國立臺灣大學電機資訊學院資訊工程學研究所 碩士論文
Graduate Institute of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
分段式語音詞向量:將語句信號自動表示為語音詞向 量序 列
Segmental Audio Word2Vec: Representing Utterances as Sequences of Audio Word Vectors
王育軒 Yu-Hsuan Wang
指導教授:李琳山 教授 Advisor: Lin-shan Lee, Ph.D.
中華民國107年1月
January, 2018
誌謝
這致謝寫在口試結束半年後,飛往美國念書的三個禮拜前。在語音實驗室待 了將近三年,轉眼間也準備邁入下一個人生階段。
首先最感謝的人當然就是我的指導教授李琳山老師。老師不只在研究所,在 我大學時就已經對我十分照顧。當初在大三下決定要出國唸書時,首先就要決定 大四專題要找哪位教授。此時腦海中想到當初大三上修語音處理概論時,那位授 課教授好像蠻喜歡我寫的報告的,甚至還請我們某些修課學生吃過飯,可能代表 我們調性很相符,於是就決定跟著老師做專題。之後大四請老師寫推薦信時十分 戰戰兢兢,因為聽說老師的推薦信不好拿,就我所知當時身邊就至少兩位同學請 老師寫推薦信被拒絕,沒想到老師爽快地答應幫我寫推薦信,讓我感念至今。然 而當時由於成績不理想,申請結果即使有老師的推薦信也是神仙難救。由於不服 輸,所以想要再全力拼搏一次,因此厚顏地請老師收我做研究生,讓我用研究所 的經歷說服國外一流大學收我作學生。老師也爽快答應,就這樣促成了這段語音 實驗室的緣分。這三年來,老師從來不用嘴巴說他心中對研究生的要求;相反 地,老師用身教將一個從事研究人員該有的精神表露無遺:大家都吃完晚餐準備 回家時,老師仍然在辦公室處理公務;深夜時間仍然批改著學生準備投稿的論 文;無視週末假日,照常到學校辦公。看不明白的人可能覺得老師帶研究生的方 法相對其他教授而言較為寬鬆因此鬆懈,然而看明白的人則會對自己時時警惕,
不敢有任何懈怠。這段時間透過投稿論文和論文口試,跟老師學習到了許多關於 研究和呈獻成果的方法。這些都是老師濃縮了數十年功力而成的精華,在未來行 走江湖的路上必定將這些心法牢記在心。
謝謝李宏毅教授宏毅哥,在研究所這段時間在許多地方都麻煩宏毅哥照顧。
只要有問題找宏毅哥幫忙,永遠都會獲得一個義不容辭相挺的答案。另外研究上
卡住的時候請教宏毅哥也都能學到一些奇招將問題迎刃而解。也由於宏毅哥默默 的到處賣臉,讓語音實驗室能有許多資源可以擴增戰艦、增加運算資源等等。雖 然宏毅哥因為過於強大所以常常到處開會,超級霹靂忙,但是只要有需要向宏毅 哥請教的時候,宏毅哥永遠都願意為我們從已經被榨乾的時間中再擠出時間和我 們討論問題,語音實驗室的研究產能如此強大宏毅哥是最大功臣!
謝謝陳縕儂教授儂大,儂大強勢回歸臺大教書成為我申請留學的最後一塊拼 圖,讓我成功一圓留學夢。申請時只要有問題都會厚臉皮的巴著儂大不放問問 題,根本把儂大當成留學顧問。在CMU和JHU間搖擺不定時,儂大以過來人的經 驗給了第一手的情報。而我去CMU參加Open House時,儂大所建立的好名聲給了 我一個跟那邊教授聊天時很好的起頭,進而相談甚歡。往後在CMU唸書時期許自 己也能成為和儂大一樣前人種樹後人乘涼,讓往後來CMU的學弟妹輕鬆給教授好 印象。
謝謝實驗室助理彤恩姐,幫我這雷人解決了各式各樣千奇百怪的問題。在尚 未入學時需要用臨時工的身份領取津貼,每次都需要勞煩彤恩姐計算各項計畫經 費,用最適合的方式給我,給彤恩姐添了不少麻煩。另外出國開會科技部補助有 問題時也幫我打電話詢問出了什麼事情。彤恩姊總是幫實驗室眾處理各種疑難雜 症,讓大家可以專注在自己的研究和課業上,根本苦海明燈。
謝謝帶我專題的學長,鍾承道學長。很幸運能有博班學長帶我,給了我很多 研究上的insights。想當初非督導式學習實驗室只有學長在做,現在大家都在做,
想來學長的眼光果然十分準確。發表第一篇論文時要不是學長在精神上的各種支 持,我可能撐不到最後。謝謝我B99的同學呂相弘,從我一進實驗室就十分照顧 我,帶著我融入實驗室的環境,讓我沒有所謂的適應期。也為了促進實驗室感情 揪了各種活動,這些活動確實讓實驗室的大家感情熱絡。謝謝廖宜修,從肌肉到
研究都十分紮實的男人,讓我了解到什麼叫實力紮實的研究生。在心中默默把宜 修哥當偶像,提醒自己世界上有人就是這麼硬派,所以也不能對自己放水。
謝謝我的實驗室同學:小豪、俊哥、永哲、家翔、Poyu、YD、資偉、賢進、
朗祺。好在有你們一起在實驗室討論想法、閒聊打屁,不然研究所的生活實在難 以想像的可怕。謝謝實驗室的碩二8+1眾:Roy、水靜、致緯、邦齊、家宏、瓊 之、球哥、佩宏(Best Pei)+舜博沒有排擠我讓我變邊緣人,在許多地方十分照顧 小弟我,不勝感激。
我相信在語音實驗室的這三年帶給我人生十分深遠的影響:如果我未來還待 在學術界的話自然不用說,從一篇論文從點子的發想,到實驗的設計與實作到最 後的論文寫作我都有了深刻的體會,這些年在大師們的身邊邊看邊學也算是學到 了一點點的皮毛。另一方面,若未來選擇待在業界,研究所訓練出的查資料、思 考問題解決問題的能力在工作上也是不可或缺。總而言之,如同老師當初在信中 跟我說的,語音實驗室確實給了我的人生更高的高度,這也是我將會一直十分感 激的一件事。
摘要
在自然語言處理中,詞向量(Word2Vec)可以用於將一個詞表示為一個一定 維數(Dimensionality)的實數向量並帶有語意資訊(語意接近的詞在向量空間中 會接近),這些向量所帶的語意並在向量空間上具有向量運算的可平移特性。另 一方面,語音詞向量(Audio Word2Vec)則能使用一定維數的實數向量表示語音 詞(一個詞的語音訊號,Spoken Word),並帶有音素結構的資訊。前人所提出的 語音詞向量雖然可以在非督導式學習的框架下訓練,然而訓練語料之音訊需要事 先標註好詞邊界。
在本論文中,我們將語音詞向量由語音詞的層級提升至整句語句的層級。
在本論文所提出的模型中,同時針對語音詞切割與語音詞向量訓練進行訓練,
讓此兩者能夠相互增強。藉由引入一切割門限至序列對序列自動編碼器,本 論文提出全新的分段式序列對序列自動編碼器(Segmental Sequence-to-Sequence Autoencoder, SSAE),並用深層強化學習(Deep Reinforcement Learning)加以訓 練。藉由此一方法,一語句能夠被自動切割為一系列的語音詞,再轉化為一系列 之語音詞向量。本論文之實驗使用詞切割與口述語彙偵測來探討所提出的分段式 序列對序列自動編碼器之效能,並在四種語言上(英文、捷克文,法文與德文)
進行實驗,實驗結果顯示此模型具有比以往方法更佳的效能。
除了分段式序列對序列自動編碼器外,本論文亦分析一種遞迴式類神經網路 內部之訊號:門限激發訊號;並發現此訊號在非督導式學習框架下與輸入音訊中 語音特性之邊界(如音素邊界)具有強烈關聯,因此可以廣泛應用於所有非督導 式學習下的遞迴式類神經網路模型中。
Contents
誌謝 . . . i
中文摘要 . . . iv
一、導論 . . . 2
1.1 研究背景及研究動機 . . . 2
1.2 研究方向 . . . 5
1.3 相關研究 . . . 5
1.4 研究貢獻 . . . 7
1.5 章節安排 . . . 8
二、背景知識 . . . 9
2.1 基於非督導式學習的遞迴式類神經網路 . . . 9
2.1.1 類神經網路 . . . 9
2.1.2 類神經網路訓練 . . . 11
2.1.3 遞迴式類神經網路 . . . 16
2.1.4 自動編碼器 . . . 17
2.2 強化學習 . . . 19
2.2.1 馬可夫決策過程 . . . 19
2.2.2 強化學習簡介 . . . 20
2.2.3 基於策略的強化學習 . . . 22
2.2.4 以遞迴式類神經網路進行之強化學習 . . . 25
