動態精細分工異質雙核心排程器的設計與分析
111
0
0
全文
(2) Design and Analysis of a Dynamic Fine-Granularity Task Scheduler for Heterogeneous Dual-Core Platforms 研 究 生:李國丞. Student:Kuo-Cheng Lee. 指導教授:蔡淳仁. Advisor:Chun-Jen Tsai. 國 立 交 通 大 學 資 訊 科 學 與 工 程 研 究 所 碩 士 論 文. A Thesis Submitted to Institute of Computer Science and Engineering College of Computer Science National Chiao Tung University in partial Fulfillment of the Requirements for the Degree of Master in Computer Science June 2006 Hsinchu, Taiwan, Republic of China. 中華民國九十五年七月 動態精細分工異質雙核心排程器的設計與分析. 2.
(3) 摘要 本論文主旨在於設計和分析非對稱式多核心平台上動態精細分工排程器的 效能。當系統平台上有著多顆不同類型的處理器,並且以某一處理器為控制整個 系統的依據,即為非對稱式異質多核心平台。通常在這種平台上,因為處理器架 構不同,所以一個程式的各個程序必須事先決定好要在那一個處理核心執行,而 預先編成該核心的執行碼,而不是動態決定每一個程序要在那一個核心執行。為 了增進複雜的嵌入式系統效能,過去我們曾提出一個能讓應用程式中的關鍵程序 在執行時才動態決定要在那個處理核心執行的架構[1][22][24]。本論文的主要目 標則是將這樣的一個作業系統核心實作出來。另外,為了能動態地把一個程序分 配給不同指令集的處理核心執行,本論文也設計了一個解決方案。 整個系統的實作是以 eCos 為基本作業系統;在其 kernel 內加入一個 Dispatcher,藉由該 Dispatcher 監控各核心工作的負載,動態即時地分配工作。實 驗所用的平台為 TI 的 OMAP 5912 OSK 發展平台。OMAP 5912 OSK 處理器採用 ARM (RISC 核心) 和 C5510 (DSP 核心) 的雙核心架構.。在本論文設計的系統中, 由 ARM 負責執行 Dispatcher,針對每一個註冊為雙核心的工作,進行動態分配, 透過這兩種不同類型的處理器的密切合作, 來達到更高的效能。另外,本論文所 提出的新的程式設計模式及作業系統 API,也讓使用者對於應用程式只需做最少 的修改,便能充分利用異質雙核心平台的能力,提高應用程式移植的便利性。. 3.
(4) Abstract In this thesis, we have implemented a dynamic fine-granularity task scheduler for heterogeneous dual-core platforms. The target platform contains more than one heterogeneous processor cores and one of them controls the whole system. For a platform which contains heterogeneous processor architecture, application designers typically solve the task partition problem during development time. Since the applications are statically partitioned, subtasks of an application can not be dynamically scheduled across processors at run-time. In order to increase performance of complex multi-tasking embedded systems, we have proposed a dynamic runtime scheduling architecture [1][22][24]. In this thesis, a system that realizes this vision is implemented. Furthermore, we have designed a solution that solves the problem of dynamically executing a function on two processor cores of different instruction set architecture. The system is based on the eCos embedded operating system. A new dispatcher is added to the eCos kernel to monitor the runtime loading of each processor and dispatch tasks accordingly. The dual-core platform used for system implementation is the TI OMAP 5912 OSK development board with an ARM core (RISC) and a C5510 core (DSP). The ARM core is in charge of running the dispatcher and the main application threads. For each function call that is registered as a dual-core module, the dispatcher will dispaches it either to ARM or DSP on-the-fly.Through the proposed tightly-coupled cooperation approach, the propsed system can achieve higher performance, especially when multiple applications are running on the platform. We also proposed a new programming model and a system API to facilitate porting of a. 4.
(5) regular software to take advantage of the heterogeneous dual-core platform.. 5.
(6) 章節目錄 1.. 簡介 ....................................................................... 11. 2.. 相關研究 ...............................................................14. 2.1. 2.2. 2.3. 2.4. 2.5. 2.6.. 多核心平台排程演算法..................................................................................14 對稱式多核心平台與非對稱式多核心平台..................................................16 同質多核心平台系統下的非對稱式排程......................................................18 動態式分工及排程..........................................................................................20 共享資源控制..................................................................................................21 靜態式分工......................................................................................................23. 3.. 理論與實作背景 ...................................................25. 3.1. 3.2.. OMAP 5912 Application Processor.................................................................25 OMAP 5912 Starter Kit:OSK 5912 (OMAP 5912 OSK) .............................30. 3.3. eCos..................................................................................................................31 3.3.1. eCos Overview.............................................................................................31 3.3.2. Configure Tool .............................................................................................32 3.3.3. Component...................................................................................................32 3.3.4. HAL .............................................................................................................34 3.3.5. The Kernel ...................................................................................................38 3.3.6. RedBoot .......................................................................................................44. 4.. eCos至OMAP 5912 OSK的移植方法.................47. 4.1. 4.2. 4.3.. 搜集硬體資料..................................................................................................48 eCos configtool使用方法 ................................................................................49 系統修改..........................................................................................................53. 4.3.1. 4.3.2. 4.3.3. 4.3.4. 4.3.5. 4.3.6. 4.3.7. 4.3.8. 4.3.9.. har_arm9.cdl ................................................................................................53 hal_cache.c...................................................................................................53 basetype.h.....................................................................................................54 mtl_OSK5912_rom.h...................................................................................54 Osk5912_misc.c...........................................................................................55 hal_arm_arm9_omap5912.cdl / hal_OSK5912.cdl......................................56 Omap5912.h.................................................................................................57 hal_omap5912_setup.h / hal_platform_setup.h ...........................................57 hal_platform_ints.h ......................................................................................58 6.
(7) 4.3.10. omap5912_redboot_comds.c / OSK5912_redboot_comds.c.......................58 4.3.11. omap5912_diag.c / hal_diag.h .....................................................................59 4.3.12. OSK5912_misc.c .........................................................................................59 4.3.13. Plf_io.h.........................................................................................................59 4.3.14. plf_stub.h .....................................................................................................60 4.3.15. Redboot_ROM-net.ecm ...............................................................................60 4.3.16. ser_omap5912.cdl ........................................................................................61 4.3.17. devs_eth_OSK5912.inl ................................................................................62 4.3.18. OSK5912_eth_drivers.cdl............................................................................64 4.4. Redboot 移植完成 ..........................................................................................64. 5.. 異質雙核心動態分工排程器實作 .......................65. 5.1. 5.2.. Scheduler API ..................................................................................................66 Service Registrar和Core Service Table ...........................................................69. 5.3. Dispatcher ........................................................................................................69 5.3.1. Task Dispatcher............................................................................................71 5.3.2. Task Terminator ...........................................................................................73 5.3.3. Loading Tables.............................................................................................73 5.4. 雙核心溝通方法..............................................................................................74 5.5.. DSP API ...........................................................................................................77. 6.. 實驗結果 ...............................................................78. 6.1. 6.2. 6.3. 6.4. 6.5.. 實驗環境..........................................................................................................78 動態排程實驗..................................................................................................79 相異處理器實驗..............................................................................................81 相異bit rate實驗 ..............................................................................................85 DSP delay實驗.................................................................................................87. 7.. 結論與展望 ...........................................................91. 8.. 參考文獻 ...............................................................93. 9.. 附錄 .......................................................................95. 9.1. 9.2. 9.3. 9.4. 9.5.. 附錄 1: configtool使用流程 ............................................................................95 附錄 2: Register 修改 .....................................................................................98 附錄 3: Interrupt vector 修正 .......................................................................103 附錄 4: 應用程式測試 .................................................................................106 附錄 5: 需修改的系統檔案 .........................................................................109 7.
(8) 9.5.1. 9.5.2. 9.5.3. 9.5.4. 9.5.5.. Flash...........................................................................................................109 Ethernet ......................................................................................................109 Serial port...................................................................................................109 HAL ........................................................................................................... 110 ARM 926EJS ............................................................................................. 111. 8.
(9) List of Figures Figure 1. Figure 2. Figure 3. Figure 4. Figure 5. Figure 6. Figure 7. Figure 8. Figure 9. Figure 10. Figure 11. Figure 12. Figure 13.. OMAP 5912 功能區塊圖 ........................................................................26 OSK 5912 正視圖...................................................................................30 eCos系統區塊圖......................................................................................34 HAL 啟動流程圖 ...................................................................................36 Kernel啟動程序.......................................................................................39 MLQ排程器運做圖.................................................................................40 Bitmap排程圖運做圖..............................................................................41 RedBoot ROM monitor 特徵區塊圖......................................................46 Redboot開機畫面 ....................................................................................64 系統架構..............................................................................................66 一般單核心 idct函數的使用方法......................................................67 HMP scheduler下 idct使用方法.........................................................68 Dispatcher架構圖 ................................................................................70. Figure 14. Figure 15. Figure 16. Figure 17. Figure 18. Figure 19. Figure 20. Figure 21. Figure 22. Figure 23.. Loading table .......................................................................................74 Parameter table.....................................................................................76 configtool 1 ..........................................................................................95 configtool 2 ..........................................................................................96 configtool 3 ..........................................................................................96 configtool 4 ..........................................................................................97 範例程式: hello.c...............................................................................106 範例程式: serial.c ..............................................................................107 範例程式: simple-alarm.c..................................................................107 範例程式: twothreads.c .....................................................................108. 9.
(10) List of Tables Table 25. Table 26. Table 27. Table 28.. 新增Register ............................................................................................98 新增Register ..........................................................................................102 修改interrupt vector...............................................................................103 新增interrupt vector...............................................................................104. 10.
