doi:10.6342/NTU202003608
國立臺灣大學進修推廣學院事業經營法務碩士在職學位學程 碩士論文
Professional Master's Program of Law in Business Administration School of Professional Education and Continuing Studies
National Taiwan University Master Thesis
人工智慧「民主化」與經濟體制變革-以限制競爭規範為出發點 Democratizing Artificial Intelligence and Reform of Economic System
-From the Restraints of Competition
莊一凡 Yi-Fan Chuang
指導教授:黃銘傑 博士 Advisor: Ming-Jye Huang, Ph.D.
中華民國 109 年 7 月 July, 2020
doi:10.6342/NTU202003608
doi:10.6342/NTU202003608
i
謝辭
在執業六年後還可以回到學校唸書,我由衷感謝民視王明玉董事長與謝國光 董事長特助的栽培;同時感謝我的指導律師李兆環博士推薦我進入臺大唸書。過去 兩年或有學習與創業的緣故而疏於問候,但是我對於您們過往的提拔與指導始終 感懷於心,謹再致上我最深的敬意與感謝。
對於一般實務工作者而言,人工智慧與競爭法都不會是容易駕馭的論文題目,
我能將二者結合完全是來自指導教授黃銘傑老師的啟發。不過在完成本論文之後,
我已經無法用感謝形容想對黃老師說的話,只能說何其有幸成為老師指導的學生,
我也歷經了一次值回票價的奇幻旅程。
特別感謝口試委員顏雅倫老師與莊弘鈺老師仔細審視我各種天馬行空的想法,
經過老師們悉心的指導我才能夠完成這個題目;同時感謝我們助教謝佳縈律師對 論文格式的建議;以及在本論文完成之際,陪我探討人工智慧民主化的莊季凡律師 與李雨樵工程師,謝謝各位寶貴的看法與建議,我早已銘記於心。
回顧科技產業趨勢,我國雖然在 1990 年代跟進半導體發展,卻從 2000 年代 的網際網路趨勢中開始掉隊,到了 2010 年代的社群網路發展更是遠遠落後鄰國,
著實可惜;展望2020 年代,人工智慧具備沛然莫之能禦的趨勢,期望我國這次能 再度跟進潮流,避免被世界邊緣化。最後希冀本論文能為人工智慧議題拋磚引玉,
謹將本論文獻給每一位勇於挑戰自己的夢想家。
2020 年 8 月 14 日 林口
doi:10.6342/NTU202003608
ii
摘要
對於經濟學家而言,社會與科技發展息息相關的理由,或許是因為科技讓某些 事物的價格變得便宜許多;如果科技能夠讓所有的事物都變得平價,科技發展就會 轉化為全面性的經濟體制變革。目前人工智慧的發展與應用,讓我們幾乎可以確認 未來就是人工智慧民主化的發展過程。我們的目標不只是促使人工智慧進行各種 深化應用而已,也必須讓人工智慧成為各領域專家都能夠運用的利器,如此才能夠 降低所有人的預測成本,迎接新經濟的到來。
法律是經濟體制不可或缺的重要基石,其對人工智慧民主化的影響不容小覷。
當人工智慧需要跨領域的商業應用時,事業或許會將價格決定交給人工智慧,從中 獲取更多的商業利益。或許人工智慧會促進整體的社會福利,但是也有可能對市場 造成限制競爭的負面結果,特別是在聯合行為與價格歧視上,人工智慧都可能會對 現有的競爭法產生衝擊。因此,本論文透過科技與經濟的多元角度,分析人工智慧 在法律上所衍生的限制競爭問題,並提出問題意識與研究結論。
在科技與法律的交互影響下,人工智慧所衍生的限制競爭問題,或許不是單靠 法律就能解決的爭議,更需要透過科技的協助才能落實競爭執法。此外,產業政策 能否與限制競爭規範相輔相成,同樣攸關人工智慧的未來發展,從而,科技也需要 適當的法律架構才能順利發展。因此,本論文將人工智慧民主化所帶來的經濟體制 變革聚焦在競爭執法層面,以建構未來的科技執法模式。
關鍵字:機器學習、區塊鏈、聯合行為、價格歧視、相對優勢地位、
法遵科技、監理科技
doi:10.6342/NTU202003608
iii
Abstract
For economists, the reason why society is so closely tied to technological development may be that technology makes some things much cheaper; if technology can make everything cheaper, then technological development will transform into a comprehensive change in the economic system. With the current development and application of artificial intelligence, it is almost certain that the future will be a process of democratizing artificial intelligence. Our goal is not only to deepen the application of artificial intelligence, but also to make it available to experts in all fields so that we can lower the cost of forecasting and usher in the new economy.
Law is an indispensable cornerstone of the economic system, and its impact on the democratization of artificial intelligence should not be underestimated. When artificial intelligence needs to be used commercially across multiple domains, companies may leave the pricing to artificial intelligence, and derive more commercial benefit from it.
Artificial intelligence may contribute to the overall welfare of society, but it may also have the negative effect of restricting competition in the marketplace, particularly in the case of concerted practices and price discrimination, which may have an impact on existing competition laws. Therefore, this thesis analyzes the legally derived competition restriction problems of artificial intelligence through the multiple perspectives of technology and economics, and proposes an awareness of the problem and a research conclusion.
Under the interaction of technology and law, the problem of competition restriction derived from artificial intelligence may not be solved by law alone, but also requires the assistance of technology to enforce competition law. In addition, whether or not industrial policy and competition restriction norms can complement each other is also crucial to the future development of artificial intelligence, and thus, technology needs an appropriate
doi:10.6342/NTU202003608
iv
legal framework to develop successfully. Therefore, this paper focuses on the changes in the economic system brought about by the democratization of artificial intelligence in the context of competition enforcement, in order to construct a future model of technology enforcement.
