组件操作指南
文档版本 01
发布日期 2021-12-28
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或暗示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
目 录
1 使用 Alluxio...1
1.1 配置底层存储系统... 1
1.2 通过数据应用访问 Alluxio...2
1.3 Alluxio 常用操作... 6
2 使用 CarbonData(MRS 3.x 之前版本)... 9
2.1 CarbonData 入门... 9
2.2 CarbonData 表简介...11
2.3 创建 CarbonData 表...12
2.4 删除 CarbonData 表...14
3 使用 CarbonData(MRS 3.x 及之后版本)... 15
3.1 概述... 15
3.1.1 CarbonData 简介...15
3.1.2 CarbonData 主要规格... 18
3.2 配置参考... 19
3.3 CarbonData 操作指导... 31
3.3.1 CarbonData 快速入门... 31
3.3.2 管理 CarbonData Table...34
3.3.2.1 CarbonData Table 简介... 34
3.3.2.2 新建 CarbonData Table... 35
3.3.2.3 删除 CarbonData Table... 37
3.3.2.4 修改 CarbonData Table... 38
3.3.3 管理 CarbonData Table 数据... 38
3.3.3.1 加载数据... 38
3.3.3.2 删除 Segments...39
3.3.3.3 合并 Segments...40
3.3.4 迁移 CarbonData 数据... 43
3.3.5 迁移 Spark1.5 的 Carbondata 数据到 Spark2x 的 Carbondata 中... 44
3.4 CarbonData 性能调优... 46
3.4.1 调优指导... 46
3.4.2 创建 CarbonData Table 的建议...48
3.4.3 性能调优的相关配置... 50
3.5 CarbonData 访问控制... 52
3.6 CarbonData 语法参考... 54
3.6.1 DDL...54
3.6.1.1 CREATE TABLE... 54
3.6.1.2 CREATE TABLE As SELECT... 57
3.6.1.3 DROP TABLE... 58
3.6.1.4 SHOW TABLES...58
3.6.1.5 ALTER TABLE COMPACTION... 59
3.6.1.6 TABLE RENAME...61
3.6.1.7 ADD COLUMNS... 61
3.6.1.8 DROP COLUMNS...62
3.6.1.9 CHANGE DATA TYPE...63
3.6.1.10 REFRESH TABLE... 64
3.6.1.11 REGISTER INDEX TABLE...65
3.6.1.12 REFRESH INDEX... 66
3.6.2 DML... 67
3.6.2.1 LOAD DATA... 67
3.6.2.2 UPDATE CARBON TABLE... 71
3.6.2.3 DELETE RECORDS from CARBON TABLE... 72
3.6.2.4 INSERT INTO CARBON TABLE... 73
3.6.2.5 DELETE SEGMENT by ID... 74
3.6.2.6 DELETE SEGMENT by DATE... 75
3.6.2.7 SHOW SEGMENTS... 76
3.6.2.8 CREATE SECONDARY INDEX... 77
3.6.2.9 SHOW SECONDARY INDEXES...78
3.6.2.10 DROP SECONDARY INDEX... 79
3.6.2.11 CLEAN FILES... 79
3.6.2.12 SET/RESET... 80
3.6.3 操作并发... 83
3.6.4 API...86
3.6.5 空间索引... 88
3.7 CarbonData 故障处理... 100
3.7.1 当在 Filter 中使用 Big Double 类型数值时,过滤结果与 Hive 不一致... 100
3.7.2 查询性能下降...101
3.8 CarbonData FAQ...101
3.8.1 为什么对 decimal 数据类型进行带过滤条件的查询时会出现异常输出?... 102
3.8.2 如何避免对历史数据进行 minor compaction?... 102
3.8.3 如何在 CarbonData 数据加载时修改默认的组名?... 103
3.8.4 为什么 INSERT INTO CARBON TABLE 失败?... 103
3.8.5 为什么含转义字符的输入数据记录到 Bad Records 中的值与原始数据不同?... 104
3.8.6 为什么 Bad Records 导致数据加载性能降低?...104
3.8.7 当初始 Executor 为 0 时,为什么 INSERT INTO/LOAD DATA 任务分配不正确,打开的 task 少于可用的 Executor?... 104
3.8.8 为什么并行度大于待处理的 block 数目时,CarbonData 仍需要额外的 executor?...105
3.8.9 为什么在 off heap 时数据加载失败?... 105
3.8.10 为什么创建 Hive 表失败?... 106
3.8.11 为什么在 V100R002C50RC1 版本中创建的 CarbonData 表不具有 Hive 特权为非所有者提供的特权? ... 106
3.8.12 如何在不同的 namespaces 上逻辑地分割数据... 107
3.8.13 为什么 drop 数据库抛出 Missing Privileges 异常?... 108
3.8.14 为什么在 Spark Shell 中不能执行更新命令?... 108
3.8.15 如何在 CarbonData 中配置非安全内存?... 109
3.8.16 设置了 HDFS 存储目录的磁盘空间配额,CarbonData 为什么会发生异常?... 109
3.8.17 为什么数据查询/加载失败,且抛出“org.apache.carbondata.core.memory.MemoryException: Not enough memory”异常?... 110
4 使用 ClickHouse...111
4.1 从零开始使用 ClickHouse... 111
4.2 ClickHouse 表引擎介绍...114
4.3 ClickHouse 表创建... 120
4.4 ClickHouse 常用 SQL 语法... 125
4.4.1 CREATE DATABASE 创建数据库... 125
4.4.2 CREATE TABLE 创建表...125
4.4.3 INSERT INTO 插入表数据... 126
4.4.4 SELECT 查询表数据...127
4.4.5 ALTER TABLE 修改表结构... 128
4.4.6 DESC 查询表结构... 129
4.4.7 DROP 删除表... 129
4.4.8 SHOW 显示数据库和表信息... 129
4.5 ClickHouse 数据迁移... 130
4.5.1 ClickHouse 访问 RDS MySql 服务...130
4.5.2 ClickHouse 导入 DWS 服务数据... 132
4.5.3 将 Kafka 数据同步至 ClickHouse... 135
4.5.4 使用 ClickHouse 数据迁移工具... 138
4.6 用户管理及认证... 141
4.6.1 ClickHouse 用户及权限管理...141
4.6.2 ClickHouse 使用 OpenLDAP 认证... 146
4.7 ClickHouse 集群管理... 149
4.7.1 ClickHouse 集群配置说明... 149
4.7.2 ClickHouse 增加磁盘容量... 152
4.7.3 ClickHouse 新增磁盘...155
4.8 通过数据文件备份恢复 ClickHouse 数据... 160
4.9 ClickHouse 日志介绍... 161
5 使用 DBService...165
5.1 DBService 日志介绍... 165
6 使用 Flink... 168
6.1 从零开始使用 Flink...168
6.2 查看 Flink 作业信息... 175
6.3 配置管理 Flink... 177
6.3.1 配置参数路径...177
6.3.2 JobManager & TaskManager... 177
6.3.3 Blob... 185
6.3.4 Distributed Coordination (via Akka)... 186
6.3.5 SSL... 191
6.3.6 Network communication (via Netty)...193
6.3.7 JobManager Web Frontend... 194
6.3.8 File Systems...198
6.3.9 State Backend...199
6.3.10 Kerberos-based Security... 201
6.3.11 HA... 202
6.3.12 Environment... 204
6.3.13 Yarn... 205
6.3.14 Pipeline... 206
6.4 安全配置... 207
6.4.1 安全特性描述...207
6.4.2 配置对接 Kafka... 208
6.4.3 配置 Pipeline... 209
6.5 安全加固... 210
6.5.1 认证和加密... 210
6.5.2 ACL 控制... 218
6.5.3 web 安全... 218
6.6 安全声明... 221
6.7 使用 Flink WebUI... 221
6.7.1 概述... 221
6.7.1.1 Flink WebUI 应用简介...221
6.7.1.2 Flink WebUI 应用流程...224
6.7.2 FlinkServer 权限管理...226
6.7.2.1 概述...226
6.7.2.2 基于用户和角色的鉴权... 226
6.7.3 访问 Flink WebUI... 227
6.7.4 在 Flink WebUI 创建应用...228
6.7.5 在 Flink WebUI 创建集群连接... 229
6.7.6 在 Flink WebUI 创建数据连接... 232
6.7.7 使用 Flink WebUI 的流表管理... 236
6.7.8 使用 Flink WebUI 的作业管理... 239
6.8 Flink 日志介绍... 245
6.9 Flink 性能调优... 247
6.9.1 DataStream 调优... 247
6.9.1.1 配置内存... 247
6.9.1.2 设置并行度...248
6.9.1.3 配置进程参数... 249
6.9.1.4 设计分区方法... 249
6.9.1.5 配置 netty 网络通信... 250
6.9.1.6 经验总结... 251
6.10 Flink 常见 Shell 命令... 251
6.11 参考... 256
6.11.1 签发证书样例... 256
7 使用 Flume...261
