粒子群最佳化演算法於估測基礎矩陣之應用 - 政大學術集成
88
0
0
全文
(2) 粒子群最佳化演算法於估測基礎矩陣之應用 Particle Swarm Optimization Algorithms for Fundamental Matrix Estimation. 研 究 生:. 劉恭良. Student:Kung-Liang Liu. 指導教授:. 何瑁鎧. Advisor:Maw-Kae Hor. 立. 政 治 大. 國立政治大學. ‧ 國. 碩士論文. 學. 資訊科學系. ‧. io. sit. y. Nat. A Thesis. er. submitted to Department of Computer Science. n. a. v. l C Chengchi University National ni. hengchi U. in partial fulfillment of the Requirements for the degree of Master in Computer Science. 中華民國一百年七月 July 2011.
(3) 粒子群最佳化演算法於估測基礎矩陣之應用. 摘要. 基礎矩陣在影像處理是非常重要的參數,舉凡不同影像間對應點之計算、座 標系統轉換、乃至重建物體三維模型等問題,都有賴於基礎矩陣之精確與否。本 論文中,我們提出一個機制,透過粒子群最佳化的觀念來求取基礎矩陣,我們的. 政 治 大. 方法不但能提高基礎矩陣的精確度,同時能降低計算成本。. 立. ‧ 國. 學. 我們從多視角影像出發,以 SIFT 取得大量對應點資料後,從中選取 8 點進 行粒子群最佳化。取樣時,我們透過分群與隨機挑選以避免選取共平面之點。然. ‧. 後利用最小平方中值表來估算初始評估值,並遵循粒子群最佳化演算法,以最小. al. er. io. sit. y. Nat. 疊代次數為收斂準則,計算出最佳之基礎矩陣。. v. n. 實作中我們以不同的物體模型為標的,以粒子群最佳化與最小平方中值法兩. Ch. engchi. i n U. 者結果比較。實驗結果顯示,疊代次數相同的實驗,粒子群最佳化演算法估測基 礎矩陣所需的時間,約為最小平方中值法來估測所需時間的八分之一,同時粒子 群最佳化演算法估測出來的基礎矩陣之平均誤差值也優於最小平方中值法所估 測出來的結果。. 關鍵字:影像處理、基礎矩陣、粒子群最佳化、最小平方中值法。. i.
(4) Particle Swarm Optimization Algorithms for Fundamental Matrix Estimation. Abstract. Fundamental matrix is a very important parameter in image processing. In corresponding point determination, coordinate system conversion, as well as. 政 治 大 important role. Hence, obtaining 立 an accurate fundamental matrix becomes one of the. three-dimensional model reconstruction, etc., fundamental matrix always plays an. ‧. ‧ 國. 學. most important issues in image processing.. In this paper, we present a mechanism that uses the concept of Particle Swarm. sit. y. Nat. Optimization (PSO) to find fundamental matrix. Our approach not only can improve. n. al. er. io. the accuracy of the fundamental matrix but also can reduce computation costs.. Ch. engchi. i n U. v. After using Scale-Invariant Feature Transform (SIFT) to get a large number of corresponding points from the multi-view images, we choose a set of eight corresponding points, based on the image resolutions, grouping principles, together with random sampling, as our initial starting points for PSO. Least Median of Squares (LMedS) is used in estimating the initial fitness value as well as the minimal number of iterations in PSO. The fundamental matrix can then be computed using the PSO algorithm.. ii.
(5) We use different objects to illustrate our mechanism and compare the results obtained by using PSO and using LMedS. The experimental results show that, if we use the same number of iterations in the experiments, the fundamental matrix computed by the PSO method have better estimated average error than that computed by the LMedS method. Also, the PSO method takes about one-eighth of the time required for the LMedS method in these computations.. Keywords: Image processing, fundamental matrix, PSO, Least Median of Squares.. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. iii. i n U. v.
(6) 致謝. 能順利完成碩士論文,要感謝何瑁鎧指導教授,從老師身上學習到如何做研 究的態度與方法。老師曾勉勵我,做任何事情都要做好,我會謹記這句話,不論 往後遇到任何困難與挑戰,都可以克服找到解決的方法。. 感謝華梵大學唐政元教授,對我不辭辛勞的幫忙,給予我磨練的機會,學習 到很多影像處理的相關知識和技術,並且提供豐富的資源讓我進行論文研究。. 政 治 大 感謝口詴委員唐政元教授和吳怡樂教授,他們給我很多寶貴的建議,讓論文 立 ‧. ‧ 國. 學. 內容可以更加完整。. 在研究所學習階段中,感謝逸帆學長、振寰學長、元彰學長、坤信學長、淑. sit. y. Nat. 怡學姐,以及立軒、瑞鴻、明龍、紹暐、姿旻、柏諺。特別要感謝博士班凱軒學. al. n. 鼓勵。. er. io. 長,給予我在課業上以及論文實驗上很多的協助,還有宏敏學長,對我的照顧和. Ch. engchi. i n U. v. 感謝政治大學教務處課務組、教學發展中心、資訊中心、政大書院提供我工 讀的機會,讓我獲得課業以外的寶貴經驗。. 最後要感謝我的父母與姐姐,一直以來的照顧與支持,陪伴著我的成長過程, 讓我有今天的成就,謝謝你們。. 恭良 2011 年 11 月. iv.
(7) 目錄. 第一章 緒論 ............................................................................................1 1.1 前言.................................................................................................................. 1 1.2 研究背景與動機.............................................................................................. 1 1.3 問題描述.......................................................................................................... 3 1.4 論文貢獻.......................................................................................................... 4. 政 治 大 文獻回顧 ....................................................................................5 立. 1.5 論文章節架構.................................................................................................. 4. 第二章. ‧ 國. 學. 2.1 粒子群最佳化演算法...................................................................................... 5 2.2 估測基礎矩陣.................................................................................................. 7. ‧. 第三章 背景技術 ..................................................................................10. y. Nat. sit. 3.1 粒子群最佳化演算法流程............................................................................ 10. n. al. er. io. 3.2 隨機取樣........................................................................................................ 14. i n U. v. 3.3 最小平方法.................................................................................................... 15. Ch. engchi. 3.4 最小平方中值法............................................................................................ 17 3.5 估測基礎矩陣流程........................................................................................ 18. 第四章 以粒子群最佳化演算法估測基礎矩陣 ..................................20 4.1 模擬基礎實驗................................................................................................ 20 4.1.1 平面中粒子群最佳化......................................................................... 20 4.1.2 圓錐近似中粒子群最佳化................................................................. 24 4.2 研究方法與流程............................................................................................ 28 4.2.1 系統架構............................................................................................. 28 4.2.2 評估基礎矩陣..................................................................................... 31 v.
(8) 第五章 實驗結果 ..................................................................................33 5.1 平面中粒子群最佳化實驗結果.................................................................... 33 5.1.1 速度未經過正規化............................................................................. 34 5.1.2 速度經過正規化................................................................................. 46 5.1.3 討論與分析......................................................................................... 55 5.2 圓錐近似中粒子群最佳化實驗結果............................................................ 55 5.2.1 限制固定疊代次數............................................................................. 55 5.2.2 對 Gbest 收斂 ..................................................................................... 57. 政 治 大 5.2.4 討論與分析......................................................................................... 64 立 5.2.3 限制 fitness 值和對 Gbest 收斂 ......................................................... 64. ‧ 國. 學. 5.3 以粒子群最佳化估測基礎矩陣實驗結果.................................................... 65 5.3.1 第一組實驗(3DMAX)資料 ................................................................ 65. ‧. 5.3.2 第二組實驗(LIDAR)資料 .................................................................. 69. sit. y. Nat. 5.3.3 討論與分析......................................................................................... 73. n. al. er. io. 第六章 結論 ..........................................................................................74. i n U. v. 6.1 結論................................................................................................................ 74. Ch. engchi. 6.2 未來工作........................................................................................................ 75. 參考文獻...................................................................................................76. vi.
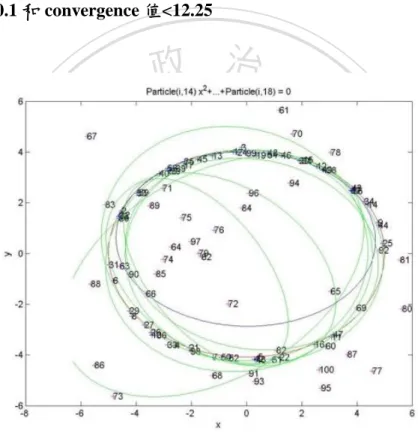
(9) 圖目錄. 圖 1.1:epipolar geometry 示意圖 ............................................................................... 3 圖 2.1:演算法經過三次演化後的路徑圖.................................................................. 6 圖 2.2:19 種估測方法時間比較................................................................................. 7 圖 2.3:圓錐體近似問題示意圖.................................................................................. 8 圖 3.1:粒子群最佳化演算法流程圖........................................................................ 11 圖 3.2:正確資料(1-e)和錯誤資料(e)示意圖 ........................................................... 14. 政 治 大. 圖 3.3:線性近似問題範例圖.................................................................................... 15. 立. 圖 3.4:最小平方中值法示意圖................................................................................ 17. ‧ 國. 學. 圖 4.1:二維平面問題示意圖.................................................................................... 21 圖 4.2:圓錐近似中粒子群最佳化演算法流程圖.................................................... 24. ‧. 圖 4.3:以粒子群最佳化演算法估測基礎矩陣流程圖............................................ 29. y. Nat. sit. 圖 4.4:計算基礎矩陣誤差示意圖............................................................................ 32. n. al. er. io. 圖 5.1:速度未正規化第一次實驗............................................................................ 38. i n U. v. 圖 5.2:速度未正規化第二次實驗............................................................................ 42. Ch. engchi. 圖 5.3:速度未正規化第三次實驗............................................................................ 46 圖 5.4:速度正規化第一次實驗................................................................................ 49 圖 5.5:速度正規化第二次實驗................................................................................ 51 圖 5.6:速度正規化第三次實驗................................................................................ 54 圖 5.7:次數為停止條件............................................................................................ 57 圖 5.8:convergence 值<12.25 為停止條件 .............................................................. 59 圖 5.9:convergence 值<9.8 為停止條件 .................................................................. 60 圖 5.10:convergence 值<7.35 為停止條件 .............................................................. 62 圖 5.11:convergence 值<6.12 為停止條件 .............................................................. 63 vii.
