東吳大學理學院數學系 碩士論文
Department of Mathematices College of Science
Soochow University
Broken Stick Model 建模與應用:以糖尿病花費金額與年齡為例
Broken Stick Modeling and Application : A Case Study on The cost of Diabetes and Age
鄒錦豪 Chin-Hao Tsou
指導教授 Advisor:
林惠文
Hui-Wen Lin
致謝
完成了這篇論文真的是要感謝很多人,最感謝的當然 是我的指導教授 林惠文教授,在整個碩士學業生涯中,
教導了許多在分析統計上的知識以及應用,並且時時給予 我在撰寫這篇論文上的幫助,讓我能順利的完成這篇論文。
再來我也要感謝口試時的召集人 孫立憲教授以及口試委 員 葉麗娜教授在口試時給予我的指導,也因此讓這篇論 文更加詳細及完整。
接著我要感謝數學系的教授、秘書、同學們,感謝他 們一路上的相伴,多年的教導,能夠完成碩士學位真的是 托了大家很大的福。
最後我也要感謝我的家人以及朋友,因為有了你們的
支持與鼓勵,讓我能繼續前進,感謝你們,也感謝學習路
上幫助以及陪伴過我的人。
摘要
近年來,糖尿病的相關報導層出不窮,現代高糖高精緻食品的環境下,
罹患糖尿病的患者年紀不斷下降,治療的花費不斷升高。因此本文將對糖 尿病患者的花費金額與年齡進行探討,使用回歸分析檢測花費金額與年齡 兩者變數間的關係,同時在 P-P 圖模型中確保了花費與年齡為常態分布。
接著使用決策樹分類模型對花費與年齡進行分類,藉由設定的分類規則所 建構出的樹狀圖,觀察出年紀在 64.5 歲為花費金額遞增遞減的分界點,小 於 65 時花費隨年紀遞增上升,大於 64.5 歲後成遞減下降。最後利用分段 模型(Broken-Stick Model)以 64.5 歲為分界點,如同前述步驟所得到的結 論,64.5 歲前成遞增,64.5 歲後縱使顯著程度不如預期,但也同樣為遞減 下降。也希望透過本文的研究過程及結論,以明確的花費數據與年齡對比,
來為社會做到一個提醒以及警惕的作用。
關鍵字 : 糖尿病、花費、年齡、迴歸分析、決策樹、分段模型
Abstract
In recent years,there have been many reports of diabetes. Due to high- sugar and high-delicacy foods,the age of diabetic is declining, implying that the cost of treatment is rising. The study will apply regression to detect the relationship between cost and age of diabetic. In the meantim e,in the P-P plot ensures the normal distribution of data. The decision tree model can be used to classify the cost and age. And to set up the tree map by the classification rules. Observe that the age 65 is the boundary point between the trend of diabetes inage. Hence, by the
classification results of 65-year-old into the Broken-Stick Model as the boundary point. We conclude that the increase trend is shown before the age 65.But after the age 65, trend of diabetes decreses inage.
Finally,hope that through the research process and the corresponding conclusion, we can make a helpful reminder for the community.
目錄
誌謝 --- Ⅰ 摘要 --- Ⅱ Abstract --- Ⅲ 目錄 --- Ⅳ 表目錄 --- Ⅵ 圖目錄 --- Ⅶ
第一章 前言 --- 1
1.1 研究背景與動機 --- 1
1.2 資料說明 --- 2
1.3 研究方法 --- 2
1.4 研究內容及流程圖 --- 4
