國 立 交 通 大 學
資訊科學與工程研究所
博
士
論
文
以權重學習與知識擷取為基礎之中文指代消解研究
Chinese Anaphora Resolution Based on Weight Learning and
Knowledge Acquisition
研 究 生:吳典松
指導教授:梁 婷 博士
以權重學習與知識擷取為基礎之中文指代消解研究
Chinese Anaphora Resolution Based on Weight Learning and
Knowledge Acquisition
研 究 生:吳典松 Student : Dian-Song Wu
指導教授:梁 婷 博士 Advisor : Dr. Tyne Liang
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
博 士 論 文
A Dissertation Submitted to
Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in
Computer Science December 2010
Hsinchu, Taiwan, Republic of China
以權重學習與知識擷取為基礎之中文指代消解研究
學生:吳典松
指導教授:梁 婷 博士
國立交通大學 資訊科學與工程研究所
摘 要
指代是一種常見的語言現象,用於避免篇章中相同敘述的重複。指代消解是 指在篇章中辨識指代詞所對應的先行詞的程序。指代消解在許多自然語言處理的 應用中扮演著不可或缺的角色,例如機器翻譯、文件摘要及資訊萃取。 在相關研究中,指代消解的方法多依靠語法規則、語意或語用的線索來辨識 指代詞,而近年來多以統計或分類方法為研究方向。然而,在以規則為基礎的方 法中,特徵分數的選取多依靠人工的方式來指定權重值,錯誤會因為主觀性的偏 見而產生。另一方面,在以分類為基礎的方法中,每個候選詞在做選擇時彼此間 是視為獨立的關係,因而無法獲得相對的偏好程度。為了克服這些問題,我們提 出以權重學習與知識擷取為基礎之中文指代消解方法。 在本論文中,我們針對中文文件中的代名詞指代、零指代以及限定性名詞指 代進行處理,並且根據個別性質提出不同的方法。我們使用詞彙知識擷取和特徵 值測量來消解代名詞指代,詞彙知識擷取以抽取相關語意特徵為目的,例如,性 別、數量及搭配相容性。特徵值測量則是以亂度為基礎的權重分配來選取先行 詞。在 1343 個指代實例中進行實驗顯示,我們所提出的方法相對於以規則為基 礎的方法獲得 7%的改善,消解成功率為 82.5%。在零指代消解問題中,我們應用案例式推理及樣式概念化來克服建構推論機 制及詞彙特徵不足的問題。在 1051 個指代實例中進行實驗顯示獲得的 F-score 為 79%,相對於以重心理論為基礎的方法獲得 13%的改善。 在限定性名詞指代消解問題中,我們使用特徵值測量的方式將所有候選詞同 時進行評估,另外也利用以網頁搜尋為基礎的方法加上外部詞典的輔助,來進行 語意相容性的判別。在 426 個指代實例中進行實驗顯示,我們所提出的方法相對 於以分類器為基礎的方法獲得 4.7%的改善,消解成功率為 72.5%。 關鍵字:指代消解、特徵權重學習、知識擷取、網路探勘
Chinese Anaphora Resolution Based on Weight
Learning and Knowledge Acquisition
Student: Dian-Song Wu Advisor: Dr. Tyne Liang
Institute of Computer Science and Engineering National Chiao Tung University
ABSTRACT
Anaphora is a commonly observed linguistic phenomenon and used to avoid repetition of expressions in discourses. Anaphora resolution denotes the process of identifying the antecedent of an anaphor in a context. Effective anaphora resolution plays an essential role in many applications of natural language processing such as machine translation, summarization, and information extraction.
In previous research, anaphora resolution methods have relied on syntactic rules, semantic or pragmatic clues to identify the antecedent. More recently, statistical-based or classification-based approaches are focused. However, in a rule-based approach, a salience score by manual weight assignment is usually adopted to select the antecedent. Errors may occur due to intuitive observations and subjective biases in selecting feature weight. On the other hand, the drawback of a classification-based approach is that it considers different candidates for the same anaphor independently. Thus it cannot effectively capture the preference relationships between competing candidates during resolution. To overcome these problems, we propose Chinese anaphora resolution methods based on weight learning and knowledge acquisition.
In this thesis, pronominal, zero, and definite anaphora in Chinese texts are addressed and different approaches are presented. We use lexical knowledge acquisition and salience measurement to resolve Chinese pronominal anaphora. The lexical knowledge acquisition is aimed to extract more semantic features, such as gender, number, and collocate compatibility. The presented salience measurement is based on entropy-based weighting on selecting antecedent candidates. The experimental results show that our proposed approach yields 82.5% success rate on 1343 anaphoric instances, enhancing 7% improvement while compared with the general rule-based approach presented.
As to Chinese zero anaphora, we apply case-based reasoning and pattern conceptualization to overcome the difficulties of constructing proper reasoning mechanisms and insufficiency of lexical features. The experimental results show that our proposed approach achieved competitive resolution by yielding 79% F-score on 1051 anaphoric instances and yielded 13% improvement while compared with the general rule-based approach.
We use two strategies to resolve Chinese definite anaphors. One is an adaptive weight salience measurement in such a way that the entire set of candidates can be estimated simultaneously. Another scheme is a Web-based knowledge acquisition model so that semantic compatibility extraction and multiple resources can be employed. The experimental results show that our proposed approach yields 72.5% success rate on 426 anaphoric instances, enhancing 4.7% improvement while compared with the result conducted by a conventional classifier.
Keywords: Anaphora Resolution, Feature Weight Learning, Knowledge Acquisition,
ACKNOWLEDGEMENT
(誌 謝)
博士論文能夠完成,首先要感謝的是我的指導教授梁婷老師,感謝她在我的 研究生涯中孜孜不倦的教誨與指導,並且在研究方法與論文寫作技巧上提供許多 寶貴的意見,使我在學術研究的道路上獲益良多。 此外,也感謝系上楊武教授、彭文志教授與胡毓志教授在各階段口試時所提 供的寶貴建議。同時感謝台灣大學資工系陳信希教授、清華大學資工系張俊盛教 授、中研院資科所陳克健教授以及大同大學資工系葉慶隆教授在口試過程中提供 許多寶貴的建議,使本篇論文趨於完善。感謝資訊擷取實驗室裡的許多研究夥伴 們,多謝你們在這段期間對我的協助與鼓勵。 最後要感謝的是我的家人的支持與鼓勵,尤其是父母親與妻子素吟的無悔付 出與關心,還有女兒怡萱和兒子彥德都是我最大的精神支柱。感謝愛犬小黑一生 的忠心守護與陪伴,僅以此論文,獻給我所摯愛的家人們。TABLE OF CONTENTS
摘 要 ...i
ABSTRACT... iii
ACKNOWLEDGEMENT...v
TABLE OF CONTENTS...vi
LIST OF FIGURES ... viii
LIST OF TABLES...ix
Chapter 1 Introduction...1
1.1 Background and Motivation ...1
1.2 Research Objectives...3
1.3 Organization of the Thesis ...4
Chapter 2 Related Work...5
2.1 A Generic Anaphora Resolution Process ...5
2.2 Rule-based Approaches...6
2.3 Statistical or Machine Learning Approaches ...8
Chapter 3 Pronominal Anaphora Resolution... 11
3.1 Chinese Pronominal Anaphora ...12
3.2 PA Resolution Framework ...13
3.2.1 Text Preprocessing ...14
3.2.2 Antecedent Candidate Identification...15
3.2.3 Lexical Resources ...17
3.2.4 Lexical Knowledge Acquisition...17
3.2.5 Feature Set ...24
3.2.6 Entropy-based Weight...26
3.2.7 Antecedent Identification ...27
3.3 Experiments ...29
3.4 Analysis and Summary ...31
Chapter 4 Zero Anaphora Resolution...34
4.1 Chinese Zero Anaphora...35
4.2 ZA Resolution Framework...38
4.2.1 CBR Approach ...39
4.2.2 Outer Lexical Resources ...40
4.2.3 Feature Extraction...41
4.2.4 Pattern Conceptualization ...45
4.2.6 Antecedent Identification ...48
4.2.7 Centering Theory in ZA Resolution...50
4.3 Experiments ...50
4.4 Analysis and Summary ...54
Chapter 5 Definite Anaphora Resolution ...56
5.1 Chinese Definite Anaphora ...56
5.2 DA Resolution Framework ...58
5.2.1 Feature Set ...59
5.2.2 Semantic Compatibility Extraction...60
5.2.3 Feature Weight Learning...62
5.2.4 Classification-based Module...62
5.3 Experiments ...63
5.4 Analysis and Summary ...65
Chapter 6 Conclusions and Future Work...67
Bibliography ...70
LIST OF FIGURES
Figure 3-1. The presented Chinese pronominal anaphora resolution procedure. ...13
Figure 3-2. The gender modifier mining algorithm. ...18
Figure 3-3. The gender-indicating pattern identification algorithm. ...20
Figure 3-4. The gender extraction procedure...21
Figure 3-5. The number extraction algorithm...22
Figure 3-6. The collocate compatibility extraction algorithm. ...24
Figure 3-7. The antecedent identification algorithm...29
Figure 3-8. The entropy-based weight for each feature. ...30
Figure 4-1. The presented Chinese zero anaphora resolution procedure...39
Figure 4-2. F-score over different k values...52
Figure 4-3. F-score after applying resolution modules...53
Figure 4-4. F-score over different case base scale. ...53
Figure 5-1. The system architecture...59
Figure 5-2. The semantic compatibility extraction algorithm. ...61
LIST OF TABLES
Table 3-1. A collocate compatibility example...12
Table 3-2. Chinese noun phrase examples. ...15
Table 3-3. The target pronominal anaphors. ...16
Table 3-4. The positional distribution of anaphor-antecedent pairs...16
Table 3-5. Gender and number statistics in the CKIP lexicon. ...17
Table 3-6. Feature vectors of antecedent candidates ...26
