人工神经网络与神经网络优化算法
人工神经网络是近年来得到迅速发展的一 个前沿课题。神经网络由于其大规模并行 处理、容错性、自组织和自适应能力和联 想功能强等特点,已成为解决很多问题的 有力工具。首先对神经网络作简单介绍,
然后介绍几种常用的神经网络,包括前向
神经网络。
人工神经网络与神经网络优化算法
人工神经网络发展简史
最早的研究可以追溯到 20 世纪 40 年代。 1943 年,
心理学家 McCulloch 和数学家 Pitts 合作提出了形式 神经元的数学模型。这一模型一般被简称 M-P 神经网 络模型,至今仍在应用,可以说,人工神经网络的研 究时代,就由此开始了。
1949 年,心理学家 Hebb 提出神经系统的学习规则,
为神经网络的学习算法奠定了基础。现在,这个规则 被称为 Hebb 规则,许多人工神经网络的学习还遵循 这一规则。
人工神经网络与神经网络优化算法
1957 年 , F.Rosenblatt 提 出 “ 感 知 器” (Perceptron) 模型,第一次把神经网络的研 究从纯理论的探讨付诸工程实践,掀起了人工神 经网络研究的第一次高潮。
20 世纪 60 年代以后,数字计算机的发展达到全 盛时期,人们误以为数字计算机可以解决人工智 能、专家系统、模式识别问题,而放松了对“感知 器”的研究。于是,从 20 世纪 60 年代末期起,
人工神经网络的研究进入了低潮。
人工神经网络与神经网络优化算法
1982 年,美国加州工学院物理学家 Hopfield 提 出了离散的神经网络模型,标志着神经网络的研 究又进入了一个新高潮。 1984 年, Hopfield 又提出连续神经网络模型,开拓了计算机应用神 经网络的新途径。
1986 年, Rumelhart 和 Meclelland 提出多层 网络的误差反传 (back propagation) 学习算法
,简称 BP 算法。 BP 算法是目前最为重要、应
用最广的人工神经网络算法之一。
人工神经网络与神经网络优化算法
自 20 世纪 80 年代中期以来,世界上许多
国家掀起了神经网络的研究热潮,可以说
神经网络已成为国际上的一个研究热点。
生物神经网
1 、构成
胞体 (Soma) 枝 蔓 ( Dendrit
e )
胞体 (Soma)
轴突( Axon
)
突触( Synapse )
2 、工作过程
生物神经网
3 、六个基本特征:
1 )神经元及其联接;
2 )神经元之间的联接强度决定信号传递的强弱;
3 )神经元之间的联接强度是可以随训练改变的;
4 )信号可以是起刺激作用的,也可以是起抑制作 用的;
5 )一个神经元接受的信号的累积效果决定该神经 元的状态;
6) 每个神经元可以有一个“阈值”。
人工神经元
神经元是构成神经网络的最基本单元(构 件)。
人工神经元模型应该具有生物神经元的六
个基本特性。
人工神经元的基本构成
人工神经元模拟生物神经元的一阶特性。
输入: X= ( x1, x2 ,…, xn)
联接权: W= ( w1, w2,…, wn) T
网络输入: net=∑xi
w
i 向量形式: net=XW
xn wn
∑ x1 w1
x2 w2
net=XW
…
激活函数 (Activation Function)
激活函数——执行对该神经元所获得的网络输 入的变换,也可以称为激励函数、活化函数:
o=f ( net )
1 、线性函数( Liner Function )
f ( net ) =k*net+c
net o
o c
2 、非线性斜面函数 (Ramp Function)
γ if net≥θ
f ( net ) = k*net if |net|<θ
-γ if net≤-θ
γ>0 为一常数,被称为饱和值,为该神经
元的最大输出。
2 、非线性斜面函数( Ramp Function )
γ
-γ
θ
-θ net
o
3 、阈值函数( Threshold Function )阶跃函数
β if net>θ
f ( net ) =
-γ if net≤ θ
β 、 γ 、 θ 均为非负实数, θ 为阈值 二值形式:
1 if net>θ
f ( net ) =
0 if net≤ θ
双极形式:
1 if net>θ
f ( net ) =
-1 if net≤ θ
3 、阈值函数( Threshold Function )阶跃函数
β
-γ