7.1 从零开始使用 Flume... 261
7.2 使用简介... 267
7.3 安装 Flume 客户端... 269
7.3.1 安装 MRS 3.x 之前版本 Flume 客户端... 269
7.3.2 安装 MRS 3.x 及之后版本 Flume 客户端... 272
7.4 查看 Flume 客户端日志... 274
7.5 停止或卸载 Flume 客户端... 275
7.6 使用 Flume 客户端加密工具...276
7.7 Flume 业务配置指南... 276
7.8 Flume 配置参数说明... 299
7.9 在配置文件 properties.properties 中使用环境变量... 324
7.10 非加密传输... 325
7.10.1 配置非加密传输... 325
7.10.2 典型场景:从本地采集静态日志保存到 Kafka... 329
7.10.3 典型场景:从本地采集静态日志保存到 HDFS... 335
7.10.4 典型场景:从本地采集动态日志保存到 HDFS... 343
7.10.5 典型场景:从 Kafka 采集日志保存到 HDFS... 350
7.10.6 典型场景:从 Kafka 客户端采集日志经 Flume 客户端保存到 HDFS...357
7.10.7 典型场景:从本地采集静态日志保存到 HBase... 362
7.11 加密传输... 368
7.11.1 配置加密传输... 369
7.11.2 典型场景:从本地采集静态日志保存到 HDFS... 378
7.12 查看 Flume 客户端监控信息... 390
7.13 Flume 对接安全 Kafka 指导... 391
7.14 Flume 对接安全 Hive 指导... 391
7.15 Flume 业务模型配置指导...394
7.15.1 概述...394
7.15.2 业务模型配置指导...395
7.16 Flume 日志介绍... 400
7.17 Flume 客户端 Cgroup 使用指导...402
7.18 Flume 第三方插件二次开发指导...403
7.19 配置 Flume 定制脚本... 404
7.20 Flume 常见问题... 406
8 使用 HBase...408
8.1 从零开始使用 HBase...408
8.2 使用 HBase 客户端... 413
8.3 创建 HBase 角色... 415
8.4 配置 HBase 备份... 418
8.5 配置 HBase 参数... 427
8.6 启用集群间拷贝功能... 428
8.7 使用 ReplicationSyncUp 工具... 430
8.8 GeoMesa 命令行简介... 431
8.9 使用 HIndex... 433
8.9.1 HIndex 介绍... 433
8.9.2 批量加载索引数据... 442
8.9.3 使用索引生成工具... 445
8.9.4 索引数据迁移...447
8.10 配置 HBase 容灾...449
8.11 配置 HBase 数据压缩和编码... 456
8.12 HBase 容灾业务切换... 458
8.13 HBase 容灾主备集群倒换... 460
8.14 社区 BulkLoad Tool... 461
8.15 自研增强 BulkLoad Tool... 461
8.15.1 按自定义方式导入数据... 461
8.15.1.1 批量导入数据... 461
8.15.1.2 组合 rowkey... 464
8.15.1.3 自定义 rowkey 实现... 465
8.15.1.4 组合字段... 466
8.15.1.5 指定字段数据类型... 466
8.15.1.6 定义不适用的数据行... 467
8.15.2 按自定义方式导入带有索引的数据... 468
8.15.2.1 批量导入数据时创建二级索引... 468
8.15.2.2 组合 rowkey... 471
8.15.2.3 自定义 rowkey 实现... 472
8.15.2.4 组合字段... 472
8.15.2.5 指定字段数据类型... 473
8.15.2.6 定义不适用的数据行... 473
8.15.3 批量更新... 475
8.15.4 批量删除... 475
8.15.5 获取行统计数... 476
8.16 配置 MOB... 477
8.17 配置安全的 HBase Replication... 478
8.18 配置 Region Transition 恢复线程... 479
8.19 使用二级索引...480
8.20 HBase 日志介绍... 481
8.21 HBase 性能调优... 485
8.21.1 提升 BulkLoad 效率... 485
8.21.2 提升连续 put 场景性能...486
8.21.3 Put 和 Scan 性能综合调优... 486
8.21.4 提升实时写数据效率... 489
8.21.5 提升实时读数据效率... 497
8.21.6 JVM 参数优化...504
8.22 HBase 常见问题... 504
8.22.1 客户端连接服务端时,长时间无法连接成功...504
8.22.2 结束 BulkLoad 客户端程序,导致作业执行失败... 506
8.22.3 在 HBase 连续对同一个表名做删除创建操作时,可能出现创建表异常...506
8.22.4 HBase 占用网络端口,连接数过大会导致其他服务不稳定... 507
8.22.5 HBase bulkload 任务(单个表有 26T 数据)有 210000 个 map 和 10000 个 reduce,任务失败... 507
8.22.6 如何修复长时间处于 RIT 状态的 Region... 508
8.22.7 HMaster 等待 namespace 表上线时超时退出... 508
8.22.8 客户端查询 HBase 出现 SocketTimeoutException 异常... 509
8.22.9 使用 scan 命令仍然可以查询到已修改和已删除的数据... 510
8.22.10 在启动 HBase shell 时,为什么会抛出“java.lang.UnsatisfiedLinkError: Permission denied”异常 ... 511
8.22.11 在 HMaster Web UI 中显示处于“Dead Region Servers”状态的 RegionServer 什么时候会被清除掉 ... 511
8.22.12 使用 HBase bulkload 导入数据成功,执行相同的查询时却可能返回不同的结果...512
8.22.13 如何处理由于 Region 处于 FAILED_OPEN 状态而造成的建表失败异常...512
8.22.14 如何清理由于建表失败残留在 ZooKeeper 中/hbase/table-lock 目录下的表名... 513
8.22.15 为什么给 HDFS 上的 HBase 使用的目录设置 quota 会造成 HBase 故障...513
8.22.16 为什么在使用 OfflineMetaRepair 工具重新构建元数据后,HMaster 启动的时候会等待 namespace 表分配超时,最后启动失败... 514
8.22.17 为什么 splitWAL 期间 HMaster 日志中频繁打印出 FileNotFoundException 及 no lease 信息... 515
8.22.18 当使用与 Region Server 相同的 Linux 用户但不同的 kerberos 用户时,为什么 ImportTsv 工具执行失 败报“Permission denied”的异常... 516
8.22.19 租户访问 Phoenix 提示权限不足...517
8.22.20 租户使用 HBase bulkload 功能提示权限不足...517
8.22.21 如何解决 HBase 恢复数据任务失败后错误详情中提示:Rollback recovery failed 的回滚失败问题..518
8.22.22 如何修复 Region Overlap... 519
8.22.23 HBase RegionServer GC 参数 Xms,Xmx 配置 31G,导致 RegionServer 启动失败...519
8.22.24 使用集群内节点执行批量导入,为什么 LoadIncrementalHFiles 工具执行失败报“Permission denied”的异常... 520
8.22.25 Phoenix sqlline 脚本使用,报 import argparse 错误...521
8.22.26 Phoenix BulkLoad Tool 限制... 521
8.22.27 CTBase 对接 Ranger 权限插件,提示权限不足... 522
9 使用 HDFS... 524
9.1 从零开始使用 Hadoop... 524
9.2 配置内存管理... 527
9.3 创建 HDFS 角色...528
9.4 使用 HDFS 客户端... 531
9.5 使用 distcp 命令... 532
9.6 HDFS 文件系统目录简介... 536
9.7 更改 DataNode 的存储目录... 543
9.8 配置 HDFS 目录权限... 546
9.9 配置 NFS... 547
9.10 规划 HDFS 容量... 548
9.11 设置 HBase 和 HDFS 的 ulimit... 551
9.12 配置 DataNode 容量均衡... 552
9.13 配置 DataNode 节点间容量异构时的副本放置策略...557
9.14 配置 HDFS 单目录文件数量... 558
9.15 配置回收站机制... 558
9.16 配置文件和目录的权限... 559
9.17 配置 token 的最大存活时间和时间间隔...560
9.18 配置磁盘坏卷...560
9.19 使用安全加密通道... 561
9.20 在网络不稳定的情况下,降低客户端运行异常概率... 562
9.21 配置 NameNode blacklist... 563
9.22 优化 HDFS NameNode RPC 的服务质量... 565
9.23 优化 HDFS DataNode RPC 的服务质量...567
9.24 配置 LZC 压缩... 568
9.25 配置 DataNode 预留磁盘百分比... 569
9.26 配置 HDFS NodeLabel... 570
9.27 配置 HDFS Mover... 575
9.28 使用 HDFS AZ Mover... 576
9.29 配置 HDFS DiskBalancer... 577
9.30 配置 HDFS EC 存储... 580
9.31 配置从 NameNode 支持读... 587
9.32 使用 HDFS 文件并发操作命令... 588
9.33 HDFS 日志介绍... 590
9.34 HDFS 性能调优... 594
9.34.1 提升写性能...594
9.34.2 使用客户端元数据缓存提高读取性能... 595
9.34.3 使用当前活动缓存提升客户端与 NameNode 的连接性能... 596
9.35 HDFS 常见问题... 597
9.35.1 NameNode 启动慢...598
9.35.2 DataNode 状态正常,但无法正常上报数据块... 598
9.35.3 HDFS Web UI 无法正常刷新损坏数据的信息...599
9.35.4 distcp 命令在安全集群上失败并抛出异常...600
9.35.5 当 dfs.datanode.data.dir 中定义的磁盘数量等于 dfs.datanode.failed.volumes.tolerated 的值时, DataNode 启动失败... 600
