國立台灣科技大學 應用外語系
National Taiwan University of Science and Technology Department of Applied Foreign Languages
A Case Study of Transforming a Magazine into a Unique Video for a Target Audience
以個案研究探討如何針對目標群眾需求 將雜誌轉拍成特製影片
學生:
田婉曲 Wan-Chu Finny Tien 許庭瑋 Ting-Wei Tina Hsu 江詠珊 Wing-Shan Angel Kong 陳春燕 Chuen-Yan May Chen
指導教授: 駱藝瑄 博士 Advisor: Dr. Yi-Hsuan Gloria Lo
中華民國一百零九年二月 February 2020
COVER LETTER
Dear AFL reviewers:
It is our honor to share our research project and products with you.
Considering that there has been burgeoning interest in applying multimodal literacies in EFL classrooms, we delved into the field of the multimodal literacies by exploring how to transform a magazine into a unique video for a target audience. As suggested by our advisor, the magazine about Hualien produced in a previous EFL course served as the starting point for our study. To publicize our magazine, we first earned approval from the Hualien Tourism Department to put the magazine on its website and then secured an ISBN number from the National Library (ISBN: 978-986-98537-0-5).
The hardcover magazine was presented together with the report for reference.
To study multimodal literacies by investigating how to transform the magazine into a unique video for a target audience, we worked hard to draft a proposal to the Ministry of Science and Technology and was privileged to receive financial support for our study (MOST:
108-2813-C-011-037-H). Under the auspices of the funding, we resumed our research by further gleaning piles of information from current literature to gain an insight into multimodality in general and multimodal literacies in particular. Grounded in the rigorous literature review, we composed introduction and literature review of the study. Our team completed the following tasks to investigate the target audience’s preferences for the content and format of the video:
• developing questionnaire components and items based on the five modes (see Appendix A)
• finalizing a questionnaire for the participants (see Appendix B)
• developing an interview (see Appendix C)
• presenting questionnaire results in figures (see Appendix D)
• compiling important notes (see Appendix F) of the interview
• composing transcripts of the interview (see Appendix G)
After understanding our target audience’s preferences for the content and format of the video, we produced two version of the video (one by the research team, and the other with the assistance of a video-editing professional). The two videos were burned to two separate CDs marked with
“version 1” and “version 2” respectively, and they were attached at the end of the report for reference. To collect the target audience’s feedback on the two videos, we carried out the following tasks:
• designing another interview (see Appendix E)
• presenting the results of the interview quantitively and qualitatively (see Appendix H)
During the research, we and the advisor had plenty of face-to-face intensive meetings to discuss how to rigorously conduct the study, and meeting minutes were created for each meeting (see Appendix I). After the first draft of our research was completed, we and the advisor rolled up our sleeves and dedicated ourselves to the ten-minute presentation of the study, all the way from culling information from the lengthy study, designing and revising presentation slides (see Appendix J), rehearsing and practicing the presentation, and preparing responses for potential questions put forward in the Q&A session (see Appendix K).
Our relentless efforts in doing the research didn’t come to a halt in the wake of the presentation.
We had been working hard to disseminate our findings of the project by submitting our paper to a
conference and a journal. We first held meetings and worked together to submit the abstract of our
research to the 2020 TEFL International Conference in Korea. Then, we worked on trimming down
our paper from nearly 20,000 to approximately 8,000 words for submission to the Journal of
Educational Technology & Society. It was a Herculean task because on the one hand, we had to
cross out a huge number of words we had laboriously drafted while still maintaining the core idea of
the research, and on the other hand, we had to go to great lengths to expand the depth and breadth of
our study by looking into a lot more studies.
• 2020 TEFL International Conference in Korea (see Appendix P)
• Journal of Educational Technology & Society (see Appendix Q)
The findings of the study yield several critical pedagogical implications for multiliteracies education in three aspects, particularly in the EFL context.
• The importance of a target audience: A well-rounded video production process should not overlook the critical roles that a target audience can play throughout different stages of the process, such as collecting target audience’s opinions, transforming written text into an oral script, filming the video, and (re-)editing the video
• The importance of interdisciplinary collaboration: The target audience’s different ratings on the same content with different multimodal forms of display bring out the importance of interdisciplinary collaboration as language majors who may command a better control of the linguistic mode may not have the capabilities to orchestrate all the modes together efficiently and effectively.
• The importance of recursive adaptation: The video production process was synergized by recursive adaptation through different parties involved, and recursive adaptability in this case refers to the capacity co-constructed by the video creators, the target audience, and the video professional to reconstruct the video by editing it repeatedly so as to improve the quality and cater for the preferences of the target audience
Lastly, we would like to give you a quick overview on some of our appendices regarding the final product and the research process:
• a quick view of the magazine (see Appendix L)
• QR codes of the two versions of our video (see Appendix M)
• screenshots of the two versions of our video (see Appendix N)
• a complete copy of the hardcover magazine
• two separate CDs on the two versions of our video
• other relevant pictures throughout the research project (see Appendix O)
We deeply appreciate you for dedicating yourself to reviewing this report. We hope that you enjoy the report, the magazine, and the two videos.
Sincerely,
Research team: Finny Tien, Tina Hsu, Angel Kong, May Chen
Advisor: Dr. Yi-Hsuan Gloria Lo
i
ACKNOWLEDGMENTS
From the bottom of our heart, the research team would like to deliver our profound appreciation to all the organizations and people who contributed to the study.
We want to show our appreciation to the Ministry of Science and Technology (科技部) for funding the study (MOST: 108-2813-C-011-037-H). The financial support allowed us to travel to Hualien for filming and to have the study proofread for submission to Journal of Educational Technology & Society.
We are bound by appreciation to the National Central Library (國家圖書館) for granting us an ISBN number (ISBN: 978-986-98537-0-5) for our magazine, which allowed the public to know more about Hualien through the detailed information in the magazine.
We are thankful to the Hualien Tourism Department (花蓮縣政府觀光局) for agreeing to put our magazine and video on its official website for international tourists interested in Hualien to refer to. The two products are still under review. When they are officially published on the website, we believe that our multimodal projects to be enjoyed and appreciated by even more people.
We want to express our sincere gratitude to our advisor and mentor Prof. Yi-Hsuan Gloria Lo (駱藝瑄) for her constructive guidance and persistent dedication. We can’t thank her enough for going out of her way to support us all along the way by providing enlightening suggestions for completing the study.
In addition to our advisor, we are deeply indebted to Prof. Sy-ying Lee (李思穎) for instructing us during the stage of producing a magazine about Hualien. When we were working hard on the magazine, they were more than happy to offer guidance and support, which inspired us to do our best to produce the magazine.