Table 3-7. Performance evaluation. ...31
Table 3-8. Anaphoric types and their success rate. ...31
Table 3-9. Error analysis of PA. ...32
Table 4-1. The positional distribution of anaphor-antecedent pairs...37
Table 4-2. Semantic classes selected from CKIP lexicon. ...41
Table 4-3. Case representation in the case base. ...42
Table 4-4. Input case representation. ...43
Table 4-5. Description of template features. ...44
Table 4-6. Statistical information of evaluation data. ...51
Table 4-7. Performance at various thresholds...51
Table 4-8. Performance evaluation with different methods. ...53
Table 4-9. Error analysis of ZA. ...54
Table 5-1. The positional distribution of anaphor-antecedent pairs...58
Table 5-2. Summary of features...60
Table 5-3. Distribution of top 10 semantic classes. ...64
Table 5-4. Performance evaluation. ...64
Table 5-5. Performance of leave-group-out evaluation. ...64
Chapter 1
Introduction
1.1 Background and Motivation
In natural language communication, anaphora plays an essential role in the cohesion of discourses. Anaphora denotes the phenomenon of referring back to previously mentioned entities in a text. The referring expression is called an anaphor and the entity to which it refers is its antecedent [33]. Anaphors are used to avoid repetition of expressions in discourses. Different kinds of anaphoric expressions can be utilized in the context, such as pronominal anaphors, zero anaphors, and definite anaphors [33][46][52]. Followings are the definitions for each addressed anaphora.
Definition 1.1: Pronominal anaphora denotes that the preceding antecedents are
referred by succeeding third personal pronouns including singular and plural forms.
Definition 1.2: Zero anaphora denotes that the preceding antecedents are referred
by succeeding ellipses which function as subjects or objects.
Definition 1.3: Definite anaphora denotes that the preceding antecedents are
referred by succeeding definite noun phrases.
For example, we have the text like “示威群眾i與警察對峙,他們i抗議違建的
拆除行動,i並與警察發生衝突。這些人i在衝突中毆打警察j,i更接著搶走了 他們j的配槍。 ”
(The demonstrating people confronted the policemen. Theyi protested the dismantling
action and had conflicts with the policemen. These people beat up the policemen in the conflict and then took away theirj guns.)
Here “他們i” (theyi) and “他們j” (theyj) are pronominal anaphors referring to “示威
群眾i” (demonstrating people) and “警察j” (the policemen) ,respectively. i is a zero anaphor referring to “示威群眾 i” (demonstrating people) and the definite
anaphor “這些人i” (these people) also refers to “示威群眾i” (demonstrating people).
1
th
The resolution to the addressed anaphoric expressions is to identify the antecedent of an anaphor in a context [33]. It relies on the employment of the lexical knowledge, context information, and real-world knowledge extracted from both the tackled contexts as well as outer resources. In addition, the presentation and comprehension of anaphora are determined by the connection of shared knowledge or background knowledge between the readers and writers. Thus, effective resolution should be able to infer the relationship between antecedents and anaphors [46]. In fact, effective anaphora resolution facilitates many applications of natural language processing (NLP). It helps the message understanding of a generated summary by a summarizer as well as translated message by a machine translator.
English anaphora resolution has been a research focus in natural language processing for decades [9][11][12][16]. The Anaphora Resolution Exercise (ARE) was organized to develop discourse anaphora resolution systems and evaluate them in a common and consistent environment. The first edition of the Anaphora Resolution Exercise was held in conjunction with the 6 Discourse Anaphora and Anaphor Resolution Colloquium (DAARC 2007) and focused only on English pronominal anaphora and noun phrase (NP) coreference. In addition, systems such as GuiTAR [41], JavaRAP [42], and MARS [34] are implemented for English anaphora resolution. In contrast to profound studies of English texts, efficient Chinese anaphora resolution has not been widely addressed [8]. Difficulties involved are mainly attributed to the
1
following factors. First, morphological clues are rare for determining gender or number of Chinese nouns [48]. Second, no capitalization feature to identify proper nouns. Third, no sufficient ontology, such as WordNet, is available for identifying hypernymy or hyponymy relation between concepts.
Essentially, anaphora resolution can be resolved by using either rules or statistical models [2][3][18][20][22][28]. A rule-based approach is based on a manual-weight salience score which evaluates each candidate. Errors may occur due to intuitive observations and subjective biases in selecting feature weight. Recently, statistical-based or classification-based approaches have been addressed [38][39][45]. Nevertheless, classification-based approaches force different candidates for the same anaphor to be considered independently [13]. Only a single candidate is evaluated at a time and the resolution proceeds in the reverse order of sentences until an antecedent is found. This may cause a real antecedent to be neglected once the classifier labels a candidate to be positive. In addition, the lack of adequate lexical or commonsense knowledge is the other obstacle to achieve accurate resolution results [40][43]. Hand-crafted lexicons are the most common resources for acquiring lexical knowledge, yet it suffers form the coverage problem. So our resolution considers the employment of the web corpus except the existing ontologies.
1.2 Research Objectives
In this thesis, pronominal, zero, and definite anaphora in Chinese texts are addressed and different approaches are presented. We use lexical knowledge acquisition and salience measurement to resolve Chinese pronominal anaphora. The lexical knowledge acquisition is aimed to extract more semantic features, such as gender, number, and collocate compatibility by employing multiple resources. The
presented salience measurement is based on entropy-based weighting on selecting antecedent candidates.
As to Chinese zero anaphora, we propose case-based reasoning (CBR) and pattern conceptualization to overcome the difficulties of constructing proper reasoning mechanisms and insufficiency of lexical features. As all cases are represented with the patterns containing semantic tags for their nouns and grammatical tags for the verbs, such pattern conceptualization will be able to efficiently reduce data sparseness in the case base.
We use two strategies to resolve Chinese definite anaphors in written texts. One is an adaptive weight salience measurement for antecedent identification in such a way that the entire set of candidates can be estimated simultaneously. Another scheme is a Web-based knowledge acquisition model to extract useful lexical knowledge so that semantic compatibility extraction and multiple resources can be employed to enhance the resolution performance.
1.3 Organization of the Thesis
The remainder of the thesis is organized as follows. In Chapter 2, we investigate the related resolution strategies in anaphora resolution literature. Chapter 3 presents our Chinese pronominal anaphora resolution using lexical knowledge and entropy-based weight in details. Chapter 4 illustrates the method of Chinese zero anaphors resolution using case-based reasoning and pattern conceptualization. In Chapter 5, we describe the Chinese definite anaphora resolution method and the web-based knowledge acquisition model. We conclude and propose future research directions in Chapter 6.
