行政院國家科學委員會補助專題研究計畫
5 成 果 報 告
期中進度報告
多協定層極寬頻無線網路之研發
—
子計畫四:
UWB 系統中通道等化與干擾抑制之設計與實現
計畫類別: 個別型計畫 5 整合型計畫
計畫編號:NSC96-2219-E-110-001
執行期間:
96 年 08 月 1 日至 97 年 07 月 31 日
計畫主持人:陳儒雅
計畫參與人員:黃俊淵、邱志賢、莊子建
成果報告類型(依經費核定清單規定繳交): 精簡報告 5完整報告
本成果報告包括以下應繳交之附件:
赴國外出差或研習心得報告一份
赴大陸地區出差或研習心得報告一份
5出席國際學術會議心得報告及發表之論文各一份
國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、列管計畫
及下列情形者外,得立即公開查詢
涉及專利或其他智慧財產權, 一年 二年後可公開查詢
執行單位:國立中山大學通訊工程研究所
摘
要
現今家庭對多媒體娛樂的需求越來越多,而電腦相關周邊所要求的的傳輸速 率也越來越高。而極寬頻系統正是一種適合於室內的高速無線網路系統,其傳輸 速率可達到1320 Mbps。在本計畫中,主要針對 DS-UWB 的接收端的設計作ㄧ 深入的探討,進而對其基頻系統提出適當實現與增強性能的演算法。 本報告主要對 DS-UWB 系統作ㄧ細部的探討,並提出收發機硬體設計方 法。在第一章與第二章中針對 DS-UWB 實體層規格做介紹,第三章中介紹 DS-UWB 系統接收機設計演算法,包含匹配濾波器、能量偵測器、時間同步器、 通道估測器、訊框起始偵測器、決策迴授等化器、威特比解碼器等。同時硬體實 現方法也一併敘述。在第四章中介紹硬體實現之規格與性能。在第五章中提出一 新的結合干擾消除之犁耙接收器架構,與傳統犁耙接收機或是碼等化器相比,此 架構可以提供更佳的性能與較低的複雜度。目錄
摘 要...i 目錄...ii 第一章 序言...1 1.1 研究背景...1 1.2 章節提要...2 第二章 DS-UWB 實體層規格...3 2.1 DS-UWB 傳送訊號規格...4 2.1.1 獲取序列...4 2.1.2 訊框起始符號...5 2.1.3 訓練序列...5 2.1.4 實體層標頭...6 2.1.5 媒體存取控制標頭...7 2.1.6 標頭檢查序列...7 2.1.7 訊框檢查序列...7 2.2 資料處理...7 2.2.1 混擾器...8 2.2.2 迴旋編碼器...9 2.2.3 交錯器...10 2.2.4 延展碼...12 2.2.5 根餘弦濾波器...12 2.3 通道模型...15 第三章 DS-UWB 接收機...19 3.1 接收機架構...203.1.2 能量偵測...21 3.1.3 最大能量獲取...22 3.1.4 通道估測...26 3.1.5 RAKE...33 3.1.6 訊框起始偵測...34 3.1.7 決策迴饋等化...37 3.1.8 實體層標頭偵測...50 3.1.9 資料解調...51 3.2 威特比解碼器...51 3.2.1 分支路徑單元...56 3.2.2 增加選擇比較單元...59 3.2.3 殘存管理單元...60 3.3 系統模擬...67 第四章 系統規格...76 第五章 干擾消除犁耙接收機...79 5.1 ISIC RAKE ...79 5.2 RAKE ISIC ...81 5.3 複雜度計算...83 5.3.1 ISIC RAKE 複雜度計算 ...83 5.3.2 RAKE ISIC 複雜度計算 ...84 5.4 系統模擬...86
5.4.1 ISIC RAKE Receiver...86
5.4.2 RAKE ISIC Receiver...91
5.4.3 效能綜合比較...97
第六章 結論...101
第一章
序言
1.1 研究背景
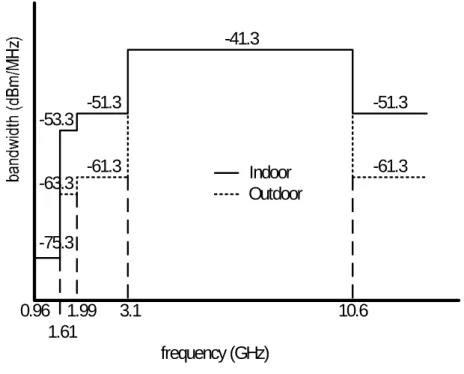
超寬頻(Ultra-Wide Band, UWB)是一種無線個人區域網路系統,原為美國 軍方使用多年的技術,運用於地面穿透雷達、穿牆影像偵測等任務。在2002 年 2 月,美國聯邦通訊委員會(Federal Communications Commission, FCC)正式立 法通過,將3.1 GHz 至 10.6 GHz 的 7.500 MHz 頻譜配置給超寬頻系統使用,允 許這些設備使用現有無線服務所佔用的頻帶,但是要在極其低的功率(-41.3 dB) 下執行,以避免出現任何干擾。
由於超寬頻系統具有低耗電與高速率傳輸等特性,開放商業化用途後,立即 成為資訊、通信與數位家電等各方業者關注的焦點。電機電子工程師學會 (Institute of Electrical and Electronics Engineers, IEEE)更成立 802.15.3a 工作小 組,著手制定以超寬頻技術為核心之個人無線區域網路的實體層(PHY)與媒體 存取控制層(MAC)標準規格。經過激烈的競爭後,剩下兩個陣營提出方案, 爭取成為最後的標準:由摩托羅拉(Motorola)與飛思卡爾(Freescale)所主導 的直接序列超寬頻技術陣營(Direct-Sequence UWB, DS-UWB),以及由英特爾 (Intel)與德州儀器(TI)的多頻段 OFDM 聯盟陣營(Multiband-OFDM Alliance UWB, MBOA-UWB)。
本報告以IEEE 802.15 Task Group 3a 於 2005 年 9 月提出的 DS-UWB Physical Layer Submission to 802.15 Task Group 3a 為基礎,在假設沒有頻率與相位偏移 下,使用每個位元24 個片碼(chips)的延展碼,並藉由一些簡單的演算法降低 複雜度,再利用軟體模擬在超寬頻通道環境下的效能,設計出 DS-UWB 基頻收 發機系統。
1.2 章節提要
本報告的章節安排如下,第二章以IEEE 802.15 Task Group 3a 提出的 DS-UWB 規格為基礎設計發射訊號與發射機,並遵守 FCC 提出的 UWB 功率頻 譜限制。第三章討論接收機架構,包含訊號能量檢測(energy detection)、最大 訊號能量位置獲取(acquisition)、訊框起始符號偵測(SFD detection)、粗略 通道估測(coarse channel estimation)、訊號能量收集、通道等化與解調變等系 統。第四章討論系統規格。第五章提出犁耙接收機結合干擾消除(ISIC RAKE 與 RAKE ISIC)。第六章對設計的超寬頻系統基頻收發機做簡單的總結。
第二章
DS-UWB 實體層規格
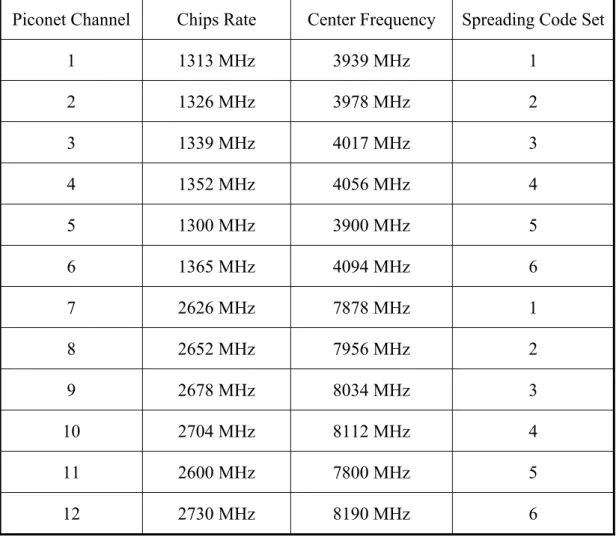
DS-UWB 是一種能提供資料高傳輸率的無線個人區域網路,採用二位元相 位鍵移(Binary Phase Shift Keying,BPSK)技術調變,使用的頻譜是由低頻帶 與高頻帶所構成。低頻帶的頻率是從3.1 GHz 到 4.85 GHz,而高頻帶的頻率則是 從6.2 GHz 到 9.7 GHz,每個頻帶分別包含 6 個微網(piconet),而且每個微網 都有獨特的中心頻率與微網獲取碼(Piconet Acquisition Code,PAC),微網獲 取碼長度為每個位元24 個片碼。表 1 為低頻帶與高頻帶各個微網的片碼率(chips rate)、中心頻率(center frequency)、延展碼編號(spreading code set)與對應的 延展碼。本文設計是採用Piconet Channel 1 的延展碼(-1,0,1,-1,-1,-1,1,1,0,1,1,1,1, -1,1,-1,1,1,1,-1,1,-1,-1,1)。
表1 DS-UWB 頻帶微網編號、片碼率、中心頻率與延展碼
Piconet Channel Chips Rate Center Frequency Spreading Code Set 1 1313 MHz 3939 MHz 1 2 1326 MHz 3978 MHz 2 3 1339 MHz 4017 MHz 3 4 1352 MHz 4056 MHz 4 5 1300 MHz 3900 MHz 5 6 1365 MHz 4094 MHz 6 7 2626 MHz 7878 MHz 1 8 2652 MHz 7956 MHz 2 9 2678 MHz 8034 MHz 3 10 2704 MHz 8112 MHz 4 11 2600 MHz 7800 MHz 5 12 2730 MHz 8190 MHz 6
