報告題名:
加權指數日報酬率之風險值預測
Forecasting Value-at-Risks of Daily Stock Returns
作者:彭奕傑、王智平
系級:統精碩一
學號:
M0805538、M0808618
開課老師:陳婉淑 教授
課程名稱:時間數列分析
開課系所:統計與精算碩士班
開課學年:
108 學年度 第 1 學期
中文摘要
本次研究主要探討具有 ARCH 效應的財務上資料之日報酬率,其中 ARCH 效應指的是財務上資料的時間序列之變異數並不是一個定值,會隨時間改變,針 對此效應,我們以ARCH 模型為基礎所延伸的 GARCH 模型(分別有下和風險矩 陣(RiskMetrics)、GARCH 模型、IGARCH 模型、GARCH-M 模型、EGARCH 模 型和GJR-GARCH 模型)並假設在 4 種不同分配(常態分配、學生 t 分配、偏態學 生t 分配以及廣義誤差分配)下,以每日那斯達克綜合指數(NASDAQ)與富時 100 指數(FTSE100)作為本研究的實證資料,資料起始時間為 2000 年 1 月 3 日,結束 時間為2019 年 12 月 27 日,並保留資料那斯達克綜合指數的最後 331 筆和富時 100 指數的最後 333 筆(2018 年 9 月 5 日到 2019 年 12 月 27 日)作為檢視樣本外 預測,透過預測與估計出21 個模型的風險值(Value-at-Risk, VaR),再經由回溯測 試(backtesting)以及違反率(Violation Rates, VRate)來從兩支加權指數中篩選出最 佳模型,結果發現那斯達克綜合指數以 IGARCH 模型並假設在偏態學生 t 分配 為最佳模型,而富時100 指數則是 GARCH 模型假設在學生 t 分配和 GARCH-M 模型假設在學生t 分配以及偏態學生 t 分配為較佳的模型。
關鍵字:
回溯測試、波動性、風險矩陣、時間序列、樣本外預測、GARCH、 Value-at-Risk (VaR)Abstract
This paper studies the heteroscedastic models for daily stock returns and examines their time-varying volatility. To do so, we employ several types of models including the GARCH family models: RiskMetrics, GARCH, integrated GARCH (IGARCH), GARCH in mean (GARCH-M), exponential GARCH (EGARCH), and GJR-GARCH models, along with four different dis-tribution error assumptions (Normal, Student-t, Skewed Student-t, and Generalized Error Dis-tributions). Our dataset contains two daily indices (NASDAQ and FTSE100) and covers the time period from January 3, 2000 to December 27, 2019. We estimate Value-at-Risk thresholds for each model and use backtests and Violation Rates to select the best model for each market. The results show that the IGARCH model with Skewed Students-t Distribution is the most ef-ficient model for NASDAQ index at the 1% and 5% level. For FTSE100 index, models that bring best-fitted results are GARCH model with Student-t Distribution, the GARCH-M model with Student-t Distribution, and GARCH-M model with Skewed Student-t Distribution.
Keywords: backtesting, GARCH, out-of-sample, RiskMetrics, time series, Value-at-Risk (VaR),
目 錄
1 緒 論 . . . 6 2 模 型 介 紹 與 研 究 方 法 . . . 9 2.1 ARCH 模型 . . . 9 2.2 GARCH 模型 . . . 12 2.3 IGARCH 模型 . . . 13 2.4 GARCH-M 模型 . . . 14 2.5 EGARCH 模型 . . . 14 2.6 GJR-GARCH 模型 . . . 15 2.7 VaR . . . 16 2.8 回溯測試 . . . 17 3 實 證 分 析 . . . 19 4 結 論 . . . 27 參考文獻 . . . 28圖 目 錄
1 那斯達克綜合指數當日收盤價時間序列圖和日報酬率波動圖 . . . 20 2 富時 100 指數當日收盤價時間序列圖和日報酬率波動圖 . . . 20 3 那斯達克綜合指數配適 IGARCH.sstd 模型圖 . . . 25 4 富時 100 指數配適 GARCH.std 模型圖 . . . 25 5 富時 100 指數配適 GARCH-M.std 模型圖 . . . 26 6 富時 100 指數配適 GARCH-M.sstd 模型圖 . . . 26表 目 錄
1 兩支加權指數報酬率敘述統計表 . . . 21
2 那斯達克綜合指數回溯測試檢定表 (樣本數為 331 筆) . . . 22
3 富時 100 指數回溯測試檢定表 (樣本數為 333 筆) . . . 23
第 1 章 緒 論