第二章 文獻回顧 --- 6
糖尿病 --- 7
線性回歸 --- 9
決策樹 --- 10
分段回歸模型 --- 11
第三章 資料分析 --- 12
第一節 資料探勘、分析 --- 12
第二節 Cook's distance --- 15
第三節 Durbin-watson Test --- 16
第四節 建立決策樹 --- 18
3.4.1 決策樹以及樹狀圖 --- 18
3.4.2 修剪決策樹 --- 21
第五節 Broken Stick Regression --- 25
第四章 結論與未來期許 --- 28
4.1 結論 --- 28
4.2 未來期許 --- 29
參考文獻 --- 30
表目錄
表 2.1.1 衛福部 國民 105 年醫療保健疾病支出 --- 6 表 2.1.1 衛福部 民國 104 年國民醫療保健支出 --- 6 表 2.1.2 行政院衛生署「國民醫療保健支出 2011」 100 年平均每人每年個人醫 療費用 --- 7 表 3.1.1 金額取 log 與年紀間可信賴度 --- 14 表 3.3.1 Durbin-watson Test d 值 --- 15
圖目錄
圖 1.1 衛福部 105 年 十大死因 --- 1
圖 1.2 本文操作流程圖 --- 4
圖 3.1.1 原始金額與年紀之線性 P-P 圖 --- 13
圖 3.1.2 log(金額)與年紀之線性 P-P 圖 --- 14
圖 3.2.1 Cook's distance 散步圖 --- 15
圖 3.3.1 金額取 log 與年齡分布、線性、曲線模型 --- 17
圖 3.4.1 決策樹分類結果 1.1 --- 19
圖 3.4.2 決策樹分類結果 1.2 --- 20
圖 3.4.3 決策樹分類結果 2.1 --- 22
圖 3.4.4 決策樹分類結果 2.2 --- 23
圖 3.4.5 決策樹分類結果 3 --- 23
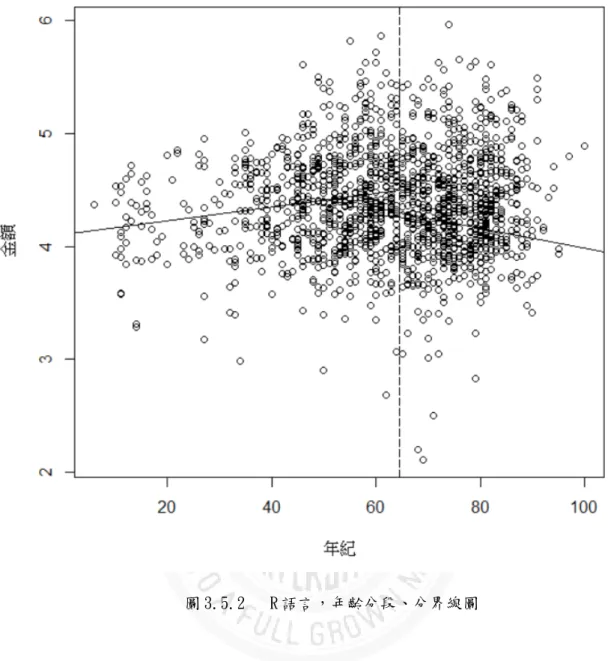
圖 3.5.1 R 語言,花費金額取 log 與年齡分布圖 --- 25
圖 3.5.2 R 語言,年齡分段、分界線圖 --- 26
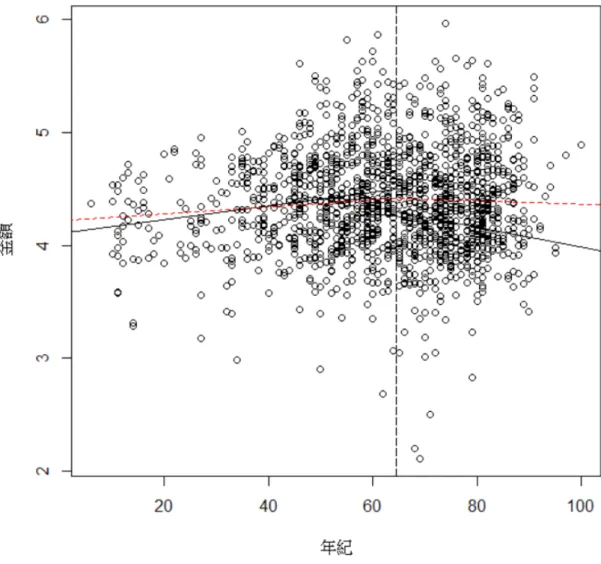
圖 3.5.3 R 語言中,Βι(x)與 Βγ(x)以及合成的 gb 函數圖 --- 27
第一章 前言
1.1 研究背景與動機
糖尿病病患每年以不斷增加的速度攀升,據統計,在 2014 年全世 界糖尿病患者已高達 4.2 億人,聯合國還因此將每年的 11 月 14 日訂為
「聯合國糖尿病日」。
近年來,糖尿病相關報導層出不窮,指出糖尿病患者罹患年紀持續下 降、糖尿病排名十大死因之一、糖尿病感染併發、糖尿病花費等,甚至身 邊親友也有了因糖尿病而差點失明亦或是每天都需要施打胰島素的案例。
圖 1.1 衛福部 民國 103-105 年 十大死因
單位:人,每十萬人口 順位
死亡原因
死亡數 死亡數 死亡數
所有死亡原因 162,886 163,574 172418
1 惡性腫瘤 46,093 46,829 47760
2 心臟疾病(高血壓性疾病除外) 19,399 19,202 20812 3 腦血管疾病 11,733 11,169 12212
4 肺炎 10,353 10,761 11846
5 糖尿病 9,846 9,530 9960
6 事故傷害 7,118 7,033 7206
7 慢性下呼吸道疾病 6,428 6,383 6787
8 高血壓性疾病 5,459 5,536 5881
9 腎炎、腎病症候群及腎病變 4,962 4,762 5226 10 慢性肝病及肝硬化 4,868 4,688 4738
103年 104年 105年
糖尿病患者需要長期施打胰島素來控制病情,或是施打、口服其他控 制血糖的藥物,造成財務上的負擔。更別說那些因糖尿病而衍生出來的併 發症,所需的治療費,甚至比原先糖尿病還高出數倍甚至無法估計,因此 有人說預防糖尿病的併發症就是在節省醫療花費。由於糖尿病病發初期並 無特別明顯的徵兆,因此在台灣,年齡在 45 歲以上民眾,建議每 3 年進行 一次篩檢,60 歲以上民眾,建議每 1 年進行一次篩檢。
因此本文將對所擁有的糖尿病住院病歷去做分析研究,探討文中提供 的資料,以年紀為主軸,花費金額為輔,再透過文中的分析過程和結果,
了解彼此之間的關聯深淺。
1.2 資料說明
本文所使用的資料為糖尿病住院患者金額花費以及年齡的次級資料,
其中並不包含患者身份及隱私,為經過轉手之後的資料,且只用於本文套 討分析使用,絕不用於本文以外或其他不正當用途。特此說明。
1.3 研究方法
