行政院國家科學委員會補助專題研究計畫 ■ 成 果 報 告
□ 期中進度報告
智慧型動態非織物電腦整合製造系統之開發與研製(3/3)
計畫類別:■ 個別型計畫 □ 整合型計畫 計畫編號:NSC-96-2221-E-011-004
執行期間: 96 年 8 月 1 日至 97 年 7 月 31 日
計畫主持人:郭中豐 教授 共同主持人:
計畫參與人員: 陳建良 張志遠 黃智達 洪司融
成果報告類型(依經費核定清單規定繳交):□精簡報告 ■完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、
列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢 執行單位:國立台灣科技大學 高分子工程系
中 華 民 國 九 十 七 年 十 月 二 十 五 日
中 文 摘 要
非織物之製造技術可分為三部份,一為棉網之製造、二為棉網之強化、三為棉 網之整理,因現今國內外尚無對動態非織物製造系統提出整體之劃,且在非織物產 品的製造技術尚有諸多之改進空間,故本計劃提出針對智慧型動態非織物整合製造 系統之研究與開發,針對不同的非織物產品提出整體性的解決方案,包括控制系統 分析與設計、感測器之架設及製造流程之規劃與設計,在控制系統分析與設計方面,
針對梳棉機及摺疊機之機構建立其系統模式及推導其動態方程式,分析控制系統之
特性及其物理意義,作為控制學理上之依據,設計合適之控制器來製造符合非織物
產品寬度與均勻厚度之棉網;並分別在梳棉機架設光感測器及在摺疊機架設對邊感
測器,測量棉網之密度、厚度及寬度,作為實務上之驗證,在非織物製造流程之規
劃與設計方面,本文利用田口方法結合灰色關聯度分析來解決多重品質最佳化之問
題,進而找出針軋非織物最佳加工參數之條件組合。首先,以 L
18(2
1x3
7)直交表規劃
對於針軋非織物製程會造成影響的加工參數,包括刺針排列方式、纖維種類、纖維
喂入量、摺疊機擺動速度、摺疊機輸送速度、針軋深度、針軋密度與刺針型號。然
後利用灰色關聯分析解決田口方法單一品質特性的缺點,再由灰色關聯分析的回應
圖得到多重品質特性的最佳加工參數組合。本實驗的品質特性為非織物的拉伸強力
及撕裂強力。並且進行信號雜音比計算與變異數分析,以對實驗結果進行探討,從
變異數分析可以得到對針軋非織物品質特性影響較大的顯著因子,亦即控制這些因
子,便可以有效控制針軋非織物的品質特性。最後,經由確認實驗以 95%信賴區間
驗證其實驗具有可靠性與再現性。
Abstract
Non-woven textiles are textile fabrics formed by fiber web, and its manufacturing comprises making, bonding and reinforcing of card web respectively. Within the textile industry, spinning is a primary process, and carding is its most important step, affecting not only the quality of the yarn, but also the secondary processes of weaving (whether there are occurrences of breaking or pilling) and dyeing (whether dyeing uniformity is achieved or if dyeing specks occur). Since carding has a key influence on product uniformity the process must have both high speed and continuous high quality production.
In this project, based on demand and reality, the system modeling, the rational transfer function, control system design and analysis, and a realizable controller will be designed.
The system dynamics, stability, nonminimum phase property, controllability, and
observability, tracking property by application to feedback control of whole
worker-stripper group will be considered. The root-locus design and neural network
technique will be employed for the controller design. Taguchi methods, together with
grey relational analysis are employed to resolve the problem as regards multiple quality
optimization, and further discover the optimal combination of processing parameters for
needle punching non-woven fabric. Firstly, orthogonal array L
18(2
1x3
7) is used to deal
with the processing parameters that may exert influence over the manufacturing of needle
punching non-woven fabric. These parameters includes the needle arrangement, fiber
variety, fiber feed quantity, swing speed and conveyor speed of the cross-lapper machine,
penetration depth, needling density and the needle model. Then grey relational analysis is
