初始階段選題對電腦適性測驗試題曝光率之比較
錢永財 劉家惠 郭伯臣
台中師範學院測驗統計研究所
[email protected]
摘要
電腦適性測驗之題庫建立不易,如不能有效控 制題庫題目曝光率,當題目過度曝光,受測者則容 易施測到相同的題目使得測驗的安全性與公平性 產生危機。在測驗開始階段三至五題時,由於能力 估計仍未精確,此時若能有效分散試題,提升題庫 中低曝光率試題的使用率,並可有效降低題庫中未 使用試題題數,對整體試題曝光率達到有效控制, 以期達到提升題庫經濟效益。 本 研 究 針 對 測 驗 前 期 三 至 五 題 採 取隨 機 選 題、McBride & Martin(1983)提出之 5-4-3-2-1 隨機 選題法及 b 值分層隨機選取等方法,比較其試題曝 光率控制效果,試圖找出有效控制題庫中未使用試 題題數、降低試題曝光率、改善施測時前後測試題 重疊率及試題重疊率的方法。 研究結果:電腦適性測驗測驗前期三至五題採 取 b 值分層隨機選取對試題題庫題目曝光率有明顯 改善。以 b 值分層選題法控制測驗測驗前期五題選 題,六至二十題採鄰近法選題在曝光率控制上的表 現最佳;若以 b 值分層選題法控制測驗測驗前期三 題選題,四至二十題採最大訊息法選題,則能力估 計誤差最小。 關鍵詞:電腦適性測驗、題目曝光率、題目反應理 論、選題法。Abstract
To maintain test security and fairness of computerized adaptive testing (CAT), the exposure rate of item pool should be well controlled. The items administered to different examinees are most frequently the same in the early stage of CAT for the estimation of latent trait of examinees were not accurate enough. It can be expected to balance the exposure rate of items in the item pool and therefore efficiently usage of the item pool.
This study compared the performance of exposure control of three methods in the early stage of CAT: random selection, 5-4-3-2-1 random selection, and b-stratified random selection. The results of percentage of unused items, exposure rate, test overlap rate and item overlap rate of these methods were presented in this study.
It was found that the b-stratified random
selection method improved the exposure control rate of the item pool significantly. To use the b-stratified random selection method combined with
Nearest-Neighborhood method performs better than other combination on item exposure control. The bias of latent trait was minimized under the b-stratified random selection method combined with maximum information method.
Keywords: computerized adaptive testing, item exposure rate, item response theory, item selection criterion.
1. 前言