本文所獲得的次級資料,給及了糖尿病患者的住院花費、支出,以及 年齡變數,在此將採用花費與年齡兩者變數在各個層級的分類中,透過線 性回歸、決策樹等分類模型,觀看所得到的結論是否有符合本文所期望的。
若結果不符合預期,則反向檢測在資料本身上的一些極點或特殊個案,若 排除這些極點和特殊個案,就能得到本文所期望的結論。
(一)、 迴歸分析
在統計中,迴歸分析是很常被使用來進行分析的其中一種使用方法,
而本文在這邊,將使用線性回歸,對單一個 X(自變數)以及 Y(因變數)進行 線性分析,並且在進行線性回歸之前,先檢測檔案本身是否符合常態分布 (normal distribution )的要求。因此本文在一開始將使用 P-P 圖來檢驗。
而在 P-P 圖觀測中,若觀測點越接近斜對角的直線的話,即代表這個觀測 值越接近常態分布,接著再觀察資料曲線的分布,判斷其意義。
(二)、 決策樹
接著本文將使用決策樹來對資料進行分類。決策樹是一種預測分類的 模型,其模型呈現上像是一顆樹的形狀,由資料本身當作起點(根)開始,
接者遇到決策節點(分枝),分割出去的即是不同種的可能(≧2),分割出去 的變數還會一直遇到機會節點,並再往外延伸,直到變數已經符合決策樹 規則而得到結果,已經不能再分割或是說分割出去的可能子集都是屬於同 一種類別,那分類就完成了,也稱為終結點。,是一種簡單但被廣泛使用 的分類工具。
(三)、 Broken Stick Model
Broken-Stick Model 起初是生物統計學家為了對植物豐富度類別進行 模型建構,因生態分布並不一定呈連續線性將線性,因此而得出的分段模 型。本文中將迴歸分析的結論與決策樹的結論相結合,比對兩者相關性並 給出花費與年齡的曲線軸以及分段的界線為何,再使用分段模型將分段的 結果表現出來。
1.4 研究內容及流程圖
在接下來的第二章中,本文將先進行文獻探討,對糖尿病以及本文 所使用到的研究方法進行解釋,並且引用一些文獻作為佐證及期望值的假 設,之後進入到資料處理並且進行分析的階段,在分析階段本文將對資料 進行以下幾大流程,並在最後一個流程中,建立本文藉由此筆資料所獲得 的糖尿病金額花費與年齡間的關係作為結論,其流程圖如下:
圖 1.2 本文操作流程圖
資料探勘、篩選
資料分析
Durbin-watson Test
建立決策樹
Broken Stick Regression Model
建立結論 Cook's Distance
第一階段的【資料探勘、篩選】將藉由探勘以及篩選,進行對資料內 容初步的了解以及簡化,選取本文將視為重要引響因子的變數,以及本文 主要探討關係的主軸。而第二階段的【初步分析、判斷結論】是將年紀與 其餘變數進行分析回歸,觀看各項變數值所得到的初步結論,從而給出第 一次的假設。在第三階段的【Cook's Distance】當中,將會使用 Cook's Distance 檢測來觀察資料當中是否存在幾筆特殊的分量會對迴歸分析以及 斜率造成影響。而在第四階段的【Durbin-watson Test】杜賓-瓦特森檢測
中,進行 d 值得檢定,判斷出殘差項間的獨立性是否存在以及相關性等。
第五階段中,【決策樹】的建構,運用另一種分類方式,相比較兩種方法 的結果為何,是否有共通的關係。第六階段裡【分段模型】將匯聚兩種方 法的共通點,建立一個可以表示結論的模型,並在最後的第六段【建立結 論】這步驟中,如同前文所講的,給出糖尿病金額花費與年齡的關係作為 結論,並說明一下本文對未來的期望。
第二章 文獻回顧
根據衛福部的統計指出,國民醫療健保支出隨著每年花費逐漸地增加,
下表為民國 105 年醫療健保疾病排名。
表 2.1.1 衛福部 國民醫療保健疾病排名
全民健康保險醫療 保健支出(單位:新 台幣百萬元)
101 年
102 年 103 年 104 年
總計 485,954 507,580 523,798 543,569 醫療給付 480,444 502,127 518,144 538,076 西醫 409,931 425,552 438,100 456,559
表 2.1.2 衛福部 民國 104 年國民醫療保健支出表
排名 疾病代碼列表 全國就醫人數
( 千人 )
醫療費用 ( 平均點 )
醫療費用 ( 占率 )
1 腎衰竭 320 151,107 7.31 %
2 口腔、唾液腺
和頜 ( 顎 ) 骨疾病 11,135 3,712 6.25 %
3 糖尿病 1,456 18,145 3.99 %
4 急性上呼吸道感染 ( 症 ) 14,538 1,799 3.95 %
5 高血壓性疾病 2,509 8,860 3.36 %
由統計表可看出,醫療花費隨著時間逐年上升。而根據行政院衛生署
「國民醫療健保支出 2011」
總計 0~9 歲 10~19 歲
20~29 歲
30~39 歲