θ o
0 net
4 、 S 形函数
压缩函数( Squashing Function )和逻辑斯特 函数( Logistic Function )。
f ( net ) =a+b/(1+exp(-d*net))
a , b , d 为常数。它的饱和值为 a 和 a+b 。 最简单形式为:
f ( net ) = 1/(1+exp(-d*net))
函数的饱和值为 0 和 1 。
4 、 S 形函数
a+b o
(0,c )
net
a c=a+b/2
2.2.3 M-P 模型
x2 w2
∑ f o=f ( net )
xn wn
…
net=XW x1 w1
McCulloch—Pitts ( M—P )模型
,也称为处理单元( PE )
2.3 人工神经网络的拓扑特性
连接的拓扑表示
AN
iw
ijAN
j10.1 人工神经网络与神经网络优化算法
10.1.2 人工神经元模型与人工神经网络模 型
人工神经元是一个多输入、单输出的非线 性元件,如图 10-1 所示。
其输入、输出关系可描述为
10.1 人工神经网络与神经网络优化算法
(10-1-1)
式中, 是从其它神经元传来的 输入信号; 是阈值; 表示从神经元到 神经元 的连接权值; 为传递函数。
1
(
j)
j
n
i ij i j
j
X f
y
x
X
) , ,
2 , 1
(
i nxi
j
iji
j
f(
)
10.1 人工神经网络与神经网络优化算法
yj θj
x0=1
∑ f
ωnj
x
1x
2. . . x
nω2j
ω1j
图 10-1
10.1 人工神经网络与神经网络优化算法
人工神经网络是由大量的神经元互连而成的网络
,按其拓扑结构来分,可以分成两大类:层次网 络模型和互连网络模型。层次网络模型是神经元 分成若干层顺序连接,在输入层上加上输入信息
,通过中间各层,加权后传递到输出层后输出,
其中有的在同一层中的各神经元相互之间有连接
,有的从输出层到输入层有反馈;互连网络模型 中,任意两个神经元之间都有相互连接的关系,
在连接中,有的神经元之间是双向的,有的是单
向的,按实际情况决定。
10.1 人工神经网络与神经网络优化算法
10.1.3 前向神经网络 (1) 多层前向网络
一个 M 层的多层前向网络可描述为:
① 网络包含一个输入层(定义为第 0 层)和 M-1 个隐层,最后一个隐层称为输出层;
② 第层包含 个神经元和一个阈值单元
(定义为每层的第 0 单元),输出层不含阈 值单元;
N
l10.1 人工神经网络与神经网络优化算法
③ 第 层第 个单元到第个单元的权值表为 ;
④ 第 层( >0 )第 个( >0 )神经元 的输入定义为 ,输出 定义为 ,其中 为隐单元激 励函数,常采用 Sigmoid 函数,即 。输入单元一般采用线性激励函数 ,阈值单元的输出始终为 1 ;
1
l i
l l
ij ,
1
l l j j
1 0
1 ,
l 1 N
i
l i l l
ij l
j y
x
) ( lj
l
j
f x
y
f(
)
)] 1
exp(
1 [ )
(x x f
x x
f ( )
10.1 人工神经网络与神经网络优化算法
⑤ 目标函数通常采用:
( 10-1-2 )
其中 P 为样本数, 为第 p 个样本的第 j 个输出分量。
Pp
N j
p j M
p j P
p
p
M
y t
E E
1 1
2 ,
1 , 1
1
( )
2 1
p
t
j,感知器网络
1 、感知器模型 2 、学习训练算法
3 、学习算法的收敛性
4 、例题
感知器神经元模型
感知器模型如图 Fig2.2.1 I/O 关系
图 2.2.1
0 0 1
0 1
{
y y n
i
i i
i
y
b p
w
y
单层感知器模型如图 2.2.2 定义加权系数
w
ij为第 i 个神经元到第 j 个神经元之间的连 接值
2 1 2
1
i
i n
in i
i
i
b
p p p w
w w
y
个个个
个
感知器神经网络模型
图2.2.2
图形解释
对 n=2 的情况
分平面为两部分
B WP
Y
b b b p
p p w
w w
w w
ww w w y
y y
n mn n
m m
n n
n
向量形式:
矩阵形式:
2
1 2
1
2 1
2 22
21
1 12
11 2
1
为一条直线
b p
w p
w
y 1 1 2 2
图形解释
