以項目反應理論比較SF-36及WHOQOL-BREF異同之研究-以肺部疾病患者為例; Comparison between the SF-36 and the WHOQOL-BREF to Measure the Quality of Life in Patients with Lung Disease:An IRT Approach
134
0
0
全文
(2) 品質量表,目前已廣泛的被應用在許多生活品質研究上 4-8,但其在內容 與量尺(Scaling)有很大的差異,在結果的解讀上若無深入比較會有很 大的不同;如:SF-36 健康量表共有 36 題,包含了八個範疇,分別為: 身體活動功能(Physical Functioning,PF)、活動功能限制情況 (Role-Physical,RP)、心理健康限制生活程度(Role-Emotional,RE)、 社交情況(Social Functioning,SF)、身體疼痛狀態(Bodily Pain,BP)、 活力狀態(Vitality,VT)、心理健康狀態(Mental Health,MH)及個人 評估身體健康之程度(General Health Perceptions,GH)和整體健康情形; 每一題分別有二到六個選項,可轉換為 0-100 分,分數愈高表示生活品質 越好 1。WHOQOL-BREF 臺灣簡明版問卷,共有 28 題,分為四個範疇: 生理(Physical) 、心理(Psychological) 、社會(Social)和環境(Environment) 方面,每一題各有五個選項,可轉換為 0-100 分,分數愈高表示生活品質 越好 2。 而健康結果測量(Health Outcome Measurement)愈來愈受到醫學界 的重視,故此領域在國外已有相當專業的健康結果測量組織,並且發展 快速,如世界衛生組織生活品質問卷完整版(WHOQOL-100)9-12 的發展, 集合了許多領域的專家共同發展,並已在許多的國家進行本土性的測試 及信效度的驗證。現今若測量技術專業仍維持在傳統的測量概念及理論 上,則所得結果被接受度將會受到相當的懷疑。古典測驗理論 13(Classical. 2.
(3) Test Theory,CTT)過去在心理測量及教育測量受到很大重視,且一直有 很完備的發展。但考量 CTT 方法的限制,例如測驗題目的難度難區分、 受測者的特性與測驗的特性很難區分、兩份不同測量結果無法做比較、 受測者的能力通常只取決於某些特定的測量等,且 CTT 以一個相同的測 量標準誤(Standard Error of Measurement),作為每位受測者的測量誤差 指標,這種作法並沒有考慮受測者能力的個別差異,所以題目的難度(Item Difficulty, β )和題目的鑑別度(Item Discrimination, α )會隨著受測者 的特性而改變 13-14;所以? 提昇健康結果測量的品質,研究學者不斷的尋 求改進,項目反應理論( Item Response Theory,IRT)目前已被廣泛重視 與應用. 15-17. 。. 許多學者預期在此 21 世紀 IRT 會被廣泛應用到健康結果測量的領 域,如在著名雜誌 Medical Care 近來對此專闢一系列的討論 16-19。實際應 用的文獻亦在增加中. 15-26. ,在自我健康評估方面 IRT 的潛在好處比 CTT. 來得好,主要是因為 CTT 主要的限制是測驗和題目的特性隨著受測者改 變而跟著改變,受測者的特性隨著測驗和題目特性的改變而改變,所以 較無法得到一穩定的測量結果 13;但在 IRT 上,其將題目的難度及人的 能力用相同的量尺來評量以穩定比較的基礎並結合應試者的反應分數, 形成一機率模式,並以之建立項目特徵曲線 13(Item Characteristic Curve, ICC)來評估題目的難度及應答的情形。 ICC 可以用數學形式表示,且在. 3.
(4) 分析前就要知道其數學程式及 P(θ)、θ等 (θ指的是個人的能力,而 P(θ) 是答對某題的正確機率,它是個人能力θ的函數),最早由 Tucker (1946) 提出這個術語,它是一種能將作業的表現水準與獨立變項,例如年齡等, 畫在一個平面上的圖形,通常這個圖形所呈現出的樣子是一個平滑且非 直線的曲線圖。ICC 可視為項目反應理論之重要結果之一有別於 CTT, ICC 可用來鑑別題目的好壞、題目的難度、測驗程度的高低及猜測部分 的得分,所以不論任何人來做,每個人的猜測參數、題目的鑑別度、題 目的難度皆為固定,不會隨著樣本的特性、組成不同而有所改變,也就 是說項目參數有不變性(Invariance of Item Parameters)13。但 CTT 會因 族群的變異性而干擾;CTT 只能求一個值代表所有受測者的健康情況, 但 IRT 可反應每題的不同特色,也可反應不同族群的適用情形. 13. 。. 隨著醫療資源的普及和生活型態的改變,人們除了要求健康外,對 於生活的品質的要求,不只限於健康狀況的品質,而是多層面的需求 (Multi-Dimensional Needs) 28。因此生活品質作為健康結果指標已成為 新的趨勢,唯缺少一套客觀標準 27。所以近年來已有許多研究應用 IRT 中特質,如不變性(Invariance),來探討生活品質問卷的適用性 21-26,因 此除以 IRT 檢視生活品質問卷在特定族群的適用性外,並可藉由 IRT 的 分析更進一步瞭解所探討族群生活品質的情形及特異性,對於不同分組 的比較及縱貫性測量結果的評估,IRT 亦是很有力的工具 20。. 4.
(5) 近幾年來台灣隨著空氣品質的惡化、吸煙量增加等因素,使得肺部 疾病之盛行率和發生率逐年上升 29,生活品質為肺部疾病患者的重要健 康層面之一。以肺癌和慢性肺部疾病病患為例,其主要症狀如咳嗽、呼 吸困難(Shortness of Breath)等,這些症狀會嚴重限制其日常生活中的 工作和社交活動,並影響其睡眠品質和情緒問題等,其影響是長時間的, 故肺部疾病健康與否嚴重影響生活品質;另一盛行率甚高的肺部疾病族 群,為慢性阻塞性肺疾病(COPD),根據衛生署 1994 年的報告,COPD 的死亡率為每十萬人有 16.6 人,為國人十大死因之ㄧ。又根據世界衛生 組織的統計,慢性阻塞性肺疾病將在 2020 年變成全球第四重大疾病之 ㄧ。故肺部疾病健康與否嚴重影響生活品質,故本研究選擇以肺部疾病 患者為族群來探討其生活品質。 由於 WHOQOL-BREF 和 SF-36 為測量生活品質常用問卷,本研究除 用此兩份問卷來探討肺部疾病患者生活品質外,並嘗試應用 IRT 來探討 兩份問卷的心理計量特質並加以比較,以期提高研究者對此兩份問卷應 用於肺部疾病患者生活品質測量時對問卷內容及使用上之瞭解,並期提 供研究者對改進或發展新測量問卷之參考。. 5.
(6) 第二節. 研究目的. 故本研究之主要目的係針對肺部疾病患者生活品質之測量: 一、比較 WHOQOL-BREF 和 SF-36 兩份問卷的基本心理計量特質。 二、比較 WHOQOL-BREF 和 SF-36 兩份問卷整體範疇的對應關係。 三、提出兩份問卷合併後可擷取的新向度及其對應題目。 四、針對兩份問卷合併後的新向度的題目,以 IRT 理論進行項目心理計 量特性分析,包括: (一)項目尺度測定(Item Calibration)分析 (二)項目參數不變性分析(Invariance of item parameters): 1.樣本獨立特質分析(Sample Independent) 2.測驗獨立特質分析(Test Independent) 五、對上述所用 IRT 模式進行適合度評估。 為驗證結果的穩定性,本研究將肺部疾病患者分為有服藥組及沒有 服藥組,上述大部份分析均針對此兩族群平行分析。. 6.
(7) 第貳章、文獻探討. 在前一章節中指出本研究的研究目的係在於應用 IRT 模式評量分析 WHOQOL-BREF 和 SF-36 生活品質問卷,因此在本章節的文獻探討將分 成生活品質的測量、古典測量理論的優點、項目反應測量理論、項目反 應理論在健康結果(Health Outcome)評量之應用的研究等;另外針對項 目反應理論應用於生活品質研究實例的文獻做探討。. 第一節. 生活品質的測量. 一、生活品質的概念 「生活品質」概念最早可由亞里斯多德所提出來的,亞里斯多德是 從「快樂(Happiness)」的角度來看生活品質,認為快樂是上帝所恩賜給 人的,是一種貞潔的心靈活動,因此快樂的人可以活得很好、事情也做 得順利 31,53。「生活品質」一詞正式出現在第二次世界大戰後,強調好的 生活品質是要有好的生活,不單只是物質上滿足而已 32,53。從研究角度來 看,早期所常使用的詞彙「幸福感( Well-being) 」 、 「快樂( Happiness)」、 「主觀幸福感(Subjective Well-being)」等,所隱含的意義不外乎是從個 人主觀認知層面、個人情緒、以及身心健康的角度來評估一個人整體生 活品質情形。隨著醫療資源的普及化和生活型態的改變,疾病型態由過 7.
(8) 去的傳染性疾病演變成至今慢性疾病為主,死亡率(Mortality)的變化或 罹病率(Morbidity)的多寡已經不再能成為代表生活品質好壞的指標。 而現今健康照顧方面也越來越重視病人個體的主觀感受(Subjective Perception) ,對生活品質的重視與要求,不再只侷限於健康狀況的品質, 亦重視全人的照顧( Holistic Approach) 。反映出生理狀況之測量只能算是 測中介的(Intermediate)生活品質結果,健康相關的生活品質 (Health-Related Quality Of Life,HRQOL)測量才是最終生活品質結果 的代表。 世界衛生組織對生活品質的定義:「生活品質是指個人在所生活的文 化價值體系中,對於自己的目標、期望、標準、關心等方面的感受程度, 其中包括一個人在生理健康、心理狀態、獨立程度、社會關係、個人信 念以及環境六大方面」9-12,所以生活品質主要是指一個人在所處環境中 主觀的感受,是屬於多層面概念( Multidimensional Concepts)的需求 28。 生活品質又可分為「廣泛性生活品質(Global QOL)」及「健康相關生活 品質( Health-related QOL) 」 。廣泛性生活品質強調個人在所處的環境中, 對一般廣泛性的生活之滿意度,是由個人的主觀感受來評斷;健康相關 生活品質則強調因為疾病、意外或治療所導致個人身體功能改變進而影 響個人在心理、社會、環境層面健康相關生活品質的改變,可由主觀判 斷及客觀測量來評量。. 8.
(9) 二、生活品質問卷的分類 生活品質的研究在最近這幾十年來逐漸受到專家學者的青睞,在各 個學術領域裡都有相關的研究陸續發表 33-38。早期有關生活品質的問卷有 許多即是專門測量與健康相關生活品質的狀況,如: Sickness Impact Profile (SIP)34、Nottingham Health Profile (NHP)39 等,這些工具並未完全 針對生活品質的概念來設計;因為隨著醫藥衛生的發達,人們對於健康 不再專注於疾病或失能,而是個人的主觀感受(Subjective Perception)與 多向度(Multidimensions)的角度來測量生活品質。 基本上目前測量生活品質的問卷分為五類 40,第一類為一般性問卷 (Generic Questionnaire) ,不限於特定疾病或屬性的族群來使用,以多層 面健康相關生活品質範疇,去測量各種不同族群,包括跨國、跨文化、 跨不同疾病的對象等,例如: SF-36 及 WHOQOL-BREF。第二類為特定疾 病問卷(Disease-Specific Questionnaire),對罹患各種身心疾病,尤其是 慢性病或絕症的病人進行生活品質的測量。第三類為個人健康測量問卷 (Individualized Questionnaire),偏向於個人化特性所表現之生活品質的 測量,可當作特殊疾病生活品質的指標。第四類是社會經濟測量(Social Economic Questionnaire)問卷,以經濟成本效益來考量,例如從社會學 或生態學觀點進行都會區生活品質的評估,可作為介入都市計畫的參 考。第五類是特定層面測量問卷(Dimension Specific Measures. 9.
