國立臺灣大學資訊網路與多媒體研究所 碩士論文
Graduate Institute of Networking and Multimedia College of Electrical Engineering & Computer Science
National Taiwan University Master Thesis
應用於中文意見分析之詞內暨詞間語法結構自動擷取研究 Automatic Extraction of Intra- and Inter- Word Syntactic
Structures for Chinese Opinion Analysis
黃挺豪
Huang Ting-Hao
指導教授:陳信希博士 Advisor: Chen, Hsin-Hsi, Ph.D.
中華民國 98 年 6 月
JUNE, 2009
誌謝
"Would you tell me, please, which way I ought to go from here?"
「可不可以請你告訴我,從這裡我應該往哪裡去呢?」
"That depends a good deal on where you want to get to," said the Cat.
「那主要還看妳想往哪裡去囉。」這貓說道。
"I don't much care where--" said Alice.
「我不太在乎是去哪裡──」Alice 說。
"Then it doesn't matter which way you walk," said the Cat.
「那麼妳往哪條路走都無所謂吧。」貓說道。
"--so long as I get somewhere," Alice added as an explanation.
「──只要能讓我走到某個地方就行了!」Alice 補充說明。
"Oh, you're sure to do that," said the Cat, "if you only walk long enough."
「噢,妳一定可以的。」貓說,「只要妳走得夠遠。」
──《愛麗絲漫遊奇境》 Chapter VI. PIG AND PEPPER. 第 45 段
感謝陳信希老師兩年多來的悉心指導與毫無保留的支持,感謝倫維學姊永遠 充滿活力的陪伴,感謝嬿朱穿行過大雪來見我,感謝少女的甜點聚會,感謝吵鬧 或脾氣差的妹妹們,感謝舜文的晚安。
只要走得夠遠,一定可以到達某一個地方。
而我終於真正走進夏天裡了。
感謝所有愛我的與我愛的,這本論文寫滿了你們。
摘要
本研究之宗旨在於「將語法資訊引入意見分析中,改善其效能」。主要分為兩 部分:詞內層次與詞間層次。
詞內層次方面,本研究首先參考各家分類方式,制定出一構詞分類架構,繼 而就此架構展開語料標記工作。語料標記完成後,我們除對構詞類別分佈狀態進 行統計外,亦對標記者間之答案ㄧ致性與人工標記時於各構詞類別之判定效能作 了分析。分析結果顯示標記者間兩兩一致性係數(Kappa)均屬於「高度一致」
範圍,肯認了此問題之信度。最後我們以《教育部國語辭典》之資訊為特徵值,
於標記完成之語料集上以各種不同分類方法進行實驗,其中以條件隨機域模型
(CRF)之效能最佳,對五大基本構詞類別可達到平均 F 分數為 0.6 的效能。
詞間層次方面,本研究首先比較意見句與非意見句之依存關係數量,藉此證 實意見句之語法結構確有其特殊性;繼而對所有意見句之語法分析樹展開「標示 意見結構」之標記工作,共標記約一萬餘句意見句,每句至少由兩位工讀生標記 之。其標記結果一則可轉換為依存關係,從而比較句中「表達意見」之結構的特 殊性,並歸納出 14 種較常用於意見表達之依存關係;另一方面,標記結果亦可直 接於語法分析樹上進行預測。本研究將問題簡化為序列式標記問題,以條件隨機 域模型直接於語法樹上標示出意見結構位置。並得到精確度(precision)極高、
回收率(recall)偏低之實驗結果。
最後本研究亦將前述之詞內與詞間語法結構資訊施用於意見分析系統中,經 實驗證實,此資訊確可改善目前之意見分析效能,致使意見句判斷達到 0.8 之 F 分數、意見詞極性判斷達到 0.6 之 F 分數。
關鍵詞:意見分析、意見擷取、構詞、語法結構、意見句、意見詞、語法關係
目錄
誌謝 ... i
摘要 ... iii
目錄 ... v
表目錄 ... ix
圖目錄 ... xi
第一章、緒論 ... 1
1.1 研究動機 ... 1
1.2 研究目的 ... 2
1.3 論文架構 ... 2
第二章、文獻探討 ... 3
2.1 中文文本意見分析 ... 3
2.1.1. 以經驗方法為基礎的中文文本意見分析 ... 3
2.1.2. 語法結構資訊於中文文本意見分析之應用 ... 3
2.2 中文語法結構研究及其自動剖析 ... 4
2.2.1. 詞內層次 ... 4
2.2.1.1. 中國大陸地區 ... 4
2.2.1.1.1. 北京大學(俞士汶、朱學鋒等) ... 5
2.2.1.1.2. 清華大學(苑春法、黃昌寧等) ... 6
2.2.1.1.3. 魯東大學(亢世勇等) ... 7
2.2.1.2. 國際研討會 ... 8
2.2.2. 詞間層次 ... 9
2.2.2.1. 賓州大學樹庫(Penn Treebank)5.1 版 ... 9
2.2.2.2. 依存關係樹 ... 9
2.2.2.3. 史丹佛語法分析套件 ... 9
第三章、中文詞內部語法結構自動分類 ...11
3.1 問題敘述 ...11
3.2 二字詞內部語法結構分類及其理論歧異 ... 13
3.3 詞彙語料標記 ... 17
3.3.1. 語料標記及過濾 ... 17
3.3.2. 標記結果分析與文獻比較 ... 19
3.4 二字詞內部結構自動分類 ... 26
3.4.1. 特徵值抽取 ... 27
3.4.1.1. 《教育部重編國語辭典修訂本》簡介 ... 28
3.4.1.2. 使用之特徵值 ... 30
3.4.2. 分類方法 ... 35
3.4.2.1. 支援向量機(SVM)分類法 ... 35
3.4.2.2. 條件隨機域(CRF)分類法... 35
3.4.2.3. 單純貝氏(Naïve Bayes)分類法... 36
3.4.2.4. 簡單機率分類法 ... 36
3.4.2.5. 表格分類法 ... 38
3.5 分類效能評估 ... 39
3.5.1. 實驗設定 ... 39
3.5.2. 實驗結果 ... 40
3.5.3. 討論 ... 42
3.6 小結 ... 43
第四章、中文詞詞間結構自動擷取 ... 45
4.1 問題敘述 ... 45
4.2 基本定義:意見句與意見段落 ... 46
4.2.1. 意見句與意見詞 ... 46
4.2.2. 意見段落 ... 47
4.3 問題初探:意見句及非意見句之依存關係樹比較 ... 47
4.3.1. 意見句標記 ... 47
4.3.2. 意見句及非意見句依存關係樹分佈比較 ... 48
4.4 中文詞詞間結構語料標記 ... 50
4.4.1. 標記目的及使用語料 ... 50
4.4.2. 詞間結構定義與分類 ... 52
4.4.3. 標記方法暨「潘恩標記系統」(Pan Annotation System)... 54
4.5 語料分析 ... 57
4.5.1. 原始標記結果分析 ... 57
4.5.2. 依存關係分析 ... 60
4.5.2.1. 依存關係轉換方法 ... 60
4.5.2.2. 轉換結果統計及分析 ... 62
4.6 詞間結構自動擷取 ... 64
4.6.1. 自動擷取方法 ... 64
4.6.2. 特徵值抽取 ... 66
4.6.3. 結構自動擷取效能評估 ... 67
4.6.3.1. 實驗設定 ... 67
4.6.3.2. 序列類型判斷 ... 67
4.6.3.3. 直接擷取腳點 ... 70
