國 立 交 通 大 學
電信工程研究所
碩 士 論 文
考慮語速影響之漢語韻律模型建立
與語音合成之應用
A Modeling of Speaking Rate Influences on Mandarin
Speech Prosody and its Application to TTS
研究生:謝喬華
指導教授:王逸如 博士
考慮語速影響之漢語韻律模型建立與語音合成之應用
A Modeling of Speaking Rate Influences on Mandarin
Speech Prosody and its Application to TTS
研 究 生:謝喬華 Student:Chiao-Hua Hsieh
指導教授 :王逸如 博士 Advisor:Dr. Yih-Ru Wang
國 立 交 通 大 學 電 信 工 程 學 系
碩 士 論 文
A Thesis
Submitted to Institute of Communication Engineering College of Electrical and Computer Engineering
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master of Science in Communication Engineering
July 2012
Hsinchu, Taiwan, Republic of China
考慮語速影響之漢語韻律模型建立與語音合成之應用
研 究 生:謝喬華 指導教授:王逸如
博士
國立交通大學電信工程研究所碩士班
中文摘要
中文摘要
中文摘要
中文摘要
本論文提出一個新方法,考慮漢語說話速度對韻律變化的影響,建立一個語速相依的漢語 階層式韻律模型(SR-HPM)。本方法修正了先前的非監督式韻律標記與模式(PLM)方法,將語 速當作一新的連續獨立變數,讓韻律聲學參數及韻律模型參數受其影響。本研究之 SR-HPM 建構於一位專業女性播報員所錄製四種不同語速之平行語料庫。實驗結果顯示語速對於模型參 數之影響符合現有的語言學知識,證實了本研究所提出之方法能系統化地量化語速對漢語韻律 之影響。 最後將本研究所提出之韻律模型應用在文字轉語音上,我們製作了一個可控制語速的中文 文字轉語音系統。實驗主觀測試結果顯示,我們所提出之方法在快、慢語速都明顯優於傳統 ML 為基礎的語速控制方法。A Modeling of Speaking Rate Influence on Mandarin
Speech Prosody and its Application to TTS
Student:Chiao-Hua Hsieh Advisor:Dr. Yih-Ru Wang
Institute of Communication Engineering
National Chiao Tung University
Abstract
In this thseis, a new approach of Mandarin-speech prosody modeling to consider the effects of speaking rate is proposed. The approach is a modification of previous prosody labeling and modeling (PLM) method to take speaking rate as a continuous independent vaiable and let prosodic-acoustic features and some parameters of prosodic models depend on it in order to account for its influences. A speaking rate-dependent hierarchical prosodic model (SR-HPM) is hence constructed from four speech corpra of a single female speaker with four different speaking rates. An analysis of the effects of speaking rate on the model parameters showed that they agreed well with our prior knowledge. So, the proposed approach provides a systematic and effective way to quantify the effects of speaking rate on Mandarin-speech prosody.
Last, an application to the prosody generation for Mandarin text-to-speech (TTS) is proposed. By using the well-trained SR-HPM, a speaking rate-controlled TTS system that can generate fluent speech for any given speaking rate is implemented.The subjective testing results indicated that the proposed methed was significantly better than the conveninal ML-based method for fast and slow rate.
致謝
致謝
致謝
致謝
對於本論文能順利完成,我要感謝很多人。首先是陳信宏老師,感謝陳老師這兩年的細心 指導,即使身兼院長之職,仍常抽空與我共進研究,實在辛苦您了;感謝我的指導教授王逸如 老師,王老師教我如何成為一個真正的研究生,而不是只會教作業的大學生,感謝您在這兩年 所給予的扎實訓練。 接著我要感謝 707 的老大性獸,一個人掌控所有研究生的研究進度,感謝你不辭辛勞地指 導我程式及研究上的問題,希望你在台北大學一切順利;感謝智合哥教我 Linux 指令,也恭喜 你拿到博士學位了;感謝分享了實驗室很多八卦的輝哥;感謝帥氣的阿德哥在 8051 方面的指 導,你真是我們北科的驕傲代表。在此也感謝前屆學長所給予的照顧:感謝最有學妹緣的文良, 祝你早日練成 KOBE;感謝最愛宵夜攤的大胖,以後要常回來一起打球;感謝最愛周星馳系列 喜劇電影的小瞎,相信你的研究終能修成正果;感謝健身王豆腐、舞林高手智障、707 小 AI 銘傑。感謝坐在我旁邊的 Syntax 之神睿詮,跟你一起修課讓我很安心;感謝人超好的 DD,以 後我去華碩面試記得罩我;感謝臉胖身不胖的胖子軒,望你回國後四顆輪子能再次啟動;感謝 南極來的聰明企鵝,學識淵博簡直是奇摩知識+;感謝樂觀開朗的 1 對 1 鬥牛球友昌祐;感謝 人很隨和的雅婷;感謝籃球很秋的小高及很機靈的昂星。也感謝諸位"我最看好的"學弟妹: 讓出 Battle 帳號的魔鬼筋肉人奕勳、聰明絕頂的優質子睿、脫臼不怕痛的柔道高手良基、講講 話很很很有有韻律的小霸王蘇蘇蘇仲銘、愛裝可愛的可撈D~亞婉君。感謝我最愛的女朋友靖 觀,一路上有妳的陪伴,讓我感到很溫暖,未來我們要繼續一起加油努力。感謝以上諸位這兩 年的陪伴,我的碩士生涯因你們而感到充實快樂。 最後要感謝我父母對我從小的栽培,尊重我在求學階段的每一個決定,當我在外地求學 時,不斷地給我關心及鼓勵,在此僅將此論文獻給你們。目錄
目錄
目錄
目錄
中文摘要……… I Abstract………. II 致謝……….. III 目錄………. IV 表目錄………. VI 圖目錄……… VII 第一章 緒論……….. 1 1.1 研究動機 ... 1 1.2 文獻回顧 ... 1 1.3 研究方向 ... 3 1.4 語料庫簡介 ... 3 1.5 章節概要說明 ... 5 第二章 語速相依之階層式韻律模型建立……….. 6 2.1 漢語語音階層式韻律架構... 6 2.2 語速韻律模型之建立方法... 7 2.3 韻律聲學特徵參數之語速正規化 ... 8 2.3.1 音節長度之語速正規化 ... 9 2.3.2 停頓時長之語速正規化 ... 9 2.3.3 音節基頻軌跡之語速正規化 ... 11 2.3.4 音節能量位階之正規化 ... 12 2.3 語速韻律模型之設計 ... 13 2.3.1 音節韻律模型 ... 15 2.3.2 停頓聲學模型 ... 172.3.3 修正型韻律狀態模型 ... 18 2.3.4 修正型停頓語法模型 ... 18 2.4 修正型 PLM 演算法之訓練過程 ... 19 2.4.1 初始化 ... 19 2.4.2 疊代訓練 ... 21 第三章 語速韻律模型訓練結果與分析……… 22 3.1 韻律模型參數之分析 ... 23 3.1.1 音節韻律模型 ... 23 3.1.2 停頓聲學模型 ... 29 3.1.3 修正型韻律狀態模型 ... 31 3.1.4 修正型停頓語法模型 ... 38 3.2 韻律標記結果之分析 ... 41 3.2.1 停頓類別標記 ... 42 3.2.2 韻律狀態標記 ... 45 第四章 可控制語速之 TTS 應用………...… 47 4.1 停頓標記預估 ... 48 4.2 韻律狀態預估 ... 49 4.3 語速相依之韻律參數產生法 ... 51 4.4 HMM 頻譜模型 ... 53 4.5 語音合成實驗結果與分析... 54 第五章 結論與未來展望……… 57 5.1 結論 ... 57 5.2 未來展望 ... 57 參考文獻……….. 59 附錄一……….. 62 附錄二……….. 64