(10) 圖 5.12:convergence 值<4.9 為停止條件 ................................................................ 63 圖 5.12:Gbestfitness < 0.1 和 convergence 值<12.25 為停止條件............................. 64 圖 5.13:3DMAX 實驗相片 ...................................................................................... 66 圖 5.14:3DMAX 拍攝場景 ...................................................................................... 66 圖 5.15:3DMAX 實驗直方圖比較 .......................................................................... 68 圖 5.16:3DMAX 實驗折線圖比較 .......................................................................... 68 圖 5.17:LIDAR 第一組實驗相片 ............................................................................ 69 圖 5.18:LIDAR 第一組實驗直方圖比較 ................................................................ 70. 政 治 大 圖 5.20:LIDAR 第二組實驗相片 ............................................................................ 71 立 圖 5.19:LIDAR 第一組實驗折線圖比較 ................................................................ 71. 圖 5.21:LIDAR 第二組實驗直方圖比較 ................................................................ 72. ‧ 國. 學. 圖 5.22:LIDAR 第二組實驗折線圖比較 ................................................................ 73. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. viii. i n U. v.
(11) 表目錄. 表 1:速度向量正規化演算法................................................................................... 23 表 2:調整 X 位置向量演算法 .................................................................................. 27 表 3:速度未經過正規化第一次實驗....................................................................... 34 表 4:速度未經過正規化第二次實驗....................................................................... 39 表 5:速度未經過正規化第三次實驗....................................................................... 42 表 6:速度正規化第一次實驗................................................................................... 47. 政 治 大. 表 7:速度正規化第二次實驗................................................................................... 49. 立. 表 8:速度正規化第三次實驗................................................................................... 52. ‧ 國. 學. 表 9:3DMAX 場景估測基礎矩陣結果 ................................................................... 67 表 10:3DMAX 場景估測基礎矩陣標準差分佈 ..................................................... 67. ‧. 表 11:LIDAR 場景估測基礎矩陣第一組結果 ....................................................... 70. y. Nat. sit. 表 12:LIDAR 場景估測基礎矩陣第一組結果標準差分佈 ................................... 70. n. al. er. io. 表 13:LIDAR 場景估測基礎矩陣第二組結果 ....................................................... 72. i n U. v. 表 14:LIDAR 場景估測基礎矩陣第二組結果標準差分佈 ................................... 72. Ch. engchi. ix.
(12) 第一章 緒論. 1.1 前言. 政 治 大 在隨機取樣(random sampling)的問題中,如何在大量的搜尋空間中,以較少 立. 取樣次數尋找最佳結果,是過去研究人員追尋的目標。在人工智慧(artificial. ‧ 國. 學. intelligence)[10] 領 域 中 , 制 訂 出 仿 效 大 自 然 生 態 中 的 演 化 機 制 (evolution. ‧. mechanism),通稱為演化式演算法(evolution algorithms),其「隨機性質」和「仿. y. Nat. 效自然」的做法有別於過去其他演算法,本研究選擇以其中一種演化式演算法:. er. io. sit. 粒子群最佳化演算法(Particle Swarm Optimization Algorithms, PSO)[13]為基礎,經 過模擬兩個基礎實驗後,接著以電腦視覺(computer vision)領域中估測基礎矩陣. al. n. v i n matrix)[16]為實驗範例,透過使用粒子群最佳化演算法,達成減少 Ch engchi U. (fundamental. 取樣次數和計算的時間成本,維持過去估測基礎矩陣方法的準確率,以便於未來 進行後續研究應用。. 1.2 研究背景與動機. 過去解決隨機取樣問題時,在沒有奢求時間成本之下,窮舉法(brute-force method)是我們可以直接採用的方法,其做法為將每種取樣組合計算後,直接比 較結果即會找到最佳解。但是在搜尋空間龐大時,我們無法在有限的時間內完成 1.
(13) 所有的取樣和計算時,要找到最佳解是不可能的事情,因此窮舉法並不適合使用 在大量搜尋空間之下。. 貪婪演算法(greedy algorithms)[17]常用於找尋最佳解,過去應用於解決很多 知名問題,他是一種由上而下(top-down)的解題方式,在解決問題時會選定集合 中任一個節點(node)出發,不斷的透過計算更新,在節點周圍空間繼續尋找較佳 解,然後移至該較佳解,直到所有節點計算結束後,最後一個計算出的較佳解就 是問題中搜尋到的最佳解,但是在搜尋空間龐大且需要計算複雜時,使用貪婪演. 政 治 大. 算法會花費大量的計算時間。在需要兼具效能和準確率的目標下,是相當費時的 解題方式。. 立. ‧ 國. 學. 參數估測(parameter estimation)是一種先將搜尋空間中取樣資料先分群的做. ‧. 法,利用計算誤差和設定門檻值的方式,將取樣的資料分為正確資料(inlier)和錯. y. Nat. 誤資料(outlier),兩者的區分在於雜訊(noise)的大小,之後過濾掉錯誤資料以便於. er. io. sit. 減少取樣次數,其中較常使用的方法為最小平方中值法(Least Median of Square, LMedS),雖然可以估測出誤差較小的結果,但是計算的次數仍然太多,也得花. n. al. 費較多的時間成本。. Ch. engchi. i n U. v. 為了能減少取樣次數並且可以維持過去學者研究方法的準確率,我們使用了 粒子群最佳化演算法,並且以估測基礎矩陣為實驗範例,希望仿效自然界中個體、 群體、群集互相影響之特性,保有演化式計算的原理之外,嘗詴結合參數估測的 工具,希望更能提升解題的效率和維持估測基礎矩陣的準確率。. 2.
(14) 1.3 問題描述. 本研究使用粒子群最佳化演算法,估測高準確率的基礎矩陣。進而可以在未 來進行影像處理後續研究。在電腦視覺領域尋找對應點的問題中,大多是利用兩 張或是多張相片。以兩張相片為例,過去有尺度不變特徵轉換(Scale Invariant Feature Transform, SIFT)[12]和擴增(propagation)[11]等方法,可以找到具特徵性質 的對應點,但是這些尋找對應點的方法,無法確保對應點的精確度,有時誤差相 當大。因此有學者提出兩部相機 OL 和 OR 拍攝同一個物體 P 時,在兩張照片上. 政 治 大 知道兩部相機在座標系上的絕對位置,因此我們透過估測基礎矩陣,可以計算出 立. 成像為 pL 和 pR。稱為極線幾何(epipolar geometry)(圖 1.1)的關係,由於我們無法. ‧ 國. 學. 兩部相機的相對位置,且任一張照片上的特徵點可以在另外一張相片繪出極線 (epipolar line)(如圖 1.1 中 EL 和 ER),我們可以在極線附近尋找對應點可能存在的. ‧. 位置,因此,估測基礎矩陣在電腦視覺領域中一直是熱門的研究重點。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 1.1:epipolar geometry 示意圖. 由於估測一組基礎矩陣,使用八點演算法,僅需要八組對應點便可以計算出 結果,因此若 n 組對應點的情況下所有搜尋空間為 C8n ,時間複雜度為 O(n !) ,如 何有效的減少取樣次數並且維持過去演算法的準確率便是我們的目標。 3.
(15) 1.4 論文貢獻. 本論文共有以下三點貢獻:. 1. 降低計算時間成本:我們使用粒子群最佳化演算法,和傳統演算法相比, 可以降低取樣次數。和過去方法相比,演算法計算複雜度較低,根據實 驗結果顯示:與強健式估測方法(最小平方中值法)比較,在接近的取樣 次數下,只需要 1/8 左右的計算時間。. 2.. 政 治 大 維持實驗準確率:跟最小平方中值法比較平均誤差值,我們提出的方法 立. ‧ 國. 學. 仍可以將誤差再縮小,根據實驗數據,粒子群最佳化演算法的標準差小 於平均值的比例較高。. ‧. y. Nat. 3. 結合其他方法及應用:除了使用粒子群最佳化演算法之外,結合過去幾. 入演算法步驟中,協助設計演算法並執行。. n. al. 1.5 論文章節架構. Ch. engchi. er. io. sit. 種參數估測工具,如應用最小平方中值法內建立最小平方中值表格,加. i n U. v. 本論文共分六章。本章為緒論;第二章為文獻回顧,介紹過去我們使用的演 算法和過去學者如何估測基礎矩陣;第三章為相關的背景技術介紹;第四章為研 究方法,描述我們如何推演套用演算法和應用;第五章為實驗結果,對於不同的 實驗條件,我們做比較與分析;第六章為結論和未來工作。. 4.
