目錄
第一章 緒論... 3
1.1 研究背景... 3
1.2 研究動機... 3
1.3 文獻回顧... 4
1.4 專題貢獻... 4
第二章 理論背景... 5
2.1. 整體架構... 5
2.2. 圖形化使用者介面主程式... 6
2.3. 影像辨識框架... 8
2.4. 哈爾級連分類器(Haar Cascade Classifier) ... 8
2.5. 局部二進制直方圖(Local Binary Patterns Histograms)... 10
2.6. 深度神經網路(Deep Neural Network)... 11
2.7. API 及伺服器架設 ... 13
2.8. 活體識別... 14
第三章 實驗成果... 17
3.1 已完成部分... 17
3.2 環境規格... 17
3.3 文件配置... 18
3.4 偵測及人臉辨識... 19
3.5 取樣建檔... 21
3.7 影片取樣建檔... 23
3.8 線上註冊... 23
3.9 活體辨識... 24
3.10 開發日誌... 26
第四章 未來發展方向與結論... 28
第五章 時間進度表(甘特圖 Gantt Chart): ... 29
第六章 參考資料:... 29
第七章 工作分配:... 31
第八章 經費表:... 31
第一章緒論 1.1 研究背景
以人類生理特徵如人臉、指紋、掌紋、血管、虹膜、語音等,或行為模式,如 簽名、步伐、敲打鍵盤(keystrokes)為辨識依據的方法,統稱為生物認證系統
(Biometrics)。目前生物認證系統有很龐大的市場需求,對人類來說,視覺是非常 直接也最容易幫助記憶的一種刺激,而在這麼多種生理特徵或行為模式中,又以人 臉最具有獨特與方便取得的特性。人臉辨識是屬於非侵入、非接觸式的方式,是較 為先進、文明且易於為大多數人接受的一種辨識方法。它對於是否戴帽、髮型的變 化或染髮、是否帶眼鏡或鬍鬚的有無變化,只要主要的人臉特徵能清楚分辨的情況 下,辨識結果都不會受到影響,這使得人臉辨識技術能廣泛的被社會接受與應用。
人臉辨識的應用也可以融入在一般生活中,諸如門禁管制系統、考勤身份辨識 系統、影像監視系統、提款卡身份辨識系統,乃至於前科犯資料庫辨識系統的建檔 等,皆對人類長久以來的日常生活習慣產生革命性的影響。譬如利用人臉的特徵來 做為門禁安全的控管,除了更有效外,可省去感應卡的管理建置費用,也能補足員 工忘記帶卡的困擾,更甚者在雙手無暇刷卡或按密碼時,特別能感受到人臉辨識技 術的好處。又例如提款機也可以加入人臉辨識的技術,結合晶片、晶片密碼、人臉 密碼三種,能夠讓整體安全性更高,就算卡片遺失也不用太擔心會被盜領的情形。
1.2 研究動機
由於電腦科技的急速發展、網路的普及化,發達的資訊已經融入了我們現實的 生活中,因此必須要更顧慮到資訊安全上的問題,目前有許多犯罪事件都是屬於資 訊犯罪的狀況,例如金融帳號或個人電腦資訊被盜用、個人資料外流的種種問題,
這意味著光靠一組密碼並無法保護個人安全。
人臉辨識的技術在這幾十年來已經有不少的研究成果,因此有不少增加辨識率 的方法被提出。但事實上提升辨識率是一個很困難的問題,相對於指紋辨識而言,
因為世界上沒有兩個人的指紋是相同的,且指紋不會隨著人的動作變化而產生變 動,以致於指紋是一個非常好的特徵,辨識準確率相當高。但對於人臉辨識來說,
畢竟人臉相像的程度太高,但在不同的姿勢與表情之下所呈現的樣子卻具有很大的 變異性,加上戴眼鏡、蓄鬍鬚、或變換髮型等裝扮,都會增加人臉辨識的難度,使 得這個研究非常具有挑戰性。
且近年來將人臉辨識應用於門禁系統已發展相當成熟,然而現有人臉辨識系統 大多需要在初次使用時本人到現場註冊,若同時有大量人員入場,將造成人龍排隊 註冊的情況,除在疫情依然嚴峻的此刻無法保持安全防疫距離,也會耗費大量時間 等待。而現有人臉辨識系統在註冊取樣時,若取樣數量太少會出現臉部角度不均,
或為了取到各角度而取過多樣本,造成人員難以通關或是在註冊人數龐大時運行速 度過慢的現象。此外,使用人臉辨識系統時,經常出現使用他人照片代為通關情 況,對於門禁等重要系統存在重大資安疑慮。為此本組決定研究出可以線上註冊人 臉活體辨識系統。
1.3 文獻回顧
本研究之線上註冊功能採用Google 雲端之各項服務達成,使用 Google 表單、
Google sheets 及 Backup and Sync from Google 同步備份等等功能,成功實作出線上 註冊及遠端接收用戶端檔案。
選擇openCV 內建的 haarcascade_frontalface 偵測器、LBPHFaceRecognizer 作 為影像辨識框架進行辨識;及基於ResNet 架構的 res10_300x300_ssd_iter_140000 深度神經網路模型偵測器、openface_nn4.small2.v1.t7 嵌入器萃取出圖像特徵向 量、sklearn 套件訓練支援向量機進行辨識並進行執行速度與辨識精確度比較。
活體識別之神經網路藉由VGGnet 架構設計及 dlib 68 point facial-landmark 映 射至三維立體模型,藉此計算人臉之角度及活體辨識。
最後加上步進馬達搭配Arduino 控制器及 PC Serial 端傳輸指令之實體門禁系 統模型。
1.4 專題貢獻
參與人員 工作項目 百分比
學生:陳冠達 學生:沈世名 學生:林益賢
