傳統關聯式資料庫暨欄導向資料庫之轉換機制研究-以台灣學術期刊搜尋引擎為例 - 政大學術集成
67
0
0
全文
(2) 致謝 輾轉兩年之間,從懵懵懂懂的大學生搖身一變成為具備一技之長以及些許實 習經驗的碩士生,心中真是百感交集。首先感謝我的媽媽,謝謝妳讓我毫無後顧 之憂地完成碩士學業,之後我一定會致力於事業上,另創人生的巔峰。再來感謝 總是耐心傾聽我冗長的報告的劉文卿老師,老師不吝指點我研究的方向、在一次 又一次的報告中匡正我的架構並給予報告方法上的建議,嚴格卻和藹地在這兩年 半中循循善誘,讓我得以有在企業實習的機會。在畢業前提前體會真實社會的環. 政 治 大. 境,使我獲益匪淺,並完成這本曠世鉅作,在此獻上至深的謝意。. 立. 感謝老是與我鬥嘴,忍受我白目個性的雅菱以及佳穎學姊,使得我在什麼都. ‧ 國. 學. 不懂的情況下,慢慢地帶領我步入正軌。陪伴我度過兩年時光的大學部應屆畢業 生學弟妹,總是很帥氣的維文、實驗室之花祖韵、酷酷的威辰、認真的承翰、愛. ‧. 家的冠緯、總是一直支持我的藝方以及肩膀很寬的冠廷,謝謝你們的鼓勵,我達. Nat. sit. y. 成了與你們一起畢業的約定。此外,大三的學弟妹們當然也不能忘,最可愛的鈺. n. al. er. io. 雯、最愛一起屁話的政瑜、謹維、柏崴、文治、庭芳、貴堯、志騰,謝謝你們一. i n U. v. 年多來的陪伴與打拼。感謝戴睿這一年來的陪伴與支持,在未來的一年裡你會是. Ch. engchi. kmlab 最強大的支柱。感謝凭哲與柏翰,論文最後三個月有你們一起陪伴完成論文, 真好。特別感謝鈺雯學妹,謝謝你在遇到挫折的時候給予扶持,用心的督促我論 文的進度,以及最後關頭的無私校稿,使得最後論文得以即時的完成,真的非常 感謝你。感謝實驗室的大家,像家人一樣一起努力不懈地奮鬥,一起歡笑,一起 出遊,我想,這是我一輩子也忘不了的,最美好的回憶,我會常常回來看大家的。 感謝碩士班的同學們支持,太多同學們我無法一一列舉,但真心感謝你們各 方面的相助,大家一起互相討論學業、玩樂、慶生,在研究所能認識你們是我最 大的榮幸。感謝同學阿葉,為了出國的夢想而打拼,達成了不可能的任務,不管 在學業、感情上都蒙受妳很大的幫助,謝謝你,往後也要繼續互相扶持。感謝系 2.
(3) 辦助教雨儒以及詩晴,謝謝你們熱心的幫我解決行政上面的問題。 感謝從小一起長大的兩位麻吉,育徵與宏哲,感謝你們在我心情低落時總是 給予我支持與鼓勵,在遇到困難時會陪著我打球洩氣,雖然我們各自擁有不同的 生活可是還是像親兄弟一樣的麻吉,謝謝你們。 最後感謝兩位口試委員,陳亦光以及楊建民老師,感謝兩位老師撥冗參加我 的論文口試,更給予我許多研究方面的建議,使得論文更臻完善。特別是亦光老 師在公司的照顧,讓我有機會體驗大公司的體制並與來自各地的好手比拚,對於 我來說是相當難得的經驗。. 政 治 大. 謹以此文,獻給無數個疲倦卻歡愉的夜晚,獻給愛我的師長、父母、同學及. 立. 學弟妹,獻給被我私自重視的你們。期許在未來人生道路上,不會辜負這份初衷. ‧ 國. 學. 以及這些日子中的所知所學,當然,還有最美的回憶。. 黃勁超. ‧. 中華民國一百年八月一日. n. er. io. sit. y. Nat. al. Ch. engchi. 3. i n U. v.
(4) 摘要 源於資訊量爆炸時代的來臨,企業面臨大量資料所帶來的挑戰:傳統關聯式 資料庫無法負荷龐大資料所造成的效能及儲存設備升級等問題。為了解決大量資 料所帶來的諸多問題,各界提出不同的理論,而其中最被廣為討論的就是雲端運 算。時至今日,許多企業及個體用戶逐漸開始使用雲端運算中,目前最具代表性 的分散式架構 Hadoop 上的資料庫代表-欄導向資料庫 HBase 來作為底層資料庫。 故本研究提出一套傳統關聯式資料庫轉換至欄導向資料庫 HBase 之轉換機制,以 台灣學術期刊搜尋引擎為例。. 立. 政 治 大. 關鍵字:HBase,Hadoop,轉換機制,關聯式資料庫,欄導向資料庫,實體關聯. ‧. ‧ 國. 學. 模型,搜尋引擎. n. er. io. sit. y. Nat. al. Ch. engchi. 4. i n U. v.
(5) 目錄 致謝 .................................................................................................................................. 2 摘要 .................................................................................................................................. 4 目錄 .................................................................................................................................. 5 圖目錄 .............................................................................................................................. 7 表目錄 .............................................................................................................................. 9. 研究背景與動機 ............................................................................ 10. 第二節. 研究架構及流程 ............................................................................ 12. 第三節. 研究目的與貢獻 ............................................................................ 14. 立. 文獻探討 .................................................................................................... 15 雲端運算 ........................................................................................ 15. 第二節. Nat. ‧. 第一節. sit. y. Google File System ....................................................................... 18. n. al. er. Apache Hadoop ............................................................................. 20. io. 第三節. 第三章. 政 治 大. 第一節. 學. 第二章. 緒論 ............................................................................................................ 10. ‧ 國. 第一章. i n U. v. 第四節. Hadoop Distributed File System(HDFS) ....................................... 22. 第五節. Map/Reduce ................................................................................... 23. 第六節. HBase............................................................................................. 25. 第七節. Avro ............................................................................................... 27. Ch. engchi. 關聯式暨欄導向轉換機制 ........................................................................ 30 第一節. 欄導向資料庫結構轉換 ................................................................ 30. 第一段. 實體關係轉換 ........................................................................ 30. 第二段. 一對一關係轉換 .................................................................... 34. 第三段. 一對多關係轉換 .................................................................... 35. 第四段. 多對多關係轉換 .................................................................... 37 5.
(6) 遞迴關係轉換 ........................................................................ 38. 第五段 第二節. 第一段. 實體關係轉換 ........................................................................ 41. 第二段. 一對一關係轉換 .................................................................... 42. 第三段. 一對多關係轉換 .................................................................... 43. 第四段. 多對多關係轉換 .................................................................... 45. 第五段. 遞迴關係轉換 ........................................................................ 46. 第三節. 小結 ................................................................................................ 47. 立. 使用技術暨環境 ............................................................................ 49. 第二節. 學術期刊資訊搜尋介面 ................................................................ 52. 學. 第一節. 欄導向資料結構轉換 ............................................................ 53. 第二段. Avro 序列化結構轉換 .......................................................... 56. Nat. sit. y. 搜尋流程 ................................................................................ 61. v. 第一段. n. al. er. Web Service ................................................................................... 63. io. 第三節. ‧. 第一段. 第三段. 第五章. 政 治 大. 系統實作 .................................................................................................... 49. ‧ 國. 第四章. Avro 序列化資料結構轉換 .......................................................... 40. 第二段. 輸出格式 ................................................................................ 63. i n U. 輸入格式 ................................................................................ 63. Ch. engchi. 結論與建議 ................................................................................................ 65. 參考文獻 ........................................................................................................................ 67. 6.
(7) 圖目錄 圖 1. 查詢 Cloud Computing 一詞之次數折線圖(引用自 Google Trend, 2012)11 圖 2. 研究流程圖 .................................................................................................. 12 圖 3. NIST 美國國家標準局對雲端運算的定義 ................................................. 15 圖 4. Google File System 架構(引用自 Ghemawat, Gobioff et al.,2003) ......... 19 圖 5. Hadoop Ecosystem integration by MapR(資料來源: http://www.mapr.com/products) ..................................................................... 21. 政 治 大. 圖 6. HDFS 架構圖(資料來源:apache.org) ........................................................ 22. 立. 圖 7. Map/Recduce 運作圖(資料來源:White, T.,2010) .................................. 23. ‧ 國. 學. 圖 8. HBase 架構圖(資料來源:George,2011) ................................................. 25 圖 9. HBase Table 概念視圖(資料來源:George,2011).................................... 26. ‧. 圖 10. 實體關係轉換示意圖(Entity Relationship Translation)............................ 32. Nat. sit. y. 圖 11. 一對一關係轉換示意圖 ............................................................................ 34. n. al. er. io. 圖 12. 一對多關係轉換示意圖 ............................................................................ 35. i n U. v. 圖 13. 多對多關係轉換示意圖 ............................................................................ 37. Ch. engchi. 圖 14. 遞迴關係(R-R)轉換示意圖 ....................................................................... 38 圖 15. 欄導向 HTable 資料結構轉換至 HTable 使用 Avro 序列化儲存示意圖 40 圖 16. Avro 實體關係轉換示意圖 ........................................................................ 41 圖 17. Avro 一對一關係轉換示意圖 .................................................................... 42 圖 18. Avro 一對多關係轉換示意圖-HA ............................................................. 43 圖 19. Avro 一對多關係轉換示意圖-HB.............................................................. 44 圖 20. Avro 多對多關係轉換示意圖 .................................................................... 45 圖 21. Avro 遞迴關係轉換示意圖 ........................................................................ 46 圖 22. Hadoop 叢集環境........................................................................................ 50 7.
(8) 圖 23. TAJ 系統架構圖 .......................................................................................... 51 圖 24. 台灣學術期刊搜尋系統 ERM 圖.............................................................. 52 圖 25. 欄導向資料結構轉換-Paper ...................................................................... 54 圖 26. 欄導向資料結構轉換-Periodical-Keyword-Author .................................. 55 圖 27. Avro 序列化結構轉換-Paper-1 ................................................................... 56 圖 28. Avro 序列化結構轉換-Paper-2 ................................................................... 57 圖 29. Avro 序列化結構轉換-Paper-3 ................................................................... 57 圖 30. Avro 序列化結構轉換-Paper-4 ................................................................... 58. 政 治 大. 圖 31. Avro 序列化結構轉換-Paper-5 ................................................................... 58. 立. 圖 32. Avro 序列化結構轉換-Publisher ................................................................ 59. ‧ 國. 學. 圖 33. N-gram 搜尋目標與搜尋標的 ERM .......................................................... 60 圖 34. Index Table Schema ..................................................................................... 60. ‧. 圖 35. 搜尋流程示意圖 ........................................................................................ 61. Nat. sit. y. 圖 36. 台灣學術期刊搜尋引擎搜尋畫面 ............................................................ 62. n. al. er. io. 圖 37. 搜尋論文全文內容結果 ............................................................................ 62. i n U. v. 圖 38. Web Service JSON 輸入格式 ..................................................................... 63. Ch. engchi. 圖 39. Web Service 輸出格式 ................................................................................ 64. 8.