常常在新聞或是報章媒體上看到昨日加權指數收盤,上漲或是下跌多少點,對於 身在商學院的我們,卻對股票一知半解,從沒想過什麼是加權指數,也不懂是利用何 種方式計算出來的,這讓我們更想要去了解所謂的加權指數是什麼。加權指數就是為 了表達一群股票的整體狀況,利用加權的方式所算出來的一個數值,簡稱就是大盤, 很多人操作股票都會以大盤指數的漲跌來決定。在此研究我們想了解兩支國外重要的 加權指數,分別是美國的那斯達克綜合指數 (National Association of Securities Dealers Automated Quotations Composite Index, NASDAQ Composite Index) 和英國的富時 100 指 數 (Financial Times Stock Exchange 100 Index, FTSE 100 Index),並對這兩支加權指數的 報酬分析、預測以及風險評估,以下為這兩支加權指數的介紹: • 那斯達克綜合指數 (NASDAQ) 美國那斯達克股票交易所是世界上第一間電子股票交易所,可以透過電話或網路 進行交易,不會受限於交易大廳,也是目前世界上第二大的證券交易所,在那斯 達克交易所上市的公司多以高科技公司為主。1971 年 2 月 5 日創立那斯達克綜合 指數,是那斯達克股票交易所內股市價格的重要指標,成分股包括所有在美國那 斯達克股票交易所上市的股份。 • 富時 100 指數 (FTSE) 富時 100 指數為倫敦股市金融時報 100 種股票平均價格指數,又稱為倫敦金融時 報 100 指數,創立於 1984 年 1 月 3 日,是由富時集團根據在英國倫敦證券交易 所上市最大一百家公司而製作的股價指數,成分股涵蓋歐陸 9 個主要國家,以 英國企業為主。富時 100 指數是英國經濟的重要指標,和德國 DAX 指數及法國 CAC40 指數並稱歐洲最三大股票指數。財務時間序列 (time series) 的波動大小是不固定的,通常使用在財務上的資料, 像是股價的時間序列,波動幅度隨時間變化 (time varying volatility),並不是一個定 值,Mandelbrot (1967) 發現了財務上的資料具有波動群聚性 (volatility clustering),也 就是大波動跟隨著大波動,小波動跟隨著小波動。本次研究主要探討具有 ARCH 效 應的財務上資料之日報酬率,其中 ARCH 效應 (ARCH Effect) 指的是財務上資料的 時間序列之變異數並不是一個定值,會隨時間改變,針對此效應,我們以 ARCH 模 型 (Autoregressive Conditional Heteroskedasticity Model, ARCH Model) 為基礎所延伸的 GARCH 模型 (Generalized AutoRegressive Conditional Heteroskedasticity Model, GARCH Model) 並假設在不同分配 (常態分配、學生 t 分配 (Student’s t-Distribution)、偏態學生 t 分配 (Skew Student’s t-Distribution) 以及廣義誤差分配 (Generalized Error Distribution)) 下 和風險矩陣 (RiskMetrics),以那斯達克綜合指數與富時 100 指數作為本研究的實證資 料。
風險值 (Value-at-Risk, VaR) 是衡量市場風險的一種方法,主要是在給定一段期間
以及信心水準α 下,預測經濟變動之組合的最大損失;而風險值的衡量方法則是根
據國際清算銀行 (Bank for International Settlements, BIS) 於 1996 年所發布的巴塞爾協定 (Basel) 修正案中,以 VaR 作為衡量市場風險的指標。文獻中有許多 VaR 估計方法可以 分為三類,可參考Chen et al. (2017) 和Chen and Sun (2018)。它們包括無參數方法 (如歷 史模擬),半參數方法 (如極值理論,動態分位數迴歸模型) 和參數方法 (含分配假設)。 我們參考第三個類型,像是Engle (1982) 提出的 ARCH 模型和Bollerslev (1986) 提出的 GARCH 模型都有指定的誤差分配。假設在 4 種不同分配 (常態分配、學生 t 分配、偏 態學生 t 分配以及廣義誤差分配) 下,以那斯達克綜合指數 (NASDAQ) 與富時 100 指 數 (FTSE100) 作為本研究的實證資料,資料起始時間為 2000 年 1 月 3 日,結束時間為 2019 年 12 月 27 日,並保留資料那斯達克綜合指數的最後 331 筆和富時 100 指數的最 後 333 筆 (2018 年 9 月 5 日到 2019 年 12 月 27 日) 作為檢視樣本外預測。
以上述兩支加權指數為例,將針對資料的日報酬率波動不平穩的條件進行模型配 適,在給定的模型及假設的分配下,分別為這兩支加權指數配適 21 組模型,並使用樣 本外預測計算 VaR。為評估 VaR 表現,本文參照Chen et al. (2012) 和Chen et al. (2017) 採用違反率 (Violation Rates, VRate) 和回溯測試 (backtesting) 來從兩支加權指數中篩選 出最佳模型。我們使用了兩種回溯測試的方法去檢定配適出的模型以及計算 VaR 的準 確度,第一種方法是Kupiec (1995) 提出的非條件涵蓋概似比檢定 (Likelihood Ratio Test for unconditional coverage,LRuc),這是一種概似比檢定 (Likelihood Ratio Test, LRT),檢
定真實的波動率是否等於信心水準α,而另一種方法是Christoffersen (1998) 提出的做區
間預測時獨立且條件涵蓋檢定 (Likelihood Ratio Test for conditional coverage, LRcc),這
是一種聯合檢定,包含波動獨立性的概似比檢定和 LRuc。
本文的架構如下,第 2 章為本研究的模型介紹和研究方法,在第 3 章進行資料實 證分析,第 4 章為分析的結果與討論。
第 2 章 模 型 介 紹 與 研 究 方 法
2.1
ARCH 模型
