Software Crash Analysis for Automatic Exploit
Generation on Binary Programs
Shih-Kun Huang, Member, IEEE, Min-Hsiang Huang, Po-Yen Huang, Han-Lin Lu, and Chung-Wei Lai
Abstract—This paper presents a new method, capable of
auto-matically generating attacks on binary programs from software crashes. We analyze software crashes with a symbolic failure model by performing concolic executions following the failure directed paths, using a whole system environment model and concrete ad-dress mapped symbolic memory in . We propose a new selec-tive symbolic input method and lazy evaluation on pseudo symbolic variables to handle symbolic pointers and speed up the process. This is an end-to-end approach able to create exploits from crash inputs or existing exploits for various applications, including most of the existing benchmark programs, and several large scale appli-cations, such as a word processor (Microsoft office word), a media player (mpalyer), an archiver (unrar), or a pdf reader (foxit). We can deal with vulnerability types including stack and heap overflows, format string, and the use of uninitialized variables. Notably, these applications have become software fuzz testing targets, but still re-quire a manual process with security knowledge to produce mit-igation-hardened exploits. Using this method to generate exploits is an automated process for software failures without source code. The proposed method is simpler, more general, faster, and can be scaled to larger programs than existing systems. We produce the exploits within one minute for most of the benchmark programs, including mplayer. We also transform existing exploits of Microsoft
office word into new exploits within four minutes. The best speedup
is 7,211 times faster than the initial attempt. For heap overflow vul-nerability, we can automatically exploit the unlink() macro of glibc, which formerly requires sophisticated hacking efforts.
Index Terms—Automatic exploit generation, bug forensics,
soft-ware crash analysis, symbolic execution, taint analysis.
ACRONYMS AND ABBREVIATIONS AEG Automatic Exploit Generation API Application Programming Interface ASLR Address Space Layout Randomization EAX Extended Accumulator Register
Manuscript received September 02, 2012; revised April 18, 2013; accepted May 20, 2013. Date of publication January 20, 2014; date of current version Feb-ruary 27, 2014. This work was supported in part by NCP, TWISC, the National Science Council(NSC-101-2221-E-009-037-MY2, and NSC 100-2219-E-009-005), and the Industrial Technology Research Institute of Taiwan (ITRI FY101 B3522Q1100).
S.-K. Huang is with the Information Technology Service Center, National Chiao Tung University, Hsinchu 30010, Taiwan (e-mail: [email protected]. tw). Associate Editor: S. Shieh.
M.-H. Huang, P.-Y. Huang, H.-L. Lu, and C.-W. Lai are with the Depart-ment of Computer Science, National Chiao Tung University, Hsinchu 30010, Taiwan (e-mail: [email protected]; [email protected]; huangpy@cs. nctu.edu.tw; [email protected]).
Color versions of one or more of the figures in this paper are available online at http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TR.2014.2299198
EBP Extended Base Register
Concolic Concrete and Symbolic Execution CVE Common Vulnerabilities and Exposures DoS Denial of Service
EIP Extended Instruction Pointer ELF Executable and Linking Format GOT Global Offset Table
IDS Intrusion Detection System IR Intermediate Representation LLVM Low Level Virtual Machine
LOC Lines of Code
NOP No Operation
ROP Return-Oriented Programming SMT Satisfiability Modulo Theories SQL Structured Query Language TCG Tiny Code Generator
OS Operating System
PC Path Conditions
POSIX Portable Operating System Interface XSS Cross Site Scripting
NOTATIONS
The symbolic read data object. The symbolic address expression. The pseudo symbolic variable. The memory snapshot.
All Dereference objects during the execution of the state.
The Boolean expression.
The mapping that maps each element of to a concrete address .
The value of under the variable assignment .
I. INTRODUCTION
C
RAFTING exploits for control flow hijacking, SQL in-jection, and cross-site scripting (XSS) attacks is typically a manual process requiring security knowledge [1]. However, 0018-9529 © 2014 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.based on recent advances in symbolic execution, several proto-type approaches to automatically generating exploits have been proposed [2]–[4]. Exploits or other types of attacks, e.g., SQL injection, and XSS [5], have been used for auditing web appli-cation security, IDS signature generation, and attack prevention. These research topics belong to dynamic taint analysis and sym-bolic execution.
The motivation of this work is straightforward. Failure of software including web applications is inevitable. Given a large number of failures, we need a systematic approach to judge whether they are exploitable. In Miller et al.’s crash report anal-ysis [6], the authors analyze crashes by BitBlaze [7]. Compared with !exploitable [8], the results show that exploitable crashes could be diagnosed in a more accurate way although still with limitations and requiring manual efforts. Moreover, crash anal-ysis plays an important role to prioritize the bug fixing process [9]. A proven exploitable crash is surely the top priority bug to fix.
Dynamic taint analysis and forward symbolic execution have been the primary techniques in security fields [10]. [4] is a recent success to generate mitigation-hardened ( and ASLR [11]) exploits by feeding concrete execution trace and triggering a tainted instruction pointer. The exploits divert the vulnerable path by concolic execution, and exploit constraints to manipulate the instruction pointer. The constraints combine with return-oriented programming (ROP) [12] payload, and feed to a decision procedure, STP [13].
Our objective is similar to , but we target a new threat model. Note that most threats are continuations [14], [15]. Con-tinuations are the explicit control abstraction to express “what to do next” or “what remains of a computation” to give a formal modeling of the goto instruction. They can be used to program non-local jumps, exception handling, and user threads. We can thus view software security threats as attackers’ explicit control on the victim programs. Attackers give explicit control of “what to do next” from the original running software, and take control of the rest of a program’s computations. For example, control flow hijacking attacks divert the input into an attacker manip-ulated continuation. The continuation results in the execution of arbitrary code. The SQL and command injections are inputs flowing into the SQL server or introducing a shell command ex-ecution. They are continuations into the SQL or command shell context. The cross-site scripting is a reflection of web pages, in-serting an explicit continuation to execute arbitrary Javascripts, impersonating as originating from the original Web server. If the continuation is symbolic, which is a concolic execution to reach the invoked site of the continuation and a symbolic expression to describe the continuation, we can generate practical attacks to exploit the continuation. A software crash can be viewed as a tainted continuation. Furthermore, if the tainted continu-ation is symbolic, an exploit can be automatically generated. We have successfully produced exploits from software crashes for control flow hijacking attacks from large applications, in-cluding Mplayer, Unrar, Foxit pdf reader, CMU’s AEG [2], and MAYHEM [16] benchmarks. We have also produced exploits (with our own shellcode) from existing exploits of Microsoft
Office Word. All processes are end-to-end, built on top of the en-vironment model of [17] (based on KLEE [18], and QEMU [19]).
The framework, called CRAX, is to act as a backend of static and dynamic program analyzers, bug finders, fuzzers, and a crash report database. Given these software failures from the frontends and the program binary, CRAX can automatically generate attacks, and practical mitigation-hardened exploits.
The primary contributions and impacts of the work are as follows.
• Address exploit generation for large software systems without source code. Concolic execution ideas have been the techniques for exploit generation since 2009. Auto-matic exploit generation has become an integration effort from existing systems, due to the rapid development of symbolic computation, processor emulation, and envi-ronment model supports. However, we have not found practical integration of exploit generation work that can produce exploits from large applications, such as MS-of-fice word, Mplayer, and Foxit pdf reader. We are the first to demonstrate such a capability though completing the exploiting process formerly regarded as a manual process. A similar scale of work is that of Catchconv [20], which performs symbolic fuzzing, taking the Mplayer as a prey. However, it only acts as a fuzzer, and succeeds to produce Mplayer crashes about as frequently as was done in zzuf [21]. In contrast, CRAX takes the crash from Mplayer and produces exploits. We have automated the exploit writing process of large binary programs.
• Prioritize crashes to be fixed. Currently, several sources of crash reports from several bug analyzers and random fuzzers are available. Too many crashes need to be fixed, and there is a pressing need to determine their priorities [9]. We have preliminarily examined the crash database for open source projects, and found that many of the crashes can be the seed input to produce exploits. The tool would be the first screen gateway to prioritize the bug fixing order. We organize the paper as follows. Sections II and III describe the exploit generation method and basic implementation. We discuss the concept of pseudo symbolic variables for dealing with symbolic pointers in Section IV, and the format string ploit generation process in Section V. Section VI reports the ex-perimental results. Section VII presents related work. We con-clude this paper in Section VIII.