applied to resolving the flaw of Taguchi methods that focus on single quality
characteristic. Next, the response table of grey relational analysis is used to obtain the
optimal combination of processing parameters for multiple quality characteristics.
Through analysis of variance, the significant factors that exert comparatively significant influence over the quality characteristic of the needle punching non-woven fabric the control factors so that the quality characteristic of the needle punching non-woven fabric can be effectively controlled. Finally, confirmation experiment is conducted within 95%
c onf i de nce i nt e r va l t o ver i f y t he e xpe r i me nt ’ s r e l i a bi l i t yand reproducibility.
目 錄
中 文 摘 要 ...I Abstract...II 目 錄 ... IV 圖 索 引 ... VI 表 索 引 ...VII
第 1 章 緒論 ... 1
1.1 前言 ... 1
1.2 研究目的 ... 1
1.3 研究步驟 ... 2
第 2 章 文獻探討 ... 4
第 3 章 研究方法 ... 6
3.1 田口式品質工程 ... 6
3.1.1 田口品質工程概述 ... 6
3.1.2 直交表 ... 8
3.1.3 品質特性之種類 ... 10
3.1.4 因子的分類 ... 12
3.1.5 變異數分析 ... 13
3.1.6 確認實驗 ... 14
3.2 類神經網路 ... 15
3.2.1 類神經網路概論 ... 15
3.2.2 類神經網路分類 ... 18
3.2.3 類神經網路之特性 ... 21
3.2.4 類神經網路之運作過程 ... 21
3.2.5 倒傳遞類神經網路 ... 22
3.3 灰關聯度分析 ... 30
3.3.1 灰關聯度分析概述 ... 30
3.3.2 因子空間(Factor Space)... 31
3.3.3 序列之可比性(Comparision)... 31
3.3.4 灰關聯測度之四大公理 ... 32
3.3.5 灰關聯度之計算 ... 32
第 4 章 結果與討論 ... 36
4.1 實驗規劃 ... 36
4.1.1 實驗設備 ... 36
4.1.2 實驗材料 ... 36
4.1.3 實驗流程 ... 39
4.2 實驗結果 ... 39
4.3 灰色關聯度分析之應用 ... 55
4.4 倒傳遞網路之應用 ... 63
第 5 章 結 論 ... 68
第 6 章 參考文獻 ... 70
行政院國家科學委員會專題研究計畫成果自評表 ... 73
可供推廣之研發成果資料表 ... 74
圖 索 引
圖 1-1 實驗流程圖... 3
圖 3-1 生物神經細胞結構圖... 17
圖 3-2 人工神經元結構圖... 17
圖 3-3 前向式架構... 20
圖 3-4 回饋式架構... 20
圖 3-5 倒傳遞神經網路架構... 22
圖 3-6 階梯函數(Step Function)... 24
圖 3-7 雙彎曲函數(Sigmoid Function) ... 24
圖 3-8 雙曲線正切函數(Hyperbolic Tangent Function)... 24
圖 3-9 灰關聯度流程圖... 35
圖 4-1 羅拉式梳棉機... 37
圖 4-2 垂直式摺疊機... 37
圖 4-3 針軋機... 38
圖 4-4 萬能拉力試驗機... 38
圖 4-5 拉伸強力(縱向)之回應圖 ... 49
圖 4-6 拉伸強力(橫向)之回應圖 ... 49
圖 4-7 撕裂強力(縱向)之回應圖 ... 50
圖 4-8 撕裂強力(橫向)之回應圖 ... 50
圖 4-9 灰關聯度之主效果分析回應圖... 62
圖 4-10 倒傳遞網路架構圖... 65
圖 4-11 類神經網路收斂圖... 66
表 索 引
表 3-1 L9(34)直交表... 9
表 4-1 控制因子及水準值... 40
表 4-2 L
18直交表表 4-3 加工水準配置... 41
表 4-3 加工水準配置... 42
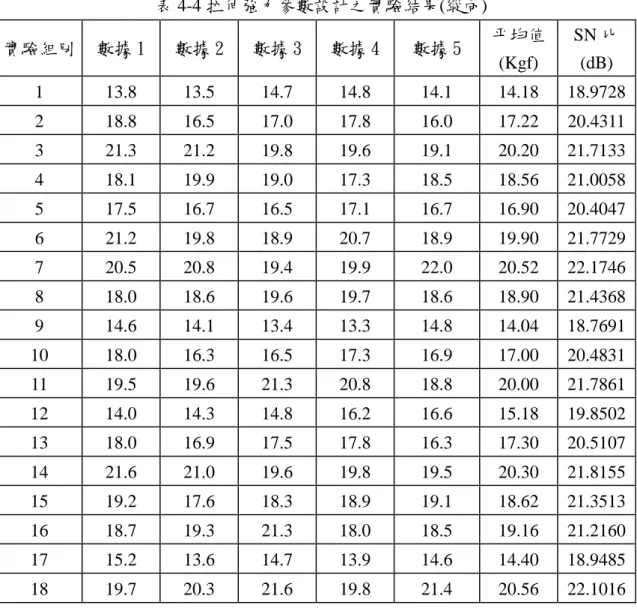
表 4-4 拉伸強力參數設計之實驗結果(縱向) ... 43
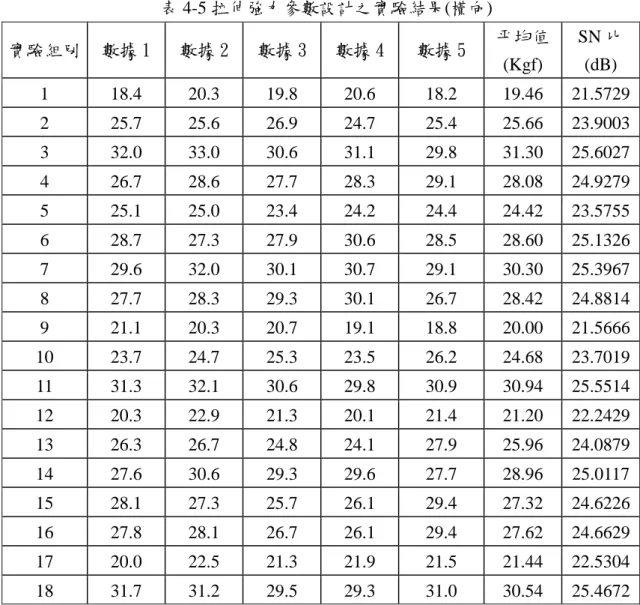
表 4-5 拉伸強力參數設計之實驗結果(橫向) ... 44
表 4-6 撕裂強力參數設計之實驗結果(縱向) ... 45
表 4-7 撕裂強力參數設計之實驗結果(橫向) ... 45
表 4-8 拉伸強力 SN 比回應表(縱向) ... 48
表 4-9 拉伸強力 SN 比回應表(橫向) ... 48
表 4-10 撕裂強力 SN 比回應表(縱向) ... 48
表 4-11 撕裂強力 SN 比回應表(橫向) ... 48
表 4-12 拉伸強力(縱向)之變異數分析表 ... 51
表 4-13 拉伸強力(橫向)之變異數分析表 ... 51
表 4-14 撕裂強力(縱向)之變異數分析表 ... 52
表 4-15 撕裂強力(橫向)之變異數分析表 ... 52
表 4-16 確認實驗表... 54
表 4-17 參考序列與比較序列... 56
表 4-18 各序列的初值化... 57
表 4-19 各序列的差序列... 58
表 4-20 各序列的灰色關聯係數... 59
表 4-21 灰色關聯度及排序... 60
表 4-22 灰關聯度之主效果分析 SN 比回應表... 61
表 4-23 確認實驗表... 62
表 4-24 控制因子正規化範圍值... 63
表 4-25 加工參數正規化之值... 64
表 4-26 測試範例預測之結果... 67