9.35.6 当多个 data.dir 被配置在一个磁盘分区内,DataNode 的容量计算将会出错...600
9.35.7 当 Standby NameNode 存储元数据(命名空间)时,出现断电的情况,Standby NameNode 启动失败
... 601
9.35.8 在存储小文件过程中,系统断电,缓存中的数据丢失... 602
9.35.9 FileInputFormat split 的时候出现数组越界... 603
9.35.10 当分级存储策略为 LAZY_PERSIST 时,为什么文件的副本的存储类型都是 DISK...603
9.35.11 NameNode 节点长时间满负载,HDFS 客户端无响应... 604
9.35.12 DataNode 禁止手动删除或修改数据存储目录...605
9.35.13 成功回滚后,为什么 NameNode UI 上显示有一些块缺失... 605
9.35.14 为什么在往 HDFS 写数据时报"java.net.SocketException: No buffer space available"异常...606
9.35.15 为什么主 NameNode 重启后系统出现双备现象... 607
9.35.16 HDFS 执行 Balance 时被异常停止,再次执行 Balance 会失败... 609
9.35.17 IE 浏览器访问 HDFS 原生 UI 界面失败,显示无法显示此页...609
9.35.18 EditLog 不连续导致 NameNode 启动失败... 610
10 使用 Hive...612
10.1 从零开始使用 Hive... 612
10.2 配置 Hive 常用参数...617
10.3 Hive SQL...618
10.4 权限管理... 620
10.4.1 Hive 权限介绍... 620
10.4.2 创建 Hive 角色... 623
10.4.3 配置 Hive 表、列或数据库的权限... 628
10.4.4 配置 Hive 业务使用其他组件的权限... 632
10.5 使用 Hive 客户端... 635
10.6 使用 HDFS Colocation 存储 Hive 表...638
10.7 使用 Hive 列加密功能... 640
10.8 自定义行分隔符... 641
10.9 配置跨集群互信下 Hive on HBase... 641
10.10 删除 Hive on HBase 表中的单行记录... 643
10.11 配置基于 HTTPS/HTTP 协议的 REST 接口...643
10.12 配置是否禁用 Transform 功能...646
10.13 Hive 支持创建单表动态视图授权访问控制... 647
10.14 配置创建临时函数是否需要 ADMIN 权限...647
10.15 使用 Hive 读取关系型数据库数据... 648
10.16 Hive 支持的传统关系型数据库语法... 649
10.17 创建 Hive 用户自定义函数... 651
10.18 beeline 可靠性增强特性介绍... 653
10.19 具备表 select 权限可用 show create table 查看表结构...654
10.20 Hive 写目录旧数据进回收站... 655
10.21 Hive 能给一个不存在的目录插入数据...655
10.22 限定仅 admin 用户能创建库和在 default 库建表...656
10.23 限定创建 Hive 内部表不能指定 location...657
10.24 允许在只读权限的目录建外表... 658
10.25 Hive 支持授权超过 32 个角色... 659
10.26 Hive 任务支持限定最大 map 数... 660
10.27 HiveServer 租约隔离使用... 661
10.28 Hive 支持事务... 663
10.29 切换 Hive 执行引擎为 Tez... 667
10.30 Hive 对接外置自建关系型数据库... 670
10.31 Hive 物化视图... 672
10.32 Hive 对接外部 LDAP... 675
10.33 Hive 日志介绍... 678
10.34 Hive 性能调优... 681
10.34.1 建立表分区... 681
10.34.2 Join 优化... 682
10.34.3 Group By 优化... 684
10.34.4 数据存储优化... 684
10.34.5 SQL 优化... 685
10.34.6 使用 Hive CBO 优化查询... 686
10.35 Hive 常见问题... 688
10.35.1 如何在多个 HiveServer 之间同步删除 UDF... 688
10.35.2 已备份的 Hive 表无法执行 drop 操作... 689
10.35.3 如何在 Hive 自定义函数中操作本地文件...689
10.35.4 如何强制停止 Hive 执行的 MapReduce 任务...690
10.35.5 Hive 复杂类型字段名称中包含特殊字符导致建表失败...690
10.35.6 如何对 Hive 表大小数据进行监控...690
10.35.7 如何对重点目录进行保护,防止“insert overwrite”语句误操作导致数据丢失...691
10.35.8 未安装 HBase 时 Hive on Spark 任务卡顿处理... 692
10.35.9 FusionInsight Hive 使用 WHERE 条件查询超过 3.2 万分区的表报错... 692
10.35.10 使用 IBM 的 jdk 访问 Beeline 客户端出现连接 hiveserver 失败... 693
10.35.11 关于 Hive 表的 location 支持跨 OBS 和 HDFS 路径的说明... 693
10.35.12 通过 Tez 引擎执行 union 相关语句写入的数据,切换 MR 引擎后查询不出来。... 693
10.35.13 Hive 不支持对同一张表或分区进行并发写数据... 694
10.35.14 Hive 不支持向量化查询... 694
10.35.15 Hive 表 HDFS 数据目录被误删,但是元数据仍然存在,导致执行任务报错处理...694
10.35.16 Hive 配置类问题... 694
11 使用 Hudi... 696
11.1 快速入门... 696
11.2 基本操作... 699
11.2.1 Hudi 表结构... 699
11.2.2 写操作指导...700
11.2.2.1 批量写入... 700
11.2.2.2 流式写入... 703
11.2.2.3 将 Hudi 表数据同步到 Hive... 704
11.2.3 读操作指导...706
11.2.3.1 cow 表视图读取... 707
11.2.3.2 mor 表视图读取... 707
11.2.4 数据管理维护... 708
11.2.4.1 Metadata Table... 708
11.2.4.2 Clustering... 709
11.2.4.3 Cleaning...711
11.2.4.4 Compaction... 711
11.2.4.5 Savepoint...713
11.2.4.6 单表并发写... 713
11.2.5 Hudi 客户端使用... 714
11.2.5.1 使用 Hudi-Cli.sh 操作 Hudi 表... 714
11.2.6 配置参考... 716
11.2.6.1 写入操作配置... 717
11.2.6.2 同步 hive 表配置... 718
11.2.6.3 index 相关配置... 719
11.2.6.4 存储配置... 721
11.2.6.5 compaction&cleaning 配置... 722
11.2.6.6 MetaData Table 配置... 724
11.2.6.7 单表并发写配置... 725
11.3 Hudi 性能调优... 726
11.3.1 性能调优方式... 726
11.3.2 推荐资源配置... 726
11.4 Hudi 常见问题... 726
11.4.1 数据写入... 726
11.4.1.1 写入更新数据时报错 Parquet/Avro schema... 726
11.4.1.2 写入更新数据时报错 UnsupportedOperationException... 727
11.4.1.3 写入更新数据时报错 SchemaCompatabilityException...727
11.4.1.4 Hudi 在 upsert 时占用了临时文件夹中大量空间...727
11.4.2 数据采集... 727
11.4.2.1 使用 kafka 采集数据时报错 IllegalArgumentException... 728
11.4.2.2 采集数据时报错 HoodieException... 728
11.4.2.3 采集数据时报错 HoodieKeyException... 728
11.4.3 Hive 同步...728
11.4.3.1 Hive 同步数据报错 SQLException... 729
11.4.3.2 Hive 同步数据报错 HoodieHiveSyncException... 729
11.4.3.3 Hive 同步数据报错 SemanticException...729
12 使用 Hue(MRS 3.x 之前版本)... 730
12.1 从零开始使用 Hue... 730
12.2 访问 Hue 的 WebUI... 731
12.3 Hue 常用参数... 732
12.4 在 Hue WebUI 使用 HiveQL 编辑器... 733
12.5 在 Hue WebUI 使用元数据浏览器...735
12.6 在 Hue WebUI 使用文件浏览器... 738
12.7 在 Hue WebUI 使用作业浏览器... 741
13 使用 Hue(MRS 3.x 及之后版本)... 743
13.1 从零开始使用 Hue... 743
13.2 访问 Hue 的 WebUI... 744
13.3 Hue 常用参数... 745
13.4 在 Hue WebUI 使用 HiveQL 编辑器... 746
13.5 在 Hue WebUI 使用 SparkSql 编辑器... 748
13.6 在 Hue WebUI 使用元数据浏览器...750
13.7 在 Hue WebUI 使用文件浏览器... 751
13.8 在 Hue WebUI 使用作业浏览器... 754
13.9 在 Hue WebUI 使用 HBase... 755
13.10 典型场景... 756
13.10.1 HDFS on Hue... 756
13.10.2 配置 HDFS 冷热数据迁移... 760
13.10.3 Hive on Hue... 767
13.10.4 Oozie on Hue...769
13.11 Hue 日志介绍...770
13.12 Hue 常见问题...772
13.12.1 如何解决使用 IE 浏览器在 Hue 中执行 HQL 失败的问题...773
13.12.2 在使用 Hive 时,输入 use database 语句失效了...773
13.12.3 如何处理使用 Hue WebUI 访问 HDFS 文件失败的问题...773
13.12.4 Hue 页面上传大文件失败如何处理... 773
13.12.5 集群未安装 Hive 服务时 Hue 原生页面无法正常显示... 774
13.12.6 Hue WebUI 中 Oozie 编辑器的时区设置问题...775
