國立臺中教育大學資訊科學學系碩士論文
隨時就定位:一個因應大規模雲端服務
之高效率服務請求分派機制
Join-Queue-Anytime: an Efficient Request
Dispatching Mechanism for
Large-Scale Cloud Services
指導教授:黃國展 教授
研究生:施博仁 撰
中華民國一百零一年六月
I
摘 要
隨著雲端運算的興起,網路應用服務的提供者能夠更便利並且以較低成本的方式取 得資源來提供使用者各式的服務。因此,近幾年來,各類網際應用服務更加蓬勃發展, 越來越豐富多元,也吸引了越來越多的線上服務使用者。像 facebook 這樣的熱門應用 服務,通常必須同時服務來自世界各地的大量使用者,因此網路應用服務提供者必須將 系統建置在成千上百台的伺服器上同時執行,才能有效地滿足使用者的需求,避免使用 者因等候服務回應的時間過久而不再嘗試使用該服務。所以,如何有效的將來自世界各 地的使用者需求分散到這些伺服器中執行,以降低服務的回應時間來提升使用經驗,便 成為一個重要的研究議題。傳統集中式的負載平衡機制採用單一請求分派器,該分派器 本身易成為整體效能的瓶頸,難以有效的應用在大規模的伺服器上,因此需要發展分散 式的請求分派機制,使用一組分散式的分派器架構來分配使用者的服務需求。然而,如 果將運用於傳統架構下,諸如「加入最短隊列」之類的負載平衡演算法,直接實作於分 散式分派器架構中的話,將造成分派器與伺服器之間過多的網路通訊需求,進而延遲了 使用者的服務請求回應時間。最近有研究人員提出了「加入閒置隊列」的方法來解決這 個問題,然而該方法在系統負載量較大時將逐漸喪失負載平衡的效果,因此在此篇論文 中,我們提出了一個「隨時加入隊列」的方法來有效解決分散式分派架構下的負載平衡 問題,以達到降低服務回應時間的目的。我們將所提出的方法實作於 CloudSim 平台上 進行模擬實驗。實驗結果顯示相較於先前文獻中的作法,我們所提出之「隨時加入隊列」 方法能有效的進一步提升效能達 31%之多。 關鍵字:雲端服務, 負載平衡, 分散式請求分派II
Abstract
Web services on the cloud have to serve a huge amount of users from all over the world simultaneously and usually deploy a large amount of servers to share the incoming workloads. A traditional centralized load balancer cannot scale well under such a large scale of servers. Instead, a set of distributed dispatchers are deployed to achieve the load-balancing goal through appropriate requesting dispatching. The distributed load-balancing structure makes traditional algorithms, such as Join-the-Shortest-Queue (JSQ), inappropriate due to large amounts of communication overheads between dispatchers and servers. A recent research proposed a Join-Idle-Queue (JIQ) algorithm to resolve the above problem for distributed load balancing. However, JIQ is not effective when system load is moderate or high. In this thesis, we propose a Join-Queue-Anytime (JQA) mechanism for achieving good load-balancing effects under moderate or high system load. The proposed mechanism has been evaluated through a series of simulation experiments implemented with the CloudSim toolkit. The experimental results indicate that the proposed JQA mechanism achieves significant performance improvement compared to the JIQ algorithm, up to 31% improvement in terms of average request response time.
III
Table of Contents
摘 要 ... I Abstract ... II Table of Contents ... III List of Figures ... IV List of Tables ... VI
Chapter 1. Introduction ... 1
Chapter 2. Related Work ... 5
Chapter 3. The Join-Queue-Anytime (JQA) Mechanism ... 9
3.1 Join‐Queue‐Anytime‐in‐Round‐Robin (JQA_RR) ... 11
3.2 Join‐Queue‐Anytime‐in‐Next‐Two (JQA_NT) ... 12
3.3 Join‐Queue‐Anytime‐in‐Random (JQA_Random) ... 14
3.4 Join‐Queue‐Anytime‐in‐Least‐Capacity (JQA_LC) ... 15
3.5 Examples ... 17
Chapter 4. Simulation Environment ... 22
4.1 CloudSim ... 22
4.2 Architecture of Simulation Environment ... 23
Chapter 5. Performance Evaluation ... 27
5.1 Experimental setting ... 27
5.2 Experimental results ... 27
5.3 Discussions ... 38
Chapter 6. Conclusions ... 43
IV
List of Figures
Figure 3.1 A scenario for JIQ ... 10
Figure 3.2 A scenario for JQA ... 11
Figure 3.3 Join-Queue-Anytime-in-Round-Robin Algorithm ... 12
Figure 3.4 Join-Queue-Anytime-in-Next-Two Algorithm ... 14
Figure 3.5 Join-Queue-Anytime-in-Random Algorithm ... 15
Figure 3.6 Join-Queue-Anytime-in-Least-Capacity Algorithm ... 17
Figure 3.7 Example for JIQ ... 18
Figure 3.8 Example for JQA_RR ... 19
Figure 3.9 Example for JQA_NT ... 19
Figure 3.10 Example for JQA_Random ... 20
Figure 3.11 Example for JQA_LC ... 20
Figure 4.1 CloudSim architecture ... 23
Figure 4.2 Source code working modle ... 25
Figure 5.1 Performance results of service time multiplied by 100 and inter-arrival time equal to 0.7 ... 30
Figure 5.2 Performance results of service time multiplied by 100 and inter-arrival time equal to 0.5 ... 30
Figure 5.3 Performance results of service time multiplied by 100 and inter-arrival time equal to 0.3 ... 30
Figure 5.4 Performance results of service time multiplied by 300 and inter-arrival time equal to 0.7 ... 31
Figure 5.5 Performance results of service time multiplied by 300 and inter-arrival time equal to 0.5 ... 31
Figure 5.6 Performance results of service time multiplied by 300 and inter-arrival time equal to 0.3 ... 31
Figure 5.7 Performance results of service time multiplied by 500 and inter-arrival time equal to 0.7 ... 32
Figure 5.8 Performance results of service time multiplied by 500 and inter-arrival time equal to 0.5 ... 32
Figure 5.9 Performance results of service time multiplied by 500 and inter-arrival time equal to 0.3 ... 32
Figure 5.10 Performance results of service time multiplied by 100 and inter-arrival time equal to 0.3 ... 34
V
Figure 5.12 Performance results of service time multiplied by 500 and inter-arrival time equal to 0.3 ... 34
Figure 5.13 Performance results of service time multiplied by 100 and inter-arrival time equal to 0.5 ... 35
Figure 5.14 Performance results of service time multiplied by 300 and inter-arrival time equal to 0.5 ... 35
Figure 5.15 Performance results of service time multiplied by 500 and inter-arrival time equal to 0.5 ... 35
Figure 5.16 Performance results of service time multiplied by 100 and inter-arrival time equal to 0.7 ... 36
Figure 5.17 Performance results of service time multiplied by 300 and inter-arrival time equal to 0.7 ... 36
VI
List of Tables
Table 3.1 Configuration of Incoming Requests ... 17
Table 3.2 Performance result ... 21
Table 4.1 Class definition of Dispatcher. ... 25
Table 4.2 Class definition of the extended Vm. ... 26
Table 5.1 Resource configuration ... 27
Table 5.2 Example for JQA_RR ... 39
Table 5.3 Example for JQA_LC ... 41
1
Chapter 1. Introduction
As cloud computing emerges, nowadays, web services have been used widely in every popular application domain; for example, e-commerce, social networking, web game, and etc. [7][8][16][23]. John McCarthy presented a model of computation as a public utility in 1960 [19], which is similar to today’s cloud computing. However, the term, cloud, first appeared in a MIT published paper in 1996 [20]. Cloud computing has become popular since Google, IBM, and a large number of universities launched a large-scale cloud computing project in 2007 [22]. Today, cloud computing are usually categorized into SaaS (Software as a Service)[17], PaaS (Platform as a Service) [33], and IaaS (Infrastructure as a service), where users can apply these services through web browsers and Internet. Common examples of these services include Salesforce.com [24] and Gmail [25] for SaaS, Google App Engine [26] and Microsoft Azure [27] for PaaS, and Amazon EC2 for IaaS[28]. Salesforce.com began to deliver business applications through web interface in 2000, which is actually a kind of SaaS applications. The first universal IaaS service was Elastic Compute Cloud (EC2) provided by Amazon since 2006 [21]. It is a commercial web service which provides small businesses and individuals to rent computing resources on demand.
Nowadays, some popular web services, such as facebook, have to simultaneously serve a huge number of users from all over the worldwide. Since short response time is crucial for all kinds of service-oriented applications, the service providers have to deploy a large-scale
server cluster for sharing the incoming workloads. Such a large-scale server cluster makes
traditional load sharing mechanisms inappropriate and requires further research. For traditional small-scale web applications, a single dispatcher is usually deployed to dispatch incoming requests evenly onto the servers. This naturally leads to a design of centralized load
2
balancing structure. However, the single-dispatcher mechanism will be overwhelmed by the huge amount of incoming requests once deployed for large-scale cloud services. Therefore, a distributed dispatching structure has to be employed to process the incoming requests efficiently through a set of dispatchers which work independently.