電腦適性測驗在測驗開始階段三至五題 時,由於能力估計仍未精確,此時若能有效 分散試題,對題庫中低曝光率試題提升使用 率,並可有效降低題庫中未使用試題題數, 對整體試題曝光率達到有效控制,以期達到 提升題庫經濟效益。若初始值假設受試者為 中等能力,在題庫中一選題法挑選的題目作 為施測的起始題;易形成每位受試者都使用 相同的題目開始,其保密性需要考量。然由 電腦隨機選題起始對初期能力估計的精確度 不佳情形下易應估計誤差大而出現極大或級 小的估計值而使受試者都使用相同的題目, 其保密性亦不佳。因此針對測驗前期三至五 題採取 b 值分層隨機選取方法使測驗前期三 至五題試題加大 b 值差異,試圖找出有效控 制題庫中未使用試題題數、降低試題曝光 率、改善施驗時前後測試題重疊率及試題重 疊率的方法。2. 文獻探討
2.1 電 腦 適 性 測 驗 (computerized adaptive testing, CAT)簡介與探討: 初始值設定: 電腦化適性測驗的基本原則是依受試者能力 提供適當的試題呈現給受試者施測,但在測 驗之始,受試者之能力高低未能得知,因此, 必須決定測驗的起始點,以選擇第一個試題 供受試者施測。常用於起始題的決定方式, 有以下幾種(王寶墉, 1995;陳麗如, 1998): 中等難度題目:即假設受試者為中等能力,在題庫中挑選難度適中的題目作為施測的起 始題;中等難度題目開始,因題目有限,若 每位受試者都使用相同的題目開始,其保密 性需要考量。由受試者之基本資料(年齡、 學習、經驗或其他測驗結果)估算受試者能 力初始值,以決定測驗起始點。自由選題: 由受試者在接受測驗的時候,自行判定自己 的程度,以決定施測的起始題。隨機選題: 由電腦隨機選題,但一般限定試題難度參數 b 介於-0.5 至 0.5 間為選取範圍。 題庫: 電腦化適性測驗與傳統紙筆測驗的不同在於 必須建立一個含有試題反應理論測驗試題參 數的題庫,題庫中之參數必須以共同量尺來 表示,才能有一致的單位。適性測驗之效度 與效率,與選題題庫大小具有密切關係(李茂 能, 2000)。若要使電腦適性測驗與傳統紙筆 測驗具有相同的測驗水準,假如電腦適性測 驗採固定長度約為傳統紙筆測驗的一半時, 選題題庫大小最好為傳統紙筆測驗的 6 至 8 倍長(Stocking, 1994)。當選題題庫長度為 3 倍以上,精確度與作答效率才有顯著差異 (Hung, 1988)。 選題策略: 一、接近難度法(Reckase, 1973; Urry,1970; Weiss,1974) 選擇試題難度 bj 最接近受測者能力估計值
θ
)
的試題,最為下一階段施測的試題; | ˆ | ) ˆ ( j j b F θ =θ− 二、KL 訊息法(Kullback-Leibler information index)(Chang & Ying,1996)定義:KL 訊息(KL information) 令
θ
0為真實參數。對任意θ
,反應為 , 則第 i 題的 KL 訊息定義為 iX
⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ≡ ) ; ( ) ; ( log ) || ( 0 0 0 i i i i i X L X L E K θ θ θ θ θ 其中E
θ0為對X
i的期望值,且 ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − − − + ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ = ) ( 1 ) ( 1 log )] ( 1 [ ) ( ) ( log ) ( ) ; ( 0 0 0 0 θ θ θ θ θ θ θ i i i i i i i i P P P P P P X L 定義:KL 測驗訊息(KL test information) 定 義 : 平 均 KL 訊 息 指 標 (average KL information index) 令 為第 n 題的能力估計值,則第 i 題的平 均 KL 訊息指標定義為 nθ
ˆ
θ θ θ θ θθ δδK d K n n n n n i n i∫
+ − = ˆˆ ( ||ˆ) ) ˆ ( 其中δ
n為平均值的計算區間大小。 此指標表示 KL 函數在θn θn 的區 域面積,若 n δ − ˆ 與ˆ +δn間 nδ
值小,則指標(式**)決定於 在 上的曲度(curvature);若 ) ˆ || ( n i K θ θθ
ˆ
nδ
n值 大,則指標易受Ki(θ||θˆn)尾端值影響。故δ
n 應隨 n 遞減到 0,並且區間( , )應 包含 n n δ θˆ − n n δ θˆ + 0θ
,又因θ
0的最大概似估計 為平均 數為 nθ
ˆ
0θ
,變異數為1 ( 0) ) (n θ I 的近似常態分 佈,故將區間設為[
