以LDA為基之英文課程文字稿摘要法
81
0
0
全文
(2)
(3) 誌謝 從踏入研究所以來我遇到了許多值得感謝的人,正因為遇到這些人, 我的研究之路才能順遂,儘管遇到許多迷惑和猶疑的事,但也仍然一路 走了過來,我真的打從心底感謝這些幫助我的人。 首先最感謝的人是我的指導教授-蕭文峰老師,入學便開始跟著老師 學習,不論是課業或研究,老師都非常認真並仔細的教導我,不僅課程, 在為人處事方面也一同的指導我,讓我不僅是學業方面,其他方面也受 惠許多,由衷的感謝您對我的教誨 另外還有謝宗翰老師、張德民老師,在共同會議上的悉心指導,使 得我的研究能更前進一步。張德民老師也擔任了我的口試委員,與陳耀 宗老師遠道而來的為我進行口試,讓我的研究論文能更加的完成,我相 當感謝這三位老師。當然系上的其他老師也在課程上盡心盡力,讓我各 方面的課程都有所學習有所成長,令我惠益良多。 感謝 100 碩班的同學,特別是宗儒、尚澤、小癸,與你們相識、有 你們的陪伴是我無比珍貴的寶物,正因為你們的相伴才會讓研究所的求 學生涯更加閃耀光輝。與你們互相幫助互相學習,我也由衷的感謝。 感謝各位學長姐,特別是絲敏學姐與可任學長,有你們的幫助與指 導,我才能讓我的研究論文有個順利的開始。感謝各位學弟,特別是仲 傑、黃喬、政龍,因為有你們的幫助,我的論文有個順利的結束。 I.
(4) 最後感謝我的家人,在這求學生涯一直不停的支持我,不論我遇到 什麼都會一再的激勵並幫助我走下去。 由衷感謝所有幫助我的人,特別再一次感謝蕭老師,我會記得您的 指導與教誨,相信在我日後的人生道路也一定有所幫助。. 邱怡菁僅致於 國立屏東大學資訊管理學系碩士班. II.
(5) 以 LDA 為基之英文文字稿摘要 研究生:邱怡菁. 指導教授:蕭文峰. 摘要 由於大規模開放式線上課程(Massive Open Online Course, MOOC)的 蓬勃發展,學習者可以註冊與修習國外著名大學的課程。為了協助學習, 這些課程都提供課程影音及文字稿供學習者下載學習,本論文認為文字 稿的摘要可以協助學習者快速查找所需課程並掌握課程的內容。因此本 論文提議使用潛在狄利克雷分配(Latent Dirichlet Allocation)對文字稿內 容來進行分析,獲取其中的主題以便整理出文字稿的摘要。由於摘要是 由句子組成的,而一個句子的基本組成是主詞、動詞、及受詞(或補語) 等三元組(triplet),因此本論文論文提議由比對句子的三元組與 LDA 的主 題來獲取摘要句。亦即,如果 LDA 的主題涵蓋了某一句子的三元組,即 代表此句子愈可能是談論此一主題的重要句子應該被選為摘要句。本論 文將比較所提方法與以傳統 LDA 進行摘要法,及 pLSA 進行摘要之優 劣。. 關鍵字: 文件摘要、LDA、主動受詞三元組、文字稿. III.
(6) Abstract Owing to the burgeoning of Massive Open Online Courses (MOOC), learners can enroll and learn courses from world-wide prestigious universities. To facilitate learning, these courses also provide learners to view and download videos and corresponding transcripts. In this study we believe the transcripts can help learners filter out the courses that they need and can help grasp the key points of the courses. Therefore, we propose to use Latent Dirichlet Allocation to analyze the transcripts to extract the topics that they contain and then obtain their summary. Since a summary consists of sentences, and a sentence consists of a triplet of subject, verb, and object (complement), therefore, we proposed to compare LDA’s topic words against sentence’s triplet to obtain summary sentences. That is, the more the triplet of a sentence covers LDA’s topic words, the more likely that this sentence is related to this topic and should be selected as a summary sentence. We compared the performances of the proposed method (triplet LDA), traditional LDA, and pLSA in extracting summary sentences. Keywords: Document Summary, LDA, SVO triplet, transcript. IV.
(7) 目錄 錄 1. 緒 緒論 .................................................................................................................. 1 1.1. 研究背 背景與動機 機 ....................................................................................... 1 1.22. 研究目 目的 ................................................................................................... 3 2. 文 文獻探討 ................ . ......................................................................................... 4 2.1. 文字稿 稿的特性 ........................................................................................... 4 2.22. 文件摘 摘要方法 ........................................................................................... 5 2.33. 機率性 性潛藏語意 意分析(proobabilisticc Latent Seemantic annalysis, pL LSA) 8 2.44. 潛在狄 狄利克雷分 分配(Latennt Dirichleet Allocatiion, LDA)) ....................... 9 2.55. 三元組 組(Triplet) ....................................................................................... 15 3. 研 研究方法 ................ . ....................................................................................... 17 3.1. 預處理 理 ..................................................................................................... 18 3.22. 處理 .......................................................................................................... 23 3.33. 摘要輸 輸出與比對 對 ..................................................................................... 25 4. 實 實驗與討論 論 ................................................................................................... 27 4.1. 實驗資 資料集 ............................................................................................. 27 4.22. LDA 工具介紹.. 工 ....................................................................................... 28 V.
(8) 4.33. 字詞數 數及主題數 數的決定 ......................................................................... 30 4.44. 實驗說 說明 ................................................................................................. 34 4.55. LDA 摘要 摘 ................................................................................................. 35 5. 結 結論與未來 來研究 ........................................................................................... 64 6. 參 參考文獻 ................ . ....................................................................................... 65 7. 附 附錄 ................................................................................................................ 69. VI.
(9) 表目錄 表 1. coursera 課程文字稿資料 .................................................................... 27 表 2 University of Waikato 課程文字稿資料 ............................................... 28 表 3. GibbLDA 和 Matlab Topic Modeling Toolbox 比較表 ....................... 28 表 4. 輸出檔的內容 ...................................................................................... 29 表 5 mLDA 輸入檔內容 ............................................................................... 30 表 6 Writing in the Sciences 的比較數據 ..................................................... 38 表 7 Automata 比較數據 ............................................................................... 47 表 8 Web Application Architectures 比較數據 ............................................ 54 表 9 全課程全摘要比對數據精確率(Precision)表 ..................................... 60 表 10 全課程全摘要比對數據召回(Recall)表 ............................................. 61 表 11 全課程全摘要比對數據 F1 表 ............................................................ 62 表 12 提示詞 F1-Measure 表 ...................................................................... 69 表 13 關係詞 F1-Measure 表 ...................................................................... 70 . VII.
(10) 圖目錄 圖 1 LDA 的生成模型 .................................................................................... 10 圖 2. 系統流程圖 .......................................................................................... 17 圖 3 圖片剖析樹 ........................................................................................... 21 圖 4. jLDA 結果統計表 ................................................................................ 31 圖 5. mLDA 結果統計表 .............................................................................. 31 圖 6. 主題數比較 .......................................................................................... 33 圖 7. 文件數比較 .......................................................................................... 34 . VIII.
(11) 1. 緒 緒論 1.1. 研究背景 景與動機. 隨著網路 路快速的發 發展,學 學習者上課 課不再侷限 限教室內 ,著名大學 學如美 國的 的麻省理工 工學院(MIT) 或史丹 丹佛大學 學(Stanford d)提供了 「大規模開 開放式 ,讓學習者 線上 上課程(Maassive Opeen Online Course, MOOC)」 M 者可以透過 過網路 來學 學習或取得 得這些學校 校的某些 些課程的課 課程資訊和 和上課影音 音。無須是 是該學 校的 的學生,只 只須註冊便 便可獲取這 這些資訊,對學習者 者來說無疑 疑是一大福 福利; 且為 為了降低語 語言的隔閡 閡,MIT 或 Stanfo ord 的許多 多課程都有 有提供對應 應的文 字稿 稿提供學習 習者下載閱 閱讀。文 文字稿對學 學習者在聽 聽取課程上 上有相當大 大的幫 助,但對於掌 掌握課程重 重點的幫 幫助卻不大 大。隨著開 開放式課程 程的發展,課程 的增 增加使得文 文字稿相對 對增加, 使用者需 需要一套文 文字稿整理 理機制,以 以便於 整理 理這些課程 程資料;若 若能提供 供文字稿之 之摘要內容 容,並對應 應影音內容 容,對 於學 學習者掌握 握和整理課 課程重點 點將會有相 相當大的助 助益。學習 習者透過了 了解文 字稿 稿的核心內 內容再聽取 取演講者 者的講解,使得更容 容易吸收課 課程內容,達到 有效 效學習目的 的。 要以現行 行的文件摘 摘要技術 術來針對文 文字稿輸出 出摘要仍有 有改善的空 空間。 將輸 輸入文件依 依特性進行 行分類, 一般所指 指的「文件 件(documeent)」,泛指 指議論 性文 文章如新聞 聞或論文等 等,具有固 固定的結構 構(例如有 有分段式的 的章節);而 而文字 1.
(12) 稿是敘述性文章不如文件有具結構性。本論文所收集的文字稿是由上課 影音檔內容呈現,當中包含較多的口語表現和重覆語句,在敘述上不如 文件擁有表格及圖片上的指引,在文字內容中會出現人為錯誤,再加上 演講者與聽講者的互動也一併收錄的可能性。若參考自動文件摘要技術, 以現有的技術來看,其輸入文件是新聞文件,無法對應的文字稿特性來 獲取摘要。本論文希望改善現有的文件摘要技術以符合文字稿特性,而 獲取具有意義的摘要內容。 現有的文件摘要的技術大致可分為三類: (1)監督式方法(2)圖形模式 (3)主題模式。監督式方法將摘要擷取視為二元分類的問題,以判斷句子 屬不屬於摘要,缺點是需耗費人力來標註資料且可能帶有雜訊,不適於 文字稿;而圖形模式,將文章的句子與句子之間表達為圖形,但以文字 稿特性來說,較多重覆語句在圖形表現上會顯得不利;最後的主題模式, 目的在於找出輸入文件的主題,並基於所獲取的主題來選擇具資訊的句 子,而文字稿包含了數個主題,可利用主題模式找出主題藉此獲取出摘 要所需的句子。 過去應用主題模式協助建立摘要的研究包括:機率性潛藏語意分析 (probabilistic Latent Semantic analysis, pLSA) (Hennig, 2009)、潛在狄利克 雷分配(Latent Dirichlet. Allocation, LDA) (Arora et al 2008; 張明慧 et al 2011)。pLSA 與 LDA 很類似,都是產生式模式(generative model) ,允許 2.
