行政院國家科學委員會專題研究計畫 成果報告
以情意計算與主動計算技術建構優質學習、休閒及睡眠之
環境(3/3)
研究成果報告(完整版)
計 畫 類 別 : 整合型 計 畫 編 號 : NSC 97-2627-E-004-001- 執 行 期 間 : 97 年 08 月 01 日至 98 年 07 月 31 日 執 行 單 位 : 國立政治大學資訊科學系 計 畫 主 持 人 : 陳良弼 共 同 主 持 人 : 蔡子傑、劉吉軒、沈錳坤、黃淑麗、廖瑞銘 廖文宏、李蔡彥、顏乃欣、楊建銘、李宏偉 報 告 附 件 : 出席國際會議研究心得報告及發表論文 處 理 方 式 : 本計畫可公開查詢中 華 民 國 98 年 11 月 02 日
以情意計算與主動計算技術建構優質學習、休閒及睡眠之環境
中文摘要 本計畫為政治大學理學院資訊科學系與心理學系兩方共同主導的智慧型生活空間研 究計畫,為期三年。其目的乃在透過情意計算與主動計算,讓科技能更貼心地融入到家 庭空間之中,例如客廳、書房與臥室等,藉此創造更為優質的未來居家生活環境。 ABSTRACTThis project is a three-year project conducted by Departments of Computer Science and Psychology in College of Science at National Chengchi University. Our objective is to create a high quality home living environment through affective and attentive computing technologies. The goals of the second year are conducting several psychological studies on basic behavioral and physiological issues and developing software prototypes for living room, bedroom and study room at home.
中文關鍵詞
智慧生活空間、情意計算、主動計算、情緒、注意力
KEYWORDS
研究緣起與目的 毫無疑問地,十數年後的優質生活空 間必然為人與科技的完美結合,因為人與 科技之間的互動是持續不斷的共同演化 歷程(co-evolutionary)。換句話說,人類的 需求會創造新的科技,而新的科技又會創 造出人類新的心理反應與需求。如此循 環,生生不息。然而,在面對未來科技如 何助益人類生活的課題時,實務界經常將 設計者與工程師對自身的體察與反省,化 身為各種饒富創意的解答。至於學術界則 經 常 著 重 於 理 論 原 則 的 嚴 謹 探 討 與 推 衍,距離具體實用的目標卻往往存在數步 之隔。為了突破這種侷限,我們邀集了政 治大學心理學系與資訊科學系學有專精 的教師群,集思廣益勾勒出未來智慧型生 活空間(smart living space)的藍圖。
對於未來智慧生活空間的模樣,我們 可以有什麼樣的想像?電影《人工智慧 (AI)》裡的小男生大衛不但具備智慧,而 且也擁有感受及表達人類感情與情緒的 能力。雖然電影情節並非現實生活,但類 似的構想卻也不是天馬行空。早在十餘年 前,麻省理工學院媒體實驗室(Media Lab, MIT)的Rosalind W. Picard就已經開始倡 導情意計算(affective computing)的理念與 實作[10]。甚至近幾年來,Picard更將情意 計算的意涵,從原本所構想的「如何令機 器人感知及表達各種人類情緒反應」,擴 展到「如何令機器人擁有並調節人類的情 緒智慧(emotional intelligence)」。很明顯 地,研究者已經從單方面站在「科技如何 造福人類」的角度,轉而將「科技與人類 視為一體兩面」。 如果科技和人類的關係能如一體兩 面般地密切,相信在未來十數年後,我們 的生活周遭中會有許多拜高科技所賜的 「新朋友」出現。這些新朋友能夠和你一 同分享喜悅與憂愁;能夠在你需要安慰和 支持的時候陪伴著你;能夠細心而體貼地 察覺你的需要並且適時提供幫助;也能夠 和你還有你的家人一同學習、成長。 譬如在書房裡,「他」是一個和藹的 老師。他知道孩子是不是正在專心閱讀? 是不是因為學習材料過於困難而感到挫 折?然後適時地調整桌椅、照明和音樂 等,幫助孩子能更專注而快樂地學習,甚 至 更 主 動 地 提 供 適 當 的 教 學 內 容 與 知 識;在客廳裡,他是一個貼心的僕人。他 知道家人現在心情好不好?主動地為他 們播放適合的音樂或電視節目。他也知道 每個家人愛看的節目有哪些,體貼地為他 們設計收視功課表,解決家人搶電視的問 題。另外,家人在收看電視時甚至不需要 手拿遙控器,利用視線和想法就能選台與 調整音量;在臥房裡,他則搖身一變成為 慈愛的褓母。他知道家人是不是不是因為 壓力太大而需要舒緩?然後適時地調整 聲響、音樂、燈光和溫濕度控制等,幫助 家人連夜好眠。他也知道家人是不是有嚴 重的失眠問題?並且敦促他們積極地尋 求專業協助。他甚至可以根據家人預定的 起床時間,找出最適當的時機和方法將他 們叫醒。 基於上述構想,本研究之主要目的即 在於「透過情意計算與主動計算(attentive computing)技術,藉由各種非侵入式(non- invasive)的測量手段隨時感知使用者的情 緒(emotion)與注意力(attention)狀態,並且 在閱讀與學習、休閒及睡眠等三個最主要 的居家生活情境中,適時地為使用者提供 各種服務。」因此,本研究分成四大部分: 第一部份旨在研發能正確偵測並分辨使 用者注意力與情緒狀態的系統原型;第二 至四部分則分別將前述核心技術實際應 用於書房、客廳與臥房中,期能滿足未來 的優質生活環境之需求。各子計畫標題如 下列述: 子計畫一 智慧型情緒與注意力感測系 統(Smart Emotion & Attention Detector, 以下簡稱SEAD)