(16) 第二章 文獻回顧. 本章節分為兩個重點,第一我們介紹粒子群最佳化演算法,並列出過去一些使用 粒子群最佳化演算法的相關文獻,第二我們介紹過去估測基礎矩陣使用的幾種方. 政 治 大. 法,並且會選擇一種過去的估測方法和我們的實驗結果做比較與分析。. 學. ‧ 國. 立. 2.1 粒子群最佳化演算法. ‧. y. Nat. 粒子群最佳化演算化是由 J.Kennedy 和 R.Eberhart 於 1995 年提出一套演化. er. io. sit. 式計算的演算法,此方法是一種基於個體、群體、群集並且結合人工智慧以解決 搜尋最佳解問題,演算法貣源於自然界中鳥群覓食的行為,作者將其推演至社會. al. n. v i n 學行為的問題。在演算法中,個體的行為會因為個體本身過去的經驗和認知影響 , Ch engchi U 並且也會受到整個群體過去的經驗和認知影響,是一個群集的活動,模擬簡化的 社會模型。演算法利用隨機分佈一定數量的粒子個體(particles)組成群體,在社群 空間中不斷演化計算,演化至下一世代之前,會根據粒子個體本身過去經驗和群 體過去經驗進行計算,並且持續不斷的在搜尋空間中找尋最佳解,直到達到我們 給予演算法的停止條件。. 每個粒子個體在搜尋空間中會有自己的位置向量、速度向量,其中向量的維 度會隨著欲解的問題不同而調整,在第四章時,我們會討論在進行主要實驗之前, 先行推演的兩個實驗,向量維度就不同。除了上述兩個向量外,粒子個體還會有 5.
(17) 區域性最佳解(Local best solution,或稱 Personal best,簡稱 Pbest),全部粒子群 體會有全域性最佳解(Global best solution,或稱 Global best,簡稱 Gbest),上述 這些數值會不斷經過數學式子計算,不斷尋找到粒子個體中區域最佳解、群體中 全域性最佳解,且根據這兩個過去經驗以求得最佳解,我們將在第三章時介紹整 個演算法流程,並說明上述幾個參數是如何推演。. 過去國內外有許多學者研究粒子群最佳化演算法,並且有各種不同的應用, 尹邦嚴等人[1]提出粒子族群最佳化的視覺化及開發工具,利用程式語言將演算. 政 治 大 以顯示在圖片上,如圖 2.1 所示。 立. 法可以視覺化的展示,讓使用者可以清楚了解粒子群最佳化的演化過程,並且可. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 2.1:演算法經過三次演化後的路徑圖,圖像取自[1]. 蔡元介等人[5]提出建立一個以 PSO 求解多點最佳路徑的行動地理資訊系統, 藉由網路服務(web services)技術,透過呼叫遠端伺服器的演算法來進行複雜的地 圖路徑計算,以求得最佳路徑;蔡賢量[6]等人提出基於粒子族群最佳化之不完 全資料處理,應用在知識發掘(knowledge discovery)的研究,透過演算法處理不 完全資料的問題,並且延伸至後續應用在中文文字處理[2]。. 6.
(18) 2.2 估測基礎矩陣. Xavier 和 Joaquim[18]於 2003 年曾提出並且整理過去一些估測基礎矩陣的方 法,在整理的 19 種方法中,又可以分為三大類,分別是線性方法(linear method)(圖 2.2 中 1~4)、疊代法(iterative methods)(圖 2.2 中 5~11)和強健式方法(robust methods)(圖 2.2 中 12~19),作者將 19 種方法實作後,用現實拍攝的影像進行實 驗,結果顯示,線性方法在對應點準確率高的情況下,實驗結果是誤差小且正確 率高。疊代法可以處理一些有高斯雜訊(gaussian noise)的情況,但是對於錯誤資. 政 治 大 在錯誤對應點的情況,因此在本研究會選一種強健式估測基礎矩陣的方法當作比 立 料太多的狀況下處理是相當沒有效率的。強健式方法可以同時處理高斯雜訊和存. ‧. ‧ 國. 學. 較範例,在第五章實驗結果時會有討論與分析。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 2.2:19 種估測方法時間比較,圖像取自[18]. 過去有許多學者持續以強健式方法為基礎進行研究,Zhang[19]於 1997 提出 一篇強健式參數估測用於圓錐體近似,由於大部份電腦視覺的問題常常會遇到雜 訊資料干擾影響估測結果,所以 Zhang 模擬圓錐體近似實驗,並且分佈資料點可 7.
(19) 能是正確資料或是錯誤資料交錯之下(如圖 2.3),因此使用線性解法並不適當, 所以 Zhang 使用了參數估測中的最小平方法(least-squares)和最小平方中值法希 望可以過濾掉錯誤資料,我們將在第三章描述其相關技術,並且在第四章以粒子 群最佳化演算法加入解題,因為圓錐體可以在二維平面上繪圖出來,所以我們先 觀察演算法用在解類似問題下是否適合,進而使用在估測基礎矩陣實驗。. 圖 2.3:圓錐體近似問題示意圖. 學. ‧ 國. 立. 政 治 大. ‧. 鄒慎財[3]提出強健式估測基礎矩陣之研究,利用強健式估測方法,如最小. y. Nat. sit. 平方中值法和隨機抽樣(RANdom SAmple Consensus, RANSAC)演算法進行估測,. n. al. er. io. 其中要使用最小平方中值法時,要注意錯誤資料需要佔全部可取樣點數的 50%. i n U. v. 之內,這部分我們會在第三章介紹此方法,而使用 RANSAN 演算法雖然可以在. Ch. engchi. 錯誤資料超過 50%情況下完成較準確的估測,但只能對特殊情況設定門檻值,並 且以票選的方式,當超過門檻值的數量大於制訂的標準後,便可以信任估測的結 果,最後提出一套判斷隨機取樣是否正確的判斷式,有 70%以上的機率,能判斷 取樣錯誤,藉此提升估測的效能。. 廖怡儂[4]提出應用在電腦視覺強健式估測之研究,使用多種強健式估測方 法,並且以線性近似(Line Fitting)和估測基礎矩陣為實驗範例,分析錯誤資料佔 全部資料在不同的百分比之下,使用何種強健式方法可以得到最好的解,最後結 合不同的強健式方法,再改善實驗結果,提供未來繼續研究的空間。 8.
(20) 賴岳宏[7][8]提出利用演化式計算做最佳化之研究,引用田口方法(taguchi method)[14]和演化式演算法中的基因演算法(genetic algorithms)[9]估測基礎矩陣, 利用模擬大自然的基因交配,留下最適合適應環境的方式,在隨機取樣的問題中, 可以透過複製、交配和突變來求取最佳解,估測出好的基礎矩陣,在實驗中,雖 然可以找到較佳的基礎矩陣,但是演化速度相當費時,較不符和計算成本。. 本研究除了以粒子群最佳化演算法估測基礎矩陣外,也結合強健式方法中的 最小平方中值法內幾個步驟,另外獨立實作最小平方中值法作為比較,我們將在. 政 治 大. 第五章列出實驗結果,並且討論與分析。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 9. i n U. v.
(21) 第三章 背景技術. 本章節我們將描述研究中應用到的各種相關技術,首先我們介紹粒子群最佳化演 算法的流程,以及我們如何進而套用在估測基礎矩陣。接著說明隨機取樣,在含. 政 治 大. 有正確資料和錯誤資料情況下,隨機取樣成功的機率是可以透過公式計算出取樣. 立. 次數,再來是兩種強健式方法,最小平方法和最小平方中值法,最後介紹估測基. ‧ 國. 學. 礎矩陣,以極線幾何關係述說兩張影像的關係,並列出相關技術。. ‧. 3.1 粒子群最佳化演算法流程. er. io. sit. y. Nat. 粒子群最佳化演算法是基於粒子個體和群體不斷演化計算的方法,目的是將. al. n. v i n 群體中每個粒子個體透過不斷移動搜尋,直到達到停止條件為止。我們一開始會 Ch engchi U 在搜尋空間中放置數個隨機取樣的粒子個體,接著隨著要解的問題不同,我們會. 制訂評估值計算方式,有了評估值之後,便可以求出 Pbest 和 Gbest 兩個值,接 著運用這兩個值可以計算出粒子個體新的速度向量,並且和原本位置向量相加後, 便可以得到新的位置,接著回到前面計算評估值,透過不斷的疊代來找到較佳解。 傳統的粒子群最佳化演算法流程可以由圖 3.1 顯示,我們將對每個步驟做詳細的 介紹。並且說明如何應用在估測基礎矩陣。. 10.
(22) 初始化. 計算評估值. 比較過去經驗 較差 較佳. 更新. 疊代速度 需要調整. 調整速度. 檢查速度向量. 治 政 疊代位置 大 不需調整. 立. 檢查位置向量. 學. 不需調整. 達到停止條件. ‧. 否. Nat. y. 是. 輸出結果. sit. ‧ 國. 需要調整. 調整位置. n. al. er. io. 圖 3.1:粒子群最佳化演算法流程圖. 初始化. Ch. engchi. i n U. v. 隨機取樣 i 組粒子個體,其中每個粒子個體包含位置向量 Xid 和速度向量 Vid, d 表示向量維度,在不同的問題下,維度大小並不一定相同。由於我們的搜尋空 間並非無限大,因此 Xid 會受限於最小和最大範圍,Vid 是粒子個體的移動速度, 通常我們會限定 Vid 的最小與最大值(負號表示方向不同),避免粒子個體在一次 疊代步驟後改變太大的距離,使得我們錯過沒搜尋到的目標。. 11.