(10) Questionnaire),從個人特質、心理壓力、社會支持及因應方式等社會心 理因素,來探討心理舒適度(Psychological Well-being)、幸福感 (Happiness)及生活品質 17。. 三、WHOQOL-BREF 台灣簡明版的發展 世界衛生組織(World Health Organization,WHO)計劃發展一份多 個地區、多種背景的人共同參與合作,並可做跨文化、跨族群比較研究 的測量生活品質工具,以作為研究、醫藥療效分析、臨床和衛生決策分 析等的參考,因此於 1991 年開始,世界衛生組織結合 15 個國家發展了 一份與健康相關生活品質問卷,被定名為「世界衛生組織生活品質問卷 (WHOQOL-100)」2,共有 100 題為一般性健康相關生活品質,稱為一 般性題目(Generic Items),這些題目以適用於不同文化健康相關生活品 質定義及看法為原則,故可被用來作為跨文化、跨族群的比較。 WHOQOL-100 問卷的內容一共可分為六大範疇(Domains) ,包括: 生理範疇(Physical Domain)、心理範疇(Psychological Domain)、獨立 程度(Level of Independence)、社會關係(Social Relationship)、環境 (Environment)、心靈 宗教 個人信念(Spirituality Religion/Personal Beliefs),六個範疇下共分為 24 個層面(Facets)。在每個層面各有四個 題目,連同整體性評量的 4 題,問卷共計有 100 題。但由於此份問卷太. 10.
(11) 長,並不適合作為需考慮時間及實用性的臨床試驗或流行病學調查使 用,WHOQOL 研究總部為了維持測量生活品質的完備性 (Comprehensiveness) ,因此由 WHOQOL-100 的 24 個層面中各選出一個 題目,並將這 24 題簡明版題目分成四個主要的範疇:生理健康範疇 (Physical Health Domain,包含原先的生理及獨立程度範疇)、心理範疇 (Psychological Domain,包含原先的心理及心靈/宗教/個人信念範疇)、 社會關係範疇( Social Relationships Domain)以及環境範疇(Environment Domain) ,也從整體性評量中挑選出兩個題目分別為「整體生活品質」與 「整體健康狀況」的題目,使問卷一共有 26 題,稱做 WHOQOL-BREF 2。 WHOQOL 問卷並允許各國依循所訂定出來的嚴格標準,將 WHOQOL-100 及 WHOQOL-BREF 原始問卷翻譯為本國文字後,並可允 許加入各文化特有的題目,稱之為國家性題目(National Items,在台灣 我們慣稱為本土性題目) ,這些題目能補足一般性題目無法測到屬於各文 化特色之下的生活品質概念。 WHOQOL 台灣版問卷發展小組於 1997 年,依照 WHOQOL 研究總 部的規定,將 WHOQOL-100 原始問卷翻譯為本國文字,並按其規定先做 問卷量尺的發展,依四個類型(能力、頻率、強度、評估)找出最接近 0, 25%,50%,75%,100%的語詞應用在問卷中,進行台灣版生活品質問卷 的研究與發展 41。. 11.
(12) 而 WHOQOL-BREF 台灣版問卷,除了包含 WHOQOL-BREF 的 26 個題目外,還加上了「被尊重及接受」以及「飲食」等兩個台灣本土性 層面的題目,因此 WHOQOL-BREF 台灣簡明版問卷共有 28 題,分為四 個範疇:生理、心理、社會和環境方面,每一題各有五個選項,可轉換 為 0-100 分,分數愈高表示生活品質越好 2(參見附錄一)。同時也出版 了一本「台灣簡明版世界衛生組織生活品質問卷之發展及使用手冊」供 使用者參考。. 四、Short-Form 36 (SF-36)健康量表的研究 SF-36 是由健康保險試驗(Health Insurance Experiment,HIE)期間 醫療照護結果的研究調查(Medical Outcome Study,MOS)時發展出來 的,由 HIE 問卷的題目中挑選出部份題目來做健康調查,研究者發現在 研究過程中會因問卷題目簡短而較不會發生個案追蹤時的缺失值的問題 (Loss to Follow-up),使得研究較易執行。所以在 1984 年 Ware JE 等人 發展出 SF-18(18-Item Short Form)健康量表,又於 1986 年在 SF-18 健 康量表中多增加了 2 題測量有關社會功能和身體疼痛題目,進而發展成 SF-20(20-Item Short Form)健康量表。而 SF-36 健康量表是在使用 SF-18 健康量表和 SF-20 健康量表後,評估其內容的廣度和測量的深度後,所 完成的新健康量表. 42-43. 。. 12.
(13) 而發展出來的 SF-36 健康量表共有 36 題,包含了八個範疇,分別為: 身體活動功能(Physical Functioning,PF)、活動功能限制情況 (Role-Physical,RP)、心理健康限制生活程度(Role-Emotional,RE)、 社交情況(Social Functioning,SF) 、身體疼痛狀態(Pain Item,BP) 、活 力狀態(Vitality,VT)、心理健康狀態(Mental Health,MH)及個人評 估身體健康之程度(General Health Perceptions,GH)和整體健康情形; 每一題分別有二到六個選項,可轉換為 0-100 分,分數愈高表示生活品質 愈好 1。(參見附錄二) SF-36 健康量表設計成可以自填、電訪或面談的問卷,因此有些研究 者針對使用的方法作探討 37,43-44。SF-36 健康量表可以使用在一般族群的 健康研究調查、疾病別族群的研究、臨床試驗的研究,亦適用在部分的 特殊族群,分別列舉如下: (一)一般族群的健康研究 SF-36 在健康測量上具有高的效度,2003 年 Stefan B 對一般族群 20~74 歲中選出沒有慢性疼痛(NCP) 、慢性局部疼痛(CRP) 、慢性全身 性疼痛(CWP)三種族群加以比較,控制三組年齡、性別、社經地位等 干擾變項,發現 SF-36 八個範疇都可以區辨出三組族群,達到不錯的效 度,且都可敏感的測量出疼痛的現況,也可預測出將來疼痛發展情況, 顯示 SF-36 健康量表可作為 20~74 歲工作族群的健康調查工具 45。Sullivan. 13.
(14) M 等人在瑞典的研究,亦顯示 SF-36 健康量表可作為 15-93 歲族群的健 康調查工具 46。 (二)疾病別族群的研究 許多研究顯示 SF-36 健康量表可適用在一般疾病別族群的健康調 查,並且能獲得不錯的信度及效度 47-48。許多學者亦評估 SF-36 健康量表 是否適用在部分臨床特殊疾病別的研究 49-51;DonaldAM 等人在 1995 年 研究慢性阻塞性肺疾病患者(COPD)的健康生活品質,測量的結果發現 除了「心理健康限制生活程度,RE」、「心理健康狀態,MH」,對於肩膀 功能障礙患者,雖不能測量出應有的健康情況,不過其餘六項範疇(身 體活動功能(PF)、活動功能限制情況(RP)、社交情況(SF)、身體疼 痛狀態(BP)、活力狀態(VT)及個人評估身體健康之程度(GH))的 健康向量,都較能預測出慢性阻塞性肺疾病患者(COPD)的健康問題 51。 (三)老人族群的研究 目前 SF-36 健康量表普遍適用在一般年紀的族群 42,46,而對於年紀較 年長族群的使用情況, Lyons R 等人將 SF-36 施用於社區健康與非健康的 老人,結果顯現出良好的內在一致性( Cronbach’s alpha scores >0.82) ,且 可以區辨出老人當時的健康狀態,代表良好的同時效度(Concurrent Validity)52。依 Hayes V 研究選擇大於 65 歲的門診病人進行自填與訪談, 發現大於 75 歲的老人較無法完成自填,但 84%的老人可在 10 分鐘之內. 14.
(15) 完成問卷,而對老人的研究結果,顯示 SF-36 健康量表仍可對老人作概 括性的健康測量 4。 (四)臨床試驗的研究 將 SF-36 健康量表使用在臨床試驗,大都採用前測與後測,亦即患 者進入研究此時先做過ㄧ次健康量表的測量,經試驗介入後,再以健康 量表測量介入後的健康狀況,以比較介入前後的差異 35。CoulterA 研究 對在月經週期有大量出血與疼痛的病患,在接受子宮切除術後,手術前 後健康狀態的改變情況,結果顯示接受切除術的婦女,幾乎在各個健康 向量上都有顯著的改善,沒做切除術只吃藥的患者都沒有顯著改善生活 品質,而沒做切除術的患者比有做切除術的患者,更顯著覺得生活品質 不好 35。. 15.
(16) 第二節. 古典測量理論. 古典測量理論主要是以「真實分數模式」為基礎。古典測量理論是 一種直線關係的數學模式,任何測量的觀察分數(X)皆由「真實分數(T) 」 與「誤差分數(E)」所構成的數學函數關係,數學公式為 X = T + E。其 中,真實分數指的是研究者真正想測量的特質,誤差分數則是研究者欲 想避免的部分。誤差又可分為「系統誤差」與「隨機誤差」,系統誤差的 發生如:問卷測量在題目語意不清,造成選填錯誤,不論對每一位受測 者都具有此誤差,此誤差並不會影響測量結果的一致性,但會使測量分 數不準確;而隨機誤差的發生如:受測者在填答時分心、猜測或受心情 影響,會造成降低測量結果的一致性,也降低測量結果的準確性 13,53。 古典測量理論模式的發展歷史悠久,且頗具規模,所採用的計算公 式簡單明瞭、淺顯易懂,適用於大多數的教育與心理測驗資料,以及社 會科學資料的分析,為目前測驗學界使用與流通最廣的理論依據。古典 測量理論之假設如下 53: (1)觀察? =真實? +誤差值,即 X = T + E。 (2)觀察? 的期望值=真實? , ε ( x ) = ε (T + E ) = T 。 (3)誤差值與真實? 不相關。也就是說測量的誤差與受測者能力高低無 關, ρ E1T 2 = 0 。. 16.
(17) (4) X 1 = T1 + E1 與 X 2 = T2 + E 2 兩份測驗,則 ρ E1E 2 = 0 ,表示兩份測驗誤差 不相關。 (5)一個測驗的誤差與另一個測驗真實? 不相關。因此在測驗某種特質 時,不受另一種測驗誤差的影響, ρ E1T 2 = 0 。 (6)真實? 相等測驗:若兩測驗符合假說(1)至(5),且兩測驗的真 實? 差一個常數,則此兩測驗稱為真實? 相等測驗。 依據以上這些假設,可以推導出信度與效度的公式。通常信度指的 是用同一種測驗重複測量某些特質,得到相同結果的程度,例如:前後 兩次測驗分數一致的情形。而效度指的是正確性,能正確測量出欲測量 的某些特質。其主要優點如下 13: 一、古典測量理論的基本概念簡單易懂。 二、古典測量理論所使用的數學模式及公式並不艱深。 三、不需要特別的電腦程式來估計古典測驗理論的參數,許多的統計工 具即可滿足需求。 四、因為古典測量理論沒有強制的假設(Weak Assumptions),多數的資料 都可符合古典測驗。 除上述各項優點外,古典測量理論卻有下列諸項先天的缺失: 一、測驗題目的難易度難區分:受測者的能力高或低取決於施測題目簡 單或容易;施測題目簡單或容易取決於受測者能力高或低。受測者. 17.