(11) 1. 簡介 在街頭上,隨處可見用手機在聊天談事情的人們;或是掛著耳機,利用 mp3 播放器在聆聽音樂的青少年;上班族也幾乎用 PDA 取代了以往紙本記事的習 慣。如此廣大流行的手持式裝置,如今越來越擴展它的應用層面,例如手機支援 百萬像素的拍照功能,使手機也有了數位相機的能力;3G 的影像電話功能,不 只是對話,也能同時看到對方的表情,讓遠距溝通變得更生動;mp3 播放器的 文字瀏覽,秀圖系統甚至影片播放功能,令單純聽音樂的 mp3 播放器提高其附 加價值,搖身一變成為微形的數位娛樂中心;另外 PDA 的衛星定位導航功能, 打破了我們一向認為 PDA 只不過是個可以帶著走的超小型桌上電腦的既有想 法,發揮了在移動力上的特性。相信未來必定會推出更強大更高品質的應用,使 得嵌入式系統的複雜度迅速地提升,相對的嵌入式系統的工作效能也必需提高。 為了諸如此類眾多新的功能,以多媒體應用來說,嵌入式系統必需完成極大 量的多媒體資料處理工作;換句話說,嵌入式系統要在相同甚至更短的時間內, 處理更大量的資料,做更多的運算工作。提高嵌入式系統的能力是必要的。就過 去電腦系統的發展史來看,提高系統的能力不外乎是提高處理器的能力為主,而 處理器的能力就直接關係到它每秒可以運算的次數,每秒可以執行的計算量,亦 即處理器的頻率。然而目前利用此一概念發展的單一核心嵌入式平台己不敷使 用。 考慮手持裝置的特性:輕巧以及移動力佳。嵌入式平台便有了體積上的限 制,其中便影響到一個重要的耗電量的問題。體積上的考量,手持裝置無法配置 大容量大體積的電池,同時顧及其移動的特性,也無法接受一再需要補充電力的 要求。提高核心頻率會消耗大量電力,這一點會成為嵌入式平台的致命傷,再者, 高核心頻率相伴而來的是產生許多的熱量,散熱方面也是一個難題。在現今市場 上,整體行動裝置效能的提升不是利用提高核心頻率的方法,而是以增加核心數. 11.
(12) (處理器數量)來平衡高核心頻率需求及大耗電量和高熱能產生的缺點。這種多個 處理器的架構,我們稱之為多核心架構(multiprocessor architecture)。 事實上,異質多核心架構(heterogeneous multiprocessor architecture)在嵌入式 系統的發展己被業界廣泛地使用,例如德州儀器公司的 OMAP(Open Multimedia Application Platform),以及 Freescale 的 MXC。在非對稱式多核心系統晶片 (system-on-chip: SoC)架構裡,會有顆一般功能的處理器(general purpose processor: GPP)核心,做為嵌入式系統作業系統的控制核心,配上一顆數位訊號處理器 (digital signal processor: DSP)核心。DSP 可以大量即時處理多媒體資料,如 MPEG 1、MPEG 2、MPEG 4 或是音訊資料等等。以德州儀器公司的 OMAP 5912 OSK (OMAP Starter Kit)為例 [1],其 GPP 採用 ARM 公司 ARM926EJS,DSP 則是德 儀自行研發的 TMS320C55X。研發人員可以依照資料處理的性質,將工作分配 給 OMAP 架構微處理器中的 ARM 微處理器或者是 DSP 微處理器去處理。非對 稱式多核心架構可有效率利的處理嵌入式系統上的工作(task),發揮系統的最大 效能,特別是對於多媒體的應用程式有令人亮眼的表現。 現存的即時作業系統(real-time operating system)對於非對稱式多核心架構大 部份是採用靜態式分工(statically partitioned)的方法。所謂靜態式分工方法是系統 設計時研發人員就做好工作的分配,屬於控制流程的工作就交由 GPP 執行,屬 於多媒體運算處理的工作多交由 DSP 執行。在這種分工架構之下,有兩個不同 的 schedulers 為兩顆核心獨立運行已分配好的工作。換句話說,兩顆核心各自處 理已分配好份內的工作,完成之後,在下一個工作來臨之前是閒置的狀態,因為 在獨立的視野裡,已是最好的效能發揮。這類型的分工方式在傳統行動通訊平台 及應用程式環境下是相當有效的法。過去常用的 GPP 核心在特殊工作處理的功 能性和速度都有所不足,意即 GPP 沒辦法勝任 DSP 的工作。並且過去的嵌入式 應用程式環境通常是單純的前景/背景(foreground/ background)工作模式,所以不 需用到複雜的動態排程。. 12.
(13) 但是新一代多媒體應用會拓展到更寬廣的層面,再加上硬體裝置上有了新的 提升。首先,多媒體應用程式已經複雜到一個境界,為了提升系統效能和減低能 量的消耗,必需用動態調整兩顆核心的工作量取代系統設計時做好的工作分配。 其次是 GPP 的能力已被大幅提高,可以幾乎和 DSP 等速地處理某些多媒體資 料,換句話說, 在這些情況下,GPP 可以用來分擔 DSP 的工作負載。接著是多 媒體應用程式在記憶體和計算量的需求己經大大超越過往,多媒體資料經常會被 包裝成運輸串流(transport stream),往返於兩顆核心之間,但是在執行時核心之 間溝通的成本並非固定,譬如傳輸時電力的消耗與總電量的關係、工作有沒有完 成時間的限制(deadline)等……,有太多因素要考量,是不可能在系統設計時就預 測到並且做好資料傳輸的設定。著眼於系統效能,靜態式分工系統設計不再合 適,即時作業系統排程器在設計上要有新的突破。 考慮以上種種原因,我們便提出一種新的動態精細分工式(tightly-coupled) 作業系統排程器[21],[22],這種新的排程法會由單一排程器監控各顆異質核心 的工作狀態,並能動態地分配工作給當下最合適的處理器核心。排程視野的廣度 上,由系統設計時就定好的靜態工作分配延伸到執行時的動態分配;而深度上, 考量整個系統即時的狀況,做出最適當的工作分配並減少微處理器的閒置浪費, 取得比靜態式分工系統更大的效能發揮。. 13.
(14) 2. 相關研究 這一章將會介紹此領域的相關研究。依順會介紹多核心平台著名的排程演算 法,對稱多核心平台及非對稱式多核心平台,非對稱式多核心平台系統的排程, 動態排程,共享資源的控制,非對稱式系統晶片 SoC,和靜態式分工系統。. 2.1. 多核心平台排程演算法 多核心處理器架構排程器的研究越來越受到重視。過去十多年來,在實用 上 , 多 核 心 排 程 演 算 法 的 發 展 重 點 是 放 在 對 稱 式 多 核 心 系 統 (symmetric multiprocessor system)上。多核心排程技巧在同質多核心平台部份可以被分成兩 類,partition scheduling 和 global scheduling[23]。 Partition scheduling 是指每一個 核心有自己的工作駐列(task queue),包括 ready 駐列和 wait 駐列。工作排程的考 慮會以各自區域的 priority 為主,與其他處理器獨立。每一個工作一旦被分配到 一個處理器,在其生命週期內都不會移到別的處理器。 Global scheduling 則是將 所有準備完成的工作放在一個共同的 priority 駐列。最高 priority 的工作會被挑選 放到一個工作量較低的處理器執行。這種 scheduling 模式在同質多核心的系統上 表現較前者佳。 以下簡單列出一些常用的多核心排程演算法[3]: z. Rate monotonic: 每一個週期性的工作有固定的 priority,priority 的順 序是根據該工作的執行頻率高低而定,例如要等待 interrupt 的工作,其 priority 相對較低。在 1973 年,Liu 和 Laylan 證明這個演算法是固定 priority 演算法中最理想的一種。. z. Earliest Deadline First: 這種演算法可將週期性和非週期性的工作一起 排程,主要概念是越早結束的工作越先執行。M. L. Dertouzos 在 1974. 14.
(15) 年證實當瞬間有許多工作等待執行時,此演算法是最有效率的。 z. Deadline Monotonic: D.M.結合上述兩種演算-- priority 的給定除了根據 該工作的執行頻率外,另外會再考慮 deadline 越早,priority 越高。. z. Background Scheduling: 此種演算法同時處理 soft real-time aperiodic task 和 hard real-time periodic task。兩種型式的工作分別置入兩個不同 的駐列。此演算法實用上雖沒有很高的利用性,但其優點在於實作很簡 單。. z. Pooling Server: P.S.可處理非週期性的工作。每個時間區塊一過,server 便服務下一個時間區塊可以執行的工作。若沒有工作在等待被執行,則 會閒置 server,等到下一個時間間隔再甦醒。. z. Deferrable Server: 此演算法類似上一個,但是若下一個時間區塊沒有 等待被執行的工作,則 server 服務可能被服務的工作,而不是閒置 sever。. z. Sporadic Server: S.S.使用於非週期性工作,可以增進其反應時間,使 得非週性工作的效能追上週期性工作的效能。. z. Dynamic Sporadic Server: 這個演算法利用 deadline 調整 priority,增進 Sporadic Server 的效能。. z. Robust Earliest Deadline: 這是 1995 年 Buttazzo 和 Stankovic 發展的 演算法,作用於 over loading 環境中的非週期性工作。此演算法不只可 以減少 deadline 預測錯誤,也可降低系統 over loading 的程度。. z. Constant Bandwidth Server: 這是在 1998 年 Buttazzo 和 Abeni 發展的 演算法,用來解決即時多媒體應用的問題。例如在串流影音的系統中, 對串流資料的傳輸和處理的 delay 和 jitter,必須要控制在一定的範圍 內。. z. Adaptative Bandwidth Reservation: Abeni 和 Buttazzo 在 1999 年提出 15.