Spreading Code Set L=24 chips 1 -1, 0,1,-1,-1,-1,1,1,0,1,1,1,1,-1,1,-1,1,1,1,-1,1,-1,-1,1 2 -1,-1,-1,-1,1,-1,1,-1,1,-1,-1,1,-1,1,1,-1,-1,1,1,0,-1,0,1,1 3 -1, 1,-1,-1,1,-1,-1,1,-1,0,-1,0,-1,-1,1,1,1,-1,1,1,1,-1,-1,-1 4 0,-1,-1,-1,-1,-1,-1,1,1,0,-1,1,1,-1,1,-1,-1,1,1,-1,1,-1,1,-1 5 -1, 1,-1,1,1,-1,1,0,1,1,1,-1,-1,1,1,-1,1,1,1,-1,-1,-1,0,-1 6 0,-1,-1,0,1,-1,-1,1,-1,-1,1,1,1,1,-1,-1,1,-1,1,-1,1,1,1,1
2.1 DS-UWB 傳送訊號規格
DS-UWB 傳送訊號組成如圖 2.1,包含有獲取序列(acquisition sequence)、 訊框起始符號(start frame delimiter,SFD)、訓練序列(training sequence)、實 體標頭(PHY header)、媒體存取控制標頭(Media Access Control header,MAC header),標頭檢查序列(Header Check Sequence,HCS)、訊框本體(frame body)、 訊框檢查序列(Frame Check Sequence,FCS)與經過資料處理所增加的位元(pad bits)。資料處理由三個階段組成:混擾器(Scrambler)、迴旋編碼器(Convolution encoder)、交錯器(Interleaver)。而需要處理的資料有媒體存取控制標頭、標 頭檢查序列、訊框本體與訊框檢查序列,至於是否經過迴旋編碼器與交錯器則依 照實體標頭內的設定。 AcquisitionSequence 512 Bits SFD 32 Bits Training Sequence 288 Bits PHY header 32 Bits X3 MAC header 80 Bits HCS 16 Bits Frame Body 0~4096 Bytes FCS 32 Bits Pad Bits 圖2.1 DS-UWB 傳送訊號序列
2.1.1
獲取序列
多路徑效應造成訊號衰減與能量分散。因此必須使用獲取序列藉由訊號能量偵測 判定訊號是否進入,並決定訊號最大能量位置來做粗略通道估測。獲取序列包含 512 個位元,是由長度 17 個暫存器的虛擬隨機產生器(pseudo random generator) 產生,圖2.2 為獲取序列產生器架構,產生方程式如下: -1 -2 -3 -4 -5 -12 -13 -14 -15 -16 -17 [ ... ] init n n n n n n n n n n n x = x x x x x x x x x x x (2.1) -3 -17 n n n x =x ⊕x (2.2) n n s =x (2.3) 此處⊕代表 modulo-2 運算,xn k- 表示經過k 個延遲,s 為獲取序列輸出訊號。設n 計上訂定系統暫存器初始值由編號1~17 分別為 1001_1100_0111_0110_1,而每 組獲取序列暫存器的初始值(initial seed)為上一組獲取序列結尾內暫存器的值。 圖2.2 獲取序列產生器
2.1.2 訊框起始符號
訊框起始符號序列包含32 個位元,是用來決定訊框起始,傳送順序由先至 後定義為1110_0011 _1100_0100_0110_1010_0110_1001。對於每一組傳送訊號的 訊框起始符號都相同,而且與任一部分獲取序列中的32 個位元有最大的漢明距 離(hamming distance)。2.1.3 訓練序列
訓練序列主要用來做通道估測與等化,包含288 個位元。使用與獲取序列虛 擬隨機產生器相同方程式,但是訓練序列產生器的初始值是固定的,並不隨不同的傳送訊號做改變,如此才能讓訓練序列在接收機是已知資料。設計上訂定訓練 序列暫存器初始值由編號1~17 分別為 1111_0000_1001_0110_0。
2.1.4 實體層標頭
實體層標頭序列是由32 個位元連續傳送三次組成,包含有訊框本體長度 (frame body length),混擾器種子識別符號(scrambler seed identifier)、前向 錯誤更正(Forward Error Correction, FEC)型態、交錯器型態(interleaver mode) 等資訊。表2 為實體層標頭規格,傳送順序由先而後為 b31~ b0。
表2 實體層標頭規格
Bits(LSB:MSB) Context Description(MSB:LSB)
b0-b15 Frame body length A 16 bit field that contains the length of the frame body, including FCS, in octets, LSB is b0, MSB is b15, e.g. 4 octets of data, is encoded as
0000000000000100.. Note that there is no FCS for a zero length frame body. b16-b23 reserved 0000_0000
b24-b25 Seed identifier 2 bits that selects the seed for data scrambler
b26-b28 FEC mode 000 = no FEC
001 = k=6 , rate 1/2 convolution code 010 = k=6 , rate 1/2 convolution code 011 = k=4 , rate 1/2 convolution code 100 = k=4 , rate 1/2 convolution code
110 = reserved (no FEC) 111 = reserved (no FEC) b29 Interleaver mode 0 = interleaver
1 = reserved (no interleaver) b30-b31 reserved 00
2.1.5
媒體存取控制標頭
媒體存取控制標頭序列是由80 個位元組成,包含媒體層需要傳送的資訊, 並遵循IEEE Std 802.15.3™-2003 規範。2.1.6
標頭檢查序列
標頭檢查序列為16 個位元,是結合實體層標頭和媒體存取控制標頭做循環 冗餘檢查碼(Cyclic Redundancy Check, CRC)計算得到,CRC-16 的多項式為16 12 5 1 x +x + + 。 x
2.1.7 訊框檢查序列
訊框檢查序列為32 個位元,是以資料做循環冗餘檢查碼計算得到,CRC-32 的多項式為x32+x26 +x23+x22+x16+x12+x11+x10+ + + + + + + 。 x8 x7 x5 x4 x2 x 12.2 資料處理
資料處理是由三部分組成,依序為:混擾器、迴旋編碼器與交錯器。混擾器 的功能是將輸入資料打亂,使輸出資料0 與 1 的個數幾乎相同,讓資料具有隨機 性。而資料隨機的程度是根據混擾器的產生多項式來決定,多項式次數越高資料 隨機程度也越高。迴旋編碼是一種前向錯誤更正碼,藉由不同的編碼率對資料進行編碼,降低資料位元錯誤率,在解碼則使用威特比演算法(Viterbi algorithm)。 DS-UWB 系統依照使用要求有兩種不同限制長度(constraint length),分別為
K 4= 與K 6= ,也可以不使用迴旋編碼。經過迴旋編碼後的資料,為了讓效能 更好,通常都會加上交錯器。交錯器的功用是把輸入資料打散,讓前後相鄰的位 元散佈在不同的位置,如此每個兩兩相鄰的位元便可以視為是互相獨立,這對於 對抗突爆錯誤(burst error)有很好的效果。
2.2.1 混擾器
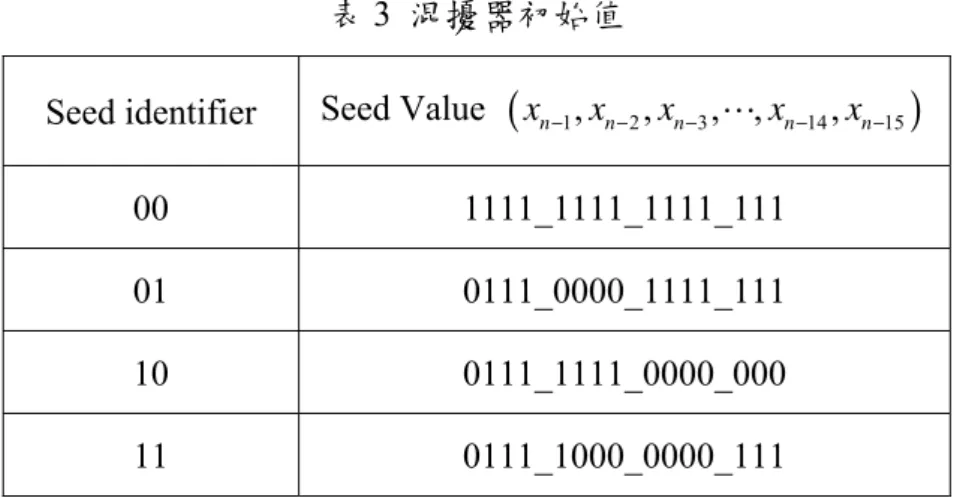
混擾器是使用長度15 個暫存器的虛擬隨機產生器產生二位元虛擬隨機序 列,再與輸入資料做modulo-2 運算,圖 2.3 為混擾器架構。 D1 D2 D14 D15 Data Output 圖2.3 混擾器 混擾序列產生方程式如下: -1 -2 -3 -4 -5 -12 -13 -14 -15 [ ... ] init n n n n n n n n n x = x x x x x x x x x (2.4) 14 15 n n n x =x− ⊕x − (2.5) n n n s = ⊕ b x (2.6) 此處⊕代表 modulo-2 運算,xn k- 表示經過k 個延遲,b 為輸入資料,n s 為輸出資n 料。表3 是混擾器初始值的四種參數,這些初始值的選擇原則是暫存器的狀態彼 此都相距8192 個,也是這種階數的混擾多項式所能達成的最遠相隔距離,相當 於傳送一個1024 個位元組訊框的分隔長度。表3 混擾器初始值
Seed identifier Seed Value
(
xn−1,xn−2,xn−3, ,⋅⋅⋅ xn−14,xn−15)
00 1111_1111_1111_111 01 0111_0000_1111_111 10 0111_1111_0000_000 11 0111_1000_0000_111
