行政院國家科學委員會專題研究計畫 成果報告
投資組合風險值之改良式模糊夏普評估模型
研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 99-2410-H-151-021-
執 行 期 間 : 99 年 08 月 01 日至 100 年 07 月 31 日
執 行 單 位 : 國立高雄應用科技大學資訊管理系
計 畫 主 持 人 : 柯博昌
計畫參與人員: 碩士班研究生-兼任助理人員:曾湘玲
碩士班研究生-兼任助理人員:謝璧全
碩士班研究生-兼任助理人員:林煜順
碩士班研究生-兼任助理人員:游家林
報 告 附 件 : 出席國際會議研究心得報告及發表論文
公 開 資 訊 : 本計畫可公開查詢
中 華 民 國 100 年 10 月 31 日
中文摘要: 傳統效率前緣的求解方法,多半適用於線性模型。然而,資金
配置最佳化為複雜的 NP-hard 問題,並不適合使用傳統方式求
解。基因演算法(Genetic Algorithm, GA)的演化機制可在大量
求解空間中求算最佳值;同時,GA 編碼演算法中的實數運算
機制,可改善二元編碼機制中最佳解不易收斂甚至是過度擴散
的現象。風險值部份,投資組合風險值(Portfolio Value at
Risk, PVaR)為延伸 VaR(Value at Risk)概念以準確捕捉投資
組合下方風險,可改善傳統風險模型需假設報酬率為常態分配
之限制。本研究考量非線性情況下,使用實數(Real)編碼機
制之基因演算法,於 PVaR 限制下發展最佳資金配置模型,並
以 PVaR 取代標準差,建構改良式 Sharpe
指標-Fuzzy-like-Sharpe,追求最大化投資組合效益;同時,進一步考量運算模
型或參數設定不同,得到的投資組合權重值也不同,所以本研
究結合 Fuzzy
運算概念,建構模糊演化式資金配置(Fuzzy-GA-PVaR)模型。經由模糊化投資組合權重值以建構報酬率及風險
值區間,再透過解模糊化運算,求解最佳資金權重值。實驗結
果發現,考量 PVaR 下運用實數編碼機制所建立之
Fuzzy-GA-PVaR 模型,對於整體投資組合確實有較好的投資效益。
英文摘要: Portfolio management plays an important role to provide
decision-makers the ability to manage investments efficiently, and make their
capital allocations for each investment asset in financial markets.
These two issues concerned with portfolio are to maximize the
investment rewards and minimize possible loss. The conventional
mean-variance analysis developed by Markowitz quantifies and
predetermines risk and expected return to calculate optimal
investment weights of portfolio. It employs linear programming
method to solve a set of simultaneous equations with efficient time
complexity. However, the asset allocation optimization is complex
and NP-complete problem. Genetic algorithm (GA) has been shown
to be able to perform efficient search with population diversity in
large problem space. Furthermore, the real-coded GA (RGA)
applies real-value encoding scheme to solve unease converging and
even diverging characteristics in binary-coding scheme. The
portfolio-value-at-risk (PVAR) extends the concept of VAR
measure used for managing risks and returns under a multiple-asset
portfolio. The aim of this paper uses RGA encoding scheme to
develop an optimization capital allocation method, which could
maximize portfolio’s return under PVAR restriction. The PVAR is
further calculated by Fuzzy-like Sharpe index, which is similar to