In small-scale web applications with single dispatchers, the dispatcher can easily track the workload on each server since all incoming requests pass through it and all responses are also sent back through it. This structure blends well with centralized load sharing algorithms, such as Join-the-Shortest-Queue (JSQ) [2], without extra communication overheads between the dispatcher and servers for load detection. However, the situation has changed as the growing large-scale cloud services have to adopt distributed dispatching structure for sharing the huge amount of incoming requests. In such structure, incoming requests are routed to a dispatcher randomly via a specific mechanism in the router. Load balancing of incoming requests across dispatchers is not a problem since the numbers of packets in service requests are usually similar. On the other hand, the service time of each request can vary largely because some requests might require the processing of a large amount of data or complicated computation [1]. Therefore, dispatchers have to balance the workload well among the large-scale of servers. However, in distributed dispatching structure, each dispatcher independently tries to balance the workload generated by the incoming requests passing through it. Unlike in the traditional centralized dispatching structure, since only a fraction of incoming requests pass through a particular dispatcher, the dispatcher has no idea of the workload on each server. This makes the implementation of traditional load balancing algorithms, such as JSQ [2], inefficient under such structure because now each dispatcher has to query every server about its current workload before making each request dispatching decision, resulting in a large amount of communication overheads between the dispatchers
3
and servers. The communication overhead will be exacerbated as the number of dispatchers and servers grows to a large scale, e.g., thousands of servers, which is becoming common for popular cloud services. Therefore, efficient distributed load balancing becomes a crucial research issue for emerging large-scale cloud services.
In a recent research [1], Lu et al. proposed a Join-Idle-Queue (JIQ) algorithm for efficient distributed load balancing, where the servers will automatically join a dispatcher for receiving incoming workload, opposite to traditional approaches in which the dispatchers have to query the workload of each server for dispatching decisions. The mechanism of JIQ can avoid the overwhelming communication costs incurred when implementing the traditional JSQ algorithm for large-scale cloud services. However, in the basic idea of JIQ, a server will join a dispatcher for receiving incoming requests only when it becomes idle. This mechanism becomes ineffective when system load is high since no servers will be idle and the dispatchers have to dispatch requests randomly with no load balancing effects. In this thesis, we propose a Join-Queue-Anytime (JQA) mechanism in which each server always registers with a particular dispatcher at anytime, avoiding the situation of random dispatching in JIQ. The JQA mechanism is expected to achieve better performance than JIQ under moderate or high system load. Four distributed load balancing methods were developed based on the JQA mechanism. The proposed methods have been evaluated through a series of simulation experiments implemented with the CloudSim toolkit [12][13]. The experimental results indicate that the proposed JQA mechanism achieves significant performance improvement
compared to the JIQ algorithm, up to 31%reduction of average response time.
The reminder of this thesis is organized as follows. Chapter 2 discusses related works on dynamic load balancing. We present our JQA mechanism in chapter 3. Chapter 4 describes our simulation environment based on the CloudSim toolkit. Chapter 5 evaluates the proposed
4
JQA-based methods and compares them with the JIQ-based approaches. Chapter 6 concludes this thesis.
5
Chapter 2. Related Work
For serving a large amount of users from all over the world, web service providers usually have to adopt a cluster of distributed servers for sharing the incoming workload. Therefore, load balancing has been an important issue on enhancing the performance of distributed servers [3][4][5][6][9][10][11][14][18]. Incoming requests should be evenly distributed among the servers to achieve quick service response. Load balancing approaches can be separated into two categories: static load balancing and dynamic load balancing. The former has priori information about the requests to process before the system starts, so it can arrange the resources and requests in advance [10]. The latter dynamically makes the decisions of request dispatching during the operation of the system [9]. For online web services, since the incoming requests cannot be predicted in advance, dynamic load balancing mechanisms are usually the choice to optimize the system performance.
Load balancing for large-scale services has been studied by many researchers and usually can be classified into two major types: redirection-based and dispatching-based approaches, respectively. The redirection-based approaches are usually adopted in a system where the computing resources belong to different administration domains or even are of different ownerships. On the other hand, the dispatching-based approaches blend well with the systems of single administration domain, ownership, and even application. In the redirection-based approaches, each server can not only execute services, but also redirect requests to other servers when it is overloaded [6]. On the other hand, in the dispatching-based approaches [31][32] there are two different components: dispatchers and servers. A dispatcher is responsible for distributing the incoming requests evenly to the pool of servers and the servers do the actual processing of the incoming requests.
6
Some kind of redirection-based approaches is usually applied in the classrooms at school, where each student has a desktop computer in front of him and all the computers in the classroom are interconnected through a local area network. Under normal circumstances, each student uses his own desktop computer to do his work. However, sometimes when a student need to execute a number of computing jobs simultaneously, his desktop computer, equipped with the load-balancing capability, will automatically redirect some of the jobs to other computers in order to get all the jobs done sooner. , Nakai, Madeira and Buzato [6] used RPS(Requests Per Second) to estimate if a request needs to be redirected to other computing resources. Each resource can set the value of RPS for limiting the maximal load on it and redirect the incoming requests to other lightly loaded resources once achieving its maximal load level.
Some previous research [29][30] proposed hierarchical redirection-based load-balancing model, where request redirection occurs between different organizations. Each organization maintains its own server cluster which contains a controller and several servers. Each server cluster is not only set up with the services for their own needs, but also deployed with some applications for serving the requests from other organizations. Under such architecture, the controller is used to monitor the status of the servers within the cluster and assign requests to appropriate servers. Controllers of different organizations can communicate with each other to conduct load-balancing activities through request redirection. The work in [29][30] proposed approaches to taking both expected server processing time and network latencies into account in order to reduce services response time. If the system load of a specific server cluster is high and the controller decide to redirect some requests to other server clusters, it will estimate which server cluster can get the requests done with the shortest response time, based on the
7
model of expected server processing time and network latency, and then redirect the requests to that server cluster.
The dispatching-based approaches can be further divided into two categories with single dispatcher and multiple dispatchers, respectively. In the single-dispatcher load-balancing architecture, all the user requests pass through the single dispatcher and are assigned to suitable resources in the server pool by the dispatcher. The SQ(d) algorithm has been studied in depth for this architecture [31][32]. At each arrival of user request, the dispatcher samples d resources and gets the number of requests at each of them. The request is sent to the resource with the least number of requests.
For traditional small-scale web applications, the single-dispatcher load-balancing architecture is usually the choice because of its simplicity and effectiveness [2]. However, such centralized dispatching structure cannot handle the huge amount of requests commonly seen in large-scale cloud services. Therefore, distributed dispatching approaches have been developed recently, adopting a set of distributed dispatchers which work independently for distributing their portions of incoming requests evenly onto the servers [15].
In [1], Lu et al. proposed a Join-Idle-Queue (JIQ) algorithm for efficient distributed dispatching. The central idea of JIQ is to decouple discovery of lightly loaded servers from request assignment. In JIQ, servers will inform particular dispatchers when they become idle, without interfering with request dispatching. This removes the load balancing work from the critical path of request processing and avoids excessive communication overheads between dispatchers and servers, making JIQ scalable for large-scale cloud services involving thousands of servers or more. However, in the basic idea of JIQ, a server will join a dispatcher for receiving incoming requests only when it becomes idle. This mechanism becomes
8
ineffective when system load is high since no servers will be idle and the dispatchers have to dispatch requests randomly. In this thesis, we try to develop a Join-Queue-Anytime (JQA) mechanism in which each server is always registered with a particular dispatcher anytime, avoiding the situation of random dispatching in JIQ. Therefore, the JQA mechanism is expected to achieve better performance than JIQ under moderate or high system load.
9
Chapter 3. The Join-Queue-Anytime (JQA)
Mechanism
JIQ is an effective distributed dispatching approach for large-scale cloud services recently proposed in [1]. However, in JIQ a server will join a dispatcher for receiving incoming requests only when it becomes idle. This mechanism becomes ineffective when system load is high since no servers will be idle and the dispatchers have to dispatch requests randomly. In this chapter, we present a Join-Queue-Anytime (JQA) mechanism to resolve the problem. Similar to JIQ, JQA adopts the communication model in reverse direction [2]. In JQA servers inform dispatchers for receiving user requests actively instead of being queried by the dispatchers passively as in the traditional JSQ algorithm [2]. This approach removes the communication overhead between dispatchers and servers from the critical path of request dispatching, resulting in reduced request response time. The communication in reverse direction is less costly because it can ride on heartbeats sent from servers to dispatchers signaling the health of the servers. Moreover, the communication costs will not increase as the numbers of dispatchers and servers grow since a server only communicates with a particular dispatcher each time. This good property makes JQA scalable and thus suitable for large-scale cloud services.