2.2.2 迴旋編碼器
迴旋編碼器有兩種限制長度,分別為K 4= 與K 6= ,如圖2.4 所示。 D3 0 n Cout 1 n Cout Data D1 D2 (a) 0 n Cout 1 n Cout (b) 圖2.4 迴旋編碼器(a)K 4= (b)K 6=K 4= 的編碼方程式為式(2.7)與(2.8),K 6= 則為式(2.9)與(2.10) 0 -1 -3 n n n n Cout = +x x +x (2.7) 1 -1 -2 -3 n n n n n Cout = +x x +x +x (2.8) 0 -1 -3 -5 n n n n n Cout = +x x +x +x (2.9) 1 -2 -3 -4 -5 n n n n n n Cout = +x x +x +x +x (2.10) 將兩種迴旋編碼器做合併,表示成式(2.11)與(2.12)。其中 x 與 x 為兩者之間差異 項,當 x 與 x 加入式子時,變成K 6= 迴旋編碼器,去除 x 且x= 時則為 K 41 = 迴 旋編碼器,將合併後的架構表示成圖2.5。在迴旋編碼後須要將暫存器狀態回復 為零,因此需要在混擾序列後增加K -1個尾隨位元(tail bits)。
(
)
0 -1 -2 -1 -3 n n n n n n Cout = +x x +x x +x (2.11)(
)
1 -2 -2 -1 -2 -3 n n n n n n n Cout = +x x +x x +x +x (2.12) D3 D4 D5 0 n Cout 1 n Cout Data D1 D2 圖2.5 迴旋編碼器2.2.3 交錯器
由於訊號傳送中可能遭遇到突爆錯誤,而迴旋編碼因為相臨位元彼此有關聯 性,所以對於突爆錯誤相當敏感,因此必須使用交錯技術先將資料打散。當遭遇料打散。在規格書中建議使用迴旋交錯(convolutional interleaver)而非使用區塊 交錯(block interleaver),是因為較低的時間延遲和較小的記憶體需求所做的考 量。 圖2.6 是一個交錯器架構,資料以串列的方式依序移入 N 排暫存器,這 N 排暫存器之中,後面一排暫存器都比前一排多J 個位元的記憶空間,第一排暫存 器沒有任何記憶空間。當每一個新的編碼位元移入時交換器會切換到下一排暫存 器,接著新的編碼位元移入暫存器而暫存器中最老的編碼位元則移出。經過N 個位元之後,交換器會回到第一排暫存器然後重新開始。解交錯器的暫存器排列 方式則正好相反,也就是說第一排暫存器的延遲是(N-1)J,而最後一排暫存器的 延遲為零,其餘程序則和交錯器相同,圖2.7 是解交錯器架構。系統設計是採用 J 7= 、N 10= 。 J 2J (N-2)J (N-1)J Interleaver bits Encoded bits 圖2.6 交錯器 J 2J (N-2)J (N-1)J DeInterleaver bits Interleaver bits 圖2.7 解交錯器
2.2.4
延展碼
設計上使用Piconet Channel 1 的延展碼, 圖 2.8 是延展碼編碼器架構,藉由 延展碼的切換並乘上資料後再輸出到根餘弦濾波器。
圖2.8 延展碼編碼器
2.2.5 根餘弦濾波器
DS-UWB 基頻脈衝響應(baseband impulse response)採用規格書中所建議 30%額外頻寬(excess bandwidth)的根餘弦低通濾波器(root- raised cosine low pass filter)作為設計基礎,並遵循美國聯邦通訊委員會提出的發射功率規定,圖 2.9 為FCC 對 UWB 系統定義的功率遮罩(mask)。 0.96 1.611.99 3.1 10.6 -41.3 -51.3 -51.3 -61.3 -61.3 -53.3 -63.3 -75.3 frequency (GHz) Indoor Outdoor 圖2.9 UWB 系統室內與室外發射功率規定
首先將理想的根餘弦波形作範圍模擬,經由比較後得到以6 個週期(T 6= )為 範圍。圖2.10 是資料經過根餘弦濾波器後,再載上載波的發射訊號功率頻譜。 圖2.10 T 6= 的發射訊號功率頻譜 接著對根餘弦波形作取樣,決定以每個週期3 個取樣點(S 3= ),圖2.11 是模 擬後的發射訊號功率頻譜。 圖2.11 T 6= 、S 3= 的發射訊號功率頻譜
最後對取樣後的根餘弦波形做量化,經過模擬後決定取樣範圍T=6、取樣頻率 S=3、量化階數 Q 5= ,圖 2.12 是參數決定後的發射訊號功率頻譜。 圖2.12 T 6= 、S 3= 、Q 5= 的發射訊號功率頻譜 當T 6= 、S 3= 時會有19 個取樣點,但是在左右兩邊的兩個取樣點量化後皆為 零,因此不列入。將所得到的量化值以二補數(two’s complement)編碼,製作 成表4,圖 2.13 則是根餘弦濾波器架構圖。 表4 根餘弦波型編碼表 取樣點 量化值 編碼 1 1 00001 2 1 00001 3 -1 11111 4 -3 11101 5 -1 11111 6 5 00101
7 12 01100 8 15 01111 9 12 01100 10 5 00101 11 -1 11111 12 -3 11101 13 -1 11111 14 1 00001 15 1 00001 D1 D2 D3 D13 D14 Output -1 1 -3 -1 1 Data Σ D12 1 1 圖2.13 根餘弦濾波器
2.3 通道模型
通道模型是根據IEEE 802.15 Task Group 3a 於 2002 年 12 月所提出的 Channel Modeling Sub-committee Report Final。基於在多次通道量測中觀察到的群集 (clustering)現象,通道模型的建構是根據 Saleh-Valenzuela 模型再輔以一些修 正。對於多重路徑所造成的增益強度(multipath gain magnitude),在模型中採 用的是lognormal 分布而非 Rayleigh 分布,因為 lognormal 分布較為符合實驗的 量測資料。除此之外,每一束群集和群集中的每一道分枝線(ray)一樣都假定
有獨立的衰減。因此,多重路徑模型是由下列的離散時間脈波響應(discrete time impulse response)所構成: , , 0 0 ( ) L K i ( i i ) i i k l l k l l k h t X α δ t T τ = = =
∑∑
− − (2.13) 其中 i, k lα 代表多重路徑增益係數(multipath gain coefficients), i l
T 是第l個群集
的延遲, i, k l
τ 是相對於第l個群集到達(cluster arrival time)第k個多重路徑成分的時 間延遲,X 代表 log-normal 的遮蔽效應(shadowing)而 i 代表第 i 個 realization。 i
由於全部多重路徑能量的 log-normal 遮蔽效應是由X 項所表示,對於每一i 個 realization 在 i, k l α 項中所包含的總能量都會正規劃(normalize)至單位能量。 此遮蔽效應可以由式子(2.14)表示: 2 20log10( )Xi ∝Normal(0,σx) (2.14) 而通道分為四種類型:
CM1:在 0 到 4 公尺內,有直視路徑(Line Of Sight, LOS)。 CM2:在 0 到 4 公尺內,無直視路徑(Non Line Of Sight, NLOS)。 CM3:在 4 到 10 公尺內,無直視路徑。
CM4:均方根延遲擴散(root mean square, RMS)延展到 25ns,比較極端的 通道環境且無直視路徑。
圖2.14 是經由程式模擬產生 4 種通道的離散時間脈波響應,其中 CM1 的路徑能 量大約分散在1 個位元內、CM2 在 2 個位元、CM3 則在 3 個位元、CM4 分散了 5 個位元時間。
(a)
(c)
第三章
DS-UWB 接收機
通訊系統中,接收機設計一直是最重要的部分,其直接影響系統性能。而 UWB 系統有著複雜的多路徑通道,多路徑效應會造成訊號能量分散與相鄰位元 干擾,必須設計通道偵測與等化補償機制,降低通道效應造成的資料錯誤。而一 般使用的演算法有相當複雜的數學運算,越複雜的運算就代表著晶片面積與成本 增加,但是系統性能比較好。因此如何降低運算複雜度,但是又不會大幅降低系 統性能是設計上重要的部分。 圖3.1 是設計的 DS-UWB 接收機架構,訊號首先經過匹配濾波器(matched filter)解回延展碼。接著進行能量偵測,用以判別訊號是否進入。當確認訊號進 入時,開始偵測訊號最大能量所在的位置(max path acquisition),接著做一個粗 略的通道估測,並使用Rake 將分散的訊號能量收集回來。訊號能量收集後,開 始偵測訊框起始,確保後續資料能夠解調。經過一段時間後,若沒有得到訊框起 始則再繼續做能量偵測;若得到訊框起始,則用已知的訓練序列作決策迴饋等化 (Decision Feedback Equalizer, DFE)。接著偵測傳送的實體層標頭序列,並將得 到的資訊用以控制解調方塊。最後進行包含解交錯(de-interleaver)、威特比解碼 器(Viterbi decoder)與解混擾(de-scrambler)等解調部分,再輸出解調資料。3.1 接收機架構
