相對移動率應用在區間時間序列預測及其效率評估 - 政大學術集成
43
0
0
全文
(2) 國立政治大學應用數學系 李治陞 君所撰之碩士班學位論文. 相對移動率應用在區間時間序列預測及 其效率評估 政 治 大 立 The Application of Relative Moving. ‧ 國. 學. Ratio for Forecasting and Performance ‧. n. al. er. io. sit. y. Nat. Evaluation in Interval Time Series Ch. engchi 業經本委員會審議通過 論文考試委員會委員:. 指導教授: 系 主 任: 中華民國 101. 年. i n U. 7. v. 月. 3. 日.
(3) 謝辭 隨著論文的完成,學生生涯也將告一個段落。此時,要感謝的人太多,能讓 我順利完成這一篇論文。 首先要感謝的便是我的指導教授劉明郎教授及吳柏林教授,若沒有吳老師提 希與照顧,劉老師耐心的指導,逐字逐句的修改論文。這一篇論文是不可能完成 的。再來,如果沒有丁媽媽在英文摘要上給予我很大的助力,坦白說,我根本寫 不出來。另外,在研究室裡首先要感謝的便是亮哥及家盛,除了給予我在學問上. 政 治 大 小哈、kinki 也陪我瘋狂的玩了許久的魔獸三國,再來就是感謝 yoyo 的貼心,能 立. 很大的指導外,同時在百忙之中爆肝陪我玩世紀帝國讓我度過快樂的暑假。沛承,. 讓我有許多煩惱時,幫我處理許多雜物使我可以無後顧之憂。感謝班上許許多多. ‧ 國. 學. 的同學,認識大家真的太好了。. ‧. 同時,還要感謝我母親給予我的支持與鼓勵。雖然囉嗦了點,但是如果沒有. y. Nat. 她,我不可能來政大唸書,更不可能畢業。. er. io. sit. 最後便是感謝智婷,給了我很多鼓勵與幫忙,在我忙得焦頭爛額時,很有耐 心的陪在我身邊,從大學時期,便花了很多時間幫助我完成許多瘋狂的事情,及. n. al. Ch. 幫助我度過很多次的難關與挫折。. engchi. i n U. v. 要感謝的人真的太多,短短一篇文章,是不可能表達對所有幫助過我的人有 無上的感謝。. 治陞 2012.7.23. IV.
(4) 相對移動率應用在區間時間序列預測及其效率評估 李治陞. 摘要 時間序列是用來預測未來趨勢的一種重要技術,然而在實務上建構時間序列 模型時,參數很難有效估計。原因可能來自於時間序列本身的模糊性質,而導致 參數的不確定性使得預測結果產生極大誤差。如果將參數模糊化引進時間序列的. 政 治 大 讓原本具有模糊性質的時間序列經由反模糊化(defuzzification)後,以點估計的方 立 式估計起始中心點,經由適當的修正調整為較佳的中心點以及半徑,建立有效的. 模型中,往往過於複雜。本論文提出相對移動率為新的模糊時間序列建構方法,. ‧ 國. 學. 區間時間序列。並將相對移動率引進門檻自廻規模型中,取代原有之門檻值設 定,並建立區間時間序列。最後,我們使用台灣加權股價指數為例,以本論文所. ‧. 提出之方法進行區間預測及效率評估。. sit. y. Nat. io. n. al. er. 關鍵字:模糊時間序列、反模糊化、區間預測、相對移動率、門檻自廻規模型. Ch. engchi. V. i n U. v.
(5) The Application of Relative Moving Ratio for Forecasting and Performance Evaluation in Interval Time Series. Li, Chih-Sheng Abstract The time series is an important technology that is used to predict future trends,. 政 治 大. however in the real world, parameter is difficult to estimate effectively when we construct a time series model due to the of the fuzzy property of the times series data.. 立. The estimated parameters in the time series will cause a big error due to the. ‧ 國. the time series model.. It is too complex to introduce the fuzzy parameters into. 學. uncertainty of fuzzy data.. In this thesis, we propose relative moving ratio as a new. ‧. criteria in constructing procedure of an interval time series. We defuzzify a fuzzy data and use point estimation to obtain an initial center, then we adjust the center and. Nat. sit. y. radius making it more appropriately. The resulting center and radius is then become We also apply. io. er. an interval time series that can be use to forecast an interval data.. relative moving ratio in threshold autoregressive models by replacing the threshold in. n. al. Ch. constructing interval time series.. i n U. v. Finally, in empirical studies chapter, we use. engchi. Taiwan weighted Stock Index as examples to evaluate the performance of the proposed two methods in building the interval time series.. Keywords:fuzzy time series, defuzzification, interval prediction, relative moving ratio, threshold autoregressive models.. VI.
(6) 目錄 謝辭 ····························································································· iv 摘要 ·····························································································. v. Abstract························································································ vi 目錄 ····························································································· vii. 第一章 緒論·················································································. 1. 第二章 模糊時間序列分析 ······························································. 3. 2.1. 序言 ················································································. 3. 2.2. 模糊時間序列模型 ······························································. 7. 2.3. 模糊時間序列模型之預測方法···············································. 9. 立. 政 治 大. 第三章 模糊時間序列模型之效率評估 ··············································· 14. ‧ 國. 學. 3.1. 模糊區間之定位及測量辦法·················································· 14. 3.2. 模糊時間序列模型之預測指標··············································· 16. ‧. 第四章 實證分析··········································································· 18. sit. y. Nat. n. al. er. io. 第五章 結論················································································· 35. Ch. i n U. v. 參考文獻 ······················································································· 36. engchi. VII.
(7) 第一章. 前言. 時間數列的發展上,自從 Box 與 Jenkins 在 1976 年發展 ARIMA 以來,已 經引起廣大學者的興趣。例如在時間數列分析導論(吳柏林,1994)中將 ARIMA 應用在空氣汙染、人口成長率、出生率、死亡率、就業率…等。但是若是用 ARIMA 分析隨機漫步上的時間數列資料,會因為假設條件太嚴苛,如資料的穩定性雖然 可以經過差分解決,但是變異數和期望值的固定卻是無法解釋隨著時間改變而使 得變異數改變的時間序列資料,所以非線性時間數列成為近來研究的重心。非線 性的模式有許多種類,例如門檻自廻歸模式(threshold autoregressive models)(Tong, 1980),雙線性模式(bilinear models, Subba-Rao 與 Gabr, 1980)、指數自迴歸模式. 政 治 大. (exponential autoregressive models)(Haggan, 1980)。這些模式當中,門檻自廻歸模 式因具有許多線性 ARIMA 模式所不能描述的特性而受到重視,從早期 Tong 與. 立. Lim (1980)利用門檻自廻歸模式分析加拿大山貓成長趨勢與太陽黑子出現情形,. ‧ 國. 學. 以及 Byers 與 Peel (1995)以門檻自廻歸模式預測六個國家的工業生產指數,和傳 統線性分析的方法比較之下,發現利用門檻自廻歸模式來分析不僅能有較佳的配. ‧. 適度也更能呈現出資料的發展趨勢。但是,光是如此,仍然不能解決期預測準確 性的問題,於是模糊時間序列便因此而誕生,因為模糊集合理論本身具有語言變. y. Nat. 數(linguistic variables)蘊含特性,這種特性可以減少在處理不確定性問題時可能. n. al. Ch. er. io. 合語言變數的分析法,以解決資料模糊性的問題。. sit. 造成的困擾,將模糊邏輯應用在時間序列的分析過程時,第一步是要考慮如何結. i n U. v. Tong (1978)提出邏輯檢查法(logical examination method)利用決策表來描述. engchi. 模糊式,但是此方法很難擴展到多變數的系統。為了獲得更精確的模糊模式, Graham 與 Newell(1989),提出了具有學習能力的方法去修正模糊模式,但此方 法相當麻煩。因此大部分的學者,常採用模糊關係方程式求解來分析。Song 與 Chissom (1993)利用模糊關係方程式,提出詳盡的模糊間序列的建構過程及模式 的理論架構。但是關於模糊時間序列階次的認定,到目前為止並未有一個有效的 辦法,在以往的文獻中都是直接給定的,這方法太過於主觀,理論基礎也相當薄 弱。因此預測結果往往會有極大誤差產生。所以,本論文將提出一種相對移動率 方法,將模糊時間序列的資料反模糊化之後,希望能夠建立一個簡單的預測模 型,能夠有更好的預測結果,同時也希望相對移動率能應用在門檻自廻規模型中。 在門檻自廻規模型中,「轉折」乃結構轉變的考量。當所採用的樣本期間較 長或是樣本期間有重大的因素發生轉變,則考慮是否因為這些因素變動,而使得 1.
(8) 過去的數據和現在的數據之間的關係發生變化 (楊奕農,2009) 。門檻自廻歸模 式和結構轉變模式非常相似,過去 Chow (1960)在線性迴歸模型下,檢定單一已 知結構改變時間點的轉折是否顯著。由於 Chow(1960) 以「時間」為結構改變的 轉折點,主觀認定結構改變的時間,方法上較不客觀,且當模型中重要資料在短 時間內持續發生大幅度變化時,可能無法診斷出模型的結構改變。以「變數」當 轉折點可避免上述缺失,關於這方面的研究,Tong (1980)首先提出以「變數」為 結構轉變的轉折點之 TAR 模式。Kumar 與 Wu (2001)發現在非線性的時間序列 藉由模糊邏輯的概念可以有效找出結構轉折。Zhou (2005)提出整合貝氏(Bayesian) 行的結構轉變分析與轉折點的判斷方法。雖然眾多學者針對結構轉變做分析,其 研究結構轉變使用的方法不計其數,但在數理的推論過程都相當的繁瑣且轉折點 的定義似乎仍無一明確的標準,因此本論文將以相對移動率,當轉折點進行 TAR. 政 治 大 由於模糊時間序列的模型的計算往往過於複雜,因此本文希望能透過返模糊 立 化的過程中,建構一個簡單但是有效的預測模糊時間序列模型,並且把新的模型 模式預測,採用「多變數」,非單一變數,希望能夠得到更有效率的預測結果。. ‧ 國. 學. 中的參數套入門檻自回歸模型中,比較其有效性。. 本論文在第二章從何謂模糊理論開始做一個簡單的介紹,進而給一個新的模. ‧. 糊區間預測模型的新方法,並把這種方法和門檻自回歸模型做一個整合。第三章. y. Nat. 從兩組區間資料的距離開始研究,給一個效率性的分析。第四章是蒐集從民國一. sit. 百年六月一號到十二月三十一號的開盤價及收盤價後,用第二章所提出的方法來. n. al. er. io. 檢討其效率性。第五章則是總結。. Ch. engchi. 2. i n U. v.