4.6.3.4. 討論 ... 71
4.7 小結 ... 71
第五章、語法結構應用於意見分析研究 ... 73
5.1 使用構詞資訊之中文詞意見自動分析 ... 73
5.2 使用詞間結構資訊之中文句子層次意見分析 ... 76
第六章、總結與展望 ... 79
參考文獻 ... 81
附錄 A:常用譯名對照表 ... 87
附錄 B:未使用之賓大樹庫句子清單 ... 88
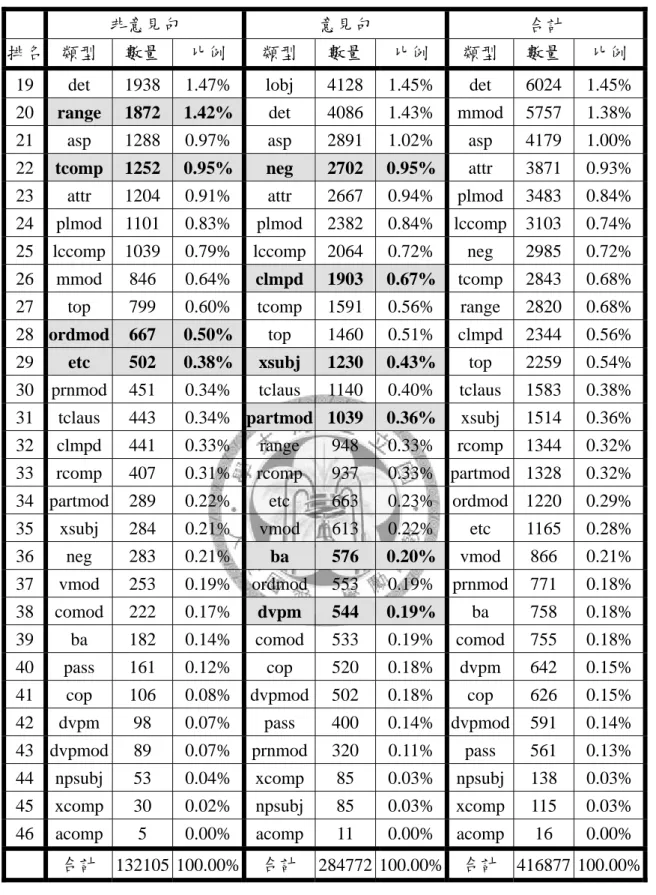
表目錄
表 3-1 各中文語料庫詞彙總量統計(%) ... 12
表 3-2 各家構詞分類法對照表... 16
表 3-3 詞彙過濾規則... 19
表 3-4 二字詞語料集標記結果分佈統計... 20
表 3-5 二字詞標記者一致性及效能分析... 21
表 3-6 二字詞標記者間一致性分析... 22
表 3-7 各家構詞分類分佈統計(%)... 25
表 3-8 基本特徵值組(以「好(ㄏㄠˇ)」為例)... 31
表 3-9 聲調特徵值(以「好(ㄏㄠˇ)」為例)... 32
表 3-10 詞首特徵值組(以「好(ㄏㄠˇ)」為例)... 33
表 3-11 詞尾特徵值組(以「好(ㄏㄠˇ)」為例) ... 34
表 3-12 完整特徵值範例(以「好(ㄏㄠˇ)」已知讀音狀況為例)... 35
表 3-13 機率公式各項說明... 37
表 3-14 詞性組合與構詞分類對照表... 38
表 3-15 自動分類於精簡集(6187 詞)上之實驗結果... 40
表 3-16 精簡集(6187 詞)與強化精簡集(8186)效能比較... 41
表 4-1 意見句與非意見句依存關係分布比較... 48
表 4-2 詞間結構標記統計表... 58
表 4-3 意見句中表達意見之依存關係比例... 62
表 4-4 序列結構辨識評估... 68
表 4-5 序列結構類別辨識評估... 69
表 4-6 腳點位置直接辨認評估... 70
表 5-1 套用構詞資訊之意見詞極性判斷評估... 76
表 5-2 套用詞間結構資訊之意見句判斷評估... 77
圖目錄
圖 2-1 現代漢語語法信息辭典樹狀結構圖... 5
圖 2-2 《現代漢語新詞語信息辭典》結構圖... 7
圖 3-1 中文字、詞與詞素之關係... 12
圖 3-2 二字詞結構分類語料標記流程圖... 18
圖 3-3 二字詞語料集標記結果分佈統計圖... 20
圖 3-4 二字詞標記者間一致性測試... 22
圖 3-5 各家構詞分類分佈統計圖(僅列詞彙量超過 5000 者)... 26
圖 3-6 《教育部國語辭典》一般詞語條目樣式(以「科學」為例)... 28
圖 3-7 《教育部國語辭典》單字資料條目實例(以「好(ㄏㄠˇ)」為例)... 29
圖 3-8 《教育部國語辭典》單字資料條目實例(以「好(ㄏㄠˋ)」為例)... 29
圖 3-9 二字詞自動分類器與標記者平均效能比較圖... 41
圖 3-10 精簡集、強化精簡集與標記者平均效能比較... 42
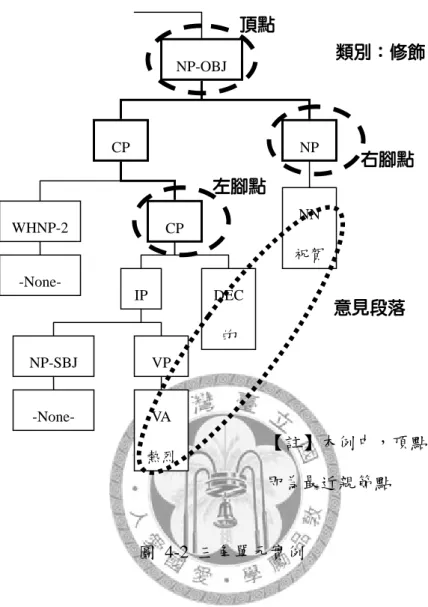
圖 4-1 意見段落與結構關係圖... 54
圖 4-2 三角單元實例... 56
圖 4-3 「潘恩標記系統」介面... 57
圖 4-4 各種傾向之意見句中意見結構分佈比較... 58
圖 4-5 各種類型意見句中意見結構分佈比較... 59
圖 4-6 各種意見結構之意見句傾向分佈比較... 59
圖 4-7 各種意見結構之意見句類型分佈比較... 59
圖 4-8 標記語料轉換為依存關係範例(轉換前)... 61
圖 4-9 標記語料轉換為依存關係範例(轉換後)... 62
圖 4-10 同親結構範例... 65
圖 4-11 非同親結構範例 ... 66
圖 4-12 詞間關係自動擷取特徵值示意圖... 67 圖 5-1 詞間結構使用方法範例... 77
1. 第一章、緒論
1.1 研究動機
文本意見分析為近年日漸興起之計算語言學研究議題,該問題主要目的為「判 斷人類文本中之意見」,為全面了解「意見內容」,該問題又細分為:意見句判斷、
「意見持有者」(opinion holder)擷取、「意見目標」(opinion target)擷取、「意見 極性」(polarity)辨別,乃至「意見句類型」自動分類等諸多不同範疇與對象之 問題;而若以文本大小區分之,則略可分為文件層次(document level)、句子層 次(sentence level)、詞彙層次(word level)等不同層級之問題。而在研究方法上,
主要可分為機器學習方法與經驗方法兩類。前者抽取適用之特徵值後繼而以機器 學習演算法訓練並預測意見內容;而後者則以語言學知識為基礎,設計計算公式,
逐步模擬各層次語義內容相互結合的行為,從而判斷意見傾向。本研究所依循並 欲改善之對象為後者。
以經驗方法進行中文文本意見分析,以(Ku, Liang et al. 2006)為代表,其方 法為以機率模型計算「漢字」之意見極性分數後直接以加法將分數加總,輔以否 定子之變號作用,得出意見詞之意見分數;而於句子層次與文件層次其概念亦同,
即以意見詞分數為基礎進行加法運算,從而得出句子及文件之意見分數。然以加 法為基礎之運算方式卻遭遇了瓶頸,試舉例說明如下:
就詞彙層次而言,如「抗菌」一詞,該詞彙之意見傾向為正向,然若以字彙 之意見分數加總計算,「抗」為負面字、「菌」亦為負面字,直接加總後自然得出
「抗菌」為負面詞之結果;而於句子層次亦有類似問題,如「他是僥倖獲勝的」
一句,顯然為負面意見句,然若以句內意見詞分數直接加總,「獲勝」為一分數極 高之正面意見詞,而「僥倖」固為負面意見詞,強度卻僅為一般程度(畢竟「僥
倖」通常意味著「雖然驚險但已成功了」),導致全句分數加總時「獲勝」之正向 分數將蓋過「僥倖」之負向分數,而得出該句為正面意見句之結論。
此問題乃肇因於「加法」並非語義結合的真正方式,欲解決此問題必須引入
「語法資訊」。如若能夠理解「抗菌」一詞之構成中,「抗」為動詞、「菌」為受詞,
則或可設計變號公式,從而得出該詞為正向詞之結果;而句子層次亦若是,若能 理解「僥倖」乃是修飾「獲勝」之副詞,則或可設計適當公式而得出合理的結果。
此即本研究之出發動機,意欲尋找適用於意見分析之詞內與詞間語法結構,藉以 改善經驗方法施用於中文意見分析之效能。
1.2 研究目的
本研究之主旨在於尋找適用於中文意見分析之語法結構資訊。無論於詞內或 詞間(即一般所稱之「語法結構」)此問題可進一步細分為三大部份:有哪些結構、
分別之定義為何?該結構之實際分佈、使用狀態如何?又該如何預測?亦即「結 構定義」、「語料分析」及「自動預測(擷取)」三主要問題。本研究於對象上切分 為「詞內」及「詞間」兩大部分,二部份均依此順序逐步展開,由結構定義(分 類)談起,明確定義後進行語料標記與標記結果分析,最後試圖對標記結果進行 預測。而其最終目的在於將此資訊引入現有之意見分析系統中,以期能改善意見 分析之效能。
1.3 論文架構
本論文主要分為「詞內」與「詞間」結構兩大部分。第 1 章為緒論,簡介本 研究全貌;第 1 章為文獻探討,將詞內與詞間結構之相關研究一併列舉之;第 3 章針對詞內結構進行探討、第 4 章則為詞間結構;第 5 章則實際將前兩章所獲得 之語法資訊套用至意見分析系統中,觀察其效能;第 6 章進行總結,而參考文獻 將列舉於第 7 章。
2. 第二章、文獻探討
本章將討論意見分析與詞內、外結構之相關研究。若未特別提及,本章所述 之相關研究均指「資訊科學」領域而言,而非傳統語言學或中國文學。而漢語構 詞分類歧異問題將於 3.2 節討論,各研究團隊所公佈之詞彙分布狀況統計將表列 於 3.3.2 節,於此章便不細究各家構詞類別的異同與實際分佈狀況。
2.1 中文文本意見分析
2.1.1.
