國立臺東大學資訊管理學系 環境經濟資訊管理碩士在職專班
碩士論文
指導教授:謝明哲 先生
運用資料採礦技術於臺東縣國中學生 中途輟學預測之研究
A Study of Student Dropout Prediction of Junior High School in Taitung County applying
Data Mining Techniques
研 究 生: 翁秉逸 撰
中華民國一○二年七月
國立臺東大學資訊管理學系 環境經濟資訊管理碩士在職專班
碩士論文
運用資料採礦技術於臺東縣國中學生 中途輟學預測之研究
A Study of Student Dropout Prediction of Junior High School in Taitung County applying
Data Mining Techniques
研究生: 翁秉逸 撰 指導教授:謝明哲 先生
中華民國一○二年七月
誌謝辭
本論文得以順利完成,首先得感謝指導教授謝明哲博士的引領、鼓勵,以及 在實務和學術經驗上的傾囊相授,更不時對於研究進度與內容指導與校正,感激 之意,不可言表。另外,謝老師所傳授的樂活(LOHAS)智慧,更是帶給我不同的 省思與啟發。也要感激口試委員吳仁和教授、劉明洲教授,不辭辛勞遠道而來,
於本論文口試期間悉心審閱,提供專業寶貴建議,讓本論文得以更為嚴謹及完整。
臺東大學的求學生活暫告一段落,十分感謝班上各位同學鼎力的協助與給予 各種建議和思考,因為你們的砥礪與相持,讓這兩年求學生活十分有趣,有你們 真好!謝謝你們。
父母親的鼓勵是我讀書求學的動力,家人們的默默打氣則是讓我堅持到底的 唯一理由,更要感謝內人無私的奉獻協助,成為我在職工作、求學期間的最佳的 靠山,讓我無後顧之憂。最後,謹以此論文呈獻給所有幫助、鼓勵過我的人。
翁秉逸 謹誌於臺東大學 中華民國 102 年 7 月
i
運用資料採礦技術於臺東縣國中學生 中途輟學預測之研究
作 者 : 翁 秉 逸
國立臺東大學 資訊管理學系環境經濟資訊管理碩士在職專班
中文摘要
透過媒體的報導,學校輔導與管教成為教育熱門的議題,相關的輔 導業務便成為教育單位十分重視的工作,其中「中輟」更是輔導工作 一項棘手的議題,除了法定的事後通報、轉介處遇,各機關也常思索 如何建立一套可預測的機制來有效預防。而近年來雲端 E 化的校務系 統蓬勃發展,也正剛好補足過去無法有效、大量收集相關資料的缺憾。
本研究以臺東縣國中學生學籍資料為主體,配合電子化學籍系統的 資料收集、分析,取得 9,259 筆有效資料,藉由 Microsoft SQL Server 2008 軟體使用資料採礦技術建立三種模型評估,比較出最適合的預測 模型為類神經網路模型,整體預測正確率為 75.6%,可找出 80.9%實際 中輟的學生,並依此模型建立實際可行的預測平台。
本研究主要貢獻為整合資料採礦技術與電子化學籍系統,將其應用
於政府相關資訊系統之評估,將可提供臺東縣政府有效的預測機制,
ii
積極的進行事先的預防措施,投注更多資源給所需要關懷的學生,以 降低學生中輟率。
關 鍵 詞 : 臺 東 縣 國 中 、 資 料 採 礦 、 中 途 輟 學 、 類 神 經 網 路 。
iii
A Study of Student Dropout Prediction of Junior High School in Taitung County applying
Data Mining Techniques
Student: Ping-I Weng Advisor: Dr. Ming-Che Hsieh Department of Information Science and Management
Systems, National Taitung University 英文摘要
Abstract
The school counseling and education have become popular topics through numerous media outlets. Educational institutions attach great importance to the work of related counseling services, especially that of
"Student Dropout", which is a difficult subject of counseling. In addition to the statutory post-notification referral at the event, the authorities often ponder how to look for effective preventive measures through predictable mechanisms in government and in school. The development of cloud technology, which is now widely used in the school system, makes up for the deficiency of large collection of relevant information before.
This research achieved 9,259 valid data by collecting in electronic school system of the student data in Junior High School in Taitung County.
We utilized SQL Server 2008 of Microsoft soft package to run Decision Tree, Artificial Neural Network and Naive Bayes models. After
comparative analysis of these models, Artificial Neural Network turned out
to be the most suitable of the three. It is able to find out 80.9% actual
iv
dropout students, and could correctly identify the variables with accuracy rate of around 81.72%. And we will build a preventive system based on this model.
We aim to provide more resources to students in need of care, and the rate of dropping out can thus decline. This result of this study will not only contribute to providing an efficacious evaluation method for Taitung
County Government so that they can actively prevent student dropout, but also predict student dropout by using Data Mining techniques and
electronic school system.
keyword:junior high school in Taitung County, data mining, dropout,
artificial neural network.
v
目 次
誌謝辭 ...
中文摘要 ... i
英文摘要 ... iii
目 錄 ... v
表目次 ... viii
圖目次 ... ix
第一章 緒 論 ... 1
1.1 研究背景與動機 ... 1
1.2 研究目的 ... 2
1.3 研究範圍與限制 ... 2
1.4 論文架構 ... 3
第二章 文獻探討 ... 5
2.1 臺東縣教育雲端系統 ... 5
2.2 中途輟學的探討 ... 7
2.2.1 中途輟學的定義與統計 ... 7