(16) 對 constant bandwidth server 的改良。對於執行時間未知的工作所能分配 到的處理器的頻寬可以經由 Adaptative Bandwidth Reservation 來控制。 在這裡,頻寬(bandwidth)一詞指的是處理器分配給工作的時間或是工作 被執行的週期。. 2.2. 對稱式多核心平台與非對稱式多核心平台 前面提到目前實用上多核心作業系統的排程演算法大部份都是以對稱式的 多核心平台為目標,比方說,Satoshi Kaneko et al在 2004提出的一個多核心平台 [4]。這個 600MHz單晶片多核心平台包括兩個M32R 32-bit CPU核心,一個 512-KB 共用的SRAM,和一個內部分享的pipeline bus。 這個平台是由 0.15um CMOS 製程製造,適用於嵌入式系統。此多核心平台 是對稱式的多程序處理平台,並且支援 modified-exclusive-shared-invalid (MESI) 的快取統一協定。該系統繼承了先前單晶片多核心平台的諸項優點,並針對嵌入 式處理器做了最佳化,以使得系統效能增加的同時也能減低電力的消耗。為了增 加核心的效能,他們在平台內部置入一個共享的 pipeline bus。此 bus 的特性是低 延遲和每秒 4.8 G-bit 的大頻寬。此外也用多個低耗電技術,例如擁有不同使用 電力的模型選擇: 睡眠模式、工作模式、和等待模式。不同系統情況下,不同核 心甚至週邊有不同的模式選擇,以達到最高的省電約 18.4%。使得此多核心平台 在 600MHz 1.5V 之下功作僅消耗 800 mW,待機時更只耗 1.5mW。 有些應用,如 3G 通訊和嵌入式多媒體應用,會同時執行控制的工作和大量 資料處理的工作。一般實作上,為了逹到最佳的性能/秏電量比值,異質多核心 (Heterogeneous Multi-Processor)的架構是一般業界常用的設計方法[1], [13]。例如 飛利浦半導體部門發展了一套 Silicon System Platform (SSP)。SSP 是零件的工具 箱,是一種一般性、開放性和可程式化的架構。主要用來產生有軟體和硬體 IP 16.
(17) blocks 的特定應用產品領域。過往研發新產品,可能必需打造整個新平台架構, 付多相當的成本花費。利用 SSP 概念,為新應用產品而修改的架構會比試著去 產生整個新架構更有實作的效率。使用 SSP 設計產品的速度很快而且技術風險 低,因為架構中軟體硬體的功能性己經驗證過,而且還可以結合其他工作元件更 容易達到設計的目標。同時其中有很大的空間讓設計團隊創造不同市場需求的產 品;一系列的產品由入門到進階的產品,只需在平台上增減功能區塊,就可有效 地減少開發時間及成本花費。日後使用者甚至可以隨著更新軟體的版本來增強或 增加產品的功能性。飛利浦的 Nexperia 平台是一個單晶片系統的 SSP,用來開發 數位視訊產品。Nexperia 平台上主要包括 MIPS 處理器和飛利浦的 TriMedia VLIW 媒體處理器,及其他 IP 元件。結合 MIPS 及 TriMedia 兩種不同的計算核 心,整合成單晶片系統。飛利浦利用此平台創造出多功能的機上盒,它可以即時 解碼多個視訊串流、執行數位錄製、壓製訊號用於視訊電話、瀏覽網站和收發電 子郵件等多項功能。其他如德州儀器(TI),飛思卡爾(Freescale)和 Toshiba 等知名大 廠都有自己的異質多核心平台,本論文在 TI OMAP 上實作,稍後章節將會詳細 介紹 OMAP 平台。 在軟體的開發過程中,軟體測試是很重要而且很昂貴的一部份。有一種軟體 測試的方法稱之為資料流測試(Data Flow Testing),使用資料流測試可以決定一個 軟體的測試是否充份且完整。Harrold 提出一個新的方法把整個資料流測試工作 量切割成適當的大小[5]。這些測試的工作量可以靜態地也可以動態地接受排 程。也可以改變成適合共用式記憶體或分散式記憶體的環境。在[5]中把資料流 測試演算法實作出單一核心平台的版本和多核心平台的版本,並根據大量的軟體 實驗來驗證資料流演算法的正確性。另外,這些實驗也可證實多核心平台的效能 優於單核心平台。平均效能上多核心平台比單核心平台加速 1.7 倍。 Annavaram 等人討論過非對稱式多核心系統的效能優於對稱式多核心系統 的看法[6]。激發此篇論文的研究動機有下例三點:首先,單晶片多核心平台上. 17.
(18) CPU 核心的數目增加,同時間可以執行的運算量上升。第二,可以利用單晶片 多核心架構優點的多執行緒軟體變得更流行。因為演算法的性質,這些多執行緒 程式被分階段連續的執行。然而 Amdahl’s law 指出平行化程式的加速將會被計算 的連續部份限制。第三,不斷增加的晶片整合層級和逐步降低使用的電壓結合使 得如何減少電量的耗損成為首要注重的設計限制。此論文的目標是最小化多執行 緒程式的執行時間。該執行緒包含平行處理和連續處理的階段,同時也保要有多 核心單晶片的電力消耗限制。為了減少 Amdahl's law 影響,在論文中對於電量 花費的計算是根據可獲得的平行度來決定處理的指令數,並以這些指令花費的電 量為準。使用該等式,電力 = 每個指令的能量(Energy per Instruction: EPI) * 每 秒指令數(Instructions per second: IPS)。假設電力固定的情況下,因此限制平行量 的多核心單晶片是低 IPS,會花較多的 EPI。相反地,高平行量時,會花較少的 EPI。根據[6]的實驗,在相同的耗電量前題下,一個複雜的系統在使用非對稱式 多核心、多執行緒執行時,會比對稱式多核心系統增加百分之三十八的效能。 隨著近年來多媒體裝置的流行,多執行緒平台研究關注的焦點已由對稱式多 核心系統轉移到非對稱式多核心系統。非對稱式多核心系統比對稱式多核心系統 有更佳的效能/時脈比,因此在多不同工作執行時非對稱式多核心系統更適合嵌 入式裝置。. 2.3. 同質多核心平台系統下的非對稱式排程 前面提過,異質多核心平台在處理通訊及多媒體相關工作時可以得到最佳的 效能/時脈比,但目前並沒有論文是針對異質多核心平台探討動態自動排程的設 計。不過倒是有不少論文是針對同質多核心平台研究非對稱式動態自動排程的可 行 性 。 Wendorf 等 人 提 出 多 個 工 作 分 配 和 排 程 方 法 [7] , 範 圍 由 非 對 稱 master/slave 排程到對稱式排程。他們在許多情況下測試這些分配和排程方法。 對於非對稱系統,結果顯示 OS Preempt 策略幾乎在所有的清況下都有最高的效. 18.
(19) 能。作業系統的工作的 priority 相對高於一般應用程式,而在兩者有相同 priority 時,作業系統的工作可以較優先得到處理器的使用權,稱之為 OS Preempt。相 對於其他策略 OS Preempt 可以減少時間耗損百分之三十到百分之六十。在許多 測試情況下非對稱的系統和對稱式的系統幾乎有一樣的效能,甚至前者有優於後 者的情況。重要的是,在對稱式系統中,作業系統工作因 functionality partition 仍需在全部可以使用的處理器中選擇執行者,相較之下非對稱式系統指定單一處 理器微理作業系統工作,更容易實作。結果也指出,在不同工作分配和排程演算 法下,process switch overhead 和多處理器之間的對於分享資源的競爭是決定系統 效能的因素中相對較不重要的。 Greenberg 提出了一個簡單的 master-slave 架構[8]。在一些電腦作業系統 下,一個程序(process)可以在 user mode 或是 system mode 的模式下執行。一個 user mode 的程序可以在執行中進行一個系統呼叫(system call)變成 system mode。這個程序在結束這些呼叫後便回到 user mode。在 master-slave 的多核心 架構下,系統呼叫如 kernel call 只可以在 master 核心執行,剩下的呼叫就被視為 如 user call,和其它工作一樣可以在 master 核心或 slave 核心執行。當 slave 核心 上的 user mode 程序欲使用 kernel call,slave 核心會將該程序交給 master 核心處 理,而非由 slave 核心處理。在 Greenberg 提出的設計中,工作會先在兩個駐列 等待。一個駐列稱為 master 駐列,另一個則稱為 slave 駐列。Master 駐列的工作 都是在系統模式,而 salve 駐列上的工作都是在使用者模式。 如前所述 master 駐列是只在 master 核心執行的駐列,slave 駐列卻是可在 master 核心或 salve 核心執行。此論文利用兩種簡單又實作的排程演算法來平衡 排程的彈性和 queue-switching 的成本花費。最後並提出一個分析公式,用來測 量硬體和 work load 參數,同時考量 master-slave 系統的電力和限制,並進而尋找 到非對稱式多核心系統中最佳 slave 核心的數量。. 19.
(20) 2.4. 動態式分工及排程 許多對時間有嚴格要求的應用都需要動態排程方能達到預定的效能。 Manimaran 等人把一個系統的效能定義為該系統能在 deadline 之前完成的工作 所佔的百分比[9]。在這篇論文中,他們提出在多核心系統上使用的一種演算法, 可以動態地對可執行的即時工作進行排程,並具有容錯的功能。系統的運作是基 於以下兩個限制條件: 一、每一個工作一旦分配給處理器以後,是不會被打斷的 (non-preemptive)。二、每個工作有兩種版本,這個假設是用來改善處理器錯誤的 問題並可以得到較高的效能。 系統的內有 N 個處理器和 N+1 個駐列,其中包含了 N 個 local 駐列和一個 global 駐列。每一個處理器和一個 local 駐列為一個組合。排程器自 global 駐列 中取得最高 priority 的工作,動態地依系統狀態和各個處理器的狀態,決定將置 入哪一個 local 駐列。提出的演算法有下列三個技巧: 1)距離概念:決定 task 駐列中兩個工作版本的相對位置。 2)彈性的系統復原:在效能和容錯等級的取捨。 3)資源的回收:回收被判定為 deadlock 的工作和己完成的工作所分配到的資 源。 利用動態排程方法和上述技巧系統的效能和容錯性達成應用上時間的限制。 Avritzer 等人發展出一個效能分析模組[10]。該模組對使用 load sharing 演算 法的高度非對稱系統做效能的評估。load sharing 演算法是基於全系統的狀態進 行排程工作。load sharing 演算法有兩種實作的層級,第一種層級在作業系統內 部,稱為 kernel 層級或 shell 層級。第二種層級為使用者層級,在 shell 的前端。 前者雖有效率上的優點,但是異質機器之間的相容性使得實作上十分困難。雖然 後者的 overhead 比前者大,但有三個理由令此論文決定使用後者實作。第一、. 20.