Keywords:
Machine Learning, Block Chain, Concerted Action, Price
Discrimination, Reletive Dominant Position, RegTech, SupTech
doi:10.6342/NTU202003608
v
目錄
目錄 ... V 圖目錄 ... X
第一章 緒論 ... 1
第一節 研究動機與背景分析 ... 1
第二節 研究方法 ... 4
一、 機器學習與實務概述 ... 4
二、 經濟學觀點與推論 ... 4
三、 文獻與案例整理 ... 4
四、 政策方向與比較法分析 ... 5
第三節 研究範圍與論文架構 ... 5
第二章 人工智慧與經濟變革 ... 8
第一節 機器學習概述 ... 8
一、 深度學習 ... 10
二、 增強學習 ... 14
三、 生成對抗網路 ... 15
第二節 人工智慧應用現況 ... 17
一、 推論與推薦 ... 18
doi:10.6342/NTU202003608
vi
二、 自然語言處理 ... 19
三、 電腦視覺 ... 20
四、 移動控制 ... 20
第三節 數據競爭與合作 ... 21
一、 人工智慧民主化 ... 22
二、 去中心化 ... 24
三、 邊緣運算 ... 25
第四節 新經濟展望 ... 26
一、 預測成本 ... 27
二、 供給效率 ... 28
三、 需求效率 ... 29
四、 判斷價值 ... 30
第五節 小結 ... 31
第三章 人工智慧與聯合行為 ... 34
第一節 明示共謀 ... 36
一、 價格偏離 ... 36
二、 價格誤判 ... 37
三、 代理人道德風險 ... 37
第二節 軸輻式共謀 ... 38
doi:10.6342/NTU202003608
vii
一、 演算法軸輻式共謀 ... 39
二、 共享經濟困境 ... 41
三、 市場效率觀點 ... 42
第三節 緘默勾結 ... 43
一、 可預測代理人 ... 44
二、 自動化運算 ... 46
三、 模擬市場環境 ... 47
第四節 小結 ... 47
第四章 人工智慧與價格歧視 ... 50
第一節 消費者剩餘移轉 ... 51
一、 差別訂價 ... 51
二、 無謂損失 ... 52
三、 貧富不均 ... 54
第二節 相對優勢地位濫用 ... 55
一、 網路效應 ... 57
二、 數據近用 ... 58
三、 雙重剝削 ... 59
第三節 違法性再建構 ... 60
一、 價格歧視容許性 ... 61
doi:10.6342/NTU202003608
viii
二、 消費者剩餘保護目的 ... 61
三、 價格歧視違法性再建構 ... 62
第四節 小結 ... 63
第五章 人工智慧與競爭執法 ... 66
第一節 國際法制與政策方向 ... 66
一、 經濟合作暨發展組織 ... 67
二、 新加坡 ... 70
三、 英國 ... 70
四、 評析 ... 72
第二節 科技執法 ... 74
一、 監理科技 ... 76
二、 法遵科技 ... 77
三、 區塊鏈 ... 79
第三節 競爭執法機構 ... 80
一、 專責機關 ... 81
二、 協同執法 ... 82
三、 問責機構 ... 83
第四節 科技治理與管制 ... 84
一、 聲譽機制 ... 85
doi:10.6342/NTU202003608
ix
二、 資訊揭露 ... 87
三、 行為管制 ... 88
第五節 小結 ... 89
第六章 結論 ... 93
一、 人工智慧是正在進行的真實議題 ... 93
二、 人工智慧民主化是動態的數據競合過程 ... 93
三、 經濟體制變革的關鍵在於平價 ... 94
四、 聯合行為的結構會更加穩固且複雜 ... 94
五、 緘默勾結是未來難解的問題 ... 95
六、 價格歧視是消費者剩餘與市場效率間的兩難問題 ... 96
七、 目前國際上對競爭執法架構的修正傾向於保守... 97
八、 以數據為導向的科技執法將成為主流 ... 98
九、 問責機構的多元視角有助於競爭執法 ... 99
十、 以科技治理為中心的未來展望 ... 100
參考文獻 ... 102
doi:10.6342/NTU202003608
x
圖目錄
圖 2-1:深度學習的概念圖 ... 11
圖 2-2:CNN 的結構 ... 12
圖 2-3:RNN 的結構 ... 13
圖 2-4:增強學習的概念圖 ... 14
圖 2-5:GAN 的運作流程 ... 16
圖 2-6:擴增智慧的概念圖 ... 31
圖 3-1:聯合行為對消費者剩餘的影響 ... 35
圖 3-2:軸輻式共謀的概念圖 ... 38
圖 3-3:演算法軸輻式共謀的概念圖 ... 40
圖 4-1:價格歧視的競爭效益分析 ... 53
doi:10.6342/NTU202003608
1
第一章
緒論
人工智慧(Artificial Intelligence,簡稱 AI)是國際上重視的科技藍圖,不僅 可望解決一般生活問題,AI 在商業上的用途也是兵家必爭之地,我們不難預見 在下一個世代的產業競爭上,拒絕擁抱AI 的事業可能會難以生存下去。然而,
現行的法律中大多認為AI 不具備責任能力,凡是因爲 AI 衍生的相關法律爭議,
以現行法而言都只能向 AI 科技的開發者或利用人究責,如果這項 AI 科技是與 他人共同開發、利用的話,相信其中的法律關係還會更加複雜,甚至儼然形成AI 發展進程中的法律障礙,而AI 衍生的複雜法律關係,也會是科技發展過程中所 難以忽視的議題。從而,本章以AI 科技發展為思考脈絡,說明本論文針對 AI 與 競爭法議題的研究動機,並從中提出相關的時代背景分析。在確立研究方向後,
本論文針對AI 議題擬定合適的研究方法,跨領域的研究方法涵蓋「機器學習」
(Machine Learning)、經濟學與法律學等相關知識,以此建構本論文所研究的 範圍與架構。
第一節 研究動機與背景分析
AI 的定義可追溯至 1950 年,當時 AI 研究先驅圖靈(Alan Turing)就電腦 像人類一樣思考所應該帶來的影響,設計出一種判讀機器有無智慧的測試方法,
圖靈稱此為「模仿遊戲」(The Imitation Game),不過 AI 研究人員從一開始就 稱為「圖靈測試」(Turing Test);圖靈測試用來界定智慧機器的方法很簡單,
就是讓普通人用打字機與電腦溝通,當其無法分辨自己溝通的對象究竟是真人或
doi:10.6342/NTU202003608
2
電腦時,成功騙過普通人的電腦就稱為思考機器 1。到了 1980 年哲學家希爾勒
(John Searle)藉由「中文房間論證」(Chinese Room Argument)說明翻閱手冊 作弊的可能性,質疑圖靈所謂騙過智慧生物就代表其具有智慧的說法2。所謂的 中文房間論證,是指在某房間裡有一位不懂中文的外國人,同時外界有人不斷將 記載中文問題的紙條遞進房間裡,外國人雖然看不懂中文問題代表的意義,但是 他有一本中英對照的萬用應答手冊,外國人可以依照手冊指示遞出中文答案紙條,
讓身在房間外面的人以為他懂中文3。就像我們不認為前述的外國人懂中文一樣,
即便是通過圖靈測試的電腦,我們也不會因此認定其是具有智慧的機器。學術界 已經很少透過圖靈測試來評估AI4。本論文也是依據機器所展現出的能力來定義 AI。第一層級稱為「狹義人工智慧」(Artificial Narrow Intelligence,簡稱 ANI)、
第二層級則稱為「通用人工智慧」(Artificial General Intelligence,簡稱 AGI)、
第三層級再稱為「超級人工智慧」(Artificial Super Intelligence,簡稱 ASI);在 功能分級標準上,ANI 是指在特定領域具備與人類相似能力的機器;AGI 則是指 在大多數領域都具備等同人類能力的機器,也就是在各方面的表現都如同真人;
ASI 更是指幾乎在所有領域都具備超越人類能力的機器 5。
儘管從ANI 發展到 AGI 還有許多的技術障礙要克服,但是與法律層面相比,
科技發展的進程卻顯得快速許多。ANI 目前已經能夠完成特定工作,其商務應用 將是科技發展成為AGI 的關鍵;這是因為具有與人類同等智慧的 AGI 在研發上
1 Judea Pearl、Dana Macken(著),甘錫安(譯)(2019),《因果革命:人工智慧的大未來》,
頁 44-45,新北:行路。
2 同上註,頁 46。
3 古明地正俊、長谷佳明(著),沈鄉吟、郭漢遜(譯)(2020),《AI 大局:鳥瞰人工智慧技 術全貌,重塑AI 時代的領導力》,頁 236,臺北:旗標。
4 同上註,頁 97。
5 Revolidis I. & Dahi A. (2018). Roboticshe Peculiar Case of the Mushroom Picking Robot: Extra- contractual Liability in Robotics. In Robotics, AI and the Future of Law (pp. 57-79). Springer, Singapore 59.