(9) 第二章. 模糊時間序列分析. 模糊集合理論是在 1965 年由美國加州大學柏克萊分校 Zadeh 教授提出的。 他認為以模糊集合理論為基礎,可以用數學的方法來解決生活中原本無法解決的 模糊現象。現在,模糊理論已經被應用到許多的領域。如:模糊時間序列(fuzzy time series)、模糊類神經網路(fuzzy neural network)模糊控制(fuzzy control)、模糊邏輯 (fuzzy logic)等,以下先簡單介紹模糊集合理論。. 第一節. 立. 序言. 政 治 大. 如果要做模糊時間序列的預測,必須要有幾樣工具。我們要先弄清楚什麼是. ‧ 國. 學. 模糊理論、隸屬度函數、模糊時間數列及區間模糊時間數列。在這一節中,我們 首先要先探討什麼是模糊理論,並且給隸屬度函數一些簡單的介紹外,再給模糊. ‧. 時間數列及區間模糊時間數列一些定義。. y. Nat. 人類的思維只要是來自於自然現象和社會現象的認知意識,所以,人類的知. sit. 識語言會因為本身的主觀意識和所接收的資訊不同而具有模糊性。例如,當有人. er. io. 說他今天心情好時,他對心情好的認知為何?要怎麼樣測量呢?如對人的好感度. al. 描述等。於是為了描述事物特徵的模糊性進而發展了模糊集合理論。. n. v i n Ch 模糊理論的概念,主要在強調個人喜好程度不需要非常清晰或數值精確,因 engchi U. 此對人類而言,模糊模式比直接指定單一物體的一個值,較適合評估物體間的多 元性。在這種情況下時,“非此即彼”的二元邏輯是無法界定的。在此,模糊集 合理論為描述這類邊界不清的事物提供了一套有效的方法,使人們有系統化、公 式化的手段處理這類事物的能力,能夠在模糊環境中解決問題,做出正確的決策。 在傳統集合理論中有個重要的概念,即特徵函數(Characteristic function)。對 Λ 的子集合 A 而言,定義 A (x) 為 A 集合的特徵函數. 1 若x A 0 若x A. A ( x) . (2.1). 如上公式(2.1)所述,若 x 為A的元素,則其特徵函數 A ( x) 1 ;反之若 x 不 為 A 的元素,則其特徵函數為 A ( x) 0 。其值域可表示成 A ( x) {0, 1} 。 3.
(10) Zadeh (1965)教授將傳統集合理論特徵函數從二元運算,推廣為可從 0 到 1 之間的任何值作選擇,這種特徵函數,稱為隸屬度函數(membership function)。 隸屬度函數是模糊理論中最基本的概念,他不僅可以描述模糊集合的性質,更可 以對模糊集合進行量化,並利用精確的數學方法分析和處理人類模糊性資訊。隸 屬度函數可以分為離散型(discrete type)和連續型(continuous type)兩種,離散型隸 屬度函數是直接給予有限模糊集合中每一個元素的隸屬度,且用向量的型式表 示。連續型隸屬度函數一般常用的有三角形、梯形、高斯函數、不規則形…等等。 函數定義的表現,可以是無限模糊集合的元素及其隸屬度之間的關係,也可 以是有限模糊集合的元素和隸屬度之間的關係。常見的連續型隸屬度函數圖形如 下: 1. 三角形隸屬度函數. (x). 立. 政 治 大. 0. b. x. c. Nat. sit. y. a. ‧. ‧ 國. 學. 1. io. al. n. 2. 梯形隸屬度函數. er. 三角形隸屬度函數. (x). Ch. engchi. i n U. v. 1. 0. a. c. b. d. 梯形隸屬度函數. 4. x.
(11) 3. 高斯隸屬度函數 (x). 1. 0. . x. 高斯隸屬度函數 4. 不規則形隸屬度函數. 立. 政 治 大. ‧. ‧ 國. 學. n. engchi. er. io. Ch. sit. y. Nat. al. 不規則形隸屬度函數. i n U. v. 介紹完模糊理論後,我們接著要給一連串的定義,以利於接下來建立區間時 間序列模型。. 定義 2.1 (Wu, 2006) X [a, b] 若 a 和 b 是隨機變數,則區間 [a, b] 為模糊隨機區間。. 定義 2.2 (Wu, 2006) 若 X [a, b] 為一個布於實數的模糊隨機區間, c ( 5. ab ) 為模糊隨機區間 2.
(12) X 之圓心,且 r (. ba ) 為模糊隨機區間 X 之半徑,則模糊隨機區間 X 可以 2. 表示為 X (c; r ) ,其中 a, b, c 皆為實數。. 例 2.1 令 X [1, 5] 為一個布於實數的模糊隨機區間,則 X [1, 5] (3; 2) 。. . 定義 2.3 (Wu, 2006) 令 X (c; r ) 布於實數 R 之隨機區間,則模糊隨機區間 X 之期望值定義為. 政 治 大. E[ X ] E(c; r ) ( E(c); E(r )) ,其中 E (c) 和 E (r ) 是為隨機變數 c 和 r 的期望. 立. 值。. ‧ 國. 學. 定義 2.4(Wu, 2006). ‧. 令{ X t [at , bt ] (ct ; rt ) , t 1, 2, , n }為一模糊時間數列,因 X t 皆為區間模. n. al. er. io. sit. y. Nat. 糊數則稱 { X t }tn1 為一區間模糊時間數列。. Ch. 定義 2.5 (Song 與 Chissom, 1993). engchi. i n U. v. 令 Y (t )(t , 0, 1, 2, ) 為一個論域且為 R 的部分集合,且令 fi (t )(i 1, 2, ) 為定義在論域 Y (t ) 中之一個模糊集合。令 F (t ) 為 fi (t )(i 1, 2, ) ,則 F (t ) 為 Y (t )(t , 0, 1, 2, ) 的一個模糊時間序列。. 定義 2.6 (Song 與 Chissom, 1993) 令 F (t ) 為模糊時間序列,且存在一個模糊關係(fuzzy relation) R(t , t 1) ,使 得 F (t ) F (t 1) R(t , t 1) ,其中 是個運算子。. 6.
(13) 定義 2.7 (Song 與 Chissom, 1993) 令 F (t ) 為模糊時間序列,且令 F (t ) 由 F (t 1), F (t 2), , F (t n) 導的,則其. n 階模糊邏輯關係可被表示為 F (t n), , F (t 2), F (t 1) F (t ) 其被稱為 單因子 n 階模糊時間序列(one-factor n-order fuzzy time series)預測模式。. 例 2.4 令 X t 為一區間時間序列且 X t [t 2, t 2] (t; 2) ,則 {X t [t 2, t 2] (t; 2), t 1, 2, , n} {[1, 3], [0, 4], [1, 5],, [n 2, n 2]} 為. . 一個區間模糊時間數列。. 立 第二節. 政 治 大. 模糊時間序列模型. ‧ 國. 學. Song 與 Chissom (1993)根據模糊集合理論首先提出模糊時間序列的定義。因. ‧. 為以此方法預測美國阿拉巴馬州的學年度學生註冊人數需要非常大量且複雜的. y. Nat. sit. 運算,所以 Chen (1996)提出了一個簡單的模糊時間序列預測模式來預測學生註. n. al. er. io. 冊人數,得到很好的預測效果。而 Chen (2002)則又提出如何利用高階模糊時間. i n U. v. 序列(high-order fuzzy time series)之預測方法用以預測學生註冊人數。進行預測時. Ch. engchi. 往前看前 n 年的資料,產生高階模糊邏輯關係(high-order fuzzy logical relationship) 產生更高的參考價值且預測值也更準確。 Tseng 與 Tzeng (1999)將模糊理論與傳統的 ARIMA 模式結合,提出 Fuzzy ARIMA 模式,並針對具季節性循環之時間序列,提出 Fuzzy Seasonal ARIMA 模 式,對季節性的時間資料,提供了不同的預測方式,並與傳統的 Seasonal ARIMA 模式做比較後,確實得到了更精準的預測值。 吳柏林與林玉鈞(2002)則提出了模糊時間數列的屬性預測,作者認為資料的 收集會因為時間的延遲及變數之間的交互影響,使得看起來是單一的數值,實際 上可能表達的是一個區間範圍的可能值,故其明確的建立模糊規則資料庫與模糊 7.
