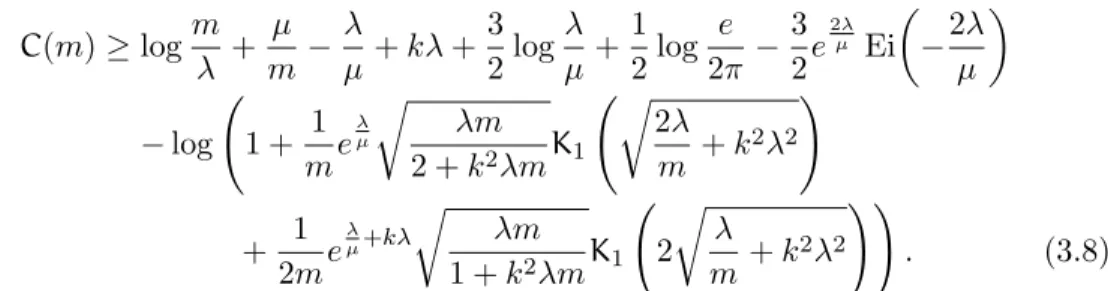Molecular Communication in a Liquid:
Bounds on the Capacity of the Additive
Inverse Gaussian Channel with Average and
流動介質中的粒༬通訊:在傳輸端有平均及最大延遲的限制下
相加性反高斯雜訊通道容量界線
Molecular Communication in a Liquid: Bounds on the Capacity of
the Additive Inverse Gaussian Noise Channel
with Average and Peak Delay Constraints
研
究 生:庭萱
Student : Ting-Hsuan Lee
指導教授:Ǒ詩台方
教授
Advisor : Prof. Stefan M. Moser
ῗ 立 交 通 大 學
電 信 工 程 學 系 碩 士 ჟ
碩 士 ࣧ ᅎ
⑸
ḋ
Submitted to Institution of Communication Engineering
College of Electrical Engineering and Computer Science
National Chiao Tung University
In partial Fulfillment of the Requirements
for the Degree of
Mater of Science
in
Communication Engineering
June 2013
Hsinchu, Taiwan, Republic of China
Information Theory
Laboratory
Dept. of Electrical and Computer Engineering National Chiao Tung University
Master Thesis
Molecular Communication in a
Liquid: Bounds on the Capacity
of the Additive Inverse Gaussian
Noise Channel with Average
and Peak Delay Constraints
Lee Ting-Hsuan
Advisor: Prof. Dr. Stefan M. Moser
National Chiao Tung University, Taiwan Graduation Prof. Dr. Chia Chi Huang
Committee: Yuan Ze University, Taiwan Prof. Dr. Hsie Chia Chang
流動介質中的粒༬通訊:在傳輸端有平均及最大延遲的
限制下 相加性反高斯雜訊通道容量界線
研究生:庭萱
指導教授:Ǒ詩台方 教授
!
!
ῗ立交通大學電信工程研究所碩士ჟ
中ᅎ摘要
在本篇ࣧᅎ中
,ሹ們探討一個相當新的通道模ሗ,此通道是藉ҹ
原༬在液體中的交換來傳輸信號。而ሹ們假設原༬在傳輸過程中,是
在一維的空間做移動。像ሹ們將奈米級的儀ዸ放入᰼管中,而此儀ዸ
在人體內和Ꭾ他儀ዸ交換訊息༫是一個很典ሗ的通訊應用。在此應用
中,ሹ們不再使用電磁波來傳輸ሹ們的信號,相反地,ሹ們將訊息放
在原༬從傳輸端釋放的時間點上。一旦原༬被釋放在液體中,將અ在
液體中進ᥳ布朗運動,進而造成ሹ們無法預估原༬到達傳輸端的時間,
換句話說,布朗運動造成接收時間的不確定性,而此不確定性༫是ሹ
們的雜訊,而ሹ們用反高斯(Inverse Gaussian)分布來描述此雜訊。此
篇的研究重點是相加性雜訊通道,在有平均以及最大延遲的限制下,
基本的通道容量趨勢。
ሹ們深入研究此模ሗ,並且分析ʃ新的通道容量的上界以及下限,
而這些界線是逐漸靠近的,也༫是說,如果ሹ們允許平均以及最大延
遲放寬到無限大,亦或是介質的流體ቴ度趨近無限大,ሹ們可以得到
K確的通道容量。
Abstract
Molecular Communication in a Liquid:
Bounds on the Capacity of the Additive
Inverse Gaussian Noise Channel with
Average and Peak Delay Constraints
Student: Lee Ting-Hsuan Advisor: Prof. Stefan M. Moser Institute of Communication Engineering
National Chiao Tung University
In this thesis a very recent and new channel model is investigated that describes communication based on the exchange of chemical molecules in a liquid medium with constant drift. The molecules travel from the transmitter to the receiver at two ends of a one-dimensional axis. A typical application of such communication are nano-devices inside a blood vessel communicating with each other. In this case, we no longer transmit our signal via electromagnetic waves, but we encode our information into the emission time of the molecules. Once a molecule is emitted in the fluid medium, it will be affected by Brownian motion, which causes uncertainty of the molecule’s arrival time at the receiver. We characterize this noise with an inverse Gaussian distribution. Here we focus solely on an additive noise channel to describe the fundamental channel capacity behavior with average and peak delay constraints.
This new model is investigated and new analytical upper and lower bounds on the capacity are presented. The bounds are asymptotically tight, i.e., if the average-delay and peak-delay constraints are loosened to infinity, the corresponding asymptotic capacities are derived precisely.
Acknowledgments
First, I want to thank to my advisor, Prof. Stefan M. Moser. Thanks to him, I am able to have such interesting topic as my master thesis. In addition, I have learnt a lot of things from him such as how to analysis problems, some methematical techniques, how to do a good presentation and how to write a good paper and slide. All of these are reallly important to me.
I am really lucky to get in the IT-lab, this lab is like second home to me. In the lab, I can do what I want to do and all members give me full support. Thanks to the IT-lab members, without their help, it is impossible that I can finish everything in time.
Finally, I want to thanks to my family. When I was upset about the thesis or had bad mood, they encouraged me which is the reason that I am able to perservered with thesis.
Contents
1 Introduction 1
1.1 General Molecular Communication Channel Model . . . 1
1.2 Mathematical Model . . . 2
1.3 Capacity . . . 4
2 Mathematical Preliminaries 7 2.1 Properties of the Inverse Gaussian Distribution . . . 7
2.2 Related Lemmas and Propositions . . . 10
3 Known Bounds to the Capacity of the AIGN Channel with Only an Average Delay Constraint 13 4 Main Result 17 5 Derivations 25 5.1 Proof of Upper-Bound of Capacity . . . 25
5.1.1 For 0 < α < 0.5 . . . 25
5.1.2 For 0.5≤ α ≤ 1 . . . . 29
5.2 Proof of Lower-Bound of Capacity . . . 30
5.2.1 For 0 < α < 0.5 . . . 30
5.2.2 For 0.5≤ α ≤ 1 . . . . 34
5.3 Asymptotic Capacity of AIGN Channel . . . 35
5.3.1 When T Large . . . 36
5.3.2 v Large . . . 37 6 Discussion and Conclusion 41
List of Figures 43
Chapter 1
Introduction
1.1
General Molecular Communication Channel Model
Usually, information carrying signals are transmitted as electromagnetic waves in the air or in wires. Recently, people are more and more interested in communication within nanoscale networks. But when we want to transmit our signal via these tiny devices, we face new problems, for example, the antenna size are restricted or the energy that could be stored is very little. We solve these problems by providing a different type of communication instead. This thesis focuses on a channel which operates in a fluid medium with a constant drift velocity. One application example is blood vessel, which has a blood drift. The nanoscale device could be any medical inspection device that is inserted in our body. The transmitter is a point source with many molecules to be emitted. The receiver waits on the other side for the molecules’ arrival. The information is encoded in the emission time of the molecules, X, which takes value in a finite set.
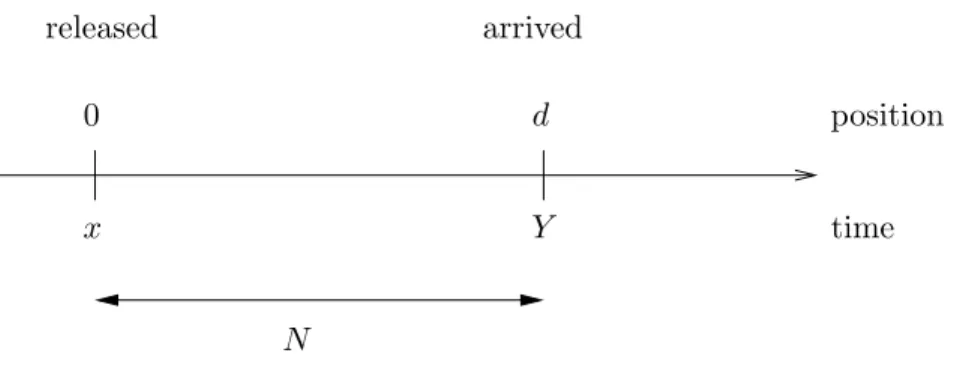
Wiener Process
w= 0 w= d Transmitter Receiver w vChapter 1 Introduction Once the nanoscale molecules are emitted into the fluid medium, beside the constant drift, they are affected by Brownian motion, which causes uncertainty of the arrival time at the receiver. We describe this type of channel noise with an inverse Gaussian distribution. The typical situation is shown in Figure 1.1, where w is the position parameter, d is the receiver’s position on w axis, and v > 0 is the drift velocity. The transmitter is placed at the origin of the w axis. It emits a molecule into a fluid with positive drift velocity v. The information is put on the releasing time. In order to know this information, the receiver ideally subtracts the average traveling time, dv, from the arrival time. Note that once a molecule arrives at the receiver, it is absorbed and never returns to the fluid. Moreover, every molecule is independent of each other.