在發射訊號進入接收機前先經過如圖3.2 的處理,首先將基頻傳送訊號載上 載波後通過 UWB 通道並加上雜訊,接著使用自動增益控制(Automatic gain control,AGC)將訊號限制在一定範圍,再將訊號降至基頻並以每個片碼 3 個取 樣點做取樣後輸入接收機。 ( ) cos 2πf tc 2 cos 2( πf tc) 圖3.2 通道模型
3.1.1 匹配濾波器
匹配濾波器包含有根餘弦濾波器與解延展碼器,接收機使用根餘弦濾波器與 傳送機的根餘弦濾波器是相同架構,如圖 3.3。解延展碼器則是將傳送機延展碼 的係數做反相排列成(1,-1,-1,1,-1,1,1,1,-1,1,-1,1,1,1,1,0,1,1,-1,-1,-1,1,0,-1),圖 3.4 為接收機解延展碼器。 D1 D2 D3 D13 D14 Output -1 1 -3 -1 1 Data Σ D12 1 1 圖3.3 根餘弦濾波器D Output 1 -1 -1 1 1 0 -1 Data Σ D D D D D 圖3.4 解延展碼器
3.1.2 能量偵測
由於訊號並非持續的傳送,因此接收到的訊號有時候只有雜訊成份,必須經 由訊號能量偵測確認是否有訊號進入。一般是將訊號取絕對值後疊加再做判斷, 但是此種方式在低訊雜比(Signal to Noise Ratio, SNR)時效果不好。考量傳送訊 號經過UWB 通道後其能量被分散的相當小,造成能量偵測相當困難。所以在獲 取序列做一些修改,將前 64 個位元都傳送 1,如此可以直接對訊號做疊加,因 為理論上雜訊做多次疊加後其平均值趨近於零。將能量檢測流程表示成圖 3.5, 首先將輸入訊號疊加 32 個位元後,判斷每個取樣點是否有超過一個臨界值 (threshold),當任一個取樣點超過臨界值就認定訊號進入。經過量化模擬後, 將臨界值定為512。 訊號 疊加32個 Bits訊號 Threshold yes no 確認訊號進入 圖3.5 訊號能量偵測圖3.6 是訊號能量偵測的成功機率,可以看到藉由上述方式作能量偵測,在 SNR=6 時成功機率趨近於 1。 圖3.6 訊號能量偵測成功機率
3.1.3 最大能量獲取
在沒有多路徑效應、干擾與雜訊下,匹配濾波器輸出的訊號在每個位元內皆 有一根脈衝(pulse),但脈衝所在的位置是未知的,必須做訊號獲取才能得到 脈衝位置。而經過多路徑效應後,訊號遭受嚴重的ISI 影響,造成更難獲取最大 訊號位置。設計上使用如圖3.7 的流程做訊號獲取,首先將輸入訊號取絕對值, 接著疊加128 個位元後,以最大值的取樣點為最大能量位置。判斷各 取樣點 最大能量位置 | . | 疊加128個Bits 訊號 訊號 圖3.7 能量位置獲取流程 將使用的訊號獲取方式與已知的等效通道經由模擬後做比較,以超過等效通道最 大能量80%的所有位置,即判定獲取位置正確。圖 3.8 為模擬後各種通道下的結 果,可以看出當疊加的位元數越多所得到的錯誤率越低,設計上取用128 個位元 作能量獲取用。
(a)
(c)
(d)
3.1.4 通道估測
常見的通道估測方式有遞迴最小平方(Recursive Least Square, RLS)演算法 與最小平均平方(Least Mean Square, LMS)演算法,都必須藉由已知訓練序列 做通道估測。一般來說LMS 較容易實現,但 RLS 卻有著較好的性能。然而在真 正把理論實作時,有許多因素如面積、成本和速度都必須考量在內,也因此必須 要對理論作一些簡化,雖然會犧牲部份的性能,但如果換取而來的是實現難度大 大地降低,這種方法往往還是會被取用。 RLS 演算法是利用最小平方差,將已知資料u
( )
n ,找出一組最適當的係數( )
n w ,使其經過相乘後的值與輸入的序列d n( )
有最小的誤差值e n( )
。RLS 演算 法如下: 首先令w( )
0 = 0 P( )
0 = δ-1I其中 = small positive constant for high SNR large positive constant for low SNR δ ⎧⎨ ⎩ 接著重複式(3.1) ~ (3.5),其中 = 1,2,...n
( )
n = -1( ) ( )
n n π P u (3.1)( )
= + H( ) ( )
( )
n n n n λ π k u π (3.2)( )
( )
H( ) ( )
e n = d n -w n-1 u n (3.3)( )
n = -1 +( ) ( ) ( )
n n e∗ n w w k (3.4)( )
-1 --1( )
-1( ) ( ) ( )
H -1 n = λ n λ n n n P P k u P (3.5) LMS 演算法與 RLS 演算法相似,但是方程式上不需要複雜的矩陣運算,LMS 演首先令w
( )
0 = 0 接著重複式(3.6)與(3.7),其中 = 1,2,...n( )
( )
H( ) ( )
e n = d n -w n u n (3.6)(
n+ =1)
( )
n +λ( ) ( )
n e∗ n w w u (3.7) 雖然RLS 比 LMS 有著更快速的收斂速度,但實現上 RLS 牽涉到複雜的矩陣運 算,有相當的困難度,一般做通道估測大多採用LMS。 但是在複雜的多路徑通道下,若要收集到大多數的訊號能量,勢必要以一定 的取樣率做LMS 演算法。以片碼為取樣率來看,將通道估測範圍設定在 N 個位 元內,則係數w( )
n 為24N 個 taps,LMS 演算法乘法個數為 72N,若將係數λ 以 2 的冪次方做運算也需要 48N 個乘法。而且參數w的更新必須經過多個乘法與加 法運算,這些動作必須在一個時脈週期內完成,造成系統工作頻率大幅下降。同 時決策迴饋等化也需要利用訓練序列,考量已知的訓練序列長度為288 個位元, 如果先做通道估測再做決策迴饋等化長度勢必不夠使用,所以使用一個粗略通道 估測方式,利用未知的獲取序列做通道估測。 首先以位元為區間,將偵測到每個位元中最大能量位置的訊號判斷為+1 或 -1 做為各區間的資料。將判斷的資料乘上該區間內各取樣點,並做疊加 128 個 位元後,成為粗略的通道,如圖3.9 流程。圖3.9 粗略通道估測 對粗略通道估測而言,將雜訊乘上±1 只是將其反相,經由持續的疊加後, 理論上雜訊項的期望值為零,因此估測出來的粗略通道主要受到通道造成的ISI 影響。而對LMS 演算法來說,雜訊會造成誤差值e n
( )
變化過於劇烈而不容易收 斂。雖然經由粗略通道估測所判斷的資料可能是錯誤的,但藉由模擬可以看到當 SNR 為 0dB 時,位元錯誤率大概在 0.25 左右,即 4 個位元有 1 個會判斷錯誤, 此影響並不大。圖3.10 是討論在最大能量位置已知下最大能量位置擺放的影響, 以24 個 taps 做粗略通道估測並結合 RAKE,經由模擬看出當最大能量放在第 9 個taps 時有最好的效能。(a)
(c)
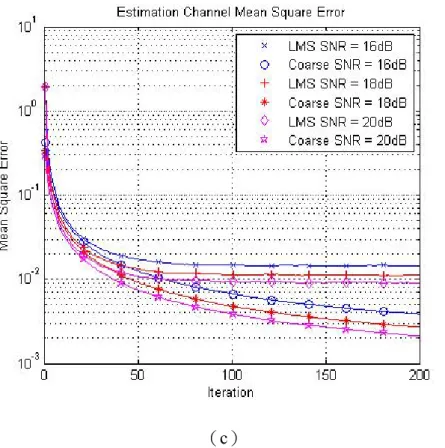
圖3.11 是比較在 128 個位元長度下以 24 個 taps 做通道估測,分別使用已知 資料且λ=0.0625的LMS 演算法與分別使用已知與未知資料的粗略通道估測,並 結合RAKE 作能量收集後統計資料的位元錯誤率。可以看到使用已知資料作粗 略通道估測的BER 是最好的,其次是使用未知資料的粗略通道估測,最後為已 知資料的LMS 演算法。 圖3.11 LMS 與粗略通道估測位元錯誤率 圖3.12 則是在各種 SNR 下,使用已知資料且λ =0.0625的LMS 演算法與未 知資料的粗略通道估測方式,計算估測通道與等效通道的均方差(Mean Square Error, MSE)。可以看出在前段部份是 LMS 演算法誤差較小,隨著次數越多,粗 略通道估測方法會比LMS 演算法的誤差更小並持續下降,但是粗略通道估測方 式的缺點在於只能估測在一個位元內的通道。
(a)
(c)
圖3.12 估測通道與等效通道的均方差(a)0~6 dB(b)8~14 dB(c)16~20 dB
3.1.5 RAKE
由於通道估測是以每個位元取24 個 taps 的 chip rate,因此將訊號也以 chip rate 輸入 RAKE 作能量收集後再以 bits rate 輸出。使用圖 3.13 的 All RAKE 架構, 將訊號輸入與通道係數相乘後累加,當累加一個位元時間後再取樣輸出。 weight D Add Input Output chip Down-Sample bit chip clear chip 圖3.13 RAKE 架構
3.1.6 訊框起始偵測
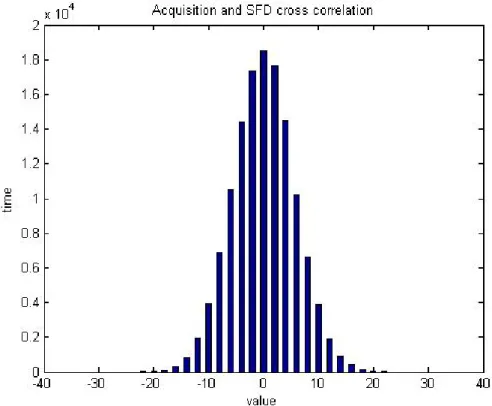