2.2.2 臺東縣國民中學中輟率統計 ... 9
2.2.3 影響中輟行為的因素 ... 9
2.3 資料採礦的定義 ... 11
2.4 資料採礦的應用 ... 13
2.5 決策樹 ... 14
2.5.1 決策樹的特性 ... 14
2.5.2 Microsoft 決策樹演算法 ... 14
vi
2.6 貝氏分類器 ... 16
2.6.1 貝氏分類的特性 ... 16
2.6.2 Microsoft 貝式機率分類演算法 ... 17
2.7 類神經網路 ... 19
2.7.1 類神經網路的特性 ... 19
2.7.2 Microsoft 類神經網路演算法 ... 20
第三章 研究方法 ... 23
3.1 研究流程 ... 23
3.2 資料來源 ... 25
3.3 資料處理 ... 25
3.4 軟硬體與採礦工具說明 ... 25
3.5 模型的評估 ... 25
第四章 資料採礦模型建置與資料分析 ... 28
4.1 資料淨化、整理 ... 28
4.2 決策樹分析 ... 31
4.2.1 建立資料來源 ... 31
4.2.2 新增採礦結構與設定參數 ... 32
4.2.3 結果分析 ... 36
4.3 貝式機率分類 ... 41
4.3.1 指定資料採礦技術與設定參數 ... 41
4.3.2 結果分析 ... 43
4.4 類神經網路模型 ... 47
4.4.1 指定資料採礦技術與設定參數 ... 47
4.4.2 結果分析 ... 49
4.5 評估比較分析模型 ... 54
vii
4.5.1 資料採礦增益圖比較 ... 55
4.5.2 預測數量與評估變數的比較 ... 56
4.6 建立線上預測系統原型 ... 59
4.6.1 系統架構 ... 59
4.6.2 程式設計與實現 ... 61
4.6.3 結合校務系統之系統原型實現 ... 64
第五章 結論與建議 ... 66
5.1 研究結論與貢獻 ... 66
5.2 建議 ... 67
參考文獻 ... 69
viii
表目次
表 1-1 我國國中小 90 學年~100 學年中輟率 ... 1
表 2-1 各國中途輟學的定義 ... 8
表 2-2 臺東縣國民中小學學生 92~100 學年中輟率 ... 9
表 2-3 影響中輟行為的因素 ... 10
表 3-1 Microsoft SQL 2008 R2 Business 所提供資料採礦演算法比較 ... 26
表 3-2 AUC 值與模型區辨能力關係表 ... 27
表 4-1 原始資料欄位說明 ... 28
表 4-2 淨化、整理後資料欄位說明 ... 29
表 4-3 本研究決策樹模型參數 ... 34
表 4-4 決策樹模型路徑規則表 ... 38
表 4-5 決策樹預測分類矩陣表 ... 40
表 4-6 本研究貝式機率分類模型參數 ... 42
表 4-7 本研究貝式機率分類模型中輟機率屬性(僅列機率 7.55%以上) .. 43
表 4-8 貝式機率分類模型預測分類矩陣表 ... 46
表 4-9 本研究類神經網路模型參數 ... 48
表 4-10 本研究類神經網路模型變數喜好屬性表(喜好值為 YES) ... 50
表 4-11 類神經網路模型預測分類矩陣表 ... 54
表 4-12 三模型的預測計數比較表 ... 56
表 4-13 三模型影響目標變數較顯著變數表 ... 57
表 4-14 傳送學生資料變數表 ... 60
表 4-15 本研究接收資料並顯示預測結果 ASP.NET(C#)程式碼 ... 62
ix
圖目次
圖 2-1 臺東縣 SFS 學籍系統平台-學生身分登錄操作畫面 ... 6
圖 2-2 臺東縣 SFS 學籍系統平台-學生成績登錄操作畫面 ... 6
圖 2-3 KDD 過程示意圖 ... 12
圖 2-4 校園資料採礦競賽官網 ... 14
圖 2-5 是否購買腳踏車的客戶資料 ... 15
圖 2-6 決策樹樹形結構 ... 15
圖 2-7 連續的資料 ... 16
圖 2-8 決策樹樹形結構 ... 16
圖 2-9 貝式分類器採礦模型應用實例示意圖 ... 18
圖 2-10 生物神經元示意圖 ... 19
圖 2-11 倒傳遞網路模型(四個輸入以及 1 個輸出) ... 22
圖 3-1 研究流程 ... 24
圖 3-2 增益圖範例 ... 27
圖 4-1 EXCEL 中淨化、整理之後的資料 ... 31
圖 4-2 學生資料匯進資料庫(樣本資料) ... 31
圖 4-3 學生資料匯進資料庫(測試資料) ... 32
圖 4-4 選擇資料採礦技術 ... 32
圖 4-5 指定分析所使用的資料行 ... 33
圖 4-6 設定資料內容類型與資料類型 ... 33
圖 4-7 設定保留測試資料為 0%... 34
圖 4-8 決策樹 A、B、C 模型參數之比較增益圖 ... 36
圖 4-9 採礦模型檢視-決策樹相依性網路 ... 37
x
圖 4-10 採礦模型檢視-決策樹 ... 37
圖 4-11 決策樹模型目標母體為 80%之增益圖 ... 39
圖 4-12 新增模貝式機率分類採礦模型 ... 41
圖 4-13 採礦模型檢視-本研究貝式機率分類模型相依性網路 ... 43
圖 4-14 貝式機率分類模型目標母體為 80%之增益圖... 47
圖 4-15 新增類神經網路模型演算法 ... 47
圖 4-16 類神經 A、B、C 模型參數之比較增益圖 ... 49
圖 4-17 本研究類神經網路模型變數比重檢視圖 ... 50
圖 4-18 類神經網路模型模型目標母體為 80%之增益圖... 52
圖 4-19 三模型的增益圖比較(母體目標值:中輟為 YES) ... 55
圖 4-20 本研究學生是否中輟預測平台系統架構圖 ... 59
圖 4-21 本研究學生是否中輟顯示代表圖案 ... 60
圖 4-22 測試平台結合校務系統實際畫面-1... 64
圖 4-23 測試平台結合校務系統實際畫面-2... 65
第一章 緒 論
1.1 研究背景與動機
近年由於教育改革與媒體的報導,學校輔導與管教成為教育熱門議題,也是 各教育單位十分重視的課題。其中學校三級輔導的機制,更是各校學務工作的重 點項目,臺東縣由於位處偏遠,幅員狹長,雖然校內輔導工作需求量大,但卻常 遭遇輔導師資、人力不足的窘境。
綜觀目前各級法定通報系統,例如兒少保護專線、113家暴專線及全國國民中 小學中輟生通報及復學系統等皆已建置E化線上通報系統,取代傳統公文紙本往返,
並加速通報效率與降低案件查核時間。然而再多、再及時的通報處置,皆比不上 事先的預測與預防來的有效與降低社會成本,若能建置一套具有參考價值的預測 機制,可讓許多在校內的隱性需關懷學生可以得到更多的照顧與資源。
由教育部統計處的資料顯示(如表 1-1),我國國中小學生中輟率由 90 學年 0.33%降至 100 學年 0.23%,也足見我國對中輟輔導機制的重視與成效,然而,從 97 學年至 100 學年,連續四年中輟率不減反增,因此我們仍須積極面對中途輟學 的成因以及預防中輟事件的發生。
表 1-1 我國國中小 90 學年~100 學年中輟率
學年 90 91 92 93 94 95 96 97 98 99 100
人數 9,464 9,595 8,605 8,168 7,453 6,194 5,768 5,043 5,131 5,639 5,379
中輟
率(%)
0.33 0.34 0.30 0.28 0.27 0.23 0.21 0.19 0.20 0.23 0.23
(資料來源:教育部統計處,2003)
2
過去已有不少研究者針對中途輟學的成因、環境、演進等問題進行探討整理,
章勝傑、陳金燕(2003)的研究指出,整體而言,雖然在預測的準確性上仍有進步 的空間,以學童國小學籍卡與輔導紀錄表上記錄的六年級資料來預測他們到國中 的輟學行為已具可行性與實用性。而最近幾年,雲端技術蓬勃發展,臺東縣政府 為了配合教育部建置教育雲的政策,也建立起全縣的雲端教育學籍、成績資料庫,
使相關資料樣本收集與分析可及性大為提升。
故本研究期盼藉由臺東縣政府E化學籍資料之分析,透過資料採礦技術達成更 精準的中途輟學行為偏差預測模型,提供各校及各級輔導單位事先預警之支援決 策系統,以期相關單位可以在有限的資源裡投注更多關心與積極措施給更需要關 懷的學生。
