©2007 National Kaohsiung University of Applied Sciences, ISSN 1813-3851
Support Vector Machines 分類技術應用於中文垃圾郵件辨別之探討
分類技術應用於中文垃圾郵件辨別之探討
分類技術應用於中文垃圾郵件辨別之探討
分類技術應用於中文垃圾郵件辨別之探討
李俊宏 李俊宏 李俊宏 李俊宏*、、、、鄭原平鄭原平鄭原平鄭原平** 國立高雄應用科技大學 電機工程學系 E-mail:*[email protected];**[email protected]
摘
摘
摘
摘 要
要
要
要
近年來隨著網際網路的發達與普及,電子郵件的使用已經成為趨勢。但是垃圾郵件所衍 生的問題也相對產生,對於擁有電子信箱的使用者而言,造成了極大的困擾,如何避免收到 不需要的垃圾郵件,成為生活上的一大課題。根據以往使用 Support Vector Machines(SVMs) 在文件分類的相關文獻中顯示,SVMs 技術在文件分類上有高效能的表現,因此本研究將電 子郵件視為文件的一種,希望藉由 SVMs 技術能夠有效地辨別垃圾郵件。本研究針對電子郵件的不同欄位內容(包含:只有主旨欄位、只有內文欄位、主旨及內文 兩者欄位)、不同的特徵選取方式(包含:只選取名詞、只選取動詞及選取名詞及動詞)、不
同的特徵選取策略(包含:二元方式(Binary)、詞彙頻率(TF)及詞彙頻率與文件頻率倒數
之乘積(TF×IDF))、不同核心函數的分類器(包含:Linear SVMs 分類器、Gaussian RBF SVMs
分類器及 Polynomial SVMs 分類器)、不同的調和係數 C 值等,透過 SVMs 分類器辨別中文垃 圾郵件之實驗,來分析其不同的實驗結果。從辨別垃圾郵件的實驗過程中,透過 Recall、 Precision、F1 值三種不同的效能量測方式,比較不同特徵選取方法在辨別垃圾郵件的效能, 以驗證不同特徵於 SVMs 分類器效能之差異。 關鍵詞 關鍵詞 關鍵詞
關鍵詞::::Support Vector Machines、、、垃圾郵件、垃圾郵件、垃圾郵件垃圾郵件、、、中文郵件中文郵件中文郵件中文郵件。。。。
1. 前
前
前 言
前
言
言
言
隨著網際網路的快速發展,使得人們越來越倚重網際網路的眾多服務作為溝通傳遞訊息 的工具;這其中又以電子郵件服務最重要,也最為普遍。隨著電子郵件使用頻率的日益增加, 以及電子郵件通訊協定設計上的不夠嚴謹,關於垃圾郵件的議題開始產生。對個人而言,垃 圾郵件最大的影響就是浪費時間去判斷與處理,而且大量的垃圾郵件佔用信箱空間,如果沒 有即時清理,連正常的信件都無法接收。電子郵件可以為我們帶來我們所想要的資訊,但是,如果收到一些我們不想要的垃圾郵件,不但浪費了網路資源,更浪費了收件者的時間與金錢。 對企業而言,垃圾郵件不但會增加資訊安全的風險,也會導致員工的生產力下降。許多垃圾 郵件夾帶木馬及惡意程式,如果員工不小心點選這些郵件,很可能會造成機密資料外洩。此 外,當郵件主機效能下降、儲存空間不足及網路塞車等問題一一出現,企業勢必須要增購更 多的設備。本論文利用 SVMs 技術在文件分類上有高效能表現的優點[9][10][11],將電子郵件 視為文件的一種,學習訓練用垃圾郵件與正常郵件的關鍵詞彙,並對測試用電子郵件作測試, 辨別是否為垃圾郵件。
2. 相關
相關
相關研究
相關
研究
研究探討
研究
探討
探討
探討
2.1 垃圾郵件之定義垃圾郵件之定義垃圾郵件之定義 垃圾郵件之定義垃圾郵件,一般通稱為 SPAM(Send Phenomenal Amounts of Mail, SPAM),所謂 SPAM 是將一份內容相同的電子郵件,未經收信人許可,大量寄送給許多人。而與 SPAM 意義相似 的名詞有 UBE = Unsolicited Bulk E-mail(未經收信人請求的大量郵件)、UCE = Unsolicited