(21) 不必考慮異質機器的相容性,容易實作。第二、對機器和使用者 load sharing 會 透明化。第三、使用者利用 shell 前端控制可以決定要不要加入負載分享的機制 當中。 Load sharing 的主心概念是要儘可能縮短整個系統的反應時間,執行方法是 把工作分配給利用率低的機器。動態的 load sharing 可分成由傳送者初始化的型 態和由接收者初始化的型態兩種。傳送者初始化的型態使用時機是系統負載不高 時,接收者初始化的型態是系統呈現高負載時使用。此論文提出了一個分界型 (threshold type)的 load sharing 演算法,此演算法會隨著某些分界值的變動而調整 最適當的工作參數,例如每個機器上的工作數量。實作上該演算法的模型是建立 以全系統為視野的全系統狀態馬克夫鏈和並計算出能在最差狀況下逹到最小 latency 的系統。此論文的結論指出在非對稱式的環境下,小心地動態調整 load sharing 的演算法,會比靜態設定 load sharing 的演算法的效能有大幅增進。. 2.5. 共享資源控制 Majumdar 提到多核心系統上程序之間會有競爭分享的資源[11],例如變數就 會儲存在分享記憶體上。保持資料一致性的機制不可缺少,如此才能確保系統的 正確性。可是這種機制又通常會降低系統效能。這篇論文研究以多核心平台為基 礎的應用程式為對象,如電話交換器和即時資料庫,控制分享資源的競爭以達到 高度 throughput 及高度 scalability。將己存在的程式改成 re-entrance 或是將程序 做適當的排程是兩種可實行的控制記憶體競爭方法。此論文著重於第二種方法。 對數種控制資源競爭的排程演算法量化其結果,可以了解系統內部的行為和每一 種演算法最重要的特性。結合數種排程演算法的特性的優點,衍生出混合式的控 制資源競爭排程演算法: Hybrid-K。Hybrid-K 可以把所有程序執行時間縮短為 依序執行每個程序所花費執行時間的 1/K。參數 K 代表系統增加的處理器數目。 因此增進的效能會依 K 的增加而上升。然而需要注意的一點是實驗使用的處理. 21.
(22) 器數目最大只到 10,因此 K 大於 10 的情況尚待驗證。 Saewong 等人指出如何安排同時存取多個資源[12],這是眾所皆知的一個 NP complete 的問題。在分散式即時系統之中,通常都是用 Decoupling 的方法來 管理點對點延遲的系統。不幸地,當利用單獨的核心來管理多個資源時, Decoupling 的方法就會失敗。利用單獨核心管理資源方式的優點是可以減少衝突 以全系統的觀點來分配資源的使用。例如控制核心可以利用裝置驅動程式、檔案 系統或協定服務(protocol service)來控制相關的資源。控制核心我們稱之為 host 核心。Host 核心具有兩個角色:其一,host 核心如一般的核心可執行應用程式。 其二,host 核心可以控制和管理其他 time-shared 的資源。此論文研究協同排程 的 控 制 和 受 控 制 資 源 的 問 題 , 提 出 合 作 排 程 伺 服 器 (Cooperative Scheduling Server :CSS)。 CSS 是一個專用的伺服器,利用固定的一個處理器來控制眾多可以分享的資 源,例如: 磁碟機和程序之間的溝通。下列兩個概念是 CSS 的目標基礎。首先, 在一個控制器上(如 CPU)先執行一個非週期性的伺服器,該伺服器可以處理所 有局部資源的使用要求。這表示 conjunctive admission control 是在控制端和受控 制端一起實行的。接著,在應用程式層級的時間限制被分割進入多個階段,每一 個階段都會被保證在一個特定的資源上完成。Real time file system (RTFS)是一個 即時的檔案系統,它可以提供在 CPU 低負載時,對磁碟頻寬的保證。有了 file system CSS (FSCSS),磁碟頻寬的保證也可以在高 CPU 負載和高磁碟工作量下達 成。以下列出協同排程演算法設計需要考慮到的因素。第一、資源異質性產生的 排程失誤問題。依受控資源的觀點,host 核心必須確保這些資源相對活動不能被 其他更高 priority 的活動過份地延遲。依 CPU 的觀點,native CPU application 又 必須保有完成的時間限制。因此會有 confliction 和 scheduling miss。第二、 conjunctive admission control;每一個受控制資源的 admission control 必須不只是 考慮自己擁有資源的存取,還有 host 核心的可獲得性。因此,要保證即時的服. 22.
(23) 務,協同排程的允許控策略需要搭配資源存取資料的反應時間和處理器排程器去 分配 CSS 程序的反應時間。第三、分享資源的同步問題。資源的存取可以平行 化處理。資源和 host 核心做好同步,可以允許每個資源達到最大平行化。 第四、 有效的資源利用。即時排程的主要目標是達到高利用率和對於應用程式的 deadline 保證。因此,除了保證多資源存取的 deadline 之外,系統應該提供整個 系統資源的高利用率。. 2.6. 靜態式分工 一 般 的 異 質 雙 核 心 系 統 架 構 ( 比 如 由 Ferrari 等 人 提 出 的 The Janus system[14],是由一個一般功能處理器和一個特殊功能處理器所組成。這兩個運 算單元共同使用一個公用匯流排(bus),而且可以自由地使用 RAM 和 ROM 等記 憶體。而其他週邊輸出輸入設備則由一般功能處理器控制。通常這兩顆處理器是 建構在單一晶片上,可以完全分享整個架構上的記憶體空間,也可以將處理器之 間的溝通所需的成本忽略成極小。如此的設計通常會將一般功能處理器視為 master 處理器,而特殊功能處理器便視為 DSP。 然而這些系統大多是設計成靜態式分工的方法。Gai 等人曾討論由 GPP 和 DSP 非對稱架構多核心排程的問題[15]。在這篇論文中,DSP 被當成是類似有計 算能力的資源,在 DSP 上執行的工作,都是由 GPP 一次一個分配過去。等到 DSP 完成工作,再回到 GPP 繼續下一個工作。如此設計是因為 DSP 對某些工作 的能力比 GPP 有效率很多,DSP 在這些工作上所省下的時間和單獨由 GPP 執行 整個工作所花的時間相較,會大於 GPP 的閒置和兩個核心的溝通所需的時間。 這種方式的實作方法是由兩個 task 駐列來完成。一個是 GPP 駐列,存放一般的 工作,並由 GPP 負責執行。另一個則是 DSP 駐列,存放給 DSP 執行的工作。 當 DSP 閒置時即是可以接受新工作,排程器選擇在這兩個駐列的頂端有最高 priority 的工作。若是選擇到 GPP 駐列,就由 GPP 來執行工作,反之 GPP 便將. 23.
(24) DSP 駐列上的工作傳給 DSP 執行。而當 DSP 正在工作,排程器只選擇 GPP 駐 列上最高 priority 的工作交由 GPP 執行。 由過去的研究顯示,非對稱式多核心平台的優點及可行性十分明顯,而且同 一個工作如果能動態根據不同核心來排程,也會大大提昇效能。下一章,我們將 提出精細分工的工作模型和相關背景。. 24.
(25) 3. 理論與實作背景 我們以動態精細分工工作模型為概念,實作出非對稱式異質多核心平台排程 器。所謂動態精細分工系統和目前廣為使用的靜態式分工(statically partitioned) 系統是相對的。在靜態式分工系統中,一項工作會分配到哪一個處理器是在系統 設計時就決定好的。為了提高整體系統的效能,我們提出了動態精細分工工作模 式。假設在系統平台上有兩個處理器核心,分別是 GPP 核心以及 DSP 核心。新 的工作被執行前,在 GPP 上的排程器將監看每個處理器核心的執行時期狀態, 和決定哪一個核心較適合執行該工作,再動態地分配給 GPP 或 DSP 執行,減少 處理器核心閒置的時間,提高處理器核心利用率,進而縮短全部工作執行時間, 增加整個系統平台的效能,這種工作模式我們稱之為精細分工工作模型。 本篇論文提出的排程器是實作於 OMAP5912 OSK 平台上,使用的作業系統 在 ARM 處理器核心部分是以 eCos 2.0 版本為基礎進行修改,在 DSP 處理器核 心的排程核心是由我們自行設計的。在本章中,我們會介紹 OMAP 5912 應用處 理器 (OMAP 5912 Application Processor)和 OMAP 59120 發展板(OMAP 5912 Starter Kit: OSK 5912),以及嵌入式作業系統 eCos 2.0 版本。過去,本驗室也曾 開發過在 Linux 下利用 DSP Gateway 及 TI 發展的 DSP/BIOS 排程器[21]。根據 過去的實驗結果,利用 DSP Gateway 的溝通機制成本太高,每秒傳輸只有 3 MBytes,不合乎精細分工系統的需求,因此我們在本論文中改用較為精簡的 eCos 作業系統,並提出有效率的 mailbox 和 shared memory 的溝通機制,以證實精細 分工系統可以得較高的效能。所有 eCos 移植到 5912 OSK 的過程將在下一章說 明。本論文研究實作的細節會在第五章詳細介紹。. 3.1. OMAP 5912 Application Processor OMAP5912 應 用 處 理 器 是 一 塊 高 度 整 合 的 SoC , 包 括 的 重 要 元 件 有 :. 25.
(26) GPP-ARM 核心、DSP 核心、和 Traffic controller 等等。OSK 5912 為使用 OMAP 5912 應用處理器的發展平台。 OMAP5912 應用處器整合 ARM 926 EJ-S RISC 核心和 TI TMS320C55x DSP 核心。ARM9 RISC 核心在嵌入式系統被廣為使用,C55x DSP 核心對於數位訊號 處理展現高效能和低耗電的特性。因此 OMAP5912 應用處理器適合多媒體嵌入 式裝置,經由切割每個應用程式為眾多工作和適切地分配工作給兩個處理器核心 執行可以有優秀的效能表現。 圖 1 為 OMAP 5912 功能區塊圖[1]。MPU(ARM9)、MPU peripheral bridge、 Memory traffic controller 以及 system DMA 四者透過 MPU BUS 溝通。MPU 由 MPU bridge 透過 public/ private peripheral bus 和其週邊溝通。DSP 透過 public/ private peripheral bus 和其 peripheral 溝通。此外 DSP 可藉由 DSP MMU 或是 MPU Interface 和系統其他部份做溝通。. Figure 1. OMAP 5912 功能區塊圖 26.