2.3 音訊切割 . . . 27
2.4 口述語彙偵測 . . . 31
2.5 語音詞向量 . . . 32
2.5.1 詞向量簡介 . . . 32
2.5.2 語音詞向量簡介與應用 . . . 36
三、門限激發訊號與音素邊界之關聯分析 . . . 42
3.1 具門限機制之遞迴式類神經網路 . . . 42
3.2 門限激發訊號與音素邊界 . . . 44
3.2.1 模型概述 . . . 45
3.2.2 實驗設計 . . . 46
3.3 預備實驗 . . . 47
3.3.1 門限激發訊號與門限激發訊號均值 . . . 47
3.3.2 實驗結果 . . . 47
3.3.3 門限激發訊號均值變化量 . . . 49
3.4 音素切割實驗 . . . 50
3.4.1 門限激發訊號在音素切割之應用 . . . 50
3.4.2 遞迴式預測模型 . . . 50
3.4.3 結合門限激發訊號之遞迴式預測模型 . . . 51
3.4.4 效能評估 . . . 52
3.4.5 不同門限實驗結果 . . . 53
3.4.6 不同模型實驗結果 . . . 55
3.5 本章總結 . . . 59
四、分段式語音詞向量之初步研究 . . . 61
4.1 分段式序列對序列自動編碼器 . . . 61
4.1.1 分段式語音詞向量 . . . 61
4.1.2 切割門限 . . . 62
4.1.3 重設機制 . . . 62
4.1.4 分段式序列對序列式訓練 . . . 63
4.2 端對端訓練下之分段式語音詞向量 . . . 63
4.2.1 端對端訓練 . . . 63
4.2.2 直通評估器 . . . 65
4.2.3 減損函數設計 . . . 66
4.3 實驗 . . . 67
4.3.1 實驗設計 . . . 67
4.3.2 實驗結果與討論 . . . 67
4.4 本章總結 . . . 71
五、基於強化學習之分段式語音詞向量 . . . 73
5.1 以強化學習訓練之分段式語音詞向量 . . . 73
5.2 訓練分段式語音詞向量之獎勵 . . . 76
5.2.1 獎勵設計 . . . 76
5.2.2 獎勵基準 . . . 78
5.3 兩步驟之迭代式訓練法 . . . 79
5.4 應用分段式語音詞向量於口述語彙偵測 . . . 82
5.5 實驗 . . . 84
5.5.1 實驗設計 . . . 84
5.5.2 預備實驗 . . . 85
5.5.3 詞切割實驗 . . . 88
5.5.4 口述語彙偵測實驗 . . . 101
5.6 本章總結 . . . 105
六、結論與展望 . . . 107
6.1 本論文主要的研究貢獻 . . . 107
6.2 本論文未來研究方向 . . . 108
參考文獻 . . . 109
圖
圖 圖目 目 目錄 錄 錄
2.1 不同種類的激發函數 . . . 10 2.2 一具有兩層隱藏層的層狀深層類神經網路模型 . . . 11 2.3 用慣量加速梯度下降法之一例。圖中不同顏色區塊表示減損函數值
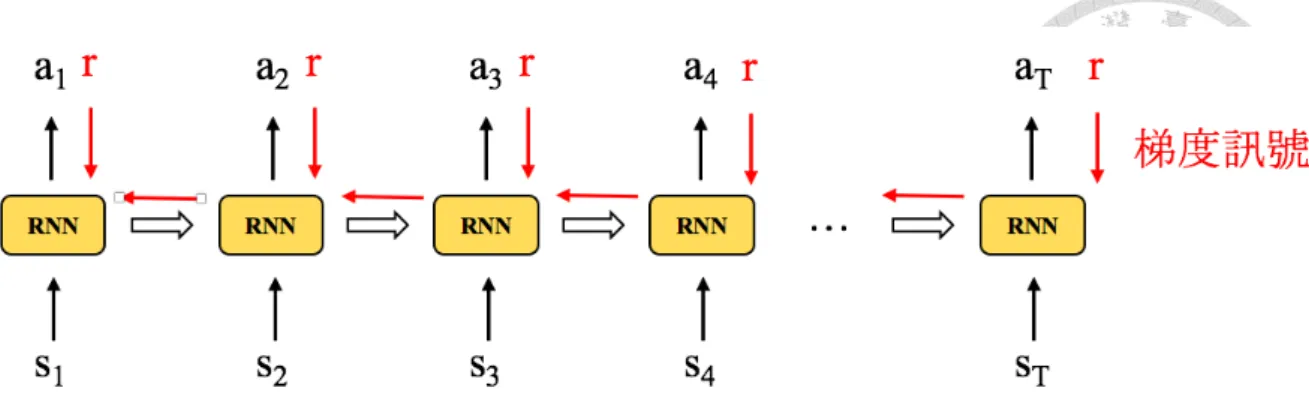
在不同參數下之大小,由外而內遞減。圖中之箭頭表示模型參數更 新之方向,箭頭數目表示模型參數更新之次數。可以發現圖(b)的例 子中使用慣量訓練法後可以加速模型參數更新至減損函數最小處的 過程。 . . . 15 2.4 遞迴式類神經網路神經單元 . . . 17 2.5 遞迴式類神經網路訓練法。上圖中不同顏色分別代表:藍色表示輸
入訊號;黃色表示編碼器;綠色表示解碼器;紅色表示輸出訊號。
在序列對序列式訓練中,前一時間點的輸出訊號會成為下一個時間 點的輸入訊號。 . . . 19 2.6 強化學習流程圖,箭頭旁之數字表示流程順序 . . . 21 2.7 使用遞迴式類神經網路以策略梯度演算法進行訓練 . . . 27 2.8 音素切割效能評估示意圖。圖(a)表示一段轉換為若干個音框的語
句,藍色音框表示音素邊界。圖(b),圖(c)與圖(d)所表示的是三組 音素切割之實驗結果,有著紅色框線之音框表示被模型認定為音 素邊界的音框。綠色框線表示容忍窗之大小,20毫秒之容忍窗為兩 個音框距離大小,因此只要被模型認定為音素邊界的音框與音素 邊界相距在兩個音框以內即認定該音素邊界被成功發掘。因此在 圖(b),圖(c)與圖(d)之音素切割結果中,與真實邊界之相符數量分 別為2,1和0。 . . . 30 2.9 跳躍文法模型。當前詞xt透過隱藏層轉換為詞向量et,再使用詞向
量分別預測當前詞xt在一個範圍大小C內的前後文:xt−C
2、xt−C
2+1、...,xt+C
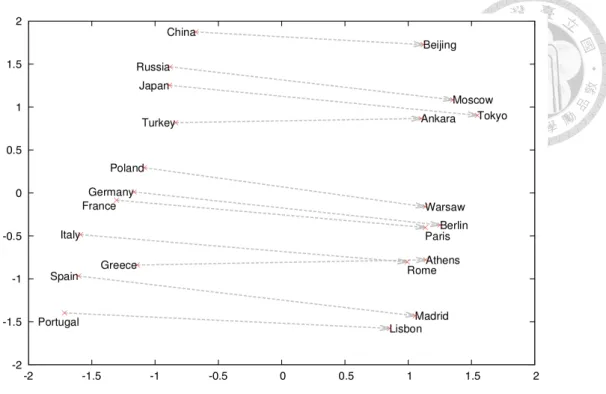
2 35 2.10 將100維之詞向量利用主成份分析(Principal Component Analysis,
PCA)投射至2維平面上之詞向量。位於左半部的各個國家之名稱 往相同方向移動可以得到其首都名稱。取自參考文獻 [1] . . . 36 2.11 使用序列對序列式自動編碼器所抽取之語音詞向量 . . . 38 2.12 將100維之語音詞向量降維至2維平面上。當第一個音素由f轉變
為n時,每個語音詞向量皆往相同方向移動。取自參考文獻 [2] . . . . 39 3.1 遞迴式類神經網路神經單元 . . . 43 3.2 在語音合成中音素邊界與長短期類神經網路忘卻門限激發訊號之關
係。圖中藍色虛線表示音素邊界之位置,而紅色曲線表示忘卻門限 激發訊號。橫軸為音框序列,縱軸表示訊號的大小。取自參考文 獻 [3] . . . 45
3.3 使用序列標註式訓練的自動編碼器,由一般類神經網路的全連接層
(Fully Connected Layer),遞迴式類神經網路的遞迴層與線性轉換
(Linear Transform)所組成。 . . . 46 3.4 不同門限激發函數與音素邊界之關係。橫軸為音框序列,縱軸為門
限激發訊號的平均值¯gt。藍色虛線表示音素邊界。 . . . 48 3.5 (a)長短期記憶類神經網路中忘卻門限之門限激發訊號均值變化
量(式3.11中的∆¯gt),(b)各神經元的門限輸出變化量(式3.12中 的∆¯gjt)與音素邊界之關係。橫軸為音框序列。藍色虛線表示音素 邊界。 . . . 50 3.6 不同模型之的準確率-召回率曲線。各曲線為同一模型下選定不同
閾值所產生之不同切割結果作圖而成,可視作模型整體的效能表 現。曲線上不同的標記代表同一模型使用不同的閾值之結果 . . . 57 3.7 門限均值變化量∆¯gt,錯誤訊號Et與其組成成分與音素切割結果之
關係圖。圖中的綠色虛線表示機器所認定之音素邊界。錯誤訊號在 每個時間點都有某一成分具有特別大的值,因此錯誤訊號Et的曲線 相較平滑,進而造成過度切割。門限均值變化量各成分數值變化相 對而言十分一致,因此避免了機器有認定過多音素邊界的情形 . . . 58 4.1 分段式序列對序列式自動編碼器。切割門限在若干時間點打開,使
用編碼器(圖中之方框ER)之輸出e作為目前輸入音訊之語音詞向 量。一長度為T 之輸入語句便可由此轉化一長度為N之語音詞向量 序列,解碼器(圖中之方框DR)再使用此向量序列重建出原本的 輸入語句。重設機制以含有斜線之箭頭表示。由於此重設機制,每 個色塊間的資訊不流通,因此可視做在一語句內同時進行若干獨立 的序列對序列式訓練 . . . 64 4.2 直通評估器。在順向傳遞時為單位階梯函數;在反向傳遞時,將單
位階梯函數視作恆等函數 . . . 66 4.3 模型產生之所切割出之音訊的平均長度的趨勢。淡色曲線為原始資
料,深色曲線為將資料經過平滑處理而繪製。模型所切割出之音訊 的平均長度在訓練初期略有起伏,但是在中後期開始所切割出之音 訊的平均長度約略等於一個語句長度,表示對於每一個語句只使用 一個語音詞向量來代表 . . . 68 4.4 閾值δ之趨勢,呈現一單調上升的趨勢 . . . 69 4.5 引入控制調適項後模型產生之所切割出之音訊的平均長度的趨勢。