]
{
( ) 12[
( )]
12}
) ˆ ( ˆ , ) ˆ ( ˆ n n n n n n c Iθ
θ
c Iθ
θ
− + 其中常數 c 依據收斂機率選擇。因I
(n)為 n 階,故可設δ
n為 n c n = δ 即第 i 題的平均 KL 訊息指標為 θ θ θ θ θ θ K d K c n n c i n n i n n∫
−+ = ˆ ˆ ) ˆ || ( ) ˆ ( KL 訊息法以此平均 KL 訊息指標選出最大訊 息者,作為適性測驗的下一階段施測的試題。 三、單點式最大訊息法 (Birnbaum,1968;Lord,1980) 選擇訊息函數 (ˆ). (ˆ) )] ˆ ( ' [ ) ˆ ( 2 θ θ θ θ j j j j Q P P I = 最大者 四、鄰近法(Nearest-Neighbors criterion,NN) 步驟一:全部題目皆有對能力最大訊息M與不 偏難度b’[
]
[
2 2/3]
2 2 ) 8 1 ( 8 20 1 ) 1 ( 8 ) ( ) ( c c c c Da I Max M − − + + − = ≡ θ θ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + + + = 2 8 1 1 log 1 ' c Da b b 步驟二:設定非遞增整數n
( k) k=1,2,…,L 步驟三:初始化能力值估計值θ
ˆ
(k) 步驟四:找新題 個,其題目不偏難度b’最 接近 ) ( kn
) (ˆ
kθ
步驟五:選 個題目中,有最大 M 的當作 (n+1)題,重新估計能力值為 ,回到步 驟三,直到停止條件成立。 ) ( kn
) 1 (ˆ
k+θ
終止條件: 電腦化適性測驗施測題目與題數因人而異, 而依測驗的目的與性質,測驗終止的標準一 般有下列方式(陳麗如, 1998;陳新豐, 1999): 設定固定的施測題數。當所有受試者答題數 達到預設之題數限制時,即終止測驗,一般 以二十至三十題之間為原則。此法常用於模 擬研究,其優點是易於設計開發,試題使用 率可較精確地預測,但可能使受試者能力估計的精確度具變動性,因此在實際情境的應 用較少。 當受試者的能力估計標準差低於預設標準 時,測驗即終止。此即能力估計的精確度已 達預定標準,使用此種終止標準通常是以貝 氏選題法為選題策略。 當題庫中未使用的試題,再也無法獲得更多 的測驗訊息時,即終止測驗。換言之,能力 的估計已穩定,再做題目已經沒有幫助,採 用此終止標準時,通常以最大訊息選題法為 選題策略。
2.2 MM 演算法(McBride and Martin, 1983) McBride 與 Martin 在 1983 年提出此法, 減少一個題目出現的次數,以增加題目的安全 性。MM 演算法是使用隨機策略使初選題目 的題目曝光率下降,其實施方法為,對某一受 試者,依能力初始值從題庫中選出 5 题最佳的 題目,從 5 题中選出一題施測並重新估計能力 值,依新估計的能力值從题庫中選出 4 题最佳 題目,從 4 题中選ㄧ題施測並重估能力值;依 新估計的能力值從题庫中選出 3 题最佳題 目,從 3 题中選ㄧ題施測並重估能力值;依新 估計的能力值從题庫中選出 2 题最佳題目,從 2 题中選ㄧ題施測並重估能力值;依新估計的 能力值,施測題庫中最佳題目。 2.3 b 值分層隨機選取法 將題庫依 b 值分層分三層測驗前期三題 採取隨機選題、分五層測驗前期五題採取隨機 選題使受試者在測驗前期施策難易度相差較 大試題。
3. 研究設計
3.1 本研究探討的自變項有三: (1)控制測驗測驗前期三至五題選題方法: 選題方法 控制題 數 代號 中間能力起始選題 無 (A1) 三題 (A2_3) 中間能力起始 MM 演算法 五題 (A2_5) 三題 (A3_3) 隨機起始能力 MM 演算法 五題 (A3_5) 三題 (A4_3) 隨機選題 五題 (A4_5) 三題 (A5_3) b 值分層選題 五題 (A5_5) (2)後期選題方法:最接近難度法、KL 訊 息函數、最大訊息法、鄰近法四種方法; (3)控制題數:三題、五題二種情形。 3.2 在資料產生部分 是以研究者自行撰寫 MATLAB 6.5 的模擬 程式。受試者為 1000 人,能力服從平均數為 0, 標準差為 1 的常態分配,亦即 N(0,1);試題 題庫共 1200 題採用三參數模式,其中 a 參數服 從 0.5 到 2.5 之間的均勻分配,b 參數服從 N (0,1),c 參數則為 0。 3.3 測驗長度: 為顯現能力估計的收斂情形,故本研究將 統一設定為 20 題 3.4 能力估計部分: 本研究採用常用的最大概似估計法(MLE) 3.5 曝光率控制效能評估指標: 題目曝光率的均勻度(χ2) 為量化曝光率,需要一個目標分配,因所 有題目應有相同的曝光率,故假設曝光率為均 勻分配。則表示每題之曝光率的期望值為平均 曝光率,故利用 Pearson 的卡方檢定檢定題目 曝光率是否呈現均勻分配,其檢定統計量為∑