(27) ARM 926 EJ-S RISC 核心如下: z. Support for 32-Bit (Thumb Mode) Instruction Sets. z. 16K-Byte Instruction cache. z. 8K-byte data cache. z. Data and program memory management unit (MMU). z. 17-word write buffer. z. Two 64-Entry Translation Look-Aside buffers (TLBs) for MMUs. TMS320C55x 核心 technical feature 如下: z. One/two instructions executed per cycle. z. Dual multipliers (two multiply-accumulates per cycle). z. Two arithmetic / logic units. z. Five internal data/ operand buses (3 read buses and 2 write buses). z. 32k x 16-bit on-chip dual-access ram(DARAM, 64k bytes). z. 48k x 16-bit on-chip single-access ram (SARAM, 96k bytes). z. Instruction cache (24K bytes). z. Video hardware accelerators for DCT, iDCT, pixel interpolation, and motion estimation for video compression. 表 1 列出 OMAP5912 應用處理器的記憶體配置[1]: Table 1. OMAP5912 應用處理器記憶體配置. 27.
(28) GBA BALL # Device Name. Start Address End address Signal Size Data access Type EMIFS. CS0. 0000 0000. 03FF FFFF 64MB. Boot ROM. 0000 0000. 0000 FFFF 64KB. 32-bit Ex/R. Rserved boot ROM. 0001 0000. 0003 FFFF 192KB. 33-bit Ex/R. Reserved. 0004 0000. 01FF FFFF. NOR flash. 0200 0000. 03FF FFFF 32MB. CS1. 0400 0000. 07FF FFFF 64MB. NOR flash. 0400 0000. 07FF FFFF 64MB. CS2. 0800 0000. 0BFF FFFF 64MB. NOR flash. 0800 0000. 0BFF FFFF 64MB. CS3. 0C00 0000. 0FFF FFFF 64MB. NOR flash. 0C00 0000. 0FFF FFFF 64MB. 8/16/32-bit Ex/R/W 8/16/32-bit Ex/R/W 8/16/32-bit Ex/R/W 8/16/32-bit Ex/R/W. EMIFF SDRAM external. 1000 0000. 13FF FFFF 64MB. Reserved. 1400 0000. 1FFF FFFF. 16-bit Ex/R/W. L3 OCP T1 Frame buffer. 2000 0000. 2003 E7FF 250KB. Reserved. 2003 E800. 2007 D7FF. TI Camera I/F. 2007 D800. 2007 DFFF 2KB. 32-bit Ex/R/W 32-bit Ex/R/W. L3 OCP T2 Reserved. 3000 0000. 3000 D7FF. TI Camera I/F. 3007 D800. 3007 DFFF 2KB. Reserved. 3007 E000. 7FFF FFFF. 32-bit Ex/R/W. DSP MPUI Interface MPUI memory + MPUI peripheral. E000 0000. E101 FFFF. Reserved. E102 0000. EFFF FFFF TIPB Peripheral and Control Registers. Reserved. F000 0000. FFFA FFFF. OMAP5912 peripherals. FFFB 0000. FFFE FFFF. Reserved. FFFF 0000. FFFF FFFF. 28.
(29) 表 2 列出 OMAP5912 應用處理器 DSP 的記憶體對應關係(mapping)[1],包括 內部記憶體 DARAM 和 SARAM。ARM 定義一個 word 等於 4 個 byte,採 byte addressing,所有週邊和擴充的 memory 以及 control register 都由 32 位元來定位。 DSP 定義一個 word 等於 2 個 byte,是採 word addressing。 Table 2. 記憶體對應關係. 0x050000-0xFF7FFFF(ARM: byte addressing)/ 0x028000-0x7FBFFF(DSP: word addressing)這塊區域,若 DSP 的 MMU 是 off:就把這塊空間直接對應到 MPU/DSP shared memory space(直接把 24bit line 對應即可) ,而此對應的區塊原 來是保留區。若 DSP 的 MMU 是 on:這 24bit line 就當成是 virtual address,由 MPU 控制 DSP 之 MMU 來重新配置這塊空間,放到 MPU/DSP shared memory space 的某一段記憶體空間。 當 ARM 對應一塊實體記憶體到 DSP 的記憶體空間,DSP 可以透過 DSP MMU 來存取該塊記憶體,同時在 ARM 的虛擬記憶中有一塊配置為 DSP 記憶體 空間,也會被對應到該塊實體記憶體。 在 OMAP5912 應用處理器上 Memory traffic controller 是一個很重要的內外 部記憶體存取元件。Memory traffic controller 可以令 DSP 和 ARM 利用 TI OCP (Open Core Protocol)存取內部共用記憶體或週邊裝置,存取外部記憶體可利用兩 種高速記憶介面來完成,分別為 External Memory Interface Fast(EMIFF)和 External Memory Interface Slow(EMIFS)。 EMIFF 相較 EMIFS 是較快速的記憶體裝置,在 OSK 5912 發展板上對應. 29.
(30) EMIFF 配置的記憶體是 SDRAM,最大可支援到 64 M Bytes。存取資料的寬度和 位址的寬度都是 16 bits,也提供了兩個 bank 選擇位元,亦即可以將 SDRAM 分 成四個區域來使用。使用者的應用程式預設是諸存到此 SDRAM。 EMIFS 所連接的外部裝置記憶是 NOR FLASH。透過介面可以 8 bits / 16 bits / 32bits 的寬度在每個 NOR FLASH 晶片上存取資料,其使用的位址寬度為 25 bits。OSK 5912 發展板上共有四塊外部 FLASH 晶片,每塊晶片最大容量為 64 M Bytes,所以可使用的總記憶體容量為 128 M Bytes。此四塊 NOR FLASH 分別為 CS0, CS1, CS2, 和 CS3。Boot ROM 位於 CS0,系統開發者設計的 boot-loader 或 作業系統則是存放在 CS3。經過設定,啟動的模式可以利用 CS0 的 boot ROM 或 是 CS3 的 boot-loader 開機。. 3.2. OMAP 5912 Starter Kit:OSK 5912 (OMAP 5912 OSK) OSK 5912 是對軟體和硬體做高度整合的平台,主要可做為視訊 圖片訊號處 理裝置和行動溝通裝置。可以使用一般的嵌入式作業系統做為 OSK 5912 上 ARM 處理器的作業系統,而 TI 提供 DSP/BIOS 做為 DSP 處理器的即時核心(real-time kernel)。Figure 2 為 OSK 5912 正視圖[19]:. Figure 2. OSK 5912 正視圖 30.
(31) Hardware Features 如下: z. ARM 926EJS 處理器核心運行於頻率 192 MHz。. z. Texas Instruments TMS320C55x 運行於頻率 192 MHz。. z. 內建音訊編碼解碼器 TLV320AIC23 codec. z. 64 Mega Bytes DDR RAM. z. 256 Mega Bytes on board Flash ROM. z. 10 MBPS Ethernet port. z. On board IEEE 1149.1 JTAG connector for optional emulation. Software Features 如下: z. Compatible with MontaVista's Linux for OSK5912. z. Compatible with OMAP Code Composer Studio from Texas Instruments. 3.3. eCos OSK 5912 所採用的原始作業系統是 MontaVista Linux,但是根據我們去年的 經驗,Linux 配合 DSP Gateway 的效能表現無法達到精細分工系統所需的要求, 故本論文沒有採用原始發展系統所採用的整合軟體。接下來介紹 ARM 端採用的 eCos 作業系統。在下一章我們會討論如何將 eCos 移植到 OSK5912 的平台下。. 3.3.1. eCos Overview eCos 是一個開放程式碼,可設定(configurable),可移植和免費的嵌入式即時 作業系統。eCos 的一項重大的技術革新是設定系統(configuration system)。設定 系統允許應用程式設計者對 run time 元件加入或調整所需的功能和實作方式。傳 統上,作業系統會限制實作的方法,無法選擇。設定系統使得 eCos 開發者創造 符合特定應用程式的特定作業系統,也使得 eCos 適合更大範圍的嵌入式應用。 31.
(32) 設定系統的使用可以保證資源的最小化,和其他不需要的功能和特徵都可以被移 除。如此便利性的因素是 eCos 它是一個元件架構的系統。eCos 被設計為可以移 植到許多目標架構和目標平台,包括 16 32 64 位元架構和 MPU, MCU, DSP。eCos 支援許多不同平台架構,如 ARM、Intel StrongARM 及 XScale、Fujitsu FR-V、 Hitachi SH2/3/4、Hitachi H8/300H、Intel x86、MIPS、Matsushita AM3x、Motorola PowerPC、Motorola 68k/Coldfire、NEC V850 和 Sun SPARC,其他尚包括許多流 行的架構和發展板。. 3.3.2. Configure Tool 嵌入式系統正被推動朝著更小更快更便宜更精緻,所以更需方便地控制系統 內所有的軟體。有不同的方法可以控制應用程式內元件的特性。eCos 元件控制 的哲學是為了減少系統大小,對資源最自由的配置。持著此設計哲學,最小化的 系統不必支援某些複雜系統上才有的強大功能。有一種在 run time 控制軟體元件 的方法,例如動態連結程式庫(Dynamic Link Libraries),不必預先對元計做設定, 但是這個方法會會導致程式大小增加。另一種方法是在 link time 時,當需要某個 特殊功能元件就會被包入,反之則除去,例如 GNU linker。這方法的特性是擁有 某元件的全部功能或都不擁有。Compile time 的元件控制,使得系統開發者可以 建立特定應用程式需要的元件,可以保持所有的程式碼都是系統所需要的。對於 嵌入式系統來說,這是解決程式碼多寡的好方法。eCos 有一套十分方便的 configure tool,讓系統開發者在 compile time 決定所需的元件和元件的能力,而 不必動手修改元件的程式本體。. 3.3.3. Component 要了解 eCos,則了解元件的基礎架構非常重要。元件基礎架構專為滿足嵌 入式系統和嵌入式設計的相關需求而存在。設計的 eCos 元件基礎架構可以控制 元件達到最小記憶體使用、允許使用者控制時間行為以符合即時性、和使用一般. 32.