(14) 關係,以人工智慧的方式將模糊數值轉換,並利用所建立的演算方法對台灣加權 股票日指數,建構預測模式。 傳統常用的時間數列方法如 AR,MR,ARMR,ARIMA 等等,是點對點的 預測,但區間時間數列無法以傳統的方法來預測,所以下列提供幾種常見的區間 時間數列的預測模型。. 1.. 中心點及半徑 ARMR 法(Hsu 2008) 令 {X t [at , bt ] (ct ; rt ), t 1, 2, , n} 為一個區間時間數列,且. 政 治 大. ct 1ct 1 pcct pc t 1 t 1 pcct pc. 立. rt 1rt 1 prrt pr t 1 t 1 qc t qr. ‧ 國. 學. 其中 t ~ N (0, 2 ) ,則. ‧. E (ct ct 1, ct 2 , , c1 ) 1ct 1 pcct pc. sit. y. Nat. E (rt rt 1, rt 2 , , r1 ) 1rt 1 pr rt pr. n. al. er. io. 且令 cˆt E (ct ct 1, ct 2 , , c1), rˆt E (rt rt 1, rt 2 , , r1) ,則區間時間數列的預 測為. Ch. engchi. i n U. v. E ( X t X t 1, X t 2 , , X t k ) [cˆt rˆt ; cˆt rˆt ] (cˆt ; rˆt ). 2.. 中心點及半徑 k 階區間移動平均法 (Hsu, 2008) 令 {X t [at , bt ] (ct ; rt ), t 1, 2, , n} 為一個區間時間數列,且. cˆt . ct 1 ct k r rt k , rˆt t 1 , t k 1, k 2, k k. 則區間時間數列的預測值為. E{X t X t 1, X t , , X k } [cˆt rˆt ; cˆt rˆt ] (cˆt ; rˆt ). 8.
(15) 3.. 左右端點 ARMR 法(Hsu,2008) 令 {X t [at , bt ] (ct ; rt ), t 1, 2, , n} 為一個區間時間數列,且. at 1ct 1 pcct pc t 1 t 1 pcct pc bt 1bt 1 pr rt pr t 1 t 1 qc t qr 其中 t ~ WN (0, 2 ) ,則. E (at at 1, at 2 , , a1) 1at 1 pcat pc E (bt bt 1, bt 2 , , b1) 1bt 1 pr rt pr. 政 治 大. 且令 aˆt E (at at 1, at 2 , , a1 ), bˆt E (bt bt 1, bt 2 , , b1 ) ,則區間時間數列的. 立. 預測為. ‧ 國. 學 ‧. 左右端點 k 階區間移動平均法(Hsu,2008). sit. y. Nat. 4.. E ( X t X t 1, X t 2 , , X t k ) [aˆt , bˆt ]. n. al. aˆt . er. io. 令 {X t [at , bt ] (ct ; rt ), t 1, 2, , n} 為一個區間時間數列,且. (at 1 at 2 at k ) k. Ch. engchi. i n U. v. (b b bt k ) bˆt t 1 t 2 k. 其中 t k 1, k 2, ,則區間時間數列的預測值為. E ( X t X t 1, X t 2 , , X t k ) [aˆt , bˆt ]. 第三節. 模糊時間序列模型的預測方法. 在這一節中,我們要利用移動平均值去尋找出中心點,並決定適當的半徑。 因為如果我們單純的把. (max{ pt } min{ pt }) 當成區間預估的圓心,這樣並不是最 2 9.
(16) 好的。所以這一節我們要將圓心調整到適當的位子。要想調整圓心,首先要定義 相對移動率。. 定義 2.8:相對移動率(relative moving ratio) i. 令 X t (ct ; rt ) 是一個區間時間序列, r 之相對移動率定義為 t 之移動平均且 0 i j 。. mt i mt j. rt k. k 0. 1,其中 mt i . i. 為半徑,則第 i 階對第 j 階. 1 i ct k 是以 ct 為圓心之第 i 階 i k 0. 政 治 大. 立. t . m3 4.83 1 1 0.342 m5 3.6. . Nat. sit. y. ‧. ‧ 國. 間時間序列,則第 3 階對第 5 階之相對移動率為. 學. 例 2.2.1:令{ X1 [0, 2] , X 2 [1, 4] , X 3 [2, 7] , X 4 [3, 4] , X 5 [5, 8] }為一區. er. io. 接下來便利用相對移動率及中心點及半徑 k 階區間移動平均法(Hsu 2008)提. al. v i n Ch 個模糊時間數列的預測方法,在上述中,我們已經定義相對移動率,令參數 t 為 U i e h n 相對移動率,當 t 0 時,我們將第 t 1g期ccˆ 上移至 c~ ,反之亦然,如公式(2.2) n. 出一種新的區間預估方法。本論文將移動平均數轉換成相對移動率之後,提出一. 所表示。. cˆ rˆ c~ t t cˆt rˆt. 若 t 0 若 t 0. 利用公式(2.2),我們可以得到一個預測的模糊時間區間 X t 1 (c~; rˆt ). 我們將上述及定義 2.8 整合之後就可以得到模糊區間預測模型。. 10. (2.2).
(17) 定義 2.9 (相對移動率區間預測法) 令 X t (ct ; rt ) 是一個區間時間序列, t 為相對移動率, cˆt . ct 1 ct k r rt k , rˆt t 1 , t k 1, k 2, ,若 t 0 則模糊區間 k k. 時間序列的預測結果為 E{ X t X t 1, X t 2 , , X t k } [cˆt ; cˆt 2rˆt ] (c~; rˆt ),若 t 0 則模糊區間時間序列的預測結果為 E{X t X t 1, X t , , X k } [cˆt 2rˆt ; cˆt ] (c~; rˆt ) 。. 例 2.3.1. 治 政 [2, 4] (3; 1) , X [3, 4] (3.5; 0.5) , X 大 [4, 6] (5; 1) , 立 3 階對第 5 階之相對移動率 [3, 7] (5; 2) ,則第. 令時間序列 {X t [1, 2], [2, 4], [3, 4], [4, 6], [3, 7]} ,其中 X1 [1, 2] (1.5; 0.5) , X5. 4. m3 4.5 1 1 0.25 0 , rˆt 1 且 c~ 5 2 7 ,所以預測的區間為 m5 3.6. 學. t . 3. ‧ 國. X2. ‧. Xˆ 6 [6, 8] (7; 1) 。. Nat. sit. y. . er. io. 接下來,本文將粗略的介紹門檻自回歸模式並嘗試著將相對移動率帶入門檻. al. v i n C h in time ),探討當模型中解釋變數發生結構改 作為結構改變的轉折點 ( piecewise U i e h n c g 變的時間點前後,與被解釋變數之間的關係是否有所不同。另一類則是以 Tong n. 值中。現在研究非線性的門檻值自回歸模型可以分為兩大類,一類是以「時間」. (1980)所提出門檻迴歸方法為基礎,以「變數」為結構改變的轉折點( piecewise in variable )分析在解釋變數門檻值之上與之下,與被解釋變數之間的關係是否有所 不同。由於以「時間」為轉折點的分析方法,必須先主觀的認定發生結構性改變 的時間點,方法上較不客觀,因此所得出的結論也就相當分歧。此外,當解釋變 數在短期間內持續地發生大幅度的變化時,以時間為結構改變轉折點的模型可能 會無法診斷出模型的結構改變。相較之下,以變數為轉折點的分析方法,可以避 免上述的缺失。 從 Tong 提出了門檻自我迴歸模型之後,它即成為非線性時間序列上最為 常用的模型之一。以下將介紹門檻自迴歸模式及其建構方法。另外,將把相對移 動率放入由Tong (1980)所提出門檻自迴歸模式中。 11.
(18) 由Tong (1980)所提出門檻自迴歸模式,它的基本觀念是把每個時間觀察值所 組成的序列中,依其變化情形,找出一轉捩點(change point)或門檻值(threshold), 來清楚劃分為二個區域(regime),且各自成一系統,服從不同的自迴歸模式。門 檻自迴歸模式本身有幾項明顯特徵,作為一般判別的標準,如具有週期循環性、 上下起伏的震盪、突然向上跳升或下降的現象,這些特徵是一般傳統線性模式難 以描述的地方。Tong發展的門檻自迴歸模型是以「變數」為結構轉變的轉折點, 模型中不同的結構是透過以門檻變數大於或小於某一門檻值來表示。本文便是將 門檻值用相對移動率(relative moving ratio)帶入嘗試建立一個上升趨勢及下降趨 勢的時間數列模型。 在建立模型前,首先要探討一個落後n期,以自身落後一期 (n 1) 為門檻變. 政 治 大. 數的兩結構門檻自迴歸模型可表示為:. 立. ‧ 國. 若X t 1 t 若X t 1 t. 學. 0, 1 1, 1 X t 1 n, 1 X t n 1t Xt 0, 2 1, 2 X t 1 1, 2 X t n 2t. (1) (2). ‧. 其中,1t 與 2t 為誤差項,且 it ~ N (0, i2 ) , E (1t | t 1 ) 0, E ( it2 | t 1 ) i2 ,. i 1, 2 ; t 1 表示前一期的訊息集合; t 為門檻值。上述門檻自廻歸模型表示當. y. Nat. 門檻變數不小於門檻值 t 時,其適用廻歸式(1)式;當門檻變數小於門檻值 t 時,. al. er. io. sit. 其適用廻歸式(2)式。當 it ~ N (0, i2 ) 成立時,(1)與(2)式可改寫為. v. n. X t (0, 1 1, 1 X t 1 n, 1 X t n 1t ) I t (0, 2 1, 2 X t 1 n, 2 X t n 2t )(1 I t ) t. Ch. engchi. i n U. 其中 I t 為指標函數定義為. 1 若 X t 1 t It 0 若 X t 1 t 且 t 為誤差項, t 1t 2t 。 本論文中將討論多變量門檻自廻歸模型,Tong (1980)的原始門檻回歸模型並 未考慮其他的解釋變數只考慮單一變數,找到時間數列之轉折點,但許多非線性 問題,會受到多個變數的牽動而影響,本文探討的台灣股價加權指數受到價格和 政策成交量…等等影響。本文將單純的把變數減少為價格,並利用相對移動率取 代外生多變數之門檻自廻歸模式。 12.