(13) 由潛 潛藏變項來 來解釋觀察 察值(曾士 士昌 2011)),但 Bleii et.al (20003) 指出 出 pLSA 模型 型並不完整 整:pLSA 在文件層 層級上沒有 有提供概率 率模型,這 這導致模型 型參數 變數 數會隨著文 文件量的增 增加而成長 長,會有「overfittiing」問題 題。而 LDA A 模型 較為 為完整,L LDA 將每 每一篇文件 件視為多個 個主題的混 混合。在 LDA 中會 會假設 其主 主題分配是 是一個 Diirichlet 事 事前分配。 。這類工具 具用於多文 文件主題的 的擷取 有一 一定的幫助 助。 本論文將 將探討 pL LSA 和 LD DA 兩者在 在摘要法在 在文字稿,兩者不同 同特性 所獲 獲取的摘要 要之差異。另外也探 探討本論 論文所提 LDA L 摘要 要法和現有 有 LDA 所獲 獲取的摘要 要之差異。. 1.2. 研究目的 的. 綜合上述 述,本論文 文具體目的 的如下列 列所述: (1). 提出應 應用於文字 字稿的 LD DA 摘要法 法。. (22). 探討所 所提之 LD DA 摘要法 法與 pLSA A 摘要法及 及其他 LD DA 摘要法 法在文 字稿摘 摘要上的優 優劣。. 3.
(14) 2. 文 文獻探討 討 2.1. 文字稿的 的特性. 由於文字 字稿包含較 較多的口 口語表達(ee.g. 片語與 與俚語)與 與較多的重 重覆語 句(重 重點會一再 再強調)(H Hori et al.,, 2003b),而且也較 較一般書面 面文件無結 結構化 (沒有 有標題與章 章節,沒有 有圖片、表 表格、或特 特殊方程式 式符號)(C Christensen n et al., 20033; Christensen et al., 2004), 因此往往 往 40 分鐘 鐘的課程其 其文字稿會 會多達 11 個 A4 頁面的長度 頁 度(10 號的 的字型)。在 在一般文件 件下,學習 習者會在圖 圖形與 表格 格所在的章 章節中找尋 尋到說明 明圖形與表 表格的重點 點文字,但 但在文字稿 稿中並 沒有 有這些指引 引,學習者 者要在其 其中抓出重 重點尤其不 不易。我們 們以下的文 文字為 例: Do we go g through h the origiin or not? ? In this ca ase, yes, bbecause th here's a zeroo over therre. In this case we ddon't go th hrough thee origin, b ecause if x and y are zzero, we don't d get three. So, llet me aga ain say sup uppose y iss zero, wh hat x do we actually get? g If y is zero, then I geet x is minus m threee. (sourcee: MIT OpeenCourseW Ware, Lineear Algebrra Lecturee 1, instrucctor: Prof.f. Gilbert Strang) S 當讀者對 對照著影音 音課程可 可很容易瞭 瞭解這是在 在平面上繪 繪製兩條線 線性方 程的 的講述過程 程,但若單 單純從文 文字的角度 度來看則容 容易混淆 。因為兩條 條方程 都是 是用"in thiis case"來 來指稱,而 而不是一個 個用 in thaat case,雖 雖然講授者 者的確 將手 手從第一條 條方程移到 到第二條方 方程才說 說"in this caase"。但在 在文字表達 達上卻 看不 不出這個動 動作,因此 此有效地從 從文字稿中 中摘取出有 有意義的重 重點 (此為 為平行 4.
(15) 結構 構,兩者應 應同時被擷 擷取出)。 與新聞文 文件的摘要 要擷取不同 同的是,一 一個文 字稿 稿(一次的課 課程)中通 通常會含有 有幾個子主 主題,因此 此在摘要的 的獲取上必 必須要 能同 同時將這些 些主題擷取 取出。另 另一方面,由於課程 程其間講授 授者常會以 以提問 的方 方式來與講 講台下的學 學生互動 動,因此課 課程的重點 點內容可能 能會散佈於 於多個 參與 與者。 依據 Zeechner (20 002b)及本 本論文的整 整理,文字 字稿的摘要 要擷取有著 著以下 的挑 挑戰:處理 理口語的 的不流暢性 性(Hori et e al., 20 003b)、辨 辨識擷取的 的單位 (Chrristensen et e al., 200 03; Christeensen et al., a 2004)、 、維持多個 個參與者的 的一致 性(Z Zechner and a Waibel, 2000aa; Zechneer, 2002a))、處理文 文字稿中的 的錯誤 (Zecchner and Waibel, 2000b; 2 Koolluru, et al., a 2005)、 、掌握口語 語的習慣用 用語及 片語 語。 2.2. 文件摘要 要方法. 文件摘要 要的優點,就如 M Mani et al. (2002)所 所提到的,「當摘要比 比例濃 縮至 至原文件的 的 17%(且 且沒有明顯 顯地降低正 正確性)時 時,決策的 的速度可以 以加速 2 倍 倍」 ;以及, 「查詢導 導向的摘要 要可以讓使 使用者更快 快速地找到 到相關的文 文件, 而不 不用再去檢 檢視全文」 」 。因此,當網路上 上的文字稿 稿愈來愈多 多時,提供 供文字 稿之 之摘要內容 容以方便學 學習者瀏 瀏覽與查詢 詢的需求便 便益形迫切 切。然而口 口說表 達與 與寫作是兩 兩種不同的 的溝通方 方式,其中 中的表達、 、對象、以 以及互動方 方式也 都有 有不同。文 文字稿為忠 忠實記錄 錄講者的表 表達及與聽 聽眾的互動 動,通常也 也會記 5.
(16) 錄講者說話的不連貫處(包括填充詞, well, um, err, …)及聽眾的反應(laugh 等),文字稿的這類特性造成現有的文件摘要無法直接套用在其上。 過去用於文件摘要的技術大致可分成三類(Nenkova et al., 2011):(1) 主題模式(topic models),由計算詞頻、詞頻反向文件頻率(tf×idf)、及詞彙 連結(lexical chain)來決定文件的主題字(topic words)或主題模式。主題模 式屬於非監督式方法。主要目的在於找出輸入文件的主題(分抽取主題字 及建立主題模式兩種),並基於所獲取的主題來選擇具資訊的句子。在抽 取主題字方面,其基本想法是重覆出現的字詞比較可能跟文件的主題有 關,因此利用主題字來建立摘要的做法包括:估計字詞權重、計算句子 權重、選擇最好的句子、更新字詞權重(避免選到重覆意義的句子)、重覆 上兩步驟直到達到摘要所需長度(Vanderwende et al., 2007; Yih et al., 2007; Haghighi and Vanderwende, 2009)。 (2)圖形式模式(graph-based models),以節點(nodes)表示句子或語段實 體(discourse entities),以邊(edges)表示句子間的相似性。圖形式模式 屬 於非監督式方法。此方法透過將句子與句子的關係表達成圖形,其中圖 形的節點(node)可以是句子或語段實體(discourse entity),而圖形的邊(edge) 則連結相似的句子或語法相關的實體。句子間的相似性可由句子之間的 tf × idf 權重向量間的距離(cosine 相似度)來計算。圖形模式的優點是同 時結合的字的頻率及句子的分群(e.g. Chen et al. 2011),並且對計算重要性 6.
(17) 提供了一個正式的模式,例如 Hsu et al. (2007)使用隨機漫步來選擇摘要: 將輸入文件表達成一個圖,接著開始由節點到節點依機率來巡行(有時會 跳至一個新節點),在經過一段時間後會停至某一節點的機率會剛好等於 此圖形模式的穩態解(stationary solution),而此機率可用來表示此句子的 權重。透過挑選權重較高的句子(i.e., 由句子的中間性來選擇句子)來形成 摘要。 (3)監督式方法(supervised methods),由定義屬性來訓練區辨模式 (discriminative model)。監督式方法用於摘要擷取可看成是一個二元分類 的問題:一個句子屬於或不屬於摘要。可以使用統計分類器依句子屬於 摘要的可能性來決定分數。 每一個句子以事先定義的屬性來決定,分類模式是由已標註的資料 來訓練,然後選擇有最高分數的句子。過去研究所定義的屬性包括: (1) 句子的長度,通常愈長的句子愈重要; (2) 句子的權重,可以計算句子與文件間的 cosine 相似度、或句中 重要字的權重和、或先使用 LSA 分析(Deerwester et al., 1990)後 再計算字詞權重; (3) 句子的位置,開頭的句子或特定章節(e.g. 結論)的句子通常比較 重要。 (4) 提示詞或片語,常出現的 n-gram 、命名實體(name entities) 、 7.
(18) 或提 提示片語(ee.g. in connclusion, th he results show)。 (5) 情境 境屬性(con ntext featuures),一個 個句子與其 其鄰近句 句子間的差 差異。. 2.3. 機率性潛 潛藏語意分 分析(prob babilistic Latent L Semantic an nalysis, pL LSA). pLSA 被提出用以 被 以改善 LS SA 缺乏統 統計基礎的 的問題,在 在許多應用 用上顯 示 ppLSA 可優 優於 LSA A。但與 LSA 相同 同地,pLS SA 通常被 被用於多文 文件的 分析 析,因此 pLSA p 也被 被用於獲取 取多文件的 的摘要(e.g. Kong aand Lee, 2006); 2 至於 於單文件摘 摘要,就我 我們所知文 文獻中仍還 還未看到。pLSA 的 的核心是觀 觀點模 式(aaspect moodel),它是 是針對一般 般共現(co o-occurren nce)資料所 所提出的一 一個潛 變數 數(latent vaariable)模 模式,用以 以對應每一 一個觀察值 值對應至一 一個無法觀 觀察到 的類 類別變數 zZ={z z Hofmann, 1999)。 1, …, zk} (H 曾士昌(22011)提出 出以句子的 的主詞與動 動詞做為該 該句的語義 語義。spLSA A 分析 「句 句子-段落((sentence - paragrapph)關係」 ,在觀點模 模式上是每 每一個句子 子中的 主、 、動詞 sS S={s1, …,, sM}在每 每一個段落 落 pP={p1, …, pN}中 中每一次 次出現, spLS SA 主、動 動詞摘要 要法認為同 同一段落中 中同一對主 主動詞不只 只出現一次 次,因 此主 主動詞具有 有代表意義 義。但此摘 摘要法有 有以下缺點 點:(1)隨著 著句子越長 長,相 對的 的處理時間 間也就越長 長(2)並非 非每一句句 句子皆可擷 擷取出主、 、動詞(3)摘 摘要法 可能 能會選出未 未擷取出主 主、動詞的 的句子。而洪絲敏 敏(2012)提出 提出 spLSA A 名詞. 8.