(18) 的能力通常取決於在測量時答對了多少題:答對愈多就愈表示能力 越好,答對愈少題就愈表示能力愈差,而且得分只知能力差,但無 法得知有多差。 二、受測者的特性與測驗的特性很難區分:測驗和題目的特性隨著受測 者改變而跟著改變,受測者的特性隨著測驗和題目特性的改變而改 變。 三、在兩份不同測量無法做比較:因為兩份問卷不論在內容或量尺上都 不盡相同。例如:受測者 A 接受甲測驗,得到 100 分,受測者 B 接 受乙測驗,得到 80 分,但無法拿來做比較,因為不能說受測者 A 能 力比受測者 B 要來的好。 四、古典測量理論在測量上,測量誤差會影響到觀察? ;古典測量理論 以一個相同的測量標準誤(Standard Error of Measurement),作為每位 受測者的測量誤差指標,這種作法並沒有考慮受測者能力的個別差 異,對高、低能力兩組極端的受測者而言,這種指標極為不合理且 不準確。不論能力好壞,每位受測者所接受的測驗都一樣。 五、古典測驗理論對信度的假設,是建立在複本(Parallel Forms)測量的概 念假設上,但是這種假設往往不存在於實際測驗情境裡。因為不可 能要求每位受試者接受同一份測驗無數次,而仍然假設每次測量間 都彼此獨立不相關,況且,每一種測驗並不一定同時都有製作複本,. 18.
(19) 因此複本測量的理論假設是行不通的,從方法學邏輯觀點而言,它 的假設也是不合理的、矛盾的。 六、古典測量理論是以測驗為主非各題目為主:在古典測量理論中特別 重視某些題目的表現,但無法得知受測者的某些特色。如:某一受 測者答對某一題的機率。 七、古典測量理論無法對受測者的能力作預測。. 19.
(20) 第三節. 項目反應測量理論. 70 年代起,項目反應理論(Item Response Theory,IRT)成為測驗學 者們研究的焦點,源其發跡要從 40 年代中葉談起,1946 年 Ledyard Tucker 提出項目特徵曲線(Item Characteristic Curve,ICC)這個詞,但是ㄧ直 到 60 年代末,測驗領域仍已強調真分數理論為主,儘管如此,真分數理 論的問題和弱點卻也逐漸突顯。古典測驗理論(Classical Test Theory, CTT)的假設弱,較容易獲得滿足,而且對使用的人而言根本不談理論 假設,也因此流行ㄧ時,甚至造成大家對數學模式、交代嚴謹的 IRT 有 些排斥或不適應。但 CTT 在測驗上有些缺點:例如測驗貨題目參數(信 度、難度及鑑別度)隨受測樣本特質而變動;且 CTT 不夠適性,無法兼 顧各個不同能力點的受測者;無法以概率的方式預測某位受測者面對一 個未曾考過題目時答對的可能;且都假設一個測驗下,所有受測者的測 驗誤差都ㄧ樣,很明顯的不適切 20。 IRT 與 CTT 主要之差距在於前者強調題目特徵曲線(Item Characteristic Curve,ICC) ,後者以強調真分數(True Score)為主。由於 CTT 無法正確評量出受測者之個人真正潛在能力(Talent),而 IRT 係以 機率模型為基礎,將潛在能力與題目難度以同一尺度標準化測定,所發 展出這套的理論,已成為近代心理測量之主流 55。. 20.
(21) 一、IRT 兩大基本假設 13: 根據 IRT 發展史,分為兩大基本假設,分別為單一向度假設和局部 獨立假設,以下分別介紹: (一)、單一向度(Uni-dimensionality)假設:測驗中的各個題目都測量 到同一種共同的能力或潛在特質;即假定同一測驗都在測單一向度。 (二) 、局部獨立(Local Independence)假設:假定所回答的每一個題目 皆局部獨立。即針對某一受試能力 ? 而言,題目彼此間不存在任何相關, 即一個題目不能為另一個題目提供線索。. 二、項目特徵曲線(Item Characteristic Curve,ICC): 早在 Binet 及 Simon(1916)編製智力量表時就已經使用了 IRT 的核 心觀念---項目特徵曲線(Item Characteristic Curve,ICC)。他們認為孩子 在各項認知性測驗上的表現會隋年齡的增長而愈來愈好,利用 ICC 的方 式來選擇測驗史上第一個智力測驗的題目 20。 項目反應理論建立在兩個基本概念上:(1)受測者(Examinee)在 某一測驗題目上的表現情形,可由一個因素來加以預測或解釋,這組因 素叫作潛在特質(Latent Traits)或能力(Abilities);(2)受測者的表現 情形與這組潛在特質間的關係,可透過一條連續性遞增的函數來加以詮 釋,這個函數便叫作項目特徵曲線(Item Characteristic Curve,ICC)。. 21.
(22) 圖一、項目特徵曲線. 由圖一顯示項目特徵曲線所表示的涵義,即是某種潛在特質的程度 與其在某一題目上正確反應的機率,二者之間的關係;這種潛在特質的 程度愈高(或愈強),其在某一題目上的正確反應機率便愈大。且不論在 族群一或族群二,只要是能力相同的人,正確反應機率就會相同。. 答. 1. 2. 3. 4. 對 的 機 率. 能力. 圖二、四個題目的單一參數項目特徵曲線. 由此圖二可顯示在項目反應理論中,每一題目反應模式就有其相對 應的一條項目特徵曲線,此一曲線通常包含一個或多個參數來描述題目 22.
(23) 的特性,以及一個或多個參數來描述考生的潛在特質,而且每條特徵曲 線範圍都位於 0~1 之間。. 三、Rasch 系列模式與單一、兩、三參數系列模式: 目前常見的 IRT 模式主要有線性模式、Guttman 的完美量尺模式、多 參數模式(1-PL、2-PL、3-PL)及類別反應模式。Rasch 為 IRT 中 Rasch 模式的創始者,此模式影響深遠。單一參數二元模式與 Rasch 計分二元 模式為相等模式。單一參數系列模式包括難度參數,兩參數系列模式包 括難度參數及鑑別度參數,三參數系列模式包括難度參數、鑑別度參數 及猜測參數。兩系列模式主要不同處在於 Rasch 系列模式強調個人潛在 特質的測量(Latent Trait Measurement)及題目難度的測定(Item Difficulty Calibration),在單一向度的假設下,個人潛在特質及題目難度在模式中 均自動轉換為相同的測量單位以利比較並探討理論特質,若資料與模式 不適合則需修正題目或限制其適用對象。而單一參數、兩參數、三參數 系列模式則基本上可藉由參數的增加來嘗試改善資料與模式的適合性, 再根據適用模式來詮釋結果,因其較具實用性故近年來發展快速。然 Rasch 系列模式在基礎理論的探討及題目比較上則扮演重要之地位。 鑑於上節所討論 CTT 的缺失,IRT 在未來有逐漸發展的優勢,而 IRT 具有以下幾項特點:. 23.
(24) (一)、IRT 受測者的特性與測驗的特性可區分:受測者的能力高或低不 會取決於施測題目簡單或容易;施測題目簡單或容易不會取決於 受測者能力高或低。 (二)、IRT 可將不同內容量尺的問卷等化至同一尺度上,使不同問卷可 做比較。 (三) 、CTT 是假設每個受測者誤差都相同,而 IRT 的誤差是與每位受測 者能力有關;對不同能力的受測者都能夠依照受測者不同的能力 而給予不同的測驗題目。對不同程度的受測者而言,任何測量對 分數並非等誤差的估計,且每位受測者所接受測驗的題目因能力 不同而不同,所以同一測驗並非每人都適用。 (四)、IRT 是各題目為主而非測驗為主:可看出某些題目的表現、知道 患者的某些特色,如:某一受測者答對某一題的機率。 (五)、IRT 可以針對受測者的能力作預測。. 四、Rasch 系列之評定量尺模式(Rating Scale Model): 目前許多的問卷都以多元尺度為測量,Rasch 系列模式中所延伸的多 元計分模式之一-----評定量尺模式(Rating Scale Model),即是用來處理 多元尺度的問卷分析,茲將此模式介紹於下: (一)、評定量尺(Rating Scale):是用來評量個人行為的一種工具。其. 24.
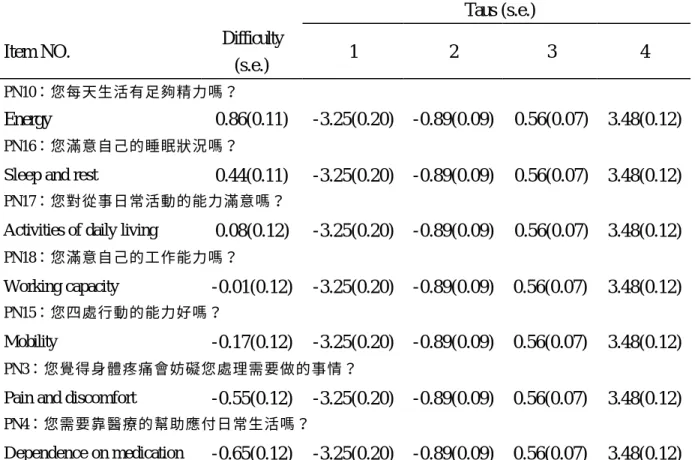
(25) 主要特徵在於對某特定行為有一系列含價值高低的選項 56。例如: WHOQOL-BREF 問卷題目有五種高低不同的回答( 1=非常不同意,2=不 同意,3=普通,4=同意,5=非常同意),就是一種評定量尺。 (二)、評定量尺模式(Rating Scale Model):根據評定量表的特性,基 於 Rasch Model,Ardrick 於 1978 發展出評定量表模式(Rating Scale Model)。通常適用在題目答案有兩個以上的選項。 評定量尺模式(Rating Scale Model)定義如下: Pnik ( x = 1 / B n , D i , F k ) =. e ( B n − ( D i + F k )) 1 + e ( B n − ( D i + F k )). Bn :為第 n 個受測者的能力值, Di :為第 i 題的難度, Fk :為第 k 個門檻的難度,第 k 個門檻表示選擇 k 與 k-1 機率相等時的能. 力值所對應的位置, Di + FK :第 i 題的難度加上第 k 個門檻的難度(i.e., Di + FK )表示為在填. 答第 i 題選第 k 個門檻的難度。 上式的 Pnik 為一條件機率,表示第 n 個人針對第 i 題在可選擇選項 k-1 及選項 k 的條件下選擇 k 的機率(即 Pnik =. f nik , f nik 表示第 n f ni( k −1) + f nik. 個人針對第 i 題選擇選項 k 的機率) ,以上模式屬於邏輯斯迴歸模式系列。 (三)、評定量尺之特徵曲線(Rating Scale Characteristic Curves):. 25.
(26) 圖三、評定量尺模式四個門檻值的對應機率 Category. Step Calibrations(S.E.). F0 (0-1scale) F1 (1-2scale). -3.15(0.20). F2 (2-3scale). -0.89(0.09). F3 (3-4scale). 0.56(0.07). F4 (4-5scale). 3.48(0.12). 由圖三為 Rasch 模式分析,顯示在同一範疇的題目量尺被分為四個 門檻值(-3.15、-0.89、0.56、3.48),可看出能力在哪的人,會較容易填 答哪個選項。 五、IRT 模式的評估: (一) 、單一向度假設 (Undimensional Assumption):同一向度的測驗中的 26.
(27) 各個題目都測量到同一種共同的能力或潛在特質,亦即假設同一向度的 題目皆測量同一種能力。利用此特性,來驗證不同測驗下同向度的題目 是否都符合同一向度的假設,若題目符合此假設,則可推論其適用於不 同族群的比較,並進而探討哪些題目較偏離此假設下,以及藉此探討兩 份問卷在測患者得分時的難易表現,以藉此瞭解如何等化此兩份問卷的 得分。 (二)、局部獨立(Local Independent)假設:局部獨立假設的評估可應 用測驗題目的獨立性分析(Test-Independent Analysis)與樣本的獨立性分 析(Sample-Independent Analysis)。 1. 樣本獨立性分析(Sample-Independent Analysis): 在同一向度的假設下,題目的難度應該是固定的,不會因為受測者而 改變,應用在不同族群同一向度的假設下,是否具有項目難度不變性的 特質。以項目差異功能( Differential Item Function,DIF)57,檢驗出於不 同族群在各題目上的潛在差異情形,例如若同一份問卷但不同語言的版 本,用以測量相同能力的兩群人,但此兩群人得分上有差異,即表示有 DIF,依此方法所得之結果能反映出哪些題目具有跨文化對等性,哪些題 目需被修改或刪除,希望達到項目參數有不變性(Invariance of Item Parameters)的特質,使得跨文化生活品質的題目得以選擇,使得跨文化 的比較得以達成。. 27.