由直线 W*P+b=0 将由输入矢量 P
1和 P
2组
成的平面分为两个区域,直线上部的输入
矢量使阀值函数的输入大于 0 ,所以使感
知器神经元的输出为 1 ;直线下部的输入
矢量使感知器神经元的输出为 0 。分割线
可以根据所选的权值和偏差上下左右移动
到期望划分输入平面的地方。
学习训练算法
learnp
) ( )
( )
(
) ( )
( )
1 (
) ( )
( )
1 (
B
W
p p
p P
1 or 0 t
t t
t T
0
n 2
1
i m
2 1
函数为 相应的
学习规则类 该算法属于
则
偏差 初始加权阵
输入向量 设有教师向量
Matlab
K Y K
T K
E
K E K
B K
B
X K E k
W k
W T
T T
Matlab 调用
该函数的调用命令为:
[dW,LS] = learnp(W, P, Z, N, A, T, E, gW, gA, D, LP, LS)
[db,LS] = learnp(b, ones(1,Q), Z, N, A, T, E, gW, gA, D, LP, LS)
各参数的具体意义可参考神经网络工具箱的
用户指南 。
训练步骤
1 )对于所要解决的问题,确定输入向量 X, 目标 向量 T, 由此确定维数及网络结构参数, n,m;
2) 参数初始化;
3 )设定最大循环次数;
4 )计算网络输出;
5 )检查输出矢量 Y 与目标矢量 T 是否相同,如果 相同时,或以达最大循环次数,训练结束,否则 转入 6 );
6 )学习
并返回 4 )。
) ( )
( )
1 (
) ( )
( )
1 (
K E K
B K
B
X K E k
W k
W T
上述的整个训练过程我们可以用 MATLAB 工具箱中的函数 train.m 来完成。其调用 方式如下:
[net,tr]=train(net,P,T,Pi,Ai)
例题
例 2.1 采用单一感知器神经元解决一个简单的 分类问题:将四个输入输入矢量分为两类,其中 两个矢量对应的目标值为 1 ,另两个矢量对应的 目标值为 0 ,即
输入矢量: P=[-0.5 –0.5 0.3 0.0;
-0.5 0.5 -0.5
1.0] 目标分类矢量: T=[1.0 1.0 0.0 0.0]
解
首先定义输入矢量及相应的目标矢量:
P=[-0.5 –0.5 0.3 0.0;
-0.5 0.5 -0.5 1.0] ; T=[1.0 1.0 0.0 0.0] ;
输入矢量可以用图 /// 来描述,
对应于目标值 0 的输入矢量用符 号‘ 0’ 表示,对应于目标值 1 的输 入矢量符号‘ +’ 表示。
输入
矢量图
训练结束后得到如图所示的分类结果,分类 线将两类输入矢量分开,其相应的训练误差的 变化如图所示。这说明经过 4 步训练后,就达 到了误差指标的要求。
下面给出本例的 MATLAB 程序
% Example pre.m
%
clf reset figure(gcf)
setfsize(300,300);
echo on
%NEWP —— 建立一个感知器神经元
%INIT —— 对感知器神经元初始化
%TRAIN —— 训练感知器神经元
%SIM —— 对感知器神经元仿真 pause % 敲任意键继续
clc
% P 为输入矢量
P = [-0.5 -0.5 +0.3 +0.0;
-0.5 +0.5 -0.5 1.0];
% T 为目标矢量 T = [1 1 0 0];
pause
% 绘制输入矢量图 plotpv(P,T);
pause
% 定义感知器神经元并对其初始化 net=newp([-0.5 0.5;-0.5 1],1);
net.initFcn='initlay';
net.layers{1}.initFcn='initwb';
net.inputWeights{1,1}.init Fcn='rands';
net.layerWeights{1,1}.init Fcn='rands';
net.biases{1}.initFcn='ran ds';
net=init(net);
echo off
k = pickic;
if k == 2
net.iw{1,1} = [-0.8161 0.3078];
net.b{1} = [-0.1680];
end
echo on
plotpc(net.iw{1,1},net.b{1 })
pause