1.2 研究目的
雲端技術的成熟,加上E化資料的普及運用,使資料採礦技術更加容易實行,
自然也就成為目前流行的資料預測技術,數位時代的來臨,不論是企業經營者,
或是教育工作者,皆必須要能夠即時反映、掌握新的訊息與策略。本研究擬以臺 東縣國中學生之學籍、成績資料等變項來探討是否影響國中學生的中輟行為表現,
進而預測發生的機率,茲將本研究的研究目的列舉如下:
(1)運用採礦技術分析學生歷史學籍成績資料,發現學生發生中途輟學行為之潛在 共同因素以及建立可預測實際中輟學生的最適採礦模型。
(2)應用最適採礦模型建立中途輟學線上預測系統原型,做為後續各級輔導單位發 展可及時反應與處理之決策支援系統的基礎。
1.3 研究範圍與限制
臺東縣從 97 年開始便全縣推廣統一版本的校務系統,其中包含學籍、成績輸 入等資料,故本研究以臺東縣國中生學籍資料為主,分析來源為 97 ~ 99 學年度 入學的國中學生學籍資料,用以預測學生是否發生連續三日以上的曠課行為。由 於資料數據來源為各校教職員所建立,且受限目前電子化校務系統現有建立資料,
3
故資料來源侷限於成績資料、一般學生身分別(低收入戶、身障、原住民、外籍子 女)、曠課日數等,相關數據結果雖然不見得符合外縣市國中現況,預測結果也非 可絕對準確,但仍可提供具有價值的參考模型給縣內教育有關單位利用與其他縣 市參考研究方式。
1.4 論文架構
本論文研究共有五章,各章節說明如下:
第一章 緒論:
說明本論文研究背景與環境及可茲研究的內容,進而產生研究動機、目的與 陳述研究範圍限制。
第二章 文獻探討:
本研究擬以臺東縣國中電子學籍資料變數來發展最適預測模型,進而建立預 測平台,故收集臺東縣教育雲端系統、中途輟學、資料採礦的相關文獻進行探討。
第三章 研究方法:
1. 描述本論文研究架構、流程。
2. 說明資料的來源取得與相關變數。
3. 資料淨化、轉化、整理的方式。
4. 本研究軟硬體等工具的使用說明。
5. 評估模型的方式。
第四章 資料採礦模型建置與分析:
整理三種資料採礦演算法模型的建置結果與比較,求得最適模型,並發展評 估預測平台與展示結果。
4
第五章 結論與建議:
為本論文研究做一份統整的結論以及未來可續研究的議題與方向提供建議。
5
第二章 文獻探討
2.1 臺東縣教育雲端系統
透過網頁建置與系統開發,可以整合發展學校的行政管理系統,簡化行政流 程與增進效能。自從政府大力推廣行政電子化的同時,校園 E 化便逐漸受到重視,
許多教師也投入心力開發各類校園行政系統,然而許多教師開始發現常有重複開 發相同及類似系統的現象,臺中縣教育網路中心於是創立了一個網站,稱為校園 自由軟體交流網,並提供一個更好的方式來整合這些程式,除了彼此分享也可避 免重複開發 (陳宏昌, 2006)。此外,為了配合教育部於民國九十年所建「九年一貫 課程學生成績評量及學籍電子資料交換規格標準」,臺中縣教育網路中心更與台南 縣教育網路中心合作,提出校園自由軟體開發計畫,以 WEB 介面為主體系統開發,
搭配 Apache、PHP、MySQL 等自由軟體共同組合建立校務系統,統一資料庫規格 及開發模組架構,並將該系統定名為 SFS (School Free Software)學務系統,希望透 過自由軟體發展的精神,吸引全國更多的有志教師加入開發與使用的行列。
臺東縣教育網路中心亦於 97 年間整合各校所架設 SFS 校務系統,改採集中代管式 伺服器架構建立臺東縣 SFS 學籍系統平台 (臺東縣教育網路中心, 2008),以雲端技 術提供全縣各國中小使用,除了減輕各校資訊網管人員的負擔,也整合全縣資料 庫版本,達成雲端學籍系統的架設目標,尤其近年來因應免試入學的業務需求,
臺東縣國民中學各校皆仰賴此系統進行學籍、成績管理與雲端運算,加快成績運 算速度也提供各校便捷、準確的學生資料管理。(系統畫面如圖 2-1、圖 2-2)
6
圖 2-1 臺東縣 SFS 學籍系統平台-學生身分登錄操作畫面
(資料來源: 臺東縣教育網路中心,2008)
圖 2-2 臺東縣 SFS 學籍系統平台-學生成績登錄操作畫面
(資料來源:臺東縣教育網路中心,2008)
7
2.2 中途輟學的探討
2.2.1 中途輟學的定義與統計
不同國家針對中途輟學的定義不盡相同(如表 2-1),依照教育部國民中小學中 途輟學學生通報及復學輔導辦法第二條中輟生定義為國民小學及國民中學學生有 下列情形之一者:
(1)未經請假、請假未獲准或不明原因未到校上課連續達三日以上。
(2)轉學生因不明原因未向轉入學校完成報到手續。
我國對「中輟」的定義相較於其他先進國家較為嚴謹,也進行了許多行政措 施預防以及建置尋回的機制,包括成立全國中輟學生復學輔導資源研究發展中心、
建置教育部中輟生通報及復學系統 (教育部, 2003)、納入教育部對各縣市政府地 方統合視導指標等,皆說明我國對此議題的重視程度,並且長期由教育部與警政 單位聯繫,積極協助尋回中途輟學的學生,再加上社工單位、學校單位的輔導工 作,讓本國的中輟率從早期 33%降至目前每年大約 20%左右。也成為各縣市政府辦 學重要指標與績效展現。而本研究所定義中輟學生便是參照我國規範,以學籍資 料庫找出連續達三日(含)以上曠課的國中學生。
8
表 2-1 各國中途輟學的定義
國家 定義
中華民國 1. 未經請假、請假未獲准或不明原因未到校上課連續達 三日以上。
2. 轉學生因不明原因未向轉入學校完成報到手續。
韓國 稱中輟學生為「學業中斷青少年」,即指中、高等學生於
學校中斷學業者而言。
日本 日本文部科學省之「學校基本調查」定義,國中國小羲務
階段學生主要因心理、情緒上之原因,無客觀上妥適理 由,而不去上學,或想去上學卻不能上學,缺席日數一年 達五十日以上者,統稱為「拒絕上學」文部科學省為追蹤 輔導,將其定義擴大,納入生病、經濟上等原因不上學、
年間缺席日數為三十日以上之學童,名稱改為「不上學」
(不登校)。
澳洲 稱為離校生,指 15 至 24 之青少年,尌學一段時日後,隔 年五月即不再入學者。
美國 依據美國教育部國家教育統計中心(National Center for Educational Statistics, 2002)的定義,「中途輟學」
(dropout)一詞係用來描述兩種情況:一是學齡學生在畢 業以前離開學校,以及學生並未在任一所學校註冊也未畢 業。如果學生係轉學至其他學校就讀,則不在計算之列。
(資料來源: 教育部訓育委員會,2003)
9
2.2.2 臺東縣國民中學中輟率統計
由於政府的重視與政令要求,全國的中輟率獲得有效的改善與控制,然而位 處偏鄉的臺東縣,在每年教育部所公布的中輟統計中總是榜上有名,有時甚至高 於全國平均數三倍以上(如表 2-2),不論原因是因為少數民族也是弱勢團體的原住 民人數較多,或是臺東縣整體人口數較少,居高不下的中輟率確是地方政府不可 忽視的重要課題。
表 2-2 臺東縣國民中小學學生 92~100 學年中輟率
學年 92 93 94 95 96 97 98 99 100
人數 284 177 -- 99 105 124 151 162 126
中輟率(%) 1.08 0.63 -- 0.37 0.40 0.52 0.61 0.68 0.56
(資料來源: 教育部統計處,2003)
2.2.3 影響中輟行為的因素
國內外文獻對中輟的成因有許多探討,原因錯綜複雜,不同時期之間也會有 不同因素導致中輟的發生,如沉迷網咖、同儕偏差次文化的影響等,教育部(2003) 依據「全國國民中小學中輟生通報及復學系統」資料所公布的中輟因素分析,在 100 學年度中輟原因中,將中輟原因分為五類:
(1)個人因素(46.68%)
生活作息不正常、精神或心理疾病、觸犯法律、智能不足等。
(2)家庭因素(23.50%)
父母或監護人管教失當、受父母監護人職業或不良生活習性影響、父母或監 護人離婚或分居。
(3)學校因素(11.71%)
對學校生活不感興趣、缺曠課太多、不適應學校課程、考試壓力過重等。
10
(4)社會因素(17.33%)
受校外不良朋友引誘、受已輟學同學影響、流連或沈迷網咖等。
(5)其他因素(0.78%)
然而各校進行「全國國民中小學中輟生通報及復學系統」通報時,只會依據 系統所指定四項因素(個人、家庭、學校、社會)選定成因通報,故其系統內的資料,
並不完全適合做為本研究預測建模之用 (陳秋玉, 2006)。