We want to show our gratitude to Joy Cheng ( 鄭 晴 文 ), a design student, for
collaborating with us on the magazine project. Employing her professional knowledge, Joy
ii
took photos of selected tourist spots in Hualien and designed the layout as well as the cover of the magazine. Without her help, we could not have produced an elaborate magazine with good photos and a neat layout.
We are grateful to Marcus Fong (馮若陽), a video-editing professional, for helping us edit the second version of our video. With his professional knowledge and rich video-editing experience, Marcus guided us to produce a better version of our video, which was much more visually-appealing than the original one.
We want to deliver special thanks to all the questionnaire respondents and interviewees who participated in the study for providing good suggestions concerning what to include in and how to present the video.
The study couldn’t have been possible without those who contributed to the study. Thank you all for your unconditional help and relentless support.
Research team: Finny Tien, Tina Hsu, Angel Kong, May Chen
Advisor: Dr. Yi-Hsuan Gloria Lo
iii
TABLE OF CONTENTS
ACKNOWLEDGMENTS ... i
TABLE OF CONTENTS ... iii
ABSTRACT ... 1
INTRODUCTION ... 2
LITERATURE REVIEW ... 6
Multimodality ... 6
Multimodal Literacies ... 6
METHODOLOGY ... 8
Participants ... 8
Instruments ... 8
Data Collection & Analysis ... 10
RESULTS ...11
RQ1: What is the process of transforming a magazine into a multimodal video? ... 11
RQ2: What is our target audience’s response to the videos? ... 21
DISCUSSION ... 24
The Role of a Target Audience in a Multimodal Literacy Project ... 24
The Orchestration of Multiple Modes ... 26
CONCLUSION & IMPLICATIONS ... 28
LIMITATIONS AND SUGGESTIONS ... 31
REFERENCES ... 32
APPENDICES ... 36
Appendix A Development of the Questionnaire Components and Items Based on the Five Modes ... 36
Appendix B Questionnaire: Target Audience's Preferences for Making a Video about Hualien ... 37
Appendix C Interview I: Exploration of the Target Audience's Preferences for Making a Video about Hualien ... 43
Appendix D Figures of the Questionnaire Results ... 46
Appendix E Interview II: Exploration of the Target Audience's Feedback on the Video about Hualien ... 47
iv
Appendix F Important Notes of Interview I ... 54
Appendix G Transcripts of Interview I ... 76
Appendix H Results of Interview II ... 104
Appendix I Meeting Minutes ... 143
Appendix J PowerPoint Slides of the Presentation ... 154
Appendix K Q&A Preparation ... 175
Appendix L The Magazine ... 179
Appendix M The QR Code of the Two Versions of the Videos ... 197
Appendix N The Screenshot of the Two Videos ... 198
Appendix O Photos throughout the Process ... 203
Appendix P Submission to the 2020 TEFL International Conference in Korea ... 215
Appendix Q Manuscript (under review) ... 216
1
ABSTRACT
There has been growing interest in applying multimodal literacies in EFL classrooms.
However, little research has demonstrated how to transition from paper formats to digital screens. In addition, previous research has failed to specify a target audience and gather their preferences for a multimodal project involving both paper and digital formats. To address these gaps, this case study demonstrates (1) how a magazine can be transformed into a video catering to a target audience’s preferences based on a multimodal framework and (2) how the target audience responds to the video. Grounded in multimodal literacies, the research employs questionnaires and in-depth interviews to solicit opinions from our target audience, based on which an adaptive multimodal framework was generated that provides effective guidelines for collecting a target audience’s opinions, transforming written text to an oral script, filming the video, and (re-)editing the video for transforming a magazine (paper) into a video (digital). The results show that content and format affect each other, which highlights the importance of interdisciplinary collaboration and recursive adaptation. This study yields significant pedagogical implications for ESP teaching/learning in the EFL context and advances our understanding of multimodality in general as well as multimodal literacies in particular.
Keywords: multimodality, multimodal literacies, ESP (English for Specific Purposes),
magazine, video
2
INTRODUCTION
The 21st century is inundated with websites (e.g., YouTube, Google), consumer electronics (e.g., smartphones, iPad), and social media (e.g., Facebook, Instagram, Twitter).
As Lim (2018) points out, multimodality has become omnipresent in interpersonal communication, which “has become intensely multimodal” (p. 5). Modes, or semiotic resources, refer to the semiotic representation used to convey information, and presenting information in different modes is called multimodal communication. Arola, Sheppard, and Ball (2014) point out five modes: linguistic, visual, aural, spatial, and gestural.
Just as websites, consumer electronics, and social media are multimodal, so are literacies. As pointed out by Kress (2000), it is now “no longer possible to understand language and its uses without understanding the effect of all modes of communication that are co-present in any text” (p. 337), which is called multimodal literacies. Walsh (2010) defines multimodal literacies as “meaning-making that occurs through reading, viewing, understanding, responding to and producing with multimedia and digital texts” (p. 213).
Many newspapers, for example, have undergone a multimodal shift. In 1971, The New York Times included words (linguistic), black and white images (visual), and a simple layout
(spatial). The New York Times today (online version) incorporates words (linguistic), various images (visual), videos (aural), a clear layout (spatial), and people’s gestures in the videos (gestural).
In multimodal literacies, language is acknowledged as “only one of several semiotic
tools for communicative purposes, which also include visuals, symbols, sounds, animation,
and images” (Yeh, 2018, p. 29). Propelled predominantly by digital technology, these
multimodal resources for the production and consumption of knowledge push for a new
pedagogical curriculum (Hull & Nelson, 2005; Jewitt, 2006; Kress, 2003; Mills, 2010; Yeh,
2018). In response to this, many studies have investigated the field of digital multimodal
3
composing (DMC), which Jiang (2017) defines as a semiotic process involving the use of digital tools to produce texts that combine multiple modes, by examining how students produce digital videos (Campbell & Cox, 2018; Hafner, 2013; Heidi, 2016; Jiang, 2018;
Karasavvvidis, 2019; Smith, 2016; Yeh, 2018). Although Hauck (2010) has showed the concern shared by other scholars that “communicating through visual, digital, or audiovisual media will displace reading and writing” (pp. 222-223), traditional literacies (reading and writing) remain essential in literacy education (Jenkins, 2006; Yeh, 2018). Wawra (2018) investigates multimodal reading and examines how political cartoons can be taught in the English lessons in secondary and higher education to develop students’ multimodal literacies in four close reading activities; Eguchi (2006), Schwieter (2010), and Wang (2004) discuss multimodal reading/writing and probe how second language or EFL students conduct magazine projects.