= − = n i i er er er 1 2 2 / ) ( χ 表示平均曝光率與觀測的題目曝光率的 變異程度,並將題庫使用的效率量化,若 值 小,則題目曝光率為均勻分配,表示題目被充 分的使用,故題庫使用有效率。 2 χ題目重複率(test overlap rate)
題目重複率(test overlap rate)是另一個評 量題目曝光控制的重要指標。題目重複率為區 塊或成對的題目在不同測驗同時讓受試者施 測的程度,Way(1997)將題目重複率定義為題 目被兩位受試者施測,所有成對比較平均的比 例。簡單的定義可將題目重複率為兩個隨機選 出的受試者施測的重複題目數,除上測驗長 度。所以若 N 為受試者人數,題目重複率可 由以下所計算:(1)計算 對受試者重 複題目數;(2)加總此 個數;(3)將 此總數除以 2 / ) 1 (N− N 2 / ) 1 (N− N 2 / ) 1 (N− LN 。理想上,任一對受試 者重複題目數應該被最小化。 能力估計誤差評估:(RMSE) 利用真實能力值
θ
與估計能力值θ
ˆ
的均方根差(root mean squared error, RMSE),評估 電腦適性測驗系統對受試者能力估計的準確 度。 2 1 1 ( ) N i i i RMSE N = θ θ =
∑
− 以及試題中未選用題數、最低曝光率、最 高曝光率、曝光率大於.3 題數、曝光率大於>.2 題數、前後測試題重疊率。4. 研究結果
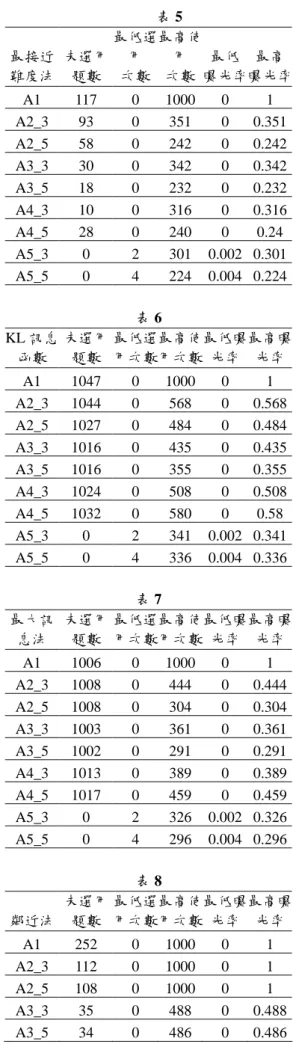
曝光率的均勻度和能力估計的準確度比較: 最接近難度法中(表一) 以 b 值分層選題法控制測驗測驗前期五 題選題曝光率的均勻度 46.9、能力估計誤 差.23 為九組中最佳。且最高曝光率.224 亦為 最低。 KL 訊息函數中(表二) 以 b 值分層選題法控制測驗測驗前期五 題選題曝光率的均勻度 128、能力估計誤差.25 為九組中最佳。且最高曝光率.336 亦為最低。 最大訊息法(表三) 以 b 值分層選題法控制測驗測驗前期五 題選題曝光率的均勻度 109 為最低但能力估 計誤差.19,比中間能力起始選題提高.02。 以 b 值分層選題法控制測驗測驗前期三 題選題曝光率的均勻度 134 為最低但能力估 計誤差.18,比中間能力起始選題提高.01。 鄰近法(表四) 以 b 值分層選題法控制測驗測驗前期五 題選題曝光率的均勻度 57.4、能力估計誤 差.21 為九組中最佳。且最高曝光率.278 亦為 最低。 b 值分層選題法控制測驗測驗前期三 題、五題等二種方法對四種選題法的未選用題 數達成明顯改善、最低曝光率達到提升效果、 最高曝光率達到下降、曝光率大於.3 題數及曝 光率大於>.2 題數均有明顯減少、前後測試題 重疊率和試題重疊率能亦達到下降。 就控制曝光率而言以 b 值分層選題法控 制測驗測驗前期五題選題,六至二十題採鄰近 法選題是最佳選擇;若考慮能力估計誤差可改 採以 b 值分層選題法控制測驗測驗前期三題 選題,四至二十題採最大訊息法選題。5. 結論與建議
電腦適性測驗測驗前期三至五題採取 b 值分層隨機選取對使用接近難度法、KL 訊息 法、最大訊息法鄰近法等選題策略,試題題 庫有以下明顯改善: (1)有效控制題庫中未使用試題題數提 升題庫建制之經濟效益 (2)降低試題曝光率延長題庫使用時限 (3)改善施驗時前後測試題重疊率及試 題重疊率 未來可將電腦適性測驗測驗前期三至五 題採取 b 值分層隨機選取結合現有整體曝光 率控制方法以達到最低曝光率提升、最高曝 光率下降控制的組合方法。參考文獻
王寶墉(1995),現代測驗理論,心理出版社,臺 北。 李茂能(2000),中文電腦化適性測驗系統之應用 與評鑑。文景書局。 陳新豐(1999),「多媒體線上適性測驗系統發展及 其相關研究」,碩士論文,國立臺南師範學院 國民教育研究所,臺南。 陳麗如(1998),「電腦化適性測驗之題庫品質管理 策略」,碩士論文,國立臺灣師範大學資訊教 育研究所,臺北。Birnbaum, A. (1968). Some latent trait model and
their use in inferring an examinee’s ability. In F.