Reading Facilitator, 以下簡稱SRF) 子計畫三 智慧型電視管理系統(Smart TV Manager, 以下簡稱STVM) 子計畫四 智慧型睡眠輔助系統(Smart Sleep Servant, 以下簡稱SSS) 研究成果綜覽 在歷經了為期三年的腦力激盪與胼 手胝足的合作研究之後,我們逐步踏實地 朝向上述研究構想與目的前進,並且確實 獲得若干豐富的基礎研究與具體實作成 果。譬如在第一年,我們首先完成生理訊 號設備及實驗環境的建置與測試,並且解 決了各類訊號之間的無線傳輸與整合等 各種問題,同時也完成許多涉及基礎議題 的生理與行為研究。在第二年的進展中, 我們不但善用既有的軟硬體架設成果,並 且更進一步地延伸探討相關基礎研究議 題,譬如探索情緒與注意力的中樞神經機 制與周邊神經機制,同時也漸次完成各種 系統原型,例如基於多重模式的情緒辨識 系統等。至於在最後一年中,我們除了積 極整合所有研究結果與系統原型之外,更 於政治大學校園內成立了一座「AAQL未 來智慧生活空間展示室」,將完整三年所 得成果具體展現出來。(有興趣的讀者, 請參考本計畫專屬網站,網址如下所列 http://aaql.cs.nccu.edu.tw。) 以下在進一步介紹本研究所得具體 成果之前,首先羅列各子計畫迄今完成論 文發表情況。 子計畫一 SEAD
z Chang, Y.-C., Huang, S.-L., & Lee, H.-W., (2009). On the exploration of surface-based attention with cuing task.
9th Annual Meeting of Vision Science Society. Naples, Florida.
z Chang, Y.-C., Huang, S.-L., Lee, A.-R., & Sun, H.-C. (2009). Discriminating different attention levels by
electrophysiological and behavioral measures. 2009 Annual Meeting of the
Cognitive Neuroscience Society, San
Francisco, CA, USA.
z Chen, K.-H., Yen, N.-S., Lai, Y.-R., & Chang, Y.-C. (2007). Emotional picture related late positive potentials are observed in Taiwanese population.
Annual meeting of the Cognitive Neuroscience Society.
z Chen, C.-Y., Yen, N.-S., Lin, H.-Y. (2009). Effects of regulation on positive and negative emotions: A study of electrophysiological responses.
16th annual meeting of the Cognitive Neuroscience Society, San Francisco,
CA, USA.
z Chung, H.-K., Chen, K.-H., & Yen, N.-S. (2008). Picture content variations in emotion-related potentials in
Taiwanese. 2008 Annual Meeting of the
Cognitive Neuroscience Society, San
Francisco, CA, USA.
z Lee, H.-W., Huang, S.-L., & Chang, Y.-C. (2008). Nonlinear functional connectivity in visual awareness: a small-world study. ASSC 12th
Annual Meeting. Taipei, Taiwan.
z Liao, W.-H., & Chi, Y.-H. (2008). Robust detection of skin color range using achromatic features. 8th
International Conference on Intelligent System Design and Applications.
z Liao, W.-H., Wang, T.-T., & Lin, Y.-K. (2007). Robust multipose face
detection in video. 20th
Computer Vision, Graphics and Image Processing.