除了上述四大構面,章勝傑、陳金燕等人(2003)曾經提出可從學籍資料預測國 中輟學行為的邏輯迴歸分析與區辨分析(如表 2-3),並建議規劃架設學生電子資料 庫以提供更準確、即時的研究資料。由於臺東縣政府已完成建置電子化學籍系統,
並擁有 5 年以上國民中學資料和運作,故本研究根據文獻將臺東縣政府所提供的 學籍資料、成績資料作為研究變項進行資料採礦。
表 2-3 影響中輟行為的因素
學者專家與機構 可供預測之變項
教育部「全國國民中小學 中輟生通報及復學系統」
個人因素、家庭因素、學校因素、社會因素
余麗華等人(2001) 不適應行為、父母低期待、家庭結構完整性 李冠蓉(2002) 學生成績、曠課時數、教師的預測
陳金燕(2003) 五六年級平均社會科成績、輔導紀錄、家庭經濟 狀況
章勝傑、陳金燕(2003) 數學科平均成績、父母婚姻狀況、家庭經濟狀況、
曠課日數、負面的生活適應等
周慧婷(2004) 父母婚姻狀況、曠課、文化資本、社會資本
(資料來源:本研究整理)
11
2.3 資料採礦的定義
資料量每年以倍數的規模在成長,資料採礦(Data Mning)便成為近年來資料庫 應用領域中相當熱門的話題之一。尤其資訊科技日新月異,許多過去難以達成的 資料蒐集與運算在今日都已不再是天方夜譚,難以達成。Fayyad (1996)等人認為資 料採礦(Data Mining,DM)是從資料庫中挖掘出不明確、前所未知以及潛在有用的資 訊過程。換言之,就是從已經存在的資料中挖掘出新的事實,以及嘗試尋找過去 專家學者尚未注意的新關係。所以,資料採礦也可說是找出隱藏在資料中的趨勢 特徵及相關性的過程。透過現今的資料採礦技術,可從大量的資料庫中,找出不 同且有用的資訊與知識支援機關或企業進行分析、預測,進而提高競爭優勢,搶 得先機 (謝邦昌、鄭宇庭、蘇志雄, 2011)。資料採礦的內涵包括了資料庫系統、知 識庫系統、機器學習、統計學、人工智慧、不確定推論等。因此,可以說資料採 礦是由這些領域知識中整合出來的定理、演算法或方法。
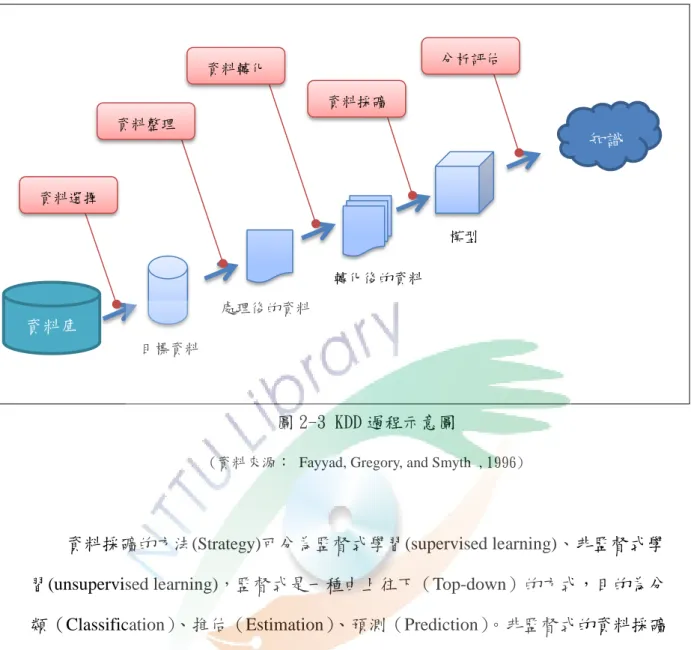
資料採礦可視為資料庫知識發掘(Knowledge Discovery In Database,KDD)的一 部份 ( Fayyad, Gregory, and Smyth, 1996),且為核心的步驟之一,KDD 的步驟如下 (如圖 2-3):
(1)資料選擇:選擇所需要的資料庫。
(2)資料整理:剔除不需要的資料、淨化資料。
(3)資料轉化:將資料轉成有用的形式。
(4)資料採礦:選擇採礦演算法進行資料挖掘。
(5)分析評估:解釋、分析並評估資料採礦的結果。
(6)獲取「知識」。
12
圖 2-3 KDD 過程示意圖
(資料來源: Fayyad, Gregory, and Smyth ,1996)
資料採礦的方法(
Strategy
)可分為監督式學習(supervised learning)、非監督式學 習(unsupervised learning),監督式是一種由上往下(Top-down)的方式,目的為分 類(Classification)、推估(Estimation)、預測(Prediction)。非監督式的資料採礦 則是將複雜的資料集合成簡單的群聚,由採礦者去發掘有用的規律 (林金火, 2007)。資料採礦的確實現了用其他方法不可能實現的方法來發現新的知識,但它更 因功能強大而應該受到規範,採礦者應當在合理的使用範圍處理資料。尤其我國 已正式公布個資法施行細則,未來不論是在學術或商業領域進行資料探採,皆應 以保護個人隱私資料為前提,小心謹慎使用資料,避免觸法以及損害他人權益。
資料庫
知識
資料選擇
資料整理
資料轉化
資料採礦
分析評估
目標資料
處理後的資料
轉化後的資料
模型
13
2.4 資料採礦的應用
目前 Data Mining 已被許多研究人員視為結合資料庫系統與機器學習技術的 重要領域,Kleuissner(1998)認為,資料採礦是發現企業資料中所隱含的知識,許 多產業界人士也認為此領域是一項增加各企業潛能的重要指標。此領域蓬勃發展 的原因:現代的企業體經常蒐集了大量資料,包括生產、財務、市場、客戶、供 應商、競爭對手以及未來趨勢等重要資訊,但是資訊爆量與雜亂無章的資料來源,
使得企業決策單位無法有效利用現存的資訊,甚至使決策行為產生混亂與誤用。
如果能透過資料採礦技術,從巨量的資料庫中,挖發掘出各種的資訊與知識出來,
作為決策支援之用,必能使企業擁有競爭優勢 (謝邦昌、鄭宇庭、蘇志雄, 2011)。
商業軟體的解決方案包含「IBM DB2 通用資料庫」、「KDnugget 數據挖掘軟體」、
「MATLAB」、「Microsoft SQL Server」、「Saksoft」、「SAS」等,業界提供許多功能 強大的應用軟體供採礦者使用。甚至近日有軟體廠商與國內銀行業者合作,舉辦 校園資料採礦競賽(如圖 2-4),顯示國內企業也十分重視相關人才培養與發掘,藉 由競賽活動,不僅提升企業品牌知名度,也預先挖掘校園相關技術高手;此活動 更可說明資料採礦確為未來企業成長、提升競爭力所需掌握的必要武器。
14
圖 2-4 校園資料採礦競賽官網
(資料來源: SAS、玉山銀行,2013)
2.5 決策樹
2.5.1 決策樹的特性
資料採礦(Data Mining)其中一項主要的技巧便是「決策樹」 (Decision Tree),
決策樹是從一或多個預測變數中,針對類別應變數的階級,預測案例或物件的關 係 (謝邦昌、鄭宇庭、蘇志雄, 2011)。決策樹分析的目的,不外乎就是要將最具預 測的可能機率顯示出來,是功能強大且相當受歡迎的分類和預測工具,其優點包 括單純、使用容易、容易理解、不會有分類衝突。
2.5.2 Microsoft 決策樹演算法
本研究以 Microsoft SQL Server 作為研究工具,Microsoft 決策樹演算法可用於 離散和連續屬性的預測模型。
15
(1)預測離散的資料:
以一個是否購買腳踏車的資料作為範例,如圖 2-5 所示,該長條圖為年齡高低 與客戶是否為買主的數據呈現,而 Microsoft 決策樹演算法會依其相互關聯建立新 節點,並且形成樹形結構(如圖 2-6)。
圖 2-5 是否購買腳踏車的客戶資料
(資料來源:本研究整理)
圖 2-6 決策樹樹形結構
(資料來源:本研究整理)
16
(2)預測連續的資料:
若是以連續的預測資料來建立決策樹模型時,樹狀圖上每一個節點便包含一 個迴歸公式。分岔會出現在迴歸公式中的非線性點上,如圖 2-7 所示。
圖 2-7 連續的資料
(資料來源:本研究整理)
圖表若以單一線段顯示則效果較差,故此模型以兩個方程式代表兩條線的回 歸方程式,如圖 2-8。
圖 2-8 決策樹樹形結構
(資料來源:本研究整理)
2.6 貝氏分類器 2.6.1 貝氏分類的特性
貝氏分類(Naïve Bayes)此名稱源自於該演算法應用貝式定理,卻未考量其相依 性,故其假設被視為天真(Naïve)之意。單純貝氏分類器 (Naïve Bayes Classifier) 是 一種簡單且實用的分類方法。 在某些領域的應用上,其分類效果並不亞於類神經 網路和決策樹。其主要的運作原理,為採用監督式的學習方式,分類前必須事先
17
知道分類型態,透過訓練樣本的訓練學習,有效地處理未來欲分類的資料 (謝邦昌、
鄭宇庭、蘇志雄, 2011)。
P(Ai)表示事前機率(Perior probability),P(Ai│B)表事後機率(Posterior probability),事件 Ai 是一原因,B 是一結果,則貝式定理如下:
2.6.2 Microsoft 貝式機率分類演算法
本研究使用 Microsoft 貝式機率分類演算法,假設給予測試目標的屬性值 (a1,a2,a3…,an),一共有 n 個學習概念屬性 A1,A2…,An,a1為 A1相對應值,目標結果 為最高機率值的類別(以 C 代表其集合),演算法如下:
(1)計算各個屬性的條件機率 P(C=cj
|A
1=a
1,…,A
n=a
n)
屬性獨立:
(2)預測新測試樣本應歸屬的類別:
n1 i
i i
j j
j j
A
| B P A P
A
| B P A P B
P B A B P
| A P
a , a , a … , a | c P(c )
P
a
… , a , a , a P
) P(c c
| a
… , a , a , a a P