(19) 摘要 要法,將句 句子中的全 全部名詞來 來取代主、動詞,並 並且執行「 「移除停用 用字」 、 「字 字根還原」 」等步驟使 使得處理 理時間更為 為快速,實 實驗顯示洪 洪絲敏所提 提摘要 法優 優於曾士昌 昌所提摘要 要法,因此 此本論文將 將洪絲敏(2012)所提 提 pLSA 名詞摘 名 要法 法為比較基 基礎。. 2.4. 潛在狄利 利克雷分配 配(Latent Dirichlett Allocatio on, LDA). 潛 在 狄 利 克 雷 分 配 (Lateent Dirich hlet. Allocation, L LDA) 由 Blei B et al.(22003)等人 人提出,用 用來彌補 ppLSA 的不 不足,LD DA 是一個 個非監督機 機器學 習技 技術,可以 以用來識別 別大型文件 件集(docu ument colleection)或 或語料庫(ccorpus) 中的 的潛藏主題 題。LDA 使用了「 「詞袋(baag of worrds) 」方法 法,這個方 方法是 將文 文件視為字 字詞頻率的 的向量, 而文字內 內容則是化 化為能方便 便以建立模 模型的 數字 字。且詞袋 袋沒有考量 量的單字 字與單字之 之間的順序 序,因而降 降低了複雜 雜度。 LDA A 假設每一 一個文件 件是由數個 個主題所構 構成的概率 率分佈,而 而每一個主 主題又 是由 由數個單字 字所構成的 的概率分佈 佈。 LDA 的 核 心 是 觀 點 模 式 (aspectt model) , 它 是 針 對 一 般 共 現 (co-occurrencce)資料所 所提出的一 一個潛變數 數(latent vaariable)模 模式,用以對 對應每 一個 個觀察值(以 以本研究 究來說,也 也就是每一 一個字詞 w∈W={w w1, …, wM}在一 篇文 文章 d∈D= ={d1,…,dN}的每一 一個出現)至 至一個無法 法觀察到 到的類別變 變數 z∈ Z={z1, …, zk}。以產生 生式模式而 而言,LD DA 可以被 被定義為: :以 Pr(d)的 的機率 9.
(20) 選取 取一篇文章 章 d,以 Pr(z|d)的機 P 機率挑選一 一個觀點 z,並以 P Pr(w|z)的機 機率產 生一 一個字詞 w。 w 對 於 語 料 庫 的 每 篇 文 件 , Blei et al.(2003 3) 定 義 L LDA 生 成 過 程 (gennerative prrocess): 1. 對每一 一篇文件 件的主題分 分佈,抽取 取其中一個 個主題。 2. 在上述 述過程所 所抽到主題 題所對應的 的單字分析 析抽出其中 中一個單字 字 3. 重複以 以上過程 程,直到抽 抽到文件的 的每一個單 單字。. 圖 1 LDA 的生成模型 的 型 以圖 1 來說明,當 來 當 i∈{1,...,M},θi 是文件 i 的主題分 的 分佈,ϕk 是主題 是 k 的單 單字分佈,α是在每 每一篇文 文件的主題 題的事前狄 狄利克參數 數,β是在 在每一 篇主 主題的單字 字分佈的事 事前狄利克 克參數,ziji 是在文件 件 i 的第 j 個 個單字的主 主題, 和而 而 wij 是代 代表特某一 一殊單字。詞彙表(v vocabulary y)是由語料 料庫的所有 有文件 的所 所有互異單 單字所組成 成,但實際 際建立模 模型時需要 要移除停用 用字(stop words) 和進 進行字根還 還原(stemm ming)等相 相關處理。 。θ和 ϕ 分別有一個 分 個帶有α和 和β的 Dirichlet 參數 數。對 M 篇文件中 中的每一個 個單字中,從該文件 件所對應的 的θ抽 10.
(21) 出一個主題 Z,然後再從主題 Z 中所對應的 ϕ 抽出一個單字 W,將上述 過程重複 N 次,就產生了一篇文件,而 N 指的是文件的單字總數。 LDA 是一個生產模式,它試圖描繪文件是如何組成的。Murray (2009) 提到它是概率模型是因為文件的建立是從原始文件的概率代表來選擇主 題和單字。建模的內在概率每一個單字的選擇源自於以下的事實:自然 語言允許我們使用不同的字來表達相同的想法。要將此想法表達在 LDA 模式之下,設想有一主題分佈,我們欲從文件集產生一個文件。那麼, 針對文件的每一個要被產生的詞彙,會從主題的 Dirichlet 分佈抽取一個 主題。而從該主題中,一個字會由該主題的另一個條件機率分佈隨機選 取出來。這個過程會一直重複直到文件被產生為止。 過去提出 LDA 的摘要有 Campr et al. (2013)、Liu et al.(2014)和 Annamalai et al.(2014),但仍屬多文件摘要的範疇。Campr et al. (2013)提 出以 LDA 多文件摘要結果與利用潛在語義分析方法的摘要進行比較。Liu et al.(2014)則是提出將輸入文件進行分群(clustering),是能提昇文件摘要 的品質。Annamalai et al.(2014)則是提出主題敏感度的演算法,藉由 LDA 區分主題的不同,並加權到句子上的權重值。 Murray(2009)對文件集詞彙進行文件預處理而得到了頻率的量測之 後,再應用到 LDA 的推論演算法,進而得到潛藏變數後,依據 Zipfian 分佈對主題中的文件建立模式。個別的字詞是對該主題的相關性進行計 11.
(22) 分,在句子中所有的詞彙分數加總所得到分數就是為句子分數,將這些 句子依分數排列,排名為前 k 句為摘要。Murray(2009)的實驗資料來自於 英文維基,維基所提供的資料集過大,有 21GB 之多,針對這些文件時 會移除非 Ascii 字元、圖片,再移除章節標題、超連結和無用資訊等,最 後得到了一千篇文件,但這些文件載入記憶體需要到 1GB 的空間容量, 但不幸的是當他用 LDA 跑文件集時,電腦無法處理 1GB 文件讀與寫, 因此,他將文件集分為十份來進行 LDA 運算。在這十份文件集中,解析 每一個詞彙並將字母轉換成小寫,並利用停用字表過濾不重要的詞彙。 然後,在詞彙列表中的每一個詞彙會計算在每一份文件的所出現頻率並 儲存為向量,接著結合所有的向量來形成 LDA 中的矩陣 A,再將 A 輸入 Blei(2003)所維護的 LDA-C 程式。設定每份文件集參數 K(主題數目)為 50, 將 α設為 1/K(約 0.02),誤差等級(tolerance)設為 10-6 和最大迭代次數為 50。在推論出潛藏變數之後,Murray(2009)使用有包含 python script 的 LDA 程式,將 100 詞彙匹配到 50 主題中。由於有 10 個文件集也就是 10 詞彙 檔案,作者將它們結合為一個大的詞彙檔案,透過這個大的詞彙檔案可 以估計推論原始文件集。決定好整合檔案的主題之後,再依據句子和主 題的相關性來排列句子,再進行一次語文過濾器的預處理(去除標點符號、 轉換小寫和移除停用字),相對於 Blei(2003)所提到的卜瓦松分佈(Poisson distribution (ξ)),Murray(2009) 假設在主題中的詞彙是依據 Zipfian 分佈, 12.
(23) 將詞彙頻率排列名次,詞彙頻率 f 與詞彙名次 r 是有相關的,Zipf 的法則 為: ∝. 1. 簡單來說,在主題列表中第一名的詞彙權重相當於第二名的詞彙權 重的兩倍,以此類推。演算法會找到列表中每一個詞彙的權重(可能為 0) 並加總,而每一句的句子的詞彙權重加總而得到句子的總分。而句子的 排列是根據句子分數並排名,選出前 K-1 句作為摘要。在 Murray 的專案 中,摘要的第一句是具有文章標題含意的。因為實驗資料來至於維基, 一般來說維基文章第一句是用來解釋文章標題。即使 K 值非常小,在 Murray 的系統所使用的加權方法,仍然會選擇文章的第一句,因為第一 句至少詳述一個主題,所以會有較高的排名,但這使得系統不夠彈性(可 能會不適於其他文件集)。 張明慧等人(2011)提出的 LDA 摘要法,是先將傳統自動文件摘要的 方式來計算文件中句子的權重值,接著結合 LDA 的概念,不僅將文件視 為主題的混合,也把句子視為主題的混合,接著用一個 K 維的向量來代 表主題的混合比例。張明慧等人(2011)認為句子和文件各自的主題的相似 度越高,作為摘要的句子的可能性也就越高,兩者的主題分佈越相似, 其句子的 LDA 特徵值也就越高,將特徵值加入先前權重值以計算一個句 子的權重,藉此判斷作為摘要的句子。提出 KL 離散度公式來計算句子與 13.
(24) 主題分佈向量和文件與主題的分佈向量之間的離散度: D. ∑. P∥Q. log. (1). 為了能計算上述公式,則需要句子和文件的主題分佈向量, LDA 模 型的θd 可獲得文件 d 在主題的分佈 P(T|D),而句子的主題分佈根據貝 式定理獲得 P(T|S),如下表示: |. P T|S. (2). 句子是詞彙所組成的,主題在句子上的分佈 P(S|T)可以從主題在詞彙 上的分佈 P(W|T)所得到,張明慧等人(2011)參考了 Arora et al. (2008)的算 法: P S|T. ∑. |. ∈. |. (3). 而主題在文件上的分佈根據貝式定理獲得 P(D|T),再將(3)和 P(D|T) 代入(2)中,句子主題混合可以表示成: P S|T. ∑. ∈. |. |. (4). 張明慧等人(2011)為了計算簡單,便假設所有的文件是等概率,也同 樣假設所有的句子是等概率,這樣在句子和文件的概率在計算 P(T|S)的時 候沒有影響,所以句子在主題分佈修改為: P S|T. ∑. ∈. |. |. (5). 由於在計算句子在主題的分佈時,使用單字概率的累加,容易使結 果選擇較長的句子,所以修改為單字概率累加的平均,公式變化為: 14.