(33) 的程式語言,如 HAL 的實作就包括 C、C++、和組語。大部份嵌入式系統本身 所支援的功能比特定應用程式需要的功能更多。通常系統內多餘的程式碼支援的 功能,卻是嵌入式程式開發者所不關心也不需要的,而且更多的程式碼使產生錯 誤的機會更大。舉 Hello world 程式為例。很多即時作業系統支援了 mutexes, task switch,卻是在此簡單程式所不需要的。eCos 給開發者最終 run time 元件的控制 權,沒必要的功能可以輕易地被移除。eCos 系統的大小可由幾百 Byte 到幾百 K-Byte 彈性地增減。 即時嵌入式系統的標準功能包括包括插斷處理,例外處理,錯誤處理,執 行緒同步,排程,計時器,和裝置驅動程式。這些標準的功能在 eCos 中由各個 元件負責,稱之為標準元件。這些標準元件由即時 kernel 為核心組成。列出元件 如下: z. Hardware Abstraction Layer (HAL)—硬體抽象層隱藏每一個支援的 CPU 和平台的特別特徵,以至於 kernel 和其他 run time 元件都是在一個容易 移植的形式。. z. Kernel—Kernel,包括記憶體、快取、插斷處理、例外處理,執行緒、 同步機制,排程器,計時器,計數器和鬧鐘。. z. ISO C and math libraries—常用標準程式庫。. z. u-ITRON and POSIC —μITRON and POSIX 應用程式者介面. z. Device drivers—裝置驅動程式,支援廣泛的裝置標準序列埠控制器, Ethernet 網路控制器,PCMCIA 控制器,USB 控制器,PCI 控制器,和 Flash Rom 等等。. z. RebBoot ROM monitor — RedBoot ROM monitor 是一個 Bootstrap 應用 程式,為了方便移植它使用 eCos HAL,而且他可以透過序例埠和網路 兩種 booting 方式。 33.
(34) z. GNU debugger (GDB) support—GNU 除錯器,提供目標平台軟體可以和 GDB host 溝通,對應用程式除錯。. z. 其它軟體元件 — SNMP,HTTP,TFTP 和 FTP。. eCos kernel 或是應用程式都是在 supervisor 模式下執行,所以在 eCos 系統 中,user 模式和 kernel 模式並沒有區分。 圖 3 為 eCos 系統區塊圖[18]:. Figure 3. eCos 系統區塊圖 下面段落將介紹三個重要的 eCos 元件,分別是 HAL、kernel、及 RedBoot。. 3.3.4. HAL HAL 將處理器架構的底層硬體和平台的底層硬體抽象化可以有效率地移植 eCos kernel 到別的平台。為了移植 eCos 到新的平台,主要的工作是修改 HAL 以適應支援新的硬體平台,因此了解 HAL 這個軟體元件的架構相當重要。HAL 有一般化的 API,把特殊的硬體行為封裝起來,由硬體來完成設計的功能,並且 34.
(35) 允許應用層直接存取硬體和任何架構特徵。例如有同樣意義的 interrupt,實際執 行插斷的程序依不同架構而相異。為了使 HAL 的可用性達到最廣的範圍,HAL 是用 C 語言和組合語言實作。另外為了 HAL 介面實作上的效率,HAL 是用 C/ CPP 巨集實作,可以使用 inline C 語言,inline 組合語言,或外部呼叫 C 語言和外部 呼叫組合語言。 HAL 含概三個不同的模組: z. Architecture. z. Variant. z. Platform. 第一個 HAL 模組定義 architecture。每個被 eCos 支援的處理器家族都被認定 為不同的 architecture。每個 architecture 模組會包含所需的 CPU 啟動程式碼, interrupt delivery 程式碼,context switching 程式碼和其他指令集架構特殊功能的 程式碼。第二個 HAL 模組定義了 variant。一個 variant 是一個處理器家族當中的 一個特定處理器。例如定義不同的 on-chip MMU 或是快取,也處理任何晶片上 的週邊,如記 memory controller 和 interrupt controller。第三個 HAL 副模組是定 義 platform。一個 platform 是一塊特別的硬體平台,它包括選擇處理器的 architecture 和 variant。傳統上這個模組包括平台啟動,晶片選擇設定,interrupt controller 和計時裝置。這三層的介定不必很清楚,因為各模組的功能性在不同 硬體平台有不同的設定。例如快取和 MMU 可以在 architecture HAL 或 variant HAL。 圖 4 是 HAL 啟動期間副程式被引用的流程圖[18]。啟動程序可能會依不同 架構和平台的使用有些微的不同。此外,啟動程序可能也因為 HAL 的一些設定 選項的不同而與此流程圖有所差異。. 35.
(36) Figure 4. HAL 啟動流程圖 1.. 系統在電力週期啟動之後開始運作。此啟動程序也是 soft reset 的啟動 方式。. 2.. 在 hard reset 或 soft reset 發生後,處理器會跳到 reset vector。Reset vector 對處理器會用到的最少數量暫存器做設定,使得系統可以繼續初始化程 序。. 3.. 接著 reset vector 會跳到 _start,是 HAL 初始化的主要開啟點。. 4.. 呼叫 hal_cpu_init,這個程式設定處理器的暫存器,如關閉指令和資料 快取。確保對於剩下的初使化程序而言,處理器在一個正常的狀態。. 5.. 下一個被呼叫的副程式叫 hal_hardware_init,硬體設定包含快取設定, 36.
(37) 設定插斷暫存器為預設狀態,關閉處理器的 watchdog,設定即時時鐘 暫存器,和設定晶片選擇暫存器,這些都是基於平台特有的硬體而不同。 6.. 接著是設定 interrupt stack 的區域,在 interrupt 發生時可以儲存處理器 狀態。在整個初始化程序中,都是利用這一段 stack 做為呼叫 C 副程式 會用到的 stack。因為此時 interrupt 是關閉的,不會有衝突發生。. 7.. 下一步執行 hal_mon_init 程式,確保預設的 exception 處理器安裝給每 一個處理器支援的例外情況。. 8.. 接著清理 BSS 部份,它包含所有未初始化的區域和全域變數。. 9.. 然後設定 stack,以致於 C 程式呼叫可以被實行,不再使用 interrupt stack。. 10. 呼叫 hal_platform_init 或呼叫 hal_if_init,初始 virtual vector table。 11. 初始化 MMU,處理 logical addresses 和 physical addresses 的轉換,同時 提供保護和快取機制。 12. 接著啟動指令快取和資料快取。 13. 執行 hal_IRQ_Init,設定 Communications Processor Module. (CPM),它. 接受和按優先順序處理內外部 interrupt。 14. 下一步,cyg_hal_invoke_constructors 呼叫所有 global C++ constructors。 Linker 會提供 global constructor 的名單,cyg_type.h 則用巨集定義這份 名單上 constructor 被呼叫的順序。 15. 如果設定當中有除錯環境而且 ROM monitor 沒有提供除錯支援,下一 個要呼叫的是 initialize_stub。initialize_stub 安裝 standard trap handler 並 把硬體設定在適合除錯的狀態。 16. 最後一個步驟是把控制權轉給 kernel。cyg_start 就是控制權由 HAL 轉 入 kernel 的點。. 37.
(38) 3.3.5. The Kernel Kernel 是 eCos 系統的中樞。Kernel 提供即時作業中的標準功能例如插斷和 例外處理、排程、執行緒和同步。在 eCos 系統下可以對這些組成 kernel 的標準 功能元件完全地設定,以達到特殊的需要。eCos kernel 以 C++實作,允許用 C++ 寫成的應用程式直接透過 C kernel API 介面和 kernel 溝通。eCos kernel 也支援標 準 u-ITRON 和 POSIX compatibility layers 介面。為了符合即時性需求,eCos kernel 依循下列準則發展: z. Interrupt latency — interrupt 回 應 和 開 始 執 行 ISR 的 時 間 要 少 而 且 deterministic。. z. Dispatch latency—執行緒準備完成可以執行的狀態到開始執行的時間 要少並且 deterministic。. z. Memory footprint—對一個設定完成的系統,程式或資料所需求的記憶 體資源要保持最小化和 deterministic。而且要確保嵌入式系統的動態記 憶體配置不會使用超出所有記憶體的量。. z. Deterministic kernel primitives—所有 kernel 的行為都要是可預期的且符 合即時性的需求。. eCos kernel API 不回傳錯誤訊息。在嵌入式系統當中,處理錯誤回傳訊息會 導致許多問題,如消耗貴重的執行週期和程式空間來檢查回傳的訊息。為了程式 發展的便利性 eCos kernel 提供 assertion,它可以被 eCos package 開啟或關閉。傳 統上,assertion 在除錯階段會開啟,允許 kernel 程式顯示錯誤檢查。如果錯誤產 生了,就會回傳一個 assertion 失敗並且會中止應用程式。除錯程序完畢之後, assertion 就在 kernel package 之中關閉。此方法有很多好處,如限制程式中錯誤 檢查的 overhead,消除應用程式錯誤檢查的需要;如果有一個錯誤發生,應用就 被暫停,可以立即知道發生錯誤的地點,而不是依賴回傳訊息再去檢查。. 38.