% 训练感知器神经元
net=train(net,P,T);
pause
% 绘制结果分类曲线 plotpv(P,T)
plotpc(net.iw{1,1},net.b{
1});
pause
% 利用训练完的感知器神经元分类 p = [-0.5; 0];
a = sim(net,p) echo off
BP 网络
将感知器网络结构扩展到多层,其作用函 数采用一种可微分的函数,这就形成了功 能比较强大的多层前向网络。
由于多层前向网络采用反向传播学习算法
( Back Propagation ),通常人们将其称为
BP 网络。
BP
主要用途
网络主要用于:( 1 )函数逼近:用输入矢量和相应的输出矢量训练网络逼 近某个函数;
( 2 )模式识别:用一个特定的输出矢量将它与输入矢量联 系起来;
( 3 )分类:把输入矢量以所定义的合适的方法进行分类;
( 4 )数据压缩:减少输出矢量维数以便于传输或存储。
在人工神经网络的实际工程应用中,特别在自动控制领域中
,大多数神经网络模型是采用 BP 网络或它的变化形式,
它也是前向网络的核心部分,体现了人工神经网络最精华 的部分。
BP 网络主要内容
1 、 BP网络模型 2 、学习训练算法
3 、对应的MATLA B训练函数 4 、例题
5 、 BP 网络设计问题 6 、限制与不足
7 、 BP 算法改进
BP 网络模型
BP 网络模型如图 2.4.1 所示 :
图 2.4.1
I/O 关系
I->H
a 1 = tansig (IW
1,1p
1+b
1)
tansig(x)=tanh(x)=(e
x-e
-x)/(e
x+e
-x)
H->O
a 2 = purelin (LW
2,1a
1+b
2)
输入层神经元个数 n
隐含层神经元个数 n1
输出层神经元个数 s2
学习(训练)
输入 q 组样本 p
1,p
2,...,p
qp
i∈R
n
期望输出 T
1,T
2,...,T
q, T ∈R
s2
网络输出 a2
1,a2
2,...,a
2qa
2∈R
s2
解决方法 误差最小
实质为一个优化问题
思路 1: 梯度法 (gradient)
找出误差与加权系数的关系
得到加权系数改变的规律
学习训练算法
(2.4.2)
1 1
2 )
2 (
2 2 2
2 2
1
(2.4.1)
)
2 2 (
B) 1 E(W,
2
1
2
i ki
i k
k
ki k k
ki ki
S
K k k
a a
f a
t
w a a
E w
w E
k i
a t
输出的权值改变有:
个 个输入到第
从第
)输出层的权值变化
(
变化及误差的反向传播 利用梯度下降法求权值
定义误差函数为:
(2.4.5)
2
, 1
(2.4.4)
1 2
2 )
2 (
1 1 1
2 2
1 1
)
2 (
2.4.3
2 2
2 2 2
2 2
2
1 2
1
ij i
s
k ki ki
i i
ij
j ij
j ki
s
k k k
ij i i
k k
ij ij
ki k
k
k k k
ki ki
bl
w e
f e
p
p f
w f
a t
w a a
a a
E w
w E
f a
t
b a a
E b
b E
同理可得:
其中:
隐含层权值变化 同理可得:
BP 算法解释
输出层误差 e
j(j=1-s2)
隐含层误差 e
i(i=1-n1)
e
i与 e
j的关系?
e
i可以认为是由 e
j加权组合形成的。由于 作用函数的存在, e
j的等效作用为 δ
jδ
i=e
jf '()
21 s
2
i ki ki
k
e w
导数
logsig
matlab 函数: dA_dN = dlogsig(N,A)
tansig
matlab 函数: dA_dN = dtansig(N,A) ( ) 1
1
'( ) ( )(1 ( )) f x
xe
f x f x f x
2
( )
'( ) 1 (1 ( )) 2
x x
x x
e e
f x e e
f x f x
BP 算法的理论分析
学习算法:
此处:
W* 为最优加权值。
由梯度法
( 1) ( ) ( )
W k W k W k ( ) ( * ( )) W k f W W k
( 1) ( )
( ) W k W k J
W k
改写成差分方程,可得
因此,传统梯度法等效为一个积分控制器
( 1) (1
1) ( )
W k z