conventional Sharpe index, but modified by fuzzy operation to
eliminate uncertainty in variable, model evaluation, and etc.
Through fuzzy-specified return and risk, the final experimental
results show that the RGA-encoded capital allocation method under
Fuzy-GA-PVAR-based portfolio could get better investment return.
行政院國家科學委員會補助專題研究計畫
▓成果報告
□期中進度報告
投資組合風險值之改良式模糊夏普評估模型
計畫類別:▓個別型計畫 □整合型計畫
計畫編號:NSC 99-2410-H-151-021
執行期間: 99 年 08 月 01 日至 100 年 07 月 31 日
執行機構及系所:國立高雄應用科技大學 資訊管理系所
計畫主持人:柯博昌老師
共同主持人:柯博昌老師
計畫參與人員:柯博昌老師、曾湘玲、謝璧全、林煜順、游家林
成果報告類型(依經費核定清單規定繳交):▓精簡報告 □完整報告
本計畫除繳交成果報告外,另須繳交以下出國心得報告:
□赴國外出差或研習心得報告
□赴大陸地區出差或研習心得報告
▓出席國際學術會議心得報告
□國際合作研究計畫國外研究報告
處理方式:除列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
中 華 民 國 一百 年 十 月 三十一 日
1 初始化族群 編碼 0 1 1 1 0 1 0 1 1 0 0 0 0 0 文字編碼 實數編碼 符號編碼 適應函數計算 是否達到 終止條件 最佳適應函數解 演化 隨機突變 均勻突變 隨機突變 單點交配 兩點交配 均勻交配 突 變 交 配 輪盤法 競爭法 菁英法 選 擇 … … … … …
一、緒論
近代投資組合理論不斷被廣泛應用於金融市場中,各金融機構皆透過組合各種金融產品的方式來進
行搭售,希望藉由建構投資組合來分散投資的風險,並獲取最大的投資效益,吸引投資者;由此可知,
對投資者而言,如何準確衡量投資組合的報酬及風險,並適當地分配投資組合權重顯得相當重要。
Markowitz 於 1952 年提出均異分析模型(Mean-Variance Model)[4],主要強調透過技術分析,探討
不同資產未來的獲利狀況,進而間接分析投資該資產的效益,奠定了投資組合的新基礎,該模型藉由整
體投資組合的總報酬及風險,來建構衡量指標;為了更完整表達資金配置效益,Markowitz 於 1959 年提
出效率前緣假說[5],在考量投資者不同的偏好下,追求風險或預期報酬相同下,最小和最大化投資組合
風險及利益的最優資產配置。於效率前緣分析中可發現:資產的數量在超過一定的數量時,每多增加一
單位資產,其風險分散的效果便相當有限;由此可知,如何在適當的資產數量下,求解最佳的投資組合
為主要關鍵。傳統求解效率前緣的方法多半應用於線性模型,當變數為非線性時,將無法捕捉到問題的
非線性特性。而 1975 年 Holland 學者提出了基因遺傳演算法[6],其演算法被證明可於大量求解空間中
尋求最佳解,因此廣為後續學者延用於投資組合中,求解最佳資金配置解。1969 年提出 Sharp 指標,用
以衡量投資組合績效,且由於其計算簡單、表達方式淺顯易懂,為後續多位學者納入投資組合中做為效
益衡量之標準[8],但其中風險衡量的方式為假設資產服從常態分配而有所限制。
本計畫將延伸投資組合風險衡量指標,使用歷史摸擬法來衡量多資產風險,並結合遺傳演算的演化
過程,建構一投資組合效益的評估模型,於準確衡量投資組合的風險及效益下,建構最佳資金配置。同
時,考量模型參數設定不同,容易造成投資權重判斷上的誤差,將進一步結合模糊理論,提出模糊演化
式資金配置模型(Fuzzy-GA-PVaR)
,詴圖透過模糊投資組合權重值及解模糊運算,求解最佳投資組合之
資金配置權重,以優化整體模型。
二、文獻探討
2.1 資金配置理論
資金配置理論主要源於投資組合均異分析模型,透過給予投資組
合中各資產不同的權重值,以建構最佳投資組合效益,即可構成一效
率前緣,然而傳統效率前緣的求解方法僅限於分析線性模型,對於非
線性問題的求解容易產生誤差。均異分析可將投資決策中無法計量的
投資風險因數予以量化,做為資金配置的依據,使投資者更能準確分
析投資標的物的狀況。為了完整表示風險和報酬間取捨下的最佳投資
組合,因此,Markowitz 於 1959 年提出效率前緣假說,追求相同風險
情況下,報酬最大化或相同報酬下,風險最小化的投資組合目標(如
圖 1)
,並透過實際分析各投資組合的效益,找出最佳的投資組合[5]。
效率前綠 投資組合變異數 (σp) E ● ● B 投 資 組 合 期 望 報 酬 率 E(Rp)圖 1 效率前緣示意圖
2.2 基因遺傳演算法
1859 年達爾文提出「物競天擇」進化論,主要闡述自然
界物種遵循「適者生存,不適者淘汰」的進化理論不斷演化之
過程,使得優良物種得以保留並延續至下一代。John Holland
於 1975 年將此最適化的過程予以發展,進而提出基因遺傳演
算法(Genetic Algorithms,GA)。GA 主要建構於數個染色體