Chapter 2
Related Work
In this chapter, we describe a generic anaphora resolution process and investigate different computational strategies used for anaphora resolution. These computational strategies are grouped into two classes: rule-based approaches and statistical or machine learning approaches.
2.1 A Generic Anaphora Resolution Process
Anaphora resolution has been considered one of the most challenging problems in NLP. The difficulty of the problem lies in its dependence on sophisticated semantic and world knowledge. Anaphora resolution systems usually aim to resolve anaphors which have noun phrases as their antecedents [33]. A generic anaphora resolution process is described as follows [15]:
Step 1: Select noun phrases to be resolved:
The Selection of noun phrases can rely on linguistic or semantic information, such as NPs that are related to a specific semantic class.
Step 2: Extract features for the selected noun phrases:
Features may be lexical, syntactic, semantic, or other heuristics. Systems can select sophisticated features that require complex NLP tools, or more superficial features acquired through shallow processing.
Step 3: (optional) Determine if the noun phrase is new in the discourse:
A system can include a module for determining whether a NP is anaphoric, before trying to find an antecedent for it. Such modules can be useful when the anaphora resolution model adopted by the system returns an antecedent in
all cases.
Step 4: Create the set of antecedent candidates:
Systems consider as possible antecedents only the NPs that occur before the anaphor in the text. Some systems consider them all, while others impose a maximum number of previous sentences to be considered.
Step 5: (optional) Filter unreasonable candidates:
Some systems exclude candidates that do not conform to some basic constraints, for example number or gender agreement.
Step 6: Score or search antecedent candidates:
This is the core part of an anaphora resolution system. It is the module that interprets the features extracted in Step 2 and determines whether two NPs are anaphorically related based on them. This module can be built by a set of hand-made heuristics or a machine-learning algorithm. Most resolution models rank all antecedents according to a computed score or a set of rules, while other systems search in a particular order for a candidate that conforms to a set of constraints.
2.2 Rule-based Approaches
Most traditional approaches are based on hand-crafted rules concerning constraints like syntactic parallelism, semantic parallelism, proximity, or parsing results [2][3][18][20][22][28][32][47].
Hobbs’ algorithm is the first syntax-oriented method presented in this research domain [18]. From the result of syntactic tree, they check the number and gender agreement between antecedent candidates and a specified pronoun. The proposed algorithm is based on various kinds of syntactic constraints on pronominal entities
which are used to search the tree. The search is done in an optimal order that performs a breadth-first search of the syntactic tree for an antecedent, accepting the first candidate which meets selectional constraints.
In RAP (Resolution of Anaphora Procedure) proposed by Lappin and Leass [22], the algorithm applies to the syntactic representations generated by McCord's Slot Grammar parser, and relies on salience measures derived from the syntactic structure. It does not make use of semantic information or real world knowledge in choosing among the candidates.
A modified version of RAP system is proposed by Kennedy and Boguraev [20]. The algorithm does not require full syntactic parsing process but has comparable result to the algorithm of Lappin and Leass. It depends only on part-of-speech tagging with a shallow syntactic parse indicating grammatical role of NPs and containment in an adjunct or noun phrase. The method was applied to personal pronouns, reflexives and possessives. The major idea is to construct coreference equivalence classes that have an associated value based on a set of ten factors. An attempt is then employed to resolve every pronoun to one of the previously introduced discourse referents by taking into account the salience value. In addition, CogNIAC (COGnition eNIAC) [2] is a system developed at the University of Pennsylvania to resolve pronouns with limited knowledge and linguistic resources. It presents a high precision pronoun resolution system that is capable of greater than 90% precision with 60% recall for some pronouns.
A knowledge-poor approach is proposed by Mitkov [32] and the approach can also be applied to different languages (English, Polish, and Arabic). The main components of this method are so-called “antecedent indicators” which are used for assigning scores (2, 1, 0, -1) against each candidate noun phrases. They play a
decisive role in tracking down the antecedent from a set of possible candidates. In addition, a set of filtration and evaluation rules are used to resolve anaphora in Chinese financial texts [49]. Another rule-based approach was described in [48] to resolve pronominal anaphora in Chinese texts by using number, gender, grammatical roles, and distance features. To obtain further structured relationship between anaphors and antecedents, Converse [8] used full parsing results from the Penn Chinese Treebank and obtained 77.6% accuracy. Similarly, Yang et al. [53] proposed pronominal resolution using the syntactic information extracted from the parse trees.
Recently, Yeh and Chen [55] presented ZA resolution with partial parsing based on centering theory and obtained 66% F-score in 150 news articles. On the other hand, Converse [8] applied full parsing results but obtained unsatisfactory ZA resolution since only few features were used by the Hobbs algorithm which is originally designed for resolving English anaphora. The main drawbacks of rule-based approaches are attributed to intuitive observations and subjective biases in selecting feature weight. The accuracy is not always guaranteed by heuristics. Moreover, it takeslaborious effort to designate new rules whenever the test data vary from original ones.
2.3 Statistical or Machine Learning Approaches
Recently, statistical or machine learning techniques have been employed in anaphora resolution [24][38][39][45]. To deal with insufficient knowledge acquired from a given corpus, the World Wide Web has been also widely used as a corpus [4][5][31][36].
A statistical approach is introduced Dagan and Itai [11], they employ the information on a corpus for disambiguating pronouns which is an alternative solution
to the syntactical dependent constraints knowledge. Their experiment makes an attempt to resolve references of the pronoun “it” in sentences randomly selected from the corpus. The model uses a statistical feature of the co-occurence patterns obtained in the corpus to find out the antecedent. The antecedent candidate with the highest frequency in the co-occurence patterns are selected to match the anaphor.
Ge et al. [16] proposed a probabilistic model for resolving third-person pronouns. The model consists of a probability equation, which is initially conditioned on a number of features and is then simplified to handle the sparseness of the training data. This approach consists of decomposing the probability equation for the model by discarding dependencies between features. The decomposition is done by making use of Bayes' rule, the chain rule and certain independence assumptions.
Bunescu [5] present an approach to solving definite descriptions in unrestricted text based on searching the web for a particular type of lexico-syntactic patterns. Using statistics on these patterns, they intend to recover the antecedents for a predefined subset of definite descriptions occurring in two types of anaphoric relations: identity anaphora and associative anaphora. Moreover, Modjeska et al. [36] utilized web search and lexico-syntactic patterns to solve the out-of-vocabulary problem in hand-crafted lexicon. They presented a machine learning approach to other-anaphora, which uses a Naive Bayes classifier and two sets of features. The first set consists of standard morpho-syntactic, recency, and semantic features based on WordNet. The second set also incorporates semantic knowledge obtained from the Web via lexico-syntactic specific to other-anaphora. Adding this knowledge resulted in an improvement of 11.4% points in the classifier’s F-measure, yielding a final F-measure of 56.9%.
the Chinese personal pronoun into two classes referring to personal entity and referring to non-personal entity. The two classes would be treated in different anaphora resolution process called PARS and IARS. This approach can solve the problem of the Chinese personal pronoun referring to inhuman entity effectively.
The traditional learning model for anaphora resolution considers the antecedent candidates of an anaphor in isolation, and thus cannot effectively capture the preference relationships between competing candidates for its learning and resolution. To deal with this problem, a twin-candidate model for anaphora resolution is proposed [54]. The main idea behind the model is to recast anaphora resolution as a preference classification problem. Specifically, the model learns a classifier that determines the preference between competing candidates, and chooses the antecedent of a given anaphor based on the ranking of the candidates.
Ng and Cardie [39] utilized C4.5 decision tree classifier for the task of coreference resolution. Bergsma and Lin [4] presented a SVM-based approach by using general features and path-coreference data which were extracted from a large parsed corpus to compensate for a paucity of data. Such approach successfully resolves 75% of 1078 anaphoric instances in English texts. Zhao and Ng [57] presented a decision tree classification approach to Chinese anaphoric zero pronouns resolution and obtained 43% F-score in 205 texts.
The major drawback of a classification-based approach is that it forces different candidates for the same anaphor to be considered independently since only a single candidate is evaluated at a time. In contrast with a classifier, a ranking approach can directly concern with the entire set of candidates at once and compare different candidate antecedents by assigning salience scores [13].