Specifically speaking, JQA differs from JIQ in when servers will inform dispatchers and which dispatcher to join. In JIQ, a server joins a dispatcher’s idle queue only when it becomes idle. Therefore, if all servers are busy, a dispatcher might have no servers waiting in its queue and have to dispatch the requests randomly. On the other hand, JQA tries to keep each server always registered in some dispatcher at any time. Each time when a server receives a request from a specific dispatcher, it knows that it has been removed from that dispatcher’s server
10
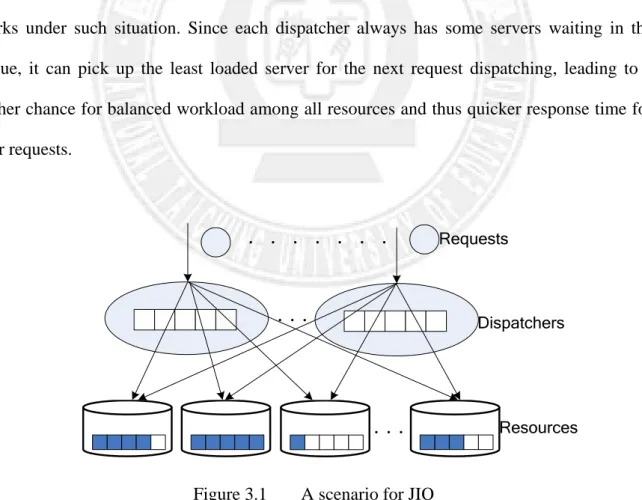
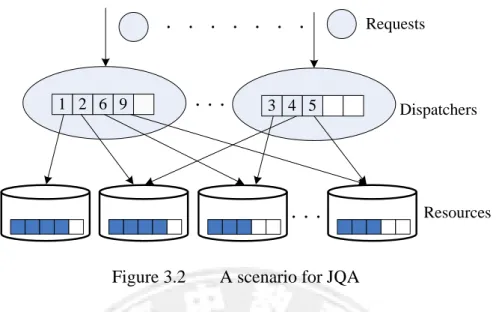
pool. Then, it immediately joins another dispatcher for sharing future requests. In addition, the server will carry its workload information when joining a dispatcher. Therefore, each dispatcher hopefully always has some servers waiting in its queue and is able to dispatch the next request to the least loaded server in the queue. The difference between JIQ and JQA lead to different performance under moderate or high system load when no servers are likely to be idle. Figure 3.1 and Figure 3.2 show an example under such situation where the shaded boxes on each resource represent the requests dispatched to that resource and the numbers in the queue within each dispatcher indicate the ID’s of the servers joining that dispatcher. In Figure 3.1 , since no servers are waiting in the queue, the dispatchers have to distribute the requests randomly. This might lead to imbalance among the workloads on resources, resulting in delayed response time for some requests. On the other hand, Figure 3.2 shows how JQA works under such situation. Since each dispatcher always has some servers waiting in the queue, it can pick up the least loaded server for the next request dispatching, leading to a higher chance for balanced workload among all resources and thus quicker response time for user requests.
Resources Requests
Dispatchers
11 2 6 9 1 3 4 5 Requests Dispatchers Resources
Figure 3.2 A scenario for JQA
In JQA, each server, when planning to register with some dispatcher, has to make a decision on which dispatcher to join. In the following sections, we propose four variations of JQA-based approaches which differ in the dispatcher selection process.
3.1 Join-Queue-Anytime-in-Round-Robin (JQA_RR)
In JQA_RR, each server selects a dispatcher to join in a round robin manner. Figure 3.3 presents this method in details. In lines 1 to 14, when a user issues a service request, the request will be sent to a dispatcher randomly which then assigns the request to the resource of the least load within its resource queue. Then the selected resource will be removed from this dispatcher’s queue and join another dispatcher which is selected in a round robin manner, as shown in lines 15 to 18.
Join-Queue-Anytime-in-Round-Robin Algorithm
Input : ServiceRequest
1: dispatcher = Get a dispatcher randomly; 2: if(dispatcher has available resources) 3: for(resource i in the dispatcher)
12
4: resourceLoading[i] = 0;
5: for(all requests in the resource)
6: resourceLoading[i] += request.getLength();
7: end for
8: end for
9: SelectedResource = the resource having the minimal resourceLoading; 10: else
11: SelectedResource = Get a resource randomly;
12: end if
//Send request to SelectedResource:
13: SelectedResource.setRquest(ServiceRequest);
//Remove resource from dispatcher:
14: dispatcher.removeResource(SelelctedResource);
//SelectedResource joins the next dispatcher in a round robin manner:
15: dispatcherIndex = roundRobinIndex % dispatcherNumber; 16: newDispatcher = the dispatcher with the ID of dispatcherIndex; 17: newDispatcher.addResource(SelectedResource);
18: roundRobinIndex++;
Figure 3.3 Join-Queue-Anytime-in-Round-Robin Algorithm
3.2 Join-Queue-Anytime-in-Next-Two (JQA_NT)
In JQA_NT, each time the server joins the next two dispatchers in a round robin manner.
Figure 3.4 presents this method in details. JQA_NT differs from other methods in lines 15 to
13
Join-Queue-Anytime-in-Next-Two Algorithm
Input :ServiceRequest
1: dispatcher = Get a dispatcher randomly; 2: if(dispatcher has available resources) 3: for(resource i in the dispatcher) 4: resourceLoading[i] = 0;
5: for(all requests in the resource)
6: resourceLoading[i] += request.getLength(); 7: end for
8: end for
9: selectedResource = the resource having minimal resourceLoading; 10: else
11: selectedResource = Get a resource randomly; 12: end if
//Send request to selectedResource:
13: selectedResource.setRquest(ServiceRequest);
//Remove resource from dispatcher:
14: dispatcher.removeResource(selectedResource);
//selectedResource joins the next two dispatchers in a round robin manner:
15: firstDispatcherIndex = nextTwoIndex % dispatcherNumber; 16: firstDispatcher =
the dispatcher with the ID of firstDispatcherIndex; 17: firstDispatcher.addResource(selectedResource);
14
19: secondDispatcherIndex = nextTwoIndex % dispatcherNumber; 20: secondDispatcher =
the dispatcher with the ID of secondDispatcherIndex; 21: secondDispatcher.addResource(selectedResource);
22: nextTwoIndex++;
Figure 3.4 Join-Queue-Anytime-in-Next-Two Algorithm
3.3 Join-Queue-Anytime-in-Random (JQA_Random)
Previous two JQA-based approaches select the dispatcher to join in a round robin manner, which might result in imbalance of server distribution among dispatchers if most servers process the requests at similar speed. To avoid the possible imbalance of server distribution, in section we present a new approach, JQA_Random, in which each server selects a dispatcher to join in a random manner. Figure 3.5 presents this method in details. JQA_Random differs from other methods in lines 15 to 17 where it selects the dispatcher to join randomly.
Join-Queue-Anytime-in-Random Algorithm
Input :ServiceRequest
1: dispatcher = Get a dispatcher randomly; 2: if(dispatcher has available resources) 3: for(resource i in the dispatcher) 4: resourceLoading[i] = 0;
5: for(all requests in the resource)
6: resourceLoading[i] += request.getLength();
15
8: end for
9: selectedResource = the resource having minimal resourceLoading; 10: else
11: selectedResource = Get a resource randomly;
12: end if
//Send request to selectedResource:
13: selectedResource.setRquest(ServiceRequest);
//Remove resource from dispatcher:
14: dispatcher.removeResource(selectedResource);
//Resource joins the next dispatcher randomly:
15: dispatcherIndex = selectedResource.randomNumber.nextInt(dispatcherNumber) 16: newDispatcher = the dispatcher with the ID of dispatcherIndex;
17: newDispatcher.addResource(selectedResource);
Figure 3.5 Join-Queue-Anytime-in-Random Algorithm
3.4 Join-Queue-Anytime-in-Least-Capacity (JQA_LC)
The previous three approaches basically try to distribute the servers among the dispatchers evenly. This can lead to satisfactory load balancing effects if each dispatcher receives almost the same amount of incoming request workload. However, it is not always the case. Once the incoming requests are distributed among dispatchers unevenly due to some unexpected or unavoidable causes, some dispatchers might soon run out of its registered servers and have to dispatch the requests randomly, leading to poor load balancing effects and worse request response time. To resolve the problem, in this section we present JQA_LC in which each server chooses the dispatcher with the least number of registered servers to join.
16
In practice, the implementation of JQA_LC might adopt different approaches to collecting the status of each dispatcher. For example, a server can query each dispatcher about its status upon making the decision of dispatcher selection or each dispatcher can automatically broadcast its capacity information to every server periodically. Although the dispatcher-capacity collecting process incurs additional communication overheads, compared to previous methods, JQA_LC is still expected to be scalable and effective for large-scale system configuration because the additional communication cost is not on the critical path of the request dispatching and processing procedure. Figure 3.6 presents JQA_LC in details.