表 5-1 針軋非織物強力之單一品質特性最佳參數組合... 68
表 5-2 針軋非織物強力之多重品質特性製程最佳化組合... 69
第1章 緒論
1.1 前言
非織物是利用具有方向性或是雜亂的纖維網,使其通過摩擦(Friction)、抱合 (Embrace)或粘合(Cohesiveness)或是這些方法之組合而相互結合製成的纖網或片狀 物。非織物之分類方法最主要是依成網方法來分類[1],依非織物製造理論及產品的 結構特徵,其成網方法可分為乾式及濕式兩大類,其中乾式製造法所生產之不織布產 品生產量約佔全球 50%以上,而本研究之針軋非織物即屬於乾式製造法之一種。
針軋非織物是一種用機械手段,即刺針的穿刺作用而將纖網加固成布,其依靠纖 維相互抱合而形成強力,與一般將緯紗(Weft)投入經紗(Warp)製成的梭織物以及用編 織而成的針織物等的結構完成不同[2]。針軋非織物製造技術與傳統的紡織製造技術 相比,其製造過程簡單、運用領域廣泛、多樣化、生產效率高及生產成本低,可依最 終產品用途,選擇適當之纖維原料與技術,而發揮纖維在非織物結構中之作用。因此 非織物已深入每個人的日常生活之中。
1.2 研究目的
非織物之生產流程是一貫化且連續地,從利用梳棉機將各種纖維梳理成棉網、
摺疊機折疊出合適之棉網,再將蓬鬆之棉網使用針札機加固而成非織物,每個機構
之控制及製造流程之規劃需緊密結合,因此本計劃針對非織物之製造流程提出整體
之規劃,包括控制系統分析與設計、感測器之架設及製造流程之規劃與設計,在控
制系統分析與設計方面,針對梳棉機及摺疊機之機構建立其系統模式及推導其動態
方程式,分析控制系統之特性及其物理意義,作為控制學理上之依據,以現代控制
理論設計合適之控制器來製造符合非織物產品寬度與均勻厚度之棉網;並架設其感
測器裝置,作為實務上之驗證,在非織物製造流程之規劃與設計方面,非織物製程
的參數設定大都憑藉經驗及試誤法,通常須耗費大量的人力、時間。如以往製程之 加工參數,大都依產品質特性而求得單一品質特性之最佳化組合,未考慮多重品質 與加工參數間之關係。且單一品質最佳化加工參數,則常無法完全表現整體品質的 加工參數最佳化。因此本研究之目的乃應用品質特性的預測模式,以期建立一最佳 化製程參數系統來降低非織物製造成本及加工時間。
1.3 研究步驟
本研究可分為四大步驟,其分述如下:
步驟一:搜集相關文獻資料及規劃整體實驗之流程,並決定符合本研究之方法與理論。
步驟二:利用田口法之直交表來規劃實驗,收集數據後,配合信號雜音比與變異數分 析,而決定製程參數之最佳水準組合,並執行確認實驗以驗證實驗之再現 性,若確認實驗結果與預測結果不吻合,則實驗過程失敗,需重新規劃實驗。
步驟三:將步驟二所收集之數據,結合灰色關聯度來整合多重品質特定,而得到最佳 參數水準組合,以改善田口法單一品質特性之缺點。
步驟四:將直交表實驗所得之數據正規化,代入倒傳遞類神經網路中,以建立加工參 數與品質特性之相關性,以針軋非織物之製程參數為輸入參數,品質特性為 輸出參數,訓練網路直至收斂為止,而推論出產品之品質特性。
本研究流程圖如圖 1-1 所示。
研究 動 機與 目的
文 獻 探討
田 口 實 驗計 劃法設計
針 軋非 織物製 造
針軋 非 織物 強力檢測
灰色 關 聯度 分 析
類神 經 網路 學 習與 訓練
建 構 預測模式
實驗 結 果與 討 論
結 論
圖 1-1 實驗流程圖
第2章 文獻探討
非織物製造是利用羅拉梳棉機將纖維梳理成單纖維狀,梳理成單纖維後經摺疊機 將纖網疊成一定厚度,最後再經針軋機針刺加固成非織物。在纖維梳理方面,馬建偉 等人[3]研究錫林、道夫、工作輥及剝取輥的速度、主要機件的速度比及相互間的隔 距和針布配置、各機件的直徑大小、原料狀況、針布上的負荷量等為影響梳理作用之 主要因素;Meng 等人[4]針對梳棉機各機件上的纖維運動及分佈做探討,認為這些運 動確保了纖維轉移之有效性、混合均勻性、生產率及纖網質量。而纖維性能、梳理針 布的特性及條件、梳理機各機件的相對速度和隔距則為影響纖維分佈及轉移特性的因 素。而在纖網摺疊方面,Sakamoto [5]及 Hirschek 等人[6]皆探討摺疊機擺動速度與輸 送速度對纖網厚度之影響,藉著兩者速度快慢之調整,而控制纖網基重。在纖網加固 方面,Watanabe 等人[7]及 Miao[8]說明非織物強力隨著針軋密度及針軋深度之增加而 增加,但超過臨界值則強力降低,造成纖維損傷,及針密越高時對纖網有較小之壓縮 張力與高壓縮率;王延熹[9]說明影響針軋非織物品質特性為纖維特性(如纖維長度、
細度、摩擦特性等)、針板上刺針排列方式、針軋密度、針軋深度、針鉤形式與尺寸、
刺針號數等;Miao[10]等人研究針軋深度、針軋密度、刺針設計、纖網厚度及纖網喂 入針軋機之方法,對纖網損傷之影響;Hearle 和 Sultan[11]使用萬能拉力試驗機來探 討在不同纖網質量參數下之靜態針刺力;Lin 等人[12]探討利用纖網排列的雜亂度來 改善纖網的向異性(Anisotropy),使各方向的力學性能趨於相似,並研究纖網在其他 方向(如 0 度、45 度及 90 度)及不同基重對拉伸斷裂強力值及伸長值之影響;Watanabe 等人[13]研究針鉤鉤取纖維的能力、針刺力及非織物的拉伸性質。
以往工業製程參數之設定,是以試誤法及經驗傳承來調整參數,造成實驗次數過
多而浪費成本及人力,田口實驗計劃法[14-15]是利用來改善製程品質,減少實驗次
數,因而降低製程之變異及提昇與保持產品之品質穩健性。為建構加工參數之預測系
統,近年來類神經網路已廣泛應用於工商業,Khaw 等人[16]利用田口法結合類神經
網路之運用,以決定類神經網路之最佳參數組合,以得到具準確性與快速收斂的網路
參數;Wang 等人[17]結合田口法低操作成本及類神經網路之優異預測學習能力,以
建立改善工程設計分析程序之方法;MacLeod 等人[18]將田口法應用於類神經網路的
訓練中,以快速檢驗出權重值與神經元之交互影響;Goh[19]證明倒傳遞類神經網路
(Back-Propagation Network) 能 解 決 工 程 上 複 雜 的 參 數 與 非 線 性 的 相 互 關 係 ;
Packiannather 等人[20]以田口法之直交表來規劃類神經網路學習參數,以改善類神經
網路以試誤法來決定訓練時的學習參數(如學習因子、學習次數、隱藏層單元個數及
慣性因子),以節省時間,並可獲得各學習參數對均方根誤差之影響,以建構準確之
預測系統;Ethridge 等人[21]利用類神經網路來預測羅陀精紡紗的性質並比較與回歸
演算法的預測能力。然因田口實驗計劃法只大都處理單一品質特性之最佳化,若品質