表
表
表
表目錄
目錄
目錄
目錄
表 2.1:韻律標記、聲學參數及語言參數之表示符號 ... 14 表 3.1:SR-Treebank 韻律聲學參數之統計資訊 ... 22 表 3.2:以音節韻律模型不同 APs 組合下音節韻律參數之 TREs ... 28 表 3.3:重建停頓時長之 RMSEs ... 31 表 3.4:停頓語法模型修正前後 entropy 之比較 ... 41 表 4.1:訓練語料之停頓標記預估辨識率 ... 48 表 4.2:測試語料之停頓標記預估辨識率 ... 49 表 4.3:韻律狀態靜態模型之語言參數列表 ... 50 表 4.4:韻律參數預估結果之 TREs ... 53 表 4.5:PD-HMM 頻譜模型之文脈相關資訊 ... 53 表 4.6:MOS 評分標準 ... 54圖目錄
圖目錄
圖目錄
圖目錄
圖 1.1:所有語句的音節數目分佈圖 ... 4 圖 1.2:語句數目在語速之分佈圖 ... 5 圖 2.1:中文語音韻律階層式架構概念圖 ... 7 圖 2.2:本研究所採用之階層式韻律架構 ... 7 圖 2.3:本研究所提出之語速韻律模型設計流程圖... 8 圖 2.4:(a)音節長度對 vs. SR,(b)音節長度之語句標準差 vs. SR ... 9 圖 2.5:(a)停頓時長與語句平均值 vs. SR,(b) 停頓時長之語句標準差 vs. SR ... 10 圖 2.6:停頓時長之語速正規化結果 ... 11 圖 2.7:spn(2)於第四聲調之語句(a)平均值 vs. SR,(b)標準差 vs. SR ... 12 圖 2.8:音節基頻軌跡與其影響因素關係圖 ... 16 圖 2.9:初始化停頓標記決策樹 ... 20 圖 3.1:疊代次數與目標總概似度 ... 23 圖 3.2:基頻軌跡聲調 APs ... 24 圖 3.3:基頻軌跡在停頓標記 B0、B1 和 B4 時的前音節連音效應 APs ... 25 圖 3.4:基頻軌跡在停頓標記 B0、B1 和 B4 時的後音節連音效應 APs ... 26圖 3.5:音節長度之(a)聲調 APs,(b)基本音節類型 APs ... 27
圖 3.6:音節能量位階之(a)聲調 APs,(b)韻母類型 APs ... 27
圖 3.7:以音節韻律模型及語速正規化參數來重建韻律聲學參數之流程圖 ... 28 圖 3.8:快語速與慢語速之五種聲調基頻軌跡模擬圖 ... 29 圖 3.9:(a)停頓音節長度,(b)音節能量低點,(c)正規化基頻跳躍值,(d)正規化音節拉長 因子 1,(e)正規化音節拉長因子 2 之決策樹根節點機率分佈 ... 30 圖 3.10:平均停頓時長 vs. SR ... 31 圖 3.11:(a)快語速,(b)慢語速於不同停頓標記下基頻韻律狀態的轉移情形 ... 33
圖 3.12:韻律標記為(a)B0,(b)B4 時基頻韻律狀態轉移 entropy vs. SR ... 34
圖 3.13:(a)快語速,(b)慢語速於不同停頓標記下音長韻律狀態的轉移情形 ... 35
圖 3.14:韻律標記為(a)B0,(b)B4 時音長韻律狀態轉移 entropy vs. SR ... 36
圖 3.15:(a)快語速,(b)慢語速於不同停頓標記下能量韻律狀態的轉移情形 ... 37
圖 3.16:停頓語法模型決策樹,節點中直方圖為各停頓標記的發生機率 ... 39
圖 3.17:(a) B4 於 PM 節點,(b) B2-2 於 non-PM, inter-word 節點,(c) B0 於 intra-word 節點之發生頻率 vs. SR ... 40 圖 3.18:停頓語法模型決策樹,節點中直方圖為各停頓標記機率對 SR 之斜率 ... 41 圖 3.19:(a)各停頓標記在語料庫所佔百分比,(b)各停頓標記在 SR 之分佈情形 ... 42 圖 3.20:(a)PW,(b)PPh,(c)BG/PG 之音節個數直方圖 ... 43 圖 3.21:(a)PW,(c)PPh 和(e)BG/PG 音節個數平均值 vs. SR;(b)PW,(d)PPh,(f)BG/PG 音節個數標準差 vs. SR ... 44 圖 3.22:語料庫平行語句之停頓標記範例 ... 45 圖 3.23:韻律狀態標記範例 ... 46 圖 4.1:可控制語速之 TTS 系統架構圖 ... 47 圖 4.2:(a)基頻,(b)音長韻律狀態預估結果 ... 51 圖 4.3:韻律參數產生範列 ... 52 圖 4.4:MOS 測試結果 ... 55 圖 4.5:Preference 測試結果 ... 55 圖 4.6:不同語速的停頓預估結果 ... 56
第一章
第一章
第一章
第一章 緒論
緒論
緒論
緒論
1.1 研究動機
研究動機
研究動機
研究動機
科技日新月益,各式創新的技術與應用使得生活越來越趨於便利與高效率,智慧型手機、 平板電腦、衛星導航等電子資訊產品近年來被快速普及,成為現代人生活中不可或缺的一部 份,而語音處理技術亦被大量使用在相關產品的人機介面溝通上,增加使用的便利性,例如語 音訂票功能及電子有聲書等,人們可以用最直接、自然的方式與機器溝通,取代以往複雜的鍵 盤輸入及文字輸出。 隨著隨藏式馬可夫模型為基礎(HMM-based)的文字轉語音(Text-To-Speech, TTS)技術興 起,語音合成品質已有不錯的表現,當中語音合成該有的韻律掌握是重要的關鍵,然而不同的 應用中會有不用的語速需求。以語音訂票系統為例,對於外藉人士或老年人來說,速度稍慢的 語音,可供足夠的反應時間聽懂內容;而對於本國藉人士,提供稍快速度的語音可以節省使用 者寶貴的時間。因此,為滿足這些實際的需求,即必須對不同語速的韻律做進一步的探討,以 利開發多語速語音合成系統。在自動語音辨識系統(Automatic Speech Recognition, ASR)方面,有很多先前的研究指出, 一定程度慢速或快速的語音,會造成辨識效能大幅度下降,如果能夠在辨識系統中補償語速所 造成的影響,則能提升極端語速語音的辨識效果。
1.2 文獻回顧
文獻回顧
文獻回顧
文獻回顧
說話速度是一個很重要的韻律參數,其影響了很多語音現象,像是音節長度、停頓時長、 基頻軌跡形狀、音素之間的 coarticulation 程度、停頓發生的機率等等。利用語音信號估計語速 [1],探索語速對於韻律及語言參數的影響[2-4]是一直被探討的議題。[2]採用階層式韻律架構 對三種不同語速(快、中、慢)之平行語料庫做分析,實驗對於語速的測量分兩類,一類為 SpeechRate(SR),定義為每秒包含停頓長度的發音音節個數,另一類為 articulation rate(AR),定義為 每秒不包含停頓時長的發音音節個數。其實驗結果發現改變說話速度對各層韻律邊界的停頓時 長為非線性的;語速的快慢會影響基頻軌跡(F0 contour)的分佈,快速語料的音高平均較高且變 動範圍較小,而慢速語料的音高平均較低、變動範圍較大。此篇文章提出一些不錯的觀點,但 語料庫的資料量不夠大,導致其分析結果不夠一致。[5]提出一階層式多短語韻律句群架構, 並使用逐步迴歸(step-wise regreesion)來估算語料中語速對韻律階層單元的影響,共分析出三種 不同語速之中文韻律詞、韻律短句及呼吸組層次的音長和音強 pattern;解析出各層次單元於音 長及音強的貢獻。其實驗結果發現,音長的韻律詞 pattern 呈現一勺子狀曲線,以中速語料的 延長/縮短效應最小,慢速最大;韻律短句在快、中速語料的短句有拉長現象而慢速卻沒有。 音強方面,發現越長的韻律詞所需能量越大,慢速語料的平均音強為最大;韻律短語層次部份, 發現越長的韻律短語需要越大的能量。