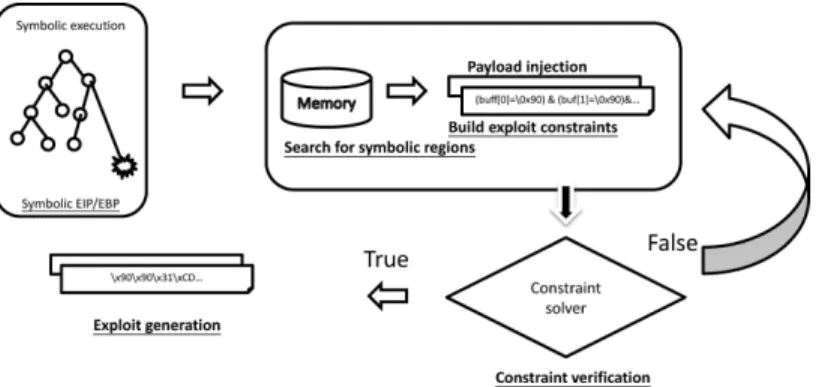
II. EXPLOITGENERATIONMETHOD
We model the exploit generation process of software attacks as the manipulation of software failures, especially introduced by software crashes. We analyze the software crash by con-structing a precise symbolic failure model, consisting of sym-bolic inputs, memory snapshots at the failure point (including concrete and symbolic values of all memory cells), and path constraints to reach the failure site. We propose a new auto-mated exploit generation method based on with path se-lection optimization, selective symbolic input, and lazy evalua-tion on pseudo symbolic variables to handle symbolic pointers.
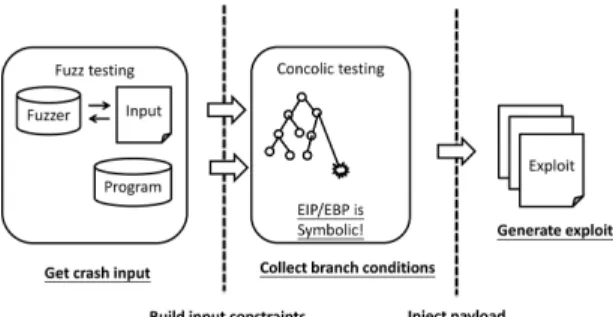
Fig. 1. The process of exploit generation from concolic-mode simulation with fuzz testing.
Concolic-mode simulation explores the failure path directly, and code selection filters complicated and unrelated library func-tions that do not affect exploit generation to reduce the overhead of symbolic executions. We view the concolic path exploring as the failure model construction process. During this process, CRAX also monitors the necessary conditions for exploit gener-ation, and triggers an exploit generation process when it detects the condition. If the process fails to generate exploits, CRAX will go back and continue concolic execution.
A. Building the Failure Model
Software failure can be modeled as a symbolic execution trace, constituted of a set of symbolic inputs, memory snapshots at the failure point, and path constraints to reach the failure site. Given a crash input, we build the failure model by exploring the path introduced by the crash input. If an input data crashes a program, the execution path introduced by the crash input is very likely exploitable. Exploring the suspicious path is more effective than searching all paths.
1) Concolic-Mode Simulation: Concolic testing is symbolic
execution, but it only explores the path introduced by concrete input. When a branch is encountered, only the direction in the concrete path will be explored, and path constraints will be up-dated so that a symbolic path will also be confined to the same direction at the branch.
When in symbolic execution, will use a constraint solver to determine the feasibility of each branch direction under cur-rent path constraints. To perform concolic execution, must follow only the direction introduced by concrete input. To im-plement this feature, we keep an extra constraint set, called input
constraints. We replace path constraints by input constraints
when is determining branch direction, and swap path con-straints back when the branch direction is determined.
Input constraints are a constraint set that restricts every sym-bolic variable to a concrete value. Under the input constraints, every symbolic branch condition has only one possible value, so replacing path constraints by input constraints ensures follows only the concrete path. During the model construc-tion process, we resolve the constraints by concrete value substitutions.
With fuzzer tools to identify an input crashing the program under test, concolic-mode simulation determines whether the path is exploitable rapidly because it focuses on only one path.
Combining fuzzer tools with concolic-mode simulation pro-vides a powerful technique for exploit generation as illustrated in Fig. 1.
2) Handling Symbolic Reads: Access violation is a common
cause of a software crash, and is often due to read from or write to symbolic pointers. Handling symbolic pointers prop-erly enables us to deal with more types of software crashes, and increase the opportunity of exploit generation. For symbolic writes, we treat them as a condition to trigger exploit generation, and will discuss this treatment in the following subsection. For symbolic reads, both solutions in and MAYHEM [16] are not suitable for symbolic pointers with large possible address ranges, which are common in corrupted pointers. So we also proposed a novel technique to handle symbolic reads with large possible address ranges.
The value read from a symbolic pointer can also be treated as a symbolic variable because we can change its value by manipu-lating the pointer. Therefore, we create a new symbolic variable to replace the result from each symbolic read, called a pseudo symbolic variable. Because the pseudo symbolic variables are unconstrained, we must put some constraints on them so that unreasonable paths will not be explored during the path explo-ration process. We will discuss two cases: concolic mode, and symbolic mode.
In the concolic mode, we use input constraints to determine the branch direction. When we create a new pseudo symbolic variable, we must add a corresponding input constraint so that only the concrete path will be explored.
The added constraint just restricts the pseudo variable to the value it should be in the concrete execution; that is, the pseudo variable is restricted to the value stored in the concrete address of the symbolic pointer (and if the value is still symbolic, get its concrete value again). The concrete value of a symbolic expres-sion can be obtained using the SMT solver used by and the input constraints.
However, if a software crash is due to the access from a corrupted pointer, the concrete path usually ends with a seg-mentation fault, and no opportunity for exploit generation. Therefore, when a symbolic read with an illegal concrete ad-dress is detected, CRAX will switch to symbolic mode, try to continue execution, and wait for future opportunities for ex-ploit generation. We have modified the solver for constraint reasoning with pseudo symbolic variables. The detail is in Section IV.
Fig. 2. The process of the exploit generation.
B. Necessary Conditions for Triggering Exploit Generation 1) Symbolic Program Counter (Symbolic EIP in x86 Ma-chines): Because the EIP register contains the address of the
next instruction to be executed, to control the register is the final target of all control-hijacking attacks. Thus, monitoring the state of the EIP register is a comprehensive, easy way to tackle different kinds of control-flow hijacking vulnerabilities. The process of detection of the symbolic EIP register and ex-ploit generation is shown in Fig. 2.
2) Symbolic Write With Symbolic Data: In addition to the
EIP register, corrupted pointers may change the control flow indirectly. Particularly, symbolic data assigned to a symbolic pointer means that arbitrary data can be written to arbitrary ad-dresses. When a symbolic write is detected, the target of the writing operation will be redirected to sensitive data, such as return addresses, .dtors section, and GOT to update the EIP reg-ister indirectly. Considering Listing 1, an off-by-one overflow vulnerability will corrupt the ptr pointer, and as a result the value of array[0] may write to arbitrary addresses. Even if this vul-nerability cannot corrupt return addresses directly, the symbolic pointer can taint the EIP register indirectly and hijack the con-trol of a program.
Listing 1. An example code for pointer corruption
void test( ) { ; int array[10]; int ; for( ; ; ) ; ; }
3) Symbolic Format Strings: The effect of a symbolic format
string is similar to symbolic writes with symbolic data. With a carefully crafted format string, we can also write arbitrary data to an arbitrary address. CRAX also triggers exploit gen-eration when a symbolic format string is detected. The detail is in Section V.
C. Exploit Generation
Given the failure model, the exploit generation process will search a variable assignment of symbolic variables that satisfy path constraints, and could redirect the control flow to the sup-plied shellcode.