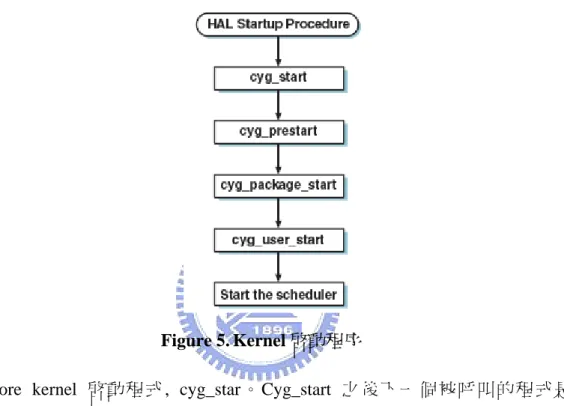
(39) kernel 提供開發多執行緒應用所需的重要功能。 在硬體都啟動完成之後,HAL 中呼叫 Kernel 啟動的程序。cyg_start 是 kernel 啟重程序的啟始點。它呼叫其他預設的啟動程式來處理不同初始化的任務。只要 在應用程式之中提供相同程式名稱,預設 kernel 啟動程式可以被簡單的替換,以 完成使用者特殊的初始化工作。Kernel 啟動程序如圖 5 [18]。. Figure 5. Kernel 啟動程序 Core kernel 啟動程式, cyg_star。Cyg_start 之後下一個被呼叫的程式是 cyg_prestart。它預設不完成任何初始任務,讓使用者自行決定在其他系統初始化 之前該被完成的初始化都可以在這裡執行。接著呼叫 cyg_package_start,在應用 程式開始之前初始化將用到的 package,如 u-ITRON 和 ISO C 程式庫。之後呼叫 cyg_user_start,它是應用程式的進入點。建議 cyg_user_start 被使用來完成任何 應用指定的初始化、產生執行緒、產生 synchronization primitives、設定鬧鐘、和 註冊任何需要的 interrupt handlers。當 cyg_user_start return 時會自動執行呼叫排 程器。 3.3.5.1.. The Scheduler. eCos kernel 的核心是排程器。排程器的工作是去選擇最適合的執行緒執行, 提供執行中執行緒同步的機制和控制 interrupt 在執行緒執行的影響。在排程器程 39.
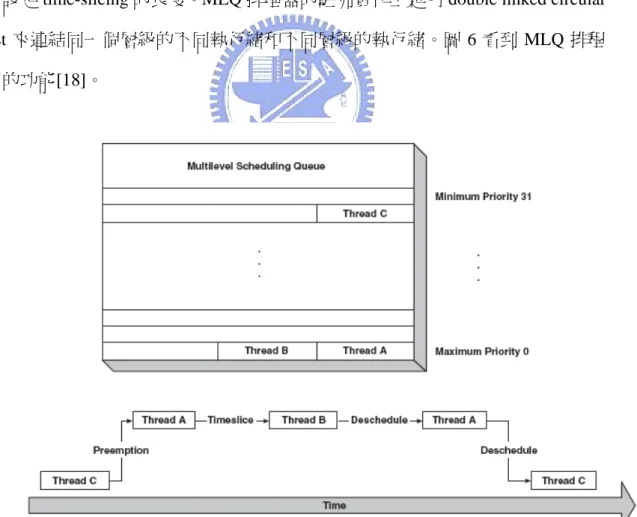
(40) 式程式碼執行期間,不會關閉 interrupt,因為 interrupt latency 十分短。排程器內 存在一個計數器,它決定排程器是自由地執行或是關閉。如果計數器非零,排程 器就被關閉,當計數器回到零,排程就會啟動。在 ISR 執行期間,HAL 預設 interrupt handler 會修改計數器來停止排程動作。執行緒也有能力開關排程器。 3.3.5.2.. Multilevel Queue Scheduler. MLQ 排程器允許同一個 priority 有多個執行緒可執行。priority 可由 1 設定 到 32,對應到數字是 0(最高)到 31(最低)。MLQ 排程器允許不同 priority 可有 preemption。Preemption 是指低 priority 執行緒的被 context switch 暫停執行,因 此高 priority 的執行緒開始執行。在同一個 priority 中,MLQ 排程器有 time-slicing 功能。每一個執行緒在一段特定的時間內執行稱之為 time-slicing,統系開發者可 以設定 time-slicing 的長度。MLQ 排程器的駐列實作上是用 double linked circular list 來連結同一個層級的不同執行緒和不同層級的執行緒。圖 6 看到 MLQ 排程 器的功能[18]。. Figure 6. MLQ 排程器運做圖. 40.
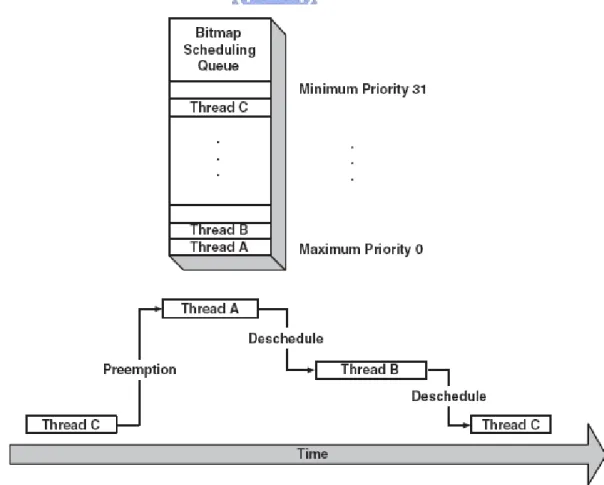
(41) 三個執行緒,執行緒 ABC,priority 分別為 0, 0, 30。當 C 開始執行之後,A 準備完畢可以執行,於是 C 發生 context switch,A 開始執行。接著 B 也準備完 成,在 A 持續到它分配的時間用完,A 發生 context switch,讓 B 開始執行。AB 輪流執行完畢,才再由 C 繼續執行。 3.3.5.3. Bitmap Scheduler Bitmap 排程器的執行緒也是有多個 priorities;然而每層級只能有一個執行 緒。這種設計簡化排程演算法,也令 bitmap 排程器非常有效率。Priority 的數量 和設定和 MLQ 相同;駐列的實作有三種,可以是 8,16 或 32 位元值,依設定的 priority 而定。因此駐列中一個位元代表一個 priority。Bitmap 排程器可以有 preemption,但是因為每個 priority 只有一個執行緒,故 time-slicing 會失去功能。 使用 bitmap 排程器時就會關閉 time-slicing。圖 7 是 bitmap 排程器的例子[18]:. Figure 7. Bitmap 排程圖運做圖 有三個不同 priority 的執行緒 ABC,其 priority 分別為 0、1、30。開始於 C. 41.
(42) 執行。接著 A 和 B 都可以執行,使得 context switch 發生,C 被置換出去。A 有 最高的 priority,所以 A 先執行,完成之後,發生 context switch,B 開始執行。 在 B 完成之後,C 才能繼續它的程序。 比較這兩種排程器,bitmap 排程器是較簡單的排程策略。但是,MLQ 排程 器可提供更多的選擇給執行緒操作,也可容納更多的執行緒,只要記憶體夠,就 沒有執行緒數量的限制。系統開發者可依應用程式的特殊需求而決定使用哪一種 排程器。 3.3.5.4. Synchronization Mechanisms eCos kernel 提供系統中執行緒溝通機制和執行緒對分享資源存取的同步機 制。提供的機制有 Mutexes、Semaphores、Condition variables、Flags、Message boxes 和 Spinlock (for SMP systems)。 Kernel 提供同步 API,應用程式可以便利地使用這些同步機制。API 程式提 供 有 blocking 功 能 或 non-blocking 功 能 。 Blocking 程 式 呼 叫 , 如 cyg_semaphore_wait, 暫停執行緒的執行,直到 API 程式可以成功地完成。 Non-blocking 程式呼叫有兩種,第一種如 cyg_semaphore_trywait,不論程式有沒 有成功地完成,會回傳訊息指出呼叫的狀態,所以執行可以繼續執行。第二種 blocking 呼叫,必需先設定等待的時間,用時間長度為暫停長短的依據,如 cyg_semaphore_timed_wait。 Mutex 的目標和其他的都不同。Mutex 允許多個執行緒安全地存取共享的資 源。它只有兩種狀態: locked 和 unlocked。並且 Mutex 有擁有者的概念,只有擁 有者(上鎖者)可以解開 mutex。其他同步機制都是被使用來做為執行緒之間互相 溝通或從 DSR 連接到相關的 interrupt handler 到一個執行緒。 Semaphore 是 一 種 用 計 數 來 指 示 資 源 已 上 鎖 或 可 以 獲 得 的 同 步 機 制 。 Semaphore 有兩種型態,分別是 counting semaphore 和 binary semaphore。Binary semaphore 很像 counting semaphore,但是它的計數決不會大於一,所以它的狀態 42.
(43) 只有 locked 和 unlocked;和 mutex 不同的是,它沒有擁有者的概念。意即每一個 執行緒都可以對 semaphore 上鎖和解鎖。Counting semaphore 依照計數值可以有 多種狀態。當執行緒 post semaphore 時增加的數值,同時也是當一個執行緒 wait 一個 semaphore 減少的數值。當 semaphore 回到零時,只有最高 priority 的執行 緒可以執行。 Condition variables 和 mutex 搭配使用允許多執行緒存取共享資源。傳統上, 一個執行緒產生資料,一個或多個執行緒等待這筆資料。當資料備妥時,產生資 料的執行可以發出 Condition variable 通知喚醒一個或喚醒全部執行緒。等待中的 執行緒就可以拿到需要的資料並處理之。 Flag 用 32 位元表現的同步機制。每一個位元代表一個狀態,允許執行緒去 等待一個或多個組成的狀態。當狀態符合,該執行緒就會被喚醒。 Message box 又叫 mail box,提供兩個執行緒交換資訊。因為 mailbox 的容 積有限,交換的資訊一般都是資料結構的指標,或是有特別設計過的訊息。 在對稱式多核心平台上,eCos kernel 提供另一種額外的同步機制。同時其他 的同步機制可以在對稱式多核心平台上運作。Spinlock 基本上是一個 flag,和其 它同步機制比較起來是更底層的操作,會依不同的硬體有不同的實作方式。有些 處理器提供 test-and-set 指令來實作 spinlock。在處理器執行一段特殊程式碼之前 要去檢查此 flag。如果 spinlock 沒有上鎖,處理器可以設定 flag 和繼續執行此執 行緒。如果 spinlock 被鎖上,執行緒就會持續地檢查 flag 直到它被解鎖,而沒有 被 suspend。 3.3.5.5. Threads and Interrupt Handling Kernel 利用一種 two-level 方法處理 interrupt。連結每個 interrupt vector 是一 個 Interrupt Service Routine (ISR),它會盡可能快速的執行來回應硬體 interrupt。 ISR 只可以做少數的 kernel 呼叫,都是和 interrupt 系統相關,但不能做喚醒執行 緒的動作。如果 ISR 偵測到 I/O 完成,一個執行應該被喚醒,ISR 就會讓連結的 43.