Commercial E-mail(未經收信人請求的商業郵件)。 只要符合下列 4 點中的任一項,即定義為垃圾郵件[12]: (1) 信件主題與內容無關,且一次傳送給多個收件者的信件。 (2) 收件者並沒有明確要求接受該信件。 (3) 短時間內重複、或大量傳送至伺服器的同一信件。 (4) 未經收件者許可即自動寄送而來,且無法透過常態性管道執行退訂動作的信件。 根據以上敘述我們從字面上似乎很容易定義垃圾郵件,但實質上垃圾郵件相較於病毒郵 件更難定義,其原因是由於病毒郵件對任何收信者而言,都是惡意的、人見人厭的郵件,而 垃圾郵件對使用者而言定義比較不明確。例如:一封新聞電子報,對使用者甲可能是有用的 資訊,對使用者乙可能就是一封毫無意義的垃圾郵件,因此要定義垃圾郵件是十分地困難。 因此,市面上大多數的垃圾郵件過濾器,除了具備管理者訂定系統之垃圾郵件過濾類別外, 也提供使用者自訂個人化垃圾郵件過濾類別。 2.2 常見的垃圾郵件處常見的垃圾郵件處常見的垃圾郵件處理方式常見的垃圾郵件處理方式理方式理方式 常見的垃圾郵件處理方式可分為:伺服器端及使用者端,說明如下: 2.2.1 伺服器端伺服器端伺服器端伺服器端:::: 大多數的企業、機關建置垃圾郵件過濾器,以「Gateway Solution」的型式較普遍。除 了購置垃圾郵件過濾器設備須花費很大的成本,多半還需要系統管理者介入管理,才能發 揮較佳的功能,且管理者所設定的過濾政策,亦無法確切地合乎所有使用者的需求。最大
的缺點則是,當垃圾郵件過濾器判斷錯誤時,使用者必須在系統發送的「被攔截的郵件明 細」或「廣告過濾報告」中,點選「接收」或「取回」被誤判之正常郵件,如此一來將造 成使用者須花費額外的時間,去處理這些被誤判而又需要的正常郵件。
2.2.2 使用者端使用者端使用者端使用者端::::
使用者收信的方式,最常見的是 Web 介面的 Web Mail 及 MUA 程式,視使用的方式不 同,垃圾郵件的處理方式也不同。使用者如使用 Web Mail,經由系統進行判斷,如判定是 垃圾郵件後,通常會將該封信放置於命名為「垃圾信件匣」或「大宗郵件匣」信件資料夾。 使用者如使用 MUA 程式,常用的如:Microsoft Outlook Express 郵件軟體。在 MUA 程式 及大部份的 Web Mail,都有提供使用者郵件分類的功能,除了可自訂黑名單、白名單之外, 也可針對信件的某幾個欄位內容自行設定過濾規則,進行以關鍵詞彙為基礎的垃圾郵件過 濾規則。此方法的缺點為只考慮規則中數個關鍵詞彙是否出現,並未全盤考量郵件內容中 所有詞彙在所有電子郵件集合中應佔的權重,而且經由人工分析並自訂能夠涵蓋並代表整 個類別的一組規則是非常困難的。由於目前垃圾郵件的寄件者、主旨、以及內文常常變化, 毫無規則可循,利用手動設定信件過濾規則來阻擋垃圾郵件,不但須常常更新過濾規則, 而且相當費時、效果實在有限。 2.3 垃圾郵件過濾的常用技術垃圾郵件過濾的常用技術垃圾郵件過濾的常用技術 垃圾郵件過濾的常用技術 垃圾郵件過濾的常用技術,包括:白名單比對、黑名單比對、RBL 名單比對、DNS 反查、 規則過濾、關鍵詞彙比對…等技術,市面上任何一種垃圾郵件過濾閘道器,幾乎沒有只用單 一判斷技術來過濾垃圾郵件,多半會提供層層過濾技術,來過濾可疑的郵件來源及特徵。搭 配多種技術一起使用,使垃圾郵件過濾效能提升[1]。 本研究是針對郵件內容進行關鍵詞彙比對。關鍵詞彙是指文件中較能代表該文件性質的 詞彙。