淡色曲線為原始資料,深色曲線為將資料經過平滑處理而繪製。模 型所切割出之音訊的平均長度在約380毫秒的長度間震盪 . . . 70 4.6 引入控制調適子後閾值δ之趨勢。淡色曲線為原始資料,深色曲線
為將資料經過平滑處理而繪製。閾值δ不斷震盪後逐漸收斂至某一 定值,不再呈現單調遞增 . . . 70
4.7 使用準確率(Precision)與召回率(Recall)所表示之詞切割效能
曲線。詞切割的效能並無隨著訓練過程而增進 . . . 71
5.1 使用遞迴式類神經網路模擬之切割門限下的分段式序列對序列自動 編碼器。與章節4.1中圖4.1架構大致相同,但切割門限改由一遞迴 式類神經網路所控制(圖中之方框S) . . . 76
5.2 本章所使用之迭代式訓練法,藍色方框表示被更新的參數。圖(a)第 一步為使用重建特徵與輸入特徵間的重建錯誤來訓練我們的編碼器 與解碼器。圖(b)第二步為使用由編碼器與解碼器所計算之獎勵來更 新切割門限的參數 . . . 80
5.3 使用切割門限所決定出之音訊片段訓練編碼器與解碼器 . . . 81
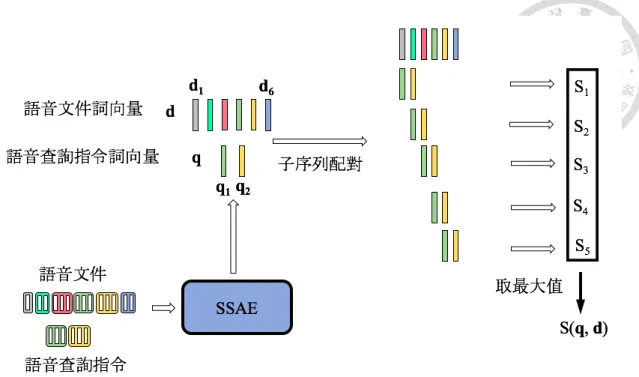
5.4 使用應用分段式語音詞向量與子系列配對所進行之口述語彙偵測。 首先使用分段式序列對序列自動編碼器將語音查詢指令和語音文件 分別轉換成語音詞向量序列q與d,接著對兩者使用子序列配對來 評估此語音查詢指令和語音文件的相關分數 . . . 82
5.5 使用不同數量之語音詞邊界示意圖。圖中的方框表示音框序列,而 紅色方框表示用於切割語句之詞邊界 . . . 86
5.6 分段式序列對序列自動編碼器使用強化學習下之獎勵曲線。淡色曲 線為原始資料深色曲線為將資料經過平滑處理而繪製。使用強化學 習的學習演算法,分段式序列對序列自動編碼器能夠藉由不斷地訓 練獲得越來越高之獎勵,最後收斂 . . . 89
5.7 捷克語上詞切割之效能曲線 . . . 90
5.8 英語上詞切割之效能曲線 . . . 90
5.9 法語上詞切割之效能曲線 . . . 91
5.10 德語上詞切割之效能曲線 . . . 91
5.11 英文上詞切割之範例。圖為英文上一語句之頻譜圖。圖中之藍色虛 線為真實詞邊界而紅色線條為分段式序列對序列自動編碼器所決 定之詞邊界,圖片下方的文字為各詞之轉寫,”sil”為無聲音訊片段 (Silence)。圖中可以發現其兩種詞邊界高度重合,顯示我們的模 型確實可以藉由強化學習學習到正確切割 . . . 92
5.12 捷克文之 (a)音素音訊長度分佈 (b)詞音訊長度分佈 . . . 94
5.13 分段式序列對序列自動編碼器對捷克文切割出的音訊片段長度分佈 . 95 5.14 英文之 (a)音素音訊長度分佈 (b)詞音訊長度分佈 . . . 95
5.15 分段式序列對序列自動編碼器對英文切割出的音訊片段長度分佈 . . 96
5.16 法文之 (a)音素音訊長度分佈 (b)詞音訊長度分佈 . . . 96
5.17 分段式序列對序列自動編碼器對法文切割出的音訊片段長度分佈 . . 97
5.18 德文之 (a)音素音訊長度分佈 (b)詞音訊長度分佈 . . . 97
5.19 分段式序列對序列自動編碼器對德文切割出的音訊片段長度分佈 . . 98
5.20 將不同音訊長度的詞輸入分段式序列對序列自動編碼器後所得之分 段數目分佈 . . . 101
5.21 使用頻譜圖展現口述語彙偵測範例。(a)為語音查詢指令,(b)至(f)分 別為Top-1至Top-5的相關語音文件之部分擷取圖。藍線表示詞邊 界,兩紅線之間的區域為模型偵測到語音查詢指令的區域。每個圖 下方的文字為該段語音之轉寫 . . . 106
表
表 表目 目 目錄 錄 錄
1 符號對照表 . . . 1 2.1 兩個詞音訊之音素序列間的編輯距離與其語音詞向量的餘弦相似度
的關係。當兩個詞之音素結構越相近(其音素序列間的編輯距離越 小),其語音詞向量間的餘弦相似度越高。取自參考文獻 [2] . . . . 39 2.2 比較語音詞向量與動態時間校準在口述語彙偵測上之效能。語音詞
向量效能比動態時間校準要出色許多。另外使用除噪型自動編碼器 來訓練語音詞向量可以更進一步提升效能。取自參考文獻 [2] . . . . 40 3.1 不同門限之音素切割結果。忘卻門限與更新門限皆為決定記憶單元
中的資訊是否應該被繼續保留,在訓練過程中會學習去捕捉輸入語 音的在時序上的結構,因此在音素切割的實驗中具有比同神經單元 中的其他門限更佳之效能 . . . 54 3.2 不同模型間音素切割結果,表中數據為R值。使用門限激發訊號增
強之四層遞迴式預測模型具有最佳的效能表現,而門限遞迴單元自 動編碼器表現次佳。另外門限激發訊號能夠顯著地增進遞迴式預測 模型的效能 . . . 57 3.3 不同語言上之實驗結果,表中數據為R值。雖然同一模型之音素切
割的效能在不同語言上各有差異,但是使用門限激發訊號之模型皆 具有顯著優異之效能 . . . 59 5.1 章節2.2中所介紹之強化學習的元素與本章中詞切割問題間的對應
關係 . . . 74 5.2 產生不同數量的詞向量來訓練編碼器與解碼器所獲得之重建錯誤。
使用真實詞邊界的重建錯誤顯著低於使用隨機產生1.2倍詞邊界的 重建錯誤,但當隨機產生之詞邊界過多時,如1.5倍詞邊界數目,
其能獲得比使用真實詞邊界更低之重建錯誤。另外當誤差窗越大時 所造成的重建錯誤越大 . . . 87 5.3 詞切割之實驗結果。分段式序列對序列自動編碼器(Segmental
Sequence-to-Sequence Autoencoder, SSAE)在詞切割上的整體效能 顯著高於另外兩種方法,尤其是在法文方面的表現,然而其在德文 上略低於門限激發訊號的效能 . . . 93 5.4 各語言上的詞音訊,音素音訊與使用分段式序列對序列自動編碼器
(Segmental Sequence-to-Sequence Autioencoder, SSAE)所切割出之 音訊長度所近似之高斯分佈的數據 . . . 99 5.5 各語言上分段式自動編碼器所切割出之音訊長度所近似之高斯分
佈Gseg分別與詞音訊的分佈Gwrd和Gphn間的平均克雷散度 . . . 100 5.6 英文與捷克文上語音查詢指令之列表 . . . 102
5.7 法文與德文上語音查詢指令之列表 . . . 103 5.8 口述語彙偵測之實驗結果,表中數據為平均準確平均值(Mean
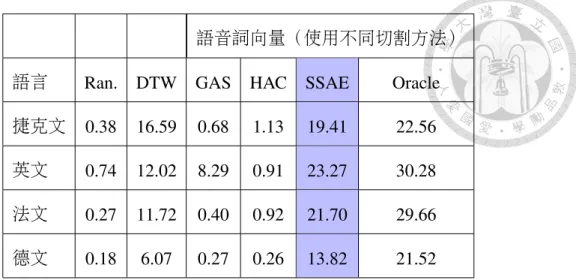
Average Precision, MAP)。第一欄為隨機基準(Ran.),最後一欄 為使用真實詞邊界(Oracle)所訓練出而得的語音詞向量,為一效 能上限。使用真實詞邊界所產生之語音詞向量所得到的效能遠比其 他方法的效能要高上許多。分段式序列對序列自動編碼器能夠獲得 比主要比較對象:動態時間校準,更佳的效能 . . . 104 1 GlobalPhone語料細節 . . . 119
符號 意涵 符號 意涵
x 模型之輸入資料 [•]T 轉置矩陣運算
exp(•) 自然指數函數運算 W 神經元權重矩陣
b 神經元閾值偏移 σ 激發函數
α 神經元輸出 y 針對輸入資料所標註之答案
yˆ 模型所輸出之答案 Θ 模型參數集
J 向量維度大小 || • ||2 方均運算
ζ 邏輯子 η 學習率
ξ 慣量係數 ct 遞迴式類神經網路於時間點t時之隱藏狀態
ht 遞迴式類神經網路於時間點t時之輸出 U 遞迴式類神經網路隱藏狀態之權重 ˆ
x 自動編碼器所重建之輸入資料 e 自動編碼器用於重建輸入資料之編碼
D 語音文件 Q 語音查詢指令
s 在強化學習中環境之狀態 a 強化學習中代理人所執行的動作
π 強化學習中之策略 r 強化學習中之獎勵
E[•] 期望值運算 ∇ 梯度運算
V 辭典大小 p 機率大小
γ 獎勵折扣係數 ft 時間點t時之忘卻門限激發訊號