所組成的母體上,其中透過每一世代中的染色體彼此相互競
爭,選擇最佳適應值(Fitness Value)的染色體予以保留,再
進行交配動作產生適應值更高的下一代,為避免錯過有效的資
訊,將再加入突變的處理,以有效的產出最佳適應值;其進化
過程為透過不斷繁衍及進化,產出較優的子代,因此被廣泛用
於大量求解空間中尋求最佳解[6]。整體架構如 圖 2 所示。
圖 2 基因遺傳演算法架構圖
2
2.3 投資組合風險值
早期投資組合理論中,風險值多半使用標準差做為衡量
標準,並假設報酬率服從常態分配;然而,金融市場中的報
酬率則多半為呈現偏態分配,其中 Mandelbrot(1963)及
Fama(1965)分別證實金融資產報酬率的分配具厚尾現象
(如圖 3)[1][2]。此時,若假設報酬率為常態分配,使用
標準差做為風險值,容易低估風險值,不易捕抓極端損失;
因此後續的學者研究皆針對該缺失,提出改良方式,詴圖捕
抓偏態分配下的極值損失及下方風險(Downside Risk)[3]。
α = 0.05 損失金額 機 率 值 損益分配 VaR VaR圖 3 報酬率呈現厚尾分配
2.4 投資組合效益衡量指標-Sharpe
效率前緣所建構之投資組合,僅能分析高報酬或低風險限制下之最佳投資組合,對於風險及報酬間
的關係並未多加著墨,對於投資者而言,並無法於報酬與風險間做取捨。因此,Sharpe 於 1969 年提出
夏普(Sharpe)指標概念,目的在於運用指標的概念,讓投資者瞭解每多承擔一單位風險可獲得之報酬
程度,來做投資組合的選擇;但該指標使用變異數或標準差來衡量風險,當報酬率非常態分配時,易錯
估風險,故許多學者便紛紛改良其指標中風險衡量方式,以建構完善衡量指標。
2.5 模糊理論與投資組合探究
L. A. Zadeh 於 1965 提出模糊集合(Fuzzy Set)的概念,詴圖模糊化統計模型中所表達的精確解,
探討所有解答之可能性[7];為了完整描述模糊的區間,Zadeh 提出了模糊理論來做詮譯,於考量所有不
確定性的情況下,尋求最佳的可能解。
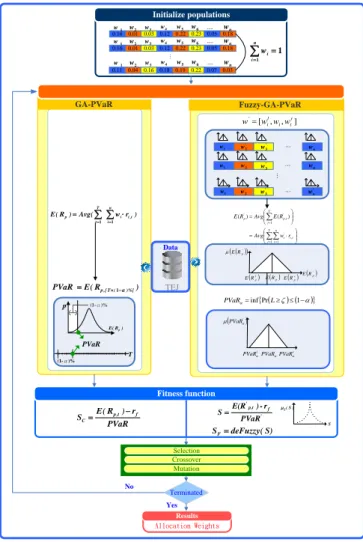
三、研究架構
3.1 研究架構
本文求解最佳權重值主要可
分
為
GA-PVaR
、
Fuzzy-GA-PVaR 兩種模型,整
體架構將於基因演算法演算
的演化機制下,求解最佳權重
值。本節將以研究架構圖(見
圖 4)來做說明。首先,各投
資標的物的權重將會先被予
以初始化,以實數編碼方式表
達於每條染色體中;接著將權
重值代入各模型中進行參數
運算,以求解各模型中所需的
參數值;再將所求之參數值放
入各模型的適應函數中,取得
各自的適應函數值後,再藉由
基 因 遺 傳 演 算 法 的 演 化 機
制,評估每條染色體的適應能
力後,選擇較優良的子代得以
延續,並透過交配及突變的過
取得最佳適應函數解,即本計
畫所求之最佳權重值。
. . . 選擇 交配 突變 終止 條件 No 最佳權重值 演化結果 Yes 0.16 0.01 0.03 0.12 0.22 0.23 0.05 0.18 0.11 0.04 0.16 0.18 0.19 0.22 0.07 0.03 PVaR r ) R ( E S p,t f C S) ( deFuzzy SF 適應函數 0.16 0.01 0.03 0.12 0.22 0.23 0.05 0.18 1 w w2 w3 w4 w5 w6 wn ) R ( E PVaR p,[T(1)%] (1-α)% ) r w ( Avg ) R ( E n i t , i i T t p 1 1 〃 1 w w2 w3 w4 w5 w6 wn 1 w w2 w3 w4 w5 w6 wn 初始化權重值 n i i w 1 1 GA-PVaR模型 ) r w ( Avg )) R ( E ( Avg ) R ( E n i t , i ' i T t T t ' t , p ' p 1 1 1 〃 n i t , i ' i ' t , p ) w r R ( E 1 〃 ) PVaR ( ' F ] w , w , w [ w i i i ' ) R ( E PVaR ' )%] ( T [ , p ' 1 資料 TEJ Fuzzy-GA-PVaR模型 參數運算 PVaR r -) E(R S ' f t p, ' )) R ( E ( ' t , p R ~ ) R ( E ' t , p ) R ( E p p … … … … PVaR ' w1 ' w2 w3' ' n w ' w1 ' w2 w' 3 ' n w ' w1 ' w2 w3' ' n w ' PVaR (1-α)% T (1-α)% T S ) S ( S ~ 圖 4 研究架構
3
表 1 研究架構符號對應表
iw
第
i
個資產的權重值
模糊化的範圍值
)
R
(
E
p投資組合 p 之期望報酬率
E
(
R
)
' p投資組合之模糊化期望報酬率
)
(
Avg
〃
取變數之平均值
E
(
R
'p,t)
投資組合 p 於第
t
期之模糊化期望
報酬率
T
投資組合觀測期間
F(
E
(
R
'p,t))
投資組合
p
於第
t
期之模糊化期望
報酬率的隸屬函數值
n
投資組合
p
全部資產數量
'PVaR
模糊化風險值集合
t ir
,i 資產於第期第 t 期報酬率
S
FFuzzy-like-Sharpe 值
信賴水準
F(