(9) 表目錄 表 1. 台灣學術期刊搜尋引擎(TAJ)技術表 ......................................................... 49 表 2. 搜尋標的資料筆數表 .................................................................................. 52 表 3. 關聯式資料庫 Table 欄位表 ...................................................................... 53. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 9. i n U. v.
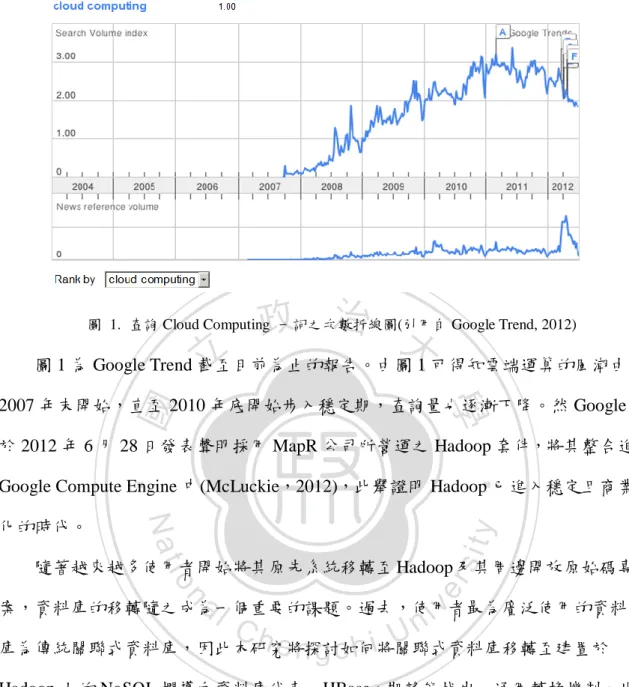
(10) 第一章. 緒論. 第一節 研究背景與動機 近年來隨著網路普及率飆高,連帶影響資訊量快速增長。全球最大能源公司 雪弗龍(Chevron's)的首席資訊長曾在一篇公開文章提及,該公司一天的資訊量成長 約在 17,592,000,000,000bits,相當於是 2TB 的巨大資料量。而在 IDC 的研究報告 (Gantz & Reinsel,2010)中更預測 2020 年的資訊成長幅度將高達 2009 年的 44 倍。 為了應付巨大資料量所造成的儲存空間問題,企業開始使用 DAS、NAS 與 SAN. 政 治 大 的演進增加,但資料存取的速度卻始終無法跟上;因此,從龐大資料中存取單一 立. 等技術動態擴增硬碟及周邊設備的儲存空間。然而,雖然資訊儲存空間隨著時代. ‧ 國. 學. 檔案的時間增加,造成系統效能問題。因此,要如何在龐大的資料中快速、精確 地搜尋到正確的資料便成為一門相當重要的課題。而之於搜尋引擎,這個課題更. ‧. 是不可或缺。. sit. y. Nat. 正當各界正為大量資料所帶來的問題苦惱時,Google 於 2003 年提出了以. io. er. Google File System(GFS)為核心的分散式儲存架構(Ghemawat, Gobioff et al. 2003),. al. v i n Ch 也應聲而出,成為目前最多企業及個體用戶所使用的分散式運算架構。分散式系 engchi U n. 奠定了雲端運算的基礎。隨後以 GFS 架構為核心的 Apache 開放原始碼專案 Hadoop. 統使用平行的 Input/Output,使大量資料能夠快速讀取,同時也令儲存空間能以 Scale-out(Greenberg, Hamilton et al.,2008)的方式增加,解決過去增加磁碟空間時, 周邊設備也必須重新更換的不便與成本增加。. 10.
(11) 政 治 大. 圖 1. 查詢 Cloud Computing 一詞之次數折線圖(引用自 Google Trend, 2012). 立. 圖 1 為 Google Trend 截至目前為止的報告。由圖 1 可得知雲端運算的風潮由. ‧ 國. 學. 2007 年末開始,直至 2010 年底開始步入穩定期,查詢量也逐漸下降。然 Google 於 2012 年 6 月 28 日發表聲明採用 MapR 公司所營運之 Hadoop 套件,將其整合進. ‧. Google Compute Engine 中(McLuckie,2012),此舉證明 Hadoop 已進入穩定且商業. sit. y. Nat. 化的時代。. n. al. er. io. 隨著越來越多使用者開始將其原先系統移轉至 Hadoop 及其周邊開放原始碼專. i n U. v. 案,資料庫的移轉隨之成為一個重要的課題。過去,使用者最為廣泛使用的資料. Ch. engchi. 庫為傳統關聯式資料庫,因此本研究將探討如何將關聯式資料庫移轉至建置於 Hadoop 上的 NoSQL 欄導向資料庫代表-HBase,期望能找出一通用轉換機制。此 外,為了印證本研究所提出的轉換機制為有效可行,本研究將建置一使用 HBase 為底層資料庫的台灣學術期刊搜尋系統,此系統實作一基於 Hadoop 的 Map/Reduce 分散式運算的轉換工具,此轉換工具方便使用者進行關聯式資料庫至欄導向資料 庫的轉換,以驗證本研究所提轉換機制之可行性及效能改善。同時,也將就使用 Map/Reduce 轉換工具之執行效能進行探討。. 11.
(12) 第二節 研究架構及流程 研究背景與動機 1. 雲端運算日趨穩定,越來越多人開始使用NOSQL資料庫建立系統 2. 需要有統一的轉換規則. 研究目的與貢獻 1. 嘗試提出關聯式資料庫轉換至欄導向資料庫之轉換機制 2. 期望促進轉換機制之發展. 文獻探討. 政 治 大. 欄導向轉換機制設計. 學. ‧ 國. 立. 系統實作 台灣學術期刊搜尋引擎. Avro序列化轉換機制設計. ‧. Nat. sit. y. 問題發現 HBase效能限制 台灣學術期刊搜尋引擎. io. n. al. er. 是否成功?. Ch. 結論與建議. engchi. i n U. v. 圖 2. 研究流程圖. 本研究首先透過兩個現象點出研究背景與動機: (1) 雲端運算日趨穩定,越來越多人開始使用 NOSQL 資料庫建立系統。 (2) 相關系統資料庫移轉時需要有統一的轉換規則作為參考設計。 而後提出本研究之目的與貢獻: (1) 提出由傳統關聯式資料庫轉換至欄導向資料庫之轉換規則。 (2) 實作出台灣學術搜尋引擎以驗證轉換規則之可行性。 12.
(13) (3) 期望刺激轉換機制的制定與 Object-Relation Mapping(ORM)的軟體 實現。 第二章介紹本研究所用到之技術:雲端運算、Google File System、Apache Hadoop、Hadoop Distributed File System、Map/Reduce、HBase、Avro 以及序列 化技術 Avro。 第三章提出兩種轉換的機制-欄導向資料結構轉換以及 Avro 序列化結構轉換。 但於第四章系統實作時發現,HBase 目前對於多 CF 的效能較差,因此重新思考提 出以 Avro 序列化結構為基礎的轉換機制;並於第四章系統實作中,重新規劃架構。 第五章針對本研究所提出的轉換機制與系統實作提出結論與日後改進之建議。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 13. i n U. v.
(14) 第三節 研究目的與貢獻 根據研究背景與動機可得知,雲端運算的發展已日漸穩健,使用雲端運算最 具代表性的分散式架構 Hadoop 建置系統的企業也越來越多,而企業不只使用 Map/Reduce 處理大量資料,也使用分散式資料庫儲存大量資料,如此一來可降低 企業所需之成本與人力。Hadoop 與基於 Hadoop 的 NoSQL 資料庫 Hbase 也因而蓬 勃發展。根據 Apache power wiki 資料顯示,有越來越多的公司開始使用 HBase 來 建構資料庫(Apache wiki,2012),如 Facebook、Adobe、Trend Micro、Twitter 等 知名公司皆採用 Hbase 以達到彈性、高速讀取寫入、隨機從硬碟讀取資料以及低 延遲的優點。. 政 治 大. 立. 這樣的特性對搜尋引擎而言尤為重要。Google 工程師發現,就算是 4 毫秒(大. ‧ 國. 學. 約是眨一次眼)的時間都太久了,即便是這一點點的耽擱也會導致使用者減少搜. 聯式資料庫在應付龐大資料量搜尋時,速度下降的問題。. Nat. y. ‧. 尋量。因此這也是本研究選擇實作搜尋引擎的動機與目的,期望幫助解決現有關. io. sit. 遠流出版公司的資訊長表示,以關聯式資料庫建立的搜尋引擎進行搜尋,其. n. al. er. 所花費的時間約為 6 秒。這樣的速度在現在的網路環境中已不敷需求,使用者需. Ch. i n U. v. 要的是更快、更精確的搜尋引擎,即使是一秒鐘的等待對使用者而言仍舊太久。. engchi. 目前的搜尋引擎龍頭 Google,其打敗眾人的關鍵也在於它迅速的回應,以及其精 準的搜尋排序。 因此,本研究之貢獻有二,其一為利用 Hadoop 及 HBase 實作一分散式搜尋引 擎,除提供以 Hadoop 建構學術期刊搜尋引擎之系統架構,也提升原先關聯式資料 庫所無法達到的快速搜尋以及精確度。其二為提供一通用關聯式至欄導向之轉換 機制,促進組織雲端化發展,也期望日後能發展出一套標準的轉換甚或是 Object Oriented Mapping(ORM)機制。. 14.