Chapter 3
Pronominal Anaphora Resolution
Pronominal anaphora is commonly used in texts. Pronominal anaphora resolution requires not only morphological and syntactic analysis but also semantic features related to candidate NPs and verbs. In general, pronouns do not carry enough semantic information. This fact forces the use of the semantic information provided by the verbs accompanied by the anaphor and the antecedent. Traditional approaches based on limited knowledge have used morphological agreement and syntactic restrictions in order to reject incompatible candidates [37]. We include the semantic information defining compatibility relations between nouns (subjects and objects) and verbs through collocation patterns in order to be applied in the resolution process.
In this chapter, a hybrid approach using two strategies is presented to resolve pronominal anaphors in Chinese written texts [50]. One is a web-based acquisition model to extract useful lexical knowledge, such as gender, number, and collocate compatibility. Another is an adaptive weight salience measurement for antecedent identification. The experimental results show that our proposed approach yields 82.5% success rate on 1343 anaphoric instances, enhancing 7% improvement while compared with the general rule-based approach presented by Wang and Mei [48].
The subsequent sections of the chapter are organized as follows. Section 3.1 introduces pronominal anaphora in Chinese texts and some of the problems encountered. Section 3.2 describes the proposed method by using lexical knowledge and entropy-based weight in detail. Section 3.3 presents the resolution results and comparisons. Section 3.4 gives a summary of our study.
3.1 Chinese Pronominal Anaphora
Pronominal anaphora resolution relies on the constraints between pronouns and antecedents, such as gender, number, grammatical role and animacy. As mentioned above, a general Chinese person’s name does not always carry gender information and a Chinese noun does not have morphological differences for indicating its singularity or plurality.
In addition, identifying the referent of a pronoun in Chinese texts is not always trivial if insufficient real-world knowledge is incorporated. Table 3-1 lists two subsequent sentences where each word is followed by its part-of-speech, the first pronoun “他們 1” (they1) refers to “示威群眾” (demonstrating people) while the second pronoun “他們2” (their2) refers to “警察” (policemen). So it is necessary for an anaphora resolver to check collocate compatibility between anaphors and their candidates.
Table 3-1. A collocate compatibility example.
示威(VA)2群眾(Na)與(Caa)警察(Na)對峙(VH),他們
1(Nh)抗議(VE)違建(Na)的 (DE)拆除(VC)行動(Na),並(Cbb)與(P)警察(Na)發生(VJ)衝突(Na)。這些(Neqa) 人(Na)在(P)衝突(Na)中(Ng)毆打(VC)警察(Na),更(D)接著(D)搶走(VC)了(Di) 他們2 (Nh)的(DE)配槍(Na)。
(The demonstrating people confronted the policemen. They1 protested the
dismantling action and had conflicts with the policemen. These people beat up the policemen in the conflict and then took away their2 guns.)
2
A detailed description of part-of-speech tag set used in this thesis is available at
http://ckipsvr.iis.sinica.edu.tw/category_list.doc. For example, “Na” denotes a common noun and “VA” means an intransitive verb.
3.2 PA Resolution Framework
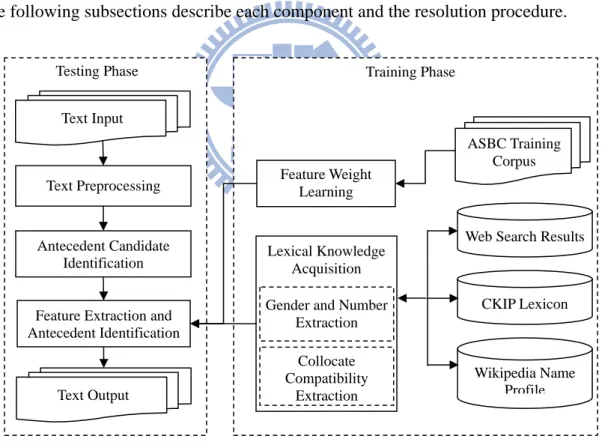
Figure 3-1 illustrates the presented pronominal anaphora resolution which is incorporated with three external resources, namely web search results, CKIP lexicon3, and Wikipedia name profile. The resolution is implemented in the training phase and the testing phase. The training phase involves lexical knowledge acquisition and feature weight learning. Three kinds of lexical knowledge are addressed, namely, gender, number, and collocate compatibility. In feature weight learning, an entropy-based approach is employed. The testing phase concerns text preprocessing, antecedent candidate identification, feature extraction, and antecedent identification. The following subsections describe each component and the resolution procedure.
Lexical Knowledge Acquisition Text Input Text Preprocessing Antecedent Candidate Identification
Feature Extraction and Antecedent Identification Collocate Compatibility Extraction Wikipedia Name Profile CKIP Lexicon Web Search Results
Gender and Number Extraction Training Phase Feature Weight Learning Testing Phase ASBC Training Corpus Text Output
Figure 3-1. The presented Chinese pronominal anaphora resolution procedure.
3
CKIP (Chinese Knowledge Information Processing Group) lexicon is available at http://www.aclclp.org.tw/use_ckip_c.php
3.2.1 Text Preprocessing
Text preprocessing includes sentence segmentation, POS tagging, named entity identification, and noun phrase chunking. The sentence segmentation and POS tagging are processed by CKIP Chinese word segmentation system4. The named entity identification is done by applying the hybrid approach presented in [48]. In an experiment of 150 news documents selected from Academia Sinica Balanced Corpus (ASBC)5, this approach yields 94% precision and 93% recall on person name identification, and 89% precision and 84% recall on organization name identification.
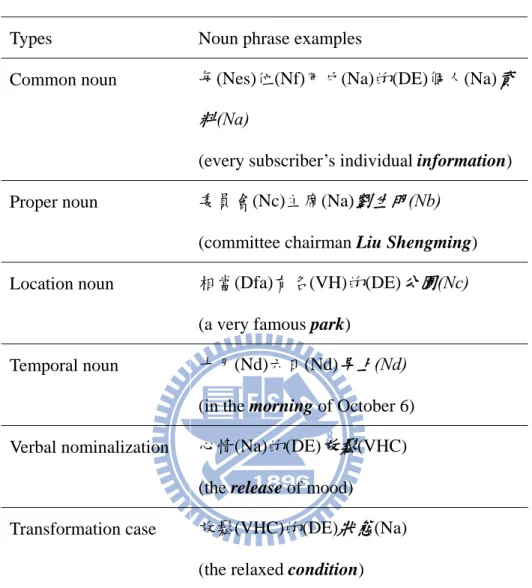
A finite state machine chunker is constructed to recognize noun phrases by their head nouns which may be common nouns, proper nouns, location nouns, temporal nouns, or pronouns [56]. In Chinese, a head noun (as indicated in italics in Table 3-2) occurs at the end of a noun phrase. Except for noun phrase chunks, the chunker is also able to recognize verbal nominalization and transformation by utilizing heuristics described in [14]. As shown in Table 3-2, all the chunks, including the one containing the verb “放鬆” (relax), will be treated as antecedent candidates and will be assigned with semantic feature values like gender, animate and number useful at antecedent candidate identification .
4
CKIP Chinese word segmentation system is available at http://ckipsvr.iis.sinica.edu.tw/
5
Table 3-2. Chinese noun phrase examples.
Types Noun phrase examples
Common noun 每(Nes)位(Nf)用戶(Na)的(DE)個人(Na)資
料(Na)
(every subscriber’s individual information) Proper noun 委員會(Nc)主席(Na)劉生明(Nb)
(committee chairman Liu Shengming) Location noun 相當(Dfa)有名(VH)的(DE)公園(Nc)
(a very famous park)
Temporal noun 十月(Nd)六日(Nd)早上(Nd) (in the morning of October 6) Verbal nominalization 心情(Na)的(DE)放鬆(VHC)
(the release of mood)
Transformation case 放鬆(VHC)的(DE)狀態(Na) (the relaxed condition)
3.2.2 Antecedent Candidate Identification
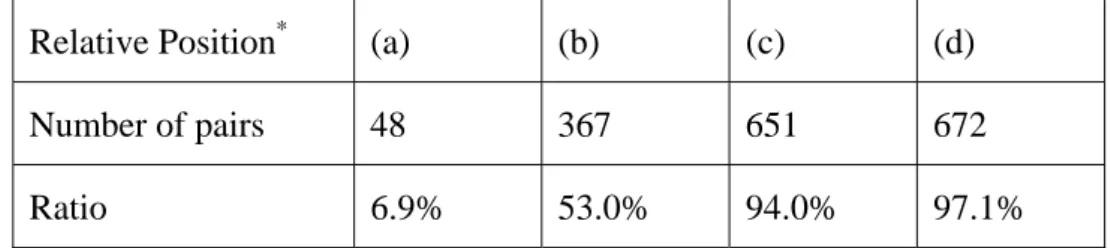
Table 3-3 lists the target pronominal anaphors to be resolved in this thesis. Unlike English pronouns, Chinese pronouns remain the same in expressing nominative and accusative cases. Table 3-4 lists the positional distribution of 692 anaphor-antecedent pairs in our training data and it shows that 94% of antecedents are in two sentences ahead of anaphors. Some antecedent candidates can be explicitly filtered out by applying the following heuristics. Here, CAN denotes an item in the
candidate set preceding the corresponding pronominal anaphor (PA). A CAN will be filtered if it satisfies any of the following patterns.