14 使用 Impala... 777
14.1 从零开始使用 Impala... 777
14.2 访问 Impala 的 WebUI... 779
14.3 使用 Impala 操作 Kudu... 782
14.4 Impala 对接外部 LDAP... 783
15 使用 Kafka... 785
15.1 从零开始使用 Kafka... 785
15.2 管理 Kafka 主题... 787
15.3 查看 Kafka 主题... 790
15.4 管理 Kafka 用户权限... 791
15.5 管理 Kafka 主题中的消息...794
15.6 基于 binlog 的 MySQL 数据同步到 MRS 集群中... 795
15.7 创建 Kafka 角色... 800
15.8 Kafka 常用参数... 801
15.9 Kafka 安全使用说明... 804
15.10 Kafka 业务规格说明... 807
15.11 使用 Kafka 客户端... 808
15.12 配置 Kafka 高可用和高可靠参数... 809
15.13 更改 Broker 的存储目录... 812
15.14 查看 Consumer Group 消费情况...813
15.15 Kafka 均衡工具使用说明... 815
15.16 Kafka 扩容节点后数据均衡... 817
15.17 Kafka Token 认证机制工具使用说明...820
15.18 Kafka 日志介绍...821
15.19 性能调优... 823
15.19.1 Kafka 性能调优... 823
15.20 Kafka 常见问题...824
15.20.1 如何解决 Kafka topic 无法删除的问题...824
15.21 Kafka 特性说明... 825
16 使用 KafkaManager... 828
16.1 KafkaManager 介绍... 828
16.2 访问 KafkaManager 的 WebUI... 828
16.3 管理 Kafka 集群... 829
16.4 Kafka 集群监控管理... 832
17 使用 Kudu... 840
17.1 从零开始使用 Kudu... 840
17.2 访问 Kudu 的 WebUI... 841
18 使用 Loader... 844
18.1 从零开始使用 Loader... 844
18.2 Loader 使用简介...845
18.3 Loader 连接配置说明... 846
18.4 管理 Loader 连接(MRS 3.x 之前版本)...848
18.5 Loader 作业源连接配置说明... 850
18.6 Loader 作业目的连接配置说明...852
18.7 管理 Loader 作业...855
18.8 准备 MySQL 数据库连接的驱动... 858
18.9 Loader 日志介绍...859
18.10 样例:通过 Loader 将数据从 OBS 导入 HDFS... 862
18.11 Loader 常见问题... 863
18.11.1 IE 10&IE 11 浏览器无法保存数据... 863
18.11.2 将 Oracle 数据库中的数据导入 HDFS 时各连接器的区别...864
19 使用 Mapreduce... 866
19.1 配置日志归档和清理机制... 866
19.2 降低客户端应用的失败率... 868
19.3 将 MR 任务从 Windows 上提交到 Linux 上运行... 868
19.4 配置使用分布式缓存...869
19.5 配置 MapReduce shuffle address...871
19.6 配置集群管理员列表...872
19.7 MapReduce 日志介绍... 872
19.8 MapReduce 性能调优... 875
19.8.1 多 CPU 内核下的调优配置...875
19.8.2 确定 Job 基线... 878
19.8.3 Shuffle 调优...880
19.8.4 大任务的 AM 调优... 883
19.8.5 推测执行... 883
19.8.6 通过“Slow Start”调优... 884
19.8.7 MR job commit 阶段优化... 884
19.9 MapReduce 常见问题... 885
19.9.1 ResourceManager 进行主备切换后,任务中断后运行时间过长... 885
19.9.2 MapReduce 任务长时间无进展... 885
19.9.3 运行任务时,客户端不可用... 886
19.9.4 在缓存中找不到 HDFS_DELEGATION_TOKEN... 886
19.9.5 如何在提交 MapReduce 任务时设置任务优先级...887
19.9.6 MapReduce 任务运行失败,ApplicationMaster 出现物理内存溢出异常... 887
19.9.7 MapReduce JobHistoryServer 服务地址变更后,为什么运行完的 MapReduce 作业信息无法通过 ResourceManager Web UI 页面的 Tracking URL 打开... 888
19.9.8 多个 NameService 环境下,运行 MapReduce 任务失败... 889
19.9.9 基于分区的任务黑名单... 889
20 使用 Oozie... 891
20.1 从零开始使用 Oozie... 891
20.2 使用 Oozie 客户端... 892
20.3 使用 Oozie 客户端提交作业... 894
20.3.1 提交 Hive 任务... 894
20.3.2 提交 Spark2x 任务... 896
20.3.3 提交 Loader 任务... 897
20.3.4 提交 DistCp 任务... 899
20.3.5 提交其它任务... 901
20.4 使用 Hue 提交 Oozie 作业... 904
20.4.1 创建工作流...904
20.4.2 提交 Workflow 工作流作业... 905
20.4.2.1 提交 Hive2 作业... 905
20.4.2.2 提交 Spark2x 作业...907
20.4.2.3 提交 Java 作业... 908
20.4.2.4 提交 Loader 作业... 908
20.4.2.5 提交 Mapreduce 作业... 909
20.4.2.6 提交 Sub workflow 作业... 910
20.4.2.7 提交 Shell 作业... 911
20.4.2.8 提交 HDFS 作业... 912
20.4.2.9 提交 Streaming 作业... 912
20.4.2.10 提交 Distcp 作业...913
20.4.2.11 互信操作示例... 914
20.4.2.12 提交 SSH 作业... 915
20.4.2.13 提交 Hive 脚本... 916
20.4.3 提交 Coordinator 定时调度作业... 917
20.4.4 提交 Bundle 批处理作业... 918
20.4.5 作业结果查询... 919
20.5 Oozie 日志介绍... 919
20.6 Oozie 常见问题... 921
20.6.1 Oozie 定时任务没有准时运行... 921
20.6.2 HDFS 上更新了 oozie 的 share lib 目录但没有生效...922
21 使用 OpenTSDB... 923
21.1 使用 MRS 客户端操作 OpenTSDB 指标数据... 923
21.2 使用 curl 命令操作 OpenTSDB... 925
22 使用 Presto... 927
22.1 访问 Presto 的 WebUI... 927
22.2 使用客户端执行查询语句... 929
22.3 在 DLF 中使用 Presto 转储... 931
22.4 配置 Presto 组件权限... 932
23 使用 Ranger(MRS 1.9.2)...934
23.1 创建 Ranger 集群... 934
23.2 访问 Ranger WebUI 及同步 Unix 用户到 Ranger WebUI... 935
23.3 在 Ranger 中配置 Hive 的访问权限...937
23.4 在 Ranger 中配置 HBase 的访问权限... 942
24 使用 Ranger(MRS 3.x)... 947
24.1 登录 Ranger 管理界面... 947
24.2 启用 Ranger 鉴权... 949
24.3 配置组件权限策略... 949
24.4 查看 Ranger 审计信息... 951
24.5 配置 Ranger 安全区... 952
24.6 普通集群修改 Ranger 数据源为 Ldap... 955
24.7 查看 Ranger 权限信息... 956
24.8 添加 HDFS 的 Ranger 访问权限策略... 958
24.9 添加 HBase 的 Ranger 访问权限策略... 961
24.10 添加 Hive 的 Ranger 访问权限策略... 965
24.11 添加 Yarn 的 Ranger 访问权限策略... 974
24.12 添加 Spark2x 的 Ranger 访问权限策略... 976
24.13 添加 Kafka 的 Ranger 访问权限策略...983
24.14 添加 Storm 的 Ranger 访问权限策略... 991
24.15 Ranger 日志介绍... 994
24.16 Ranger 常见问题... 996
24.16.1 安装集群过程中,Ranger 启动失败...996
24.16.2 如何判断某个服务是否使用了 Ranger 鉴权...996
24.16.3 新创建用户修改完密码后无法登录 Ranger...997
24.16.4 Ranger 界面添加或者修改 HBase 策略时,无法使用通配符搜索已存在的 HBase 表...997
25 使用 Spark... 999
25.1 使用前须知... 999
25.2 从零开始使用 Spark... 999
25.3 从零开始使用 Spark SQL...1003
25.4 使用 Spark 客户端... 1005
25.5 访问 Spark Web UI 界面...1006
25.6 Spark 对接 OpenTSDB... 1009
25.6.1 创建表关联 OpenTSDB... 1009
25.6.2 插入数据至 OpenTSDB 表... 1010
25.6.3 查询 OpenTSDB 表... 1010
25.6.4 默认配置修改... 1011
26 使用 Spark2x...1012
26.1 使用前须知...1012
26.2 基本操作... 1012
26.2.1 快速入门... 1012
26.2.2 快速配置参数... 1015
26.2.3 常用参数... 1022
26.2.4 SparkOnHBase 概述及基本应用... 1039
26.2.5 SparkOnHBasev2 概述及基本应用... 1041
26.2.6 SparkSQL 权限管理(安全模式)... 1043
26.2.6.1 SparkSQL 权限介绍... 1043
26.2.6.2 创建 SparkSQL 角色... 1047
26.2.6.3 配置表、列和数据库的权限... 1050
26.2.6.4 配置 SparkSQL 业务使用其他组件的权限...1052
26.2.6.5 客户端和服务端配置... 1054
26.2.7 场景化参数... 1056
26.2.7.1 配置多主实例模式...1056
26.2.7.2 配置多租户模式... 1056