This molecular communication channel model was proposed by Srinivas, Adve and Eckford [1].
1.2
Mathematical Model
Let W (x) be the position of a molecule at time x that travels via a Brownian motion medium. Let 0≤ x1 < x2<· · · < xk be a sequence of time indices ordered
from small to large. Then, W (x) is a Wiener process if the position increment Ri = W (xi−1)− W (xi) are independent random variables with
Ri∼ N!v(xi− xi−1), σ2(xi− xi−1)
"
(1.1) where σ2 = D2 with D being the diffusion coefficient, which depends on the temper-ature and the stickiness of the fluid and the size of the particles. Assuming that the molecule is released at time x = 0 at position W (0) = 0, the position at time ˜x is W(˜x)∼ N!vx, σ˜ 2x˜". The probability density function (PDF) of W is given by:
fW(w; ˜x) = 1 √ 2πσ2x˜exp # −(w− v˜x) 2 2σ2x˜ $ . (1.2) In our communication system, instead of looking at the position of the molecule at a certain time, we turn our focus on its arriving time at the receiver of a fixed distance d.
We release the molecule at time x from the origin, W (x) = 0 and x ≥ 0. After traveling for a random time N , the molecule then arrives at the receiver for the first time at time Y ,
Y = x + N. (1.3) Hence, our channel model is characterized by an additive noise in the form of the random propagation time N . This is the only uncertainty we have in the system. When we assume a positive drift velocity v > 0, the distribution of the traveling time N is well known to be an inverse Gaussian (IG) distribution. As a result, we
1.2 Mathematical Model Chapter 1 x Y released arrived N time 0 d position
Figure 1.2: The relation between the molecule’s time and position.
call this channel the additive inverse Gaussian noise (AIGN) channel. Since the PDF of N is fN(n) = ( λ 2πn3exp ) −λ(n−µ)2µ2n2 * n >0, 0 n≤ 0, (1.4) we get the conditional probability density of output Y given the channel input X = x as fY |X(y|x) = ( λ 2π(y−x)3 exp ) −λ(y−x−µ)2µ2(y−x)2 * y > x, 0 y≤ x. (1.5) There are two important parameters for the inverse Gaussian distribution: the av-erage traveling time
µ= d v =
distance between transmitter and receiver
drift velocity , (1.6) and a parameter
λ= d
2
σ2 (1.7)
that describes the impact of the noise. Usually we write N ∼ IG(µ, λ). By calcula-tion, we get E[N ] = µ = d v, (1.8) Var(N ) = µ 3 λ = dσ2 v3 . (1.9)
If the drift velocity v increases, the variance decreases, in other words, the distri-bution is more centered. If the drift velocity is slowed down, we will have a more spread-out noise distribution. Without loss of generality, we normalize the propa-gation distance to d = 1.
For practical reasons, we constrain the transmitter to have a peak delay con-straint T and a average delay concon-straint m at the transmitter, i.e., the input X are
Chapter 1 Introduction subject to the two constraints:
Pr[X > T] = 0, (1.10) E[X]≤ m. (1.11) We denote the ratio between the allowed average delay and the allowed peak delay by α
α ! m
T (1.12)
where 0 < α≤ 1. Note that for α = 1 the average-delay constraint is inactive in the sense that it has no influence on the capacity and is automatically satisfied whenever the peak delay constraint is satisfied. Thus, α = 1 corresponds to the case with only a peak-delay constraint. Similarly, α& 1 corresponds to a dominant average-delay constraint and only a very weak peak-delay constraint.
1.3
Capacity
Since we introduced a new type of channel, the AIGN channel, we are interested in how much information it can carry. In [2], Shannon showed that for memoryless channels with continuous input and output alphabets and an corresponding condi-tional PDF describing the channel, and under input constraints Pr[X > T] = 0 and E[X]≤ αT, the channel capacity is given by
C(T, αT)! sup
fX(x) : Pr[X>T]=0, E[X]≤αT
I(X; Y ) (1.13) where the supremum is taken over all input probability distributions f (·) on X that satisfy (1.10) and (1.11). By I(X; Y ) we denote the mutual information between X and Y . For the AIGN channel, we have
sup fX(x) : Pr[X>T]=0, E[X]≤αT I(X; Y ) = sup fX(x) : Pr[X>T]=0, E[X]≤αT + h(Y )− h(Y |X), (1.14) = sup fX(x) : Pr[X>T]=0, E[X]≤αT + h(Y )− h(X + N|X), (1.15) = sup fX(x) : Pr[X>T]=0, E[X]≤αT + h(Y )− h(N|X), (1.16) = sup fX(x) : Pr[X>T]=0, E[X]≤αT h(Y )− h(N) (1.17) = sup fX(x) : Pr[X>T]=0, E[X]≤αT h(Y )− hIG(µ,λ), (1.18)
1.3 Capacity Chapter 1 where (1.17) holds because N and X are independent. The mean constraint (1.11) of the input signal translates to an average constraint for Y :
E[Y ] = E[X + N ] (1.19) = E[X] + E[N ] (1.20) = E[X] + µ (1.21) ≤ αT + µ. (1.22)
Chapter 2
Mathematical Preliminaries
In this chapter, we will introduce some mathematical properties of the inverse Gaus-sian random variable and other useful lemmas for future use in this thesis.
2.1
Properties of the Inverse Gaussian Distribution
In [1], the differential entropy of an inverse Gaussian random variable was given in a complicated form that is unyielding for analytical analysis. So we try to modify the original expression and derive a cleaner form for mathematical derivation. Proposition 2.1 (Differential Entropy of the Inverse Gaussian Distribution).
hIG(µ,λ)= 1 2log 2πµ3 λ + 3 2exp # 2λ µ $ Ei # −2λµ $ +1 2 (2.1) where Ei(·) is the exponential integral function defined as
Ei(−x) ! − - ∞ x e−t t dt = - −x −∞ et t dt, x >0. (2.2) In MATLAB, the exponential integral function is implement as expint(x)=− Ei(−x).
Proof: see [3].
Next, when we want to make an IG random variable add with another IG random variable and end up also in IG distributed, there is a specific way to reach it. Only certain type of IGs will add up to be IG distributed.
Proposition 2.2(Additivity of the IG distribution). Let M be a linear combination of random variables Mi: M = l . i=0 ciMi, ci >0, (2.3) where Mi ∼ IG(µi, λi), i= 1, . . . , l. (2.4)
Chapter 2 Mathematical Preliminaries Here we assume that Mi are not necessarily independent, but summed up under the
constraint that λi ciµ2i = κ, for all i. (2.5) Then M ∼ IG . i ciµi, κ 1 . i ciµi 22 (2.6)
Proof: The proof can be found in [4, Sec. 2.4, p. 13].
Remark 2.3. If we simply add two inverse Gaussian random variables, as long as they are in the same fluid, which means they have the same v and σ2, the result is
still inverse Gaussian.
Consider a Wiener process X(t) beginning with X(0) = x0 with positive drift v
and variance σ2. Choose a and b so that x0 < a < b and consider the first passage
time T1 from x0 to a and T2 from a to b. Then T1 and T2 are independent inverse
Gaussian variables with parameters µ1 = a− x0 v , λ1 = (a− x0)2 σ2 (2.7) and µ2 = b− a v , λ2 = (b− a)2 σ2 . (2.8)
Now consider T3 = T1+ T2, therefore, c1 = c2 = 1 and
λi
µi
= v
2
σ2 = constant, (2.9)
T3 is also an inverse Gaussian variable. That is
T3 ∼ IG # µ1+ µ2, v2(µ1+ µ2)2 σ2 $ . (2.10) Since µ1+ µ2 = b−xv0, T3 ∼ IG# b − x0 v , (b− x0)2 σ2 $ . (2.11) The last observation also follows directly from the realization that T3 is the first
passage time from x0 to b [4].
Proposition 2.4 (Scaling). If N ∼ IG(µ, λ), then for any k > 0
kN ∼ IG(kµ, kλ). (2.12) Proof: The proof can be found in [4, Sec. 2.4, p. 13].
2.1 Properties of the Inverse Gaussian Distribution Chapter 2 Proposition 2.5. If N is a random variable distributed as IG(µ, λ). Then
E[N ] = µ; (2.13) E5 1 N 6 = 1 µ+ 1 λ; (2.14) E7N28= µ2+ µ 3 λ; (2.15) E5 1 N2 6 = 1 µ2 + 3 λ2 + 3 µλ; (2.16) Var (N ) = µ 3 λ; (2.17) Var# 1 N $ = 1 µλ+ 2 λ2; (2.18) E[Nν] = 9 2λ π e λ µµν−12K ν−12 # λ µ $ , ν ∈ R. (2.19) where Kγ(·) is the order-γ modified Bessel function of the second kind.