(19) 定義 2.10 令 X t 為一個時間數列, yt 、 zt 為其外生對應的變數, t 為門檻值,含外生 多變數之門檻自迴歸模型為. 0, 1 1, 1 X t 1, t 1 若 f ( y, z ) t X t 1 0, 2 1, 2 X t 2, t 1 若 f ( y, z ) t. 例 2.3.2 令 X t 為一個時間數列, yt 、 zt 為其外生對應的時間數列變數, t 為門檻值, y 外生變數函數 f ( y, z ) t 為相除效果,即 zt. 立. . 學. ‧ 國. 政 治 大. yt 2 0.8 X t 1, t 1 若 z 1 t X t 1 yt 4 0.3 X t 2, t 1 若 1 zt. ‧. 例 2.3.2 將門檻值設為 t 1 ,是將定義 2.8 中的 t 1 0 移項得到的。. n. er. io. sit. y. Nat. al. Ch. engchi. 13. i n U. v.
(20) 第三章. 第一節. 模糊時間序列的效率評估. 模糊區間的定位及測量辦法. 在作效率評估之前,我們要先給區間的反模糊化及區間之間的距離作一些定 義。並做一些調整及修改,Wu (2011)將區間的距離給了以下的定義並舉了例子。 定義 3.1 (Wu, 2011) 令 X [a, b] (c; r ) 為區間模糊數,定義區間模糊數之反模糊化為. 立. 定義 3.2 (Wu, 2011). ln(1 | b a |) |ba|. 政 治 大. RX c . ‧ 國. 學. 令 U 為一個論域,且 {X i [ai , bi ], i 1, 2} 為 U 中的一個時間數列,其中原心. ‧. ai bi b ai ,且半徑 ri i ,則 X i 和 X j 的距離定義為 2 2. ln (1 | bi a i |) ln (1 | b j a j |) | | bi a i | | b j a j |. n. al. er. io. sit. Nat. d ( X i , X j ) ci c j |. y. ci . i n U. v. 例 3.1 令兩區間集合 X1 [2, 5] , X 2 [3, 7] 則 X1 (3.5; 1.5) , X 2 (5; 2) ,且 X 1 和 X 2 的距離為. Ch. engchi. d ( X1, X 2 ) 3.5 5 ln(1 1.5 2 ) 1.9. . 但是這種定義對區間中的元素數字越大是越不精確的。如下例 3.2 例 3.2 令兩區間集合 X1 [7000, 7010] , X 2 [5790, 6210] 則 X1 (7005; 5) , X 2 (6000; 210) ,且 X 1 和 X 2 的距離為. d ( X1, X 2 ) 7005 6000 |. ln(1 10) ln(1 420) | 1005.225 10 420 14. .
(21) 由例 3.2 ,我們可以發現,當兩個區間的圓心距離越遠,我們幾乎都是用圓 心的距離來表示兩個區間的距離。針對此種狀況,我們再給以下一個例子。 例 3.3 令兩區間集合 X1 [6000, 7500] , X 2 [7300, 8000] 。則 X1 (6750; 750) , X 2 (7650; 350) ,且 X 1 和 X 2 的距離為. d ( X1, X 2 ) 7650 6750 |. ln(1 1500) ln(1 700) | 900.004 1500 700. . 我們將例子 3.1 和 3.2 ,3.3 做一個比較,我們會發現定義 3.2 將距離計算 分成兩個部分,可以觀察出,第一項是圓心的距離,第二項是干擾項,且將干擾. 政 治 大 區間距離時,如果區間裡的元素很大時,不管區間大小,區間是否重疊,我們皆 立 只要計算圓心距離就好。這似乎和現實不大符合。除此之外,我們可以大膽猜測, 項定為圓心距離的百分。所以我們可以做出一個結論就是當我們用定義 3.2 計算. ‧ 國. 學. 隨著區間元素的數字放大,用定義 3.2 去計算的結果誤差會越大。相反的,如果 區間元素的數值為個位數,則定義 3.2 是一個好的區間距離衡量方式。由於本文. ‧. 探討的區間為加權指數區間,數字元素非常大,為了避免有誤差的情形,我們將 定義 3.1 和定義 3.2 做了些微調整,得到定義 3.3 及定義 3.4 。. sit. y. Nat. n. al. RX c . Ch. |ba| ln(e | b a |). engchi. er. io. 定義 3.3 令 X [a, b] (c; r ) 為區間模糊數,定義區間模糊數之反模糊化為. i n U. v. 定義 3.4 令 U 為一個論域,且 {xi [ai , bi ], i 1, 2} 為 U 中的一個時間數列,其中原心 ci . ai bi a b ,且半徑 ri i i ,則 X 1 和 X 2 的距離定義為 2 2. d ( X i , X j ) | ci c j | |. | b j a j | | bi ai | | ln (e | bi ai |) ln (e | b j a j |). 有了定義 3.4,使用例 3.1,3.2 與 3.3 相同的資料,我們重新定義兩區間的 距離分別為例 3.4,3.5 與 3.6。. 15.
(22) 例 3.4 令兩區間集合 X1 [2,5],X 2 [3,7] 則 X1 (3.5;1.5),X 2 (5;2),且 X 1 和 X 2 的距離為. d ( X1, X 2 ) 3.5 5 |. |52| | 7 3| | 1.88 ln (e 3) ln (e 4). . 用定義 3.1 的計算方法為 1.9,但是用修改後的方法計算值為 1.517,兩者差 距不大,這是因為區間裡的元素都是個位數的。所以可以印證前述的猜測。 例 3.5 令兩區間集合 X1 [7000, 7010] , X 2 [5790, 6210] 則 X1 (7005; 5) , X 2 (6000; 210) ,且 X 1 和 X 2 的距離為. 政 10治 大 420 | 1070.53 ln (e 10) ln (e 420). d ( X1, X 2 ) 7005 6000 |. 立. ‧. ‧ 國. 學. 例 3.6. . io. 1500 700 | 998.27 ln (e 1500) ln (e 700). . er. d ( X1, X 2 ) 7650 6750 |. sit. Nat. X 2 (7650; 350) ,且 X 1 和 X 2 的距離為. y. 令兩區間集合 X1 [6000, 7500] , X 2 [7300, 8000] 。則 X1 (6750; 750) ,. al. n. v i n Ch 比較定義 3.2 及定義 3.4 計算的結果,我們可以發現,當區間元素的數值變 engchi U. 大時,區間之間的距離也變大了,這是比較符合現實的。因為隨著區間元素的數 值變大,區間之間的干擾項應該也會變大。這避免了干擾項為圓心距離百分比的 情況。所以在第四章,我們做實證分析時計算區間的距離將採用定義 3.4 的計算 方式。. 第二節. 區間預估模型的效率評估. 在這一章節中,我們要考慮的是區間模糊預測模型的有效性。當然,隨著各 種區間模糊預測的模型出現,探討其有效性的方法就越來越多。Hsu (2011)中提 到 MSEI,概念就是把區間的位置,長度找出來,再求取兩區間的長度差。如果 16.
(23) 我們沒有定義 3.4 ,因為本文探討的對象為加權指數,所以也可以考慮用這種方 式去做區間之間的距離及效率的評估。最直覺的想法便是,如果區間之間的距離 越小,表示我們的區間模糊預測模型越準確,但是怎麼樣才算是一個好的預測模 型呢?我們需要一種指標來告訴我們模糊預測的精確性,因為如果區間內的元素 如果太大,相對的,利用定義 3.4 的公式,得到的距離是會越大的,這是無法直 覺的辨別預測的精確性。所以,如果透過指數函數希望能把區間之間的距離能夠 用一個介於 [0, 1] 之間的表示方法來評斷。因此本文引用了 Wu (2011)中的 IOE。 定義 3.3 (Wu, 2011) 令 U 為一個論域且 OI (co , ro ) ,為 U 中區間觀測值, EI (ce , re ) 為 U 中區 間預測值。則區間觀測值與區間預測值之模糊距離指標定義為 c c r r IOE exp{[| o e | ln(1 | o e |)]} ce re. 政 治 大 其中 c 和 c 為區間預測值及區間觀測值之圓心。 立 e. 學. ‧ 國. o. 為了讓模糊區間預測模型的有效性有一個準則,我們將把 IOE 定義於 0 到 1 之間。當 IOE 值越高時,表是模糊區間預測模型的方法是越有效率的。當. ‧. IOE 0 ,我們可以觀察出是完全無效率的。如果 IOE 1,代表模糊區間預測模. n. al. er. io. sit. y. Nat. 型的建構是完全有效率的。. Ch. engchi. 17. i n U. v.
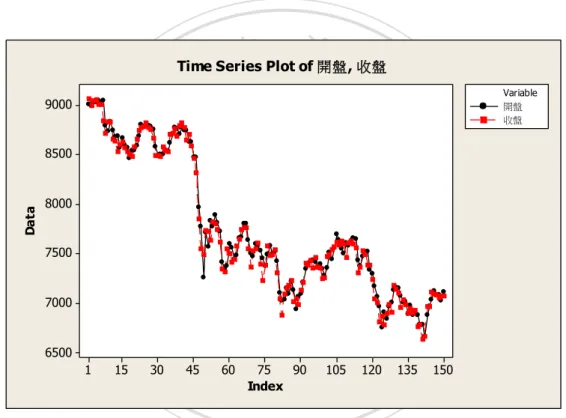
(24) 第四章. 實證分析. 本文收集從民國 100 年 6 月 1 號至民國 100 年 12 月 30 號的 150 筆歷史資料 開盤價格與收盤價格做為區間,分別以點預測,模糊相對移動率預測模型,以及 利用相對移動率為門檻值之 ARIMA 自廻規模型三種方法來預測民國 101 年 1 月 2 號的開盤價格與收盤價格的區間預測,並利用第三章的定義 3.2 以及定義 3.3 比較其誤差距離及預估之準確性。以下將這 150 筆資料標記為 { X t }tn1 ,下圖 4.1 為其走勢圖. 政 治 大. Time Series Plot of 開盤, 收盤. 立. 9000. y. sit. io. 7000. n. al. er. Data. ‧ 國 Nat. 7500. ‧. 8000. 學. 8500. 6500 1. 15. Variable 開盤 收盤. 30. 45. C 60h. 75 90 105 eIndex ngchi. iv n 120 135 U. 150. 圖 4.1:民國 100 年 6 月 1 號至民國 100 年 12 月 30 號之指數走勢圖 在做預測分析前,為了表現出預估誤差的重要性,先簡單的用 MINITAB 中 的 moving average 指令來預測下一期的模糊區間預測,這種預測方法和本文所提 供的預測方法是息息相關的,在稍後介紹移動平均波動率時,本文會再詳細介紹 其相關性。而圖形 4.2 是用收盤價的 10 日移動平均線來預測未來一期的收盤價, 並用 95%的信賴區間來表示其收盤價可能落入之範圍,如圖形 4.2 所示。. 18.