以經驗方法為基礎的中文文本意見分析文本意見分析大致主要可分為「經驗方法」(heuristic)與「機器學習方法」
(machine learning)兩大類,本研究所依循並意圖改善者為以「經驗方法」為主 之意見分析研究。該類方法以語言學知識為基礎,試圖自詞彙、句子乃至文件層 次,由下而上,逐步建構出簡潔而有效的意見分析模型。可將(Ku, Wu et al. 2005)
視為發軔之嘗試,該研究提出以漢字為基礎的意見分析模型,從而擘畫出詞彙、
句子、文件層次的意見分析架構,並提出了一套語料建置的方法。此時意見分析 問題尚處於發展初期,並未進一步探究意見強度與傾向問題,而僅對「是否含有 意見」進行評估;隔年發表之(Ku, Liang et al. 2006)則將意見分析應用於部落格 語料上;再次年發表(Ku, Lo et al. 2007),其意見分析架構已臻成熟,提出更為 完整之意見句標記與評估方法,將本僅由一人標記之意見答案擴增為可整合三人 之標記結果,影響所及,除可得到更精確之標記結果外,亦可進一步探討意見強 度與標記結果信度之問題,為意見分析問題逐漸發展成熟之指標。
2.1.2.
語法結構資訊於中文文本意見分析之應用將語法結構資訊應用於中文意見分析方面,詞內層次尚未有相關研究發表;
詞間層次則有浙江大學所發表之(Qiu, Liu et al. 2007)與(Qiu, Wang et al. 2008)
兩篇。二研究均在「意見詞已知」之情況下展開,前者藉辨識 6 種特定的依存樹
(dependency tree)結構找出「意見主題」(topic);後者則利用依存關係樹中副 詞語尾「地」與形容詞語尾「的」兩種結構1,進行意見傾向的「變號」。吾人不 難發現此二者均為語法結構資訊之初步應用,既未影響意見分數之絕對值結果(即 強度結果),能施用之情況亦相當有限。然由此可看出,以經驗方法為基礎之中文 意見分析研究,世界各地之團隊均遭遇了語義資訊有限的瓶頸,並逐漸開始嘗試 將語法資訊引入系統中。本研究即試圖對此問題提出一宏觀之解答。
2.2 中文語法結構研究及其自動剖析 2.2.1.
詞內層次2.2.1.1. 中國大陸地區
自然語言處理領域中對漢語構詞問題著力最甚者莫過於中國大陸,早在 1986 年始籌劃之《現代漢語語法信息辭典》中便包含了詞彙內部結構的資料欄位2,此 後多部語素資料庫與構詞資料庫亦紛紛在國家級科學基金挹注下展開編纂,為構 詞問題提供極可觀之研究資源。其成果固多非發表於國際期刊及研討會,但有鑒 其成果之豐、規模之鉅,不可輕忽其代表性,故特闢專節討論之。本節將以中國 大陸地區長期關注漢語構詞問題之三個主要團隊為軸,簡介各團隊之研究成果,
並比較其與本論文在目的、範疇、方法上之異同。考量此三團隊相似之研究脈絡:
均以語料庫建構為發軔,繼而就其所建之語料庫展開分析,故本節在介紹各團隊 時,均以其所建構之語料庫為主。
1 該研究使用哈爾濱工業大學信息檢索研究室所開發之語法分析套件。可參考:http://ir.hit.edu.cn/demo/ltp/
2 如離合詞分庫下之「結構」欄位。
2.2.1.1.1. 北京大學(俞士汶、朱學鋒等)
z 語料庫:《現代漢語語法信息辭典》、《現代漢語語素庫》、《現代漢語合成詞結 構數據庫》
《現代漢語語法信息辭典》為北京大學計算語言研究所自 1986 起以十餘年人 力物力所編纂之大型電子辭典。該辭典遵循朱德熙先生提出之「詞組本位語法」
精神(亢世勇 2001),其編輯宗旨並不在收錄大量詞彙(至 2004 年止,該辭典包 含詞彙數約 7.3 萬左右,尚不及《教育部國語辭典》詞條數之一半),而在於盡可 能收錄大量「組成短語或新詞」的「詞部件」(包括語素、詞或固定短語),並詳 細標註其構詞能力及組合規則,從而成為一個包含「詞部件資訊」與「構詞知識」
的語料庫(王惠 and 朱學鋒 1994)。該詞典將漢語詞彙分為 26 個詞類3,合有 32 個資料庫:總庫 1 個、各類詞庫 23 個(嘆詞、擬聲辭、非語素字不獨立建庫), 代詞下又設有「人稱代詞」、「指示/疑問代詞」2 分庫,動詞下則有「體賓動詞」、
「謂賓動詞」、「雙賓動詞」、「動結式」、「動趨式」、「離合詞」6 個分庫(朱學鋒, 俞士汶 et al. 1995),可表為一樹狀結構圖:
圖 2-1 現代漢語語法信息辭典樹狀結構圖(李普霞 and 劉雲 2004)
3 18 個「基本詞類」:名詞(n)、時間詞(t)、處所詞(s)、方位詞(f)、數詞(m)、量詞(q)、區別詞(b)、
代詞(b)、動詞(v)、形容詞(a)、狀態詞(z)、副詞(d)、介詞(p)、連詞(c)、助詞(u)、語氣詞(y)、
擬聲詞(o)、嘆詞(e),此外也收錄了一部份較基本詞類為大的單位:成語(i)、習用語(l)、簡稱略語(j),
以及一些較小的單位:前接成分(h)、後接成分(k)、語素字(g)、非語素字(x)、中文的標點符號(w),
共 26 個詞類。
在語法辭典初步完成後,為深入研究未知詞辨識問題,1999 年北京大學計算 語言研究所針對 GB/T2312-1980 下的全部漢字建立了一個單音節的「語素庫」。每 一筆記錄均包含漢字、讀音、類別、同形、組合、位置、姓、人名、地名、水名、
書面、方古、義項、備註等欄位,合有 7223 筆記錄。語素庫完成後,更進一步與
《現代漢語語法信息辭典》集成,將語法辭典中全部詞條以「成份語素」為索引 重新排序(如此雙語素詞便會擴充為兩筆紀錄、三語素詞為三筆),成為一更完備 的漢語知識庫(朱學鋒, 俞士汶 et al. 1999; 俞士汶, 朱學鋒 et al. 1999; 俞 士汶, 朱學鋒 et al. 2001)。
而後於 2000 年,(劉雲, 俞士汶 et al. 2000)進一步將《現代漢語語法信 息辭典》中的 39370 個二、三音節詞取出(不包含人名、地名),標註詞語、讀音、
詞類、同形、構詞、義項、備註、層次、前字/後字等屬性,建立了《現代漢語 合成詞結構數據庫》。
2.2.1.1.2. 清華大學(苑春法、黃昌寧等)
z 語料庫:《漢語語素數據庫》
《漢語語素數據庫》為北京清華大學於 1997 年所完成之大型資料庫,該資料 庫可概分為兩部份,一是「漢語語素」,二是「由語素所構成之詞」(簡稱「語素 所構詞」)。
漢語語素方面,該資料庫定義「語素」為「音義結合的最小單位」,即只要「音」
或「本義」中有一者相異,便獨立成為一「語素」(若音義相同但字型不同,原則 上視為同一語素);而考量語用之情況,同一「本義」之語素在文本中或會產生「引 申義」或「比喻義」,故每一「語素」下又有「語素項」,茲舉該語素之所有可能 義項。「語素項」即為該資料庫的最小錄單位(entry),每一語素項均標註意義、
類別、成詞/不成詞/半成詞、前位/中位/後位/不定位等資訊。合錄有語素
10442 個、語素項 17470 個。
語素所構詞方面,該資料庫蒐集由漢語語素組成之二、三、四字詞,每個詞 均標註詞型、讀音、詞類、構詞方式、類序、多義、字義組合等資訊。在刪除重 覆詞彙後,合有二字詞 45960 筆、三字詞 3930 筆、四字詞 4820 筆。
(苑春法 and 黃昌寧 1998)以基因演算法於語料庫中學習出最主要之構詞 原理,並將結果與語言學知識對照,而得到一定程度的肯認。
2.2.1.1.3. 魯東大學(2006 年前原山東煙臺師範學院)(亢世勇等)
z 語料庫:《現代漢語新詞語信息辭典》、《現代漢語新詞語構詞法數據庫》、《現 代漢語語義構詞數據庫》
為創建漢語新詞語研究之基礎平臺,山東煙臺師範學院於 1999 年起展開《現 代漢語新詞語信息辭典》的編纂。以盡量蒐集 1978 年後產生之「新詞語」為目標,
參考《現代漢語語法信息辭典》之架構,該辭典目前已收納近 40000 個新詞語。
除語法辭典固有欄位外,每筆新詞另標註有產生途徑、應用領域、來源、時間等 新詞語資訊,以及構詞法資訊(如:單音/多音、單純詞/合成詞、聯合/偏正
/補充/動賓/主謂/補充),以便對產生新詞之構詞法進行研究。該辭典之結構 亦可以表為一樹狀圖:
圖 2-2 《現代漢語新詞語信息辭典》結構圖(亢世勇 2002)
其中「構詞法庫」詳細標記了每一詞語之構詞部件、構詞法與詞性資訊,為
新詞構詞研究提供了極充分之語料(亢世勇 2001; 亢世勇 2002)。而後(亢世勇
2003)又自該辭典中挑選出兩萬多個詞語另編為《新詞語大辭典》,供一般語言學 研究之用。
其研究成果方面,(亢世勇, 徐豔華 et al. 2005)對產生新詞彙之構詞法進
行統計研究;而(亢世勇, 許小星 et al. 2005)則以現代漢語語義構詞數據庫 進行構詞原理之探討。
然如(傅愛平 2003)所陳,以上諸多研究所習得之構詞律卻鮮少直接應用在 未知詞辨識上,是以後續中國大陸諸多學者均將目光轉往「語義結合」而非「語 法結合」之思維處理構詞問題,而不繼續於構詞領域著墨。
2.2.1.2. 國際研討會
於國際研討會中發表之研究成果中,對此問題較著心力者有(Tseng and Chen 2002)及(Lu, Asahara et al. 2008)。前者於(Tseng and Chen 2002)中首先提出一
「自動構詞分析器」,以規則方法為基礎,對未知詞之構詞類別進行自動分類;繼 而又於(Tseng, Jurafsky et al. 2005)中提出可幫助辨識未知詞構詞類別之特徵值 組,並以「最大化熵馬可夫模型」(Maximum Entropy Markov Models,MEMM)
進行預測實驗。其自動構詞分析器於未知詞上可達 80%之正確率,而其 MEMM 實驗可達平均 90%之正確率。然綜觀其研究,可發覺其研究目的與對象均聚焦於
「未知詞」上,其所使用之特徵值(或規則)多基於「構詞部件常為已知詞」此 一假設而來。如「攝影展」之構詞部件為「攝影」及「展」,此二者均為已知詞,
可透過外部語料獲取大量資訊,藉以判斷構詞類別。然「未知詞」固亦為本研究 所涵蓋之對象,但本研究所欲處理之問題更全面,除未知詞外亦包括更多已知詞,
即該研究所使用之未知詞特徵(多由已知詞構成)本研究無法沿用;而另一相關
研究者為(Lu, Asahara et al. 2008),其碩士論文(Lu 2008)亦有可觀處。其主要 貢獻在於定義了一適合計算語言學之漢語合成詞分類架構,及提出以樹狀結構分 析長詞構詞資訊之概念。該研究並利用互訊息(Mutual Information,MI)及 SVM 進行初步實驗,獲致 94%之準確度。然而,該研究視二字詞為一不可分割之最小 語義單位,故其研究之主要對象為三字以上之長詞。而本研究之目的在於改善實 際意見分析系統,而二字詞又為漢語多字詞之最主要成分(此於 3.1 節中將詳述), 其重要性自不可輕忽,故該研究內容雖於本論文有啟發性作用,但實際研究範疇 仍是相異的。
2.2.2.
