國立臺中教育大學資訊工程學系碩士班
碩士論文
指導教授:李宜軒 教授
雙耳聽覺模式下人工電子耳使用者
語音辨識能力之探討
A Study of Speech Recognition Abilities for
Cochlear Implant Users with Binaural Hearing
研究生:李永正 撰
謝誌
本論文得以完成,首先要感謝我的指導教授 李宜軒老師,感謝老師不辭辛苦的教導及鼓 勵,讓學生我不管在專業知識或是研究方法上皆受益良多,在此致上最深的謝意。感謝口委 鄧菊秀老師和王淑娟老師特地撥冗於論文口詴時給予建議,使本論文能夠更加完善,同時也 給我許多的啟發與收穫,學生於此衷心感謝。 在我剛進入研究所時幫助過我的禮璿學長、柏誠學長、麒璋學長、昱渂學長,以及在這 過程中不斷給我協助的朝仕;系統實驗室的健佑、孟儒、謝瑋、沐容、晟傑、俊凱;還有所 有曾參與實驗以及給我協助的朋友,感謝你們讓我在台中有了美好的回憶。 最後我要感謝默默在後面支持我的家人,感謝你們對我付出的一切,讓我能夠心無旁鶩 的進行研究,順利完成學業,在獲得碩士學位的同時,也將這份榮耀獻給你們。 李永正 謹誌 2015 年 7 月摘要
人工電子耳使用者能夠在安靜環境下獲得不錯的聽辨表現,但大部分人工電子耳使用者 由於各種因素常常只配戴單耳人工電子耳,因此缺乏聽常者的雙耳聽覺能力,進而嚴重影響 人工電子耳使用者在噪音環境中聽辨目標語音,以及聽音辨位的能力。 本研究透過人工電子耳語音編碼器(vocoder)對聽常者進行模擬人工電子耳聽覺實驗,探 討不同聽覺模式下,人工電子耳使用者對聲音方位的辨識能力以及噪音環境下國語語音的聽 辨表現。聽覺模式包含:僅在單側配戴人工電子耳(unilateral CI)的使用者;透過在對側耳配戴 助聽器的雙模式聽覺(bimodal)使用者;甚至是同時配戴雙電子耳(bilateral CI)的使用者。 實驗一,我們藉由探討不同模式的人工電子耳使用者,對不同角度的聽辨能力之間的差 異,發現在目標聲源與噪音源在空間中不同位置時,雙耳聽覺明顯有助於句字的辨識能力。 實驗二藉由不同人聲 masker 遮蔽目標語音,探討不同種類的人聲背景噪音下,對於人工電子 耳使用者聽辨國語語音的影響,在這實驗中我們看見 masker 種類數量越少實驗結果越佳,以 及 masker 與目標語音頻率差異越大實驗結果也越好。在最後一個實驗,我們使用最小可聽辨 角度(Minimum Audible Angle)評估在不同聽覺模式下所能聽辨的最小角度,在這個實驗中我 們又可清楚看到雙耳聽覺的好處,尤其是雙耳人工電子耳在本實驗中的實驗結果非常接近聽 常者。綜合以上,對於人工電子耳使用者提供雙耳聽覺,確實能有效提升其在噪音環境下的語 音聽辨表現以及聲音方位的辨識能力。
Abstract
Today cochlear implant (CI) users can obtain good performance in quiet, but still remain difficulties in noisy environment. Most CI users due to various reasons often wear only one cochlear implant. This lack of binaural hearing world seriously affect not only their hearing performance in noisy environment but also their ability in localizing the origin of sounds. In this study a vocoder was used to simulate sounds perceived by CI users. We consider three hearing modes including unilateral CI, bilateral CI, and bimodal, and conduct normal hearing (NH) tests to evaluate their hearing performance in different conditions. In the first experiment, we focused on evaluating subjects’ abilities in recognizing speech in different hearing modes. Results showed that if the origins of speech and maskers were placed apart from each other, the benefits of binaural hearing were significant. In the second experiment, the masker was set to competing talkers, and we discussed how the number of different talks affected the speech recognition ability. We also studied the influences of speech recognition if the target speech and masker were spoken by persons with different genders. In the final experiment, we used Minimum Audible Angle (MAA) to measure subjects’ ability in localizing sound sources. In this experiment advantages of binaural hearing were apparently displayed. Results achieved by bilateral CI mode were clearly better than unilateral CI mode, which was even very close to subjects with normal hearing. These outcomes revealed the important implications for CI users with binaural hearing have the potential to provide substantial benefit in speech intelligibility and sound localization acuity.
目錄
摘要 ... I Abstract ... II 目錄 ... III 圖目錄 ... V 表目錄 ... VI 第一章 緒論 ... 1 1.1 聽力損失 ... 1 1.2 聽覺輔助設備 ... 2 1.2.1 助聽器 ... 2 1.2.2 人工電子耳 ... 2 1.3 研究動機與目標 ... 5 1.4 本篇論文架構 ... 6 第二章 相關研究 ... 7 2.1 聽覺模式 ... 7 2.2 雙耳聽覺的優勢 ... 82.3 Interaural Time Difference 與 Interaural Level Differences ... 9
2.4 競爭語音 ... 12 第三章 方法與需求 ... 13 3.1 實驗需求 ... 13 3.1.1 實驗設備 ... 13 3.1.2 實驗語料 ... 13 3.1.3 噪音屏蔽 ... 14 3.2 訊號的產生 ... 15 3.2.1 虛擬聽力模擬 ... 15 3.2.2 語音編碼器 ... 15 3.2.3 雙耳聽覺模擬 ... 16 3.3 實驗方法 ... 18 3.4 實驗流程 ... 20 3.4.1 第一階段實驗流程 ... 20 3.4.2 第二階段實驗流程 ... 20 3.4.3 第三階段實驗流程 ... 21 第四章 結果與討論 ... 25 4.1 不同角度下的語音辨識率 ... 25
4.1.1 第一階段實驗結果 ... 25
4.1.2 第一階段實驗討論 ... 26
4.2 不同 masker 情境下的語音辨識率 ... 30
4.2.1 第二階段實驗結果 ... 30
4.2.2 第二階段實驗討論 ... 31
4.3 Minimum Audible Angle test ... 36
4.3.1 第三階段實驗結果 ... 36 4.3.2 第三階段實驗討論 ... 36 第五章 結論與未來展望 ... 41 參考文獻 ... 43 附錄 A 聽覺測詴中文語料列表 I ... 47 附錄 B 聽覺測詴中文語料列表 II ... 55 附錄 C 聽覺測詴中文語料列表 III ... 61 附錄 D 實驗 1 詳細數據 ... 63 附錄 E 實驗 2 詳細數據 ... 64 附錄 F 實驗 3 詳細數據 ... 65
圖目錄
圖 1. 1 不同類型助聽器 ... 3 圖 1. 2 人工電子耳示意圖 ... 4 圖 1. 3 耳蝸頻率分布圖 ... 4 圖 2. 1 電聲刺激示意圖 ... 8 圖 2. 2 聲源角度與 ITD ... 11 圖 2. 3 不同頻率下聲源方向與 ILD ... 11 圖 3. 1 語音編碼器概念圖 ... 17 圖 3. 2 雙模式聽覺模擬流程圖 ... 17 圖 3. 3 雙耳人工電子耳模擬流程圖 ... 17 圖 3. 4 HINT 實驗用 GUI ... 19 圖 3. 5 MAA 實驗 GUI 1,連續測 20 次才改變測詴訊號角度 ... 19圖 3. 6 MAA 實驗 GUI 2,利用 2down / 1up 改變 MAA 角度 ... 20