PVaR
')
模糊化風險值之隸屬函數值
)
(
R
p,[T(1)%]E
投資組合 p
於第[總期間乘上(1-信賴水準)]期之期望報酬率
)
(
R
'p,[T(1)%]E
投資組合 p 於第[總期間乘上(1-信
賴水準)]期之模糊化期望報酬率
ob
Pr
事件發生之機率
deFuzzy
(
)
取變數之解模糊化值
'w
模糊化權重值之集合
圖 4 中研究架構中的染色體編碼機制及 GA-PVaR、Fuzzy-GA-PVaR 兩種模型中,各自的參數運算、
適應函數運算,將於以下各小節詳述。由於本計畫架構圖中符號繁多,為方便以下各小節的內容解說,
在此將以列表的方式先做簡述(見表 )。
3.2 染色體編碼機制
於基因遺傳演算法中,二進元編碼機制最廣為被使用;但於投資組合資金配置中,需限制資金配置
的權重值總合為 1,使用二進位元編碼方式經由交配、突變等步驟後,並無法確保權重值總合為 1,且
經由交配、突變的演化過程,使得各基因值間的關係改變,影響基因遺傳演算法的收斂速度,甚至造成
無法收斂的狀況發生;且基因空間只能以 0、1 表示,必須使用其他種編碼方式取代。
因此本文編碼方式,將改以實數的方式表示,不同於過去常用的二進位編碼,使用實數編碼可省去
繁複的編碼、解碼過程並可表達的精確度更為完整,且可直接表示各投資資產權重值;以圖 5 為例,其
中以
C
表示某一染色體,
w 為第
ii
個投資資合資產於演算過程中的投資比例,每個
w 值為一實數,且
i整條染色體基因加總之合必須為 1,限制式如方程式(1)所示
C
w
1w
2w
3…
w
n圖 5 實數編碼權重值示意圖
R
w
,
w
,
w
,
w
w
w
1
2
3
n
1
0
i
1
i
(1)
3.3 GA-PVaR 模型運算機制
3.3.1
參數運算
運算參數部份主要可分為投資組合預期報酬率(
E
(
R
p)
)及投資組合風險值(
PVaR
)兩種。
3.3.1.1
投資組合預期報酬率
投資組合之預期報酬率,為各期投資組合預期報酬率加總之平均值來做為代表,如方程式
(2)所示:其中
E
(
R
p,t)
為各期投資組合預期報酬率,
r
i,t為每一期中各投資資產報酬率,
w
i為
資產之權重值;投資組合
p
之整體投資組合的預期報酬率(
E
(
R
p)
),為各期投資組合預期報酬
率(
E
(
R
p,t)
)加總之平均值來做為代表;其中各期投資組合預期報酬率
E
(
R
p,t)
又為各期中各投
資資產報酬率
r
i,t乘上對應之權重值
w
i之加總。
T t n i t , i i T t t , p p)
r
w
(
Avg
)
)
P
(
E
(
Avg
)
R
(
E
1 1 1〃
(2)
4
3.3.1.2
投資組合風險值
投資組合風險值(PVaR)的衡量方式有許多種,在本計畫中將使用歷史模擬法來做運算;
歷史模擬法(Historical Simulation)即假設風險變動程度會和過去相同前提下,尋求最大損失點。
假設
r
i,t為第
i
支股票於第 t 期之報酬率,其中 i=1,2,…,n 為觀測的樣本數量,t=1,2,…,T 為觀測樣
的最大時間,透過所求得投資標的物的最佳權重
w
i乘上過去各期報酬率
r
i(如方程式(3))
,即
可求算出該投資組合過去期間的各期預期投資報酬率
E
(
R
p,t)
。
t , i T j n i t , i t , p)
w
r
R
(
E
1 0〃
i
1
,
2
,
n
w
i
R
(3)
接下來,將各期報酬率依序排列,於設定的信賴水準
下尋求投資組合風險值臨界點,該
臨界值即代表整體投資組合的總風險值。假設投資組合中所有資產數量為 n ,在信賴準水準
下,其投資組合風險值(
PVaR
)如方程式(4)所示:
)
R
(
E
PVaR
p,[T(1% )](4)
其中
T
為該投資組合觀測期間,
(
1
%)
為 1-信賴水準,
T
〃
(
1
%)
為臨界點,則
PVaR
即為擷取排序後各期報酬率該臨界點之投資組合報酬率。透過圖 6 可看出各投資組合之期望報
酬率分配,將其予以排序後可得圖 7,即為倒數第
T
〃
(
1
%)
個報酬率之精確值。
(1-α%) ) R ( E p ob Pr圖 6 投資組合之期望報酬率分配
(1-α%)T
'PVaR
圖 7 PVaR 示意圖
3.3.2
適應函數(like-Sharpe)
GA-PVaR 模型的適應函數主要延伸 Sharpe 指數的概念,使用 PVaR 取代整體投資組合風險
的衡量指標。Sharpe 指數於考量資本市場與無風險利率下,探討風險與報酬間的關係;透過該
指數可看出每承擔一單位的風險可獲得的超額報酬,值愈大表示該投資組合的效益愈高;由於
Sharpe 風險衡量存在需假設報酬率為常態分配的限制,因此本計畫以 PVaR 取代標準差做為風險
衡量指標,並將改良後的 Sharpe 指數以 like-Sharpe(以
S 為代表)
C,做為染色體的適應值。如
方程式(5)所示:
PVaR
r
)
R
(
E
S
C p,t f 1(5)
3.4 Fuzzy-GA-PVaR 模型運算機制
3.4.1
參數運算
於 Fuzzy-GA-PVaR 研究模型中,延伸 GA-PVaR 模型,納入 Fuzzy 權重的概念來最佳化資金配
置。以下將針對模型中主要參數:模糊化權重值(
' iw
)
、模糊化投資組合預期報酬率(
E
(
R
')
p)及
模糊化投資組合風險值(