詞間層次2.2.2.1. 賓州大學樹庫(Penn Treebank)5.1 版
賓州大學樹庫(Penn Treebank,簡稱賓大樹庫)為一以人工斷詞、標記語法 分析樹之大型語料庫,有英文及簡體中文版本。其簡體中文 5.1 版合計含有 890 份文件,每份文件均標示一 FID,而每一文件中之每一句子均標有 SID,共有 18782 句,為一極具可靠性且廣為計算語言學界所使用之大型語料庫。
2.2.2.2. 依存關係樹
依存關係樹由許多「依存關係」(dependency relation)所構成;「依存關係」
為兩詞彙間之關係,其精神在於將詞彙間之語義連結視為「掌權者」與「依賴者」
之位階關係,從而將一句中之兩兩詞彙以「依存關係」連接起來,構成一依存關 係樹。依存關係樹常由語法分析樹轉換而來。
2.2.2.3. 史丹佛語法分析套件
由美國史丹佛大學所開發之開放原始碼語法分析套件。其遵循賓大樹庫所制
定之文法標準,可將原始文本解析為語法分析樹,亦可將符合賓大樹庫格式之語 法分析樹轉換為依存關係樹。為一免費且可靠之語法分析套件。該語法分析套件 中,對英文共訂有 48 種依存關係,對中文則有 46 種。
3. 第三章、中文詞內部語法結構自動分類
3.1 問題敘述
本段研究旨在為「意見詞分析」提供可用之詞內語法結構資訊。
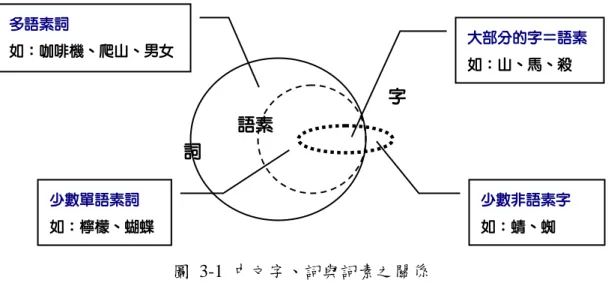
欲深究此問題,首先當談漢語中「字」、「詞」與「詞素」之關係。本論文所 指之詞素,乃指「語言中攜帶意義的最小單位」。意即語素可組成更大的語言表意 單位(如詞彙、詞組、句子、文章),卻無法拆解為更小且均帶有意義的語言單位。
如「山」字,可視為一語素,由於其本身即含有完整之意義,且無法繼續拆解,
故為漢語中攜帶意義的最小單位;而如「蝴蝶」,亦為一語素,由於該詞若拆為「蝴」
與「蝶」,則「蝴」字本身將無法表意(即「蝴」字並非語素),是以我們將「蝴 蝶」視為一語素,在詞彙層次中則稱之為「單語素詞」。
漢語中「詞彙」、「字」與「語素」之關係可表為圖 3-1。漢語中大部分單字 皆為語素,而凡語素字皆能成詞(即單字詞),如「山」字,於斷詞時會被斷為一 詞;而僅有極少部份漢字既非語素亦無法成詞,如蝴蝶的「蝴」、蜘蛛的「蜘」。 此類字多屬漢語連綿詞之詞首,亦即於古漢語中為方便發音之襯字,而不帶有語 義,須與另一字合成為詞方具意義。如「蜻」加「蜓」方成「蜻蜓」,獨立作「蜻」
時是不帶義的。而詞彙方面,除既為字也為語素的單字詞外,多字詞部分亦可分 為兩類:「單語素詞」及「多語素詞」。大部分多字詞為多語素詞(就邏輯上這亦 是合理的,因漢字多為語素),即可拆解為更小的語言單位,如「咖啡機」可拆為
「咖啡」與「機」,「爬山」可拆為「爬」與「山」;然亦有少部份詞彙無法拆為更 小的表意單位,如翻譯詞(如「檸檬」、「沙發」、「涅盤」等)、連綿詞(如「蝴蝶」、
「蜻蜓」等)、習慣語(如「降子」)等等,此類詞本身即為語素,故稱為「單語 素詞」。
圖 3-1 中文字、詞與詞素之關係
本研究以任何「經斷詞系統所分出之詞彙」為輸入,以「該詞彙之構詞方式」
為輸出。「該詞彙之構詞方式」實可分為數個子問題,包括「該詞彙是否為多語素 詞」;若是,則可問「該詞彙如何斷為子語素」(更甚者可問「該斷到什麼程度」,
如「高山湖」可斷為「高山/湖」,或更進一步斷為「『高/山」/湖」);斷為組 成部件後,最後才問「該數個組成部件間是何種關係」,而若將此視為分類問題,
則亦有「共有哪些關係」此一分類框架之問題。而考量本研究之目的在「為意見 分析提供有用之語法結構資訊」,吾人首先對三種不同性質之語料進行如表 3-1 的統計:
表 3-1 各中文語料庫詞彙總量統計(%)
詞長(字數) 14 2 3 4 ≧5 Penn Treebank 5.1 48.04 44.09 5.98 1.10 0.79 NTCIR CIRB040 51.16 42.00 5.66 0.93 0.24 新華新詞語辭典 - 58.7 17.6 14.7 8.7
表 3-1 中所分析之三個項目分別為不同性質語料之代表:賓大樹庫(Penn Treebank 5.1)為一由人工斷詞之大型語料庫、NTCIR CIRB040 則為以機器斷詞 後之大型語料庫,而新華新詞語辭典則為人工編纂之辭典。然而無論語料為何,
4 包含標點符號。
詞
語素
多語素詞
如:咖啡機、爬山、男女
少數單語素詞 如:檸檬、蝴蝶
大部分的字=語素 如:山、馬、殺
少數非語素字 如:蜻、蜘
字
均可明顯觀察得知「二字詞」為漢語多字詞之最大宗,且在數量上具有極大的優 勢,若欲將構詞資訊作為後續意見分析之線索,則必須以「二字詞」為最主要研 究對象。在此目的上,(Tseng and Chen 2002)或(Lu, Asahara et al. 2008)均無法 提供足夠之資訊。考量二字詞其數量上之壓倒性優勢,本研究首先將問題限定於
「二字詞」之詞內結構擷取。限於二字詞之另一優點為:二字詞若為多語素詞,
則必由兩字所組成,該二字即為語素字。如此一來吾人便可專注於構詞關係分類 上,而無須考慮「斷詞」的問題。
此外,分類架構方面,本研究將參考諸多計算語言學與漢語構詞學所提出之 構詞結構分類定義,討論其異同及對意見分析之適用性,訂出最宜應用於意見分 析之分類綱目。而更基礎之「該詞是否為多語素詞」問題,考量「多語素詞」本 為漢語詞之大宗,遂僅將「單語素詞」視為分類架構下之一項,不另作特別處理。
此外,考量本研究之對象為「所有二字詞」,亦包括未知詞在內。即非對任何 輸入之二字詞均能得到詞彙外部資訊(如詞性、詞頻等),亦無法保證在實際系統 中可取得前後文,是以本研究進一步將範圍縮小,禁止使用任何「詞彙層次之資 訊」,限制以組成字為線索,直接判斷構詞類別。意即將問題限制於資訊最少、亦 最困難之範疇。
至此,吾人可擘畫出系統之概貌:以「斷詞系統分出之二字詞」為輸入,由 於無需考量斷詞方式,故僅以「該詞之構詞分類」為輸出。如輸入「男女」,則將 輸出「並列」一類;而如輸入「跑步」,則將輸出「動賓」;而若輸入「檸檬」,則 由於無法分割為更小單位,將輸出「其他」。構詞分類架構之細節將於次節中詳述。
3.2 二字詞內部語法結構分類及其理論歧異
本節首先介紹我們所採之二字詞內部結構分類,繼而討論目前中文自然語言 處理領域對詞內結構分類方式之各家異同,藉此闡明選擇此分類架構之考量。
本研究所採之二字詞內部結構分類,原則上以(程祥徽 and 田小琳 1995)
為基準,主要分為五類,並因應意見擷取實務而稍作修改。詳述如下:
(1) 並列關係(Parallel,又稱聯合關係)
兩語素於「語法地位」上處於平行、平等的位置,彼此並無互相修飾之 關係。而語義上則無特定的限制,有兩語素意義相近或相同者如「海洋」、
「城市」、「明亮」;有意義相類、概念範疇等級相近者如「尺寸」、「牛馬」、
「山海」;也有完全相對、相反者如「男女」、「買賣」、「深淺」等等。為 簡化問題,疊字詞亦歸於此類,不另立為類。
(2) 修飾關係(Substantive-Modifier,又稱偏正關係)
第一個語素用以修飾第二個語素、第二個語素被第一個語素所修飾。若 以第二個語素之詞性分述之,被修飾的對象可能是名詞性的,如「高山」、
「大海」;可能是形容詞性的,如「筆直」、「雪白」、「火熱」;亦可能是 動詞性的,如「狂奔」、「痛哭」、「輕視」等等。為單純化問題,此處我 們限制被修飾者必為第二個語素。極少數漢語之例外,或部分由方言轉 譯而來的二字詞如「人客」(「人」為主、「客」為偏),則直接歸為「其 他」。
(3) 主謂關係(Subjective-Predicate,又稱陳述關係)
第一個語素為被陳述的對象、第二個語素為陳述語,即如句法中主詞與 謂語的關係,好似一個主謂句濃縮於二字詞中。如「地震」、「火燒」、「耳 熟」、「膽大」等等。
(4) 動賓關係(Verb-Object,又稱支配關係)
第一個語素往往為動詞性的,第二個語素則為其賓語(受詞),常為名詞 性的。如「輸血」、「登陸」、「簽名」、「賣命」等等。