Miaoli, Taiwan.
z Liao, W.-H., Wang, T.-T., & Huang, L.-W. (2009). Facial expression recognition using directional edge maps. INSIGHT成果發表會. z Tsai, T.-C., & Chen, J.-J. (2008).
physiological signals. Joint Conference
on Medical Informatics in Taiwan (JCMIT).Taipei, Taiwan.
z Tsai, T.-C., & Chen, J.-J. (2008). Personalized emotion recognition system with physiological signals.
2008 Symposium on Digital Life Technologies: Human-Centric Smart Living Technology, Tainan.
z Tsai, T.-C., Chen, J.-J., & Lo, W.-C. (2009). Design and implementation of mobile personal emotion monitoring system. The First International
Workshop on Mobile Urban Sensing (MobiUS 2009). Taipei, Taiwan
z Wang, C., & Liao, W.-H. (2007). Robust multipose face detection in indoor environments. International
Symposium on Multimedia.
z Yen, N.-S., Chen, K.-H., Chung, H.-K., & Wang, C.-C. (2007). Sound-evoked emotion related ERP is observed in P2, P3 and late slow-waves. Annual
Convention of the Association for Psychological Science, Washington.
z Yen, N.-S., Chen, C. -Y., Han, C.-C., Kao, C.-H., Chen, K.-H. (2009).
Effects of different regulation strategies for picture-induced negative emotion on eye-movement pattern and
psychophysiological responses. 3rd Social and Affective Neuroscience Meeting, New York, U.S.A.
z 林裕凱、廖文宏(2008)。人聲分類中 的特徵擷取。第十三屆人工智慧與應 用研討會。中華民國人工智慧學會。 z 蔡宗欽、李宏偉(2009)。神經生理指 標探索情緒分類論與向度論。台灣心 理學會第48屆年會。台灣大學。 子計畫二 SRF
z Chiu, S.-C., Shan, M.-K., & Huang, J.-L. (2009). Automatic system for the arrangement of piano reductions, IEEE
International Workshop on Advances in Music Information Research AdMIRE,
San Diego, CA.
z Chiu, S.-C., Shan, M.-K. Shan, Huang, J.-L., & Li, H.-F. (2009). Mining polyphonic repeating patterns from music data using bit-string based approaches, IEEE International
Conference on Multimedia and Expo ICME, New York, NY.
z Chiu, S.-C., Shan, M.-K., Li, H.-F., & Huang, J.-L. (2009). Discovering polyphonic repeating patterns in music data using bit-string approaches,
Pattern Recognition Letters. (under
review.)
z Shan, M.-K. (2009). Melodic motivic analysis for music education,
International Workshop on Multimedia Technology for Education IWMTE,
Taipei, Taiwan.
z Yen, N.-S., Chen, P.-L., Hsieh, S.-S., & Lin, H.-Y. (2009). The eye movement patterns in reading emotional passage under different emotional music and question types. 15th
European Conference on Eye Movements,
Southampton, UK.
z Yen, N.-S., Tsai, J.-L., Chen, P.-L., Wang, C.-C., & Lin, H.-Y. (2007). The effects of font type, character size, and character space in reading Chinese.
European Conference on Eye Movements, Potsdam.
子計畫三 STVM
z Chen, P.-L., & Li, T.-Y. (2006). Realizing emotional autonomous virtual agents in a multi-user virtual environment. International Computer
Symposium 2006, Taipei, Taiwan.
z Lee, H.-W., Liao, W.-H., Huang, S.-L., Chang, Y.-C., Chen, Y.-S., & Li, T.-Y. (2009). A prototype of smart interactive TV. Intelligent Buildings and Smart
Homes Conference 2009 (iBASH). Taipei, Taiwan.
z Lin, Y.-H., Liu, C.-Y., Lee, H.-W., Huang, S.-L., & Li, T.-Y. (2008). Verification of expressiveness of procedural parameters for generating emotional motions. 8th
International Conference on Intelligent Virtual Agents. Tokyo, Japan.
z Lin, Y.-H., Liu, C.-Y., Lee, H.-W., Huang, S.-L., & Li, T.-Y. (2009). Evaluating emotive character animations created with procedural animation. 9th
International Conference on Intelligent Virtual Agents. NEMO, Amsterdam.
z Liu, P.-Y., Hsu, S.-W., Li, T.-Y., Lee, H.-W., Huang, S.-L. (2007). An experimental platform for smart interactive TV in digital home.