1. Conjunction pattern: PA[c]CAN or CAN[c]PA
c{跟, 和, 與, 同, 及, 向, 對, 面對, 或, 或是, 或者, 亦或, 以及, 還 是, 還有}
2. Verb pattern: PA[Vt]CAN or CAN[Vt] PA Vt denotes a transitive verb in a sentence. 3. Preposition pattern: PA[p]CAN or CAN[p]PA
p{在, 對, 到, 朝, 給, 向, 比}
Table 3-3. The target pronominal anaphors.
Singular Plural Possessive(Singular) Possessive(Plural) Male 他(he, him) 他們(they, them) 他的(his) 他們的(their, theirs)
Female 她(she, her) 她們(they, them) 她的(her, hers) 她們的(their, theirs)
Neutral 它(it) 它們(they, them) 它的(its) 它們的(their, theirs)
Table 3-4. The positional distribution of anaphor-antecedent pairs.
Relative Position* (a) (b) (c) (d) Number of pairs 48 367 651 672
Ratio 6.9% 53.0% 94.0% 97.1%
*
Relative Position:
(a) Pairs are in the same clause. (b) Pairs are in the same sentence.
(c) Antecedents are in the previous sentence. (d) Pairs are in the same paragraph.
3.2.3 Lexical Resources
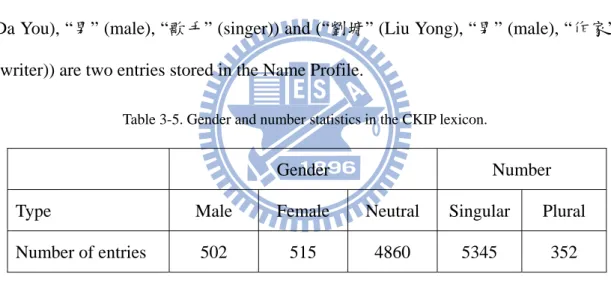
We use two lexical resources to acquire number and gender features for anaphora resolution. One is the CKIP lexicon [1] and out of which we annotated 5,697 nouns with gender and number. For example, “硬漢” (tough guy) and “姑丈” (uncle) are marked as male nouns; “反對黨” (opposition party) and “考察團” (investigation group) are marked as plural. Table 3-5 shows the statistics of the annotated data in the tagged lexicon. The other resource, denoted as “Wikipedia Name Profile”, was constructed by extracting 780 common Chinese person names from Wikipedia6 and, for each name, the gender and role are tagged by hands. For instance, (“羅大佑” (Luo Da You), “男” (male), “歌手” (singer)) and (“劉墉” (Liu Yong), “男” (male), “作家” (writer)) are two entries stored in the Name Profile.
Table 3-5. Gender and number statistics in the CKIP lexicon.
Gender Number
Type Male Female Neutral Singular Plural Number of entries 502 515 4860 5345 352
3.2.4 Lexical Knowledge Acquisition
Lexical knowledge acquisition involves the extraction of gender, number, and collocate compatibility from reliable patterns constructed at training phase. In this subsection, we describe detail extraction procedures as follows.
The gender extraction aims to classify each noun phrase to be male, female or
6
Common Chinese person names are available at
http://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%90%8D%E8%A1%A8&variant=zh-t w
unknown with the help of so-called gender-indicating pattern (GP) and Web mining results. All the gender modifiers are mined from the Web in advance by implementing the procedure as shown in Figure 3-2. Moreover, there are six kinds of GPs (denoted as “GPi” and 1 i6) and each GP is utilize to identify the occurrence of masculine
pattern or feminine pattern as shown in Figure 3-3.
Algorithm 3.1. The gender modifier mining algorithm
Input: Randomly select 100 male name mi and 100 female names fi, respectively
Output: Top 5 clue words for male and female, respectively Procedure Gmod():
Step 1: Submit each name to the search engine Google and acquire at most 50 snippets
Step 2: Retain nouns, verbs, adjectives, and adverbs in snippets as set
W={w1,w2,…, wn} Step 3: For each do
Calculate cntm: the frequency that appears with male names
Calculate cntf: the frequency that appears with female names
W wi i w i w
Step 4: Select the set Wm={ w1,w2,…, wi }, where 0.8
m f m cnt cnt cnt
Select the set Wf={ w1,w2,…, wj }, where 0.8 m f f cnt cnt cnt
Step 5: Use Bayesian Parameter Learning (Equation (1)) [35] and rank words in the ascending order of . The frequencies of words collocating with male names and female names are
2 1 and 1 , respectively ) 1 ( ) ( 2 2 (1) Step 6: Output top n clue words from Wm and Wf , respectively
Algorithm 3.2. The gender-indicating pattern identification algorithm
Input: 1. A candidate noun phrase Ni
2. The count of masculine patterns Cm and feminine patterns Cf
Output: The number feature fgnd, where fgnd {male, female, unknown}
Procedure Gender():
Step 1: Search Attachment titles pattern (GP1): Ni is followed by a gender-marked title
(a). If GP1 is Ni+[先生], then Cm++
(b). Else if GP1 is Ni+ [女士|小姐|夫人], then Cf++
Step 2: Search Opposite roles pattern (GP2): Ni acts as a possessive of some specific nouns
(a). If GP2 is Ni+[的]+ [太太|妻子|夫人|老婆|女友|未婚妻], then Cm ++ (b). Else if GP2 is Ni+[的]+ [先生|丈夫|老公|男友|未婚夫], then Cf ++ Step 3: Search Reflexives pattern (GP3): Ni is followed by a reflexive
(a). If GP3 is Ni+[他自己], then Cm++ (b). Else if GP3 is Ni+[她自己], then Cf++
Step 4: Search Possessives pattern (GP4): Ni is followed by a possessive (a). If GP4 is Ni+[他的], then Cm++
(b). Else if GP4 is Ni +[她的], then Cf++
Step 5: Search Complement derivation pattern (GP5): Person nouns are subjects and gender-marked nouns are in the predicate position. Gender-marked nouns are identified by using the tagged CKIP lexicon
(a). If GP5 is Ni+[是]+Modifier+Male-noun, then Cm++ (b). Else if GP5 is Ni+[是]+Modifier+Female-noun, then Cf++ Step 6: Search Gender-modifier pattern (GP6): Ni is modified by a
gender-modifier which is mined by Gmod() as shown in Figure 3-2 (a). If GP6 is gender-modifier +Ni and gender-modifier like “英俊”
(handsome), then Cm++
(b). Else if GP6 is gender-modifier +Ni and gender-modifier like “溫柔” (tender), then Cf++
Step 7: Calculate the feature value fgnd =Gender(Ni)
otherwise unknown if female if male N
Gender female male
female male i , , , ) ( (2)
f m f female f m m male C C C C C C Step 8: Output fgnd
Figure 3-3. The gender-indicating pattern identification algorithm.