1) Shellcode Injection: To inject the shellcode, we must find
all memory blocks that are symbolic and large enough to hold the payload. Even if a symbolic block consists of many different variables, it could still be used to inject a shellcode as long as the block is contiguous. However, it is difficult to analyze source code manually to find a contiguous memory region that is tainted by user input and combined with variables. In addition, because the compiler often changes the order or the allocated size of variables for optimization, it is difficult to find a shell-code buffer manually. We automate this process by searching the maximum contiguous symbolic memory systematically.
2) NOP Sled and Exploit Generation: When the location
of the shellcode is determined, NOP sled will try to insert a sequence of NOP instructions in front of the shellcode. This padding helps exploits against the inaccurate position of shellcode among different systems, or to extend the entry point of shellcode. Finally, the EIP register corrupted by symbolic data will point to the middle of NOP padding. All exploit constraints, including shellcode, NOP sled, and EIP register constraints, are passed to an SMT solver with path conditions to determine whether the exploit is feasible or not. If it is not feasible, the exploit generation goes back to the step of shellcode injection to change the location of shellcode until an exploit being generated or no more usable symbolic buffer.
D. Optimizations
1) Code Selection: Because performs symbolic execu-tion on the entire operating system, the large number of path constraints will become an issue when the symbolic data are passed to the library or kernel. The constraints induced by the library or kernel are usually complex and huge, and constraint solvers often get stuck trying to solve them. For example, if the first argument of the fopen() function, which is a path of the file to be opened, is symbolic, then the constraint solvers will get a time-out error or hang in . Those paths in the library or kernel are often irrelevant to exploit generation. To avoid ex-ploring those irrelevant paths, those library functions should run on concrete execution.
One of the essential features of is selective symbolic ex-ecution, which enables us to specify the region that should be
concrete executed. We can concretely execute library and kernel functions, and no path constraints will be added during the con-crete execution. When this irrelevant function finishes, we can switch back to symbolic execution. will handle the switch between the concrete and symbolic values of each variable.
2) Input Selection: The size of the symbolic execution trace
of the failure model is influenced by the number of symbolic input variables, the number of branch conditions carrying sym-bolic expressions, and the data flow to the failure event. Re-ducing the amount of symbolic input variables will also re-duce the size of the symbolic execution trace. According to the observation, not all of the input will take part in the event manipulating process. That is, we can selectively use part of the input to speed up the failure model reconstruction. It is similar to unique pattern generations used by metasploit [22], which divert limited bytes of tainted inputs into the instruction pointer. Taintscope [23] uses a similar concept, called the se-lected inputs, as hot bytes to identify significant bytes for po-tential fuzzing operations, such as mutation, generation, or sym-bolic solution finding. If we can find the significant input bytes that will directly or indirectly (either consecutively or not) in-fluence the continuations, we will be able to mark these inputs as symbolic. In metasploit’s unique pattern generator, it is quite tricky to generate identifiable string patterns that taint the EIP or other registers. In with the proposed fast concolic method, we can partition the input into several smaller parts (100 byte units), making these parts symbolic individually. The hot bytes will be identified if the continuations are detected as symbolic.
III. BASICIMPLEMENTATION
The exploit generation steps are: 1) collect necessary run-time information, 2) build exploit constraints, and 3) pass the exploit constraints to the constraint solver to produce an exploit. The memory model in is also an important key to imple-menting the proposed methods. In addition to return-to-memory exploits, we also implement two other types of exploits, re-turn-to-libc and jump-to-register exploits, to bypass some pro-tections so that the exploit generation can be useful in real-world systems.
A. Symbolic Environment and Concrete Address Mapped Symbolic Memory
Symbolic environment is the primary way to attain the end-to-end capability. Concrete address mapped symbolic memory is the key for exploit generation on binary programs. Without full symbolic environment support, users must modify the source code to declare and make the input symbolic. is a whole system symbolic emulator, and all kinds of envi-ronment inputs in the operating system can be declared as symbolic including device inputs, network packets, sockets, files (including stdin), environment variables, and command arguments. The cost to take advantage of this feature is low. We use pipes to emulate symbolic stdin, and mmap to emulate symbolic files; all other environments can be easily emulated. With concrete address mapped symbolic memory, we can index symbolic memory by concrete addresses. Ordinary symbolic execution engines including KLEE, CUTE [24], DART [25], and CREST [26] can only index symbolic memory by abstract
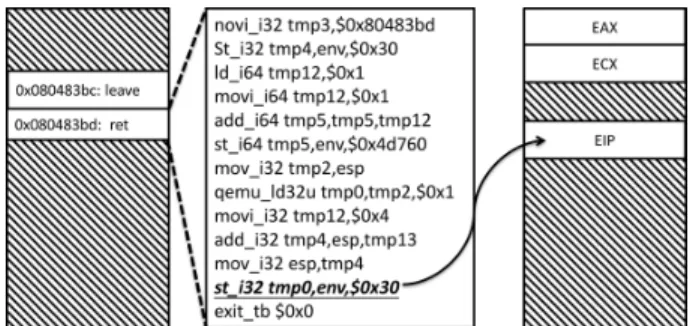
Fig. 3. The process of translating the ret instruction in QEMU.
addresses. A practical exploit generation process is to search a usable address range to divert the failure event. Without concrete address mapped symbolic memory, we cannot analyze binary programs. The source code-based AEG is not sound, and must have an exploit validation process to revise the exploit address range.
B. Detection of Continuation Based Symbolic Registers
In QEMU, the CPUX86State structure is used to simulate the states of the x86 CPU, and all register references in a guest op-erating system will be turned into memory references on this structure. When is started, this structure is divided into two parts stored separately: CpuRegistersState, and
CpuSystem-State. The CpuRegistersState is a symbolic area which stores
all the data in front of the EIP register in the CPUX86State structure, such as general-purpose registers. The CpuSystem-State part is a concrete-only area that stores the other data in-cluding the EIP register.
translates every guest instruction into TCG IRs, and then translates those TCG IRs into host instructions or LLVM IRs. For instance, the ret instruction is separated into more detailed operations as shown in Fig. 3, and the operation of updating the EIP register is converted to a store instruction. In QEMU, all memory access operations are handled by a softmmu model to map the guest addresses to host addresses. Whenever accessing memory data, checks whether the value of the data point is symbolic or not in the softmmu model. If the value is symbolic, will rerun this translated block from the current instruction in KLEE to perform symbolic execution. To detect EIP register corruption, must check whether the writing target is the location of the EIP register, and whether the source value is symbolic whenever KLEE performs a store memory operation on symbolic execution.
When the EIP register is updated by symbolic data, the ex-pression of symbolic data must be recorded because it describes which variable and which part of the symbolic data will update the EIP register. For example, given an expression that repre-sents 32-bit symbolic data at the first element of an array named
buf denoted as
we can build a constraint to control the value of symbolic data, e.g., a constraint limiting the 32-bit data to zero as shown by
The current continuation has been set by the data, with con-straints described by symbolic expressions. Next, we inject the shellcode into memory, and determine where the EIP register should point.
C. Exploit Generation
1) Memory Model in : In , the memory consists of
MemoryObject objects, and the actual contents of these objects
are stored in ObjectState objects. In an object of ObejectState, symbolic data are stored separately from concrete data. The ex-pressions of symbolic data are stored in an array that consists of Expr objects, with pointers named knownSymbolics pointing to them. The concrete data are stored in an array of uint8_t, and pointed by a pointer named concreteStore. In each ObejectState object, a BitArray object named concreteMask is used to record the state of each byte, i.e., the byte is concrete or symbolic.
2) Finding Symbolic Memory Blocks: The default size of
the storage in an ObjecetState object is 128 bytes. To find contiguous symbolic data in a memory region, we check the value of concreteMask structures sequentially, object by object. An object can be skipped easily whenever the values of its
concreteMask structure are all ones; otherwise, the locations of
every zero in the concreteMask structure must be recorded to compute the continuous size. For the symbolic blocks crossing different objects, it is necessary to check whether the current symbolic block is connected with the last symbolic block in the last object checked. The above procedure is shown in Algorithm 1.