(25) ∑. P S|T. |. ∈. |. (6). 將 P(T|S S)和 P(T|D D)代入(1))計算句子 子的主題特 特徵距離 ,計算句子 子主題 分佈 佈相似度特 特徵公式為 為: f. S. λ. D. P T|S ∥ P T|D (7). 其中λ取 取-1,其特 特徵值為 L LDA 的特 特徵值。. 2.5. 三元組(T Triplet). 所謂的三 三元組是句 句子的主詞 詞、動詞以 以及受詞 詞。本論文 文參考 Russu et al. (20008)所提的 的方法來獲 獲取句子的 的三元組。我們假 假設句子(S S)已經被表 表示為 剖析 析樹,其中 中包含三個 個子樹:名 名詞片語((NP)、動詞 詞片語(V VP)、及句號 號(.)。 首先,句 句子的主詞 詞是透過 過搜尋名詞 詞片語(NP P)的子樹來 來獲得的。這通 常是 是透過寬度 度優先搜尋 尋法(breatth-first seaarch)來獲 獲得。由選擇 擇 NP 的第 第一個 是名 名詞的子樹 樹來作為主 主詞。名詞 詞可以在 在以下的四 四個子樹中 中獲得: Subttree. The typ pe of nounn found. NN. noun, common, c ssingular orr mass. NNP P. noun, proper, p sinngular. NNP PS. noun, proper, p pluural. NNS S. noun, common, c pplural. 其次,動詞是藉由 動 由搜尋 VP 子樹來獲 獲得的。所要 要搜尋的 的是動詞片 片語(VP). 15.
(26) 最深的動詞子代,它是本論文要搜尋的真正動詞。動詞可以在以下的子 樹中獲得: Subtree. The type of noun found. VB. verb, base form. VBD. verb, past tense. VBG. verb, present participle or gerund. VBN. verb, past participle. VBP. verb, present tense, not 3rd person singular. VBZ. verb, present tense, 3rd person singular 最後,受詞是由搜尋三個不同的子樹來獲得。這三個子樹是由上一. 步驟所獲得(包含真正動詞)的動詞片語(VP)子樹的兄弟姊妹(sibling)所獲 得。這三個子樹包括:介系詞片語(PP)、名詞片語(NP)及形容詞片語(ADJP)。 在 NP、PP 中是搜尋第一個名詞,而在 ADJP 是搜尋第一個形容詞。形容 詞是下列子樹中獲得: Subtree. The type of noun found. JJ. adjective or numeral, ordinal. JJR. adjective, comparative. JJS. adjective, superlative 現時有許多工具可剖析出研究所需的剖析樹,如:史丹佛句子剖析. 器(stanford-parser)、OpenNLP Parse Tree、LINK PARSER 等等,本論文在 後續章節將提到利用史丹佛句子剖析器來剖析,進而得到三元組。. 16.
(27) 3. 研 研究方法 法. 本論文流 流程為:((1)預處理 理:文字稿 稿讀入,移 移除停用字 字並重整句 句子, 並匯 匯出 LDA 工具所需 工 需的資料檔 檔和句子檔 檔案,接著 著針對句子 子檔案進行 行剖析, 使用 用史丹佛句 句子剖析 析器剖析出 出三元組資 資料。(2))處理:使 使用 LDA A 工具 JGibbbLDA 和 Matlab Topic T Moddeling Too olbox 得到 到每一個主 主題的概率 率和該 主題 題下的字的 的概率,藉 藉由各位置 置的字詞在 在 LDA 中所獲得的 中 的概率值加 加總得 到權 權重值進來 來排序。(3 3) 摘要輸 輸出與評估 估:由指定 定的摘要比 比例來獲得 得摘要 的句 句子數。所 所得到摘要 要和課程 程投影片進 進行比對,匯出比對 對資料。程 程式流 程圖 圖如圖 2: : 預處理. 處理 處. 摘要 要輸出與評 評估. 讀 讀入文字稿 稿. 排序 序句子. 產 產生摘要 要. 句子 子資料輸出 出. 主題字 字詞表. 摘 摘要輸出 出. 資 資料剖析. 以 LDA 抽取主題 抽. 投 投影片比對 對. 圖 2. 系統流 流程圖. 17.
(28) 3.1. 預處理. 將文字稿 稿載入,利 利用史丹 丹佛自然語 語言處理器 器先將句子 子重新整理 理。文 字稿 稿的句子常 常會因文字 字排版關 關係在不正 正確的位置 置做切割 ,為方便摘 摘要的 擷取 取,本論文 文使用史丹 丹佛自然 然語言工具 具為句子進 進行斷句 。例如某一 一文字 稿原 原內容為: : So. G Given thiss data, let''s say you have a friennd who ow wns a housse that is, say 750 squaare feet annd hoping to sell thee house and they wantt to know how h muchh they can get ffor the houuse. 在利 利用史丹佛 佛自然語言 言處理器將 將句子重 重新組合成 成完整的句 句子後如下 下: So. Giveen this datta, let's sa ay you havve a friend d who own ns a housee that is, say s 750 squaare feet annd hoping to sell thee house an nd they wa ant to know w how mu uch they can get for thee house. 可看到「So.」被 被獨立成一 一句,這是 是因為史丹 丹佛自然語 語言處理器 器判定 So 後 後的句號比 比較可能 能是句子的 的結束,因此 此判定它 它為一個句 句子。雖說如 如此, 本論 論文論文認 認為一個句 句子至少應 應由三個 個單字組成 成,且句子 子的字元數 數最少 要大 大於 15 個字元數, 個 如此才可 可能含有充 充份的語意 意。因此當 當句子少於 於三個 字或 或小於 15 個字元我 我們便將下 下方的句子 子結合至目 目前的句子 子。以這樣 樣的規 則去 去把從史丹 丹佛自然語 語言處理 理器所得到 到的句子再 再一次重新 新組合新的 的句子, 18.
(29) 藉此取得更完整的句子。這些處理後的句子會被記錄,以供後續摘要句 子的擷取。上述句子經由處理之後的結果如下: So . Given this data , let 's say you have a friend who owns a house that is , say 750 square feet and hoping to sell the house and they want to know how much they can get for the house . 由於 LDA 分析的對象是文件中出現的字詞,因此我們進一步將句子 轉成字詞。這其中包括移除標點符號、將字元轉成小寫及移除停用字。 這些動作可以有效的減少字詞的數量,協助獲取文件的重要概念。. 3.1.1. 資料剖析 三 元 組 (Triplet) 是 由 三 個 元 素 所 組 成 : 主 詞 - 述 語 - 受 詞 (subject-predicate-object)。要如何取得三元組,本論文使用史丹佛句子 剖析器(stanford-parser)來獲取,例如將下列句子放入句子剖析器: I saw a girl who is in red cloth. 經 由 剖 析 器 可 取 得 剖 析 樹 及 史 丹 佛 型 態 相 依 表 示 法 (Stanford Dependencies representation),本論文藉由這兩者來取得三元組。剖析器可 依使用者的需求輸出文字或圖片的剖析樹,以下為上方句子的出文字剖 析樹:. 19.
(30) (ROOT [62.714] (S [62.561] (NP [3.898] (PRP I)) (VP [57.528] (VBD saw) (NP [47.461] (NP [12.838] (DT a) (NN girl)) (SBAR [32.322] (WHNP [1.874] (WP who)) (S [29.998] (VP [29.721] (VBZ is) (PP [23.545] (IN in) (NP [21.320] (JJ red) (NN cloth)))))))) (. .))) 若用史丹佛句子剖析器所提供的程式可得到圖的剖析樹,見圖 3:. 20.
(31) 圖 3 圖片剖 剖析樹 下列文字則 則是史丹佛 佛型態相依 依表示法: nsubj(saw w-2, I-1) root(ROO OT-0, saw w-2) det(girl-44, a-3) dobj(saw w-2, girl-4)) nsubj(is--6, girl-4) rcmod(giirl-4, is-6)) amod(clooth-9, red--8) prep_in(iis-6, cloth h-9). 21.
(32) 3.1.2. 三元組輸出. de Marneffe and Manning (2008)解釋了史丹佛型態相依表示法,如: nsubj(saw-2, I-1) nsubj 指的是括號中的兩個單字的關係,其中 nsubj 指的關係為一般主詞 (nominal subject),也就是括號中的單字 saw 和 I 的關係為一般主詞,而 單字後的數字是指該單字的節點位置。 本論文藉由解析史丹佛型態相依表示法來篩選所需要的三元組,與 主詞有關的表示法為 nsubj 和 csubj(clausal subject),在句子「I saw a girl who is in red cloth.」中所提供的關係: nsubj(saw-2, I-1) nsubj(is-6, girl-4) 從這裡程式可以藉由解析該單字在剖析的詞性,如 I 為 PRP (Personal pronoun),而 saw 為 VBD(Verb),這兩種的組合為主詞和述語常見組合之 一,可用來篩選是否為三元組,藉由多種組合來篩選是否為三元組其中 之二。接下來與受詞有關的表示法有 dobj(direct object)、iobj(indirect object) 和 pobj (object of preposition),而範例句子所提供的相關關係有: dobj(saw-2, girl-4) dobj 為直接受詞,它是動詞的直接受詞。girl 詞性為 NN(Noun),當關係 為 dobj,其中一方單字為 NN,該 NN 為受詞。. 22.
(33) 在前一節 節提到的經 經由重整 整所獲得的 的句子資料 料,將每一 一句放入剖 剖析器 取得 得剖析樹及 及史丹佛型 型態相依 依表示法後 後,再依上 上述方來獲 獲取三元組 組。之 後儲 儲存每一句 句的三元組 組並輸出 出文字檔案 案,做為後 後續流程的 的使用。將 將三元 組的 的主詞-述語 語-受詞,每一位置 置的詞性來 來對應就是 是名詞-動 動詞-名詞,因此 本論 論文所獲取 取的動詞與 與名詞分別 別輸出為 為 LDA 所需 需要的檔案 案,進一步 步單獨 把動 動詞與名詞 詞進行 LD DA,各自 自取得潛藏 藏的主題。 。. 3.2. 處理. 本論文藉 藉由 LDA 工具取得 得所需潛藏 藏的主題,LDA 工具 具可設定所 所需要 的主 主題數,依 依對應的文 文字稿的 的主題需要 要而取得多 多個主題 。而在每一 一個主 題底 底下都有單 單字的分佈 佈,一篇文 文字稿包 包含多個單 單字,LDA A 工具會將 將文字 稿的 的單字逐一 一分配各個 個主題之 之下,而每 每一個主題 題底下單字 字各自都有 有概率 值,例如其中 中一主題及 及底下的單 單字和概 概率: Topic 1 mod del. 0 0.055044. docu ument 0.030312 0 sd. 0 0.027159. scorre. 0 0.025220. 以 modeel 來說,是 是屬於 Toopic1 之中 中的單字且 且概率值為 為最高的。由此 我們 們可取得從 從各主題底 底下單字概 概率排行 行。所以可 可將概率值 值作為權重 重值。 23.