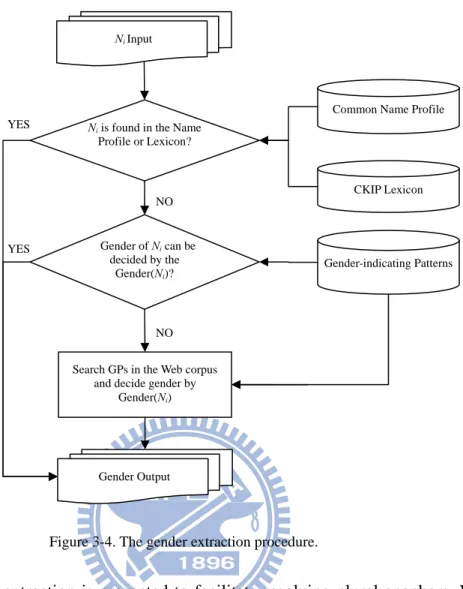
Figure 3-4 illustrates the overall three-layer gender feature extraction for each Ni
of an input document Di and it is described as follows:
Step 1: If Ni is matched with the tagged CKIP lexicon or Common Name Profile7,
then return the corresponding gender.
Step 2: Else Search Di with the help of gender-indicating patterns and gender
information statistics Gender(Ni) defined in Equation (2). If the gender feature
can be decided as male or female, then return the corresponding gender. Step 3: Else transform Ni to queries according to each kind of GPs. For example, “Ni
+[先生]”, “Ni+[他自己]”. Search the Web corpus for each gender-indicating
pattern and calculate Gender(Ni). If the gender feature can be decided as male
or female, then return the corresponding gender.
Step 4: For other cases, the gender feature is marked unknown.
7
Common Chinese person names are available at
http://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%90%8D%E8%A1%A8&variant=zh-t w
Search GPs in the Web corpus and decide gender by
Gender(Ni)
Gender Output
Common Name Profile
Ni is found in the Name
Profile or Lexicon? Gender of Ni can be decided by the Gender(Ni)? YES YES NO NO Gender-indicating Patterns CKIP Lexicon Ni Input
Figure 3-4. The gender extraction procedure.
The number extraction is presented to facilitate resolving plural anaphors. With the collection of numerical and quantitative clue words, the extraction is implemented as shown in Figure 3-5.
Algorithm 3.3. The number extraction algorithm for assigning the number feature to each candidate noun phrase of input sentences
Input: 1. A candidate noun phrase NP
2. The set of quantifiers Q
3. The set of collective quantifiers P={群, 夥, 堆, 對, 隊, 些, 組, 伙, 雙, 疊, 批}
4. The set of plural numerals R={全部, 所有, 數個, 許多, 有些, 少數, 少許, 多數, 諸多, 一些, 這些, 那些, 若干}
Output: The number feature fnum, where fnum{singular, plural, unknown}
Procedure Number():
Step 1: Identify head noun HNP of the candidate noun phrase NP
Step 2: If NP satisfies any of the following conditions, then return fnum = singular
(i) HNP is a person name (ii) NP contains a title
(iii) NP{[這|那|該|某|一] +{Q-P}+noun }
Step 3: Else if NP satisfies any of the following conditions, then return fnum =
plural
(i) HNP is an organization name (ii) The last character of NP{們, 倆} (iii) NP contains plural numbers+Q (iv) NP follows r, where rR
Step 4: For other cases, return fnum = unknown
Figure 3-5. The number extraction algorithm.
The presented collocate compatibility extraction measures binding strength between candidates and anaphors. We consider three types of collocate patterns, namely subject-verb, verb-object, and possessive-noun, and use collocate statistics to evaluate the preference of candidates. The collocate compatibility extraction is implemented as shown in Figure 3-6.
1. For each pronominal anaphor, replace it with its antecedent candidates accordingly.
collocate pattern is extracted for each candidate.
For instance, consider Table 3-1 mentioned above, anaphors “他們1” and “他們2” are the subject-verb and possessive-noun patterns, respectively. Therefore the collocate patterns for “他們1” are “群眾遊行” and “警察遊行”. Accordingly, “群 眾的配槍” and “警察的配槍” are patterns for “他們2”. For each candidate, its collocate compatibility with the anaphor is calculated by Equation (3). In the case of the anaphor “他們1”, three queries are formed for each candidate and they are submitted to Google search engine. For candidate “群眾”, the pattern query is “群 眾遊行”. Accordingly, the candidate query and the attach query are “群眾” and “遊行” , respectively.
Algorithm 3.4. The collocate compatibility extraction algorithm
Input: A candidate noun phrase can, a pronominal anaphora ana
Output: The value of Sem_Com for pair can and ana
Procedure Col_Com():
Step 1: Consider ana in the following cases:
Case 1: subject -verb //ana is an subject of a verb Case 2: verb-object //ana is an object of a verb
Case 3: possessive-noun //ana is a possessive of a noun Step 2: If Case 1, then
pattern=can+verb, candidate=can, attach=verb
Step 3: Else if Case 2, then
pattern=verb+ can, candidate=can, attach=verb
Step 4: Else if Case 3, then
pattern=can+ noun, candidate=can, attach= noun
Step 5: Acquire the numer of pages cntpat by submitting pattern as query
Acquire the numer of pages cntm by submitting candidate as query
Acquire the numer of pages cntn by submitting attach as query
Step 6: Calculate ) ( ) ( ) ( ) , ( _ n m pat 2 cnt p cnt p cnt p log ana can Com Col (3) total pat pat cnt cnt cnt p( ) total m m cnt cnt cnt p( ) total n n cnt cnt cnt p( )
where cnttotal is the number of Google pages Step 7: Output the value of Col_Com(can,ana)
Figure 3-6. The collocate compatibility extraction algorithm.
3.2.5 Feature Set
There are seventeen features concerned at our antecedent identification as follows. C denotes an antecedent candidate and P denotes the pronominal anaphor. For each feature, we set its value to be 1 if an antecedent candidate satisfies the
feature constraint; otherwise we set its value to be 0.
1. Same_Pro: C and P are the same pronouns, for example, C is “她” (she) and
P is “她” (she) as well.
2. Reflexive: P is a reflexive of C, such as “劉生明他自己” (Liu Shengming himself) in which “劉生明” (Liu Shengming) is an antecedent candidate. 3. Role: C is the agent of a verb, namely, C precedes a transitive verb or an
intransitive verb.
4. Parallel: C and P are the same grammatical roles. For example, C and P are both subjects of sentences.
5. Gender: C and P are the same gender. The gender feature is identified by the way mentioned in the previous subsection gender extraction.
6. Number: C and P are the same number. The number feature is determined by the way mentioned in the previous subsection number extraction.
7. Animate: C is an animate entity and P is a male or female pronoun. We utilize the semantic class of CKIP lexicon to annotate animate entities. In addition, person names and organization names are regarded as animate entities, too.
8. NE_Per: C is a person name and P is a male or female pronoun. A person name is identified by using a classifier presented in (Liang, Yeh, & Wu, 2003).
9. NE_Org: C is an organization name and P is a plural pronoun. An organization name is identified by the way described above.
10. Col_Com: The value of Col_Com(C,P) is maximum. Equation (3) is used to calculate the value for each antecedent candidate.
punctuation marks like “,”, “。”, “;”, “!”, and “?”.
12. Same_Sent: C and P are in the same sentence. A sentence is bounded by punctuation marks like “。”, “;”, “!”, and “?”.
13. Same_Para: C and P are in the same paragraph. 14. Clause_Lead: C is the first noun phrase in the clause. 15. Sent_Lead: C is the first noun phrase in the sentence. 16. Repeat: C repeats more than once in the context.
17. Definite: C is a definite noun phrase. For example, “這本雜誌” (the magazine) is a definite noun phrase.
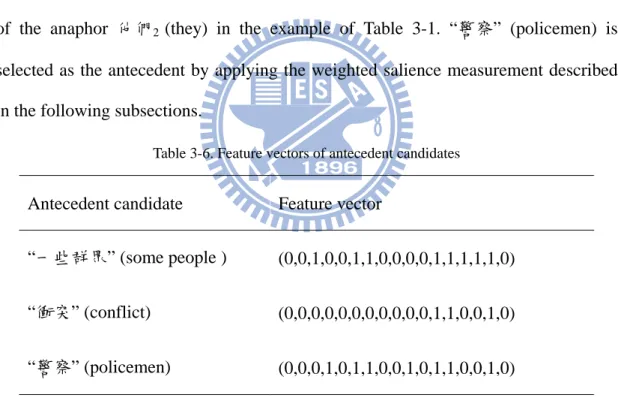
Table 3-6 shows the feature vectors associated with some antecedent candidates of the anaphor 他們2 (they) in the example of Table 3-1. “警察” (policemen) is selected as the antecedent by applying the weighted salience measurement described in the following subsections.