'PVaR
)運算過程做描述。
3.4.1.1
模糊化權重值
模糊化權重值部份,本計畫將以三角模糊函數建構模糊權重值集合;其中模糊化的範圍將
以訓練出的權重值乘上設定值做為依據,其中設定值部份可,模糊化後的權重值表示方式見方
程式(6),以表示
'w 模糊化後投資權重值集合,該集合範圍為第 i 個投資資產權重值(
w )加
i減模糊化的範圍值(
)所構成;以圖示方式表達見錯誤! 找不到參照來源。所示,其中假設
w
i表示第 i 個資產的投資權重,模糊化的過程為
w
i
w
i
,其中
0
1
,模糊化後的
(
w
')
為
'w 集
合中個元素值的隸屬函數值,
' lw
為模糊化權重值的左邊界,
' rw 為模糊化權重值的右邊界,整體
5
構成之模糊函數為一正規化三角模糊數。
]
w
,
w
,
w
[
w
'
i
i i
(6)
) w ( ' w~' ' w ' i w i i i w ) ( w w 1 i i i w ) ( w w 1 ' r w ' l w圖 8 模糊權重值(
' iw
)示意圖
) w ( ' F 'w
iw
1圖 9 修正模糊權重值(
w
i)示意圖
但是,
' rw 的值可能會大於 1,如果發生大於 1 的情況,那麼圖形將修正為錯誤! 找不到參照來
源。。
即取
' rw 和 1 之最小值,如方程式(7)所示,修正後圖形如圖 10 所示。
otherwise
,
w
w
,
)
,
w
(
Min
' r ' r ' r1
1
1
(7)
(w' ) w~' ' w ' i w Min(w' , ) r 1 ' l w圖 10 修正後模糊權重值(
' iw
)示意圖
3.4.1.2
模糊化投資組合預期報酬率
模糊化投資組合
p
預期報酬率
E
(
R
'p)
為各期投資組合預期報酬率加總之平均值來做為代
表,如方程式(8)所示。
)
r
w
(
Avg
))
R
(
E
(
Avg
)
R
(
E
n i t , i ' i t j t j ' t , p ' p
1 1 1〃
(8)
其中
(
')
,t pR
E
為各期模糊化投資組合預期報酬率,
r
i,t為各期投資資產報酬率,為
' iw
第 i 個資
產之模糊化權重值。各期投資組合預期報酬率
(
')
,t pR
E
為各期中各投資資產報酬率
r
i,t乘上對應之
模糊化權重值
' iw
之加總。
各期模糊化投資組合預期報酬率
(
')
,t pR
E
相加運算如方程式(9)所示:
))
R
(
E
)
R
(
E
),
R
(
E
(
)
R
(
E
[
))
R
(
E
),
R
(
E
(
))
R
(
E
),
R
(
E
(
r , , p r , , p l , , p l , , p r , , p l , , p r , , p l , , p 2 1 2 1 2 2 1 1
(9)
各期投資組合預期報酬率取平均值後即為
E
(
R
'p)
,其模糊數圖形如圖 11 所示。其中
E
(
R
p',l)
為投資組合
'p 之模糊化報酬率集合之左邊界,
E
(
R
'p,m)
為投資組合
'p 之模糊化報酬率集合之中心
點,
E
(
R
'p,r)
為投資組合
'p 之模糊化報酬率集合之右邊界。
)) R ( E ( ' p F ) R ( E ' l , p ) R ( E ' m , p E(R' ) r , p ) R ( E ' p圖 11 投資組合
E
(
R
p)
之模糊化期望報酬
3.4.1.3
模糊化投資組合風險值
模糊化投資組合風險值
'PVaR
為將
E
(
R
')
t , p排序後,於設定的信賴水準
下尋求投資組合風
6
險值臨界點,該臨界值即代表整體投資組合的總風險值。假設投資組合總數量為 n,在信賴準水
準
下,其模糊化投資組合風險值(
'PVaR )如方程式(10)所示:
)
R
(
E
PVaR
'
'p,[T〃(1% )](10)
其中
T
為該投資組合觀測期間,
(
1
%)
為 1-信賴水準,
T
〃
(
1
%)
為臨界點,則
'PVaR
即
為擷取排序後之投資組合報酬率該臨界點的模糊化投資組合報酬率。如
圖 12 所示,
'PVaR
為一區間值。
(1-α%)T
'PVaR
圖 12 模糊化風險值(
'PVaR
)示意圖
) PVaR ( ' F ' PVaR ' m PVaR ' l PVaR ' r PVaR圖 13 投資組合之期望報酬率分配
'PVaR 之模糊數表示方式見
圖 13,其中
' lPVaR 為
'PVaR 之左邊界值,
' mPVaR 為
'PVaR 之中心點,
' rPVaR 為
'PVaR 之右
邊界值,
(
PVaR
')
F
為
'PVaR 之隸屬函數。
3.4.2
模糊適應函數(Fuzzy-like-Sharpe)
Fuzzy-GA-PVaR 模型中模糊適應函數的求解主要可分為兩個流程,第一步為計算適應函數
(Fuzzy-like-Sharpe)之模糊函數,其中需要經由除法運算來求解;第二步為解模糊化,本計畫將
以重心法求解適應函數之模糊函數,將其集合解轉換為一具代表整體集合之精確值,用以代表整體
投資組合之最佳權重值。以下將針對 Fuzzy-like-Sharpe 之模糊數運算及解模糊化過程做詳述。
3.4.2.1
Fuzz-like-Sharpe 之模糊數運算
Fuzzy-GA-PVaR 模型之適應函數亦延伸 Sharpe 指數的概念,使用模糊化風險值(