(28) "Physical" DIF. WHOQOL-BREF(w/ med). 1.5 1 0.5 0 -2. -1.5. -1. -0.5. 0. 0.5. 1. 1.5. -0.5 -1 -1.5 Trait Level WHOQOL-BREF(w/o med). 圖四、項目差異功能(DIF):WHOQOL(n=229)和 WHOQOL(n=166). 由圖四可知,以相同的題目去測兩組不同族群,利用兩條 95%信賴 區間去檢測這些題目在不同族群上是否具有項目參數不變性;若題目不 位於 95%信賴區間內,顯示此題目具有項目差異,即不具有項目參數不 變性。 2、測驗獨立性分析(Test-Independent Analysis): 受測者能力不變性的分析,看不同問卷是否測得同一向度的能力, 從偏離? 可看出問卷對不同能力的人的測量敏感度。. 28.
(29) 圖五、項目差異功能(DIF):WHOQOL 和 SF-36. 由圖五可知,利用兩條 95%信賴區間去檢測兩份不同問卷在相同一 群人上是否具有樣本不變性;若受測者不位於 95%信賴區間內,顯示此 這群人在不同問卷有不同的能力值,表示不具有樣本獨立的特性。如果 顯示出不同問卷得到的能力分數呈線性關係,則表示符合樣本獨立性。. (二)、模式契合度的評估(Goodness of Fit): 1.未加權的均方適合統計量---OUTFIT MNSQ 期望值為 1,期望值範圍介於 0 至無限大。OUTFIT MNSQ 值若等於 1, 則表示題目具有局部獨立的特性,題目與資料適合。Outfit 是建立在標 準化殘差平方和(sum of squared standardized residuals)的基礎所發展 的指標,假設標準化殘差為常態分佈( a unit normal distribution) ,故均. 29.
(30) 方和逼近於卡方分佈(?² distribution),其數學公式為: Z 2 = ( X − E ) / σ 2 , OUTFIT = ∑ Z ni2 / N , 2. X 為觀察? ,E 為期望值, σ 2 為期望值的變異數,N 為觀察? 的數目. OUTFIT MNSQ 有高的敏感度用來測量受測者在填達此題時,題 目是否會太簡單或太困難。若 OUTFIT MNSQ 逼近 0,則表示此題目在 測量上有過度預期的效果。若大於 1.3,則表示此題目與資料不合適。. 2.加權的均方適合統計量---INFIT MNSQ Infit 是 Outfit 經訊息加權後之形式( Information-Wieghted Form) ,此加 權過程將減低較偏離主要研究對象能力所在範圍部份所造成的影響, 此時, σ 2 為經加權處理後的殘差的變異數,則 Infit 數學公式為:. (. ). ( ). INFIT = ∑ Z 2 − σ 2 / ∑ σ 2 = ∑ ( X − E ) / ∑ σ 2 2. 若 INFIT MNSQ 值逼近於 1,則表示題目具有局部獨立的特性,亦 是題目與資料適合。INFIT MNSQ 若接近 0,則表示此題目在測量上有 過度預期的效果。若大於 1.3,則表示此題目與資料不合適。. 30.
(31) 第 四 節 項 目 反 應 理 論 在 健 康 結 果 ( Health Outcome)評量之應用. 由於 CTT 的項目統計量,如:題目難度(Difficulty) 、題目的鑑別度 (Discrimination) 、和測量的信度(Reliability)等,這些項目統計量都是 依賴受測者的分數所計算而來的,因此項目統計量會因為使用的受測者 特性的不同而有所改變,且 CTT 以一個相同的測量標準誤(Standard Error of Measurement),作為每位受測者的測量誤差指標,這種作法並沒有考 慮受測者能力的個別差異,對高、低能力兩組極端的受測者而言,這種 指標極為不合理且不準確 13-14,所以有測驗題目的依賴性(Test-Depend) 和樣本的依賴性(Group-Depend),因而有項目反應理論(Item Response Theory,IRT)的發展。 在自我健康評估方面 IRT 的潛在好處比 CTT 來的好。因為對不同能 力的受測者都使用相同的測驗,最好的方式是能夠依照受測者不同的能 力而給予不同的測驗題目,但在 IRT 上,會結合應試者的反應分數,形 成一機率模式,為項目特徵曲線(Item Characteristic Curve,ICC),ICC 可描述 IRT 之重要結果之一,可用來鑑別題目的好壞、題目的難度、測 驗總分及猜測參數,所以不論任何人來做,每個人的猜測參數、題目的 鑑別度、題目的難度皆為固定,不會隨著樣本的特性、組成不同而有所 改變,也就是說項目參數有不變性(Invariance of Item Parameters)6,13,. 31.
(32) 即測驗題目的獨立性(Test-Independent)和樣本的獨立性 (Group-Independent)。. IRT 在健康結果評量的應用部份為. 13,53. :. 一、測驗的編製:運用題目和測驗訊息函數來參與編製測驗的工作。挑 選出對滿足某份特殊測驗所需的訊息總量最有貢獻的題目,以編製 成可以達成測量目標的測驗卷。所以可以在任何能力水準上,挑選 出最能精確測量(亦即該測量標準誤差最小)到該能力範圍的題目, 以編製成所需要的測驗。 二、測驗分數的等化:主要目的是在將兩份測驗的項目參數估計值,轉 換到同一量尺上,以便進一步進行測驗分數的等化工作。 三、題目偏差的診斷:利用 IRT 的方法可用來檢驗出於不同問卷(例如 不同語言版本問卷)在各題目上的潛在差異情形,即所謂的項目差 異功能( Differential Item Function,DIF) ,檢驗出於不同族群在各題 目上的潛在差異情形,例如若同一份問卷但不同語言的版本,用以 測量相同能力的兩群人,但此兩群人得分上有差異,即表示有 DIF, 依此方法所得之結果能反映出哪些題目具有跨文化對等性,哪些題 目需被修改或刪除,希望達到項目參數有不變性(Invariance of Item Parameters)的特質,使得跨文化生活品質的題目得以選擇,使得跨. 32.
(33) 文化的比較得以達成。 四、電腦化適性測驗(Computerized Adaptive Testing,CAT):在電腦化 適性測驗裡,呈現給受測者的題目順序,是依據受測者在前一個題 目上的表現好壞來作決定的。根據受測者先前的表現好壞,給受測 者作答的下一個題目,便是對受測者能力估計精確性有最大訊息量 的題目。這樣測驗的長度便可以縮短,並且也不會犧牲任何的測量 精確性;因為對於高能力的受測者,可以不必給他相當容易的題目 作答,對於低能力的受測者,也可以不必給他極度困難的題目作答; 這樣一來,對每位受測者都能精確評估其生活品質,也可以節省許 多施測時間和成本。. 33.
(34) 第五節. 項目反應理論與生活品質研究實例. 近年來由於人們越亦重視生活品質,所以為了發展出好的健康測量 表就越顯得重要,因此許多研究應用 IRT 來探討這些生活品質問卷的適 用性 21-25,除檢視這些問卷在特定族群的適用性外並可藉由 IRT 的分析更 進一步瞭解所探討族群生活品質的情形及特異性,IRT 更適用於不同分組 的比較及縱貫性測量結果的評估 20。 Hays RD 等人研究測量人類免疫缺乏症候群(HIV)病人的生活品 質,利用項目反應理論的特性,每一題有其難度與鑑別度,能夠區辨出 不個人有不同的情況,因此較能精確的評估出實際生活品質情況,對於 個人或者是族群能夠給予較好的生活品質。因而發現 IRT 在二十一世紀 上健康結果測量將被廣泛應用 17。 1999 年 Wolfe F 利用 IRT 去分析 WOMAC 問卷,由 2205 個骨質關 節炎、風濕性關節炎、肌膜炎病人所填寫;為了提升健康測量,所以利 用 IRT去評估題目難度、範疇的單一性、題目的延展性,研究發現WOMAC 問卷在骨質關節炎、風濕性關節炎、肌膜炎整體測量上都滿不錯的,在 適合度檢定上只有某些題目可能需要刪除,因為會造成天花板效應 (Ceiling Effect) 、地板效應(Floor Effect) ,所以無法得到較大的資訊 25。 2000 年 McHorney CA 等人欲建立一個測量身體功能性狀況的題庫,. 34.
(35) 將現有測量身體功能性狀況的問卷(ADLs 和 IADLs)做等化,挑出合適 的題目進入題庫,將不好的題目刪除,研究結果顯示普遍六個範疇的題 目皆不錯,只有少數幾題需刪除,且可將問題再細分,不要問的太廣, 另外也可以將其它功能方面的題目考慮進去,更可以達到電腦適性測驗 (CAT)的完整性 22。 Badia X.等人在 2002 年想針對骨質疏鬆症的病人在臨床上生活品質 的測量,發展出一份更適性簡短的問卷;利用 Rasch Model 理論將兩份已 知問卷 OQLQ 和 QUALEFFO 進行題目特性分析、項目等化、再進行項 目縮減,最後再請專家檢視效度,而發展出一份簡短式問卷(ECOS-16), 使更能針對骨質疏鬆症去測量出其在臨床上生活品質的改善情形 21。 2003 年 Jakob B 等人利用 IRT 去評估頭痛病人生活品質,以電腦適 性測驗方式,將現有評估頭痛的四份問卷 MSQ、HDI、HIMQ、MIDAS 集合成一題庫,利用 IRT 特性去區分題目的難度與鑑別度,電腦就能利 用頭痛病人在電腦上選擇的答案,而給予更適性的題目,避免掉不合適 的題目,漸漸去逼近病人的真實分數,進而了解病人的生活品質情況, 且還可利用所得的分數來互相比較 24。 2004 年 Noerholm V 等人想要建立一個丹麥族群的生活品質常模,同 時以 Rasch Mode(單一參數)和 IRT Model(兩參數)去評估 WHOQOL-BREF 問卷效度;研究結果顯示,WHOQOL-BREF 問卷整體. 35.
(36) 來說比較適合 IRT Model(兩參數),因為 WHOQOL-BREF 問卷四個範 疇相關性強,所以用 IRT Model 兩個參數去評估四個範疇,是較適合的; 但若將四個範疇分別去評估,以 Rasch Model 去檢測 WHOQOL-BREF 問 卷,則只有生理與心理範疇適合 Rasch Model26。 Prieto L 等人評估慢性阻塞性肺疾病(COPD)患者的健康相關生活 品質,選取 SF-36 和 Nottingham Health Profile(NHP)兩份一般性問卷做 比較,比較兩份問卷的信度、效度、分數的分佈,還包含了 Rasch Model 分析。研究結果顯示,SF-36 得分有較少的天花板效應(Ceiling Effect) 和地板效應(Floor Effect),較屬常態分佈,同質性較高;兩份問卷都能 鑑別出疾病嚴重程度不同的患者,不過 SF-36 的鑑別效度較好;在量尺 評估與信效度分析上,SF-36 都比 NHP 問卷來的好。SF-36 題目與範疇 的相關性除了社會功能範疇相關性較低外,其餘範疇相關性都很高。而 在 Rasch Model 分析上,可看出 SF-36 的題目較適中,不會太困難、也不 會太簡單,不過 SF-36 的難度大部分都集中在同一範圍,而 NHP 問卷則 是題目的難度較廣,較能測到 39。 2000 年 Bonom AE 等人評估 WHOQOL-100 問卷,在測量不同疾病 的族群、疾病嚴重的族群或不同文化族群的生活品質信度與效度;選取 15 個不同的國家,選有慢性疾病、健康族群及分娩婦女,發現 WHOQOL-100 問卷有很高的信度與效度;在收斂效度上,WHOQOL-100. 36.