… , a , a , a
| C P
j n j
3 2 1
n 3 2 1
j n j
3 2 1 n
3 2 j 1
n1 i
1 j n j
3 2
1
, a , a … , a | c P(a | c )
a P
i
i j j
n 3
2 j 1
) c
| P(a max c
arg
a
… , a , a , a
| max c
C arg
C P c
C P c
j j NB
18
只要貝式機率分類演算法所學習的屬性,滿足彼此間互相獨立的條件,貝式分 類器便可得到最大可能的分類結果 CNB,如果要建置貝式機率分類演算法模型,應 符合底下需求:
(1)單一索引資料:每個模型皆應包含一組能夠唯一識別的紀錄值,不允許重 複的紀錄。
(2)可預期的資料:至少需要有一個可預期的資料行,其屬性必須為離散或離 散化(Discretization)的值。
(3)輸入的變數:在貝式機率分類模型裡,所有的資料紀錄皆必須為離散或離 散化的資料。
貝式分類器訓練的模型適合用於評估預測一件事情發生的條件機率,例如某量 販店希望能尋找潛在的辦理會員卡客戶群,假設已可得的客戶資料屬性有「性別」、
「年齡」、「收入」、「是否有信用卡」等,分類目標為「是否辦會員卡」,有「會辦 卡」、「不會辦卡」兩種可能。以歷史客戶的資料訓練貝式分類器的模型便會預測 出擁有「男性」、「男 20~35 歲之間」、「收入高」、「有信用卡」的客戶是否會辦理 會員卡(如圖 2-9)。
圖 2-9 貝式分類器採礦模型應用實例示意圖
(資料來源:本研究整理) 以歷史客戶資料建置
之貝式分類器模型
輸入客戶屬性 預測是否
辦會員卡
19
2.7 類神經網路
2.7.1 類神經網路的特性
如果想以電腦來取代人腦,是個有趣的議題,事實上,透過先進技術的高速 運算,超級電腦可以打敗人腦也已經不是個新鮮事。但人類的大腦功能一直以來 皆是科學家們有興趣但很難窺得全面的領域,科學家自 1940 年起,便開始仿造最 簡單的神經元模式,建立原始的類神經網路(Artificial Neural Network ,ANN) (謝邦 昌、鄭宇庭、蘇志雄, 2011)。
以定義而言,「類神經網路是一種計算系統,包括軟體與硬體,它使用大量簡 單的相連人工神經元來模仿生物神經網路的能力。人工神經元是生物神經元的簡 單模擬,它從外界環境或者其它人工神經元取得資訊,並加以非常簡單的運算,
並輸出其結果到外界環境或者其它人工神經元。」 (葉怡成, 1999)。
類神經網路為模仿生物神經系統,由高等生物「腦神經」想法而來,生物的 神經系統由上億個神經元所組成,如圖 2-10 所示,其中包含了神經核、神經軸、
神經樹、神經節等。
圖 2-10 生物神經元示意圖
(資料來源:王進德、蕭大全,1994)
20
也因為類神經網路仿生物神經網路的能力,因此其所擅長的剛好與人類相似 的特性說明如下:
(1)平行處理的特性。
類神經網路採用大量平行計算,經由許多不同的人工神經元來做運算處理,
有別於傳統的范紐曼式(Von Neumann)電腦(即目前的數位電腦)。
(2)容錯的特性。
即使有一成的神經網路失效,仍能運作,即是在操作中有很高的容忍度,整 個神經網路都會餐與解決問題的運作。
(3)結合式記憶的特性。
在神經網路中並沒有所謂的記憶區,但是網路卻可以記住曾經訓練過的輸入 樣式以及對應的理想輸出值。
(4)解決最佳化。
可以處理非演算法(或演算法處理費時)表示的問題,這類問題可借助類神經 網路來協助解決。
(5)超大型積體電路實作
類神經網路的結構具有高度的互連性(Interconnection),而且簡單,有規則性,
易以超大型積體電路來實現。
(6)能處理一般演算法難以處理的問題。
在非常龐大的問題中,為了增加效率,可利用分治法( divide – and – conquer) 的方法,來求得一條正確可行的方式。
2.7.2 Microsoft 類神經網路演算法
在以 Microsoft 類神經網路演算法建立的類神經網路中,使用「多層認知」
(Multilayer Perceptron) 網路,亦稱為「倒傳播差異規則」(Back-Propagated Delta Rule) 網路,有 3 種神經類型:
21
(1)輸入神經(Input neurons)
輸入神經會提供資料採礦模型的輸入屬性值。針對離散輸入屬性,輸入神經通 常代表輸入屬性的單一狀態。如果該屬性的定型資料包含 Null 值,這就包含遺 漏值。有兩個以上之狀態的分散輸入屬性會為每一個狀態產生一個輸入神經,如 果定型資料中有任何 Null 值,則為遺漏狀態產生一個輸入神經。連續輸入屬性 會產生兩個輸入神經:一個神經用於遺漏狀態,而另一個神經用於連續屬性本身 的值。輸入神經會提供輸入給一或多個隱藏神經。
(2)隱藏神經(Hidden neurons)
隱藏神經會接收來自輸入神經的輸入,並提供輸出給輸出神經。
(3)輸出神經(Output neurons)
輸出神經代表資料採礦模型的可預測屬性值。針對分隔輸入屬性,輸出神經通 常代表可預測屬性的單一預測狀態,包括遺漏值。例如,二進位可預測屬性會產 生一個描述遺漏狀態或現有狀態的輸出節點,指出該屬性的值是否存在。用來做 為可預測屬性的布林資料行會產生 3 個輸出神經:一個用於 True 值的神經,一 個用於 False 值的神經,以及一個用於遺漏狀態或現有狀態的神經。有兩個以上 之狀態的分隔可預測屬性會為每一個狀態產生一個輸出神經,並為遺漏狀態或現 有狀態產生一個輸出神經。連續可預測資料行會產生兩個輸出神經:一個用於遺 漏狀態或現有狀態的神經,一個用於連續資料行值本身的神經。
倒傳遞神經網路是一種應用訓練樣本的輸入值向量 X,和一目標輸出向量 T,
修正網路加權 W,進而達成學習預測目的,基本原理是將誤差函數予以最小化。
每當輸入一個訓練範例,網路即小幅調整連結加權值的大小,調整的幅度和誤差 函數對該加權值的敏感程度成正比,即與誤差函數對加權值的偏微分值大小成正 比 (葉怡成, 1999),一般以誤差函數 E 表示,誤差函數(或稱能量函數)表示學習的 品質。E 愈大表示誤差愈大,品質愈差,反之,則愈佳。
22
Tj:訓練範例之輸出層第j 個輸出單元的「目標輸出值」。
Aj:訓練範例之輸出層第j 個輸出單元的「推論輸出值」。
圖 2-11 為四個輸入以及 1 個輸出的倒傳遞網路模型示意圖,此網路由三層神 經單元所組成,左邊為輸入層,接收樣本不同變數特徵,透過固定強度連結到偵 測單元後,再傳送到輸出單元,最終,每個輸出單元對應到某一特定分類。
輸入層 隱藏層 輸出層
X1
X2
X3
X4
圖 2-11 倒傳遞網路模型(四個輸入以及 1 個輸出)
(資料來源: 謝邦昌、鄭宇庭、蘇志雄,2011)
Y1
·
·
·
T
jA
jE 2
1
23
第三章 研究方法
本研究以 Microsoft SQL Server 2008 R2 作為本研究分析處理的軟體工具,對 資料探勘來說,演算法(Algorithm)可說是建立探勘模型的方法,演算法決定了如何 分析資料以及尋找樣式趨勢的方式。不同的資料屬性以及不同的分析目的各有其 合適的演算法。因此,為了於本研究使用資料探勘的分類技術對資料進行分類與 歸納。就 Microsoft SQL Server 2008 R2 工具所能運用的分類演算法而採用對於預 測最具代表性的「決策樹」、「貝式分類」、「類神經網路」等三種分類技術為主,
從所搜集評估的案例資料來建置預測模型。第一節將介紹本研究的研究架構,第 二節說明本研究的資料來源,第三節說明本研究資料處理方式,第四節針對本研 究所使用的軟硬體作說明。
3.1 研究流程
本研究流程如圖 3-1 所示,為順利進行本研究,取得準確有效的樣本,本研究 函文向臺東縣政府教育處申請學生學籍、成績資料,獲取相關資料後,以 Microsoft Excel 軟體將相關資料進行前置作業處理、轉化,產出樣本資料與測試資料兩資料 庫。第二階段包含 3 個實驗,應用 SQL Server2008 R2 Business 工具,包含產生決 策樹模型、貝式分類模型、類神經網路模型,並進行參數調整至取得最佳預測模 型。第三階段則為各模型的比較說明,並探討最適模型的可行性,然後利用最適 模型建置預測系統平台進行實際測驗與驗證,最後章節則是進行總結與研究建 議。
24
樣本資料
台東縣國中學籍資料
資料處理
測試資料