doi:10.6342/NTU202003608
3
所費不貲,而ANI 創造的經濟價值除了能夠支應 AGI 研發經費以外,AGI 科技 發展也仰賴 ANI 運作過程中累積的相關數據。其中,運用 AI 進行「價格決定」
(Determine Price)的跨領域商務應用,也就是事業透過 AI 找到其產品或服務的 最適訂價,或許就是能立即讓事業獲得報酬的AI 投資途徑,可望對於 AI 的發展 產生正面影響。然而,當事業透過AI 進行價格決定後,事業間也可能聯合壟斷 商品或服務的價格而衍生限制競爭疑慮。反過來說,如果競爭法在商務應用上的 認定過於保守,則運用AI 進行商業判斷就有違反限制競爭規範的高度法律風險,
導致早期參與 AI 應用的事業未受其利而反受其害,甚至產生 AI 科技發展停滯 的疑慮。換言之,影響AI 發展的原因不只是科技本身而已,其實限制競爭規範 也正在影響著AI 科技的發展進程。
當然,AI 科技進程並不是我們追求的絕對價值,近年來,以 Google 為首的 科技巨擘持續收購 AI 科技公司,已經讓人們開始擔憂 AI 科技如果過度集中於 少數事業或國家手中,AI 甚至可能成為他們用來控制一般人生活的工具。於是 以 AI 去中心化為理念的科技新創紛紛出現,他們以讓所有人都能分享 AI 科技 的理念推出平台服務。Google、Microsoft 等科技巨擘也開始推出機器學習平台,
例如使用者可以在 Google 提供的雲端空間中,訓練屬於自己的機器學習模型。
因此,無論從何者的角度去探索未來,AI 都將是被迅速導入到各行各業的科技,
未來AI 不是只有少數事業才能使用的科技,此一趨勢稱為「人工智慧民主化」
(Democratizing AI)6。在AI 民主化的潮流中,本論文透過競爭法角度加以分析 AI 所衍生的限制競爭樣態,並提出維護產業政策與自由競爭環境的執法模式,
以因應AI 時代的到來。
6 郭家蓉(2018),〈從 Google AutoML 推出看 AI 民主化發展〉,檢自:
https://www.moea.gov.tw/MNS/doit/industrytech/IndustryTech.aspx?menu_id=13545&it_id=168
(最後瀏覽日:2020/08/12)
doi:10.6342/NTU202003608
4
第二節 研究方法
一、機器學習與實務概述
AI 的研究可以追溯至上個世紀,其發展歷史相當漫長,不論技術或應用上 都已經發展出許多子領域,近年來則以機器學習領域的發展最為熱門,一般認為 模仿人類思考方式的機器學習,就是AI 主要的發展方向,尤其在「深度學習」
(Deep Learning)、「增強學習」(Reinforcement Learning)與「生成對抗網路」
(Generative Adversarial Networks,簡稱 GAN)等技術上,機器學習都已經帶來 前所未見的變革。因此,本論文以機器學習的理論與現況發展為科技背景,進而 分析AI 所涉及的競爭法相關議題。
二、經濟學觀點與推論
本論文以AI 民主化所涉及的競爭法議題為核心,其中論述的許多狀況尚未 發生於本論文撰寫當下,因此需要以經濟學的理論為基礎來建構相關模型,再以 經濟學觀點來分析AI 所涉及的競爭法議題;另外就 AI 所帶來的經濟體制變革,
本論文也會援引經濟學家相當重視的「平價」要素,進一步推論AI 民主化發展 可能適合的技術架構與科技治理模式。
三、文獻與案例整理
目前已有許多學者針對演算法(algorithm)涉及的競爭法議題進行相關研究,
尤其訂價演算法目前在商務上的應用已經逐漸趨於成熟,其對自由競爭可能產生 的傷害,更是競爭法學者最為關注的焦點。由於演算法是AI 科技發展過程中的 必經途徑,因此本論文整理以演算法為主的相關文獻,藉以比較演算法與AI 在 競爭法議題上的差異,並從中提出可能適合AI 時代的科技治理與管制。此外,
doi:10.6342/NTU202003608
5
金融科技與隱私保護領域都有許多與數據相關的參考文獻,其在執法層面上更是 已經有了以數據時代為背景的監理手段,其產業也是率先導入AI 的特殊領域,
而對未來跨領域的競爭執法有高度參考價值。從而,本論文案例整理範圍不限於 競爭法議題,也包含對AI 應用與經濟學上的情境說明,期望藉由多重面向加以 分析AI 民主化與經濟體制變革。
四、政策方向與比較法分析
國家可能因應不同產業特性規劃具體政策,並體現在個別領域的產業需求上,
在AI 民主化的願景完全實現以前,某些產業就會先受到科技的影響而出現變革。
從而,政策方向對於往後全面性的科技發展而言,具有高度的參考價值。因此,
本論文在AI 科技執法議題中即借鏡金融領域目前的發展,在競爭執法章節中也 援引隱私保護領域的設置方案,期望在國際間的比較法分析以外,也藉由不同的 政策方向思考脈絡,試著針對AI 民主化的跨領域特性加以分析,並推導初步的 論述框架。
第三節 研究範圍與論文架構
與研究演算法競爭議題的多數文獻不同,本論文研究範圍以AI 為核心議題,
也就是以「具有自我學習能力」的AI 為研究標的。演算法可以定義為系列規則 或指令,進而完成某些工作項目,因此也可以稱其為「計算程式」;演算法必然 是自動的(automatic),不過並非所有的自動裝置(automation)都有演算過程,
也並非所有的演算法都有自我學習能力7。本論文雖然援引演算法相關文獻而為 論述基礎,但是為釐清本論文研究的範圍,同時尊重其他不特別區分演算法是否
7 陳和全(2020),〈訂價演算法與競爭法議題初探〉,《公平交易季刊》,28 卷,2 期,頁 96。
doi:10.6342/NTU202003608
6
具有自我學習能力的相關文獻原意,本論文所稱的「演算法」或「訂價演算法」
在未說明其具有自我學習能力時,宜先推定為「不具有自我學習能力」的演算法。
至於本論文所稱的AI 則是指具有自我學習能力的 ANI、AGI 或 ASI。換言之,
本論文探討的時代背景大致介於ANI 與 AGI 之間,也就是本論文撰寫當下的 AI 科技水準,並以AGI 為發展目標的科技狀態。
在論文架構上,第一章「緒論」以AI 民主化為時代背景,除了將本論文所 研究的AI 加以定義以外,也以事業透過 AI 進行價格決定為例,藉由 AI 在發展 進程中所遇到的瓶頸與困境,說明AI 衍生的法律問題將與科技發展息息相關。
進而延伸事業利用AI 實施限制競爭行為的問題意識,並說明本論文的研究方法 與架構。
第二章「人工智慧與經濟變革」是對AI 民主化藍圖的具體描繪,從技術面、
應用面與經濟面為出發點,第一節以機器學習理論基礎來介紹AI 的運作與訓練 方式;第二節以AI 應用現況來敘述科技發展的程度;第三節則植基於 AI 理論與 現況,提出AI 民主化時代可能適合的技術與社會架構;第四節則透過經濟學的 觀點來看待AI 發展,並歸納 AI 民主化與經濟體制變革的初步見解。
第三章「人工智慧與聯合行為」是針對目前主要的限制競爭規範加以分析,
探討 AI 在聯合行為中的功能或所扮演的角色,第一節著重在 AI 貫徹人類意志 的明示共謀(Explicit Collusion),具體說明聯合行為組織利用 AI 穩固共謀協議 的各種樣態;第二節從演算法軸輻式共謀(Hub and Spoke Conspiracies)出發,
探討 AI 與演算法在軸輻式共謀上的異同;第三節針對 AI 主動進行的緘默勾結
(Tacit Collusion)樣態,分析 AI 對市場可能帶來的影響。
第四章「人工智慧與價格歧視(Price Discrimination)」探討 AI 讓事業掠奪 消費者剩餘(consumers’ surplus)的問題,第一節描述 AI 讓過去幾乎不存在的
「一級差別訂價」實現,導致消費者剩餘被事業所掠奪的結果;第二節以垂直的 交易關係為視角,探討事業濫用相對優勢地位的問題;第三節提出關於價格歧視 的問題意識,並以現行限制競爭規範為基礎再建構其違法性。
doi:10.6342/NTU202003608
7
第五章「人工智慧與競爭執法」在評估AI 民主化帶來經濟體制變革之後,
將AI 科技與限制競爭規範收斂至執法層面,第一節以演算法涉及的競爭法議題 為主,分析國際間對於演算法議題的初步看法;第二節除了以金融領域進行中的 科技監理,並探討「區塊鏈」(Block Chain)在競爭執法上所扮演的角色,進而 分析未來的科技執法模式;第三節針對競爭執法機構設置,參考隱私保護領域中
「問責機構」(Accountability Agent)的設置議題,進而探討具有初步可行性的 競爭執法機構設置方案;第四節以AI 民主化與經濟體制變革為時代背景,提出 科技治理與管制的思考脈絡。
doi:10.6342/NTU202003608
8
第二章
人工智慧與經濟變革
自圖靈測試與小說家艾西莫夫(Isaac Asimov)描繪的「機器人三大法則8」 問世以來,過去一個世紀人類對於 AI 從來不缺乏想像。隨著人工神經網路
(Artificial Neural Network,簡稱 ANN)的發明,我們對於 AI 發展的願景更加 清晰。在技術層面上,雖然目前人類掌握的AI 科技還是介於 ANI 與 AGI 之間,
但是對於ASI 的開發,我們卻很確信不會是人類應該煩惱的問題。一旦科技達到 AGI 的程度,那麼 ASI 也必然會隨之問世9。因為根據AGI 的定義,我們將可以 預期持續學習的AGI 能夠自我進化成 ASI,從而,這樣一個未來可能會突飛猛進 的科技,現在開始探討AI 科技是絕對有其必要的。
不過在探討 AI 所衍生的相關法律議題前,我們還是需要先去了解 AI 科技 目前的運作方式,才能夠分辨AI 與不具有自我學習能力的演算法,將研究重心 收斂至AI 衍生的競爭法議題。因此,除了分析 AI 的應用現況以外,我們也相當 關注AI 的未來發展,其中,促使 AI 應用趨於成熟的機器學習領域,更是一般人 認為能讓AI 科技達到 AGI 程度的關鍵所在。因此,本章從機器學習的角度出發,
探討AI 未來可能的運作機制,並分析 AI 民主化帶來的經濟變革。
第一節 機器學習概述
8 Dervanovic ́ D. (2018). I, Inhuman Lawyer: Developing Artificial Intelligence in the Legal Profession.
In Robotics, AI and the Future of Law (pp. 209-234). Springer, Singapore 221, ( “First Law: A robot may not injure a human being or, through inaction, allow a human being to come to harm. Second Law:
A robot must obey orders given it by human beings, except when such orders conflict with the First Law.