Algorithm 1: Searching for symbolic blocks
Input: Objects : All ObjectState objects to be searched. Output: V : A set of address and size.
1 foreach do 2 if then 3 4 for to 127 do 5 if then 6 7 else if then 8 9 if then 10 ; / A
part of the last block / 11 else
12
/ An independent block / 13
It is also required to determine the search range of memory regions. In Linux memory layout, the stack starts from the top at address 0xbffffffff and grows downward. It is easy to search the stack region from this address downward, but the heap and data segments are not necessarily located at a fixed address for dif-ferent programs. Therefore, those starting locations need to be obtained dynamically. According to the ELF executable layout, the top of the executable files is the program header, which records all segment information. We can get the location and size of the data segment by analyzing the program header, which will be loaded to the address of 0x08048000.
On the other hand, because the heap region is behind the data segment and grows upward, the base address of the heap can be obtained by adding the starting address and size of the data segment.
3) Shellcode Injection: To determine whether shellcode can
be stored in the potential buffers found by the previous step, each symbolic expression of a symbolic block needs to be read to build constraints that restrict each byte of symbolic data to a byte of shellcode sequentially byte by byte. This is an example showing the constraints that inject the shellcode into an array named buf:
.. .
Next, the shellcode constraints are passed to an SMT solver with path conditions to validate their feasibility.
The best location for the shellcode is selected by having the NOP sled as large as possible. Therefore, all the symbolic blocks are sorted by size, and the shellcode is first injected from the end of the largest symbolic block. In addition to building the shell-code constraints, a new constraint needs to be added to ensure the EIP register can point to a range between the starting address of the shellcode and the top of the symbolic block. Even if the EIP register cannot point to the starting location of the shellcode precisely, it may be feasible because the NOP sled will extend the entry point later. If all of those constraints are infeasible, the location of the shellcode injection is shifted by one byte forward to try a new location iteratively.
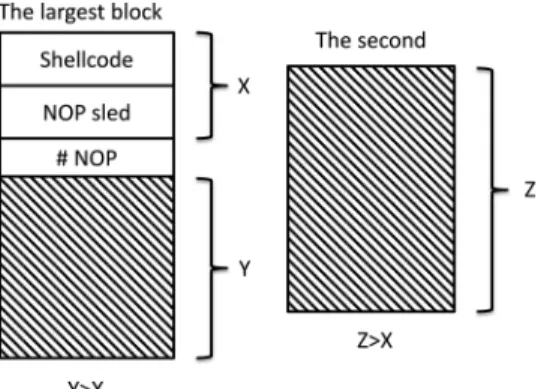
In addition, shellcode will keep being injected into the current block or next blocks when those sizes are larger than the sum of the shellcode size and the current longest NOP sled size. For ex-ample, consider Fig. 4; the sum of the shellcode size and current NOP size is , but it is smaller than and , so the shellcode and NOP sled will keep being injected into the next blocks and the current block. The algorithm is shown in Algorithm 2.
Algorithm 2: Injecting shellcode
Input: V : A set of address, and size of symbolic blocks.
Shellcode : A shellcode string. PC : Path conditions.
Output: ShellcodeAddress : The starting location of shellcode
injection. MaxNopSize : The max size of NOP sled.
1 foreach do
Fig. 4. The process of searching symbolic blocks. 3 4 5 while do 6 / Build shellcode constraints / 7 /
Build eip constraints /
8 if then 9 10 if then 11 12 13 if then 14 15 else 16 break 17 else 18
4) NOP Sled: NOP sled aims to generate the more reliable
exploits that increase the chance of success. CRAX will insert NOP instructions in front of the shellcode, as many as possible, and adjust the EIP register within the range. For efficiency, a binary search-like algorithm is used to determine the longest length of NOP sled rather than insert NOP instructions byte by byte. Whenever the binary search finds a range that the EIP register can point to, NOP instructions will be tried to fill this range sequentially to check whether both conditions are feasible simultaneously. If it is infeasible, the range is reduced; other-wise, the range is extended. The detailed algorithm is shown in Algorithm 3.
Algorithm 3: NOP sled
Input: Start : The starting address of NOP sled. End : The end
address of NOP sled. PC : Path conditions.
Output: NopSize : The size of NOP sled.
1 2 3
4 while do
5 / Build eip constraints
/ 6 if then 7 / Build NOP constraints / 8 if then 9 10 11 else 12 13 else 14 15
After the longest length of the NOP sled is obtained, the next step is to make the EIP register point close to the middle of the NOP sled. Because the number of NOP sleds may be large, the constraint solver is used to reason out the suitable location where the EIP register points. To help a constraint solver to com-pute the address as close to the middle of the NOP sled as pos-sible, a constraint is added to limit the range. First, the range is a point in the middle of the NOP sled, and the constraints are passed to a constraint solver to get the solution. If it is infeasible, the range is extended twice larger each time, and so on. This process can obtain a solution because the previous step guaran-tees that the EIP register can point to the range of the NOP sled. The algorithm is shown in Algorithm 4.
Algorithm 4: Determining the value of the EIP register. Input: NopSize : The size of NOP sled. Start : The start address
of shellcode. PC : Path conditions.
Output: EipAddress : The address where EIP register points at.
1 2 3 repeat
Fig. 5. The process of return-to-libc exploit generation. 5 6 else 7 8 if then 9 10 else 11
12 / Build eip constraints /
13 if then 14 15 else 16 17 until ; 18
Finally, the starting address of the shellcode, the size of the NOP sled, and the location EIP register points are to be deter-mined if they are feasible. The constraint solver will solve the final path conditions to generate the exploit that performs the malicious task in the shellcode.
D. Other Types of Exploit
1) Return-to-Libc: A return-to-libc attack is a technique to
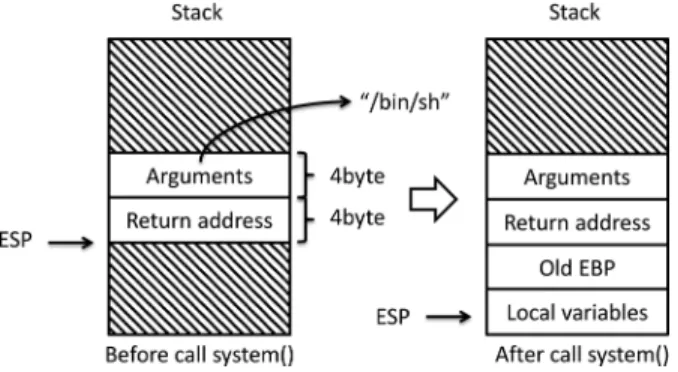
bypass non-executable memory regions, such as pro-tection. It redirects control flow to functions in the C runtime li-brary, such as system(), and injects the arguments of the function into the stack manually to fake the behavior of function callers. Because the runtime library is always executable and loaded by operating systems, a return-to-libc attack can perform malicious tasks by executing library code, and bypass the executable space protection. Fig. 5 shows the process of calling the system() func-tion of libc. The argument containing the command string will be pushed into the stack. It does not matter where the libc func-tion call returns, but the arguments are the key to perform the tasks in which we are interested.
Taking system(“/bin/sh”) as an example, which will open a shell, the only argument is a pointer that points to the string
TABLE I
THEDIFFERENCES BETWEENRETURN-TO-MEMORY ANDRETURN-TO-LIBCEXPLOIT
Fig. 6. The process of jump-to-register exploit generation.
“/bin/sh” as shown in Fig. 5. The process of return-to-libc ex-ploit generation is similar to return-to-memory. We also need to inject shellcode and NOP sled, just with different contents, as shown in Table I.
Shellcode injection injects the string “/bin/sh” instead of a shellcode, and NOP sled fills the stack with white space charac-ters rather than NOP instructions.
2) Jump-to-Register: The stack is the most common memory
region for shellcode injection, but ASLR randomizes the base address of the stack so that control flow does not jump to shell-code accurately. A large NOP sled may bypass ALSR, but it is not always feasible. A jump-to-register attack is a technique to bypass ASLR. It uses a register that points to a shellcode as a trampoline to execute the malicious tasks. For example, the Ex-tended Accumulator Register (EAX) is usually used to store the return value of functions. The strcpy() function returns a pointer that points to the location of buffer, and the EAX is often used to store the address. If a “call %eax” instruction can be found in the code segment, and shellcode can be injected into the buffer that the EAX register points to, then flow control will be redi-rected to execute this instruction and jump to shellcode.