特性非為單一時,則應用灰關聯度分析法來解決多重品質特性之問題,灰關聯度分析
法主要能對事物的不確定性、多變量輸入、離散的數據及數據的不完整性作有效的處
理。Tarng 等人[22]利用田口法結合灰關連分析來解決弧形銲接之多重品質特性問
題,藉由將田口法之 SN 比值轉換成灰關聯度來進行灰關聯度分析,以得到多重品質
特性之最佳加工參數組合;Deng[23]針對資料量缺乏或不明確訊息之系統,以灰關連
等灰色理論來建立其系統模型,並對其基本理論進行說明及討論。本研究利用田口實
驗計劃法結合灰色關聯度分析法以得到多重品質最佳加工參數,並利用倒傳遞類神經
網路來做加工參數之預測。
第3章 研究方法
3.1 田口式品質工程
品質是一種滿意度的感覺,品質的定義有許多種說法,如朱蘭 (Juran)、戴明 (Deming)、克勞斯比(Crosby)、費根堡(Feigenbaum)等人均曾對品質下過定義:如符 合 規 格 (Conformance to the Specification) 、 滿 足 顧 客 需 求 (To be Cus t ome r ’ s Satisfaction)、第一次就做好(Do it Right the First Time)等等。而田口博士也對品質下 了定義,即「每一個產品使用期間對社會所造成的損失最小」。意謂好品質的產品,
在每次使用都要正確的表現其目標績效(Target Performance),同時也不可有任何副 作用危害社會[24]。因此理想的產品品質應該是對社會的損失為零。產品功能偏離 目標值愈遠,則表示變異愈大,對社會所造成的損失也就隨之增大。田口博士之品 質工程的基本概念就是以穩健設計找到產品變異小的設計或製程,使得大量生產的 產品上市後對社會所造成的平均損失成本最小。其強調的再現性(Reproducibility)好 的設計也就是變異小,且可以大量生產的產品設計,也就是穩健設計,而穩健設計 是一種工程最佳化方法,比其他方法更有效,適合工程師使用,其可改善目前的科 技、產品與製程設計,使其績效最佳化。
3.1.1 田口品質工程概述
田口式品質工程之品管活動可分為線上(On-Line)品管及線外(Off-Line)品管兩 大類,線外品管發生在產品發展及設計階段。田口博士所提倡的品質工程技術重點 在線外品管,對於品質工程在技術開發或產品/製造之設計時,田口將其分為三個階 段[25]:
1.系統設計(System Design)
此階段主要是檢視各種可能達成「想要的機能」的系統或技術,然後選擇一個
最適當的。系統設計在降低製造成本及雜音因子靈敏度有其重要之貢獻。品質機能 展開(Quality Function Deployment)、實驗設計(Design Of Experiments)、基準法 (Benchmarking)和一般問題分析與解決之方法都是可應用於此階段之有效工具。
2.參數設計(Parameter Design)
在此階段中,主要是要最佳化「系統設計」,利用實驗以確定可控因子水準的 組合,使系統對雜音因子不敏感,而提升系統的穩健性。亦即,決定系統設計可控 因子水準之最佳設定,以減少品質損失。參數設計主要在降低對雜音因子的效果,
而不是在控制雜音,為一個有效的低成本方法。在使用參數設計時,需先確定品質 特性,找出控制因子及雜音因子,再以直交表及信號雜音比(SN 比)來作為選擇最佳 參數組合之工具,利用 SN 比之特性,而求得品質特性平均最佳值及最小變異數,
SN 比越大,其損失越小,代表此參數水準組合及品質特性是最佳的,在此參數水 準下所產製的產品,其變異性最小。再依所要求之品質特性進行回應表及回應圖之 建立,以求出因素 F 的各水準平均回應值 F
i及主效應值 ΔF ,將這些數據製成回應 表及回應圖,進行各因素的效應分析,若主效應 ΔF 愈大,則表示該因素對系統的 影響比其他因素大,其計算方式如下:
m1 j
j
i
y
m
F 1 (3-1)
F1, F
2, , F
n min F1, F
2, , F
n
, F
2, , F
n
ΔF max (3-2)
n 表示因素的水準別
m 表示在直交表因素行中,水準為 i 的個數 y
j則表示各 j 水準列所產生的 SN 比
參數設計之基本步驟分為九個步驟,其九個步驟可分為三大階段:
第一階段:實驗規劃
步驟一:選擇產品品質特性。
步驟二:確認產品品質特性。
步驟三:選擇信號因子的範圍及重要的雜音因子及其水準。
步驟四:確認控制因子及其水準。
第二階段:實驗執行
步驟五:選擇直交表進行實驗計劃。
第三階段:實驗結果之分析與確認。
步驟六:執行實驗,紀錄實驗數據。
步驟七:資料分析。
步驟八:執行確認實驗。
步驟九:執行結果。
3.允差設計(Tolerance Design)
本階段主要是要調整公差範圍以最佳化設計參數。若作完參數設計,品質要求已 在規格之內,則得到成本最低的設計,而無需進入允差設計階段。但若作完參數設計 後,仍未能滿足規格要求,則必須進行允差設計,使用較好的零件、設備,增加製造 成本以降低產品的變異。允差設計應該是在參數設計之後才進行,否則將導致不必要 的高製造成本。品質損失函數及變異數分析(ANOVA)可決定各因子變異的貢獻程 度,是允差設計中的重要工具。
3.1.2 直交表
直交表(Orthogonal Arrays)為 Professor C. R. Rao 於 1947 年所創,其以較少之實
驗獲得更可靠的因子效果估計量,為穩健設計的一個重要技巧。同時亦可做為評估產
品與製程設計之重要工具。田口博士利用直交表之應用以簡化實驗計劃,所謂直交
(Orthogonal)係將各因子及其水準值,以直交排列的方式組合在一起的一種實驗計劃
配置表。利用直交表進行實驗,事實上是進行完全要因實驗(Complete Factorial Experiment)中之部份要因實驗(Fractional Factorial Experiment),其可以獨立和均衡的 求出每一可控因子的主效果。使用直交表之好處為(1)實驗次數較少。(2)由直交表實 驗所獲得結論,在整個實驗範圍裡都是成立的。(3)具有良好再現性。(4)資料分析簡 單。(5)可用來查核加法模式是否成立。而田口博士認為高次交互作用對實驗結構影 響較小,因此忽略高次交互作用之效果,只考慮低次交互作用或不考慮其交互作用,
因此可大量減少實驗次數,節省時間及成本。所以在建構一直交表時,須先知道(1) 因子數,(2)每個因子的水準數,(3)特別要估計的二因子交互作用,和(4)在進行實驗 時可能發生的困難。當這些條件都知道後,便可選擇一適當的直交表,進行因子的配 置以執行實驗。表 3-1 為 L