W k
MATLAB 函数
旧版下的训练函数为: trainbp.m
Tp=[disp_freq max_epoch err_goal lr];
[w,b,epochs,errors]=trainbp(w,b,’F’,P,T,Tp);
‘F’ 为网络的激活函数
名:‘ tansig’,’logsig’,’purelin’
而在新版下完全不同:
首先建立一个网络 net=newff([-2 2],[5 1], {‘tansig’ ‘purelin’},’traingd’);
计算输出: y1=sim(net,P);
绘图: plot(P,T,’*’);
训练: [net,tr]=train(net,P,T);
训练函数有很多种,如:
traingd,traingdm,traingdx,trainlm
在训练之前要对网络进行初始化,并设置好训练参数。
初始化: net.iw{1,1}=W10;
net.b{1}=B10;
net.lw{2,1}=W20;
net.b{2}=B20;
参数设置:
net.trainParam.epochs=100; % 最大训练次数
net.trainParam.goal=0.01; % 训练所要达到的精度
net.trainParam.show=10; % 在训练过程中显示的 频率
net.trainParam.lr=0.1; % 学习速率
例题—函数逼近
例 2.3 应用两层 BP 网络来完成函数逼近的任务,其中隐含的 神经元个数选为 5 个。网络结构如图 2.4.1 所示。
图: 2.4.1
解 首先定义输入样本和目标矢量 P=-1:.1:1;
T=[-.9602 -.5770. –.0729 .3771 .6405 .6600 .4609 …. 1336 -.2013 -.4344 -.5000 -.3930 -.1647 .0988 …
.3072 .3960 .3449 .1816 -.0312 -.2189 -.3201];
上述数据的图形如图 2.4.2 所示。
图: 2.4.2
利用函数 newff 建立一个 bp 神经元网络
net=newff(minmax(P),[5 1],{‘tansig’
‘purelin’}, ‘traingd’, ‘learngd’, ‘sse’);
然后利用函数 train 对网络进行训练 net.trainParam.show=10;
net.trainParam.epochs=8000;
net.trainParam.goal=0.02;
net.trainParam.lr=0.01;
[net,tr]=train(net,P,T);
图2.4.3至图2.4.6给出了网络输出值随训练次数的增
加而变化的过程。图 2.4.7 给出了 454 次训练后的最终 网络结果,以及网络的误差纪录。
同时还可以用函数 sim 来计算网络的输出 a1=sim(net,P)
下面给出本例的 MATLAB 程序
图 2.4.3 训练 100 次的结果 图 2.4.4 训练 200 次的结果
图 2.4.5 训练 300 次的结果 图 2.4.6 训练 400 次的结果
图 2.4.7 训练结束后的网络输出与误
差结果
% Example 3.13
%
clf;
figure(gcf)
setfsize(500,200);
echo on
%NEWFF — 建立一个 BP 网络
%TRAIN — 对 BP 网络进行训练
%SIM — 对 BP 网络进行仿真 pause
P = -1:.1:1;
T = [-.9602 -.5770 -.0729 . 3771 .6405 .6600 .4609 ...
.1336 -.2013 -.4344
-.5000 -.3930 -.1647 .0988 ...
.3072 .3960 .3449 . 1816 -.0312 -.2189 -.3201];
plot(P,T,'+');
title('Training Vectors');
xlabel('Input Vector P');
ylabel('Target Vector T');
pause
net=newff(minmax(P),[5 1],{'tansig'
'purelin'},'traingd','l earngd','sse');
echo off
k = pickic;