Engle (1982) 提出的 ARCH 模型中文譯為自迴歸條件異質變異數模型,主要是針對 變異數不平穩,也就是變數時間序列的波動大小是不固定的,通常使用在財務上的資 料,像是股價的時間序列,波動幅度隨時間變化,並不是一個定值,Mandelbrot (1967) 發現了財務上的資料具有波動群聚性,也就是大波動跟隨著大波動,小波動跟隨著 小波動,而且Mandelbrot (1967) 和Fama (1965) 都指出股價資料的分配會呈現高峽峰 (leptokurtic) 並且厚尾 (fat-tailed) 的型態,也就是資料的分布中間特別細長而兩側尾端 較大,並不服從常態分配,基於以上原因無法使用傳統的時間序列模型或方法去分析, 於是Engle (1982) 提出 ARCH 模型能準確模擬時間序列波動性的變化,其模型如下: rt =at, at =σtϵt, ϵt i.i.d.∼ N(0, 1), σ2 t =α0+α1a2t−1+· · · +αma2t−m, 其中 rt 為當期報酬率,可以是 AR(1) 模型的形式,at 為收益殘差,並假設 ϵt 獨立且相同分配 (independent and identically distributed, i.i.d.) 為常態分配,σ2
t 為當期的波
動性,也就是變異數,隨著時間 t 改變,且α0 > 0,對於 i > 0,αi > 0,也就是每
期收益以非負數的線性組合 (linear combination),另外 at 是具有條件獨立 (conditional
independent) 的隨機變數,假設如下:
其中 Ft−1為前一期的歷史資料,也就是在給定前一期的歷史資料,假設當期收益的殘 差會服從常態分配,也可以假設 at 服從其他後尾的分配,像是學生 t 分配、偏態學生 t 分配或是廣義誤差分配,後兩個分配為不對稱分配。 若要使用 ARCH 模型,需要先對資料做檢定,檢定資料是否為常態分配、檢定資 料是否具有 ARCH 效應,也就是時間序列的變異數不具有同質性 (homogeneity),常用 的檢定有以下三種: • Jarque-Bera Test
Bera and Jarque (1980) 提出檢驗資料是否具有服從常態分配的偏度與峰度的檢定, 其假設如下: H0 : Normality(S =0, K =3), H1 : Non-normality. 其中 S 為資料的偏態係數 (skewness),K 為資料的峰態係數 (kurtosis),資料為常 態分配時,S=0,K =3,其檢定統計量為 JB = n 6(S 2+1 4(K−3) 2), 其中 n 為觀測數,當 S 不接近 0,K 不接近 3,都會使統計量愈大,而資料會愈 不趨近於常態分配。 • Ljung-Box Test
關,其假設如下: H0 :ρ1=ρ2 =· · · = ρh =0, H1 : at least oneρi ̸=0, i=1, 2,· · · , h. 檢定統計量為 Q=n(n+2) h
∑
t=1 (n−t)−1r2t, 其中 h 為落後 (lag) 最大考慮的期數,n 為時間序列資料的觀測數,r2 t 為當期報酬 率的平方。• Testing for ARCH Effect
Engle (1982) 為了檢定 ARCH 效應提出的檢定,考慮的是殘差平方的序列{a2t}, a2t =α0+α1a2t−1+· · · +αma2t−m+et, t=m+1,· · · , T, 其中 et為誤差項,m 為預先設定的正整數,T 為樣本數 H0 : α1 =α =· · · = αm =0, H1 : at least oneαi ̸=0, i=1, 2,· · · , m. 檢定統計量為 F = (SSR0−SSR1)/m SSR1/(T−2m−1),
其中 SSR0 = ∑Tt=m+1(a2t −ω¯)2, ¯ω = T1 ∑Tt=1a2t 為 a2t 的樣本平均數,SSR0 = ∑T t=m+1 ˆe2t,檢定統計量服從 F 分配,自由度為 m 和 T−2m−1。
2.2
GARCH 模型
ARCH 模型也存在了一些限制,像是正的波動和負的波動對波動率影響相同,但 實際上股價的報酬率中正、負波動對波動率影響不同,較大的負波動比正波動所引起 的波動更大,所以Bollerslev (1986) 提出了 GARCH 模型,又稱為廣義 ARCH 模型,其 模型如下: rt =ϕ1rt−1+at, at =σtϵt, ϵt i.i.d.∼ N(0, 1), σ2 t =α0+ m∑
i=1 αia2t−i+ s∑
j=1 βjσt2−j.與 ARCH 模 型 相 似, 只 是 變 異 數 的 部 分 改 用 ARMA 模 型 (Autoregressive Moving Average Model, ARMA Model) 來表示,其中α0 >0,αi > 0,βj > 0,∑max
(m,s)
i,j=1 (αi+
βj) < 1,GARCH 模型的優點為更能節約參數,避免過度配適,也能去探討波動性的
問題,所以 GARCH 模型較為廣泛使用,Bollerslev et al. (1992) 提出 GARCH(1,1) 足以 分析大部分的資料,而 GARCH 模型在後續也有一些延伸。
2.3
IGARCH 模型
Bollerslev and Engle (1986) 提出了 IGARCH 模型 (Integrated GARCH Model, IGARCH Model),也稱為整合 GARCH 模型,對原本的 GARCH 模型參數做限制,其模型如下:
rt =at, at =σtϵt, ϵt i.i.d.∼ N(0, 1), σ2 t =α0+ p
∑
i=1 (1−βi)a2t−i+ q∑
i=1 βiσt2−i. 將原本的 GARCH 模型αi變成 1−βi,也就是αi+βi = 1,IGARCH 模型常用在國外 的交易市場。 RiskMetrics 風險矩陣是 JP Morgan 公司在 1996 年提出 (Morgan, 1996),但最一開始是當時的董事 長兼執行長 Weatherstone (1989) 要求公司,在每天下午 4:15 要完成一份衡量並解釋公 司風險的報告。其模型為 IGARCH 模型當α0 =0 的特例,模型如下: rt =at, at =σtϵt, ϵt i.i.d.∼ N(0, 1), σ2 t = (1−λ)a2t−i+λσt2−i, 0 <λ<1, 其中λ 通常在 0.9 到 1 的區間內,在日資料為 0.94,月資料為 0.97。2.4