1.機器學習、python、環境架設練習 2.主程式介面及功能
3.影片建檔訓練模型 4.線上註冊及接收影片 5.CUDA 設置 GPU 加速 6.活體辨識模型架構設計 7.自動取樣程式
8.人臉樣本蒐集 9.訓練活體辨識模型 10.門禁系統實體 11.立體視覺
80%
指導教授:陳建中
1.召開專題會議 2.引導專題題目
3.審視各層面問題 15%
實驗室學長:蘇建安
1.程式技術指導 2.協助解決程式問題
5%
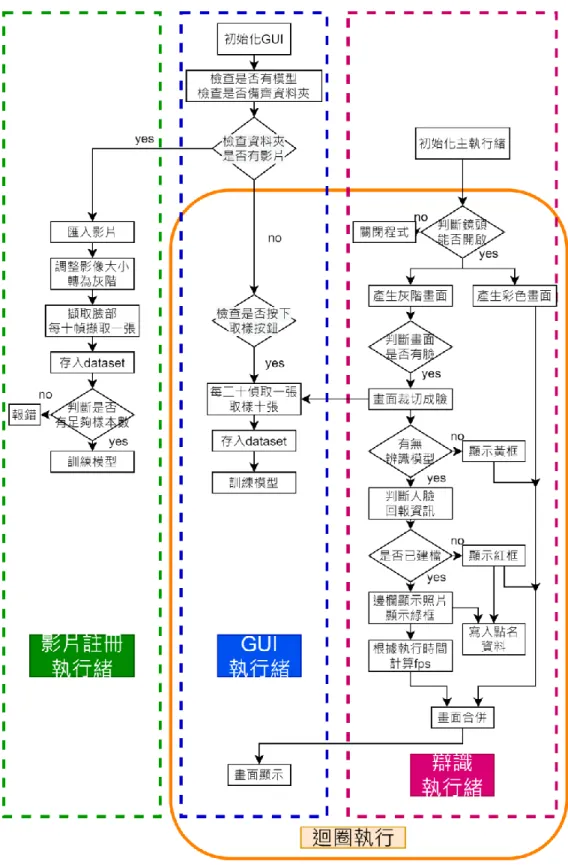
第二章理論背景 2.1. 整體架構
本研究主要分為四大技術項目:
(一)主程式:於PC 端執行之能夠註冊、偵測、辨識、簽到,具 GUI 之主 程式
(二)人臉辨識框架:比較Haar/LBP/DNN/CNN 辨識準確度及效率差異
(三)API 及伺服器架設:架設接收用戶註冊資料的 Linebot 及樹梅派伺服器
(四)活體識別:於辨識時加入活體識別功能,防範代點名情況
圖2.1-1 整體系統運行架構圖
2.2. 圖形化使用者介面主程式
現今主流撰寫python 圖型化界面有 Tkinter 與 PYQT5 兩種套件,經比較 Tkinter 撰寫出的介面功能較為單調,且使用程式碼撰寫圖形化介面較為困難。本 研究選擇使用PYQT5 撰寫,搭配操作簡易且功能完善的 Qt Designer 軟體以繪圖方 式生成.ui 檔,再使用 cmd 指令將其轉為.py 檔。
圖2.2-1 主程式圖形化介面及各元件說明 本研究程式撰寫特點如下:
1.使用介面與邏輯分離寫法,避免程式功能受到介面樣式更動時影響。
2.使用 Qthread 實現多執行序,將辨識、模型訓練和介面顯示各自分為執行序處 理,增加執行速度。經多執行序化撰寫後,辨識時的畫面更新率能夠從5fps 改善 為穩定保持在30fps。
3.模組化編寫程式所需的各種子功能,使主程式碼保持簡潔、提升易讀性,易於維 護及更動。
4.導入版本控制概念及撰寫開發日誌。
圖2.2-2 主程式執行流程圖
2.3. 影像辨識框架
本研究以openCV 作為影像處理架構,進行影像擷取、色階轉換、翻轉、調整 大小、偵測、裁切、辨識、檔案寫出入等處理程序。
現今較常使用於臉部的影像辨識方式,有較為古典的HOG(Histogram of Oriented Gradient 方向梯度直方圖)、LBP(Local Binary Patterns 局部二值模式)、
Haar(哈爾特徵)等演算法,以及基於神經網路技術發展出的 DNN(Deep Neural Network 深度神經網路)、CNN(Convolutional Neural Network 卷積神經網路) 、 MTCNN(Multi-task Cascaded Convolutional Networks),其中還有基於 cascade 架構 的R-CNN、Fast R-CNN、Faster R-CNN,及單一網路架構的 SSD(Single Shot MultiBox Detector)、YOLO(You Only Look Once)等類神經網路模型。
然而,受限於本研究目的是在無GPU 環境下運行,經比較發現 CNN 模型在 CPU 上運算極為耗時,實測辨識速度低至 0.5FPS、高至 2FPS,運用於即時影像辨 識速度過慢,並無太大實務使用價值。
考慮到openCV 相容性及根據市面上現有辨識套件,本研究前後分別使用 openCV 內建的 haarcascade_frontalface 偵測器,搭配 LBPHFaceRecognizer 進行訓 練及辨識;以及基於ResNet 架構的 res10_300x300_ssd_iter_140000 深度神經網路 模型偵測器,搭配openface_nn4.small2.v1.t7 嵌入器萃取出圖像特徵向量、sklearn 套件訓練支援向量機進行辨識;並且比較兩者執行速度、偵測容錯率及精準度、辨 識精準度。
2.4. 哈爾級連分類器(Haar Cascade Classifier)
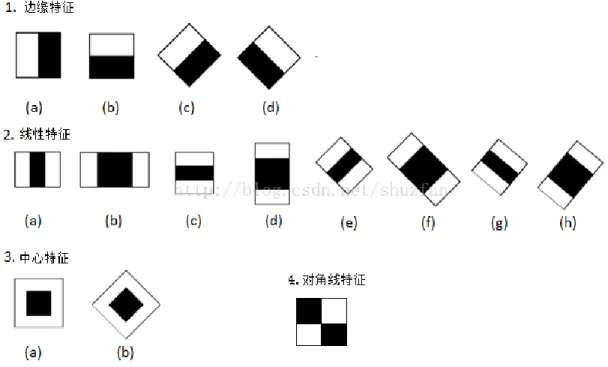
哈爾特徵運算用於偵測辨識圖像特徵,其定義為將灰階圖像進行矩形裁切,於 矩形範圍內計算黑和白像素總數,將該矩形白色像素和減去黑色像素和,即為哈爾 特徵值。哈爾特徵可以表示灰階變化情況,用於臉部辨識時可以用明亮變化程度檢 測器官位置,如眼睛灰度比臉要深、鼻子兩側灰度比鼻子要深。藉由不斷調整矩陣 大小及位置,便能夠窮舉出圖片中的哈爾特徵值。而根據其矩陣黑白分布位置,可 分為邊界特徵、線特徵、中心特徵及對角線特徵(有一說是將對角線特徵歸類為線 特徵)。
圖2.4-1 圖像經灰階處理後,標記出各部位哈爾特徵矩陣
圖2.4-2 哈爾特徵各式型態示意圖
接著將偵測到的特徵一步步篩選判斷是否為特定特徵,如符合則繼續進行下一 步判斷,如此篩選到最後即可判斷畫面中是否具有人臉。此篩選機制以二元樹表示 即為級聯(串級)模型。
圖2.4-3 級聯(串級)模型示意圖
經實測內建的haarcascade_frontalface 偵測器準確度並不是很好,常無法偵測 正確框取臉部位置,只要臉部上下傾斜、側臉、遮擋到邊緣部位(尤其是眉毛)、光
源不足皆會造成偵測失敗,或是將他處判斷為人臉。
圖2.4-4 Haar 要將眉毛露出才能正確偵測,並且常偵測錯誤