The studies above demonstrate the essential concurrence of traditional and new literacies. In this sight, Hafner (2013) reports how his students produced a multimodal composing ensemble by first creating a multimodal scientific documentary (digital format) shared through YouTube with a general audience of nonspecialists and then completing a written lab report (paper format) for a specialist audience. Considering that traditional literacies are as essential as new literacies, it is valid to look into the reverse—how to transition from a paper to a digital format (a magazine to a video in the case study).
Two studies—Hafner (2013) and Yeh (2018)—offer two different frameworks. Hafner (2013) proposes six steps: reading, data collection, scripting and storyboarding, filming, editing, and sharing. Yeh (2018) maps out three steps: composing the scripts, enacting the scripts, and editing the videos. Hafner (2013) mentions that one of the “main sources of rhetorical challenge” for his students during video production is “multimodal orchestration”
(p. 668) and that his students identify “a wide range of semiotic resources, including moving
images and animation, charts and tables for scientific data, subtitles, different camera angles
4
and lighting, background music, sound effects, interesting locations, interesting participants, and facial expression” (p. 669). In a similar vein, Yeh (2018) mentions that her students have to “come up with different innovative ways of presenting their topics through the combination of multiple modes to present their core themes” (p. 30) when enacting the scripts and to “combine multiple modes such as adding text, pictures, subtitles, effects, narrations, soundtracks, and PowerPoint slides, to tie all their ideas together to construct the videos” (p. 31) when editing. While Hafner (2013) and Yeh (2018) both emphasize the importance of multimodality, how multiple modes are orchestrated or combined to create a multimodal video is not explored in detail.
Another important element concerning video production is the audience. In Hafner (2013), the multimodal scientific documentary is dedicated to “a general audience of nonspecialists” (p. 655). In Yeh (2018), the video project is related to Taiwan’s culture and created for “authentic audiences in online communities” (p. 29). However, both studies fail to specify a target audience based on whose voice a video is made. As defined by Wiechmann (1993), a target audience is a specific group made up of individuals categorized by age, sex, or other demographic factors, for whom advertisers promote or design their products. The lack of a specific target audience creates difficulty in assessing whether a video project communicates its intended message effectively. Although Hafner (2013) mentions that his students feel the “rhetorical challenge in getting the attention of the YouTube audience” (p. 669), the students do not assess the effectiveness of the visuals and script. Similarly, in Yeh’s (2018) study, the videos are assessed by “the research team using the rubric for summative assessment” (p. 30) instead of by their intended audiences.
In this case study, we hope to achieve two purposes: first, to document the process of
transforming a magazine (paper format) into a multimodal video (digital format) for a
specific target audience and second, to collect our target audience’s responses as the
yardstick to assess our success. Specifically, this study addresses two research questions: (1)
5
What is the process of transforming a magazine into a multimodal video for a target
audience? (2) What is our target audience’s response to the videos?
6
LITERATURE REVIEW
Multimodality
One of the most far-reaching influences of websites and social media is that a “visual or pictorial turn” of communication dominates in the “multimodal” trend that has recently been established (Jewitt, 2011, pp. 3-4). This recognition leaves us with the question: What is multimodality? Multimodality can be defined in a binary way. In terms of discipline, multimodality is a trans- or inter-disciplinary field of research (Machin, 2016). In terms of mode and modality, multimodality is the integration of various modes or semiotic resources to channel meaning (Guichon and Cohen, 2016).
Studies on multimodality usually delve into the interplay of different modes or semiotic resources for meaning-making (Kress, 2010; Jewitt, Bezemer, & O’Halloran, 2016). Arola, Sheppard, and Ball (2014) identify five types of modes: linguistic: written or spoken words, including word choice, delivery, and organization of words into sentences; visual: images and characters, including color, style, size, layout, and perspective; aural: sound, including music, sound effects, tone, etc.; gestural: the interpretation of movement, including facial expressions, body language, etc.; and spatial: organization and arrangement of the text. The five modes work in tandem to create successful multimodal projects. Whether texts are produced on a computer, printed on a paper or generated by other types of technology, if they communicate a message via a combination of modes, they are multimodal texts (Arola, Sheppard, & Ball, 2014).
Multimodal Literacies
With its origin in social semiotics, multimodal literacies are the study of language with the combination of more than one mode of meaning (Mills, 2011; Mills & Unsworth, 2017).
Young people today, both inside and outside of school, “are composing with multiple
7
modes—image, word, sound, movement—to produce videos, blogs, photo- essays, podcasts, virtual worlds, and multimedia presentations” (Smith & Bridget, 2016, p. 719). This shift in compositional practices gives urgency to the need to expand writing practices by giving students opportunities to use both paper and digital formats (Bruce, 2010).
In terms of paper format, a myriad of studies discusses how students conduct a magazine project as a multimodal composing assignment (Eguchi, 2006; Schwieter, 2010; Wang, 2004).
Another format is digital multimodal composing (DMC), defined in language education as a semiotic process involving the use of digital tools to produce texts with the combination of multiple modes (Jiang, 2017). Many studies examine how students produce a video as a multimodal composing project (Campbell & Cox, 2018; Hafner, 2013; Heidi, 2016; Jiang, 2018; Karasavvvidis, 2019; Smith & Bridget, 2016; Yeh, 2018).
The multimodal texts mentioned above (i.e., magazines and videos) involve two significant elements: design and materiality. According to Kress (2010), design is the multimodal process where the author is involved in the production of a text and uses semiotic resources to put himself or herself in a frame (genre) and where more than one kind of mode is used. In the context of the classroom, learners are prompted to become active designers who select and mix semiotic resources to arrange and rearrange the presentation of the intended meanings (Yang, 2012). Materiality is defined as a tangible, physical quality (Mills
& Unsworth, 2017). For instance, images (visual mode) can be exhibited on different
materials, such as paper (e.g., newspapers or magazines) or digital screens (e.g., videos or
e-books).
8
METHODOLOGY
Participants
Respondents. According to the latest data from the Department of Statistics, Ministry of Education
1, international students in Taiwan are increasing year by year (117,000 in 2016, 121,000 in 2017, 127,000 in 2018), and one of the reasons why they come to Taiwan is that they want to experience Taiwan’s culture (Pan & Zhang, 2019). Therefore, international students became the target audience of the study. Prior to the study, fifty international students were recruited for two criteria: (1) who stayed in Taiwan for a semester; (2) who had expressed strong interest in Hualien from a university in Northern Taiwan, which boasts a high number of international students
1, to participate in our case study.