(15) 第二章. 文獻探討. 本章節首先就目前最廣為人知的雲端運算、雲端運算分散式架構 Hadoop、分 散式儲存及 Map/Reduce 作概念性介紹。再細說本研究使用、運行於 Hadoop 上方 的欄導向資料庫 HBase,包含其 Table 儲存格式、應用及其限制。. 第一節 雲端運算 雲端運算為近年來學術界及業界相當重視的議題,市場甚至預期在未來五至 十年內會有許多新的應用跟技術改變人們使用資訊科技的方式。雲端運算自分散. 政 治 大 資源,並將複雜的運算與儲存工作分散到網路雲端並隱藏起來。維基百科表示, 立 式平行運算與網格運算發展出來,專注於大量資料的密集處理,需要充足的運算. ‧ 國. 學. 雲端運算是一種基於網際網路的運算方式,透過這種方式,共享的軟硬體資源和 信息可以按需求提供給運算機和其他設備。而雲端運算應提供基於虛擬化技術的. ‧. 服務,使使用者能快速部署資源,並按需求及其資源使用量付費。除此之外,雲. sit. y. Nat. 端運算使用戶可方便地通過網際網路獲取海量信息處理之服務,並降低用戶對於. io. n. al. er. IT 專業知識的依賴(Wikipedia,2012)。. Ch. engchi. i n U. v. 圖 3. NIST 美國國家標準局對雲端運算的定義. 根據 National Institute of Standards and Technology (NIST)定義,雲端運算為使 15.
(16) 用無所不在、便利、隨需應變的網路,共享廣大的運算資源,如網絡、伺服器、 儲存、應用程式以及服務等,可透過最少的管理工作與服務供應者互動,快速提 供各項服務(Mell and Grance ,2011)。 這些服務可以包含五大基本特徵(Essential Characteristic)及四個佈署模型 (Deployment Models)與三種服務模式(Service Model)。 五項基本特徵分別為: 1.. On-demand self-service:使用者可依自己的需求直接於網路上取得所需之 雲端服務,如網路硬碟或虛擬伺服器等服務,而不需經過人工作業的方 式。. 2.. 立. 政 治 大. Broad network access:使用者可以使用電腦、手機或是更小的部件,以標. ‧ 國. 3.. 學. 準的溝通機制透過網路取得服務。. Resource Pooling:多人共享資源,如頻寬、儲存空間、運算資源以及記. ‧. 憶體。. Nat. 5.. Measured Service:服務是能夠被監控與測量其狀態的。. 1.. sit. er. al. n. 四種佈署模型分別為:. y. Rapid elasticity:使用者能夠彈性且快速地重新佈署他們所需的服務。. io. 4.. Ch. engchi. i n U. v. Private Cloud:意指企業自行建置雲端運算平台,其建置成本較為昂貴, 但因為企業擁有伺服器控管的權限,所以在安全性及隱私權上的防護較 佳。大型企業通常會建置企業本身的私有雲。. 2.. Public Cloud:意指建置於遠方租賃的伺服器或是虛擬服務平台,甚至是 服務本身,使企業不用做資源或是伺服器的控管,並且可以彈性的調整 租用量。但因為企業所有的資訊應用資料皆放置於遠端的公有雲上,因 此在安全性與隱私權的威脅相對而言較高。. 3.. Community Cloud:意指多個組織間互相友善,合作建置共有的社群雲, 使得組織間可以共享其他組織所釋出的資源以及分攤雲端的維護費用。 16.
(17) 4.. Hybrid Cloud:將以上三種雲混和即為混和雲,是較為複雜的結構,會出 現這種現象通常為私有雲加公有雲。因為某些大型企業會有極大的資源 處理需求,然私有雲的建置費用極其昂貴,因此會動態調用遠方的服務 幫助其運算。. 而三種服務模式則分別為: 1.. Infrastructure as a service, IaaS:提供運算、儲存以及網路等基礎設備的服 務,以提供內外部使用者存取之用。為了幫助內外部使用者存取使用,IaaS 通常透過虛擬化技術(Virtualization)來完成伺服器整合的基本作業。目前. 政 治 大. 市面上的 IaaS 以 Amazon EC2(Amazon Elastic Cloud 2), Google Compute. 立. Engine 以及 IBM Smart Cloud 最廣為人知。. ‧ 國. 學. 2.. Platform as a Service, PaaS:服務提供商提供運算平台給外部開發人員或 使用者,並提供整合的 API 及相關管理套件方便開發人員構建、開發以. ‧. 及佈署其系統,但平台管理成本相對昂貴。目前最有名的為 Google 所推. Nat. sit er. al. n. 3.. io. S3。. y. 出的 Google App Engine(GAE), Windows 推出的 Azure 以及 Amazon 的. i n U. v. Software as a Service, SaaS:用戶向服務提供商租用雲端應用服務,使用. Ch. engchi. 者透過多種溝通協定對其所租用的軟體進行操作或取得運算結果。所有 軟體的管理以及運轉皆由服務提供商負責,對使用者管理負擔以及成本 的降低有不小的助益。 更深入而言,雲端運算是一種模式,其依照需求方便地存取網路上所提供的 電腦資源,這些電腦資源包括網路、伺服器、儲存空間、應用程式、以及服務等, 可以快速地被供應,同時減少管理的工作,降低成本並提昇效能。. 17.
(18) 第二節 Google File System 第一章中提到,由 Google 所提出的 Google File System(GFS)分散式檔案系統, 對於分散式計算非常重要;因為當資料被放置在不同的機器上時,需要檔案系統 來做適當的管理以及備份。 Google 於 2003 年所提出的 GFS 是一種相當容易擴大檔案系統容量的架構 (Ghemawat, Gobioff et al. 2003),主要應用在大規模、分散式以及需要對大量資料 進行運算的應用。GFS 的運行並不需要企業等級的高階伺服器,它的特點在於能 夠運行在一般使用者的 Personal Computer(PC)上,雖然一般 PC 在損壞率上較伺服. 政 治 大. 器來得差,但 GFS 提供了相當完整的容錯備援機制,使得即使在較差的環境下依. 立. 然能夠快速地運行。這樣的一個特性使得企業或一般使用者在不需要花費大量資. ‧ 國. 學. 金的情況下也能夠獲得企業級伺服器的運算能量,節省企業資源也使得原本應該 要廢棄的老舊機器得以有再被利用的機會。. ‧. 然而 GFS 與過往的檔案系統最大的不同點在哪呢?. Nat. y. 備援機制:硬體的故障是有可能經常性的發生,因為資料會經常性的存取,雖. sit. 1.. n. al. er. io. 然在企業級伺服器上故障的機率較低,但是仍然是一定機率發生的。一旦故障,. i n U. v. 企業即會損失相當多的檔案以及花費高昂的價格來維修。然 GFS 建置於分散. Ch. engchi. 的系統上,提供了資料備份的機制,也使用 Heart Beat 的機制來隨時監控硬體 狀況,當有問題時,會立刻提供預先儲存的備份資料來即時回應。 2.. Big Data 資料儲存:GFS 的誕生是由於資訊量的爆炸產生,使得系統的儲存空 間得以 Scale out 的方式增加,意即購置額外的 PC 或者硬碟即可增加儲存容 量,不需更換既有的設備。同時 GFS 能對大型檔案做有效的管理,在處理大 量資料時,能夠即時的回應。. 3.. 大部分對於存在 GFS 的處理模式為在檔案結尾處增加資料,比較少的情況是 修改既有的資料。因為存在 GFS 檔案系統的資料通常都是很大的單一檔案, 所以對一個檔案的隨機寫入操作通常是不存在的。取而代之的是大量的程式對 18.
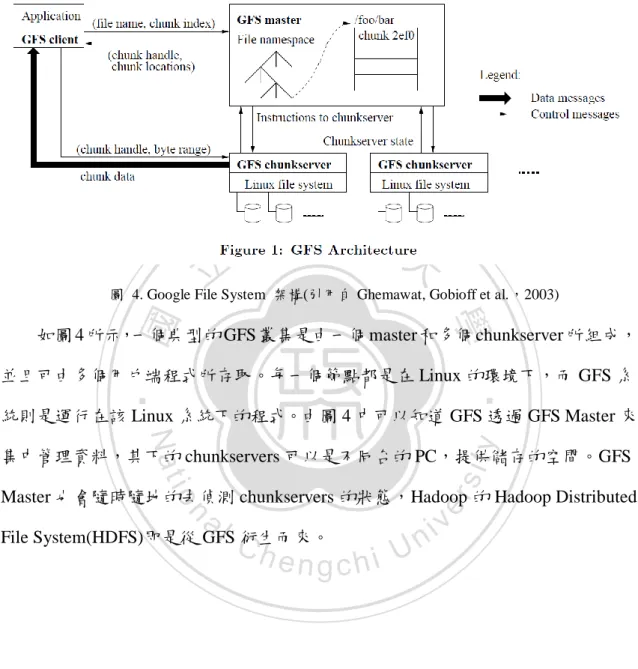
(19) 單一檔案進行依序的讀取或寫入動作,因此必須對此動作進行最佳化以及保證 大量的程式同時寫入或是讀取時彼此之間不能混淆。. 立. 政 治 大. 圖 4. Google File System 架構(引用自 Ghemawat, Gobioff et al.,2003). ‧ 國. 學. 如圖 4 所示,一個典型的 GFS 叢集是由一個 master 和多個 chunkserver 所組成,. ‧. 並且可由多個用戶端程式所存取。每一個節點都是在 Linux 的環境下,而 GFS 系 統則是運行在該 Linux 系統下的程式。由圖 4 中可以知道 GFS 透過 GFS Master 來. y. Nat. io. sit. 集中管理資料,其下的 chunkservers 可以是不同台的 PC,提供儲存的空間。GFS. n. al. er. Master 也會隨時隨地的去偵測 chunkservers 的狀態,Hadoop 的 Hadoop Distributed. Ch. File System(HDFS)即是從 GFS 衍生而來。. engchi. 19. i n U. v.
(20) 第三節 Apache Hadoop Hadoop 是 Apache 軟體基金會(Apache Software Foundation)底下的開放原始碼 計畫。Hadoop 以 java 為基礎,提供大量資料在分散式架構的環境下做運算以及儲 存。Hadoop 的核心主要由 Hadoop Distributed File System(HDFS)以及 Map/Reduce 組成。 Hadoop 是由 Apache Lucene 專案中的搜尋引擎 Nutch 衍生而來。Nutch 為能夠 爬網頁資料並提供搜尋功能的系統,不過 Nutch 的開發團隊逐漸發現建構一個網 路搜尋引擎是一個雄心勃勃的目標,不僅是要撰寫一個可以處理複雜網站的資料、. 政 治 大. 抓取以及建立索引的軟體,還需要團隊的大量財力支持。根據 Mike Cafarella 以及. 立. Doug Cutting 的估計(White,2011),一個提供一憶個網頁索引的硬體需要花費將近. ‧ 國. 學. 一百萬美元,每月的運行費用還需要三萬元的驚人數字。不過他們相信這是個值 得開發的目標。很快地在 Nutch 營運一年後,也就是西元 2003 年,正當 Nutch 營. ‧. 運團隊一籌莫展之際,Google 發表了一篇關於 Google File System 的論文,Nutch. Nat. sit. y. 的創辦人 Doug Cutting 很快地發現這是一個幫助他們搜尋引擎變革的一個契機。. n. al. er. io. GFS 檔案系統可以解決抓取大量網頁和建立索引時所產生的檔案,並節省對. i n U. v. 檔案管理上的時間,這對 Nutch 團隊來說相當有幫助,他們便很快速地採用 GFS. Ch. engchi. 的論文於系統中實作,產生 Nutch Distributed File System(NDFS),也就是 HDFS 的 前身。然而,Google 於 2004 年又提出了 Map/Reduce 的分散式運算架構,Nutch 於 2005 年中便將 Nutch 所使用的演算法移植到 Map/Reduce 的環境上面。 在 Nutch 計畫中 NDFS 與 Map/Reduce 的應用已經超過搜尋領域,於是 Nutch 團隊便從 Nutch 中抽離出一個 Lucene 的子計畫並命名為 Hadoop。直至現在,Hadoop 已經成為 Apache 的頂級計畫,成為一個多樣性且熱絡的社群。使用 Hadoop 的公 司相當多,如 Yahoo!、Last.fm、Facebook,甚至是到現在 Google 也宣布與 MapR 合作採用 Hadoop 作為基礎運算架構。(Mell and Grance, 2011). 20.