(25) Moving Average Plot for 收盤 Variable Actual Fits Forecasts 95.0% PI. 9000. 8500. Mov ing Av erage Length 10. 8000. 收盤. Accuracy Measures MAPE 2.5 MAD 186.4 MSD 60051.5. 7500. 7000. 6500 15. 立. 30. 45. 60. 75 90 Index. 105 120. 135 150. 學. ‧ 國. 1. 政 治 大. 圖 4.2:收盤價之 10 日平均線的預測結果. ‧. 在圖形 4.2 中,充分的顯示出移動平均的一個很重要的缺陷,就是預估出來. Nat. sit. y. 的範圍太廣泛了。最後一期的可能收盤價範圍從 6700 到 7500 左右,已經有 800. io. er. 點左右的誤差,這在現實世界中,是不被投資大眾所接受的。當然,不能否認的, 移動平均所創造出來的模糊區間預測還是非常重要的。本文便是利用類似的概. n. al. 念,但是修改其範圍的誤差所創造出來的模型。. Ch. engchi. i n U. v. 為了預測分析方便,我們先把一些建立模型時所需要的基本參數呈列於下表 4.1。. 19.
(26) 收盤價. 最高價. 最低價. 圓心價. 半徑. 100/06/01. 8999.84. 9062.35. 9089.47. 8999.84. 9031.10. 31.255. 100/06/02. 8981.71. 8991.36. 9036.27. 8977.67. 8986.54. 4.825. 100/06/03. 9024.54. 9046.28. 9052.18. 8997.35. 9035.41. 10.870. 100/06/07. 9025.21. 9057.10. 9059.19. 8981.44. 9041.16. 15.945. 100/06/08. 9044.85. 9007.53. 9070.25. 9007.53. 9026.19. 18.660. 100/06/09. 9020.60. 9000.94. 9045.44. 8996.08. 9010.77. 9.830. 100/06/10. 9042.35. 8837.82. 8940.09. 102.265. 100/06/13. 8791.67. 政9053.39治 8837.82 大. 8712.95 立. 8811.97. 8703.52. 8752.31. 39.360. 100/06/14. 8737.24. 8829.21. 8836.51. 8737.24. 8783.23. 45.985. …. …. …. …. …. …. 6780.64. 6633.33. 6780.64. 6609.11. 6706.99. ‧. 73.655. 100/12/20. 6654.67. 6662.64. 6696.93. 6646.30. 6658.66. y. 3.985. 100/12/21. 6878.63. 6966.48. 6966.48. 6878.63. sit. 43.925. 100/12/22. 6968.22. 100/12/23. 7035.10. 100/12/26. 7125.04. 7092.58. 7125.67. 7078.06. 7108.81. 16.230. 100/12/27. 7085.50. 7085.03. 7107.67. 7043.64. 7085.27. 0.235. 100/12/28. 7086.10. 7056.67. 7093.47. 7036.92. 7071.39. 14.715. 100/12/29. 7026.86. 7074.82. 7074.82. 6998.97. 7050.84. 23.980. 100/12/30. 7109.85. 7072.08. 7139.03. 7054.79. 7090.97. 18.885. 100/12/19. 6922.56. io. er. …. 學. 開盤價. Nat. 日期. ‧ 國. 表 4.1 模型建立所需參數. n. 6989.59 6940.85 a6966.35 v 6967.29 i l C n 7072.92 7110.73h 7122.28 7035.10 U engchi. 0.935 37.815. 我們先使用 150 期來預測下一期的結果,預測方式分為三種且預測結果如 1:點預測: 利用公式(2.3.2)我們可以很容易的求出一月二號的收盤預估價格應該為 20.
(27) Xˆ 151 E{ X151 X150, X149, , X1 } 7733.03. 但是民國 101 年 1 月 2 號收盤價為 6952.21 ,很顯然的,利用點預測來預測 未來的指數就有一段不小的差距。同理,利用公式(2.3.2)我們可以求出民國 101 年 1 月 2 號的開盤預估價格應該為. Xˆ 151 E{ X151 X150, X149, , X1 } 7750.92. 民國 101 年 1 月 2 號開盤價為 7071.35 ,所以我們可以結論出如果光用點預 測,是很容易產生出及大的誤差。當然,我們也可以用類似移動平均的概念來計 算點預測。例如從我們的資料庫中,把最後 5 天的收盤價考慮就好,其他的捨去, 可以得到。. 立. 政 治 大. 學. ‧ 國. Xˆ 6 E{ X 6 X 5 , X 4 , , X1 } 7076.24 這個數字,就和實際收盤價接近許多。但是如同上述,其誤差範圍太廣泛了,因 此,如何利用移動波動率來修飾誤差範圍將是本文稍後研究的重心。同理,用 5. y. sit. Nat. Xˆ 6 E{ X 6 X 5 , X 4 , , X1 } 7086.67. ‧. 日平均開盤價格去預估民國 100 年 1 月 2 號的開盤價格結果為. io. 其誤差利用圖形表示在圖 4.2 和圖 4.3 中。. n. al. Ch. engchi. 21. er. 比用 150 日去估計還要好很多。我們把用 5 日平均開盤價及收盤價的預測結果及. i n U. v.
(28) Moving Average Plot for 開盤 Variable Actual Fits Forecasts 95.0% PI. 9000. 8500. 開盤. Mov ing Av erage Length 5 Accuracy Measures MAPE 1.8 MAD 137.9 MSD 36934.0. 8000. 7500. 7000. 15. 立. 30. 45. 60. 75 90 Index. 105. 120. 135. 150. 學. 圖 4.3:平均 5 日開盤價預測結果. ‧. ‧ 國. 1. 政 治 大. 2:相對移動率:. Nat. sit. y. 討論移動平均波動率的實證分析時,我們先從移動平均線開始介紹,台灣的. io. er. 移動平均線是使用一段時間的收盤價格來計算平均值,這和上述點預測是類似的 概念,且預測天數通常是用 12 天,24 天,及 144 天為基準。由於本文的資料庫. n. al. i n U. v. 只有 150 天,所以將以 12 天及 24 天為例子,把 12 天及 24 天的平均價格由表. Ch. 4.2 呈列出來並用圖 4.5 表示。. engchi. 22.
(29) 表 4.2:12 天及 24 天收盤價格平均線的比較 日期. 12 天收盤價格平均 24 天收盤價格平均. 100/07/05. 8612.79. 8750.87. 100/07/06. 8637.27. 8740.96. 100/07/07. 8651.92. 8731.88. 100/07/08. 8662.62. 8719.52. 100/07/11. 8670.84. 8703.21. 100/07/12. 8667.35. 8681.69. 100/07/13. 8666.35. 100/07/14. 立. …. …. 學. 6870.46. 6932.76. 100/12/22. 6871.30. 6921.62. 100/12/23. 6877.78. 6924.46. 6886.92. 6928.31. 6902.90. 6939.92. y. n. al. sit. io. 100/12/27. er. 100/12/26. ‧. 100/12/21. Nat. ‧ 國. …. 治 8660.32 政 大8645.47 8666.55. 100/12/28. Ch. 6911.86. engchi. i n U. v. 7056.67. 100/12/29. 6926.74. 7074.82. 100/12/30. 6939.20. 7072.08. 23.
(30) Time Series Plot of 收盤, 收盤24日平均線, 收盤12日平均線 Variable 收盤 收盤24日平均線 收盤12日平均線. 9000. Data. 8500. 8000. 7500. 7000. 6500 1. 15. 30. 45. 立. 60. 75 90 Index. 105 120 135 150. 政 治 大. 圖 4.5:12 天及 24 天價格平均線及實際值. ‧ 國. 學. 由圖所知,隨著平均天數的增加,平均線會越趨於圓滑,這也代表離真實的. ‧. 股價收盤數誤差會越來越大。相反的,如果選取的平均數太小,則波動太大,這 並非是一種好的預估模式。所以,如何選取一個有效的樣本參數去估計真實的情. sit. y. Nat. 況是一門很值得研究的學問。在找出相對移動率之前,我們必須根據觀測期數的. io. 我們有. er. 開盤價與收盤價找出一系列的圓心及半徑。如上表 4.1 所示。於是根據定理 2.5,. al. n. v i n C],h[8981.71, 8991.36]U {X t } { [8999.84, 9062.35 e n g c h i , , [7109.85, 7072.08]}. 其中. X1 [8999.84, 9062.35] (9031.10; 31.255) X 2 [8981.71, 8991.36] (8986.54; 4.825). X150 [7109.85, 7072.08] (7090.97; 18.885). 很顯然的,如果我們取估計的參數為 150,我們的區間估計誤差會很大。這 道理和移動平均的誤差是一樣的。這也是我們為何在討論相對移動率時,要先研 24.