此篇研究提出了不少新發現,但因其語料庫不為同一語 者所發音,導致部份實驗結果有不一致現象。 在 ASR 及 TTS 的應用中,如何建立模型去考慮語速效應也是很重要的議題。在 ASR 方 面,主要針對快速和慢速的語音做補償[6-9],[6]提出對語速正規化方法,依據語速調整音框 長度去求得動態頻譜特徵參數(dynamic spectral feature),用此方式來補償語速對 ASR 的影響。 [7]提出語速對於聲學模型的補償方法,依據每個音框所屬的語速去調整 HMM 的混合權重 (mixture weight)和轉移機率。[8]發現語速快於某程度之語音會使 ASR 的辨識效能嚴重下降, 並提出三種補償方法,分別為 Baum-Welch 碼本(codebook)的調適、HMM 轉移機率的調適、 發音字典的修正,其中方法二使相對錯誤率(relative error rate)降低了 4-6%。[9]提出利用兩個 平行特定語速的聲學模型去對快速與慢速語音做辨認,實驗結果提升了 1.9%的絕對正確率。 對於 TTS 來說,語速控制在人機介面的使用是必須的[10-12],在一些特別的應用,例如 快速的合成語音會較適合視障人士[13-14]。[10]進行大規模主觀測試三種語速控制的方法,分 別為:(1)針對目標語速選取相近語速之語料來訓練 HMM 模型,(2)依比例去伸縮合成語句的 發音長度,及(3)基於 ML 準則去決定狀態長度(state duration),這些方法都是建立於 HMM-based 的語音合成系統,實驗結果發現方法(2)最適合用於快語速合成語音,而方法(1)較適合慢速語
音。[11]研究關於語速對於韻律參數造成的影響,進而將語速調整加入到中文 TTS 系統;其研 究的重點在於韻律架構、音長、基頻分佈以及口音位置對於語速的變化。[12]提出控制音素時 長(phoneme duration)的方法,以 HMM-based 合成系統為基礎,配合快速、正常、慢速音素時 長模型之間的內插,達到目標語速的合成語音。
1.3 研究方向
研究方向
研究方向
研究方向
本研究考慮語速對中文語音韻律的影響,提出的新方法將延續過去的研究。主要是基於[15] 提出之非監督式中文語音韻律標記及韻律模式(unsupervised joint Prosody Labeling and Modeling, PLM)演算法,此演算法可用來對語音做韻律標記及韻律模擬,相關的說明如下:[3]利用 PLM 演 算法對一女性語者的四種不同語速平行語料庫各別建立階層式韻律模型(Hierocical Prosodic Model, HPM),利用此演算法模擬韻律中的音節基頻軌跡(syllable F0 contour)、音節長度(syllable duration)、音節能量位階(syllable energy level)、停頓時長(pause duration),從信號的角度出發, 自動對不同語速的語音做韻律標記和韻律結構分析,探討相異語速在各層韻律單元上的韻律參 數變化,以及韻律斷點和語言參數之間的關係。 在過去的研究中,發現語速的確對於各個韻律層造成影響。本論文以 PLM 演算法為基礎, 提出一語速韻律模型之建立方法,將語速當作一連續變數引入模型,修正原本的 PLM 演算法, 使其與語速相依,最後對四個不同語速的平行語料庫建立一個語速相依的 HPM(SR-HPM)。最 後結合於 HMM-based 語音合成器來實現一個可控制語速之 TTS 系統。
1.4 語料庫簡介
語料庫簡介
語料庫簡介
語料庫簡介
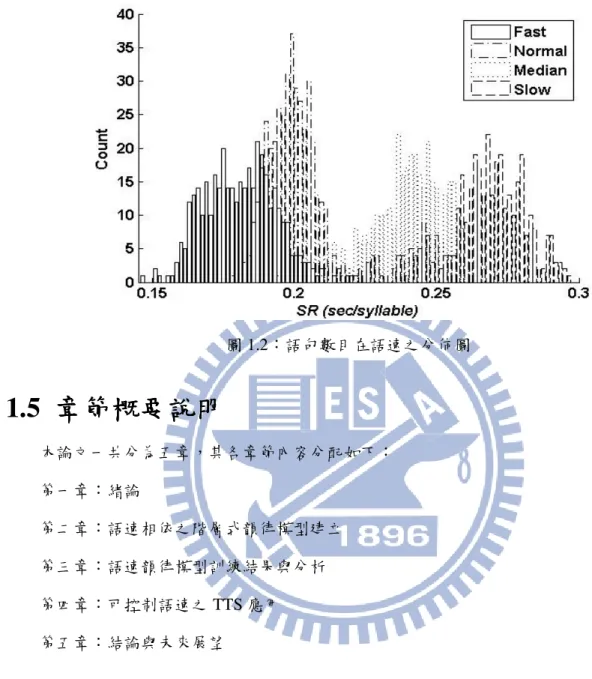
本論文所使用的實驗語料庫,是由一位專業女性播音員讀稿錄製之快速、正常、中速及慢 速平行語料庫,總計 1478 個音檔,共有 203746 個音節,每個語料庫的平均音節長度分別為快 語速的 0.181 秒、正常語速的 0.198 秒、中語速的 0.244 秒及慢語速的 0.264 秒,音檔均為 20kHz 的取樣頻率及 16-bit 之 PCM 格式,只有正常速度語料庫為 16kHz 取樣頻率,語料庫的錄製文字為 Sinica Treebank 語料庫中選出的短篇文章,主要內容大多摘錄自新聞、網路文章,由數個 句子所組成的段落,音檔的字數分佈如圖 1.1 所示,平均每個語句(utterance)音節數為 138。所 有的音節切割標記和基頻的偵測均先自動由 Hidden Markov Model Tool Kit(HTK)[16]和 WaveSurfer[17]完成,明顯錯誤再以人工方式修正。本論文假設每個語句唸的速度是穩定的, 以平均音節長度代表該語句的語速 SR(Speaking Rate),四個語料庫的語句數目在 SR 之分佈如 圖 1.2 所示,整體語料庫 SR 分佈範圍在 0.147-0.297 second/syllable (or 3.4-6.8 syllables/sec)之 間,且語料庫間有嚴重的重疊部份。
圖 1.2:語句數目在語速之分佈圖
1.5 章節概要說明
章節概要說明
章節概要說明
章節概要說明
本論文一共分為五章,其各章節內容分配如下: 第一章:緒論 第二章:語速相依之階層式韻律模型建立 第三章:語速韻律模型訓練結果與分析 第四章:可控制語速之 TTS 應用 第五章:結論與未來展望第二章
第二章
第二章
第二章 語速
語速
語速
語速相依之
相依之
相依之
相依之階層式
階層式
階層式
階層式韻律模型
韻律模型
韻律模型
韻律模型建立
建立
建立
建立
本章節以江振宇博士所提出之 HPM 為基礎[15],引入語速當作新的影響因子,提出新的 演算法來建立語速韻律模型。2.1 漢語語音階層式韻律架構
漢語語音階層式韻律架構
漢語語音階層式韻律架構
漢語語音階層式韻律架構
依據語言學家的研究[18],語音的韻律結構是呈階層式架構。[19]提出韻律標記的概念並 定義了階層式多短語韻律句群(Hierarchical Prosodic Phrase Grouping, HPG)架構,如圖 2.1 所 示,最底層為音節層次(SYLlable layer,SYL),為漢語最基本的字義,其中聲調為最強烈的影響 因素,不只影響音節基頻軌跡之走向,也影響了音節長度及能量位階;往上發展依序為韻律詞 層次(Prosodic Word layer,PW),由雙音節或多音節所構成的詞組,通常在句法和語意上關係緊 密;韻律短語層次(Prosodic Phrase layer, PPh),由一或多個韻律詞所組成,結尾常會帶有不明 顯但可察覺之停頓;呼吸組層次(Breath Group,BG),由單一或數個韻律短語組成的句子,其結 尾通常帶有明顯停頓;最上層為韻律組句(Prosodic phrase Group,PG),由一個或數個呼吸組構 成。停頓標記是用來區分韻律組成份子的邊界,B0 和 B1 區分了 SYL 的邊界,其中 B0 表示 reduced syllabic boundary,而 B1 表示 normal syllabic boundary,這兩種停頓類別通常都不具明 顯停頓;B2 和 B3 分別是韻律詞和韻律短語的邊界;B4 則代表了呼吸組的邊界,和 B2、B3 比較起來會有較明顯的停頓;至於 B5 定義了韻律句組邊界,代表一個完整的段落結束,通常 句尾會有音節長度拉長(final lengthening)及能量減弱等現象。
圖 2.1:中文語音韻律階層式架構概念 [19]
本研究使用之語料庫為大段落的語音,因此就以 HPG 架構為基礎,經過進一步的修改後, 利用此韻律階層架構來建立本論文所提出之韻律模型。首先將 B2 再細分為 B2-1、B2-2、B2-3, 分 別 代 表 明 顯 音 高 重 置 (pitch reset) 、 短 停 頓 (short pause) 及 含 有 音 節 拉 長 效 應 (duration lengthening)之韻律詞邊界等不同現象。接著將 BG 和 PG 合併為同一層,因為這兩層所描述的 韻律特性相近,B4 則和 B5 合成為 B4。整個架構從 5 層變成 4 層,如圖 2.2 所示。最後採用的 7 種韻律邊界停頓(break type)為 B={ B0, B1, B2-1, B2-2, B2-3, B3, B4},以此來標記四種韻律單 元:音節(SYL)、韻律詞(PW)、韻律短語(PPh)、呼吸組/韻律句組(BG/PG)。 圖 2.2:本研究所採用之階層式韻律架構
2.2 語速
語速
語速
語速韻律
韻律
韻律
韻律模型
模型
模型之建立方法
模型
之建立方法
之建立方法
之建立方法