訊框起始序列其傳送順序由先至後為1110_0011_1100_0100_0110_1010_01 10_1001,在接收機則使用步階延遲架構(Tapped Delay Line, TDL)做為訊框起 始偵測器。圖3.14 是接收機訊框起始偵測器,首先將 RAKE 輸出資料判斷為+1 或− ,接著通過訊框起始偵測器,當輸出超過一個臨界值後,即判斷訊框起始1 正確。 D1 D2 D3 D30 D31 Output -1 1 -1 1 Data Σ D29 1 D4 -1 1 1 Theshold 圖3.14 訊框起始偵測器 由於在訊框起始序列前有獲取序列,因此先將兩個序列做交相關(cross correlation)統計,如圖 3.15 可以看到獲取序列經過交相關,最大值只會發生在 22 ± 。
圖3.15 獲取序列與訊框起始序列交相關統計
假設臨界值分別為±23、±25、±27,經過模擬各種通道下的狀況,如圖3.16 為 3 種臨界值的訊框起始偵測錯誤率與獲取序列錯誤偵測機率。由結果中得知,相 同訊雜比下臨界值越大越不容易偵測到,且獲取序列也越難偵錯。經由取捨後, 決定以±25為臨界值。
(a)
(c) 圖3.16 訊框起始偵測錯誤率(a)±23(b)±25(c)±27
3.1.7 決策迴饋等化
UWB 通道嚴重的多路徑效應,對於相鄰位元的干擾相當嚴重。當使用粗略 通道估測結合RAKE 收集到的訊號,仍然遭受到相鄰位元干擾,所以需要藉由 等化器降低相鄰位元干擾。設計上採用最小均方值決策迴饋等化器(least mean square - decision feedback equalizer,LMS-DFE),LMS-DFE 包含兩部分:前饋(feed-forward)部分和回授(feedback)部分。前饋序列uf
( )
n 使用的是輸入資料,回授序列ub
( )
n 使用的是已知的訓練序列,當訓練結束後則將等化後的訊號經由判斷再輸入回授部分。其中wf
( )
n 與wb( )
n 分別為前饋與回授係數,d n( )
為已知的訓練序列,演算法如下:
接著重複式(3.8)與(3.9),其中 = 1,2,...n
( )
( )
(
H( ) ( )
H( ) ( )
)
e n = d n - wf n uf n +wb n ub n (3.8)(
)
( )
( ) ( )
(
)
( )
( ) ( )
1 + e 1 + e f f f b b b n n n n n n n n λ λ ∗ ∗ ⎧ + = ⎪ ⎨ + = ⎪⎩ w w u w w u (3.9) 圖3.17 為一個前饋 3 級和回授 5 級的 LMS-DFE 架構,當訓練結束後會將開關切 換到判斷的部份,同時令λe n( )
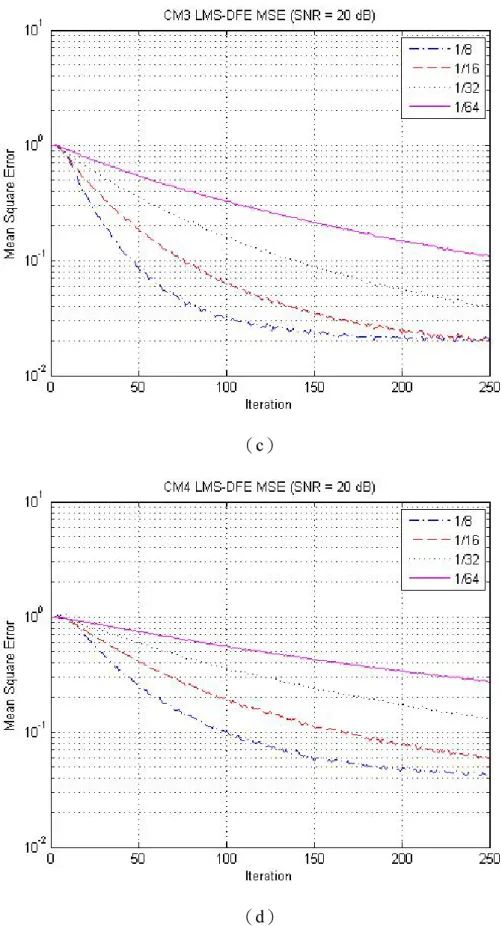
為零。 2 wf 1 wb wb0 4 wb wb3 wb2 Output D Input 0 wf wf1 D ( ) e n λ D D ( ) e n λ D ( ) e n λ D D D D D D D D D D ( ) e n λ λe n( ) λe n( ) λe n( ) λe n( ) Training sequence -+ ( ) e n λ λ ( ) e n 1 ± 圖3.17 前饋 3 級和回授 5 級的 LMS-DFE 架構 將收集回的訊號結合一個前饋3 級和回授 5 級的 LMS-DFE 做模擬驗證,觀 察在不同參數λ 下效能,圖 3.18 是在各種通道下只使用 RAKE 與結合 LMS-DFE 後的位元錯誤率。由結果觀察到不同的係數λ 在不同的通道環境,與單純使用 RAKE 時的性能各有好壞。圖 3.19 則是在 SNR=20dB 下與已知訓練序列的均方 差,可以看到係數λ 越小收斂越快。而在使用長度 250 個位元下,大多數的係數(a)
(c)
(d)
(a)
(c)
(d)
由於λ 越大收斂越快,所得到的等化係數震盪幅度越大,系統效能差;而 λ 越小收斂越慢,但所得到的等化係數震盪幅度較小,系統效能較好。基於訓練序 列長度只有288 個位元,且就模擬結果觀察到當λ =1/ 8時,大約只需要128 個 位元即可收歛。所以對係數λ 做調整,前 128 個位元使用λ=1/ 8做快速收歛, 後128 個位元則進行微調。圖 3.20 是對後 128 個位元所需要的係數λ 模擬,其 中λ =1/ 64在各種通道環境下效果最好,且都比只使用RAKE 下的 BER 低。所 以在LMS-DFE 採用兩段式係數λ ,前 128 個位元使用λ=1/ 8,後128 個位元使 用λ =1/ 64。 (a)
(b)
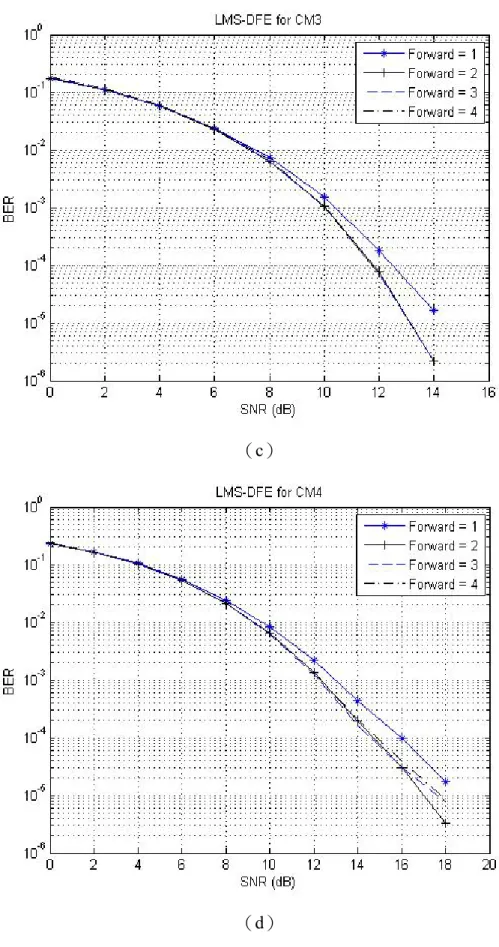
(d) 圖3.20 LMS-DFE 在不同係數λ 下位元錯誤率(a)CM1(b)CM2 (c)CM3(d)CM4 在決定使用分段係數λ 後,就前饋與回授的級數做討論。先固定回授為 5 級,就前饋部分比較如圖3.21。在 CM1 ~ CM3 時使用 1~4 級差異都不大,在 CM4 時使用 1 級則 BER 較差,所以就前饋部分採用 2 級。接著以前饋 2 級就回 授級數做比較如圖3.22,在 CM1 ~ CM2 時使用 1~5 級差異不大,在 CM3 ~ CM4 時使用1、2 級則 BER 較差。因此決定 LMS-DFE 前饋為 2 級,回授為 3 級。
(a)
(c)
(d)
圖3.21 LMS-DFE 前饋級數比較(a)CM1(b)CM2 (c)CM3(d)CM4
(a)
(c)
(d)
圖3.22 LMS-DFE 回授級數比較(a)CM1(b)CM2 (c)CM3(d)CM4
3.1.8 實體層標頭偵測
傳送訊號中,實體層標頭序列是由32 個位元連續傳送 3 次組成。接收機使 用的偵測方式有兩種:Case 1 是先判斷為+1 或-1 後,將 3 次相對應的位元做相 加,再判斷為正或負做為判斷位元,如圖3.23。Case 2 是不先做判斷直接相加, 最後再判斷為正或負做為判斷位元。前者的做法比較簡單且複雜度低,後者較精 確但是複雜度較高。 -1 -1 -1 -1 -1 +1 -1 +1 -1 -1 -1 +1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 +1 -1 -1 +1 -1 -1 -1 +1 -1 +1 正確 PHY header 接收PHY header 偵測後 -1 -1 -1 -1 -1 +1 -1 +1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 +1 -1 +1 +1 -1 -1 -1 +1 -1 +1 -1 -1 -1 -1 -1 +1 +1 +1 -1 -1 -1 -1 -1 -1 +1 -1 -1 -1 -1 -1 -1 -1 +1 -1 +1 +1 -1 +1 -1 +1 -1 +1 -1 -1 -1 -1 -1 +1 -1 +1 -1 +1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 +1 +1 -1 -1 -1 +1 -1 +1 -3 -3 -3 -3 -3 +3 -1 +3 -3 -1 -3 -1 -3 -3 -1 -3 -3 -3 -3 -3 -3 -3 +1 -3 +1 +3 -3 -1 -3 +3 -3 +3 -1 -1 -1 -1 -1 +1 -1 +1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 +1 -1 +1 +1 -1 -1 -1 +1 -1 +1 判斷後 圖3.23 實體層標頭判斷方式 圖3.24 是將兩種方式藉由模擬比較位元錯誤率,雖然 Case 2 的錯誤率比較低, 但是在高SNR 下兩種方式錯誤率都很低。考量 Case 1 的加法位元數比較少,所 以在設計上採用Case 1 的方式。圖3.24 實體層標頭偵測錯誤率
3.1.9 資料解調
接收機的解調方塊包含了解交錯器、威特比解碼器與解混擾器。解交錯器在 2.2.3 節已經提過是將交換器做相反順序交換,就可以達到解交錯。威特比解碼 器將在3.2 節做更詳細的解釋。而解混擾只需要將資料再經過一次混擾器,即可 以把混擾序列消除。3.2
威特比解碼器
本節將對威特比解碼器做詳細的說明,以K=4 的迴旋編碼為例子,如圖 3.25。其中 0 n C 與 1 n C 為編碼輸出, X 為輸入序列。令暫存器內的值X X X 表n-1 n-2 n-3 示為狀態 n-1 n-2 n-3 4 X 2 X X S i + i + ,狀態總個數M=2 。 K-1D3 0 n Cout 1 n Cout Data D1 D2 圖3.25 K=4 迴旋編碼器 由架構上可以得知,當目前狀態為S2i時,輸入0 則狀態改變為Si;輸入1 則狀 態改變為SM 2+i。目前狀態為S2 1i+ 時,輸入0 則狀態改變為Si;輸入1 則狀態改 變為SM 2+i,其中M 是暫存器所有狀態個數。圖 3.26 表示輸入資料後,狀態改變 的蝴蝶圖(Butterfly),實線代表輸入為 0,虛線代表輸入為 1。 M 2 S +i 2 Si 2 1 Si+ Si n-2 X n-1 X n-2 X n-1 X n-2 X n-1 X n-2 X n-1 X 圖3.26 狀態改變蝴蝶圖 由上述可以知道狀態改變是有一定關係,因此將輸出編碼與狀態改變整理成表 5,圖 3.27 則是迴旋編碼格子圖(Trellis)。