In addition, jump-to-esp is also a common, reliable attacking technique which doesn’t need to insert NOP sled and guess the stack offset in Windows and old versions of Linux. When a func-tion returns its results, the return address will be popped, and the ESP register will point to the stack entry next to the entry that stores the return address. We can inject shellcode behind the return address, and use the ESP register as a trampoline. If a “jmp %esp” instruction can be found in the code segment, a jump-to-esp exploit can be generated to bypass the ASLR. The process is shown in Fig. 6.
To generate jump-to-register exploits, a code segment must be searched to find the related instructions such as “call %eax” and “jmp %esp”. If the related instructions are found, and the memory region that the register points to is symbolic, shellcode will be injected into the location, and the EIP register will be redirected to execute the related instruction. In addition, if there
Fig. 7. An example for code selection.
is not any usable instructions in the code segment, the data seg-ment may be searched to find two-byte symbolic data to inject into the related instruction because the data segment is unaf-fected by ASLR. For example, the “jmp %esp” instruction is 0xffe4 and the “call %eax” instruction is 0xffd0.
E. Concolic-Mode Simulation
To simulate concolic testing on , we execute the program under test with input data, such as arguments and environment variables, while the main tasks are building input constraints and collecting branch conditions. According to the memory model in , the concrete values are stored separately from symbolic data, but the concrete values are ignored because the variables are marked as symbolic. To build input constraints, we must obtain concrete input data at run time, which can be done by reading the last concrete value of the symbolic variables from the concreteStore structure. A vector container is used to save all input constraints because it is easy to delete some constraints when they are unnecessary, and to combine every constraint into a complete input constraint when it is needed.
In symbolic execution, if a symbolic branch condition is only feasible in one direction, there is no need to add the branch con-dition to path constraints. In concolic execution, we must collect every symbolic branch conditions into path constraints because we only follow the concrete path, and never use the solver to determine the feasibility of each branch direction.
In addition to branches, symbolic addresses also cause state forks on symbolic execution. When accessing a memory address whose value is symbolic, cannot determine where it should access. forks executions to try to access every address to which the symbolic address can refer. In concolic mode, input constraints are still used to help SMT solvers determine a loca-tion on a symbolic address.
It is easy to switch between concolic-mode simulation and original symbolic execution because the memory model of is not modified. If symbolic execution will be performed, we just set the input constraints to be true because path conditions will not be changed when they perform an AND logical operation with a true expression.
F. Detection of Pointer Corruption
When accessing a memory address, will check whether the address is symbolic or not. If it is symbolic, must de-termine an explicit location before keeping program execution. uses a binary search to find all locations that the symbolic
address can point to, and forks executions to explore each ad-dress. Before handles a symbolic address, the address can try to point to sensitive data, such as a return address or a GOT. If it is feasible, those sensitive data will be tainted and corrupt the EIP register later. Otherwise, the symbolic address will be changed to taint other concrete data because it may help ex-ploit generation if other vulnerabilities corrupt the EIP register later. For example, we can change the address to taint the data segment so that the shellcode can be injected to bypass ASLR protection.
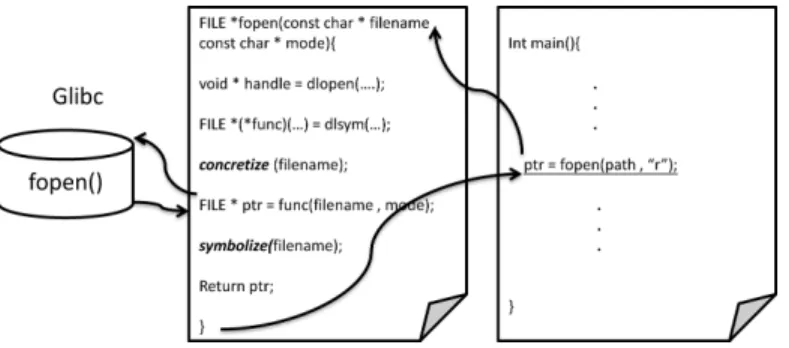
G. Code Selection
Because has built-in selective symbolic execution, it is easy to use this capability to select the code to run on concrete execution or symbolic execution. In Linux, the LD_PRELOAD environment variable can intercept the library functions, and jump to the functions. With the help of this environment vari-able, we can intercept those irrelevant library functions and concretely execute them. Fig. 7 shows an example that inter-cepts the fopen function and performs concrete execution on it. In addition, some functions just print messages to the screen without a return value, such as perror(), so those functions can be skipped using this method directly to speed the process of exploit generation.
IV. REASONINGWITHPSEUDOVARIABLES
Vulnerabilities that involve corrupted pointers, like heap overflow, cannot be exploited without a proper symbolic pointer handling mechanism. However, mechanisms in and MAYHEM [16] are not suitable for corrupted pointers because they can only handle symbolic pointers with small address ranges. Hence, we introduce a new approach that enables CRAX to handle symbolic pointers with large address ranges. We have introduced pseudo symbolic variables and lazy evaluation for resolving possible pointer values for exploit generation.
A. Pseudo Symbolic Variable for Memory Management Helpers
We modified the memory management helpers of . When symbolic read occurs, we first check whether the sym-bolic pointer can refer to a legal address under the current path constraints. If not, we concretize the pointer. If the symbolic pointer can refer to a legal address, we then create a new symbolic variable (called the pseudo symbolic variable) to
replace the read result and record all information needed for future constraint solving.
Information from the symbolic read is packed into a data ob-ject named Dereference, in which we have the fields Derefer-ence.address, Dereference.value, and Dereference.memory cor-responding to the symbolic address expression, the pseudo sym-bolic variable created for this read, and the memory snapshot at the moment that the symbolic read occurs, respectively. For each state, we maintain a set that contains all Dereference objects created during the execution of the state. Newly created Dereference objects will be stored in the set.
For the memory snapshot, rather than scanning all possible addresses, we instrument to fork a state (called meta state), and remove the meta state from the execution queue. has a built-in copy-on-write mechanism to keep track of the memory content of every state. Because the meta state has never been executed, we can access the memory content (using the read-Memory method) at the moment when the meta state is forked.
B. Lazy Evaluations of Pseudo Symbolic Variables by Late Address Assignment
We treat the result of a symbolic read as a newly created, un-constrained pseudo symbolic variable. Because the value read is determined by the address, if we pass an expression that contains pseudo symbolic variables to the constraint solver, we will likely obtain an infeasible answer. We implement a modi-fied version of the constraint solver routines so that the consis-tency of symbolic reads can also be ensured.
The following are typical constraint solver routines used by , where is a Boolean expression.
1) : Check if there is some variable as-signment that can make become true.
2) : Check if there is some variable
assignment that can make become false.
3) : Check if is provably true
(no variable assignment can make it false).
4) : Check if is provably false
(no variable assignment can make it true).
Every routine can be implemented by any other one.
For example, can be implemented as
. Therefore, we only implement a modified version of , and the other three can be easily implemented. In the following discussions, we use
to denote the original solver routine, and to denote the modified version. The other three routines are denoted similarly.
For the routine, we must determine
whether we can find a variable assignment (including the assignment to pseudo symbolic variables) that makes true, and also preserve the consistency of all symbolic reads. More formally, if is a variable assignment, and e is a sym-bolic expression (Boolean or numerical), we define to be the value of e under the variable assignment . The goal of is to determine whether there exists a variable assignment that satisfies
(1) We can reuse the power of the original solver routine by trans-forming the problem into determine whether there exists a map-ping that maps each element of to a concrete address
, and satisfies equation (2) at the bottom of the page.
Note that may also be a symbolic
expression.
Determining the satisfiability of (1) is equivalent to deter-mining that of (2). If (2) can be satisfied, we must have a vari-able assignment that satisfies equation (3) at the bottom of the page.
This condition is what is designed to answer. Obviously the variable assignment also satisfies (1). In the reverse direction, if we can find a variable assignment that satisfies (1), then we take the mapping
The mapping also satisfies (2).