(23) 計算評估值. 計算評估值(fitness),演算法中最重要的步驟,是將粒子個體和目標之間透 過公式計算出的一個數值,若能制訂良好,就能幫助演算法提升解題效率,相反 的,若制訂不佳,很有可能會產生退化問題甚至會影響最後實驗數據,這邊退化 問題是指計算成本不減反增,失去原先使用此演算法的意義。我們會根據不同的 問題找尋評估好壞的依據,進而制訂計算評估值的公式。. 政 治 大. 比較過去經驗. 立. 粒子個體過去最佳的經驗,我們稱為 Pbest,表示過去曾經到過最好位置;. ‧ 國. 學. 群體過去最佳的經驗,我們稱為 Gbest,表示群體中某一粒子個體曾經到達過最. ‧. 好的位置,這邊表示的最好位置,便是由前一步驟計算出來的 fitness 值當作評. y. Nat. 估的好壞。之後計算出的結果較前面好時,我們會取而代之前者,倘若計算結果. n. er. io. al. sit. 沒有比較好,便直接進行疊代速度。. 更新. Ch. engchi. i n U. v. 第一次計算時,每組粒子個體都會更新本身的 Pbest,再來會從全部的粒子 個體中挑選出 Gbest,當再次更新 Pbest 時,我們會紀錄較好的評估值和位置向 量,並在群體中檢查 Gbest 是否也有較好的評估值,當有較好時我們也會紀錄 GBest 的評估值和位置向量。. 12.
(24) 疊代速度、檢查速度向量、疊代位置、檢查位置向量. 由初始化產生的 Xid 位置向量和 Vid 速度向量,會經由數學式子(式 3.1、3.2) 的計算,得到粒子群最佳化演算法第二回合或是往後幾個回合開始時的 Xid 向量 和 Vid 向量。. Vid w Vid C1 rand 0,1 PbestX id - X id . (3.1). C2 rand 0,1 GbestX d - X id . 治 政 大 X X V t 立 id. id. (3.2). id. ‧ 國. 學. 權重值 w 是參考上一回合速度向量的一個加權值,rand(0,1)是隨機產生 0 到. ‧. 1 之間的亂數,目的是要讓新的速度向量有機會產生更多種組合,PbestXid 為過. y. Nat. 去第 i 個粒子個體的經驗中最佳位置向量,GbestXd 為過去群體經驗最佳位置向. er. io. sit. 量,C1 和 C2 是兩個加速度的權重值,C1 表示參考 Pbest 的權重,C2 則是參考 Gbest 的權重,一般會設定為常數,但也有學者研究會隨著疊代次數改變 C1 和 C2[15]。. n. al. Ch. engchi. i n U. v. 當實驗中有限制速度向量的最大值和最小值時,我們要判斷是否有超過的情 況,同樣地,若有限制位置範圍時,在位置疊代的步驟也要檢查。. 達到停止條件. 若達到,將輸出一組最佳評估值和每個粒子個體最後結果,若尚未達到,則 往下一步驟繼續進行實驗,其中停止條件的設定也會根據解的問題不同而有不同 的制訂方式,如何制訂停止條件在粒子群最佳化也是相當重要。. 13.
(25) 由於使用八點演算法下,估測基礎矩陣僅需八組對應點,因此我們會將維度 設定為八維空間,而我們進行的實驗,便是初始分佈數個粒子個體後在八維空間 中進行搜尋,我們將在第四章詳細討論。. 3.2 隨機取樣. 隨機取樣在機率學中是可以用數學表示成功機率(S)的,如圖 3.2,假設在樣 本空間中存在正確資料(1-e)%和錯誤資料(e)%時,若我們計算一組答案需要取樣. 政 治 大. p 個正確資料時,機率便為(1-e)p,結合前面幾個參數,我們可以將隨機取樣表示. 立. 為式 3.3。. ‧. ‧ 國. 學. 1-e. e. er. io. sit. y. Nat. al. v. n. 圖 3.2:正確資料(1-e)和錯誤資料(e)示意圖. Ch. engchi. p S 1 1 1 e . i n U. m. (3.3). 其中 m 表示為需要取樣的次數,即當我們取樣 m 次樣本時,可以在錯誤資 料佔有 e%的情況下,達到 S 的機率會有一次一組取樣內容皆是正確資料。. 我們在實作最小平方中值法時,會結合隨機取樣,並且設定機率 S 值,如此 會計算出不同的取樣次數,利用這些不同的次數會有不同的實驗結果,我們將在 第四章說明詳細流程。 14.
(26) 3.3 最小平方法. 在有兩點或是多點的二維座標系中,我們要找到一組(a,b)集合解,在線性近 似問題中(如圖 3.3),求出一條最逼近、誤差值最小的直線方程式(如式 3.4),最 小平方法是一個好的解題方法。. y ax b. 立. (3.4). 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. n. a圖l 3.3:線性近似問題範例圖 i v n Ch U engchi. 由於每個座標點並不在我們近似的直線上,因此每個點皆可以代入式 3.4, 計算出來一組殘餘誤差值 r(如式 3.5)。為了避免統計誤差時正負值會抵消,所以 採用誤差平方和為最小( min ri 2 )。. ri axi b yi. (3.5). 15.
(27) 當有 n 個點的時候,我們可以寫成 n 組直線方程式(如式 3.6)。. axi b yi. x. i,. (3.6). yi | i 1, 2,3..., n. 接著經過微積分的計算後,我們可以寫出式(3.7、3.8)計算出 a、b,並且將 (a,b)代回式 3.4 後,即完成解線性近似問題。. y x 治 政 大 x y N (3.7) b立 i. i. N. b. ‧ 國. x. i. N. (3.8). io. er. i. ‧. Nat. a. y. 學. 2. y. xi xi N . 2. sit. i. i. al. n. v i n 使用最小平方法的前提是分佈的點雜訊要盡可能的很小,以圖 3.3 的範例看 Ch engchi U. 來,在接近 X 軸和 Y 軸的地方皆有錯誤資料,很有可能會因為少許的錯誤資料,. 雖然計算出來的誤差是最小,但卻無法是幾個正確資料計算誤差最小,也就是說, 最小平方法會受到錯誤資料的影響,而且無法排除,因此我們將在下一小節介紹 最小平方中值法,希望可以改善存有錯誤資料的問題。. 16.
(28) 3.4 最小平方中值法. 是一種強健式估測方法,由於錯誤資料是無法避免並且常常會佔有一定的比 例,因此當我們使用最小平方中值法時,希望可以有效率的過濾掉錯誤資料。在 計算的過程中,會產生最小平方中值表格,我們將所有的誤差值經過排序後,捨 棄誤差值較大的 50%資料,保留前 50%的值,希望讓平均值以上的資料可以繼 續被留下來應用,進行後續的實驗,如圖 3.4 所示。. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat 圖 3.4:最小平方中值法示意圖. n. al. Ch. engchi. i n U. v. 我們採用最小平方中值法,並且應用在計算一組粒子個體的評估值,當我們 估測出一組結果時,可以將原先所有資料代入計算,這時每組資料都會有一組殘 餘誤差值(如 3.3 小節中式 3.5),接著我們會將誤差值由小到大排序,並且取中位 數,當作我們的評估值,這表示我們相信前面 50%的資料,後續實驗會以這樣的 做法來取評估值。. 17.
(29) 3.5 估測基礎矩陣流程. Hartley 的書中曾提過八點演算法(式 3.9),即表示有八組對應點座標時,即 可以計算出一組基礎矩陣,在第一章時我們曾介紹極限幾何關係(圖 1.1),接著 我們將對一些參數做說明。. pRT FpL 0. (3.9). 政 治 大. 其中 pL 為第一張相片上的特徵點,座標為(u,v,1)T,F 表示基礎矩陣,pR 表. 立. 示 pL 對應在第二張相片上的對應點,座標為(u’,v’,1)T。對左右兩張相片上的每組. ‧ 國. 學. 對應點 pL、pR,上述算式皆會成立,我們可以將式 3.9 改寫成式 3.10,看出基礎 矩陣中包含的幾個參數。. ‧. n. Ch. engchi. sit er. io. al. y. Nat. F11 F12 F13 u u ', v ',1 F21 F22 F23 v 0 F31 F32 F33 1 . i n U. (3.10). v. 若我們有八組對應點,並且給予編號 1~8 時,代入式 3.10 後,可以得到以 下式子如 3.11。. u1u1' u1v1' u1 v1u1' v1v1' ' ' ' ' u2u2 u2 v2 u2 v2u2 v2 v2 ' ' ' u8u8 u8v8 u8 v8u8 v8v8'. v1 v2 v8. F11 1 F 1 12 u1' v1' F13 1 ' ' u2 v2 F21 1 1 F22 u8' v8' F23 1 F 1 31 F32 1 18. (3.11).
(30) 要估測出基礎矩陣,需要求解 3.11 聯立方程式,只要有八組對應點,就可 以有一組答案,但我們主要問題在於估測出來的基礎矩陣要是好的。倘若基礎矩 陣解出來不好,在後續找密集對應點的過程中會產生錯誤,我們該如何使用粒子 群最佳化演算法幫助初始隨機取樣後的結果呢,將在第四章時會說明。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 19. i n U. v.
(31) 第四章 以粒子群最佳化演算法估測基礎矩陣. 本章第一小節介紹兩個基礎實驗,分別是粒子群最佳化演算法應用於二維平面和 圓錐近似兩個實驗,透過模擬的實驗,我們可以更清楚演算法的流程和運作,第. 政 治 大. 二小節是估測基礎矩陣的研究方法與流程,會詳細說明每個步驟和設計的想法, 實驗結果將在第五章。. 立. ‧ 國. 學 ‧. 4.1 模擬基礎實驗. y. Nat. er. io. sit. 4.1.1 平面中粒子群最佳化. al. n. v i n 本實驗將在平面中模擬粒子群最佳化演算法,由於三維以上的空間我們很難 Ch engchi U. 想像,因此我們用一個最簡單的例子,如圖 4.1,是一個二維平面找尋最佳解的 問題,我們將最佳解的目標假定在平面裡其中一個座標點位置,並且在限制位置 大小的範圍隨機分佈粒子個體,最終我們希望初始分散的所有粒子個體,可以逼 近至我們假定的最佳解目標,以及達到停止條件制訂的門檻值,實驗流程可以參 考圖 3.1。. 20.