GARCH-M 模型
Engle et al. (1987) 認為當條件變異數變動時,風險也隨著變動,也就是風險溢 酬 (risk premium) 會隨時間變動而變動,於是提出了 ARCH–M 模型 (ARCH in Mean Model),將條件變異數放入條件平均數中,之後Chou (1988) 推廣成 GARCH-M 模型 (GARCH in Mean Model),以最基本 GARCH(1,1) 模型來展示,其模型如下:
rt =µ+cσt2+at, at =σtϵt, ϵt i.i.d.∼ N(0, 1), σ2 t =α0+α1a2t−1+β1σt2−1, 其中 c 可以解釋為風險溢酬,GARCH-M 模型在日後廣泛運用在金融資產上,是驗證 資產報酬率與波動風險關係最常使用的模型。
2.5
EGARCH 模型
Nelson (1991) 提出了 EGARCH 模型 (Exponential GARCH Model, EGARCH Model), 也稱為指數 GARCH 模型,是不對稱模型,修正對稱型的 GARCH 模型中,對於正波 動與負波動對條件變異數影響都相同的設定,用來觀察非預期報酬率影響對報酬率 波動性的不對稱影響 (asymmetric effect),以最基本 EGARCH(1,1) 模型來展示,可參
考Tsay (2014),其模型如下: rt = at, at =σtϵt, ϵt i.i.d.∼ N(0, 1), σ2 t =exp{α0+α1|αt−1| +σ γ1αt−1 t−1 +β1ln(σ12)}, g(ϵt−1) =θϵt−1+γ(|ϵt−1| −√2/π), 其中係數γ+θ 為表示 at 為正或負的影響,因為負波動通常產生較大的影響,所以預 期θ<0。
2.6
GJR-GARCH 模型
Glosten et al. (1993) 提出了以他們的名字命名的 GJR-GARCH 模型 (GJR-GARCH Model),修正了 GARCH 模型,允許正波動與負波動對條件變異數有不同程度的影響, 認為波動不對稱影響是來自於槓桿效應 (leverage effect) 的結果,導致當期的股價受負 波動而下跌時,權益資本相對債務資本比值下降,使得財務槓桿程度上升,造成股票 風險上升,非預期報酬變異因此增大,以最基本 GJR-GARCH(1,1) 模型來展示,其模 型如下: rt =at, at =σtϵt, ϵt i.i.d.∼ N(0, 1), σ2 t =α0+α1a2t−1+β1σt2−1+γIt−1a2t−1, It−1 = { 1, if at−1<0, 0, otherwise, 其中α1+γ≥0,α1≥0,α1+β1+0.5γ <1。
2.7
VaR
VaR 是目前最廣受使用而且是有效的風險控管工具,是以一個淺顯易懂的數字來 描述在當前複雜的金融環境下,投資部門或管理階層所承擔的風險和面臨的最大損失, 也正由於簡單、易懂的特性,使得我們所採用估計模型與解釋時必須特別的小心,因 為使用不同的模型,在不同的假設及不同的參數使用下,會估計出不同的風險值。估 計風險值的成敗與否,在於採用的機率分配是否能有效捕捉並預測出金融市場即將發 生的極端事件,例如金融風暴,因此如何將金融商品報酬的機率分配尾端 (tail) 特性真 實的呈現出來,才是風險值模型所應考量的課題。 所謂 VaR 為一個估計值,是因為在給定信心水準α 下以及在正常的交易市場, VaR 表示投資組合於固定期間內最大可能損失金額。通常 VaR 的評估期間為一日,而 信心水準為 95%。針對不同的模型估計出的 VaR,可以利用違反率去比較,參見Chen et al. (2012) 和Chen et al. (2017),其公式如下:VRate = ∑
n+m
t=n+1I(rt < (−VaR)t)
m ,
其中 n 為預測值的起點,m 為預測的資料筆數,使用一步預測 (one-step-ahead) 估計出 的 VaR,總共預測 m 次。VRate 是一個簡單且容易去比較模型的 VaR,由於估計出的
VaR 是損失的概念,所以 VaR<0,在給定的信心水準α 下,將信心水準 α 與 VRate 進
行比較,若 VRate> 信心水準α,模型配適不佳可能導致清償風險,若 VRate< 信心水
準α,模型估計出結果過於保守,所以會希望 VRate 愈接近信心水準 α,表示配適的模 型愈好。
2.8
回溯測試
為了比較不同的模型,本研究使用了回溯測試來做檢定,目的在於計算某段時間 內,實際損失超過所估計 VaR 的次數是否與預期的次數一致,常用的檢定方法有以下 兩種: 非條件涵蓋概似比檢定 (LRuc) Kupiec (1995) 提出LRuc,用來測試非條件涵蓋概似比是否與 VaR 所預定的信賴水 準具有統計上的ㄧ致性,其假設如下: H0: π = p, H1: π ̸= p, 其中 ˆπ 為模型所測試的真實失敗率,p 為模型預定的失敗率,當實際損失大於預測 VaR 估計值則稱為失敗,檢定統計量為 LRuc =−2 ln [ pn(1−p)T−n ˆ πn(1−πˆ)T−n ] ∼χ2(1),其中 ˆπ = n/m 為失敗率,是 p 的最大概似估計量 (Maximum Likelihood Estimation,
MLE),n 服從 Bernoulli 分配,代表在總觀察值 m 下的失敗總次數。
條件涵蓋概似比檢定 (LRcc)
因為 LRuc 考慮到時間區間內所有的離群值,而這些離群值可能會有群聚性的情形
發生,也就是離群值彼此間並不獨立,在這樣的情況下模型將無法捕捉到市場真實的 波動,LRuc 將失去準確度。因此Christoffersen (1998) 發展出 LRcc,在做 LRuc 及序列
獨立檢定的聯合檢定,檢定統計量為 LRcc = LRuc+LRind,LRind 是用來檢定這些離
群值是否為獨立,其假設如下:
H0 : Correct exceedances and independence of failures,
H1 : Neither correct exceedances nor independence of failures.