Remark 2.6. From formula [5, (8.486.16)], we get
K−ν(z) = Kν(z) (2.20)
we can also write (2.19) as E7N−ν8= 9 2λ π e λ µµ−ν−12K ν+1 2 # λ µ $ . (2.21) Proof: The proofs are based on [4, (2.6)], [6, Proposition 2.15], [4, (8.36)] and [5, 3.471 9.].
Proposition 2.7. If N ∼ IG(µ, λ), then E[log N ] = e2λµ Ei # −2λ µ $ + log µ; (2.22) E5 N µ + µ N 6 = 2 +µ λ. (2.23)
Proof: A proof is shown in [7].
Proposition 2.8. If Ni are IID ∼ IG(µ, λ), then the sample mean from that
dis-tribution will be 1 n n . i=1 Ni = ¯N ∼ IG(µ, nλ), for i = 1, . . . , n. (2.24)
Chapter 2 Mathematical Preliminaries Lemma 2.9. Under the three constraints
E[log X] = α1, (2.25)
E[X] = α2, (2.26)
E7X−18= α3, (2.27)
where α1, α2 and α3 are some fixed values, the maximum entropy distribution is the
inverse Gaussian distribution.
Proof: From [8, Chap. 12] we know that if we have the three constraints above, the optimal distribution to maximize the entropy will have the form
f(x) = eλ0+λ1log x+λ2x+λ3x (2.28)
= xλ1eλ0+λ2x+λ3x , (2.29)
which is exactly the form of the inverse Gaussian.
2.2
Related Lemmas and Propositions
In this section, we will show some lemmas and properties that will be used in our proof of bounds.
Proposition 2.10. Consider a memoryless channel with input alphabet X = R+0
and output alphabet Y = R, where, conditional on the input x ∈ X , the distribution on the output Y is denoted by the probability measure fY |X(·|x). Then, for any distribution fY(·) on Y, the channal capacity under a peak-delay constraint T and
an average-delay constraint αT is upper bound by C(T, αT)≤ EQ∗
7
D!fY |X(·|X)||fY(·)
"8
, (2.30) where Q∗ is the capacity-achieving distribution satisfying Q∗(X > T) = 0 and
EQ∗[X]≤ αT. Here, D(·||·) denotes relative entropy [8, ch. 2].
Proof: For more details see [9]
There are two challenges in using (2.30). The first is in finding a clever choice of the law R that will lead to a good upper bound. The second is in upper-bounding the supremum on the right-hand side of (2.30). To handle this challenge we shall resort to some further bounding.
Next, we will list some propositions related to the Q-function. Definition 2.11. TheQ-function is defined by
Q (x) ! √1 2π
- ∞
x
2.2 Related Lemmas and Propositions Chapter 2 Note that Q (x) is the probability that a standard Gaussian random variable will exceed the value x and is therefore monotonically decreasing with an increasing argument.
Proposition 2.12 (Properties for theQ-function). Bounds for Q-function 1 √ 2πxe −x2 2 # x 1 + x2 $ <Q (x) < √1 2πxe −x2 2 , x >0; (2.32) Q (x) ≤ 1 2e −x2 2 , x≥ 0. (2.33) and Q (x) + Q (−x) = 1. (2.34) Proof: see [10]
Remark 2.13. Let Φ(·) denote the cumulative distribution function (CDF) of the standard normal distribution:
Φ(x) = √1 2π - x −∞ e−t2/2dt. (2.35) Then Q (x) = Φ(−x), (2.36) 0 0.5 1 1.5 2 2.5 3 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 Q (x) Lower bound of (2.32) Upper bound of (2.32) Upper bound of (2.33) x
Chapter 2 Mathematical Preliminaries Proposition 2.14 (Upper and Lower Bound for Exponential Integral Function). We have 1 2e −xln # 1 + 2 x $ <− Ei(−x) < e−xln # 1 +1 x $ , x >0, (2.37) or −e−xln # 1 + 1 x $ <Ei(−x) < −1 2e−xln # 1 +2 x $ , x >0. (2.38)
Chapter 3
Known Bounds to the Capacity
of the AIGN Channel with Only
an Average Delay Constraint
We can always bound the capacity with peak and delay constraints by the capacity with only an average delay constraint since adding more constraints will make the capacity smaller. For the case with only an average delay constraint, an upper bound of capacity has been derived in [1]. The entropy maximizing distribution f∗(y) with
a mean constraint E[Y ]≤ m + µ is the exponential distribution with parameter 1 m+µ
[8, (12.21)]:
f∗(y) = 1 m+ µe
−m+µy , y ≥ 0. (3.1)
The entropy of such a distribution is
h∗(Y ) = 1 + ln(m + µ). (3.2) This can be used to derive a upper bound on the capacity of the AIGN channel:
C(m)! sup fX(x) : E[X]≤m I(X; Y ) (3.3) = sup fX(x) : E[X]≤m + h(Y )− hIG(µ,λ), (3.4) = sup fX(x) : E[X]≤m h(Y )− hIG(µ,λ) (3.5) = 1 + ln(m + µ)− hIG(µ,λ). (3.6) Hence, C(m)≤ 1 2log λ(m + µ)2 2πµ3 − 3 2exp # 2λ µ $ Ei # −2λµ $ +1 2 (3.7)
Chapter 3
Known Bounds to the Capacity of the AIGN Channel with Only an Average Delay Constraint In [3], the choice of the input X ∼ Exp!m1" get the asympototically tight lower bound: C(m)≥ logm λ + µ m− λ µ+ kλ + 3 2log λ µ+ 1 2log e 2π− 3 2e 2λ µ Ei # −2λ µ $ − log 1 1 + 1 me λ µ 9 λm 2 + k2λmK1 19 2λ m + k 2λ2 2 + 1 2me λ µ+kλ 9 λm 1 + k2λmK1 1 2 9 λ m + k 2λ2 22 . (3.8) where K1 is type one bessel function.
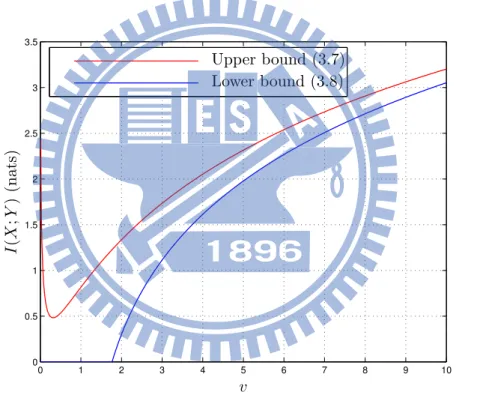
We can see in Fig. 3.3 that for the capacity with only a average delay constraint is aympototically tight in both m and v.
0 1 2 3 4 5 6 7 8 9 10 0 0.5 1 1.5 2 2.5 3 3.5 Upper bound (3.7) Lower bound (3.8) I (X ;Y ) (nat s) m
Chapter 3 0 1 2 3 4 5 6 7 8 9 10 0 0.5 1 1.5 2 2.5 3 3.5 Upper bound (3.7) Lower bound (3.8) I (X ;Y ) (nat s) v
Chapter 3
Known Bounds to the Capacity of the AIGN Channel with Only an Average Delay Constraint
Chapter 4
Main Result
To state our results we distinguish between two cases, 0 < α < 0.5 and 0.5≤ α < 1. For the first case, the difference between upper-bound and lower-bound tends to zero as the allowed peak delay tends to infinity, thus, revealing the asymptotic capacity at high power.
Theorem 4.1(Bounds for 0 < α < 0.5). For 0 < α < 0.5, C(T, αT) is lower-bounded C(T, αT)≥ log T − log β∗+ log)1− e−β∗*−λ
µ+ β∗ T (αT + µ) + : 2λ# λ 2µ2 − β∗ T $ −12log2πeµ 3 λ − 3 2e 2λ µ Ei # −2λµ $ (4.1) for T≥ 2β∗µ 2 λ . (4.2) And upper-bounded by C(T, αT)≤ Q−− Q+− 2!Q−− Q+"log (Q−− Q+) − 2(1 − Q−+ Q+) log(1− Q−+ Q+) + max+0, (Q−− Q+) log!µ(Q−+ Q+) + αT(Q−− Q+)" ,+ αβ∗ − log αβ∗+ log(αT + µ) + log
# 1− e− αβ∗(T +δ) αT+µ−αT(Q−−Q+)−µ(Q−+Q+) $ −12log2πeµ 3 λ − 3 2e 2λ µ Ei # −2λµ $ (4.3) for T> 1 α 1 αβ∗e−αβ∗ 1− e−β∗min ! 1,α µδ0 " − µ 2 (4.4)
Chapter 4 Main Result where δ0 is the minimum value of δ, and
Q− ! Q 1: λ µ 1: δ µ − 9 µ δ 22 (4.5) Q+ ! e2λµQ 1: λ µ 1: δ µ+ 9 µ δ 22 (4.6) Here, δ > µ is free parameter, and β∗ is the unique solution to
α= 1 β∗ −
e−β∗
1− e−β∗ (4.7)
A suboptimal but useful choice of the free parameter in (4.3) is
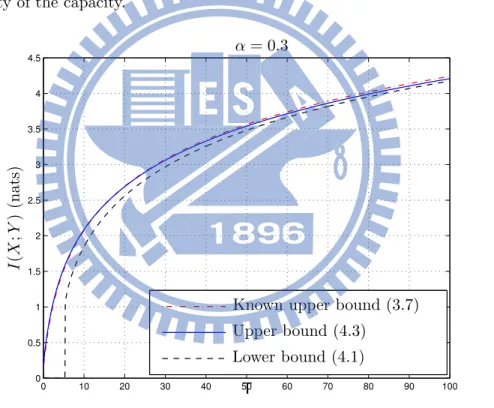
δ = log(T + 1) + 10µ. (4.8) Fig. 4.5 and Fig. 4.6 show the bounds of Theorem 4.1 for α = 0.3 as a function of T and v, respectly.