9(3
4)直交表,其中 4 表示四個控制因子,3 表示每一控制 因子有三種水準值,9 表示所須實驗之次數為 9 次。田口方法即以此種排列方式進行 實驗。
表 3-1 L9(34)直交表 因子
實驗編號 A B C D
1 1 1 1 1
2 1 2 2 2
3 1 3 3 3
4 2 1 2 3
5 2 2 3 1
6 2 3 1 2
7 3 1 3 2
8 3 2 1 3
9 3 3 2 1
3.1.3 品質特性之種類
信號雜音比(Signal-to-Noise Ratio,SN 比)為用來設計最佳化一產品或製程之穩健 性,其可作為量測系統的品質特性。SN 比最大者,為最佳之參數水準組合,在此參 數水準下所產製的產品,其損失最少,變異性最小。而品質特性具有三種標準型態如 下[26]:
3.1.3.1望小特性(Smaller the Better)
品質特性 y 為非負的連續隨機變數,最佳狀態值應為 0,不需要調整因子,其目 標為同時最小化平均值及變異。例如產品不良率、零件磨耗、汽車排氣污染等等。
望小特性 SN 比為:
n
1 i
2
y
in 10log 1 10log[MSD]
SN (3-3)
i 2 2
2 2n
1 i
2
i
(y u) u σ u
n y 1 n
MSD 1
(3-4)
式中:MSD (mean squared deviation) 為偏離目標值的均方差 y
i為品質量測值
n 為量測總數
u 為品質特性平均值 σ為變異數
由公式中可得知:放大 SN 比,則如同縮小 MSD;而縮小 MSD 則如同縮小每一個
y
i2,亦如同縮小信號效應平均值 y 一般。但信號和雜訊是向同一個方向增減的,極小
化 MSD 即極小化 u
2和 σ
2。
3.1.3.2望大特性(Larger the Better)
品質特性為非負的連續隨機變數,但最佳狀態值則愈大愈好,不需要調整因子,
品質目標期望值最大化,即為望大特性。例如產品的強度、產品使用壽命、燃料效率 等等。
望大特性的 SN 比為:
n
1 i
2
y
i1 n log 1 10 MSD
log 10
SN (3-5)
2
2
2 n
1 i
2
i
u
1 3σ u
1 y
1 n
MSD 1 (3-6)
欲極大化 SN 比時,亦即極小化 MSD,也就是極大化 u 和極小化σ。只要找出 一組可控因子的最佳組合時,就可以使 SN 比極大,並找到最大的品質特性平均值及 最小的品質特性變異數。
3.1.3.3望目特性(Nominal the Best)
品質特性 y 為非負的連續隨機變數,此特性具有一特定目標值。品質特性為連續 且非負值,目標值為一有限值且不為零,其需要調整因子。品質目標期望值能趨近其 目標值,即為望目特性。例如產品黏度、產品尺寸規格、產品間隙等等。
望目特性的 SN 比公式為:
e e m
2 2
V V n S
1 10log σ
10log u SN
(3-7)
n 2
1 i
i
m
y
n
S 1
(3-8)
n 2
1 i 2 i
e
n 1
u σ y
V
(3-9)
式中:Sm 為數據的平方和、Ve 則是實驗樣本的變異。
3.1.4 因子的分類
影響產品品質特性的因子分為三種,分別為信號因子、控制因子及雜音因子,其 分述如下:
3.1.4.1信號分子(Signal Factor)
信號因子為使特性變數增減之因子,其所表達的品質特性,可由產品使用者或操 作者設定。信號因子是依產品需求與工程知識而做選擇,通常信號因子與品質特性之 間具有輸入及輸出之關係。例如汽車之速度,可用油門來控制,油門就是信號因子。
如駕駛汽車時踩油門之大小會影響汽車速度之快慢。
3.1.4.2控制因子(Control Factor)
控制因子之水準可由設計者所決定,為使品質特性的損失最小,設計者必須決定 控制因子之水準尋求最佳參數組合,而使品質特性符合產品之要求。本文利用針軋機 製造非織物,品質特性為非織物之強力,而影響此品質特性之控制因子為針軋機之針 軋深度、針軋密度、刺針號數(針葉號數)及針板排列方式等。
3.1.4.3雜音因子(Noise Factor)
雜音因子為使機能特性偏離目標值(Target Value)的因素,為設計人員無法控制之
因子,此種因子會造成變異性,而使產品品質受損,會造成消費者與生產者時間及金 錢上之品質損失,而構成社會之損失。一般雜音因子可分為下列三種:
1.外部雜音(External Noise):產品使用時,因使用條件而造成產品機能之變異,此類 條件為外部雜音,如溫度、濕度、灰塵等環境因素。
2.內部雜音(Internal Noise):產品在使用過程中,隨時間之經過,而造成產品組件劣 化之情形,使產品壽命消耗而造成產品績效逐漸偏離目標值。
3.產品間之變異(Unit-to-Unit Variation):在既定之製造條件下,製程變化所造成產品 間之變異,稱之產品間變異,雖然規格值一定,而製程中無法避免的會造成每件產品 特性值不一致。
穩健設計(Robust Design)之主要目的為使產品機能特性對雜音因素影響最小化,
以縮小產品品質特性之變異來改善品質。
3.1.5 變異數分析
經直交表規劃實驗,獲得產品品質特性數據後,則進行 SN 比計算及變異數分析。
而變異數分析法的目的是在檢驗實驗之誤差,求出誤差項的變異,以瞭解各加工參數 對成品品質影響之大小,做為估計實驗誤差之參考[30]。變異數公式包括下列各項:
1.總平方和 (Total Sum of Squares, TSS)
總平方和為所有實驗數據值平方和減去校正數,即 CF
y TSS
N
1 i
2
i
(3-10) 式中之 CF 為平均變異平方和
2 i
N ) y
CF ( (3-11)
平方和所對應的總自由度為 N-1 (N 為所有實驗數據值的數目)。
2.主效果的平方和
對於一因子 A,具有 P 水準,且每一水準有 n 個實驗數據值,其因子平方和為
N CF
) A ( ...
) A ( ) A SSA (
2 p 2
2 2
1
(3-12)
A
1為因子
A在水準
i之實驗數據值總和,i =1, 2, …. , P。
3.誤差平方和 (Sum of Square, SSE)
SSE 為總平方和減去主效果平方和及所有交互作用效果平方和。
4.均方(Mean Square, MS)
MS=SS/DF (3-13)
其中,SS 為各變異來源之平方和,DF 為自由度。
5.自由度 (Degrees of Freedom, DF)
自由度是指估計資訊來源所需的量測數目,自由度愈大其所獲得的情報量愈多,
為該加工參數的水準數減一,而實驗的執行次數為總自由度加一,總自由度為每個因 子的自由度和。