圖 2.3 為本研究所提出之語速韻律模型建立流程圖。首先,對語句 k 求得平均音節長度 sd µ (不包含停頓時長),以此當作該語句的語速量測 SR(k);接著利用此量測值與語速正規化函數,對該語句之韻律聲學特徵參數進行語速正規化,目的為補償語速對於韻律聲學特徵參數造 成的影響;最後提出一修正型 PLM 演算法來訓練語速韻律模型,同時產生韻律標記。在此修 正型 PLM 演算法中,將語速影響加入到 HPM 的兩個子模型,分別為停頓語法模型和韻律狀 態模型,目的是補償語速對於韻律架構上層(PW、PPh、BG/PG)所造成的影響。 圖 2.3:本研究所提出之語速韻律模型設計流程圖
2.3 韻律聲學
韻律聲學
韻律聲學
韻律聲學特徵
特徵
特徵參數之語速正規化
特徵
參數之語速正規化
參數之語速正規化
參數之語速正規化
此節中,本研究提出語速正規化方法來消除語速對於韻律特徵聲學參數的影響,其中待正 規化的聲學參數包括音節長度、停頓時長、音節基頻軌跡及音節能量位階,將在以下四個小節 分別介紹其正規化方法。在先前的研究當中[20],韻律聲學特徵參數被依每個語句去做正規 化,以音節長度為例[20],先對該語句估計音節長度的平均值和標準差,接著做高斯正規化。 雖然此種方法簡易有效率,但亦可能造成過度正規化(over-normalization),例如圖 2.4(b),有些 語句 SR 相近但標準差卻相異甚遠,若以語句為單位做正規化,可能將導致部份除語速外的影 響因子被壓制,以本論文所採用語料為例,文章組成架構不同會使讀者閱讀方式有所差異。因 此,本論文採取較為保守的方法,使用平滑的曲線來模擬每個語句正規化參數(例如音節長度 的標準差)與語料庫中 SR 影響因素的關係;最後估算出平滑曲線參數來形成語速正規化函數 (SR-specific normalization functions),並用以補償韻律聲學特徵參數中的語速效應。2.3.1 音節長度之語速正規化
音節長度之語速正規化
音節長度之語速正規化
音節長度之語速正規化
在韻律聲學特徵參數中,音節長度受語速影響最明顯,又漢語音節長度可近似於高斯分 佈。因 此,我 們 對語 句 k 的音 節長度 採取高 斯正 規化法 ,使用 之正 規化參 數平均值為 ( ) sd k SR k µ = ,標準差則是以已平滑化標準差取代原始估計的。圖 2.4(a)顯示音節長度對 SR 的 分佈圖,(b)為語句標準差對 SR;由圖可發現音節長度之標準差會隨著 SR 增加而增加,故在 此使用二階多項式曲線來模擬不同 SR 的音節長度標準差,其音節長度的正規化函數如下所示:(
sd)
sd( ( )) sd sd n n k g g sd′ = sd − µ σ% SR k ×σ +µ (2.1) 其中 ( ) 1( )
2 1 1 sd SR a SR b SR cσ
% = + ⋅ + (2.2) 為平滑化後的標準差,sdn和sd′n分別代表原始音節長度和語速正規化後的音節長度; sd g µ 和 sd g σ 為語料庫整體的音節平均值與標準差。 0.15 0.2 0.25 0.3 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 SR (sec/syllable) s e c Syllable duration Utt. mean 0.15 0.2 0.25 0.3 0.04 0.05 0.06 0.07 0.08 0.09 0.1 0.11 SR (sec/syllable) s e c Fast Normal Median Slow Fitting Curve (a) (b) 圖 2.4:(a)音節長度 vs. SR,(b)音節長度之語句標準差 vs. SR2.3.2 停頓
停頓
停頓時長
停頓
時長
時長之語速正規化
時長
之語速正規化
之語速正規化
之語速正規化
經由觀察停頓時長pd 的分佈,我們發現伽瑪分佈(Gamma distribution)比高斯更適於模擬pd的分佈,它的表示式如下: f pd( ; , )
α β
=β
αΓ( ) (α
−1 pd)α−1e− ⋅β pd, for x≥0 and ,α β
>0 (2.3) 由於語句 k 的伽瑪分佈參數 pd k α 和 pd k β 可用該語句的平均值 pd k µ 和標準差 pd k σ 來表示,因此我 們可先求取平滑化的平均值µ%pd(SR k( ))和標準差σpd(SR k( )) % ,以此形成語速正規化函數。圖 2.5(a) 顯示平均值µ
kpd 對 SR 的分佈圖,(b)則是語句標準差 pd k σ 對 SR,我們可觀察到兩者皆隨著 SR 而增加。與 2.3.2 小節類似,使用二階多項式曲線來模擬不同 SR 的平均值和標準差,其數學 式如下: ( ) 2( )
2 2 2 pd SR a SR b SR c µ% = + ⋅ + (2.4) ( ) 3( )
2 3 3 pd SR a SR b SR cσ
% = + ⋅ + (2.5) 接著以已平滑化µ%pd(SR k( ))和σ%pd(SR k( ))去對 pd 的分佈正規化,其正規化方法如下: 1 = G (G ( , pd( ( )), pd( ( ))), pd, pd) g g pd′ − pd α SR k β% SR k α β % (2.6) 其中G (pd, , )α β 為伽碼分佈累積密度函數(Cumulative Density Function, CDF);α%pd(SR k( ))=(µ%pd(SR k( ))) / (2 σ%pd(SR k( )))2 (2.7) β%pd(SR k( ))=(σ%pd(SR k( ))) /2 µ%pd(SR k( )) (2.8) 為平滑過的伽碼分佈參數,αgpd 和 pd g β 為語料庫整體的平均值和標準差。 0.15 0.2 0.25 0.3 0 0.5 1 1.5 2 SR (sec/syllable) s e c Pause duration Utt. mean Fitting curve 0.15 0.2 0.25 0.3 0.1 0.2 0.3 0.4 0.5 SR (sec/syllable) s e c Fast Normal Median Slow Fitting Curve (a) (b) 圖 2.5:(a)停頓時長與語句平均值 vs. SR,(b) 停頓時長之語句標準差 vs. SR
圖 2.6 比較了原始pd和正規後的pd ′,在此分三種音節邊界觀察:詞內邊界(intra-word)、 非標點符號詞外邊界(non-PM, inter-word)及標點符號詞外邊界(PM, inter-word)。由圖觀察可得 知所提出的方法適當地正規化了兩種 inter-word 邊界的 pd,而 intra-word 本身受 SR 影響不大, 故正規化後並無太大差異,此結果符合原本的認知。 0 0.5 1 1.5 0.15 0.2 0.25 0.3 0 0.5 1 1.5 0.15 0.2 0.25 0.3 0.15 0.2 0.25 0.3 (a) (b) (c)
圖 2.6:音節邊界在(a) intra-word, (b) non-PM inter-word, (c) PM inter-word 的 pd (上)和pd ′(下) vs. SR。(y-axis: pause duration(sec), x-axis: SR(sec/syllable))
2.3.3 音節基頻軌跡之語速正規化
音節基頻軌跡之語速正規化
音節基頻軌跡之語速正規化
音節基頻軌跡之語速正規化
本研究將音節基頻軌跡進行正交展開(orthogonal expansion) [21],投影到四個 Legendre 多 項式基底,以所得之四維正交參數表示基頻軌跡,即 0 1 2 3 T n n n n n sp = a a a a ,四維正交參數分別代表 軌跡的平均值、斜率、加速率和彎曲率。由於spn於漢語五個聲調的分佈差異極大,故依詞彙聲 調(lexicon tone)對spn每一維做語速正規化,其數學式如下: ( ) ( ) ( ( ), , )( ( ), , ) ( , ) ( , ) sp sp sp n n n sp g n g n n sp i SR k t i sp i t i t i SR k t i µ σ µ σ − ′ = % × + % (2.9)
其中 ( , , ) 4( , ) 4( , ) sp SR t i b t i SR c t i
µ
% = ⋅ + (2.10) ( , , ) 5( , ) 5( , ) sp SR t i b t i SR c t iσ