2.5. 局部二進制直方圖(Local Binary Patterns Histograms)
局部二進制圖樣(LBP)數學模型用於反映圖片紋理信息,其原始定義為以灰階 圖像每3*3 格之中心像素為閾值,將周圍的 8 個像素與其比較,若值較高則標記為 1、較低則標記為 0,再將 8 位數值進行二進位編碼,得到 256 種組合,即為中心 像素的LBP 特徵值。
圖2.5-1 LBP 數值處理示意圖
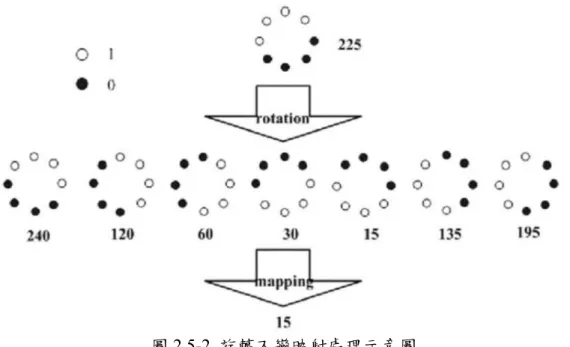
而後續研究將LBP 改進,將 3*3 的方格範圍改為以半徑計的圓形範圍,偵測 十調整半徑大小以應對不同尺度的紋理訊息;將經過旋轉的相同圖案所產生的8 種 LBP 二進制編碼映射處理,全部對應到單一十進位數值,達成灰度及旋轉不變的 特性;將LBP 二進制編碼中 0 和 1 變換數量作為分類依據,將變換次數相同的稱 為等價模式,其餘稱為混合模式,經過此處理能夠將二進制模式種類大幅減少,減 少特徵向量維度。
圖2.5-2 旋轉不變映射處理示意圖
然而在辨識人臉時不可能完全符合樣本邊緣位置,因此會將圖像分割成若干子 區域,統計子區域內每個像素點LBP 特徵值,建立個別子區域數值直方圖
(histogram),此即為局部二進制直方圖(LBPH),並且計算和樣本差異度,差異度最 小的樣本為辨識結果,藉此進行人臉識別。
本研究使用Haar cascade front face classifier 偵測出圖像中人臉,經過裁切、調整大 小、灰階處理、標記姓名ID 後,取樣十張存入資料庫,再使用 LBPH recognizer 對資料庫圖像訓練.yml 模型,攝影機畫面便以此模型進行辨識功能。
實測後發現,LBPH 模型辨識精準度並沒有很理想,常出現誤認他人的狀況,對於 門禁或點名系統有十分嚴重的安全疑慮,因此本研究後續嘗試將偵測及辨識方式更 改為使用深度神經網路。
2.6. 深度神經網路(Deep Neural Network)
本研究使用caffe 深度神經網路框架中,基於 ResNet(residual neural network)架 構預訓練好的res10_300x300_ssd_iter_140000 SSD(single shot detector) model 作為 人臉偵測器,搭配使用pytorch 機器學習庫中基於 triplet loss 的
openface_nn4.small2.v1.t7 模型作為嵌入器(embedder),提取臉部 128 維嵌入向量資 訊寫入.pickle 檔,再使用 sklearn 套件存取向量特徵值及個人資訊,生成支援向量 機(support vector machine, SVM)進行人臉識別。
ResNet 使用殘差學習(residual learning)方式解決了在深度學習中,增加隱藏層 層數所產生錯誤率增加的現象,稱為退化問題(degradation prolem)。
此處我們定義x 為單一層輸入值,f(x)為輸出值,d(x) = f(x) – x 為殘差值;由此 可將原運算式x → f(x) 轉換為 x → x + d(x);當輸入等於輸出時,殘差值為 0,
x → x,此時這一層就稱為恆等映射(identify maping),並不會造成模型退化的現 象。藉此能夠有效增加深度學習隱藏層數,降低卷積運算量。
圖2.6-1 殘差學習單元示意圖
圖2.6-2 SSD 模型架構示意圖
經實驗,ResNet SSD 偵測器相較於 Haar cascade 偵測器能夠有效克服在側 臉、上下傾斜、部分遮蔽、光源不足等偵測失敗原因,對環境變化適應力改善許 多;而擷取框較為高而窄,臉部邊緣有納入下巴但並無擷取到耳部位置,目前尚未 觀察到對模型訓練有顯著影響;然而使用此偵測器時速度上有顯著降低,相較於使 用Haar cascade 時畫面更新率能夠達到 30fps,ResNet SSD 偵測時最高只能達到 5fps,實際使用上僅勉強能夠接受。
圖2.6-3 ResNet SSD 和 Haar cascade 偵測器框取範圍比較
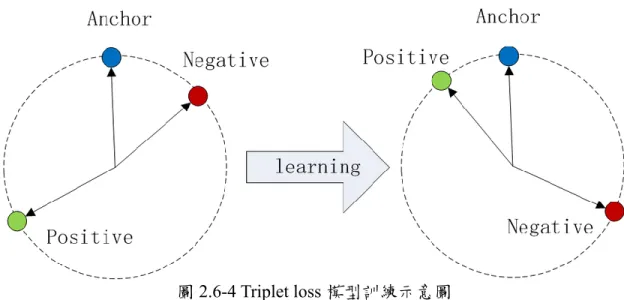
triplet loss 通常用於學習人臉向量表現方式,相較於其他損失函數計算方式,
加入了兩個輸入差異性變量,能夠對細節進行更精密的建模。
計算triplet loss 需有三項元素:anchor(基準正例)、positive(正例)、negative(反 例),在人臉識別中 anchor 和 positive 為同一人,negative 則為其他人;訓練模型的
目的是將anchor 和 positive 的權重拉近,同時將 negative 權重推遠,藉此能夠明確 分辯人臉的不同。本研究中使用取樣的第一張作為anchor,其餘九張作為
positive,另外還有一組六張標記為 unknown 的隨機路人照片作為 negative。然而 使用內建攝影機取樣時,角度及燈光變化並不會很大,positive 和 anchor 無法非常 有效的拉進權重,在實務上需要使用更多多樣性照片進行訓練會較為有效。
圖2.6-4 Triplet loss 模型訓練示意圖
2.7. API 及伺服器架設
本研究選擇Google 作為本系統和用戶溝通媒介平台,以 Google drive(Google 雲端)為基礎,使用 Google Forms(Google 表單)及 Back up and sync from Google 來 遠端接收用戶端之辨識影片檔案。