(34) 接著藉由每一主題底下的單字,去尋找有含該單字的句子,將其中 所含單字的概率加總來為作為該句子的權重值,但主題字詞表是統一的, 為突顯個別文字稿的差異,本論文加入了關係詞來微調句子權重值,而 所選取的關係詞必須與該文字稿相關,本論文以文字稿的章節標題作為 該文字稿的關係詞,每一份文字稿都有屬於自己的關係詞。接著加入提 示詞(Cue phrase)來近一步微調權重值。提示詞不如關鍵字那麼重要,但 往往能達到提示的作用如: 「for example」、「the purpose of」等。由於含 有提示詞的句子可作為重要句子後補的機率較高,在權重值的設定上比 相關詞來得高,後續的實驗結果收錄在附錄並提到相關詞與提示詞的權 重值設定。藉由多個高權值加總所找到的句子,可作為放入候補句。 經由這樣的過程,所有主題底下都有候補句。要從候補句子選取摘 要句子的方式是:將主題的概率值排序,從最高概率的主題中選取最高 權重值的句子,接著再往第二高概率主題選取第一句,依序選完所有主 題的第一句之後,再重新的一輪從最高概率的第二句不停排下去,直到 所有的句子被選取為止。上一節所提到的三元組的資料,同樣是結合上 述作法,從每一句的三元組資料去比對各主題底下的單字,符合的單字 既是三元組元素也是潛藏主題的單字。後續如同所前方所述找到含有該 單字的句子,本論文認為既是三元組也具有高概率的單字,其句子更適 合作為摘要句。此這作法是提取句子的主詞(Subject)動詞(Verb)、受詞 24.
(35) (Objject),各取 取第一個 個字母來稱 稱呼。所以 以後續章節 節會稱為 S SVOLDA A。. 3.3. 摘要輸出 出與比對. 如 3.4 節所提,系 節 系統會依主 主題字詞表 表進而產生 生的摘要,每堂課程 程的每 一章 章的每一節 節都有各自 自的文字 字稿,我們 們的系統輸 輸出的摘要 要是以一個 個文字 稿為 為一個單位 位,針對內 內一個文 文字稿所有 有句子中所 所選出的重 重要句子來 來作為 摘要 要句子,因 因此一個課 課程的摘 摘要數量是 是對應的一 一個課堂的 的文字稿數 數量。 為評 評估系統所 所產生摘要 要,我們選 選擇與課 課程投影片 片進行比較 較。因為 MOOC M 為了 了能讓使用 用者容易理 理解課程 程內容,大 大部分的課 課程會以選 選擇播放投 投影片 並加 加以講解課 課程,因此 此文字稿 稿的內容與 與投影片息 息息相關 ,而投影片 片是將 課程 程重點擷取 取出來和收 收錄課程 程上重要的 的筆記,且 且以人工方 方式編寫,適合 與摘 摘要來進行 行比對,並 並且以一 一對一的方 方式進行比 比對,而所 所以對應投 投影片 也正 正是該節的 的上課用投 投影片,因 因此投影片 片檔案數量 量會與文字 字稿檔案相 相同。 為能 能公平比對 對,輸出摘 摘要時, 摘要的字 字詞數必須 須和投影片 片字詞數相 相近, 因此 此在輸出時 時會依投影 影字數詞來 來做為輸 輸出的依據 據。 測量方式 式為使用精 精確率(Prrecision)、召回率(R Recall)、F F1-Measurre 來評 估摘 摘要的優劣 劣。 AbstractW Word AbstracttSize. 精確 確率 Preccision. AbstractWordd 為系統所 所產生摘要 要是投影片 片內容的 的字數,Ab AbstractSizze 為摘 25.
(36) 要總字數。 召回率 Recall. AbstractWord SlideSize. SlideSize 為投影片總字數。 F1. Measure. 2. Precision Recall Precision Recall. 26.
(37) 4. 實 實驗與討 討論 4.1. 實驗資料 料集 為了測試 試本論文 文所提方法 法在文字 字稿摘要的 的效果,我 我們首先蒐 蒐集了 courrsera, 和 University U y of Waikaato 等課程 程平台所提 提供之資訊 訊領域相關 關的課 程文 文字稿、投 投影片、及 及影音檔 檔。其中影 影音檔純粹 粹僅供內容 容比對用,以釐 清文 文字稿中的 的錯誤或可 可能的誤解 解,本論文 文並未處理 理影音資訊 訊。表 1 與表 與 2 為本 本論文所下 下載的課程 程的相關資 資訊。 表 1. courrsera 課程 程文字稿資 資料 課程 程名稱. 單元 數 5. 課程長 長 度 6週. 總句數 數. 8. 8週. 7806. Un niversity oof 7 Melbourne M / Professo or Paascal Van Heentenryckk 16 Sttanford Unniversity/ Tiim Roughggarden. 9週. 13306. 6週. 12508. Un niversity oof London n 6 /D Dr Lorenzoo Cavallarro. 6週. 23565. Sttanford Unniversity/ Krristin Sainnani. 8週. 9395. 開課校系/教 開 教師. Webb Applicattion Archhitectures. Un niversity oof New Mexico M /Grreg Heeileman Beginning Gaame niversity oof Un Proggrammingg with Co olorado Syystem/ Drr. C# Tiim Disccrete Optiimization Algoorithms: Desiign and Anaalysis, Partt 1 Malicious Softtware and its Undderground Econnomy Twoo Sidees to Everyy Storry Writting in thee Scieences. 27. 8. 7908.
(38) Natuural Languuage Proccessing. Co olumbia U University// Michael M Coollin. 20. 10 週. 7540. Sociial Networrk Anaalysis. Un niversity oof Michigan/ M L Lada Ad damic Sttanford Unniversity/ Jeff Ullmann. 8. 9週. 4033. 23. 6週. 4780. Autoomata. 表 2 University U of Waikatto 課程文 文字稿資料 料 課程 程名稱. 開課校系/教 開 教師. Dataa Mining with w Wekka. Prrof Ian H. Witten/ Un niversity oof Waikato o. 單 元 課 程 長 總句數 數 數 度 9 11469 9週. 4.2. LDA 工具 具介紹. 為避免工 工具本身偏 偏差的執 執行結果,本論文探 探討了文獻 獻中最常被 被引用 的L LDA 工具 具:一者為 JGibbLD DA(以下簡 簡稱 jLDA),另一者 者為 Matlab b Topic Moddeling Toolbox(以下 下簡稱 mL LDA)。前 前者由 JAV AVA 開發 ,可直接修 修改執 行,後者由 MALTAB M 開發,但 但提供界面 面供 JAVA 呼叫。因 因此我們以 以 JAVA 撰寫 寫程式轉換 換文件成它 它所需要的 的格式接 接著透過 MALTAB M 所 所提供的界 界面呼 叫m mLDA 進行 行分析。我們進行 行 LDA 分析 析,而得 得到表 3: 表 3. 3 GibbLD DA 和 Mattlab Topic Modeling g Toolbox 比較表 系統 統語言 提供 供主題機率 率 提供 供字詞機率 率 輸入 入格式 秒數 數. JAVA A 有(存於.p 有 phi 檔) 有 文字檔 檔 10..83 秒(20 個主題) 13..13 秒(30 個主題) 28. TAB MALT 有 有 MAT 檔 11.86 秒(200 個主題) 11.77 秒(300 個主題).
(39) 備註. 提供多種 LDA 模型 http://psiexp.ss.uci.edu/rese http://jgibblda.sourceforge arch/programs_data/toolbo .net/ x.htm 提供三種模式選擇. 下載網址. 要進行 LDA 執行前,都需要將所得到的資料匯整成一或兩個檔,以 便於執行 LDA,其輸入格式如下: JGibbLDA 的資料檔只需一個,其要求為 [M] [document1] [document2] ... [documentM] M 為文件數量,[documentj]為第幾份件,同時[documentj]的組成是由 [wordi1] [wordi2] ... [wordiN],其中[wordij] (i=1..M, j=1..N),也就是第 i 個文 件的第 j 個單字。執行之後輸出資料的檔案如表 4:. 表 4. 輸出檔的內容 <model_name>.others <model_name>.phi. 為存放 LDA 模式的參數設定 文件包含「單字-主題」(word-topic)的概率, 也就是 p(wordw|topict) <model_name>.theta 文件包含「主題-文件」(topic-document)的概 率,也就是(topict|documentm) <model_name>.tassign 包含單字的主題分配訓練資料,每一行是文 件<wordij>:<topic of wordij>的列表的組成 Note:JGibbLDA 的主題編號是從 0 開始, 所以會出現 70:0 的組合,代表 ID 為 70 的單 字是分到 topic 0。 29.
(40) <moodel_file>.twords worddmap.txt. 該模型下 下,最優 優的 topN 單字其概率 單 率 單字和單 單字的 ID D. Matlab Topic T Mod deling Tooolbox 所需 需資料檔為 為兩個,執 執行 LDA 前,需 將資 資料轉換成 成M檔才行 行。資料 料檔可以分 分單字檔和 和位置檔 ,單字檔是 是儲存 文件 件所有的單 單字,而位 位置檔有特 特定的輸 輸入要求。如表 5: 表 5m mLDA 輸入 入檔內容 容 單 單字檔內容 容 applle. 位置 置檔內容 1 2 10 2 2 6 2 5 7……. basic com mputer ….. 上表 表的位置檔 檔內容:1 1 2 10 2 2 6,以三個 個數值為 為一個組:「在第一份 份文件 中,在單字檔 檔中第二個 個單字「bbasic」出現了 10 次」 次 ,後三 三個為: 「在 在第二 份文 文件中,在 在單字檔中 中第三個單 單字「com mputer」出現了 出 6次 次」 ,以此類 類推。. 4.3. 字詞數及 及主題數的 的決定. 建立 LD DA 主題模 模型時需設 設定 alphaa 與 beta 值,本論 值 論文依 LDA A 工具 的預 預設值,將 將 alpha 值設為 值 50//K(K 為主 主題數),b beta 值 0.001,而參數 數中的 主題 題數量的設 設定則是依 依據課程的 的章節進 進行設定。LDA 會依 依據亂數的 的設定 值會 會使得執行 行結果不只 只有一種 種解且有多 多種解。接 接著觀察在 在多個亂數 數種子 30.