% = ⋅ + (2.11) 分別代表spn第 i 維、第 t 聲調平均值與標準差之語速正規化函數所表示,正規化函數由一階 多項式所形成;µgsp( , )t i 和 ( , ) sp g t i σ 為整體語料庫的平均值與標準差。 圖 2.7 為一例子,為 spn(2)(即軌跡斜率a )在第四聲調的語句(a)平均值與(b)標準差對 SR1n 之分佈。由(a)發現 a1 平均值隨著 SR 增加而負增加,表示第四聲調在慢語速的基頻軌跡斜率 較快語速來得陡峭;由(b)可看出 a1 標準差會隨著 SR 一起增加,表示第四聲調的基頻軌跡在 慢語速的變動範圍較大。 0.15 0.2 0.25 0.3 -0.2 -0.18 -0.16 -0.14 -0.12 -0.1 -0.08 -0.06 SR (sec/syllable) a 1 Utt. mean Fitting curve 0.15 0.2 0.25 0.3 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 SR (sec/syllable) a 1 Utt. std. Fitting curve (a) (b) 圖 2.7:spn(2)於第四聲調之語句(a)平均值 vs. SR,(b)標準差 vs. SR2.3.4 音節能量位階
音節能量位階
音節能量位階
音節能量位階之
之
之
之正規化
正規化
正規化
正規化
一般來說,音節能量與錄音條件相關性甚大,例如麥克風與語者距離、麥克風錄音品質、 錄音環境等等因素,亦藉由觀察音節能量分佈,確實發現每個語句的能量位階受錄音條件影 響,遠大於受語速之影響。因此,本研究的音節能量採語句為基礎的高斯正規化。2.3 語速
語速
語速
語速韻律模型之設計
韻律模型之設計
韻律模型之設計
韻律模型之設計
本節提出一修正型 PLM 演算法來訓練一個語速相依韻律模型,訓練結果包括四個韻律子 模型及兩種韻律標記結果,兩種標記分別為韻律狀態標記及停頓標記,四個韻律子模型主要為 描述觀察到的韻律聲學特徵參數、語言參數及韻律階層架構之間的關係。本研究假設語速在韻 律聲學特徵參數所造成的影響,已被 2.2 節所提出之正規化方法合理消除。因此,我們可使用 修正型 PLM 演算法對這些不同語速的語句訓練一個 HPM,但仍需要使部份 HPM 模型參數與 語速相依,以補償語速對於韻律高層次的影響。由於停頓發生的頻率與語速有極大相關性[3], 例如:語者說話速度快時,會產生詞邊界停頓易被遺漏之現象,而說話速度很慢時,停頓則容 易被強調,因此本研究對 HPM 中的停頓語法子模型考慮語速影響,詳細將介紹於 2.3.4 小節; 另外,在先前的研究[3]亦發現,韻律狀態的轉移受到語速影響,最明顯的例子為長停頓發生 時,語速越快則韻律狀態的轉移範圍越大,反之語速越慢其轉移範圍越小,故同樣地對韻律狀 態子模型進行修正,使其考慮語速影響因子,詳細將介紹於 2.3.3 小節。 修正型 PLM 演算法可視為一個韻律標記過程,並同時更新模型參數。在給定語料庫之韻 律聲學特徵參數集合 A、相對應的語言參數集合 L 及語速 SR 之下,找出一組最佳韻律標記集 合 T,整個過程可以看成一參數最徍化問題,即* =arg max (P , )=arg max ( ,P , )
T T T T | A, L SR T A | L SR (2.12) 韻律標記集合 T={B, PS}包含兩種重要的韻律訊息,第一種為音節邊界的停頓標記(Break Type),用來表示階層式架構的韻律組成份子邊界,本論文定義韻律邊界停頓標記集合為 B={B0, B1, B2-1, B2-2, B2-3, B3, B4};第二種韻律標記為音節韻律狀態分為 PS={p, q, r},其所代表意 義分別為經過正規化和量化的音節基韻律態 p、音節長度韻律狀態 q 及音節能量韻律狀態 r, 正規化後的韻律狀態扣除了音節層次的貢獻,以基頻韻律狀態來說,扣除聲調和連音的影響因 素,音長或能量韻律狀態則扣除聲調、基本音節類型或韻母類型等影響因素。 本論文韻律聲學參數 A={X, Y, Z}分為兩類,第一類為音節本身的聲學參數 X={sp, sd, se},分別為音節基頻軌跡 sp、音節長度 sd 及音節能量位階 se,本研究假設此類聲學參數與韻
律狀態標記有很大相關性,與音節邊界停頓標記相關性非常小,本論文稱 X 為音節韻律參數 (syllable prosodic feature);第二類為音節邊界的聲學參數{Y, Z}={pd, ed, pj, dl, df},分別為音 節邊界的停頓時長(pause duration, pd)、能量低點位階(energy-dip level, ed)、正規化基頻差 (normalized pitch jump, pj)及兩種正規化長度拉長因子(normalized duration lengthening factor, dl and df)等,假設此類型的聲學參數與停頓標記有很大相關性,與韻律狀態標記的相關性很小, 本論文稱 Y={pd, ed}為音節內韻律參數(inter-syllabic prosodic feature)、Z={pj, dl, df}為差分韻 律參數(differential prosodic feature);最後 SR 為本論文所定義的語速測量值,即語句的平均音 節長度。
在語言參數方面,用 L 表示所有的語言參數集合。其中特別將音節聲調、基本音節類型 與韻母類型從 L 中獨立出來,用意在於這三個語言參數對音節基頻軌跡、音節長度及音節能 量位階有顯著的影響,把剩餘的語言參數統一定義為 l(reduced linguistic feature set)。完整的符 號定義整理於表 2.1。
表 2.1:韻律標記、聲學參數及語言參數之表示符號
T: prosodic tag B: break type={B0, B1 ,B2-1, B2-2, B2-3, B3, B4}
PS: prosodic state p: pitch prosodic state
q: duration prosodic state
r: energy prosodic state
A: prosodic feature X: syllable prosodic feature sp: syllable pitch contour
sd: syllable duration
se: syllable energy level
Y: inter-syllabic prosodic feature pd: pause duration
ed: energy-dip level
Z: differential prosodic features pj: normalized pitch jump
dl: normalized duration lengthening factor 1
df:normalized duration lengthening factor 2
SR: speaking rate
L: linguistic feature l: reduced linguistic feature set
t: syllable tone sequence
s: base-syllable type sequence
綜合上述之討論,可將P T A L SR( , | , )改寫成以下形式: ( , | , ) ( | , ) ( | , ) ( , , | , , ) ( , | , ) ( | , , ) ( , | , ) ( | , ) ( | , ) P P P P P P P P P = = ≈ T A L SR A T L T L SR X Y Z B PS L B PS L SR X B PS L Y Z B L PS B SR B L SR (2.13) 其中P X B PS L( | , , )稱為音節韻律模型,用來敍述音節韻律參數受到停頓標記B、、、、韻律狀態PS 和 語言參數 L 之間的影響而產生的變化;P Y Z B L( , | , )稱為停頓聲學模型,用以敍述在各個不同 停頓標記B和語言參數L下,其韻律邊界的聲學特性;P PS B SR( | , )稱為修正型韻律狀態模型, 描述了韻律狀態在不同停頓標記B及不同語速SR下的轉移變化;P B L SR( | , )稱為修正型停頓 語法模型,描述在不同的語言參數L 及不同語速下,各種停頓標記出現的頻率。以下將分四小 節針對這四種韻律模型做更深入的探討。
2.3.1 音節韻律模型
音節韻律模型
音節韻律模型
音節韻律模型
音節韻律模型P X B PS L( | , , )可進一步分解成三個獨立子模型,分別用來模擬音節基頻軌 跡、音節長度及音節能量位階,其數學式如下: 1 -1 -1 1 1 1( | ,
, )
(
| , , ) ( | , , , ) ( | , , , )
(
|
,
,
)
(
| , , , )
(
| , , , )
N N N n n n n n n n n n n n n n n n n n n np
p
p
p
p
B
p t
+p sd q t s u
p se r t f u
= = =≈
≈
∏