Interviewees. Before the video production, 10 out of the 50 survey respondents who agreed to participate in an in-depth interview were invited to elaborate on their responses to the survey. After the video was produced, another 10 international students provided feedback on the video.
Instruments
Magazine. The magazine was a multimodal project previously designed for an EFL course. It combines three modes: linguistic (carefully-crafted words), visual (pictures), and spatial (professional layout and aesthetic cover design). Hualien was chosen as the topic because the latest data from the Ministry of Transportation and Communications
2identifies a
1Department of Statistics, Ministry of Education (2018). Education Statistics. Retrieved from
http://stats.moe.gov.tw/files/brief/107 年大專校院境外學生概況.pdf (教育部統計處 (2018)。教育統計簡訊。
取自: http://stats.moe.gov.tw/files/brief/107 年大專校院境外學生概況.pdf)
2Tourism Bureau, Ministry of Transportation and Communications (2019). 2018 Annual Survey Report on Visitors Expenditure and Trends in Taiwan. Taipei: National Bookstore. (交通部觀光局 (2019)。中華民國 107 年來臺旅客消費及動向調查報告。台北: 國家書店。)
9
need to promote this idyllic place: among the four areas of Taiwan, Eastern Taiwan (Hualien and Taitung) was ranked last. In the area, Hualien is more famous than Taitung, so Hualien was chosen to be the topic. The magazine seeks to offer foreign tourists an in-depth introduction to Hualien in three categories: natural landscape, period of Japanese colonization, and aboriginal groups. For detailed information on how the magazine was produced, please refer to Lee, Lo, and Chin (2019).
Two videos. Two versions of our video catering to a target audience’s preferences were produced, one by the research team and the other with the assistance of a video-editing professional. The target audience were presented with the two videos and invited to provide feedback. For details of the differences between the two videos, please refer to Results.
Survey. The survey was designed and shaped by five modes (see Appendix A) in order to understand the target audience’s preferences for the WHAT (content) and the HOW of a video about Hualien (see Appendix B) and was distributed to 50 international students online.
The first part seeks to find out what the target audience wants to see in the video and contains three sections, as in the magazine. The participants were asked to choose three options in the first section, two options in the second section and rank them according to personal preference, and to choose one option in the third section. The second part investigates the format based on the five modes: linguistic [wording of the subtitles], visual [hosing style, subtitles, special effects], visual and spatial [style], aural [background music, sound effects], gestural [gestures], and others [length].
Interviews. Face-to-face interviews based on the results of the questionnaire were conducted in English with 10 of the 50 respondents to elicit further elaboration on the questionnaire items (see Appendix C).
After the two videos were produced, one-on-one interviews were held in English with 10 international students to further understand the target audience’s views on the two videos.
The first part of the interview investigated how much (on a scale of 1 to 10) an interviewee
10
liked the five tourist spots, and the second part how much (on a scale of 1 to 10) an interviewee enjoyed the video presentation (overall style, length, hosting style, subtitles, background music, sound effects, and special effects). Next, the interviewees were asked to elaborate on their ratings (see Appendix F).
Research trip to Hualien. A three-day research trip was conducted in Hualien to explore the place and culture in person and to shoot the video according to the results of the first survey and interview. In the trip, location scouting was done, video-shooting was conducted, and video-editing was discussed.
Data Collection & Analysis
Before the video was produced, both quantitative (questionnaire) and qualitative (interview) data were collected to give us an idea what to include in the video and how the video should be presented. To start with, the questionnaire was distributed with the help of Google Forms; then, two sets of interview data were collected with voice recorders and written notes before and after the videos were produced.
Microsoft Excel software was employed to analyze the results of the questionnaire.
Descriptive data were coded to obtain the quantitative description of the target audience’s
preferences. The two interview data sets were read several times, coded, and categorized to
seek major themes to address the research questions.
11
RESULTS
RQ1: What is the process of transforming a magazine into a multimodal video?
Grounded in the five modes of multimodality, a four-step framework for transforming a magazine into a multimodal video emerged: (1) collecting target audience’s opinions, (2) transforming written text to an oral script, (3) filming the video, and (4) (re-)editing the video.
Collecting target audience’s opinions
The 50 questionnaires and 10 interviews were employed to obtain an understanding of WHAT the target audience wanted to see in the video and HOW they would like the video to
be presented.
In the first section, our target audience (50 in total) showed what they wanted to see in the video by ranking 3 of 5 items in “natural landscape” from 1 to 3, 2 of 4 items in “period of Japanese colonization” from 1 to 2, and 1 of 2 items in “aboriginal groups.”
For “natural landscape,” the ranking results showed that Qingshui Cliff (40%), Taroko Gorge (38%), and Yanzikou Trail (42%) were ranked 1 to 3 respectively. For “periods of Japanese colonization,” the ranking results demonstrated that Pine Garden was ranked first (54%), followed by Ji-An Shrine (40%). For “aboriginal groups,” the ranking results revealed that the Amis was ranked first (64%) followed by the Truku (36%).
In the second section, the target audience were asked about nine aspects related to how they wanted the video to be presented. The results are based on the questionnaires and the interviews.
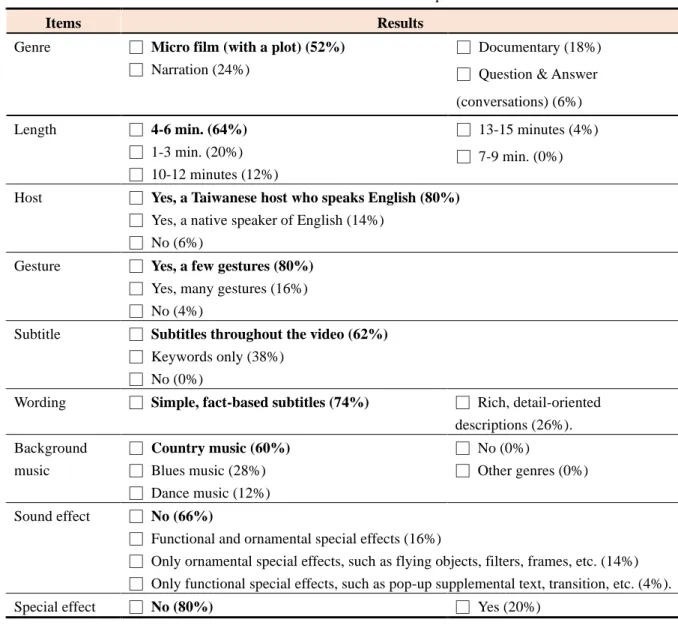
Genre. Among the four options—narrative, documentary, micro film (with a plot), and
question & answer (conversations), micro film (with a plot) received 52% of the votes. Most
of the interviewees expected the micro film to be supplemented with funny elements, so it
12
could be “less boring” (Interviewee 5), and they could enjoy the video much more.