最適模型
研究結論 測試資料驗證模型
圖 3-1 研究流程
(資料來源:本研究整理)
決策樹 模型
貝式分 類模型
類神經 網路模型
建立預測系統
25
3.2 資料來源
本研究來源為求準確性及考量學生個資安全問題,向臺東縣政府教育處申請 剔除敏感個資後的臺東縣 22 所國民中學 97~99 年入學之學生學籍與成績資料,考 量學校實際使用狀況與系統限制,其中成績資料包含學生在學第一學期國語成績、
數學成績、英語成績等各領域成績;學籍資料則包含入學年、曠課日數、是否為 低收入戶、是否為原住民、是否為外籍或大陸配偶子女(新移民)、性別、在學期間 記功、記過次數、是否有中輟紀錄等。
3.3 資料處理
資料的前置處理為資料採礦中最重要的階段,主要的目的在於取得最高預測 以及讓模型結果符合使用者需求,主要包含:資料淨化、資料轉換籍資料整合等。
(1)資料淨化:將所得資料中不須使用的資料欄位予以刪除。
(2)資料轉換:為使所得資料之內容更可容易進行資料採礦,須將部分資料轉換 為可用的型態。
(3)資料整合:將所得的不同相關資料進行整理合併,俾利後續使用分析。
3.4 軟硬體與採礦工具說明
本研究所使用的硬體環境為 Inter Core i7-2600 CPU,4G 記憶體;軟體則包含 Windows 7 中文專業版、Microsoft Office Excel 2007、SQL Server2008 R2,資料探 勘主要以 SQL Server2008 R2 Business 工具來完成。
3.5 模型的評估
Microsoft SQL Server2008 R2 Business 所提供資料採礦演算法如表 3-1,由表 中可知本論文所適合的演算法為決策樹、貝式機率分類、類神經網路三種,主因 為本研究目標是要求出學生中輟事件的機率,並傳回使用者介面,因此本研究採 用上述三種模型演算法進行評估。
26
表 3-1 Microsoft SQL 2008 R2 Business 所提供資料採礦演算法比較
演算法名稱 主要使用目的 本研究是否採用
關聯規則 找尋變數間的關聯性
集群分析 資料分群分類
決策樹 可預測連續及離散資料出現的機率 是
線性迴歸 瞭解自變與應變數的線性關係
羅吉斯迴歸 分析二分類或次序變數的迴歸模式
類神經網路 模擬生物神經元,可預測出現機率 是
貝式機率分類 依貝式定理判斷出現機率預測 是
時序集群 考量時間先後順序的資料
時間序列 時間相關的連續性數值預測
(資料來源:Microsoft,2010)
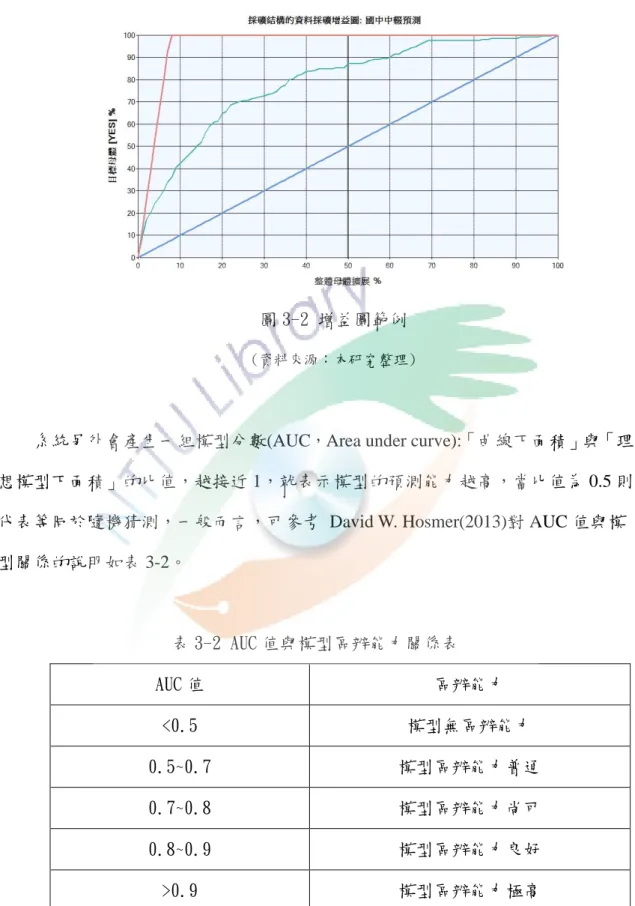
為了分析三種演算法模型(決策樹、貝式機率分類、類神經網路),本研究使用 增益圖評估最佳模型,模型建立之後,分別帶入保留之 30%測試資料,SQL Server2008 R2 Business 可產出增益圖提供分析。以圖 3-3 為例,X 軸代表資料採 礦模型根據機率從高至低排序後的名單占整體測試資料百分比,Y 軸代表此模型 中目標母體(本研究目標母體代表中輟值為 YES)的人數百分比,圖中藍色 45 度對 角線段代表隨機預測結果(隨機猜測之意),至於最上方紅色線段則代表理想模型。
一般正常預測模型曲線則介於紅、藍線段之中,曲線越向上彎曲,表示模型效果 越好(邱宏彬、許依宸,2011)。
27
圖 3-2 增益圖範例
(資料來源:本研究整理)
系統另外會產生一組模型分數(AUC,Area under curve):「曲線下面積」與「理 想模型下面積」的比值,越接近 1,就表示模型的預測能力越高,當比值為 0.5 則 代表等同於隨機猜測,一般而言,可參考 David W. Hosmer(2013)對 AUC 值與模 型關係的說明如表 3-2。
表 3-2 AUC 值與模型區辨能力關係表
AUC 值 區辨能力
<0.5 模型無區辨能力
0.5~0.7 模型區辨能力普通
0.7~0.8 模型區辨能力尚可
0.8~0.9 模型區辨能力良好
>0.9 模型區辨能力極高
(資料來源:本研究整理)
28
第四章 資料採礦模型建置與資料分析
本章共分為五節,主要是要說明本研究所進行三種模型建置的過程與結果,
前四節說明模型的建置方式,第五節針對三模型做評估與說明。
4.1 資料淨化、整理
由臺東縣政府教育處所提供 97~99 學年度入學學生(共 9,461 位)的原始學籍、
成績資料欄位如表 4-1 所示。
表 4-1 原始資料欄位說明
項次 欄位名稱 說明
1 學校名稱 學校中文名稱
2 流水號 僅為資料匯出時的流水號
3 性別 男或女
4 學生班級 學生學生班級
5 曠課日數 學生第一學期曠課日數
6 是否有中輟紀錄 學生國中在學時期是否有連續三天曠
課紀錄
7 國語 學生第一學期國語成績
8 數學 學生第一學期數學成績
9 英語 學生第一學期英語成績
10 社會 學生第一學期社會成績
11 自然 學生第一學期自然成績
12 藝文 學生第一學期藝文成績
13 健體 學生第一學期國語成績
29
項次 欄位名稱 說明
14 低收 學生是否為低收入戶註記
15 本人身障 學生本人是否為身障註記
16 家長身障 學生的家長是否為身障註記
17 原住民 學生是否為原住民註記
18 新移民 學生是否為新移民註記
19 記過 學生第一學期記過次數
20 記功 學生第一學期記功次數
(資料來源:本研究整理)
為增加變項數目以供實驗,加入「領域成績平均(七科平均)」、「功過相抵後數 量」兩欄位,另為了減少資料敏感,將學校名稱改以代號顯示(A 校、B 校、C 校…),
以及將各欄位數值轉換成程式可運算數值如表 4-2。
表 4-2 淨化、整理後資料欄位說明
項次 欄位名稱 值 說明
1 學校 代號(A、B、C…)
2 流水號 不改變,可作為索引 僅為資料匯出時的流水
號 3 性別 轉化 1 代表男, 2 代表女
學生班級(刪除) 本研究不需要
4 曠課日數 數值 學生曠課日數
5 是否有中輟紀錄 YES 或 NO 學生是否有連續三天曠
課紀錄
6 國語 數值 學生第一學期國語成績
30
項次 欄位名稱 值 說明
7 數學 數值 學生第一學期數學成績
8 英語 數值 學生第一學期英語成績
9 社會 數值 學生第一學期社會成績
10 自然 數值 學生第一學期自然成績
11 藝文 數值 學生第一學期藝文成績
12 健體 數值 學生第一學期國語成績
13 低收 轉化 1 代表是,0 為否 學生是否為低收入戶註 記
14 本人身障 轉化 1 代表是,0 為否 學生本人是否為身障註 記
15 家長身障 轉化 1 代表是,0 為否 學生的家長是否為身障 註記
16 原住民 轉化 1 代表是,0 為否 學生是否為原住民註記 17 新移民 轉化 1 代表是,0 為否 學生是否為新移民註記
18 記過 數值 學生第一學期記過次數
19 記功 數值 學生第一學期記功次數
20 成績平均(新增) 數值 國語、數學、英語、社會、
自然、藝文、健體科平均 分數
21 功過相抵(新增) 數值 記功數量-記過數量=功
過相抵數量
(資料來源:本研究整理)
31
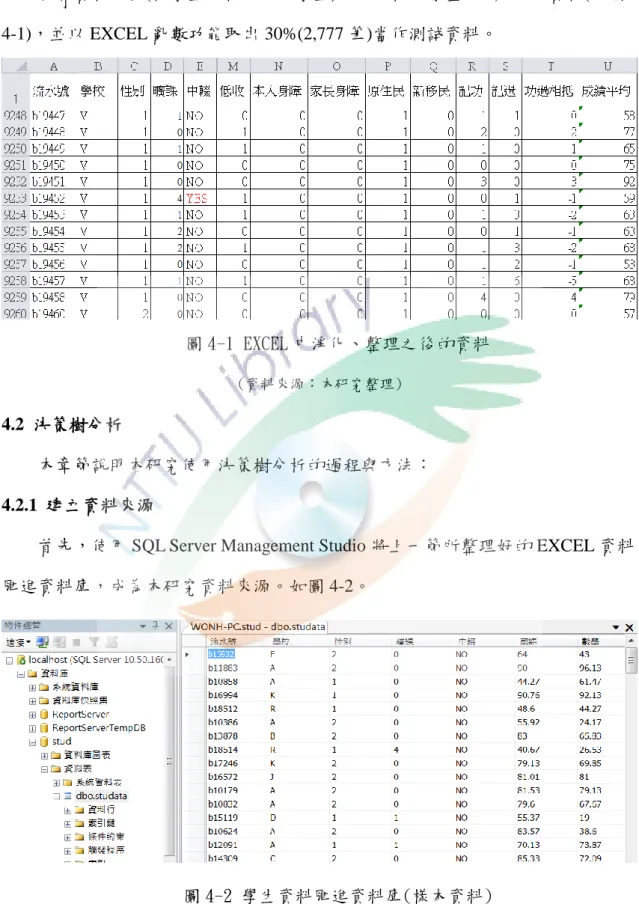
扣除資料不全(轉學生、特殊班級學生),可得樣本數量共 9,259 筆資料(如圖 4-1),並以 EXCEL 亂數功能取出 30%(2,777 筆)當作測試資料。
圖 4-1 EXCEL 中淨化、整理之後的資料
(資料來源:本研究整理)
4.2 決策樹分析
本章節說明本研究使用決策樹分析的過程與方法:
4.2.1 建立資料來源
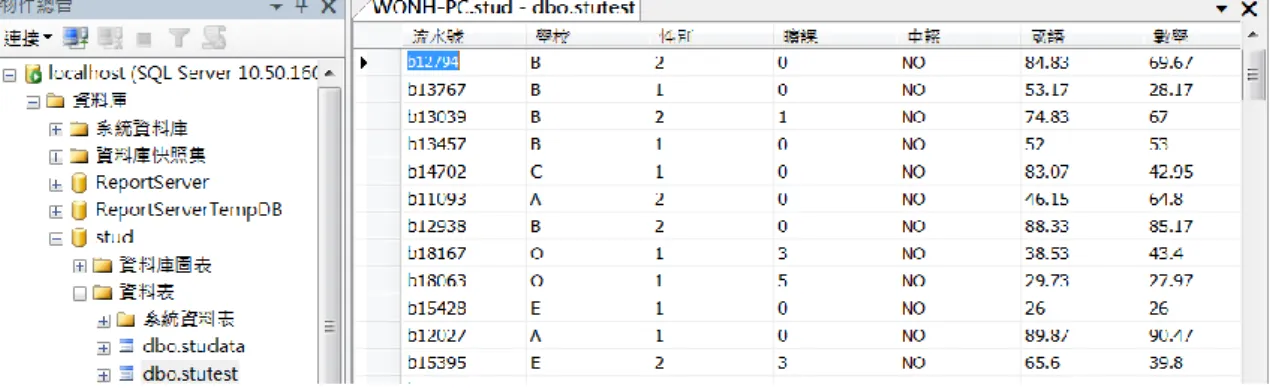
首先,使用 SQL Server Management Studio 將上一節所整理好的 EXCEL 資料 匯進資料庫,成為本研究資料來源。如圖 4-2。
圖 4-2 學生資料匯進資料庫(樣本資料)
(資料來源:本研究整理)
32
另外將以亂數取出 30%資料匯入作為測試資料庫如圖 4-3。
圖 4-3 學生資料匯進資料庫(測試資料)
(資料來源:本研究整理)
4.2.2 新增採礦結構與設定參數
開啟 SQL Server Business Intelligence Development Studio 建立專案,指定資料 來源並決定資料採礦技術為 Microsoft 決策樹,採礦資料結構則將中輟欄位設為可 預測,流水號設為索引鍵,其他欄位設為輸入(如圖 4-4、圖 4-5)。