Corollary 4.2 (Asymptotics for the case of 0 < α < 0.5). If 0 < α < 0.5, then lim T↑∞ + C(T, αT)− log T , = αβ∗− log β∗+ log)1− e−β∗* −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λ µ $ (4.9) and lim v↑∞ + C(v)−3 2log v ,
= log T− log β∗+ log)1− e−β∗*
+ αβ∗+1 2log
λ
2πe. (4.10) Theorem 4.3 (Bounds for 0.5 ≤ α ≤ 1). If 0.5 ≤ α ≤ 1, then C(T, αT) is lower-bounded by C(T, αT)≥ log T −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λµ $ (4.11) and upper-bounded by C(T, αT)≤ Q−− Q+− 2!Q−− Q+"log (Q−− Q+) − (1 − Q−+ Q+) log(1− Q−+ Q+)
+ (Q−− Q+) max;0, log!µ(Q−+ Q+) + αT(Q−− Q+)"<+ log(T + δ) −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λ µ $ . (4.12) for T>1− min δ (4.13) where Q− and Q+ are given in the (4.5) and (4.6), respectively.
Here, δ > µ is free parameter, and β∗ is the unique solution to (4.7). A suboptimal but useful choice of the free parameter in (4.12)
Chapter 4 Corollary 4.4 (Asymptotics for the case of 0.5≤ α ≤ 1). If 0.5 ≤ α ≤ 1, then
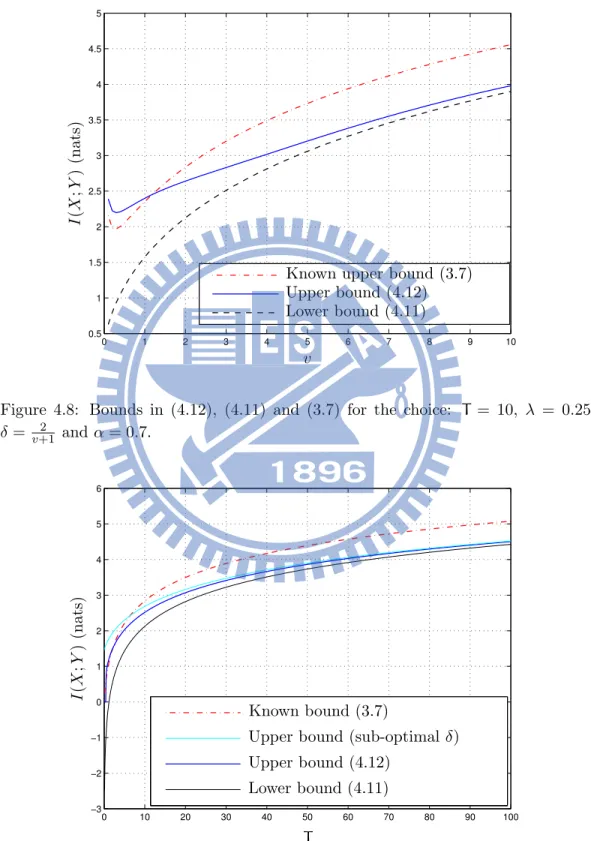
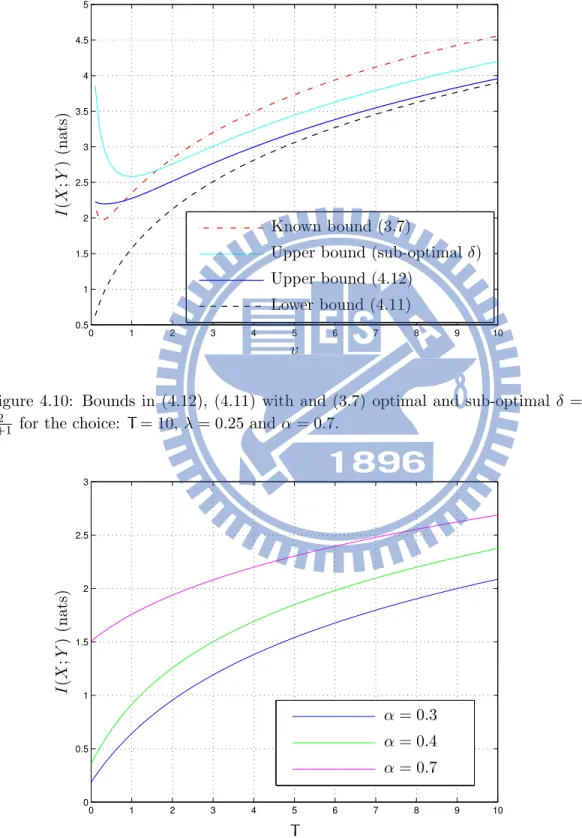
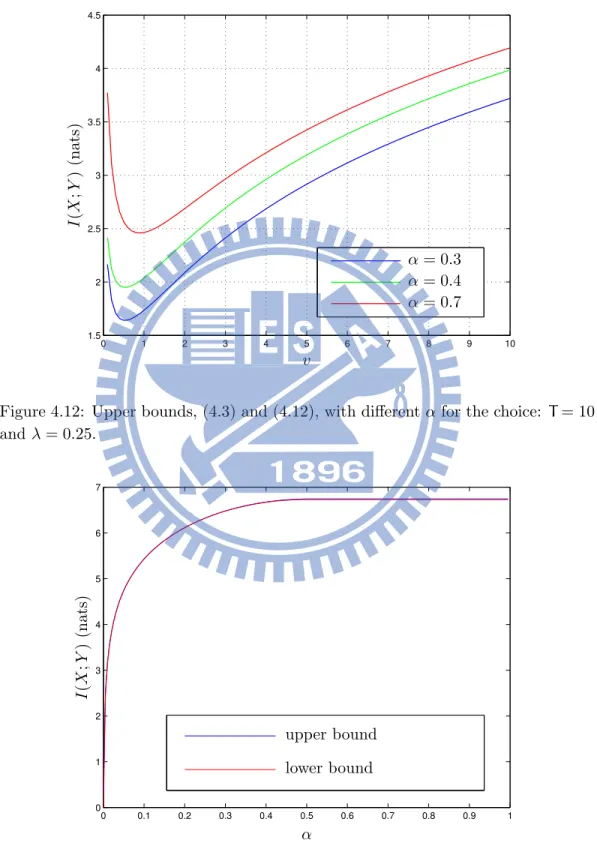
lim T↑∞ + C(T, αT)− log T,=−1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λµ $ (4.15) and lim v↑∞ + C(v)−3 2log v , = log T +1 2log λ 2πe (4.16) Fig. 4.7 and Fig. 4.8 show the bounds of Theorem (4.3) for α = 0.7. In addition, Fig. 4.11 and Fig. 4.12 show how the bounds in (4.3) and (4.12) performance with different α. Fig. 4.9 and Fig. 4.10 show that the difference of the choice of different δ, the blue line is the numerical optimal δ. Furthermore, the Fig. 4.13 shows the continuity of the capacity.
0 10 20 30 40 50 60 70 80 90 100 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5
Known upper bound (3.7) Lower bound (4.1) I (X ;Y ) (nat s) T α= 0.3 Upper bound (4.3)
Figure 4.5: Comparison between the upper and lower bound in (4.3) and (4.1) and known upper bound (3.7) for the choice: µ = 0.5, λ = 0.25, and α = 0.3.
Chapter 4 Main Result 0 1 2 3 4 5 6 7 8 9 10 0 0.5 1 1.5 2 2.5 3 3.5 4
Known Upper bound (3.7) Lower bound (4.1) Upper bound (4.3) I (X ;Y ) (nat s) v α= 0.3
Figure 4.6: Upper bound in (4.3) and (4.1) compare to the (3.7) for the choice: T= 10 λ = 0.25, δ = log(T + 1) + 10µ and α = 0.3. 0 10 20 30 40 50 60 70 80 90 100 −3 −2 −1 0 1 2 3 4 5 6
Known upper bound (3.7)
I (X ;Y ) (nat s) T Upper bound (4.12) Lower bound (4.11)
Figure 4.7: Bounds in (4.12), (4.11) and (3.7) for the choice: µ = 0.5, λ = 0.25, and α= 0.7.