Symposium on Digital Life and Internet Technologies, Tainan.
z Liu, P.-Y., Lee, H.-W., Li, T.-Y., Huang, S.-L., & Hsu, S.-W. (2008). An
experimental platform based on MCE for interactive TV. European
Interactive TV Conference 2008. Salzburg, Austria. z 劉炳億、王財得、廖文宏、李宏偉、 黃淑麗、李蔡彥(2008)。建立以情境 感知為基礎的互動電視實驗平台 -SITV。第十三屆人工智慧與應用研 討會。中華民國人工智慧學會。 z 劉炳億、李宏偉、王財得、黃淑麗、 廖文宏、陳映似、李蔡彥(2008)。智 慧型互動電視原型之設計與實作。 INSIGHT成果發表會。 子計畫四 SSS
z Chou, C.-Y., & Yang, C.-M. (2009). The effect of the fast and slow tempo music on sleep inertia and arousal. Sleep, 32 (Abstract Suppl.), p. A410. (23rd Annual Meeting of the Associated
Professional Sleep Societies, Seattle,
Washington, USA)
z Huang, S.-U., & Liao, W.-H. (2006). The analysis of sleeping event video.
Multimedia and Networking Systems Conference.
z Huang, S.-U., Liao, W.-H., Yang, C.-M., & Tsai, M.-C. (2007). Analyzing and processing the video of sleeping event.
Taiwan Society of Sleep Medicine.
z Liao, W.-H. Kuo, J., &Yang, C.-M. (2009). iWakeUp: an intelligent video-based alarm clock. Intelligent
Buildings and Smart Homes Conference 2009 (iBASH). Taipei,
Taiwan.
z Liao, W.-H., & Lin, Y.-K. (2009). Feature selection in the classification of human sounds. Communications of the
IICM, 2009.
z Liao, W.-H., & Lin, Y.-K. (2009). Classification of human sounds: feature selection and snoring analysis. IEEE
SMC Conference 2009.
z Liao, W.-H., Wang, C., & Lin, Y.-K. (2007). Robust multipose face detection in video. 20th
IPPR Conference on Computer Vision, Graphics and Image Processing.
z Liao, W.-H., & Su, Y. (2006). Classification of audio signals in all-night sleep studies. 18th
International Conference on Pattern Recognition, Hong Kong Baptist
University.
z Liao, W.-H., & Yang, C.-M. (2008). Video-based activity and movement pattern analysis in all night sleep studies. 19th International Conference on Pattern Recognition. z 廖文宏、黃思瑜(2006)。睡眠研究中 的視訊分析與處理。2006多媒體及通 訊系統研討會。義守大學。