圖 4-4 選擇資料採礦技術
(資料來源:本研究整理)
33
圖 4-5 指定分析所使用的資料行
(資料來源:本研究整理)
設定各欄位資料內容類型與資料類型,將流水號設為 Key,其餘資料依其屬性 設置,如圖 4-6。
圖 4-6 設定資料內容類型與資料類型
(資料來源:本研究整理)
34
為確保測試資料一致以及可用性,本研究另外準備 30%學生測試資料,故系 統內的測試集資料功能可不用,設定保留測試資料為 0%,如圖 4-7。
圖 4-7 設定保留測試資料為 0%
(資料來源:本研究整理)
本研究使用 Microsoft 決策樹演算法,所設定演算法參數經反覆測試得出最佳 預測值如表 4-3。
表 4-3 本研究決策樹模型參數
參數 本研究
設定值
說明
complexity_penalty 0.9 控制決策樹的成長。低值會增加
分岔數目,而高值會減少分岔數 目。
FORCE_REGRESSOR 空白 強制演算法使用指定的資料行做
為迴歸輸入變數,不考慮演算法
35
參數 本研究
設定值
說明
計算出來之資料行的重要性。
MAXIMUM_INPUT_ATTRIBUTES 255 定義在叫用特徵選取之前,演算 法可以處理輸入屬性的數目。
MAXIMUM_OUTPUT_ATTRIBUTES 255 定義在叫用特徵選取之前,演算 法可以處理輸出屬性的數目。
MINIMUM_SUPPORT 10 決定要在決策樹中產生分岔所需
的最小分葉案例數目。
SCORE_METHOD 4 決定用於計算分岔準則的方法。
1: Entropy
3: Bayesian with K2 Prior 4: Bayesian Dirichlet Equivalent (BDE) Prior
SPLIT_METHOD 3 決定用於分岔節點的方法。
1: Binary: 表示不管屬性的實際 數目為何,樹狀結構都會分岔為 兩個分支。
2: Complete: 表示樹狀結構可以 建立與屬性值一樣多的分岔。
3: Both: 指定 Analysis Services 可以決定應該使用二進位還是完 整分岔來產生最佳的結果。
(資料來源:本研究整理)
36
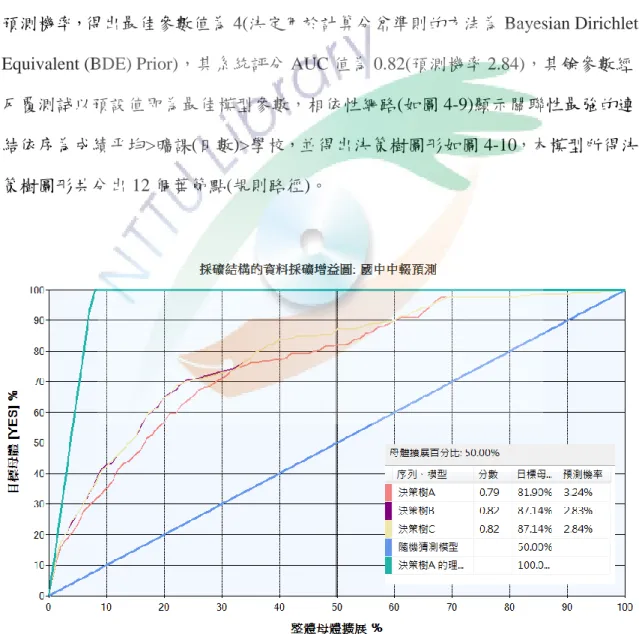
4.2.3 結果分析
經由上述建置參數與類型,本研究案例總計 6,482 筆,為了比較不同
SCORE_METHOD 參數以取得最佳參數值,本研究進行三次不同參數之決策樹模 型建置,並以目標母體為中輟等於「YES」,匯入之前保留之 30%測試資料得增益 圖形如圖 4-8 ,其中「決策樹 A」模型代表 SCORE_METHOD 參數為 1、「決策樹 B」模型代表 SCORE_METHOD 參數為 3、「決策樹 C」模型代表 SCORE_METHOD 參數為 4,經比較增益圖於整體母體擴展 50%時,各參數模型目標母體的百分比及 預測機率,得出最佳參數值為
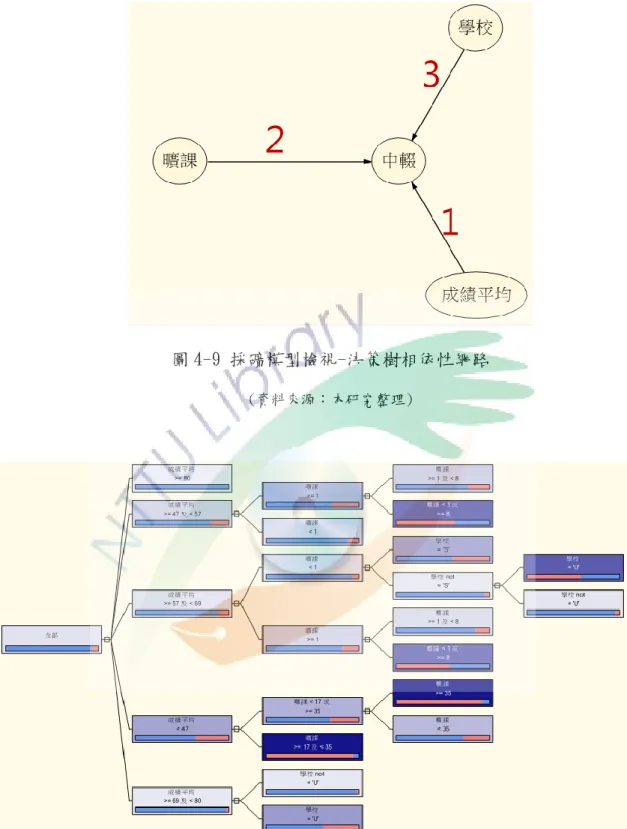
4(決定用於計算分岔準則的方法為 Bayesian Dirichlet Equivalent (BDE) Prior),其系統評分 AUC 值為 0.82(預測機率 2.84),其餘參數經 反覆測試以預設值即為最佳模型參數,相依性網路(如圖 4-9)顯示關聯性最強的連
結依序為成績平均>曠課(日數)>學校,並得出決策樹圖形如圖 4-10,本模型所得決
策樹圖形共分出 12 個葉節點(規則路徑)。圖 4-8 決策樹 A、B、C 模型參數之比較增益圖
(資料來源:本研究整理)
37
圖 4-9 採礦模型檢視-決策樹相依性網路
(資料來源:本研究整理)
圖 4-10 採礦模型檢視-決策樹
(資料來源:本研究整理)
38
由決策樹模型檢視可得規則及其意涵如下表 4-4,以規則三為例,表示當學生 成績平均 >= 57 分 及 < 69 分 且 曠課日數 >= 8 日時,本模型所預測該學生中輟 機率為 56.8%,不中輟的機率則為 43.2%。
表 4-4 決策樹模型路徑規則表
編號 路徑 值 案例 機率
規則一
成績平均 >= 80 NO 20 98.9%
YES 20 1.0%
規則二
成績平均 >= 57 及 < 69 及 曠課 >= 1 及 < 8
NO 387 84.4%
YES 71 15.5%
規則三
成績平均 >= 57 及 < 69 及 曠課 >= 8
NO 15 43.2%
YES 20 56.8%
規則四
成績平均 >= 57 及 < 69 及 曠課 < 1
NO 1,068 93.3%
YES 31 6.6%
規則五
成績平均 >= 47 及 < 57 及 曠課 >= 1 及 < 8
NO 201 76.3%
YES 62 23.6%
規則六
成績平均 >= 47 及 < 57 及 曠課 >= 8
NO 18 37.2%
YES 31 62.8%
規則七
成績平均 >= 47 及 < 57 及 曠課 < 1
NO 379 87.4%
YES 54 12.5%
規則八
成績平均 < 47 及 曠課 >= 35
NO 0 2.1%
YES 10 97.8%
規則九
成績平均 < 47 及 曠課 < 17
NO 153 71.6%
YES 60 28.3%
39
編號 路徑 值 案例 機率
規則十
成績平均 < 47 及 曠課 >= 17 及 < 35
NO 0 1.4%
YES 15 98.5%
規則十一
成績平均 >= 69 及 < 80 及 學校 not = 'U'
NO 1,717 97.1%
YES 49 2.8%
規則十二
成績平均 >= 69 及 < 80 及 學校 = 'U'
NO 13 61.8%
YES 8 38.1%
(資料來源:本研究整理)
為比較三種演算法模型,指定本研究保留 30%學生測試資料庫進行案例測試 得出決策樹模型增益圖如圖 4-11,模型分數(AUC 值)達 0.82,為區辨能力良好的 模型。
圖 4-11 決策樹模型目標母體為 80%之增益圖
(資料來源:本研究整理)
為達預測目標 80%實際中輟學生,將採礦模型預測準則設為預測中輟值為
「YES」機率為 6.66%以上則判斷預測為「有中輟」,進行實際案例測試,SQL Analysis Services 預測查詢語法如下:
40
SELECT
t.[流水號], t.[中輟], PredictProbability([決策樹].[中輟],'YES') AS [Probability] From [決策樹] PREDICTION JOIN
OPENQUERY([Stud],'SELECT [流水號],[中輟],[學校],[曠課],[成績平均]
FROM [dbo].[stutest]') AS t ON [決策樹].[學校] = t.[學校] AND [決策樹].[曠課] = t.[曠課] AND [決策樹].[中輟] = t.[中輟] AND [決策樹].[成績平均] = t.[成績平均]
依據上述語法預測,統計測試結果得表 4-5 分類矩陣,其中橫軸代表預測的計 數,縱軸則是實際的計數。以本研究的測試資料庫顯示,決策樹模型所預測中輟 學生共 1127 位,實際中輟人數則為 176 位,準確率為 169/1127=15.6%,預測非中 輟學生 1650 位,有 34 位學生實際曾經中輟,因此,為達預測 80%實際中輟學生 目標,本模型整體準確率為 64%。
表 4-5 決策樹預測分類矩陣表
預測 實際有中輟 實際無中輟
有中輟 176 951
無中輟 34 1,616
(資料來源:本研究整理)
決策樹模型預測正確率=(176+1616)/(176+951+34+1616)=64%
(預測正確率:預測出正確的名單佔整體預測名單的比率) 決策樹模型目標正確預測比率=176/(176+34)=83.8%
(目標正確預測比率:預測為中輟生佔實際中輟生的比率)
41
決策樹模型預測中輟學生精準率=176/(176+951)=15.6%
(預測中輟學生精準率:預測為中輟生且實際為中輟生佔預測為中輟生的比率)
4.3 貝式機率分類
4.3.1 指定資料採礦技術與設定參數
本章節說明本研究使用貝式機率分類模型分析的過程與方法,首先開啟 SQL Server Business Intelligence Development Studio 專案,指定資料來源資料庫同上節 決策樹模型方法,但本節使用新增資料採礦技術為 Microsoft 貝式機率分類,設定 如圖 4-12,該模型所設定演算法參數則如表 4-6。