Third Law: A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.” )
9 Revolidis I. & Dahi A., supra note5 at 59.
doi:10.6342/NTU202003608
9
自1956 年達特矛斯(Dartmouth)AI 研討會後,人類一直都渴望打造出 AGI,
但是隨即遭遇研發資金短缺及相關技術理論發展停滯等困境,導致人類分別在 1970 年代,以及 1980 年代末期至 1990 年代初期,歷經總共兩次的「AI 寒冬」
(winter of AI)10。直到AI 的分支「機器學習」領域在 2006 年以後逐漸成熟後,
AI 科技發展才又再看見曙光。機器學習並非以人類手動編寫的程式來執行任務,
而是先透過大量數據與演算法去「訓練」機器,讓它學習如何執行任務同時從中 得到新的演算法,再透過新的演算法加以分析特定數據,進而得到判斷或預測的 結果11。
機器學習依演算法的訓練過程分為三類12:監督式學習(Supervised Learning)、 非監督式學習(Unsupervised Learning)與增強學習 13。監督式學習的訓練資料 會搭配正確答案讓機器學習,最具代表性的是影像辨識與迴歸(regression)等任 務;非監督式學習則不會提供正確答案,通常是讓機器執行分群(clustering)任 務;增強學習雖然也不會提供正確答案,但是會針對輸出資料給予獎懲機制的回 饋,其對於AlphaGo 這類棋藝 AI 是典型的學習方式14。
機器學習與人類的經驗相當類似,監督式學習就如同我們最初依賴教育理解 世界的過程;非監督式學習好比我們自行找出各種事物的特徵與脈絡並彙聚思想
10 Pagallo, U., Corrales, M., Fenwick, M., & Forgó, N. (2018). The rise of robotics & AI: technological advances & normative dilemmas. In Robotics, AI and the Future of Law (pp. 1-13). Springer, Singapore 5.
11 Michael Copeland(2016),〈人工智慧、機器學習與深度學習間有什麼區別?〉,檢自:
https://blogs.nvidia.com.tw/2016/07/whats-difference-artificial-intelligence-machine-learning-deep- learning-ai/ (最後瀏覽日:2020/08/12)
12 另有分成三類的區分標準,即再增加半監督式學習,不過在 AI 的實際應用中,經常有演算法 交互搭配的狀況,半監督式學習在分成三類標準中似乎應該理解是一種比例上的概念。
13 Organization for Economic Cooperation and Development[OECD] (2017). Algorithms and collusion- competition policy in the digital age, 9. Retrieved from http://www.oecd.org/daf/competition/
Algorithms-and-colllusion-competition-policy-in-the-digital-age.pdf (Last Visited: 2020/08/12)
14 古明地正俊、長谷佳明(著),沈鄉吟、郭漢遜(譯)(2020),前揭註 3,頁 36-37。
doi:10.6342/NTU202003608
10
一般,另外由於個人思考會受到外界的制約,例如我們受到師長肯定後選擇自己 志趣發展,正是一種增強學習的歷程。既然機器學習與人類的思考方式如此相似,
那麼機器學習也很可能是從ANI 進展到 AGI 的關鍵所在。因此,本論文將介紹 當前幾種被廣泛討論的機器學習演算法,這將有助於我們了解AI 的學習方式與 運作過程。
一、深度學習
自1950 年代電腦發明以來,科學家就希冀透過電腦實現 AI,但是因為當時 硬體運算效能低落及數據量不足等困境而陷於第一次的 AI 寒冬;到了 1986 年 被譽為深度學習之父的辛頓(Geoffrey Hinton)等人提出「反向傳播演算法」
(Backpropagation Algorithm)後才讓人工神經網路再度開始興起,不過隨即卻又 遭遇「梯度消失問題」(Vanishing Gradient)讓多層神經網路效能受限而沈寂15。 如果將人工神經網路比喻成樓梯,反向傳播演算法就像在玩「矇眼下樓梯的遊戲」, 我們必須從終點回頭修正更好的矇眼下樓梯方法,接著從起點戴上眼罩再下一次 樓梯;當人工神經網路層數量增加,也就是樓梯變得更長時,我們可能從某一層 階梯開始就無法提出更好的修正方法;這是因為反向傳播演算法的修正方式,是 透過微積分中的偏微分而來,但是連續性的偏微分卻容易讓變化率歸零,讓我們 在修正第五階至第六階時,就因為可能變化率歸零而無法修正剩下的數十上百階,
這就是梯度消失問題 16。這些問題一直到 2006 年辛頓提出「限制玻爾茲曼機」
(Restricted Boltzmann Machines)及「深度信念網路」(Deep Belief Network)等
15 Lynn(2017),〈耗時三十年,深度學習之父 Hinton 是怎麼讓一度衰頹的類神經網路重迎曙 光的呢?〉,檢自:https://kopu.chat/2017/11/03/dl-hinton/ (最後瀏覽日:2020/08/12)
16 王柏鈞(2020),〈(文科友善)深度學習與梯度下降〉,檢自:https://medium.com/
@bc165870081/文科友善-深度學習與梯度下降-c6826a79d45f (最後瀏覽日:2020/08/12)
doi:10.6342/NTU202003608
11
重要的概念後,才終於成功解決反向傳播的優化問題;辛頓多年堅持不懈的研究,
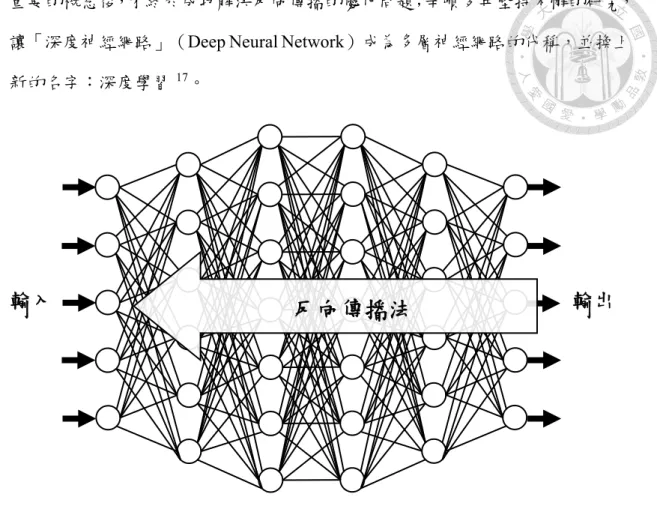
讓「深度神經網路」(Deep Neural Network)成為多層神經網路的代稱,並換上 新的名字:深度學習17。
圖 2-1:深度學習的概念圖18
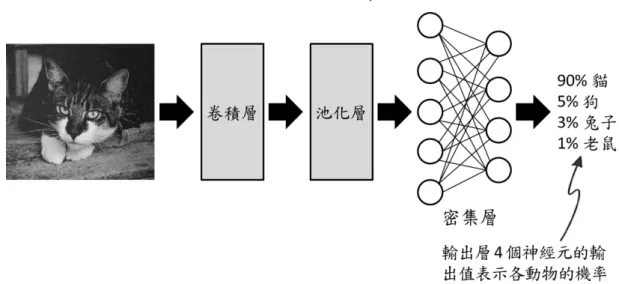
隨著科技發展與分散式運算技術趨於成熟,深度學習目前已經被廣泛應用在 我們的日常生活;其中,卷積神經網路(Convolutional Neural Network,簡稱 CNN)
近年來更是在電腦視覺應用上取得豐碩的成果 19。CNN 的運作原理可以追溯至 1960 年代,研究者觀察到貓腦皮層在使用局部感知與方向選擇的神經元時,能
17 Lynn,前揭註 15。
18 我妻幸長(著),吳嘉芳(譯)(2020),《決心打底!Python 深度學習基礎養成》,頁 1- 6,臺北:旗標。
19 陳乃瑋(2018),《基於卷積核冗餘的神經網路壓縮機制》,國立政治大學資訊科學系碩士論 文,頁 1。
反向傳播法 輸出
輸入
doi:10.6342/NTU202003608
12
有效降低神經網路的複雜性,進而提出了CNN 的概念20。由於圖片特徵值數量 龐大,為了在有限的數據量下保持學習能力,CNN 會在密集的人工神經網路前 增加卷積層(Convolutional Layer)與池化層(Pooling Layer)進行圖片特徵萃取
(Feature Extraction),避免圖片特徵值數量過多的問題 21。因此深度學習能運 用反向傳播的方法,以類似人類大腦運作方式進行實例學習,例如輸入一系列貓 與狗的照片,就能夠強化貓與四隻腳物體的關聯性,並且同時強化貓與狗概念上 的連結,在大量輸入不同種類的照片後,機器就學會如何區分貓與狗22。