(5) 動補關係(Verb-Complement,又稱補充關係)
第一個語素帶有謂語之性質,常為動詞性或形容詞性,而後一個語素則 從不同角度補充前一個語素,常為副詞性的。如「擴大」、「記住」、「標
明」、「充滿」等等。
除上述主要五類外,考量意見擷取任務之特殊性,若一語素之語義為「確認」
或「取消」後方語義,功能即類似數學中之正負號。其特徵明顯、易於辨認,於 意見傾向計算時亦具特殊性,故另立為類,即「肯定」與「否定」二類:
(6) 否定(Negation)
第一個語素之語義功能為否定後方語素之語義,此語素又稱為「否定 子」。常見的否定子如「非」、「否」、「不」。
(7) 肯定(Confirmation)
第一個語素之語義在於肯定後方語素之語義,此語素又稱為「肯定子」。 常見的肯定子如「有」。
以上分類架構已臻完備,下節分析中亦將顯示此七類可含括 95%以上之二字 詞。然仍有極少數例外無法為此架構所容納,如翻譯詞、俗語、簡寫,或部分虛 詞如「以為」、「所以」等等。為使本研究趨於完善,另增「其他」一類:
(8) 其他(Others)
無法歸於前七類之二字詞即屬此類,包括前綴詞(如「阿嬤」)、後綴詞
(如「牛仔」)、翻譯詞(如「檸檬」)、簡稱(如「立委」)、連綿詞(如
「鴛鴦」、「蝴蝶」,又稱單詞素詞)、部分虛詞與功能詞(如「而且」、「以 為」、「因為」)等等。
上述之八種分類即為本研究所使用之完整分類架構。然而,構詞分類方式本 為語言學研究課題之一,學說絕非獨尊一家,而是百家爭鳴,無論於漢語語言學 或計算語言學領域皆有諸多學者提出其構詞分類。此處茲將本研究之分類方式與
其他研究團隊之分類作一對照,如表 3-2:
表 3-2 各家構詞分類法對照表 數量 並列 修飾 主
謂 動
賓 動補 其他
本研究 8 並列 修
飾 肯定 否 定
主 謂
動
賓 動補 其他
現代
漢語5 8 並列 重疊式 修飾 主 謂
動
賓 動補 附加式 其他 亢世勇6 8 聯合 狀中 定中 主
謂 動
賓 補充 加前綴 加後綴 劉雲7 8 聯合 連動 狀中 定
中 名 量
主 謂
述
賓 述補 -
石秀雙8 5 聯合 偏正 主 謂
動
賓 補充 -
穆克婭9 5 聯合 偏正 主 謂
動
賓 補充 -
傅建紅10 6 聯合 偏正 主 謂
述
賓 述補 其他
苑春法11 16 體 素 聯 合
謂 素 聯 合
重 疊
定中 偏正
狀 中 偏 正
量 補
主 謂
述 賓
述 補
述 介
前 綴
後 綴
簡 稱
數 詞 縮 語
固 定 詞 組
未 注 標 記
表 3-2 顯示以上諸多分類方式仍大致可歸於五大基本類別;而參酌其他研究
5 程祥徽 and 田小琳 (1995). 現代漢語, 三聯書店 香港.
6 亢世勇, 徐豔華, et al. (2005). 基於語料庫的現代漢語新詞語構詞法統計研究. International Conference on Chinese Computing, Singapore.
7 劉雲, 俞士汶, et al. (2000). 現代漢語合成詞結構數據庫. 第二屆中文電化教學國際研討會, 廣西師範 大學出版社.
8 石秀雙 (2007). "現代漢語雙音復合詞結構關系考察——以 z 字母下雙音復合詞為例進行分析." 晉中學 院學報 2007(6): 1-8.
9 穆克婭 (2008). "新雙音節複合動詞語素構詞規律研究." 現代語文 2008(12): 42-44.
10 傅建紅 (2009). "論《現代漢語詞典》F類雙音複合詞的結構關係." Ibid. 2009(3): 49-50.
11 苑春法 and 黃昌寧 (1998). "基於語素數據庫的漢語語素及構詞研究." 語言文字應用 1998(3): 83-88.
團隊之統計文獻亦可發現(本研究後續進行之標記分析亦得到此結果),真實詞彙 中構詞分類之分布極不平衡,前三大類別幾乎可佔去八成左右的詞彙,是以若分 類過細,則許多次要類別將過小,而導致分類與應用時極為困難。是以本研究仍 選擇遵循現代漢語之構詞分類架構展開後續標記與預測之研究。
3.3 詞彙語料標記
提出結構分類架構後,為進一步分析各類詞彙之分佈狀況,並為後續分類器 實驗提供訓練及測試語料,我們接著展開語料標記工作。6500 筆語料標記完成 後,除分析各類分佈狀況外,考量許多研究團隊亦曾進行構詞分類之統計,本研 究亦將標記結果與其他研究團隊之數據進行比較,分析其異同。本論文首先於 3.3.1 中描述語料標記細節,並於 3.3.2 節對標記結果進行分析。
3.3.1.
語料標記及過濾我們首先將 NTCIR CIRB040 大型語料集以機器斷詞,繼而從中隨機抽取出 6500 個二字詞。該語料集由臺灣地區之新聞文章組成,為一繁體中文之大型語料 庫。使用 CIRB040 語料,一方面符合本研究以繁體中文為基礎之出發點,另一方 面機器斷詞較之人工斷詞語料(如 Penn Treebank 或中研院平衡語料庫)更貼近實 際應用環境,亦更能模擬意見擷取系統之真實狀態。
本研究聘請至少六位中國文學系大學部在學學生擔任標記者,及一位甫畢業 於中文系之應屆畢業生12擔任專家(expert),以對歧異性較大之詞彙進行判斷。
所有標記者均先經過一小時語法規則講解及標記練習,方得開始正式標記語料。
每位標記者須將分配得之二字詞分入 3.2 節所定義之 8 類中,標記時並未提供詞 性資訊,標記者得參考相關資料(如線上字典),但為探討個人主觀之影響,彼此
12 本語料標記時間為暑假。
不得交談。若遇有歧義之詞彙,則由實驗設計者統一規定該詞之語義,此情況本 實驗中僅有「東西」(「方位」或「物件」)與「學會」(「學生自治會」或「習得」) 兩例,前者統一規定為「物件」義、後者則訂為「習得」義。
標記流程如下:首二位標記者A、B之標記答案若相同,則接受為標準答案;
若不同,則再由第三位標記者C標記之,若三者中有兩答相同,則接受為標準答 案;若不同,則交由前述之專家,由三答中選出一答作為標準答案。本標記法之 出發點除節省成本外,其宗旨在於獲取大多標記者對詞彙之理解方式,並將之視 為標準答案。此與「字典編纂」的邏輯互異,本研究並非意圖產出一語言學上之 標準答案,而是針對「意見分析」此目的,試圖探求大眾讀者對辭彙理解的傾向。
其流程可表為圖 3-2:
圖 3-2 二字詞結構分類語料標記流程圖
標記完成後,為使自動分類問題單純化,部分具明顯特徵、得以字串比對方 式直接予以分類之詞彙先自語料集中刪除;另外,由於後續詞彙層次意見傾向判 斷實驗是在(Ku, Liang et al. 2006)提供之 836 個意見詞彙上進行評估,為免投機 取巧之嫌,加以 836 意見詞彙集與原始集之交集甚小,對分類效能評估影響有限,
故亦將與 836 意見詞彙集重疊之詞彙刪除。上述步驟簡稱為「過濾」,過濾規則整 理於表 3-3。
由此可得到一 6187 詞彙構成之較小語料集。吾人稱前述 6500 詞彙之語料集 否
否 是
是
標記結果 標記者A
標記者B
答案一致
兩答一致
標記者C 專家三答選一
稱為「原始集」;此較小語料集稱為「精簡集」。 表 3-3 詞彙過濾規則
特徵 刪除理由
全字特徵 疊字 可直接歸於「並列」
末字特徵 末字為「仔」 可直接歸於「其他」
首字為「非」、「不」、「否」 可直接歸於「否定」
首字為「有」 可直接歸於「肯定」
首字特徵
首字為「阿」、「啊」 可直接歸於「其他」
存在 Ku 之 836 意見詞彙集中 避免內部測試之嫌
另外,本研究展開初期,為進行簡單初步測試,曾聘請前述之專家,標記《教 育部國語辭典》中「較易標記」之二字詞。其標記方法如下:抓取《教育部國語 辭典》之全部二字詞,請專家逐一標記,若無法立刻決定分類者即直接跳過,若 可立即決定者即標記之並保留。最後得到 2234 詞之標記語料。此集固無法模擬真 實詞彙分佈、資料量稍嫌不足且明顯有偏(bias),然其於後期實驗中仍扮演了強 化語料的角色。此 2234 詞彙構成之語料集稱為「簡易集」;而將「原始集」與「簡 易集」合併後以表 3-3 方式過濾,可得到一 8186 詞之語料集,稱為「強化精簡 集」。
3.3.2.