(37) 的生理範疇與 SF-36 的活力狀態(Vitality,0.65) 、身體疼痛狀態( Bodily Pain,0.55) 、個人評估身體健康之程度(General Health Perceptions,0.53) 皮爾森相關係數很高。而在 WHOQOL-100 的心理範疇方面與 SF-36 的心 理健康狀態(Mental Health,0.66)、活力狀態(Vitality,0.62)、社交情 況(Social Functioning,0.59)皮爾森相關係數很高 8。. 根據上述相關文獻討論,我們可以得到結論: 一、可利用 IRT 評估問卷題目是否具有不同族群的可比性及該問卷較適 合測試哪些族群。 二、可利用 IRT 整合不同問卷相同向度的題目,並從中挑出適當難度和 好的鑑別度的題目,作為改進測量之參考。 三、可利用 IRT 建立題庫,以之發展電腦適性測驗。 四、 IRT 可幫助研究者更深入對題目本身及題目之間的瞭解,也因之可 應用於問卷間心理計量特質的比較,評估在特定族群中題目的敏感度。 五、 IRT 已漸漸被應用在健康結果的測量上,並受到很大的重視。. 37.
(38) 第參章、研究方法和步驟 第一節. 研究架構. 資料來源: 2001 年國民健康局”國民健康訪問調查”生活品質 資料,包括 SF-36 問卷資料(訪員填寫)及 WHOQOL-BREF 問卷資料(自填). 針對肺部疾病患者(有服藥族群及沒有服藥族群) 比較 WHOQOL-BREF 和 SF-36 兩份問卷的基本心 理計量特質及對應關係。. CTT 分析: 1. 研究對象的基本資料 2. 問卷基本資料描述 3. 因素分析與相同向度的擷取. IRT 分析: 1. 量尺尺度測定分析 2. 項目參數不變性分析 3. 模式適合度的評估. 統計分析、書面資料整合、論文撰寫. 38.
(39) 第二節. 研究對象. 本研究資料來自於 2001 年國民健康局的國民健康訪問調查,有家戶 問卷、12 歲以上個人問卷(包含 SF-36 問卷) 、12 歲以下個人問卷、20-65 歲生活品質問卷(WHOQOL-BREF) ,共有 20855 人,除 WHOQOL-BREF 生活品質問卷為自填問卷外,其餘皆為訪員問卷,此研究選擇在問卷上 “您是不是曾經患有肺部方面的疾病?”填答“有”,且“是醫護人員 告訴您的”,選有被確診為患有肺部疾病的患者 395 人(235 位男性和 160 位女性),年齡從 15 到 66 歲(平均年齡 42.8± 12.3 歲)。為驗證結果 的穩定性,本研究再根據“您現在有沒有在服用治療肺部疾病的藥?” 的選項,將肺部疾病患者分成有無服藥兩組:組別一:有服藥物者(166 人) ,組別二:沒有服藥物者(229 人) ,本研究大部份結果均針對此兩族 群進行平行分析。. 第三節. 研究工具. 本研究使用 WHOQOL-BREF 臺灣簡明版,2000 版,和 Short-Form 36 (SF-36)問卷,1994 版,兩份問卷皆為評量個人生活品質,其介紹如下: 一、WHOQOL-BREF 臺灣簡明版 2。根據 WHOQOL 研究總部所發展 的 WHOQOL-BREF 而來。原來的 26 題,再加上本土性題目 2 題, 39.
(40) 共有 28 題,分為四個範疇:生理、心理、社會和環境方面,每一題 各有五個選項,可轉換為 0-100 分,分數愈高表示生活品質愈好。 (請 見附錄一) 二、Short-Form 36(SF-36) 1。SF-36 是發展於醫學研究結果,有 36 題,分為八個範疇:身體活動功能(Physical Functioning,PF)、活 動功能限制情況(Role-Physical,RP)、心理健康限制生活程度 (Role-Emotional,RE) 、社交情況(Social Functioning,SF) 、身體疼 痛狀態(Bodily Pain,BP)、活力狀態(Vitality,VT)、心理健康狀 態(Mental Health,MH)及個人評估身體健康之程度(General Health Perceptions,GH)和整體健康情形;每一題分別有二到六個選項, 可轉換為 0-100 分,分數愈高表示生活品質愈好。(請見附錄二) 三、心理計量軟體 WINSTEPS 用以進行 Rasch 系列模式中的評定量尺模 式(Rating Scale Model)的分析,統計套裝軟體 SAS 8.2 版用以進行 資料處理、敘述統計、t 檢定、信度分析、相關分析及因素分析。. 第四節. 研究方法與步驟. 本研究目的為比較 SF-36 和 WHOQOL-BREF 兩份問卷的心理測量 學特性。研究方法與步驟如下: 步驟一、問卷整體性分析(Survey Analysis)。在此部份此研究將針對兩 40.
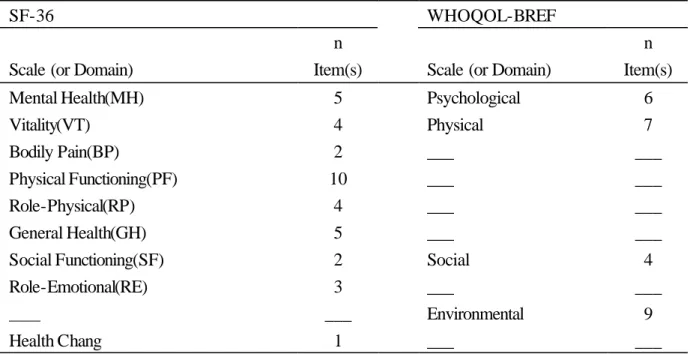
(41) 份問卷作整體性分析。其主要內容包含:分析問卷基本描述性統 計、兩份問卷之層面與範疇的心理測量學特性;另有兩份問卷信 度分析(以 Cronbach’s alpha coefficient 分析)、範疇得分分數的 分佈及天花板及地板效應(Ceiling effect and floor effect)的討論。 步驟二、問卷架構分析(Survey Structure)。基於問卷使用手冊所設定之 問卷範疇,將兩份問卷的範疇配對,進行題目探索性因素分析 (Exploratory Factor Analysis, 分別以直交(Varimax)及 斜交 (Promax)轉軸法來探討, 並以 Eigenvalue > 1 來擷取因素) 、各 範疇間之相關(Pearson’s Correlation Coefficient)分析。最後再 以專家角度進行對問卷整體內容及各題目陳述進行效度評估,藉 以分析與比較兩份問卷,進而嘗試找出兩份問卷相同的架構。 如:WHOQOL-BREF 的生理方面相對應於 SF-36 的身體疼痛狀 態及活力狀態;或 WHOQOL-BREF 的心理方面相對應於 SF-36 的心理健康狀態。 步驟三、項目屬性分析(Item Property)。根據 IRT 中 Rasch 系列模式中 的評定量尺模式( Rating Scale Model)探討題目難度的量尺測定 (Item Calibration)、及題目難度的順序(Item Ordering),進ㄧ 步分別對 WHOQOL-BREF 與 SF-36 進行兩組項目屬性分析,來 評估題目對慢性肺部疾病患者兩組的合適性。. 41.
(42) 步驟四、項目參數不變性分析(Invariance of item parameters),根據評定 量尺模式(Rating Scale Model)的結果進行下列的探討: (一)樣本獨立(Sample Independent)分析 亦即題目在不同族群間的穩定性分析。在同一向度的假設下,題 目的難度應該是固定的,不會因為受試者而改變,此處以項目差 異功能(Differential Item Functioning,DIF)來探討在服藥組及沒 有服藥組間各題目是否具有題目難度不變性的特質,也就是是否 各題目具有樣本獨立的特質,使得題目的難度不會隨著樣本不同 而不同。 (二)測驗獨立(Test Independent)分析 亦即受測者能力在不同問卷間的穩定性分析。此處利用同一個受 測者同時填寫兩份問卷來探討同一個受測者的能力是否因填寫不 同問卷而改變。測驗獨立(Test Independent)特質分析,可看不 同問卷是否可測得同一向度的能力,並可從偏離? 看出不同問卷 對不同能力的人在測量上的適用性。 步驟五、模式適合度的評估(Evaluation of model fit) :以適合度指標 INFIT 及 OUTFIT 來評估資料與 IRT 模式的適合度,適若 INFIT > 1.4 或 OUTFIT > 1.4 則顯示題目與資料並不合適。. 42.
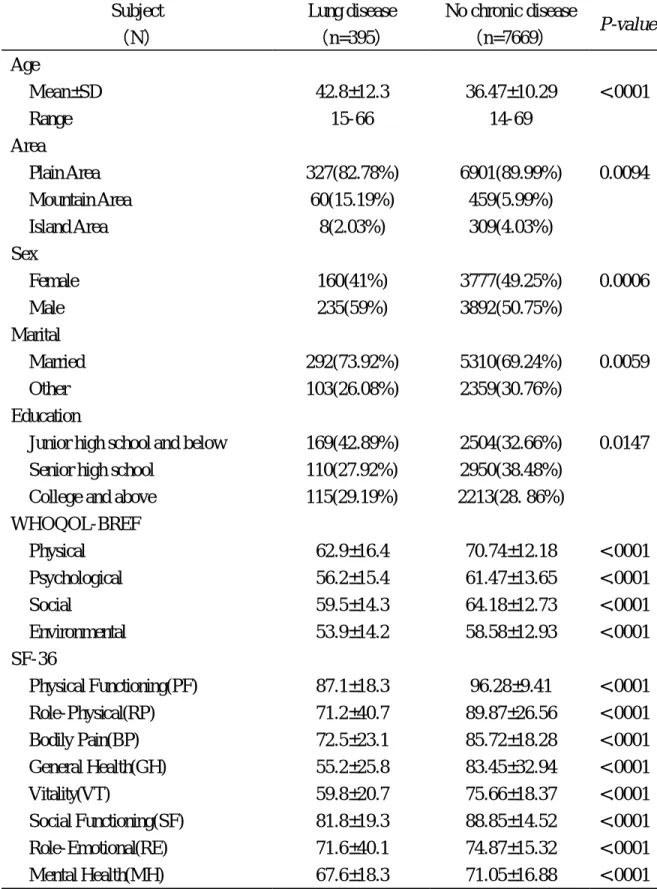
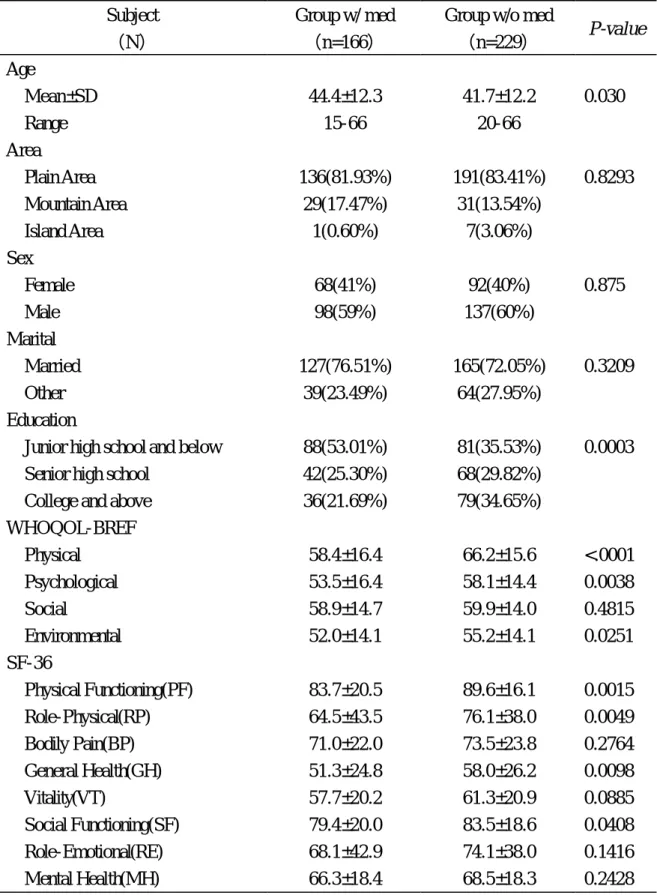
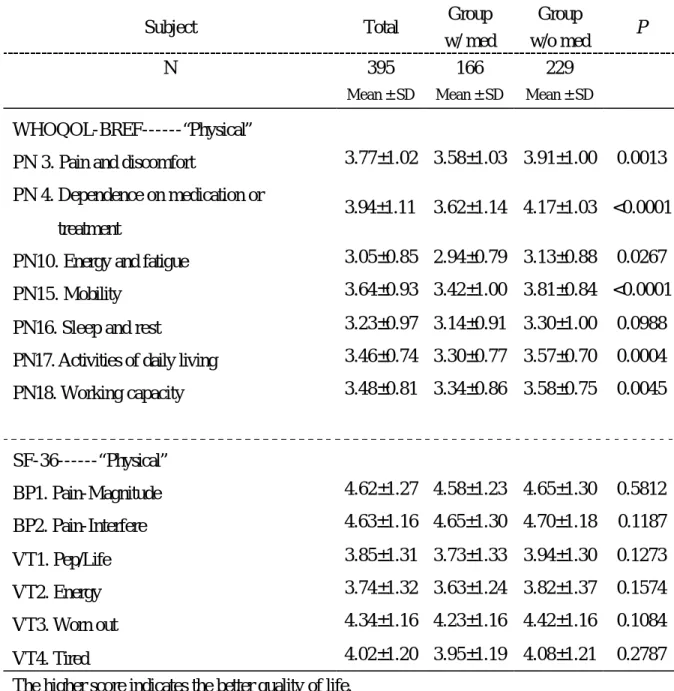
(43) 第肆章、結果. 第一節. 研究對象的基本資料. 由表一顯示研究對象之基本資料,研究對象主要是 15 歲以上的族 群,樣本個數為 395 人,年齡從 15 到 66 歲,全部樣本平均年齡為 42.8± 12.3 歲,男性 235 人,佔 59%,女性 160 人,佔 41%。表一同時列有同 次調查中沒有慢性疾病的族群之資料以資比較。兩族群在年齡、居住地 區、教育程度、性別、婚姻狀況皆有顯著的差異;所有樣本皆同時填寫 SF-36 和 WHOQOL-BREF 問卷,SF-36 由訪視員訪問填寫,而 WHOQOL-BREF 則由受訪者自行回答。而在生活品質得分上,分數愈高 表示生活品質愈好,在本論文所有分析中均依此規則,結果顯示 WHOQOL-BREF 四個範疇和 SF-36 八個範疇生活品質得分在兩族群皆有 顯著的差異(p<0.0001),有肺部疾病族群各範疇生活品質得分均顯著低 於沒有慢性疾病的族群。 再根據最近有無服藥物將資料分成兩組:有服藥物組( 166 人)與沒 有服藥物組(229 人)。由表二顯示兩組研究對象之基本資料 兩組樣本除了在年齡及教育程度上有所差異(p = 0.03 及 p=0.0003),其 餘的人口變項(居住地區、性別、婚姻狀態)皆無顯著差異。兩組樣本. 43.