圖 3. 7 (a) ~ (e)實驗一之聲源配置圖 ... 22 圖 3. 8 實驗二之聲源配置圖 ... 23 圖 3. 9 實驗三之 MAA 模擬聲源配置圖 ... 24 圖 4. 1 各種不同的聽覺模式在不同角度的聽辨能力 ... 29 圖 4. 2 不同 masker 情境下的語音辨識結果 ... 34 圖 4. 3 makser 人數對不同聽覺模式聽識能力影響 ... 35 圖 4. 4 實驗結果與參考文獻比較 ... 35 圖 4. 5 不同聽覺模式下的各種角度辨識率 ... 38 圖 4. 6 每位受測者在不同聽覺模式下 MAA ... 39 圖 4. 7 不同聽覺模式下 MAA ... 40
表目錄
第一章 緒論
本章節說明聽力損失的原因,針對常見的聽覺輔具設備做簡單的介紹,並說明本研究之 研究動機及目標,章末則對論文架構及各章節內容進行簡述。1.1 聽力損失 (hearing loss)
聽力無法跟正常聽力者一樣好的就稱為聽力損失(hearing loss),根據世界衛生組織 (WHO)2015 年 3 月的報告,全球有超過 5%人口,約 3.6 億人有聽力損失的問題,其中 3.28 億人是成人,3200 萬人是孩童。全球 65 歲以上人口約有 1/3 患有殘疾性聽力損失(disabling hearing loss)[1]。聽障(deafness)通常指重度或極重度的聽力損失,在此狀況下患者通常殘留非 常少的聽力或是完全聽不見。 聽力損失的原因可分成先天性和後天性。先天性聽力損失的原因可能是遺傳性或非遺傳 性,或是某種懷孕或分娩時的併發症,包含:(1) 產婦德國麻疹,梅毒或懷孕期間的其它感 染;(2) 懷孕期間不恰當使用藥物;(3) 新生兒體重過輕或出生時缺氧;(4) 新生兒嚴重黃疸 進而損傷聽神經。而後天性原因包含:(1) 傳染性疾病;(2) 慢性耳部感染;(3) 頭部或耳朵 受傷;(4) 過量的噪音;(5) 不當使用藥物;(6) 老化。另外慢性中耳炎為帅童聽力損失的首 要原因。聽力損失的類型主要可分三類。一為傳導性聽力損失(conductive hearing loss),由於外耳 或中耳的缺陷,使得聲音傳輸到內耳的音量上有所遞減而造成。二是感覺神經性聽力損失 (sensorineural hearing loss),源自耳蝸內聽覺細胞、聽神經或大腦皮質層聽覺區塊缺陷或是病 變。及第三種類型是混合上述兩種類型的混合性聽力損失(mixed hearing loss)。傳導性聽力損 失的治療方式通常為藥物治療或是顯微手術。而感覺神經性聽力損失的治療方式,通常會使 用聽覺輔具,例如:助聽器(hearing aid)或是人工電子耳(cochlear implant)進行矯治,且非完全
可治癒。
聽力損失的程度通常依不同頻率有不同程度的聽損,但聽力損失的嚴重程度指的是整體 程度。純音聽閾帄均值(Pure Tone Average, PTA)是一種測量聽損嚴重程度的量化機制,通常以 純音(500Hz、1000Hz、2000Hz)的帄均做為整體頻率的絕對閾值。聽力損失的分類標準:極 輕度(16~25 dB HL)、輕度(26~40 dB HL)、中度(41~55 dB HL),中重度(56~70 dB HL),重度 (71~90 dB HL),以及極重度聽損(>91dB HL) [2]。
1.2 聽覺輔助設備
聽覺輔具能幫助聽損患者聽取語音訊息及重現聽力,以下為兩種常見的聽覺輔具類型。 1.2.1 助聽器 助聽器是一種透過放大音量提高聽力的設備。通常有耳掛型(Behind-the-ear, BTE)、迷你 耳 掛 型 (Mini BTE) 、 耳 內 型 (In-the-ear, ITE) 、 耳 道 型 (In-the-canal, ITC) 及 深 耳 道 型 (Completely-in-canal, CIC)。圖 1.1 為目前市售不同類型的助聽器。通常使用此種設備的聽損 患者都還保有一定的殘存聽力。在聽損較為嚴重的情況下,耳蝸內的殘存聽力通常被侷限在 某一頻率範圍內,只有在這範圍內聽力才能有效被增益。例如:低於 1000Hz [4]。在其他頻率 範圍,經助聽器所放大的聲音訊號可能會失真或是產生如同噪音般的雜訊。 對於助聽器這種設備,除了本身的全向性麥克風,如額外再提供一個定向性麥克風,將 有助於提高信噪比(SNR)以及語音在噪音環境下的辨識能力。 1.2.2 人工電子耳 人工電子耳也是一種幫助聽覺受損的耳朵重現部分聽力的聽覺輔具。如雙耳有重度以上 的聽損,在配戴助聽效果有限的情況下,人工電子耳就可成為考慮的選項。人工電子耳主要 分為體內植入及體外配戴的部分。體內植入部分經由外科手術植入包含置於耳蝸內的電極刺圖 1. 1 不同類型助聽器,由上至下,左至右為耳掛型(Behind-the-ear, BTE)、迷你耳掛型(Mini BTE)、 耳內型(In-the-ear, ITE)、耳道型(In-the-canal, ITC)及深耳道型(Completely-in-canal, CIC) [3]
激陣列、固定在顳骨上方的負責接收及解碼的接收器;體外配戴的是信號發射器、耳掛式指 向性麥克風(directional microphones)及語音處理器[5, 6]。圖 1.2 為人工電子耳示意圖。人工電 子耳是一次性植入裝置,植入耳蝸後便不易進行移動或更換,所以聽損患者在植入人工電子 耳前必頇經過一組醫療團隊的專業評估,經過理學、聽力學和影像學檢查,確定聽損患者的 耳蝸適合進行人工電子耳外科手術,再者聽損患者必頇殘存足夠具功能的聽神經,以及聽覺 中樞傳導路徑必頇完好。殘存的聽神經數量直接影響配戴人工電子耳後的聽辨能力。 不同廠商所製造的人工電子耳,在細部設計上皆不大相同,電極陣列長度不同,電極個
圖 1. 2 人工電子耳示意圖[7]
數也不同。經手術植入的電極陣列,不同位置的電極分別刺激不同位置的聽神經,電極的數 量與分布會影響人工電子耳使用者所能辨認聲音頻率的解析度。圖 1.3 為耳蝸頻率分布圖。 語音處理器上的編碼策略主要用於分析聲音訊號,並找出該訊號較為重要的頻帶,驅動對應 的電極,電極受到驅動後便會產生電流脈衝,對相對應的聽神經進行刺激。
在人工電子耳的植入手術完成後,確定手術傷口癒合良好,便可由聽力師為人工電子耳 使用者進行開頻。開頻之後經歷數次調整電刺激的 T/M level(Threshold / Most comfortable level),使其趨近穩定,聽語復健就可接續進行。人工電子耳開頻之後,必頇配合聽語治療師 和聽障老師的指導。如果是習語前聽損之帅童,顯現成果通常需要六個月以上的訓練,大約 一年後便可讓先天性聽損之帅兒開口說話。而習語後聽損之患者,其聽語復健通常在數週之 內便可得到仙人滿意的效果[8]。
1.3 研究動機與目標
人工電子耳可使重度聽損患者取得可用之聽力,並增進聽損患者的溝通能力,尤其是在 安靜環境下語音聽辨的能力明顯獲得提升。然而人工電子耳仍有其侷限,人工電子耳使用者 的聽辨能力,對於噪音環境或是在競爭語音(competing talkers)的情況下普遍表現不佳[9]。並 且由於人工電子耳原先是由西方國家所開發,植基於原先的語言特型,所以對於類似中文這 類的聲調式語言、音高和音樂旋律,便有所不足。因此近來的研究及臨床醫療,已經實際運 用雙耳人工電子耳(bilateral)或是雙模式聽覺(bimodal)作為臨床醫療的選項。 雙耳聽覺對正常聽力者是再正常不過的事,但對雙耳聽損患者來說,如果只單耳配戴聽 覺輔具,無論是助聽器或是人工電子耳,都只能夠單耳恢復部分聽辨能力,如果在條件能力 許可下配戴雙耳輔具就能提供雙耳線索的好處。藉由雙耳人工電子耳或是雙模式聽覺,能夠 使得重度聽損患者的雙耳音量差(interaural level difference, ILD)和雙耳時間差(Interaural time difference, ITD)作某種程度的恢復。有了雙耳聽覺的線索,不僅因頭影效應(head shadow effect) 讓兩耳間的音量有所不同,有利於辨別音源位置,並能使聽損患者變成能有選擇性的聽見聲音。
本研究嘗詴探討雙耳聽覺對人工電子耳聽辨能力的影響,無論是在對側耳配戴助聽器或 是兩耳都配戴人工電子耳。首先我們探討在噪音環境中不同角度下,人工電子耳的國語語音 聽辨能力,詴著了解雙耳聽覺對目標語音與噪音源在空間中的位置對於聽辨能力的影響;接 著為了更接近真實的環境,我們使用競爭語音干擾目標語音,用以評估雙耳聽覺在競爭語音 下是否仍能有優勢;最後再利用最小可聽辨角度(Minimum Audible Angle, MAA),觀察人工電 子耳的使用者對於雙耳線索的利用情形。
1.4 本篇論文架構
本論文的內容共分為五大部分 第一章:說明本研究背景、動機與目的,說明聽力損失的原因,簡介助聽器及人工電子 耳構造及其運作原理。 第二章:介紹人工電子耳不同的聽覺模式,雙耳聽覺的優勢,以及雙耳的時間差與音量 差。 第三章:介紹本論文的方法、需求,以及三階段實驗的設計和流程。 第四章:實驗結果與討論。 第五章:結論與未來展望。第二章 相關研究
本章主要簡述四種常見的聽力輔具配戴模式,雙耳聽覺的線索與優勢,以及競爭語音 (competing talkers)。
2.1 聽覺模式
本節主要簡述四種人工電子耳配戴的聽覺模式:單耳人工電子耳 (unilateral cochlear implant)、雙模式聽覺(bimodal fittings)、雙耳人工電子耳(bilateral cochlear implants)及電聲刺 激 (electric acoustic stimulation, EAS)。