比較常用的垃圾郵件過濾技術是利用關鍵詞彙比對,此類過濾技術通常是透過檢視郵 件的內容,比對郵件的主旨(subject)或內文(content)裡是否有「在垃圾郵件中經常出現 的關鍵詞彙」,例如:「偷拍」、「想賺錢嗎?」、「無碼影片」、「援交」、「色情」、「創業」、「致 富」、「低利貸款」…等詞彙,如果有這些詞彙的出現,就有可能會被歸類成垃圾郵件而加以 攔截。關鍵詞彙比對就是比對垃圾郵件過濾器所收集到的關鍵詞彙,因為垃圾郵件內容不一, 所以樣本越多,成功攔截垃圾郵件之機率就越高。但有個問題是,若某些正常郵件的內容與 垃圾郵件的內容有相同的詞彙存在時,就會發生誤判的情形,所以垃圾郵件過濾器之管理者 如果要使用此方式的話,需要非常小心,避免正常郵件被誤判成垃圾郵件而被攔截。關鍵詞 彙比對是比較有效的方式,但是比較耗費系統資源,且成功率是依收集到的樣本多寡而定, 故必須仰賴大量樣本的累積以及精確演算法的幫助,對於存有變化性的垃圾郵件,就需要不 斷地更新關鍵詞彙之資料庫,才能維持垃圾郵件過濾的品質。
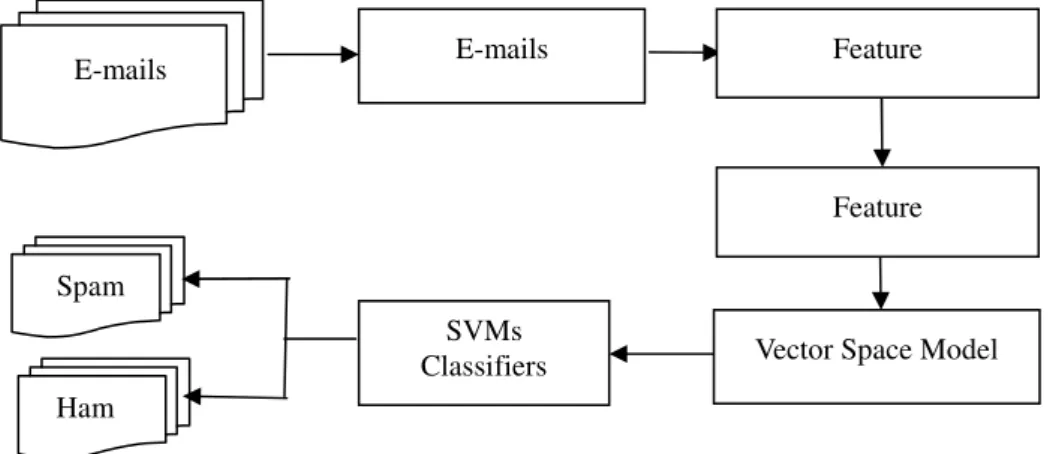
2.4 資料前處理資料前處理資料前處理 資料前處理 資料前處理的目的在於辨別垃圾郵件前,將電子郵件資料有效地做初步的處理,由於電 子郵件內容十分繁雜,本實驗只使用在信件訊息之主旨及內文兩個欄位的詞彙,作為特徵的 候選人,不考慮多媒體、URL、圖形以及其他格式的郵件內容。進行辨別垃圾郵件工作前必 須透過一些適當的前處理(包括:利用中央研究院中文詞庫小組所開發的之中文自動斷詞系 統(CKIP)進行斷詞及去除標點符號)的工作,將電子郵件內容的詞彙萃取出來,並存入資 料庫,才能成為實驗的資料,以利系統易於後續處理資料,這個步驟稱為資料前處理。 電子郵件集合包含多筆電子郵件資料,在經過資料前處理過程(Pre-processing)後,透 過特徵萃取(Feature Extraction)及不同的特徵選取(Feature Selection)策略,將電子郵件資 料所萃取出來的特徵透過向量空間模型(Vector Space Mode)來表示,最後利用已建構好的 向量空間模型經由 SVMs 分類器作訓練及測試,辨別是否為垃圾郵件(即:垃圾郵件與正常 郵件,共 2 個類別),此過程為辨別垃圾郵件之處理流程,如圖 1 所示:
圖 1 辨別垃圾郵件之處理流程
2.5 Support Vector Machines 理論理論理論理論
SVMs 是起源於統計學習法則中的結構風險最小化(Structural Risk Minimization:SRM) [4]為基礎發展出的機器學習(Machine Learning)演算法,由 Vapnik [6][7]及其團隊於 AT&T 之貝爾實驗室中所發展出來,Vapnik 透過統計方法證明 SVMs 在資料量趨近無限大時,也可 以在有限的次數中找到最佳解。最初始的設計是處理二元分類(Binary Classification)之問題, 運算兩類別樣本空間之最佳分割超平面(Optimal Separate Hyper-plane)進而保證最小錯誤分 類率,不但如此 SVMs 另一個特點就是可以處理線性不可分割的分類問題,將原始空間中無 法分割的低維度樣本向量轉換到更高維度的特徵空間中進行線性分割;或者是導入柔性邊界 (Soft Margin)機制,允許若干個樣本在訓練階段可以錯誤分類,將原始空間中無法線性分 割二類訓練樣本的問題轉化成可以線性分割[10]。 E-mails Pre-processing E-mails Feature SVMs Classifiers Feature Selection Spam Ham