(21) 立. 政 治 大. 圖 5. Hadoop Ecosystem integration by MapR(資料來源:http://www.mapr.com/products). ‧ 國. 學. Hadoop 的核心是由 HDFS 以及 Map/Reduce 組成,因為開放社群的關係,許 多程式設計師開始針對 Hadoop 進行周邊套件的研發,並以動物的名稱來命名周邊. ‧. 的套件,如 Hive、Zookeeper、Sqoop 等套件。ZooKeeper 提供散式且高可用性的. sit. y. Nat. 協調服務,為建置分散式系統提供分散式鎖定等原始鎖定功能。Pig 是超大資料集. io. er. 的資料流語言以及執行環境,可在 HDFS 和 MapReduce 叢集環境中執行。Hive 為. al. 分散式資料倉儲,透過 Hive 可管理存放於 HDFS 的資料,並提供根據 SQL 發展. n. v i n 的查詢語言來查詢資料。SqoopC提供 資料導入。Avro 提供高效能、跨語 h eRDBMS ngchi U 言以及可保存資料的 RPC 資料序列化系統。. 如圖 5 所示,這些周邊的套件組合成為了 Hadoop 的生態系統(Hadoop Ecosystem),但也因為各項套件獨立開發,在版本上面會有相容性的問題,所以許 多商業化軟體的公司便開始整合 Hadoop 的生態系統套件,調整效能與佈署機制, 如 Cloudera、MapR、Hortonworks 等。這樣的整合使得 Hadoop 更蓬勃發展,也日 趨穩定,成為了雲端分散式運算的翹楚。. 21.
(22) 第四節 Hadoop Distributed File System(HDFS) HDFS 由 NDFS 衍生而來,唯一分散式的檔案系統,採用主從(Master/Slave) 結構的模型,一個 HDFS 叢集是由一個 Namenode 和許多個 Datanode 組合而成的。 其中以 Namenode 作為主要的伺服器,管理檔案系統的命名空間和使用者端對檔案 的讀取操作;而叢集中的 Datanode 則負責管理儲存的資料。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 6. HDFS 架構圖(資料來源:apache.org). 圖 6 為 HDFS 的架構圖,由圖中可得知 HDFS 會將資料以檔案的形式儲存, 並切割或合併成多個檔案區塊,每個檔案區塊預設為 64MB。HDFS 以檔案區塊作 為讀取的單位,每個檔案區塊的大小是固定的,並會複製數份,除了拿來做資料 的容錯機制和可靠性外,也增加了執行 Map/Reduce 運算時取得資料的速度。讀取 資料時,使用者會先訪問 Namenode 後,由 Namenode 告知資料所在的 Datanode, 再由使用者直接連線到該 Datanode 取得資料。. 22.
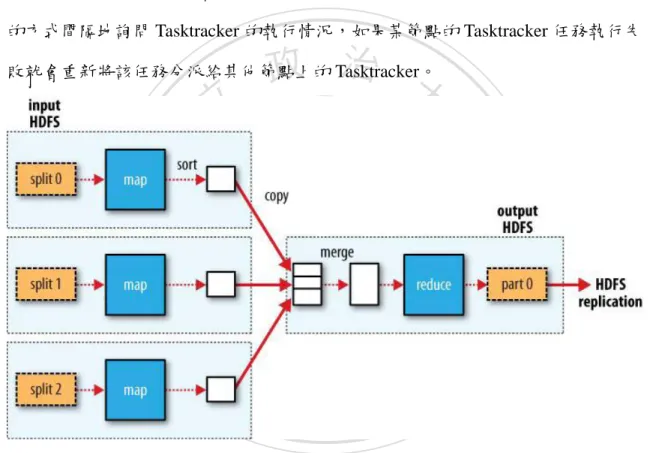
(23) 第五節 Map/Reduce Map/Reduce 是一種平行程式設計模式,這種模式使得軟體開發者可以很輕易 的撰寫出分散式平行程式。Map/Reduce 是一個簡單易用的軟體框架,由一個運行 於主節點上的 Jobtracker 和執行在每個叢集節點的 Tasktracker 所組成。Jobtracker 負責分配工作給底下的 Tasktracker 執行,Jobtracker 在接收到 Job 的傳送作業以及 設定資訊後,就會傳送 Job 的設定資訊到底下的各 Tasktracker,並指定運算的作業 內容。此外,Jobtracker 負責監控排程 Tasktracker 的執行狀況,使用心跳(Heart Beat) 的方式間隔地詢問 Tasktracker 的執行情況,如果某節點的 Tasktracker 任務執行失. 政 治 大. 敗就會重新將該任務分派給其他節點上的 Tasktracker。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 7. Map/Recduce 運作圖(資料來源:White, T.,2010). Map/Reduce 的任務分別由 Map 跟 Reduce 組成,在執行 Map/Reduce 任務時需 先定義 input,也就是運算的資料來源;透過 Jobtracker 會將資料來源根據 Map 數 量進行資料切割成為資料片段 Splits,並將各 Splits 分別傳送到執行 Map 動作的 Tasktracker 上。經過 Map 分散運算後的資料會以 Key Value 的方式丟出,並依據輸 出的 Key 值進行洗牌(Shuffle)跟排序(Sort);洗牌是 Map 任務與 Reduce 任務之間的 資料流,而排序則是依據 Key 值來進行組合的動作。洗牌將 Map 任務輸出的 Record 23.
(24) 複製到 Reduce 任務執行的機器上,當 Map 輸出的 Record 已經複製完成後,會針 對檔案進行排序的動作;更正確來說,應該是合併的程序,用來合併 map 輸出且 維持排序的順序。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 24. i n U. v.
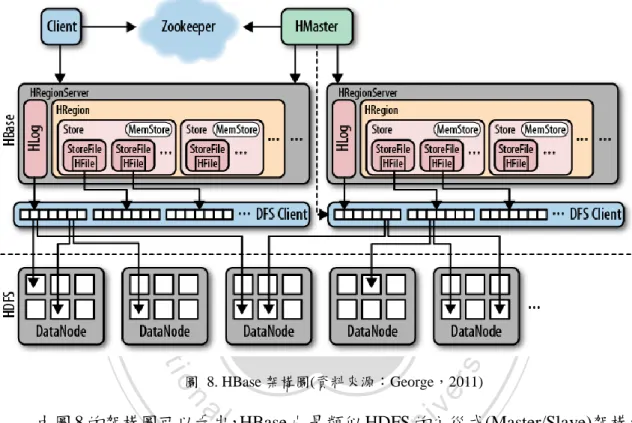
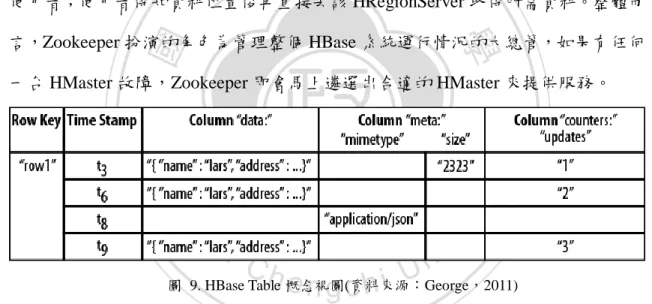
(25) 第六節 HBase HBase 是一個以 HDFS 為基礎的高可靠性、高性能、欄導向、可彈性伸縮的 分散式資料庫,適用於使用者需要即時讀取或隨機存取大量資料時。HBase 專案開 始於 2006 年,其參考了 Google 所提出的 Bigtable 概念並加以實作。其原先是 Hadoop 的子專案,後來獨立出來成為 Apache 的頂層專案。. 立. 政 治 大. ‧. ‧ 國. 學. io. sit. y. Nat. n. al. er. 圖 8. HBase 架構圖(資料來源:George,2011). Ch. i n U. v. 由圖 8 的架構圖可以看出,HBase 也是類似 HDFS 的主從式(Master/Slave)架構,. engchi. 由一個 HMaster 以及多個 HRegionServer 組成。一個 HBase 可以佈署多個 Master, 但同時間只有一台 Master 是活躍的,其透過領袖選取演算法(Leader Election Algorithm)來確保只有一台 Master 在工作。HMaster 負責初始化叢集、紀錄 Table 的區塊(Region)位置、監控 HRegionserver 的運行狀況。區塊(Region)指的是 Table 水平切割的區塊,HBase 會依照 Table 的大小,將其切割為數個區塊儲存,並將之 分散在 HRegionserver 中。HRegionserver 則是負責儲存這些被切割的 Table 區塊。 HBase 的 table 是一個稀疏的、長期存儲的、多維度的、排序的映射表。Table 由 Column Family(CF)、Column Qualifier(CQ)、Row Key(RK)、Time Stamp 及 Cell 25.
(26) 所組成。每個 Cell 可以視為是關聯式資料庫的一個值,Column Qualifier 可以視為 關聯式資料庫的一個屬性,在 HBase 中將同樣類型的屬性歸類到同一 Column Family 底下。每個 CF 與 CQ、RK 以及 Timestamp 的組合會搭配一個 Cell 值,如 此的一個搭配便形成了一張可儲存的大表。邏輯上,HBase 是一張大表,但實際上 儲存的單位卻是以 Key Value 的方式儲存,Key 的組成是 CF 與 CQ、RK 以及 Timestamp 的組合,而 Cell 則為 Value。這樣的特性使得資料容易被切割且分散式 的儲存在多個位置,適合於分散式環境運作。 當使用者想取得資料時,會先向 Zookeeper 詢問 HMaster 的狀況並把請求傳送. 政 治 大. 給運行中的 HMaster,再由 HMaster 將資料區塊所在的 HRegionServer 位置傳回給. 立. 使用者;使用者得知資料位置後再直接去該 HRegionServer 取得所需資料。整體而. ‧ 國. 學. 言,Zookeeper 扮演的角色為管理整個 HBase 系統運行情況的大總管,如果有任何 一台 HMaster 故障,Zookeeper 即會馬上遴選出合適的 HMaster 來提供服務。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 9. HBase Table 概念視圖(資料來源:George,2011). 如圖 9 所示,一個表可以想像成一組映射關係,透過 Row key,或者是 Row key 加 Timestamp 就可以定位一行的資料。由於是稀疏資料,所以邏輯上某些列可以 是空白的。這樣的一個結構就形成了欄導向的資料庫。. 26.