Table 3-6. Feature vectors of antecedent candidates
Antecedent candidate Feature vector
“一些群眾” (some people ) (0,0,1,0,0,1,1,0,0,0,0,1,1,1,1,1,0) “衝突” (conflict) (0,0,0,0,0,0,0,0,0,0,0,1,1,0,0,1,0) “警察” (policemen) (0,0,0,1,0,1,1,0,0,1,0,1,1,0,0,1,0)
3.2.6 Entropy-based Weight
The weight function in Equation (4) is motivated from the decision tree learning which utilizes the concept of entropy to select an attribute [35]. The entropy value denotes the uncertainty associated with a random variable. In our case, a feature with
lower entropy denotes that it can reduce uncertainty in selecting correct antecedents. Therefore, a feature with lower entropy is given a higher weight, and vice versa. During the training phase, positive instances were annotated manually. Other candidates between the positive pairs were used to form the negative instances.
n p n log n p n n p p log n p p S entropy S entropy S S S entropy S entropy 1 weight 2 2 j v 1 j j i i i
) ( ) ( ) ( ) ( (4) whereS: the set of training instances
Sj: the subset of training instances in which fvali has value j
p: the number of positive instances n: the number of negative instances
3.2.7 Antecedent Identification
The task of antecedent identification is to select the most likely candidate from the candidate set by Equation (5). Each candidate is filtered by checking its gender, number, and animate agreement. “Agreementk” is a binary function that has a value 0/1. It is noticed that the value of Rank(can,ana) will be set to be zero if one of the three agreements is zero. A candidate with the highest value is selected as the antecedent for the target definite anaphor. The antecedent identification is implemented as shown in Figure 3-7.
Algorithm 3.4. The antecedent identification algorithm
Input: A document D
Output: Anaphor-antecedent pairs (ana, ant)p
Procedure Resolve():
Step 1: Build the internal representation data structure of input document D. For example, sentence offset, word offset, and word POS.
Step 2: For each sentence in D do
Identify noun phrases in each sentence by the NP chunker described above Step 3: Identify all target anaphors anap throughout D
Step 4: For each anap do
Collect candidate set S. All antecedent candidates canq in S are in a
distance of two sentences ahead of anap
For each candidate canq S do
(i) Assign feature values to canq
(ii) Rank pairs by Equation (5)
3 1 1 1 ) ) (max( ) ( ) , ( k k j j n j i n i i agreement weight val f weight fval ana can Rank (5) wherecan: a candidate for a specified anaphor ana: an anaphor to be resolved
fvali: the ith feature value
max(fvali): the maximum value of the ith feature value
agreementk: number, gender, and animate agreement
(iii) A candidate canq with the highest Rank value is selected as
antecedent antp for a definite anaphor
Step 5: Output (ana, ant)p
Figure 3-7. The antecedent identification algorithm.
3.3 Experiments
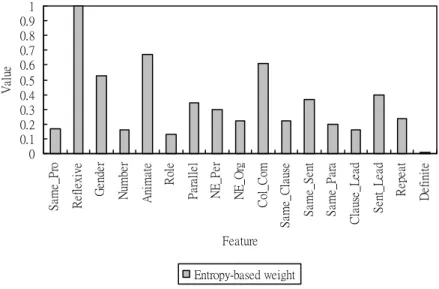
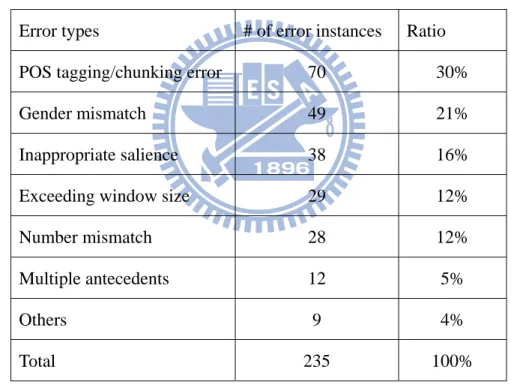
We extract 307 news documents from ASBC as our resolution corpus and from this corpus 1343 anaphor-antecedent pairs are identified by experts. The resolution performance is evaluated in terms of success rate defined by Equation (6) and is implemented by five-fold cross-validation. Figure 3-8 illustrates the entropy-based weight for each feature. It is found that features with top five weights are Reflexive,
Animate, Col_Com, Gender and Sent_Lead, respectively. This result indicates that Reflexive, Animate and Gender features are three dominant features for animate
entities if anaphors are gender-marked. In addition, the Col_Com feature shows the significance of collocate compatibility in selecting antecedents. Sent_Lead justifies the fact that Chinese is a topic prominent language.
identified cases anaphora of number total cases resolution correct of number rate success (6)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Sa m e_ Pr o Re fl ex iv e Ge nd er Nu m be r An im at e Ro le Pa ra ll el NE _P er NE _Or g Co l_ Co m S am e_C la us e Sa m e_ Se nt Sa m e_ Pa ra C lau se_ L ea d S ent _L ea d Re pe at De fi ni te Feature Va lu e Entropy-based weight
Figure 3-8. The entropy-based weight for each feature.
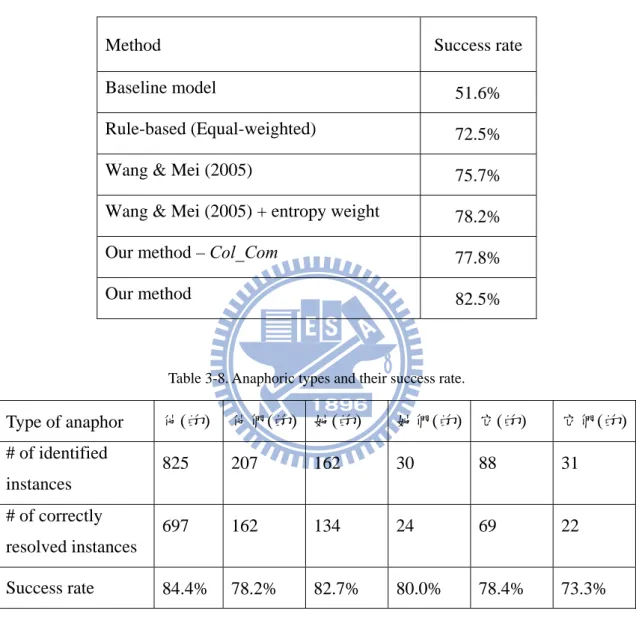
We implemented five resolution models for comparison. The baseline model was implemented by using number and gender agreement only, and the most recent subject was selected as the antecedent from a candidate set. The second model assigned equal-weight to all seventeen features and selected the top-weight candidate as the antecedent. The third and fourth models were implemented by considering four features only, namely number, gender, grammatical, and distance features. However, the third model assigned the features the same manual weight as described in [48] while the fourth model adopted our presented entropy-based weight. To evaluate how useful the collocate compatibility feature is in our method, we conduct a leave-one-out evaluation in the fifth model. The success rate decreases 4.7% when feature Col_Com is disabled.
Table 3-7 shows that our method yields 82.5% success rate on 1343 anaphoric instances by employing entropy-based weight scheme and lexical knowledge. It improves about 7% success rate while compared with a rule-based model like the one presented in [48].
rate. It is found that anaphors with gender-mark are more easily to be resolved than the neutral ones. Similar conclusion can be found for those singular anaphors.
Table 3-7. Performance evaluation.
Method Success rate
Baseline model 51.6%
Rule-based (Equal-weighted) 72.5% Wang & Mei (2005) 75.7% Wang & Mei (2005) + entropy weight 78.2% Our method – Col_Com 77.8%
Our method 82.5%
Table 3-8. Anaphoric types and their success rate.
Type of anaphor 他(的) 他們(的) 她(的) 她們(的) 它(的) 它們(的) # of identified instances 825 207 162 30 88 31 # of correctly resolved instances 697 162 134 24 69 22 Success rate 84.4% 78.2% 82.7% 80.0% 78.4% 73.3%
3.4 Analysis and Summary
The resolution errors are summarized in Table 3-9. As we can see, most of errors are attributed to preprocessing and gender constraints. Preprocessing errors denote that the system is unable to extract all valid antecedents and incorporate them into the
set of competing candidates. In gender mismatch, one reason is that pronouns “他” (he) and “他們” (they) are often incorrectly used to identify female entities in Chinese texts. There is still room for improvement by carefully taking into account this kind of errors. Gender agreement should be applied more loosely and animate agreement can be enforced. Examples of gender mismatch cases are listed as follows:
(1) 依據傳說以古代那個楊貴妃,他皮膚很漂亮很漂亮。 (2) 我那個女兒他讀三年級,他每次看那個電視,
(3) 以有錢有閒的太太們為多,他們吃不多,
Table 3-9. Error analysis of PA.