6.F 比值
在變異數分析中,以 F 值來表示因子效果對誤差變異的關係,其為計算每一加工 參數在目標函數中的影響力。F 值愈大,該因子對系統的影響就愈重要。
3.1.6 確認實驗
確認實驗是用來評估實驗值與預測值之差異性,確認其是否符合信賴區間,以驗
證由資料分析所獲得之結論是否正確。
r 1 n V 1 F
CI
eff e
V , 1
;
SN 2
(3-14)
式中 F
;1,V2具顯著水準 的 F 值, 為顯著水準, V
2為合併誤差變異數之自由度, V
e為合併誤差變異數(Pooled Error Variance), n
eff為有效觀測數, r 為確認實驗所需樣 本。其中 ˆ 為 SN 平均值, 為預測之平均值,因此可推論 的 95%信賴區間 (Confidence Interval)為 ˆ CI
SN ˆ CI
SN。
3.2 類神經網路
類神經網路起源於 1957 年,由於「感知機」(perceptron)之提出,曾風靡一時,
此為最早的類神經網路模式,感知機通常被拿來做分類器使用。而在 1960 年中期,
由於研究人員注重人工智慧之研究,加上類神經網路的理論無法突破,因此類神經 網路並沒有受到很大的重視。一直到 1980 年代中期之後,由於倒傳遞類神經網路被 提出,以及解決樣本識別、機器學習等人工智慧之難題,類神經網路理論才開始受 到重視。而類神經網路訊息處理之原理方法與應用為涉及生化、醫學、心理學、物 理、數學、電腦等多種學科之綜合性高科技,而隨著類神經網路理論不斷之發展,
其應用領域也愈佳廣泛[27]。
本研究將影響針軋非織物強力的 8 個控制因子設為倒傳遞類神經網路之輸入參 數,而拉伸及撕裂強力設為輸出參數,將田口直交表實驗後所得之數據代入倒傳遞 類神經網路中,以作為訓練及測試資料,並計算其預測值與實驗值之誤差,以建構 針軋非織物之預測系統。
3.2.1 類神經網路概論
類神經網路(Artificial Neural Network)又稱人工神經網路,它是由生物學上所得到
之靈感,是一種計算系統,包含硬體與軟體。它使用大量簡單相連人工神經元來模仿 生物神經網路的能力。人工神經元是生物神經元的簡單模擬,它從外界環境或其他人 工神經元取得資訊,並加以簡單的運算,且輸出其結果到外界環境或者其他人工神經 元[28]。要瞭解類神經網路,就必須先瞭解生物神經網路,生物神經網路是由約 10
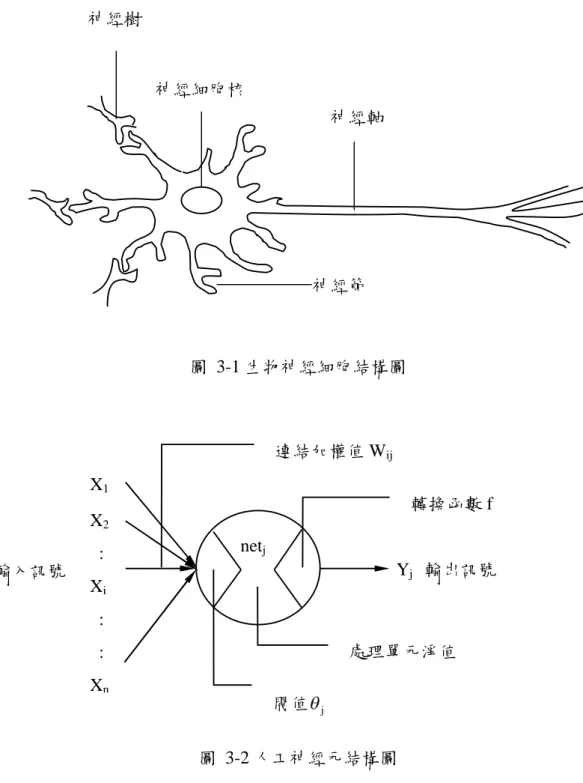
11個神經細胞,又稱為神經元(Neuron)所組成的,神經元是腦組織的基本單元,神經元 內部的運作機制如下:(如圖 3-1)。
1.神經核(Soma):它是神經細胞的中心體,其作用為將神經樹收集到的信號,在此作 加總後再作一次非線性轉換,再經由神經軸將信號傳送到其他的神經細胞中。
2.神經軸(Axon):連接在神經細胞核上,用來傳送由神經細胞核產生的信號至其他的 神經細胞中。
3.神經樹(Dendrites):神經樹分為兩種:輸入神經樹及輸出神經樹。在圖 3-1 中左邊 接到神經核的神經樹是用來接收其他神經細胞傳來的信號,稱為輸入神經樹。而在圖 3-1 右側接到神經軸的神經樹是用來傳送信號至其他神經細胞,稱為輸出神經樹。故 神經樹是神經細胞呈樹枝狀的輸出入機構。
4.神經節(Synapse):輸入神經樹和輸出神經樹相連接的點稱為神經節,如圖 3-1 中以 小圓圈框起來的接點即是。每個神經細胞大約有 1000 個神經節。神經節是神經網路 上的記憶體,它表示兩個神經細胞間的聯結強度,將此聯結強度以一個數值來表示,
並稱之為加權值(Weight)。一般而言,當神經網路在進行學習時,外界刺激神經細胞
所產生的電流會改變神經節上的加權值。在學習過程中,外界刺激所產生的電流反覆
在神經網路上流動,神經節上的加權值也反覆地改變,最後會慢慢的驅向穩定,此時
代表學習已經完成。若神經網路是處於認知或辨識的過程中,由外界刺激所產生的電
流,在進入神經網路後,會與儲存在神經節上的加權值做簡單之運算處理。當處理後
之信號為可辨識的信號時,則外界事物即是神經網路可認知或辨識的事物了。
圖 3-1 生物神經細胞結構圖
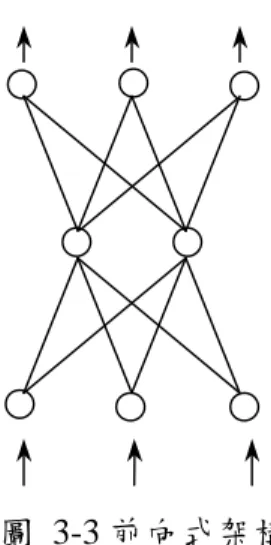
圖 3-2 人工神經元結構圖
類神經網路是由許多的人工神經細胞 (Artificial Neuron) 所組成,人工神經細胞 又稱類神經元、人工神經元或處理單元(Processing Element)。每個處理單元的輸出 以扇狀送出,成為其他處理單元的輸入。圖 3-2 表示一個人工神經元結構圖。處理單 元為類神經網路組成之基本單位。而輸出值與輸入值之間的關係可以下列方程式來表 示:
輸入訊號 Y
j輸出訊號
X
1X
2: X
i: : X
nnet
j處理單元淨值 閥值
j連結加權值 W
ij轉換函數 f 神經節
神經細胞核
神經軸
神經樹
) X
W ( f Y
i
j i ij
j
(3-15)
其中,
Y
j=模仿生物神經元模型的輸出訊號。
f =模仿生物神經元模型的轉換函數(Transfer Function),是一個用將從上一層處理單 元的輸入值以加權乘積和轉換成處理單元輸出值的數學公式。
W
ij=模仿生物神經元模型的神經節點強度,又稱連結加權值。
X
i=模仿生物神經元模型的輸入訊號。
j=模仿生物神經元模型的閥值。
介於處理單元間的訊號傳遞路徑稱為連結(Connection)。每一個連結上有一個加 權值 W
ij,它是用以表示第 i 處理單元對第 j 個處理單元之影響強度。
3.2.2 類神經網路分類
類神經網路一般依照學習策略與網路架構來分類:
學習策略可分為以下四類:
1.監督式學習網路(Supervised Learning Network):
從問題領域中取得訓練範例(有輸入變數值,也有輸出變數),並從中學習輸入 變數與輸出變數的內部對應規則,以應用於新的案例(只有輸入變數值,而須推論輸 出變數值的應用)。分類應用(如疾病診斷)與預測應用(如經濟預估)屬於此類。常見 之模式為:
(1)感知機網路(Perceptron)
(2)倒傳遞網路(Back-Propagation Network, BPN)
(3)機率神經網路(Probabilistic Neural Network, PNN)
(4)學習向量量化網路(Learning Vector Quantization, LVQ)
(5)反傳遞網路(Counter-Propagation Network, CPN)
2.無監督式學習網路(Unsupervised Learning Network):