it 時間點t時之輸入門限激發訊號 ot 時間點t時之輸出門限激發訊號
˜
ct 時間點t時之候選隱藏狀態 zt 時間點t時之更新門限激發訊號 rt 時間點t時之重設門限激發訊號 tanh(•) 雙曲正切函數運算
以單元為單位之矩陣相乘 gt 時間點t時之一特定門限之門限激發訊號
δ 閾值 Et 遞迴式預測模型在時間點t時的錯誤訊號
w 線性內插之權重 λ 減損函數中需要調整之超參數
ψt 切割門限在時間點t時的輸出 µ 高斯函數中之平均值 v 高斯函數中之變異數
表 1: 符號對照表
第 第
第 一 一 一 章 章 章 導 導 導論 論 論
1.1 研 研 研究 究 究背 背 背景 景 景及 及 及研 研 研究 究 究 動 動 動機 機 機
伴隨著網路時代的來臨以及智慧電子產品的普及,全世界每分每秒都有巨量的資 料產生並且發佈在網路上向全世界的人展示,如影音社群YouTube中的影音,社 群網路Facebook上的照片及貼文等等。任何人只要連上網際網路都能夠輕易地獲 得這些資料,也因此有許多人將現在稱作為巨量資料(Big Data)的時代。這些 大量的資料為科技提供了進步的能量,因此近年來人們不管在是語音處理,自然 語言處理或是影像辨識上皆有了突破性的發展。
另一方面,曾經沈寂一時的類神經網路(Neural Networks)在近年重新嶄露 頭角,於這些突破性發展中扮演著不可或缺的角色。在過去,使用多層類神網路 模型進行訓練十分曠日費。然而由於硬體設備的進步,讓模型訓練時間大幅縮 短。又因多層的類神經網路模型的效能顯著優異於淺層的模型,因此把模型疊
「深」成為這波類神經網路發展的主要共識,因此這波類神經網路革命也稱為深 層學習(Deep Learning)。
伴隨著因深層不斷加深而模型複雜度不斷上升的模型,深層學習模型的訓練 需要大量的資料。巨量資料時代的來臨恰好提供了讓深層學習大放異彩的能量,
也因此深層學習發展出了各式各樣的架構:針對抽取圖像特徵的卷積類神經網 路(Convolutional Neural Networks) [4]、能夠獲取時間資訊的遞迴式類神經網路
(Recurrent Neural Networks, RNN) [5] 等等。其中遞迴式類神經網路與語音科技 密切相關。對於語音的應用而言,時間資訊十分重要,每個時間點的資訊皆彼此 息息相關。遞迴式類神經網路藉由隱藏狀態(Hidden State)的傳遞來捕捉時間點 間彼此的關係,也因此遞迴式類神經網路成為了處理語音資料時最常被使用的一
種類神經網路 [6]。而在遞迴式類神經網路的架構上,又發展出了各式各樣的神經 網路。其中最著名的為加入了門限(Gate)的機制,使表現更加突出的長短期記 憶神經網路(Long Short-term Memory Networks, LSTM) [7]。
目前成效最顯著的深層學習模型是經由督導式學習(Supervised Learning)
而得 [8] [9]。所謂的督導式學習,是給予模型經過標註(Annotation)的資料並 以其訓練之,令訓練模型使其在測試資料上也能判斷出正確的答案。以語音 辨識為例,會給予模型一段語音和這此段語音經由專家標註而得的音素轉寫
(Phoneme Transcription),訓練模型由聲音判斷出對應的音素轉寫。督導式學 習模型雖然表現卓越,但其致命傷是標註訓練資料的成本高昂;縱然網路上有 成千上萬的資料,但有經過標註可供督導式學習使用的資料只是冰山一角。
因此,近年來人們也試著利用未標註的資料進行非督導式訓練(Unsupervised Learning) [10] [11] [12]。相較於督導式訓練,非督導式需要從沒有標註的資料中 擷取出有意義的資訊,以往普遍被認為是相當困難的問題。然而非督導式訓練並 非沒有成功的例子。人們在學習語言的過程中就有很大的一部分是非督導式訓 練;嬰幼兒在成長過程中接受了來自於父母及週遭人們大量的說話聲音,而且幼 兒並不會每接收到一段聲音就有人告訴他這段聲音是什麼音素,或者是什麼詞。
然而在上述情況下,大多數的幼兒依舊能夠從這些大量未經標註的聲音中自然地 學習語言 [13]。近年來使用類神經網路來模擬人腦的研究風氣日盛,模擬嬰幼兒 學習語言的非督導式學習也被認為具有極大的潛力和進步空間。
語音領域中若能在應用非督導式學習上獲得成功,將能讓此領域邁向另一個 新的里程碑。首先,需要大量專業語言知識的標註工作可以省去,語音技術便可 以推廣至缺乏系統性專業語言知識的語言,如地方方言。再者,非督導式學習能 與巨量資料時代相互配合,網路上大量未標註的資料都能被其利用。機器學習的
概念中,資料量常與模型表現呈現正相關,因此可以期待大量的資料能夠帶給非 督導式學習模型更佳的效能表現。
近年來許多非督導式學習演算法已經被使用在訓練深層學習的模型上,並且 在包含語音的眾多領域中獲得十分重要之研究成果 [14] [15] [16] [17]。 在這眾多 的結果中,最具有突破性發展的莫過於輸入特徵的抽取 [18] [19] [20]。以語音而 言,以往抽取音訊特徵的方式為應用聲學知識,創造出近似人耳聽覺系統的特 徵:梅爾倒頻譜係數(Mel Frequency Ceptral Coefficients, MFCCs) [21]。然而此 種由人為所定義之音訊特徵受限於人類聲學知識之發展,要定義出能顯著提升效 能之新音訊特徵並非易事。另一方面,使用深層模型所抽取之音訊特徵完全由資 料本身決定,資料越多則模型所能學習之資訊也越多,所獲得之特徵也越佳。因 此在巨量資料的時代下,使用深層學習模型可以獲得比以往人為定義法更佳的特 徵 [22]。
使用深層學習模型來抽取特徵時,可以針對不同領域與應用之需要設計深 層學習模型,進而抽取出各式各樣的特徵。在電腦視覺上,深層學習模型可從 輸入模型之圖片抽取出重要資訊,進而顯著提升圖片分類的效能 [23];在文字 領域的自然語言處理上,深層學習模型可透過閱讀大量文章,從中學習出每 個詞之間的關係,進而學習出每個詞最適切的特徵為何,此特徵稱為詞向量
(Word2Vec) [1]。語音方面,近年來重要的突破莫過於能保留輸入音訊中音素 資訊之語音詞向量(Audio Word2Vec) [2]。與詞向量概念相同,只是此時深層學 習的模型輸入不是文字,而是許多以詞為單位的音訊。深層學習模型可以透過聆 聽大量音訊,藉由每個詞中不同的音素進而學習出每個音訊間的關係。學習到此 關係後,模型便可將一個詞的音訊以一個特徵向量表示,稱為語音詞向量。如同 詞向量被廣泛應用在眾多文字領域的應用中,語音詞向量可以被使用在許多語音
領域的應用中,如口述語彙偵測(Spoken Term Detection)。
雖然語音詞向量能夠透過非督導式學習的深層學習所獲得,然而在語音領域 中非督導式學習的框架下所能獲得之輸入音訊通常為語句,語句中的詞邊界為一 不可得之資訊。理想狀況下的語音詞向量應是模型能將一語句轉化為語音詞向量 序列,序列中每個語音詞向量所代表的是語句中的一個詞的語音。有鑒於語音詞 向量之應用潛力,如何將語音詞向量的輸入由詞的層級提升為語句層級,使其成 為一完整之非督導式學習架構成為一十分吸引人之研究方向。
1.2 研 研 研究 究 究方 方 方向 向 向
本論文主要研究向為探討如何在無任何標註的情境下,將一輸入語句轉化為語音 詞向量序列,每個語音詞向量所代表的是語句中的一個詞之語音,主要包含以下 兩點:
• 第一部份主要探討深層學習模型內部訊號與語音中邊界的關聯,並探討將其 應用於切割輸入語句之可能性
• 第二部份則是探討如何訓練深層學習模型,使其能將一輸入語句轉化為語音 詞向量序列
1.3 相 相 相關 關 關研 研 研究 究 究
以 往 語 音 領 域 的 非 督 導 式 學 習 旨 在 透 過 隱 藏 馬 可 夫 模 型 (Hidden Markov Model, HMM) 來 將 語 音 中 不 同 等 級 的 音 訊 , 如 次 詞 (Subwords) 與 音 素