'PVaR )
取代標準差做為風險衡量指標,並將改良後的 Sharpe 指數以 Fuzzy-like-Sharpe 為代表,做為染
色體的適應值。如方程式(11)所示:
S
代表
Fuzzy
like
Sharpe
之集合,
E
(
P
p',t1)
為模糊
化之投資組合預報酬率,
r
f為無風險利率。
PVaR
r
)
R
(
E
S
f ' t , p(11)
)]
R
(
E
/
)
R
(
E
),
R
(
E
/(
)
R
(
E
),
R
(
E
/
)
R
(
E
),
R
(
E
/(
)
R
(
E
(
Max
)),
R
(
E
/
)
R
(
E
),
R
(
E
/(
)
R
(
E
),
R
(
E
/
)
R
(
E
),
R
(
E
/(
)
R
(
E
(
Min
[
))
R
(
E
),
R
(
E
/(
))
R
(
E
),
R
(
E
(
' r , , p ' r , , p ' l , , p ' r , , p ' r , , p ' l , , p ' l , , p ' l , , p ' r , , p ' r , , p ' l , , p ' r , , p ' r , , p ' l , , p ' l , , p ' l , , p ' r , , p ' l , , p ' r , , p ' l , , p 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 2 1 1
(12)
其中模糊函數的除法運算如方程式(12)所示,為簡化方程式之表達,其中將以
A
、
B
分
別代表第 1、2 期之模糊化投資組合報酬率集合(
E
(
R
'p 1,)
、
E
(
R
'p 2,)
)。由於本計畫之模糊函數為
一正規三角函數,因此新模糊函數的中心點即為左右邊界之平均值。
經由運算後所求之
Fuzzy
like
Sharpe
集合(
S
)圖示如圖 14 所示,其中
S 、
lS 、
mS 分
l別為
Fuzzy
like
Sharpe
之左邊界、中心點及右邊界。
) S ( F m S l S Sr S
7
圖 14 Fuzzy-like-Sharpe 之模糊函數
該函數之隸屬函數如方程式(13),其中
S 為
iS
集合中第
i
個元素,
S~(
S
)
為第
i
個元素之隸屬
函數值。
l i r i r i m r m r r m i m i l l m l l m i S ~S
S
or
S
S
,
S
S
S
,
S
S
S
S
S
S
S
S
S
,
S
S
S
S
S
S
)
S
(
0
(13)
r l r l S S i i S~ S S i i i S~ F)
S
(
S
)
S
(
S
〃
(14)
3.4.2.2
Fuzzy-like-Sharpe 之解模糊化運算
解模糊化公式如方程式(14)所示,L 為所有可能之首先將集合中所有可能元素值代入模
糊函數中求解各元素之隸屬函數值後,乘上各元素值除上各元素之隸屬函數值。即可求得整體
模糊函數之重心值(最佳適應函數值)
。
四、實驗設計與結果
4.1 樣本選取與資料來源
本計畫實驗資料取樣依據為使用 TESC(Taiwan Stock Exchange Corporation,臺灣證券交易所)2007
年 12 月 15 日所公佈的台灣五十指成份股為樣本來建構投資組合,主要考量各公司的股價報酬率來配置
資金權重;各樣本資料以月為單位,期間為 2002 年 1 月至 2006 年 12 月止,其中剔除月報酬率資料不
滿五年,即資料嚴重缺漏值之樣本,完整可供分析研究的樣本共計 36 間公司,總樣本資料為 2160 個股
價月報酬率,資料來源為台灣經濟新報資料庫(Taiwan Economic Journal database;TEJ)。
4.2 實驗環境
本計畫實驗中,軟體部份將於作業系統 Windows XP 下進行,以 Matlab 2008 為主要實驗工具,所
使用的工具箱為 Genetic Algorithm。藉由 Matlab 運算能力,於大量求解空間中,求算最佳值,同時,結
合 Excel 2003 來分析、彙整樣本資料及運算結果。
4.3 實驗設計
本實驗將以模糊演化式所建構之資金配置模型,藉由台灣五十指建構之成份股的各別股市資訊進行
驗證。本節將依序介紹實驗期間、實驗參數、各期風險值運算及實驗設計。
4.3.1
實驗期間
以月報酬率為單位,本計畫總樣本期間為 2002 年 1 月至 2007 年 12 月, 2002 年 1 月至 2006
年 12 月做為訓練期間,2007 年 1 月至 2007 年 12 月為測詴期間。訓練及測詴期間劃分如圖 14 所
示。
2007/1~2007/12 2002/1~2006/12 訓練 測詴 2002 …… 1 2007 1 2 3 2 3 …… 12圖 14 訓練及測詴期間
4.3.2
實驗參數設定
於模糊理論演化機制模型中,建構最佳資金配置模型之相關 GA 參數設定詳見表,Fuzzy 參數
設定見表,其中交配率及突變率的設定將依 Srinivas(1994)所實證之分析結果:當群體大小為 30
時,交配率設定為 0.9,突變率設定為 0.01,為較好的設。
表 2 GA 參數設定
參數名稱
參數設定
代數
144
表 3 Fuzzy 參數設定
參數名稱
參數設定
模糊函數