M. Lord and M. R. Novick, Statistical theories of mental test scores. Reading, Mass: Addison Wesley.
Chang, H. H. & Ying, Z. (1996). A global information
approach to computerized adaptive testing.
Applied Psychological Measurement, 20, 3, 231-229.
Cheng P. E., & Liou, M. (2003). Computerized
adaptive testing using the nearest neighbors criterion. Applied Psychological Measurement,
24, 257-265.
Cover, T. M., & Thomas, J. A. (1991). Elements of
information theory. New York: Wiley.
Davey, T., & Parshall, C. G.(1995,April). New
algorithms for item selection and exposure control with computerized adaptive testing. Paper
presented at the annual meeting of American Educational Research Association, San Francisco.
Hambleton, R. K., & Swaminathan, H. (1985). Item
response theory: Principles and applications.
Hingham, MA: Kluwer Boston, Inc.
Lord, F. M. (1980). Applications of item response
theory to practical testing problems. Hillsdale, N.
J. : Lawrence Erlbaum.
Stocking, M. L. (1994). Three practical issues for
modern adaptive testing item pools. Educational
Testing Service, Princeton, N. J. (ERIC Document Reproduction Service No. ED 385 551)
Veerkamp, W. J. J., & Berger, M. P. F. (1997). Some
Journal of Educational and Behavioral Statistics, 22, 203-226.
Way, W. D. (1997, March). Protecting the integrity of
computerized testing item pools. Paper presented
at the annual meeting of the National Council on Measurement in Education, Chicago.
表 1 最接近
難度法
A1 A2_3 A3_3 A4_3 A5_3
2
χ 170 103 72.06 57.46 57.5
RMSE 0.26 0.26 0.27 0.25 0.26
A2_5 A3_5 A4_5 A5_5
2 χ 80.53 69.9 48.79 46.9 RMSE 0.26 0.27 0.26 0.23 表 2 KL 訊息 函數
A1 A2_3 A3_3 A4_3 A5_3
2
χ 333 280.4 223.7 257.6 153 RMSE 0.28 0.27 0.29 0.28 0.25
A2_5 A3_5 A4_5 A5_5
2 χ 255.3 215.9 282.3 128 RMSE 0.27 0.27 0.29 0.25 表 3 最大訊 息法
A1 A2_3 A3_3 A4_3 A5_3
2
χ 227 187.3 174.3 193.5 134 RMSE 0.17 0.17 0.18 0.18 0.18
A2_5 A3_5 A4_5 A5_5
2
χ 169.3 163.6 224.5 109
RMSE 0.17 0.17 0.19 0.19 表 4
鄰近法 A1 A2_3 A3_3 A4_3 A5_3
2
χ 173 168.6 77.06 91.96 73.2 RMSE 0.2 0.25 0.24 0.21 0.21
A2_5 A3_5 A4_5 A5_5