圖 4-12 新增模貝式機率分類採礦模型
(資料來源:本研究整理)
42
表 4-6 本研究貝式機率分類模型參數
參數 本研究設定值 說明
MAXIMUM_INPUT_ATTRIBU TES
255
指定在叫用功能選項之前,演算法 可以處理輸入屬性的最大數目。將 此值設定為 0,會停用輸入屬性的 功能選項。預設值為 255。
MAXIMUM_OUTPUT_ATTRIB UTES
255
指定在叫用功能選項之前,演算法 可以處理輸出屬性的最大數目。將 此值設定為 0,會停用輸出屬性的 功能選項。預設值為 255。
MINIMUM_DEPENDENCY_PR OBABILITY
0.5
指定介於輸入和輸出屬性之間的 最小相依機率。這個值會用來限制 演算法所產生之內容的大小。此屬 性可設定為 0 到 1。越大的值會 減少模型內容中的屬性數目。預設 值為 0.5。
MAXIMUM_STATES 100
指定演算法所支援屬性狀態的最
大數目。如果屬性擁有的狀態數目 大於狀態的最大數目,演算法會使 用屬性最常用的狀態並將其餘的 狀態視為遺漏。預設值為 100。
(資料來源:本研究整理)
43
4.3.2 結果分析
經由反覆測試上述建置參數與類型,改變各參數皆得同樣增益圖與結果,故 各參數以預設值設定即可得最佳預測模型,本研究案例總計 6,482 筆,得出相依性 網路(如圖 4-13)則顯示關聯性最強的連結依序為成績平均>曠課(日數)>國語(分 數)>英語(分數)>數學(分數)>社會(分數)>自然(分數)>藝文(分數)>記過(次數)>健體 (分數)>功過相抵>是否為原住民>記功次數>性別>是否為低收入戶。
圖 4-13 採礦模型檢視-本研究貝式機率分類模型相依性網路
(資料來源:本研究整理)
為顯示各變數群的基本屬性機率(有中輟的機率),以下表 4-7 說明機率 7.55%
以上的變數屬性。
表 4-7 本研究貝式機率分類模型中輟機率屬性(僅列機率 7.55%以上)
屬性 值 機率
功過相抵 -2 ~ 5 89.076%
記過次數 3 ~ 6 88.866%
44
屬性 值 機率
記功次數 0 ~ 1 78.361%
是否為低收入戶 否 78.151%
性別 男 65.546%
是否為原住民 是 58.403%
曠課日數 0~1 43.478%
是否為原住民 否 41.597%
數學成績 < 39.5 39.076%
曠課日數 1~8 36.975%
英語成績 < 37.48 36.134%
成績平均 57 ~ 69 35.084%
英語成績 37.48 ~ 52.83 34.837%
性別 女 34.454%
數學成績 39.5 ~ 52.7 34.244%
國語成績 43.3 ~ 59.1 33.824%
成績平均 47 ~ 57 30.882%
是否為低收入戶 是 21.849%
成績平均 40 ~ 47 17.875%
曠課日數 8 ~ 17 11.345%
自然分數 43 ~ 52 10.490%
社會成績 0 ~ 60.5 9.571%
記過次數 0 ~ 3 8.403%
英語成績 69 ~ 85 7.80%
(資料來源:本研究整理)
45
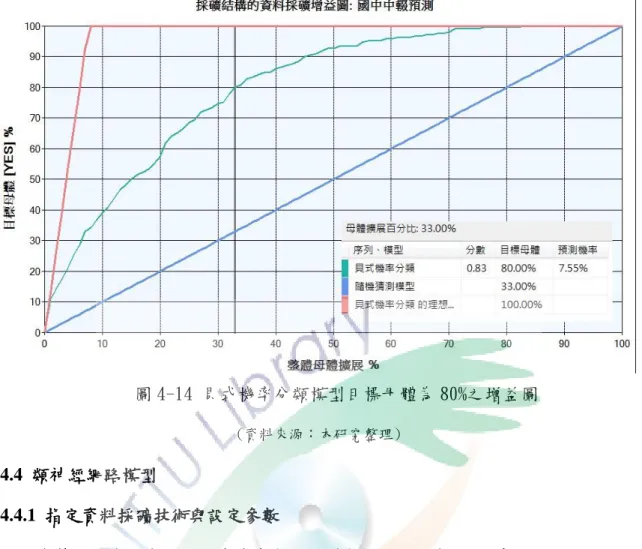
使用 SQL SERVER 2008 所提供採礦精確圖表功能,指定本研究保留 30%學生 測試資料庫進行案例測試得出貝式機率分類模型增益圖(如圖 4-14)、為進行本研究 比較模型目的,預測目標為 80%實際中輟學生,將採礦模型預測準則設為若預測 中輟值為「YES」的機率限定 7.55%以上則判斷預測為「有中輟」,並進行實際案 例預測,預測查詢語法如下:
SELECT t.[流水號], t.[中輟], PredictProbability([貝式機率分類].[中 輟],'YES') AS [Probability]
From [貝式機率分類] PREDICTION JOIN
OPENQUERY([Stud], 'SELECT [流水號],[中輟], [性別],[曠課],[國語],[數 學],[英語],[社會],[自然],[藝文],[健體],[低收],[原住民], [記功],[記過],[功過相 抵],[成績平均] FROM [dbo].[stutest] ') AS t ON
[貝式機率分類].[性別] = t.[性別] AND [貝式機率分類].[曠課] = t.[曠課] AND [貝式機率分類].[中輟] = t.[中輟] AND [貝式機率分類].[國語] = t.[國語] AND [貝式機率分類].[數學] = t.[數學] AND [貝式機率分類].[英語] = t.[英語] AND [貝式機率分類].[社會] = t.[社會] AND [貝式機率分類].[自然] = t.[自然] AND [貝式機率分類].[藝文] = t.[藝文] AND [貝式機率分類].[健體] = t.[健體] AND [貝式機率分類].[低收] = t.[低收] AND [貝式機率分類].[原住民] = t.[原住民] AND
46
[貝式機率分類].[記功] = t.[記功] AND [貝式機率分類].[記過] = t.[記過] AND
[貝式機率分類].[功過相抵] = t.[功過相抵] AND [貝式機率分類].[成績平均] = t.[成績平均]
依上述語法進行預測可得統計結果數據如表 4-8 分類矩陣,其中橫軸代表預測 的計數,縱軸則是實際的計數。以本研究的測試資料庫顯示,決策樹模型所預測 中輟學生共 918 位,實際中輟人數則為 169 位,準確率為 169/918=18.4%,預測非 中輟學生 1860 位,有 42 位學生實際曾經中輟,因此,為達預測 80%實際中輟學 生目標,本模型整體準確率為 71.5%。
表 4-8 貝式機率分類模型預測分類矩陣表
預測 實際有中輟 實際無中輟
有中輟 169 749
無中輟 42 1,818
表 4-7 貝式機率分類模型預測分類矩陣表
(資料來源:本研究整理)
貝式機率分類模型預測正確率=(169+1818)/(169+749+42+1818)=71.5%
貝式機率分類模型目標正確預測比率=169/(169+42)=80.0%
貝式機率分類模型預測中輟學生精準率=169/(169+749)=18.4%
47
圖 4-14 貝式機率分類模型目標母體為 80%之增益圖
(資料來源:本研究整理)
4.4 類神經網路模型
4.4.1 指定資料採礦技術與設定參數
本節說明本研究使用貝式機率分類模型分析的過程與方法,先開啟 SQL Server Business Intelligence Development Studio 專案,指定資料來源資料庫同上節,但本 節使用新增資料採礦技術為 Microsoft 類神經網路演算法(如圖 4-15),為達最佳預 測模型,所設定演算法參數如表 4-9。
圖 4-15 新增類神經網路模型演算法
(資料來源:本研究整理)
48
表 4-9 本研究類神經網路模型參數
參數 本研究設定值 說明
HIDDEN_NODE_RATIO 0.0
指定隱藏神經與輸入和輸出神經的比
例。預設值為 4.0。
HOLDOUT_PERCENTAGE 30
指定用來計算鑑效組錯誤之培訓資料內
的案例百分比,這可作為培訓採礦模型 時停止準則的一部份。預設值為 30。
HOLDOUT_SEED 0
在演算法隨機決定鑑效組資料時,指定
用來植入虛擬隨機產生器的數字。預設 值為 0。
MAXIMUM_INPUT_ATTRI BUTES
255
決定在運用功能選項之前可提供給演算 法之輸入屬性的最大數目。將此值設定 為 0,會停用輸入屬性的功能選項。預 設值為 255。
MAXIMUM_OUTPUT_ATT RIBUTES
255
決定在運用功能選項之前可提供給演算 法之輸出屬性的最大數目。將此值設定 為 0,會停用輸出屬性的功能選項。
預設值為 255。
MAXIMUM_STATES 100
指定演算法支援的每個屬性之分隔狀態
的最大數目。預設值為 100。
SAMPLE_SIZE
10,000 指定用來培訓模型的案例數目。預設值
為 10,000。
(資料來源:本研究整理)