本研究使用google 當作我們的資料庫及線上註冊功能,藉由 google 表單,即 可讓使用者從客戶端將自己的影片上傳至接收端,也就是上傳至google 雲端,並 且Backup and Sync from Google 更可將這些使用者之辨識影片同步到電腦同步資料 夾供程式辨識使用,由此即可遠端取得使用者的辨識影片。
圖2.7-1Google Form
取得影片之後還必須記錄是那位使用者之影片,此部份我們嘗試過兩種方法,
(1)請使用者上傳影片時自行更改檔名為使用者 ID 及電子信箱,此方法使得程式在 抓取影片辨識時即可藉由檔名,獲取該使用者之ID 及電子郵件並記錄至 log 檔 中。(2)請使用者上傳影片的同時,在表單另外填下 ID 及電子郵件,接者利用 google sheets Api、google 客戶端套件及 python spread sheet,即可將記錄在 google sheets 上之使用者資料串接至程式中使用。
圖2.7-2 同步資料夾取得影片
兩種方法比較下來,我們決定使用方法(1),相較於方法(2),此方法可以使用 更少的額外套件達成註冊之功能。
2.8. 活體識別
現今主流活體辨識方法有使用深度攝影機、3D 人臉、DNN 模型判別、紋理分 析、臉部運動偵測等方式,其中我們選擇使用VGGNet 神經網路
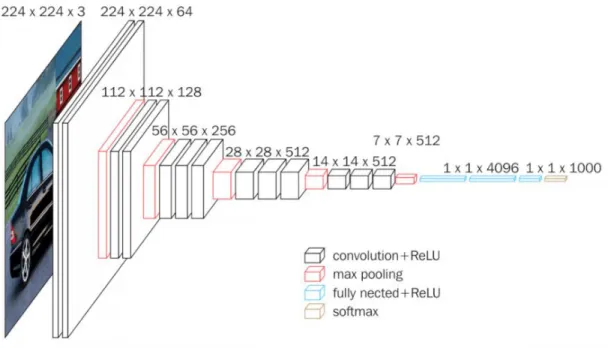
VGGNet 探索了卷積神經網絡的深度與其性能之間的關係,成功地構築了 16~19 層深的卷積神經網絡,證明了增加網絡的深度能夠在一定程度上影響網絡最 終的性能,使錯誤率大幅下降,同時拓展性又很強,遷移到其它圖片數據上的泛化 性也非常好。到目前為止,VGG 仍然被用來提取圖像特徵。VGG 結構簡潔,由 5 層卷積層、3 層全連接層、softmax 輸出層構成,層與層之間使用 max-pooling(最 大化池)分開,所有隱層的激活單元都採用ReLU 函數。
圖2.8-1VGG 結構圖
VGG 使用多個較小卷積核(3x3)的卷積層代替一個卷積核較大的卷積層,一 方面可以減少參數,另一方面相當於進行了更多的非線性映射,可以增加網絡的擬 合能力。
小卷積核是VGG 的一個重要特點,雖然 VGG 是在模仿 AlexNet 的網絡結 構,但沒有採用AlexNet 中比較大的卷積核尺寸(如 7x7),而是通過降低卷積核 的大小(3x3),增加卷積子層數來達到同樣的性能(VGG:從 1 到 4 卷積子層,
AlexNet:1 子層)。
圖2.8-2VGG 卷積堆疊原理
VGG 的作者認為兩個 3x3 的卷積堆疊獲得的感受野大小,相當一個 5x5 的卷 積;而 3 個 3x3 卷積的堆疊獲取到的感受野相當於一個 7x7 的卷積。這樣可以增加 非線性映射,也能有效地減少參數。
VGG 全部採用 2x2 的池化核。VGG 網絡第一層的通道數為 64,後面每層都 進行了翻倍,最多到 512 個通道,通道數的增加,使得更多的資料可以被提取出
來,由於卷積核專注於擴大通道數、池化專注於縮小寬和高,使得模型架構上更深 更寬的同時,控制了計算量的增加規模。
VGG 之全連接轉卷積在網絡測試階段將訓練階段的三個全連接替換為三個卷 積,使得測試得到的全卷積網絡因為沒有全連接的限制,因而可以接收任意寬或高 為的輸入,這在測試階段很重要。
圖2.8-3 全連接轉卷積替換過程
這個「全連接轉卷積」的思路是VGG 作者參考了 OverFeat 的工作思路,
OverFeat 將全連接換成卷積後,則可以來處理任意解析度上計算卷積,這就是無需 對原圖做重新縮放處理的優勢。
在電腦視覺中,角度偵測特別是指目標物相對於鏡頭之相對方向。而參考點即 是攝影鏡頭之視野。角度偵測通常稱為 n 點透視問題,或稱為電腦視覺之PNP 問 題,而定義這個問題的部分則藉由給定參考點的一組立體位置(3D Points)和攝影 鏡頭獲取之對應 2D 圖像來簡化達成。
圖2.8-4 PNP problem statement
方程式左側代表攝影鏡頭取得之 2D 圖片,方程式右側之矩陣從左到右分別為 代表攝影鏡頭之矩陣、選轉與平移量及臉部的 3D 模型。f(x,y)是聚焦長度,γ 是 偏斜參數,通常為 1,(u0,v0)代表圖片之中心點,r、t 分別為旋轉及平移量。
偵測及預測人臉來解決PNP 到最後能達成我們的預期,也就是人臉角度偵 測,我們需要先偵測出人臉,為此我們選擇使用dlib 及 opencv 提供之 API 將六個 座標點,鼻尖、下巴、左上角之左眼、右上角之右眼及嘴角的數值提取為目標點 (objectivePoints),搭配 solvePNP,將目標點(objectivePoints)、圖像點
(imagePoints)、cameraMatrix、distCoefs 進行計算,使 API 返回旋轉向量及平移向 量矩陣,藉此得到角度估測結果。
第三章實驗成果 3.1 已完成部分
本研究分別開發Haar/LBPH 辨識架構的 version 1.2 版,及 ResNet/Triplet loss 辨識架構的version 2 beta 版,均完成基礎的偵測、辨識、取樣建檔、訓練模型、
簽到記錄、匯入影片建檔訓練模型功能。
3.2 環境規格
(1) 硬體