Chapter 4 0 1 2 3 4 5 6 7 8 9 10 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
Known upper bound (3.7)
I (X ;Y ) (nat s) v Lower bound (4.11) Upper bound (4.12)
Figure 4.8: Bounds in (4.12), (4.11) and (3.7) for the choice: T = 10, λ = 0.25, δ = v+12 and α = 0.7. 0 10 20 30 40 50 60 70 80 90 100 −3 −2 −1 0 1 2 3 4 5 6 I (X ;Y ) (nat s) T Lower bound (4.11) Upper bound (4.12) Known bound (3.7)
Upper bound (sub-optimal δ)
Figure 4.9: Bounds in (4.12), (4.11) with and (3.7) optimal and sub-optimal δ = log(T + 1) + 10µ for the choice: µ = 0.5, λ = 0.25 and α = 0.7.
Chapter 4 Main Result 0 1 2 3 4 5 6 7 8 9 10 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 I (X ;Y ) (nat s) v Lower bound (4.11) Upper bound (4.12) Known bound (3.7)
Upper bound (sub-optimal δ)
Figure 4.10: Bounds in (4.12), (4.11) with and (3.7) optimal and sub-optimal δ =
2
v+1 for the choice: T = 10, λ = 0.25 and α = 0.7.
0 1 2 3 4 5 6 7 8 9 10 0 0.5 1 1.5 2 2.5 3 α= 0.3 α= 0.4 α= 0.7 I (X ;Y ) (nat s) T
Figure 4.11: Upper bounds, (4.3) and (4.12), with different α for the choice: µ = 0.5 and λ = 0.25.
Chapter 4 0 1 2 3 4 5 6 7 8 9 10 1.5 2 2.5 3 3.5 4 4.5 α= 0.3 α= 0.4 α= 0.7 I (X ;Y ) (nat s) v
Figure 4.12: Upper bounds, (4.3) and (4.12), with different α for the choice: T = 10 and λ = 0.25. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 1 2 3 4 5 6 7 upper bound lower bound I (X ;Y ) (nat s) α
Figure 4.13: Upper bounds and lower bounds with different α for the choice: T = 1000, µ = 0.5, and λ = 0.25.
Chapter 5
Derivations
5.1
Proof of Upper-Bound of Capacity
5.1.1 For 0 < α < 0.5
The derivation of the upper bounds (4.3) is based on Proposition (2.10) with the following choice of output distribution:
fY(y) = β(1−p) T # 1−e−β(1+ δT) $e −βy T if 0≤ y ≤ T + δ, νpe−ν(y−T−δ) if y > T + δ, (5.1) where β, p, ν and δ are free parameters with following constraints:
β >0, (5.2)
δ≥ 0, (5.3)
ν >0, (5.4) 0≤ p ≤ 1. (5.5) The capacity is upper bounded as follow:
C(T, αT)≤ EQ∗ 7 D!fY |X(·|X)||fY(·)"8 (5.6) ≤ −h(N) − EQ∗ - T+δ 0 fY |X(y|x) log β(1− p) T # 1− e−β ! 1+δ T "$ e− β Ty dy − EQ∗ 5- ∞ T+δ
fY |X(y|x) log)pνe−ν(y−T−δ)*dy 6 . (5.7) Since fY |X(y|x) = : λ 2π(y− x)3 exp # −λ(y− x − µ) 2 2µ2(y− x) $ I{y ≥ x}, (5.8)
Chapter 5 Derivations plugging fY |X into (5.7) then we can get
C(T, αT)≤ −h(N) − log p − log ν − ν(T(1 − α) + δ + µ) + EQ∗[c1(X)] · 1 log1− e −β(1+δ T) β + log T + log pν 1− p+ ν(T + δ) 2 + # β T −ν $ EQ∗[Xc1(X) + c2(X)] , (5.9) where c1(x) = - T +δ−x 0 9 λ 2πt3e −λ(t−µ)2 2µ2t dt, (5.10) c2(x) = - T +δ−x 0 9 λ 2πte −λ(t−µ)2 2µ2t dt. (5.11)
To further bound c1(x) and c2(x), we let w = ut, τ (x) = T+δ−xµ and ρ = λ µ c1(x) = - T +δ−x 0 9 λ 2πt3e −λ(t−µ)2 2µ2t dt (5.12) = - 1 τ(x) 0 9 ρ 2πw3e−ρ (w−1)2 2w dw (5.13) = 1− Q 1 √ρ1: 1 τ(x) − F τ(x) 22 + e2ρQ 1 √ρ1: 1 τ(x)+ F τ(x) 22 (5.14) c2(x) = - T +δ−x 0 9 λ 2πte −λ(t−µ)2 2µ2t dt (5.15) = - 1 τ(x) 0 µw 9 ρ 2πw3e−ρ (w−1)2 2w dw (5.16) = µ G 1− Q 1 √ρ1: 1 τ(x) − F τ(x) 22 − µe2ρQ 1 √ρ1: 1 τ(x) + F τ(x) 22H . (5.17) Since 0≤ x ≤ T, so τ(x) must satisfy
0≤ τ(x) ≤ µ
δ. (5.18)
Noted that because of (5.18), c1(x) and c2(x) are both monotonically decreasing in
5.1 Proof of Upper-Bound of Capacity Chapter 5 the bound of c1(x) and c2(x) by using (5.18)
0≤ 1 − Q 1: λ µ 1: δ µ− 9 µ δ 22 + e2λµQ 1: λ µ 1: δ µ + 9 µ δ 22 ≤ c1(x)≤ 1 (5.19) 0≤ µ G 1− Q 1: λ µ 1: δ µ − 9 µ δ 22H − µe2λµQ 1: λ µ 1: δ µ+ 9 µ δ 22 ≤ c2(x)≤ µ. (5.20)
To simplify the notations, we use the shorthand given in (4.5) and (4.6):
0≤ 1 − Q−+ Q+ ≤ c1(x)≤ 1 (5.21)
0≤ µ(1 − Q−− Q+)≤ c2(x)≤ µ (5.22)
Next, we choose for the free parameters p and ν:
p! 1 − EQ∗[c1(X)] (5.23)
ν ! 1− EQ∗[c1(X)]
µ+ αT− EQ∗[Xc1(X) + c2(X)]
(5.24) From (5.21), we know that
0≤ 1 − EQ∗[c1(X)]≤ 1 (5.25)
and
αT+ µ− EQ∗[Xc1(X) + c2(X)]≥ 0, (5.26)
so that 0≤ p ≤ 1 and ν ≥ 0 as required. Plugging p and ν into the (5.9) then we get the following bound:
C(T, αT)≤ −h(N) + (1 − EQ∗[c1(X)]) # 1− (T + δ)(1− EQ∗[c1(X)]) µ+ αT− EQ∗[Xc1(X) + c2(X)] $ − 2 (1 − EQ∗[c1(X)]) log ! 1− EQ∗[c1(X)] " + (1− EQ∗[c1(X)]) log ! µ+ αT− EQ∗[Xc1(X) + c2(X)] " + EQ∗[c1(X)] #
log T− log β + log # 1− e−β ! 1+δ T "$$ +β TEQ∗[Xc1(X) + c2(X)]− EQ∗[c1(X)] log EQ∗[c1(X)] (5.27) then we choose β as:
β = TEQ∗[c1(X)] EQ∗[Xc1(X) + c2(X)]
αβ∗ (5.28) where β∗ is non-zero solution to α = 1
β∗ −
e−β∗
1−e−β∗ for 0 < α < 0.5. Furthermore,
− log β = − log(αT) − log β∗− log EQ∗[c1(X)] + log!EQ∗[Xc1(X) + c2(X)]" (5.29)
Chapter 5 Derivations and log # 1− e−β ! 1+δ T "$ = log 1 1− e−(T +δ) EQ∗ [c1(X)] EQ∗ [Xc1(X)+c2(X)]αβ∗ 2 (5.31) ≤ log # 1− e− αβ∗(T+δ) αT+µ−αT(Q−−Q+)−µ(Q−+Q+) $ (5.32) Hence, for 0 < α < 0.5 C(T, αT)≤ −h(N) + (1 − EQ∗[c1(X)]) # 1− (T + δ)(1− EQ∗[c1(X)]) αT(Q−− Q+) + µ(Q−+ Q+) $ − 2 (1 − EQ∗[c1(X)]) log!1− EQ∗[c1(X)]" + (1− EQ∗[c1(X)]) log ! µ(Q−+ Q+) + αT(Q−− Q+)" + EQ∗[c1(X)] 1
αβ∗− log α − log β∗+ log(αT + µ) + log # 1− e− αβ∗(T+δ) αT+µ−αT(Q−−Q+)−µ(Q−+Q+) $ 2 − 2EQ∗[c1(X)] log EQ∗[c1(X)] (5.33)
It can be shown that for t > √1 e+1