檢定統計量為 LRcc = LRuc+LRind =−2 ln [ pn(1−p)T−n ˆ πn01 01 (1−πˆ01)n00πˆ n11 11 (1−πˆ11)n10 ] ∼χ2(2), 其中 nij 為緊跟值 j 的第 i 個觀察值個數,i, j = 0, 1, ˆπ01 = n01/n01 + (n01), ˆπ11 = n11/n10+ (n11)。
第 3 章 實 證 分 析
本研究的實證資料取自於雅虎財經頻道 (Yahoo Finance),是雅虎網路中的媒體資 產,提供了當日行情、大盤走勢、類股走勢、期貨與選擇權分類報價、港滬深股、美 股、財務新聞、數據和評論等資訊,也提供了一些用於個人理財管理的線上工具。 本次的資料是使用的兩支國外加權指數的資料,分別為那斯達克綜合指數 (股票代 碼為 ^IXIC) 和富時 100 指數 (股票代碼為 ^FTSE),資料期間分別開始於 2000 年 1 月 4 日和 2000 年 1 月 3 日,結束時間同為 2019 年 12 月 27 日,資料筆數分別為 5029 筆和 5100 筆,原始資料紀錄了該支加權指數當日的開盤價、收盤價、最高點、最低點、股 數以及調整價格。本研究使用兩支加權指數的日報酬率作為實證資料,計算各自的連 續複利報酬率 (Continuously Compounded Return),將當期收盤價除以前一期收盤價之 後再取自然對數 (ln(·)) 並乘以 100%,也就是rt =ln(PPtt−1)×100%,其中 rt 為加權指數在第 t 期連續複利下的日報酬率,Pt 為加權指數在第 t 期的收盤價。
本 研 究 使 用 軟 體 R 語 言, 以 及 其 內 部 套 件 quantmod(Ryan and Ulrich, 2018) 和
rugarch(Ghalanos, 2020) 進行分析,軟體 R 語言的 quantmod 軟件包旨在幫助定量交
易者開發,測試和部署基於統計的交易模型,本研究用此套件下載那斯達克綜合 指數和富時 100 指數的數據,並對這兩支加權指數配適 GARCH 模型、IGARCH 模 型,RiskMetrics,GARCH-M 模型、EGARCH 模型和 GJR-GARCH 模型,參數設定皆 為(1, 1),並對日報酬率 rt 配適 AR(1),也就是 rt = ϕ1rt−1+at,接著考慮不同的分
配,分別是常態分配 (norm)、學生 t 分配 (std)、偏態學生 t 分配 (sstd) 和廣義誤差分配 (ged),再針對兩種信心水準下,分別為 1% 和 5%,估計出不同模型的 VRate,最後比 較模型並選出最佳模型。首先繪製兩支加權指數的當日收盤價時間序列圖和日報酬率 波動圖,如以下圖 1和圖2。
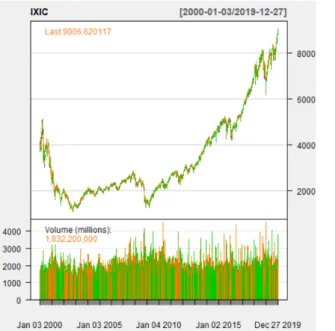
圖 1: 那斯達克綜合指數當日收盤價時間序列圖和日報酬率波動圖 由圖1那斯達克綜合指數的當日收盤價時間序列圖可以看到,在 2000 年 3 月突破 了 5000 點,是當時的歷史新高,後來那斯達克綜合指數進行調整,歷經兩年半的熊 市,在 2002 年 8 月跌到最低點,隨後趨於穩定,直到 2008 年金融風暴期間又下跌至 接近最低點,而金融風暴後不斷上升,至今甚至突破 8000 點。 圖 2: 富時 100 指數當日收盤價時間序列圖和日報酬率波動圖
由圖2富時 100 指數的當日收盤價時間序列圖可以看到,在 2002 年 7 月跌至最低 點,之後不斷回升,直到金融風暴期間又跌至新低,而金融風暴後不斷上升,雖然又 有一度下跌,但下跌幅度不大,至今仍突破 7500 點。 由圖 1和圖2兩支加權指數的日報酬率波動圖可以看到波動群聚性的現象。接著對 於兩支加權指數的日報酬率進行敘述統計,如以下表 1。 表 1: 兩支加權指數報酬率敘述統計表
Stock Mean Stdev Skewness Kurtosis Minimum Maximum JB Q(5) Q(10) ARCH(5) ARCH(10)
p−value p−value p−value p−value p−value
NASDAQ 0.02 1.56 −0.01 5.97 −10.17 13.25 <0.05 <0.05 <0.05 <0.05 <0.05 FTSE100 0.00 1.16 −0.16 6.54 −9.26 9.38 <0.05 <0.05 <0.05 <0.05 <0.05
由表 1可以看到兩支加權指數的偏態係數皆 <0,表示日報酬率呈現左偏,而兩支 加權指數的峰態係數皆 >3,表示日報酬率呈現高狹峰並且厚尾的型態,其中 JB 為
Jarque-Bera Test 檢定統計量的 p−value,檢定結果皆為顯著,表示資料皆不服從常態
分配,Q 為 Ljung-Box Test 檢定統計量的 p−value,ARCH 為 Testing for ARCH Effect
檢定統計量的 p−value,後方的括號內數字代表落後的期數,因為一週交易日通常為
5 天,我們考慮一週及兩週的資料來檢驗是否有 ARCH 效應,得出的檢定結果皆為顯 著,兩支加權指數皆有 ARCH 效應。
我們從兩支加權指數中各自取出從 2018 年 9 月 5 日到 2019 年 12 月 27 日的資料 作為本次分析的樣本外 (out-sample) 預測,那斯達克綜合指數的樣本數為 331 筆,富時 100 指數的樣本數為 333 筆,並進行移動視窗法 (Rolling Window Method),每次加入一 筆資料預測下一筆資料,以 ARCH 模型為基礎,再利用前章節所提出的方法配適出其 延伸模型,在本研究我們一共為這兩支加權指數,各自配適 21 個模型並考慮不同分 配,除了 RiskMetrics 是只考慮常態分配,其餘五個模型都是考慮 4 種分配,並且為所
有模型進行回溯測試,分別是 LRuc和 LRcc,最後計算出每個模型的 VRate,利用上述