(Phonemes),模擬為不同的音型(Tokens),藉此將一輸入語句以音型序列來 表示 [24] [25]。此音型序列與用來模擬不同音型的隱藏馬可夫模型參數則被使用
於後續的語音應用上。
而今在深層學習的框架下,隱藏馬可夫模型被深層學習模型所取代,所輸入 之語句直接透過深層學習模型抽取特徵,並用於後續的語音應用上。由於深層學 習模型能夠從資料中抽取出抽象概念的特徵(如一張手寫數字圖片其所代表的數 字) [23],因此在後續的應用上能夠獲得更佳的效能。
詞向量(Word2Vec)是由米氏(Thomas Mikolov)等人所發展出的一套使用 深層學習模型抽取文字特徵的方法 [26] [1] [27]。將一篇文章中的每個詞輸入模 型並要求模型必須判斷出此詞的上下文(Context),藉此讓模型學習出詞與詞 彼此間的關係。此模型針對各個詞所抽取出之向量表示(Representations)稱為 詞向量,為模型考量了詞與詞間彼此的關聯所產生之表示法,因此帶有語意
(Semantics)的資訊。語意的資訊在處理文字的自然語言處理中具有十分重要 的地位,因此詞向量被廣泛應用於後續許多自然語言處理相關的研究與應用 中 [28] [29]。
另一方面,語音詞向量(Audio Word2Vec)則是由鍾氏(Yu-An Chung)等人 所發表之用來表示一段音訊之新方法 [2]。在訓練深層學習模型時,模型首先需要 將輸入之語音以一特徵向量表示,此特徵向量接著會被用來產生輸入模型之語音 訊號。透過此種方式,模型在使用一特徵向量表示輸入語音時,此特徵向量必須 含有關於輸入語音之重要資訊,否則無法憑此特徵向量便能產生輸入模型之語音 訊號,而語音中最重要的資訊莫過於音素的資訊。由於輸入的音訊為各個詞之語 音,因此每段語音中包含許多音素。鍾氏(Yu-An Chung)等人發現透過此法訓 練模型,模型能夠從大量的音訊中學習出語音中音素的結構,進而將語音中音素 結構之資訊有效地以一特徵向量表示。在後續應用中,此一特徵向量即可代表輸 入語音,進而大量減少運算與記憶體用量。
然而語音詞向量的輸入音訊為以詞為單位之語音訊號,在非督導式學習的框 架下,輸入語音通常為語句且詞邊界為不可得之資訊。因此在完整的非督導式學 習框架下,機器需要能夠從輸入語句中自動判斷出詞邊界,進而將輸入語句以語 音詞向量序列表示。近年已有學者發現語音中邊界的判斷可以仰賴深層學習模型 之內部訊號。在語音合成(Speech Synthesis)的應用中,吳氏(Zhizheng Wu)等 人發現深層學習模型中用來溝通內部各元件的訊號變化與輸入音訊之音素邊界
(Phoneme Bounadries)具有強烈的關聯 [3]。因此如何利用深層學習模型之內部 訊號來作為詞邊界的判斷標,讓機器能夠自動決定語句中之詞邊界為一十分具有 價值之研究方向。
1.4 研 研 研究 究 究貢 貢 貢獻 獻 獻
本論文主要研究貢獻為在前人所提出之語音詞向量的基礎上,將其進行延伸:讓 輸入音訊從詞變為語句,使語音詞向量不再需要詞邊界之資訊,成為一完整之非 督導式學習架構下之語音模型,在本論文中將此延伸後的語音詞向量稱之為分段 式語音詞向量(Segmental Audio Word2Vec)。分段式語音詞向量透過兩種實驗進 行效能評估,詞切割與口述語彙偵測。在這兩個實驗上分段式語音詞向量皆具有 比傳統方法具有更佳之效能。
另外本論文也分析非督導式學習下之一存在於深層學習中的內部訊號與輸 入語音之音素邊界間的強烈的關聯性,此訊號在本論文中稱為門限激發訊號
(Gate Activation Signals)。其關聯透過音素切割(Phoneme Segmentation)實驗 來展示。在音素切割實驗中,我們發現使用門限激發訊號能夠比傳統的遞迴式類 神經網路的方法更加準確及穩健(Robust)的切割音素。
上述實驗結果並不侷限在英文,另外在其他語言如捷克文,法文與德文上皆
有相似實驗結果,說明本論文前述之貢獻能夠概括化得應用在不同語言上,符合 非督導式學習之精神。
1.5 章 章 章 節 節 節安 安 安排 排 排
本論文接下各章節簡述如下:
• 第二章:首先介紹深層學習中非督導式學習的遞迴式類神經網路架構與基本 訓練方法。第二部份介紹強化學習:一個同樣不需標註來訓練模型之學習方 式。在第三部份及第四部份則分別介紹音訊切割與口述語彙偵測和其效能評 量方式。在最後部份針對語音詞向量做深入介紹。
• 第三章:探討遞深層學習模型中門限激發訊號與音素邊界的關聯性,並利用 音素切割實驗量化其關聯和強健性
• 第四章:介紹分段式語音詞向量之基本模型架構,並探討使用端對端訓練之 可能性
• 第五章:介紹如何使用強化學習訓練分段式語音詞向量,並以詞切割及口述 語彙偵測來評估模型效能
• 第六章:總結本論文的研究成果與未來展望
第
第 第 二 二 二 章 章 章 背 背 背景 景 景知 知 知識 識 識
2.1 基 基 基於 於 於 非 非 非督 督 督導 導 導式 式 式學 學 學習 習 習的 的 的遞 遞 遞 迴 迴 迴式 式 式類 類 類神 神 神經 經 經網 網 網路 路 路
2.1.1 類 類 類神 神 神經 經 經網 網 網路 路 路
類神經網路是由生物的神經系統結構得到靈感所發展出的一套數學模型。在生物 的神經系統中,神經元(Neurons)彼此由樹突、軸突連結。每個神經元的激發與 否由閾值(Threshold)決定。在類神經網路的數學模型中,一個神經元會接受多 個輸入(Input)的刺激,將這些刺激的總和通過一個激發函數來做為這個神經元 的輸出(Output)。由於神經元彼此間的連結程度不同,來自不同神經元的輸入 會分別乘以不同權重(Weights)。另外每個神經元各自不同的閾值則使用閾值偏 移(Threshold Bias)來表示。在使用這類神經網路的模型時,我們會將一個神經 元的所有輸入以一個向量x表示,x = [x1, x2, x3, x4..., xn]T,稱之為輸入向量。給 定一輸入向量,一個神經元的數學式可表示如下:
α = σ(
n
X
i=0
wixi+ b ) (2.1)
其中wi為此神經元對第i個輸入的權重,b代表閾值偏移而α則為此神經元最後的輸 出。σ為激發函數,通常為一非線性函數。
若沒有使用激發函數σ,類神經網路的訊號傳遞為線性轉換。使用非線性激 發函數能將類神經訊號的傳導轉變為非線性轉換,增加模型的複雜度。最常見的 激發函數為S型函數(Sigmoid Function):
sigmoid(x) = 1
1 + exp(−x) (2.2)
10 5 0 5 10 0.2
0.0 0.2 0.4 0.6 0.8 1.0
(a) S型函數
4 2 0 2 4
2 1 0 1 2 3 4 5
(b) 整流線性單元
圖 2.1: 不同種類的激發函數
S型函數的優點為處處可微分。而另一經常使用的激發函數為整流線性單元
(Rectified Linear Unit, ReLU) [30]:
ReLU (x) = max(0, x) (2.3)
此種激發函數在輸入訊號大於0時直接將訊號無損輸出;然而當輸入訊號小於0時 則將此訊號壓縮為0。
深層類神經網路模型通常是將神經元規劃成層狀結構,每層均有數個神經 元,每層神經元的輸出會傳遞給下一層的神經元作為輸入。整個類神經網路模 型的輸入向量由輸入層(Input Layer)傳入,經過許多的隱藏層(Hidden Layer),
由最後一層神經元,稱為輸出層(Output Layer)輸出此模型的輸出向量,如 圖2.2。事實上,對於處於同一層的神經元來說,由於它們輸入向量相同,所以此 層的輸出可以利用矩陣乘法進行運算,如下式:
α = σ(Wx + b) (2.4)
𝑥#
𝑥$ 𝑥%
…
𝑥&
輸入層 隱藏層1 隱藏層2 輸出層
𝑦#
𝑦$ 𝑦%
…
𝑦(
圖 2.2: 一具有兩層隱藏層的層狀深層類神經網路模型
其中W = [w1w2w3...wn]T,而wi,i = 1, ..., n 代表這層中n個神經元對於輸入訊 號各自不同的權重。而神經元各自的閾值偏移則由向量b表示。此層神經元的輸 出由α表示。