SVMs 技術在中文文件分類上有高效能的表現,而且在國外的研究中顯示[2][4][5][8]: 使用 SVMs 作為英文垃圾郵件辨別之核心分類器也是可行的,故本研究探討使用 SVMs 作 為辨別中文垃圾郵件之核心分類器,希望藉由 SVMs 技術能夠有效地辨別中文垃圾郵件,進 而達到減少垃圾郵件數量及降低正常郵件的誤判率。 圖 2 SVMs 分類器架構[6]
3. 研究方法與實驗設計
研究方法與實驗設計
研究方法與實驗設計
研究方法與實驗設計
統計特徵辨識(Statistical Pattern Recognition)方法已經有一些成功設計在商業用途的辨
識系統,其辨識系統以兩個數學模型來運算:一個是訓練(學習),另一個是分類(測試)[3]。 本研究實驗資料庫,包括:垃圾郵件與正常郵件。經仔細察看本實驗所收集的「日常生 活中所接收的真實垃圾郵件集合」,其中有很多垃圾郵件之主旨皆相同,只是寄件人或內文不 同。本實驗為使結果更加精確,已將相同主旨之垃圾郵件先予以刪除。雖然垃圾郵件的主旨 會隨著時間的改變而有所不同,但大部份還是以「營利」為目的,例如:「免費無碼影片下載、 免費債務協商諮詢、超值優惠貸款、成本最低廣告、想賺錢嗎?…等等」,並常常利用人性貪 小便宜的弱點,在主旨或內文中加入「優惠」、「最低價」、「免費」、「賺錢」…等吸引人的相 關詞彙,使收件者更容易地去閱讀該信件,以達到廣告商濫寄垃圾郵件的目的。 由於現實生活所接收的正常郵件,其主旨、內文之內容皆不一、類別也不同,且大部份 信件又涉及隱私,很難去收集,故本實驗之正常郵件是收集「透過寄送網路新聞方式」所產 生的郵件。 本論文的實驗是透過不同的實驗,分別針對電子郵件的不同欄位內容(包含:只有主旨 欄位、只有內文欄位、主旨及內文兩者欄位)、不同的特徵選取方式(包含:只選取名詞、只 選取動詞及選取名詞及動詞)、不同的特徵選取策略(包含:透過二元方式(Binary)、詞彙 w.x + b = +1 Hyper-plane w.x + b = 0 w.x + b = -1 d+ d- Support Vector Margin: || w || 2
頻率(TF)及詞彙頻率與文件頻率倒數之乘積(TF×IDF))、不同核心函數的分類器(包含: Linear SVMs 分類器、Gaussian RBF SVMs 分類器及 Polynomial SVMs 分類器)、不同的調和 係數 C 值等,經由 SVM-Light 程式,先透過訓練集合訓練,再將測試集合作測試,以辨別是 否為垃圾郵件。
4. 實驗結果與討
實驗結果與討
實驗結果與討論
實驗結果與討
論
論
論
一般分類器效能的測量方法除了取決於系統運算能力之外,對於分類器在運算的正確率 也是重要的效能評估指標,在資訊檢索領域中評估分類器效能的方法主要透過以下三個評估 值來衡量:檢出率(Recall)、精確率(Precision)及 F1 量測值,而分類系統將資料分類的情 況,如表 1 所示。 表 1 電子郵件判定情形 實際為垃圾郵件(+1) 實際為正常郵件(-1) 系統判定垃圾郵件(+1) A B 系統判定正常郵件(-1) C D 在表 1 中, A 為分類器正確分類類別“+1”的垃圾郵件數。 B 為分類器錯誤分類類別“+1”的正常郵件數。 C 為分類器錯誤分類類別“-1”的垃圾郵件數。 D 為分類器正確分類類別“-1”的正常郵件數。 每個效能衡量的計算方式如下: (1) 檢出率(Recall): R= C A A + ,也稱為垃圾郵件成功攔截率。垃圾郵件成功攔截率=(成功攔截的 spam /(成功攔截的 spam +沒攔截到 spam)),效能良好的 Anti-SPAM 方法,此比例值要越高越好。