40~49 歲
50~59 歲
60~69 歲
70~79 歲
80 歲 以上 個人醫療
費用(百萬 元)
795,313 43,808 39,121 50,300 74,527 99,006 148,21 5
135,53 8
121,30 7
83,491
100 年中人 口數(萬
人)
2319 209 308 343 384 376 338 183 116 62
平均每人 每年個人 醫療費用
34,290 20,922 12,704 14,673 19,387 26,348 43,838 73,984 104,79 9
134,69 3
表 2.1.3 行政院衛生署「國民醫療保健支出 2011」 100 年平均每人每年個人 醫療費用
根據上述表所示,個人醫療費用直到 60 歲前隨年紀逐年增加,過了 60 歲後因人口減少,總花費開始下降,而在平均每人每年個人醫療費用,
除了 0~9 歲高於前幾階層之外,其餘 10 歲之後則是依樣隨年紀增逐年增加。
在衛生署這篇統計中也有提到幾點:
一、 100 年男女性均於 50-79 歲花費較高的醫療費用。
二、 100 年個人醫療費用較 94 年增加 25.7%,其中男性增加 23.8%,女性增加 27.5%。
三、 100 年男性個人醫療費用分別以 50-59 歲及 70-79 歲居首;女性則均以 50-59 歲居首。
糖尿病 (DM)
糖尿病(拉丁語:diabetes mellitus,縮寫為 DMs,簡稱 diabetes)
據資料指出,糖尿病為一種代謝異常的慢性疾病,無法根治,但能靠藥物 或飲食來控管甚至是預防的疾病。糖尿病是指血糖長期高於標準值,一般 來說正常人在空腹的時候血糖值是<110mg/dl,而在進食後的兩個小時內 會稍微上升,但血糖值依舊是<140mg/dl,而糖尿病患者,在空腹的狀態 血糖值就已經≧126mg/dl,而進食後的兩個小時內甚至上升到
≧200mg/dl。而一般來說,糖尿病的成因主要有兩種:
一.胰臟無法產生足夠的胰島素
二.細胞對胰島素反應不敏感,使得胰島素無法發揮功能
而在持續高血糖的狀態下,容易產生:「多食、多飲、多尿以及體重 下降」三多一少的症狀,糖尿病患者還會有其餘一些症狀,例如:視力衰 退、容易疲勞、皮膚發炎、傷口不易癒合等症狀產生。除此之外,糖尿病 也是一個影響身體器官系統、血管、神經最多的疾病,尤其在因糖尿病所 造成的其他併發症,如:引起失明、視網膜病變、心血管疾病、中風、腎 臟衰竭、神經病變等多種併發症甚至死亡。
糖尿病主要分為四種: 一.第一型糖尿病 二.第二型糖尿病 三.妊娠 期糖尿病 四.其他類型糖尿病
第一型糖尿病 : 身體無法產生足夠的胰島素或是根本無法產生
先天性疾病,因此大多數發病期為青少年時期之前),因無法產生足夠的胰 島素,因此患者必須長期持續施打胰島素。
第二型糖尿病 : 胰島素功能異常或細胞對胰島素反應不構靈敏,
而胰臟本身卻並沒有甚麼問題,又被稱為非胰島素糖尿病或成人型糖尿病,
是由於大量進食精緻飲食及高反脂肪的食物影起的,而主要的症狀有「多 食、多飲、多尿」。
其中,第二型糖尿病佔糖尿病患者中的九成,剩餘的一成為第一型 糖尿病以及妊娠期糖尿病。
線性回歸 (Linear regression)
迴歸分析為統計學上對資料、數據的一種分析方法,用來檢測數據間 是否有相互關聯性、方向、以及彼此間的強弱,以及探究一個或是個自變 數(X)和一個因變數(Y)之間的關係以及構圖,並且依此結論來解釋或者預 測因變數(Y)的期望值。
線性回歸分析的模型是根據一個或多個自變數所組成的回歸模型,其線 性回歸模型表示如下:
Yι=β0+β1X1+β2X2+...+βιXι+ει, ι=1,...,n
在此模型中,Yι為因變數,Xι為自變數,βι為回歸模型中的係數, ει則 是誤差值。而本文中所使用的則是單變量的線性回歸模型,自變數和因變數各為 單一變數,分別為年齡和金額花費,並將兩者帶入下列模型:
Y=α+β X+ε
決策樹 (Decision tree)
決策(Decision making),如字面所意,即為做出決定或做出選擇,既 然要做出決定,那必定會有一開始的問題、結尾的目標以及過程中的篩選。
而決策樹(Decision tree)就是一個藉由像樹狀圖的決策圖,以及在形成這 種樹狀圖的過程中,各個資料間的。是一種有效且高度受到運用的分類工 具。
決策樹的演算法有好幾種,像由Ross Quinlan 提出的 ID3(Iterative Dichotomiser 3 )演算法,以及後來提出類似於擴張的C4.5 都是其中一 種演算法。