if k == 2
net.iw{1,1} = [3.5000; 3.5000;
3.5000; 3.5000;
3.5000];
net.b{1} = [-2.8562;
1.0774; -0.5880; 1.4083;
2.8722];
net.lw{2,1} = [0.2622 -0.2375 -0.4525 0.2361 -0.1718];
net.b{2} = [0.1326];
end
net.iw{1,1}
net.b{1}
net.lw{2,1}
net.b{2}
pause echo on me=8000;
net.trainParam.show=10;
net.trainParam.goal=0.02;
net.trainParam.lr=0.01;
A=sim(net,P);
sse=sumsqr(T-A);
for i=1:me/100 if
sse<net.trainparam.goal, i=i-1;break,end
net.trainParam.epochs=10 0;
[net,tr]=train(net,P,T);
trp((1+100*(i-1)):
(max(tr.epoch)+100*(i- 1)))=tr.perf(1:max(tr.ep och));
A=sim(net,P);
sse=sumsqr(T-A);
plot(P,T,'+');
hold on plot(P,A) hold off pause
end
message=sprintf('Traingd, Epoch %%g/%g, SSE %
%g\n',me);
fprintf(message,(max(tr.epoch)+100*(i-1)),sse) plot(trp)
[i,j]=size(trp);
hold on
plot(1:j,net.trainParam.goal,'r--') hold off
title('Error Signal') xlabel('epoch')
ylabel('Error') p = 0.5;
a = sim(net,p)
BP 网络训练的几种模式
1)
批处理模式 (batch mode)
训练过程以所有样本为一个 epoch 。训练时计 算出所有样本的整体误差后,加权系数才调整。
matlab 函数
trainb ,非直接调用,用 net.trainFcn 说明
2)
模式学习模式 (pattern mode)
训练过程输入一个样本,计算学习误差,调整 加权系数。
matlab 函数
trainc , trains, trainr 非直接调用,用
net.trainFcn 说明
BP 网络设计问题
在进行 BP 网络的设计时,一般应从网络的层数,
每层中的神经元个数和激活函数、初始值以及学习速 率等几个方面来进行考虑。下面讨论各自的选取原则。
1. 网络的层数;
2. 隐含层的神经元数;
3. 初始权值的选取;
4. 学习速率;
5. 期望误差的选取。
网络的层数
理论上已经证明:具有偏差和至少一个 S 型隐含 层加上一个线性输入层的网络,能够逼近任何有理 函数。
增加层数可以进一步的降低误差,提高精度,
但同时也使网络复杂化。
另外不能用仅具有非线性激活函数的单层网络 来解决问题。因为能用单层网络完美解决的问题,
用自适应线性网络也一定能解决,而且自适应线性
网络的运算速度还要快。而对于只能用非线性函数
解决的问题,单层精度又不够高,也只有增加层才
能达到期望的结果。
隐含层神经元数
网络训练精度的提高,可以通过采用一个隐 含层,而增加其神经元数的方法来获得,这在结 构实现上,要比增加更多的隐含层要简单的多。
为了对隐含层神经元数在网络设计时所起的
的作用有一个比较深入的理解,下面先给出一个
有代表性的实例,然后从中得出几点结论。
例:用两层 BP 网络实现“异或”功能。
网络要实现如下的输入 / 输出功能:
对于一个二元输入网络来说,神经元数 即为分割
线数。所以隐含层神经元数应≥ 2 。
0 1 1 0
1 ,
0 1 0
1 0 0
0
T
P
图 2.4.8 ( a )中,输出节点与隐含层节点相同,
显然该输出层是多余的,该网络也不能解决问题,
因此需要增加隐含层的节点数。
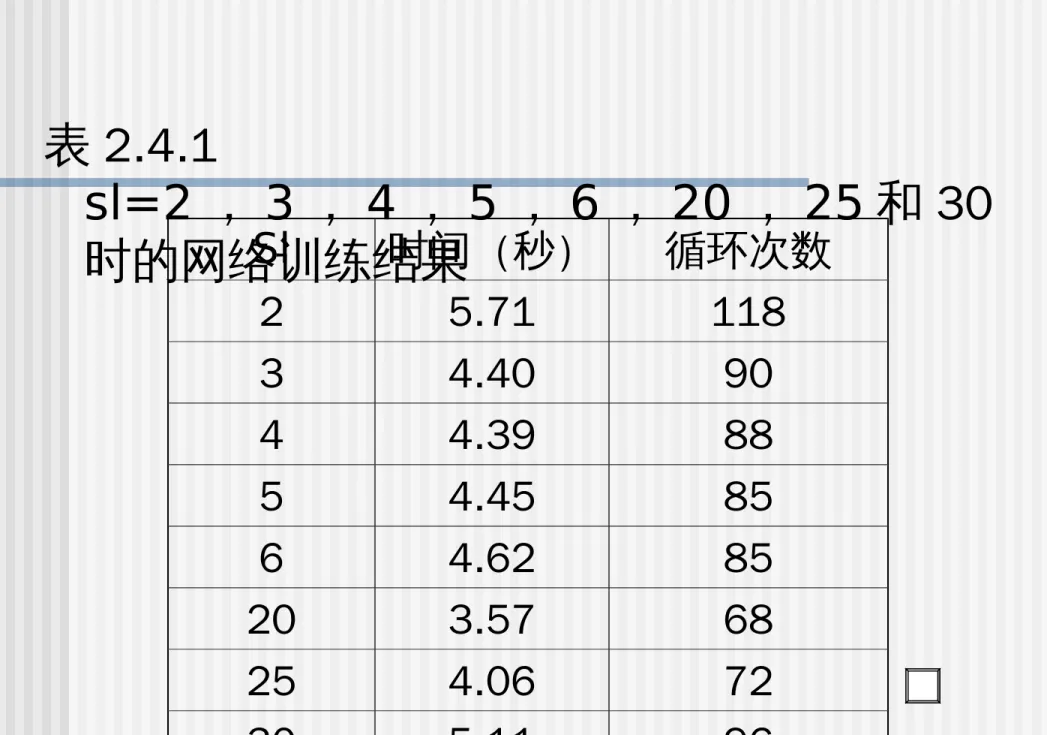
在此例中,隐含层中神经元数为多少时最佳?