垃圾郵件攔截率越高,漏攔的垃圾郵件機率也就越小。 (2) 精確率(Precision): P= B A A + ,即為垃圾郵件的判定率。精確率數值越高,正常郵件誤判成垃圾郵件的機率 也就較低。 正常郵件誤判率(False positive)FP= B A B + ,效能良好的垃圾郵件過濾器,FP 比例的數
值要越低越好,因一封正常郵件被誤判成垃圾郵件而被系統攔截,所造成的困擾應遠大 於多看一兩封垃圾郵件被誤判成正常郵件,人們往往不希望將正常郵件誤判成垃圾郵件 而被系統攔截,因此垃圾郵件精確率愈高的系統(即正常郵件誤判率愈低的系統),通常 也是系統效能的重要評估。 (3) F1 衡量(F1-measure): F1= R P R P + × 2 ,是檢出率和精確率的調和平均值,F1 量測值是將 Recall、Precision 兩者同 時綜合考慮,可透過兩者之乘積運算作為效能評估指標之另一方式。 4.1 實驗一實驗一實驗一實驗一 0% 20% 40% 60% 80% 100% 郵件欄位 F1(+1) 過濾名詞及動詞 82.48% 63.21% 80.71% 只過濾名詞 80.26% 61.93% 79.57% 只過濾動詞 73.20% 51.50% 71.86% 主旨內文兩者 只有主旨 只有內文 圖 3 核心函數為 Linear,以 Binary 特徵選取策略於不同的郵件欄位及不同的特徵選取方式之 F1(+1) 評估值 0% 20% 40% 60% 80% 100% 郵 件 欄 位 F1(+1) 過 濾 名 詞 及 動 詞 76.66% 59.50% 74.77% 只 過 濾 名 詞 75.54% 57.36% 73.94% 只 過 濾 動 詞 68.38% 50.70% 67.03% 主 旨 內 文 兩 者 只 有 主 旨 只 有 內 文 圖 4 核心函數為 Linear,以 TF 特徵選取策略於不同的郵件欄位及不同的特徵選取方式之 F1(+1) 評估 值
0% 20% 40% 60% 80% 100% 郵件欄位 F1(+1) 過濾名詞及動詞 64.91% 49.01% 63.52% 只過濾名詞 66.51% 49.71% 65.22% 只過濾動詞 61.42% 41.21% 59.13% 主旨內文兩者 只有主旨 只有內文 圖 5 核心函數為 Linear,以 TF×IDF 特徵選取策略於不同的郵件欄位及不同的特徵選取方式之 F1(+1) 評估值 0% 20% 40% 60% 80% 100% 特徵選取策略 F1(+1) 過濾名詞及動詞 82.48% 76.66% 64.91% 只過濾名詞 80.26% 75.54% 66.51% 只過濾動詞 73.20% 68.38% 61.42% Binary TF TF×IDF 圖 6 在主旨及內文兩者欄位,核心函數為 Linear,不同的選取特徵策略及不同的特徵選取方式之 F1(+1) 評估值 在實驗一之二元方式(Binary)、詞彙頻率(TF)及 TF×IDF 特徵選取策略分類結果,可 得到下列三點: (1) 由於主旨之文字內容通常較少,而內文之文字內容通常較多,相對地,由內文得到之特 徵詞彙會比由主旨得到之特徵詞彙較多,故分類結果 F1 值會較高。同理,主旨、內文 兩個欄位之文字內容最多,其分類結果 F1 值會比主旨或內文單一欄位較高。 (2) 只過濾名詞會比只過濾動詞的分類結果 F1 值較高,且過濾名詞及動詞會比只過濾名詞 或只過濾動詞的分類結果 F1 值較高。 (3) 以二元方式(Binary)特徵選取策略之分類結果 F1 值,比 TF、TF×IDF 來得高。