(27) 第七節 Avro Avro 是 Hadoop 的一個子項目,由 Hadoop 的創始人 Doug Cutting 領頭開發, 當前最新版本為 1.7.0。Avro 是一個資料序列化(Data Serialization)系統,設計用於 支援大批資料交換的應用。它的主要特點為:支援二進位序列化方式,可以便捷、 快速地處理大量資料;支援動態語言(Dynamic Language),使動態語言(如:Java, C#) 可以更方便地處理序列化資料。 當前市場上有很多類似的序列化系統,如 Google 的 Protocol Buffers, Facebook 的 Thrift。這些序列化系統運行良好,完全可以滿足資料序列化應用的需求。因此. 政 治 大. Avro 的開發,使許多人產生疑問:為何要重複開發一個全新資料序列化的系統?. 立. Doug Cutting 撰文解釋道:Hadoop 現存的 RPC 系統遇到一些問題,如性能瓶頸(當. ‧ 國. 學. 前採用 IPC 系統,它使用 Java 自帶的 DataOutputStream 和 DataInputStream)、伺服 器端和用戶端必須運行相同版本的 Hadoop、只能使用 Java 開發等問題。且現存的. ‧. 序列化系統自身也存在問題;以 Protocol Buffers 為例,它需要使用者先定義資料. Nat. sit. y. 結構,然後根據這個資料結構生成代碼,再組裝資料。如果需要操作多個資料來. n. al. er. io. 源的資料集,那麼需要定義多套資料結構並重複執行多次上面的流程,如此一來. i n U. v. 就不能對任意資料集做統一處理。其次,對於 Hadoop 中 Hive 和 Pig 這樣的腳本. Ch. engchi. 系統來說,使用代碼生成是不合理的。並且,Protocol Buffers 在序列化時考慮到資 料定義與資料可能不完全匹配,允許在資料中添加註解,這會讓資料變得龐大並 拖慢處理速度。而其它序列化系統也存在如 Protocol Buffers 類似的問題。所以為 了 Hadoop 未來的穩定性考慮,Doug Cutting 主導開發一套全新的序列化系統,也 就是 Avro。Avro 於 2009 年加入 Hadoop 專案家族中。 以上透過與 Protocol Buffers 的對比,大致了解 Avro 被設計出來的原因及其試 圖改善的部分;以下則著重於 Avro 設計細節。 Avro 依賴 Schema 來實現資料結構定義。Schema 定義每個 datum (Avro 支援的 資料型態) 物件結構可以包含哪些屬性,因此可以根據 Schema 來產生任意多個 27.
(28) datum 物件。對 datum 物件序列化/反序列化操作時,Avro 都需要知道 Schema 的具 體結構。因此,在應用 Avro 作為資料交換的一些場景下,如檔案儲存或網路通訊, 都需要 Schema 與資料同時存在。Avro 資料以 Schema 來決定如何讀、寫(Apache, 2012),且寫入的資料不需要再加入其它標識,使序列化時速度快且結果內容長度 也相對較小,解決上述其他序列化系統序列化速度慢的問題。 Avro 的 Schema 主要由 JSON 物件表示,包含一些特定的屬性,用以描述某種 資料類型(Type)的不同形式。Avro 支援八種基本類型(Primitive Type)和六種複雜類 型(Complex Type)。. 政 治 大. Primitive Type:. 立. 學. ‧ 國. [1] Null: no value. [2] Boolean: a binary value [3] Int:32-bit signed integer. ‧. [4] Long:64-bit signed integer. Nat. sit. y. [5] Float:single precision (32-bit) IEEE 754 floating-point number. n. al. er. io. [6] Double:double precision (64-bit) IEEE 754 floating-point number [7] Bytes:sequence of 8-bit unsigned bytes. Ch. engchi. [8] String:unicode character sequence. i n U. v. Complex Type: [1] Records:紀錄,支援五種屬性。 A.. Name:提供 Record 之名稱。. B.. Namespace:用以識別名稱的域名。. C.. Aliases:Name 的別名,為一陣列。. D.. Doc:其餘資訊。. E.. Fields:為一陣列型態,儲存多個 Field,每個 Field 可包覆一 Avro 複雜型態。 28.
(29) [2] Enums:列舉,提供 Name、Namespace、Aliases、Doc 及 Symbol 屬性。 Symbol 為一 JSON 物件陣列,儲存多個常數。 [3] Arrays:陣列,提供 Items 屬性放置陣列內的元素。元素可以是 Avro 之複 雜型態。 [4] Maps:地圖,提供一組 Key Value 的 Collection,Key 的資料型態必須為 String,Value 可以是 Avro 之複雜型態,使用 Values 作為其參數。 [5] Unions:提供 Fields 中型態之選擇,使 Field 可包含的型態不只一種,也 可為 null。. 政 治 大. [6] Fixed:用以限制型態內的長度,提供 Name、Alias 兩種參數。另提供 Size. 立. 作為 bytes 數的限制參數。. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 29. i n U. v.
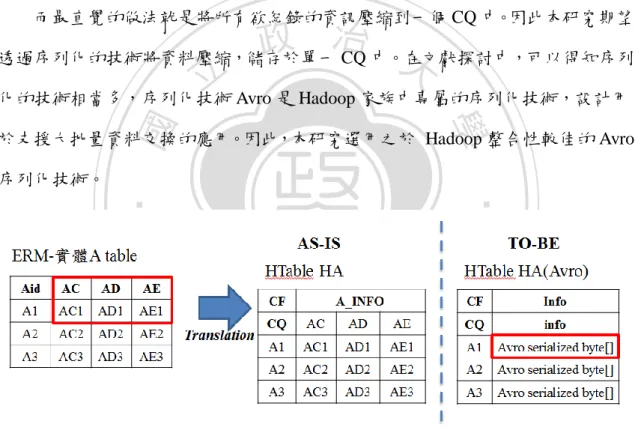
(30) 第三章. 關聯式暨欄導向轉換機制. 大部分的傳統關聯式資料庫(Relational Database, RDB)皆以 Entity-Relationship Model(ERM)設計 Table 的概念模型,因此本研究將從 ERM 的觀點來說明關聯式資 料庫(RDB)暨欄導向資料庫(Column-oriented database, CDB)的轉換機制。ERM 實體 之間存在三種關係,分別為一對一(1-1)關係、一對多(1-m)關係、及多對多(m-n)關 係。假設一個實體 A 跟實體 B 發生關係,實體 B 又與實體 C 發生關係,這樣的一 個關係鏈,我們稱之為實體 A 與實體 C 擁有遞迴關係(Recursive Relation, R-R)。除 此之外,我們也定義兩實體間的 R-R 距離(R-R Length)為中間的實體數加 1。以上. 治 政 大 B+1)。 述之例而言,實體 A 與實體 C 的 R-R 距離為 2(中間的實體 立 本章節原先計畫依上述五種關係進行關聯式資料結構轉換至欄導向資料結構 ‧ 國. 學. 之探討,但因研究過程中發現 HBase 之先天效能限制,轉換過程中的資料結構表. ‧. 現不佳;因此另尋解決辦法,最後決定以 Avro 序列化之結構來進行轉換機制的探 討。因此本章分為兩節:第一節介紹欄導向資料庫的結構轉換,第二節介紹 Avro. y. Nat. er. io. sit. 序列化資料結構轉換。. 第一節 欄導向資料庫結構轉換 a. n. iv l C n 本研究提出五種標準的轉換規則幫助使用者從 h e n g c h i UER 模型轉換至 CDB 的資料模. 型。包含:(1)實體關係轉換(2)一對一關係轉換(2)一對多關係轉換(3)多對多關係轉 換。 第一段. 實體關係轉換. ERM 中,一個實體代表一個關聯 Table。一個關聯 Table 包含一個主鍵(Primary Key)以及數個非主鍵的屬性(Field);主鍵可能是由數個 Field 組成。在欄導向資料 庫中,一個 CF 包含了多個擁有相同特性的 CQ,每個 CQ 在 CF 中都是唯一的。 在關聯 Table 中,一個主鍵的值識別了一個特定的列(Row)。同樣的,在欄導向資 料庫中,一個 RK 也識別了 HBase 中一張 Table 的特定列。因此,關聯式資料表的 30.
(31) 中的主鍵值可以被視為是 HTable 中的 RK。而對於主鍵是由多個 Field 組成的實體 Table,我們將該主鍵列中的每個 Field 中的值以「:」作為區隔符號合併為單一的 值。轉換方法如下所述: 假設: Let tables.. {. be a relational database, that is. } is a set of relational. { Let be a column-based database, that is set of HTables, where is the mapping table of relational table be null when is a relational table for a weak entity. . For a table. } is a might. ,. , we define that. , may consists of one or more fields 政 治 大. o Let be the primary key of where are called primary key fields. { } o Assumes that. 立. the number of non-primary key fields in ,. {. y. }. sit. 轉換步驟:. .. has primary values. Nat. o has a set of tuples . For any { }. and field values. . We have. ‧. ‧ 國. 學. , be the set of primary key fields, where k is the number of primary key fields in . { } o A set of non-primary key fields , where is. er. io. For each table , an HTable with a set of row keys is constructed. The construction of includes two steps, the first step is to define. al. n. v i n C second the row key for and the is to define the column family for U h e nstep i h gc which are described as follows. o o. each primary key { as the value of the row key in Step 2: A column family is constructed for Step. every field. 1:. For. , there is a column qualifier. o For each tuple , a key value pair each of , in which row key equals to , is the value.. 31. in. }. in. ,. , take. . in. , such that for. .. will be constructed for is the column qualifier and.