Length. Among the five options—1-3 minutes, 4-6 minutes, 7-9 minutes, 10-12 minutes, and 13-15 minutes, 64% wanted the video to be 7-9 minutes long.
Host. Of the three options—no host; yes, a native speaker of English; yes, a Taiwanese who speaks English. 80% wanted to have a host and expected the host to be a Taiwanese who speaks English. Three samples featuring hosts with different styles were provided in the subsequent interview, and most of the interviewees chose the hostess who spoke “clearly with a much more formal style” (Interviewee 4) and interacted “naturally with the local people”
(Interviewee 8).
Gestures. The 94% of the target audience who wanted to have a host in our video were asked to proceed to the next question on whether they wanted the host to use gestures. 80%
wanted the host to use “a few gestures.” Most of the interviewees preferred random lower hand gestures (below the shoulders). The interviewees also did not want the host to hold things because it was “awkward” (Interviewee 9).
Subtitles. Of the three options—no subtitles; keywords only; subtitles throughout the video. 62% chose “subtitles throughout the video.” Four subtitle samples were presented to interviewees, and the top choice had both “Chinese and English subtitles” (Interviewees 4, 9) and thus looked “more professional” (Interviewees 6, 7).
Wording. For the wording, two options were provided—simple, fact-based narration and rich, detail-oriented descriptions. 74% preferred simple, fact-based narration.
Background music. Of the five options, country music received 60% of the votes. Four samples of country music were offered in the interview, and most of the interviewees chose the sample with “a more relaxing tone” (Interviewee 2) and “a brisk rhythmic pace”
(Interviewee 8). Some interviewees suggested that the sample could be used throughout the video (Interviewees 2, 3, 5, 6, 8, 10).
Special effects & sound effects. The four options for special effects were—no special
13
effects; functional and ornamental special effects; only ornamental special effects; only functional special effects. The “no special effects” won out (66%). For sound effects, 80%
did not want sound effects.
Table 1. Results of section 2 in the questionnaire
Items Results
Genre □ Micro film (with a plot) (52%)
□ Narration (24%)
□ Documentary (18%)
□ Question & Answer (conversations) (6%) Length □ 4-6 min. (64%)
□ 1-3 min. (20%)
□ 10-12 minutes (12%)
□ 13-15 minutes (4%)
□ 7-9 min. (0%)
Host □ Yes, a Taiwanese host who speaks English (80%)
□ Yes, a native speaker of English (14%)
□ No (6%)
Gesture □ Yes, a few gestures (80%)
□ Yes, many gestures (16%)
□ No (4%)
Subtitle □ Subtitles throughout the video (62%)
□ Keywords only (38%)
□ No (0%)
Wording □ Simple, fact-based subtitles (74%) □ Rich, detail-oriented descriptions (26%).
Background music
□ Country music (60%)
□ Blues music (28%)
□ Dance music (12%)
□ No (0%)
□ Other genres (0%)
Sound effect □ No (66%)
□ Functional and ornamental special effects (16%)
□ Only ornamental special effects, such as flying objects, filters, frames, etc. (14%)
□ Only functional special effects, such as pop-up supplemental text, transition, etc. (4%).
Special effect □ No (80%) □ Yes (20%)
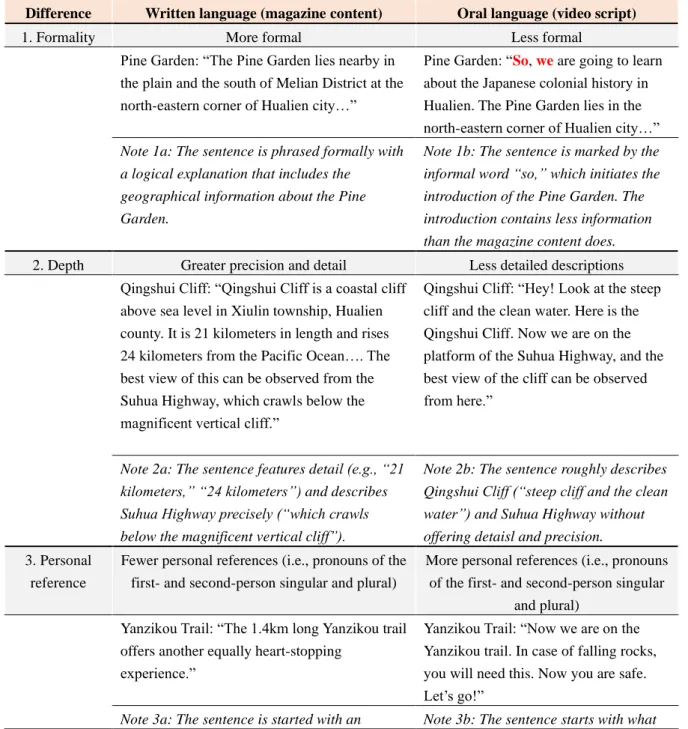
Transforming the written text to an oral script
Based on our respondents’ preferences, the scripts were composed and featured simple, fact-based oral language. To have a better understanding of the nature of oral language, we looked into the differences between written and oral language as laid out by applied linguists with regards to formality (Einhorn, 1978), depth (Einhorn, 1978; Schallert, Kleiman, &
Rubin, 1977), personal references (Einhorn, 1978; Strauss, Feiz, & Xiang, 2018), word
14
choice (Einhorn, 1978; DeVito, 1965; Miller, 2011), and syntax (Miller, 2011; Wilkinson, 1971). Table 2 below presents the major differences between written and oral language in terms of formality, depth, personal references, word choice, and syntax. Table 3 demonstrates the comparison between the written text in the magazine and the oral script in the video, and the written text was transformed into the oral script based on the marked differences between written and oral language pinpointed by applied linguists.
Table 2. Differences between written and oral language
Difference Written language (magazine content) Oral language (video script)
1. Formality More formal Less formal
Pine Garden: “The Pine Garden lies nearby in the plain and the south of Melian District at the north-eastern corner of Hualien city…”
Pine Garden: “So, we are going to learn about the Japanese colonial history in Hualien. The Pine Garden lies in the north-eastern corner of Hualien city…”
Note 1a: The sentence is phrased formally with a logical explanation that includes the
geographical information about the Pine Garden.