We define the address assignment of as a mapping that maps every element of to a concrete address. An address assignment of satisfies if (2) is true. We extend these definitions to the subset of by replacing with in the above definitions (and also (2)). We also define the address assignment of a single object to be the concrete address that will be mapped from the object.
(2)
The goal of is to find an address assignment of that satisfies , or determine that such an assignment does not exist.
1) Searching Address Assignment of a Singleton Subset: We
must find an address assignment of a singleton subset of that satisfies . Because the address assignment only contains one concrete address, we use binary search for every possible concrete address, and use solver to determine the satisfiability of bExpr under each assignment. The process is shown in Al-gorithm 5. However, we still need optimization techniques for general cases.
Algorithm 5: FindSatisfyingAddress
Input: bExpr : The constraint. d : The dereference object.
addrMin : The starting address. addrMax : The end address.
Output: addr : The address satisfies the constraint.
1 if The address range[addrMin, addrMax] is unmapped then 2 return null 3 if then 4 return null 5 if then 6 if then 7 return addrMin 8 return null 9 else 10 11 12 if then 13 return addr 14 15 if then
Fig. 8. Alter searching order; the original order is from the lower address to the higher address, and the altered order is searching symbolic blocks first.
16 return addr 17 return null
Value Based Filtering: If strictly constrains but with few constraints on , we must perform almost solver queries to find a satisfying address assignment. However, if is constrained to a few con-crete values, we can collect all the possible values of
(using similar binary search technique). Before recursively searching an address range, we first check if any memory cell in the range contains possible values. If not, there is no need to search into the address range.
Currently, we will trigger this optimization when has fewer than 5 possible values, and the address range (that is,
) is smaller than 1024.
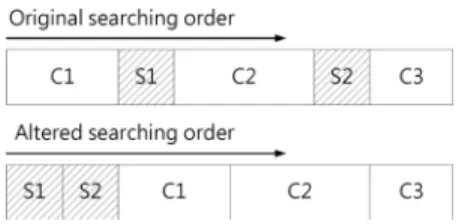
Searching Symbolic Blocks First: may put no constraint on or , but on their relationship, for example, may look like
. In this case, the optimization technique intro-duced previously is useless. To handle this case, we alter the searching order to search the symbolic blocks first, as Fig. 8 illustrated.
If we cannot find a satisfying address assignment from sym-bolic blocks, we will try the concrete blocks. However, this may take a long time, so we also impose a timeout value when searching concrete blocks, and judge that there is no satisfying address assignment if the timeout is reached.
The FindNextSatisfyingAddress function will find an address assignment of d that is greater than or equal to addr in the searching order. The GetNextAddress function will return the next address of addr in the searching order. We also implement a modified version of the two functions to follow the altered searching order.
2) Searching Address Assignment of : The intuitive way
to search an address assignment of satisfying is to select an element of , find a satisfying address assignment of , and recursively search the address assignment of the set
that satisfies .
In most cases, the unsatisfiability of can be judged by examining only a few key Dereference objects, but if those objects are examined in deep recursions, we would waste time backtracking, as illustrated in Fig. 9. In Fig. 9, each round corner rectangle stands for an initial or recursive call of
HasAssignment, and arrays of squares are memory snapshots
of each Dereference object passed by the second parameter of HasAssignment. The selected object is denoted below
Fig. 9. The searching process of Algorithm 6 without re-selection of in .
Fig. 10. The searching process of Algorithm 6.
the memory snapshot, and the memory cell pointed by the lastAddress field is denoted by a thick border. Although (at line 4 of Algorithm 6) we can use a smarter heuristic to select the Dereference object to solve, there is no guarantee that the heuristic always makes the best decision.
Therefore, we change the Dereference object we are solving. The selection heuristic at line 13 has one direction to follow: se-lect the Dereference object that we just failed to find a satisfying assignment at the recursive call of line 10 because it is likely to be one of the key Dereference objects mentioned before. Fig. 10 illustrates the searching process of Algorithm 6 with the same example as Fig. 9; we can see that, after the second recursion
fails, the first recursion re-selects a Dereference object, which is the one for which the second recursion just failed to find a satisfying assignment.
Additionally, we can prove that Algorithm 6 will eventually terminate by induction on the size of ; Algorithm 6 must termi-nate if . Assume Algorithm 6 will terminate if ; then when the , line 10 must terminate because . If the recursive call at line 10 returns true, then Algorithm 6 terminates; otherwise, d.lastAddr will be incre-mented, so we will not try the same with the same
Algorithm 6: HasAssignment
Input: bExpr : The constraint. D : The Dereference object set. Output: Result : if there exists an address assignment
satisfying the constraint. 1 if is empty set then
2 return true 3 Select an element of 4 repeat 5 6 if then 7 return false 8 9 10 if then 11 return true 12 13 Re-select an element of 14 until false;
C. Exploiting the Unlink Process of Free()
With the symbolic pointer handling mechanism, we can au-tomatically exploit the unlink macro used by free() in an early version of glibc. The following code is the unlink macro. When heap metadata are overwritten by symbolic data, P will be sym-bolic, and FD and BK will become the result of symbolic reads, so CRAX will produce two pseudo variables to replace the value of FD and BK. Because FD also becomes symbolic, line 5 will become a symbolic write, which allows us to redirect the GOT entry or return address to the shellcode.
Listing 2. The unlink macro / Take a chunk off a bin list / #define unlink(P, BK, FD) { ; ; ; ; }
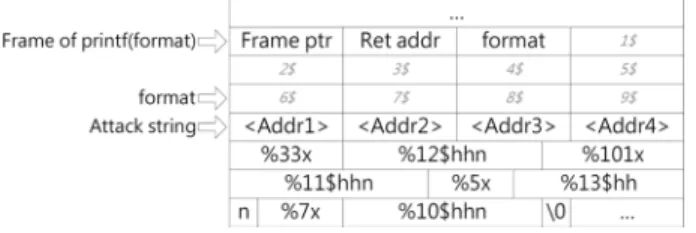
Fig. 11. The stack layout when attacking printf; italic text denotes the $-offset needed to access the cell.
However, there will be a second symbolic write at line 6, and the target is just 8 bytes after the shellcode address, which will corrupt the shellcode. To handle this condition, we add a jump instruction at the beginning of the shellcode to jump over the corrupted area, and we do not try to insert NOPs when we are exploiting heap overflow vulnerabilities.
V. FORMATSTRINGEXPLOITGENERATION
Format string vulnerability is a common vulnerability caused by misuse of formatting functions such as printf or syslog. Attackers can overwrite an arbitrary address with an arbitrary value by injecting a carefully crafted attack string into the format string. Fig. 11 demonstrates the common pattern of attack string used in CRAX’s format string exploit. The first 4 addresses point to the location we want to overwrite, usually the GOT entry of some library function. Because only one byte would be overwritten for each %hhn formatting, we need 4 addresses to overwrite the 4-byte GOT entry. In the remaining part of the attack string, we repeatedly use the %x formatting to manipulate the length of the printed string, and the %hhn formatting to write the string length to the address specified in the beginning of the attack string.
There is another problem: we must ensure that each %hhn for-matting can refer to one of the addresses at the beginning of the attack string. This referencing can be done by using the ‘$’ for-matting option, which assigns the argument with pointer values. As in Fig. 11, the number before the ‘$’ formatting option (de-noted as $-offset) specifies which argument to use. Because the arguments are passed by the stack, we can access any portion of the attack string (with carefully chosen $-offset) if the attack string is also located in the stack.
Currently, CRAX only supports format string exploit gener-ation in Linux. To capture invocgener-ations of formatting functions in the guest OS, we use the LD_PRELOAD environment vari-able to pre-load the re-implementations of formatting functions. Once formatting function invocation is captured, the exploit generation process is triggered. The generation process of the format string exploit consists of several steps: 1) format string vulnerability detection, 2) $-offset detection, and 3) constraint reasoning and exploit generation.