從問題領域中取得訓練範例(只有輸入變數值),並從中學習範例的內在集群規 則,以應用於新的案例(有輸入變數值,而須推論它與那些訓練範例屬同一集群的應 用)。無監督式應用可作為監督式應用之前端處理。常見之模式為:
(1)自組織映射圖網路(Self-Organizing, SOM)
(2)自適應共振理論網路(Adaptive Resonance Theory Network, ART)
3.聯想式學習網路(Associate Learning Network):
從問題領域中取得訓練範例(狀態變數值),並從中學習範例的內在記憶規則,
以應用於新的案例(只有不完整的狀態變數值,而需推論其完整的狀態變數值的應 用)。資料的擷取應用與雜訊過濾應用皆屬之。常見之模式為:
(1)霍普菲爾網路(Hopfield Neural Network, HNN)
(2)雙向聯想記憶網路(Bi-direction Associative Memory, BAM) 4.最適化應用網路(Optimization Application Network):
對於一問題決定其設計變數值,使其在滿足設計限制條件的情況下,達到最佳 設計目標的應用。此類應用的網路架構大都與聯想式學習網路相似。常見之模式為:
(1)霍普菲爾-坦克網路(Hopfield-Tank Neural Network, HTN) (2)退火神經網路(Annealed Neural Network, ANN)
網路架構可分為以下兩類:
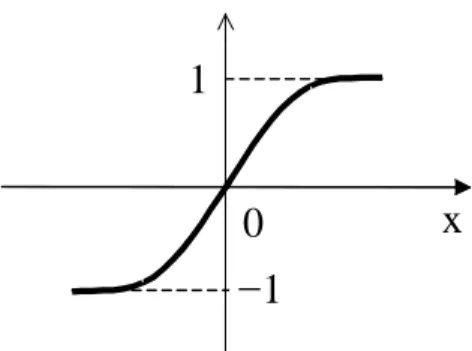
1.前向式架構(forward):
神經元分層排列,形成輸入層、隱藏層及輸出層。每一層只接受前一層的輸出
當作輸入者,稱為前向式架構,如圖 3-3 所示,倒傳遞網路(Back-Propagation Network,
圖 3-3 前向式架構
2.回饋式架構(Feedback):
從輸出層回饋到輸入層,或是層內各處理單元間有連結者,亦或神經元不分層 排列,只有一層,各神經元均可相互連結者稱回饋式網路,如圖 3-4 所示,Hopfield 神經網路(Hopfield Neural Network, HNN)與退火神經網路(Annealed Neural Network, ANN)即屬之。
圖 3-4 回饋式架構
3.2.3 類神經網路之特性
一般而言,類神經網路具備下列五種特性[29]:
1.平行處理(Parallel Processing)
類神經網路採用大量平行計算,經由許多不同的人工神經元來運算處理。
2.錯誤容忍度(Fault Tolerance)
類神經網路在運作時具有很高的錯誤容忍度,如果輸入資料混雜有少許的雜訊 干擾,仍然不會影響其運作的正確性。即使有部份人工神經元失效,整個類神經網 路仍能有效地運作。
3.聯想記憶(Associative Memory)
在回歸型類神經網路中,並沒有所謂的資料記憶區,但網路卻可記住需記憶的 訓練範例。若對其輸入訊號進行運算,整個網路藉由運算過程可聯想出相對應的輸 出值。此種記憶方式稱為聯想式記憶。而它的聯想過程稱為內容定址(Content Addressing),以別於目前電腦所採用的記憶體位址定址。
4.解決最佳化問題(Optimization)
所謂最佳化問題為在一問題領域中,希望找到一組設計變數值,使其在滿足設 計限制下,使整個設計目標達到最佳化狀態。
5.超大型積體電路實現(VLSI Implementation)
類神經網路的結構具有高度之互連性(Interconnection),且簡單並具規則性,易 以超大型積體電路來實現。
3.2.4 類神經網路之運作過程
類神經網路之運作過程係分為二個階段:
1.學習過程(Learning)
網路連結的加權值。
2.回想過程(Recalling)
在回想過程中,網路接受外來輸入,網路依回想演算法,以輸入資料決定網路 輸出資料的過程。
3.2.5 倒傳遞類神經網路
倒傳遞類神經網路模式是目前類神經網路學習模式中最具代表性,最普遍的模 式,其為一種具有學習能力的前向式網路。此種網路為 Rumelhart and Mcclelland 在 1985 年所提出的,此網路之原理是利用最陡坡降法(The Gradient Steepest Descent Method)的觀念,將誤差函數予以最小化[30]。其與感知機網路相比較,倒傳遞類神 經網路作了下列改進:
1.增加隱藏層,使得網路可表現輸入處理單元間的交互影響。
2.改用平滑可微分的轉換函數,使得網路可應用最陡坡降法導出修正網路加權值的 公式。倒傳遞類神經網路為屬於監督式學習網路,適合診斷、預測等應用,其網 路架構如圖 3-5 所式,包括:
Y1 Yk
X1 Xi
隱藏層 輸出層
輸入層
圖 3-5 倒傳遞神經網路架構
(1)輸入層-用以表現網路的輸入變數,其處理單元的數目依問題而定。使用線性轉換 函數,即 f(x)=x。
(2)隱藏層-用以表現輸入處於單元間的交互影響,為接受輸入層的訊號,對訊號進 行處理,處理單元的數目常以試驗方式決定其最佳數目。使用非線性轉換函數。
網路可以不只一層隱藏層,也可以沒有隱藏層
(3)輸出層-用以表現網路的輸出變數,其處理單元數目依問題而定。使用非線性轉換 函數,以表示輸出的結果。
倒傳遞類神經網路之網路架構,包含輸入層、隱藏層及輸出層,一般隱藏層可 以不只一層,其每一層皆由一些神經元所組成,但同一層中之神經元彼此不相連,
而不同層間的神經元則彼此相連,且信號的流向是由輸入層向輸出層單向傳遞。
轉換函數(Transfer Function)之目的是將作用函數輸出值以轉換成處理單元的輸 出,而一般常用之轉換函數包括下列三種:
1. 階梯函數(Step Function ),如圖 3-6 所示。
**
x x if 0
x x if ) 1
x (
f (3-16)
2. 雙彎曲函數(Sigmoid Function),如圖 3-7 所示。
e
x1 ) 1 x (
f
(3-17)
3. 雙曲線正切函數(Hyperbolic Tangent Function),如圖 3-8 所示。
x x
x x
e e
e ) e
x (
f
(3-18)
圖 3-6 階梯函數(Step Function)
圖 3-7 雙彎曲函數(Sigmoid Function)
圖 3-8 雙曲線正切函數(Hyperbolic Tangent Function)
而雙彎曲函數(Sigmoid Function)為倒傳遞類神經網路最常用之非線性轉換函 數,此種函數當自變數趨於正負無限大時,函數值趨於常數,其函數值域在[0,1] 之 間。
f(x)