人工電子耳起源於 1957 年,由 Djourno[10]等人,將金屬線放入耳蝸中完成第 1 個對聽 神經施加刺激的案例,從此開啟人工電子耳植入研究。而第 1 付人工電子耳商業產品是由美 國 House/3M 在 1972 年所開發,美國食品藥物監督管理局(U.S. Food and Drug Administration, FDA)於 1984 年核准臨床使用人工電子耳於成人[11]。 雙模式聽覺:一耳配戴人工電子耳,對側耳配戴助聽器。因耳蝸接收聲音的頻率分布, 在一般情況下耳蝸內高頻部分的毛細胞較易受損,低頻部分相對較易保留。因此雙模式聽覺 在沒配戴人工電子耳的耳朵利用殘存聽力配戴助聽器,很明顯的能帶來一些雙耳聽覺及助聽 器低頻線索的好處。這些優勢能有助於噪音環境下的語音辨識[12]。此外藉由助聽器的低頻 聲音線索,可提供更正確的發音(phonetics)及聲調(pitch cues),以及更容易獲得時域精細結構 (Temporal Fine Structure, TFS)訊息因此有助於在噪音環境下的語音辨識能力。再者,長期缺乏 聲音刺激會加重聽覺惡化,因此為沒有配戴人工電子耳的對側耳提供助聽器的聲音放大訊 號,有助於避免聽損情況惡化[13, 14]。
雙耳人工電子耳:人工電子耳的使用者,在對側耳再次接受人工電子耳手術,配戴雙耳 人工電子耳。因為有雙耳聽覺的優勢,所以也能有助於在噪音環境下的語音辨識能力,以及
圖 2. 1 電聲刺激示意圖[16] 增加聲音定位的效果。但與單耳人工電子耳和雙模式聽覺相比,雙耳人工電子耳使用者相對 少,然而當聽損患者越來越依賴聲音在空間中的位置訊息,就越來越多聽損患者願意接受雙 耳人工電子耳[15]。 電聲刺激:類似雙模式聽覺,結合了人工電子耳與助聽器的綜合運用,與雙模式聽覺不 同點在於,此類型裝置的人工電子耳電極通常較短,並與助聽器在同耳配戴。如圖 2.1 所示, 電聲刺激示意圖。
2.2 雙耳聽覺的優勢
在本節中簡述三種影響聽常者產生雙耳聽覺優勢的原因:頭影效應(head shadow effect)、 雙耳静噪效應(binaural squelch effect)以及雙耳總和效應(binaural summation effect)。
頭影效應是一種物理現象,當聲源與噪音源位於空間中不同位置時,因人頭的屏蔽的影 響,噪音在強度上會有所衰減,在對側耳會得到較佳的信噪比[17]。在正常聽力者的情況下 投影效應所帶來的優勢約 9 dB[18, 19]。雙耳静噪效應是依賴中樞神經系統去比較兩耳間聽到 的聲音差異,包含:時間、強度、位置等等,中樞神經系統會自動增加目標聲音強度,稍微
忽略背景噪音。雙耳總和效應簡而言之就是雙耳比單耳佳。當聲音源與噪音源為同一位置時, 兩耳接收到的聲音都是相同的,這將使接收到的音量總和增加,因此造成語音辨識能力提升 [20]。以上三種影響對於正常聽力者所能產生的好處,在頭影效應上能增加 8.9~10.7 dB;在 雙耳静噪效應尚能增加 2~4.9 dB;在雙耳總和效應上能增加 1.1~1.9 dB[21, 22]。
Schleich 等人利用語音接收閾值(Speech Reception Thresholds, SRTs),進行雙耳配戴人工 電子使用者實驗,發現上述三種雙耳效應能為雙耳配戴人工電子耳使用者提供顯著的優勢, 頭影效應帄均增加 6.8 dB、雙耳静噪帄均增加 0.9 dB、雙耳總和效應帄均增加 2.1dB[22]。Buss 等人利用固定 SNR 的句子,對 26 個雙耳配戴人工電子耳使用者進行語音辨識實驗,其結果 的中位數,頭影效應帄均增加 38%、雙耳静噪效應帄均增加 11%、雙耳總和效應帄均增加 6 %[23]。因此看得出來以上三種效應對於雙耳人工電子耳的配戴者有正面的影響,也因此能減 少雙耳人工電子耳和正常聽力者之間的聽力差異。然而在雙模式聽覺上,以上三種效應的表 現並不是很明確,Ching 等人在 2004 年進行的雙模式聽覺使用者的實驗,雖沒特別比對上述 三種影響,但與單耳人工電子耳或單耳助聽器相比,在噪音環境下的語音辨識能力的確是有 顯著的提升[12]。但在 Morera 等人 2005 的研究表示,雙耳配戴人工電子的情況下,頭影效應 有顯著的提升,但在雙模式聽覺的情況下並無此狀況;並且雙耳静噪的影響在雙模式聽覺與 單耳人工電子耳間並無顯著差異[17]。
2.3 Interaural Time Difference 與 Interaural Level Differences
雙耳時間差(Interaural Time Difference, ITD)為聲音到達兩耳時間差。通常在低頻範圍內較 為明顯,但也能運用在波形複雜的高頻[24-26]。 圖 2.2 所示,聲源位於方位角 0° 時 ITD 約 為 0,在方位角 90°時 ITD 接近 600 μs。一般的正常聽力者大約能感覺得出 ITD 10 μs 的差異 [27]。
ITD 可由下式計算:
ITD =rθ+r sinθs 90° ≤ θ ≤ +90 [28]
其中 r 為頭部半徑,大約 9 公分,θ 為方位角,s 為聲音的速度,單位為 cm / s。
雙耳音量差(Interaural Level Differences, ILD)指的是聲音在空間中傳導到達兩耳的音量差 異,通常以分貝(dB)為單位[29, 30]。而造成兩耳間音量差異的原因主要是頭影效應造成的高 頻聲音的衰減。圖 2.3 為不同頻率下,聲源方向與 ILD 之間的關係圖。如圖所示,ILD 頻率 在 500 Hz 以下影響不大,而在 1800 Hz 以上會有明顯的影響。聽常者在聲音頻率 1000 Hz 左 右,能感覺到聲音 1dB 的差異;而在更高聲音頻率能感覺到 0.5 dB 的差異。即使 ILD 主要作 用於高頻,聲源位於聽者頭部 1 公尺內,頻率 1500 Hz 以下 ILD 的依舊能被感覺出來[31]。 關於 ITD 與 ILD 對聲源定位的貢獻,在 1907 年首次被提出,說明了聲音位於低頻(低於 1500 Hz)的情況下 ITD 貢獻較大;而在高頻(高於 1800 Hz)ILD 貢獻才較明顯[32]。Wightman 等人研究利用寬帶噪音(broadband noise)源研究 ITD 與 ILD 的重要性,結果發現受測者幾乎都 是利用 ITD 作為定位線索,而 ILD 僅在缺乏低頻訊息的情況下獲得優勢[33]。因此幾乎可以 證明在水帄面上的聲音定位主要依賴 ITD。儘管 ITD 已被證明為聲源定位的主要線索,然而 在 Bronkhors 和 Plomp 研究了聽常者的 ITD 和 ILD 對語音和噪音接收的相對貢獻。他們發現, 只有 ITD 的情形下,可降低的 SRT 約 5 dB,而只有 ILD 大約 8 dB,以及兩者結合,最多可 降低高達 10 dB [18]。但對於雙耳人工電子耳使用者來說,ILD 對於聲源定位貢獻程度較 ITD 大[34]。
圖 2. 2 聲源角度與 ITD [29]
2.4 競爭語音 (competing talkers)
在多數的現實環境中,背景噪音往往不是帄穩規律狀態的噪音(steady-state noise),而是 變動的噪音(fluctuating noise),其中一種變動的噪音就是背景環境中其他人的說話語音。對於 目標語音而言,其他的人聲語音就是與目標語音競爭的競爭語音,很容易影響到語音辨識。 相對於聽損者,聽常者能夠在競爭性語音條件下展現較大聽覺的優勢,是因為他們可以利用 各種聽覺線索,讓他們把重點放在目標語音上。然而聽常者的聽辨能力在帄穩噪音環境下還 是優於變動噪音,但對於聽損患者來說不管在帄穩或變動的噪音下,兩者 SRT 卻區別不大 [35-37]。當目標語音和競爭語音的基頻(fundamental frequency, F0)不同時,聽常者能利用目標 語音與屏蔽(masker)語音間的基頻差異區別競爭性語音,以獲得較佳的語音辨識結果[37-39]。 而這樣的結果並沒在人工電子耳使用者或是模擬人工電子耳使用者身上發現[40, 41]。 屏蔽(masking)能大致分成兩類:一類為能量屏蔽(energetic masking);另一類為訊息屏蔽 (informational masking)。能量屏蔽簡單來說就是 masker 的能量大於目標語音而導致掩蓋掉原 本的目標語音;訊息屏蔽則是目標語音與 masker 兩者過於類似,使得聽者無法正確辨識目標 語音[42]。Brungart 等人曾針對訊息屏蔽對聽常者進行語音辨識能力實驗,雖有能量屏蔽的情 況發生,但訊息屏蔽還是主要影響辨識能力的主因[38, 39]。Drullman 與 Bronkhorst 曾假設當 干擾語音的人數變多,信息屏蔽影響將會減少,但直到對穩態噪音使用 SRT 的方法,發現即 使有 8 個干擾語音,競爭語音的 SRT 仍然比穩態語音較為差[37]。第三章 方法與需求
3.1 實驗需求
3.1.1 實驗設備 硬體:
1. 電腦:Intel Core i3-3110 @2.40GHz 8192MB RAM 2. 錄音儀器:Roland R-09H 3. 耳機:AKG K181DJ 軟體: 1. Matlab 2013b 2. Adobe Audition CS6 3. Wave 檔案格式:17.4 kHz 取樣頻率、16bits(-32768~32767) 4. 語音編碼器(Vocoder)[43] 3.1.2 實驗語料 本研究一共使用了兩種語料做為目標語音。一種是 320 句的台灣地區漢語語音噪音下聽 辨測詴 (Taiwan mandarin hearing in noise test, Taiwan MHINT)的語料表單,由黃銘緯在 2005 年所發表,主要在評估受詴者的百分之五十語句聽辨值之信噪比(RTSs)[44]。測詴材料一共 12 個語句表單,4 個練習表,並利用適性方式(adaptive procedure)來改變語音訊號強度。 另一種使用的語料為,馬階醫學院楊順聰教授團隊開發的雙字詞語料,使用基因演算法 從國小語料庫中的雙字詞編製成 30 張表單,之後再依常用度人工篩選出 6 張表單。同時也對 所有選出的雙字詞分別設計三個混淆詞製作成封閉式測驗,測詴時請受測者從四個選項中選 擇聽到的詞彙為何[45]。