4.2 實驗二實驗二實驗二 實驗二 0% 20% 40% 60% 80% 100% d (F1(+1)+F1(-1))/2 數列1 83.59% 46.00% 18.07% 13.52% 13.33% 14.15% 15.57% 15.93% 17.80% 19.01% 1 2 3 4 5 6 7 8 9 10 圖 7 在主旨及內文兩者欄位,過濾名詞及動詞,二元方式分類,固定調和係數 C=1,核心函數 (Polynomial)及不同的核心參數(d)之(F1(+1) +F1(-1))/2 評估值 在主旨及內文兩者欄位,過濾名詞及動詞,二元方式分類,固定調和係數 C=1,以特徵 選取策略為 Binary 及核心函數為 Polynomial 之不同核心參數(d),以 d=1 之 F1 值較佳。 0% 20% 40% 60% 80% 100% g (F1(+1)+F1(-1))/2 數列1 78.43% 96.55% 84.72% 65.84% 0.89% 0.84% 0.84% 0.84% 0.0001 0.001 0.01 0.1 1 10 100 1000 圖 8 在主旨及內文兩者欄位,過濾名詞及動詞,二元方式分類,固定調和係數 C=1,核心函數(RBF) 及不同的核心參數(g)之(F1(+1) +F1(-1))/2 評估值 在主旨及內文兩者欄位,過濾名詞及動詞,二元方式分類,固定調和係數 C=1,以特徵 選取策略為 Binary 及核心函數為 RBF 之不同核心參數(g),g=0.001 之 F1 值較佳。
4.3 實驗三實驗三實驗三 實驗三 0% 20% 40% 60% 80% 100% 特徵選取策略 (F1(+1)+F1(-1))/2 Linear 83.95% 78.52% 68.23% Polynomial(d=1) 83.95% 78.56% 68.20% RBF(g=0.001) 96.63% 64.17% 73.42% Binary TF TF×IDF 圖 9 在主旨及內文兩者欄位,選取名詞及動詞,固定調和係數 C=1,不同的特徵選取策略,在不同 核心函數之 SVMs 分類器之(F1(+1) +F1(-1))/2 評估值 在實驗三,可得到的結果是以特徵選取策略為 Binary 及核心函數為 RBF(g=0.001)之 F1 值較佳。 4.4 實驗四實驗四實驗四 實驗四 0% 20% 40% 60% 80% 100% C (F1(+1)+F1(-1))/2 Binary 96.55% 95.15% 89.94% 79.25% 79.72% 80.78% 81.57% 82.20% 82.25% 82.52% TF 63.59% 68.90% 72.90% 75.10% 76.54% 77.18% 77.44% 77.99% 78.45% 78.48% TF×IDF 73.55% 75.26% 75.29% 75.18% 75.13% 75.21% 75.18% 75.19% 75.21% 75.21% 1 2 3 4 5 6 7 8 9 10 圖 10 在主旨及內文兩者欄位,選取名詞及動詞,核心函數為 RBF(g=0.001),不同調和係數 C 及不 同的特徵選取策略之(F1(+1) +F1(-1))/2 評估值 在實驗四,在訓練階段,可得到下列二點: (1) 選取不同的調和係數 C 值,以特徵選取策略為 Binary 所得到之分類結果比 TF、TF×IDF 之 F1 值較佳。