(44) 在 WHOQOL-BREF 的生理(p < 0.0001)、心理(p = 0.0038)與環境(p = 0.0251)範疇有統計上顯著差異,在 SF-36 的身體活動功能(PF,p = 0.0015)、活動功能限制情況(RP,p = 0.0049)、個人評估身體健康之程 度(GH,p = 0.0098)與社交情況(SF,p = 0.0408)範疇有統計上顯著 差異。. 第二節. 問卷基本資料描述. 由表三顯示,WHOQOL-BREF 各項目的平均數、中位數、地板效應 及天花板效應。各題目中平均數最高的是 PN4(3.94)、PN3(3.77),這兩題 亦有最高的天花板效應(37.72%, 24.30%),其餘還有 PN15(3.64)、 YN6(3.40)、YN11(3.55)、EN28(3.53)平均數也較高,也有高的天花板效 應(皆>10%);而各題目中平均數最低的是 YN5(2.54)、EN12(2.64),這 兩題也造成有高的地板效應(12.66%, 15.95%);大致上來說, WHOQOL-BREF 大部分的題目分佈呈常態,沒有高比例的天花板效應 (Ceiling Effect)和地板效應(Floor Effect)。 由表四顯示,SF-36 各題目的平均數、中位數、地板效應及天花板效 應。因 SF-36 各題目的回答尺度由 2 分到 6 分,故不適合做平均數的比 較,也因此針對尺度較少的題目較容易產生天花板效應或地板效應。整 體而言,在 SF-36 中除了活力狀態(VT)範疇的題目外,其他範疇的題 44.
(45) 目都具有高比例的天花板效應(Ceiling Effect)和地板效應(Floor Effect)。 由表五顯示 WHOQOL-BREF 及 SF-36 的題數分布,WHOQOL-BREF 有四個範疇,其題數生理六題、心理七題、社會四題、環境九題,SF-36 有八個範疇,其題數身體活動功能(PF)十題、活動功能限制情況(RP) 四題、心理健康限制生活程度(RE)三題、社交情況(SF)兩題、身體 疼痛狀態(BP)兩題、活力狀態(VT)四題、心理健康狀態(MH)五 題及個人評估身體健康之程度(GH)五題和整體健康情形一題。 表六為兩份生活品質問卷在內部一致性上的表現,以全部樣本而言 WHOQOL-BREF 的生理、心理、社會、環境範疇的內部一致性 Cronbach’s alpha 值分別為 0.83、0.78、0.73、0.81,都大於 0.7,表示內部一致性高, 其中又以生理範疇最高(0.83) ,社會範疇最低(0.73) ;全部樣本中,SF-36 整體的內部一致性也很高,在 SF-36 的 PF、RP、BP、GH、VT、SF、RE、 MH 的內部一致性 Cronbach’s alpha 值介於 0.63-0.92,除了社交情況(SF) Cronbach’s alpha(0.63)較低外,其餘皆在 0.8 以上,其中又以活動功能 限制情況(RP=0.92) 、身體活動功能(PF=0.89) 、身體疼痛狀態(BP=0.89) 範疇為最高;顯示兩份問卷在大部分範疇上內部一致性高。分組的結果, 其趨勢大致相同,除 BP、GH、VT、MH 外,服藥組之內部一致性較高 於沒有服藥組。在 BP 沒有服藥組(0.91)高於有服藥組(0.85),其餘. 45.
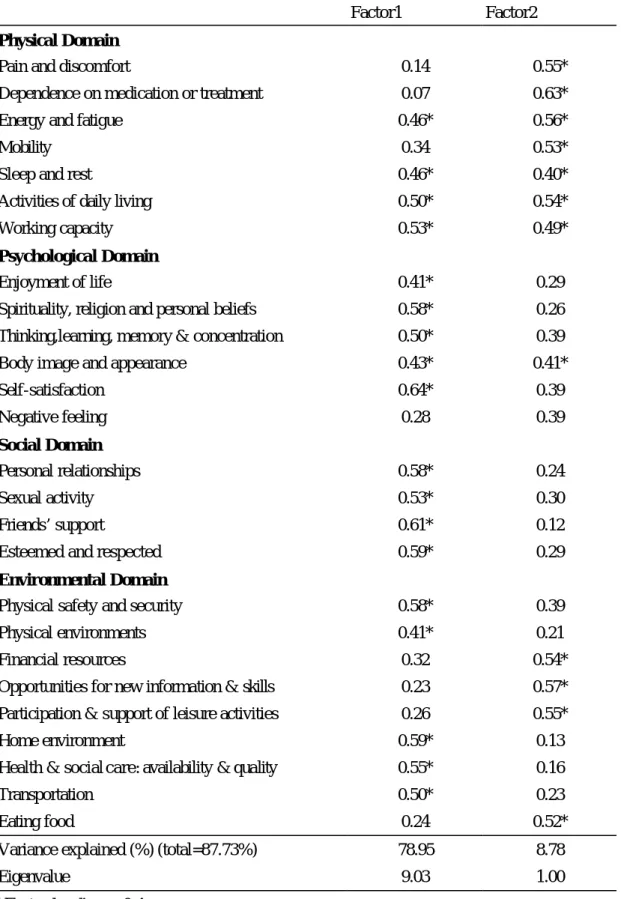
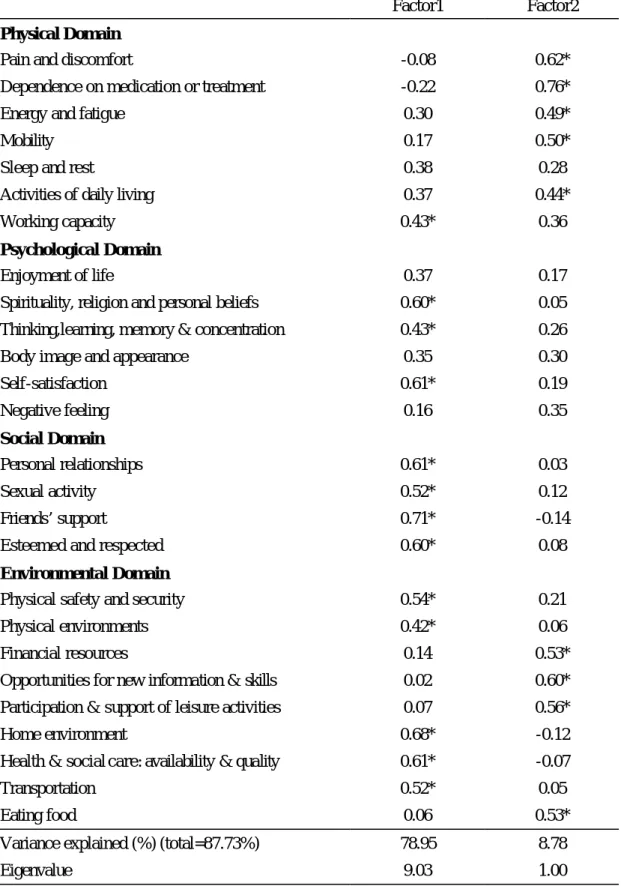
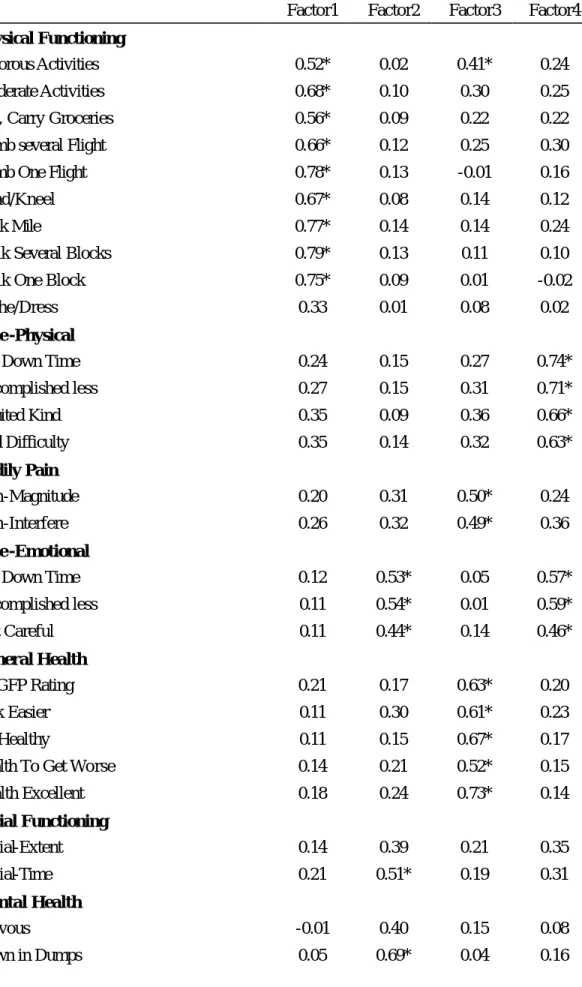
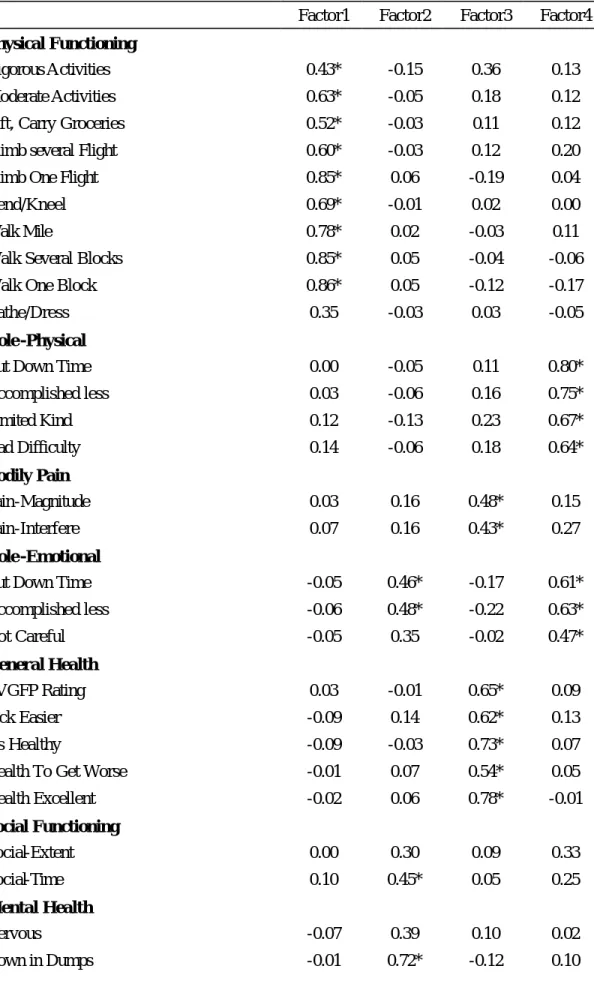
(46) GH、VT、MH 則差距不大,均顯示沒有服藥組略高於有服藥組。 圖一、圖二顯示各範疇的得分分佈圖,在尺度上均依照原問卷轉換 分數的規則將範疇總分轉為 0-100 以利比較,由圖一、圖二可看出 WHOQOL-BREF 問卷在四個範疇分佈上較屬常態分佈,SF-36 八個範疇 分佈較屬偏態,尤其是 PF、SF、BP,而 RP、RE有較高的天花板效應 (Ceiling Effect)及地板效應(Floor Effect) ,此應是 RP、RE 兩個範疇是屬二分法 (Yes/No)所致。. 第三節. 因素分析與相同向度的擷取. 因 素 分 析 — WHOQOL-BREF 表七、表八為 WHOQOL-BREF 探索性因素分析結果,表七為直交轉 軸法(Varimax)所得結果,而表八為斜交轉軸法(Promax)所得結果; 兩表均顯示 WHOQOL-BREF 有兩個因素被擷取出來,第一個因素中因素 負荷量大的題目,主要為心理、社會、還有約一半環境範疇的題目,第 二個因素中因素負荷量大的題目,主要為生理範疇及另外ㄧ半環境範疇 的題目,兩個因素解釋的變異量分別為 78.95%及 8.78%。 因 素 分 析 — SF-36 表九、表十為 SF-36 探索性因素分析結果,表九為直交轉軸法 (Varimax)所得結果,而表十為斜交轉軸法(Promax)所得結果;兩表 46.
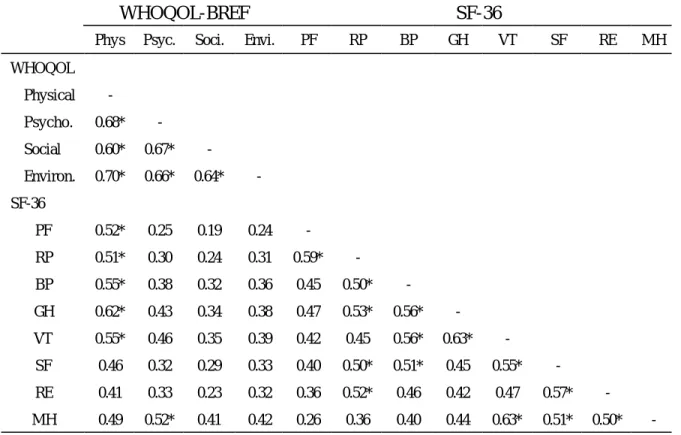