(32) 政 治 大. 立. ‧. ‧ 國. 學. 初始化. 圖 4.1:二維平面問題示意圖. sit. y. Nat. al. er. io. 同 3.1 小節,在本實驗我們將維度設為二維,因為這是在平面中模擬的實驗,. v. n. 位置向量的範圍即是二維的範圍,速度向量範圍會依據可移動的位置向量範圍做 調整。. Ch. engchi. i n U. 計算評估值. 同 3.1 小節,在平面實驗中,我們制訂了一個公式用來計算評估值 f,如 式 4.1。在這個模擬實驗我們假定最佳解是知道的,目的是為了觀察粒子個體 的移動。. f . X i Goalx . 2. . Y Goal i. y. 21. 2. (4.1).
(33) 比較過去經驗、更新. 和 3.1 小節皆相同。. 疊代速度、檢查速度向量、疊代位置、檢查位置向量. 因為在平面中搜尋範圍是有限制的,我們必須控制粒子個體的移動範圍、速 度向量,舉例來說,假設是 1000x1000 的搜尋空間,粒子個體在疊代步驟計算後,. 政 治 大 來確保粒子特體會存在範圍內。 立. 位置向量很有可能超過我們預設的搜尋空間,因此我們這邊多了一個判斷的步驟. ‧ 國. 學. 其中速度向量在二維實驗中若有調整時,可再細分為兩種,速度向量正規化. ‧. 和速度向量未正規化,表 1 是速度向量正規化演算法,第五章列出實驗結果實我. n. al. er. io. sit. y. Nat. 們會比較兩種做法的實驗結果,以及適合使用的時機。. Ch. engchi. 22. i n U. v.
(34) 表 1:速度向量正規化演算法 輸入:疊代速度後需要調整的速度向量(Vxi,Vyi) 輸出:正規化計算後的速度向量(Vxi,Vyi) 1. if (Vxi > Vmax) then tx = Vmax / Vxi else if (Vxi < Vmin) then tx = Vmin / Vxi else tx = 1 2. if (Vyi > Vmax) then ty = Vmax / Vyi else if (Vyi < Vmin) then ty = Vmin / Vyi else ty = 1. 立. 3. tmin = min(tx , ty). 政 治 大. ‧ 國. 學. Vxi = Vxi * tmin Vyi = Vyi * tmin. ‧. sit. n. al. er. io. 達到停止條件. y. Nat. 其中 tx、ty 和 tmin 為實驗暫存數值,跟實驗結果沒有直接關係。. Ch. engchi. i n U. v. 在二維實驗中,實驗的停止條件是對所有粒子個體的 fitness 值皆小於 0.1, 因為貣先制訂計算 fitness 值的公式時(式 4.1),可以發現我們是用粒子個體座標 和目標有直接的計算關係,因此當值小於到一定的程度後,便可以在圖上顯示所 有粒子個體皆已經逼近至預設的目標。. 透過此實驗,我們可以更清楚了解粒子群最佳化演算法是一種在搜尋空間中 不斷跑動搜尋,逼近最佳解的演算法。. 23.
(35) 4.1.2 圓錐近似中粒子群最佳化. 本實驗是將圓錐近似當作實驗範例,加入粒子群最佳化演算法的模擬實驗, 我們假定最佳解的目標在平面中一個二元二次方程式的橢圓(式 4.2),粒子個體 初始分佈是採用一定比例的正確資料和錯誤資料,仿造估測基礎矩陣的幾個實驗 條件,同樣要進行隨機取樣,希望可以有效逼近假定的最佳解,並且藉由幾個實 驗條件的設定,得到一些結論與分析,流程圖稍做修改如圖 4.1。. 初始化 治 政 大 六維空間. 學. 計算評估值. ‧. ‧ 國. 立. 比較過去經驗 較差. Nat. y. 較佳. n. 疊代速度. Ch. 調整速度. er. io. al. sit. 更新. i n U. v. eng chi 檢查速度向量. 需要調整. 不需調整. 疊代位置 需要調整. 調整位置. 檢查位置向量 不需調整. 達到停止條件. 否. 是. 輸出結果. 圖 4.2:圓錐近似中粒子群最佳化演算法流程圖. 24.
(36) Q xi , yi Axi 2 2Bxi yi Cyi 2 2Dxi 2Eyi F 0. (4.2). 本研究中會將式 4.2 做正規化,將 A C 1 C 1 A ,則式 4.2 可以改寫 成為式 4.3。. Q xi , yi A xi 2 yi 2 2Bxi yi 2Dxi 2Eyi F yi 2. (4.3). 經由線性代數轉換成以下式 4.4。. 立. 政 治 大. ‧ 國. 學. A B 2xi yi 2 xi 2 yi 1 D yi 2 i5 i1 E F 51. xi 2 yi 2. (4.4). ‧. io. y. sit. i. al. er. i. Nat. x , y | i 1, 2,3..., N . v. n. 再將式子簡化,可以寫成 Ap b Ap b 0i1 ,其中 A 集合表示式 4.4. Ch. engchi. i n U. 中 ix5 矩陣,p 集合表示式 4.4 中 5x1 矩陣,b 集合表示式 4.4 中 ix1 矩陣,殘餘 誤差值 r 可以寫成 r Ap b 0i1 。. 在推導過後,可以由式 4.5 求得 p 集合解。. p AT A AT b 1. (4.5). 25.
(37) 求出 p 集合後,我們代回式 4.3 得到一組二元二次方程式,並且在平面上繪 出圖形,這是以一組取樣六個座標點可以計算出一組圖形的方法,接著我們對圖 4.1 的流程圖介紹步驟。. 初始化. 在本實驗中初始化要先決定所有點的分佈情形,例如正確資料和錯誤資料的 比例分配,並且對每個點給予編號,接著是分配一定數量的粒子個體,每個粒子. 政 治 大. 個體內會隨機取樣六個點,再來給予初始的速度向量,本實驗將有六個維度。. 立. 六維空間. ‧ 國. 學 ‧. 和平面中的實驗條件不同,由於這邊六個點我們可以看成獨立事件,彼此之. y. Nat. 間並不會互相影響,因此我們將粒子個體內的六個點編號進行由小到大排序,並. 度內進行粒子群最佳化演算法的步驟。. n. al. 計算評估值. Ch. engchi. er. io. sit. 且分割為六個維度,如此一來,每個粒子個體在後面程序時,便可以依照不同維. i n U. v. 本實驗的評估值計算和先前不同,我們會用到最小平方中值法中的其中一 個步驟,建立最小平方中值表格,即一組粒子個體可以計算出一組橢圓方程式, 接著將初始每個點都代入方程式後,可以計算出殘餘誤差值,將誤差值由小到 大排序過後,我們取中位數當作我們的 fitness 值,這樣採用評估值的好處是, 我們相信前 50%誤差較小的點,是可以當作參考的依據。. 26.
(38) 比較過去經驗、更新. 和 3.1 小節相同,. 疊代速度、檢查速度向量. 和 3.1 小節相同,但需要特別注意,每個維度之間都要遵守最大的移動速度, 若有超過,皆需要調整回最大。. 疊代位置、檢查位置向量. 立. 政 治 大. ‧ 國. 學. 本實驗中搜尋空間是以初始分佈的點數量決定,舉例來說,當我們分佈 n. ‧. 個點時,一個維度的搜尋空間就是 1~n,在這邊實驗內,需要透過六個不同的點. y. Nat. 計算出一組方程式,所以不能挑選重複的點,因此在疊代位置時是要注意的部份,. er. io. sit. 當有重覆的情況產生時,便要透過我們設計的調整位置向量演算法,如表 2。. n. al. i n 表 2:調整 C h X 位置向量演算法 engchi U. v. 輸入:疊代位置完後的粒子個體. 輸出:粒子中六個點編號皆不重複 1. 對粒子個體六個點編號檢查,從第 1 個開始,判斷是否有重覆。 2. 用氣泡旋轉方式檢查,若出現最大值,則前者-1,若出現最小值時,則後者 +1,一般正常狀況是後者直接+1。 3. 重複步驟 2-3,直到所有粒子檢查結束。 4. 輸出各組粒子的六個不重複點編號。. 27.
(39) 達到停止條件. 在圓錐近似這個問題中,其實較難去設置停止條件,因此我們採用了幾種不 同的停止條件並觀察其結果,分別是:限制疊代次數,對 Gbest 收斂,其中收斂 又可以調整收斂的範圍,第三是限制 fitness 值和對 Gbest 收斂,我們將在第五章 時呈現實驗結果。. 圓錐近似的問題中,我們嘗詴用粒子群最佳化演算法加入解題,並且仿效估. 政 治 大 在下一小節,將著重在本研究中的問題,設計研究方法與實驗流程。 立. 測基礎矩陣問題中假設一些實驗條件,有助於我們繼續進行估測基礎矩陣的研究,. ‧ 國. 學. 4.2 研究方法與流程. ‧. al. er. io. sit. y. Nat. 4.2.1 系統架構. v. n. 在前面章節中,已經介紹估測基礎矩陣的原理和流程,因此在本節我們將. Ch. engchi. i n U. 直接加入粒子群最佳化演算法,和前面基礎實驗中不同的是,實驗資料是兩張 相片中,先取得大量且可靠的對應點,因為 SIFT 可以針對平移和旋轉的照片 尋找對應點,所以在本研究中採用 SIFT 方法,之後將找到的對應點給予編號, 接著會根據相片解析度,切割為數個固定大小的籃子(bucket),因為從幾何關 係的角度上,倘若隨機取樣的對應點有共平面發生時,會影響我們估測的結果, 所以我們先將尋找到的對應點,依照座標位置落在各個籃子中,在各個籃子的 對應點也給予編號,我們只要先選取籃子,再選取籃子內的對應點,就可以盡 量避免共平面問題。. 28.