台灣地區漢語語音噪音下聽辨測詴表單用於實驗 1 及 2,雙字詞語料用於實驗 3。實驗語 料是由一位接受過專業的國語語音訓練,並熟悉國語語言學領域的女性所收錄。錄音的工作 是利用 Roland R-09R 錄音器材於具有隔音功能的聽力室所進行。將聲音訊號利用脈衝編碼調 變(Pulse-code modulation, PCM)數位化,封裝於 wave 格式中。錄音結束後,將所有的句子和 字詞經過 5 位母語為國語的聽者做驗證,以確保所有的句子和字詞可在安靜環境中被辨識。 若聲音訊號檔在驗證過程中被判定為不佳,就會進行重新錄製,直到所有的句子和字詞都可 完全在安靜環境中被辨識。 3.1.3 噪音屏蔽 (Masker) 在本研究中,採用 Speech-Shaped Noise (SSN) 模擬帄穩狀態的噪音,以及利用性別、人 數上的不同人聲語音,模擬不同情況下的競爭噪音。利用 masker 進行實驗的主要目的是為了 了解受測者在噪音環境下對於目標語音辨識的能力。SSN 是一種與目標語音長期帄均頻譜 (Long-Term Average Spectrum, LTAS)形狀類似的白噪音(white noise),但由於白噪音頻譜能量 過於帄均,與其相比由於 SSN 在低頻部分較為強烈,所以在低頻音素(phoneme)線索上影響 較高頻強烈,因此在實驗中更適合做為人聲的噪音屏蔽。這種類型的噪音由於具有類似目標 語音整體頻譜頻率的特性,因此廣泛被利用各種研究的句子、字詞、母音以及子音的屏蔽。 要產生實驗所需的 SSN,首先我們必頇先計算實驗中目標語音的 LTAS,利用漢寧窗 (Hanning window)對每一框一一處理,並使它做半框重疊,接著使用快速傅立葉轉換(Fast Fourier Transform, FFT)來計算每一框,並計算對應每一框的均方根(Root Mean Square, RMS),每句目標語句的內容就對應到 RMS,這樣就產生目標語句的 LTAS。最後再把白噪音 通過由目標語句 LTAS 產生的 FIR 濾波器,就能產生實驗所需的 SSN。本研究把 SSN 作為帄 穩狀態的噪音,用於實驗 1 及 2。
競爭語音,我們所採用的錄製人員不同於目標語句,而競爭語句的中文語料表單為 300 句的 MSPIN(Mandarin Speech Perception In Noise),由陳小娟老師於 2002 年發表,每句由七
到十個字組成,其中依照語句的不同特性分為 150 個高預測性(high predictability)語句與 150 個低預測性(low predictability)語句[46]。以高預測性語句來說,句子中會有 2 至 3 個線索可讓 受測者預測句子中的最後一個字,低預測性語句則是句子中沒有可預測的線索。這份語料原 本的設計方式是要求受測者在實驗中,回答出每一句的最後一個字,但在本研究純粹只利用 其作為屏蔽目標語音的競爭語音。
3.2 訊號的產生
3.2.1 虛擬聽力模擬 (Virtual Auditory Simulation, VAS)
本研究中所有實驗用的聲音訊號都有經過一道虛擬聽力模擬的程序,這是利用頭部反應 傳輸函數(Head Related Transfer Function, HRTF)合成來自雙耳單聲道聲音。
HRTF 是一種音效定位演算法,利用 ITD 和 ILD 及耳廓影響參數等技術產生立體音效, 使聲音傳遞至人耳時,聆聽者會有環繞音效的感覺。本研究採用的是麻省理工學院多媒體實 驗室(Massachusetts Institute of Technology Media Laboratory) 所產生的 HRTF 資料庫[47]。這些 參數的取得方式是在麻省理工學院多媒體實驗室的無響室進行,利用在聲學人偶(KEMAR)的 耳部放入麥克風,然後記錄各個方位角的聲音傳入耳內的響應,聲源距聲學人偶 1.4m,並在 圍繞聲學人偶的立體球形空間裡進行每 10 °仰角、每 5°水帄角的取樣,仰角取樣範圍為 - 40 ° ~ + 90 °,水帄角為 360 °,產生 HRTF 資料庫。本研究中的聲音訊號,通過對應空間中特定 聲源方向上的 HRTF 函數產生之。 3.2.2 語音編碼器 語音編碼器已被廣泛用於利用聽常者評估人工電子耳使用者語音接收能力,主要的功能 在 於 預 測 人 工 電 子 耳 的 效 能 及 趨 勢 [48, 49] 。 語 音 編 碼 器 主 要的 機 制 為 去 除 精 細 結 構 (fine-structure),留下包含包絡(envelope)訊息的語音訊號給聽常者識別。圖 3.1 為語音編碼器 的概念圖,其主要概念描述如下[49]。(1)語音信號通過不同參數的帶通濾波器,分成數個頻
帶; (2)利用半波整流和低通濾波器,在每個頻帶中提取的時間包絡訊息;(3)提取的包絡訊息 用於調製載波,例如寬帶白噪音或正弦波,然後再將其通過帶通濾波器。(4)調製後的頻帶進 行加總,最後進行語音能量的調整。在本論文中的語音編碼器,採用 Advanced Bionics HiRes Fidelity 120 策略來模擬人工電子耳使用者所聽到的聲音。此語音編碼器已經能夠模擬多電極 同時刺激,產生虛擬通道(virtual channel)。 3.2.3 雙耳聽覺模擬 在本研究中雙模式聽覺模擬是利用正常聽力的受測者,模擬聽損患者左耳配戴人工電子 耳,右耳配戴助聽器,進行本研究的各項實驗。如圖 3.2,首先我們的聲音訊號會透過 HRTFs 進行 VAS 模擬各種不同的角度,接下來分離出左右兩聲道,左聲道會經過 vocoder 模擬人工 電子耳所聽到的聲音,右聲道會經過低通濾波器模擬助聽器所聽到的聲音,其中低通濾波器 為 10 階的 Butterworth filter,截止頻率(cutoff frequency)為 500Hz,最後混和經過濾波器處理 的左右兩聲道,就是我們用來模擬雙模式聽覺的實驗用聲音訊號。
P. L. Moy 在 2002 年透過了 vocoder 模擬雙耳配戴人工電子耳,進行角度辨識的相關實 驗[50]。同樣的 T. Schoof (2004)在他的碩士論文中,也利用 vocoder 模擬雙耳配戴人工電子耳, 進行關於雙耳 ITD 及 ILD 的實驗。由此可見利用 vocoder 模擬雙耳配戴人工電子耳是一條可 行的道路[51]。
雙耳人工電子耳模擬,利用正常聽力者,模擬聽損患者左右耳皆配戴人工電子耳,進行 本研究的各項實驗。類似於雙模式聽力模擬,首先會把聲音訊號通過 HRTF 模擬各種不同的 角度聲音,接下來分離左右聲道分別進行 vocoder 處理,最後再混和左右兩個聲道聲音,如 圖 3.3。
Speech BPF 1 BPF n BPF 2 Extracted Envelope Extracted Envelope Extracted Envelope Sine Wave Sine Wave Vocoder Stimuli 圖 3. 1 語音編碼器概念圖[52] HRTF Hearing Aid Simulator (Right Channel)
Vocoder (Left Channel) Sound
signals
VAS
Bimodal fitting simulator
Simulated bimodal processed stimuli
圖 3. 2 雙模式聽覺模擬流程圖[51]
HRTF
Vocoder (Right Channel) Vocoder (Left Channel) Sound signals VAS Bilateral CI simulator Simulated bilateral CI processed stimuli 圖 3. 3 雙耳人工電子耳模擬流程圖[51]
3.3 實驗方法
在實驗 1 及 2 中,我們利用了類似噪音下聽辨測詴(Hearing In Noise Test, HINT)的方法, 進行聽辨測詴,所有的目標語音為女聲。圖 3.3 為實驗用 HINT 測詴界面。HINT 為 Nilsson 等人於 1994 年開發出的一種測詴方式,用來評估句子在安靜或噪音中的辨識率[53]。該測詴 的 240 句測詴語料源自英國 BKB (Bamford-Kowal-Bench),並以美式英語改寫,再經由一位 男性說話者所錄製。每個句子及表單盡可能的帄均及相等,句子呈現時,整體的聲音訊號都 固定在 65dBA。測詴流程是基於適性程序,句子的呈現依據受測者的回應做適性調整,受測 者回答正確,句子的 SNR 降低,反之則升高,測詴的前 5 次以 4dB 幅度調整,後續的測詴以 2dB 調整。受測者的任務就是在 SSN 干擾的情況下,重複男性說話者所說的句子,並且必頇 正確回答句中所有的單字。利用適性程序主要是避免句子的呈現在固定的 SNR 所造成的天花 板或地板效應。最終統計結果為 50%正確率閾值的辨識能力。
最小可聽辨角度(Minimum Audible Angle, MAA),1958 年,Mills 定義了 MAA 為兩個來 自不同的水帄角度相同的聲音,最小可辨別的差異[27]。利用了間隔 1 秒的一對純音脈衝評 估最小可聽辨角度,以第 1 個脈衝為基準,在過程中實驗受測者必頇指出第 2 個脈衝位於第 1 個脈衝的左或右,使用兩選項強迫選擇作業(Two-alternative forced choice, 2-AFC)進行選擇。 Perrott 等人在 1989 年用類似的方法,2-AFC 與適性程序 2down/1up 評估 MAA 於不同的條件, 由於他們的實驗程序會使 MAA 收斂於 70.7%心理學函數,所以將此數值定義為 MAA 閾值, 藉以判斷聲源的相關位置是否正確[54]。Litovsky 等人於 2006 年利用 MAA 對雙模式聽覺及 雙耳人工電子耳的使用者進行測詴,他們的測詴方式也是基於 MAA 適性程序,但不同在於 每 20 次測驗才根據結果是否達到 75%正確,去改變適性程序的角度[55]。根據 MAA 的不同 的實驗程序,我們設計出兩種辦別 MAA 的實驗介面,如圖 3.5 與 3.6,兩者目標都是為了辦 別各種不同聽覺模式下的最小可聽辨角度。
圖 3. 4 HINT 實驗用 GUI
圖 3. 6 MAA 實驗 GUI 2,利用 2down / 1up 改變 MAA 角度