Error types # of error instances Ratio POS tagging/chunking error 70 30%
Gender mismatch 49 21%
Inappropriate salience 38 16% Exceeding window size 29 12%
Number mismatch 28 12%
Multiple antecedents 12 5%
Others 9 4%
Total 235 100%
Our contributions are that we proposed three innovative methods for lexical knowledge acquisition and our study is the first one that utilizes entropy-based weight in anaphora resolution. Compared with the manual weight scheme, the presented entropy-based weight scheme is more capable to estimate the likelihood that a candidate turns out to be an antecedent. Moreover, the presented lexical knowledge
acquisition is indeed able to acquire more semantic information from contexts and Web resources. In comparison with a general rule-based approach, the presented resolution can achieve 7% improvement when lexical knowledge learning and entropy-based weight are implemented.
Chapter 4
Zero Anaphora Resolution
Zero anaphora is the major anaphora occurring in Chinese texts [52] [55]. It means that most of the anaphors appearing in Chinese texts can be unspecified if they are inferable from the contexts. The omitted grammatical constituent is called a zero anaphor (ZA). Zero anaphors may occur in a single sentence or in consecutive sentences. Essentially, the recovery of zero anaphors relies on contextual information, semantic inference, and world knowledge [23][46].
However, efficient Chinese ZA resolution has not been widely addressed. Hence, an effective ZA resolution is presented in this thesis with the aim to facilitate Chinese message understanding. A novel ZA resolution approach is proposed by applying case-based reasoning (CBR) and pattern conceptualization [51]. This is because CBR is able to exploit the previous experience that might be useful for the novel problem. In this thesis, we utilize the antecedent features of the retrieved cases to predict the antecedent of a novel case. As all cases are represented with the patterns containing semantic tags for their nouns and grammatical tags for the verbs, such pattern conceptualization will be able to efficiently reduce data sparseness in the case base. Moreover, the presented resolution is incorporated with a filtering mechanism to identify those non-anaphoric cases such as cataphora and non-antecedent instances in order to enhance the overall resolution performance. The experimental results show that our proposed approach achieved competitive resolution by yielding 79% F-score on 1051 ZA instances and yielded 13% improvement while compared with the general rule-based approach.
The subsequent sections of this chapter are organized as follows. Section 4.1 introduces the commonly-seen zero anaphora instances in Chinese texts. Section 4.2 describes the resolution approach by using CBR-based learning. Section 4.3 describes the procedure of zero anaphora resolution and the experimental results. Section 4.4 presents the final summary.
4.1 Chinese Zero Anaphora
According to [19][25], a Chinese sentence is generally integrated by complete syntactic components and expresses an intact meaning. It is composed of one or more clauses and is explicitly identified with punctuation marks like “。, !, ?”. A Chinese clause is an utterance which is identified with punctuation marks like “,, ; , :, 。, !, ?” and grammatically it may or may not be a complete syntactic component. As mentioned above, ZA is the most common anaphora displaying in Chinese texts and it can be intra-sentential when a ZA appears in a single-clause sentence or inter-sentential when it appears in multiple-clause sentences. In the following examples, we list some typical ZA and use “” to denote zero anaphors which may play as subject or object roles in Chinese sentences and their referents are noun phrases.
(A) Inter-sentential ZA:
1. Subject-role case: The subject (like “Xiaoming” in the example) appears overtly once in the first clause, but later mentions of the same subject are left unspecified in a multiple-clause sentence.
(e1) 小明 1 打開 在 地上 的 箱子, 1 拿出 兩 本 故事書 後, 1 回到 自己 的 房間。
storybooks. (Xiaoming) went back to his room.)
2. Object-role case: The object (like “new album” in the example) is unspecified in the second clause if it can be understood or inferred from the first clause in a multiple-clause sentence.
(e2) 張三 買 了 新 唱片2,許多 朋友 都 向 他 借 2。
(Zhangsan bought a new album. Many of his friends borrowed (a new album) from him.)
(B) Intra-sentential ZA:
1. Subject-role case: The same subject (like “Lisi” in the example) is unspecified if it is shared from the previous verb in a single-clause sentence with one more verbs.
(e3) 李四3 參加 演講 比賽 3 贏得 冠軍。
(Lisi participated in a lecture contest and (Lisi) won the first honor.) 2. Object-to-subject case: The subject (like “Wangwu” in the example) of the
second verb is unspecified if it is the object of the first verb in a pivotal sentence.
(e4) 李四 允許 王五 4 再 重做 一 份 報告。
(Lisi allowed Wangwu (and Wangwu) redo a report again.)
As mentioned previously, a Chinese sentence expresses one complete meaning. However, it is usually observed that a sentence might be incorrectly segmented into a sequence of clauses with punctuations like “,” and some of them are just a noun phrase or a prepositional phrase as shown in the following examples (e5 and ex6). So it is required for a ZA resolver to identify such kind of anaphoric relations in the adjacent clauses for a multiple-clause sentence.
(Premier Schroeder, (Premier Schroeder) declared that Germany will hold a council election.)
(e6) 人 的 生活 空間6,6 和 自然 環境 發生 了 對立。
(Human living space, (human living space) and environment brought about conflict.)
As mentioned above, the antecedent of a zero anaphor occurs in the previous expressions. However, there are also cases that antecedents are not specified in the previous context, called non-anaphoric zero anaphora (as shown in example (e7)). Therefore, effective zero anaphora resolution relies on not only the identification of antecedents but also the elimination of non-anaphoric cases.
Non-anaphoric zero anaphora case: In this example, 7 refers to “time” but the antecedent “time” is not specified previously.
(e7) 7 過 了 兩 天 ,警察 找到 了 犯罪 的 證據。 (After two days, the police found the criminal evidence.)
Table 4-1 lists the positional distribution of 793 anaphor-antecedent pairs in our training data and it shows that 96.7% of antecedents are in a distance of two sentences.
Table 4-1. The positional distribution of anaphor-antecedent pairs.
Relative Position* (a) (b) (c) Number of pairs 710 767 789
Ratio 89.5% 96.7% 99.4%
*
Relative Position:
(a) Pairs are in the same complex sentence. (b) Pairs are in two complex sentences. (c) Pairs are in the same paragraph.
4.2 ZA Resolution Framework
Figure 4-1 illustrates the proposed ZA resolution at the training and testing phases. At training phase, the kernel case-based reasoning module is built in three major steps, namely, feature extraction, pattern conceptualization, and feature weight learning. As a result, a case base, which contains both anaphoric and non-anaphoric ZA cases, is constructed for case retrieval at testing phase. At the testing phase, an input text is processed by a pipeline of text preprocessing, zero anaphor detection, and antecedent (ANT) identification. Moreover, a weighted k-nearest-neighbor (WKNN) algorithm is presented to measure the similarities of cases at case retrieval. The antecedent features of the retrieved cases are applied for antecedent selection. The following subsections describe each component and the resolution procedure in detail.
Case-based Reasoning Module Testing Data Text Preprocessing ZA Detection and Cataphora Filter
ANT Identification and Candidate Filter Feature Extraction Case Base Lexical Resources Resolution Results Training Data Training Phase Testing Phase Pattern Conceptualization Feature Weight Learning WKNN Similarity Measure Text Preprocessing
Figure 4-1. The presented Chinese zero anaphora resolution procedure.
4.2.1 CBR Approach
CBR is an incremental learning technique that has been successfully used for building knowledge systems and aiding knowledge acquisition [1][7][29]. The main concept of CBR is to exploit the previous experience that might be useful for the novel problem. In this thesis, we utilize the antecedent features of the retrieved cases to predict the antecedent of a novel case. In the case base, those anaphoric cases (treated as positive cases) will be encoded with more features than the non-anaphoric cases (treated as negative cases) and all the cases will be transformed into conceptual