JQA_LC differs from other methods in lines 11 to 14 where it selects the dispatcher with the
least number of servers to join.
Join-Queue-Anytime-in-Least-Capacity Algorithm
Input : ServiceRequest
1: dispathcher = Get a dispatcher randomly 2: for(resource i in the dispatcher)
3: resourceLoading[i] = 0;
4: for(all requests in the resource)
5: resourceLoading[i] += request.getLength(); 6: end for
7: end for
8: selectedResource = the resource having minimal resourceLoading;
//Send request to selectedResource:
9: selectedResource.setRquest(ServiceRequest);
//Remove resource from dispatcher:
17
//Resource joins the dispatcher with the least resource capacity:
11: broadcast status query to all dispatchers to get resourceNumber where resourceNumber[i] = dispatcher[i].getVmList().size();
12: dispatcherIndex = ID of the dispatcher having the minimum resourceNumber; 13: newDispathcher = the dispatcher with the ID of dispatcherIndex;
14: newDispathcher.addResource(selectedResource);
Figure 3.6 Join-Queue-Anytime-in-Least-Capacity Algorithm
3.5 Examples
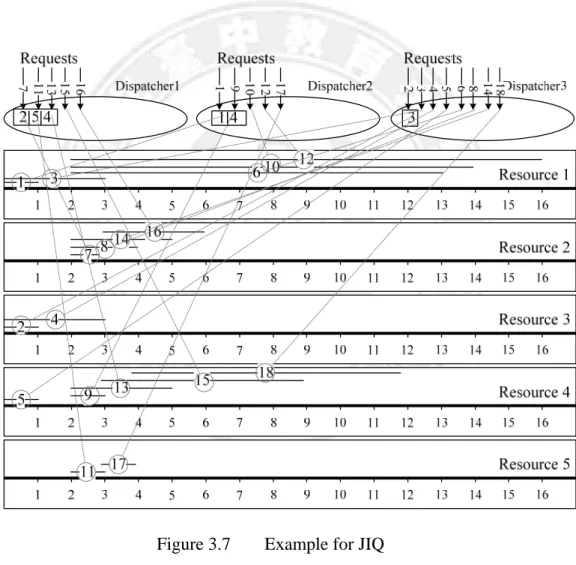
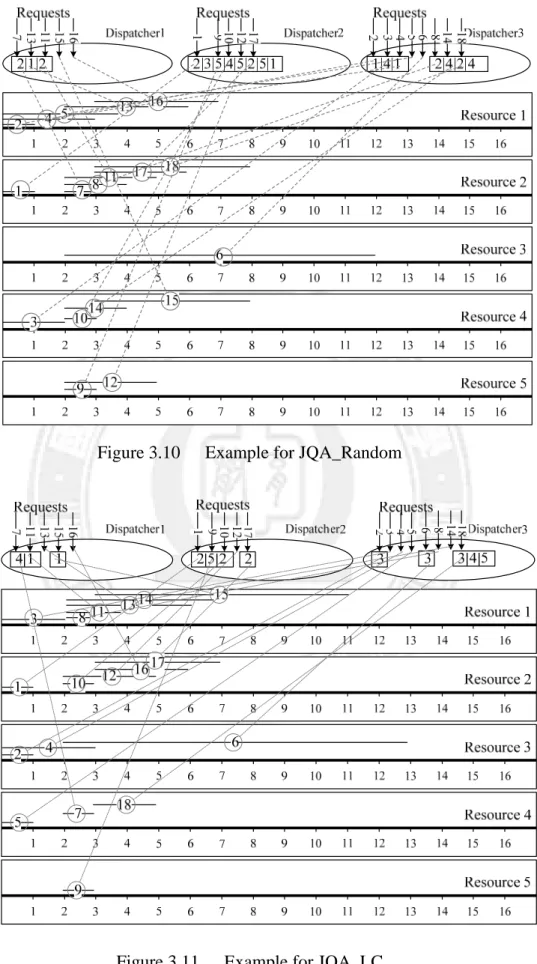
In this section, we use an example to illustrate how the proposed JQA-based approaches work and demonstrate that the JQA approaches have potential to achieve better system performance than JIQ. In the example, there are two dispatchers and five resources for processing eighteen requests which arrive at different time instants and require different lengths of service time as shown in Table 3.1.
Table 3.1 Configuration of Incoming Requests
Arrive Time (ms)
0 2 3
ID 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Length 1 1 2 2 1 10 1 1 1 1 1 2 2 1 4 1 1 2
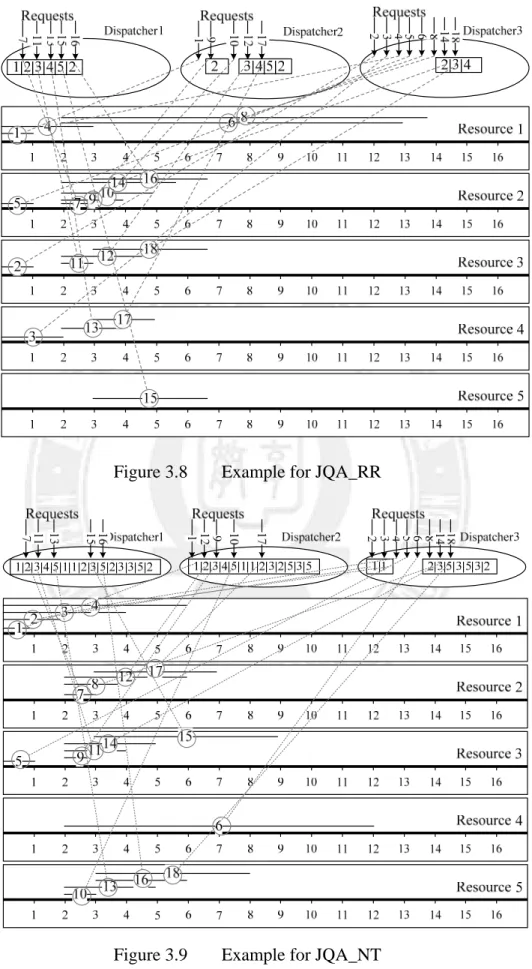
Figure 3.7 to Figure 3.11 depict the processes of dispatching and executing the requests on the dispatchers and resources for JIQ, JQA_RR, JQA_NT, JQA_Random, and JQA_LC, respectively. In each dispatcher, the registered servers are indicated by their ID’s and the dispatching decision of each request is also shown. In each resource, the time scale is in milliseconds. The horizontal line represents the execution duration of a corresponding request. The number in the middle of the line indicates the request ID and the length of the line
18
represents the response time of the request including actual service time and waiting time on that resource. Table 3.2 summarizes and compares the performance of the five approaches in terms of total and mean request response time. The total request response time is the summation of the request response time of all the eighteen requests and the mean request response time is simply the total request response time divided by eighteen. Table 3.2 clearly indicates that our JQA approach achieves significantly better performance than JIQ.
19
Figure 3.8 Example for JQA_RR
20
Figure 3.10 Example for JQA_Random
21
Table 3.2 Performance result
JIQ JQA_RR JQA_NT JQA_Random JQA_LC
Total ResponseTime 75.0 61.0 59.0 55.0 54.0
22
Chapter 4. Simulation Environment
This chapter presents the simulation environment we developed for conducting the performance evaluation experiments which will be presented in chapter 5.
4.1 CloudSim
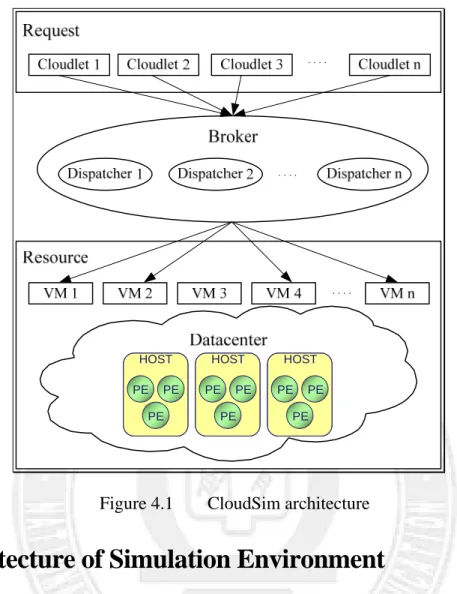
Our simulation environment was developed based on the CloudSim toolkit [12][13], which is a simulation system built by the Cloud Computing and Distributed Systems (CLOUDS) Laboratory of University of Melbourne. CloudSim provides a platform for the providers and researchers of cloud services to conduct simulation experiment. CloudSim was built based on the GridSim toolkit and SimJava framework. It offers basic components, such as host, datacenter, VM, service brokers, application allocation policies, for simulating large-scale cloud computing environments.