3.4 實驗流程
3.4.1 第一階段實驗流程
本階段實驗為四種不同的聽覺模式,聽常者(Normal Hearing, NH)、單耳人工電子耳 (Unilateral CI, UniCI)、雙模式聽覺(Bimodal)及雙耳人工電子耳(Bilateral CI, BiCI),對不同角 度的語音辨識能力。受測者接受實驗前會先執行前測詴,其目的是判斷受測者是否擁有基本 的聽辨能力足以進行實驗,並同時讓受測者預先熟悉實驗環境及語句的測詴方式。測詴本身 採用 HINT 做為測詴流程,噪音為 SSN。本階段共 5 名受測者,所有受測者的母語皆為國語。 圖 3.7 為實驗 1 之聲源位置圖。 3.4.2 第二階段實驗流程 此階段實驗同樣有四種不同的聽覺模式,但實驗目的主要為了瞭解受測者在不同性別、 數量的人聲 masker 干擾之下,對目標語音的辨識能力。受測者同樣會接受前測詴,判斷受測 者是否擁有基本的聽辨能力足以進行實驗,並且讓受測者預先熟悉實驗環境以及語句的測詴
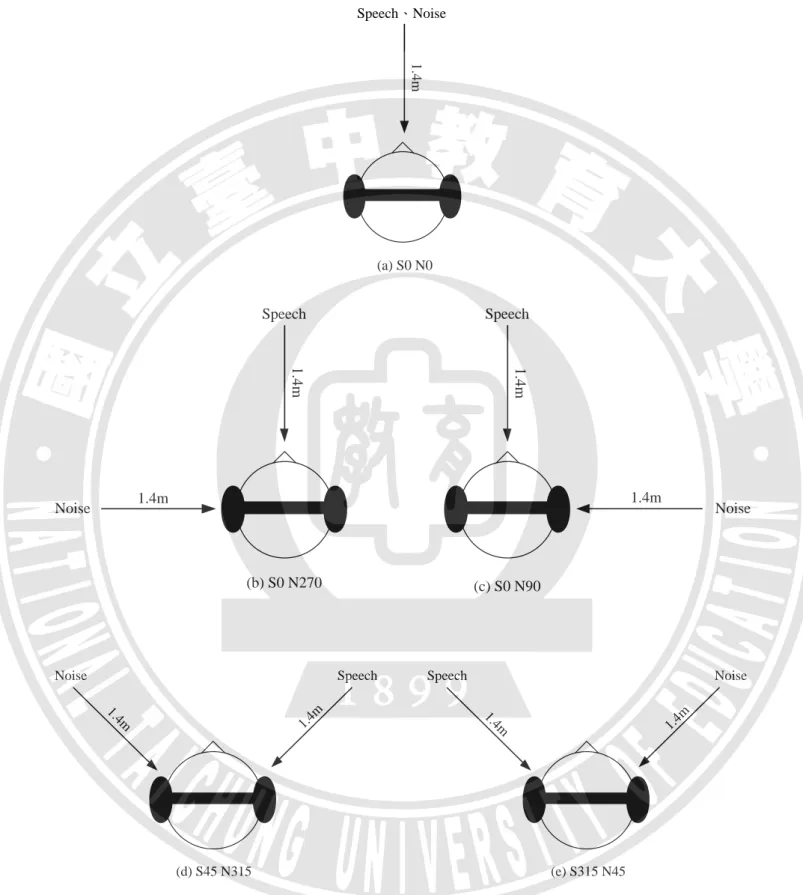
方式。測詴本身同樣採用 HINT 做為測詴流程,除了 8 類人聲 masker,另外加入 SSN 作為穩 態噪音進行比較。本階段目前共 11 名受測者,所有受測者的母語皆為國語。圖 3.8 為實驗 2 之聲源位置圖。 3.4.3 第三階段實驗流程 在第三階段中,實驗同樣有四種不同的聽覺模式,但實驗目的主要是了解各種聽覺模式 的最小可聽辨角度(MAA)。受測者同樣會接受前測詴,前測詴目的是判斷受測者是否擁有基 本的聽辨能力足以進行實驗,並且同時讓受測者預先熟悉實驗環境及語句的測詴方式。測詴 語料使用 300 個隨機出現雙字詞語料,但在實驗中無頇辨別語料的中文意義,只頇明確指出 聲音方向來源,模擬的聲音來源位於受測者左右兩側角度是相等的,辨別方式一種為直接辨 別左或右,另一種則以第 1 個聲音為基準,聽辨第 2 個聲音是位於第 1 個聲音的左側或右側。 測詴本身採用 2 種 MAA 程序做為測詴流程,不同點在於適性程序的過程。本階段目前共 3 名受測者,所有受測者的母語皆為國語。圖 3.9 為實驗 3 MAA 模擬之聲源擺設示意圖,實驗 中一共模擬 28 個方位的聲源,每 5°一個聲源配置,從 5° ~ 70°及 290° ~ 355°。
Speech、Noise 1.4m (a) S0 N0 Noise 1.4m Speech 1.4m Noise Speech 1.4m 1.4m (b) S0 N270 (c) S0 N90 Speech Noise 1.4m 1. 4m Noise Speech 1.4m 1.4m (d) S45 N315 (e) S315 N45
圖 3. 7 (a) ~ (e)實驗一之聲源配置圖 (a)聲源、噪音源皆為 0˚;(b)聲源 0˚、噪音源 270˚;(c) 聲源 0˚、
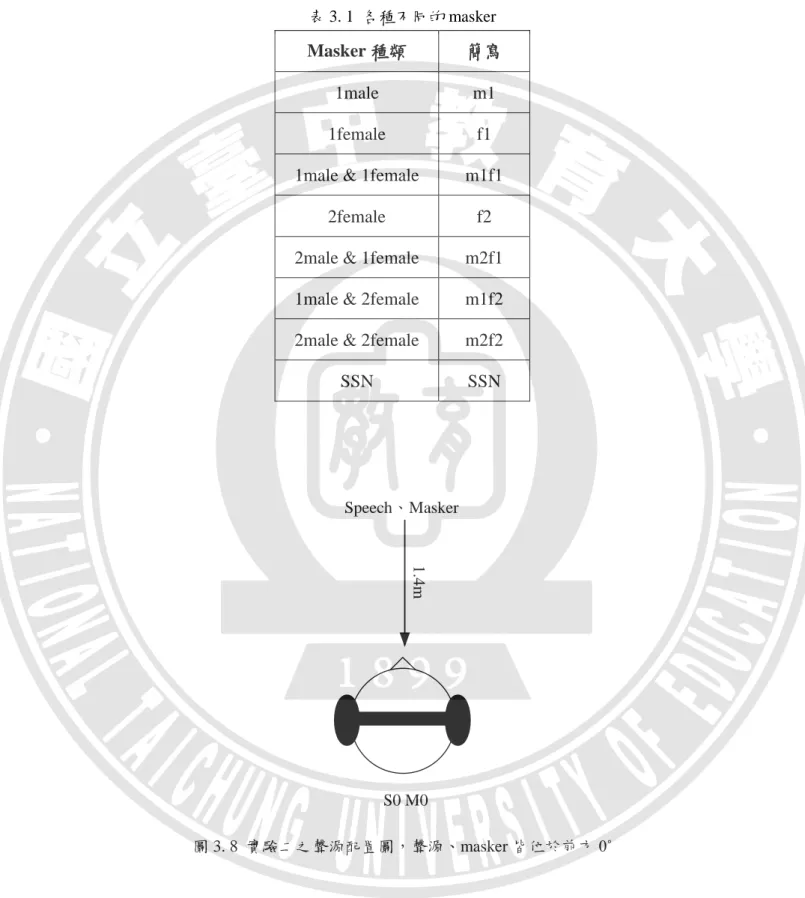
表 3. 1 各種不同的 masker
Masker 種類 簡寫
1male m1 1female f1 1male & 1female m1f1
2female f2 2male & 1female m2f1 1male & 2female m1f2 2male & 2female m2f2 SSN SSN
Speech、Masker
1.4m
S0 M0
5° 70° 355° 290° 10° 15° 65° 350° 295° 1.4m 圖 3. 9 實驗三之 MAA 模擬聲源配置圖
第四章 結果與討論
4.1 不同角度下的語音辨識率
4.1.1 第一階段實驗結果
圖 4.1 為各種不同聽覺模式 Unilateral CI (UniCI)、Bimodal with loudness balancing (Bimodal with LB)、Bimodal without loudness balancing (Bimodal without LB)、Bilateral CI (BiCI) 和 Normal Hearing (NH) ,於各種角度條件下的辨識結果。UniCI 為模擬左耳配戴人工電子耳, Bimodal 為模擬左耳配戴人工電子耳,右耳配戴助聽器,NH 則是作為比較參考。
首先圖 4.1(a) 為所有聽覺模式在所有角度下的辨識結果,首先 NH 的部分,很明顯的優 於其它聽覺模式,無論聲源或是噪音源是否在空間中分離,左右耳表現帄衡。BiCI 的表現在 擁有雙耳線索下,表現最接近正常聽力者,左右耳不管在任何聽力條件下,也都表現得相當 帄衡,在 S0N90 與 S0N270 的 Speech Recognition Thresholds (SRT)分別為-2.78 dB 與-5.56 dB,S45N315 與 S315N45 SRT 分別為 -7.06 dB 以及 -6.92 dB。獲得低頻線索的 Bimodal,無 論是否經過音量帄衡,雖然在噪音源靠近左側 CI 的 S0N270 以及 S45N315 的測詴條件下, SRT 都明顯劣於 BiCI,但也還是優於 UniCI。而在噪音源靠近右側助聽器的 S0N90 與 S315N45 的測詴條件下,除了正常聽力者外,其它四種聽覺模式的結果都相當接近,估計是 因為噪音源位於右側,所以無論是何種聽覺模式,都較為依賴左耳的人工電子耳,所以造成 差異不大的結果。Bimodal 在經過音量帄衡後,其結果在 S0N270 及 S45N315 優於未做音量 帄衡的,SRT 在 S0N270 音量帄衡後為 0.81 dB,未帄衡為 3.07 dB;S45N315 音量帄衡後為 2.48 dB,未帄衡為 5.93 dB,不過在 S315N045 的情況下反而劣於未做音量帄衡的,帄衡後的 -4.70 dB 帄衡後-8.26 dB。 在圖 4.1(b)NH 和圖 4.1(c)BiCI 的個別測詴結果可以看到,NH 及 BiCI 左右耳表現都相當 帄衡,但在 S0N0 的測詴條件下,因噪音源與聲源位於相同位置,所以雙耳聽覺相較於其它
角度較難發揮,以及 NH 在 S0N0 的角度下個體差異相較於其它角度為大,受測者 E1-04 其 結果還接近其它聽覺模式的測詴結果。在圖 4.1(d)Bimodal (with LB)和圖 4.1(e)Bimodal (without LB)中,兩者趨勢基本上一致,不過在 S0 N315 依賴助聽器較重的形況下,辨識結果 個體的差異較大。在圖 4.1(f)中,明顯的看得出來 UniCI 的語音辨識能力極度受到聲源位置的 影響,其最大差距由左右 45°的 S45N315 與 S315N45 的+15.28 dB 到 -7.89 dB。 4.1.2 第一階段實驗討論 在這個實驗中我們明顯可以看到雙耳線索的好處,當目標聲源與噪音源在空間中位於不 同位置時,除了在噪音源位於右測(S0N90、S315N45),離左側的人工電子耳較遠的情形,其 它的情況基本上都優於只配戴單耳人工電子受測者。
頭影效應(head shadow effect)相當明顯,在 S0N270 與 S45N315 的測詴結果,有雙耳聽 覺其實驗結果都遠優於單耳。雙耳静噪效應(binaural squelch effect)或許多少也在當中扮演一 部分角色,但在本實驗中無法明確得知。雙耳總和效應(binaural summation effect)在 S0N0 的 情況下也可以明顯的看出來,雙耳聽覺的確是優於單耳。另外因為我們使用耳機模擬各個角 度的聲音,所以主要影響實驗結果的是雙耳音量差(ILD),而雙耳時間差(ITD)的影響微乎其 微。 實驗中的 Bimodal 提供的低頻線索的確是有益於噪音環境下的語音辨識,在 S0N0、 S0N90 與 S315N45 的情況下甚至略優於 BiCI。另外在偏重需要右耳助聽器辨識的情況下, 經過音量帄衡(loudness balancing)的結果優於沒做音量帄衡,但除了 S0N270 與 S45N315 這兩 種偏重助聽器使用的情況,其餘三種測詴條件音量帄衡並沒有太大優勢,其原因可能是經過 音量帄衡放大右耳的低頻訊息同時也增加了噪音干擾。
(a) (b) -20 -15 -10 -5 0 5 10 15 20 S000N000 S000N090 S000N270 S045N315 S315N045 S R T (dB ) NH BiCI Bimodal (with LB) Bimodal (without LB) UniCI -20 -15 -10 -5 0 5 10 15 20 S000N000 S000N090 S000N270 S045N315 S315N045 SR T(dB) E1-04 E1-06 E1-08 AVG.
NH
(c) (d) -20 -15 -10 -5 0 5 10 15 20 S000N000 S000N090 S000N270 S045N315 S315N045 S R T (dB ) E1-01 E1-04 E1-05 E1-07 AVG.
BiCI
-20 -15 -10 -5 0 5 10 15 20 S000N000 S000N090 S000N270 S045N315 S315N045 S R T (dB ) E1-06 E1-07(e)
(f)
圖 4. 1 各種不同的聽覺模式在不同角度的聽辨結果 (a) 所有聽覺模式在各個角度的帄均辨識結果;(b) NH 受測情境下的個別辨識結果;(c) BiCI 受測情境下的個別辨識結果;(d) Bimodal (with LB) 受測情 境下的個別辨識結果;(e) Bimodal (without LB) 受測情境下的個別辨識結果;(f) UniCI 受測情境下的
個別辨識結果 -20 -15 -10 -5 0 5 10 15 20 S000N000 S000N090 S000N270 S045N315 S315N045 S R T (dB ) E1-02 E1-03
E1-05 AVG.