2 χ 169.2 76.75 92.35 57.4 RMSE 0.25 0.26 0.2 0.21 表 5 最接近 難度法 未選用 題數 最低選 用 次數 最高使 用 次數 最低 曝光率 最高 曝光率 A1 117 0 1000 0 1 A2_3 93 0 351 0 0.351 A2_5 58 0 242 0 0.242 A3_3 30 0 342 0 0.342 A3_5 18 0 232 0 0.232 A4_3 10 0 316 0 0.316 A4_5 28 0 240 0 0.24 A5_3 0 2 301 0.002 0.301 A5_5 0 4 224 0.004 0.224 表 6 KL 訊息 函數 未選用 題數 最低選 用次數 最高使 用次數 最低曝 光率 最高曝 光率 A1 1047 0 1000 0 1 A2_3 1044 0 568 0 0.568 A2_5 1027 0 484 0 0.484 A3_3 1016 0 435 0 0.435 A3_5 1016 0 355 0 0.355 A4_3 1024 0 508 0 0.508 A4_5 1032 0 580 0 0.58 A5_3 0 2 341 0.002 0.341 A5_5 0 4 336 0.004 0.336 表 7 最大訊 息法 未選用 題數 最低選 用次數 最高使 用次數 最低曝 光率 最高曝 光率 A1 1006 0 1000 0 1 A2_3 1008 0 444 0 0.444 A2_5 1008 0 304 0 0.304 A3_3 1003 0 361 0 0.361 A3_5 1002 0 291 0 0.291 A4_3 1013 0 389 0 0.389 A4_5 1017 0 459 0 0.459 A5_3 0 2 326 0.002 0.326 A5_5 0 4 296 0.004 0.296 表 8 鄰近法 未選用 題數 最低選 用次數 最高使 用次數 最低曝 光率 最高曝 光率 A1 252 0 1000 0 1 A2_3 112 0 1000 0 1 A2_5 108 0 1000 0 1 A3_3 35 0 488 0 0.488 A3_5 34 0 486 0 0.486
A4_3 258 0 322 0 0.322 A4_5 289 0 287 0 0.287 A5_3 0 2 300 0.002 0.3 A5_5 0 4 278 0.004 0.278 表 9 最接近 難度法 r>=0.3 r>=0.2 前後測試 題重疊率 試題重疊 率 A1 5 10 0.41 0.55 A2_3 5 9 0.33 0.47 A2_5 0 15 0.29 0.42 A3_3 2 6 0.27 0.39 A3_5 0 10 0.28 0.41 A4_3 1 4 0.24 0.36 A4_5 0 3 0.21 0.31 A5_3 1 5 0.25 0.38 A5_5 0 3 0.22 0.33 表 10 KL 訊 息函數 r>=0.3 r>=0.2 前後測試 題重疊率 試題重疊 率 A1 14 35 0.69 0.78 A2_3 17 37 0.65 0.69 A2_5 14 40 0.61 0.62 A3_3 14 40 0.54 0.49 A3_5 12 42 0.53 0.48 A4_3 18 37 0.54 0.50 A4_5 19 36 0.52 0.49 A5_3 6 23 0.48 0.47 A5_5 3 18 0.42 0.41 表 11 最大訊 息法 r>=0.3 r>=0.2 前後測試 題重疊率 試題重疊 率 A1 5 17 0.73 0.76 A2_3 7 21 0.68 0.71 A2_5 1 23 0.64 0.68 A3_3 4 27 0.63 0.65 A3_5 0 22 0.64 0.65 A4_3 9 31 0.61 0.64 A4_5 11 33 0.57 0.59 A5_3 2 18 0.57 0.59 A5_5 0 13 0.48 0.51 表 12 鄰近法 r>=0.3 r>=0.2 前後測試 試題重疊 題重疊率 率 A1 5 8 0.49 0.60 A2_3 5 9 0.41 0.55 A2_5 5 9 0.41 0.54 A3_3 1 12 0.29 0.44 A3_5 1 8 0.29 0.41 A4_3 1 6 0.35 0.44 A4_5 0 5 0.30 0.38 A5_3 1 6 0.34 0.44 A5_5 0 5 0.29 0.38 圖 1 試題曝光率的均勻度 0 100 200 300 400
A1 A2_3 A2_5 A3_3 A3_5 A4_3 A4_5 A5_3 A5_5
最接近難度法 KL訊息函數 最大訊息法 鄰近法 圖 2 能 力 估 計 誤 差 評 估 0.1 0.150.2 0.25 0.3 0.35 A1 A2_5 A3_5 A4_5 A5_5 最 接 近 難 度 法 KL訊 息 函 數 最 大 訊 息 法 鄰 近 法