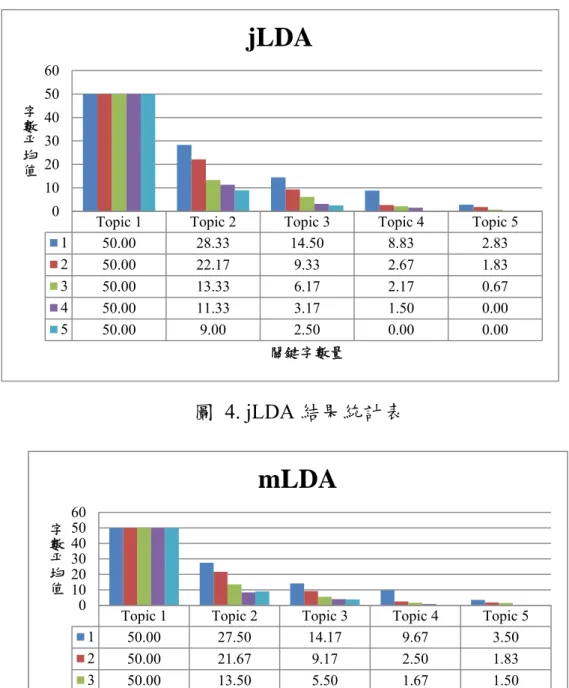
(41) 中所得到的 LDA 結果是否有相同解,使得分類結果更有明確性。首先針 對一般論文來進行實驗:抽取五份論文執行 LDA,其設定值為一至五個 主題和一至五個字詞,共計二十五個結果。隨機選取 50 個亂數種子,取 相同結果中最高值並且平均,結果如圖 4 和圖 5:. jLDA 60 字數平均值. 50 40 30 20 10 0. Topic 1 50.00 50.00 50.00 50.00 50.00. 1 2 3 4 5. Topic 2 28.33 22.17 13.33 11.33 9.00. Topic 3 14.50 9.33 6.17 3.17 2.50. Topic 4 8.83 2.67 2.17 1.50 0.00. Topic 5 2.83 1.83 0.67 0.00 0.00. 關鍵字數量. 圖 4. jLDA 結果統計表. mLDA 字數平均值. 60 50 40 30 20 10 0 1 2 3 4 5. Topic 1 50.00 50.00 50.00 50.00 50.00. Topic 2 27.50 21.67 13.50 8.33 9.00. Topic 3 14.17 9.17 5.50 4.00 3.83. Topic 4 9.67 2.50 1.67 0.83 0.33. 關鍵字數量. 圖 5. mLDA 結果統計表 31. Topic 5 3.50 1.83 1.50 0.00 0.00.
(42) 從結果表來看,主題數越多或是關鍵字數量越多其數值逐漸降低, 這是正常的結果。但我們可以從主題數的角度去觀察,觀察從一到五的 主題數的次數變化,在某一數主題數下,次數會急據下降,這也許代表 了該份論文適合的主題數量。從平均值來看,一份論文潛藏的主題數是 二到三個主題。. 為瞭解主題數和文件數對執行時間的影響,我們分別由固定文件數 來變化主題數,及固定主題數來變化件數來瞭解兩個工具的執行效率。 當設定的主題數越多,每一主題數下的字詞不盡相同,即使同一主題同 一字詞的概率值也有些微差異。說明了兩者工具在不同主題下,字詞分 佈是不盡相同的。 兩者執行時以前處理加上 LDA 工具執行時間進行計算,首先我們固 定文件數為 500 件和底下關鍵字設定 20 個單字,而針對主題數的變化來 看執行秒數,所得到的結果是執行十次進行平均的平均秒數,如圖 6。. 32.
(43) 70. 平均秒數. 60 50 40 30 20 10 0. jLDA. 5. 10. 20. 30. 40. 50. 12.650238 21.145441 30.193327 42.197125 48.961128 57.862169. mLDA 15.92654 19.641478 26.182953 36.471905 40.957176 41.036573. 主題數 圖 6. 主題數比較 如圖 6 所示,jLDA 在主題數 5~10 個平均秒數和 mLDA 相近,但隨 著主數題增加,秒數也隨之增加,這可以看出執行秒數值也會隨著主題 數增加而有所不同。當主題數越高,mLDA 執行速度會勝過於 jLDA。 接著,將主題數固定為 20,針對輸入文章數的不同測試秒數的差異, 以執行十次進行平均的平均秒數如圖 7。. 33.
(44) 45. 平均秒數. 40 35 30 25 20 15 10 5 0. jLDA. 100 0. 200. 300. 400. 500. 600. 2101 16.1662202 19.43756 64 27.973846 6 30.193327 41.704631 7.5402. m mLDA 9.7857 7185 13.9728806 15.09857 71 23.017563 3 26.182953 35.032169. 文件數 文 圖 7. 文件 件數比較 隨著文件 件數的變化 化,在會發 發現 mLD DA 執行平 平均秒數逐 數逐漸勝於 於 jLDA 的平 平均秒數,但一開始 始的 100~2200 份的文 文件上是 jLDA j 表現 現上會比 mLDA 好。 。這可以說 說明 mLD DA 較適合 合執大量文 文件的 LD DA。. 4.4. 實驗說明 明. 本論文的 的摘要種類 類有:由 jLDA 和 mLDA 的主題字詞 的 詞表所產生 生的命 名為 為 JGibbLD DA 和 MaatlabLDA A,動詞和 和名詞的 jL LDA 和 m mLDA 的主 主題字 詞表 表所產生的 的命名為 JGibbLDA J A_noun、MatlabLD M DA_noun、JGibbLDA A_verb、 MattlabLDA_vverb 以 及 SVOL LDA 所 產 生 的 命 名 為 SV VOJGibbL LDA 、 SVO OMatlabLDA。最後 後為曾士昌 昌(2011)所 所提供的 plsa p 程式所 所產生的摘 摘要簡 稱為 為 pLSA。共計九種 種種類。 34.
(45) 4.5. LDA 摘要 要 為能評估 估 LDA 摘要的是否 摘 否有達到標 標準,本論 論文設定 Baseline 作為最 作 低依 依據, 將文 文字稿視 視為摘要直 直接與投影 影片直接進 進行比對進 進而得到精 精確率、 召回 回率和 F1--Measure。 精確率 率 Precisio on. 召回率 率 Recall F F1. 文字 字稿單字與 與投影片單 單字中相 相同的單字 字 文字稿的總 文 總字詞數 文字稿 稿單字與 與投影片單 單字中相同 同的單字 投影 影片的總字 字詞數 2. Meassure Baseeline. Precission Reecall Precision Recaall. 將得 得到的 F1--Measure 做為本研 研究的 Basseline 值。 。 實驗集依 依課程類型 型加以分類 類可分為 為三種: Com mputer Sciience: Sofftware Enggineering Com mputer Sciience: Theeory Hum manities:B Biology & Life Sciennces 以下 下將在此三 三種分類各 各挑出一堂 堂課程,再以說 明。 明. 以 Courssera 的「W Writing inn the Scien nces」的第 第一章為例 例,該章節 節說明 到何 何謂是一篇 篇好的文章 章,又說 說明該怎麼 麼寫出好的 的文章的概 概念,並提 提出即 使是 是一篇科學 學學術論文 文,文章 章句子還是 是必須清晰 晰明理讓讀 讀更能理解 解作者 所要 要表達的含 含意。該章 章節為 388 個句子,本論文藉 藉由 LDA A 的結果所 所抽取 的句 句子為 12 句,摘要 要的 12 句 句是為了與 與本章節投 投影片進行 行比對,而 而兩者 的總 總字詞必須 須相近。本 本論文擷取 取了 JGib bbLDA 摘要的前 摘 1 2 句如下: 35.
(46) Writing in the Sciences 第一章第一節 摘要: Because the whole point of scientific writing is to get your ideas across , get your results across to other scientists , to policy makers . Right ? And I think what actually happens when a lot of people sit down to write is they 're worried about , about two up there . So I really want you to in this question keep your focus on that . The main point of writing is to get your idea across clearly and effectively . And I think a lot of things get associated with good writers . So , I think a lot of people think that in order to be a good writer , you 've got to have some sort of inborn talent . And once you 've learned them it 'll be a lot easier for you to write in a clear and effective and effecient way . Another thing I hear from a lot of students is , I can only write when I 'm inspired . Also in this course I 'm going to try to give you a lot of tips to help make your writing easier . There are a lot of ways that you can ease the writing process . So , a lot of scientists do n't spend enough time on revisioning . It will really improve your writing . We 're going to talk a lot about cutting clutter from your work at this first week of the course . 而比對用投影片擷取了 15 句內容如下: Writing in the Sciences 第一章第一節 投影片 1 Writing in the Sciences. Unit 1 : Introduction ; principles of effective 36.
(47) writing 2 Writing in the Sciences Module 1.1 : Introduction 3 1.1 Introduction What makes good writing ? 1 . Good writing communicates an idea clearly and effectively . 2 . Good writing is elegant and stylish . Takes time , revision , and a good editor ! Takes having something to say and clear thinking . 4 What makes a good writer ? Inborn talent ? Years of English and humanities classes ? An artistic nature ? The influence of alcohol and drugs ? Divine inspiration ? 1.1 Introduction 5 What makes a good writer : Having something to say . Logical thinking . A few simple , learnable rules of style ( the tools you 'll learn in this class ) . Take-home message : Good writing can be learned ! 1.1 Introduction 6 In addition to taking this class , other things you can do to become a better writer : Read , pay attention , and imitate . Write in a journal . Let go of `` academic '' writing habits ( deprogramming step ! ) Talk about your research before trying to write about it . Write to engage your readers -- try not to bore them ! Stop waiting for `` inspiration . '' Accept that writing is hard for everyone . 37.