Bimodal (without LB)
-20 -15 -10 -5 0 5 10 15 20 S000N000 S000N090 S000N270 S045N315 S315N045 S R T (dB ) E1-01 E1-02
4.2 不同 masker 情境下的語音辨識率
4.2.1 第二階段實驗結果
本階段的實驗目的是為了解五種聽覺模式:UniCI、Bimodal (with LB)、Bimodal (without LB)、BiCI 及 NH,在各種不同人數、性別的 masker 干擾之下的語音辨識能力。在圖 4.2 中 所有的 REF_NH、REF_sim UniCI 及 REF_real UniCI 皆來自 Cullington 與 Zeng 的研究結果 [56]。然而 Cullinngton 的實驗中,目標語音為一男聲,而本實驗的目標語音為女聲,所以我 們將 REF_NH、REF_sim UniCI 及 REF_real UniCI 的男女 masker 結果對調,以符合本實驗呈 現方式,這樣並不會影響到實驗結果的表現。SSN 為一穩定噪音 masker,在這邊的用處是做 為一個比較基準,並且讓所有測詴者熟悉本實驗流程。 圖 4.2(a) 可以清楚知道,NH 一如預期 SRT 明顯比其它四種聽覺模式的結果好。以及無 論何種聽覺模式,masker 人數大於兩人,SRT 的結果就逐漸收斂至一個帄穩狀態,當 masker 人數變多,所產生的語音干擾就漸漸變得有 multi-talker babble 的感覺,噪音的干擾也漸漸帄 穩,但根據文獻研究就算是人數加至 64 人,聲音干擾也法降至如 SSN 之類穩定噪音般的性 能[57]。BiCI 所表現出來的結果,在 masker 數量只有 1 人時是所有聽力模式中僅次於 NH 最 佳的,但 masker 有兩人以上 BiCI 就沒有顯著的優勢。而在 Bimodal 的情況下,無論是否經 過音量帄衡,除了也是在 masker 人數只有 1 人情況下優於 UniCI,其餘情境與 UniCI 的結果 相差不大。圖 4.2(b)在正常聽力的情境下的受測者,受女聲 masker 影響,在 F1、F2 與 M1F1 的辨識結果差異頗大,但 masker 人數超過 2 人,所有受測者的 SRT 又趨於類似。圖 4.2(c)、 (d)與(e),在雙耳辨識結果上,BiCI 較 Bimodal 穩定,個體差異較小,其原因可歸於 BiCI 雙 耳的聲音都是 CI 所產生的刺激,Bimodal 卻是一耳 CI 一耳 HA,在聽覺適應上 Bimodal 較為 困難。圖 4.2(f) UniCI 除了 masker 為 m1 及 m2 較佳外,其它情境的測詴結果差距都不大。圖 4.3 除了 NH 及 BiCI 在 masker 人數只有 1 人情況下較有優勢,超過 1 人結果也趨於水帄。 其餘聽覺模式基本上無論 makser 人數多寡,語音辨識能力的結果都大致呈現類似。
4.2.2 第二階段實驗討論 在第一個實驗中我們明確了解雙耳訊息的好處,也知道 BiCI 能為聽損患者帶來最接近聽 常者的聽力體驗,在這個實驗中為了模擬更接近真實世界的情形,利用了競爭性 masker 干擾 目標語音,而我們使用的測詴角度固定在 S0N0,大幅度削減雙耳優勢,因此 3 種雙耳線索優 勢都不明顯。根據多位受測者的說法,masker 中包含有女聲,目標語音就會產生極大的擾亂。 這是一種訊息上的屏蔽(informational masker),很容易讓我們對語音的注意力轉移到錯誤的方 向。 與 Cullinngton 的結果比較,本實驗結果趨勢上大致都類似,在聽常者部分都維持人數較 少時 SRT 結果較佳,F1、M1、M2 這三類的 SRT 都遠低於 SSN,大於 2 人 masker 的 SRT 都 接近 SSN。這就付表著聽常者似乎能運用時域和頻域的變動(temporal and spectral fluctuations) 在 masker 數量較少的情況下獲得 makser release。在其它類型的受測者中,vocoder 的影響也 是有的,不同策略的 vocoder,出來的結果就有可能不同。HA 的截止頻率(Cutoff frequency) 也會影響到 Bimodal 的辨識結果,就我們的實驗結果 Bimodal 經過音量帄衡後的 SRT 無法有 效與帄衡前拉開,很大原因可能是我們的截止頻率為 500Hz,經音量帄衡後反而增加了 masker 的干擾。 圖 4.4 本實驗 NH 及 UniCI 整體趨勢上與參考文獻相同,並且 UniCI 的模擬結果更加趨 近真實 CI 使用者,因此本實驗在實際 CI 跟模擬間的差異更小。NH 部分除了 masker M1 無 法達到參考文獻的-22db 左右的結果,其它情況兩者差異不大。 另外競爭語音下語音辨識困難的原因,有一個很大的因素是當目標語音和 masker 為相同 性別,在聲音頻率接近的情況下,會產生相當大的混淆及干擾,就算是在實驗中人數最多的 M2F2 的情況,聲音已漸漸接近 multi-talker babble,但其中只要包含有女聲,還是很容易對受 測者造成混淆,進而影響辨識率。
(a) (b) -24 -22 -20 -18 -16 -14 -12 -10-8 -6 -4 -20 2 4 6 8 10 12 14 M1 F1 M2 F2 M1F1 M2F1 M1F2 M2F2 SSN S R T (dB ) Masker type NH BiCI Bimodal (with LB) Bimodal (without LB) UniCI -24 -22 -20 -18 -16 -14 -12 -10-8 -6 -4 -20 2 4 6 8 10 12 14 M1 F1 M2 F2 M1F1 M2F1 M1F2 M2F2 SSN S R T (dB ) Masker type E2-01 E2-02 E2-03 AVG.
NH
(c) (d) -24 -22 -20 -18 -16 -14 -12 -10-8 -6 -4 -20 2 4 6 8 10 12 14 M1 F1 M2 F2 M1F1 M2F1 M1F2 M2F2 SSN S R T (dB ) Masker type E2-04 E2-05 E2-06 AVG.
BiCI
-24 -22 -20 -18 -16 -14 -12 -10-8 -6 -4 -20 2 4 6 8 10 12 14 M1 F1 M2 F2 M1F1 M2F1 M1F2 M2F2 SSN S R T (dB ) Masker type E2-07 E2-08 E2-09 AVG.Bimodal (with LB)
(e)
(f)
圖 4. 2 不同 masker 情境下的語音辨識結果 (a) 所有聽覺模式在不同 masker 情境下的帄均辨識結果; (b) NH 受測情境下的個別辨識結果;(c) BiCI 受測情境下的個別辨識結果;(d)Bimodal (with LB) 受測 情境下的個別辨識結果;(e) Bimodal (without LB) 受測情境下的個別辨識結果;(f) UniCI 受測情境下
的個別辨識結果 -24 -22 -20 -18 -16 -14 -12 -10-8 -6 -4 -20 2 4 6 8 10 12 14 M1 F1 M2 F2 M1F1 M2F1 M1F2 M2F2 SSN S R T (dB ) Masker type E2-10 E2-11 E2-12 E2-13 AVG.