26.2.7.3 配置多主实例与多租户模式切换...1058
26.2.7.4 配置事件队列的大小... 1059
26.2.7.5 配置 executor 堆外内存大小...1060
26.2.7.6 增强有限内存下的稳定性...1060
26.2.7.7 配置 WebUI 上查看聚合后的 container 日志... 1062
26.2.7.8 配置 YARN-Client 和 YARN-Cluster 不同模式下的环境变量...1063
26.2.7.9 配置 SparkSQL 的分块个数...1064
26.2.7.10 配置 parquet 表的压缩格式...1065
26.2.7.11 配置 WebUI 上显示的 Lost Executor 信息的个数... 1066
26.2.7.12 动态设置日志级别... 1066
26.2.7.13 配置 Spark 是否获取 HBase Token... 1068
26.2.7.14 配置 Kafka 后进先出...1068
26.2.7.15 配置对接 Kafka 可靠性... 1070
26.2.7.16 配置流式读取 driver 执行结果... 1071
26.2.7.17 配置过滤掉分区表中路径不存在的分区... 1072
26.2.7.18 配置 Spark2x Web UI ACL... 1073
26.2.7.19 配置矢量化读取 ORC 数据... 1074
26.2.7.20 Hive 分区修剪的谓词下推增强... 1075
26.2.7.21 支持 Hive 动态分区覆盖语义...1076
26.2.7.22 配置列统计值直方图 Histogram 用以增强 CBO 准确度... 1076
26.2.7.23 配置 JobHistory 本地磁盘缓存...1078
26.2.7.24 配置 Spark SQL 开启 Adaptive Execution 特性...1079
26.2.7.25 配置 eventlog 日志回滚...1081
26.2.8 使用 Ranger 时适配第三方 JDK...1082
26.3 Spark2x 日志介绍... 1083
26.4 获取运行中 Spark 应用的 Container 日志... 1086
26.5 小文件合并工具... 1086
26.6 CarbonData 首查优化工具... 1088
26.7 Spark2x 性能调优... 1090
26.7.1 Spark Core 调优...1090
26.7.1.1 数据序列化...1090
26.7.1.2 配置内存... 1091
26.7.1.3 设置并行度...1091
26.7.1.4 使用广播变量... 1092
26.7.1.5 Yarn 模式下动态资源调度...1092
26.7.1.6 配置进程参数... 1094
26.7.1.7 设计 DAG...1095
26.7.1.8 经验总结... 1097
26.7.2 SQL 和 DataFrame 调优...1098
26.7.2.1 Spark SQL join 优化...1099
26.7.2.2 优化数据倾斜场景下的 Spark SQL 性能...1100
26.7.2.3 优化小文件场景下的 Spark SQL 性能... 1102
26.7.2.4 INSERT...SELECT 操作调优... 1103
26.7.2.5 多并发 JDBC 客户端连接 JDBCServer... 1103
26.7.2.6 动态分区插入场景内存优化... 1104
26.7.2.7 小文件优化...1104
26.7.2.8 聚合算法优化... 1105
26.7.2.9 Datasource 表优化... 1106
26.7.2.10 合并 CBO 优化... 1107
26.7.2.11 跨源复杂数据的 SQL 查询优化... 1108
26.7.2.12 多级嵌套子查询以及混合 Join 的 SQL 调优... 1111
26.7.3 Spark Streaming 调优... 1113
26.8 Spark2x 常见问题... 1114
26.8.1 Spark Core... 1114
26.8.1.1 日志聚合下,如何查看 Spark 已完成应用日志... 1115
26.8.1.2 Driver 返回码和 RM WebUI 上应用状态显示不一致... 1115
26.8.1.3 为什么 Driver 进程不能退出... 1115
26.8.1.4 网络连接超时导致 FetchFailedException... 1116
26.8.1.5 当事件队列溢出时如何配置事件队列的大小... 1117
26.8.1.6 Spark 应用执行过程中,日志中一直打印 getApplicationReport 异常且应用较长时间不退出... 1118
26.8.1.7 Spark 执行应用时上报“Connection to ip:port has been quiet for xxx ms while there are outstanding requests”并导致应用结束... 1118
26.8.1.8 NodeManager 关闭导致 Executor(s)未移除... 1120
26.8.1.9 Password cannot be null if SASL is enabled 异常... 1120
26.8.1.10 向动态分区表中插入数据时,在重试的 task 中出现"Failed to CREATE_FILE"异常...1121
26.8.1.11 使用 Hash shuffle 出现任务失败... 1121
26.8.1.12 访问 Spark 应用的聚合日志页面报“DNS 查找失败”错误... 1122
26.8.1.13 由于 Timeout waiting for task 异常导致 Shuffle FetchFailed...1123
26.8.1.14 Executor 进程 Crash 导致 Stage 重试...1123
26.8.1.15 执行大数据量的 shuffle 过程时 Executor 注册 shuffle service 失败... 1124
26.8.1.16 在 Spark 应用执行过程中 NodeManager 出现 OOM 异常... 1125
26.8.1.17 安全集群使用 HiBench 工具运行 sparkbench 获取不到 realm...1126
26.8.2 SQL 和 DataFrame... 1127
26.8.2.1 Spark SQL 在不同 DB 都可以显示临时表... 1127
26.8.2.2 如何在 Spark 命令中指定参数值... 1128
26.8.2.3 SparkSQL 建表时的目录权限...1128
26.8.2.4 为什么不同服务之间互相删除 UDF 失败...1129
26.8.2.5 Spark SQL 无法查询到 Parquet 类型的 Hive 表的新插入数据... 1130
26.8.2.6 cache table 使用指导... 1130
26.8.2.7 Repartition 时有部分 Partition 没数据... 1131
26.8.2.8 16T 的文本数据转成 4T Parquet 数据失败...1131
26.8.2.9 当表名为 table 时,执行相关操作时出现异常...1132
26.8.2.10 执行 analyze table 语句,因资源不足出现任务卡住... 1133
26.8.2.11 为什么有时访问没有权限的 parquet 表时,在上报“Missing Privileges”错误提示之前,会运行一 个Job?...1133
26.8.2.12 执行 Hive 命令修改元数据时失败或不生效...1134
26.8.2.13 spark-sql 退出时打印 RejectedExecutionException 异常栈...1134
26.8.2.14 健康检查时,误将 JDBCServer Kill...1134
26.8.2.15 日期类型的字段作为过滤条件时匹配'2016-6-30'时没有查询结果...1135
26.8.2.16 为什么在启动 spark-beeline 的命令中指定“--hivevar”选项无效...1135
26.8.2.17 在 spark-beeline 中创建临时表/视图时,报 HDFS 目录无权限操作的错误... 1136
26.8.2.18 执行复杂 SQL 语句时报“Code of method ... grows beyond 64 KB”的错误... 1136
26.8.2.19 在 Beeline/JDBCServer 模式下连续运行 10T 的 TPCDS 测试套会出现内存不足的现象...1137
26.8.2.20 连上不同的 JDBCServer,function 不能正常使用... 1137
26.8.2.21 用 add jar 方式创建 function,执行 drop function 时出现问题... 1139
26.8.2.22 Spark2x 无法访问 Spark1.5 创建的 DataSource 表...1140
26.8.2.23 为什么 spark-beeline 运行失败报“Failed to create ThriftService instance”的错误... 1141
26.8.3 Spark Streaming... 1142
26.8.3.1 Streaming 任务打印两次相同 DAG 日志...1142
26.8.3.2 Spark Streaming 任务一直阻塞...1143
26.8.3.3 运行 Spark Streaming 任务参数调优的注意事项... 1144
26.8.3.4 为什么提交 Spark Streaming 应用超过 token 有效期,应用失败...1144
26.8.3.5 为什么 Spark Streaming 应用创建输入流,但该输入流无输出逻辑时,应用从 checkpoint 恢复启动 失败... 1145
26.8.3.6 Spark Streaming 应用运行过程中重启 Kafka,Web UI 界面部分 batch time 对应 Input Size 为 0 records... 1147
26.8.4 访问 Spark 应用获取的 restful 接口信息有误... 1148
26.8.5 为什么从 Yarn Web UI 页面无法跳转到 Spark Web UI 界面... 1149
26.8.6 HistoryServer 缓存的应用被回收,导致此类应用页面访问时出错...1150
26.8.7 加载空的 part 文件时,app 无法显示在 JobHistory 的页面上...1150
26.8.8 Spark2x 导出带有相同字段名的表,结果导出失败... 1151
26.8.9 为什么多次运行 Spark 应用程序会引发致命 JRE 错误...1151
26.8.10 IE 浏览器访问 Spark2x 原生 UI 界面失败,无法显示此页或者页面显示错误... 1151
26.8.11 Spark2x 如何访问外部集群组件... 1152
26.8.12 对同一目录创建多个外表,可能导致外表查询失败... 1154
26.8.13 访问 Spark2x JobHistory 中某个应用的原生页面时页面显示错误... 1154
26.8.14 对接 OBS 场景中,spark-beeline 登录后指定 loaction 到 OBS 建表失败...1155
26.8.15 Spark shuffle 异常处理... 1156
27 使用 Sqoop... 1157
27.1 从零开始使用 Sqoop... 1157