CHAID 是由 Sonquist 以及 Morgan 兩位學者在 1960 年初提出,經過多 位學者的修改討論,最後在 1980 年由 Kass 正式命名,CHAID 演算法是利用 卡方分析(Chi-Square Test) ,利用輸入變數找出一種分類方法,將資料
分成兩個或兩個以上不同的子節點,並且持續的進行分割、篩選,直到最 後的終結點無法滿足顯著水準而停止。
CART 是由 Leo Breimany 在 1984 年提出,是一種二分遞迴的回歸分類
法,所以在每個節點當中,都會在產生兩個子節點,這是相較於其他演算 法的不同之處,此外,在 CART 演算法中,自變數以及因變數本身的類型也 不受限制,因此在分析的使用上較為方便,而 CART 會進行分類到所有新的 節點都是終結點時才會停止。
分段模型回歸
broken stick mode 又稱折枝模型,是由 MacArthur(1957,1960)所提 出的,起初 MacArthur 是為了針對生態學的分布跡象所提出的幾種假設,
為得是在描述物種的豐富程度,而其中一種就成為了分段模型。
broken stick regression 是利用 R 語言將兩筆分段的資料進行合成 並且加以分析回歸。其原始公式為:
上述公式中 x 值為資料中的變數(自變數),而公式中的 c 值,即是資 料中所選擇切段結合的位置。
接著再將公式中的兩個函數Βι(x)與Βγ(x)進行合並以及給予參數 ε,如下
本文即是把年齡設入上述公式內的自變數 x 當中,c 值為本文在第三 章中第三節、第四節內分析所得到的分界年齡 64.5 歲,Βι 與Βγ 分別 為小於 64.5 歲和大於 64.5 歲的函數,並進行合成。
第三章 資料分析
本章節將詳述本篇研究的過程以及遇到的問題。從第一節的觀察資 料、進行初步分析,接著第二節觀察極端值、刪除極端值、再次進行分析,
第三節將去除極端值後的資料運用決策樹進行分類,第四節將上述的兩種 結論進行合併,並運用 R 語言的繪圖功能,建立出模型。
第一節 資料探勘、分析
在本文所獲得的糖尿病患者住院次級資料,檔案以 SPSS 程式輸出,其 中資料內容以英文以及數字編碼組成,包含一些醫令代表和類別,因此,
為了方便進行後續的分析方法和建模,本文將進行資料前處理的作業,進 行篩選以及轉換的動作。
在前處理的步驟中,首先要了解到的是本文分析研究中主要探討的兩 個變數為"花費金額"以及"年紀",因此透過醫令代碼的說明進行轉換,運 用 SPSS 程式語言,分別給出可以代表花費金額以及年紀兩者的新變數,轉 換完成之後,透過排序發現到,資料中有著重複多筆的狀況,為此需要做 進一步的篩選,選取同位患者在資料內的單筆資料,刪除額外重複的多筆 以及除了花費金額和年紀以外的變數,最後將呈現每筆資料皆為不同患者 且僅有花費金額以及年紀這兩項變數的資料,同時資料前處理也就告一個 段落。
前置作業完成後,將進入本節主要內容,對檔案進行分析。本文篩選 出本研究的主要目標,花費金額以及年紀,對這個因變數和自變數進行分 析。
本文使用 SPSS 程式將金額放入因變數、年紀放入自變數進行線性回歸,
觀看花費金額以及年紀兩者的 P-P 圖,以觀測兩者間是否呈現線性分布。
圖 3.1.1 原始金額與年紀之線性 P-P 圖
觀察出原始檔案中的金額與年紀並沒有如本文預期的一樣在 P-P 圖中 呈現線性分布。因此本文在此步驟中將花費金額取 log 之後,使用取 log 後的花費金額與年齡,兩者再次進行 P-P 圖的建構。
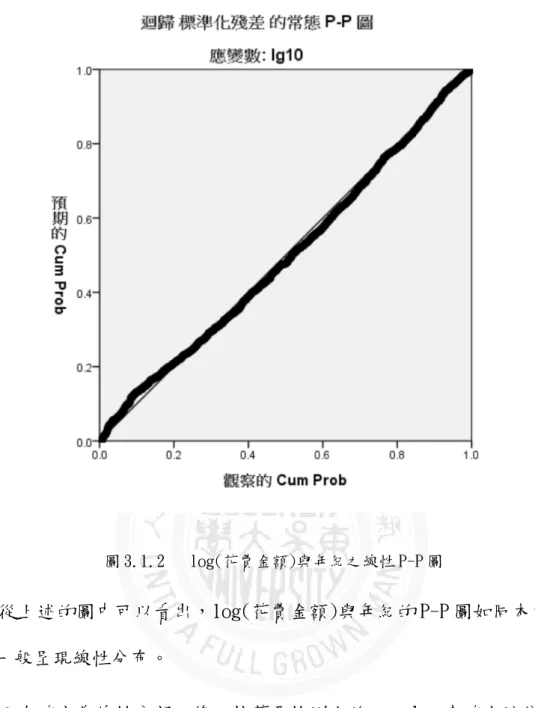
圖 3.1.2 log(花費金額)與年紀之線性 P-P 圖
從上述的圖中可以看出,log(花費金額)與年紀的 P-P 圖如同本文所預 期的一般呈現線性分布。
而在確定為線性分部之後,接著要檢測它的 p-value 來確定這份資料 的可信賴度。
係數a
非標準化係數 標準化係數 顯著性
年齡 .001 1.484 .138
a.應變數:金額取 log
表 3.1.1 花費金額取 log 與年紀間可信賴度
第二節 Cook's distance
在這小節中,本文將使用 Cook's distance 檢測來對資料進行檢定,
觀察 Cook's 所產生的距離值來判斷資料的影響程度。
Cook's distance
Cook's distance 檢測距離主要是用來檢定資料中,各分量之間,觀 察應變數(Y)是否有存在一些距離群體過於遙遠的特殊值,進而影響到迴歸 係數變化影響過大。若 Cook's distance 檢測所產生的檢測值有過大的現 象,本文將進一步討論是否在資料中刪除這些資料。
圖 3.2.1 Cook's distance 散步圖