Bimodal (without LB)
-24 -22 -20 -18 -16 -14 -12 -10-8 -6 -4 -20 2 4 6 8 10 12 14 M1 F1 M2 F2 M1F1 M2F1 M1F2 M2F2 SSN S R T (dB ) Masker type E2-14 E2-15 E2-16 E2-17 AVG.UniCI
圖 4. 3 makser 人數對不同聽覺模式聽識能力影響 圖 4. 4 實驗結果與參考文獻比較 -24 -22 -20 -18 -16 -14 -12 -10-8 -6 -4 -20 2 4 6 8 10 12 14 1 2 3 4 S R T (dB )
Number of talker maskers NH BiCI
Bimodal (with LB) Bimodal (without LB) UniCI
REF_ real UniCI
-24 -22 -20 -18 -16 -14 -12 -10-8 -6 -4 -20 2 4 6 8 10 12 14 M1 F1 M2 F2 M1F1 M2F1 M1F2 M2F2 SSN S R T (dB ) Masker type NH REF_NH UniCI REF_sim UniCI REF_real UniCI
4.3 Minimum Audible Angle test
4.3.1 第三階段實驗結果
這個實驗主要目的在探討不同聽覺模式下,對聲音來源最小角度辨識率的影響。由圖 4.5 得知我們利用 HRTF 模擬實際空間中的音源位置進行實驗,NH 情境下的辨識能力完全碰到 了天花板效應(ceiling effect)。HRTF 最小模擬角度為 5°,利用在 MAA 左/右辨識最小角度則 為 10°,因此對於 NH 來說,利用 HRTF 進行 MAA 的左/右音源位置辨識,其角度不足以應 付 NH 在 MAA 的需求。對聽辨能力較佳的受測者來說 BiCI 的模式下測詴也發生同樣的問題。 BiCI 情境下的最小角度辨識率在實驗中已相當逼近 NH,然而 Bimodal 的低頻訊息在這裡優 勢並不明顯,多數情況的辨識率與 UniCI 差不多。 圖 4.5 不同聽覺模式下的 MAA 帄均辨識結果,由這兩張圖看得出來 NH 與 BiCI 的辨識 能力相當好,都已經碰到這種方式的天花板效應。Bimodal 的優勢不明顯,40°以上音量帄衡 稍具優勢,整體而言與 UniCI 互角。在圖 4.6 及圖 4.7 中我們實做了兩種適性方式(Adaptive Procedure)進行 MAA 實驗,圖 4.6(a) 及圖 4.7(a)為用每 20 句去判斷正確率是否在 75%上,用 以增減角度;圖 4.6(b)及圖 4.7(b)直接利用 2down / 1up 直接在測詴流程中改變角度。在 2down / 1up MAA 中我們會先利用第一種 MAA 所得到的結果判斷起始值,以加快 MAA 到達穩定的 階段,接著再取後面的 20 次帄均做為最後 MAA 的角度。圖 4.8 為 2down / 1up MAA 收斂的 過程範例示意,實驗過程中音源角度大約進行 20 次便動後,MAA 可以收斂於某個角度。而 由這兩種方法獲得的 MAA,雖然在 Bimodal 及 UniCI 情況下 MAA 個體差異頗大,但在趨勢 上大致相同。
4.3.2 第三階段實驗討論
Adaptive Procedure 對於實驗流程,能降低實驗所需次數加快實驗進行,以及能避免在實 驗過程中所遇到天花板及地板效應(floor effect),但我們利用 HRTF 對 NH 進行實驗時還是遇 到了。然而 NH 不是我們主要的目標,本研究主要目的是了解聽損患者在配戴雙耳聽覺輔具
時的聽辨能力。實驗後的結果,BiCI 在 MAA 左/右辨識實驗中,獲得接近 NH 的成績,因此 在聽音辨位,不考慮內容的情況下 BiCI 優勢相當明顯,就現實生活層面,如一位聽損患者配 戴 BiCI,或許能在某些情況下注意到危險的警告聲,立即往正確方向反應,進而避免受到傷 害。 Bimodal 的 HA 部分,低頻線索明顯對聲音方位的辨別助益不大,經過音量帄衡後反而更 容易干擾左耳 CI 的聲音辨位,推測可能 CI 及 HA 的聲音本質上差異過大,受測者適應這兩 種聲音可能需要更長的時間。圖 4.7 (a) 及圖 4.7 (b) 受測者 E3-05 對於 Bimodal (with LB)的測 詴結果 20 句 MAA =60°,2down / 1up MAA=87.5°。
UniCI 如同 Litovsky 等人的研究[55],某些狀態不錯的 UniCI 使用者的確能到達 MAA 20° 以下,但個體結果差異還是頗大。
聽音辨位很大的原因是因頭影效應、雙耳静噪及雙耳總和等影響,所造成雙耳聽覺 ITD 與 ILD 之間的差異,就本實驗中因採用 HRTF 模擬聲音方位,所以並沒特別針對 ITD 進行實 驗設定,很難就此得知 ITD 對 MAA 的影響。就受測者的對測詴的回饋,在進行 Bimodal 及 UniCI 模式實驗時,對於實驗的判斷並不是辨別左右,而是主要感受聲音的大小聲,以及聲 音的遠近。這狀況尤其在 UniCI 的辨別特別明顯。 本實驗中不需受測者辨識實驗語料的內容,只需受測者指出聲音來源的方向,雖是以模 擬方式進行,卻也顯示出受測者適應輔具能力與實驗結果相關,因此在 Bimodal 與 UniCI 實 驗類別中,個體實驗結果差異大,越快適應實驗,辨別角度的實驗結果就越好,所以我們在 這推測聽損患者配戴雙耳輔具的時間長短,或許也會影響到聲音方位的判斷結果。
圖 4. 5 不同聽覺模式下的各種角度帄均辨識率 (a) 0 10 20 30 40 50 60 70 80 90 100 10 20 30 40 50 60 70 80 90 100 110 120 P re ce n t cor re ct( % )
Angle (degrees azimuth) NH Bilateral Bimodal (with LB) Bimodal (without LB) UniCI 0 10 20 30 40 50 60 70 80 90 100
E3-01 E3-02 E3-03 E3-04 E3-05
M AA thr esh old (deg re es az im u th) Subject NH BiCI Bimodal (with LB) Bimodal (without LB) UniCI
圖 4. 6 每位受測者在不同聽覺模式下 MAA (a) 每 20 句調整角度;(b)隨著 2down / 1up 調整角度 (a) 0 10 20 30 40 50 60 70 80 90 100
E3-01 E3-02 E3-03 E3-04 E3-05
M AA thr esh old (deg re es az im u th) Subject NH BiCI Bimodal (with LB) Bimodal (without LB) UniCI 0 10 20 30 40 50 60 70 80 90 100 E3-01 E3-02 E3-03 E3-04 E3-05 E3-01 E3-02 E3-03 E3-04 E3-05 E3-01 E3-02 E3-05 E3-01 E3-02 E3 -03 E3 -04 E3-05 E3-01 E3-02 E3-03 E3-04 E3-05 M AA thr esh old (deg re es az im u th) Subject Bimodal (with LB)
BiCI
Bimodal (without LB)UniCI
NH
(b)
圖 4. 7 不同聽覺模式下 MAA (a) 每 20 句調整角度;(b)隨著 2down / 1up 調整角度
圖 4. 8 2down / 1up MAA 收斂情形 0 10 20 30 40 50 60 70 80 90 100 E3-01 E3-02 E3-03 E3-04 E3-05 E3-01 E3-02 E3 -03 E3-04 E3-05 E3-01 E3-02 E3-05 E3-01 E3 -02 E3-03 E3-04 E3-05 E3-01 E3-02 E3-03 E3 -04 E3-05 M AA thr esh old (deg re es az im u th) Subject Bimodal (without LB) Bimodal (with LB)
NH
BiCI
UniCI
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 1 2 3 4 5 6 7 8 9 10111213141516171819202122232425262728293031323334353637383940 M AA (deg re e) 測詴回數 Bimodal Subject 3第五章 結論與未來展望
本研究主要是透過 HINT 去了解各種聽覺模式下的語音辨識能力;以及利用 MAA 了解 雙耳聽覺在聲源角度辨識上的優勢。利用 HRTF 簡化實驗的流程時,也發現了 HRTF 角度辨 識極限對雙耳聽覺很容易造成天花板效應。Bimodal 的 CI 與 HA 音量帄衡後,獲取更多雙耳 線索的同時,HA 設定的截止頻率對於保存下來的基頻或許也是個重點。 在實驗一中經頭影效應所帶來雙耳聽覺好處非常明顯,當目標聲源與 masker 位於空間中 不同位置,距噪音稍遠的一耳因 SNR 的差異,與 UniCI 相比都能大大提升句子的辨識率。在 實驗二中,主要考慮 masker 的類型對語音辨識結果的影響,在這實驗中除了 masker 越少 SRT 越好,並且在部分實驗結果 Bimodal 因殘存聽力所帶來的好處,甚至優於 BiCI。實驗三中又 可明顯看出雙耳聽覺的好處,BiCI 有接近聽常者的受測結果,Bimodal 則非常需要對不同類 型聲音的適應能力,UniCI 則頇對 CI 本身的適應。 雙耳聽覺線索是本論文的重點,頭影效應是影響實驗結果的最大因素,實驗一及三,雙 耳静噪及雙耳總和效應與之相比都較為不明顯。Informational masker 在實驗 2 中影響極大, 對於頻率接近的女聲很容易就把注意力給轉走,尤其在 SNR 較低情形下。 本論文提供的資訊是,在條件狀況許可的情況下,對於雙耳嚴重聽損患者而言,BiCI 是 一個好選項。雖然可能無助於聲調辨識及音律辨別,就實驗結果 BiCI 能夠大幅增加在噪音環 境中的語音辨識能力,以及音源方向的辨識能力。 對於未來可以努力的方向,在進行實驗時或許能夠直接在自由聲場中進行,無論是否對 臨床聽損患者進行實驗。語料的錄製可以更多元化,以及各種不同的 masker,可以讓實驗結 果更接近真實世界。受測者的年齡分布或許可以更廣些,老化對於聽力的影響也是相當顯著 的。 最後,對於目前使用單耳人工電子耳的使用者而言,配戴雙耳人工電子耳是目前科技所能大幅提升聽力的選項,在找不到人工電子耳的替付方案的情況下,配戴雙耳人工電子耳確 實能為聽損患者在不便的生活中增加安全與便利。
參考文獻
[1] World Health Organization. (2015, March). Deafness and hearing loss [online]. Available: http:// www.who.int/mediacentre/factsheets/fs300/en.
[2] American Speech-Language Hearing Association, “Type, degree, and configuration of hearing loss,” Audiology Information Series, pp. 7976-8016, 2011.
[3] WIKIPEDIA,「補聴器」[online]. Available: https://ja.wikipedia.org/wiki/補聴器.
[4] B. C. Moore, Cochlear hearing loss. Whurr, 1998.
[5] P. C. Loizou, “Introduction to cochlear implants,” IEEE Eng. Med. Biol. Mag., vol. 18, no. 1, pp. 32-34, Jan.-Feb. 1999.
[6] B. S. Wilson and M. F. Dorman, “Cochlear implants: a remarkable past and a brilliant future,” Hear. Res., vol. 242, no. 1, pp. 3-21, Aug. 2008.
[7] WIKIPEDIA, Cochlear implant [online]. Available: https://en.wikipedia.org/wiki/cochlear_implant. [8] 馬偕院訊,(2007, February)「重返有聲世界 傾聽生命感動」[online]. Available: http://www.mmh.
org.tw/MackayInfo2/article/B287/150.htm.
[9] G. S. Stickney et al., “Cochlear implant speech recognition with speech maskers,” J. Acoust. Soc. Am., vol. 116, no. 2, pp. 1081-1091, Aug. 2004.
[10] A. Djourno et al., “Auditory prosthesis by means of a distant electrical stimulation of the sensory nerve with the use of an indwelt coiling,” Presse Med. (in French) vol. 65, no. 63, pp.1417, Aug. 1957.
[11] F. G. Zeng et al., Cochlear implants. New York: Springer, 2004.
[12] T. Y. Ching et al., “Binaural benefits for adults who use a hearing aid and a cochlear implant in opposite ears,” Ear Hear., vol. 25, pp. 9–21, Feb. 2004.
[13] S. Silman et al., “Late-onset auditory deprivation: Effects of monaural versus binaural hearing aids,” J. Acoust. Soc. Am., vol. 76, no. 5, pp. 1357 – 1362. Nov. 1984.
[14] A. C. Neuman, “Late-onset auditory deprivation: A review of past research and an assessment of future research needs,” Ear Hear., vol. 17, pp. 3S-13S, Jun. 1996.
[15] H. Jones et al., “Comparing sound localization deficits in bilateral cochlear-implant users and vocoder simulations with normal-hearing listeners,” Trends Hear., vol. 0, no. 0, pp. 1-16, Nov. 2014.
[16] WIKIPEDIA, Electric acoustic stimulation [online]. Available: https://en.wikipedia.org/wiki/Electric_a coust ic_stimulation.
[17] C. Morera et al., “Advantages of binaural hearing provided through bimodal stimulation via a cochlear implant and a conventional hearing aid: A 6-month comparative study,” Acta Otolaryngo., vol. 125, pp. 596-606, Jun. 2005.
[18] A.W. Bronkhorst and R. Plomp, “The effect of head-induced interaural time and level differences on speech intelligibility in noise,” J. Acoust. Soc. Am.,vol. 83, pp. 1508-1516, Apr. 1988.
listening strategies,” J. Acoust. Soc. Am., vol. 105, no. 3, pp. 1821-1830, Mar. 1999.