我們若將此層神經元的所有輸出視為一個特徵向量,我們便可以此特徵向量 作為下一層神經元的輸入,如此不斷迭代堆疊,此類神經網路便可不斷疊深。多 層的類神經網路模型我們稱為深層類神經網路(Deep Neural Networks, DNN)。
2.1.2 類 類 類神 神 神經 經 經網 網 網路 路 路訓 訓 訓練 練 練
對於每一個輸入x,我們希望類神經網路模型能夠給予我們所希望的答案y。以語 音辨識為例,給予一個語音的特徵向量,我們希望類神經網路模型能夠正確判斷 此語音是屬於哪一個音素。我們透過訓練類神經網路模型使其能夠完成這件事 情。要了解如何訓練類神經網路模型之前,我們需要先對模型的參數進行分類。
所有參數可分為兩類,第一類為可以調整的參數,像是類神經網路模型中每個神 經元對於輸入的權重,閾值偏移等等。這種參數會在訓練模型的過程中不斷地被
調整。然而第二類的參數是必須在進行訓練前就設定好,而且在訓練過程中會一 直保持不變的參數,稱為超參數(Hyper Parameters)。在類神經網路模型的訓練 中,超參數通常為隱藏層的層數,一個隱藏層含有多少神經元等等。我們以Θ表 示類神經網路模型中所有第一類參數所形成的集合。
類神經網路的訓練目標是希望其輸出,以ˆy表示,能讓減損函數(Loss Function)最小化。所謂的減損函數,是由此輸入x,和模型參數集Θ以及此筆輸 入的答案y所計算而得。減損函數代表的是此模型的效能表現,我們通常將減損 函數設計為越低表示效能越好。類神經網路的訓練過程即尋找一組能夠最小化減 損函數的模型參數Θ∗。
Θ∗ = arg min
Θ loss(x, y; Θ) (2.5) 上式中的loss(•)就是減損函數,,因此在式2.5中我們所要尋找的是能夠使減損函 數最小化的模型參數。
根據模型目標的不同,所設計出之減損函數也會不同。在處理迴歸問題
(Regression Problems)時,最常使用的減損函數分別為均方差(Mean Squared Error, MSE),數學式表示分別為:
loss(x, y; Θ)M SE = ky − ˆyk2 (2.6)
其中ˆy表示將x輸入類神經網路後所得到的輸出,而k • k2為方均運算,為方均根
(Root Mean Square, RMS)之平方。均方差減損函數是以答案y和模型之輸出ˆy間 的歐幾里德距離(Euclidean Distance)作為評估,其精神為統計學上的迴歸分析
(Regression Analysis)。
另一方面,在處理分類問題(Classification Tasks)時則是最常使用交叉熵
(Cross Entropy, CE)減損函數。若總共可能的類別有J種,此種問題所給予的答 案y會是一個維度為J之獨一餘零的向量(One-hot Vector),如[0, 1, 0, 0..., 0]T。此 種向量只會有一個維度為1其餘為0。為1的那個維度所對應的類別就是該輸入的正 確類別,以前述中的獨一餘零向量為例,第二個維度所對應到的類別就是該輸入 的正確類別。而類神經網路模型之輸出則同樣是一個J維的向量,每一個維度的 值對應到將輸入x分至某一類別的信心指數,最後會以信心指數最高的類別作為 此類神經網路模型的判斷類別。
在使用交叉熵減損函數前,我們會需要將前述代表各類別信心指數的J維向 量通過軟性最大化轉換(Softmax),轉變成機率分佈的輸出作為整個模型的最後 輸出ˆy,也就是各維度總和為1且各維度皆為一不小於0的實數。軟性最大化運算 如下式:
ˆ
yj = exp(ζj) PJ
j=1exp(ζj) (2.7) ζj表示第j類的信心指數,這些透過軟性最大轉換前的信心指數又被稱為邏輯子
(Logits)。最後使用模型輸出ˆy與答案y所計算之交叉熵之減損函數如下式:
loss(x, y; Θ)CE = 1 J
J
X
j=1
−yjlog(ˆyj) (2.8)
以獨一餘零向量所表示的答案y配合軟性最大轉換,便可發現交叉熵減損函 數的精神在類神經網路模型將預測正確類別的機率予以最大化。式2.8中,只有正 確類別的機率會被交叉熵減損函數所評估,然而在最大化這個類別的機率的同 時,由於軟性最大化轉換的緣故,其他類別的機率也相對的被降低了,因此交叉 熵減損函數和軟性最大化轉換的這個組合在分類問題的應用上十分有效。
針對不同問題定義好減損函數後,接著需要找出一組能夠獲得最小減損函
數的模型參數。實務上在訓練類神經網路模型時,我們通常會使用梯度下降法
(Gradient Descent),以迭代(Iterative)的方式進行訓練。所謂的梯度下降法是 計算減損函數的梯度,接著將模型參數往此梯度的反方向做更新,以此來降低減 損函數。藉由不斷迭代更新參數,減損函數便會不斷往最低點前進。具體而言,
對於一個模型參數θ,我們以下式將θ更新為θ0:
θ0 = θ − η∂loss(x, y; Θ)
∂θ (2.9)
其中η被稱為學習率(Learning Rate),表示依據梯度更新的幅度大小。
學習率越大表示更新的幅度越快,通常減損函數下降的速度也越快,然而容 易遇到無法收斂在最低點的狀況。學習率小雖然減損函數下降的速度比較慢,但 是因為更新參數的方式較為精細,最終收斂的減損函數值通常比學習率大的更新 方式為低。
由於一個類神經網路的參數眾多,對每一個參數都各別以式2.9進行計算和更 新不免曠日費時。反向傳播演算法(Backpropagation Algorithm)是個對類神經網 路模型而言具有高度效率的更新參數方式。首先一個N層的類神經網路模型會由 輸入端給予輸入,順向傳播(Feedforward Pass)至第N層的神經元,也就是輸出 端產生輸出。將此輸出和答案計算減損函數後,便可以得到第N層神經元參數的 梯度。利用鏈鎖率,我們可以快速得到第N − 1層神經元參數的梯度。接著不斷重 複,直到計算出第一層的神經元參數的梯度。整個過程就好像將梯度訊號從輸出 層反向傳播回輸入層一樣,因此稱之為反向傳播演算法。
依照模型學習演算法的不同,類神經網路模型的訓練方式十分有彈性。最基 本的梯度下降演算法為每次迭代都計算一次梯度,並依照式2.9更新參數。此種訓 練方式在更新參數時並不考慮從前的梯度。相反地,加入了慣量(Momentum)
(a)無慣量之梯度下降法 (b)具備慣量之梯度下降法
圖 2.3: 用慣量加速梯度下降法之一例。圖中不同顏色區塊表示減損函數值在不同 參數下之大小,由外而內遞減。圖中之箭頭表示模型參數更新之方向,箭頭數目 表示模型參數更新之次數。可以發現圖(b)的例子中使用慣量訓練法後可以加速模 型參數更新至減損函數最小處的過程。
觀念的慣量訓練法則是會考慮從前的梯度資訊 [31]。對模型的某一參數θ,最基本 的慣量訓練法可以用下式表示:
∆θt+1= ξ∆θt+∂loss(x, y; Θ)
∂θ
θ=θt
(2.10)
其中ξ為慣量係數,用以調控慣量的比例。由於慣量的觀念是考慮所有計算過的梯 度,因此模型在更新參數時能保有更多資訊來決定梯度方向,因而加速模型參數 的收斂。如圖2.3所示,圖中不同顏色區塊表示減損函數值在不同參數下之大小,
由外而內遞減。圖中之箭頭表示模型參數更新之方向,箭頭數目表示模型參數更 新之次數。可以發現圖2.3(b)的例子中使用慣量訓練法後可以加速模型參數更新至 最佳點(Optimal Point),也就是減損函數最小處的過程。慣量的觀念衍生出許 多不同的慣量訓練法,如ADAM訓練法 [32]。這些訓練法們針對慣量的調控各自 有許多更為精細方法,在實務上都有很不錯的效果。
2.1.3 遞 遞 遞 迴 迴 迴式 式 式類 類 類神 神 神經 經 經網 網 網路 路 路
根據輸入資料的種類不同,深層類神經網路也發展出不同的變型。對於語音這種 序列式資料(Sequential Data)而言,每一個時間點的資料並非彼此獨立,而是息 息相關的。以語音辨識為例,在辨識第t個時間點的音素時,若能夠有此時間點之 前t − 1個時間點的資料,辨識結果一定能夠更為準確。也因此,遞迴式類神經網 路就是設法將從前的輸入資料中重要的資訊以隱藏狀態(Hidden State)的形式保 留下來,在處理當前輸入資料時便能夠擁有更多的資訊。