圖 2-2:CNN 的結構 23
自然語言處理主要是在遞歸神經網路(Recurrent Neural Network,簡稱 RNN)
的架構下進行深度學習。RNN 是一種善於處理「序列資料」(Sequence Data)的 神經網路;序列的概念就像是我們在騎自行車時,會根據不同位置、速度的行人
20 同上註,頁 8。
21 我妻幸長(著),吳嘉芳(譯)(2020),前揭註 18,頁 7-3、7-4。
22 Ajay Agrawal、Joshua Gans、Avi Goldfarb(著),林奕伶(譯)(2018),《AI 經濟的策略 思維:善用人工智慧的預測威力,做出最佳商業決策》,頁 60,臺北:天下雜誌。
23 我妻幸長(著),吳嘉芳(譯)(2020),前揭註 18,頁 7-4。
doi:10.6342/NTU202003608
13
或汽車,在未來時間點所產生的變化,而決定前進的路徑24。在自然語言處理的 應用領域中,AI 需要學習到人類通常是依靠既有的知識與記憶來理解問題,並 透過時間序列來組織自然語言。換言之,人類閱讀本身並不是著墨在個別單詞的 涵義上,我們總是能夠透過既有的知識或內容上下文來進行學習;RNN 正是將 人類這種遞歸的概念引入深度學習當中,目前有許多深度學習的模型就是從 RNN 進一步優化而來,例如能夠改善 RNN 無法在較長序列資料進行有效學習的 長短期記憶(Long Short-Term Memory)模型25。RNN 的學習架構如圖 2-3 所示,
隨著輸入不同的時間序列資料,RNN 會在許多人工神經網路所在的隱藏層中,
不斷反饋過去所累積的數值,讓輸出的數據具有遞歸效果。
圖 2-3:RNN 的結構 26
24 我妻幸長(著),吳嘉芳(譯)(2020),前揭註 18,頁 8-2。
25 TengYuan Chang(2019),淺談遞歸神經網路(RNN)與長短期記憶模型(LSTM),檢自:
https://medium.com/@tengyuanchang/淺談遞歸神經網路-rnn-與長短期記憶模型-lstm-300cbe5efcc3
(最後瀏覽日:2020/08/12)
26 古明地正俊、長谷佳明(著),沈鄉吟、郭漢遜(譯)(2020),前揭註 3,頁 217。
doi:10.6342/NTU202003608
14
二、增強學習
增強學習是透過代理人(Agent)與環境間互動來訓練的模型,代理人會在 每一期接收到所處環境的「狀態」,在代理人選擇採取的「動作」後會在下一期 獲得「獎勵」,學習目標是讓代理人在一系列動作後獲取的獎勵數值最大化27。 增強學習能夠對應到心理學上關於制約的學習理論,其中最具代表性的動物實驗 非「巴夫洛夫的狗」莫屬,俄國生理學家巴夫洛夫(Ivan Petrovich Pavlov)透過 聲音促使狗分泌出唾液的實驗獲得了1904 年諾貝爾生理醫學獎。因此,我們能 將增強學習簡單理解成一種模擬人類受環境制約而學習的過程。
圖 2-4:增強學習的概念圖28
27 劉上瑋(2017),《深度增強學習在動態資產配置上之應用—以美國 ETF 為例》,國立政治 大學金融學系研究所碩士學位論文,頁 7-9。
28 我妻幸長(著),吳嘉芳(譯)(2020),前揭註 18,頁 8-14。
代理人(Agent)
行動
環境
報酬
doi:10.6342/NTU202003608
15
Q 學習(Q-learning)是最具代表性的增強學習,Q 學習能在狀態轉變機率 與獲得報酬未知情況下直接估算最佳的Q 值函式(Q Value Function),也就是 從眾多動作價值函式(Action Value Function)中推導出最佳策略;Q 學習也運用 在多代理人系統(Multi-Agent Systems),因為獨立代理人所得到的報酬不單單 是依據其本身的行為而已,此時也會考量到其他代理人的行為29。具備多代理人 同步合作的學習能力,這也讓Q 學習在物聯網(Internet of Things,簡稱 IoT)上 有著相當高的應用價值。
三、生成對抗網路
生成對抗網路(GAN)是 2014 年才被發明提出的機器學習概念,其原理是 透過「生成」(Generator)與「判別」(Discriminator)神經網路模型互相對抗 的方式進行機器學習;具體的操作是先從「潛在空間」(Latent Space)隨機採樣,
並透過生成模型加以形成為最接近真實資料的數據;判別模型則必須把生成模型 所輸出的數據從真實資料當中分辨出來。如圖 2-5 所示,GAN 神經網路會重複 對抗來更新彼此的參數,直到判別模型分辨不出真實資料與生成模型輸出的數據 為止,即完成 GAN 的訓練 30。目前GAN 在影像處理上有高度應用價值,例如 GAN 能增加老舊影片的解析度,讓原本不存在影像中的畫素被生成出來,然而 其造偽功能也常被惡意使用在假訊息的散布上,以假亂真的電腦合成影像讓各國 政府感到相當頭痛。
29 劉繡禎(2013),《結合 Q-Learning 與混合學習方法於足球代理人系統》,國立臺北科技大 學電資學院電資碩士班碩士學位論文,頁 4-5。
30 陳文輝、黃玠元(2018),〈應用於行為識別資料擴增之改良生成對抗網路〉,《先進工程學 刊》,13 卷,3 期,頁 144。
doi:10.6342/NTU202003608
16
圖 2-5:GAN 的運作流程31
GAN 在技術層面的另一個重要意義是「小資料學習」,過去我們對大數據 的第一印象通常在數量上,也就是透過大量數據來進行精準的預測,這讓許多人 對未來保持悲觀的想法,認為一般人只靠自己無論怎麼努力都無法設計出更好的 AI,因為數據可能早就被少數事業所壟斷,設計者缺乏數據量就不可能有優良的 AI 產出。這種刻板印象可能隨著 GAN 的問世而有所改變,設計者可以輸入少量 的訓練資料,透過GAN 取得具有競爭優勢的 AI。例如影像處理方面,目前已經 有研究團隊開發出只需要單張圖片就能夠訓練GAN 模型32,展現出GAN 在 AI 科技上的發展潛力。
31 古明地正俊、長谷佳明(著),沈鄉吟、郭漢遜(譯)(2020),前揭註 3,頁 224。
32 Hinz, T., Fisher, M., Wang, O., & Wermter, S. (2020). Improved Techniques for Training Single- Image GANs. arXiv preprint arXiv:2003.11512. Retrieved from https://arxiv.org/abs/2003.11512 (Last Visited: 2020/08/12)
doi:10.6342/NTU202003608
17
GAN 二種以上演算法互相配合的特性,使得 GAN 在實務上的應用往往與 其他機器學習架構同時併存,並將AI 帶往更多元的方向發展。例如在新藥研發 中,GAN 能夠結合深度增強學習找出具有治療潛力的候選藥物分子,透過分析 數百萬個樣本與各種疾病特性,篩選出可能適合成為標靶的蛋白質,再針對標靶 蛋白質生產對應的新藥分子33。機器學習架構互相支援的例子不僅止於深度學習、
增強學習及 GAN 而已,目前被開發出來的 AI 不計其數,其中絕大部分是人類 為了改善AI 在實務上的應用,所開發的機器學習架構。因此,AI 發展當然不能 只探討到技術層面為止,對於AI 應用現況的關注也相當重要,除了 AI 應用能夠 為其研發帶來所需要的資金以外,優化AI 應用現況更是維繫其研發動能的源頭 所在。
第二節 人工智慧應用現況
儘管ANI 被界定為弱人工智慧,但是 AI 分類標準僅代表了其在應用領域上 的局限性,並非指 ANI 在預測或判斷能力上仍然低於人類;相反的,目前 ANI 不僅表現出令人驚豔的智慧,在特定領域上甚至已經超越人類的預測能力。但是 這依然不代表我們未來就能遠離AI 寒冬,回顧過去 AI 發展上受挫的原因,除了 運算量能及數據量不足以支應AI 演算法以外,最主要失敗的原因是財務問題。