27.2 Sqoop1.4.7 适配 MRS 3.x 集群... 1161
27.3 Sqoop 常用命令及参数介绍... 1163
27.4 Sqoop 常见问题...1165
27.4.1 报错找不到 QueryProvider 类... 1165
27.4.2 使用 hcatalog 方式同步数据,报错 getHiveClient 方法不存在... 1166
27.4.3 连接 postgresql 或者 gaussdb 时报错...1167
27.4.4 使用 hive-table 方式同步数据到 obs 上的 hive 表报错... 1168
27.4.5 使用 hive-table 方式同步数据到 orc 表或者 parquet 表失败... 1168
27.4.6 使用 hive-table 方式同步数据报错...1169
27.4.7 使用 hcatalog 方式同步 hive parquet 表报错...1169
27.4.8 使用 Hcatalog 方式同步 Hive 和 MySQL 之间的数据,timestamp 和 data 类型字段会报错... 1170
28 使用 Storm... 1171
28.1 从零开始使用 Storm... 1171
28.2 使用 Storm 客户端... 1172
28.3 使用客户端提交 Storm 拓扑... 1173
28.4 访问 Storm 的 WebUI...1174
28.5 管理 Storm 拓扑... 1175
28.6 查看 Storm 拓扑日志... 1176 28.7 Storm 常用参数... 1177 28.8 配置 Storm 业务用户密码策略...1178 28.9 迁移 Storm 业务至 Flink... 1180 28.9.1 概述... 1180 28.9.2 完整迁移 Storm 业务...1180 28.9.3 嵌入式迁移 Storm 业务... 1182 28.9.4 迁移 Storm 对接的外部安全组件业务... 1182 28.10 Storm 日志介绍... 1183 28.11 性能调优... 1187 28.11.1 Storm 性能调优... 1187
29 使用 Tez...1190
29.1 使用前须知...1190 29.2 Tez 常用参数... 1190 29.3 访问 TezUI...1190 29.4 日志介绍... 1191 29.5 常见问题... 1193 29.5.1 TezUI 无法展示 Tez 任务执行细节... 1193 29.5.2 进入 Tez 原生界面显示异常... 1193 29.5.3 TezUI 界面无法查看 yarn 日志... 1194 29.5.4 TezUI HiveQueries 界面表格数据为空... 1195
30 使用 Yarn... 1196
30.1 Yarn 常用参数... 1196 30.2 创建 Yarn 角色... 1199 30.3 使用 Yarn 客户端...1201 30.4 配置 NodeManager 角色实例使用的资源... 1202 30.5 更改 NodeManager 的存储目录... 1203 30.6 配置 YARN 严格权限控制... 1207 30.7 配置 Container 日志聚合功能... 1208 30.8 启用 CGroups 功能... 1212 30.9 配置 AM 失败重试次数...1214 30.10 配置 AM 自动调整分配内存... 1215 30.11 配置访问通道协议... 1216 30.12 检测内存使用情况... 1217 30.13 配置自定义调度器的 WebUI... 1218 30.14 配置 YARN Restart 特性... 1218 30.15 配置 AM 作业保留... 1220 30.16 配置本地化日志级别... 1221 30.17 配置运行任务的用户... 1222 30.18 Yarn 日志介绍...1223 30.19 Yarn 性能调优...1226 30.19.1 抢占任务... 1226
30.19.2 任务优先级...1228 30.19.3 节点配置调优... 1229 30.20 Yarn 常见问题...1234 30.20.1 任务完成后 Container 挂载的文件目录未清除... 1234 30.20.2 作业执行失败时会抛出 HDFS_DELEGATION_TOKEN 到期的异常...1234 30.20.3 重启 YARN,本地日志不被删除...1234 30.20.4 为什么执行任务时 AppAttempts 重试次数超过 2 次还没有运行失败... 1235 30.20.5 为什么在 ResourceManager 重启后,应用程序会移回原来的队列... 1235 30.20.6 为什么 YARN 资源池的所有节点都被加入黑名单,而 YARN 却没有释放黑名单,导致任务一直处于运 行状态... 1236 30.20.7 ResourceManager 持续主备倒换... 1236 30.20.8 当一个 NodeManager 处于 unhealthy 的状态 10 分钟时,新应用程序失败... 1237 30.20.9 Superior 通过 REST 接口查看已结束或不存在的 applicationID,返回的页面提示 Error Occurred. 1237 30.20.10 Superior 调度模式下,单个 NodeManager 故障可能导致 MapReduce 任务失败... 1237 30.20.11 当应用程序从 lost_and_found 队列移动到其他队列时,应用程序不能继续执行...1238 30.20.12 如何限制存储在 ZKstore 中的应用程序诊断消息的大小... 1239 30.20.13 为什么将非 ViewFS 文件系统配置为 ViewFS 时 MapReduce 作业运行失败...1239 30.20.14 开启 Native Task 特性后,Reduce 任务在部分操作系统运行失败... 1240
31 使用 ZooKeeper...1241
31.1 ZooKeeper 权限设置指南... 1241
32 附录...1245
32.1 修改集群服务配置参数... 1245 32.2 访问集群 Manager... 1249 32.2.1 访问 MRS Manager(MRS 3.x 之前版本)... 1249 32.2.2 访问 FusionInsight Manager(MRS 3.x 及之后版本)... 1255 32.3 使用 MRS 客户端... 1259 32.3.1 安装客户端(3.x 及之后版本)... 1259 32.3.2 安装客户端(3.x 之前版本)... 1264 32.3.3 更新客户端(3.x 及之后版本)... 1268 32.3.4 更新客户端(3.x 之前版本)... 1270
1 使用 Alluxio
1.1 配置底层存储系统
用户想要通过统一的客户端API和全局命名空间访问包括HDFS和OBS在内的持久化存 储系统,从而实现了对计算和存储的分离时,可以在MRS Manager页面中配置Alluxio 的底层存储系统来实现。集群创建后,默认的底层存储地址是hdfs://hacluster/,即将 HDFS的根目录映射到Alluxio。
前提条件
● 已安装Alluxio服务的集群。
● 获取用户“admin”帐号密码。“admin”密码在创建MRS集群时由用户指定。
配置 HDFS 作为 Alluxio 的底层文件系统
说明
开启Kerberos认证的安全集群不支持该功能。
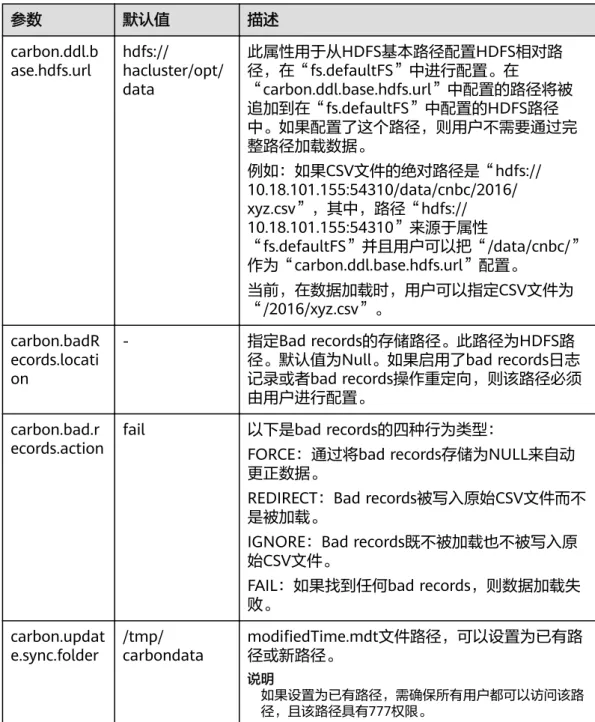
步骤1 请参考修改集群服务配置参数,进入Alluxio的“全部配置”页面。
步骤2 在左侧边栏中选择“Alluxio > 底层存储系统”,修改参数
“alluxio.master.mount.table.root.ufs”的值为“hdfs://hacluster/XXX/”。
例如:若想将“HDFS根目录/alluxio/”作为alluxio的根目录,则修改参数
“alluxio.master.mount.table.root.ufs”的值为“hdfs://hacluster/alluxio/”。
图1-1 HDFS 作为 Alluxio 的底层文件系统
步骤3 单击“保存配置”,并在弹出窗口中勾选“重新启动受影响的服务和实例。”
步骤4 单击“确定”重启Alluxio服务。
----结束
配置 Huawei OBS 作为 Alluxio 的底层文件系统
方法一:
步骤1 给集群配置有OBS OperateAccess权限的委托,具体请参见配置存算分离集群(委托 方式)。
步骤2 请参考修改集群服务配置参数,进入Alluxio的“全部配置”页面。
步骤3 在左侧边栏中选择“Alluxio > 底层存储系统”,修改参数
“alluxio.master.mount.table.root.ufs”的值为“obs://<OBS_BUCKET>/
<OBS_DIRECTORY>/”。OBS_BUCKET为一个已有的OBS文件系统名,
OBS_DIRECTORY为该文件系统下的目录。
图1-2 OBS 作为 Alluxio 的底层文件系统
步骤4 单击“保存配置”,并在弹出窗口中勾选“重新启动受影响的服务和实例。”
步骤5 单击“确定”重启Alluxio服务。
----结束 方法二:
步骤1 给集群配置有OBS OperateAccess权限的委托,具体请参见配置存算分离集群(委托 方式)。
步骤2 登录主Master节点,主节点请参考如何确认MRS Manger的主备管理节点。
步骤3 执行如下命令,配置环境变量。
source /opt/client/bigdata_env 说明
/opt/client为举例当前集群客户端的安装目录,请根据实际情况修改。
步骤4 执行如下命令将OBS容器内部的目录挂载到Alluxio的/obs目录。
alluxio fs mount /obs obs://<OBS_BUCKET>/<OBS_DIRECTORY>/
----结束
1.2 通过数据应用访问 Alluxio
访问Alluxio文件系统的端口号是19998,即地址为alluxio://<alluxio的master节点ip>:
19998/<PATH>,本节将通过示例介绍如何通过数据应用(Spark、Hive、Hadoop MapReduce和Presto)访问Alluxio。
使用 Alluxio 作为 Spark 应用程序的输入和输出
步骤1 以root用户登录集群的Master节点,密码为用户创建集群时设置的root密码。
步骤2 执行如下命令,配置环境变量。
source /opt/client/bigdata_env
步骤3 如果当前集群已启用Kerberos认证,执行如下命令认证当前用户。如果当前集群未启 用Kerberos认证,则无需执行此命令。
kinit MRS集群用户 例如, kinit admin
步骤4 准备输入文件,将本地数据复制到Alluxio文件系统中。
如在本地/home目录下准备一个输入文件test_input.txt,然后执行如下命令,将 test_input.txt文件放入Alluxio中。
alluxio fs copyFromLocal /home/test_input.txt /input 步骤5 执行如下命令启动spark-shell。
spark-shell
步骤6 在spark-shell中运行如下命令。
val s = sc.textFile("alluxio://<Alluxio的节点名称>:19998/input") val double = s.map(line => line + line)