Figure 4.1 Figure 4.1 shows the architecture of CloudSim in which user requests are called cloudlets. The request execution time has to be set up when creating a cloudlet. A resource for executing cloudlets is called a VM residing in a host. A host may contain several PE’s (processing elements). A set of hosts are put together to form a datacenter. Before a simulation starts, both cloudlets and VM’s should be created and configured properly. It is the module called broker in the figure that dynamically assigns cloudlets to specific VM’s for execution according to a predefined resource allocation policy.
23 HOST PE PE PE HOST PE PE PE HOST PE PE PE HOST PE PE PE HOST PE PE PE HOST PE PE PE HOST PE PE PE HOST PE PE PE HOST PE PE PE
Figure 4.1 CloudSim architecture
4.2 Architecture of Simulation Environment
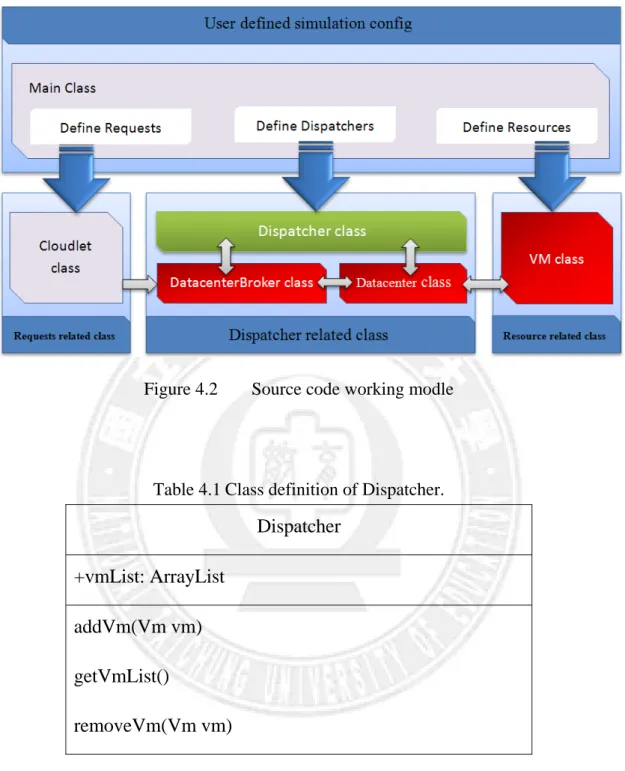
The designer of CloudSim advises that users should design their own resource allocation policies fitting their research purposes before doing simulations. Therefore, we modified and extended some modules in CloudSim for our simulation experiments. Figure 4.2 shows the layered architecture of our simulation environment. The rectangle with green background represents the class that we designed for the simulation environment, while the rectangles with red background indicate that the classes were derived from the original components in CloudSim. In the main class, we can define requests (cloudlets), dispatchers and resources (VM). During the simulation, the DatacenterBroker class will send cloudlets to the Datacenter
24
class for dispatching them onto the VM’s according to the specified allocation policy. Therefore, our JQA mechanism was implemented within the Datacenter class.
In order to implement the dispatcher which is able to record a set of VM’s ready for accepting requests, we designed the Dispatcher class whose definition was shown in Table 4.1. When the Datacenter class wants to assign a cloudlet to a VM, it will get a dispatcher randomly and call it’s getVmList( ) member function to search for a suitable VM and assign the cloudlet to that VM. Then, it will remove that VM from the dispatcher by the removeVM( ) member function and insert the VM into another dispatcher’s vmList by the addVM( ) member function. We also extended some attributes and member functions in the original VM class for recording the allocated cloudlets as shown in Table 4.2. When a cloudlet is assigned to a suitable VM by the Datacenter class, it calls the addAllocatedCloudlets( ) member function to record the allocated cloudlet in the VM. Later, when the cloudlet is finished, the DatacenterBroker class will call the removeAllocatedCloudlets( ) member function to remove the cloudlet from the VM. We also modified the DatecenterBroker class to simulate the online behavior of incoming requests which arrive at different time instants according to a controllable exponential distribution.
25
Figure 4.2 Source code working modle
Table 4.1 Class definition of Dispatcher.
Dispatcher +vmList: ArrayList
addVm(Vm vm) getVmList()
26
Table 4.2 Class definition of the extended Vm.
Vm +allocatedCloudlets: ArrayList addAllocatedCloudlets(Cloudlet cl) getAllocatedCloudlets()
27
Chapter 5. Performance Evaluation
5.1 Experimental setting
In the following experiments, we simulated a datacenter containing one hundred physical machines with one thousand homogeneous virtual machines running on them for processing the user requests. There were ten dispatchers performing distributed load balancing. Table 5.1 shows the detailed information about the resource configurations.
Table 5.1 Resource configuration Physical Machine
Processers MIPS Memory Storage
10 1 3 GB 1200 GB
Virtual Machine
Processers MIPS Memory Storage
1 1 256 MB 100 GB
We generated 200000 service requests in each experiment. The required service time for each request may be different, conforming to an exponential distribution. We adopted two different approaches to simulating different levels of system load. The first approach multiplies the service time generated from the random number generator by three different weights: 100, 300, and 500. The second approach adjusts the inter-arrival time between consecutive requests by setting different mean values in the random number generator. Three different mean values were used in the experiments: 0.3, 0.5, and 0.7.
5.2 Experimental results
Figure 5.1 to Figure 5.9 show the performance results of the simulation experiments. They can be divided into three groups each containing three figures. The three groups of figures present the results under different levels of system load controlled with multiplying the original
28
service time by the three different weights, 100, 300, and 500, respectively. In each group, the three figures differ in the mean inter-arrival time of consecutive requests. Each figure compares ten different approaches including six JIQ-based approaches in [1] and four our JQA-based approaches.
In [1], Lu et al. proposed two variations of JIQ approaches: JIQ_Random and JIQ_SQ(2), indicated by JIQ and JIQ_SQ(2), respectively, in the figure. With JIQ-Random, an idle server chooses a dispatcher at random, while with JIQ-SQ(2), an idle server randomly chooses 2 dispatchers first and then joins the one with the smaller queue length. In [1] the authors are also aware that JIQ might lead to a situation where a dispatcher has no servers waiting in its queue and has to dispatch the requests randomly when the system load is high and all servers are busy. Therefore, they proposed an extension approach in which a server might join a dispatcher even though it is not idle [1]. The extension approach mainly determines the threshold value of the server load under which the server should join a dispatcher, and therefore can cooperate with JIQ_Random and JIQ_SQ(2) mechanisms.
In the following experiments, we experimented with the JIQ extension using two different threshold values: 1 and 2 which are the same as in [1]. The JIQ extension approaches with the two different threshold values are indicated by Ext(1) and Ext(2), respectively, in the figures. For Ext(1) ,the server will join a particular dispatcher for receiving user requests once its workload has decreased to only one job in the queue and will join another dispatcher again when it becomes idle. For Ext(2) ,the server will join a particular dispatcher for receiving user requests once it has only two jobs or one job in the queue and will join the third dispatcher when it becomes idle.
29
The results in Figure 5.1 to Figure 5.9 indicate that our JQA-based approaches, in general, outperform the JIQ-based approaches significantly. The three groups of figures all reveal that the performance improvement increases as the mean inter-arrival time decreases. This demonstrates the advantages of JQA-approaches which can achieve significantly better performance than JIQ-based approaches when the system load is moderate or high.