中央處理器:Intel Core i7-7500U @2.7GHz 顯示卡(內顯):Intel HD Graphics 620 記憶體:16GB DDR4
硬碟:M.2 256GB SSD 攝影鏡頭:解析度1280*720 (2) 軟體
version 1.2:
python == 3.7.7 numpy == 1.18.4
opencv-python == 4.2.0.34 pyqt5 ==5.15.0
openpyxl == 3.0.4 gspread == 3.6.0 pillow == 7.1.2 version 2 beta:
python == 3.7.7 numpy == 1.18.4
opencv-python == 4.2.0.34 pyqt5 ==5.15.0
openpyxl == 3.0.4 gspread == 3.6.0 pillow == 7.1.2 imutils == 0.5.3
sklearn == 0.0
3.3 文件配置
version 1.2:
├── main.py:主程式
├── ui.py:GUI 程式碼
├── tr.py:訓練模組
├── fr.py:辨識模組
├── sn.py:簽到模組
├── exl.py:Excel 寫入模組
├── fps.py:fps 計算模組
├── vp.py:影片處理模組
├── ui:存放 QT Designer 原始碼檔案夾
│ └── ui.ui:QT Designer 原始碼
├── log:存放簽到資料檔案夾
│ ├── log.txt:文字檔形式簽到資料
│ └── log.xlsx:試算表形式簽到資料
├── model:存放辨識模型檔案夾
│ └── model.yml:辨識模型
├── video:存放用於建檔影片檔案夾
├── dataset:存放建檔用照片檔案夾
├── classifier:存放分類器檔案夾
│ └── haarcascade_frontalface_default:Haar 分類器
├── _pycache_:python 直譯快取文件檔案夾
├── readme.txt:程式說明文件
└── requirements.txt:用於快速安裝套件文件 version 2 beta:
├── main.py:主程式
├── ui.py:GUI 程式碼
├── tr.py:訓練模組
├── fr.py:辨識模組
├── sn.py:簽到模組
├── exl.py:Excel 寫入模組
├── fps.py:fps 計算模組
├── vp.py:影片處理模組
├── ui:存放 QT Designer 原始碼檔案夾
│ └── ui.ui:QT Designer 原始碼
├── log:存放簽到資料檔案夾
│ ├── log.txt:文字檔形式簽到資料
│ └── log.xlsx:試算表形式簽到資料
├── model:存放辨識模型檔案夾
│ ├── embeddings.pickle:已序列化臉部嵌入值
│ ├── le.pickle:姓名和 ID 標記檔
│ └── recognizer.pickle:人臉識別 SVM 模型
├── video:存放用於建檔影片檔案夾
├── haardataset:存放用於 haar 模型建檔用照片檔案夾
├── dnndataset:存放用於 dnn 模型建檔用照片檔案夾
├── classifier:存放分類器檔案夾
│ ├── haarcascade_frontalface_default:Haar 分類器
│ ├── deploy.prototxt:DNN 模型結構
│ ├── openface_nn4.small2.v1.t7
│ └── res10_300x300_ssd_iter_140000.caffemodel:DNN 模型權重
├── _pycache_:python 直譯快取文件檔案夾
├── readme.txt:程式說明文件
└── requirements.txt:用於快速安裝套件文件
3.4 偵測及人臉辨識
畫面中於已註冊人臉顯示ID 及綠框,未註冊人臉顯示 unknown 及紅框。側邊 資訊欄則顯示建檔時照片及ID、姓名等資訊。
圖3.4-1 主程式 GUI 操作介面 - 使用 HaarCascade 及 LBPH
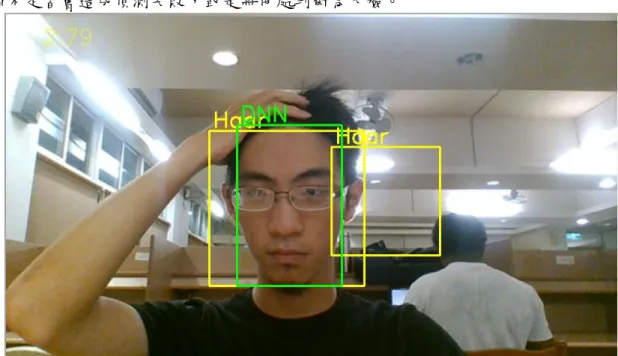
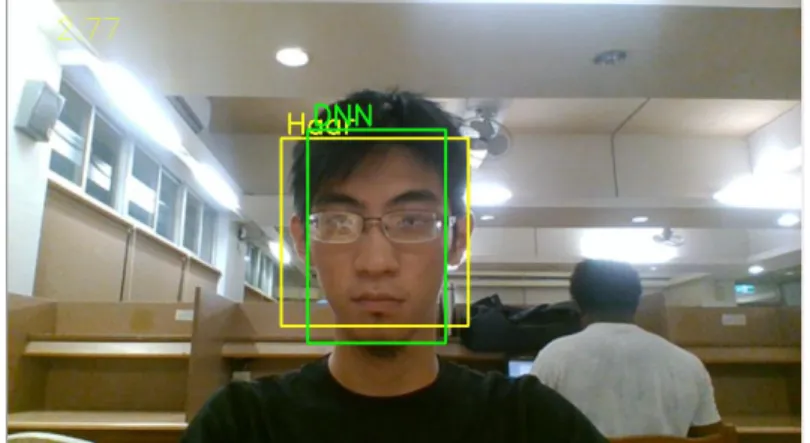
圖3.4-2 openCV Haar/Resnet、dlib HoG 偵測器比較
Haar 偵測器需要在眉毛完全露出、光線充足、正臉的情況下才能夠運作 ResNet 偵測器具有極強的抗干擾能力,執行速度僅此於 Haar,本研究選擇使用作 為辨識時的臉部偵測器,而Dlib HoG 偵測器和 dlib facial-lankmark 具有最為精確 的匹配效果。
圖3.4-3 辨識功能
辨識成功時(有此人資料且攝影機前為真人),會顯示綠色框框,右側欄位顯示 建檔照片及 ID,並將當時日期時間 ID 紀錄於 txt 及 excel 的 log 文件中
當辨識失敗時(無此人資料或攝影機前為假人),則會顯示紅色框框
圖3.4-4 角度偵測
將dlib 68 point facial-landmark 映射至三維立體模型上,再將此模型套用至人 臉上,計算出人臉目前面向之角度。
3.5 取樣建檔