A. Format String Vulnerability Detection
Once the formatting function call is detected, we first check whether this call is vulnerable. That is, we check whether the format string contains symbolic data. If it does, we continue the remaining exploit generation process; otherwise we redi-rect control flow to the original formatting function in libc as
nothing happens. Currently, we try to generate format string ex-ploits only when the format string contains more than 50 bytes of symbolic data.
B. $-Offset Detection
If a vulnerable formatting function call is detected, then we will try to generate an exploit. The first information we must obtain is the $-offset that can reach the beginning of the format string. Although we do not have to put the attack string at the beginning of the format string, we must know the $-offset to reach the attack string, which can be computed by the $-offset to the beginning of the format string plus the distance between the formatting string and the attack string. Perhaps we can compute the $-offset directly by the distance between the current frame pointer and the location of the format string, but for different formatting functions, there may be variations in their $-offset so that we should compute it case by case. However, the offsets usually are small numbers, so we instead adopt a linear search method. We just try every natural number starting with 1, and test whether it is the correct $-offset.
Algorithm 7: Search$-offset
Input: FormatString : the format string. Output: Offset : Searching $-offset.
1 2 3 repeat 4 if then 5 6 if then 7 break 8 else 9 10 else 11 NormalTerminateOnMemoryAccess(M) 12 13 OriginalFormattingFunction(FormatString) 14 ErrorTerminate() 15 until false;
The pseudo code of how we discover the correct $-offset is shown in algorithm 7. We implement a set of POSIX-fork like API for a guest OS program to control the state fork in . When the pre-loaded library detects format string vulnerability, it will enter a loop continually trying each possible $-offset. The trials are done in the child state, and the parent state will be in-formed of successful trials by the exit status of the child state. The child state tests the given $-offset by replacing the head
of the format string with a special test string, which is prefixed by a 4-byte magic number , and followed by a format-ting with the given $-offset. When prinformat-ting the modified format string with correct $-offset, the formatting will reference the magic number in the beginning of the test string, and cause a memory write to address M. Before printing the format string, the child state will use the API to instruct to capture such a memory write. If such a memory write is captured, the child state will be terminated, and the parent state will be informed of a successful trial.
C. Constraint Reasoning and Exploit Generation
Now that we have all the information needed for generating an attack string, the only thing left is inserting the shellcode and NOP sled into some symbolic memory blocks, and inserting an attack string to overwrite the pre-specified GOT entry into the address of the shellcode. Shellcode and NOP sled are discussed previously, and the role of the attack string is similar to the EIP constraint in the previous discussions. However, inserting an at-tack string is more complicated than manipulating a symbolic EIP. We don’t have a dedicated symbolic EIP expression, but we have a symbolic formatting string. We have to generate an attack string. If the attack string is shorter than the formatting string, we can insert the attack string in different locations in the formatting string. Because we don’t have the symbolic EIP ex-pression, we cannot use the binary search mechanism to assign the EIP register to the address nearest to the middle of the NOP sled. Hence, we currently just iteratively try each possible lo-cation within the formatting string where we can put the attack string, and for each possible location we also try each possible address to which we can overwrite the GOT entry (we must gen-erate different attack strings for different addresses), with the priority that the addresses near the middle of the NOP sled are tried first. Once a satisfactory setting is found, we can pass the shellcode, NOP sled, and attack string constraints to the con-straint solver to produce an exploit.
VI. EXPERIMENTALRESULTS
We conducted five types of experiments to evaluate the work for automatic exploit generation. The first experiment is with five different common control-flow hijacking vulnerabilities. The experiment demonstrates that the proposed method can handle all vulnerabilities that symbolically update the EIP register, and some vulnerabilities that symbolically update pointers. The second experiment is with return-to-libc and jump-to-register exploit generations to demonstrate that the method could bypass some mitigation protections in real-world systems. In the third experiment, we generated exploits for 33 real-word programs, most chosen from the benchmark of AEG and MAYHEM, to demonstrate that our method can handle at least most of all cases that AEG and MAYHEM addresses. Al-though we are conducting the whole system symbolic execution and AEG is on the application level, our method is still faster than AEG because we reduce the number of constraints by performing concolic execution on selected code and input. The fourth experiment reveals the performance speedup between the original concolic method and the improved method. The speedup can achieve 7000 times faster execution than our initial
TABLE II
THERESULTS OFEXPLOITGENERATION FORSAMPLECODE
attempt, due to this performance tuning. We also demonstrate the power of CRAX to produce exploits of large applications, including Microsoft office word, foxit pdf reader, and Mplayer.
A. Testing Method and Environment
All of the experiments are performed on a 2.66 GHz Intel Core 2 Quad CPU with 4 GB of RAM, and the host environ-ment is Ubuntu 10.10 64-bit. The guest environenviron-ment is Debian 5.0 32-bit with default settings of QEMU, which is a 266 MHz Pentium II (Klamath) CPU with 128 MB of RAM.
Most of the programs under test are compiled by GCC 4.3.2, and run on Glibc 2.7, which are the default in Debian 5.0. The other programs use GCC 3.4.6 and Glibc 2.3.2 to generate exploits. The default version of GCC protects the main func-tions against stack buffer overflow, and performs heap integrity checks to stop heap overflow.
We use an end-to-end approach to generate exploits on binary executables without modifying the source code. Our approach is to fork a new process to execute the program under test, and pass the symbolic data to it from the outside. Symbolic data are created by the control process and passed to the target by in-terprocess communication methods. For example, the control process maps a buffer to a file by mmap(), and make this buffer as symbolic. Whenever the target program accesses the memory mapped file (with the corresponding memory as symbolic), will start symbolic executions. Other kinds of symbolic environ-ment can be simulated in the same way.
In Debian 5.0, ASLR is enabled by default so that the based address of stack and heap is randomized. Therefore, ASLR is disabled in our experiments for generating and testing all ex-ploits except jump-to-register exex-ploits.
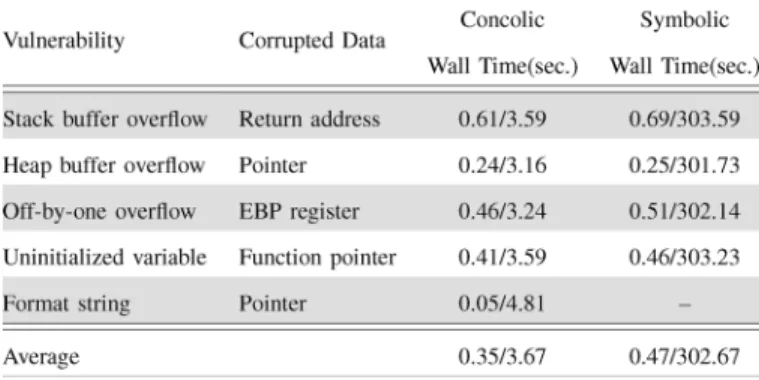
B. Sample Code
Because our method is based on detection of a symbolic EIP register, it can handle different types of vulnerabilities. In the first experiment, we design code examples for five different vul-nerabilities and four types of corrupted data, and perform au-tomated exploit generation on them. The results are shown in Table II, where the wall time is expressed by (exploit reason
time/total time).
In this experiment, the inputs of all sample codes are argu-ments, and the length of all inputs are 100 characters. We com-pare the efficiencies of concolic-mode simulation with tradi-tional symbolic execution. In symbolic execution, depth-first
TABLE III
THERUN-TIMEINFORMATION OFRERUN-TO-LIBCEXPLOITGENERATION
search (DFS) is used to explore a symbolic execution tree. The heap overflow code is executed on Glibc 2.3.2 because some protections that check pointer consistency have been included in Glibc since version 2.3.6. In addition, this exploit generation cooperates with the libfmtb library to build format strings to ex-ploit format string vulnerabilities.
In the five vulnerabilities considered in the first experiment, stack buffer overflow and uninitialized variable vulnerability corrupt the EIP register directly, and the other three vulnerabili-ties taint the EBP register or pointers to corrupt the EIP register indirectly. As the results show, the average total time is 3.67 seconds in concolic mode, and the exploit reason time is 0.35 seconds. On average, symbolic execution spent 302.67 seconds on generating an exploit, and 0.47 seconds on reasoning it out. Concolic mode was faster by about 100 times than symbolic execution because it just explored only one suspicious path. In the experiments of symbolic execution, format string vulnera-bility got an out-of-memory error because symbolic execution attempted to explore all paths in the snprintf() function, which performs a complex behavior.