首先我們先針對每個模型的進行回溯測試,在這邊我們使用了 LRuc 以及 LRcc方 法檢定,假設為 H0 : α =α0和 H1 : α ̸= α0其中 α0 =1%, 5%,如果檢定結果具有顯 著水準就代表拒絕 H0。 表 2: 那斯達克綜合指數回溯測試檢定表 (樣本數為 331 筆) NASDAQ Model MSE 1% LRuc 1%LRcc 5%LRuc 5%LRcc
P−value P−value P−value P−value
GARCH.norm 1.474 0.003 0.009 0.008 0.018 GARCH.std 1.477 0.182 0.367 0.047 0.137 GARCH.sstd 1.474 0.182 0.367 0.077 0.176 GARCH.ged 1.476 0.076 0.178 0.077 0.035 IGARCH.norm 1.474 0.028 0.074 0.399 0.206 IGARCH.std 1.477 0.182 0.367 0.047 0.137 IGARCH.sstd 1.474 0.385 0.635 0.280 0.144 IGARCH.ged 1.476 0.182 0.367 0.190 0.394 RiskMetrics 1.474 0.003 0.009 0.280 0.455 GARCH-M.norm 1.476 0.003 0.009 0.004 0.016 GARCH-M.std 1.487 0.076 0.178 0.008 0.030 GARCH-M.sstd 1.478 0.182 0.367 0.077 0.176 GARCH-M.ged 1.483 0.076 0.178 0.015 0.034 EGARCH.norm 1.471 0.000 0.001 0.077 0.176 EGARCH.std 1.473 0.028 0.074 0.027 0.063 EGARCH.sstd 1.471 0.076 0.178 0.280 0.144 EGARCH.ged 1.471 0.076 0.178 0.077 0.176 GJR-GARCH.norm 1.472 0.010 0.027 0.280 0.144 GJR-GARCH.std 1.474 0.028 0.074 0.027 0.063 GJR-GARCH.sstd 1.472 0.028 0.074 0.280 0.144 GJR-GARCH.ged 1.475 0.028 0.074 0.124 0.271 .norm 表示配適模型並假設在常態分配,.std 表示配適模型並假設在學生 t 分配, .sstd 表示配適模型並假設在偏態學生 t 分配,.ged 表示配適模型並假設在廣義誤差分 配。 經過檢定,根據表2中標記為粗體的模型為兩個檢定都通過的模型,共有 6 個模 型,分別為 GARCH.sstd 模型、IGARCH.sstd 模型、IGARCH.ged 模型、GARCH-M.sstd 模型、EGARCH.sstd 模型和 EGARCH.ged 模型,可發現都是考慮 sstd 或 ged 這兩種分 配所配適的模型有通過檢定,表示在考慮不對稱分配配適出的模型結果較好。
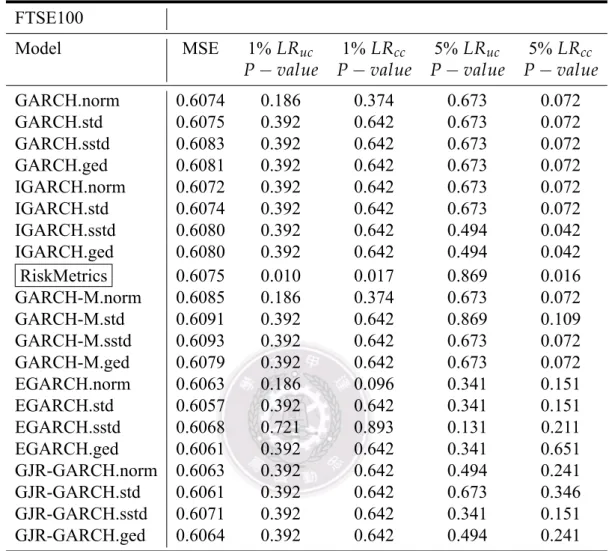
表 3: 富時 100 指數回溯測試檢定表 (樣本數為 333 筆) FTSE100
Model MSE 1%LRuc 1%LRcc 5%LRuc 5%LRcc
P−value P−value P−value P−value
GARCH.norm 0.6074 0.186 0.374 0.673 0.072 GARCH.std 0.6075 0.392 0.642 0.673 0.072 GARCH.sstd 0.6083 0.392 0.642 0.673 0.072 GARCH.ged 0.6081 0.392 0.642 0.673 0.072 IGARCH.norm 0.6072 0.392 0.642 0.673 0.072 IGARCH.std 0.6074 0.392 0.642 0.673 0.072 IGARCH.sstd 0.6080 0.392 0.642 0.494 0.042 IGARCH.ged 0.6080 0.392 0.642 0.494 0.042 RiskMetrics 0.6075 0.010 0.017 0.869 0.016 GARCH-M.norm 0.6085 0.186 0.374 0.673 0.072 GARCH-M.std 0.6091 0.392 0.642 0.869 0.109 GARCH-M.sstd 0.6093 0.392 0.642 0.673 0.072 GARCH-M.ged 0.6079 0.392 0.642 0.673 0.072 EGARCH.norm 0.6063 0.186 0.096 0.341 0.151 EGARCH.std 0.6057 0.392 0.642 0.341 0.151 EGARCH.sstd 0.6068 0.721 0.893 0.131 0.211 EGARCH.ged 0.6061 0.392 0.642 0.341 0.651 GJR-GARCH.norm 0.6063 0.392 0.642 0.494 0.241 GJR-GARCH.std 0.6061 0.392 0.642 0.673 0.346 GJR-GARCH.sstd 0.6071 0.392 0.642 0.341 0.151 GJR-GARCH.ged 0.6064 0.392 0.642 0.494 0.241 .norm 表示配適模型並假設在常態分配,.std 表示配適模型並假設在學生 t 分配, .sstd 表示配適模型並假設在偏態學生 t 分配,.ged 表示配適模型並假設在廣義誤差分配。 在表3的結果中,除了 RiskMetircs 模型外 (框起來處),其餘模型的檢定結果都有 通過,代表大部分的模型都相當理想的。 在經由回溯測試後,我們利用 VaR 方法去計算出每個模型所估計出來的 VRate 為 多少,我們設定信心水準為 1% 和 5%,在這項方法中,選取 VRate 最接近設定信心水 準的模型作為最理想模型,並希望選取 VRate 不要超過設定信心水準的模型,因為可 能會導致清償風險。