三角模糊數
8
族群大小
36
染色體長度
36
選擇
競爭法
交配率
0.9
交配點
兩點交配
突變率
0.01
模糊化範圍
各權重值 × 0.5
解模糊
重心法
4.3.3
各期風險值(PVaR)運算
承如圖 15 所述,本計畫中投資組合風險值將採用歷史模擬法,為考量於測詴期間風險值估算
正確性,將動態納入各樣本於的月報酬率,以確實評估各投資組合之風險。研究中,樣本資料切割
為「訓練五年,測詴一年」
,透過 2002 年到 2006 年資料訓練最佳權重後,納入 2007 年各月報酬率
資料,計算 2007 年各月份之報酬率;投資組合總風險值部份將透過視窗的移動,動態納入最新月
份之報酬率為樣本做為風險值衡量之依據。
樣本外資料樣本外資料 樣本外資料 樣本內資料 訓練 測詴 … 2002 …… 1 2007 1 2 3 2 3 …… 12 樣本外資料樣本外資料 樣本外資料樣本外資料 樣本內資料 樣本內資料 樣本內資料圖 15 投資組合風險值衡量之移動視窗
4.3.4
實驗設計
為驗證本計畫建立之模型效益,本計畫實驗將針對二個方面,各自驗證內容如下:
4.3.4.1
訓練期間:
分析最佳的訓練期間,即分析不同訓練期間下其投資組合報酬率,驗證資金配置模型的較適訓
練期間。
4.3.4.2
效益分析:
考量金融資訊誤差下,納入模糊理論以最佳化資金配置模型,以改良後的 Sharpe 為基準,以傳
統 MV 模型、未模糊化之 GA-PVaR 模型與 Fuzzy-GA-PVaR 模型做比較。
4.4 實驗結果與分析
本計畫的實驗目的為驗證模糊演化式資金配置模型之效益。驗證實驗部份將針對訓練期間、效益分
析做探究,其中效益分析又可再依據不同信賴水準來做探究。實驗結果如下。
4.4.1
訓練時間長短
本實驗為分析訓練期間的長短對於投資組合權重值所造成的影響;由於實驗中的權重值皆由
GA 根據過去的資料訓練而得,而過去訓練時間的長短是否對權重值的結果有影響,將是本小節實
驗的重點。實驗期間分為五年、三年、一年,並經由訓練出來的權重代入測詴樣本,檢視訓練期間
長短對於資金配置的影響,進而推論出最適訓練期間;為檢定驗證結果之穩定性,將以年平均報酬
率及測詴十次之平均報酬率做比較。
年平均報酬率
以不同的測詴期間訓練出的權重值,代入 2007 年 1 月~12 月份測詴資料,求得之投資組合
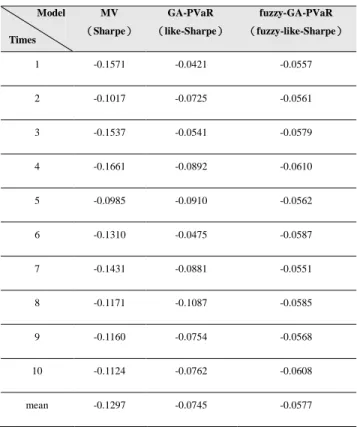
效益分析如表 1,透過表格中最後一列(平均)可發現,訓練五年之報酬率較訓練三年及一年佳,
由此可知,訓練時間較長,其資金配置效益愈佳,整體投資組合效益愈好。
表 1 投資效益表(以月為單位)
9
訓練五年
訓練三年
訓練一年
平均值
0.0234
0.0227
0.0159
測詴十次之年平均報酬率
為驗證其穩定性,將以年為單位重覆詴驗,結果如表 2 所示;透過表 2 中平均值可發現訓
練時間愈長,所獲得之投資組合報酬率愈佳,訓練五年所獲得之投資組合報酬率普遍愈高。也
就是說,當訓練時間愈長,可取得較確切的資金配置結果。
表 2 投資效益表(以年為單位)
訓練五年
訓練三年
訓練一年
平均值
0.0234
0.0227
0.0159
4.4.2
效益分析
本小節實驗將依據 4.4.1 小節分析之結果,設定訓練期間為五年、以年平均值為單位、實驗次
數為十次,來探討各模型的效益;模型部份主要分為 MV 模型、GA-PVaR 模型、Fuzzy-GA-PVaR
模型三種模型進行比較,並考量投資者風險偏好的不同下,設定不同信賴水準來檢視模型分析的效
益。以下將分別設定各模型於信賴水準為 90%、95%、99%下,各別投資組合效益做分析,最後,
再求每個實驗的平均值,綜合比較不同信賴水準下各模型分析的結果。
4.4.3
綜合比較
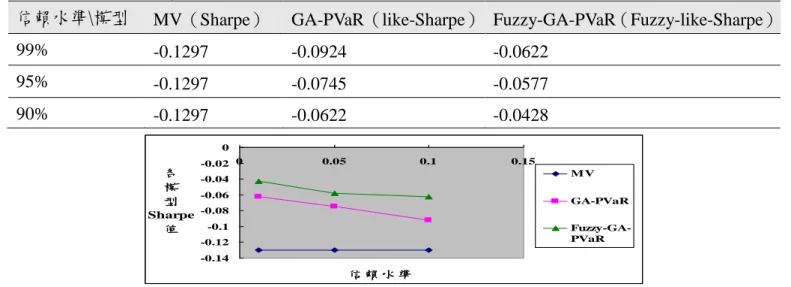
綜合於不同的信賴水準下各模型的比較,從表 1 中可發現整體 like-Sharpe 值由高到低分別為
Fuzzy-GA-PVaR 模型、GA-PVaR 模型、MV 模型;其中又以 Fuzzy-GA-PVaR 模型的數據較其他模
型來得高, MV 模型的 like-Sharpe 最低。經由圖形化呈現各數值變化可發現,GA-PVaR 模型、
Fuzzy-GA-PVaR 模型可根據信賴水準的不同而建構最佳資金配置,其中又以 Fuzzy-GA-PVaR 模型
的資金配置效益最佳。
表 3 各模型資金配置效益綜合比較
信賴水準\模型
MV(Sharpe)
GA-PVaR(like-Sharpe) Fuzzy-GA-PVaR(Fuzzy-like-Sharpe)
99%
-0.1297
-0.0924
-0.0622
95%
-0.1297
-0.0745
-0.0577
90%
-0.1297
-0.0622
-0.0428
-0.14 -0.12 -0.1 -0.08 -0.06 -0.04 -0.02 0 0 0.05 0.1 0.15 信賴水準 各 模 型 Sharpe 值 MV GA-PVaR Fuzzy-GA-PVaR圖 16 各模型資金配置效益綜合比較圖
綜合上述實驗結果可發現,建構模糊演化式資金配置模型(Fuzzy-GA-PVaR)的訓練期間愈長對於
整體權重值訓練結果較好,且整體投資組合報酬較好。於效益分析部份可發現,使用 Fuzzy-GA-PVaR 模