表5 迴旋編碼與狀態改變(a)K=4 (b)K=6 輸入0 輸入1 輸入0 輸入1 原始狀態 狀態 編碼 狀態 編碼 原始狀態 狀態 編碼 狀態 編碼 0 000 0 00 4 11 4 100 2 11 6 00 1 001 0 11 4 00 5 101 2 00 6 11 2 010 1 01 5 10 6 110 3 10 7 01 3 011 1 10 5 01 7 111 3 01 7 10 (a) 輸入0 輸入1 輸入0 輸入1 原始狀態 狀態 編碼 狀態 編碼 原始狀態 狀態 編碼 狀態 編碼 0 00000 0 00 16 11 16 10000 8 10 24 01 1 00001 0 11 16 00 17 10001 8 01 24 10 2 00010 1 01 17 10 18 10010 9 11 25 00 3 00011 1 10 17 01 19 10011 9 00 25 11 4 00100 2 11 18 00 20 10100 10 01 26 10 5 00101 2 00 18 11 21 10101 10 10 26 01 6 00110 3 10 19 01 22 10110 11 00 27 11 7 00111 3 01 19 10 23 10111 11 11 27 00 8 01000 4 01 20 10 24 11000 12 11 28 00 9 01001 4 10 20 01 25 11001 12 00 28 11 10 01010 5 00 21 11 26 11010 13 10 29 01 11 01011 5 11 21 00 27 11011 13 01 29 10 12 01100 6 10 22 01 28 11100 14 00 30 11 13 01101 6 01 22 10 29 11101 14 11 30 00 14 01110 7 11 23 00 30 11110 15 01 31 10 15 01111 7 00 23 11 31 11111 15 10 31 01 (b)
圖3.27 迴旋編碼格子圖 了解迴旋編碼特性後,接下來就威特比解碼演算法做說明。首先將訊號與所 有可能編碼輸出求出漢明距離(hamming distance),接著對各狀態總距離與其 可能出現編碼距離做相加後,下一個狀態選擇以來源狀態最小距離為進入路徑, 稱為殘存距離(survivor path)。經由不斷重複上述步驟直到所有接收訊號完成 比較,最後比較每個狀態總漢明距離,將總距離最小的狀態設定為回溯起點,回 溯路徑後可以得到原本傳送訊號。圖3.28 是一個威特比演算法例子,資料為 (10011010),經過迴旋編碼後得到編碼(11 11 01 00 00 10 01 00),接收後得 到訊號(11 10 01 00 10 10 01 00)。藉由路徑選擇後得到最後在狀態(010)時 有最小總距離2。由狀態(010)開始做路徑回溯,最後解出資料(10011010)。
0 0 0 0 0 1 0 1 0 0 1 1 1 0 0 1 0 1 1 1 0 1 1 1 Data 1 0 0 1 1 0 1 0 Code 11 11 01 00 00 10 01 00 Receiver 11 10 01 00 10 10 01 00 2 4 3 4 0 4 3 4 0 3 3 3 3 3 3 3 3 4 1 3 3 3 1 4 4 1 4 3 4 3 4 1 3 4 3 2 1 4 4 2 4 2 2 4 4 3 2 2 3 4 4 2 3 2 4 2 4 4 3 2 4 2 3 4 4 3 2 4 4 3 4 4 2 0 1 1 0 0 1 1 1 1 0 0 1 1 0 0 1 1 0 2 1 1 2 0 1 1 0 0 1 1 0 0 1 1 0 1 1 0 0 1 1 0 0 1 1 0 0 2 0 1 1 0 0 1 1 0 2 1 1 0 0 1 1 2 圖3.28 威特比演算法例子 在設計上如果依照演算法做資料回溯解碼,則需要相當大的記憶體來儲存 狀態路線,因此一般在設計上必須做路徑管理來降低記憶體面積。圖3.29 是一 個威特比解碼器架構,包含了有:分支路徑單元(branch metrics unit,BMU)、 增加選擇比較單元(add compare select unit,ACSU)、殘存管理單元(survivor management unit,SMU)。分支路徑單元計算接收訊號與所有可能編碼的漢明距 離,然後傳送給增加選擇比較單元與來源狀態的總漢明距離做累加並決定下個狀 態路徑輸入,最後將比較結果以一個判斷位元存入記憶體,殘存管理單元對記憶 體做儲存判斷位元管理與資料回溯並輸出資料。而解碼有兩種方式:暫存器交換 架構(register exchange)與追蹤回溯架構(trace back)。暫存器交換架構需要相 當複雜的電路但是延遲時間短,追蹤回溯架構電路複雜度低但是延遲時間長。因 此使用追蹤回溯電路複雜度低和暫存器交換延遲時間短的特性,做為威特比解碼 器設計基礎。
圖3.29 威特比解碼器架構
3.2.1 分支路徑單元
分支路徑單元是用來計算接收訊號與編碼距離,做法有兩種:硬決定(hard decision)與軟決定 (soft decision)。硬決定是依照訊號調變方式,將接收訊號以界限劃分回復為界限內所期望的 訊號值,再與各種可能編碼的訊號值做距離計算;軟決定則是直接以接收訊號值與各種可能編碼 的訊號值做距離計算。圖3.30是表示為接收訊號S 與各界限內訊號的座標圖,並將各編碼與訊 號的距離整理成 表6,其中 R1與R2分別為接收訊號S 在座標軸 Q1與Q2的座標,M0與M1 則是編碼0 與 1 的座標值。 表6 訊號編碼距離 編碼 分支路徑距離 00 2 2 1 0 2 0 (R -M ) +(R -M ) 01 2 2 1 0 1 2 (R -M ) +(M -R ) 10 2 2 1 1 2 0 (M -R ) +(R -M ) 11 2 2 1 1 1 2 (M -R ) +(M -R )圖3.30 訊號座標圖 將 表6 中各編碼的分支路徑距離做展開如下: 2 2 2 2 2 2 1 0 2 0 1 1 0 0 2 2 0 0 (R -M ) +(R -M ) = R -2R M +M +R -2R M +M (3.10) 2 2 2 2 2 2 1 0 1 2 1 1 0 0 1 2 1 2 (R -M ) +(M -R ) = R -2R M +M +M -2R M +R (3.11) 2 2 2 2 2 2 1 1 2 0 1 1 1 1 2 2 0 0 (M -R ) +(R -M ) = M -2R M +R +R -2R M +M (3.12) 2 2 2 2 2 2 1 1 1 2 1 1 1 1 1 2 1 2 (M -R ) +(M -R ) = M -2R M +R +M -2R M +R (3.13) 因為使用的是BPSK 調變,其中M 與0 M 分別為+1 與-1,且1 R M0 0 =-R0。可以 化簡成相對距離如下,並整理成表7 訊號編碼相對距離。 2 2 1 0 2 0 1 2 (R -M ) +(R -M ) ⇒ R +R (3.14) 2 2 1 0 1 2 1 2 (R -M ) +(M -R ) ⇒ R - R (3.15) 2 2 1 1 2 0 1 2 (M -R ) +(R -M ) ⇒ -R +R (3.16) 2 2 1 1 1 2 1 2 (M -R ) +(M -R ) ⇒ -R - R (3.17) 表7 訊號編碼相對距離 編碼 分支路徑距離 00 R +R 1 2 01 R - R 1 2 10 -R +R 1 2
11 -R -R 1 2 簡化方程式後,將分支路徑單元架構表示成圖3.31。 圖3.31 分支路徑單元 由於軟決定能保留訊號原本大小,但是卻需要相當多的位元做距離累加運 算,同時又會影響解交錯器的輸入與輸出位元個數,所以必須藉由模擬系統效能 才能做取捨。圖 3.32 是比較兩種方式的位元錯誤率,結果中可以看到軟決定會 比硬決定好大約2 到 3dB,但是每增加一個位元則需要增加一組一位元的解交錯 器,所以為了節省晶片面積,設計上使用硬決定。
圖3.32 軟決定與硬決定位元錯誤率
3.2.2 增加選擇比較單元