標記結果分析與文獻比較本節主要分為三部份:首先針對上節產生之四個語料集進行統計分析,觀察 各類的分布情況;繼而為確保語料的可靠性,以進一步確保本問題之信度,對各 標記者進行一致性分析;最後將結果與其他研究團隊之標記結果比較,討論其異 同。
首先,經上節標記與過濾步驟後可得到四組語料集,其類別分佈狀態如表
3-4:
表 3-4 二字詞語料集標記結果分佈統計 語料
集名 稱
詞彙數 並列 修飾 主
謂 動賓 動補 其
他 肯定 否定 斷詞錯誤 數量 1514 2935 85 826 704 269 43 11 113 原始
集 6500 比例
(%) 23.29 45.15 1.31 12.71 10.83 4.14 0.66 0.17 1.74 數量 1433 2927 85 824 704 214
精簡
集 6187 比例
(%) 23.16 47.31 1.37 13.32 11.38 3.46備註 原始集過濾後之結果。
數量 791 850 54 461 56 22 簡易
集 2234 比例
(%) 35.41 38.05 2.42 20.64 2.51 0.98備註
教育部國語辭典中「較易 標記」之二字詞由一人獨 力標記之結果。
數量 2141 3681 134 1239 755 236 強化
精簡 集
8186 比例
(%) 26.15 44.97 1.64 15.14 9.22 2.88備註原始集與簡易集合併後 再行過濾之結果。
上述四組語料之各類分佈比例可表為圖 3-3:
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
原始集 精簡集 簡易集 強化精簡集
並列 修飾 主謂 動賓 動補 其他 肯定 否定 斷詞錯誤
圖 3-3 二字詞語料集標記結果分佈統計圖
此類別分布結果與前述「類別分佈極不平均」之宣告吻合,原始集中前三大
類:並列、修飾、動賓,即佔總詞彙量八成以上,而剩下兩成則需分予包含斷詞 錯誤在內的 6 個類別,以此而論,選擇「五加三」的分類方式的確較更細緻之分 類法妥當。
其次,為確保語料之可靠性,我們對其中六位標記者(編號為A、B、C、
D、E、F)進行了一致性分析。方法如下:首先從精簡集(6187 詞)中隨機抽 取 340 個詞13,令六位標記者標記之,標記時不得彼此交談(但可查詢資料)。標 記完成後對每位標記者的標記結果計算:答題正確率、對標準答案的 Kappa 一致 性係數14(κa),以及每一構詞類別的 F-分數。此一致性測試之目的在於分析讀 者獨力理解一詞彙時,與全部讀者平均行為的一致性程度,就反面言,亦可觀察 每一標記者的歧異程度。其結果如表 3-5:
表 3-5 二字詞標記者一致性及效能分析 F-measure 標記者 κa 正確率
其他 並列 修飾 主謂 動賓 動補 A 0.73 0.83 0.22 0.76 0.90 0.36 0.81 0.80 B 0.73 0.82 0.22 0.71 0.88 0.50 0.90 0.85 C 0.66 0.76 0.34 0.77 0.83 0.40 0.82 0.78 D 0.84 0.89 0.64 0.84 0.93 0.40 0.93 0.83 E 0.70 0.79 0.33 0.83 0.83 0.31 0.88 0.86 F 0.83 0.85 0.64 0.78 0.90 0.62 0.90 0.83 平均 0.75 0.82 0.40 0.78 0.88 0.43 0.87 0.83
同時我們亦計算兩兩標記者間之 Kappa 一致性係數,結果可見表 3-6 與圖
13 母體量為 6187 時,於信賴區間 5%、信心水準 95%、母體比例 70%(即假設只答對 70%)的情況下,
所需的最小樣本數為 307 個。
14 此處使用未加權之簡單 Kappa 一致性係數公式:
c c
P P P
−
= − 1
κ 0 ,其中 P0為「觀測一致性(observed agreement)」,即前後兩種測量結果一致的百分比;Pc為「期望一致性(chance agreement)」,即前後兩種測 量結果預期相同的機率。
3-4:
表 3-6 二字詞標記者間一致性分析 A B C D E F A 0.79 0.62 0.70 0.68 0.68 B 0.62 0.73 0.68 0.68 C 0.61 0.66 0.63
D 0.64 0.72
E 0.66
F
0 0.2 0.4 0.6 0.8 1
B D F D E E F F E F E F C C D
A B D A B A B A C E D C A B C
標記者配對
Kappa值
圖 3-4 二字詞標記者間一致性測試
以 Kappa 一致性係數而言,其分數大小與一致性程度關係如下:0.0-0.20 為
「極低(slight)」,0.21-0.40 為「一般(fair)」,0.41-0.60 為「中等(moderate)」,
0.61-0.80 為「高度(substantial)」,而 0.81-1 則為「幾乎完全吻合(almost perfect)」。 由上述結果可看出,無論是標記者對答案之κa,抑或標記者間兩兩之 Kappa 值均 落於「高度一致」之範圍(其中κa稍高一些,此極合理,緣於答案本就是由標記
者中之多數所產生的)。而標記者間之 Kappa 值亦高,考量標記者於標記時彼此 不得交談,此結果代表「二字詞構詞分類」問題乃為一有信度之問題,此問題對 一般讀者而言,大多時候乃是可以清楚辨別的。
然標記者間之表現仍有部份岐異性,我們對標記者答錯較多之詞彙進行分 析,整理出造成歧異之四個主要原因:
(1) 字義理解之歧異
如「文物」,部分標記者認為「文物」乃指「物」而「文」為「文化、民 俗」之意,卻有標記者認為「文」與「物」乃是並列關係,是「文字、字 畫」與「物品」之意;又如「馴養」,部分標記者認為「馴」為「馴化」
之意,乃用以修飾「養」;而有標記者認為「馴」與「養」均為動作,為 並列關係。此類字義理解之歧異往往不會影響整體詞義(如「馴養」和「文 物」的意義並無曖昧處),卻會影響構詞分類。
(2) 字彙詞性判斷之歧異
如「跑走」一詞,於該詞彙中「跑」與「走」之字義並無歧異,「跑」為 跑之動作,而「走」則指離開某處。然於理解「詞性」時部份標記者認為
「走」乃指離開的「動作」、是動詞,而標為「並列」;卻有部份標記者認 為「走」乃是離開的「狀態」,是副詞性的,而標為「動補」。其他如「迎 合」、「舉起」亦發生此現象。
(3) 構詞方式不明
如「政治」,此詞彙中之「政」與「治」二字字義均堪稱明確,然此二字 是以何方式構成「政治」之義卻令人費解;又如「文化」、「自由」等詞,
其構詞方式本就極不明確,對大多標記者而言均難以清楚回答,從而造成 歧異。
(4) 對詞義認知程度之歧異