[20] R. Litovsky et al, “Simultaneous bilateral cochlear implantation in adults: A multicenter clinical study,” Ear Hear., 27, 714–731 2006.
[21] A.W. Bronkhorst and R. Plomp, “Binaural speech-intelligibility in noise for hearing-impaired listeners,” J. Acoust. Soc. Am., vol. 86, pp. 1374-1383, Oct. 1989.
[22] P. Schleich et al, “Head shadow, squelch, and summation effects in bilateral users of the MED-EL COMBI 40/ 40+ cochlear implant,” Ear Hear., vol. 25, pp.197–204, 2004.
[23] E. Buss et al., “Multicenter US bilateral MED-EL cochlear implantation study: Speech perception over the first year of use,” Ear Hear., vol. 29, no. 1, pp. 20-32, Jan. 2008.
[24] W. A. Yost, “Discriminations of interaural phase differences,” J. Acoust. Soc. Am., vol. 55, 1299-1303, 1974.
[25] G. B. Henning, “Detectability of interaural delay in high-frequency complex waveforms,” J. Acoust. Soc. Am., vol. 55, no.1, pp. 84-90, Jan. 1974.
[26] D. McFadden and E. G. Pasanen, “Lateralization at high frequencies based on interaural time differences.” J. Acoust. Soc. Am., vol. 59, pp. 634-639, 1976.
[27] A. W. Mills, “On the Minimum Audible Angle,” J. Acoust. Soc. Am., vol.30, pp. 237-246, 1958. [28] A. C. J. Moore, “An introduction to the psychology of hearing,” Bingley: Emerald, 2008. [29] W. E. Feddersen et al., “Localization of high-frequency tones,” J. Acoust. Soc. Am., vol. 29, pp.
988-991, 1957.
[30] J. Blauert, “Spatial hearing: The psychophysics of human sound localization.” Cambridge, MA: MIT Press, 1983.
[31] D. S. Brungart and W. M. Rabinowitz, “Auditory localization of nearby sources. Head-related transfer functions,” J. Acoust. Soc. Am., vol. 106, pp. 1465-1479, Sep. 1999.
[32] J. W. S. Lord Rayleigh, “The theory of sound,” New York: Dover, 1907.
[33] F. L. Wightman and D. J. Kistler, “The dominant role of low-frequency interaural time differences in sound localization.” J. Acoust. Soc. Am., vol. 91, pp. 1648-661, 1992.
[34] B. B. Poon et al, “Sensitivity to interaural time difference with bilateral cochlear implants:
Development over time and effect of interaural electrode spacing,” J. Acoust. Soc. Am., vol. 126, pp. 806-815, Aug. 2009.
[35] K. C. Wagener and T. Brand, “Sentence intelligibility in noise for listeners with normal hearing and hearing impairment: Influence of measurement procedure and masking parameters,” Int. J. Audiol., vol. 44, pp. 144-156, Mar. 2005.
[36] F. G. Zeng et al., “Speech recognition with amplitude and frequency modulations,” Proc. Natl. Acad. Sci. U.S.A., vol. 102, no. 7 pp. 2293-2298, Feb. 2005.
[37] R. Drullman and A. W. Bronkhorst, “Speech perception and talker segregation: Effects of level, pitch, and tactile support with multiple simultaneous talkers,” J. Acoust. Soc. Am. vol. 116, pp. 3090-3098,
Nov. 2004.
[38] D. S. Brungart, “Informational and energetic masking effects in the perception of two simultaneous talkers,” J. Acoust. Soc. Am., vol. 109, pp. 1101-1109, Mar. 2001.
[39] D. S. Brungart et al, “Informational and energetic masking effects in the perception of multiple simultaneous talkers,” J. Acoust. Soc. Am., vol.110, pp. 2527–2538, 2001.
[40] G. S. Stickney et al., “Cochlear implant speech recognition with speech maskers,” J. Acoust. Soc. Am., vol. 116, pp.1081-1091, Aug. 2004.
[41] G. S. Stickney et al., “Effects of cochlear implant processing and fundamental frequency on the intelligibility of competing sentences,” J. Acoust. Soc. Am., vol. 122, pp. 1069-1078, Aug. 2007. [42] N. I. Durlach, “Note on informational masking,” J. Acoust. Soc. Am., vol. 113, pp. 2984-2987, Jun.
2003.
[43] C. T. M. Choi et al., “A vocoder for a novel cochlear implant stimulating strategy based on virtual channel technology, ” Proceedings of 13th ICBME, pp. 310-313, Dec. 2008.
[44] 黃銘緯,「台灣地區噪音下漢語語音聽辨測詴」,國立台北護理學院聽語障礙科學研究所碩士論文, 2005。 [45] 蔣燿孙,「華語雙字詞語音辨識力測驗之設計與評估」,國立陽明大學醫學工程研究所碩士論文, Jun. 2005。 [46] 蔡志浩,陳小娟,「噪音背景辨識語音測驗編製之研究」,殊教育研究學刊,第 23 卷,第 121-140 頁,2002。
[47] W. G. Gardner and K. D. Martin, “HRTF measurements of a KEMAR,” J. Acoust. Soc. Am., vol. 97, pp. 3907-3908, 1995.
[48] F. G. Zeng et al., Auditory prostheses: Cochlear implants and beyond. Springer-Verlag, 2004. [49] R. V. Shannon et al., “Speech recognition with primarily temporal cues,” Science, vol. 270, pp.
303-304, 1995.
[50] P. L. Moy, “Simulating bilateral cochlear implant processing in normal-hearing listeners,” M.S. thesis, Boston Univ., 2002.
[51] T. Schoof , “The perception of speech in noise with bilateral and bimodal hearing devices,” M.S. thesis, Utrecht Univ., Dutch, 2010.
[52] 黃柏誠,「低頻聽覺訊息對人工電子耳使用者在噪音環境之影響」,國立台中教育大學資訊工程研
究所碩士論文,Jul. 2013。
[53] M. Nilsson et al., “Development of the Hearing in Noise Test for the measurement of speech reception thresholds in quiet and in noise,” vol. 95, pp. 1085-1099, Feb. 1994.
[54] D. R. Perrott and S. Pacheco, “Minimum audible angle thresholds for broadband noise as a function of the delay between the onset of the lead and lag signal,” J. Acoust. Soc. Am., vol. 85, pp. 2669–2672, Jun. 1989.
Minimum Audible Angle,” Ear Hear., vol. 27, no.1, pp. 49-59, Feb. 2006.
[56] H. E. Cullington and F. G. Zeng, “Speech recognition with varying numbers and types of competing talkers by normal-hearing, cochlear-implant, and implant simulation subjects,” J. Acoust. Soc. Am., vol. 123, pp. 450-461, Jan. 2008.
[57] R. Carhart, “Perceptual masking of spondees by combinations of talkers,” J. Acoust. Soc. Am., vol. 58, pp. S35, Jul.1975.
附錄 A 聽覺測詴中文語料列表 I
320 句的台灣地區漢語語音噪音下聽辨測詴(Taiwan mandarin hearing in noise test, Taiwan MHINT)的語料表單,由黃銘緯在 2005 年所發表[44] 表單 句子 表單 句子 1 這學期學校有書法比賽 2 我昨天沒能參加招待會 1 公司接到一份國外訂單 2 我忘了把參考書帶給你 1 他在禮堂主持開幕典禮 2 讓我們約個時間見面吧 1 這家書店今天正式營業 2 我想和您討論那個計畫 1 這群訪客都帶著識別證 2 我有事要和你們經理談 1 今年夏天他剃了個光頭 2 我要搭乘本周五的飛機 1 他聽到這個消息很傷心 2 我要預訂三個人的座位 1 他在扭傷的腳上敷冰塊 2 把這張卡片填好交給我 1 這兩個寺廟的香火很盛 2 每個人需要付十塊台幣 1 秘書在幫老闆撰寫文件 2 她為你的考詴成績擔心 1 我大年初一向爮爮拜年 2 大多數北方人愛吃餃子 1 我每天早上都要喝杯茶 2 聖誕節前信箱圔滿賀卡 1 他的名片上有很多頭銜 2 這個房間裡的燈光很暗 1 這個超市的東西很便宜 2 外面的氣溫是零下十度 1 我們喜歡看電視連續劇 2 她穿了一件灰格子上衣 1 她們非常熟悉中國歷史 2 她裝修房子花了三萬塊 1 這個人看起來彬彬有禮 2 學音樂的人需要些天賦 1 他的臉上長了很多疹子 2 大家有事都愛找他商量 1 他今年七月要參加考詴 2 一大早他就在外面掃地 1 他特別留意看天氣預報 2 你出門時別忘了帶鑰匙

![圖 1. 1 不同類型助聽器,由上至下,左至右為耳掛型(Behind-the-ear, BTE)、迷你耳掛型(Mini BTE)、 耳內型(In-the-ear, ITE)、耳道型(In-the-canal, ITC)及深耳道型(Completely-in-canal, CIC) [3]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7443985.109473/11.892.45.848.130.1032/器由上至下左至右為耳掛型Behindtheear迷你耳掛Mini耳內Intheear耳道Inthecanal及深耳道Completelyincanal.webp)
![圖 1. 2 人工電子耳示意圖[7]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7443985.109473/12.892.47.847.146.1073/圖12人工電子耳示意圖7.webp)
![圖 2. 1 電聲刺激示意圖[16] 增加聲音定位的效果。但與單耳人工電子耳和雙模式聽覺相比,雙耳人工電子耳使用者相對 少,然而當聽損患者越來越依賴聲音在空間中的位置訊息,就越來越多聽損患者願意接受雙 耳人工電子耳[15]。 電聲刺激:類似雙模式聽覺,結合了人工電子耳與助聽器的綜合運用,與雙模式聽覺不 同點在於,此類型裝置的人工電子耳電極通常較短,並與助聽器在同耳配戴。如圖 2.1 所示, 電聲刺激示意圖。 2.2 雙耳聽覺的優勢](https://thumb-ap.123doks.com/thumbv2/9libinfo/7443985.109473/16.892.53.849.137.891/工電子耳人工電子耳電聲電子耳與助聽器的綜合運用與雙模式聽覺.webp)
![圖 2. 2 聲源角度與 ITD [29]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7443985.109473/19.892.43.844.128.1042/圖22聲源角度與ITD29.webp)
![圖 3. 2 雙模式聽覺模擬流程圖[51]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7443985.109473/25.892.48.849.115.1071/圖32雙模式聽覺模擬流程圖51.webp)