增加選擇比較單元是將分支路徑距離與路徑來源狀態的距離累加後,再比較 總距離來選擇下個狀態的來源路徑,並傳送判斷位元。由狀態改變蝴蝶圖將增加 選擇比較單元架構表示成圖3.33,這是用編碼 00 與 11 為例子,其中D 為狀態 ii 的總距離,d 為訊號與編碼 00 的距離,00 B 是狀態 i 的判斷位元,在此是指來源i 狀態的最小位元。當來源狀態為2i 1+ 時為 1;來源狀態為 2i 時為 0。d00 d11 Compare D2i D2i+1 D2i+d11 D2i+d00 D2i+1+d11 D2i+1+d00 Bi Bi+M//2 Di Di+M/2 Compare Select Select 圖3.33 增加選擇比較單元
3.2.3 殘存管理單元
殘存管理單元是做判斷位元的管理,並藉由狀態的總距離做解碼輸出,一般 使用兩種方式,分別為暫存器交換架構與追蹤回溯架構。 暫存器交換架構是使用暫存器做判斷位元的交換,所以可以在最後直接將序 列做輸出,減少了追蹤的時間。但是由於暫存器間彼此必須做交換,所以電路相 當複雜。圖3.34 是一個暫存器交換的例子,經過連續的路徑選擇與暫存器交換, 最後可以看到在狀態2 時有最小總距離 2。狀態 2 內暫存器值(10011010)即為 解碼輸出,與資料(10011010)相同。圖3.34 暫存器交換 追蹤回溯架構則是使用記憶體儲存判斷位元,當每塊記憶體儲存完後就開始 回溯,回溯起點為總距離最小的狀態。由前面的討論可以知道,判斷位元是指來 源狀態的最小位元,也就是狀態做跳躍時被擠掉的位元,並由圖 3.26 狀態跳躍 蝴蝶圖可以知道狀態間彼此的關係。當回溯時先讀取路徑狀態內記憶體的判斷位 元,並將路徑狀態的最高位元去掉後做移位,接著在最後一個位元補上判斷位元 即可得到上個狀態,而去除的最高位元為解碼輸出。圖 3.35 是一個追蹤回溯的 例子,將訊號經由追蹤後得到在狀態 2(010)時有最小總距離,讀取狀態 2 個 判斷位元(1),接著刪除狀態 2 的最高位元並做移位(10 ),將判斷位元補入得 到狀態5(101),其中刪除的最高位元為解碼輸出(0)。然後繼續讀取狀態 5 個 判斷位元(1),接著刪除狀態 5 的最高位元並做移位(01 ),將判斷位元補入得 到狀態 3(011),解碼輸出為(01)。經過這樣的方式回溯後,最後得到解碼 (01011001),將解碼做反轉得到(10011010)並輸出。
圖3.35 追蹤回溯
當必須處理的資料相當多時,若從資料結束才開始回溯,則需要儲存判斷位 元的記憶體區塊相當大,因此對資料做分段回溯。圖 3.36 是追蹤回溯記憶體管
理方式,使用3 塊長為 L、寬為2( )K-1
,執行方式為:當BANK0 執行寫入資料時
(WR),BANK2 執行距離比較計算(TB),而 BANK1 執行解碼;當 BANK1 執行寫入資料時(WR),BANK0 執行距離比較計算(TB),而 BANK2 執行 解碼;當BANK2 執行寫入資料時(WR),BANK1 執行距離比較計算(TB), 而BANK0 執行解碼。經由上述方式一直循環,可以持續做解碼。
WR WR WR TB TB DC DC
BANK0 BANK1 BANK2
TB DC 圖3.36 追蹤回溯記憶體管理 記憶體長度L 是影響解碼性能的關鍵,藉由圖 3.37 記憶體長度比較可以看 到,當使用超過5K 記憶體長度時,PER 則近似無窮長度。 圖3.37 追蹤回溯架構記憶體長度比較 接著考量在做距離比較計算時,必須先將各區塊寫入結束時的總距離做儲 存。但是總距離的位元數相當多,要全部儲存則必須有很大的記憶體,而且做比
較判斷也是相當大的元件。所以採用一個初始狀態暫存器交換的方式,將每塊記 憶體附上暫存器,藉由暫存器將初始狀態做交換,達成不需要比較總距離即可知 道前一塊記憶體回溯起點。圖3.38 是一個結合追蹤回溯與暫存器交換的例子, 每個狀態暫存器內的值,為來源狀態暫存器內的值,經過持續的交換後,最後每 個狀態暫存器內的值皆相同,可任意挑選一個即可知道來源狀態是由狀態0 開 始。 圖3.38 結合追蹤回溯與暫存器交換 上述的暫存器狀態交換雖然可以節省總距離比較,但是也可能因為長度不夠 導致最後所有狀態暫存器內的值不相同。圖3.39 是統計傳送 128 個位元且能夠 正確解回資料下,狀態暫存器全部相同所需要的長度,可以看到需要的長度都不 超過5K,所以在設計上採用大小為 32×32 的記憶體。
(a)
(c)
(d)
3.3 系統模擬
決定接收機架構後,必須再對系統方塊做量化位元決定與消除,才能在系統 性能與晶片面積間取得平衡。圖3.40 是 UWB 收發機與通道架構,假設傳送訊號 每個位元能量為1,UWB 通道總能量為 1,接收機以每個片碼 3 個取樣點輸入。 Preamble BPSKScrambler FEC encoder Interleaver
Framing ShapingPulse
6 Spreading Code Data 2 2 Matched Filter Acquisition Coarse Channel Estimation
Rake InterleaverDe- DecoderViterbi Scrambler
De-yes no Tx Rx Energy Detection DetectionSFD Gain Control yes no Data DAC ( ) cos 2πf tc LPF ( ) 2cos 2πf tc ADC Tx Rx UWB channel AWGN AGC DFE 6 9 8 15 11 1 圖3.40 DS-UWB 收發機與通道架構 首先做量化範圍決定,圖3.41 是在各種通道下不同量化範圍的 BER,由結果觀 察到在量化範圍為±0.3時,BER 貼近原始曲線,所以接收訊號量化範圍為±0.3。
(a)
(c)
(d)
設定量化範圍為±0.3後,開始做量化位元模擬。圖3.42 是在各種通道下的 BER, 可以看到使用6 Bits 做量化時,就能夠貼近原始曲線。所以在接收訊號處理上, 使用每個片碼3 個取樣點,量化範圍為±0.3,並做6 Bits 量化後輸入匹配濾波器。
(a)
(c)
(d)
接收訊號範圍與量化位元決定後,接著做系統各方塊位元消除。首先是對根 餘弦濾波器,輸入6 Bits 訊號經過根餘弦濾波器後會有 12 Bits 輸出,但是較低 的幾個位元因為影響系統性能較小則可以刪去。圖3.43 是模擬根餘弦濾波器輸 出位元影響系統性能的比較,可以看到保留最高的8 Bits 即可接近原始曲線。
(c)
(d)
再依序對各方塊做位元消除模擬後,將輸入與輸出位元整理成表8。 表8 各方塊輸入輸出與消除位元統計表 系統方塊 輸入 輸出(消除後) 低位元消除 根餘弦濾波器 6 8 4 解延展碼器 8 11 2 粗略通道估測 11 11 8 RAKE 11、11 20 6 決策回饋等化 20 1 由表中可以看到當經過越多方塊運算後位元數會越來越多,是因為消除的只有較 低不影響系統效能的位元,但是較高的位元可能也是不需要的,所以再做高位元 的消除,整理成表9。 表9 系統方塊高位元與低位元消除 系統方塊 輸入 輸出(消除後) 高位元消除 低位元消除 根餘弦濾波器 6 8 0 4 解延展碼器 8 9 2 2 粗略通道估測 9 8 1 8 RAKE 8、9 11 4 6 決策回饋等化 11 1 收發機架構與各方塊位元決定後,藉由傳送機傳送資料並使用接收機解出資 料做錯誤率統計。首先在傳送訊號搭載8192 個位元的資料,而資料是用一個長 度23 個暫存器的虛擬隨機產生器產生,產生多項式為 23 1 1 1 n n n x+ =x + + 。接著讓x 傳送訊號經過各種UWB 通道環境,最後使用接收機解調資料做 PER 的統計,
第四章
系統規格
考量傳送與接收機間有許多架構相同或相似,為了能提高元件的利用率來減 少晶片面積,所以將傳送與接收機間的元件做進一步的整合。圖4.1 是整合後的 收發機架構,藉由傳送與接收需求的切換來控制共用部分。整合的部分有:根餘 弦濾波器、延展碼編碼器與匹配濾波器、訓練序列產生器、混擾與解混擾器、交 錯與解交錯器。 Pulse Shaping PN coder and decoder Viterbi Decoder Training Sequence Scrambler and De-Scrambler FEC encoder Interleaver and De-Interleaver TxData Acquisition Sequence SFD Sequence PHY header TxOutput RxInput Energy Detection Acquisition Coarse Channel Estimation no yes RxData BPSK Rake no SFD Detection DFE yes TxReset Framing PHY Header Detection Control Tx Reg Control TxRegEnable TxRegIn TR Mode TRmode TxReset RxReset 圖4.1 UWB 收發機架構 在傳送訊號前,必須先將表10 中的調變參數依照圖 4.2 的訊號格式輸入 Tx Reg 中,藉由這些調變參數來控制各調變方塊。接著以一個時脈週期的方波訊號 TxReset 輸入獲取序列產生器,做為傳送起始訊號,如圖 4.3。TxReset 同時也會 啟動TR Mode 將系統切換到傳送模式,在傳送完訊號後再切回接收模式。而調後的928 個位元週期再輸入,經由上述的操作就可以完成傳送訊號。而接收訊號 部分,當TR Mode 切換在接收模式下,處理後的接收訊號 RxData 會自動輸出, 並以一個訊號RxReset 做為判斷 RxData 起始與結束,如圖 4.4。