(32) 圖 10. 實體關係轉換示意圖(Entity Relationship Translation). 圖 10 中,創建了與實體 A 對應的 Htable-HA,HA 包含一個名為 A_INFO(使 用者可以自行定義)的 CF,用以群組實體 A 的 Field,並將每個 Field 視為 A_INFO 中的一個 CQ。. 立. 政 治 大. has may consists of one or more. ‧. For the relational table A, we define that o Let be the primary key of , fields where are called primary key fields. { } o Assumes that. 學. . ‧ 國. 為了方便定義轉換規則,我們預先定義 Table 的參數數學表示式如下:. sit. n. al. A has a set of tuples . For any { }. and field values . Ch. ,. er. io. o. y. Nat. , be the set of primary key fields, where k is the number of primary key fields in . { } o A set of non-primary key fields , where is the number of non-primary key fields in A. We have .. v ni. has primary values. engchi U. {. }. For relational table , we define that B o Let be the primary key of , may consists of one or more fields where are called primary key fields. { } in o A set of non-primary key fields , where is the number of non-primary key fields in . We have . { } o A set of primary fields, , be the set of primary key fields, where z is the number of primary key fields in . o B has a set of tuples . For any , has primary values { }. and field values. 32. {. }.
(33) 根據以上定義的 Table 參數表示式,本研究定義單一實體的轉換規則如下:. entity(A) 假設: . Let. be a relational table for translation.. 轉換步驟: For table , an HTable with a set of row keys is constructed. The construction for includes two steps, the first step is to define the row key for and the second step is to define the column family for , which are described as follows. o o. each primary key { as the value of row key in Step 2: A column family is constructed for Step. 1:. For. 政 治 大. 立, there is a column qualifier. in. ,. take. . in. , such that for. in . will be constructed for is the column qualifier and. ‧ 國. 學. every field o For each tuple , a key value pair each of , in which row key equals to ,. }. is the value.. ‧. HBase 中,唯一識別資料列的只有 RK,因此使用者只能透過 RK 來取得資料,. Nat. sit. y. 並不能做跨 table 間的 Join 或者是其他 SQL 查詢。在取得資料時,可以使用掃描(scan). n. al. er. io. 每個 RK 的方式取得資料,並依需求加入針對 RK、CF 以及 CQ 的 Filter 來過濾資. i n U. v. 料;但因為是使用掃描的方式來取得資料,在資料量相當大的情況下,必須走訪. Ch. engchi. 每一列的資料,需花費相當長的時間來回應,因此效能相當的差。也因此,為了 方便進行快速存取我們必須針對資料的欄位建立索引。. 33.
(34) 第二段. 一對一關係轉換. 除了上一段所闡述的實體關係轉換之外,實體間也存在著一對一的關係,因 此本段將針對一對一的關係轉換來做探討。. 立. 政 治 大. ‧ 國. 學. 圖 11. 一對一關係轉換示意圖. 一對一關係的兩個實體使用 Foriegn Key(FK)紀錄兩實體之間的關係。圖 11 中,. ‧. A table 使用 Bid 作為 FK 紀錄 A 與 B 之間的關係。兩個擁有一對一關係的實體在. sit. y. Nat. 關聯式資料庫中,會使用 Full outer join 儲存在一張 table 中,也就是使用其中一個. io. er. 實體的主鍵來當作該 table 的主鍵。因此,轉換規則就變得相當簡單,只要把由 full. al. outer join 產生的 table 做實體轉換至一張 HTable。是否要對兩邊做 Full outer join. n. v i n C h,將 A 與 B 做 fullUouter join 然後將其產生之 table 則依照使用者的需求。如圖 10 所示 engchi 做實體關係轉換即可。一對一的關係又可以分為 1-0 以及 1-1,如果為 1-0 則以 1 方為主鍵;如果是 1-1 則使用者可以依照使用者需求選擇任一邊做為主鍵。. 1-1(A,B): 假設: Assume A entity and B entity has 1-1 relationship, C is the actual table stored in the relational database taking A’s primary key as C’s primary key. 轉換步驟: . The translation includes two steps as follows: o Step 1: 34.
(35) Generate C table by A table full outer join B table on A’s foreign key equals to B’s primary key. o Step 2: Execute entity(C) which accept C table as input and produce an HTable HC. 從以上的轉換規則我們得到 HA 如圖 11 所示,HA 拿 A 的主鍵當 RK 然後保 留 B 的所有 Field 在 HA 的 A_INFO 中。 一對多關係轉換. 立. 政 治 大. ‧. ‧ 國. 學. Nat. 圖 12. 一對多關係轉換示意圖. sit. y. 第三段. n. al. er. io. 在一對多的關係中,一方對於多方來說是一對一的關係。因此,對於這樣的. i n U. v. 關係我們可以先對多方進行一對一的轉換,也就是 1-1(B, A),而得到 HB 如圖 12. Ch. engchi. 所示。HB 紀錄了 B 連結 A 的外鍵所對應的資料,並使用 CF(A_INFO)來群組 A 的所有 Fields。 然而,在一方的觀點中我們必須去儲存多方的所有 Field,根據 HBase 的特性, CQ 是可以彈性延伸的,適合用以處理一對多的關係。因此我們創建一個 CF 給每 個多方的 Field,然後以多方的 RK 來當作 CQ,儲存與多方的關係。這樣的轉換, 稱之為一對多關係轉換。然而,多方的 RK 可能會由多個 Fields 組成,且由於我們 使用 CQ 值來識別每筆多方資料的關係,CQ 值必須是唯一的。在這樣的情況之下, 就必須合併多方 RK Fields 的值而形成單一值,這與一對一中 RK 值的合併是相同 的。為了定義轉換的方便起見,我們首先定義一對多關係中一方的轉換規則- 35.
(36) 1-m-single(A, B),其中 A 為一方而 B 為多方。. 1-m-single(A,B): 假設: Let A and B to be the 1-m relationship table in RDB, A is at the 1-side and B is at the m-side. . HA and HB is constructed for the mapping HTables in CDB.. 轉換步驟: Execute entity(A) to have HA. In HA, a column family field in .. is constructed for each B’s non-primary key. 政 治 大. . ‧ 國. 立. 學. Base on the 1-m relationship, a tuple with primary key { } in has a group of tuples , such that for any tuple , has as its foreign key. , a key value pair is constructed with o For each non-primary key field of as its row key, the primary key and take the value of. as column qualifier in. as the value.. ‧. 由上述的一對多轉換規則中可以得知一對多的轉換包含一方的轉換與多方的. Nat. sit. y. 轉換,一方的轉換與一對一關係的轉換規則相同。因此我們定義整個一對多的轉. 假設:. al. n. 1-m -multi(A,B):. er. io. 換為 1-m-multi(A,B),轉換規則如下:. Ch. engchi. i n U. v. Assume A entity and B entity has 1-m relationship, A is the 1-side and B is the m-side. 轉換步驟 . The translation includes two steps as follows: o Step 1: Execute 1-1(B, A), which takes B’s primary key as row key generating an HTable HB. o Step 2: Execute 1-m-single(A,B), which generates an HTable HA preserving B’s data related to A. 36.
(37) 第四段. 多對多關係轉換. 圖 13. 多對多關係轉換示意圖. 學. ‧ 國. 立. 政 治 大. ‧. 多對多的關係可以視為兩個一對多的關係。因此對 A 與 B 分別進行兩個一對 多的轉換。圖 13 中,A 與 B 擁有多對多的關係,其關係利用 table C 來記錄。經. y. Nat. io. sit. 過兩個一對多的轉換後,HA 利用兩個 CF:BE、BF 來保留 B 的 Fields 資訊,HB. n. al. er. 則是利用 AD 與 AE 來保留 A 的 Fields 資訊。然而,我們仍然必須儲存 A 與 B 之. Ch. i n U. v. 間關聯 table C 的額外資訊,如圖中的 C 的 Field CE。對於 table C 來說 A 與 C、B. engchi. 與 C 也是一對多的關係,因此也必須針對 A 與 C、B 與 C 做一對多的轉換。在此 我們定義多對多轉換規則為 m-n(B,C),其規則如下:. m-n(A, B, C): 假設: Assume A entity and B entity has m-n relationship, C is relational table generated by A and B. 轉換步驟: . Execute 1-m(A, B), 1-m(B, A). Execute 1-m(A, C), 1-m(B, C). 37.
(38) 第五段. 遞迴關係轉換. 立. 政 治 大. ‧. ‧ 國. 學 圖 14. 遞迴關係(R-R)轉換示意圖. sit. y. Nat. 第一段至第四段的轉換機制幾乎已經可以囊括所有的關係轉換,但是在. io. al. 使用者必須從一次性的讀取中取得所需的資料。. er. Google Bigtable 中提到,一個 table 應該要可以包含所有的資訊,為了增加效能,. n. v i n 也就是說假如有 A、B、CC 三個 與 B 有一對多的關係,B 對 C 也有 h etable,A ngchi U. 一對多的關係,我們希望透過 A 來取得 C 的資訊。雖然在上述的 4 項轉換規則中 已經將所有的關係描述定義了,但為了增加效能,有別於過去的多個 table join, 我們希望能夠透過一次性的讀取取得需要的資料。意即,能夠透過一次性的讀取 A 就取得 C 的資料,這樣一來 A 就必須保留 C 的資訊。上述的 ABC 關係,稱之 為遞迴關係。 我們可以將遞迴關係解釋為多個一對多關係的連結,首先處理所有 table 一對 多關係的轉換。如圖 14 所示,我們可以發現 HTable HB 儲存了對應的 C 的所有 資訊。對於 A 來說識別 C 的資訊必須透過 B,因此透過 B 與 C 主鍵的結合可以 38.
(39) 用來識別相對應的 C 關係。又 C 對於 A 來說也是多方的關係,因此可以拿 C 的 Fields 來當作 A 的 CF,B 與 C 主鍵的結合來當作 CQ。以上的動作可以透過遞迴 地 Full outer join 的所有子 table 的方式來達成。以上述的 ABC table 為例,首先創 建一個 table D 來暫時儲存 full outer join 的結果。再遞迴地把 D full outer join 子 tables(table B、table C),如此一來 table D 便會是一張以 A 為主鍵並包含 C Fields 的大表,只要透過存取這張大表即可取得 C 之資訊。最後再對這張大表進行實體 關係的轉換即完成遞迴關係轉換。以數學式定義遞迴關係的轉換規則(r-r)如下:. r-r translation(A, C): 假設::. 政 治 大 Assume that A and 立C are two relational tables having the R-R relationship. ‧ 國. ‧. 轉換步驟:. 學. with R-R length n. Let A be the 1-side and C be the m-side. { } Let be the set of relational tables in the R-R relationship between A and C, excluding A and C.. y. sit. for (i = n-1; i < 1; i--){. io. er. . Nat. Construct a temporary relational table D = C.. D = full_outer_join( . D). al. n. } return 1-m(A, D). Ch. engchi. 39. i n U. v.