1
0 x* x
1
0 x* x
0 x 1
0 x 1
1
3.2.5.1倒傳遞類神經網路之重要參數
倒傳遞網路之幾個重要的參數,包括隱藏層處理單元數目、隱藏層層數及學習 速率。
1.隱藏層處理單元數目
通常隱藏層處理單元之數目愈多,收斂愈慢,但可達到更小的誤差值,特別是訓 練範例誤差。但超過一定數目後,再增加則對降低測試範例誤差幾乎沒幫助,只會增 加執行時間。這可解釋成隱藏層處理單元之數目太少,不足以反映輸入變數間的交互 作用,因而造成較大的誤差。而數目越多,雖可達到更小的誤差值,然因網路較複雜,
導致收斂較慢。為平均品質與成本,以取適當之數目為宜。一般隱藏層處理單元數目 的選取原則如下:
(1)隱藏層單元數目=(輸入層單元數+輸出層單元數)/2 (3-19)
(2)隱藏層單元數目=(輸入層單元數×輸出層單元數)
1/2(3-20) 2.隱藏層層數
通常隱藏層之數目在一到二層時有最好的收斂性質,太多層或是太少層其收斂效 果均較差,這可解釋成沒有隱藏層不能反應此問題輸入單元間的交互作用,因而有較 大的誤差,而有一、二層已足以反應此問題的輸入單元間的交互作用,更多的隱藏層 反而使網路過度複雜,造成更多局部最小值,使得在修正網路加權值時易陷入一個誤 差函數的局部最小值,而無法收斂。一般問題可取一層隱藏層,較複雜的問題則取二 層隱藏層。
3.學習速率
通常較大的學習速率,有較大的網路加權值修正量,可較快逼近函數最小值。但
過大的學習速率將導致網路加權值修正過量,易造成數值振盪而難以達到收斂的目
的。因此學習速率之大小對學習有很大的影響,一般經驗取 0.1 到 1.0 間的值作為學
習速率,大都可以得到良好的收斂值性。
4.慣性因子
慣性項之加入可以改善倒傳遞類神經網路收斂中之振盪現象及加速收斂速度。
3.2.5.2倒傳遞類神經網路演算法
倒傳遞演算法是應用一個訓練範例的輸入值向量 X,與一目標輸出向量 T,修 正網路加權值 W,以達學習之目的,而在倒傳遞網路中,第 n 層第 j 個單元輸出值 為第 n-1 層單元輸出值的非線性函數
) net ( f
A
nj
nj(3-21)
其中,
) net
(
nj集成函數
i
j 1 n i ij
A
W (3-22)
f 轉換函數
因為監督式學習旨在降低網路輸出單元目標輸出值與推論輸出值之差距,故以能 量函數(或稱誤差函數) E 表示學習品質:
2j
j
j
A
2 T
E 1 (3-23)
其中:
j
T 輸出層目標輸出值
j
A 輸出層推論輸出值
網路的學習過程變成使上述誤差函數最小化的過程,通常以最陡坡降法使誤差函
數最小化,當輸入一個訓練範例,網路即小幅調整加權值之大小,學習過程中調整的
幅度和誤差函數對該加權值的敏感程度成正比,即與誤差函數對加權值的偏微分值大
小成正比:
ij
ij
W
W E
(3-24)
其中:
ij
W 介於第 n 1 層的第 i 個處理單元,與第 n 層的第 j 個處理單元間的連結加權值。
學習速率(Learning Rate),控制每次以最陡坡降法最小化誤差函數的步幅。
而 W
ijE
可用微積分學的連鎖律(Chain Rule)求得:
ij n j n
j
ij
W
net net
E W
E (3-25)
ij n j n
j n j n
j
ij
W
net net
A A
E W
E (3-26)
其中,
1 n i j
k
1 n k kj ij
ij n
j
W A A
W W
net
(3-27)
nj nn j j n
j n
j
f net f net
net net
A
(3-28)
處理
nA
jE
時可分成兩種情況:
1.第 n 層為最終層,即網路的輸出層,則
j nj
k
n 2 k n k
j n
j
A T A
2 T 1 A A
E
(3-29)
2.第
n 層不是最終層,是網路的隱藏層之一,可用連鎖律得
n j 1 n kk
1 n k n
j
A
net net
E A
E
(3-30)
將(3-22)式代入(3-26)式可得
jk i
k n i n ik
j n
j 1 n
k
W A W
A A
net
(3-31)
為簡明定義
n n k
net
kE
(3-32)
將(4-14)、(4-15)式代入(4-13)式得
k
jk 1 n n k
j
A W
E (3-33)
總結 W
ijE
可分成兩種情況:
1.
Wij處於輸出層與隱藏層之間,將(3-27)、(3-28)、(3-29)式代入(3-26)式,以及 (3-27)、(3-32)式代入(3-25)式後,結果相比較後可得
j j
nj nj
T Y f net
(3-34)
2.
Wij非處於輸出層與隱藏層之間,將(3-27)、(3-28)、(3-33)式代入(3-26)式,以及 (3-27)、(3-32)式代入(3-25)式後,結果相比較後可得
nj jkk 1 n k n
j
W f net
(3-35)
不論 W
ij是否處於輸出層與隱藏層之間,
W
ijE
均可寫成
1 n i n j ij
W A
E
(3-36)
其中:
ij 1 n
i
W
A
所連接之較低層的處理單元之輸出值
ij n
j
W
所連接之較上層的處理單元之差距量
將(3-36)式代入(3-24)式得
1 n i n j
ij
A
W
(3-37)
同理可證
n j
j
(3-38)
通常可將學習公式加上一個慣性項,即加上某比例的上次加權值的變量,以改 善收斂過程中振盪現象及加速收斂。所以可將(3-37)式及(3-38)式改寫成
1 m ij 1
n i n j m
ij
A W
W
(3-39)
1 m j n
j m
j
(3-40)
其中
m
W
ij =加權值 W
ij第 m 次改變量,其餘類推。
=慣性因子,控制慣性項之比例,0 <1。
此學習過程通常以一次一個訓練範例的方式進行,直到學習完成所有的訓練範 例,稱為一個學習循環(Learning Cycle),ㄧ個網路可以將訓練範例反覆學習數個學習 循環,直至達到收斂。
為了檢驗學習的成果,通常在學習前的範例收集階段,將範例隨機分成二部份,
一部份作為訓練範例,另ㄧ部份作為測試範例。在網路學習階段,可每個學習幾個學 習循環,即將測試範例載入網路,測試網路的誤差程度是否收歛。網路的誤差程度除 了可用前述之誤差函數作為基準外,另有二種方式:
1.誤差均方根(Root Mean Square Error, RMSE),如下式
N M
Y T RMSE
M
p N
j
p 2 j p j
(3-41) 其中
p
T
j第
P個範例的第 j 個輸出單元之目標輸出值。
p
Y
j第 P 個範例的第 j 個輸出單元之推論輸出值。
M