(48) Revise . Nobody gets it perfect on the first try . Learn how to cut ruthlessly . 如 3.3 節所提,所產生的摘要與相對應的投影片進行比對,進而得到數據。 所得到比對的數據如表 6: 表 6 Writing in the Sciences 的比較數據 FileName 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 26 27 28. Precision 0.054441 0.177931 0.141611 0.173649 0.169978 0.163342 0.108839 0.102933 0.254545 0.170813 0.114879 0.18346 0.139004 0.117103 0.114804 0.189662 0.291753 0.078862 0.234195 0.026827 0.036505 0.250992 0.116461 0.111881 0.084204 0.239849 0.156056. Baseline Recall 0.703704 0.678947 0.565684 0.772932 0.729858 0.74221 0.723684 0.66791 0.724919 0.704274 0.85567 0.721495 0.773308 0.880309 0.692483 0.672304 0.638833 0.659864 0.570728 0.508772 0.725714 0.857627 0.776119 0.590078 0.323339 0.64358 0.400491. F1 0.101064 0.281967 0.226516 0.283586 0.275739 0.267757 0.18922 0.178376 0.376787 0.274942 0.202563 0.292535 0.235649 0.206709 0.196955 0.29586 0.400568 0.140886 0.332111 0.050967 0.069513 0.388335 0.202532 0.188098 0.133612 0.349461 0.224595 38. Precision 0.276923 0.437173 0.31016 0.455604 0.375 0.5 0.331878 0.408922 0.510511 0.390863 0.438619 0.452465 0.46051 0.356322 0.393574 0.37656 0.413981 0.31348 0.405817 0.158333 0.243243 0.522364 0.371528 0.288288 0.233939 0.448142 0.288783. PLSA Recall 0.333333 0.439474 0.310992 0.470677 0.383886 0.515581 0.333333 0.410448 0.550162 0.394872 0.44201 0.480374 0.461686 0.359073 0.446469 0.382664 0.42002 0.340136 0.410364 0.166667 0.257143 0.554237 0.399254 0.292428 0.234603 0.450584 0.297297. F1 0.302521 0.43832 0.310576 0.463018 0.379391 0.507671 0.332604 0.409683 0.529595 0.392857 0.440308 0.466002 0.461097 0.357692 0.418356 0.379588 0.416979 0.326264 0.408078 0.162393 0.25 0.537829 0.384892 0.290343 0.234271 0.44936 0.292978.
(49) 29 30 31 32 33 34 39 40 41 42 43 44 45 46 48 49 50 平均值 FileName 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16. 0.443393 0.279779 0.106635 0.130315 0.077986 0.056951 0.137689 0.175412 0.123511 0.143638 0.072994 0.079277 0.137985 0.109864 0.093715 0.082887 0.101313. 0.431379 0.606322 0.546559 0.766194 0.696035 0.701031 0.61206 0.608929 0.737828 0.7225 0.635496 0.656682 0.749147 0.78481 0.827655 0.868984 0.369863. 0.437304 0.382882 0.178453 0.222745 0.140257 0.105345 0.224806 0.272364 0.2116 0.239635 0.130948 0.141474 0.233046 0.192746 0.168365 0.151339 0.159057. 0.437146 0.459071 0.286275 0.473259 0.276316 0.275748 0.318271 0.313725 0.337931 0.354988 0.278195 0.306488 0.443886 0.287212 0.341085 0.334204 0.204082. 0.437223 0.459291 0.295547 0.474696 0.277533 0.285223 0.325628 0.342857 0.367041 0.3825 0.282443 0.315668 0.452218 0.28903 0.352705 0.342246 0.205479. 0.437185 0.459181 0.290837 0.473977 0.276923 0.280405 0.321908 0.327645 0.351885 0.368231 0.280303 0.31101 0.448014 0.288118 0.346798 0.338177 0.204778. 0.144498 0.673325 0.226347 0.361156 0.373298 0.367001 Precision 0.326087 0.274809 0.226316 0.403587 0.228448 0.370879 0.303879 0.367742 0.396825 0.319605 0.342604 0.414179 0.380407 0.334615 0.259091 0.33637. JGibbLDA Recall 0.347222 0.284211 0.230563 0.406015 0.251185 0.382436 0.309211 0.425373 0.404531 0.331624 0.349227 0.414953 0.381865 0.335907 0.259681 0.338266. F1 0.336323 0.279431 0.22842 0.404798 0.239278 0.376569 0.306522 0.394464 0.400641 0.325503 0.345884 0.414566 0.381134 0.33526 0.259386 0.337316 39. MatlabLDA Precision Recall F1 0.326087 0.347222 0.336323 0.274809 0.284211 0.279431 0.226316 0.230563 0.22842 0.394775 0.409023 0.401773 0.228448 0.251185 0.239278 0.351351 0.368272 0.359613 0.303879 0.309211 0.306522 0.367742 0.425373 0.394464 0.396825 0.404531 0.400641 0.319605 0.331624 0.325503 0.342604 0.349227 0.345884 0.38674 0.392523 0.38961 0.380407 0.381865 0.381134 0.334615 0.335907 0.33526 0.259091 0.259681 0.259386 0.33637 0.338266 0.337316.
(50) 17 18 19 20 21 22 23 24 26 27 28 29 30 31 32 33 34 39 40 41 42 43 44 45 46 48 49 50 平均值. 0.409433 0.285714 0.309408 0.214876 0.222222 0.458401 0.34629 0.260816 0.222445 0.339286 0.248815 0.443393 0.440437 0.273267 0.380665 0.268398 0.281356 0.359719 0.33101 0.404181 0.370647 0.266667 0.268966 0.419784 0.324597 0.363118 0.314961 0.222973. 0.410463 0.306122 0.310924 0.22807 0.24 0.476271 0.365672 0.275457 0.224878 0.340078 0.257985 0.431379 0.444444 0.279352 0.382591 0.273128 0.285223 0.360804 0.339286 0.434457 0.3725 0.267176 0.269585 0.430887 0.339662 0.382766 0.320856 0.226027. 0.409947 0.295567 0.310164 0.221277 0.230769 0.467165 0.355717 0.267937 0.223655 0.339681 0.253317 0.437304 0.442431 0.276276 0.381625 0.270742 0.283276 0.360261 0.335097 0.418773 0.371571 0.266921 0.269275 0.425263 0.331959 0.372683 0.317881 0.22449. 0.409433 0.28254 0.309408 0.214876 0.222222 0.442211 0.34629 0.264968 0.222445 0.336695 0.248815 0.443393 0.440437 0.273267 0.380665 0.268398 0.281356 0.359719 0.344948 0.404181 0.37296 0.266667 0.268966 0.419784 0.324597 0.363118 0.309278 0.222973. 0.410463 0.302721 0.310924 0.22807 0.24 0.447458 0.365672 0.27154 0.224878 0.337743 0.257985 0.431379 0.444444 0.279352 0.382591 0.273128 0.285223 0.360804 0.353571 0.434457 0.4 0.267176 0.269585 0.430887 0.339662 0.382766 0.320856 0.226027. 0.409947 0.292282 0.310164 0.221277 0.230769 0.444819 0.355717 0.268214 0.223655 0.337218 0.253317 0.437304 0.442431 0.276276 0.381625 0.270742 0.283276 0.360261 0.349206 0.418773 0.386007 0.266921 0.269275 0.425263 0.331959 0.372683 0.314961 0.22449. 0.325847 0.334734 0.330148 0.324415 0.334047 0.329077. JGibbLDA_noun FileName Precision Recall F1 1 0.262712 0.287037 0.274336 2 0.315789 0.315789 0.315789 3 0.323684 0.329759 0.326693 4 0.39291 0.4 0.396423 5 0.327801 0.374408 0.349558 40. MatlabLDA_noun Precision Recall F1 0.262712 0.287037 0.274336 0.315789 0.315789 0.315789 0.323684 0.329759 0.326693 0.39291 0.4 0.396423 0.326087 0.35545 0.340136.
(51) 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 26 27 28 29 30 31 32 33 34 39 40 41 42 43 44 45 46 48. 0.389356 0.326226 0.361486 0.493631 0.345118 0.419769 0.41527 0.416137 0.422642 0.280973 0.337999 0.37995 0.307443 0.345942 0.207792 0.197044 0.482471 0.40293 0.273177 0.215813 0.387244 0.285885 0.443393 0.436754 0.279297 0.381694 0.35 0.331058 0.315582 0.395722 0.457746 0.406542 0.265655 0.312073 0.443522 0.456033 0.413127. 0.393768 0.335526 0.399254 0.501618 0.350427 0.421392 0.416822 0.418263 0.432432 0.289294 0.340381 0.381288 0.323129 0.352241 0.280702 0.228571 0.489831 0.410448 0.288512 0.216775 0.396887 0.293612 0.431379 0.438218 0.289474 0.396761 0.370044 0.333333 0.321608 0.396429 0.486891 0.435 0.267176 0.315668 0.455631 0.470464 0.428858. 0.391549 0.330811 0.379433 0.497592 0.347752 0.420579 0.416045 0.417197 0.427481 0.285073 0.339185 0.380618 0.315091 0.349063 0.238806 0.21164 0.486123 0.406654 0.280635 0.216293 0.392006 0.289697 0.437304 0.437485 0.284294 0.389082 0.359743 0.332192 0.318566 0.396075 0.471869 0.42029 0.266413 0.31386 0.449495 0.463136 0.420846 41. 0.389356 0.326923 0.361486 0.488889 0.345118 0.419769 0.41527 0.416137 0.422642 0.280973 0.337999 0.37995 0.307443 0.345942 0.207792 0.197044 0.482471 0.40293 0.273177 0.215813 0.387244 0.285885 0.443393 0.437111 0.279297 0.381694 0.35 0.331058 0.315582 0.395722 0.457746 0.406542 0.265655 0.312073 0.443522 0.456612 0.413127. 0.393768 0.335526 0.399254 0.498382 0.350427 0.421392 0.416822 0.418263 0.432432 0.289294 0.340381 0.381288 0.323129 0.352241 0.280702 0.228571 0.489831 0.410448 0.288512 0.216775 0.396887 0.293612 0.431379 0.437739 0.289474 0.396761 0.370044 0.333333 0.321608 0.396429 0.486891 0.435 0.267176 0.315668 0.455631 0.466245 0.428858. 0.391549 0.331169 0.379433 0.49359 0.347752 0.420579 0.416045 0.417197 0.427481 0.285073 0.339185 0.380618 0.315091 0.349063 0.238806 0.21164 0.486123 0.406654 0.280635 0.216293 0.392006 0.289697 0.437304 0.437425 0.284294 0.389082 0.359743 0.332192 0.318566 0.396075 0.471869 0.42029 0.266413 0.31386 0.449495 0.461378 0.420846.