型建構之資金配置效益於信賴區間 90%、95%、99%下,效果皆優於 MV 及 GA-PVaR 兩種比較模型,
由此可知,使用 Fuzzy-GA-PVaR 模型所建構之資金配置模型之效益較其他兩種模型來得好。
此 外 , 透 過 實 驗 中 設 定 不 同 信 賴 水 準 下 , 進 行 資 金 配 置 的 結 果 可 發 現 , GA-PVaR 模 型 及
Fuzzy-GA-PVaR 模型可依據使用者偏好的不同,調整信賴水準的設定,以建構最佳資金配置策略,但
MV 模型卻無法依使用者偏好來做設定,即無法根據使用者對於風險偏好的差異來做調整;同時,在信
賴水準 99%下,其投資者為風險趨避者,其所獲得之投資組合報酬率應較低;而在信賴水準 90%下,其
10
投資者為風險愛好者,其獲得之投資組合報酬率應較高,經由實驗結果亦可證明此現象。整體而言,模
糊演化式資金配置模型(Fuzzy-GA-PVaR)可提供給投資者制定資金配置策略時較佳的參考,同時可針
對投資者對於風險的偏好不同下,提供適當的投資策略。
五、結論與建議
傳統投資組合中,由於整體風險值估算及資金配置運算易受資產數量限制;其中風險值估算部份尚
需假設報酬率服從常態分配的限制,容易使得整體投資組合風險易被低估;然而運用基因遺傳演算法最
佳化投資組合資金配置,雖可使得整體報酬最大化,但資產數量過多時,使用傳統字串編碼,易花費大
量的時間於編碼及解碼上的運算。因此,於傳統投資組合模型中,易受到投資標的物數量及分配限制,
而無法準確提供投資者良好的資金配置決策。
本計畫結合基因遺傳演算法可於大量求解空間中,求算最佳解的特性,使用實數編碼,並納入 PVaR
的概念,使用歷史模擬法計算風險值,提出 GA-PVaR 模型,希望可在簡化投資組合資金配置運算下,
同時正確衡量整體投資組合風險值;該模型延伸了 Sharpe 指標的應用,使用 PVaR 值取代變異數,用以
衡量整體所建構之投資組合效益,以追求承擔單位風險下最大化整體投資組合報酬。經由實驗結果發
現,考量整體投資組合風險下,使用 PVaR 運算其獲得之投資組合效益確實優於其他模型,亦即 GA-PVaR
模型優於傳統投資組合。
透過實驗結果可得知於 GA-PVaR 模型納入模糊運算的概念,可使得整體實驗結果較其他模型佳,
使用 Fuzzy-GA-PVaR 模糊進行資金配置,可獲得較佳的效果;同時,Fuzzy-GA-PVaR 模型除了可正確
捕捉完整下方風險外,亦可根據使用者的風險偏好來制定合適的資金配置策略,對於投資者在做資金配
置時,可提供良好的參考。
模糊演化式資金配置模型可改善傳統資金配置模型無法捕捉非線性問題的風險,其中不需假設報酬
率為常態分配,即可完整衡量投資組合風險,並於追求 Fuzzy-like-Sharpe 指標最大下,建構最佳的資金
配置策略;可依投資者對於風險的偏好程度,提供適合投資者的投資策略。
經本計畫歸納及整理後,若後續進行相關研究時,可納入選股策略,直接保留較佳之投資標的物進
行分析;同時,可使用不同的風險值計算模型或參數設定,來探究不同方法及參數設定下,對於整體投
資組合效益的影響,或納入其他解釋變數,如行為財務或整體環境走勢…等,來完善整體模型架構;甚
至,可考量不同金融商品及相關限制下,來建構不同投資標的物之投資組合資金配置模型,此外,權重
值部份更可納入移動視窗來動態調整。
六、參考文獻
[1] B. Mandelbrot, 1963, “The Variation of Certain Speculative Prices”, Journal of Business, Vol. 36, pp.
294-419,.
[2] E. F. Fama, 1965, “The Behavior of Stock Market Prices”, Journal of Business, Vol. 38, pp. 34-105.
[3] G. Alexander, A. Baptista, 1999, “Value at risk and mean-variance analysis”, Working paper, University of
Minnesota.
[4 ] H. Markowitz, 1952, “Portfolio selection”, Journal of Finance, Vol. 7, pp. 77-91.
[5] H. Markowize, 1959, “Portfolio Selection: Efficient Diversification of Investments”, Wiley, New York,.
[6] J. H. Holland, 1975, “Adaptation in Natural and Artificial Systems”, University of Michigan Press: Ann
Arbor, MI.
[7] L. A. Zadeh, 1975, “The concept of a linguistic variable and its application to approximate reasoning – I”,
Information Science, Vol. 8, pp. 199-249.
行政院國家科學委員會補助國內學者參與國際學術會議報告
100 年 4 月 25 日
報告人姓名
柯博昌
服務機構
高雄應用科技大學資管系職稱
教授