換言之,邁向AGI、ASI 等強人工智慧時代的關鍵,除了機器學習技術要能持續 發展以外;ANI 在商務應用層面上能否為 AI 研究發展帶來所需要的資金,同樣 是重要的觀察指標。因此,本節透過AI 科技應用現況的觀察,包括推論與推薦
(Reasoning and Recommendation)、自然語言處理(Natural Language Processing)、
33 Youngsook Park、Jerome Glenn(著)、宋佩芬(譯)(2020),《區塊鏈、AI、生技與新能 源革命、產業重新洗牌,接下來10 年的工作與商機在哪裡?》,頁 235-236,臺北:高寶國際。
doi:10.6342/NTU202003608
18
電腦視覺(Computer Vision)以及移動控制(Motion and Manipulation)四大領域
34,藉以一窺AI 發展的現況與潛力。
一、推論與推薦
在機器學習崛起以前,人類主要以統計學為基礎的預測方法進行數據推論。
多變數迴歸分析(multivariate regression)是當時有效的預測方法,只要取得數據 使 用 者 就 能 夠 找 出 將 預 測 錯 誤 降 至 最 低 的 方 法 , 也 就 是 使 所 謂 的 適 合 度
(goodness of fit)達到最大,就能獲得相當不錯的推論;在 2004 年杜克大學 Teradata 中心一場預測顧客流失率的數據科學比賽裡,獲勝者正是依靠迴歸模型 贏過使用機器學習的參賽對手;不過到2016 年機器學習卻成了預測顧客流失率 的最佳模型,其中又以深度學習模型的預測表現最佳,因為在數據量與運算量能 都大幅提升的環境中,與開發新迴歸方法需要先證明理論上的可行性相比,重心 放在實務運作上的機器學習顯得更有效率35。如今,隨著各項資料的深化應用,
AI 已經不再局限於邏輯知識庫上的推理,數據同時提升 AI 針對問題進行全面性 的分析與情境掌握能力;例如行車路徑規劃,不僅能根據地理資訊建議最短路徑,
更能綜合考量天候、車流等資訊,再依照使用者的需求進行情境分析,最後提供 客製化的最佳行車路徑36。
推薦系統在多數情況下可以被概括為「估計用戶對未知商品評分的問題」,
除了能夠讓使用者在網站上接收到合適的購物資訊或廣告以外,推薦系統在許多
34 陳凱迪(2018),〈人工智慧發展對金融業之衝擊與因應〉,《財金資訊季刊》,93 期,
頁 14,檢自:https://www.fisc.com.tw/Upload/842a6ffa-3e6f-4949-b018-b4a204b51170/TC/9303.pdf
(最後瀏覽日:2020/08/12)
35 Ajay Agrawal、Joshua Gans、Avi Goldfarb(著),林奕伶(譯)(2018),前揭註 22,頁 54- 56。
36 陳凱迪,前揭註 34,頁 15。
doi:10.6342/NTU202003608
19
影音串流平台上也扮演著相當重要的角色,具體方式可分為:基於內容的推薦
(content-based recommendations),即透過用戶本身的行為數據來推算其偏好;
協同過濾推薦(collaborative recommendations),則是先針對用戶進行分群,再 透過與其具有相似品味的用戶數據來進行推薦 37。目前在影音服務上AI 能同時 運用各種方式來優化推薦系統,或許此刻AI 已經比我們更了解自己對影音內容 的喜好,不僅促使用戶主動付出更多時間在享受影音服務上,也讓影音平台增加 了用戶黏著度,為商務應用帶來顯著的效益。
二、自然語言處理
在人機溝通層面,隨著資料庫應對的記憶處理能力提高,AI 能透過上下文 來理解提問者的意圖與情緒,因此回答的用字也更加精確,並且能完成較長段落 的文章撰寫,不再僅是單詞片語而已;AI 跟使用者聊天的互動模式,例如透過 聊天機器人(chatbot)找出並解決使用者的真正問題,在商用自動化服務有極高 的發展價值38。
聊天機器人不只能夠取代客服,並且進入了創作的領域。在新詩創作方面,
微軟公司從聊天機器人「小冰」自行創作的1 萬多篇詩中,挑選 139 篇集結成冊 出版詩集《陽光失了玻璃窗》;在小說創作方面,2016 年日本《日經新聞》獎的 徵文比賽上,評審團在不知情的狀況下,讓其中一篇名為《電腦寫小說的一天》
通過第一輪審查,此正是由AI 按照人類設定情節來寫出文句的小說,儘管這篇 小說只有一部分是AI 所撰寫的,不過研究團隊宣稱,他們的目標是在往後幾年 開發出不用人類幫助就能寫出完美句子的AI39。
37 臺大科教中心(2019),〈Netflix 與 YouTube 的「推薦系統」如何挑選影片給我?〉,檢自:
https://www.thenewslens.com/article/117821 (最後瀏覽日:2020/08/12)
38 陳凱迪,前揭註 34,頁 15。
39 Youngsook Park、Jerome Glenn(著)、宋佩芬(譯)(2020),前揭註 33,頁 118-120。
doi:10.6342/NTU202003608
20
三、電腦視覺
AI 在物件辨識與互動效率上的提升,足以即時判斷出物件行為與環境情境,
例如識別出蛋糕、蠟燭、禮物以及人物的動作後,AI 就能夠判斷出是生日聚會 的情境,並即時作出相對應的回應 40。電腦視覺的應用在感官上相當豐富多元,
「動作轉化」(Motion Transfer)是其中一個相當精彩的表演。柏克萊加州大學 研究團隊以GAN 架構開發動作轉化 AI,其能將專業舞者的動作複製在業餘人士 身上,藉以生成由業餘人士跳出專業舞步的影片;相同的道理,AI 也大幅提升 電腦合成影像技術,不僅能夠修正影像中的人臉表情變化,也能自行創造出一張 全新的面孔 41。在電腦視覺應用領域,拍攝影片的場景與演員都能透過AI 自行 生成出來,為影視產業開啟了一個全新的創作大道。
四、移動控制
在AI 四大應用領域中,移動控制是直接改變實體世界的應用,過去機器人 與機器學習其實都是AI 概念下各自獨立的研究領域,但是在深度學習崛起之後,
彼此的界線已經越來越模糊。目前機器人從原本需要預先設定程式以及持續進行 人工校正的運作模式,發展成能透過自行分析與環境間的因果關係,而自主修正 的機器學習模式,不論在人與機器人之間、或機器人彼此之間,都能夠往更好的 協作應用方向發展42。
由於移動控制與其他應用領域在物理上的差別,其能夠直接降低實體世界的 勞力支出,因此所帶來的經濟效益可能大幅超越其他應用領域。不過,我們同時
40 陳凱迪,前揭註 34,頁 15。
41 Youngsook Park、Jerome Glenn(著)、宋佩芬(譯)(2020),前揭註 33,頁 127。
42 陳凱迪,前揭註 34,頁 15-16。
doi:10.6342/NTU202003608
21
也必須更加審慎判斷有關移動控制的商用化標準,因為在多數狀況下,我們可能 需要同時將「預測」與「判斷」完全交給機器人來執行,而不是單純由AI 協助 我們如何判斷而已。換言之,我們或許還沒有準備好讓機器人提供全面性的勞務,
也還沒有建立有關機器人的責任體系,從而,即使移動控制潛在的商業價值相當 可觀,但是我們可能仍然難以期望單靠機器人帶來的效益,就能支應AI 未來所 需要的研發經費。
第三節 數據競爭與合作
一般認為提升事業數位競爭力的方法與資訊數量息息相關,必須收集所有的 數據加以分析,事業才能從中獲得最精準的預測結果。不過,「大數據思維」在 AI 時代或許並非完全正確。由於強 AI 的目標是擁有人類智慧,並與人類交談,