(52) 49 50. 0.348371 0.371658 0.359638 0.348371 0.371658 0.359638 0.143791 0.150685 0.147157 0.167785 0.171233 0.169492. 平均值. 0.352217 0.36426 0.357945 0.352653 0.364116 0.358114. JGibbLDA_verb FileName Precision Recall F1 1 0.285068 0.291667 0.28833 2 0.404199 0.405263 0.404731 3 0.32199 0.329759 0.325828 4 0.354745 0.365414 0.36 5 0.383562 0.398104 0.390698 6 0.335979 0.359773 0.347469 7 0.451754 0.451754 0.451754 8 0.36 0.369403 0.364641 9 0.446602 0.446602 0.446602 10 0.399329 0.406838 0.403048 11 0.388041 0.393041 0.390525 12 0.390597 0.403738 0.397059 13 0.415829 0.422733 0.419253 14 0.309859 0.339768 0.324125 15 0.241685 0.248292 0.244944 16 0.365035 0.367865 0.366444 17 0.331668 0.334004 0.332832 18 0.311037 0.316327 0.313659 19 0.332645 0.338235 0.335417 20 0.212329 0.27193 0.238462 21 0.231183 0.245714 0.238227 22 0.461794 0.471186 0.466443 23 0.319865 0.354478 0.336283 24 0.302597 0.304178 0.303385 26 0.22501 0.225284 0.225147 27 0.356313 0.357977 0.357143 28 0.284841 0.286241 0.285539 29 0.443393 0.431379 0.437304 30 0.409287 0.409483 0.409385 31 0.23301 0.242915 0.237859 32 0.387652 0.387652 0.387652 42. MatlabLDA_verb Precision Recall F1 0.285068 0.291667 0.28833 0.401575 0.402632 0.402102 0.32199 0.329759 0.325828 0.354745 0.365414 0.36 0.383562 0.398104 0.390698 0.335979 0.359773 0.347469 0.451754 0.451754 0.451754 0.36 0.369403 0.364641 0.446602 0.446602 0.446602 0.399329 0.406838 0.403048 0.388041 0.393041 0.390525 0.390597 0.403738 0.397059 0.415829 0.422733 0.419253 0.309859 0.339768 0.324125 0.241685 0.248292 0.244944 0.365035 0.367865 0.366444 0.329347 0.332495 0.330914 0.311037 0.316327 0.313659 0.332645 0.338235 0.335417 0.212329 0.27193 0.238462 0.231183 0.245714 0.238227 0.461794 0.471186 0.466443 0.319865 0.354478 0.336283 0.302597 0.304178 0.303385 0.22501 0.225284 0.225147 0.356313 0.357977 0.357143 0.284841 0.286241 0.285539 0.443393 0.431379 0.437304 0.409287 0.409483 0.409385 0.23301 0.242915 0.237859 0.387652 0.387652 0.387652.
(53) 33 34 39 40 41 42 43 44 45 46 48 49 50 平均值. 0.304167 0.282895 0.326673 0.34669 0.366337 0.36 0.278409 0.238411 0.453696 0.343096 0.379242 0.334225 0.169935. 0.321586 0.295533 0.328643 0.355357 0.41573 0.36 0.280534 0.248848 0.455631 0.345992 0.380762 0.334225 0.178082. 0.312634 0.289076 0.327655 0.35097 0.389474 0.36 0.279468 0.243517 0.454662 0.344538 0.38 0.334225 0.173913. 0.304167 0.276451 0.326673 0.34669 0.366337 0.36 0.278409 0.243534 0.453696 0.343096 0.379242 0.334225 0.169935. 0.321586 0.278351 0.328643 0.355357 0.41573 0.36 0.280534 0.260369 0.455631 0.345992 0.380762 0.334225 0.178082. 0.312634 0.277397 0.327655 0.35097 0.389474 0.36 0.279468 0.25167 0.454662 0.344538 0.38 0.334225 0.173913. 0.338197 0.347225 0.342507 0.338055 0.347003 0.342324. SVOJGibbLDA FileName Precision Recall F1 1 0.30531 0.319444 0.312217 2 0.369898 0.381579 0.375648 3 0.226913 0.230563 0.228723 4 0.390602 0.4 0.395245 5 0.269231 0.298578 0.283146 6 0.386059 0.407932 0.396694 7 0.343284 0.35307 0.348108 8 0.333333 0.347015 0.340037 9 0.536741 0.543689 0.540193 10 0.315789 0.328205 0.321878 11 0.39467 0.400773 0.397698 12 0.431734 0.437383 0.43454 13 0.393881 0.394636 0.394258 14 0.377163 0.420849 0.39781 15 0.242424 0.255125 0.248613 16 0.329648 0.336152 0.332868 17 0.407444 0.412978 0.410192 18 0.332268 0.353741 0.342669 19 0.353549 0.359244 0.356374 20 0.141667 0.149123 0.145299 43. SVOMatlabLDA Precision Recall F1 0.317972 0.319444 0.318707 0.398458 0.407895 0.403121 0.273458 0.273458 0.273458 0.416544 0.42406 0.420268 0.313364 0.322275 0.317757 0.408219 0.422096 0.415042 0.405702 0.405702 0.405702 0.313333 0.350746 0.330986 0.511111 0.521036 0.516026 0.416244 0.420513 0.418367 0.359356 0.373711 0.366393 0.426716 0.429907 0.428305 0.422419 0.425926 0.424165 0.498168 0.525097 0.511278 0.222462 0.234624 0.228381 0.352694 0.35518 0.353933 0.412826 0.414487 0.413655 0.309904 0.329932 0.319605 0.349616 0.35084 0.350227 0.2 0.201754 0.200873.
(54) 21 22 23 24 26 27 28 29 30 31 32 33 34 39 40 41 42 43 44 45 46 48 49 50 平均值. 0.25 0.44702 0.356364 0.290116 0.215292 0.409195 0.282767 0.443393 0.426806 0.302632 0.444995 0.327511 0.261146 0.343719 0.392361 0.385666 0.3725 0.266423 0.224176 0.430025 0.369835 0.358974 0.322078 0.202703. 0.285714 0.457627 0.365672 0.295039 0.216775 0.415564 0.286241 0.431379 0.430077 0.325911 0.454453 0.330396 0.281787 0.343719 0.403571 0.423221 0.3725 0.278626 0.235023 0.432594 0.377637 0.364729 0.331551 0.205479. 0.266667 0.452261 0.360958 0.292557 0.216031 0.412355 0.284493 0.437304 0.428435 0.31384 0.449675 0.328947 0.271074 0.343719 0.397887 0.403571 0.3725 0.272388 0.229471 0.431306 0.373695 0.361829 0.326746 0.204082. 0.19337 0.448276 0.34507 0.292249 0.211638 0.423664 0.299387 0.443393 0.429862 0.303327 0.428141 0.353712 0.302752 0.339512 0.374138 0.392727 0.410891 0.295802 0.292517 0.416058 0.377823 0.391813 0.379581 0.121212. 0.2 0.462712 0.365672 0.300261 0.215154 0.431907 0.299754 0.431379 0.43295 0.313765 0.431174 0.356828 0.340206 0.349749 0.3875 0.404494 0.415 0.295802 0.297235 0.437713 0.388186 0.402806 0.387701 0.136986. 0.196629 0.455379 0.355072 0.296201 0.213382 0.427746 0.29957 0.437304 0.431401 0.308458 0.429652 0.355263 0.320388 0.344554 0.380702 0.398524 0.412935 0.295802 0.294857 0.426611 0.382934 0.397233 0.383598 0.128617. 0.341075 0.351713 0.346227 0.354443 0.363491 0.358842. 從第一節來看,本論文所提的八種摘要法皆優於 Baseline,但動詞與 名詞的摘要法卻輸給了 pLSA,一般的 LDA 摘要與 SVOLDA 摘要稍微優 秀一些,但整個課程的平均值來看,所有的摘要皆輸給了 pLSA,從表 6 看出數節的數值拉滑了整個平均。但以確定的是在「Writing in the Sciences」 課程上,一般的 LDA 結果能比較適合輸出摘要。 44.
(55) 接著以「Automata」進行觀察,該課程與上一個課程不同處在於所 屬分不同,比較能區分不同領域我們的研究是否有所差異,該分類為: 「Computer Science: Theory」 。本次所選的章節為:第一章第一節「Course outline and motivation」 ,該節是簡單介紹 Automata 概論以及可以運用的 地方。該節約 121 行,藉由 LDA 的結果所抽取句子為 19 句,本論文擷 取了前 12 句如下: Automata 第一章第一節 摘要: This theory plays an important role in computer science . So computer science graduates naturally sided out in conducting programming courses as the one they used the most , No surprise here . They also have been used for decades to model electronic circuits , and in particular to help design good circuits . They have also been used to model protocols , and we 'll give some examples later in this course . Especially [ inaudible ] underlie the body of techniques known as model checking , Which has been used to verify the correctness of both communication protocols and large electronic circuits . There are fundamental limitations on our ability to compute . Mm-hm . One limitation is undecidability there are problems that can not be solved by computation . You ca n't do this . We 're going to prove that there is no way to tell whether a program will ever print a particular word Or even if it will 45.
(56) ever print anything at all . Often the trickiest parts of a program deal with trees , graphs , or other recursive structures . We 're also going to learn about a number of important abstractions : finite automata , regular expressions , context-free grammars , and varieties of pushdown automata and Turing machines . Some of the essential parts of this course are proving equivalences among the models , that is , any example of one model can be simulated by some instance of another model . Machines that can magically turn into many machines that each do something independently but with a coordinated effect . 課程投影片會盡量保留原樣,但同時也會包含少量程式及公式,擷取了 前 15 句: Automata 第一章第一節 投影片: Welcome to the Stanford. Automata Theory Course. Why Study. Automata ? What the Course is About 2 Why Study Automata ? A survey of Stanford grads 5 years out asked which of their courses did they use in their job . Basics like intro-programming took the top spots , of course . But among optional courses , CS154 stood remarkably high . X the score for AI , for example . 3 How Could That Be ? Regular expressions are used in many systems . 46.
數據



相關文件
and Dagtekin, I., “Mixed convection in two-sided lid-driven differentially heated square cavity,” International Journal of Heat and Mass Transfer, Vol.47, 2004, pp. M.,
In recent years, many of researches have already put forward various methods to detect R wave, for example, filter banks, artificial intelligence algorithms, Hidden Markov
The experimental results show that the developed light-on test methodology can effectively detect point defects (bright point, dark point, weak point), line defects (bright line,
近年來,國內積極發展彩色影像顯示器之產業,已有非常不錯的成果,其中 TFT-LCD 之生產研發已在國際間佔有舉足輕重的地位,以下針對 TFT-LCD 之生
There are Socket Dimensions Measurement, Actuation Force Measurement, Durability Test, Temperature Life Test, Solder Ball Deformation, Cycle Test, Contact Inductance &
This is why both enterprises and job-finding people need a more efficient human resource allocation channels, and human resources websites are becoming a new media between the
Keywords:Micro-array Biological Probes, E-Beam Evaporator, Active RFID, Laser Annealing, Bioelectric Impedance, Thin Film Transistor
In this study, we report the preparation of metal Zinc (Zn) and Zinc oxide (ZnO) nanoparticles using an evaporation/condensation aerosol process via horizontal tube furnace