(40) 當這些資料準備就緒後,即可以開始進行粒子群最佳化演算法估測基礎矩陣, 流程圖我們將以圖 4.2 表示。. 初始化. 八維空間. 計算評估值. 比較過去經驗. 政 治更新 大. 較差. 較佳. 立. ‧ 國. 學. 疊代速度 需要調整. 檢查速度向量. ‧. 調整速度. 不需調整. y. 需要調整. n. al. 檢查位置向量. Ch. er. io. sit. Nat. 疊代位置. i n U. 不需調整. e n g達到停止條件 chi. v. 否. 是. 輸出結果. 圖 4.3:以粒子群最佳化演算法估測基礎矩陣流程圖. 29.
(41) 初始化. 初始化在 SIFT 尋找對應點和分配至籃子工作完成後,便決定粒子個體的數 目,這邊為了避免共平面,我們是採用先隨機取有對應點的籃子,決定八個籃子 後,再從挑選出的籃子內隨機取一組對應點,接著藉由籃子和籃子內的編號,可 以推回去原本的對應點編號,接著在分配速度向量,本實驗會有八個維度。. 八維空間. 政 治 大 取樣的八個點編號會進行由小到大排序,並且分割為八個維度,接著便可以 立. 設定 i 為我們取樣的粒子個體數量,d 為維度,代入 3.1 節中公式 3.1、3.2 進行. ‧ 國. ‧ er. io. sit. y. Nat. 計算評估值. 學. 實驗。. 挑選完八組對應點後,我們可以計算出一組基礎矩陣,接著將 SIFT 找到. al. n. v i n 的對應點逐次代入這組基礎矩陣後,可以得到每組對應點計算出的殘餘誤差值, Ch engchi U 接著建立最小平方中值表格後,取中位數當作 fitness 值,因為 SIFT 在尋找對 應點上可以相信有 50%以上的準確率,因此我們這樣子決定 fitness 值的制訂 方法是合理的。. 比較過去經驗、更新. 和 3.1 小節相同。. 30.
(42) 疊代速度、檢查速度向量. 和 4.1.2 小節相同。. 疊代位置、檢查位置向量. 本實驗搜尋空間是以 SIFT 找到的對應點數量決定,舉例來說,當我們找到 n 個點時,一個維度的搜尋空間就是 1~n,在估測基礎矩陣實驗中,需要八組不. 政 治 大 用籃子幫忙挑選對應點,因此在疊代位置時,雖是用對應點編號進行疊代,但確 立. 同的對應點計算出一組基矩矩陣,所以不能挑選重複的點,在初始化時我們曾利. 會用籃子編號進行檢查,當有籃子編號重複時,我們便會回到疊代速度步驟,計. ‧ 國. 學. 算新的速度向量,直到算出來的位置向量不需調整,便可以進行下一步驟。. ‧ er. io. sit. y. Nat. 達到停止條件. 本實驗用疊代次數當作停止條件,因為每一個粒子個體經過一次疊代後,都. al. n. v i n 會有新的一組結果,為了和過去幾種估測方法比較 ,我們選擇用接近的取樣次數, Ch engchi U 來比較實驗結果,至於該怎麼衡量估測基礎矩陣的好壞,便需要地面實況(ground truth)資料輔助我們計算結果好壞。. 4.2.2 評估基礎矩陣. 和先前實驗較不同的地方在於,平面和圓錐近似兩個實驗可以繪製在圖形上 顯示出結果,直接在圖上判斷結果好壞,但是若我們要評估基礎矩陣的好壞,並 沒有辦法畫在圖上,只能由兩張相片的極線幾何關係評估,將第一張影像上任一 組特徵點,透過估測出來的基礎矩陣在第二張相片上畫出極線,接著計算第一張 31.
(43) 影像上特徵點在第二張影像上的對應點,由這個對應點,和極線計算距離誤差, 同理,將第二張影像上的特徵點,經由同樣的方法,也可以在第一張相片上畫出 極線,由對應在第一張影像上的點進行計算距離誤差,若是同一組對應點時,可 以取平均值當作最後的一組誤差,當我們統計的點數越多時,越可以清楚知道我 們估測基礎矩陣的好壞。圖 4.3 是計算誤差的示意圖,計算公式如式 4.6。. d (m, L) . ax by c a 2 b2. (4.6). 治 政 大 ax by c 0, m 為對應點的座標,L 為 m 在另外一張相片畫出的極線方程式 立. 公式帶入後求出的 d 值即為誤差值。. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 4.4:計算基礎矩陣誤差示意圖. 32.
(44) 第五章 實驗結果. 在本章,我們會展示第四章兩個基礎實驗和本研究估測基礎矩陣實驗的結果,並 且說明與討論,首先我們先列出平面中粒子群最佳化實驗,除了驗證粒子群最佳. 政 治 大. 化演算法的執行效率和適合解最佳化問題之外,我們假設並配置幾個實驗條件,. 立. 解決於平面中找尋一個最佳座標點的問題,再來以圓錐近似中粒子群最佳化為第. ‧ 國. 學. 二個實驗,除了和先前的演算法略有變動之外,我們首次採用以調整點編號決定 取樣的方式,希望能用粒子群最佳化演算法有效的達到圓錐近似的目標,最後,. ‧. 我們列出本研究中主要問題,以粒子群最佳化估測基礎矩陣實驗結果。. n. Ch. engchi. er. io. al. sit. y. Nat 5.1 平面中粒子群最佳化實驗結果. i n U. v. 在 4.1.1 小節時我們曾提過速度正規化的觀念,為了驗證結果,我們在平面 中粒子群最佳化進行兩次實驗,分別為速度未經正規化和速度經過正規化,雖然 都可以達到實驗目標,但兩者花費的疊代次數是有明顯差別的。. 在平面中我們假設搜尋空間為 1000*1000,近似目標為座標點(500,500), fitness 值的制訂如式子 4.1,每次實驗我們會列出初始分佈和結束時的數據表格, 並列出每經過 100 次疊代後粒子移動後的圖形。. 33.
(45) 5.1.1 速度未經過正規化. 在速度未經正規化的實驗中,我們列出其中三次實驗結果,實驗數據放在表 3、4、5,實驗流程在 4.1.1 小節,初始化採取隨機分佈 20 組粒子,以表 3 為例, 粒子 1 初始 fitness 值經過計算為 103.793,經過 526 次疊代計算後,停止的 fitness 值為 0.657727。其餘粒子我們也將記錄初始 fitness 值,實驗停止條件為所有粒 子的 fitness 值皆要小於 0.1,實驗即停止,同時我們也記錄了初始 Gbest 和實驗 停止後的 Gbest,受限於篇幅,我們無法列出所有座標點的詳細(x,y)座標,但可. 政 治 大. 由圖 5.1~圖 5.3 看出實驗進行的過程。. 立. 學 表 3:速度未經過正規化第一次實驗 停止 fitness. 粒子 1. 103.793. 0.657727. 粒子 2. 229.591. 0.439575. 粒子 3. 760.094. 0.67022. 717.948. 0.436645. n. 粒子 6. e566.149 ngchi. i n U 0.33785. 525.407. 0.531189. 粒子 7. 362.133. 0.464233. 粒子 8. 802.881. 0.299561. 粒子 9. 674.612. 0.717736. 粒子 10. 713.37. 0.772005. 粒子 11. 220.923. 0.801949. 粒子 12. 567.248. 0.852063. 粒子 13. 709.616. 0.540056. 粒子 14. 838.282. 0.739844. 粒子 15. 183.477. 0.847061. 粒子 16. 717.795. 0.68312. 粒子 17. 684.133. 0.830808. 34. sit. er. io. a粒子 4 l C 粒子 5 h. y. 初始 fitness. Nat. 粒子編號. ‧. ‧ 國. 速度未經正規化第一次實驗. v.
(46) 粒子 18. 392.376. 0.93267. 粒子 19. 495.773. 0.172525. 粒子 20. 844.203. 0.894932. Gbest. 103.793. 0.172525. 平均值. 555.49. 0.631088. 標準差. 226.697. 0.211664. 疊代次數. 526. 在圖 5.1(a)中,是實驗初始 20 個粒子的分佈圖,我們採取了影像處理的座標 模式,將 X 座標置於圖的上方,Y 座標維持在圖的左方,可以看出,初始的隨 機分佈在圖中相當分散。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi (a). 35. i n U. v.
(47) 經過 100 次疊代計算後,可以看出 20 個粒子已經漸漸收斂至我們假定的最 佳座標點,但是因為尚未達到實驗停止條件,因此實驗繼續進行,在 200 次疊代 計算後,其實粒子群變動的幅度已經不明顯,都收斂在最佳座標點附近,直到最 後實驗停止條件達成後,我們將實驗停止,並且列出最後結果。. 立. 政 治 大. y. ‧. ‧ 國. 學. Nat. n. er. io. al. sit. (b). Ch. engchi. (c) 36. i n U. v.
(48) 立. 政 (d) 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. (e). 37. i n U. v.
(49) 立. 政 (f)治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. (g) 圖 5.1:速度未正規化第一次實驗 (a)初始分佈 (b)疊代 100 次後 (c)疊代 200 次 後 (d)疊代 300 次後 (e)疊代 400 次後 (f)疊代 500 次後 (g) 實驗停止. 38.