Note 1b: The sentence is marked by the informal word “so,” which initiates the introduction of the Pine Garden. The introduction contains less information than the magazine content does.
2. Depth Greater precision and detail Less detailed descriptions Qingshui Cliff: “Qingshui Cliff is a coastal cliff
above sea level in Xiulin township, Hualien county. It is 21 kilometers in length and rises 24 kilometers from the Pacific Ocean…. The best view of this can be observed from the Suhua Highway, which crawls below the magnificent vertical cliff.”
Qingshui Cliff: “Hey! Look at the steep cliff and the clean water. Here is the Qingshui Cliff. Now we are on the platform of the Suhua Highway, and the best view of the cliff can be observed from here.”
Note 2a: The sentence features detail (e.g., “21 kilometers,” “24 kilometers”) and describes Suhua Highway precisely (“which crawls below the magnificent vertical cliff”).
Note 2b: The sentence roughly describes Qingshui Cliff (“steep cliff and the clean water”) and Suhua Highway without offering detaisl and precision.
3. Personal reference
Fewer personal references (i.e., pronouns of the first- and second-person singular and plural)
More personal references (i.e., pronouns of the first- and second-person singular
and plural) Yanzikou Trail: “The 1.4km long Yanzikou trail
offers another equally heart-stopping experience.”
Yanzikou Trail: “Now we are on the Yanzikou trail. In case of falling rocks, you will need this. Now you are safe.
Let’s go!”
Note 3a: The sentence is started with an Note 3b: The sentence starts with what
15
Difference Written language (magazine content) Oral language (video script) objective description, which shows what it feels
like to visit Yanzikou Trail.
tourist may need to have to explore Yanzikou Trail and features the personal pronouns as “we” and “you.” While saying this, the host seems to talk to the audience.
4. Word choice Longer and less common words Shorter and more common words The Amis: “The Amis hold a variety of
glamorous festivals for celebration. These festivals include Sea Festival, also known as Catching-Fish Festival, Harvest Festival, and other minor festivals.”
The Amis: “They hold various festivals, such as Catching-Fish Festival, Harvest Festival, Water-Fetching Festival, etc.”
Note 4a: The sentence contains a less common word “glamorous” and a long phrase “a variety of.”
Note 4b: The common word “various”
replaces the long and less common phrase “a variety of.”
5. Syntax Syntactically more complex Syntactically simpler
Taroko Gorge: “Each passage informed me that the gorge was a natural wonder, which has captivated the human race since its discovery.”
Taroko Gorge: “The gorge has been a natural wonder since its discovery.”
Note 5a: The excerpt features complex sentences (a noun clause and an adjective clauses).
Note 5b: The sentence, a simple sentence, is syntactically simpler.
Table 3. Comparison between the magazine content and the video script
Items Magazine Video script
Qingshui Cliff “Qingshui Cliff is a coastal cliff above sea level in Xiulin township, Hualien county. It is 21 kilometers in length and rises 24
kilometers from the Pacific Ocean…. The best view of this can be observed from the Suhua Highway, which crawls below the magnificent vertical cliff.” (p. 22)
“Hey! Look at the steep cliff and the clean water. Here is the Qingshui Cliff.”
“Now we are on the platform of the Suhua Highway, and the best view of the cliff can be observed from here.”
“Along the trail leading to the Qingshui Cliff, you can see down here a train track, a cave…”
“Wow, is that a train!?”
“Yes! And sometimes a train rushing forward.
The tourist spot adjoins the Pacific Ocean and features a steep cliff and multi-colored seawater.”
Taroko Gorge “To really appreciate the wonder of Taroko National Park, we need to go back hundreds of millions [of] years ago…. Each passage informed me that the gorge was a natural wonder, which has captivated the human race since its discovery. When I got the opportunity to experience the beauty of the gorge in
“Hi! We are on the Shakadang Trail, part of the Taroko Gorge. Let’s go inside to take an adventure.”
“The origin of the Taroko National Park, where Taroko Gorge is located, dates back to hundreds of millions of years ago. The gorge has been a natural wonder since its discovery.”
16
Items Magazine Video script
person, I was truly stunned by the superlative landscape…. The marble silently tells the story of its formation though eons of time.”
(p. 10-13)
*The poem is in page 12.
“The superlative landscape is partially created by the Liwu River, and the cliff silently tells the story of its formation.”
“I am pondering on the esoteric meanings behind your silence in the venal coldness dotted with drizzling / Your expansiveness turns out to be a deep intimacy (by Li Chen)”
Yanzikou Trail “The 1.4km long Yanzikou trail offers another equally heart-stopping experience. As a result of the strength of the marble and its dramatic erosion due to the Liwu River…. On the opposite side of the trail is the mountain wall which has many tiny caves dotted throughout called potholes…. Looking toward the east and west of the trail you can notice gneiss and marble respectively, both rocks creating a distinctive impression on the landscape….
The trail allows explorers to observe the dramatic steep gorge…” (p. 18)
“Now we are on the Yanzikou trail. In case of falling rocks, you will need this. Now you are safe. Let’s go!”
“To the right and left of the trail, you can see spectacular rocks.”
“The 1.4 kilometer-long Yanzikou trail is created by the erosion of the Liwu River.”
“If you look toward the right and left of the trail you can see spectacular rocks, various potholes, and steep gorges.”
Pine Garden “The Pine Garden lies nearby in the plain and the south of Melian District at the
north-eastern corner of Hualien city, and it dominates Hualien city and the estuary of Meilun river. There are a dozen of aged pine trees outside the Pine Garden…. In the back of the Pine Garden’s main structure is a wooden public dormitory house.” (p. 28)
“So, we are going to learn about the Japanese colonial history in Hualien. The Pine Garden lies in the north-eastern corner of Hualien city, and it dominates Hualien city and the estuary of Meilun river. In each corner of the garden stand pine trees.”
“Let’s take a look at this. In the back of the Pine Garden is a [wooden] public dormitory house dating back to the Japanese colonial period. Let’s go inside. どうぞ (Please.)”
Ji-An Shrine “Constructed during the period of Japanese occupation (1895-1945), Qingxiu Yuan, Ji’an was the best-preserved Japanese-style temple in Taiwan. It was the center of worship for an immigrant Japanese village…. In addition to providing religious services, the center also served as a facility for medical, educational, and funeral-related purposes.” (p. 30)
“Constructed during the Japanese colonial period, Ji’an Qingxiu Yuan was the best-preserved Japanese-style temple in Taiwan, and now let’s go inside.”