(47) 均顯示 SF-36 有四個因素被擷取出來,第一個因素中因素負荷量大的題 目,主要屬於身體活動功能(PF)範疇,第二個因素中因素負荷量大的 題目,主要屬於心理健康限制生活程度(RE)、社交情況(SF)、心理健 康狀態(MH)及活力狀態範疇(VT)範疇,第三個因素中因素負荷量 大的題目,主要屬於活力狀態(VT)、身體疼痛狀態(BP)及個人評估 身體健康之程度(GH)範疇,第四個因素中因素負荷量大的題目,主要 屬於活動功能限制情況( RP)範疇,四個因素解釋的變異量分別為 58.38%、15.46%、7.60%及 7.16%。 由因素分析結果可看出 WHOQOL-BREF 由原理論四個範疇併為兩 個範疇,SF-36 由原理論八個範疇併為四個範疇,如預期結果,許多範疇 彼此相關性高,故併為同一因素,除少數例外,大多數的題目均與自己 同範疇的題目在同一個因素中,此結果可作為下列兩份問卷同向度題目 擷取的基礎。 相關分析 表十一為兩份問卷各範疇分數的相關分析,WHOQOL-BREF 的四個 範疇相關性都很高,皆介於 0.6-0.7;SF-36 八個範疇相關性則較低,大都 在 0.35 以上,介於 0.26-0.63,只有兩組大於 0.6,分別為 GH 和 VT(0.63) 及 VT 和 MH(0.63) 。在兩問卷相關分析上,選擇相關性大於 0.5 的範疇, 發現 WHOQOL-BREF 的生理範疇與 SF-36 的個人評估身體健康之程度. 47.
(48) (GH)、活力狀態(VT)、身體疼痛狀態(BP)、身體活動功能(PF)、 活動功能限制情況(RP)相關性較高,皮爾森相關係數分別為 0.62、0.55、 0.55、0.52、0.51;WHOQOL-BREF 的心理範疇與 SF-36 的心理健康狀態 (MH)相關性較高,皮爾森相關係數為 0.52;WHOQOL-BREF 的社會 與 SF-36 的社交情況(SF)相關性很低,皮爾森相關係數只有 0.29,可 能是因 SF-36 的社交情況範疇主要是測量因為生理或心理不舒服對社交 活動與社會關係的影響,而 WHOQOL-BREF 的社會範疇則是測量對人際 關係、朋友或家人的支持及性生活方面的滿意度,故兩份問卷在社會範 疇中所代表的意義不同以致相關性低。而 WHOQOL-BREF 在環境範疇 上,則未與 SF-36 任何範疇有較高的相關,皆低於 0.42。圖三為兩份問 卷範疇的對應關係,雙箭頭所指為相關性大於 0.5 的關係。 向 度 的 擷 取 — 〝 Physical〞 向 度 及 〝 Mental〞 向 度 從上述結果中我們提出兩組向度的對應,並將之命名為〝Physical〞 向度及〝Mental〞向度,其中〝Physical〞向度,包括 WHOQOL-BREF 的生理範疇(Physical)、SF-36 的身體疼痛狀態(BP)及活力狀態(VT) 的題目, 〝Mental〞向度,包括 WHOQOL-BREF 的心理範疇(Psychological) 及 SF-36 的心理健康狀態(MH)的題目。雖然相關分析結果顯示 WHOQOL-BREF 的生理範疇與 SF-36 的 BP、VT、PF、RP、GH 相關性 皆大於 0.5,但在提出新向度時並未將 PF、RP、GH 併入〝Physical〞向. 48.
(49) 度,所考慮的原因為(1)WHOQOL-BREF 的生理範疇主要為主觀的感受, 而 SF-36 的 PF 則屬較客觀的身體功能受限情形,故不併入同一向度, (2) SF-36 的 GH 屬整體性健康,理論上屬全方位性的題目,故將之排除,(3) 針對 RP,其題目內容雖與 WHOQOL-BREF 的生理範疇相似,但 WHOQOL-BREF 為五分法的量尺,而 RP 量尺為二分法,在尺度的合併 上其特質不容易放在同一測量基礎上討論,故亦將之排除。(參見附錄 三、附錄四) 新 向 度 〝 Physical〞 題 目 的 基 礎 敘 述 統 計 量 表十二顯示在新向度〝Physical〞中各題目的基礎敘述統計量及兩組 的比較,在〝Physical〞中 WHOQOL-BREF 的題目中以“PN4 您需要靠 醫療的幫助應付日常生活嗎?(反向題)”得分最高(3.94),“PN10 您每天 的生活有足夠的精力嗎?”得分最低(3.05),SF-36 以“BP2 身體疼痛對 日常生活妨礙程度如何?(反向題)” 得分最高(4.63),“VT2 您精力充沛 嗎?” 得分最低(3.74),WHOQOL-BREF 與 SF-36 兩者因計分標準不 同,無法在同一標準下做難度的比較。進一步比較有服藥物組與沒有服 藥物組在各題目得分之差異,可看出 WHOQOL-BREF 在〝Physical〞向 度中的題目除了’PN16 睡眠狀況’兩組沒有顯著差異外(p=0.0988),其餘 題目皆有統計的顯著差異;而 SF-36 在〝Physical〞向度中的題目在有無 服藥兩組皆無顯著的差異。. 49.
(50) 新 向 度 〝 Mental〞 題 目 的 基 礎 敘 述 統 計 量 表十三顯示在新向度〝 Mental〞中各題目的基礎敘述統計量及兩組的 比較,在〝Mental〞中 WHOQOL-BREF 的題目中以“YN11 您能接受自 己的外表嗎?” 得分最高(3.55),“YN5 您享受生活嗎?” 得分最低 (2.54),SF-36 以“MH2 你覺得沮喪嗎?(反向題)” 得分最高(4.68), “MH3 您覺得心情平靜嗎?” 得分最低(4.16),WHOQOL-BREF 與 SF-36 兩者因計分標準不同,無法在同一標準下做難度的比較。進一步比 較有服藥物組與沒有服藥物組在各題目得分之差異,可看出 WHOQOL-BREF 在〝Mental〞向度中的題目除了’YN7 集中精神能力’ ( p=0.256)與’YN26 常有負面感受(反向題)’( p=0.4599)在有無服藥 兩組無顯著差異外,其餘題目皆有顯著的差異;而 SF-36 在〝Mental〞向 度中的題目在有無服藥兩組皆無顯著的差異。. 第四節. 量 尺 尺 度 測 定 分 析 ( Item Calibration). 本節針對上述所提出的新向度〝Physical〞及〝Mental〞 ,以 IRT 中的 Rasch 模式進行量尺尺度測定分析,首先分析個別問卷題目,再分析兩份 問卷合併後題目。? 驗證結果的穩定性,以上所有分析均針對有服藥組 及沒有服藥組進行探討。 〝 Physical〞 尺 度 測 定 分 析 — WHOQOL-BREF (服 藥 組 ) 50.