由上述的散步圖可以看出,Cook's distance 檢測所檢定出來的距離 值,有九成以上聚集在 0.05 至 0.00 間的範圍,而最大值為 0.014 左右還 不到 0.015 的範圍,遠小於 1.0,代表各分量間以及對整體分布所產生的斜 率影響程度非常小,所以這也說明了,資料本身並不存在會特別影響到迴 歸分析的分量。
第三節 Durbin-watson Test
Durbin-watson Test 杜賓-瓦特森檢測用於檢定分析回歸的項數是否 存在相關性以及獨立性。
模型 Durbin-watson .893
應變數:花費金額
預測值:年齡
表 3.3.1 Durbin-watson Test d 值
藉由 Durbin-watson 檢測所產生的數值可以了解到,d 值為 0.893,介 在 (0,2) 之間,具有獨立性,並且呈現正相關。
接下來本文將觀測花費金額取 log 後與年齡間的分布圖,並繪出兩者 間的線性模型以及其曲線模型,並藉由模型中所展現的樣貌來判斷兩者間 的分布呈現何種含意。
如下圖:
圖 3.3.1 刪除特殊值-金額取log與年齡分布、線性、曲線模型
由上圖所呈現的,實現的部分為此資料分析中花費金額取 log 與年齡 的線性線,而斜線部分就是此資料分析中的曲線模型,而在曲線模型中,
可以清楚看出它呈現一個下凹的形狀。接著觀測下凹處,發現端點切在年 紀為 65 處。年齡小於 65 的時候,花費金額與年齡的曲線模型為正數上升。
而年齡大於 65 的時候,花費金額與年齡的曲線模型為負數向下。
代表在 65 歲前,糖尿病住院的患者,所需的花費金額會跟著病患的年 紀呈正比的增加,而在過了 65 歲之後的患者,所需的花費金額則會跟著年 紀呈反比的遞減。
第三節 建立決策樹
3.4.1 決策數以及樹狀圖
本文在使用 SPSS 對資料進行完分析,得出花費金額與年齡有常態分布 以及彼此間的顯著關係,並且進一步找出年齡在 65 時為一個分界點,小於 65 時花費金額與年齡成正比,大於 65 時花費金額與年齡成反比,因此接下 來,本文將使用決策數模型來對同一筆資料進行分類,觀測其給出的圖形 和註解是否與先前使用線性回歸時得到的結論相符合。
在建立此模型上,本文使用 CRT 演算法進行決策樹的建構,金額花費 一樣放置在因變數,年齡放置在自變數。
在樹狀圖方面,第一次本文先採用程式原先設定好的規則來觀看,結 構方向由上往下採遞減方式,並附加建立統計資料以及節點定義,最下層 節點為終結點,深度也就是本文分類的層級最高定為 5 層,最小觀察數也 就是本文分類出來的各數上層要大於 20,子節點要大於 5。
以上就是本文所使用決策數中 CRT 分類層級最初的規則。而得到的樹 狀圖如下:
圖 3.4.1 決策樹分類結果 1.1
圖 3.4.2 決策樹分類結果 1.2
使用 CRT 演算法本身的法則去進行分類時,發現產生了過多的分枝節 點,使得決策樹的樹狀圖分枝過於繁雜,觀察數也很不平均,因此本文將 進行修剪樹枝的工作。
3.4.2 修剪決策樹
由於一開始給定的分類規則中所產生出來決策樹樹狀圖過於繁雜,因 此本文將對此決策樹進行剪枝的動作。對上述原先第一次進行分類的規則 進行調整,給定的變數同樣為花費金額不做改變,結構以及延伸的方向也 不做改變,至於在分類產生的準則方面,本文將成長限制內的分類層級最 高層調整為給定
3
層,以及在最小觀測值的個數方面調高上限,上層節點要大於
100
,下層節點要大於35
,節點必須同時滿足上述兩者條件下才得 以產生下一步的子節點,否則將視為終結點並同時結束分類。由於在第一 次的分類準則中,在給定的最小觀測值方面,設定的上層節點數以及下層 節點數的準則值過低,造成第一次決策樹樹狀圖過於容易產生子節點,才 會形成圖中過多的分枝,而在進行修改準則的此步驟將大大縮減原先分類 準則中所產生的過中繁雜分枝,給出較為主要的分類結果。依此樹狀圖成長規則來對資料做進行決策樹分類前的修剪動作,以達 到限制樹枝的成長和避免如前一次結果中的分類過於細小。並且一樣選取 自變數統計資料以及節點敘述。
而本文再次分類所得到的樹狀圖如下
:
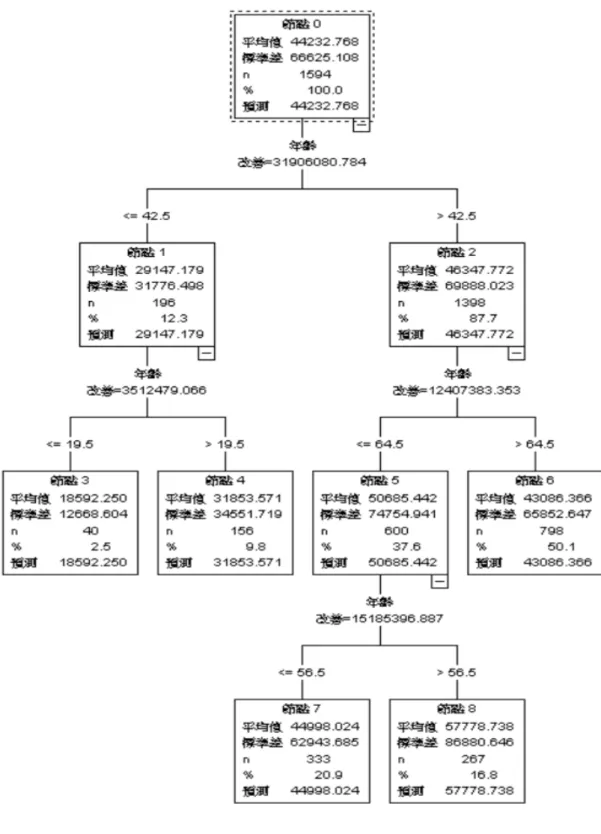
圖 3.4.3 決策樹分類結果 2.1
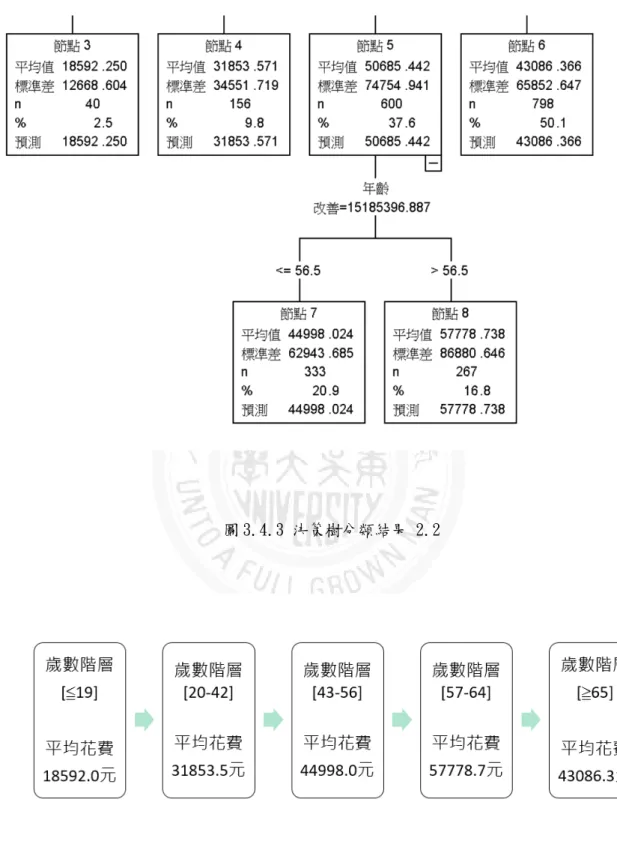
圖 3.4.3 決策樹分類結果 2.2
圖 3.4.5 決策樹分類結果 3
由以上這兩次的分類結果可以看出,第二次的樹狀圖明顯較第一次來 的纖細,這就是本文進行修剪之後的結果。
從第二次的分類樹狀圖中可以看出,第一次的分節點為年齡 42.5 歲,
根據節點敘述來看,小於 42.5 歲的平均花費大約為兩萬九千元,而大於 42.5 歲的平均花費大約為四萬六千,兩者間的差距將近要一倍,而此時的 子節點中,各數滿足分類準則的要求,因此又產生了下一層的子節點,直 到第四層中的子節點無法再滿足分類準則的要求,視為終結點,並停止分 類。