如「探花」即一例。此詞中大多標記者均標為「其他」,然卻有部份高年
級標記者將之標為「動賓」,緣於該詞彙之語源為「到各名園採摘鮮花,
迎接狀元」之意;又如「睡覺」一詞,大多標記者將之標為「動賓」,然 卻有部分標記者將之標為「並列」。因「覺」原為「醒」之意,「睡」與「覺」
本為並列,乃因後世多誤用,因沿成習,而出現了「睡個覺」此種類於動 賓之用法。
舉凡以上四點歧異原因,均不會影響對辭彙之整體理解,卻會影響構詞方式。
此為漢語極幽微之處,即便一般以中文為母語、且主修中文者亦難以判斷,可將 之視為以資訊方法難以駕馭的效能上界(upper bound)。
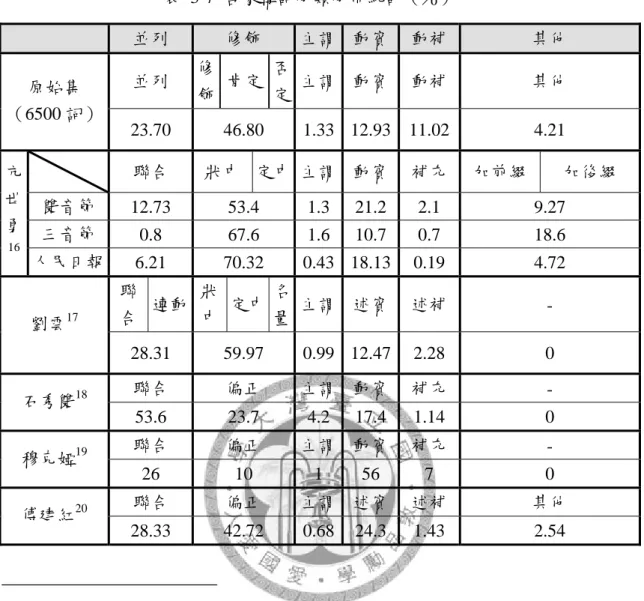
最後,如表 3-2 所述,構詞分類架構已為諸多研究者所提出,且諸家分類架 構大多可歸於五大基本類別。於語料標記完成後,一可行之嘗試為:將其他研究 團隊所公佈之構詞分佈統計與本研究之標記結果相互對照,便可分析其異同。我 們於是將各家已公佈之構詞分部情況整理為表 3-7(見 25 頁);若將表 3-7 中詞 彙量超過 5000 之研究成果繪製為橫條比例圖,則如圖 3-5(見 26 頁)。
由圖 3-5 中可發現,本研究所得出之各類分佈狀態與其他研究者之結果無甚 大差異(「亢世勇三字詞」一行「並列」明顯較少乃緣於三字詞之並列必須為三個 字均處於平行地位,如「中日韓」,此例極少),唯「動補」一類明顯較大。由於 該研究團隊之語料取得不易,本研究僅得推測此類較大之可能原因,可能原因有 二:其一,其他研究團隊所收錄之字彙量均遠大於 6500,可能「並列」或「修飾」
詞彙數量對動補造成了擠壓;其二,比較其他團隊與本研究,可發現其他研究者 均以「建構辭典」或「編纂資料庫」之思維展開語料標記,唯本研究乃自大型語 料庫中隨機抽取二字詞作為語料,或許辭典編纂者較不喜將「動補」一類詞彙編 入。此想法看似詭怪,實則亦有理可循。動補一類之詞彙如「落下」、「離開」、「走 掉」等等,多為詞義單純、字義明確之詞彙,就辭典編纂者角度而言,確無大量 將之編入的必要。
表 3-7 各家構詞分類分佈統計(%)15
並列 修飾 主謂 動賓 動補 其他
並列 修
飾 肯定 否
定 主謂 動賓 動補 其他
原始集
(6500 詞)
23.70 46.80 1.33 12.93 11.02 4.21 聯合 狀中 定中 主謂 動賓 補充 加前綴 加後綴 雙音節 12.73 53.4 1.3 21.2 2.1 9.27 三音節 0.8 67.6 1.6 10.7 0.7 18.6 亢
世 勇
16 人民日報 6.21 70.32 0.43 18.13 0.19 4.72 聯
合 連動 狀
中 定中 名
量 主謂 述賓 述補 -
劉雲17
28.31 59.97 0.99 12.47 2.28 0
聯合 偏正 主謂 動賓 補充 -
石秀雙18
53.6 23.7 4.2 17.4 1.14 0
聯合 偏正 主謂 動賓 補充 -
穆克婭19
26 10 1 56 7 0
聯合 偏正 主謂 述賓 述補 其他
傅建紅20
28.33 42.72 0.68 24.3 1.43 2.54
15 若該數據中有「斷詞錯誤」一類便刪去該類比例,重新標準化;而若有未寫出之分類,則勝於比例加 進「其他」類中。
16 亢世勇, 徐豔華, et al. (2005). 基於語料庫的現代漢語新詞語構詞法統計研究. International Conference on Chinese Computing, Singapore.;「二字詞、三字詞」為在《新詞語構詞法數據庫》中的統計(合有雙音節 詞 15751 個、三音節詞 6502 個);「人民日報」為將 1998 年 4 月 1 日至 10 日的《人民日報》70 萬字語料,
經機器斷詞後抽取所有未知詞(合有 1627 個),以人工標記的結果。
17 劉雲, 俞士汶, et al. (2000). 現代漢語合成詞結構數據庫. 第二屆中文電化教學國際研討會, 廣西師範 大學出版社.;《漢語合成詞結構數據庫》中將 32711 個二字詞刪去單純辭、人名、地名後,餘下 32711 個合 成詞的統計結果。
18 石秀雙 (2007). "現代漢語雙音復合詞結構關系考察——以 z 字母下雙音復合詞為例進行分析." 晉中學 院學報 2007(6): 1-8.;為《現代漢語辭典》中z字母下雙音節詞(合計 3059 個)的統計結果。
19 穆克婭 (2008). "新雙音節複合動詞語素構詞規律研究." 現代語文 2008(12): 42-44.;《新華新詞語辭 典》(共包含 2200 個詞條)中雙音節詞的統計結果。合計雙音節詞 529 個。
20 傅建紅 (2009). "論《現代漢語詞典》F類雙音複合詞的結構關係." Ibid. 2009(3): 49-50.;為《現代漢語 辭典》中f字母下雙音節詞(合計 1613 個)的統計結果。
並列 修飾 主謂 動賓 動補 其他 體
素 聯 合
謂 素 聯 合
重 疊
定中 偏正
狀 中 偏 正
量
補 主謂 述賓 述 補
述 介
前 綴
後 綴
簡 稱
數 詞 縮 語
固 定 詞 組
未 注 標 記 苑春法21
21.16 53.24 0.98 18.12 2.36 4.14
0% 20% 40% 60% 80% 100%
亢(二字詞)
亢(三字詞)
亢(人民日報)
劉(構詞庫)
苑(語素庫)
原始集(6500)
並列 修飾 主謂 動賓 動補 其他
圖 3-5 各家構詞分類分佈統計圖(僅列詞彙量超過 5000 者)
3.4 二字詞內部結構自動分類
我們已於 3.2 節提出二字詞內部結構的分類框架,並於 3.3 節中標記完成數組 質量兼具之可靠語料。本節將在此基礎上,展開二字詞內部結構自動分類研究。
由於(傅愛平 2003)已說明規則方法於實際應用時缺乏效度,故我們選擇以機器 學習(machine learning)方法處理此問題。機器學習方法通常可分為兩部份:特 徵值(feature)抽取,及以演算法自特徵值中學習從而產生分類模型(model)。
3.4.1 節將介紹本研究特徵值選取之精神,及以《教育部重編國語辭典修訂本》為 知識庫並從中擷取特徵值之細節;3.4.2 節則將介紹五種施用於實驗中的分類演算
21 苑春法 and 黃昌寧 (1998). "基於語素數據庫的漢語語素及構詞研究." 語言文字應用 1998(3):
83-88.;《漢語語素數據庫》中 78230 個雙音節詞的統計。
法:條件隨機域模型(Conditional Random Field,簡稱 CRF)、支援向量機模型
(Support Vector Machine,簡稱 SVM)、單純貝氏(Naïve Bayes)模型,以及本 研究所提出之兩種簡易分類法,並於 3.5 節中評估其效能。
3.4.1.