double.saveAsTextFile("alluxio://<Alluxio的节点名称>:19998/output") 说明
<Alluxio的节点名称>:19998,请根据实际情况替换为AlluxioMaster实例所在所有节点的节点名 称与端口号,各个名称与端口之间以英文逗号间隔,例如:node-ana-coremspb.mrs-
m0va.com:19998,node-master2kiww.mrs-m0va.com:19998,node-master1cqwv.mrs- m0va.com:19998
步骤7 使用“Ctrl + C”退出spark-shell。
步骤8 通过alluxio命令行alluxio fs ls /查看alluxio根目录下存在一个输出目录/output,其中 包含了输入文件input的双倍内容。
----结束
在 Alluxio 上创建 Hive 表
步骤1 以root用户登录集群的Master节点,密码为用户创建集群时设置的root密码。
步骤2 执行如下命令,配置环境变量。
source /opt/client/bigdata_env
步骤3 如果当前集群已启用Kerberos认证,执行如下命令认证当前用户。如果当前集群未启 用Kerberos认证,则无需执行此命令。
kinit MRS集群用户 例如, kinit admin
步骤4 准备输入文件,如在本地/home目录下准备一个输入文件hive_load.txt, 内容为
1, Alice, company A 2, Bob, company B
步骤5 执行如以下命令,将hive_load.txt文件放入Alluxio中。
alluxio fs copyFromLocal /home/hive_load.txt /hive_input 步骤6 执行如下命令启动hive beeline。
beeline
步骤7 在beeline中运行如下命令,根据Alluxio中的输入文件进行创表。
CREATE TABLE u_user(id INT, name STRING, company STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
LOAD DATA INPATH 'alluxio://<Alluxio的节点名称>:19998/hive_input' INTO TABLE u_user;
说明
<Alluxio的节点名称>:19998,请根据实际情况替换为AlluxioMaster实例所在所有节点的节点名 称与端口号,各个名称与端口之间以英文逗号间隔,例如:node-ana-coremspb.mrs-
m0va.com:19998,node-master2kiww.mrs-m0va.com:19998,node-master1cqwv.mrs- m0va.com:19998
步骤8 执行如下命令查看创建的表。
select * from u_user;
----结束
在 Alluxio 上运行 Hadoop Wordcount
步骤1 以root用户登录集群的Master节点,密码为用户创建集群时设置的root密码。
步骤2 执行如下命令,配置环境变量。
source /opt/client/bigdata_env
步骤3 如果当前集群已启用Kerberos认证,执行如下命令认证当前用户。如果当前集群未启 用Kerberos认证,则无需执行此命令。
kinit MRS集群用户 例如, kinit admin
步骤4 准备输入文件,将本地数据复制到Alluxio文件系统中。
如在本地/home目录下准备一个输入文件test_input.txt,然后执行如下命令,将 test_input.txt文件放入Alluxio中。
alluxio fs copyFromLocal /home/test_input.txt /input 步骤5 通过yarn jar执行wordcount作业。
yarn jar /opt/share/hadoop-mapreduce-examples-<hadoop版本号>-mrs-<mrs 集群版本号>/hadoop-mapreduce-examples-<hadoop版本号>-mrs-<mrs集群版本 号>.jar wordcount alluxio://<Alluxio的节点名称>:19998/input alluxio://<Alluxio 的节点名称>:19998/output
说明
● <hadoop版本号>请根据实际情况替换。
● <mrs集群版本号>替换为MRS的大版本号,如MRS 1.9.2版本集群此处为mrs-1.9.0。
● <Alluxio的节点名称>:19998,请根据实际情况替换为AlluxioMaster实例所在所有节点的节 点名称与端口号,各个名称与端口之间以英文逗号间隔,例如:node-ana-coremspb.mrs- m0va.com:19998,node-master2kiww.mrs-m0va.com:19998,node-master1cqwv.mrs- m0va.com:19998
步骤6 通过alluxio命令行alluxio fs ls /查看alluxio根目录下存在一个输出目录/output,包含 了wordcount的结果。
----结束
使用 Presto 在 Alluxio 上查询表
步骤1 以root用户登录集群的Master节点,密码为用户创建集群时设置的root密码。
步骤2 执行如下命令,配置环境变量。
source /opt/client/bigdata_env
步骤3 如果当前集群已启用Kerberos认证,执行如下命令认证当前用户。如果当前集群未启 用Kerberos认证,则无需执行此命令。
kinit MRS集群用户 例如, kinit admin
步骤4 启动hive beeline在alluxio上创建表。
beeline
CREATE TABLE u_user (id int, name string, company string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION 'alluxio://<Alluxio的节点名称
>:19998/u_user';
insert into u_user values(1,'Alice','Company A'),(2, 'Bob', 'Company B');
说明
<Alluxio的节点名称>:19998,请根据实际情况替换为AlluxioMaster实例所在所有节点的节点名 称与端口号,各个名称与端口之间以英文逗号间隔,例如:node-ana-coremspb.mrs-
m0va.com:19998,node-master2kiww.mrs-m0va.com:19998,node-master1cqwv.mrs- m0va.com:19998
步骤5 启动Presto客户端,具体请参见使用客户端执行查询语句的步骤2~步骤8。
步骤6 在Presto客户端中执行查询语句select * from hive.default.u_user; 查询alluxio上创 建表。
图1-3 Presto 查询 alluxio 上创建的表
----结束
1.3 Alluxio 常用操作
前期准备
1. 创建安装Alluxio组件的集群。
2. 以root用户登录集群的主Master节点,密码为用户创建集群时设置的root密码。
3. 执行如下命令,配置环境变量。
source /opt/client/bigdata_env
使用 Alluxio Shell
Alluxio shell包含多种与Alluxio交互的命令行操作。
● 要查看文件系统操作命令列表。
alluxio fs
● 使用ls命令列出 Alluxio 里的文件。例如列出根目录下所有文件。
alluxio fs ls /
● 使用copyFromLocal命令可以复制本地文件到 Alluxio 中。
alluxio fs copyFromLocal /home/test_input.txt /test_input.txt 命令执行后回显:
Copied file:///home/test_input.txt to /test_input.txt
● 再次使用ls命令列出Alluxio中的文件,可以看到刚刚拷贝的test_input.txt文件。
alluxio fs ls / 命令执行后回显:
12 PERSISTED 11-28-2019 17:10:17:449 100% /test_input.txt
输出显示test_input.txt 文件在 Alluxio 中,各参数含义为文件的大小、是否被持 久化、创建日期、Alluxio中这个文件的缓存占比、文件名。
● 使用cat命令打印文件的内容。
alluxio fs cat /test_input.txt 命令执行后回显:
Test Alluxio
Alluxio 中的挂载功能
Alluxio 通过统一命名空间的特性统一了对存储系统的访问。详情请参考:https://
docs.alluxio.io/os/user/2.0/cn/advanced/Namespace-Management.html 这个特性允许用户挂载不同的存储系统到Alluxio命名空间中并且通过Alluxio命名空间 无缝地跨存储系统访问文件。
1. 在 Alluxio 中创建一个目录作为挂载点。
alluxio fs mkdir /mnt
Successfully created directory /mnt
2. 挂载一个已有的OBS文件系统到Alluxio(前提:给集群配置有OBS
OperateAccess权限的委托,具体请参见配置存算分离集群(委托方式))。此处 以obs-mrstest文件系统为例,请根据实际情况替换文件系统名。
alluxio fs mount /mnt/obs obs://obs-mrstest/data
Mounted obs://obs-mrstest/data at /mnt/obs
3. 通过Alluxio命名空间列出OBS文件系统中的文件。使用ls命令列出OBS挂载目录下 的文件。
alluxio fs ls /mnt/obs
38 PERSISTED 11-28-2019 17:42:54:554 0% /mnt/obs/hive_load.txt 12 PERSISTED 11-28-2019 17:43:07:743 0% /mnt/obs/test_input.txt
新挂载的文件和目录也可以通过Alluxio WebUI查看。
4. 挂载完成后,通过 Alluxio 统一命名空间,可以无缝地从不同存储系统中交互数 据。例如,使用ls -R命令,递归地列举出一个目录下的所有文件。
alluxio fs ls -R /
0 PERSISTED 11-28-2019 11:15:19:719 DIR /app-logs 1 PERSISTED 11-28-2019 11:18:36:885 DIR /apps
1 PERSISTED 11-28-2019 11:18:40:209 DIR /apps/templeton
239440292 PERSISTED 11-28-2019 11:18:40:209 0% /apps/templeton/hive.tar.gz ...
1 PERSISTED 11-28-2019 19:00:23:879 DIR /mnt 2 PERSISTED 11-28-2019 19:00:23:879 DIR /mnt/obs
38 PERSISTED 11-28-2019 17:42:54:554 0% /mnt/obs/hive_load.txt 12 PERSISTED 11-28-2019 17:43:07:743 0% /mnt/obs/test_input.txt ...