甚至指導人類;其中的技術關鍵在於AI 是否具備現實世界模型 43。因此,目前 AI 已經有了往模擬環境發展的趨勢,具體方法或許是讓 AI 掌握沒有真正發生的
「反事實」(Counterfactual)。對於人類而言,反事實是我們探索並影響世界的 重要元素;雖然我們無法同時踏上森林中的兩條小路,但是在許多狀況下,我們 仍然能夠知道這兩條路上的景物44。
以移動控制為例,在AI 沒有掌握反事實前,如果自動駕駛的研究人員希望 機器能夠對新狀況產生不同反應,就必須在自行添加新數據,否則AI 不會自己 判斷拿著威士忌酒瓶的行人聽到喇叭聲會有不同反應45。因此,過去自動駕駛的 研究是透過車輛行駛於現實道路上來取得相關數據,基於他人用路安全上的考量,
車輛必須有測試員隨時準備切換駕駛控制權,這大大增加了研究數據的取得成本。
43 Judea Pearl、Dana Macken(著),甘錫安(譯)(2019),前揭註 1,頁 39。
44 同上註,頁 285。
45 同上註,頁 40。
doi:10.6342/NTU202003608
22
與透過現實道路來取得的行駛數據相比,AI 創造的模擬環境更有利於移動控制 領域發展,未來如果需要對自動駕駛進行相關的研究發展,可以從模擬環境直接 提取數百萬公里的反事實行駛數據,從中節省的研發時間不僅促進了科技發展與 產業競爭,同時也不用擔心車輛測試員在取得行駛數據的過程中,有可能會危及 其他用路人的安全。
儘管模擬環境的AI 本身也需要訓練數據,不過這並非代表大數據思維仍是 唯一的途徑,其實與收集所有數據相比,掌握特定領域的「關鍵數據」更加重要。
關鍵數據並非單純維繫在數量上,隨著運算量能的與時俱進,未來我們將能併用 各種機器學習的架構來產生關鍵數據,例如透過深度學習、增強學習與GAN 的 綜合應用,運用複數AI 來創造與真實相仿的模擬環境,進一步開展 AI 新應用。
為了完善各領域的AI 應用,我們未來會需要具備該領域知識的專家來提供關鍵 數據,從而需要先將集中的AI 科技分散出去,讓各領域的專家熟悉並開始運用 AI,促使專家們主動將自己掌握的關鍵數據,透過 AI 科技發掘其中的價值。
換言之,AI 時代可能不是我們在某些科幻電影看到的那樣,是少數事業或 國家執掌AI 來監控全民的社會,而是由每一位掌握關鍵數據的多數人民,透過
「去中心化」(Decentralized)及「邊緣運算」(Edge Computing)等技術,進行
「數據競爭與合作」(簡稱數據競合)的榮景。
一、人工智慧民主化
近年來Google、Microsoft 等科技巨擘,都在積極提供能夠促進 AI 民主化的 開發環境,這能讓AI 的利用與開發變得更容易 46。在不久的將來,我們就會發 現 AI 科技開始擴散到各行各業甚至是在每一個人的手上。例如 2018 年科技巨
46 古明地正俊、長谷佳明(著),沈鄉吟、郭漢遜(譯)(2020),前揭註 3,頁 4。
doi:10.6342/NTU202003608
23
擘Google 所發表的 AutoML Vision 即標榜著 AI 民主化,讓事業不用透過資料科 學家,只要自行將圖片上傳到雲端,AutoML Vision 服務就能幫事業訓練其所需 要的機器學習模型47。由於AI 民主化讓演算法變得平易近人,隨著 AI 科技易用 性增加,就會有更多人願意導入 AI 到各自的應用領域中,群眾參與 AI 的開發 後,不僅會促使AI 商機擴大,也會讓預測成本變得更加平價,持續為 AI 的蓬勃 發展帶來正向循環。
無獨有偶,科技新創也開始將自家的演算法無償提供給用戶。各種科技公司 會將其高價收購或辛苦研發的演算法提供給大眾使用,正是因為AI 開發過程中,
如果只有資料科學家參與顯然是不足的,AI 最終還是要在各領域有其應用價值 才能夠繼續發展下去。就算資料科學家可以在網路上收集相關資料,也不可能在 各個領域裡都勝過其中的專家,從而,將 AI 的控制權分散,透過平台即服務
(Platform as a Service,簡稱 PaaS)的經營模式,讓掌握關鍵數據的使用者可以 輕鬆訓練AI,不僅讓使用者邁過了開發 AI 的技術門檻,而獲得對自己工作有用 的AI,也讓科技事業獲得能與其他 AI 平台競爭的優勢,促使 AI 在各領域進行 深化應用。
當然對於科技巨擘而言,將AI 控制權分散給大眾使用未必符合自身利益;
因此,最初的AI 民主化主要是為用戶提供雲端服務,這樣不僅用戶只需要上傳 數據就能夠訓練AI,科技巨擘也可以透過硬體建設鞏固自己的競爭優勢。然而,
當大眾開始對AI 科技習以為常時,就會如同最近大眾逐步重視個人資料的保護 一般,開始重視自己擁有的數據價值,並試圖透過科技新創提供的去中心化架構 來獲取報酬;而科技巨擘為了避免用戶流失,就必須開發更優良的演算法來挽留
47 王宏仁(2018),〈【2019 年關鍵趨勢 1】事業發展 AI 問 How 不再問 Why,上手簡單但專 精更難〉,檢自:https://www.ithome.com.tw/news/127946 (最後瀏覽日:2020/08/12)
doi:10.6342/NTU202003608
24
用戶。因此,AI 民主化將是各方進行數據競合的動態過程,未來也會帶動新的 科技產業競爭。
二、去中心化
區塊鏈在「比特幣」(Bitcoin)中是能夠確保虛擬通貨功能與安全性的技術;
其可以逐步記錄各使用者所持有的比特幣與交易資料,並將帳本記錄交給大量的 使用者複製與保管48。從而,區塊鏈是金融科技(FinTech)領域中,最能夠代表 去中心化概念的技術,區塊鏈透過先進的密碼技術,能在沒有銀行等第三方機構 存在的前提下,有效減輕在傳統金融的中心化架構下,交易資料過度集中在少數 機構所衍生的流弊。
區塊鏈對於保護智慧財產權也有高度應用價值,例如透過區塊鏈與AI 建立 能夠在網路上註冊與驗證所有歌曲的全球音樂整合數據庫;當數據資料無法竄改 且能公開使用時,人們就不會懷疑其排名與原創性49。區塊鏈應用於商業領域的
「智慧合約」(Smart Contract),則能在廣為公開且高度透明性的「分散式帳本」
(Distributed Ledger Technology)技術中,在各節點間進行合約的自動處理,讓 各種作業在區塊鏈上執行50。與全球音樂整合數據庫的概念結合,區塊練能針對 使用者同意的內容,自動執行音樂創作者的收入分潤,讓音樂產業的商業模式比 現在更加透明化51。
48 松尾真一郎(著)、何蟬秀(譯)(2019),〈區塊鏈的四個難題〉,松尾真一郎(等著)、
何蟬秀(譯),《區塊鏈技術的未解決問題》,頁 46,臺北:五南。
49 Youngsook Park、Jerome Glenn(著)、宋佩芬(譯)(2020),前揭註 33,頁 85。
50 林達也(著)、何蟬秀(譯)(2019),〈世界與日本的區塊鏈〉,松尾真一郎(等著)、何 蟬秀(譯),《區塊鏈技術的未解決問題》,頁 167,臺北:五南。
51 Youngsook Park、Jerome Glenn(著)、宋佩芬(譯)(2020),前揭註 33,頁 85。
doi:10.6342/NTU202003608
25
此外,區塊鏈也能夠解決物聯網容易被駭客入侵的問題;傳統的物聯網系統 依賴集中式系統,此類系統在軟體套件擴充上相當有限,且有可能存在數十億個 網路安全漏洞;如果運用區塊鏈上的智慧合約,就能設定物聯網裝置於完成特定 要求後再執行傳輸任務,進行更安全的自動調控,並將相關數據分散儲存,防止 他人惡意盜用數據52。從而,去中心化或許是較能被人類所接受的AI 發展模式,
除了基於資訊安全上的考量,避免少數AI 遭到駭客入侵或出錯時造成系統性的 災難以外,另一方面也可以藉由AI 控制權的分散,減少所謂 AI 反過來奴役人類 的疑慮。
在AI 民主化時代,去中心化在技術上也能夠有效分散系統的負擔,讓大量 的傳輸數據獲得分流,同時讓去中心化的AI 進行學習優化。例如在物聯網中,