圖3.5-1 主程式 GUI 操作介面 - 使用 ResNet SSD 及 Triplet loss
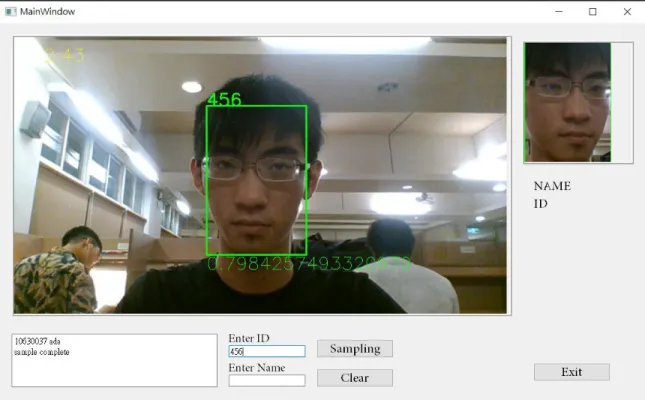
於GUI 操作介面中 Enter ID 和 Enter Name 欄位中分別輸入 ID 和姓名(若為 空白狀態欄會顯示錯誤訊息),接著按下Sample 按鍵以開始取樣,攝影機會以每十 幀有偵測到人臉的畫面取一張以讓人有充足時間轉頭以照到不同角度(若取樣到一 半時無偵測到人臉會取樣暫停直到再次偵測到人臉),擷取臉部後以先前輸入的 ID、姓名及擷取編號命名照片,並且存入 dataset 中。
圖3.5-2 根據角度取樣
註冊時畫面會顯示五個紅色框,分別代表待取樣的五個方位,此時會於鼻子上 繪製綠色指示棒顯示目前面向之方位。當轉頭時,取樣成功之紅框會轉為綠框,並 將擷取之人臉經過人眼對齊後存入資料庫。
下圖為資料庫中取樣完成之照片,平均取到各角度之臉部,且每張照片之人臉 皆已水平對齊眼睛位置,確保每次辨識時皆能以眼睛為基準位置進行比較,透過此 種取樣方法能夠在不讓資料庫過度取樣的情況下提升辨識準確度。
3.6 影片取樣建檔
當系統初始化時會自動偵測video 檔案夾中有無影片,若有影片則開啟影 片處理執行序,將影片一幀一幀匯入,每二十幀偵測到人臉的畫面取樣一張,
再根據影片名稱的姓名及ID 資訊存入 database。
圖3.6-1 從影片擷取存於 database 的人臉
3.7 線上註冊
圖3.7 線上註冊
使用google 表單讓使用者上傳人臉影片,透過 Backup and Sync from Google 下載影片至PC 端進行影片註冊,從用戶上傳的影片名稱獲取 ID 及 email,根據取 樣結果發送email 通知使用者是否註冊成功。
3.8 活體辨識
圖3.8-1 活體識別
偵測器會擷取以臉部框向左右延伸各1.3 倍 (藍色框)之範圍,根據框取範圍內 是否有手機邊框或相片邊框等特徵判斷為真人、手機畫面、或證件照片。
活體識別神經網路模型使用VGG 架構設計,共 4 層卷積層及 1 層全連結層,
使用程式自動抓取影片中真人、證件照、手機照片各1500 張的樣本進行訓練,下 圖顯示程式自動取樣之手機畫面、真人、證件照訓練集。
圖3.8-2 活體訓練集
圖3.8-3 實體閘門展示模型
使用PC Serial 端傳輸指令給 Arduino 控制步進馬達,展示實體門禁系統,辨識 為true 即開啟閘門,反之則不開啟。
圖3.8-4 立體視覺
使用兩個網路視訊鏡頭形成視角差,經校正匹配後計算影像深度,使用自行撰 寫之GUI 調整參數,辨識出物體輪廓,便能夠判斷鏡頭前是否為真人,藉此實現 活體識別
然此項功能經不斷嘗試後效果仍不盡理想,因此改為使用前述VGG 神經網路 邊框辨識法為此研究主要活體識別法。
3.9 開發日誌
09/14
* [功能完成]完成 DNN 模型訓練功能 * [功能完成]完成 DNN 辨識功能 * [功能完成]完成寫入照片建檔功能 * [新增測試]新增 tt.py 進行功能測試
* [新增測試]嘗試修正 cv2 和 dnn 模組中 RGB 順序不同問題,尚在修正 * [新增測試]嘗試修正 imutils.resize 出現分母為 0 的狀況,尚在修正 * [新增測試]嘗試於 label incoder 新增儲存姓名功能,尚在測試
* [新增測試]嘗試理解在無模型時報錯樣本過少問題,當樣本數大於等 於三位時能夠正常運作
* [錯誤修正]修正寫入檔案時無法進入子目錄問題 09/13
* [錯誤修正]修正 dnn 無法以 PIL 開啟圖片問題
* [程式修改]將 tr 中 getIDandLables func 合併進 sampleTraining * [程式修改]將 dataset 結構改為分個別資料夾儲存照片
* [新增測試]嘗試改為 dnn 訓練及辨識,待完成
* [新增測試]嘗試將螢幕畫面改為 1255*700,然而會造成 fps 顯著 下降,降為853*480
09/12
* [進度標記]因 windows 環境不支援 NCS1,中止 openVINO 開發支線 * [錯誤修正]修正取樣時資訊欄無法顯示圖片問題
* [程式修改]將 main 中 getIDandNAME func 合併進 sampling 09/11
* [程式修改]將 training 模組中使用 haar 偵測部分刪除 09/10
* [功能完成]將人臉偵測模組更換為 opencv-dnn 09/07
* [進度標記]開始 v2beta 版開發 09/06
* [功能完成]完成多執行序 loopThread,改善 fps 下降問題 * [功能完成]完成多執行序 vpThread,改善初始化過久問題 * [功能完成]增加人臉標示框根據通過與否改變顏色功能 * [錯誤修正]修正 fps class 分母變成 0 的狀況
* [錯誤修正]修正因 thread 和 GUI 執行速度不同所造成的取樣過快問題 * [進度標記]釋出 v1.1 版本
09/02
* [新增測試]嘗試修正 video process 模組中無法接收不同解析度問題 ,待解決
* [新增測試]嘗試使用 rpi 架設伺服器,待完成 09/01
* [新增測試]使用 Heroku 連結 linebot,但無法儲存影片資料放棄使用 08/31
* [功能完成]架設 linebot 完成 08/24