z(t) = 1− t − 2(1 − t) log(1 − t) − 2t log t (5.34) is monotonically decreasing. In our proof, we choose t = EQ∗[c1(X)], as long as
1− Q−+ Q+ ≥ √1
e+1, EQ∗[c1(X)] always larger than 1 √
e+1. In addition, for δ ≥ µ
this requirement always be satisfied. In addition,
(T + δ)(1− EQ∗[c1(X)])
αT(Q−− Q+) + µ(Q−+ Q+) >0. (5.35)
Hence, we can get the upper bound for 0 < α < 0.5:
C(T, αT)≤ −h(N) + Q−− Q+− 2!Q−− Q+"log (Q−− Q+) − 2(1 − Q−+ Q+) log(1− Q−+ Q+) + (Q−− Q+) max;0, log!µ(Q−+ Q+) + αT(Q−− Q+)"< + EQ∗[c1(X)] 1 αβ∗− log αβ∗+ log(αT + µ) + log # 1− e− αβ∗(T +δ) αT+µ−αT(Q−−Q+)−µ(Q−+Q+) $ 2 (5.36) To further bound the capacity, we have to let
T> 1 α 1 αβ∗e−αβ∗ 1− e−β∗min ! 1,α µδ0 " − µ 2 , (5.37)
5.1 Proof of Upper-Bound of Capacity Chapter 5 where δ0 is the minimun value of δ, then it can be shown that
αβ∗− log αβ∗+ log(αT + µ) + log # 1− e− αβ∗(T +δ) αT+µ−αT(Q−−Q+)−µ(Q−+Q+) $ >0. (5.38) Hence, in (5.36), the EQ∗[c1(X)] need to be upper-bounded, finally we get the upper
bound of capacity when 0 < α < 0.5:
C(T, αT)≤ Q−− Q+− 2!Q−− Q+"log (Q−− Q+) − 2(1 − Q−+ Q+) log(1− Q−+ Q+)
+ (Q−− Q+) max;0, log!µ(Q−+ Q+) + αT(Q−− Q+)"<+ αβ∗ − log αβ∗+ log(αT + µ) + log
# 1− e− αβ∗(T +δ) αT+µ−αT(Q−−Q+)−µ(Q−+Q+) $ −12log2πeµ 3 λ − 3 2e 2λ µ Ei # −2λµ $ . (5.39) 5.1.2 For 0.5≤ α ≤ 1
For proving (4.12), we use different output distribution: fY(y) =
I1−p
T+δ if 0≤ y ≤ T + δ,
νpe−ν(y−T−δ) if y > T + δ, (5.40)
where p, ν and δ are free parameters with following constraints:
δ ≥ 0, (5.41)
ν >0, (5.42) 0≤ p ≤ 1. (5.43) From similar derivation in section 5.1.1, choosing
p! 1 − EQ∗[c1(X)] , (5.44) ν ! 1− EQ∗[c1(X)] µ+ αT− EQ∗[Xc1(X) + c2(X)] . (5.45) We get: C(T, αT)≤ −h(N) + (1 − EQ∗[c1(X)]) # 1− (T + δ)(1− EQ∗[c1(X)]) µ+ αT− EQ∗[Xc1(X) + c2(X)] $ − 2 (1 − EQ∗[c1(X)]) log ! 1− EQ∗[c1(X)] " + (1− EQ∗[c1(X)]) log ! µ+ αT− EQ∗[Xc1(X) + c2(X)] " − EQ∗[c1(X)] log EQ∗[c1(X)] + EQ∗[c1(X)] log(T + δ) (5.46)
It can be shown that for t > 14(√5− 1)2
Chapter 5 Derivations is monotonically decreasing. Same as before, we choose t = EQ∗[c1(X)], as long
as 1− Q−+ Q+ ≥ 1 4(
√
5− 1)2, the E
Q∗[c1(X)] always larger than 14(√5− 1)2. In
addition, for δ ≥ µ this requirement always be satisfied. Hence, we get the upper bound for 0.5≤ α ≤ 1:
C(T, αT)≤ Q−− Q+− 2!Q−− Q+"log (Q−− Q+) − (1 − Q−+ Q+) log(1− Q−+ Q+)
+ (Q−− Q+) max;0, log!µ(Q−+ Q+) + αT(Q−− Q+)"<+ log(T + δ) −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λµ $ . (5.48) where T≥ 1 − min δ (5.49) 1− Q−+ Q+≥ 1 4( √ 5− 1)2 (5.50)
5.2
Proof of Lower-Bound of Capacity
5.2.1 For 0 < α < 0.5
One can always find a lower bound on capacity by dropping the maximization and choosing an arbitrary input distribution fX(x) in (1.13). To get a tight bound,
this choice of fX(x) should yield a mutual information that is reasonably close
to capacity. From [3], we know the lower-bound is tight when the input is an exponential distribution; however, since we have a peak constraint, we only can choose the cut exponential as our input distribution, fX(x), and fN(n) denotes the
channel distribution, fX(x) = β T(1− e−β)e −β T xI{0 ≤ x ≤ T}, (5.51) fN(n) = 9 λ 2πn3 exp # −λ(n − µ)2 2µ2n $ I{n ≥ 0} (5.52) where β > 0 is free parameter. Therefore, the channel output fY(y) is
fY(y) = (fX ∗ fN)(y) (5.53) = - ∞ −∞ fN(x)fX(y− x)dx (5.54) = - ∞ −∞ 9 λ 2πx3exp # −λ(x − µ)2 2µ2x $ I{x ≥ 0} ·T(1 β − e−β)e −β T (y−x)I{0 ≤ y − x ≤ T} dx. (5.55)
5.2 Proof of Lower-Bound of Capacity Chapter 5 To calculate the convolution, we separate it to two cases, y− T ≤ 0 and y − T > 0. and follow a similar calculation as given in [11].
For the first case, y≤ T, we have:
fY(y) = 9 λ 2π β T(1− e−β)e λ µ− β Ty - y 0 x−32e−x ! λ 2µ2− β T " −2xλ dx J KL M I1(y) (5.56)
Let a2 = λ2 and b2 = 2µλ2 −βT. We assume b2 ≥ 0, so
T≥ 2βµ 2 λ . (5.57) Then I1(y) is I1(y) = - y 0 x−32e−x ! λ 2µ2− β T " −λ 2xdx (5.58) = - y 0 x−32e− a2 x−xb2dx. (5.59) Let t = x−12, I1(y) = 2 - ∞ 1 √y exp # −a2t2−b 2 t2 $ dt (5.60) from the Abramowitz and Stegun, 7.4.33 [12]:
I1(y) = √ π 2a N e2ab 5 1− erf # b√y+√a y $6 + e−2ab 5 1− erf # −b√y+√a y $6O (5.61) = 9 2π λ I e % 2λ! λ 2µ2− β T " Q 1: 2y# λ 2µ2 − β T $ + : λ y 2 + e− % 2λ! λ 2µ2− β T " Q 1 − : 2y# λ 2µ2 − β T $ + : λ y 2P . (5.62) Similary, for the case that y− T > 0
fY(y) = 9 λ 2π β T(1− e−β)e λ µ− β Ty - y y−T x−32e−x ! λ 2µ2− β T " −2xλdx J KL M I2(y) (5.63)
Chapter 5 Derivations where I2(y) = - y y−T x−32e−x ! λ 2µ2− β T " −2xλdx (5.64) = - y y−T x−32e− a2 x−xb2dx (5.65) = 2 - & 1 y−T 1 √y exp # −a2t2−b 2 t2 $ dt (5.66) = 2 1- ∞ 1 √y exp # −a2t2−b 2 t2 $ dt− - ∞ 1 √ y−T exp # −a2t2−b 2 t2 $ dt 2 (5.67) = √ π 2a N e2ab 5 1− erf # b√y+√a y $6 + e−2ab 5 1− erf # −b√y+√a y $6O + √ π 2a N e2ab 5 1− erf # bFy− T +√ a y− T $6 + e−2ab 5 1− erf # −bFy− T + √ a y− T $6O (5.68) = 9 2π λ I e % 2λ! λ 2µ2− β T " Q 1: 2y# λ 2µ2 − β T $ + : λ y 2 + e− % 2λ! λ 2µ2− β T " Q 1 − : 2y# λ 2µ2 − β T $ + : λ y 2P − 9 2π λ I e % 2λ! λ 2µ2− β T " Q 1: 2(y− T)# λ 2µ2 − β T $ + : λ y− T 2 + e− % 2λ! λ 2µ2− β T " Q 1 − : 2(y− T)# λ 2µ2 − β T $ + : λ y− T 2P (5.69) = I1(y)− ˜I2(y) (5.70)
where ˜I2(y) > 0 for all y.