(50) 速度未經正規化第二次實驗. 表 4:速度未經過正規化第二次實驗 粒子編號. 初始 fitness. 停止 fitness. 粒子 1. 149.632. 0.578291. 粒子 2. 638.63. 0.427444. 粒子 3. 564.287. 0.993407. 粒子 4. 447.188. 0.776515. 粒子 5. 687.002. 0.162064. 粒子 6. 408.185. 0.106686. 粒子 7. 717.215. 0.903953. 549.638. 0.794998. 298.593. 0.694554. 粒子 10. 726.188. 0.361354. 粒子 11. 551.012. 0.952971. 粒子 12. 257.057. 0.706375. 粒子 13. 851.436. 0.842508. 粒子 14. 452.254. 0.681268. 粒子 15. 728.446. 0.910115. 粒子 16. 610.096. 0.462617. 粒子 17. 306.009. 0.334668. al. 608.081. 0.81664. 434.919. 0.204055. Gbest. 149.632. 0.106686. 平均值. 507.419. 0.608242. 標準差. 193.873. 0.269995. 疊代次數. 345. i n U. e162.511 n g c h i 0.45435. 39. y. ‧ 國. n. 粒子 20. ‧. io. Ch. 粒子 19. 學. Nat. 粒子 18. sit. 粒子 9. 立. 政 治 大. er. 粒子 8. v.
(51) 立. 政 (a) 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. (b). 40. i n U. v.
(52) 立. 政 (c) 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. (d). 41. i n U. v.
(53) 立. 政 (e) 治 大. 圖 5.2:速度未正規化第二次實驗 (a)初始分佈 (b)疊代 100 次後 (c)疊代 200 次. ‧ 國. 學. 後 (d)疊代 300 次後 (e)實驗停止. ‧. 速度未經正規化第三次實驗. sit. y. Nat. n. al. er. io. 表 5:速度未經過正規化第三次實驗. i n C 粒子 1 h 761.193 U e n g c h i0.035626. v. 粒子編號. 初始 fitness. 停止 fitness. 粒子 2. 454.543. 0.924146. 粒子 3. 493.851. 0.915178. 粒子 4. 597.644. 0.902284. 粒子 5. 237.22. 0.300982. 粒子 6. 312.296. 0.880012. 粒子 7. 331.675. 0.535077. 粒子 8. 164.403. 0.893676. 粒子 9. 627.888. 0.767696. 粒子 10. 569.72. 0.64459. 粒子 11. 338.389. 0.846648. 粒子 12. 608.325. 0.856534. 粒子 13. 445.57. 0.94182. 42.
(54) 粒子 14. 648.885. 0.276665. 粒子 15. 342.906. 0.575668. 粒子 16. 317.728. 0.928936. 粒子 17. 849.757. 0.600338. 粒子 18. 828.211. 0.687454. 粒子 19. 642.811. 0.854468. 粒子 20. 644.612. 0.321167. Gbest. 164.403. 0.035626. 平均值. 510.881. 0.684448. 標準差. 191.859. 0.261441. 疊代次數. 430. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi (a). 43. i n U. v.
(55) 立. 政 (b) 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. (c). 44. i n U. v.
(56) 立. 政 (d) 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. (e). 45. i n U. v.
(57) 立. 政 (f) 治 大. 圖 5.3:速度未正規化第三次實驗 (a)初始分佈 (b)疊代 100 次後 (c)疊代 200 次. ‧ 國. 學. 後 (d)疊代 300 次後 (e)疊代 400 次後 (f)實驗停止. ‧. 平均疊代次數:433.67. sit. y. Nat. n. al. er. io. 5.1.2 速度經過正規化. Ch. engchi. i n U. v. 在速度經過正規化的實驗中,我們同樣列出三次實驗結果,實驗數據放在表 6、7、8,初始化採取隨機分佈 20 組粒子,以表 6 為例,粒子 1 初始 fitness 值 經過計算為 103.793,經過 526 次疊代計算後,停止的 fitness 值為 442.915。其 餘粒子我們也將記錄初始 fitness 值,實驗停止條件為所有粒子的 fitness 值皆要 小於 0.1,實驗即停止,同時我們也記錄了初始 Gbest 和實驗停止後的 Gbest,受 限於篇幅,我們無法列出所有座標點的詳細(x,y)座標,但可由圖 5.4~圖 5.6 看出 實驗進行的過程,可以看出,平均花費的疊代次數減少。. 46.
(58) 速度經過正規化第一次實驗. 表 6:速度正規化第一次實驗 粒子編號. 初始 fitness. 停止 fitness. 粒子 1. 442.915. 0.529885. 粒子 2. 303.232. 0.946604. 粒子 3. 293.222. 0.667126. 粒子 4. 622.15. 0.399617. 粒子 5. 317.972. 0.877642. 粒子 6. 220.954. 0.76358. 粒子 7. 425.336. 0.464154. 379.04. 0.96982. 605.182. 0.266683. 粒子 10. 953.246. 0.568593. 粒子 11. 682.272. 0.815373. 粒子 12. 748.466. 0.427144. 粒子 13. 433.882. 0.623231. 粒子 14. 347.484. 0.976441. 粒子 15. 460.372. 0.405031. 粒子 16. 497.879. 0.269902. 粒子 17. 953.001. 0.72099. al. 477.157. 0.921068. 886.227. 0.569809. Gbest. 27.3446. 0.266683. 平均值. 503.867. 0.646745. 標準差. 239.743. 0.224104. 疊代次數. 172. i n U. e27.3446 n g c h i0.752216. 47. y. ‧ 國. n. 粒子 20. ‧. io. Ch. 粒子 19. 學. Nat. 粒子 18. sit. 粒子 9. 立. 政 治 大. er. 粒子 8. v.
(59) 立. 政 (a) 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. (b). 48. i n U. v.
(60) 立. 政 (c) 治 大. 圖 5.4:速度正規化第一次實驗 (a)初始分佈 (b)疊代 100 次後 (c)實驗停止. ‧ 國. 學. 速度經過正規化第二次實驗. 初始 fitness. 1 a粒子 l C 粒子 2 h. 停止 fitness. er. io. 粒子編號. 0.733114. 450.85. 0.673877. 粒子 4. 615.589. 0.2485. 粒子 5. 465.285. 0.77931. 粒子 6. 475.661. 0.694566. 粒子 7. 897.519. 0.137358. 粒子 8. 268.075. 0.240469. 粒子 9. 636.28. 0.505828. 粒子 10. 652.821. 0.652019. 粒子 11. 177.831. 0.25602. 粒子 12. 755.394. 0.260135. 粒子 13. 525.956. 0.82313. 粒子 14. 520.188. 0.850336. 粒子 15. 362.682. 0.579484. n. 643.208. 粒子 3. i n U. e58.9923 n g c h i0.767924. 49. sit. y. ‧. Nat. 表 7:速度正規化第二次實驗. v.
(61) 粒子 16. 678.823. 0.097698. 粒子 17. 512.375. 0.811489. 粒子 18. 241.005. 0.927598. 粒子 19. 519.15. 0.4073. 粒子 20. 233.833. 0.907129. Gbest. 58.9923. 0.097698. 平均值. 484.576. 0.567664. 標準差. 205.052. 0.267629. 疊代次數. 180. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. (a). engchi. 50. i n U. v.
(62) 立. 政 (b) 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. (c) 圖 5.5:速度正規化第二次實驗 (a)初始分佈 (b)疊代 100 次後 (c)實驗停止. 51.
(63) 速度經過正規化第三次實驗. 表 8:速度正規化第三次實驗 粒子編號. 初始 fitness. 停止 fitness. 粒子 1. 355.052. 0.824258. 粒子 2. 258.278. 0.627105. 粒子 3. 846.919. 0.987563. 粒子 4. 546.953. 0.968214. 粒子 5. 365.001. 0.729819. 粒子 6. 492.569. 0.615142. 粒子 7. 397.198. 0.529327. 487.533. 0.572341. 934.751. 0.290347. 粒子 10. 639.637. 0.558223. 粒子 11. 192.907. 0.740161. 粒子 12. 544.694. 0.544433. 粒子 13. 602.618. 0.394315. 粒子 14. 742.149. 0.461306. 粒子 15. 580.34. 0.441606. 粒子 16. 461.531. 0.775901. 粒子 17. 667.653. 0.740729. al. 591.082. 0.203654. 573.84. 0.909929. Gbest. 192.907. 0.203654. 平均值. 560.994. 0.634178. 標準差. 196.626. 0.209261. 疊代次數. 247. i n U. e939.177 n g c h i 0.76918. 52. y. ‧ 國. n. 粒子 20. ‧. io. Ch. 粒子 19. 學. Nat. 粒子 18. sit. 粒子 9. 立. 政 治 大. er. 粒子 8. v.
(64) 立. 政 (a) 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. (b). 53. i n U. v.
(65) 立. 政 (c) 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. (d) 圖 5.6:速度正規化第三次實驗 (a)初始分佈 (b)疊代 100 次後 (c)疊代 200 次後 (d) 實驗停止. 平均疊代次數:199.67. 54.
(66) 5.1.3 討論與分析. 在 5.1.1 和 5.1.2 兩節中我們將兩種實驗結果用表格記錄和繪製到平面圖上, 從數據中我們可以得到,有做速度正規化的疊代次數會比速度未正規化來的少, 也驗證了我們在 4.1.1 節時曾提到當兩個維度具有相依性時,是需要做速度正規 化的,另外可以從表 3~8 和圖 5.1~5.6 中可以發現,一開始粒子的分佈是很分散 的,所以初始 fitness 值計算出來都相當大,直到經過一定的疊代次數後,發現 各組粒子會越來越逼近我們假定的最佳點座標,直到達到停止條件後,我們可以. 政 治 大 訂出的門檻值,在此條件下,所有粒子的(x,y)座標會和最佳點座標誤差會在 立. 看到所有粒子在表格中停止 fitness 值皆會小於 0.1,這是我們經過多次實驗後制. 0.05pixel 之內。. ‧ 國. 學 ‧. 5.2 圓錐近似中粒子群最佳化實驗結果. sit. y. Nat. al. er. io. 在本節中,我們將列出圓錐近似中的幾次實驗結果,我們嘗詴了三種不同的. v. n. 停止條件,後面章節的圖中,x、y 軸接表示座標,點旁邊的數字表示點編號。. Ch. engchi. i n U. 5.2.1 限制固定疊代次數. 本節實驗我們是採取疊代次數當作停止條件,但因為隨機分佈的狀況不同, 利用固定的實驗次數是相當不保險的做法,圖 5.7 是我們進行 5000 次疊代後的 實驗結果。. 55.