C. Return-to-Libc, and Jump-to-Register Exploits
In the second experiment, we implemented return-to-libc and jump-to-register exploit generation, and the generated exploits could bypass non-executable stacks or ASLR protection.
Because return-to-libc and jump-to-register exploit genera-tion do not apply to all cases, we choose the sample code of stack buffer overflow vulnerability to conduct the experiment. Fur-thermore, the experiment was conducted on the concolic mode. In the experiment on return-to-libc exploits, we use the system() function to execute a ”/bin/sh” command. The run-time information at exploit generation is shown in Table III. The top of the stack (which is the location that stores the argument of the system() function) is symbolic, so we can manipulate the argument (which is a pointer point to the command string) so that it points to our shellcode buffer. And the potential shell-code buffers were large enough to insert the string ”/bin/sh”. Therefore, this vulnerable program satisfied all the conditions for return-to-libc exploit generation. The time spent on the exploit reason was 0.34 seconds, while the total time of this experiment was 3.25 seconds.
Table IV shows the run-time information at jump-to-register exploit generation. A call %eax instruction was found at address 0x0804839f, and the EAX register pointed to the starting lo-cation of a symbolic region exactly. Therefore, this vulnerable
TABLE IV
THERUN-TIMEINFORMATION OFJUMP-TO-REGISTEREXPLOITGENERATION
TABLE V
THERESULTS OFEXPLOITGENERATION FORREAL-WORLDPROGRAMS
WITHOUTSELECTIVEINPUT
program can generate a jump-to-register exploit to bypass the ASLR. Only 0.06 seconds were spent on reasoning out the ex-ploit while the total execution time was 3.16 seconds.
D. Real-World Programs Without Selective Symbolic Input
In the third part of the experiments, we generate exploits for real-world programs. Because real-world programs are larger and more complex than the sample code, this experiment demonstrates that our method is effective and practical in real-world applications.
We choose several programs from benchmarks of AEG, and three new vulnerable programs released in recent years, to per-form this experiment. The 16 real-world programs are evaluated by an end-to-end approach, and the vulnerabilities of these pro-grams are all stack buffer overflow. Concolic-mode simulation is used to perform exploit generation on all programs, and code selection intercept functions associating with file-related oper-ations or pure error feedback, such as fopen() and perror(), to speed up the process. Table V shows the results of 16 real-word programs.
According to the results, the time was proportional to the length of the program input because the more symbolic data that exist, the more code may perform on symbolic execution.
TABLE VI
THECOMPARISONS OFDIFFERENTOPTIMIZATIONS OFCRAX
In addition, the longer the symbolic data will bring huge, com-plex constraints, and SMT solvers must spend a lot of time on constraint solving.
To reduce the overhead of the SMT solvers and speed up the process, code selection was used to concretize arguments of irrelevant functions. In this experiment, aeon, htget, and
acon intercepted fopen(); ncompress intercepted __lxstat()
and perror(); gif2png intercepted fopen() and perror(); expect intercepted open(); rsync intercepted vsnprintf(); hsolink inter-cepted system(). Those functions related with file operations often make constraint solvers stick, and the perror() function just print error messages without return values or influencing exploit generation, so we filtered these functions to speed up the process.
In this experiment, we performed exploit generation on real-world programs, and produced exploits for those applications successfully. The results show that the worst total time was about six minutes to generate an exploit for real-world pro-grams, and the quality of exploits was good because they con-tained the longest NOP sled to increase the chances of suc-cessful attacks.
E. Constraint Optimization and Large Applications
In the ordinary concolic execution, the path constraints and the input constraint, along with the exploit constraints, are com-bined to be solved. We have tried to separate the constraint re-solving processes, with two exclusive conditions: 1) path con-straints and branch constraint, and 2) input constraint and branch constraint. The symbolic model construction process has min-imal uses of the constraint solver, and in most of the cases, con-crete value substitutions are used. We called this process the fast concolic process. After this process, along with selective symbolic input, the performance speed increase can achieve a multiple as high as 7251, as shown in Table VI. In Table VI, CRAX (raw) is the initial attempt without constraint reductions (indicated by ). CRAX(fast concolic, denoted as ), is with a
TABLE VII
THERESULTS OFEXPLOITGENERATION FORLARGEPROGRAMSWITHOUTSELECTIVEINPUT
single path concolic evaluation. CRAX(selective input, ) tries to filter out insignificant input as symbolic input.
The best speed increase between the initial CRAX and op-timized CRAX is on gif2png. , where the fast concolic speed increase is 79, and the selective input speed in-crease is 92.
In Table VII, for the case of unrar, the original time is 3958 seconds, reduced to 13.5 seconds, with 293 times faster. The selective input method cannot reduce the symbolic input space of the foxit reader in the windows platform. The exploit genera-tion process for foxit pdf reader still takes 4 hours, with the 1.8 M symbolic LOC executed, and 3.9 M constraints. It reveals that the automated process is made to symbolically resolve a large number of symbols, emulating the manual exploit writing process.
In Table VIII, we have summarized the exploit generation time for Linux and Windows platforms, and for different vul-nerability types. All are optimized with the fast concolic and selective input methods.
F. Discussions
1) Comparisons of AEG Features: With the complete
sym-bolic models supported by , CRAX uses less than 100 LOC to implement symbolic environment. And the concrete address indexed symbolic memory and selective symbolic execution are also built-in features of . We reduce the cost of failure model reconstructions by revising the KLEE symbolic executor, implementing plugins for selective code, path, and input, using about 6,000 LOC. In addition to simpler modeling, we do not make any assumptions on the failure situations. Our auto-matic exploit generation system supports various types of soft-ware crashes, including those introduced by tainted continua-tions, forged format strings, heap overflows by integer signed-ness, and uninitialized variable uses. The method is more gen-eral, without limiting the types of software vulnerability, and the recognition capability is delegated to the power of constraint solvers. The system we have developed is faster, even though the CRAX process is conducted in the whole system emulation level, compared with other methods in the process level. Our method can be at best 50 times faster than the existing systems by the selective input process (similar to the hot bytes finding process by taintscope and unique pattern generation by
metas-ploit). The detailed comparisons are listed in Table IX.
2) Impacts of AEG Development:
• Exploit generation will become a powerful bug diagnosis technique. Viewing software crash as a tainted tion, we detect exploits by producing symbolic continua-tions. That is, bug diagnosis is conducted by generating ar-bitrary process continuation to better understand the crash behaviors of various programs. Therefore, users can con-trol the crash at will, manipulate the crash to the extent of their need (e.g., able to continue execution as usual), and dynamically patch the vulnerable running service, even if the system state has been corrupted.
• Zero-day exploit generation will become an automated process for average users, similar to Metasploit [22] acting as a shell code framework for common use. Stuxnet [27] like projects for physical infrastructure attacks can be developed easier than before.
• The link between software bugs and vulnerabilities can be bridged. Because 8lgm and rootshell announced the vul-nerabilities in the form of real exploits, vulnerability is thought of as a security research topic, but few recognize that the vulnerability is closely related to software quality problems. CRAX urges an emphasis of quality assurance of released software, instead of releasing vulnerable soft-ware just for time-to-market consideration. Once crashes occur in uses of common users, an exploit is produced. • Using a software bug as a backdoor becomes feasible. A
sophisticated backdoor in a software program can be em-bedded as a symbolic continuation with a payload. We don’t need to write explicit backdoors like the trapdoored login [28]. We can embed a bug for an implicit backdoor. • Software security can be measured in terms of the software
reliability and exploitability of the failure. Software relia-bility can be modeled as the mean time between failures. Exploitability can be expressed as the difficulty to build the failure symbolic model and exploit the failures, with a cer-tain strength of mitigation strategies.
VII. RELATEDWORK
APEG (Automatic Patch-based Exploit Generation) [29] compares the differences of a program between its buggy version and a patched version, and generates the exploits to fail the added check in the patched program. This work needs a patched version of the program, and is feasible only when the