Hence, we have output distribution fY(y):
fY(y) = ( λ 2π β T(1−e−β)e λ µ− β TyI 1(y) y≤ T ( λ 2π β T(1−e−β)e λ µ− β TyI 2(y) y > T. (5.71) This now yields the following lower bound on capacity:
C! max fX(x) I(X; Y ) (5.72) ≥ I(X; Y )QQ X∼f(x) (5.73) = (h(Y )− h(Y |X))QQ X∼f(x) (5.74) = h(Y )QQ X∼f(x)− h(N) (5.75) = EY[− log fY(Y )] Q Q X∼f(x)− h(N) (5.76)
5.2 Proof of Lower-Bound of Capacity Chapter 5 = Pr[Y > T]E[− log fY(Y )|Y > T] + Pr[Y ≤ T]E[− log fY(Y )|Y ≤ T]
− h(N) (5.77) =−h(N) +!Pr[Y > T] + Pr[Y ≤ T]" · 1 − log 9 λ
2π+ log T− log β + log )
1− e−β*−λ µ
2 + Pr[Y ≤ T]# βTE[Y|Y ≤ T] − E[log I1(Y )|Y ≤ T]
$ + Pr[Y > T]# β TE[Y|Y > T] − E R log (I1(Y )− ˜I2(Y )) Q Q QY >T S$ (5.78) ≥ −h(N) + − log 9 λ
2π + log T− log β + log ) 1− e−β*−λ µ +β TE[Y ]− E[log I1(Y )] (5.79) ≥ − log 9 λ
2π + log T− log β + log (1 − e−β)− λ µ+
β
T(αT + µ)
− E[log I1(Y )]− h(N) (5.80)
We further bound the log term, I1(y) = 9 2π λ I e % 2λ! λ 2µ2− β T " Q 1: 2y# λ 2µ2 − β T $ + : λ y 2 + e− % 2λ! λ 2µ2− β T "G 1− Q 1: 2y# λ 2µ2 − β T $ − : λ y 2HP (5.81) = 9 2π λe − % λ2 µ2− 2λβ T I 1− Q 1: λ µ 1: y µ # 1−2µλT2β $ −9 µy 22 + e2λµ & 1−2µ2βλT Q 1: λ µ 1: y µ # 1−2µ2β λT $ +9 µ y 22P , (5.82) because the function
y)→1 − Q 1: λ µ 1: y µ # 1− 2µ2β λT $ −9 µ y 22 + e2λµ & 1−2µ2βλT Q 1: λ µ 1: y µ # 1−2µλT2β $ +9 µ y 22 (5.83) is monotonically increasing, so we upper-bounded it by y goes infinity, then (5.83) is bouned by 1, i.e. I1(y)≤ 9 2π λ e − % λ2 µ2− 2λβ T (5.84)
Chapter 5 Derivations which does not depend on y anymore, so we can get rid of the expectation directly. Finally, we get the lower bound of capacity:
C(T, αT)≥ log T − log β + log)1− e−β*−λ µ+ β T(αT + µ) + : 2λ# λ 2µ2 − β T $ −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λµ $ (5.85) = log T− log β∗+ log)1− e−β∗*
−λµ+β∗ T (αT + µ) + : 2λ# λ 2µ2 − β∗ T $ −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λµ $ (5.86) Here, we choose β as solution of β∗ which satisfied α = β1∗ −
eβ∗
1−eβ∗ for 0 < α < 0.5.
5.2.2 For 0.5≤ α ≤ 1
For 0.5≤ α ≤ 1, we choose uniform distribution as our input distribution: fX(x) =
1
T ·I{0 ≤ x ≤ T} (5.87) since E[X] = 0.5, the average delay constraint is always satisfied.
Hence, fY(y) = (fX ∗ fN)(y) (5.88) = - ∞ −∞ fN(x)fX(y− x) dx (5.89) = 1 T - ∞ −∞ 9 λ 2πx3e −λ(x−µ)2 2µ2x I{x ≥ 0}I{0 ≤ y − x ≤ T} dx (5.90)
Similary, we separate it to two cases, y− T ≤ 0 and y − T > 0. For the first case, y− T ≤ 0:
fY(y) = 1 T - y 0 9 λ 2πx3e −λ(x−µ)2 2µ2x dx (5.91)
Note that the integration is like the c1(x) we use in the upper bound, the only
different thing is the range of the integration. So, we have: fY(y) = 1 T - y µ 0 : λ 2πµw3e− λ(w−1)2 2µw dw (5.92) = 1 T G 1− Q 1: λ µ #9 y µ− 9 µ y $2 + e2λµQ 1: λ µ #9 y µ+ 9 µ y $2 H (5.93) ! I3(y) (5.94)
5.3 Asymptotic Capacity of AIGN Channel Chapter 5 For the second case, y− T > 0:
fY(y) = 1 T - y y−T 9 λ 2πx3e −λ(x−µ)2 2µ2x dx (5.95) = 1 T G - y 0 9 λ 2πx3e −λ(x−µ)2 2µ2x dx− - y−T 0 9 λ 2πx3e −λ(x−µ)2 2µ2x dx H (5.96) = I3(y)− ˜I3(y) (5.97)
where ˜I3>0 for all y. Hence, we have output distribution fY(y):
fY(y) =
I
I3(y) y ≤ T I3(y)− ˜I3(y) y > T
(5.98) This now yields the following lower bound on capacity:
C! max fX(x) I(X; Y ) (5.99) ≥ I(X; Y )QQ X∼f(x) (5.100) = (h(Y )− h(Y |X))QQ X∼f(x) (5.101) = h(Y )QQ X∼f(x)− h(N) (5.102) =−EY[log fY(Y )] Q Q X∼f(x)− h(N) (5.103)
= Pr[Y > T]E[− log fY(Y )|Y > T] + Pr[Y ≤ T]E[− log fY(Y )|Y ≤ T]
− h(N) (5.104)
=−h(N) − Pr[Y ≤ T]E[log I3(Y )|Y ≤ T]
− Pr[Y > T]ERlog (I3(Y )− ˜I3(Y ))
Q Q QY >T S (5.105) ≥ −h(N) − E[log I3(Y )] (5.106)
We futher bound I3(y):
I3(y) = 1 T G 1− Q 1: λ µ #9 y µ − 9 µ y $2 + e2µλQ 1: λ µ #9 y µ+ 9 µ y $2 H (5.107) ≤ 1T. (5.108)
Equation (5.108) is because (5.107) is monotonically decreasing in y. Hence, we get the lower bound for 0.5≤ α ≤ 1:
C(T, αT)≥ log T −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λµ $ . (5.109)
5.3
Asymptotic Capacity of AIGN Channel
In this section, we try to figure out how the capacity behaves when the drift velocity v or the peak-delay constraint T tend to infinity.
Chapter 5 Derivations
5.3.1 When T Large
From chapter 4, we have for 0 < α < 0.5: C(T, αT)≥ log T − log β∗+ log)1− e−β∗*−λ
µ+ β∗ T (αT + µ) + : 2λ# λ 2µ2 − β∗ T $ −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λµ $ (5.110) when T goes to infinity, we get
C(T)≥ log T + αβ∗− log β∗+ log)1− e−β∗* −12log2πeµ 3 λ − 3 2e 2λ µ Ei # −2λµ $ + o(1) (5.111) and the capacity upper-bounded by
C(T, αT)≤ Q−− Q+− 2!Q−− Q+"log (Q−− Q+) − 2(1 − Q−+ Q+) log(1− Q−+ Q+)
+ !(Q−− Q+) log!µ(Q−+ Q+) + αT(Q−− Q+)""++ αβ∗ − log αβ∗+ log(αT + µ) + log
# 1− e− αβ∗(T +δ) αT+µ−αT(Q−−Q+)−µ(Q−+Q+) $ −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λµ $ (5.112) where Q− ! Q 1: λ µ 1: δ µ − 9 µ δ 22 (5.113) Q+ ! e2λµQ 1: λ µ 1: δ µ+ 9 µ δ 22 (5.114) As T goes to infinity, the capacity become:
C(T, αT)≤ log T + αβ∗− log β∗+ log ) 1− e−β∗* + o(1) −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λ µ $ (5.115) Here, (5.115) is because when T goes to infinity, Q− and Q+ will go to zero. From (5.111) and (5.115). Note that the upper bound and lower bound coincide, which gives us lim T↑∞ + C(T, αT)− log T , = αβ∗− log β∗+ log)1− e−β∗* −12log2πeµ 3 λ − 3 2e 2λ µ Ei # −2λµ $ (5.116)
5.3 Asymptotic Capacity of AIGN Channel Chapter 5 For 0.5≤ α ≤ 1: C(T, αT)≥ log T −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λµ $ (5.117) when T goes to infinity, we get the same equation:
C(T, αT)≥ log T −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λµ $ (5.118) and the upper bound, from (4.12):
C(T, αT)≤ Q−− Q+− 2!Q−− Q+"log (Q−− Q+) − (1 − Q−+ Q+) log(1− Q−+ Q+)
+ (Q−− Q+) max;0, log!µ(Q−+ Q+) + αT(Q−− Q+)"<+ log(T + δ) −12log2πeµ 3 λ − 3 2e 2λ µ Ei # −2λµ $ . (5.119)
where Q− and Q+ are same as (5.113) and (5.114).