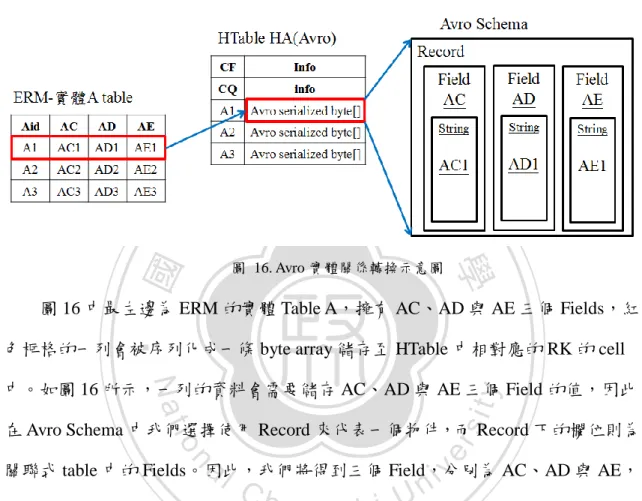
(40) 第二節 Avro 序列化資料結構轉換 前一節中介紹了關聯式資料結構轉換至欄導向資料結構之機制。然而,HBase 官方文件中指出:「HBase currently does not do well with anything above two or three column families so keep the number of column families in your schema low.」(The Apache HBase Book,2012)。且於系統實作中發現,資料的寫入及掃描速度相差十 倍之多,因此希望將 Column Family(CF)以及 Column Qualifier(CQ)的數量減少,以 增加存取的速度。 而最直覺的做法就是將所有欲紀錄的資訊壓縮到一個 CQ 中。因此本研究期望. 政 治 大. 透過序列化的技術將資料壓縮,儲存於單一 CQ 中。在文獻探討中,可以得知序列. 立. 化的技術相當多,序列化技術 Avro 是 Hadoop 家族中專屬的序列化技術,設計用. ‧ 國. 學. 於支援大批量資料交換的應用。因此,本研究選用之於 Hadoop 整合性較佳的 Avro. ‧. 序列化技術。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 15. 欄導向 HTable 資料結構轉換至 HTable 使用 Avro 序列化儲存示意圖. 圖 15 是相較於上一節的資料庫結構設計的對照圖。AS-IS 是上一節中提到之 實體關係轉換後的資料結構。但因 HBase 效能的關係,本研究期望將 CF 與 CQ 數 量減少,因此利用 Avro 將圖 15 紅色框格的一列資料序列化為 TO-BE 中的 byte array, CF 與 CQ 的數量都降為 1,期望藉由此種作法增加讀取寫入之效能。 要將資料結構序列化,必須於 Avro 定義 Schema 結構,於文獻探討中,我們 40.
(41) 得知 Avro 的資料型態支援八種基本類型(Primitive Type)和六種複雜類型(Complex Type),因此本研究將依照 ERM 實體間的五種關係,並利用 Avro 所提供的型態來 設計複雜的資料結構。 第一段. 實體關係轉換. 立. 政 治 大. ‧ 國. 學. 圖 16. Avro 實體關係轉換示意圖. 圖 16 中最左邊為 ERM 的實體 Table A,擁有 AC、AD 與 AE 三個 Fields,紅. ‧. 色框格的一列會被序列化成一條 byte array 儲存至 HTable 中相對應的 RK 的 cell. Nat. sit. y. 中。如圖 16 所示,一列的資料會需要儲存 AC、AD 與 AE 三個 Field 的值,因此. n. al. er. io. 在 Avro Schema 中我們選擇使用 Record 來代表一個物件,而 Record 下的欄位則為. i n U. v. 關聯式 table 中的 Fields。因此,我們將得到三個 Field,分別為 AC、AD 與 AE,. Ch. engchi. 且其底下的資料型態設定為 String;此處的資料型態可以與使用者欲儲存的資料型 態相對應。以圖片為例,其 Field 可能會有照相地點、曝光度、光圈等屬性;因此, 一張圖片會是 Avro 的一筆 Record,而照相地點、曝光度、光圈為其底下的 Fields。 又資料型態可依 Field 的類型設定,如照相地點可以設定為 String 而焦距則可以設 定為 int。. 41.
(42) 第二段. 一對一關係轉換. 政 治 大 本段將探討 ERM 中 table 之轉換機制。圖 17 中左方為擁有 1-1 關係的兩個實 立 圖 17. Avro 一對一關係轉換示意圖. ‧ 國. 學. 體 A 與 B,於前一節中可以知道一對一的關係可以合併為一張 HTable 並由其中一 實體的主鍵當作其 RK,至於哪個實體被當作 RK 則依使用者之需求來決定。為了. ‧. 儲存一對一的關係,B 的資訊也必須被儲存到 A 的 table 中。本轉換機制中,將其. y. sit. io. al. 假設 A 與 B 為 ERM 中具有一對一關係的兩個實體 Table,並欲以 A 為主要存. n. 1.. er. 轉換步驟:. Nat. 定義為三個步驟:. 取 table。. Ch. engchi. i n U. v. 2.. 對 A 做 Entity(A)之轉換,對於每個列資料可以得到一 Avro Record-R(A)。. 3.. 將實體 table A 中,外鍵所對應的 RK(B)擁有的所有屬性轉換為 R(A)中之 Fields, 並將其值賦予給該 Field。. 42.
(43) 第三段. 一對多關係轉換. 立. 政 治 大. ‧ 國. 學 圖 18. Avro 一對多關係轉換示意圖-HA. ‧. 圖 18 之兩實體 A 與 B 擁有一對多之關係,A 為一方而 B 為多方。轉換規則. Nat. n. al. er. io. 必須將關係分別儲存至 A 與 B 之 table 中。. sit. y. 中,定義每個實體為 HTable 中之一 table,因此為了保存 A 與 B 之一對多關係,. i n U. v. 對於 A 方來說,會擁有多個實體 B。簡單的來想,必須將多個實體 B 資訊儲. Ch. engchi. 存至 A 中,因此在 Avro Schema 中會先使用 Entity(A)的方式得一保存 A 資訊之 Record;而為了保留 B 資訊,本研究選擇 Avro 複雜形態中的 Map 來儲存多個 B 實體。因此在 A 中增加一 Field 並以 Map 複雜型態儲存 B 資訊。Map key 儲存對 應 B 之 RK,Value 儲存 B 之 Record。如圖所示,Field B 儲存兩筆 B Record。 從上述邏輯推演,本研究定義一對多之單方轉換規則如下:. 1-m-single(A, B) 假設: 1.. 假設實體 A 與實體 B 擁有一對多關係,A 為一方而 B 為多方。. 轉換步驟: 43.
(44) 1.. 對 A 進行 Entity(A)轉換. 2.. 進行 Entity(B)轉換,得到 B Record 並將此 Record 塞入對應 A 之 Map 中,B 之 RK 為 Map Key。. 3.. 回傳 A Record。 然而在一對多的轉換中,多方也必須轉換為一張 HTable 供使用者進行存取。. 根據 Google Bigtable 的觀念,應該於 table 中盡量儲存大量資訊,因此多方必須儲 存一方之資訊。對於多方來說與一方是一對一的關係,因此第一步必須進行實體 關係的轉換。對於多方來說,一的多方會擁有一個一方的 Record;為了保留與一. 政 治 大. 方間的關係,另創一 Field 來儲存對應之 A 方 Record。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 19. Avro 一對多關係轉換示意圖-HB. 如圖 19 所示,HB 擁有三個 Fields。BE 與 BF 的資料型態為 String,儲存原 B 之資訊,而 Field A 的資料型態為 Record,儲存經 Entity(A)轉換後之 A Record。A Record 為與 B Record 外鍵所對應之紀錄。 本研究定義轉換規則如下: 44.
(45) 1-m-multi(A, B) 假設: 1.. 假設實體 A 與實體 B 擁有一對多關係,A 為一方而 B 為多方。. 轉換步驟: 1.. 對 A 進行 1-m-single(A, B)轉換得到 table HA。. 2.. 進行 Entity(B),得到 table HB,另創一 Field 儲存與 B 對應之 A Record。. 3.. 回傳 table HA、HB。. 第四段. 多對多關係轉換. 政 治 大. 多對多可以視為兩個一對多關係的轉換,因此可以視為兩個一對多關係的轉. 立. 換,如果兩個實體間有一方為弱實體則不需進行該方之轉換。. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 20. Avro 多對多關係轉換示意圖. 圖 20 為經 m-n 轉換後的 HA table。可以由圖中看出 Record A 利用 Map 形式 來儲存與 B 一對多的關係。另外,由於 table C 仍有依賴於 A、B 的 C 資料,因此 也必須記錄於 HA 與 HB 兩 table 中。對於 HA 來說 C 的資訊依靠 B 之 RK 而來, 所以可以視為處理 B 與 C 之一對多關係。對於 B 來說 C 為一方,因此 C 將成為 B 45.
(46) 下之一 Field。 本研究定義轉換規則如下:. m-n(A, B) 假設: 1.. 假設實體 A 與實體 B 擁有多對多關係,兩實體皆不為弱實體。. 轉換規則 1.. 進行 1-m(A, 1-m(B, C))。. 2.. 進行 1-m(B, 1-m(A, C))。. 第五段. 遞迴關係轉換. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 21. Avro 遞迴關係轉換示意圖. 如圖 21 所示,遞迴關係可以視為多個一對多關係轉換,以 ABC 三個具有遞 迴關係的實體 Table 為例假設 Record T 為暫時儲存的 Record。先處理 B 與 C 的一 對多關係,並將結果產生之 Record 賦予 T。由於遞迴之關係,T 具有與 A 一對多 之關係,因此再對 T 與 A 進行一對多關係之轉換。具體轉換規則如下:. 46.
(47) R-R(A, C) 假設: 1.. 假設實體 A 與實體 C 擁有遞迴關係,實體 AC 之間具有多個一對多關係之節 點。. 2.. 使得. C. { r}. 為 AC 遞迴關係中之一組關聯 tables,不包含. A table 與 C table。 轉換機制: 1.. 創建一暫存之 Record K。. 2.. for (i = n-1; i < 1; i--){. 立. T = 1-m( . K). ‧ 國. 學. }. 政 治 大. return 1-m(A, K). ‧ sit. y. Nat. 第三節 小結. n. al. er. io. HBase 屬於 NoSQL 資料庫的一種。NoSQL 資料庫的興起是源於現代典型的關. v. 聯式資料庫在一些必須快速存取大量資料的應用中表現非常差,例如巨量文檔建. Ch. engchi. i n U. 立索引、高流量網站的網頁服務、以及發送流式媒體等應用。關聯式資料庫的實 現主要被調整用於執行規模小而讀寫頻繁,或者大批量極少寫入訪問的事務。 NoSQL 的結構通常提供弱一致性的保證,如最終一致性,或交易(transaction)僅限 於單個的數據項。 又因為 NoSQL 常被用來處理大量資料的存取,因此為了增加資料存取的便利 性,本研究忽略了原先關聯式資料庫的避免資料重複存放(Data Redundancy)與資料 一致性(Data Consistency)原則,使得各 table 可以獲取的資訊量增加。這樣的處理 方式,能使在需要快速的回應或大量資料處理分析的系統,減少與磁碟 Input/Output (I/O)的次數,增加處理的效能。舉例來說,於欄導向資料結構轉換中,一對多關 47.