特徵值抽取欲單就二字詞之字面(而無詞性與前後文資訊)推測其構詞分類,唯一可用 之特徵值便為組成該詞之成分字的特徵。而一直覺之想法是:成分字之詞性(亦 即語素之詞性)與構詞方式強烈相關。舉例而言,對「主謂」一類,若首字之詞 性極可能為名詞、而末字之詞性極可能為動詞,則此詞為主謂結構之機率便相當 大;而又如對「動賓」一類,若首字之詞性極可能為動詞、而末字之詞性極可能 為名詞,則此詞為動賓結構之機率亦較其他詞性組合高出許多。故以此想法出發,
若可取得代表每一漢字之「詞性傾向強度」之資訊,便可作為預測構詞分類之特 徵值。
然需注意的是,此處所言之「詞性」乃指「該字(語素)於該詞內之詞性」,
而非獨自成詞時之詞性。如「書桌」一例,「書」獨自成詞時多為名詞,然於「書 桌」詞中,「書」成為「桌」之修飾語,詞性便為形容詞;又如「國家」之「國」,
獨自成詞時幾全為名詞,然於詞首時則多為修飾後方詞彙之形容詞。是以必須尋 找可模擬「漢字於詞彙內部時詞性傾向」之資訊,無法單純以外部語料集之詞性 統計作為特徵值。然而,由於正體中文並無如簡體中文般已存在標記完整之語素 或構詞資料庫,欲滿足以上之特徵值需求,便需尋找帶有語素語義、語素詞性強 度、甚是構詞方法之知識庫,並試圖從中抽取出可用之特徵值。考量知識之完整 性及易取得程度,本研究選擇以《教育部重編國語辭典修訂本》臺灣學術網路第 四版 ver.2 作為知識庫。
3.4.1.1. 《教育部重編國語辭典修訂本》簡介
《教育部國語辭典》籌備於 1926 年,1931 年展開編輯,至 1945 年竣工;1976 至 1979 年,又以《國語辭典》為基礎進行重編,於 1981 年付印;1987 年成立專 案小組進行「重編國語辭典」之修訂工作,於 1994 年修訂完成,並於同年完成網 路版;1997 年推出光碟版。此後網路版經多次更新及修改,本研究所使用之「臺 灣學術網路第四版 ver.2」更新於 2007 年 12 月(方便起見,以下簡稱為《教育部 國語辭典》)。
辭典格式方面,該辭典以「形+音」為主鍵(primary key),共有單字資料 11930 筆(含多音字)、異體字 1848 筆、詞語 152398 筆(含多音詞),合計 166176 筆記錄。其規格說明中特將「單字資料」與「詞語」分開列目,乃緣於該辭典對
「單字」提供了較「一般詞彙」更形豐富之資料,此亦即本研究選擇該辭典為單 字特徵值來源知識庫的最主要原因。
對一般詞彙(非單字詞)而言,該辭典提供該詞之「注音(一式、二式)」、「漢 語拼音」及「詞義」(詞義後常有一到數句不等之例句)資訊。其中若有多義者,
則依序編號清列之。如圖 3-6:
圖 3-6 《教育部國語辭典》一般詞語條目樣式(以「科學」為例)
對「單字資料」而言,該辭典除「注音(一式、二式)」、「漢語拼音」外,該 字之所有義項均以「詞性」分門別類,再依序編號。該辭典共定義九種詞性:名 詞、形容詞、動詞、副詞、助詞、連接詞、介詞、代詞、歎詞。而每條字義後常
有一到數句不等之「例句」或「例詞」。如圖 3-7:
圖 3-7 《教育部國語辭典》單字資料條目實例(以「好(ㄏㄠˇ)」為例)
如前所述,該字典之主鍵為「形+音」。故對同一字而言,若有多種相異發音,
則每種發音均獨立列目。以「好」為例,讀「ㄏㄠˇ」時條目如圖 3-7,而若讀 作「ㄏㄠˋ」時則有另一條目,見圖 3-8:
圖 3-8 《教育部國語辭典》單字資料條目實例(以「好(ㄏㄠˋ)」為例)
觀察以上實例,可歸結出幾點結論:首先,教育部國語辭典中於單字條目下 所列之「詞性」並非特指該字單獨成詞時之詞性,亦包括該字於一般詞彙中之詞 性;其次,中文字之字義會因發音之不同而相異,其詞性傾向亦若是。以「好」
字為例,讀作「ㄏㄠˇ」時傾向形容詞性與副詞性,而讀作「ㄏㄠˋ」時則傾向 動詞與名詞性;最後,大致而言,該字較傾向之詞性,則列於該詞性下之義項數 亦較多。如「好(ㄏㄠˇ)」便無名詞性之義項,且形容詞及副詞下之義項最多。
以此諸概念為基礎,便可自教育部國語辭典中抽取出適當之特徵值模擬「某 字之詞性傾向」了。細節將於次節中詳述。
3.4.1.2. 使用之特徵值
由於本研究之問題範疇限制為「不使用詞外資訊」,故此節介紹之特徵值皆為 單一「中文字」之特徵值。實際於機器學習時之特徵值應用方法(如兩字之特徵 值直接合併、推導為機率,或依順序排列等等)則依所使用之演算法而各不相同,
此將於 3.4.2 節中詳述。
本研究自《教育部國語辭典》中抽取特徵值之最主要概念為:「以該詞性下之
『義項數』模擬該字於詞彙中為該詞性之傾向」。由於教育部國語辭典所定義之詞 性共有 9 種,意即「各詞性下之義項數」為 9 個非負實數,也就是最基本的 9 個 特徵值,稱為「基本特徵值組」。表 3-8 以「好(ㄏㄠˇ)」為例,詳細示範基本 特徵值組之算法與意義(見 31 頁)(實際辭典內容請參考圖 3-7)。
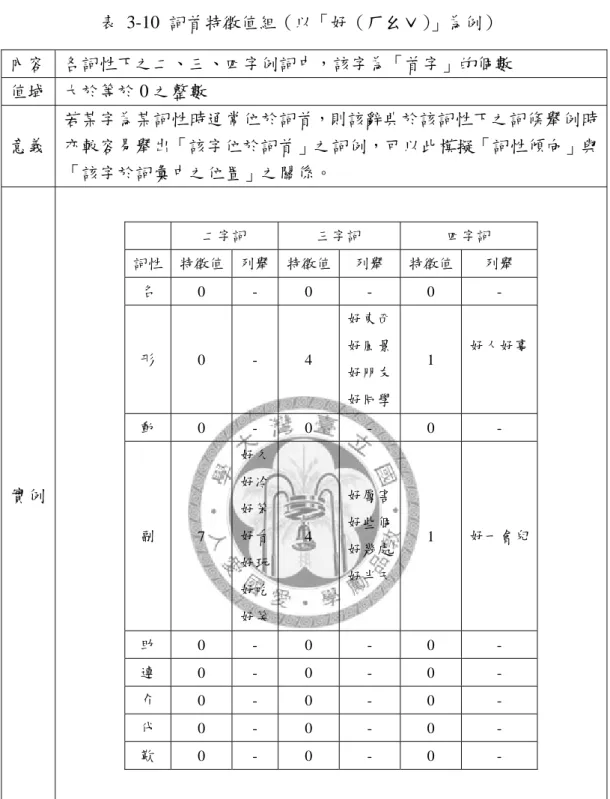
其次,我們觀察發現,部分漢字於二字詞中之詞性傾向亦與「該字於詞彙中 之位置」有關。舉例而言,「戲」若為某詞之尾字,如「看戲」、「排戲」、「聽戲」,
則詞性傾向於名詞;但若位於首字,如「戲弄」、「戲耍」之「戲」為副詞,「戲子」、
「戲精」中則為形容詞,即無強烈的名詞性;又如「好(ㄏㄠˇ)」字做動詞用時 幾乎不會出現首字而多為尾字,如「友好」、「病好」。欲以特徵值呈現此現象,應
需一大型構詞資料庫,以統計每一漢字之各詞性的位置傾向(如動詞傾向於詞首、
名詞傾向於詞尾等等)。然如前所述,正體中文缺乏標記完善之大型構詞語料庫。
即便以本研究所標之八千餘二字詞,分予九千餘漢字、每一字下又有 9 種詞性,
亦將造成極嚴重之資料空缺(data sparse)問題。
表 3-8 基本特徵值組(以「好(ㄏㄠˇ)」為例)
特徵值說明 內
容 各詞性下之義項數 值
域 大於等於 0 之整數 意
義
某字較傾向之詞性,則列於該詞性下之義項數亦較多,故可以詞性下之義項 數模擬該字之詞性傾向。
實 例
詞性 特徵值 詳列 名 0 -
形 3
(1) 美、善,理想的。
(2) 友愛的。
(3) 完整的、沒壞的。
動 2 (1) 相善、彼此親愛。
(2) 痊癒。
副 7
(1) 很、非常。
(2) 完成、完畢。
(3) 容易。
(4) 以便、便於。
(5) 可以、應該。
(6) 置於某些動詞之前,表效果佳。
(7) 置於數量詞或時間詞之前,表示多或久的意思。
助 0 - 連 0 - 介 0 - 代 0 -
歎 2 (1) 表示稱讚或允許。
(2) 表示責備或不滿意的語氣。
而觀察《教育部國語辭典》,可發覺其每一漢字條目下之每一詞條常有「例 詞」。我們或可做一假設:若某字為某詞性時通常位於詞首,則該辭典於該詞性下 之詞條舉例時,亦較容易舉出「該字位於詞首」之詞例(此假設顯然是基於對該 辭典「編纂時對所有詞條均採同一標準」之信任而來)。以此概念出發,我們遂決 定以漢字「各詞性下例詞中,該字為『首字』/『尾字』的個數」為特徵值,分 別稱為「詞首特徵值組」與「詞尾特徵值組」。而「例詞」之定義為「引號內無任 何標點符號者」,以與「例句」分開。
然我們亦觀察到,部分例詞之詞首或詞尾字並不具有代表性,如「家(ㄐㄧ ㄚ)」之例詞有「住戶不滿十家」,此詞彙頗長,已具有句子特性,其中之「家」
顯然作一獨立詞彙之用,而非作為詞彙內部之語素;又如「向」之例詞,「向有研 究」與「向前看」等,其中之「向」似亦因三、四字詞彙稍有句子特性而作獨立 詞彙使用,與二字詞內之「志向」、「方向」用法殊異。為減低此影響,本研究將
「詞首/詞尾特徵值組」所指涉之例詞先刪去五字以上者,再以「例詞之詞長」
分為二、三、四字詞三個子類。仍以「好(ㄏㄠˇ)」為例,最後完成之特徵值組 細節即如表 3-10(見 33 頁)與表 3-11(見 34 頁)。
最後,依現代漢語之常識,部分單字若作動詞用時會轉聲調為四聲或三聲(古 仄聲字)。如「衣(ㄧ)」作動詞用則轉為「ㄧˋ」;「飯(ㄈㄢˋ)」作動詞用則會 轉為「ㄈㄢˇ」。故本研究亦將聲調列為特徵值之一。如表 3-9:
表 3-9 聲調特徵值(以「好(ㄏㄠˇ)」為例)
內容 聲調
值域 輕聲(˙)或四聲( ˊˇˋ)22 意義 部份漢字轉品時聲調亦會改變。
實例 好(ㄏㄠˇ):「ˇ」
22 不另轉為實數表示,因某些機器學習工具可以字串為特徵值(如 CRF++),而非必為數字。