(67) 立. 政 治 大 (a). ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. (b). 56. i n U. v.
(68) 立. 政 治 大 (c). ‧. ‧ 國. 學. 圖 5.7:疊代次數為停止條件(a)第一次(b)第二次(c)第三次 實驗結果. 5.2.2 對 Gbest 收斂. sit. y. Nat. al. er. io. 利用收斂當作停止條件其實有一部分是參考平面中的 fitness 值制訂,我們. v. n. 計算收斂值公式是利用各組粒子中的六個點編號和 Gbest 的六個點編號計算出來, 式 5.1 是我們計算的公式。. 6. convergence . N 1. Ch. engchi. Particle. iN. GbestiN. . 2. i n U. (5.1). 其中 Particlei 表示第幾個粒子個體,N 表示第幾個點編號,c 表示我們計算 出的收斂值,接著我們將收斂值 convergence 值調整後,有以下的幾次實驗。. 57.
(69) convergence 值<12.25. 立. 政 治 大. ‧ 國. 學. (a). ‧. n. er. io. sit. y. Nat. al. Ch. engchi. (b). 58. i n U. v.
(70) 立. 政 治 大 (c). ‧. ‧ 國. 學. 圖 5.8:convergence 值<12.25 為停止條件(a)第一次(b)第二次(c)第三次 實驗結果. convergence 值<9.8. n. er. io. sit. y. Nat. al. Ch. engchi. (a). 59. i n U. v.
(71) 立. 政 治 大 (b). ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. (c) 圖 5.9:convergence 值<9.8 為停止條件(a)第一次(b)第二次(c)第三次 實驗結果. 60.
(72) convergence 值<7.35. 立. 政 治 大. ‧ 國. 學. (a). ‧. n. er. io. sit. y. Nat. al. Ch. engchi. (b). 61. i n U. v. \.
(73) 立. 政 治 大 (c). ‧. ‧ 國. 學. 圖 5.10:convergence 值<7.35 為停止條件(a)第一次(b)第二次(c)第三次 實驗結果. convergence 值<6.12. n. er. io. sit. y. Nat. al. Ch. engchi. (a). 62. i n U. v.
(74) 立. 政 治 大 (b). ‧. ‧ 國. 學. 圖 5.11:convergence 值<6.12 為停止條件(a)第一次(b)第二次 實驗結果. convergence 值<4.9. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 5.12:convergence 值<4.9 為停止條件第一次實驗結果. 63.
(75) 5.2.3 限制 fitness 值和對 Gbest 收斂. 在本節實驗停止條件是限制 Gbest 的 fitness 值小於一定的門檻值,再利用收 斂當作我們的停止條件,因為在 5.2.2 節中只用收斂到 Gbest 這組粒子個體當作 停止條件,會發現很有可能還沒有近似到一定的準確率時就已達停止條件,因此 我們再修改了停止條件,目前先進行了幾次實驗如下。. Gbestfitness < 0.1 和 convergence 值<12.25. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 5.12:Gbestfitness < 0.1 和 convergence 值<12.25 為停止條件第一次實驗結果. 5.2.4 討論與分析. 在 5.2.1、5.2.2 和 5.2.3 節中我們將三個不同實驗停止條件放在圓錐近似的實 驗中,得到的結果也不盡然相同,但目前仍有再改善的空間,目前幾個可能的問 題如下,在 5.2.1 節中,只單純的限制疊代次數是風險較大的做法,因為我們沒 64.
(76) 有過去經驗告訴我們說粒子群最佳化演算法可以在一定的計算次數中找尋到最 佳解,5.2.2 節內收斂算是合理的做法,但是還有一些細節的問題是我們待釐清 的,因為透過收斂的步驟,本意上是往 Gbest 收斂了,離他的距離會隨著 c 值越 小而越靠近,但是這邊的靠近指的是點編號的靠近,由於我們在圓錐近似中粒子 的組成是採取六個點編號的方式,因此光是編號的靠近,是否真的可以當作是一 個評估的標準,還是有待驗證的地方,5.2.3 小節內結合限制 fitness 值和收斂的 做法,限制 fitness 值是一個不錯的方式,因為先前章節有提到,當 fitness 值制 訂的好,fitness 值便是很好的一個參考依據,所以我們未來實驗依然可以從限制. 政 治 大 但是當 fitness 值收斂到一定的值,可能會變得很有意義,並且可以提升實驗結 立. fitness 值出發,搭配收斂也是不錯的方法,雖說光是編號靠近尚無法驗證其好壞,. 果,這是未來可以研究的部分。. ‧ 國. 學 ‧. 5.3 以粒子群最佳化估測基礎矩陣實驗結果. sit. y. Nat. al. er. io. 在本節我們將列出估測基礎矩陣的兩組實驗結果,第一組資料是由 3DMAX. v. n. 模擬場景,由兩台相機拍攝多視角影像,由於場景是我們模擬配置,因此可以取. Ch. engchi. i n U. 得 ground truth 資料,第二組資料是由 Christoph[20]提供多視角影像和光達點雲 資料,也可以由投影矩陣計算出多視角相片中的 ground truth 資料幫助計算誤差, 我們將透過三種方法比較實驗結果,分別是 PSO、LMedS_PSO、LMedS,最後 做討論與分析。. 5.3.1 第一組實驗(3DMAX)資料. 我們用 3DMAX 建模並且假設兩台相機拍攝兩張相片(圖 5.13),圖 5.14 顯示 我們的實驗場景,相片解析度為 800x600,籃子大小為 80x60,共有 100 個,初 65.
(77) 始找尋對應點時採用 SIFT 演算法,共可以找到 2494 組對應點,而用來驗證的 ground truth 資料,則有 1306 組對應點。. 政 治 大 圖 5.13:3DMAX 實驗相片 立 ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 5.14:3DMAX 拍攝場景. 我們採用較接近的疊代次數來比較實驗結果,PSO 實驗採用 10 組隨機取樣 的粒子個體經過疊代計算 117 次,共進行 1170 次疊代,而 LMedS_PSO 方法先 計算成功取樣機率為 80%,正確資料為 50%的一組結果,套用隨機取樣公式需 66.
(78) 要 412 次,接著隨機取樣 9 組粒子個體後,結合 LMedS 的一組結果,之後 10 組再進行疊代 76 次,共需要 1172 疊代次數,而 LMedS 的方法直接將成功取樣 機率設為 99%,正確資料為 50%,需要疊代 1177 次。. 完成上述的步驟後,我們稱為進行一組實驗,在本研究中,將使用 1000 組 資料的平均誤差當作實驗結果,如表 9、10。. 表 9:3DMAX 場景估測基礎矩陣結果 1000 組標準差 政 治 大 0.077 像素 0.0547 像素 立. 方法. 1000 組平均誤差. PSO. 0.0548 像素. LMedS. 0.097 像素. 0.0548 像素. 18 小時 41 小時. ‧. ‧ 國. 0.086 像素. 5 小時. 學. LMedS_PSO. 1000 組需要時間. LMedS. y. sit. 小於 0~1 倍. 667 個 a l678 個 v i n C個h 632 i U個 e n g c h629. n. LMedS_PSO. io. PSO. 小於平均標準差. er. 方法. Nat. 表 10:3DMAX 場景估測基礎矩陣標準差分佈. 581 個. 小於 1~2 倍 11 個. 577 個. 3個 4個. 從表 9、10 中我們可以發現,PSO 的平均誤差和花費的時間皆是最少的,而 小於平均標準差的數量也是最多,接著我們統計三種方法的一千組結果,計算總 平均和標準差,繪製出直方圖和累積的折線圖,如圖 5.15、5.16。. 67.
(79) 圖 5.15:3DMAX 實驗直方圖比較. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. v. n. 圖 5.16:3DMAX 實驗折線圖比較. Ch. engchi. i n U. 從圖表中我們看出,PSO 的方法在接近的疊代次數中,時間成本和平均誤差 值皆是表現最好的,接著下一節我們將列出第二組實驗結果。. 68.
數據
Outline
相關文件
隨機實驗是一種過程 (process),是一種不能確定預知會
記錄在電子課本 P.11。.. 播放「不同物料的傳熱速度」影片,請學生觀察實驗過程及 結果,並記錄在電子課本 P.13 上。.. 10. 課後
2-1 化學實驗操作程序的認識 探究能力-問題解決 計劃與執行 2-2 化學實驗數據的解釋 探究能力-問題解決 分析與發現 2-3 化學實驗結果的推論與分析
推理論證 批判思辨 探究能力-問題解決 分析與發現 4-3 分析文本、數據等資料以解決問題 探究能力-問題解決 分析與發現 4-4
• 透過觀察和實驗 透過觀察和實驗 透過觀察和實驗, 透過觀察和實驗 , , ,強化 強化 強化 強化、 、 、 、修訂 修訂 修訂
2.注重實地演練,角色扮演、跟隨經驗、實地參訪及邀請業界主管演講方 式,使學生能從「經驗中學習」
在這一節中,我們將學習如何利用 變數類 的「清 單」來存放資料(表 1-3-1),並學習應用變數的特
本章將對 WDPA 演算法進行實驗與結果分析,藉由改變實驗的支持度或資料 量來驗證我們所提出演算法的效率。實驗資料是以 IBM synthetic data generator