有著成千上萬的設備需要收集數據並優化AI 代理人,如果是在中心化的架構下,
所有數據都必須上傳至中央伺服器進行機器學習,這時AI 體系的結構複雜程度 會隨著代理人數量增加而線性上升,最終龐大數量的代理人,會讓彼此難以獲得 即時有效的訓練;反觀在「去中心化學習」(Decentralized Learning)的架構下,
每一個設備雖然還是需要收集數據,但是由於代理人不再上傳數據至中央伺服器,
只需要與自己任務相似程度高的「鄰居」交流數據,透過「多代理人增強學習」
(Multi-Agent Reinforcement Learning)完成即時的學習與優化53。
三、邊緣運算
目前AI 運作架構主要是將所有的資料上傳至雲端,然後以深度學習為主的 運算結果回傳至AI 物件,難以滿足各種即時反應的需求,因而促使分散式架構
52 Youngsook Park、Jerome Glenn(著)、宋佩芬(譯)(2020),前揭註 33,頁 88。
53 MC.AI (2018). Decentralized and Scalable Multi-Agent Reinforcement Learning. Retrieved from https://mc.ai/decentralized-and-scalable-multi-agent-reinforcement-learning/ (Last Visited: 2020/08/12)
doi:10.6342/NTU202003608
26
的邊緣運算技術興起;邊緣運算透過嵌入或外加的運算設備,分層處理各種不同 的運算任務,讓AI 在接近資料源或用戶端處完成運算,有效縮短網路運輸延遲,
實現即時運算的需求,運用在自駕車、無人機等用途上,可能在微秒(microsecond)
間快速整合各種資料運算,避免時間延遲而產生問題54。
隨著資訊科技的發展,人們越來越離不開各種能夠聯網的電子設備(device),
這些電子設備具有傳統電腦的運算功能,透過邊緣運算可以讓其中被閒置的效能 釋放出來,為AI 將來的發展準備好基礎建設。另一方面,AI 民主化如果是透過 雲端運算來實踐,其難以打消去中心化理念對控制權集中的質疑,且對特別重視 資料安全的使用者來說,也可能會因此抗拒AI 科技導入該領域;對此邊緣運算 提供了另一種解決方案,讓使用者可以自行選擇使用數據的方式,例如國防單位 可以選擇自行採購數量眾多的 AI 設備,透過 AI 設備間的邊緣運算來完成指定 任務,以同時兼顧機敏性資料的安全需求。
第四節 新經濟展望
當世上多數人都沈浸在AI 帶來的革命性創新時,經濟學家仍然是透過供給 與需求、生產與消費、價格與成本等力量所控制的框架來看待世界55。如果要求 經濟學家說明 AI 帶來的重大經濟意義,那可能會是 AI 讓某些重要的東西變得 便宜許多56。關於平價在經濟學上的重要程度,能夠以人造光線為例具體說明,
根據2018 年諾貝爾經濟學獎獲得者之一諾德豪斯(William Nordhaus)所精細的
54 魏茂國(2018),〈邊緣運算加速 AI 技術應用普及〉,《工業技術與資訊月刊》,315 期,
頁 26-27,檢自:https://www.itri.org.tw/WebTools/FilesDownload.ashx?Siteid=1&MmmID=1036452 026061075714&fd=PublicationsCont_Files&Pname=P26-27-封面故事-邊緣運算.pdf (最後瀏覽日:
2020/08/12)
55 Ajay Agrawal、Joshua Gans、Avi Goldfarb(著),林奕伶(譯)(2018),前揭註 22,頁 23。
56 同上註,頁 28。
doi:10.6342/NTU202003608
27
觀察,1800 年代初期人們可能需要花費相當於現代 400 倍的價格才能取得相同 亮度的照明57,在這樣的情境下,人們晚上閱讀一本書都可能要再三考量,但是 隨著照明價格急遽下跌,我們不僅將燈光成本排除在閱讀的考量因素以外,更讓 我們從此能在自然光無法穿透的高樓大廈裡生活與工作;如果人造光線成本沒有 跌落到微不足道,如今我們擁有的一切都可能不會實現了 58。在科技的層面上,
AI 民主化能夠將技術門檻向各行各業降低;在經濟的層面上,則會讓預測成本 明顯下跌。對AI 民主化與經濟體制變革而言,「平價」所帶來的 AI 非稀有性,
其影響甚至可能比科技進程更為深遠。
一、預測成本
增加數據量能否帶來更多對應的價值,在統計學與經濟學上有不同看法;以 統計學的角度,數據會有報酬遞減的現象,例如每增加一個單位的數據,對預測 的改善程度都比先前少;也就是第十次觀測值對預測的改善程度,會比第一千次 的觀察值來得大;但是從經濟學來看,關係就不那麼明確;例如在大量數據庫裡 增加更多的數據,可能會比在少量的數據庫裡增加大量數據來得好 59。AI 民主 化背後所帶來的經濟意義亦是如此,個別用戶提供的數據或許只能讓群體預測能 力有微幅程度改善,對於該群體而言,在統計學上的報酬確實正在遞減;然而靠 著微幅的預測改善程度,或許就能夠使該群體的預測能力超越競爭對手,接著吸 引大量的用戶加入再深化其競爭優勢,其經濟學的意義相當顯著。
57 Nordhaus, W. D. (1996). Do real-output and real-wage measures capture reality? The history of lighting suggests not. In The economics of new goods (pp. 27-70). University of Chicago Press. Retrieved from https://www.nber.org/chapters/c6064.pdf (Last Visited: 2020/08/12)
58 Ajay Agrawal、Joshua Gans、Avi Goldfarb(著),林奕伶(譯)(2018),前揭註 22,頁 26。
59 同上註,頁 75-76。
doi:10.6342/NTU202003608
28
AI 民主化很有可能是一個數據競合的動態過程,科技巨擘在 AI 民主化初期 能夠為大眾降低的預測成本或許有限,但是在大眾熟悉運用AI 處理事務後,AI 商機就會加速擴大,讓更多潛在競爭者投入AI 平台服務;此時擁有競爭優勢的 事業仍然會追求其用戶最大化,並藉由用戶掌握的關鍵數據持續優化其預測能力,
進而提供更能降低用戶預測成本的AI 演算法。用戶除了在數據競合中享受 AI 所 帶來的便利以外,也會更加重視自己擁有的關鍵數據,可能透過去中心化的模式 與他人交換數據,或透過智慧合約將數據轉化成利潤,促使數據競合的效應提升。
整體而言,所有人的預測成本都將隨之下降,當預測成本下降到如同人造光線般 微不足道的程度,或許人類就不用再考量AI 取代人力的成本,進而帶來全面性 的經濟體制變革。
二、供給效率
AI 確實可能讓許多既有的工作逐漸消失,以產線自動化來降低事業對人力 的需求,但是AI 能夠減少的生產成本並不只是取代人力而已,AI 同時也降低了 包含庫存在內的各種管理成本。此外,資本支出也影響著事業的獲利,過去已經 有許多事業考量當地人力成本上升而將生產任務外包給海外的代工廠,這樣可以 有效降低資本支出,讓事業專注在更複雜的工作上。因此,事業如果能透過 AI 讓複雜工作更進一步的簡化,就可以將需要精密儀器進行生產等資本支出較高的 業務外包處理,創造更好的生產條件。例如當AI 不僅可以預測天氣狀況,也能 將因應天氣相關干擾的最佳方案提供給航空公司時,大型航空公司就可以在契約 明訂相關偶發狀況的處理方式,而將飛行的任務外包給區域性航空公司來執行,
以此減少大型航空公司擁有的飛機等高昂資本支出,並能夠繼續掌握相關航線的 營運60。
60 同上註,頁 223。