* [功能完成]完成匯入影片訓練功能 08/20
* [新增測試]新增 video process class,尚在製作匯入影片訓練功能 08/16
* [進度標記]釋出 v1.0 版本
* [功能完成]新增 signer class,完成簽到功能 * [功能完成]於 tr 和 sn 中增加自動生成資料夾功能 * [功能完成]增加 fps class,完成顯示 fps 功能
* [新增測試]因牽涉到變更 ui 介面功能,sampling class 建立失敗 08/15
* [錯誤修正]修正因編譯器產生的 tab/space 錯誤 08/15
* [新增測試]嘗試取樣功能獨立為為 sampling class,尚在測試 08/14
* [功能完成]新增辨識時於資訊欄顯示 ID 功能 * [功能完成]新增辨識時於資訊欄顯示照片功能 08/04
* [新增測試]新增 excel class,尚在製作簽到功能
* [錯誤修正]新增 checkTrainer,修正在無模型時報錯問題 08/02
* [功能完成]新增 FaceRecognition class,完成辨識功能 * [功能完成]新增 Training class,完成模型訓練功能 08/01
* [錯誤修正]新增 toPixmap void,修正圖片顯示 glitch 和 crash 問題 07/31
* [錯誤修正]新增 sampleBufferCount,修正取樣時畫面延遲問題 * [程式修改]移除 setInterval func
* [功能完成]於 ui.py 新增 button_clear,用以清除輸入欄位 * [程式修改]將 button_exit 功能移至 ui.py 中
07/30
* [錯誤修正]新增 sampleTrigger void,修正取樣時因時間間隔過短取 樣速度過快問題
07/28
* [功能完成]完成取樣建檔功能 07/26
* [功能完成]完成 GUI 介面
* [功能完成]完成顯示攝影機畫面功能 * [功能完成]完成人臉偵測功能
* [功能完成]完成退出功能 07/13
* [進度標記]開始 v1beta 版開發 05/13
* [進度標記]完成 v1alpha 版開發
* [錯誤修正]修正因 python 版本不同的 LBPHFaceRecognizer 指令錯誤 04/29
* [新增測試]sublime 安裝套件後仍無法使用執行時輸入功能,改為使 用anaconda powershell
04/23
* [新增測試]於 VisualBox Ubuntu 環境中無法開啟攝影機,改為 windows 環境開發
04/20
* [進度標記]開始 v1alpha 版開發 第四章 未來發展方向與結論
本研究分別以Haar cascade/LBPH 架構和 ResNet SSD/Triplet loss 架構建立出不 同版本的人臉辨識系統,實作取樣、影片取樣、模型訓練、偵測、辨識、簽到功 能,並且檢測兩者的辨識精準度及辨識速度;經比較Haar cascade/LBPH 架構準度 較低但速度較快,ResNet SSD/Triplet loss 架構準度較高但速度較慢。
原先計畫使用Intel Movidius NCS(neural compute stick)神經運算棒補足硬體設 備算力不足的問題,然而實驗室的第一代運算棒只能在linux 作業系統環境下運 行,並不符合研究動機題目所設定的windows 環境;而第二代 NCS2 搭配
openVINO 能夠在 windows 環境下運行,未來若有機會取得 NCS2 將會測試其對於 運算加速效果,更甚者將辨識系統移植到linux 環境,搭配 NCS2 於 raspberry pi 上 運行,降低硬體設備架設成本,有助於使用者及市場推廣。
本研究採用Google 之各項功能與服務來達成遠端接收檔案及線上註冊,但還 是得請使用者自行更改檔名,且必須預錄好影片,事實上還是有漏洞。未來我們將 做出一套完整的網頁及資料庫系統,或者功能完善的APP,讓使用者可以更簡 單、方便地使用本研究系統,藉由這完整的系統,讓使用者不再對於遠端註冊失敗 感到困擾。
第五章時間進度表(甘特圖 Gantt Chart):
■已完成 ■正在進行
第六章 參考資料:
[1] Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao YOLOv4: Optimal Speed and Accuracy of Object Detection, 2020
[2] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng- Yang Fu, Alexander C. Berg SSD: Single Shot MultiBox Detector, 2016
[3] Hengliang Tang ; Yanfeng Sun ; Baocai Yin ; Yun Ge Face recognition based on Haar LBP histogram, 2010
[4] Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, Senior Member, IEEE, and Yu Qiao, Senior Member, IEEE Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks, 2016