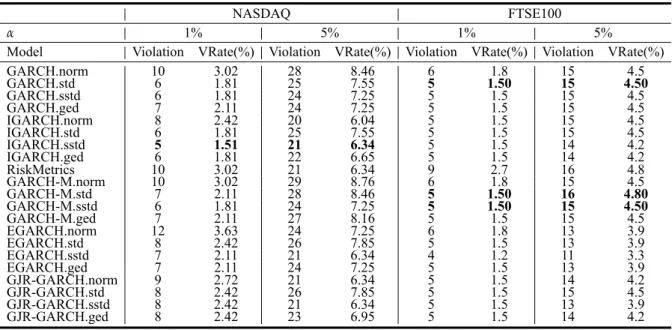
表 4: 兩支加權指數 VRate 表 (樣本數分別為 331 和 333 筆)
NASDAQ FTSE100
α 1% 5% 1% 5%
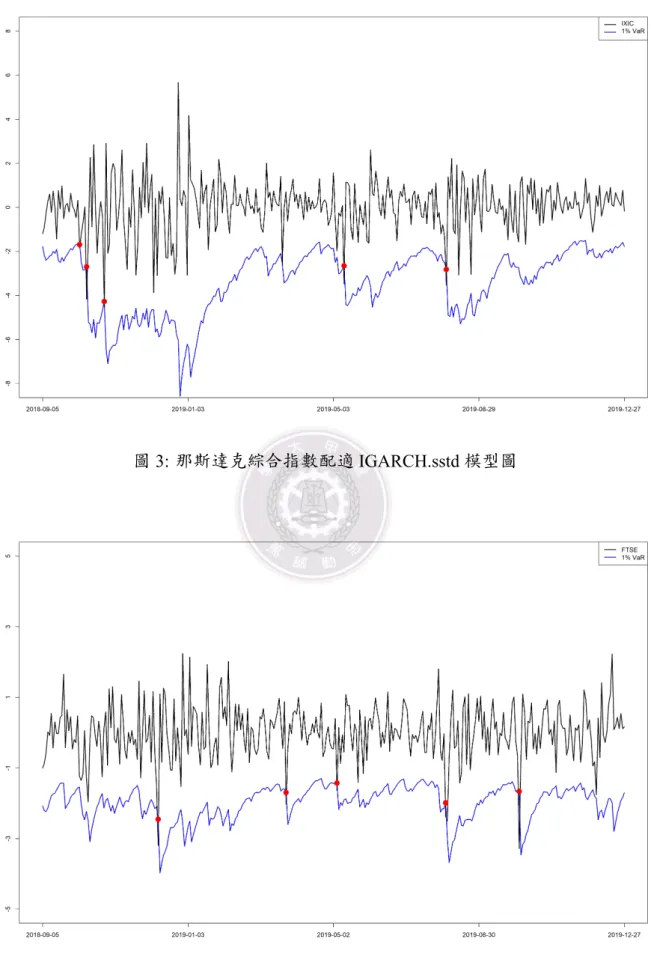
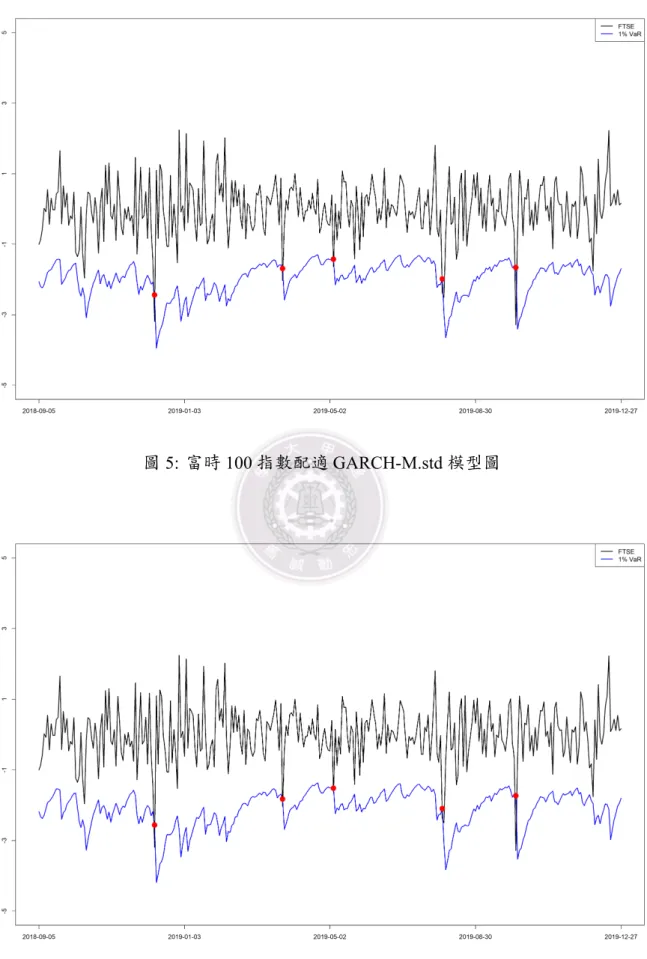
Model Violation VRate(%) Violation VRate(%) Violation VRate(%) Violation VRate(%) GARCH.norm 10 3.02 28 8.46 6 1.8 15 4.5 GARCH.std 6 1.81 25 7.55 5 1.50 15 4.50 GARCH.sstd 6 1.81 24 7.25 5 1.5 15 4.5 GARCH.ged 7 2.11 24 7.25 5 1.5 15 4.5 IGARCH.norm 8 2.42 20 6.04 5 1.5 15 4.5 IGARCH.std 6 1.81 25 7.55 5 1.5 15 4.5 IGARCH.sstd 5 1.51 21 6.34 5 1.5 14 4.2 IGARCH.ged 6 1.81 22 6.65 5 1.5 14 4.2 RiskMetrics 10 3.02 21 6.34 9 2.7 16 4.8 GARCH-M.norm 10 3.02 29 8.76 6 1.8 15 4.5 GARCH-M.std 7 2.11 28 8.46 5 1.50 16 4.80 GARCH-M.sstd 6 1.81 24 7.25 5 1.50 15 4.50 GARCH-M.ged 7 2.11 27 8.16 5 1.5 15 4.5 EGARCH.norm 12 3.63 24 7.25 6 1.8 13 3.9 EGARCH.std 8 2.42 26 7.85 5 1.5 13 3.9 EGARCH.sstd 7 2.11 21 6.34 4 1.2 11 3.3 EGARCH.ged 7 2.11 24 7.25 5 1.5 13 3.9 GJR-GARCH.norm 9 2.72 21 6.34 5 1.5 14 4.2 GJR-GARCH.std 8 2.42 26 7.85 5 1.5 15 4.5 GJR-GARCH.sstd 8 2.42 21 6.34 5 1.5 13 3.9 GJR-GARCH.ged 8 2.42 23 6.95 5 1.5 14 4.2 .norm 表示配適模型並假設在常態分配,.std 表示配適模型並假設在學生 t 分配, .sstd 表示配適模型並假設在偏態學生 t 分配,.ged 表示配適模型並假設在廣義誤差分配。 根據表4,標記為粗體的模型為最理想的模型,那斯達克綜合指數最理想模型是 IGARCH.sstd;然而在富時 100 指數這邊,則是 GARCH-M.std 最為理想,除此之外, 還有一些模型是可以被列入考慮的,像是 GARCH-M.std 和 GARCH-M.sstd。 將上述所選取的兩支加權指數配適較好的模型估計出的 VaR 和該指數的日報酬率 繪製時間序列圖,如以下圖3−圖6。紅點表示真實資料的日報酬率跌出模型估計出的 VaR,表示當日的報酬率已經超出最能承受的最大風險,可以看到那斯達克綜合指數配 適 IGARCH.sstd 模型有 5 個紅點,而富時 100 指數所配適的三個模型,也是有 5 個紅 點,而且紅點發生的時間點相同。
圖 3: 那斯達克綜合指數配適 IGARCH.sstd 模型圖
圖 5: 富時 100 指數配適 GARCH-M.std 模型圖
第 4 章 結 論
在本研究中,我們一共使用了 21 個有母數模型配適兩個加權指數的日報酬率,風 險值估計在兩種回溯測試中都有著不錯的結果,我們將在本文中所使用的兩種方法 (回 溯測試以及 VRate) 進行交叉比對以篩選出最理想的模型,不僅通過回溯測試的檢定, 同時也要在表4中估計出來的 VRate 最接近我們所設定的信心水準。 首先在那斯達克綜合指數中,雖然我們在回溯測試中有 6 個模型都通過檢定, 但通過的模型中並非每個模型都接近們所設定的信心水準,因此最後我們選出了 IGARCH 模型並假設在偏態學生 t 分配 (IGARCH-sstd);然而用同樣的方式中,在富時 100 指數我們則是發現了有數個模型相當理想,其中最理想的為 GARCH-M 模型並假 設在學生 t 分配 (GARCH-M.std)。 結合上面兩段的敘述可以得知,即便在回溯測試中檢定通過的模型,之後在計算 VRate,不一定會接近信心水準。而兩支加權指數中理想的模型並不相同,那斯達克綜 合指數僅有一個,富時 100 指數則有數個模型可被使用,可以理解出股票的波動性千 變萬化,可以被使用的模型也就不同,根據波動性的分布,可以使用數種模型去解釋, 承如上述,可以得知為何在當今社會中,操作股票是一個難度極高的課題。參 考 文 獻
Bera, A. K. and Jarque, C. M. (1980). Efficient tests for normality, homoscedasticity and serial independence of regression residuals. Economics letters, 6:255–259.
Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of