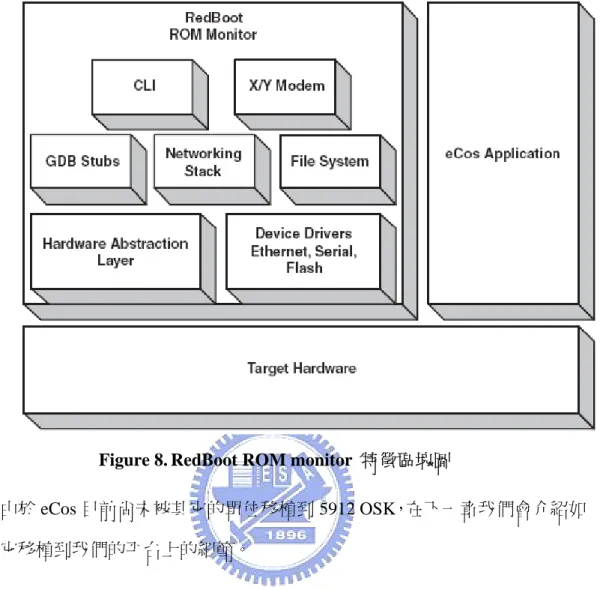
(44) DSR 去執行。DSR 可以使用更多 kernel 呼叫,如發 condition variable 訊號或 post a semaphore。關閉 interrupt 可以阻止 ISR 執行,但系統中很少機會關閉 interrupt, 如果有也是很短一段時間。執行緒關閉 interrupt 的主要理由是改變一些 ISR 之間 共享的狀態設定。例如,如果一個執行緒會增加 linked list 的 node,而且 ISR 可 能在任何時候自 linked list 移除一個 node,此執行緒就要在操作 list 時關掉 interrupt。. 3.3.6. RedBoot RedBoot 是 Red Hat Embedded Debug and Bootstrap 的縮寫。它是一個為嵌 入式系統提供一個除錯和 bootstrap 環境而設計的程式。RedBoot 是一個以 eCos 為基礎的應用程式,並且使用 eCos HAL 為它的基礎。下例為 RedBoot 的特性: z. 支援 boot scripting. z. Command line 介面,用於監視和控制. z. 可經序列埠或網路存取. z. 支援 GDB. z. 支援 Flash image 系統. z. 支援 X/ Y 模式傳輸. z. 支援網路 bootstrap,利用 BOOTP 或靜態 IP 位址設定. RedBoot 包括 GDB stub,可以從 PC 上的 GDB host 連接到平台上除錯。連 接方式可以是透過 serial port 或是 Ethernet port。除了除錯外,RedBoot 主要的功 能是 booting,支援三種 booting 方式,分別稱為 ROM, RAM, 和 ROMRAM。其 含意為 RedBoot 的 binary image 放置於何種記憶和由何種記憶體執行。ROM 和 RAM 即代表 image 放置和執行都在 ROM 或 RAM,ROMRAM 指的是放置在 ROM,欲執行前拷貝到 RAM,才在 RAM 執行。在 RAM 資源有限的情況下,. 44.
(45) 經常使用 ROM 模式的 booting。Image 是被放置在 flash 或 EPROM。由於 flash 命令不能寫入 RedBoot image 本身存放的區塊,所以為了更新 RedBoot,必需使 用 RAM 模式來達成。可以使用 ROM 和 ROMRAM 模式直接 booting,除非配合 其他 ROM monitor,否則不能直接使用 RAM 模式 booting。 RedBoot 會在 memory map 的底部,保留 RAM 空間結 run time 的資料和 CPU exception/ interrupt tables。在 memory map 頂空的空間則保留給 net stack、zlib 解 壓空間、等等平台的特殊需求。 依設定選項和 package,可以建立最經濟的 RedBoot,只包含該平台所需的 最小數元件。圖 8 顯示出 RedBoot ROM monitor 部份特徵的區塊圖[16]。由此圖, 可以看到 RedBoot 提供的功能全包含在 RedBoot 程式 image 之中。RedBoot 可以 只提供簡單的 image 載入和執行功能,提供簡易 flash file system,或是透過命令 列對應用程式做監控和除錯功能。在市面上有很多產品使用 RedBoot: z. Intel Residential Gateway. z. Intel XScale Development Board. z. ‧Intel StrongARM Development Boards. z. MIPS Malta 4kc/5kc/20kc Development Board. z. MIPS Atlas 4kc/5kc/20kc Development Board. 45.
(46) Figure 8. RedBoot ROM monitor 特徵區塊圖 由於 eCos 目前尚未被其它的單位移植到 5912 OSK,在下一章我們會介紹如 何將它移植到我們的平台上的細節。. 46.
(47) 4. eCos 至 OMAP 5912 OSK 的移植方法 因為本論文所設計的動態分工異質雙核心排程器是架構在 eCos 系統之下, 所以實作之前必須先把 eCos 移植到目標平台上。目前 eCos 的公開程式碼計畫 並沒有支援 OMAP 5912 OSK,所以本章先描述如何將 eCos 移植到目標平台上。 移植的流程分為三個階段,分別是移植 architecture HAL、variant HAL、和 platform HAL。每個 HAL 的功能及含義已在上一章敘述。這裡大略介紹移植流程,之後 段落將每個細節再詳加說明。 Architecture HAL 的移植:這部份的程式是根據處理器核心的大體架構而設 計的。因為 5912 OSK 的核心處理器是 ARM,由於 ARM 的 architecture HAL 己 經存在現有的 eCos 中,所以我們可以直接延用。 Variant HAL 的移植:Variant HAL 主要是處理每一類嵌入式處理器核心在架 構上的小調整。比如同樣是 ARM 9 的處理核心,有些有 MMU,有些沒有,有 些有訊號處理指令集,有些則支援 Java 加速。由於目前在 eCos 下還沒有 ARM 926EJS 核心的移植,所以我們以 ARM 925T 的程式碼為基礎開始進行移植工作。 首先取得需要的硬體資料(詳見下一節),接著修改各部份的內容設定,例如 instruction cache 和 data cache。還要在 eCos.db 檔之中新增 ARM926EJS package。 Platform HAL 的移植:由於 OMAP 5912 OSK 是承續 OMAP Innovator 的設 計,因此可以用 OMAP Innovator 為基礎來移植。但仍舊必需取得所需之硬體資 料。5912 OSK 的 Ethernet 是 LAN91C96,與 Innovator 相同,故可以使用,但 必需新增 Ethernet_5912 package 於 eCos.db 之中,並指出其使用 LAN91C96,此 外還得給定其 base address。Flash 是兩顆 Micron Q Flash MT 28F128J3,並沒有 現存的 package,但是它和 Intel Strata Flash 28F128J3 相容,可以借用其 package, 之後我們必需新增 Flash_5912 package 於 eCos.db 之中,並指定使用 Intel Strata 28F128J3。Serial port 使用 UART, Innovator package 中沒有檔案可以直接使用, 47.
數據
![圖 1 為 OMAP 5912 功能區塊圖[1]。MPU(ARM9)、MPU peripheral bridge、 Memory traffic controller 以及 system DMA 四者透過 MPU BUS 溝通。MPU 由 MPU bridge 透過 public/ private peripheral bus 和其週邊溝通。DSP 透過 public/ private peripheral bus 和其 peripheral 溝通。此外 DSP 可藉由 DSP MMU 或是 MPU I](https://thumb-ap.123doks.com/thumbv2/9libinfo/8262212.172236/26.892.161.709.549.1091/功能區塊以及透過溝通MPU由週邊溝通DSP透過和其溝通此外可藉I.webp)
![表 2 列出 OMAP5912 應用處理器 DSP 的記憶體對應關係(mapping)[1],包括 內部記憶體 DARAM 和 SARAM。ARM 定義一個 word 等於 4 個 byte,採 byte addressing,所有週邊和擴充的 memory 以及 control register 都由 32 位元來定位。 DSP 定義一個 word 等於 2 個 byte,是採 word addressing。](https://thumb-ap.123doks.com/thumbv2/9libinfo/8262212.172236/29.892.172.792.340.481/內部記憶和定義一個等於所有週邊和擴充的以及都由位元來定定義.webp)

![圖 3 為 eCos 系統區塊圖[18]:](https://thumb-ap.123doks.com/thumbv2/9libinfo/8262212.172236/34.892.202.726.401.848/圖3為eCos系統區塊圖18.webp)
+7


相關文件
相關分析 (correlation analysis) 是分析變異數間關係的
如圖,空間中所有平行的直線,投影在 image 上面,必會相交於一點(圖中的 v 點),此點即為 Vanishing Point。由同一個平面上的兩組平行線會得到兩個
Classifying sensitive data (personal data, mailbox, exam papers etc.) Managing file storage, backup and cloud services, IT Assets (keys) Security in IT Procurement and
(approximation)依次的進行分解,因此能夠將一個原始輸入訊號分 解成許多較低解析(lower resolution)的成分,這個過程如 Figure 3.4.1 所示,在小波轉換中此過程被稱為
服務提供者透過 SOAP 訊息將網路服務註冊在 UDDI 中,服務需求者也可以透 過 SOAP 向服務仲介者查詢所需的 Web Service 並取得 Web Service 的 WSDL 文件,2.
當 Bundle 啟動後會將自身所提供的服務註冊到 Service Registry 中,如圖 2-12,Service Registry 會對部署在 OSGi Framework 的 Bundles 發送新加入 Bundle 的 Service
Excel VBA 乃是以 Visual Basic 程式語言為基礎,提供在 Excel 環境中進 行應用程式開發的能力。在 Excel 環境中「Visual Basic 編輯器」提供了一個
在軟體的使用方面,使用 Simulink 來進行。Simulink 是一種分析與模擬動態