一個最簡單的遞迴式類神經網路模型在處理第t個時間點的輸入時可以用以下 數學式表示 [33]:
ct= σh(Wcxt+ Ucct−1+ bc) (2.11)
ht= σh(Whct+ bh) (2.12)
其中ct與ht分別表示時間點t時此遞迴式類神經網路的隱藏狀態與輸出,U則是運 算過程中考量隱藏狀態之權重,下標c與下標h則分別表示在計算隱藏狀態與神經 網路輸出時所使用的不同參數。然而,此種遞迴式類神經網路容易遇到梯度消 失(Gradient Vanishing)的問題 [34]。具門限(Gate)機制的遞迴式類神經網路
(Gated Recurrent Neural Networks)因此被提出,其中最著名的架構為長短期記 憶神經網路(Long Short-term Memory Networks, LSTM) [7]。一個長短期記憶神 經網路的神經單元由記憶單元(Memory Cells)、忘卻門限(Forget Gate),輸入 門限(Input Gate)以及輸出門限(Output Gate)所組成。記憶單元用以儲存輸入 過的資訊。忘卻門限則是控制是否要將記憶單元中的資訊清除。輸入門限以及輸 出門限則分別控制輸入以及輸出資訊的多寡。門限機制的加入讓梯度訊號可以經 由門限傳遞,避免了梯度消失的問題。另一著名的遞迴式類神經網路架構則為門
𝑐̃
輸入端
輸出端
𝑐
輸出門限, 𝑜 輸入門限, 𝑖
忘卻門限, 𝑓
記憶單元, 𝑐
(a)長短期記憶神經網路單元
ℎ ℎ# 輸入端
重設門限, 𝑟 更新門限, 𝑧
輸出端
(b)門限遞迴單元
圖 2.4: 遞迴式類神經網路神經單元
限遞迴單元(Gated Recurrent Unit, GRU) [35]。門限遞迴單元可視為長短期記憶 神經網路的簡化版。雖然同樣具有門限機制,但門限遞迴單元中隱藏狀態c即為神 經網路輸出h且是門限遞迴單元只有兩個門限,分別為更新門限(Update Gate)
與重設門限(Reset Gate),因此參數相較之下少了許多。因為參數量較少的關 係,訓練起來也簡單許多。兩種具門限機制的神經單元架構如圖2.4所示。
2.1.4 自 自 自動 動 動編 編 編碼 碼 碼器 器 器
自動編碼器(Autoencoder)是一種資料壓縮(Data Compression)的深層類神經網 路模型 [22] [14]。此深層類神經網路模型通常由一編碼器(Encoder)和一解碼器
(Decoder)相接而成。編碼器將輸入壓縮為一個編碼(Code),此編碼通常維度 會比輸入要小。而解碼器則是需要利用此編碼來還原(Reconstruction)出原來的 輸入。由於解碼器在進行解碼時的依據只有編碼器所產生的編碼,因此此編碼被 視為輸入端資料的一種壓縮後的表示法(Representations)。自動編碼器的訓練並 不需要任何標註,因此是最常被使用在非督導式學習的類神經網路模型。自動編 碼器通常使用均方差減損函數來訓練,此減損函數主要是評估輸入資料x和解碼
器還原出的輸入資料ˆx之間的均方差:
loss(x, ˆx) = kx − ˆxk2 (2.13)
和深層類神經網路的自動編碼器相比,基於遞迴式類神經網路的自動編碼 器在編碼時能夠考慮從前輸入過的資訊,同樣地在解碼時也能考慮從前看過 的編碼,此種特性使其在訓練方式上也更加富有彈性。訓練方式主要分為兩 種,分別為序列標註式訓練(Sequence Labeling Training)以及序列對序列式訓練
(Sequence to Sequence Training) [36],如圖2.5。序列標註式訓練與深層類神經 網路訓練方式相同,在每個時間點皆會輸出一個編碼,而解碼器利用此編碼解碼 出該時間點的輸入。由於遞迴式類神經網路能夠保留從前的資訊,因此在進行時 間t的解碼時,能夠保有時間t = 1至t = t − 1的資訊:
ˆ
xt= RN N (x1, x2, ..., xt−1) (2.14)
序列對序列式訓練是較為特殊的一種訓練方式,此種訓練方式是將所有的輸 入資料皆輸入遞迴式類神經網路的編碼器,過程中不輸出編碼。直到最後一筆輸 入資料輸入後,將此時類神經網路中的記憶單元取出,當作是這一整個序列資 料的編碼e。解碼器需要利用此編碼解碼出所有時間點的輸入資料。在解碼時間 點t時,會將解碼器所解碼出的前一個時間點的資料和編碼串接(Concat)後當作 此時間點解碼器的輸入。此種訓練方式下的自動編碼器被稱作遞迴式自動編碼器
(Recurrent Autoencoder),其解碼可用下式表示:
ˆ
xt = RN N (e, ˆx1, ˆx2, ..., ˆxt−1) (2.15)
(a) 序列標註式訓練 (b) 序列對序列式訓練
圖 2.5: 遞迴式類神經網路訓練法。上圖中不同顏色分別代表:藍色表示輸入訊 號;黃色表示編碼器;綠色表示解碼器;紅色表示輸出訊號。在序列對序列式訓 練中,前一時間點的輸出訊號會成為下一個時間點的輸入訊號。
2.2 強 強 強化 化 化學 學 學習 習 習
2.2.1 馬 馬 馬可 可 可夫 夫 夫決 決 決策 策 策過 過 過程 程 程
強化學習(Reinforcement Learning)可用來解決馬可夫決策過程(Markov Deci- sion Process, MDP)的問題。所謂馬可夫決策過程係為一代理人(Agent)需在一 環境中(Environment)連續做出許多決策的過程,由下列五個成分所組成:
• 狀態(State, s):指環境目前的狀態,也是代理人能掌握到的資訊。例如在 圍棋中,狀態可以指目前的盤面。然而狀態的訂法不只一種,同樣以圍棋為 例,可以指目前的盤面,也可以指前十步所有的盤面狀況。通常而言,當給 予代理人的狀態包含資訊越多,則代理人能夠習得越佳的表現。
• 動作(Action, a):每個狀態下代理人所能執行的動作。以圍棋而言,可以 做的動作為盤面上尚未落子之處。
• 策略(Policy, π):為代理人之行為模式,也就是其在每個狀態下採取各種 應對動作的選擇或方法,此成分需要由代理人與環境互動進而學習出一套策 略。
• 轉移機率(Transition Probability):當代理人在狀態s下,做出動作a時,狀 態會轉移到s0的機率。以圍棋作為例子而言,在某盤面的情況下,代理人做 出了一個動作,也就是在某處落子,則下次輪到代理人落子時的各盤面機率 則為此二盤面間的轉移機率。此項目可以代表環境的動態變化。
• 獎勵(Rewards, r):獎勵為系統設計者根據系統目標,針對代理人所定義 出的一套回饋機制,旨在透過獎勵讓代理人了解每個執行動作的好壞,進而 摸索出能夠達到系統目標的動作。當代理人在狀態s下,執行了動作a後轉移 至狀態s0,系統會根據此過程給予代理人一個獎勵,代表代理人所執行的動 作是否符合系統目標。越大的獎勵代表代理人所執行的動作越符合系統目 標,而代理人的學習目標便是盡力獲得越大的獎勵。
在轉移機率已知時,可以應用動態規劃(Dynamic Programming)來解決馬可 夫決策問題。然而在多數的現實問題中,轉移機率為不可知資訊,因此無法使用 動態規劃來處理馬可夫決策問題,需要應用強化學習。
2.2.2 強 強 強化 化 化學 學 學習 習 習簡 簡 簡介 介 介
在現實生活中的馬可夫決策問題通常複雜度高而且狀態間的轉移機率為未知資 訊,因此無法使用動態規劃求出最佳解,需要轉而使用機器學習的方法來處理。
機器學習中的強化學習即是為了處理馬可夫決策問題所發展出的學習演算法。
圖2.6為使用強化學習之學習流程。首先在環境當前的狀態s(圖中例子為環境中 有一杯水)會被作為輸入資料被輸入代理人,在強化學習中此代理人即為需要進
環境 代理人
狀態(s):
在桌上有一杯水
可執行動作1:
打翻這杯水
可執行動作2:
無任何動作
可執行動作3:
拿起水
執行動作機率:0.7 執行動作機率:0.2 執行動作機率:0.1
策略𝜋
1.