econometrics, 31:307–327.
Bollerslev, T., Chou, R. Y., and Kroner, K. F. (1992). Arch modeling in finance: A review of the theory and empirical evidence. Journal of econometrics, 52:5–59.
Bollerslev, T. and Engle, R. F. (1986). Modelling the persistence of conditional variances.
Econometric reviews, 5:1–50.
Box, G. E. P. and Ljung, G. M. (1978). On a measure of lack of fit in time series models.
Biometrika, 65:297–303.
Chen, C. W. S., Gerlach, R., Lin, E. M. H., and Lee, W. C. W. (2012). Bayesian forecasting for financial risk management, pre and post the global financial crisis. Journal of Forecasting, 31:661–687.
Chen, C. W. S. and Sun, Y. W. (2018). Bayesian forecasting for tail risk, in v. kreinovich et al. (eds.), predictive econometrics and big data, studies in computational intelligence. 753:122– 145.
Chen, C. W. S., Weng, M. M. C., and Watanabe, T. (2017). Bayesian forecasting of value-at-risk based on variant smooth transition heteroskedastic models. Statistics and Its Interface, 10:451–470.
Chou, R. Y. (1988). Volatility persistence and stock valuations: Some empirical evidence using garch. Journal of Applied Econometrics, 3:279–294.
Christoffersen, P. F. (1998). Evaluating interval forecasts. International economic review, 39:841–862.
Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica: Journal of the Econometric Society, 50:987– 1007.
Engle, R. F., Lilien, D. M., and Robins, R. P. (1987). Estimating time varying risk premia in the term structure: The arch-m model. Econometrica: journal of the Econometric Society, 55:391–407.
Fama, E. F. (1965). The behavior of stock-market prices. The journal of Business, 38:34–105.
Ghalanos, A. (2020). rugarch: Univariate garch models. R package version 1.3-8. URL https://
CRAN.R-project.org/package=rugarch.
Glosten, L. R., Jagannathan, R., and Runkle, D. E. (1993). On the relation between the ex-pected value and the volatility of the nominal excess return on stocks. The journal of finance, 48:1779–1801.
Kupiec, P. (1995). Techniques for verifying the accuracy of risk measurement models. The J.
of Derivatives, 3:73–84.
Mandelbrot, B. (1967). The variation of some other speculative prices. The Journal of Business, 40:393–413.
Nelson, D. B. (1991). Conditional heteroskedasticity in asset returns: A new approach.
Econo-metrica: Journal of the Econometric Society, 59:347–370.
Ryan, J. A. and Ulrich, J. M. (2018). quantmod: Quantitative financial modelling framework.
R package version 0.4-13. URL https://CRAN.R-project.org/package=quantmod.