输出显示了Alluxio文件系统根目录(默认值是HDFS的根目录,即hdfs://
hacluster/)中来源于挂载存储系统的所有文件。/app-logs和/apps目录在HDFS 文件系统中,/mnt/obs/目录在OBS 中。
用 Alluxio 加速数据访问
由于Alluxio利用内存存储数据,它可以加速数据的访问。例如:
1. 上传一个文件test_data.csv(文件是一份记录了食谱的样本)到obs-mrstest文件 系统的/data目录下。通过ls命令显示文件状态:
alluxio fs ls /mnt/obs/test_data.csv
294520189 PERSISTED 11-28-2019 19:38:55:000 0% /mnt/obs/test_data.csv
输出显示了该文件在Alluxio中缓存占比为0%,即不在Alluxio内存中。
2. 统计该文件中单词"milk"出现的次数,并计算耗时。
time alluxio fs cat /mnt/obs/test_data.csv | grep -c milk
52180
real 0m10.765s user 0m5.540s sys 0m0.696s
3. 第一次读取数据后会将数据放在内存中,Alluxio再次读取时可以提高访问该数据 的速度。例如:在通过cat命令获取文件后,用ls命令再查看文件的状态。
alluxio fs ls /mnt/obs/test_data.csv
294520189 PERSISTED 11-28-2019 19:38:55:000 100% /mnt/obs/test_data.csv
输出显示文件已经 100% 被加载到 Alluxio 中。
4. 再次访问该文件,统计单词“eggs”出现的次数,并计算耗时。
time alluxio fs cat /mnt/obs/test_data.csv | grep -c eggs
59510
real 0m5.777s user 0m5.992s sys 0m0.592s
对比两次耗时可以看出存储在Alluxio内存中的数据,数据访问耗时明显缩短。
2 使用 CarbonData(MRS 3.x 之前版本)
2.1 CarbonData 入门
MRS 3.x之前版本参考本章节,MRS 3.x及后续版本请参考使用CarbonData(MRS 3.x及之后版本)。
本章节介绍使用Spark CarbonData的基本流程,所有任务场景基于spark-beeline环 境。CarbonData快速入门包含以下任务:
1. 连接到Spark
在对CarbonData进行任何操作之前,需要先连接到Spark。
2. 创建CarbonData表
连接CarbonData之后,需要创建CarbonData Table,用于加载数据和执行查询操 作。
3. 加载数据到CarbonData表
用户从HDFS中的CSV文件加载数据到所创建的表中。
4. 在CarbonData中查询数据
在CarbonData表加载数据之后,用户可以执行所需的查询操作,例如groupby或 者where等。
前提条件
已安装客户端,具体参见使用MRS客户端。
操作步骤
步骤1 连接到Spark CarbonData。
1. 根据业务情况,准备好客户端,使用root用户登录安装客户端的节点。
例如在Master2节点更新客户端,则在该节点登录客户端,具体参见使用MRS客 户端。
2. 切换用户与配置环境变量。
sudo su - omm
source /opt/client/bigdata_env
3. 启用Kerberos认证的集群,执行以下命令认证用户身份。未启用Kerberos认证集 群无需执行。
kinit Spark组件用户名 说明
用户需要加入用户组hadoop、hive,主组hadoop。
4. 执行以下命令,连接到Spark运行环境:
spark-beeline
步骤2 执行命令创建CarbonData表。
CarbonData表可用于加载数据和执行查询操作,例如执行以下命令创建CarbonData 表:
CREATE TABLE x1 (imei string, deviceInformationId int, mac string, productdate timestamp, updatetime timestamp, gamePointId double, contractNumber double)
STORED BY 'org.apache.carbondata.format' TBLPROPERTIES
('DICTIONARY_EXCLUDE'='mac','DICTIONARY_INCLUDE'='deviceInformationId' );
命令执行结果如下:
+---+--+
| result | +---+--+
+---+--+
No rows selected (1.551 seconds)
步骤3 从CSV文件加载数据到CarbonData表。
根据所要求的参数运行命令从CSV文件加载数据,且仅支持CSV文件。LOAD命令中配 置的CSV列名,需要和CarbonData表列名相同,顺序也要对应。CSV文件中的数据的 列数,以及数据格式需要和CarbonData表匹配。
文件需要保存在HDFS中。用户可以将文件上传到OBS,并在MRS管理控制台“文件管 理”将文件从OBS导入HDFS,具体请参考导入导出数据。
如果集群启用了Kerberos认证,则需要在工作环境准备CSV文件,然后可以使用开源 HDFS命令,参考5将文件从工作环境导入HDFS,并设置Spark组件用户在HDFS中对文 件有读取和执行的权限。
例如,HDFS的“tmp”目录有一个文件“data.csv”,内容如下:
x123,111,dd,2017-04-20 08:51:27,2017-04-20 07:56:51,2222,33333
执行导入命令:
LOAD DATA inpath 'hdfs://hacluster/tmp/data.csv' into table x1 options('DELIMITER'=',','QUOTECHAR'='"','FILEHEADER'='imei,
deviceinformationid,mac,productdate,updatetime,gamepointid,contractnumb er');
命令执行结果如下:
+---+--+
| Result |
+---+--+
+---+--+
No rows selected (3.039 seconds)
步骤4 在CarbonData中查询数据。
● 获取记录数
为了获取在CarbonData table中的记录数,可以执行以下命令。
select count(*) from x1;
● 使用Groupby查询
为了获取不重复的“deviceinformationid”记录数,可以执行以下命令。
select deviceinformationid,count (distinct deviceinformationid) from x1 group by deviceinformationid;
● 使用条件查询
为了获取特定deviceinformationid的记录,可以执行以下命令。
select * from x1 where deviceinformationid='111';
说明
在执行数据查询操作后,如果查询结果中某一列的结果含有中文字等其他非英文字符,会导致查 询结果中的列不能对齐,这是由于不同语言的字符在显示时所占的字宽不尽相同。
步骤5 执行以下命令退出Spark运行环境。
!quit ----结束
2.2 CarbonData 表简介
简介
CarbonData表与RDBMS中的表类似,RDBMS数据存储在由行和列构成的表中。
CarbonData表存储的也是结构化的数据,具有固定列和数据类型。CarbonData中的 数据存储在表实体文件中。
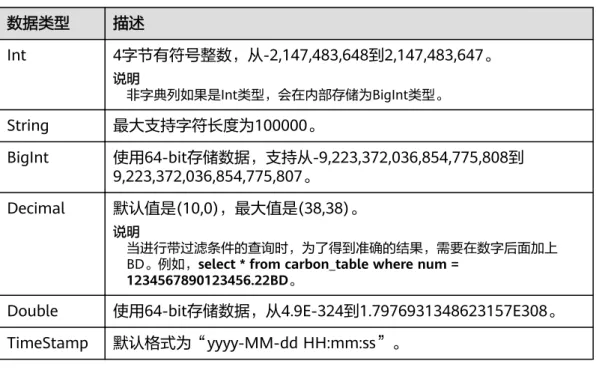
支持的数据类型
CarbonData表支持以下数据类型:
● Int
● String
● BigInt
● Decimal
● Double
● TimeStamp
表2-1对所支持的数据类型和对应的范围进行了详细说明。
表2-1 CarbonData 数据类型
数据类型 描述
Int 4字节有符号整数,从-2,147,483,648到2,147,483,647。
说明非字典列如果是Int类型,会在内部存储为BigInt类型。
String 最大支持字符长度为100000。
BigInt 使用64-bit存储数据,支持从-9,223,372,036,854,775,808到 9,223,372,036,854,775,807。
Decimal 默认值是(10,0),最大值是(38,38)。
说明
当进行带过滤条件的查询时,为了得到准确的结果,需要在数字后面加上 BD。例如,select * from carbon_table where num =
1234567890123456.22BD。
Double 使用64-bit存储数据,从4.9E-324到1.7976931348623157E308。
TimeStamp 默认格式为“yyyy-MM-dd HH:mm:ss”。
说明
所有Integer类型度量均以BigInt类型进行处理与显示。
2.3 创建 CarbonData 表
操作场景
使用CarbonData前需先创建表,才可从表中加载数据和查询数据。
使用自定义列创建表
可通过指定各列及其数据类型来创建表。启用Kerberos认证的分析集群创建
CarbonData表时,如果用户需要在默认数据库“default”以外的数据库创建新表,则 需要在Hive角色管理中为用户绑定的角色添加指定数据库的“Create”权限。
命令示例:
CREATE TABLE IF NOT EXISTS productdb.productSalesTable ( productNumber Int,
productName String, storeCity String, storeProvince String, revenue Int)
STORED BY 'org.apache.carbondata.format' TBLPROPERTIES (
'table_blocksize'='128',
'DICTIONARY_EXCLUDE'='productName', 'DICTIONARY_INCLUDE'='productNumber');
上述命令所创建的表的详细信息如下:
表2-2 表信息定义
参数 描述
productSalesTable 待创建的表的名称。该表用于加载数据进行分析。
表名由字母、数字、下划线组成。
productdb 数据库名称。该数据库将与其中的表保持逻辑连接以便于 识别和管理。
数据库名称由字母、数字、下划线组成。
productNumber productName storeCity storeProvince revenue
表中的列,代表执行分析所需的业务实体。
列名(字段名)由字母、数字、下划线组成。
说明CarbonData暂不支持设置列是否允许为空、默认值以及主键。
table_blocksize CarbonData表使用的数据文件的block大小,默认值为 1024,取值范围为1~2048,单位为MB。
● 如果“table_blocksize”值太小,数据加载时将生成过 多的小数据文件,可能会影响HDFS的使用性能。
● 如果“table_blocksize”值太大,数据查询时索引匹配 的block数据量较大,导致读取并发度不高,从而降低 查询性能。
一般情况下,建议根据数据量级别来选择大小。例如:GB 级别用256,TB级别用512,PB级别用1024。
DICTIONARY_EXCLUD
E 设置指定列不生成字典,适用于数值复杂度高的列。系统
默认为String类型的列做字典编码,但是如果字典值过多,
会导致字典转换操作增加造成性能下降。
一般情况下,列的数值复杂度高于5万,可以被认定为高复 杂度,则需要排除掉字典编码,该参数为可选参数。
说明在非字典列中,只支持String和Timestamp数据类型。
DICTIONARY_INCLUD
E 设置指定列生成字典,适用于数值复杂度低的列,可以提
升字典列上的groupby性能,为可选参数。一般情况下,
字典列的复杂度不应该高于5万。
2.4 删除 CarbonData 表
操作场景
用户根据业务使用情况,可以删除不再使用的CarbonData表。删除表后,其所有的元 数据以及表中已加载的数据都会被删除。
操作步骤
步骤1 运行如下命令删除表。
DROP TABLE [IF EXISTS] [db_name.]table_name;
“db_name”为可选参数。如果没有指定“db_name”,那么将会删除当前数据库下 名为“table_name”的表。
例如执行命令,删除数据库“productdb”下的表“productSalesTable”:
DROP TABLE productdb.productSalesTable;
步骤2 执行以下命令查询表是否被删除:
SHOW TABLES;
----结束