2.
4. 3.
執行動作:打翻這杯水 給予處罰
圖 2.6: 強化學習流程圖,箭頭旁之數字表示流程順序
行訓練之強化學習模型。在獲得了當前的狀態s後,代理人會對於所有可執行動衡 量出執行之機率,這些動作之機率分佈稱作策略。代理人接著從所有動作中依照 策略來挑選動作執行,在圖中的例子為代理人選擇打翻環境中的這杯水。環境可 給予代理人所執行之動作一個獎勵。若打翻水為一不被允許之動作,則此獎勵將 轉變為處罰,藉此讓代理人學習到不應該打翻水。
透過上述過程,強化學習模型不斷在各種狀態下執行動作,與環境互動獲得 獎勵。而設計環境之系統設計者對於強化學習模型有一個希望其表現之行為模 式,也可稱作系統目標。藉由獎勵大小來告訴強化學習模型其執行之動作是否符 合系統目標,藉由不斷互動來修正模型的行為模式,使其逐漸符合系統目標。
雖然乍看之下強化式學習似乎是一種督導式學習(Supervised Learning),只 是把預測答案的正確與否改由獎勵大小表示。然而實際上強化式學習與監督式學 習本質上有許多差異。督導式學習在進行訓練之前,對於每一筆輸入資料需要有
完整標註好的答案;強化學習只需要定義好計算獎勵的準則,根據每一筆輸入資 料便可計算出獎勵以進行模型訓練。
隨著時間的演進,強化學習也發展出了各式各樣的學習演算法。這些 演算法主要可以分為兩類:基於價值(Value-based)的強化學習與基於策略
(Policy-based)的強化學習。基於價值的強化學習旨在訓練一個評分員(Critic)
來根據當前狀態s為不同策略(Policy)π打分數,因此可以可以藉由此評分員來 選出最適合的策略。另一方面基於策略的強化學習則是利用獎勵直接針對代理人 的策略進行調整,並無評分員的存在。在本論文中所使用的強化學習演算法為後 者,因此在後續章節中僅針對基於策略的強化學習作介紹。
2.2.3 基 基 基於 於 於 策 策 策略 略 略的 的 的強 強 強化 化 化學 學 學習 習 習
基於策略的強化學習可以想像是希望尋找一個策略函數π(s)將每個狀態s對應至一 個最適切的動作a:
a = π(s) (2.16)
在簡單的問題中,此策略函數可以使用人為制定的規則(Rule-based)來將每 一個狀態對應至一個動作,然而此方法並不適用於高複雜度的問題上。近年來 深層學習也被應用於基於策略的強化學習,策略函數之輸出由深層類神經網路
(Neural Network, NN)所決定。實作上類神經網路會依照輸入狀態s來為每個動 作決定出一個分數ζ。假定所有可執行之動作共有J種,類神經網路便會輸出一 個J維大小的向量ζ,其中每個維度為對應動作之分數ζj。而這些分數會通過一個 軟性最大化(Softmax)後得到執行每一個動作之機率pj,最後策略函數之輸出為 具有最大機率的動作a。上述過程可以使用式2.17至式2.19表示。
ζ = N N (s) (2.17)
pj = exp(ζj) PJ
j=1exp(ζj) (2.18)
a = arg max
j [p1, p2, ..., pJ] (2.19) 目前強化學習已發展出許多演算法來訓練前述之類神經網路 [37] [38] [39],
其中主流的訓練法為策略梯度(Policy Gradient)訓練法 [37],本文中亦使用此技 術,因此在接下來的文字中將介紹此訓練方法。為求說明精簡,我們接下來使用 式2.20來表示式2.17至式2.19之過程。
a = π(Θ)(s) (2.20)
其中Θ為類神經網路模型之參數集。
使用策略梯度訓練法時,其訓練目標為尋找一組前述之類神經網路參數Θ來 最大化代理人所獲得之獎勵的期望值。因此定義目標函數J(Θ)如下:
J (Θ) = Eπ(Θ)[r] (2.21)
右式期望值E之下標π(Θ)表示此為代理人根據策略函數π(Θ)所獲得之獎勵期望值。
針對每一個由策略函數π(Θ)所決定之動作a,環境會給予一個獎勵r,此獎勵 將被用在更新參數集Θ上。
在說明更新參數集Θ的數學式之前,我們首先需要說明獎勵r如何被用來更新 參數。由於強化學習所處理之馬可夫決策過程(Markov Decision Process, MDP)
為一連續決策問題,因此在此過程中代理人需要與系統連續執行若干動作。每當
代理人執行一個動作a後,其會從系統設計者所設計之環境獲得一個獎勵r代表該 動作是否符合系統目標。亦即若代理人持續與環境互動T 次,則獎勵也會是一個 長度為T 的序列,[r1, r2, ..., rT]。為了完整考慮時間點t時所執行之動作at在馬可夫 決策過程中之好壞,我們會將該時間點t後所有獲得之獎勵納入考慮,因此實際上 對於時間點t時所執行之動作at的獎勵估計為:
˜ r =
T
X
i=t
γi−tri (2.22)
其中ri為時間點i時代理人所獲得之獎勵。γ為折扣係數,為一小於1之正實數。為 求符號簡潔與一致,以下不特別列出代表時序的符號t,僅需將˜r理解為環境所給 予代理人執行動作a之一個含有未來資訊的獎勵即可。
在將參數集Θ更新為Θ0時,首先利用似然比值技法(Likelihood Ratio Trick)
計算目標函數之梯度 [40] [41]:
∇ΘJ (Θ) = Ea∼π(Θ)[˜r∇Θlog(pa)], (2.23)
式中的˜r為前述之環境根據代理人所執行的動作a所給予的獎勵,右式期望值之下 標a ∼ π(Θ)表示此動作由策略函數π(Θ)所決定。pa表示式2.18中由策略函數π(Θ)所 輸出之動作a的機率。由上式不難看出若獎勵˜r為一大於零之實數,則代理人所執 行的動作a之機率將會被放大,反之則是縮小。其物理意義為若環境認為代理人所 執行之動作a符合目標行為模式,其給予的獎勵便為正值,藉此鼓勵代理人執行此 動作;反之給予的獎勵則為負值,讓代理人在未來避免執行該動作。
計算完目標梯度後,接著使用梯度上升法(Gradient Ascent)來更新參數 集Θ,藉此將目標函數最大化:
![圖 2.11: 使用序列對序列式自動編碼器所抽取之語音詞向量 的編輯距離與其語音詞向量的餘弦相似度的關係。由表可以看出當兩個詞之音素 結構越 相近(其音素序列間的編輯距離越小),其語音詞向量間的餘弦相似度越 高。 語 音詞向量的特點除了音素結構相近者具有較高之餘弦相似度外,與詞向量 相呼應的是在音素結構上也被發現具有向量運算的特性。在詞向量中,不同語意 被包含在向量空間中的不同方向上(如每個國家的名稱往相同方向移動後便可得 到其對應首都名稱) [54]。 而在語音詞向量中,鍾氏(Yu-An Chung)等人](https://thumb-ap.123doks.com/thumbv2/9libinfo/9608616.634139/51.892.259.696.123.529/使用序列對序列式自動編碼器所抽取之語音詞向量編輯向量間相呼應.webp)