∏
∏
X B PS L
sp B p t
sd q t s u
se r t f u
sp
(2.14) 1 -1 -1 ( n| nn , n,nn ) p sp B p t+ 用以模擬第 n 個音節基頻軌跡spn,在此假設所觀察到的spn受到的影響因素(Affecting Pattern, AP)為:目前的聲調tn、目前的基頻韻律狀態pn、以及在給定停頓標記Bn−1和
n B 時,前後各一個音節聲調tn−1和t 所造成的連音影響,此處n -1=( -1, ) n n n n B B B , 1 -1 ( -1, , 1) n n n n n t + = t t t+ 。而spn
是將音節基頻軌跡進行正交展開(orthogonal expansion),投影到四個Legendre多項式基底所得 到的四維正交參數[21],依以上描述可將spn表示成 1 1,n1 ,n n n n n n n r f b n = n + t + p + B− t− + B t+ + sp sp sp β β β β µ (2.15) 在(2.15)式中,
tp
n是tone pair 1 ( , 1) n n n n t + t t + = ,βtn及βpn則分別為目前音節音調tn及目前音節韻律狀態pn的APs,其中韻律狀態的影響只限制對目前音節的LogF0 level,故將βpn 的四維正交係 數,僅第一維設為非零值; 1, 1 n n n f B− t− β 及 1 ,n n n b B t+ β 分別是第n-1個和第n+1個音節所貢獻的前後連音
效應APs;
µ
sp為總體平均值(global mean),僅第一維為非零值;r n sp 為正規化後的spn,即spn 扣除βtn、βpn、 n1,nn1 f B− t− β 、 1 ,n n n b B t+ β 和µsp的殘餘值(residual),圖 2.8 顯示出spn與這些影響因子之 間的關係,在此假設 r n sp 為一平均值為零的高斯分佈隨機變數,即N sp 0 R( rn; , sp),因此得到 1 1 1 1 1 1 , , ( | , , ) ( ; n n , ) n n n n n n n t f b n n n t n t p B t B t sp sp p p B t N + − − + − − = + + + + sp sp β β β β µ R (2.16) 其中Rsp定義為 r n sp 的共變數矩陣(covariance matrix)。 1 n− sp Bn−1 spn Bn spn+1 1, 1 n n f B− tp− β , n n b B tp β n t β n p β 圖2.8:音節基頻軌跡與其影響因素關係圖 依此類推,第二個模型和第三個模型可表示成:
(
|
,
, )
(
;
,
)
n n n n n n n n t s q sd sdp sd
q s t
=
N sd
γ
+
γ
+
γ
+
µ
R
(2.17)(
|
,
, )
(
;
,
)
n n n n n n n n t f r se sep se
r
f t
=
N se
ω
+
ω
+
ω
+
µ
R
(2.18) (2.17)式模擬了音節時長sdn,其中γ
tn、γ
sn和γ
qn分別為聲調、基本音節類型和韻律狀態對sdn 的 APs,µ
sd和R
sd分別為sdn總體平均及其殘餘值之變異數;(2.18)式模擬了音節能量位階 n se,其中ω
tn、ω
sn和ω
qn分別為聲調、聲母類型和韻律狀態對sen的APs,µse和R
se則分別為sen 總體平均及其殘餘值之變異數。2.3.2 停頓聲學模型
停頓聲學模型
停頓聲學模型
停頓聲學模型
將停頓聲學模型P Y Z B L( , | , )做進一步分解 1( ,
, )
( ,
, )
(
,
,
,
,
|
,
)
N n n n n n n n nP
P
p pd ed
pj dl df
B
=≈
≈
∏
Y Z | B L
Y Z | B l
l
(2.19) 在此使用音節內及差分韻律參數{Y, Z}={pd, ed, pj, dl, df}描述韻律邊界的聲學特性,pdn為第n 個音節跟隨的接合點(juncture n,之後以第n個接合點表示)停頓長度;edn為第n個接合點的 能量下降程度;pjn為跨越第n個接合點的正規化基頻差,其定義如下: pjn =(spn+1(1)−β
tn+1(1)) (− spn(1)−β
tn(1)) (2.20) 而兩種正規化長度拉長因子dl和df定義如下:dl
n=
(
sd
n−
γ
tn−
γ
sn) (
−
sd
n−1−
γ
tn−1−
γ
sn−1)
(2.21)df
n=
(
sd
n−
γ
tn−
γ
sn) (
−
sd
n+1−
γ
tn+1−
γ
sn+1)
(2.22) 由於對韻律停頓而言l 的空間仍太大,故n 本研究藉由分類樹與決策樹(Classification andRegreesion Tree, CART)演算法來估計p pd ed( n, n,pj dl dfn, n, n|B ln, n),其節點分類標準依據最大概
似函數增益(maximum likelihood gain)搭配一個事先設計好的問題集去實施CART演算法,依據 不同的韻律邊界停頓將所有音節邊界的pdn、edn、pjn、dln、dfn做好分類,並於決策樹的每
個終止節點(leaf node)統計參數分佈。在此我們將pdn以伽瑪分佈(Gamma distribution)來模擬,
而 edn 、 pjn 、 dln 、 dfn 以 高 斯 分 佈 模 擬 , 假 設 五 種 聲 學 間 彼 此 互 相 獨 立 , 因 此 ( n, n, n, n, n| n, n) p pd ed pj dl df B l 會是一個伽瑪分佈和四個高斯分佈的乘積,其數學式如下:
{
}
1 2 , , , , , , 1 2 2 , , , , , , , , 2 , , , ,(
,
,
,
,
|
,
)
(
;
,
) (
;
,
)
(
;
,
) (
;
,
)
(
;
,
)
n n n n n n n n n n n n n n n n N n n n n n n n n N n B L B L n ed B L ed B L n n pj B L pj B L n dl B L dl B L n df B L df B Lp pd
ed
pj
dl df
B
g pd
N ed
N pj
N dl
N df
α
β
µ
σ
µ
σ
µ
σ
µ
σ
= =≈
∏
∏
l
(2.23)2.3.3 修正型韻律狀態模型
修正型韻律狀態模型
修正型韻律狀態模型
修正型韻律狀態模型
韻律狀態模型P PS B SR( | , )進一步以三個子模型近似之,如下式所示:
P(PS | B SR, )≈P(p | B SR, ) (P q | B SR, ) (P r | B SR, ) (2.24)
分別用來模擬音節基頻、長度及能量三種韻律狀態。本研究假設目前的韻律狀態僅與前一韻律 狀態及前一停頓標記有關,使用一階馬可夫模型(1 order Markov Model)實現之,並以bin來區 分不同語速所造成的影響,P p | B SR( , )、P q | B SR( , )、P r | B SR( , )最後被表示如下: 1 1 1 1 n 2 ( , ) ( |bin( )) ( | , , bin( )) N n n n n P p p SR p p p− B− SR = ≈
∏
p | B SR , (2.25) 1 1 1 1 n 2 ( , ) ( |bin( )) ( | , , bin( )) N n n n n P p q SR p q q− B− SR = ≈ ∏
q | B SR , (2.26) 和 1 1 1 1 n 2 ( , ) ( |bin( )) ( | , , bin( )) N n n n n P p r SR p r r− B− SR = ≈ ∏
r | B SR (2.27)其 中 p p( 1|bin(SR1)) 、 p q( |bin(1 SR1)) 及 p r( |bin(1 SR1)) 表 示 三 種 韻 律 狀 態 的 初 始 機 率(initial
probability); p p( n| pn−1,Bn−1, bin(SRn))、p q( n |qn−1,Bn−1, bin(SRn))及 p r( |n rn−1,Bn−1, bin(SRn))表示三
種韻律狀態,在給定停頓標記Bn−1及語速SRn之情況下,從第n-1個音節的韻律狀態到第n個音
節韻律狀態之轉移機率(transition probability);bin(.)為索引函數(index function)。
2.3.4 修正