(31) 究移動平均線的原因。在移動平均線裡,如同上述所示,平均天數的選取會影響 移動平均線的好壞,同理,如何選取一個有效的觀測天數,對相對移動率而言也 會有很直接的影響,在本文中,我們簡單的用 5 天 10 天來當作我們估計的參數。 會想用 5 天及 10 天作文參數,是因為越短期的預估(例如預測單位為一天),則 股價振幅會越大,較容易失真。所以,本文希望能在短期投資當中,讓振幅不要 這麼大,卻又不失其精確性,所以採用 5 個交易日及 10 個交易日的天數套入相 對移動率區間預估參數。在表 4.3 中我們利用定理 2.11 求出相對移動率其中 rˆt 的 參數為 5。 表 4.3:相對移動率的各種參數 5 日圓心. 日期. 均價( m5 ). 立. 10 日圓心. 相對移動. 移動平均 半徑( rˆt ). ) 率( ) 政均價( m治 大 10. t. 8943.95. 0.0089596. 39.729. 100/06/16. 8801.09. 8910.55. 0.0122848. 46.304. 100/06/17. 8743.82. 8877.27. 0.0150328. 29.386. 100/06/20. 8714.35. 8834.23. 0.0135698 0.0129635. 100/06/22. 8636.61. 8750.21. 0.0129800. al. 8707.56. 0.0107000. n. 8614.03. Ch. …. …. 100/12/21. 6778.33. 100/12/22. er. io. 100/06/23. 29.733. y. 8788.59. 36.361. sit. 8674.66. Nat. 100/06/21. ‧. ‧ 國. 學. 8863.81. 100/06/15. e n…g c h i. i n U. v. 33.774 28.620. …. …. 6855.44. 0.0112479. 35.479. 6807.91. 6852.09. 0.0064478. 24.707. 100/12/23. 6865.68. 6870.15. 0.0006495. 32.063. 100/12/26. 6946.05. 6884.79. 0.0088970. 20.578. 100/12/27. 7031.37. 6904.35. 0.0183969. 19.828. 100/12/28. 7061.14. 6919.73. 0.0204346. 19.828. 100/12/29. 7077.85. 6942.88. 0.0194396. 18.595. 100/12/30. 7081.46. 6973.57. 0.0154707. 14.809. 25.
(32) 接下來,本文將利用上述的參數去預估民國 101 年 1 月 2 號至 1 月 6 號的平 均開盤價格,並探討其準確性。 5. ri. 16.23 0.235 14.715 23.98 18.885 14.809 5 5 其中 t1 5 , t2 10 則相對移動率 t 為 rˆt . i 1. . t . mt1 mt 2. 1 . 7081.46 1 0 6973.57. 因為 t > 0,利用公式(2.3.3),我們可以得到一個新的圓心 c~ c~ cˆ rˆ 7090.97 14.809 7105.779. 政 治 大 (c~; rˆ ) 7105.779; 14.809. 有了新圓心之後,再利用公式(2.3.4),我們可以得到一個預測的模糊區間. 立. Xˆ t 1. t. ‧ 國. 學. ‧. 比較需要注意的是,這組新的模糊預測區間為下 5 個交易日的模糊預測區 間,並非下一個交易日,因為半徑的參數 rˆt 為 5,這代表的意義是最近 5 日交易 日中的振幅,所以代表下 5 個交易日時最有可能產生之振幅,也就是 rˆt 。如果想. sit. y. Nat. 要預測的模糊區間的時間單位為下一交易日,只要改參數 t1 、 t 2 和半徑的時間參. io. n. al. er. 數就可以,建議是把時間縮短找出合適的預估振福。本文在此不再贅述。. i n U. v. 在民國 101 年 1 月 2 號至 1 月 6 號之平均開盤價格為 7071.35,平均收盤價. Ch. engchi. 格為 7120,這和我們用相對移動率所預測的模糊區間幾乎吻合。圖 4.6 將每日的 模糊預測區間顯示出來。. 接下來,我們要利用第三章的公式來探討相對移動率模型的有效性。本文將 直接利用定義 3.2 來求民國 101 年 1 月 2 號至 1 月 6 號那一週的模糊預測價格區 間及實際價格區間之間的距離,並利用定義 3.3 求出其 IOE。 X EI (c~; rˆt ) (7105.78; 14.81) [7090.97, 7120.58] X OI (c; r ) (7095.5; 24.5) [7071, 7120]. 則實際股價區間以及預測股價區間的距離為 29.61 49 d ( X OI , X EI ) 10.25 | | 14.15 ln (e 29.61) ln (e 49). 26.
(33) Time Series Plot of 下界, 上界 9000. Variable 下界 上界. 8500. Data. 8000. 7500. 7000. 6500 1. 15. 30. 45. 政 治 大. 60. 立. 75 90 Index. 105. 120. 135. ‧ 國. 學. 圖 4.6:相對移動率之預估結果. 150. ‧. 就實際考量而言,我們利用相對移動率所預測出來的區間,和民國 101 年 1 月 2 號至 1 月 6 號的平均開盤價格與平均收盤價格之區間相差只有 20 點。有了. y. Nat. 模糊預測價格區間及實際價格區間之間的距離之後,接下來本文便要測試模糊相. sit. 對移動率預測模型在預測民國 101 年 1 月 2 號至 1 月 6 號的平均開盤價格與平均. er. io. 收盤價格之效率性,根據定義 3.3. al. v i n EI (ce ; re ) C (7105 U.97, 7120.58] h e.78n; 14g.81c)h [i7090 n. OI (co ; ro ) (7095.5; 24.5) [7071, 7120]. 則相對移動率所預測區間效率性. IOE e. (|. co c e r r | ln(1| o e |)) ce re. 0.603. 由於 IOE 是介於 0~1 之間且越靠近 1 預測效率越高。就預測民國 101 年 1 月 2 號至 1 月 6 號這一週的預測而言呢,效率算是好的。本文利用表 4.4 來表示 從民國 100 年 6 月 15 號起每 5 天的實際區間和利用模糊移動平均波動率所預測 區間之間的距離及其 IOE。. 27.
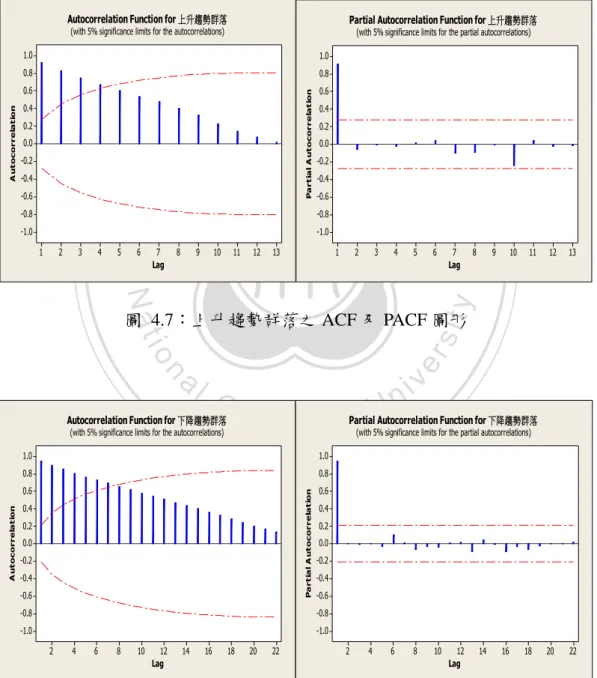
(34) 表 4.4:模糊移動平均波動率之預測距離及效率評估 日期. 實際圓心. 預測圓心. 距離. IOE. 100/06/15. 8832.66. 8792.93. 77.692. 0.678045. 100/06/16. 8697.14. 8650.84. 56.835. 0.703371. 100/06/17. 8653.78. 8624.39. 26.785. 0.606569. 100/06/20. 8604.92. 8568.56. 47.544. 0.652864. 100/06/21. 8584.78. 8555.05. 31.827. 0.840819. 100/06/22. 8642.45. 8608.68. 37.76. 0.865146. 100/06/23. 8584.22. …. …. 100/12/23. 7072.92. 22.69. 0.730781. 7085.27. 7105.10. 23.71. 0.732541. 7071.39. 7085.38. 30.630. 0.519463. 7050.84. 7069.44. 13.881. 0.597833. 7105.78. 28.697. 0.604827. 7090.97. n. al. 3:門檻自廻規模型:. Ch. engchi. y. sit. ‧ 國. 7129.39. er. 100/12/30. 7108.81. Nat. 100/12/29. 38.13. ‧. 100/12/28. …. 7040.86. 學. 100/12/27. 0.842029. io. 100/12/26. 立. 8555.60 31.7531 政 …治 大 …. i n U. v. 0.505261. 此方法為移動平均波動率之應用,利用移動平均波動率做為門檻值,代入 ARIMA模型中,解出預測值之後在利用 rˆt 將數值模糊化為預測結果。建立模型 前,要先決定落後期數。在建構二個具有相同參數之模型時,建構過程中每多增 加一個變項可以降低殘差值的和,可是會增加將來預測的複雜性,同樣地,在時 間數列模型建構過程中,模型的複雜度增加也許可以降低對資料的變異性,卻也 增加了偏差性。為了估計模型的品質並避免模型參數過度配適的情形,Akaike (1973)提出了以懲罰多餘參數的AIC (Akaike information criteria)準則,其定義如 下: AIC (M ) 2 ln L(ˆ ) 2M 此處的 M 為模型中參數 的個數,L 為 的概似函數(likelihood function),ˆ 為 的最大概似估計量,對含有 n 個有效觀測值之ARIMA模式其概似函數為 28.