30 JI Q , 1 54. 32 JI Q _ E x t( 1), 154. 32 JI Q _ E x t( 2), 1 54. 32 JI Q _ S Q (2), 1 5 4 .3 2 JI Q _ S Q (2 )_E x t( 1), 154 .32 JI Q _ S Q (2)_ E x t( 2 ), 154. 32 JQ A _ R R , 323. 82 JQA_ NT , 1 5 8 .2 2 JQ A _ Ra ndom , 172 .13 JQ A _ L C , 154 .32 0.00 50.00 100.00 150.00 200.00 250.00 300.00 350.00 Me an R esp o n se Tim e (m s) Exponential(1,0.7) Multiplied by 100 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.1 Performance results of service time multiplied by 100 and inter-arrival time equal to 0.7
JI Q , 288. 73 JI Q _ E x t( 1), 325.10 JI Q _E xt (2) , 403. 35 JI Q _S Q (2) , 250. 57297 JI Q _ S Q (2) _ E x t( 1), 306.76 JI Q _ S Q (2 )_ E x t( 2), 381.45 JQ A _R R , 5 52.04 JQ A _N T , 233. 35 JQ A _R andom , 318.4 6 JQ A _L C , 197. 14 0.00 100.00 200.00 300.00 400.00 500.00 600.00 Me a n R espo n se Ti m e (m s) Exponential(1,0.5) Multiplied by 100 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.2 Performance results of service time multiplied by 100 and inter-arrival time equal to 0.5
31 JI Q , 15462 JI Q _E xt (1), 15463 JI Q _E xt (2), 15451 JI Q _S Q (2) , 15475 JI Q _S Q (2)_E xt (1), 1546 9 JI Q _S Q (2)_E xt (2), 15472 JQ A _ RR, 15945 JQ A _N T , 14 931 JQ A _ Ra ndom , 14933 JQ A _ L C , 14931 14400 14600 14800 15000 15200 15400 15600 15800 16000 Me a n R e sp o n se Tim e (ms ) Exponential(1,0.7) Multiplied by 300 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.4 Performance results of service time multiplied by 300 and inter-arrival time equal to 0.7
JI Q , 31207 JI Q _ E x t( 1), 31187 JI Q _ E x t( 2), 31193 JI Q _ S Q (2 ), 31209 JI Q _ S Q (2 )_E x t( 1), 31201 JI Q _ S Q (2 )_E x t( 2), 31196 JQ A _ RR , 31025 JQ A _N T , 30938 JQ A _ Ra ndom , 30592 JQ A _L C , 30595 30200 30300 30400 30500 30600 30700 30800 30900 31000 31100 31200 31300 Me a n Re sp o n se Ti m e (m s) Exponential(1,0.5) Multiplied by 300 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.5 Performance results of service time multiplied by 300 and inter-arrival time equal to 0.5
JIQ , 4311 3 JIQ _E xt (1 ), 43124 JIQ _ E xt (2), 43116 JIQ _S Q (2), 431 18 JIQ _S Q (2)_E xt (1), 431 26 JIQ _ S Q (2 )_ E xt (2 ), 43098 JQ A _RR , 42 602 JQ A _ N T , 42599 JQ A _Ra nd om , 42520 JQ A _L C , 4251 8 42200 42300 42400 42500 42600 42700 42800 42900 43000 43100 43200 Me an Re sp o n se Tim e (ms ) Exponential(1,0.3) Multiplied by 300 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
32 JI Q , 46 640 JI Q _E xt (1), 4661 8 JI Q _ E x t( 2), 4 6634 JI Q _S Q (2), 466 57 JI Q _S Q (2) _ E xt (1), 4662 9 JI Q _ S Q (2)_E x t( 2), 4 6615 JQ A _RR , 4656 0 JQA_ NT , 4 6 3 3 7 JQ A _Ra n dom , 4565 6 JQ A _L C , 456 49 45000 45200 45400 45600 45800 46000 46200 46400 46600 46800 Me an R esp o n se Ti m e (ms ) Exponential(1,0.7) Multiplied by 500 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.7 Performance results of service time multiplied by 500 and inter-arrival time equal to 0.7
JI Q , 62 391 JI Q _E xt (1), 6236 9 JI Q _ E x t( 2), 6 2385 JI Q _S Q (2) , 62381 JI Q _S Q (2)_E xt (1), 623 73 JI Q _S Q (2)_E xt (2), 623 49 JQ A _RR , 6173 2 JQ A _N T , 61 675 JQ A _R andom , 6 1354 JQ A _ L C , 613 60 60800 61000 61200 61400 61600 61800 62000 62200 62400 Me an R esp o n se Ti m e (ms ) Exponential(1,0.5) Multiplied by 500 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.8 Performance results of service time multiplied by 500 and inter-arrival time equal to 0.5
JI Q , 742 94 JI Q _ E x t( 1), 742 78 JI Q _ E x t( 2), 742 78 JI Q _ S Q (2), 7 433 9 JI Q _ S Q (2)_E x t( 1), 743 05 JI Q _ S Q (2)_E x t( 2), 743 02 JQA_ R R , 7 3 3 6 8 JQA_ NT , 7 3 3 5 5 JQ A _R and om , 732 79 JQ A _L C , 73 283 72800 73000 73200 73400 73600 73800 74000 74200 74400 Me an R esp on se Tim e (ms ) Exponential(1,0.3) Multiplied by 500 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
33
To make thorough performance comparison, in the following Figure 5.10 to Figure 5.18, we partition the performance results into three different groups based on the mean inter-arrival time. In each group, there are three figures which differ in the required service execution time controlled with multiplying the original service time by the three different weights, 100, 300, and 500, respectively. All the three groups of figures indicate that JQA-based approaches lead to more significant performance improvement as the multiplied weight grows. This demonstrates that JQA-approaches can achieve better load-balancing effects than JIQ-based approaches since a bigger multiplied weight means larger variation in the service execution time.
34 JI Q , 1 19 55 JI Q _ E x t( 1 ), 11 94 9 JI Q _ E x t( 2 ), 11 95 2 JI Q _ S Q (2 ), 1 195 5 JI Q _S Q (2)_ E xt (1 ), 11 95 5 JI Q _ S Q (2 )_ E xt (2) , 11 9 64 JQ A _R R , 118 58 JQ A _ N T , 1 184 5 JQ A _R and om , 1 17 56 JQ A _ L C , 11 75 6 11650 11700 11750 11800 11850 11900 11950 12000 Me an R e sp o n se Ti m e (m s) Exponential(1,0.3) Multiplied by 100 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.10 Performance results of service time multiplied by 100 and inter-arrival time equal to 0.3
JI Q , 43 113 JIQ _ E xt (1), 43 124 JI Q _ E x t( 2) , 43 1 16 JI Q _S Q (2), 43 118 JIQ _S Q (2)_E xt (1 ), 43 12 6 JI Q _S Q (2)_E x t(2), 4 30 98 JQ A _R R , 426 02 JQ A_ NT , 4 2 5 9 9 JQ A _ R ando m , 4 252 0 JQ A _ L C , 42 51 8 42200 42300 42400 42500 42600 42700 42800 42900 43000 43100 43200 Me an Res p o n se Tim e (m s) Exponential(1,0.3) Multiplied by 300 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.11 Performance results of service time multiplied by 300 and inter-arrival time equal to 0.3
JI Q , 7 42 94 JI Q _ E x t( 1) , 74 27 8 JI Q _ E xt (2) , 74 27 8 JI Q _ S Q (2 ), 7 43 39 JI Q _ S Q (2 )_ E x t( 1) , 74 30 5 JI Q _ S Q (2 )_ E x t( 2) , 74 30 2 JQ A _ RR , 73 36 8 JQA_ NT , 7 3 3 5 5 JQ A _ R and om , 73 27 9 JQ A _L C , 73 28 3 72800 73000 73200 73400 73600 73800 74000 74200 74400 Me a n R esp o n se Tim e (ms ) Exponential(1,0.3) Multiplied by 500 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
35 JI Q , 288. 73 JI Q _E xt (1), 32 5.10 JI Q _ E x t( 2) , 403.3 5 JI Q _S Q (2) , 250.5 7297 JI Q _S Q (2) _E xt (1), 306. 76 JI Q _ S Q (2) _ E x t( 2), 381 .45 JQ A _RR, 552. 04 JQ A_ NT , 2 3 3 .3 5 JQ A _Ra ndom , 3 18.46 JQ A _ L C , 1 97.14 0.00 100.00 200.00 300.00 400.00 500.00 600.00 Me a n R e sp o n se Ti m e (ms ) Exponential(1,0.5) Multiplied by 100 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.13 Performance results of service time multiplied by 100 and inter-arrival time equal to 0.5
JI Q , 31207 JI Q _ E x t( 1) , 3118 7 JI Q _ E x t( 2) , 3119 3 JI Q _ S Q (2) , 3120 9 JI Q _ S Q (2) _ E x t( 1 ), 312 01 JI Q _ S Q (2) _ E x t( 2 ), 311 96 JQ A _ RR, 3 1025 JQ A _ N T , 3 0938 JQ A _Ra nd om , 30 592 JQ A _ L C , 3 0 595 30200 30300 30400 30500 30600 30700 30800 30900 31000 31100 31200 31300 Me a n R e sp o n se Tim e (ms ) Exponential(1,0.5) Multiplied by 300 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.14 Performance results of service time multiplied by 300 and inter-arrival time equal to 0.5
JI Q , 62 391 JI Q _E xt (1), 6236 9 JI Q _E x t( 2) , 62385 JI Q _S Q (2), 623 81 JI Q _ S Q (2)_E xt (1) , 62373 JI Q _ S Q (2)_E xt (2) , 62349 JQ A _RR, 61732 JQ A _N T , 61 675 JQ A _Ra ndom , 6 1354 JQ A _L C, 6 1360 60800 61000 61200 61400 61600 61800 62000 62200 62400 Me a n R e sp o n se Ti m e (ms ) Exponential(1,0.5) Multiplied by 500 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
36 JI Q , 154.32 JI Q _E xt (1), 154.32 JI Q _E xt (2), 154 .32 JI Q _S Q (2 ), 154.32 JI Q _S Q (2)_E xt (1), 154 .32 JI Q _S Q (2)_E x t( 2), 15 4. 3 2 JQ A _RR , 32 3. 8 2 JQ A_ NT , 1 5 8 .2 2 JQ A _R andom , 1 72.13 JQ A _L C , 154.32 0.00 50.00 100.00 150.00 200.00 250.00 300.00 350.00 Me an R esp o n se Ti m e (ms ) Exponential(1,0.7) Multiplied by 100 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.16 Performance results of service time multiplied by 100 and inter-arrival time equal to 0.7
JI Q , 1 54 62 JI Q _ E x t( 1 ), 15 46 3 JI Q _ E x t( 2 ), 15 45 1 JI Q _ S Q (2 ), 1 5 4 7 5 JI Q _ S Q (2 )_ E x t( 1 ), 15 46 9 JI Q _S Q (2 )_ E x t( 2 ), 15 47 2 JQA_ R R , 1 5 9 4 5 JQA_ NT , 1 4 9 3 1 JQ A _ Ra n d o m , 14 933 JQA_ L C , 1 4 9 3 1 14400 14600 14800 15000 15200 15400 15600 15800 16000 Me a n R e sp o n se Tim e (ms ) Exponential(1,0.7) Multiplied by 300 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
Figure 5.17 Performance results of service time multiplied by 300 and inter-arrival time equal to 0.7
JI Q , 4664 0 JI Q _ E x t( 1 ), 466 18 JI Q _ E x t( 2 ), 4663 4 JI Q _S Q (2) , 46 657 JI Q _S Q (2) _E xt (1) , 46 629 JI Q _ S Q (2 )_E x t( 2 ), 4661 5 JQ A _RR , 46 560 JQ A _ N T , 4633 7 JQ A _ Ra ndom , 45 656 JQ A _ L C , 4564 9 45000 45200 45400 45600 45800 46000 46200 46400 46600 46800 Me an R e sp o n se Ti m e (m s) Exponential(1,0.7) Multiplied by 500 JIQ JIQ_Ext(1) JIQ_Ext(2) JIQ_SQ(2) JIQ_SQ(2)_Ext(1) JIQ_SQ(2)_Ext(2) JQA_RR JQA_NT JQA_Random JQA_LC
37
In summary, the proposed JQA approach can achieve significantly better performance than JIQ, up to 31% performance improvement in terms of average request response time.