(51) 表十四為有服藥組在〝Physical〞向度下 WHOQOL-BREF 分析結果。 此表表示在量尺上每個題目難度的校準測定刻度(Calibration)和標準差 以及門檻值(Threshold Valve)的估計值。WHOQOL-BREF 在有服藥的 ∧. ∧. 題目難度範圍介於( β = -0.65~ β = 0.86),最簡單的題目為“PN4 您需要 ∧. 靠醫療的幫助應付日常生活嗎?(反向題)”( β = -0.65) ,最困難的題目為 ∧. “PN10 您每天的生活有足夠的精力嗎?”( β = 0.86)。 〝 Physical〞 尺 度 測 定 分 析 — WHOQOL-BREF (沒 有 服 藥 組 ) 表十五為沒有服藥組在〝Physical〞向度下 WHOQOL-BREF 分析結 果。此表表示在量尺上每個題目難度的校準測定刻度(Calibration)和標 準差以及門檻值(Threshold Valve)的估計值。在沒有服藥的題目難度範 ∧. ∧. 圍介於( β = -1.39~ β = 1.17),最簡單的題目為“PN4 您需要靠醫療的幫 ∧. 助應付日常生活嗎?(反向題)”( β = -1.39),最困難的題目為“PN10 您 ∧. 每天的生活有足夠的精力嗎?”( β = 1.17)。 〝 Physical〞 尺 度 測 定 分 析 —. SF-36 (服 藥 組 ). 表十六為有服藥組在〝Physical〞向度下 SF-36 分析結果。此表表示 在量尺上每個題目難度的校準測定刻度(Calibration)和標準差以及門檻 值(Threshold Valve)的估計值。SF-36 在有服藥的題目難度範圍介於 ∧. ∧. ( β = -0.69~ β = 0.67),最簡單的題目為“BP2 身體疼痛對日常工作妨礙 ∧. 程度如何?(反向題)”( β = -0.69),最困難的題目為“VT2 您精力充沛 51.
(52) ∧. 嗎?”( β = 0.67)。 〝 Physical〞 尺 度 測 定 分 析 — SF-36 (沒 有 服 藥 組 ) 表十七為沒有服藥組在〝Physical〞向度下 SF-36 分析結果。此表表 示在量尺上每個題目難度的校準測定刻度(Calibration)和標準差以及門 檻值(Threshold Valve)的估計值。在沒有服藥的題目難度範圍介於 ∧. ∧. ( β = -0.80~ β = 0.70),最簡單的題目為“BP2 身體疼痛對日常工作妨礙 ∧. 程度如何?(反向題)”( β = -0.80),最困難的題目為“VT2 您精力充沛 ∧. 嗎?”( β = 0.70)。 〝 Physical〞 尺 度 測 定 —. 個別問卷分析圖. 圖四為表十四、表十五、表十六、表十七的題目難度整合,可看出 在 WHOQOL-BREF 的〝Physical〞向度下,不論在有無服藥上兩組題目 難度順序都相同,沒有服藥的族群題目難度範圍比有服藥族群題目難度 還要來的廣,尤其是“PN4 您需要靠醫療的幫助應付日常生活嗎?(反向 題)”位於最左端且與其他值隔一段距離、而“PN10 您每天的生活有足夠 的精力嗎?” 位於最右端且與其他值有一段距離。而在 SF-36 的 〝Physical〞向度下,不論在有無服藥上兩組題目難度順序都相同,沒有 服藥的題目難度範圍與有服藥的難度範圍都差不多一樣。 〝 Physical〞 尺 度 測 定 分 析 —. 兩 問 卷 合 併 (服 藥 組 ). 將 WHOQOL-BREF 和 SF-36 〝Physical〞向度的題目合併後帶入. 52.
(53) Rasch 模式中分析,表十八與圖五顯示在有服藥族群,題目難度範圍介於 ∧. ∧. ∧. ∧. ∧. ∧. ( β = -0.68~ β = 0.79),整體而言,SF-36 的〝Physical〞難度 ( β = -0.68~ β = 0.44)比 WHOQOL-BREF 的〝Physical〞難度 ( β = -0.44~ β = 0.79)還來得簡單,最簡單的題目為 SF-36 的題目“BP2 ∧. 身體疼痛對日常生活妨礙程度?(反向題)”( β = -0.68) ,最困難的題目為 WHOQOL-BREF 的題目“PN10 您每天的生活有足夠的精力嗎?” ∧. ( β = 0.79)。 〝 Physical〞 尺 度 測 定 分 析 —. 兩 問 卷 合 併 (沒 有 服 藥 組 ). 表十九與圖五顯示在沒有服藥族群,題目難度範圍介於 ∧. ∧. ∧. ∧. ( β = -1.29~ β = 0.94) ,SF-36 的〝Physical〞難度介於( β = -0.54~ β = 0.61) , ∧. ∧. 而 WHOQOL-BREF 的〝Physical〞難度介於( β = -1.29~ β = 0.94), WHOQOL-BREF 題目難度範圍比 SF-36 題目難度還要來的廣,最困難與 最簡單的題目都是 WHOQOL-BREF 的題目,最簡單的題目為“PN4 您需 ∧. 要靠醫療的幫助應付日常生活嗎?(反向題)”( β = -1.29) ,最困難的題目 ∧. 為“PN10 您每天的生活有足夠的精力嗎?”( β = 0.94)。在比較有無服 藥兩組的題目難度順序並不一致。 〝 Mental〞 尺 度 測 定 分 析 — WHOQOL-BREF (服 藥 組 ) 表二十顯示有服藥族群在〝Mental〞向度下,WHOQOL-BREF 題目 ∧. ∧. 難度範圍介於( β = -0.71~ β = 1.81),最簡單的題目為“YN11 您能接受自 53.
(54) ∧. 己的外表嗎?”( β = -0.71),最困難的題目為“YN5 您享受生活嗎?” ∧. ( β = 1.81)。 〝 Mental〞 尺 度 測 定 分 析 — WHOQOL-BREF (沒 有 服 藥 組 ) 表二十一顯示沒有服藥族群在〝Mental〞向度下,WHOQOL-BREF ∧. ∧. 題目難度範圍介於( β = -0.78~ β = 1.44),最簡單的題目為“YN11 您能接 ∧. 受自己的外表嗎?”( β = -0.78),最困難的題目為“YN5 您享受生活 ∧. 嗎?”( β = 1.44)。 〝 Mental〞 尺 度 測 定 分 析 — SF-36 (服 藥 組 ) 表二十二顯示有服藥族群在〝Mental〞向度下,SF-36 題目難度範圍 ∧. ∧. 介於( β = -0.39~ β = 0.31),最簡單的題目為“MH2 覺得非常沮喪(反向 ∧. 題)?”( β = -0.39),最困難的題目為“MH3 覺得心情平靜?” ∧. ( β = 0.31)。 〝 Mental〞 尺 度 測 定 分 析 — SF-36 (沒 有 服 藥 組 ) 表二十三顯示沒有服藥族群在〝Mental〞向度下,SF-36 題目難度範 ∧. ∧. 圍介於( β = -0.50~ β = 0.33) ,最簡單的題目為“MH2 覺得非常沮喪(反向 ∧. 題)?”( β = -0.50),最困難的題目為“MH3 覺得心情平靜?” ∧. ( β = 0.33)。 〝 Mental〞 尺 度 測 定 —. 個別問卷分析圖. 由圖六為表二十、表二十一、表二十二、表二十三的題目難度整合,. 54.
(55) 可看出在 WHOQOL-BREF 的〝Mental〞向度下,不論在有無服藥兩組題 目難度除了“YN7 集中精神能力”與“YN26 常有負面感受(反向題) ”順 序不同之外,其餘題目難度順序都相同,但在“YN5 您享受生活嗎?” ∧. 此題難度很高( β = 1.44) 。而在 SF-36 心理範疇,在有服藥物這組的題目 難度分佈較平均,但在沒有服用藥物這組有三題難度很接近(“MH3 您 ∧. ∧. 覺得心情平靜”( β = 0.33)、“MH5 您是一個快樂的人”( β = 0.22)、 ∧. “MH1 您是一個非常緊張的人(反向題)”( β = 0.28)),除了“MH5 您是 一個快樂的人”與“MH1 您是一個非常緊張的人(反向題) ”順序不同之 外,其餘題目難度順序都相同。 〝 Mental〞 尺 度 測 定 分 析 —. 兩 問 卷 合 併 (服 藥 組 ). 將 WHOQOL-BREF 和 SF-36〝Mental〞向度的題目合併後帶入 Rasch 模式中分析,表二十四與圖七顯示在有服藥族群,題目難度範圍介於 ∧. ∧. ∧. ∧. ∧. ∧. ( β = -0.73~ β = 1.62),整體而言,SF-36 的題目〝Mental〞難度 ( β = -0.73~ β = -0.14)比 WHOQOL-BREF 的〝Mental〞難度 ( β = -0.18~ β = 1.62)來得簡單,最簡單的題目為 SF-36 的題目“MH2 ∧. 覺得非常沮喪(反向題)?”( β = -0.73) ,最困難的題目為 WHOQOL-BREF ∧. 的題目“YN5 您享受生活嗎?” ( β = 1.62)。由圖中可看出“YN5 您享 受生活嗎?”這個題目位於最右端,且與第二困難的題目相隔甚遠。 〝 Mental〞 尺 度 測 定 分 析 —. 兩 問 卷 合 併 (沒 有 服 藥 組 ). 55.
(56) 表二十五與圖七顯示在沒有服藥族群,題目難度範圍介於 ∧. ∧. ∧. ∧. ∧. ∧. ( β = -0.68~ β = 1.44),整體而言,SF-36 的〝Mental〞難度 ( β = -0.68~ β = -0.01)比 WHOQOL-BREF 的〝Mental〞難度 ( β = -0.43~ β = 1.44)來得簡單,最簡單的題目為 SF-36 的題目“MH2 ∧. 覺得非常沮喪(反向題)?”( β = -0.68) ,最困難的題目為 WHOQOL-BREF ∧. 的題目“YN5 您享受生活嗎?”( β = 1.44) 。由圖中可看出“YN5 您享受 生活嗎?”這個題目位於最右端,且與第二困難的題目相隔甚遠。 在比較有無服藥兩組的題目難度順序,除了最困難(“YN5 您享受 生活嗎?”)與最簡單兩題(“MH2 覺得非常沮喪?(反向題)”, “MH4 覺得悶悶不樂和憂鬱?(反向題))的題目順序相同外,其餘題目難度順序 ∧. ∧. 不太相同,但題目難度大都在介於 β = -0.43~ β = 0.39 之間。. 第五節. 項 目 參 數 不 變 性 分 析 ( Item Invariance Analysis). 本節分樣本獨立(Sample Independent)特質分析與測驗獨立(Test Independent)特質分析兩部份,前者可用來檢視每個題目的難度是否在不 同族群(有服藥組與沒有服藥組) 間仍能維持其穩定度,後者用來檢視每 個受試者的能力值是否在不同問卷(WHOQOL-BREF 及 SF-36)間仍能維 持其穩定度。. 56.
數據
+7
Outline
相關文件
6 《中論·觀因緣品》,《佛藏要籍選刊》第 9 冊,上海古籍出版社 1994 年版,第 1
Promote project learning, mathematical modeling, and problem-based learning to strengthen the ability to integrate and apply knowledge and skills, and make. calculated
Wang, Solving pseudomonotone variational inequalities and pseudocon- vex optimization problems using the projection neural network, IEEE Transactions on Neural Networks 17
Milk and cream, in powder, granule or other solid form, of a fat content, by weight, exceeding 1.5%, not containing added sugar or other sweetening matter.
Later, though, people learned that Copernicus was in fact telling the
Although Taiwan stipulates explicit regulations governing the requirements for organic production process, certification management, and the penalties for organic agricultural
ithout an broad foundation in ph s-iolog or patholog and ignorant of the great processes of disease no amount of technical skill can hide from the keen e es of colleagues defects
First Taiwan Geometry Symposium, NCTS South () The Isoperimetric Problem in the Heisenberg group Hn November 20, 2010 13 / 44.. The Euclidean Isoperimetric Problem... The proof