由每層分類的最終節點可以看出,64.5 歲以前平均花費與年齡是成正 比的增加,而 64.5 歲之後的平均花費與年齡成反比遞減,值得一提的是 19.5 歲之後以及大於 64.5 歲之後沒有再往下的子節點,這是因為本文第二 次設定的條件,子節點最小觀測值要大於 35,代表年齡大於 64.5 歲的狀態 下,再進行分類的個數 n 會小於 25,因此大於 64.5 歲就是一個終結點而不 再繼續往下分類。這剛好呼應了本文前半段第三節中,使用線性回歸進行 分析時,得出的結論在 65 歲前後同樣的花費金額與年齡為遞增以及遞減的 現象,也再次加深了本次研究的結論,花費金額與年齡間的關聯性以及遞 增遞減的分界線。而兩者結論間的微小差異,可能是兩種模型內彼此的參 數有些微差別,或是一些係數項的不同,因此本文可以把這兩個結論的年 紀取個約略值,在大於 65 歲左右之後的年紀,糖尿病住院病患者的花費金 額會隨著年紀呈現遞減。
第五節 Broken Stick Regression
本文在這節將採用決策樹中給定的
64.5
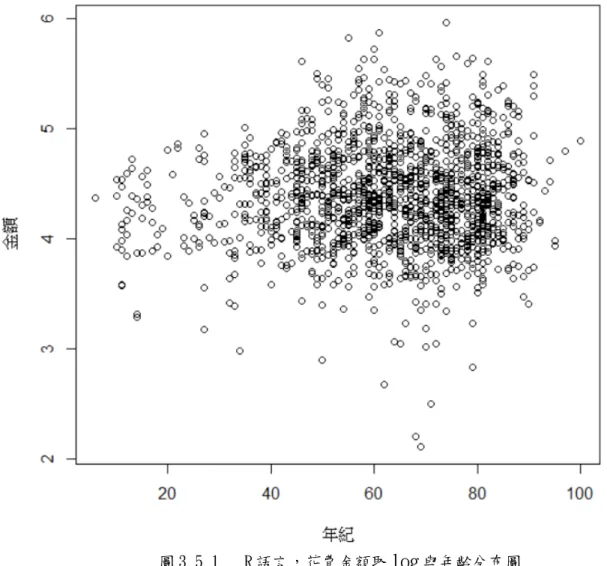
歲這個分界點帶入到 Broken Stick Regression 中的變數 c,進行回歸並劃出 Broken model 。首先我們將資料由 SPSS 轉成 DTA 檔案類型,並匯入到 R 語言中,接者 選出花費金額取 log 為變數 y,年齡為變數 x,並將分布圖劃出。
圖 3.5.1 R 語言,花費金額取log與年齡分布圖
接著將 g1,也就是年齡小於 64.5 歲的變數,以及 g2,年齡大於 64.5 的變數線性分段標出,再將 64.5 歲這條分界線標出,就會得到下列的圖示:
圖 3.5.2 R 語言,年齡分段、分界線圖
畫好上述的分段圖以及分界線後,可以明確地看出,花費金額在年齡 64.5 歲前後果真呈現了一個分段的樣貌,接下來就是將我們的變數帶入公 式中的Βι(x)與Βγ(x)。函數Βι(x)為年齡變數 x 小於本文所選取的分 界線 c 值 64.5,而Βγ(x)即是年齡變數 x 大所選取的分界線 c 值 64.5。
因此函數Βι(x)與Βγ(x)範圍值分別為:「64.5-x」和「x-64.5」,
再將Βι(x)與Βγ(x)兩個函數合成到函數 gb 中,年齡變數 x 的總範圍給 定為[0,100],並將回歸線標出,如下:
圖 3.5.3 R 語言中,Βι(x)與 Βγ(x)以及合成的 gb 函數圖
從上述的圖中可以看出,64.5 歲的確是一個分段的界線,而也如同第 三節、第四節所得到的結論,64.5 歲以前金額花費隨著年紀成正項遞增成 長,64.5 歲以後金額花費則隨著年紀成負向遞減下降,而本文主題所求的 Broken Stick Model 建模也宣告完成。
第四章 結論與未來期許
經過第三章的眾多步驟之後,第五章將以上所獲得的初步結論作結合 以及統整,並給出本文最終的末章以及未來的期許。
4.1 結論
第三章的第一節,本文分析出了每位病患可能都有不一樣的習性與思 維的不同,同樣是糖尿病的住院患者,多數人都依照著醫生或是醫院的指 示,遵循著醫師的處方以及安排,花著一定的金額在面對糖尿病這種慢性 疾病上,但也有患者可能因為過度的緊張、擔憂,而願意花大筆的費用在 診療、或是眾多的檢測身上,造成整次住院的花費金額遽升,產生了資料 中的特殊值,也影響了本文研究分析的準確度。
也可以看出金額花費確實與年紀有著一定的關聯,也呈現常態分布,
並且了解到隨著年齡的上升,花費的金額也會隨之提升,這個現象將持續 到 64.5 歲時會是一個分界線,往後所花費的金額會隨著年紀增加,反而漸 緩的遞減下來,或許這是因為年紀越高,所擁有的資料數會相對減少,而 造成分析不夠完整,但相信也會與本文的分析結論相去不遠。
同時也藉由本文分析的過程了解到,縱使是 20 歲以下的糖尿病患者,
在住院治療的花費上也高達將近貳萬元,而隨著年紀越高,平均每成長一 歲就會增加伍仟至陸千元的花費。
4.2 未來期許
在現今這種高糖高精緻飲食社會下,糖尿病患者年齡不斷下降,人數 不斷攀升,高額花費、生活品質降低、親友的負擔,這些問題也不斷不斷 的出現在身活周遭以及新聞報導上。
而透過本文中三種不同的分析、分類模型的結果,都顯現出了金額花 費與年齡確確實實的有著一定的關係,而且也朝著與年齡正比的遞增,縱 使可能到達一定歲數後(如本文中所找出的 64.5 歲左右),花費會呈現遞減 狀態,但在到達此歲數時已是高額的花費,既使成反比遞減,也已然是一 大筆開銷,也藉由第三章第四節樹狀圖,分類終結點的敘述看出每個階層 的平均花費,最年輕的終結點 20 歲以下,平均花費也都將近達貳萬元以上,