(2) 在核心函數為 RBF(g=0.001),以特徵選取策略為 Binary,調和係數 C=1,F1 值最佳(F1(+1) 值為 96.63%,(F1(+1) +F1(-1))/2 值為 96.55%)。 4.5 實驗五實驗五實驗五 實驗五 0% 20% 40% 60% 80% 100% 特徵選取方式 F1(+1) 至少出現1次 96.63% 94.59% 88.88% 至少出現2次 96.06% 94.64% 88.53% 至少出現3次 96.11% 94.32% 88.13% 至少出現4次 96.12% 94.50% 87.66% 過濾名詞及動詞 只過濾名詞 只過濾動詞 圖 11 在主旨及內文兩者欄位,特徵選取策略為 Binary,不同的特徵選取方式,比較保留至少出現 1 次詞彙、至少出現 2 次詞彙、至少出現 3 次詞彙、至少出現 4 次詞彙之 F1(+1) 評估值 由實驗五之特徵選取策略為 Binary 分類結果,可得到下列二點: (1) 不論比對保留至少出現 1 次含以上(即全部之詞彙)、或至少出現 2 次(含)以上、或 至少出現 3 次(含)以上、或至少出現 4 次(含)以上,其 F1(+1)值幾乎相同,出現 4 次(含)以上比出現 1 次含以上(即全部之詞彙)之詞彙數量已減少一半以上,相對地, 其維度也減少一半以上,故其運算時間可大大地縮短,一般常見的方式:保留出現 3 次 (含)以上之詞彙,可縮短其維度,且較不影響其準確率。 (2) 不論是過濾名詞及動詞、或者只過濾名詞、或者只過濾動詞,所得到的結果幾乎相同。 4.6 實驗六實驗六實驗六 實驗六 0% 20% 40% 60% 80% 100% 電子信箱 F1(+1) 數列1 75.78% 88.89% 59.15% 63.01% 96.37% Yahoo Gmail Mail2000 中華數位 Pchome
由於每個人對垃圾郵件的定義不盡相同,垃圾郵件過濾的效能也會不同。每一種電子信 箱所採用的過濾技術不同,且其過濾政策有可能是訂定較寬鬆或較嚴謹,故每一種電子信箱 的過濾效能也不同,說明如下: (1) 過濾效能為較高 F1 值:會抓到絕大多數的垃圾郵件,但是有時也可能會抓到某些一般 的正常郵件,故其缺點為:須常常檢查「垃圾郵件」資料夾,瀏覽是否有被誤判的正常 郵件,其優點為:在「正常郵件」資料夾會找到較少的垃圾郵件。 (2) 過濾效能為較低 F1 值:將最明顯的垃圾郵件移至「垃圾郵件」資料夾,其優點為:不 用常常檢查「垃圾郵件」資料夾,被誤判的正常郵件的機率相對較小,但其缺點為:在 「正常郵件」資料夾會找到較多的垃圾郵件。 (3) 在五個電子信箱,以 PChome 之 F1(+1)值為最高(96.37%)。在實驗四之訓練階段之 F1(+1) 值最佳(96.63%),可見適當地選取特徵選取策略、分類器及調和係數等,其辨別垃圾 郵件的效能可與市面上之電子信箱相媲美。
5. 結
結
結 論
結
論
論
論
防堵垃圾郵件的方式有很多,大部分的單一種技術或方法都無法達到「垃圾郵件的高阻 擋率及正常郵件的低誤判率」的要求。如果垃圾郵件的阻擋率不高,收信人還是需要花上許 多的時間去處理垃圾信件;如果正常郵件之誤判率太高,信件可能會因此而被攔截,讓收信 人需要花更多的時間、精力去把被誤判的信件救回來。本研究的目的是希望藉由使用 SVMs 作為辨別中文垃圾郵件之核心分類器,針對郵件內容進行關鍵詞彙的比對,進而達到較高比 率的垃圾郵件阻擋率及較低比率的正常郵件誤判率。 在經過本研究的實驗之後,我們得到的結論:根據以往使用 SVMs 在文件分類的相關文 獻中顯示,SVMs 技術在文件分類上有高效能的表現,因此本研究將電子郵件視為文件的一 種,經由 SVMs 分類技術進行中文垃圾郵件辨別,且適當地選取:「電子郵件欄位資料、特徵 選取方式、特徵選取策略、核心函數(含核心參數)、及調和係數等」,則可提高辨別垃圾郵 件之效能。 (1) 選取主旨及內文兩者欄位。 (2) 選取過濾名詞及動詞。 (3) 選取二元方式(Binary)。 (4) 核心函數(kernel function):RBF(g=0.001)。 (5) 調和係數 C=1。 本實驗如果符合上述五個條件時,其辨別垃圾郵件之(F1(+1) +F1(-1))/2)可高達約 96.55%, 因此可以證明於本研究中使用 SVMs 辨別中文垃圾郵件是有一定的成效。參考文獻