(48) 係需將多方的資訊「完全」儲存在一方,這對於一方原本只需保存多方的 RK 來說 是一種額外的資訊儲存,最明顯的錯誤就是資料重複存放,另一個錯誤就是資料 的不一致。 但是在需要快速的回應或大量資料處理分析的系統,抑或資料不需經常性修 改的系統中,資料的重複存放可以增加資料的存取速度,使得回應時間減少。舉 例來說-搜尋引擎是需要快速回應的一種系統,其底下資料不需要經常性的變更 以及修改。又於 GFS 的論文中提到,現在大量的系統多在 Appending 資料,而極 少在做寫入的操作。因此在這種情況下,這兩種錯誤可以被有條件性的忽略,而. 政 治 大. 交給使用者的應用程式來維護資料一致性。由此可得出一結論:少量、經常性修. 立. 改的資料可以儲存在傳統關聯式資料上面;而不需經常性修改、被大量存取進行. ‧ 國. 學. 分析的資料可以儲存在 NoSQL 的資料庫中。. 於本章所提出之轉換關係中,一對多、多對多及遞迴關係,皆存放各自關係. ‧. 中的實體,而於原先關聯資料庫中僅需存放 RK 即可。這樣的情形會造成上述提及. Nat. sit. y. 之重複存放的問題,但因為所取之資料為不經常變動之資料,為了方便快速存取,. n. al. er. io. 依照使用存取需求的不同可以犧牲此兩種問題,或只進行 RK 的儲存。. Ch. engchi. 48. i n U. v.
(49) 第四章. 系統實作. 為了驗證轉換規則之有效性,本研究實作一台灣學術期刊搜尋引擎(Taiwan Academic Journal Search Engine)。本章的開端先介紹搜尋引擎所使用之技術。. 第一節 使用技術暨環境 台灣學術期刊搜尋引擎所使用系統技術如下表: 技術類別. 使用技術. 前端畫面. JSP、Java Servlet. 政 治Hadoop大 分散式演算法 Map/Reduce 立 分散式環境. 資料交換. Memcached. 序列化技術. Avro. ‧. ‧ 國. HBase. 學. 資料庫. y. sit. Nat. 表 1. 台灣學術期刊搜尋引擎(TAJ)技術表. io. al. er. 本搜尋引擎使用 JSP 做為前端畫面的呈現,底層使用 Hadoop 分散式環境佈署,. n. 並使用 Memcached 作為資料交換快速存取之中介。資料庫則是使用 HBase,並搭. Ch. 配 Avro 序列化轉換後之資料結構。. engchi. 本系統所使用之 Hadoop 叢集環境如下:. 49. i n U. v.
(50) Role: JobTracker TaskTracker Namenode Datanode HMaster HRegionServer WebServer. HadoopMaster Ram:16GB Disk:400GB SSH. Role: TaskTracker Datanode SecodaryNamenode HRegionServer. ‧. Role: TaskTracker Datanode SecodaryNamenode HRegionServer. io. sit. Nat. Role: TaskTracker Datanode SecodaryNamenode HRegionServer. 大. HadoopSlave08 Ram:8GB Disk:400GB. 學. ‧ 國. 立. HadoopSlave05 治 政 Ram:8GB Disk:400GB. al. 圖 22. Hadoop 叢集環境. er. HadoopSlave01 Ram:8GB Disk:400GB. SSH. y. SSH. n. v i n 本搜尋引擎使用 9 台 VM C 作為 Hadoop 叢集之節點,主節點 HadoopMaster 擁 he ngchi U. 有 16GB 之記憶體與 400GB 硬碟,8 台子節點 HadoopSlave 各擁有 8GB 記憶體與 400GB 硬碟。為充分運用硬體資源,本研究令 HadoopMaster 擁有 JobTracker、 Tasktracker、Namenode、Datanode、HMaster、HRegionServer 與 WebServer 等 6 種 任務角色,其餘 Slaves 則擁有 Tasktracker、Datanode、SecondaryNamenode 與 HRegionServer4 種任務角色。. 50.
(51) Presentation Layer. Web Service. Search Web Page Author Name. Chapter Title. Paper Content. Publisher Name. Abstract. Keyword. Upload. Journal Title Query. Precise/Fuzzy Search Ajax(JSON). Commands Query. Insert. Rank. 政 治 大. TableController. Semantic Analysis. 立. Parser. ‧ 國. Business Objects Author. Paper. 學. Business Logic Layer. Task. Journal. Memcached. Publisher. ‧. Hbase Client API. Nat. y. Data Access Layer. n. al. Delete. Update. er. io. Get. sit. Hbase Helper. Ch. HBase. engchi. i n U. v. 圖 23. TAJ 系統架構圖. 本搜尋引擎系統架構圖如圖 23 所示,於前端提供兩種服務(一)學術期刊資訊 搜尋介面(二)期刊資訊之增刪改查 Web Service;其搜尋之工作由 Task Controller 掌 控並分派給其下之 Command 進行搜尋之動作。底層以 HBase 為基礎提供快速讀取 寫入服務;此外,以 Memcached 做為資料交換區域,凡欲存取 HBase 之資料會先 詢問 Memcached 該資料是否存在,如不存在則進入 HBase 進行搜尋。搜尋後之結 果會存入 Memcached 以供下次同樣之搜尋。以下篇章將以這兩項服務作為主軸, 詳細說明之。 51.
(52) 第二節 學術期刊資訊搜尋介面 本搜尋引擎針對期刊論文內容(Paper)、期刊論文摘要(Abstract)、期刊論文抬 頭(Paper title)、關鍵字(Keyword)、作者名稱(Author name)、期刊名稱(Periodical title)、 與出版商名稱(Publisher name)等七項標的進行搜尋。各自擁有資料量如下表所示: 資料類型. 筆數. Paper content. 131,478. Paper title. 131,478. Author name. 118,642. Publisher name. 3,250. Abstract. 131,478. 學 ‧. ‧ 國. 政 治 2,268大 Periodical title 立 Keyword 387,281. 表 2. 搜尋標的資料筆數表. y. Nat. n. al. Ch. engchi. er. io. 料進行檢索,各標的資料間關係如下圖所示:. sit. 表 2 為七項搜尋標的之資料筆數表,針對 13 萬餘筆台灣學術期刊論文資. i n U. v. 圖 24. 台灣學術期刊搜尋系統 ERM 圖 52.
(53) 圖 24 中,綠色標號之節點,為與 Paper 具有 R-R 關係之節點;紫色標號之節 點,為與 Periodical 具有 R-R 遞迴關係之節點。為了減少搜尋結果之時間,本研究 期望於存取 Paper Content 實體時,也能同時存取此作者名稱與期刊名稱之資訊, 而不需透過 Join 或者是多次的 Table I/O 存取。因此本研究欲將此三節點進行 R-R 關係之轉換。以下將依第三節所介紹之欄導向資料結構轉換,與 Avro 資料結構轉 換分別作介紹。 欄導向資料結構轉換. Table 名稱. Table 欄位. 政 治 大. object_title_language. Object. object_id. Paper. paper_id. text_id. Abstract. chapter_id. abstract_language. abstract_title. Chapter_title. chapter_id. chapter_title_language. chapter_title. Author_Title. object_id. author_title_language. Keyword. paper_id. keyword_title. Publisher_title. content_id. publisher_language. publisher_title. Periodical. content_id. Periodical_title. content_id. periodical_langauge. periodical_title. content_id. text_language. Nat. y. chapter_id. io. er. ‧ 國. 立. object_title. ‧. object_id. 學. Object_title. sit. 第一段. n. a l 表 3. 關聯式資料庫 Table 欄位表i v n Ch U engchi. 53. content_text.
(54) 立. 政 治 大. 圖 25. 欄導向資料結構轉換-Paper. ‧ 國. 學. 依圖 25 所示之 ERM,Paper 為主要存取之 table,亦即所有搜尋結果將會以 Paper 之內容作為最後呈現。因此根據第三節所闡述之概念先進行一對一與一對多. ‧. 之轉換:m-n(Author, Paper Content)、1-m(Periodical, Paper Content)、1-m(Keyword,. sit. y. Nat. Paper_content)、1-m(Paper Content, Paper Title)、1-m(Author, Author name)、. io. er. 1-m(Periodical, Periodical Title)。至於 R-R 關係之轉換,本研究依照需求(以 paper 為. al. 主要存取 table)選擇進行 R-R(Paper_Content, Author_name)、R-R(Paper_Content,. n. v i n C h Publisher_Title)轉換。轉換結果如圖 Periodical Title)以及 R-R(Paper_Content, 26 所 engchi U 示。. 而除了 Table Paper 以外之其餘 Table,則依照本研究之需求,保留三個基礎 table, 分別為:(1)Periodical (2) Author 與 (3)Keyword。. 54.
數據

+7

Outline
相關文件
此外, 圖書館亦陸續引進英美文學、外語學習與研究等 相關資料庫,如 19 世紀以前出版的經典文學名著 Literature Online, Early English Books Online 與 Naxos
例如,參閱:黃啟江,《因果、淨土與往生:透視中國佛教史上的幾個面 相》〈第六章·從佛教研究法談佛教史研究書目資料庫之建立〉,(台北:臺 灣學生書局,2004 年),頁 237-252; Yasuhiro
電機工程學系暨研究所( EE ) 光電工程學研究所(GIPO) 電信工程學研究所(GICE) 電子工程學研究所(GIEE) 資訊工程學系暨研究所(CS IE )
根據研究背景與動機的說明,本研究主要是探討 Facebook
二、此研究可偵測出 misfire 產生的正確時間,而 misfire 對引擎所 產生的影響甚鉅,期望提供汽車工程相關的控制,如引擎的 損耗轉換成引擎剎車控制系統 (
本研究採用的方法是將階層式與非階層式集群法結合。第一步先運用
近年來,國內外已經有很多學術單位投入 3D 模型搜尋的研究,而且在網路 上也有好幾個系統提供人使用,例如台灣大學的 3D Model Retrieval
本研究旨在使用 TI-Nspire CAS 計算機之輔助教學模式,融入基礎 統計學的應用,及研究如何使用 TI-Nspire CAS