我们针对 sl=2 , 3 , 4 , 5 , 6 以及为 20 、 25 和 30 时 对
网络进行设计。选择误差目标为 err_goal=0.02, 并通 过对网络训练时所需的循环次数和训练时间的情况
来观察网络求解效果。整个网络的训练结果如表 2.4.1 所示。
表 2.4.1
sl=2 , 3 , 4 , 5 , 6 , 20 , 25 和 30 时的网络训练结果 Sl 时间(秒) 循环次数
2 5.71 118
3 4.40 90
4 4.39 88
5 4.45 85
6 4.62 85
20 3.57 68
25 4.06 72
我们评价一个网络设计的好坏,首先是它的精度,
再一个就是训练时间。
从表 2.4.1 总可以看出下面几种情况:
1 )神经元数太少,网络不能很好的学习,需要训 练的次数也多,训练精度也不高;
2 )一般而言,网络隐含层神经元的个数 sl 越多,
功能越大,但当神经元数太多,会产生其它的问题。
3 )当 sl=3,4,5 时,其输出精度都相仿,而 sl=3 是 的
训练次数最多。
一般的讲,网络 sl 的选择原则是:在能够解决问 题的前提下,再加上一个到两个神经元以加快误差的下 降速度即可。
初始权值的选取
一般取初始权值在( -1 , 1 )之间的随机数。
另外,威得罗等人在分析了两层网络是如何对一 个函数进行训练后,提出一种选定初始权值的策略:
选择权值的量级为 ,其中 s1 为第一层神经元数, r 为输入个数。在旧版 MATLAB (版本低于 5.2 )工具箱 中可采用函数 nwlog.m 或 nwtan.m 来初始化隐含层权
值。
而在新版 MATLAB 工具箱中,统一用函数 init.m 对网络进行初始化。
s1 r
学习速率
学习速率决定每一次循环训练中所产生的权 值变化量。大的学习速率可能导致系统的不稳定;
但小的学习速率导致较长的训练时间,可能收敛 很慢,不过能保证网络的误差值不跳出误差表面 的低谷而最终趋于误差最小值。所以一般情况下
倾向于选取较小的学习速率以保证系统的稳定性。
学习速率的选取范围在 0.01~0.8 之间。
对于较复杂的网络,在误差曲面的不同部位
可能需要不同的学习速率。为了减少寻找学习速
率的训练次数以及训练时间,比较合适的方法是
采用变化的自适应学习速率,使网络的训练在不
同的阶段设置不同大小的学习速率。
期望误差的选取
在设计网络的训练过程中,期望误差值也应
当通过对比训练后确定一个合适的值,这个所谓
的“合适” , 是相对于所需要的隐含层的节点数来确
定的。一般情况下,作为对比,可以同时对两个
不同期望误差值的网络进行训练,最后通过综合
因素的考虑来确定采用其中一个网络。
限制与不足
( 1 )需要较长的训练时间
这主要是由于学习速率太小所造成的。可采用变 化的学习速率或自适应的学习速率来加以改进。
( 2 )完全不能训练
这主要表现在网络的麻痹上。通常为了避免这种 情况的产生,一是选取较小的初始权值,二是采用较 小的学习速率。
( 3 )局部最小值
采用多层网络或较多的神经元,有可能得到更好 的结果。
BP 算法的改进
BP 算法改进的主要目标是为了加快训练速度,
避免陷入局部极小值和改善其它能力。本节只讨论 前两种性能的改进方法的有关内容。
( 1 )带动量因子算法;
( 2 )自适应学习速率;
( 3 )改变学习速率的方法;
( 4 )作用函数后缩法;
( 5 )改变性能指标函数。
带动量因子算法
该方法实在反向传播法的基础上在每一个权值 的变化上加上一项正比于前次权之变化的值,并根 据反向传播法来产生新的权值变化。带有附加动量 因子的权值调节公式为:
( 2.4.6 ) 其中 k 为训练次数, mc 为动量因子,一般取 0.95
左右。
) ( )
1 ( )
1 (
) ( )
1 ( )
1 (
k b mc mc
k b
k w mc
p mc
k w
i i
i
ij j
i ij
附加动量法的实质是将最后一次权值变化的 影响,通过一个动量因子来传递。以此方式,当 增加动量项后,促使权值的调节向着误差曲面底 部的平均方向变化,当网络权值进入误差曲面底 部的平坦区时, 将变得很小,于是,
从而防止了 的出现 ,有助于使网络从 误差曲面的局部极小值中跳出。
i) ( )
1
( k w k
w
ij
ij
0 )
(
wij k
在 MATLAB 工具箱中,带有动量因子的权值修 正法是用函数 learnbpm.m 来实现的。对网络进行训 练可用函数 traingdm.m 。我们可以用函数 newff.m
建
立一个用附加动量法训练的 BP 网络:
net=newff(minmax(P),[5 1],{'tansig'
'purelin'},'traingdm','learngm','sse');
自适应学习速率
对于一个特定的问题,要选择适当的学习速率并 不是一件容易的事情。对训练开始初期功效很好地学 习速率,不见得对后来的训练合适。为了解决值一问
题,人们自然会想到在训练过程中自动调整学习速率。
下面给出一个自适应学习速率的调整公式:
( 2.4.7 ) 初始学习速率 (0) 的选取范围可以有很大的随意性。
其它
)
(
) ( 04
. 1 ) 1 (
)
( 7 .