“Back in the days, it was the center of worship for an immigrant Japanese village. Besides, the center also served as a medical, educational, and funeral occasion.”
The Amis “The Amis, also known as Pangcah (our people), is the largest indigenous tribe in Taiwan, with its population over 190 thousand…. The Amis hold a variety of glamorous festivals for celebration. These festivals include Sea Festival, also known as Catching-Fish Festival, Harvest Festival, and other minor festivals…. Here are three of the
“Hey! Do you know what is the largest indigenous tribe in Taiwan? Let’s look at it.”
“It is the Amis, with its population over 190 thousand.”
“Welcome to the Hualien Indigenous Tribe Museum. We will know more about the Amis here.”
“They hold various festivals, such as
17
Items Magazine Video script
Amis’s special scrumptious foods: (1) wild vegetables, (2) pigeon pea, and (3) rain-coming mushroom…. Men’s clothes include a hat, a bandana, a round-necked short-sleeved shirt, a vest, a chest cloth, a short skirt, a girdle, a corset, a shawl, leg-coverings, and buckskin-made shoes.
Women’s apparel features a bandana, a chest cloth, a round-necked short-sleeved shirt, two long skirts, and a girdle…. The Amis’s rattan weaving techniques are pretty mature.”
(p. 43-56)
Catching-Fish Festival, Harvest Festival, Water-Fetching Festival, etc.”
“The Amis female clothes include a bandana, a round-necked short-sleeved shirt, a girdle, a chest cloth, and two long skirts.”
“The Amis male clothes include a hat, a bandana, a round-necked short-sleeved shirt, a girdle, a vest, a chest cloth, a long skirt, leg-coverings, and buckskin-made shoes.”
“Their food culture features wild vegetables, pigeon peas, and rain-coming mushrooms.”
“The Amis are pretty good at weaving; they even have their own unique weaving
techniques. Here you can see an instrument to catch fish.”
Filming the video
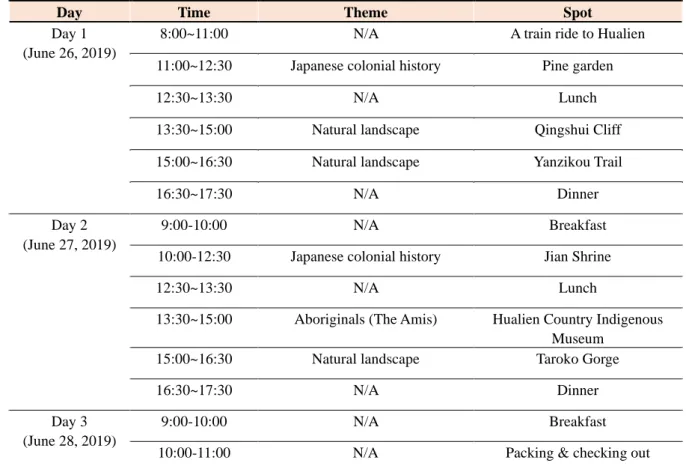
We visited Hualien from January 26, 2018 to January 28, 2019. A detailed itinerary is presented below (see Table 4).
Table 4. Trip schedule to Hualien
Day Time Theme Spot
Day 1 (June 26, 2019)
8:00~11:00 N/A A train ride to Hualien
11:00~12:30 Japanese colonial history Pine garden
12:30~13:30 N/A Lunch
13:30~15:00 Natural landscape Qingshui Cliff
15:00~16:30 Natural landscape Yanzikou Trail
16:30~17:30 N/A Dinner
Day 2 (June 27, 2019)
9:00-10:00 N/A Breakfast
10:00-12:30 Japanese colonial history Jian Shrine
12:30~13:30 N/A Lunch
13:30~15:00 Aboriginals (The Amis) Hualien Country Indigenous Museum
15:00~16:30 Natural landscape Taroko Gorge
16:30~17:30 N/A Dinner
Day 3 (June 28, 2019)
9:00-10:00 N/A Breakfast
10:00-11:00 N/A Packing & checking out
18
Day Time Theme Spot
11:00-13:30 Design of a video Discussion & lunch
13:30-15:40 N/A A train ride back to Taipei
The video-filming process was shaped by the five modes of multimodality.
Linguistic mode. First, the video script was composed in the previous step based on the differences between written and oral language in terms of formality, depth, personal references, word choice, and syntax, and it serves as the core basis for step 3. Second, the two hosts rehearsed the oral script several times to make sure they could enunciate the words clearly and that they were familiar with their lines. Lastly, during the filming, the two hosts added some impromptu phrases to make their speech more natural, for example, adding the impromptu sentence “Here is the Qingshui Cliff” to signal to the audience that the introduction to Qingshui Cliff was about to start.
Visual mode. First, the scenes were chosen to correlate with the hosts’ introduction to the scene. For example, when talking about Taroko Gorge, one of the hosts opened the introduction by announcing, “Hi! We are on the Shakadang Trail, part of the Taroko Gorge.
Let’s go inside for an adventure.” The opening was filmed at the entrance to Shakadang Trail
(part of Taroko Gorge) to prepare the audience for the trip into the tourist attraction (Picture
1). Second, the proportions of the host to the background were adjusted so that the audience
could see both. For example, when talking about the Amis’s weaving techniques, one of the
hosts stood in front of a weaving handicraft, and the camera captured the handicraft so that
the audience could view the handicraft during the introduction (Picture 2). Third, a
smartphone and a camera were used simultaneously to film the video: The smartphone
captured supplemental materials from the sidelines, while the camera in front of the hosts
filmed the main footage. Employing both the smartphone and the camera created different
layers of visual experience (Pictures 3, 4). Lastly, we adjusted the light in the video so that
the audience could easily see the hosts and the tourist attractions. For example, when talking
19
Picture 2: A host in front of a woven basket typical of the
Amis’s culture
Picture 3: A photographer recording a video with a single-lens reflex camera Picture 1: A host at the
entrance of Taroko Gorge
Picture 5: A host in front of a cliff on Yanzikou Trail Picture 4: A photographer
recording the two hosts taking a walk with a
smartphone
Picture 6: Two hosts carrying voice amplifiers
about Yanzikou Trail, the host found a spot where there was sufficient light to reveal its visual appeal (Picture 5).
•
Aural mode. To ensure that the audience can easily hear them, the two hosts used voice amplifiers. Amplifiers were especially important when the attraction was noisy (Picture 6).
For example, in the Pine Garden, a lot of cicadas were chirping in the trees. In addition, the hosts did not begin until all people and cars had left the area.