也因此希望透過這篇論文能督促現代這種罹患糖尿病高風險環境下的人們,
應該要時時刻刻醒自己飲食、身體狀況要隨時注意,這也是本文所期望的。
參考文獻
[1] 李語嫣(2010). 運用資料探勘技術由健康檢查與生活習慣資料建立疾病預測
模型—以糖尿病為例. 國立成功大學醫學資訊研究所碩士論文, 1-85.
[2] 江明諺(2016). 大數據下的糖尿病醫療管理–以 D 診所為例. 國立中山大學企
業管理學系碩士論文, 1-70.
[3] 楊巧暄(2015). 運用資料探勘與模糊邏輯技術建立糖尿病診斷系統. 義守大學
資訊管理所碩士論文.
[4] 鄭淵仲(2002). 模糊決策樹於資料探勘的運用-以台股為例. 國立中山大學資
訊管理學系研究所碩士論文.
[5] 陳銘樹; 王建智; 王麗雁. 應用決策樹演算法以探究高科技員工潛在的糖
尿病
之危險因子. 健康管理學刊,2008,6.2:135-146.
[6] 皇甫偉. SPSS 相關分析與線性回歸分析在英語考試成績分析中的應用. 中國
電力教育月刊. 2007.10:52-53.
[7] 馬亮亮; 田富鵬. 基於糖尿病與民族因素的多元線性回歸分析. 山西大同大學
學報(自然科學版). 2009;25.4:3-4.
[8] 趙爽; 文瑾; 施心陵. 基於邏輯描述的決策樹算法及其 Prolog 實現.雲南大
學學報 (自然科學版), 2005, 27.3: 211-215.
[9] 蔡明足; 翁林仲; 蔡維河; 蔡景耀; 周歆凱; 林敬恆; 周碧瑟. 台灣地區糖尿
病病患及其視網膜病變的醫療資源耗用. 臺灣公共衛生雜誌. 2008;27.2:101-09.
[10] 張俊郎;張鈺芳. 運用資料探勘與糖尿病高危險群早期療育之研究. 中華民國
[11] 張俊郎; 陳啟浩; 曾輝鈺. 結合類神經網路與決策樹於糖尿病前期診斷之研
究. 中華民國品質學會第 43 屆年會暨第 13 屆全國品質管理研討會. 2007.
[12] 翁政雄; 洪令莊; 呂培豪; 陳學瀚; 郭家佑; 施博惟; 謝孟哲. 應用決策
樹於心臟病預測之研究. 第 19 屆資訊管理暨實務研討會. 2013.
[13] 全球糖尿病報告. 2016. 世界衛生組織.
http://www.who.int/diabetes/global-report/en/
[14] 國家衛生研究院 http://www.nhri.org.tw/NHRI_WEB/nhriw001Action.do
[15] 決策 MBA 智庫百科 http://wiki.mbalib.com/zh-tw/%E5%86%B3%E7%AD.
%96#_note-0
[16] 糖尿病關懷基金會 http://www.dmcare.org.tw/
[17] 衛生福利部 https://www.mohw.gov.tw/mp-1.html
[18] 衛生福利部國民健康署 https://www.hpa.gov.tw/home/index.aspx [19] 衛生福利部中央健康保險署 https://www.nhi.gov.tw/
[20] 社團法人中華民國糖尿病衛教學會 https://www.tade.org.tw/
[21] 全民健康保險統計動向,行政院衛生署中央健康保險局編印,2011
[22] Baczkowski, A. J. (2000). The broken-stick model for species
abundances: an initial investigation.
[23] De Vita, J. (1979). Niche separation and the broken-stick model.
The American Naturalist, 114(2), 171-178.
[24] Itoh, Y., Ueda, S., & Hasegawa, M. (1980). The broken-stick model
for amino acid composition in proteins. Journal of molecular evolution,
16(1), 69-72.
[25] Smart, J. S. (1976). Statistical tests of the broken-stick model of
species-abundance relations. Journal of theoretical biology, 59(1), 127-
139.
[26] Wilson, J. B. (1993). Would we recognise a Broken-Stick community
if we found one?. Oikos, 181-183.