[5] Takeshi Mita, Toshimitsu Kaneko, Osamu Hori Joint Haar-like Features for Face Detection, 2005
[6] Suma S L , Sarika Raga Real Time Face Recognition of Human Faces by using LBPH and Viola Jones Algorithm, 2018
[7] Hyung-Keun Jee, Sung-Uk Jung, and Jang-Hee Yoo Liveness Detection for 月次
工作項目
9~12 月
1~2 月
3~4 月
5~6 月
7~8 月
9~10 月
11~12 月
1~2 月 機器學習、基
礎練習
Python 基礎練 習
人臉辨識基礎 實作
架設GUI 介面 實作GUI 功能 表單設置及同 步檔案功能 調整辨識框架 辨識加速及最 佳化
進度累計 百分比
5% 10% 20% 35% 65% 80% 90% 100%
Embedded Face Recognition System, 2016
[8] Yaojie Liu, Amin Jourabloo, Xiaoming Liu, Learning Deep Models for Face Anti- Spoofing: Binary or Auxiliary Supervision, 2018
[9] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun Deep Residual Learning for Image Recognition, 2015
[10] Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, Yu Qiao Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks, 2016
[11] IoT Programming Workshop:Lamp-server from https://workshop-iot- programming.devbit.be/lamp-server/
[12] Adrian Rosebrock, Pyimagesearch: Liveness Detection with OpenCV, 2019, from https://www.pyimagesearch.com/2019/03/11/liveness-detection-with-opencv/
[13] Adrian Rosebrock, Pyimagesearch: OpenCV Face Recognition, 2018, from https://www.pyimagesearch.com/2018/09/24/opencv-face-recognition/
[14] Adrian Rosebrock, Pyimagesearch: Face detection with OpenCV and deep
learning, 2018, from https://www.pyimagesearch.com/2018/02/26/face-detection- with-opencv-and-deep-learning/
[15] Marcelo Rovai, Real-Time Face Recognition: An End-To-End Project, 2018, from https://towardsdatascience.com/real-time-face-recognition-an-end-to-end-project- b738bb0f7348
[16] Nicholas Cage, Retrieved 2020, from
https://www.pinterest.com/pin/458733912018036467/
[17] Smartuil, 知乎:人脸识别的对比–OpenCV, Dlib and Deep Learning, 2020, from https://zhuanlan.zhihu.com/p/111925661
[18] 默一鸣, CSDN:人脸检测--LBPH-局部二进制编码直方图, 2017, from https://blog.csdn.net/yimingsilence/article/details/64505198
第七章 工作分配:
工作項目 負責人員
機器學習基礎練習 陳冠達、沈世名、林益賢
Python 基礎練習 陳冠達、沈世名、林益賢
環境架設練習 陳冠達、沈世名、林益賢
主程式圖形化介面 陳冠達
主程式偵測、建檔、訓練、辨識、註冊功能 陳冠達
影片建檔訓練模型功能 陳冠達
線上註冊及接收影片系統 沈世名、林益賢、陳冠達
主程式功能最佳化改版 陳冠達
CUDA GPU 加速測試 林益賢
活體辨識模型架構設計、自動取樣程式 陳冠達
人臉樣本蒐集 沈世名、林益賢、陳冠達
訓練活體辨識模型 沈世名、陳冠達、林益賢
門禁系統實體展示模型 沈世名
立體視覺、GUI 測試介面 陳冠達
第八章 經費表:
項目 數量 單價 金額
C370 鏡頭 2 700 1400