修正
修正
修正型停頓語法
型停頓語法
型停頓語法
型停頓語法模型
模型
模型
模型
首先,修正型停頓語法P B L SR( | , )模型可先簡化為P B l SR( | , ),並假設每個音節邊界可分 開模擬,因此可表示成 1 n 1 ( , ) ( | , ) N n n n P p B SR − = =∏
B | l SR l (2.28) 其中p B( n|ln,SRn)由兩個步驟建構而成,第一步:使用 CART 演算法去對標記結果Bn訓練一顆 決策樹,並對決策樹所有終止節點估計 (p Bn|ln);第二步:對步驟一所建構的決策樹所有終止節點之七種停頓標記,使用一階多項式曲線來模擬停頓標記出現頻率對SR的關係,其數學式 如下:
, ,
, ,
all break types all break type
(
| ,
)
(
| ,
)
(
| ,
)
n n n m j n m j n n n n n n x j n x j x xP B
m
SR
c
SR
d
P B
m
SR
P B
x
SR
c SR
d
∈ ∈=
+
=
=
≈
=
+
∑
∑
l
l
l
(2.29) 其中 j 為語言參數向量l 所對應到決策樹的終止節點索引值;n cm j, 及dm j, 為停頓標記 m、終止節 點 j的線性迴歸係數。2.4 修正型
修正型
修正型
修正型 PLM 演算法之訓練過程
演算法之訓練過程
演算法之訓練過程
演算法之訓練過程
此章節將介紹如何使用修正型PLM演算法來訓練2.3節所提出之韻律模型,PLM演算法 是基於最大概似度法則(Maximum Likelihood, ML),對所有語句找出最佳的韻律標記,並估計 模型參數。首先,我們依2.3節所設計之8個模型定義一目標函數(objective function)如下: 1 -1 1 1 1 1 1 1 1 1 1 1 n 1 1 n 1 1 n 2 ( | , , ) ( | , , ) ( | , , ) ( |bin( )) ( |bin( )) ( |bin( ))( | , , bin( )) ( | , , bin( )) ( | , , bin( ))
N n n n n n n n n n n n n n n n N n n n n n n n n n n Q p p B t p sd q t s p se r t f p p SR p q SR p r SR p p p B SR p q q B SR p r r B SR + − = − − − − − − = =
∏
∏
sp(
)
1 n 1 ( , , , , | , ) ( | , ) N n n n n n n n n n n p pd ed pj dl df B p B SR − = ∏
l l (3.21) 接著再採取一連串的最佳化程序,逐項估計各個子模型的模型參數及標記韻律標記,重複 執行此程序直到收斂。整個演算法的實現分成兩個部份:初始化及疊代訓練,我們將在 2.4.1 和2.4.2分別介紹。2.4.1 初始化
初始化
初始化
初始化
初始化過程分兩部份:(a)標記所有音節邊界的初始停頓標記,(b)使用 ML法則估計 8個 子模型的初始模型參數及標記每個音節的初始韻律狀態。(a) 標記所有音節邊界的初始停頓標記
初始停頓標記方法是採取[22]所提出之決策樹來實現,如圖 2.9 所示。建構決策樹主要是 由音節邊界之聲學特性配合一般所認知的語言特性所設計出來的,其中Tr1~Tr8是由韻律邊界 的聲學特性所決定,詳細決定Tr1~Tr8的演算法如附錄一所示。我們期望以此決策樹來使初始 停頓標記符合以下之定義:首先,對於大多的PM音節邊界會有長的停頓時長,容易被標為主
要停頓(major break),對應於階層式韻律架構B3及B4;其次,在non-PM, inter-word的音節邊
節中,具有中等停頓時長定義為 B2-2、具有中等基頻跳躍定義為 B2-1、具有中等音節時長拉 長為B2-3,這些停頓類別皆屬次要停頓(minor break);最後,大多數intra-word的邊界停頓時 長都很短,屬非停頓(non-break),對應到韻律架構中的B0及B1,其中B0屬於緊密連接(tightly
coupling)的韻律邊界,相對於 B1 有較小的基頻停頓(pitch pause)和較大的能量低點位階
(energy-dip level)。 1 n pd ≥Th 2 n pd ≥Th 3 n pd ≥Th 6 and n ed ≥Th 6 and n ed ≥Th 圖2.9:初始化停頓標記決策樹 (b) 估計8個子模型的初始模型參數及標記每個音節的初始韻律狀態 有了初始化停頓標記後,我們使用CART演算法來建構停頓聲學模型及停頓語法模型,再 使用(2.29)式修正停頓語法模型,其中 Θ 為CART所使用之問題集,詳細內容如附錄二所示。
至於 音節韻律模 型則是用一個漸進式的估測程序,首先估 測總體平均 值(global mean)的
APs{µ,µ ,d µ }e ,接下來依序估測聲調APs{βt,
γ
t,α
t}、基本音節類型與韻母類型APs{γ
s,α
f}、連音效應APs{βB tpf, ,βbB tp, }和韻律狀態APs{βp,
γ
q,α
r}。其中初始的韻律狀態則是將音節基頻軌 跡、長度及能量位階各別扣除其它APs的殘餘值做向量量化(vector quantization, VQ),將量化 之後的碼字(codeword)當作初始韻律狀態。最後,修正型韻律狀態模型P p B SR( | , )、P q B SR( | , ) 和P r B SR( | , )則是利用已初始化停頓標記及韻律狀態估計而成。2.4.2 疊代訓練
疊代訓練
疊代訓練
疊代訓練
經初始化後,我們使用一疊代過程來訓練模型,其步驟如下: 步驟1:固定其它APs,更新聲調的APs{β ,tγ
t,α
t}。 步驟2:固定其它APs,更新連音效應的APs{ f, B tp β , b, B tp β },接著更新共變數矩陣R。 步驟3:固定其它APs,更新基本音節類型及韻母類型的APs{γ
s,α
f },接著更新變異 數Rd和Re。 步驟4:利用維特比(Viterbi)演算法重新標記所有語句之韻律狀態序列,使得目標函數Q 達到最大值,然後更新韻律狀態的ARs{βp,γ ,q α }r ,最後更新修正型韻律狀態 模型P p B SR( | , )、P q B SR( | , )和P r B SR( | , )以及共變數矩陣 R 、變異數R 和d R 。e 步驟5:利用維特比(Viterbi)演算法重新標記所有語句之停頓標記序列,使得目標函數Q 達到最大值,接著更新修正型韻律狀態模型P p B SR( | , )、P q B SR( | , )與P r B SR( | , ) 以及共變數矩陣R、變異數R 和d R 。e 步驟6:利用CART演算法和 Θ 重新建構決策樹,分別更新停頓聲學模型 p pd ed pj dl df B l( n, n, n, n, n| n, )n 及修正型停頓語法模型P B( n| ,ln SRn)。 步驟7:重複步驟1到7的過程直到收斂為止。第三章
第三章
第三章
第三章 語速韻律模型訓練結果與分析
語速韻律模型訓練結果與分析
語速韻律模型訓練結果與分析
語速韻律模型訓練結果與分析
本實驗所使用訓練語料為SR-Treebank語料庫,共1478句,總音節數為203746個,快、 正常、中等和慢語速四個語料庫韻律聲學參數的統計資料列於表3.1。由表可觀察到音節Log-F0 軌跡變異數向量的第二、三、四維都隨著語速變慢而上升,表示在語速慢時,基頻軌跡的變化 幅度較為劇烈,而語速快時,常發出不完整基頻軌跡,動態變化被侷限在較小範圍;音節長度 與語速相關性最大,其平均值或變異數皆隨著語速變慢而增加;至於音節能量位階,由於正常 語速語料庫的錄音條件與其它三者不同,故統計結果有所差異。 表3.1:SR-Treeabk韻律聲學參數之統計資訊 音節 Log-F0平 均值 音節Log-F0軌跡共 變數矩陣 音節長 度平均 值 音節長度 變異數 音節能 量位階 平均值 音節能 量位階 變異數 Fast 5.28 [422, 51, 11, 3]×10−4 0.18 400×10−5 52.5 22.3 Normal 5.31 [546, 90, 17, 5] 4 10− × 0.20 380 5 10− × 60.0 48.6 Median 5.25 [407, 89, 17, 5]×10−4 0.24 510×10−5 53.1 22.7 Slow 5.25 [433, 94, 18, 4]×10−4 0.26 650×10−5 53.0 23.5 將以上韻律聲學參數和停頓時長經過語速正規化後,採取修正型PLM演算法疊代訓練至71次達到收斂,其對應的目標總概似度(total likelihood of objective function)如圖3.1所示。接 下來的章節將對模型訓練結果及韻律標記結果進行分析。