(35) n 1 n ln L( ) ln( 2 2 ) 2 t2 ( , , ) 2 2 t 1 其中 , , 已知下可簡化求得. AIC (M ) n ln 2 2M 最佳模式之選取是由 AIC(M)之最小值所決定。除此之外,也可以用 ACF 及 PACF 之圖形判定。由圖 4.7,4.8 表示出 AR 及 MR 之落後期數為各為 1。. Autocorrelation Function for 上升趨勢群落. Partial Autocorrelation Function for 上升趨勢群落. (with 5% significance limits for the autocorrelations). (with 5% significance limits for the partial autocorrelations). 1.0. 1.0. 0.8. 0.8. 政 治 大 Partial A utocorrelation. 0.4. 立. 0.2 0.0 -0.2 -0.6 -0.8 -1.0 1. 2. 3. 4. 5. 6. 0.4 0.2 0.0. -0.2 -0.4 -0.6 -0.8 -1.0. 7 Lag. 8. 9. 10. 11. 12. 13. 1. 2. 3. 4. 5. 7 Lag. 8. 9. 10. 11. Nat. 12. 13. 20. 22. y. 6. ‧. ‧ 國. -0.4. 0.6. 學. A utocorrelation. 0.6. er. io. sit. 圖 4.7:上升趨勢群落之 ACF 及 PACF 圖形. n. al. Ch. Autocorrelation Function for 下降趨勢群落. engchi. (with 5% significance limits for the partial autocorrelations). 1.0. 1.0. 0.8. 0.8. 0.6. 0.6. 0.4 0.2 0.0 -0.2 -0.4 -0.6. 0.4 0.2 0.0 -0.2 -0.4 -0.6. -0.8. -0.8. -1.0. -1.0 2. 4. 6. 8. 10. 12 Lag. 14. 16. 18. 20. v. Partial Autocorrelation Function for 下降趨勢群落. Partial A utocorrelation. A utocorrelation. (with 5% significance limits for the autocorrelations). i n U. 22. 2. 4. 6. 8. 10. 12 Lag. 圖 4.8:下降趨勢群落之 ACF 及 PACF 圖形. 29. 14. 16. 18.
(36) 決定落後期數後根據定義 2.11,可以得到下列的模型 A。 模型 A: 令 X t 為一個時間數列, yt m5 , zt m10 為其外生對應的變數, t 1 為門 檻值,則含外生多變數之門檻自迴歸模型為. yt 1, 1 1, 2 X t 1t 1 若 z t t X t 1 yt 2, 1 2, 2 X t 2t 1 若 t zt 有了模型之後,需要將資料利用門檻值分類,本文利用相對移動率的經濟意 義將資料分成兩類,第一類組為上升趨勢群落,第二類組為下降趨勢群落,分別. 政 治 大. 以阿拉伯數字 1 及 2 代表第一類組及第二類組,分組之結果以表 4.5 來表示。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 30. i n U. v.
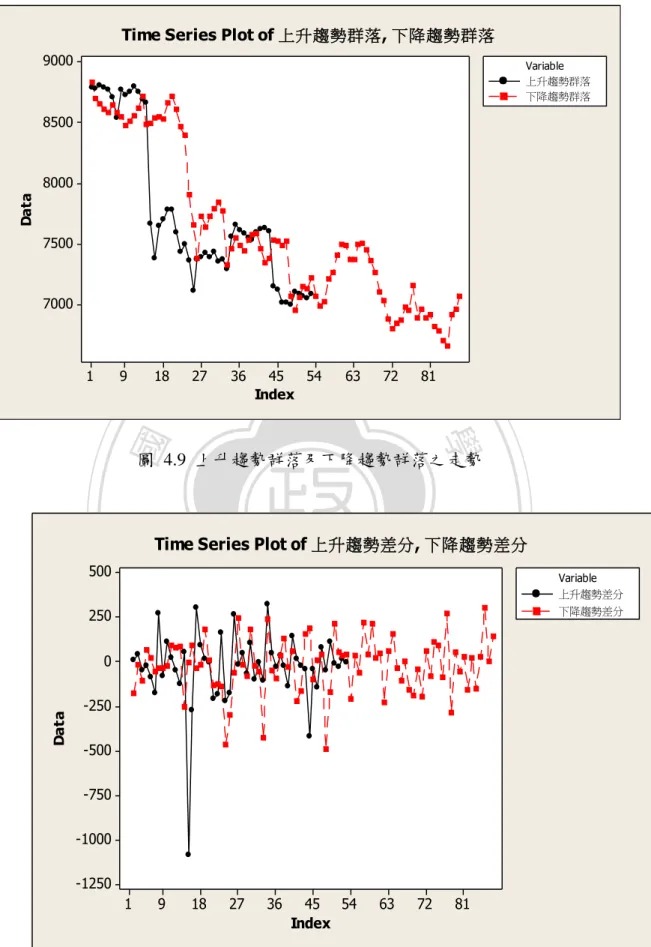
(37) 表 4.5 台灣加權指數分類表 日期. 台灣加權指數分類. 100/06/15. 2. 100/06/16. 2. 100/06/17. 2. 100/06/20. 2. 100/06/21. 2. 100/06/22. 2. 100/06/23. 2. 100/06/24. 2. 2 治 政 100/06/28 2 大 100/06/29 2 立. 100/12/15. 2. 100/12/16. 2. 100/12/19. 2. 100/12/20. 2. 100/12/21. 2. n. al. 100/12/22. Ch. 100/12/23 100/12/26. i n 2U 2. engchi. y. …. sit. …. er. io. 1. ‧. Nat. 100/06/30. 學. ‧ 國. 100/06/27. v. 1. 100/12/27. 1. 100/12/28. 1. 100/12/29. 1. 100/12/30. 1. 分類完成後,要先檢定資料是否穩定。由於股價的走勢圖為隨機漫步(random walk),所以分類完後並不是穩定的狀態,以圖 4.9 顯示上升趨勢群落及下降趨勢 群落的趨勢圖。. 31.
(38) Time Series Plot of 上升趨勢群落, 下降趨勢群落 9000. Variable 上升趨勢群落 下降趨勢群落. 8500. Data. 8000. 7500. 7000. 9. 18. 27. 立. 36. 45 54 Index. 63. 72. 81. 學. ‧ 國. 1. 政 治 大. 圖 4.9 上升趨勢群落及下降趨勢群落之走勢. ‧. sit. io. 250. n. al. er. 500. y. Nat. Time Series Plot of 上升趨勢差分, 下降趨勢差分. Data. 0. Ch. -250. engchi. i n U. v. -500 -750 -1000 -1250 1. 9. 18. 27. 36. 45 54 Index. 63. 72. 81. 圖 4.10 差分過後第一類及第二類圖形 32. Variable 上升趨勢差分 下降趨勢差分.
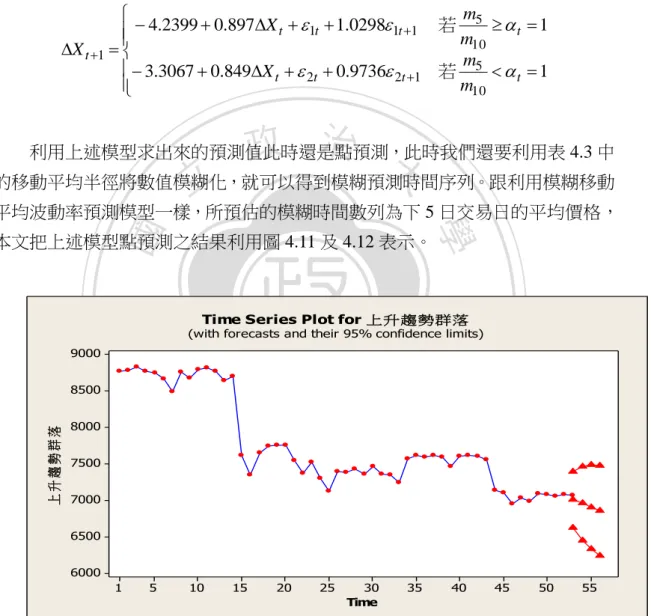
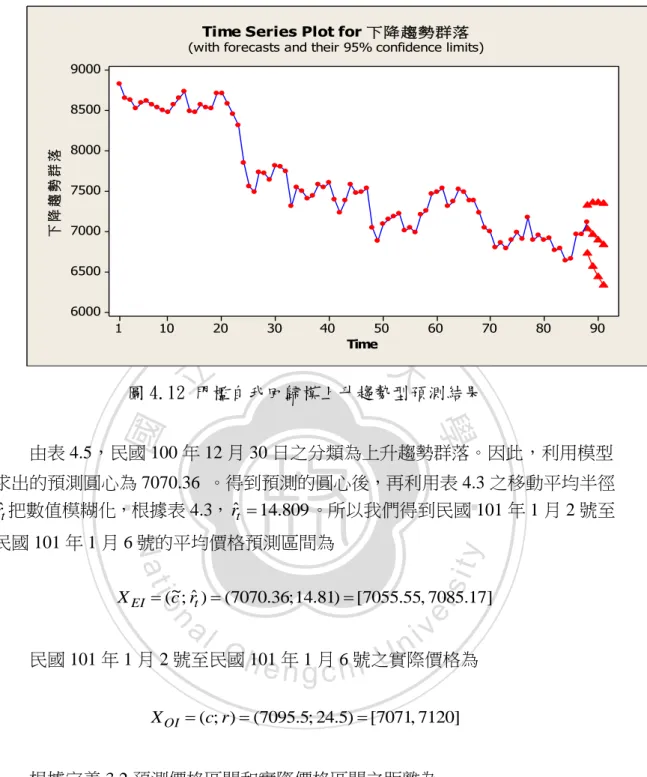
(39) 由於分類過後的資料是不穩定,因此我們將利用差分(difference)使其期望值 穩定,將資料轉換成穩定型態。如果差分一次後並不能使資料呈顯穩定狀態,則 繼續差分直到資料呈現穩定狀態為止。圖 4.10 表示差分一次後的圖形。 差分完畢後,資料呈現弱穩定狀態,於是我們利用 MINITAB 求出模型係數。 可以得到下列門檻值自廻規模型。. m 4.2399 0.897X t 1t 1.02981t 1 若 5 t 1 m10 X t 1 m 3.3067 0.849X t 2t 0.9736 2t 1 若 5 t 1 m10 . 政 治 大 的移動平均半徑將數值模糊化,就可以得到模糊預測時間序列。跟利用模糊移動 立. 利用上述模型求出來的預測值此時還是點預測,此時我們還要利用表 4.3 中. 平均波動率預測模型一樣,所預估的模糊時間數列為下 5 日交易日的平均價格,. ‧ 國. 學. 本文把上述模型點預測之結果利用圖 4.11 及 4.12 表示。. sit. n. al. er. io. 8500. y. Nat. 9000. 上升趨勢群落. ‧. Time Series Plot for 上升趨勢群落. (with forecasts and their 95% confidence limits). 8000 7500. Ch. engchi. i n U. v. 7000 6500 6000 1. 5. 10. 15. 20. 25. 30 Time. 35. 40. 45. 圖 4.11 門檻自我回歸模上升趨勢型預測結果. 33. 50. 55.