We choose δ = log T, then as T goes to infinity, Q−and Q+will go to zero. Therefore,
we get asymptotically upper bound: C(T, αT)≤ log T −1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λµ $ + o(1) (5.120) We can see (5.118) and (5.120) are coincide as T goes to infinity. Hence we get the asympototic capacity when T goes to infinity for 0.5≤ α ≤ 1:
lim T↑∞ + C(T, αT)− log T , =−1 2log 2πeµ3 λ − 3 2e 2λ µ Ei # −2λ µ $ (5.121) 5.3.2 v Large
We rewrite the bound (4.3) by using v = µ1, for 0 < α < 0.5: C(v)≥ log T − log β∗+ log)1− e−β∗*− λv +β
∗ T # αT+ 1 v $ + : 2λ# λv2 2 − β∗ T $ −12log2πe λv3 − 3 2e 2λvEi(−2λv) (5.122)
≥ log T − log β∗+ log)1− e−β∗*
− vλ +βT∗ # αT+ 1 v $ + : 2λ# v 2λ 2 − β∗ T $ +3 2log v + 1 2log λ 2πe+ 3 4log # 1 + 1 2vλ $ (5.123) where (5.123) is simply plugging in the lower bound of Ei(·) from Proposition 2.14. Its asymptotic lower bound is:
C(v)≥ log T − log β∗+ log)1− e−β∗*+ αβ∗+ 3
2log v + 1 2log
λ
Chapter 5 Derivations Similary, we rewrite (4.12): C(v)≤ Q−− Q+− 2!Q−− Q+"log (Q−− Q+) − 2(1 − Q−+ Q+) log(1− Q−+ Q+) + (Q−− Q+) max N 0, log# 1 v(Q −+ Q+) + αT(Q−− Q+) $O + αβ∗ − log αβ∗+ log(αT + 1 v) + log 1 1− e− αβ∗(T +δ) αT+ 1v −αT(Q−−Q+)− 1 v (Q−+Q+) 2 −1 2log 2πe λv3 − 3 2e 2λvEi(−2λv) (5.125) where Q−! Q 1 √ λv 1 √ δv− 9 1 vδ 22 (5.126) Q+! e2λvQ1√vλ1√vδ+ 9 1 vδ 22 (5.127) We choose δ = √1v, then when v goes to infinity, it is obvious that Q− will go to
zero. For Q+: e2λvQ1√vλ1√vδ+ 9 1 vδ 22 ≤ 1 2e −vλ 2 !√ vδ+&1 vδ "2 (5.128) which will also goes to zero as v goes to infinity. Therefore, we get asymptotically upper bound:
C(v)≤ log T − log β∗+ log ) 1− e−β∗* + αβ∗+3 2log v + 1 2log λ 2πe + o(1). (5.129) We can see (5.124) and (5.129) are coincide as v goes to infinity. Hence we get the asympototic capacity for v goes to infinity:
lim v↑∞ + C(v)− 3 2log v ,
= log T− log β∗+ log)1− e−β∗*+ αβ∗+1 2log λ 2πe (5.130) For 0.5≤ α ≤ 1: C(v)≥ log T −1 2log 2πe λv3 − 3 2e 2vλEi(−2λv) (5.131) ≥ log T +32log v +1 2log λ 2πe+ 3 4log # 1 + 1 2vλ $ (5.132) where (5.132) is simply plugging in the lower bound of Ei(·) from Proposition 2.14. Its asymptotic lower bound is:
C(v)≥ log T +3 2log v + 1 2log λ 2πe+ o(1) (5.133)
5.3 Asymptotic Capacity of AIGN Channel Chapter 5 and the upper bound, from (4.12):
C(T, αT)≤ Q−− Q+− 2!Q−− Q+"log (Q−− Q+) − (1 − Q−+ Q+) log(1− Q−+ Q+) + (Q−− Q+) max N 0, log# 1 v(Q −+ Q+) + αT(Q−− Q+) $O + log(T + δ) − 12log2πe λv3 − 3 2e 2λvEi( −2λv) . (5.134) where Q− and Q+ are defined by (5.126) and (5.127).
Similary, we choose δ = √1v, as v goes to infinity, Q− and Q+ will go to zero. Therefore, we get asymptotically upper-bound for 0.5≤ α ≤ 1:
C(v)≤ log T +3 2log v + 1 2log λ 2πe+ o(1) (5.135) We can see (5.133) and (5.135) are coincide as v goes to infinity. Hence we get the asympototic capacity when v goes to infinity for 0.5≤ α ≤ 1:
lim v↑∞ + C(v)−3 2log v , = log T +1 2log λ 2πe (5.136)
Chapter 6
Discussion and Conclusion
This thesis provide new upper bound and lower bound on the capacity of the AIGN channel in the situation of both a peak delay constraint and average delay constraint. We have derived the upper bound and lower bound of capacity, and they are very tight when either T or v goes to infinity. We also have found that as α increased, our upper bound become the difference between known upper bound is increased. For the first point, it is because for fixed peak delay constraint, the average delay constraint become weaker and weaker as α growing;however, as α increased, the peak constraint become stronger, and that’s the main reason for the second phenomenon. Moreover, when the fluid velocity, v, is extremely small, from the Fig. 4.6 and Fig. 4.8, the noise caused by Brownian motion actually helps the transmission.
With the help of [11], we were able to compute the exact output distribution of an exponential input. This lower bound (4.1) was much tighter than the known bound with respect to both v and T. It turned out that together with the known upper bound, this lower bound allowed us to derive the asymptotic capacity at high T and high v.
For future research, we propose the following problems related to the additive inverse Gaussian noise channel:
• Derivation of the channel capacity when T and v is small. • Proof for α ≥ 0.5, the capacity dose not depend on the α.
List of Figures
1.1 Wiener process of molecular communication channel. . . 1
1.2 The relation between the molecule’s time and position. . . 3
3.3 Known bounds for the choice: µ = 0.5, λ = 1 respect to m. . . 14
3.4 Known bounds for the choice: m = 1, λ = 1 respect to v. . . 15
4.5 Comparison between the upper and lower bound in (4.3) and (4.1) and known upper bound (3.7) for the choice: µ = 0.5, λ = 0.25, and α = 0.3. . . 19
4.6 Upper bound in (4.3) and (4.1) compare to the (3.7) for the choice: T= 10 λ = 0.25, δ = log(T + 1) + 10µ and α = 0.3. . . . 20
4.7 Bounds in (4.12), (4.11) and (3.7) for the choice: µ = 0.5, λ = 0.25, and α = 0.7. . . 20
4.8 Bounds in (4.12), (4.11) and (3.7) for the choice: T = 10, λ = 0.25, δ= v+12 and α = 0.7. . . 21
4.9 Bounds in (4.12), (4.11) with and (3.7) optimal and sub-optimal δ = log(T + 1) + 10µ for the choice: µ = 0.5, λ = 0.25 and α = 0.7. . . . 21
4.10 Bounds in (4.12), (4.11) with and (3.7) optimal and sub-optimal δ = 2 v+1 for the choice: T = 10, λ = 0.25 and α = 0.7. . . 22
4.11 Upper bounds, (4.3) and (4.12), with different α for the choice: µ = 0.5 and λ = 0.25. . . 22
4.12 Upper bounds, (4.3) and (4.12), with different α for the choice: T = 10 and λ = 0.25. . . 23
4.13 Upper bounds and lower bounds with different α for the choice: T = 1000, µ = 0.5, and λ = 0.25. . . 23
Bibliography
[1] K. V. Srinivas, R. S. Adve, and A. W. Eckford, “Molecular communication in fluid media: The additive inverse Gaussian noise channel,” December 2010, arXiv:1012.0081v2 [cs.IT]. [Online]. Available: http://arxiv.org/abs/1012.0081 v2
[2] C. E. Shannon, “A mathematical theory of communication,” Bell System Tech-nical Journal, vol. 27, pp. 379–423 and 623–656, July and October 1948. [3] H.-T. Chang and S. M. Moser, “Bounds on the capacity of the additive inverse
Gaussian noise channel,” in Proceedings IEEE International Symposium on In-formation Theory (ISIT), Cambridge, MA, USA, July 1–6, 2012, pp. 304–308. [4] R. S. Chhikara and J. L. Folks, The Inverse Gaussian Distribution — Theory,
Methodology, and Applications. New York: Marcel Dekker, Inc., 1989.
[5] I. S. Gradshteyn and I. M. Ryzhik, Table of Integrals, Series, and Products, 6th ed., A. Jeffrey, Ed. San Diego: Academic Press, 2000.
[6] V. Seshadri, The Inverse Gaussian Distribution — A Case Study in Exponential Families. Oxford: Clarendon Press, 1993.
[7] T. Kawamura and K. Iwase, “Characterizations of the distributions of power inverse Gaussian and others based on the entropy maximization principle,” Journal of the Japan Statistical Society, vol. 33, no. 1, pp. 95–104, January 2003.
[8] T. M. Cover and J. A. Thomas, Elements of Information Theory, 2nd ed. New York: John Wiley & Sons, 2006.
[9] A. Lapidoth and S. M. Moser, “Capacity bounds via duality with applications to multi-antenna systems on flat fading channels,” June 25, 2002, submitted to IEEE Transactions on Information Theory, available at <http://www.isi.ee.ethz.ch/∼moser>. [Online]. Available: http://www.isi .ee.ethz.ch/∼moser
[10] S. M. Moser, Information Theory (Lecture Notes), version 1, fall semester 2011/2012, Information Theory Lab, Department of Electrical Engineering,
Bibliography National Chiao Tung University (NCTU), September 2011. [Online]. Available: http://moser.cm.nctu.edu.tw/scripts.html
[11] W. Schwarz, “On the convolution of inverse Gaussian and exponential ran-dom variables,” Communications in Statistics — Theory and Methods, vol. 31, no. 12, pp. 2113–2121, 2002.
[12] M. Abramowitz and I. Stegun, Handbook of Mathematical Functions With For-mulas, Graphs, and Mathematical Tables, 10th ed. New York: Dover Publica-tions, 1965.