圖3.1:疊代次數與目標總概似度
3.1 韻律模型參數之分析
韻律模型參數之分析
韻律模型參數之分析
韻律模型參數之分析
此節針對四個韻律子模型的訓練結果進行探討與分析,並與語料庫為基礎之 HPM[3] (Corpus-based HPM)做比較。3.1.1 音節韻律模型
音節韻律模型
音節韻律模型
音節韻律模型
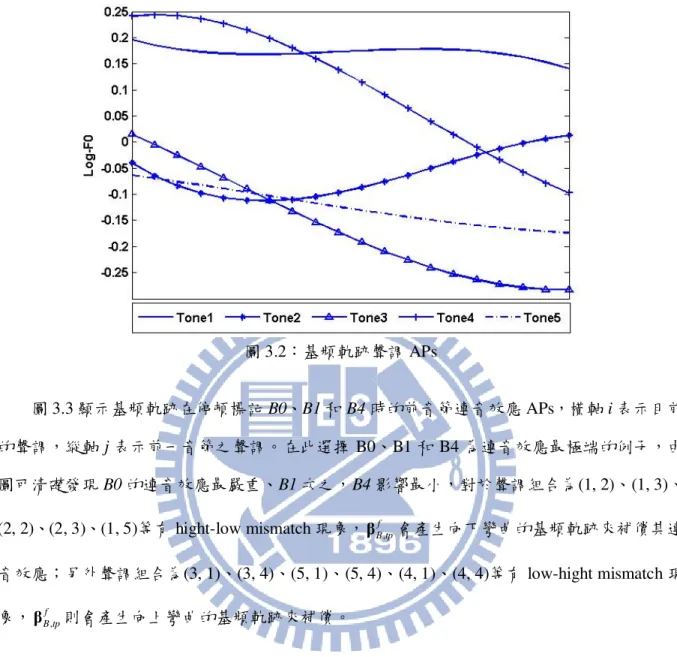
音節韻律模型可分成三個子模型,分別用以模擬音節基頻軌跡、音節時長及音節能量位 階,本節將探討各種APs對於音節韻律所造成的影響,以及模型參數與語速間的關係變化。 首先,由音節基頻軌跡韻律模型開始,影響因子包含聲調、連音效應和韻律狀態。圖 3.2 顯示基頻軌跡的聲調APs,此結果與過去研究[15]所得之基頻軌跡相符合。圖3.2:基頻軌跡聲調APs 圖3.3顯示基頻軌跡在停頓標記B0、B1和B4時的前音節連音效應APs,橫軸i表示目前 的聲調,縱軸j表示前一音節之聲調。在此選擇 B0、B1 和B4為連音效應最極端的例子,由 圖可清礎發現B0的連音效應最嚴重、B1次之,B4影響最小,對於聲調組合為(1, 2)、(1, 3)、 (2, 2)、(2, 3)、(1, 5)等有hight-low mismatch現象, f, B tp β 會產生向下彎曲的基頻軌跡來補償其連 音效應;另外聲調組合為(3, 1)、(3, 4)、(5, 1)、(5, 4)、(4, 1)、(4, 4)等有low-hight mismatch現 象, f, B tp β 則會產生向上彎曲的基頻軌跡來補償。
圖3.3:基頻軌跡在停頓標記B0、B1和B4時前音節連音效應APs,在此tp = (i, j) 圖3.4顯示基頻軌跡在停頓標記B0、B1和B4時的前音節連音效應APs,橫軸i表示目前 的聲調,縱軸j表示下一音節聲調。由圖觀察到,比較於前音節連音效應 f, B tp β ,後音節連音效 應 b, B tp β 變化範圍明顯小了很多,表示後音節連音效應的影響程度不如前音節,此結果與先前研 究[24]符合。其中,特別注意到聲調組合為(3, 3)時, b, B tp β 產生劇烈上揚的曲線,這是因為此聲
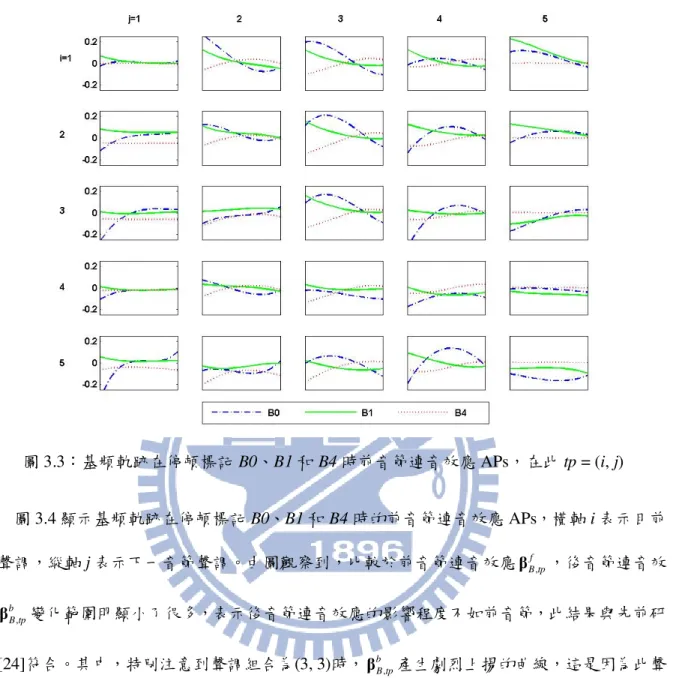
圖3.4:基頻軌跡在停頓標記B0、B1和B4時後音節連音效應APs,在此tp = (i, j)
接下來為音節長度韻律模型分析,影響因子包含聲調、基本音節類型和韻律狀態。圖3.5(a)
顯示音節長度的聲調APs,其中漢語一、二聲的音節長度都較長,五聲特別短,圖3.5(b)顯示音 節長度的基本音節類型APs,此基本音節類型是把漢語411基本音節類型依發音特性分成82
類,其中第19類的音節發音最長,此類對應到411音節類型包括” qu”、 ” du” 和” bu”;第59
(a) (b)
圖3.5:音節長度之(a)聲調APs,(b)基本音節類型APs
最後是音節能量位階韻律模型,影響因子包含聲調、韻母類型及韻律狀態。圖3.6(a)顯示 音節能量位階的聲調APs,其中漢語以一、四聲音節能量位階最大,二、三和五聲則較小,圖
3.6(b)顯示音節能量位階的韻母類型APs,在此韻母類型有40類,其中第19類的”wu”音節能量
位階最小,此韻母類型對應到411音節類型如”su”、 ”tu”等;第26類的”wa”音節能量位階最大, 此韻母類型對應到411音節類型如”zhua”、 ”gua” 等。
(a) (b)
圖3.6:音節能量位階之(a)聲調APs,(b)韻母類型APs
利用修正型PLM演算法所標記出來的{B, PS},搭配其所對應之語言參數{t, s, f},可以圖
再利用語速正規化參數將sp, sd, se^ ^ ^ 還原回各自原本的語速,得到最後的sp , sd , se 。 ' ' ' ( | , , ) P X B PS L ,q,r B, PS ={p },{t, s, f} ^ ^ ^ sp,sd,se ' ' ' sp ,sd ,se SR 圖3.7:以音節韻律模型及語速正規化參數來重建韻律聲學特徵參數之流程圖
表3.2列 出以不同APs組合 下,各韻 律參數重建 之總殘餘 誤差值(Total Residual Error, TRE),即扣除各種APs組合後,韻律參數殘餘值變異數與原始韻律參數變異數之比值。其中, 加入韻律狀態APs後,各韻律參數之TRE都變得非常小,為所有影響因素中最重要的APs。
表3.2:使用音節韻律模型不同APs組合下音節韻律參數之TREs
Log-F0 Duration Energy level
APs TRE APs TRE APs TRE
+Tone 66.9% +Tone 70.2% +Tone 61.2%
+Coarticulation 60.1% +Base-syllable 51.1% +Final 47.7%
+Prosodic state 0.7% +Prosodic state 1.1% +Prosodic state 1.4%
圖3.8利用βt和
γ
t來模疑快語速與慢語速之五種聲調的音節基頻軌跡。從圖可發現不管快 速或慢速,聲調五的長度皆為最短,其餘四個聲調長度則差異不大。基頻軌跡整體來說,快語 速的基頻軌跡動態範圍(dynamic range)較慢語速小,因說話速度快使得基頻軌跡不完整,而說 話慢時會產生較完整的五種聲調基頻軌跡,故快語速的基頻軌跡可視為慢語速中間的一部份 [3]。接下來各別分析快慢語速的五種聲調:(1)一聲的基頻軌跡形狀大致無差異,(2)二聲的基 頻軌跡會上揚,在慢速上揚程度最大,(3)三聲在慢速的基頻軌跡尾端會往下走,而快速較為 平坦,(4)四聲基頻軌跡在慢速時的起始點較高、斜率較陡且動態範圍較大,快速則反之,(5)輕聲的基頻軌跡在快速時較為平坦,在慢速時像低階的三聲。此模擬結果與[3]一致。 圖3.8:快語速與慢語速之五種聲調基頻軌跡模擬圖
3.1.2 停頓聲學模型
停頓聲學模型
停頓聲學模型
停頓聲學模型
停頓聲學模型由CART演算法建構而成,用以描述七種停頓標記B、語言參數l以及音節間 韻律參數{Y}={pd, ed}和音節差韻律參數{Z}={pj, dl, df}之間的關係。圖3.9顯示在不同停頓標記 下,決策樹根節點(root node)五種韻律參數的機率分佈。由圖可發現越上層韻律架構的停頓標 記如B3、B4,擁有較長的停頓時長、較低的能量低點、較明顯的基頻跳躍及音節拉長因子; 而B0、B1的停頓時長都非常的短,但B0的能量低點較大,表示B0為兩音節緊密連接的邊界; B2-2則有中等的停頓時長;B2-1和B2-3的能量低點與停頓時長分佈與B1相似,但B2-1擁有較明 顯的基頻跳躍,B2-3則是音節拉長因子較為明顯。這些韻律參數的特性分佈符合本研究最初所 定義之停頓標記特性。(a) (b) (c) (d) (e) 圖3.9:(a)停頓音節長度,(b)音節能量低點,(c)正規化基頻跳躍值,(d)正規化音節拉長因子1, (e)正規化音節拉長因子2之決策樹根節點機率分佈,其中括號中數值為分佈平均值 停頓時長為停頓標記中最重要的聲學參數,圖3.10顯示了七種停頓標記的平均停頓時長 vs. SR,圖上標出的值,為corpus-based HPM訓練結果[3]。此結果符合預期,B0、B1、B2-1和 B2-1等不具明顯停頓時長的停頓類別幾乎不受SR影響;而B2-2、B3和B4等具明顯停頓時長的
![圖 2.1:中文語音韻律階層式架構概念 [19]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8653593.194196/17.918.123.790.100.919/圖21中文語音韻律階層式架構概念19.webp)


![圖 3.1 :疊代次數與目標總概似度 3.1 韻律模型參數之分析 韻律模型參數之分析 韻律模型參數之分析 韻律模型參數之分析 此節針對四個韻律子模型的訓練結果進行探討與分析,並與語料庫為基礎之 HPM[3] (Corpus-based HPM) 做比較。 3.1.1 音節韻律模型 音節韻律模型音節韻律模型 音節韻律模型 音節韻律模型可分成三個子模型,分別用以模擬音節基頻軌跡、音節時長及音節能量位 階,本節將探討各種 APs 對於音節韻律所造成的影響,以及模型參數與語速間的關係變化。 首先,由音](https://thumb-ap.123doks.com/thumbv2/9libinfo/8653593.194196/33.918.117.801.106.723/韻律子音節韻律模型音節韻律模型音節韻律音節三個子對於音節由音.webp)