(40) Time Series Plot for 下降趨勢群落. (with forecasts and their 95% confidence limits) 9000. 下降趨勢群落. 8500 8000 7500 7000 6500 6000 1. 10. 政 治 大. 20. 30. 立. 40. 50 Time. 60. 70. 80. 90. 圖 4.12 門檻自我回歸模上升趨勢型預測結果. ‧ 國. 學. 由表 4.5,民國 100 年 12 月 30 日之分類為上升趨勢群落。因此,利用模型. ‧. 求出的預測圓心為 7070.36 。得到預測的圓心後,再利用表 4.3 之移動平均半徑 rˆt 把數值模糊化,根據表 4.3, rˆt 14.809 。所以我們得到民國 101 年 1 月 2 號至. y. sit. Nat. 民國 101 年 1 月 6 號的平均價格預測區間為. er. io. X EI (c~; rˆt ) (7070.36; 14.81) [7055.55, 7085.17]. al. n. v i n C h101 年 1 月 6 號之實際價格為 民國 101 年 1 月 2 號至民國 engchi U X OI (c; r ) (7095.5; 24.5) [7071, 7120]. 根據定義 3.2 預測價格區間和實際價格區間之距離為 29.62 49 d ( X OI , X EI ) 7070.36 7095.5 | | 29.04 ln (e 29.62) ln (e 49) 根據定義 3.3 預測價格區間和實際價格區間之效率為. IOE e. (|. 25.14 9.69 | ln(1| |)) 7070.36 14.81. 0.602. 這結果和利用模糊移動平均波動率模型所預測出來的結果成效是很接近的。. 34.
(41) 第五章. 結論. 由於人類的思考複雜,社會上各種現象的影響,傳統的點估計預測已經不敷 使用,模糊區間預測是由傳統的點預測所發展出來的預測方式,他既可以解決一 些點預測無法處理的問題,又不違背傳統點預測的精神。雖然點預測方式有其較 強的理論基礎。但是,數據收集程序可受一些不可預知的因素,而降低準確性。 如果我們利用這種人為的準確性做因果分析,這可能導致偏差因果關係的判斷, 誤導決策。 本文應用模糊時間數列法,提出一個相對移動率模糊時間序列預測模型來預 測加權指數的開盤價及收盤價,此種方法解決了傳統上時間序列模型複雜的計算. 政 治 大. 量,也可以和門檻自廻歸模型搭配使用,除此之外,本論文也將 Wu(2011)提出 區間時間數列的距離,做了一些修改,解決了在修正項調整影甚小的結果。本論. 立. 文模型的最大特色為,藉著調整估計的參數來達到區間預測的功效。方法不僅簡. ‧ 國. 準。. 學. 單便利,也可以藉著參數的改變,對於短期或中長期區間預測也有一定的預測水. ‧. 本論文提出以區間數據,在常見的區間模糊時間數列方法外,再提供一種新 的預測方式。但有關於影響圓心的選取,會因其相對移動率的權重不同而不同。. y. Nat. 因此,在未來如何選取一個恆常而且有效的相對移動率,為後續研究者所探討. io. sit. 的。又因為影響加權股價指數的因素,除了可衡量的經濟因素外,還有政治因素、. er. 政府干預、投資者的預期心理變數等,這些皆是無法量化的變數。再加上,如何. al. n. v i n Ch 有效的衡量方法將其量化之外,還有以研究如何選取一個有效的估計參數。 engchi U. 選取一個有效的估計參數也是一門很大的學問。因此,在未來可以考慮如何採取. 35.
(42) 參考文獻 吳柏林(1995),時間數列分析導論,華泰書局,台北。 吳柏林(2005),模糊統計導論方法與應用,五南出版社,台北。 吳柏林、阮亨中(2000),模糊數學與統計應用,俊傑書局,台北。 吳柏林、林玉鈞(2002),模糊時間數列分析與預測—以台灣地區加權股價指數為 例,應用數學學報,第 25 卷,第一期,頁 67-76。 楊奕農(2009),時間序列分析:經濟與財務上之應用,雙葉書廊,台北。 Akaike, H. (1973). Information theory and an extension of maximum likelihood principle, Second International Symposium on Information Theory 1, 267-281. Box, G. P. and Jenkins, G. M. (1976). Time series analysis forecasting and control. San Francisco: Holden-Day.. 政 治 大. Byers, J. D. and Peel, D. A. (1995). Evidence on volatility spillovers in the interwar. 立. floating exchange rate period based on high/low prices, Applied Economics. ‧ 國. 學. Letters 2(10), 394-396.. Chow, G. C. (1960), Tests of equality between sets of coefficients in two linear regressions, Econometrica 28(3), 591-605.. ‧. Donald W. K. A. and Werner P. (1994). Optimal tests when a nuisance parameter is. y. Nat. present only under the alternative, Econometrica 62(6), 1383-1414.. n. al. er. io. process. Fuzzy sets and system 31, 47-65.. sit. Graham, B. P. and Newell, R. B. (1989). Fuzzy adaptive control of a first-order. iv n Series, O. U. Haggan V. and Ozaki T. (1980). Amplitude-dependent exponential AR model fitting. Ch. engchi. for non-linear random vibrations, in Time North-Holland, Amsterdam.. D. Anderson ed.,. Hsu, H. L. (2011). Interval Time Series Analysis with Forecasting Efficiency Evaluation, Doctorial Thesis, Department of Mathematical Science, National Chengchi University, Taipei, Taiwan. Kumar, K. and Wu, B. (2001). Detection of change points in time series analysis with fuzzy statistics, International Journal of Systems Science 32(9), 1185-1192. Subba R. T. and Gabr M. (1980). A test for linearity of stationary time series analysis, Journal of Time Series Analysis 1(1), 145-158. Tong, R. M. (1978). Synthesis of fuzzy models for industrial processes. Int. J. Gen. 4, 143-162. Tong H. and Lim K. S. (1980). Threshold Autoregressive, Limit Cycles and Cyclical Data (with Discussion), Journal of the Royal Statistical Society. Series B 42(3), 36.
(43) 245-292. Wu, B. (2011). Efficiency Evaluation in Time Management for School Administration with Fuzzy Data, Technical Report, Department of Mathematical Science, National Chengchi University, Taipei, Taiwan. Zadeh, L. A. (1965). Fuzzy sets, Information and Control 8, 338-353. Zhou H. D. (2005). Nonlinearity or structural break - data mining in evolving financial data sets from a Bayesian model combination perspective, Proceedings of the 38th Hawaii International Conference on System Sciences, Hawaii, U.S.A.. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 37. i n U. v.
(44)
數據


![圖 4.5:12 天及 24 天價格平均線及實際值 由圖所知,隨著平均天數的增加,平均線會越趨於圓滑,這也代表離真實的 股價收盤數誤差會越來越大。相反的,如果選取的平均數太小,則波動太大,這 並非是一種好的預估模式。所以,如何選取一個有效的樣本參數去估計真實的情 況是一門很值得研究的學問。在找出相對移動率之前,我們必須根據觀測期數的 開盤價與收盤價找出一系列的圓心及半徑。如上表 4.1 所示。於是根據定理 2.5, 我們有 ]}08.7072,85.7109[,,]36.8991,71.8981[],3](https://thumb-ap.123doks.com/thumbv2/9libinfo/8271657.172762/30.892.147.748.123.974/由圖所是一種好去估計真況是一門很值得研究的學問在找出一系列.webp)
+6
![圖 4.6:相對移動率之預估結果 就實際考量而言,我們利用相對移動率所預測出來的區間,和民國 101 年 1 月 2 號至 1 月 6 號的平均開盤價格與平均收盤價格之區間相差只有 20 點。有了 模糊預測價格區間及實際價格區間之間的距離之後,接下來本文便要測試模糊相 對移動率預測模型在預測民國 101 年 1 月 2 號至 1 月 6 號的平均開盤價格與平均 收盤價格之效率性,根據定義 3.3 ]7120,7071[)5.24;5.7095();(c o r oOI ]58.7120,97.70](https://thumb-ap.123doks.com/thumbv2/9libinfo/8271657.172762/33.892.143.749.131.845/就實際和民國間之間之後接下來本文便要測試模糊相測民國與平均.webp)
Outline
相關文件
下圖一是測量 1994 年發生於洛杉磯的 Northridge 地震所得 到的圖形。任意給定一個時間 t ,從圖上可看出此時間所對
名稱 功能性評估重點 評估工具/方式 預估評 估時間
動態時間扭曲:又稱為 DTW(Dynamic Time Wraping, DTW) ,主要是用來比
目標 目標 策略 策略 策略 策略 成功準則 成功準則 成功準則 成功準則 評估方法 評估方法 評估方法 評估方法 時間 時間 時間 時間. 表 表
也就是設定好間隔時間(time slice)。所有的 程序放在新進先出的佇列裡面,首先CPU
目標 策略 策略 策略 策略 成功準則 成功準則 成功準則 成功準則 評估方法 評估方法 評估方法 評估方法 時間表 時間表 時間表 時間表 負責人 負責人 負責人 負責人
[r]
[r]