38
5.3 Discussions
The performance results shown in the previous section indicate that our JQA-based approaches, in general, can reduce the mean service response time significantly in almost all situations. However, the performance results also present several interesting phenomena. For example, in some cases such as Figure 5.1 and Figure 5.2, JQA_RR led to even worse mean service response time than JIQ-based approaches. We made a deep investigation and found out the cause. Table 5.2 is an example to illustrate the phenomenon, which shows the entire process of handling twelve requests with two dispatchers and five VM’s.
In Table 5.2, T represents the time instants of request arrivals, C is the cloudlets in CloudSim representing user requests, D represents dispatchers, and V stands for VM which is the resource for executing requests. Each column of C indicates which cloudlet arrives at which dispatcher at what time. The column of D records the VM’s waiting in a particular dispatcher at different time instants. The columns of V1,V2,V3,V4 and V5 show the cloudlets waiting in a particular VM for execution at different time instants and the number in the parentheses indicates the estimated total execution time of all the cloudlets waiting in that VM. Each row in the table shows the status of every dispatcher and VM when a cloudlet arrives at a specific time instant.
In this illustrative example, we found that when all servers join the dispatchers in a round robin manner, a situation like Table 5.2 might occur, where a majority of servers join the same dispatcher, if most servers process the requests at a similar speed. For example, in the tenth row of Table 5.2, all VMs are registered in dispatcher 1. Therefore, when cloudlet10 arrives at dispatcher 2, there are no available VM’s for it and it is then dispatched randomly to a VM, V2, with the highest load unfortunately, leading to a longer service response time. We also found
39
that this undesirable property of JQA_RR becomes less significant when the inter-arrival time of requests is smaller as shown in Figure 5.3. This is because as the requests come quickly the VM’s on a particular dispatcher have more chance to be assigned requests and then join another dispatcher sooner, greatly reducing the possibility of imbalance in the server distribution among the dispatchers.
The undesirable property of JQA_RR motivated us to develop the JQA_NT, JQA_Random and JQA_LC approaches. According to the experimental results, we found that JQA_NT is relatively stable than JQA_RR and JQA_Random and JQA_LC can perform even better than the previous two approaches.
Table 5.2 Example for JQA_RR
T C D1 D2 V1 V2 V3 V4 V5 0 C1toD2 V1,V2,V3,V4,V5 0 C2toD1 V1,V2,V3,V4,V5 C1,(1) 1 C3toD2 V2,V3,V4,V5 V1 C2,(1) C1,(1) 1 C4toD1 V2,V3,V4,V5,V1 C2,C3,(3) C1,(1) 1 C5toD1 V3,V4,V5,V1 V2 C2,C3,(3) C4,(2) C1,(1) 4 C6toD2 V4,V5,V1 V2,V3 C3,(1) 4 C7toD2 V4,V5,V1,V2 V3 C3,(1) C6,(10) 4 C8toD1 V4,V5,V1,V2,V3 C3,(1) C6,(10) C7,(1) 4 C9toD2 V5,V1,V2,V3 V4 C3,(1) C6,(10) C7,(1) C8,(1) 4 C10toD2 V5,V1,V2,V3,V4 C3,(1) C6,(10) C7,(1) C8,C9,(2) 4 C11toD2 V5,V1,V2,V3,V4 C3,(1) C6,C10,(11) C7,(1) C8,C9,(2) 4 C12toD1 V5,V1,V2,V3,V4 C3,C11,(2) C6,C10,(11) C7,(1) C8,C9,(2)
Another interesting phenomenon is that in some cases JQA_Random outperforms JQA_LC slightly as shown in Figure 5.5. This observation contradicts our original expectation
40
that JQA_LC would achieve the best load-balancing effects since the server chooses the dispatcher with the least number of registered servers to join. We also made a deep investigation into this phenomenon and found that JQA_LC sometimes might run into an undesirable situation. Table 5.3 is an example to illustrate the undesirable situation.
Sometimes it might happen that several consecutive requests are directed to the same dispatcher such as cloudlet1 to cloudlet5 and dispatcher 2 in Table 5.3. These cloudlets would be assigned to VM2 or VM4 which are registered with dispatcher 2. According to the mechanism of JQA_LC, VM2 and VM4 would soon re-join dispatcher 2 and receive more requests as shown in the table since dispatcher 2 has a less amount of servers than dispatcher 1. This leads to a situation that VM2 and VM4 are soon overloaded, but the requests arriving at dispatcher 2 are still continuously sent to them. For example, the load of available VMs in dispatcher 2 is higher than the load of available VMs in dispatcher 1 when cloudlet 4 arrives at dispatcher 2, resulting in that cloudlet 4 is sent to a VM, VM4, with higher workload. This deteriorates the load-balancing effects and leads to worse service response time. This situation can be avoided in JQA_Random since V2 and V4 would not always registered with dispatcher 2, allowing dispatcher 2 to have a chance to assign the incoming requests to a lightly loaded VM even through random dispatching.
41
Table 5.3 Example for JQA_LC
T C D1 D2 V1 V2 V3 V4 V5 0 C1toD2 V1,V3, V5 V 2, V 4 0 C2toD2 V1,V3,V5 V4 C1,(1) 1 C3toD2 V1,V3,V5 V2,V4 C2,(2) 2 C4toD2 V1,V3,V5 V4,V2 C3,(6) C2,(1) 2 C5toD2 V1,V3,V5 V2 C3,(6) C2,C4,(4) 7 C6toD1 V1,V3,V5 V4,V2 C3,C5,(2) 7 C7toD2 V3,V5 V4,V2 C6,(20) C3,C5,(2) 7 C8toD1 V3,V5 V2 C6,(20) C3,C5,(2) C7,(1) 7 C9toD1 V5 V2 C6,(20) C3,C5,(2) C8,(1) C7,(1) 7 C10toD1 V2 C6,(20) C3,C5,(2) C8,(1) C7,(1) C9,(1) 7 C11toD1 V2 C6,C10,(21) C3,C5,(2) C8,(1) C7,(1) C9,(1) 8 C12toD2 V1,V3,V5 V2,V4 C6,C10,(20) C11,(2) 9 C13toD2 V1,V3,V5 V4,V2 C6,C10,(19) C12,(4) C11,(2) 9 C14toD2 V1,V3,V5 V2 C6,C10,(19) C12,(4) C11,C13,(6) 11 C15toD2 V1,V3,V5 V4,V2 C6,C10,(17) C12,C14,(6) C13,(4)
Although sometimes JQA_Random might outperform JQA_LC slightly, in general JQA_LC performs better because the performance of JQA_Random varies largely as shown in Figure 5.1 and Figure 5.2. Table 5.4 is an example illustrating when JQA_Random would perform poorly. Dispatcher 2 assigns VM5 to execute cloudlet8 and unfortunately VM5 re-registers to dispatcher 2 again at random. Therefore, when cloudlet 13 arrives at dispatcher 1, it can only be assigned to a VM of higher workload than VM5, in this case V1. This undesirable situation can be avoided if JQA_LC is adopted, since dispatcher 1 has less servers than dispatcher 2 and some lightly loaded servers would join dispatcher 1 instead of dispatcher2.