Gestural mode. First, the photographer asked the hosts to walk along the tail having a
casual conversation to foster a relaxing feeling. (Picture 7). Also, the hosts used gestures and
facial expressions when they were introducing a tourist attraction. For example, at the Ji-An
Shrine one of the hosts signaled the numbers 1, 2, 3 with her fingers (Picture 8) to emphasize
the three functions of the shrine and smiled to demonstrate her amiability.
20
Picture 7: Two host ambling along the trail leading to Qingshui Cliff
Picture 8: A host speaking with gestures in a hall inside Ji-An Shrine
Picture 9: A scenic view inside Taroko Gorge Picture 10: A host introducing the food culture of the Amis
Spatial mode. During the filming, we considered how everything should be presented on the screen during the editing process. First, when one of the hosts was reciting a poem about Taroko Gorge, the photographer captured the natural scenery only and did not include the host so that the poem could be put on the screen with the natural scenery as the backdrop and the recitation as the background voice (Picture 9). When one of the hosts was introducing the distinctive foods of the Amis, she stood on the right instead of in the middle because pictures of the foods would be on her left (Picture 10).
(Re-)editing the video
As soon as the first version of our video was produced, an internal review by the research team found that three aspects of the video needed to be improved. First, the pace was too slow. Second, only one song was used for background music as suggested by our target audience, but the result was that it was difficult for the transitions between different sections to be perceived; third, the color and size of the subtitles made it difficult to read them.
Therefore, the research team turned to a video-editing professional for guidance in creating a
21
second versions to eliminate the flaws we identified. Table 5 below compares the two versions of our video.
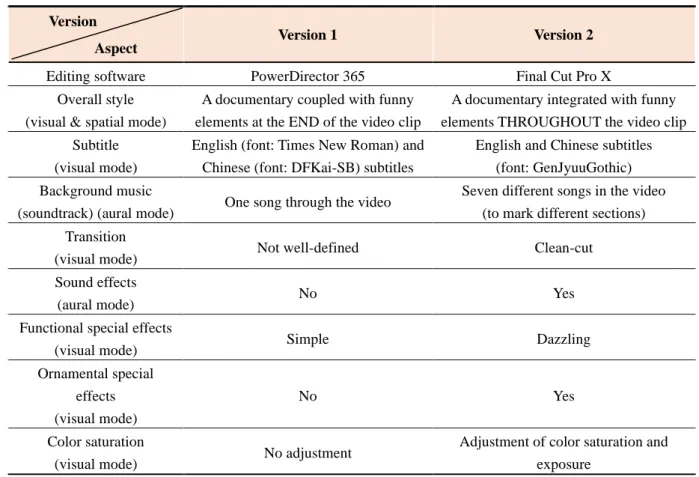
Table 5. Differences between the two versions of our video Version
Aspect
Version 1 Version 2
Editing software PowerDirector 365 Final Cut Pro X
Overall style (visual & spatial mode)
A documentary coupled with funny elements at the END of the video clip
A documentary integrated with funny elements THROUGHOUT the video clip Subtitle
(visual mode)
English (font: Times New Roman) and Chinese (font: DFKai-SB) subtitles
English and Chinese subtitles (font: GenJyuuGothic) Background music
(soundtrack) (aural mode) One song through the video Seven different songs in the video (to mark different sections) Transition
(visual mode) Not well-defined Clean-cut
Sound effects
(aural mode) No Yes
Functional special effects
(visual mode) Simple Dazzling
Ornamental special effects (visual mode)
No Yes
Color saturation
(visual mode) No adjustment Adjustment of color saturation and
exposure
RQ2: What is our target audience’s response to the videos?
To answer the second research question, we interviewed 10 foreigners to gather their responses to the two versions of the video. Most of the interviewees preferred the content and format in the second version (see Table 5). It was interesting that though the content was the same in the two versions, the scores differed. For example, Qingshui Cliff got a higher score in the second version (M= 7.5) than in the first (M= 6.3). A possible explanation is that the format created a different visual and audio experience for the interviewees: When Interviewee 5 was asked why she preferred Ji-An Shrine in the second version (M= 8) to Ji-An Shrine in the first version (M= 6), she said, “The special effects and sound effect[s]
make this part fun.”
22
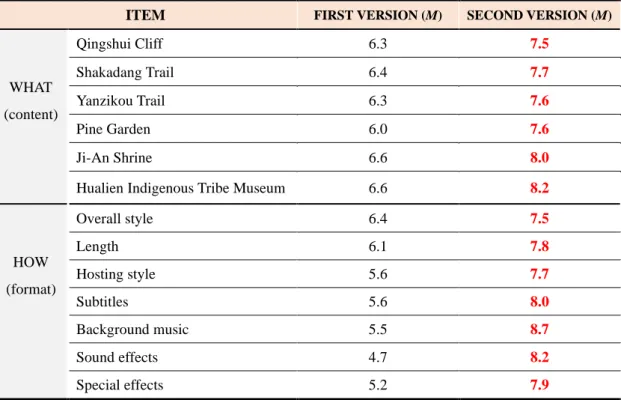
Table 6. Target audience’s responses to the videos
Overall style. The interviewees preferred the overall style of the second version (M= 6.4) to that of the first version (M= 7.5). Both versions were documentaries; what set them apart was that the first version ended with NG clips and interviews with locals in Hualien, while NG clips were integrated into the second vision and the interview footage was deleted. The second version was “more attractive,” (Interviewee 3) “more interesting,” (Interviewee 5) and thus “more appealing” (Interviewee 3) with “the NG clips inserted throughout the video”
(Interviewee 3).
Length. The interviewees liked the length of the second version (08:05) (M= 7.8) more than that of the first version (09:04) (M= 6.1). Although the length of two versions was similar, most of our interviewees did not perceive that the second version was “actually one minute shorter than the first one” (Interviewee 2) because it was “a bit more interesting to watch” (Interviewee 8) with “improved audio quality” and “great special effects”
(Interviewee 4).
Hosting style. The interviewees liked the hosting style of the second version (M= 7.7)
ITEM FIRST VERSION (M) SECOND VERSION (M)
WHAT (content)
Qingshui Cliff 6.3 7.5
Shakadang Trail 6.4 7.7
Yanzikou Trail 6.3 7.6
Pine Garden 6.0 7.6
Ji-An Shrine 6.6 8.0
Hualien Indigenous Tribe Museum 6.6 8.2
HOW (format)
Overall style 6.4 7.5
Length 6.1 7.8
Hosting style 5.6 7.7
Subtitles 5.6 8.0
Background music 5.5 8.7
Sound effects 4.7 8.2
Special effects 5.2 7.9