表10 傳送調變參數位元對照實體層標頭位元
Context Tx Reg tpye PHY header type Interleaver mode b0 b29
FEC mode b1-b3 b28-b26 Seed identifier b4-b5 b25-b24 Frame body length b6-b18 b12-b0
圖4.2 TxReg 資料輸入格式
Clk
RxReset
RxData b0 b1 b2 b3 b4 bN-3 bN-2 bN-1
第五章
干擾消除犁耙接收機
5.1 ISIC RAKE
本節我們將針對超寬頻系統通道設計接收機,將結合犁耙接收機和干擾消除 器,消除因密集性通道而產生的符際間干擾。由於超寬頻系統通道為室內的通 道,故超寬頻通道將會有非常密集性的多重路徑,傳送訊號的能量將會散佈到通 道上難以回收起來。因此,必須利用犁耙接收器把通道上的能量再次收集起來。 但如果是在不良的通道環境下(如 CM4)且展頻碼並非正交,訊號會受到強烈的符 際間干擾,將會影響到犁耙接收器的效能。 如圖5.1,此為訊號散佈在通道意識圖,因為環境為超寬頻系統通道,所以, 訊號將漫延許多個位元長度。由圖中兩條藍線所隔為第 i 個位元散佈在通道的區 間,在這個區間可以很明顯的看出第 i 個位元會受到過去傳送位元和未來傳送位 元強烈的干擾,在犁耙接收機收集通道能量的同時,也納入了很多的干擾進來, 進而影響到接收機效能。因此,我們必須將訊號在經過犁耙前,先經過符際間 干擾消除,以增進其效能。 圖5.1 訊號散佈在通道意識圖。 如上圖所示,第 i 個位元會同時受到過去和未來位元干擾,所以,我們除了 消除過去位元的干擾外,我們也設法將未來位元的干擾消除。根據上述,我們提出系統如圖5.2 所示,當我們要解的訊號為b i
( )
,我們將消去過去位元和下一個 位元b i( )
+1 的干擾。干擾消除後的訊號rISIC( )
n 如下式表示( ) ( )
( )
(
)
( )
(
)
( ) ( )
(
)
(
)
( )
(
) ( )
1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 2 0 0 ˆ ˆ i N L ISIC j l k i p j l k i N L j l j l i N L j l k i p j l k i N L j l k i j l r n r n b k c h n kN j l b i c h n iN j l b k b k c h n kN j l b k c h n kN j l n n δ δ δ δ + − − = − = = ≠ − − = = + − − = − = = ≠ ∞ − − = + = = = − ⋅ ⋅ ⋅ − − − = ⋅ ⋅ ⋅ − − − + − ⋅ ⋅ ⋅ − − − + ⋅ ⋅ ⋅ − − − +∑ ∑∑
∑∑
∑ ∑∑
∑ ∑∑
(5.1) 當干擾消除很完美時,我們的訊號將只受到雜訊和未來位元 b(j)的干擾,其中 j > i+1,即( ) ( )
(
)
( )
(
) ( )
1 1 0 0 1 1 2 0 0 N L ISIC j l j l N L j l k i j l r n b i c h n iN j l b k c h n kN j l n n δ δ − − = = ∞ − − = + = = = ⋅ ⋅ ⋅ − − − + ⋅ ⋅ ⋅ − − − +∑∑
∑ ∑∑
(5.2) 因此,受到的干擾較小即可增進犁耙接收機的效能。 圖5.2 ISIC RAKE 接收機 如圖5.2 我們利用符際間干擾消除器(ISI Cancellation)將過去的位元和下一 個位元的訊號減去,再使用犁耙接收器將訊號收集,最後再判別資料。由此可知,統輸出判別拉回,而下一位元的判別,我們將用最小均方線性切片等化器從第 i 個位元接收訊號的觀察區間等化出下個位元的訊號b i
( )
+1 ,其代價函數可寫成( )
2 1 H J =E b i⎡⎢ + − ⎤⎥ ⎣ r w ⎦ (5.3) 最後加入通道的資訊並重建其訊號,將干擾消除後經過犁耙接收機,即為此 系統架構。在此系統的觀察區間和之前說明的一樣,犁耙接收機將選等效通道中 能量最大的區間。因為接收機中主要接收為後方犁耙接收機,前面的最小均方線 性切片等化器只是等化出下一位元進而進行干擾消除,所以,最小均方線性切片 等化器的觀察區間之選取將從犁耙接收機所接收的區間中選出下個位元 b (i+1) 能量最大的區間。5.2 RAKE ISIC
根據之前所敘述的ISIC RAKE,是將訊號經過犁耙接收機之前先消去會產 生符際間干擾的訊號,此方法要將已判別出的資料加以重建成接收端所收到的訊 號,如下式:( )
1 1 1( )
0 0 ˆ ( ) k L i N ISI j l k i p j l k i r n b k c h δ n iN j l − + − = − = = ≠ =∑ ∑ ∑
⋅ ⋅ ⋅ − − − (5.4) 已判別的訊號要乘上展頻碼和通道的權重,最後相加起來。因為這些處理皆是在 切片階層(chip level)下進行的,這樣所需的加法器數量將很高,且如果我們假設 通道已知,我們試著將干擾消除器移至犁耙接收機之後,已降低複雜度。這樣的 作法必須先將每一個位元在犁耙接收機後所造成的干擾計算出來,之後再乘上已 判別的資料,相加即為符際間干擾的大小。接著即可對經過犁耙接收機的訊號作 干擾消除,最後進行判別,我們將此接收機命名為RAKE ISIC,架構圖如圖 5.3。圖5.3 RAKE ISIC 架構圖
如上圖所示,訊號的主要路線(架構圖上半部)為犁耙接收機路線,接收訊號 經過犁耙接收機後,將干擾減去再判別訊號。另一路線(架構圖下半部)為計算干 擾大小,這一路線將得到犁耙接收機後的符際間干擾,我們將計算過去 p 個位元 和下一個位元所造成的干擾大小。過去位元資訊由「Decision Device」輸出回授, 下一個位元由「Next Bit Detection」得到,我們將使用最小均方線性切片等化器 得到下一個位元的資訊。而方塊「ISI Weight Control」為計算犁耙接收機後這些 干擾位元對於第 i 個位元的干擾大小,因為通道為假設已知,所以干擾大小可以 事先計算得到。再此我們令過去第 k 個位元所造成的干擾大小為 Bk,其中 k=1,…, p;下一個位元造成的干擾則令為 F1。最後,虛線所框的部分為計算符際間干擾 的總合,我們將判別後的位元各自乘上對應的干擾大小後相加,即可得到第 i 個 位元的符際間干擾。 此方法和ISIC RAKE 不同的地方為干擾消除拉至犁耙接收機後,但犁耙接 收機為一個線性的方塊,且所消除的干擾皆相同,所以,這種作法將得到與ISIC RAKE 相同的效能,我們將可從之後的模擬結果中得到驗證,且較 ISIC RAKE 有較低的複雜度,將在下一節作說明。
5.3 複雜度計算
接下來將介紹我們所提出ISIC RAKE 和 RAKE ISIC 的複雜度計算,觀察 RAKE ISIC 是否與 ISIC RAKE 相比擁有較低的複雜度。
5.3.1 ISIC RAKE 複雜度計算
如下圖表示,ISIC RAKE 將需要的元件有:一個最小均方線性切片等化器 偵測下一個位元、干擾消除和犁耙接收機。 圖5.4 ISIC RAKE 接收機 其中最小均方線性等化器長度為 ME,犁耙接收機的長度為 MR,所以,最小均方 線性等化器的複雜度即為2ME+1 個乘法器個數和 2ME個加法器個數;犁耙接收 機的複雜度 MR為個乘法器個數和 MR+N-2 個加法器個數,N 為展頻碼長度。接 下來,將討論剩下重建和干擾消除這一部分的複雜度。在此假設通道已知,我們 將用軟體模擬等效通道 he(n)=c(n)∗h(n),所以重建訊號可表示成( ) (
)
1 1ˆ
( )
i e k k iRr n
b k
h n
kN
+ = ≠=
∑
⋅
−
(5.5) 最後,我們將接收訊號與重建訊號相減,即是作干擾消除。( )1 ( ) b i− ⋅Eh n ( 2) ( ) b i− ⋅Eh n ( 3) ( ) b i− ⋅Eh n ( ) ( ) b i ⋅Eh n ( )1 ( ) b i+ ⋅Eh n 圖5.5 訊號散佈在通道意識圖 由上圖,我們必須減去過去位元的干擾和下一個位元的干擾。MR為接下來犁耙 接收機所要接收的區間長度,i 為此區間到原點的長度。我們需要減去過去的位0 元數有 p 個,且p=⎢⎣(L−i0) N⎥⎦,L 為等效通道的長度。所以對於過去位元的干 擾消除需要的加法器數目為