42
Table 5.4 Example for JQA_Random
T C D1 D2 D3 V1 V2 V3 V4 V5 0 C1toD2 V4, V2,V3,V5 V1, 0 C2toD1 V4,V2, V3,V5 V1, c1,(1) 1 C3toD3 V2, V3,V5,V4 V1, c2,(2) 2 C4toD1 V2, V3,V5,V4,V1 c3,(6) 2 C5toD2 V3,V5,V4,V1 V2, c3,(6) c4,(4) 7 C6toD3 V5,V4,V1,V3 V2, 7 C7toD3 V2, V5,V4,V1,V3 c6,(20) 7 C8toD2 V2, V5,V4,V1,V3 c6,c7,(21) 7 C9toD2 V2, V4,V1,V3,V5 c6,c7,(21) c8,(1) 7 C10toD3 V2, V1,V3,V5,V4 c6,c7,(21) c9,(1) c8,(1) 7 C11toD2 V2, V1,V3,V5,V4 c6,c7,(21) c9,c10,(2) c8,(1) 8 C12toD3 V2,V1, V3,V5,V4 c11,(2) c6,c7,(20) c10,(1) 9 C13toD1 V2,V1, V3,V5,V4 c12,(4) c6,c7,(19) 9 C14toD1 V2, V3,V5,V4,V1 c12,c13,(8) c6,c7,(19) 11 C15toD2 V3,V5,V4,V1,V2, c12,c13,(6) c6,c7,c14,(19)
43
Chapter 6. Conclusions
Web services on the cloud have to serve a huge amount of users from all over the world simultaneously and usually deploy a large amount of servers to share the incoming workloads. Traditional centralized load-balancing approaches with single dispatcher cannot scale well under such a large-scale of servers. Therefore, distributed dispatching structure has been developed for efficient request processing through a set of dispatchers working independently. However, traditional load-balancing algorithms, such as Join-the-Shortest-Queue (JSQ), cannot be implemented efficiently under such distributed dispatching structure. Effective and efficient distributed load balancing thus becomes a crucial research issue for large-scale cloud services. A recent research by Lu et al. proposed a Join-Idle-Queue (JIQ) algorithm for efficient distributed load balancing. However, JIQ is not effective when system load is moderate or high and no servers are idle. In this thesis, we propose a Join-Queue-Anytime (JQA) mechanism with four variations: JQA_RR, JQA_NT, JQA_Radnom and JQA_LV, aiming for resolving the inefficiency of JIQ under moderate or high system load. The proposed mechanism has been evaluated through a series of simulation experiments implemented with the CloudSim toolkit. The experimental results indicate that the proposed JQA mechanism outperforms JIQ significantly, achieving up to 31% performance improvement in terms of average request response time.
44
Reference
[1] Y. Lu, Q. Xie, G. Kliot, A. Geller, J. R. Larus, and A. Greenberg, "Join-Idle-Queue: A novel load balancing algorithm for dynamically scalable web services," Performance
Evaluation, vol. 68, pp. 1056-1071, 2011.
[2] V. Gupta, M. Harchol Balter, K. Sigman, and W. Whitt, "Analysis of
Join-The-Shortest-Queue routing for web server farms," Performance Evaluation, vol. 64, pp. 1062-1081, 2007.
[3] S. Shahand, S. J. Turner, W. Cai, and M. Khademi H, "DynaSched: a dynamic web service scheduling and deployment framework for data-intensive Grid workflows,"
Procedia Computer Science, vol. 1, pp. 593-602, 2010.
[4] B. Benatallah, F. Casati, and F. Toumani, "Web service conversation modeling: a cornerstone for e-business automation," Internet Computing, IEEE, vol. 8, pp. 46-54, 2004.
[5] Z. Qi and T. Yanliao, "A load balancing based model for dynamic web service selection," in Computational Intelligence and Design, 2009. ISCID '09. Second International
Symposium on, 2009, pp. 501-505.
[6] A. M. Nakai, E. Madeira, and L. E. Buzato, "Load balancing for internet distributed services using limited redirection rates," in Dependable Computing (LADC), 2011 5th
Latin-American Symposium on, 2011, pp. 156-165.
[7] P. Hofmann and D. Woods, "Cloud Computing: The limits of public Clouds for business applications," Internet Computing, IEEE, vol. 14, pp. 90-93, 2010.
[8] W. Yi and M. B. Blake, "Service-Oriented computing and Cloud computing: challenges and opportunities," Internet Computing, IEEE, vol. 14, pp. 72-75, 2010.
45
systems," Internet Computing, IEEE, vol. 3, pp. 28-39, 1999.
[10] T. Wenting and M. W. Mutka, "Load distribution via static scheduling and client
redirection for replicated web servers," in Parallel Processing, 2000. Proceedings. 2000
International Workshops on, 2000, pp. 127-133.
[11] J. Cao, Y. Sun, X. Wang, and S. K. Das, "Scalable load balancing on distributed web servers using mobile agents," Journal of Parallel and Distributed Computing, vol. 63, pp. 996-1005, 2003.
[12] CLOUDS Laboratory, University of Melbourne. (2012, June). CloudSim: A framework
for modeling and simulation of Cloud computing infrastructures and Services. Available: http://www.cloudbus.org/cloudsim/
[13] R. N. Calheiros, R. Ranjan, A. Beloglazov, C. A. F. De Rose, and R. Buyya, "CloudSim: a toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms," Software: Practice and Experience, vol. 41, pp. 23-50, 2011.
[14] V. C. Emeakaroha, I. Brandic, M. Maurer, and I. Breskovic, "SLA-aware application deployment and resource allocation in Clouds," in Computer Software and Applications
Conference Workshops (COMPSACW), 2011 IEEE 35th Annual, 2011, pp. 298-303.
[15] N. Ahmad, A. G. Greenberg, P. Lahiri, D. Maltz, P. K. Patel, S. Sengupta, and K. V. Vaid, "Distributed load balancer," 2008 , Aug 11.
[16] T. Phan and W.-S. Li, Vertical Load distribution for Cloud computing via multiple
implementation options handbook of Cloud computing, B. Furht and A. Escalante, Eds.,
ed: Springer US, 2010, pp. 277-308.
[17] J. Junjie and Z. Jian, "Research on open SaaS software architecture based on SOA," in
46
2010, pp. 144-147.
[18] J. Yang and W. Wei, "Design and implementation of load balancing of
distributed-system-based web server," in Electronic Commerce and Security (ISECS),
2010 Third International Symposium on, 2010, pp. 337-342.
[19] J. McCarthy, "Recursive functions of symbolic expressions and their computation by machine, Part I," Commun. ACM, vol. 3, pp. 184-195, 1960.
[20] G. Sharon Eisner, I. Administration Of The, K. Edited Brian, and K. James, "The
self-governing internet: coordination by design," Coordination and Administration of the Internet Workshop at Kennedy School of Government, Harvard University September 8-10, 1997.
[21] Amazon. (2012, June). Amazon mechanical turk: Artificial Intelligence. Available:
https://www.mturk.com/mturk/welcome
[22] S. LOHR. (2007, October). Google and I.B.M. Join in 'Cloud computing' research.
Available: http://www.nytimes.com/2007/10/08/technology/08cloud.html?_r=1
[23] A. Khalid, "Cloud computing: applying issues in small business," in Signal Acquisition
and Processing, 2010. ICSAP '10. International Conference on, 2010, pp. 278-281.
[24] salesforce.com. (2012, June). salesforce. Available: http://www.salesforce.com/
[25] Google. (2012, June). Gmail. Available: http://mail.google.com
[26] Google. (2012, June). Google App Engine. Available:
http://code.google.com/intl/en/appengine
[27] Microsoft. (2012, June). Microsoft Azure Platform. Available:
http://www.windowsazure.com
[28] Amazon. (2012, June). Amazon Elastic Compute Cloud (Amazon EC2). Available:
47
[29] M. Pathan and R. Buyya, "Resource discovery and request-redirection for dynamic load sharing in multi-provider peering content delivery networks," Journal of Network and
Computer Applications, vol. 32, pp. 976-990, 2009.
[30] S. Ranjan and E. Knightly, "High-Performance resource allocation and request redirection algorithms for web clusters," Parallel and Distributed Systems, IEEE
Transactions on, vol. 19, pp. 1186-1200, 2008.
[31] M. Bramson, Y. Lu, and B. Prabhakar, "Randomized load balancing with general service time distributions," SIGMETRICS Perform. Eval. Rev., vol. 38, pp. 275-286, 2010. [32] C. Graham, "Chaoticity on path space for a queueing network with selection of the shortest queue among several," Journal of Applied Probability, vol. 37, pp. 192-211, 2000.
[33] J. N. Hoover and R. Martin. (2008) Demystifying the Cloud. InformationWeek Research