0.05 ( ) ( 1) ( ) 1
) 1 (
K
k SSE k
SSE
Kk SSE k SSE k k
MATLAB 工具箱总带有自适应学习速率进行反向 传播训练的函数为: traingda.m 。使用方法为:
[net,tr]=traingda(net,Pd,Tl,Ai,Q,TS,VV) 或者,
先设置 net.trainFcn=‘traingda’
然后进行训练 net=train(net,P,T);
例 2.4 沿用例 2.3 中的输入矢量和目标矢量。
同其他训练函数的调用方法一样,这个训练过程
函数的应用非常简单。下面给出本例的 MATLAB 程序。
% Example
%
clf;
figure(gcf)
setfsize(500,200);
echo on
%NEWFF — 建立一个 BP 网络
%TRAIN — 对网络进行训练
%SIM — 对网络进行仿真 pause
P = -1:.1:1;
T = [-.9602 -.5770 -.0729 . 3771 .6405 .6600 .4609 ...
.1336 -.2013 -.4344 -.5000 -.3930 -.1647 .
0988 ...
.3072 .3960 .3449 .
plot(P,T,'+');
title('Training Vectors');
xlabel('Input Vector P');
ylabel('Target Vector T');
pause
net=newff(minmax(P) ,[5 1],{'tansig' 'purelin'},'traingd a','learngd','sse')
;
echo off
k = pickic;
if k == 2
net.iw{1,1} = [3.5000;
3.5000; 3.5000; 3.5000;
3.5000];
net.b{1} = [-2.8562;
1.0774; -0.5880; 1.4083;
2.8722];
net.lw{2,1} = [0.2622 -0.2375 -0.4525 0.2361 -0.1718];
net.b{2} = [0.1326];
end
net.iw{1,1}
net.b{1}
net.lw{2,1}
net.b{2}
pause echo on
net.trainparam.lr_inc=1.0 5;
net.trainParam.epochs=800 0;
net.trainParam.show=10;
net.trainParam.goal=0.02;
net.trainParam.lr=0.01;
[net,tr]=train(net,P,T);
pause
A=sim(net,P);
plot(P,T,'+');
hold on plot(P,A) hold off p = 0.5;
a = sim(net,p)
仅训练了 121 次就达到了误差目标 0.02 的目的。
图 2.4.9 给出了学习速率在训练过程中的纪录。误 差平方和的记录在图 2.4.10 中。
图 2.4.9 图 2.4.10
训练中的学习速率 训练中的误差纪录
从中可以看出:在训练的初始阶段,学习速率 是以直线形式上升。当接近误差最小值时,学习速 率又自动的下降。注意误差曲面有少于的波动。
可以将动量法和自适应学习速率结合起来以利 用两方面的优点。 MATLAB 工具箱中 traingdx.m 函 数可以实现此功能。其调用方式和函数 traingda.m 的 调用方式一样。
改变学习速率方法
学习速率的局部调整法基于如下的几个直观的推 断:
1 )目标函数中的每一个网络可调参数有独立的学 习速率;
2 )每一步迭代中,每个学习速率参数都能改变;
3 )在连续几次迭代中,若目标函数对某个权导 数的符号相同,则这个权的学习速率要增加;
4 )在连续几次迭代中,若目标函数对某个权导 数的符号相反,则这个权的学习速率要减小。
- 规则
式( 2.4.8 )的学习规则虽然和上述 推断一致,但在应用时还存在一些潜在的 问题。
习速率调整步长。
是一个正实数,称为学 式中,
则
的学习速率 为
设
(2.4.8)
)
1 (
) 1 (
) (
) (
) (
) ) (
1 (
) ( )
(
k w
k E k
w k E
k k k E
k w k
ij ij
ij ij
ij ij
例如 , 若在连续两次迭代中,目标函数对某个权 的导数具有相同的符号,但他们的权值很小,则对 应于那个权值的学习速率的正调整也很小。另一方 面,若在两次连续的迭代中,目标函数对某个权的 导数具有相反的符号和很大的值,则对应于那个权 学习速率的负调整也很大。在这两种情况下,就难 于选择合适的步长参数。
上述问题可以用 -bar- 方法来克服。
-bar- 方法
。
为:
由使用者确定。典型值 和
是一个正实数。参数 式中,
其它 若 若 则来确定:
可按如下调整规 的学习速率。学习速率
为这次迭代对应于该权
神经元的连接权。令 神经元到
次迭代 为第
令
7 . 0 1
. 0 , 5 1
. 0 , 1 . 0 10
b a,
(2.4.11)
)
1 (
) 1 (
) 1
( ) (
(2.4.10)
) (
) ) (
(
0
(2.4.9)
0
) ( )
1 (
S
) (
0 )
( )
1 (
S
)
1 (
) ( )
(
4
ij ij
b a
k S k
D k
S
k w
k k E
D
k D k
k ba
k D k
a k
a
k a j
i k
k w
ij ij
ij
ij ij
ij ij
ij ij
ij ij