’
responses. For examples, in a scenario that was designed to elicit a manner question meiguahua hui zenme ci-shang ren, our subjects might produce a casual question like meiguahua weishme hui ci-shang ren instead of a manner question. In the literature, it has been found that children interpreted ‘how’ questions as ‘why’ questions and give reasons to manner questions (Cairns and Hsu 1978, Ervin-Tripp 1970). As mentioned
by Miao (1985), when children are faced with more difficult wh-questions, they tend to treat them as other easier wh-questions and give the correspondent answers to them.
In the present study, we were not able to tell from our comprehension task if our subjects did interpret manner questions hui zenme as causal questions due to the task that our design was a picture selection task rather than a task asking children to answer the questions. If we turn to the proper response to manner scenarios, it can be found that our subjects adapted other patterns rather than hui zenme. For example, they replaced hui zenme with yong sheme fongfa/dongxi, and used the wh-word sheme. Hence, it is plausible for us to generalize that children interpret how questions as other easier wh-questions, as shown in the previous studies, and that they also produced the wh-question that are easier in order to replace the more difficult ones, that is hui zenme and zenme hui in the present study.
4.6 Summary of Chapter Four
This chapter has presented and discussed the major findings of the present study.
In Section 4.1, the subjects’ performance on hui zenme and zenme hui was investigated. It was found that zenme hui (why questions) was easier than hui zenme (how questions) in spite of the fact that no statistical significance was achieved between their overall performance of hui zenme and zenme hui. In Section 4.2, agency effects were found in the subjects’ performances. The experimental group had better abilities in dealing with zenme questions with an agent subject than questions with a nonagent subject. In addition, the younger children were found to be more influenced by the agency effects. In Section 4.3, the generity effects were discussed. our children preferred the zenme questions in nongeneric conditions. Furthermore, they had difficulty responding to manner questions in generic conditions. In Section 4.4, the formats of the two tasks were found to be influential. The subjects had better ability in
comprehension than in production. Finally, patterns other than the target patterns were analyzed and it was found that casual questions were easier for the subjects to prouce than manner questions either in causal or manner scenarios.