參考文獻
參考文獻
參考文獻
[1] Mertz, D., ”Spam filtering techniques”, http://www-106.ibm.com/developerworks/linux/ library/l-spamf.html, September 2002.
[2] Drucker, H., Wu, D., and Vapnik, V. N., “Support Vector Machines for Spam Categorization,” IEEE Transactions on Neural Networks, Vol. 10, No. 5, 1999, pp. 1048-1054.
[3] Mao, J. D., “Statistical Pattern Recognition: A Review”, IEEE Tran. on Pattern Analysis and Machine Intelligence, Jan. 2000.
[4] Matsumoto, R., Zhang, D. and Lu, M., ”Some Empirical Results on Two Spam Detection Methods”, Proceedings of the 2004 IEEE International Conference on ,2004, pp.198-203. [5] Liu, S., Pan, C., ”Study on the Spam-Filtering System based on Feature Selection Mechanism
and Improved SVM Classification”, IEEE, 2006, pp.1143-1146. [6] Vapnik, V. N., “Statistical Learning Theory”, Wiley , 1998.
[7] Vapnik, V. N., “An Overview of Statistical Learning Theory”, IEEE Trans. on Neural Networks,Vol. 10, No.5,Sept. 1999.
[8] Wang, Z., Sun, X., Li X., Zhang, D., “An Efficient SVM-Based Spam Filtering Algorithm” , IEEE ,Proceedings of the Fifth International Conference on Machine Learning and Cybernetics, Dalian, 13-16 August, 2006, pp.3682-3686.
[9] 李柏毅,Support Vector Machines 技術應用於中文文件自動分類之探討,高雄應用科技大 學電機工程系,碩士論文,2004。
[10] 徐豐智,Support Vector Machines 技術應用於文件相關性量測之探討,高雄應用科技大學 電機工程系,碩士論文,2005。
[11] 陳廷忠,一個以多重類別架構為主的多國語言文件分類技術之開發研究,高雄應用科技 大學電機工程系,碩士論文,2006。
[12] 林 佳 明 , 資 安 案 例 分 享 - e-mail 社 交 工 程 及 防 護 , http://61.57.42.3/upload/security/ emailAA/content/06_e-mail.pdf。