以下分別針對每一子計畫,就其主要 目的、基礎研究、系統實作與成果檢討加 以列述。 子計畫一 智慧型情緒與注意力感測系統 (SEAD) 1.1 主要目的 SEAD為本研究主要核心技術所在, 旨在透過心理學基礎研究的實證結果,提 供資訊科學領域在建構軟硬體,以主動偵 測使用者情緒與注意力狀態時,得有學理 支持與佐證。因此,本子計畫之基礎研究 著重於探討「使用者受引發而產生各種情 緒狀態時,其生理與行為指標為何?」以 及「使用者受引發而產生各種注意力狀態 時,其生理與行為指標為何?」等兩項議 題。至於本子計畫之實作目標,則在於建 置包含下列模組的系統原型:聲音偵測模 組、臉部表情偵測模組、生理訊號偵測模 組,以及空間位置與身體姿態偵測模組。 1.2 基礎研究 1.2.1 情緒狀態生理與行為指標之探索 本系列研究之主要目的,在於探討當 「 參 與 者 受 引 發 而 產 生 各 種 情 緒 狀 態 時 , 將 分 別 展 現 出 哪 些 生 理 與 行 為 指 標?」 首先探討的議題是「觀看情緒圖片所 引發的周邊生理反應」。藉由向參與者呈 現IAPS (International Affective Picture System)[1]圖片以引發其情緒反應,進而 測量參與者相對應的周邊生理訊號,以利 確認生理訊號和情緒之間的關係。例如: 藉由觀看嬰兒玩耍的照片來引起正向情 緒,或藉由觀看排泄物的照片來引起負向 情 緒 。 本 實 驗 共 有35 位 參 與 者 , 並 以 Infiniti系統測量膚電反應、心跳及臉部肌 肉反應。實驗結果顯示:(1)在心跳速率 上,負向圖片導致心跳速率變慢,和正向 與中性圖片有顯著差異;(2)在臉部肌肉的 反應上,皺眉肌和圖片的正負向有顯著的 負相關,而微笑肌和正向圖片顯著的正相 關,和負向圖片顯著的負相關;(3)膚電反 應雖然與參與者的情緒強度成正比,但僅 限於當參與者觀看情緒引發強度較強的 圖片,譬如血腥、激情、威脅等圖片,上 述相關關係才較明顯(如圖1.1所示)。因 此,針對由圖片所引發的情緒狀態,建議 可以利用心跳速率與臉部肌肉反應做為 主動偵測的依據指標。 圖1.1 情緒狀態與周邊生理指標。(A)負向情緒時 引起皺眉肌(Corrugator)反應;(B)正向情緒引起臉 頰顴骨肌肉(Zygomatic)反應;(C)心跳反應的原始 訊號;(D)膚電反應隨著情緒性圖片的呈現而急遽 上升。 其次探討的議題是「觀看情緒圖片所 引發的中樞神經反應」,亦即當參與者看 到IAPS圖片而引發各種情緒狀態時,其相 對應的腦電波變化為何?本實驗除了利 用SynAmps2系統進行腦電波測量外,更 使用事件關聯電位(event-related potentials, ERPs)做為主要分析方法。在進行分析 時,我們將IAPS圖片分成四類,亦即將正 向圖片再分成激情類與非激情類,而負向 圖片則再分成傷殘/威脅類,及非傷殘/威 脅類。結果發現:(1)無論正、負向圖片皆 會引發較中性圖片較大的正向緩波;(2) 在正向圖片中,激情類圖片比非激情類圖
片引發較大的正向緩波;(3)在負向圖片 中,傷殘/威脅類較非傷殘/威脅類引發較 大的正向緩波(如圖1.2所示)。顯示ERP的 正向緩波可以做為標示情緒類別與強度 之指標。 圖1.2 情緒狀態與中樞神經指標。正向情緒(包括 激情類Ero+與非激情類Ero-)比負向情緒(包括傷 殘/威脅類M/A+與非傷殘/威脅類M/A-)及中性情 緒(即Neutral組)有較高的正向緩波。而激情或傷殘 /威脅類等具有較高情緒激起強度者,又比非激情 類或非傷殘/威脅類等激起程度較低者,具有較高 的正向緩波。 第三個令我們感興趣的議題是「觀看 情緒影片所引發的周邊生理與中樞神經 反應」。由於國內目前尚無可有效引發參 與者產生各種情緒狀態的影片資料庫,而 國外雖有學者曾經做過類似研究[5][9], 但其所列舉影片過時而難以取得,而且甚 至還有文化差異的問題參雜其中。因此, 建置情緒影片資料庫遂成為本研究的首 要任務。透過一系列嚴謹而完整的剪輯、 施測、篩選及驗證程序,我們先取得可以 激發參與者參生強烈情緒反應的影片片 段36部。而且依照這些影片所激發的情緒 類別,可以將它們概略分為快樂、悲傷、 憤怒、恐懼及噁心等五大類。 接著,我們再找來另一群參與者,記 錄他們在觀賞這些情緒誘發影片時的周 邊生理與中樞神經反應。這些生理反應包 括呼吸、脈搏、膚溫、膚電,以及12個腦 電波通道的Gamma波段(定為40-60赫茲) 強度。然後,利用因素分析(factor analysis) 做 為 降 低 維 度(dimension reduction) 手 段,從16個生理向度中萃取出2個具有代 表性的維度。最後再利用線性轉換的方 式,重新評估參與者在觀賞這36部影片時 的情緒狀態,在此低維度空間中的聚落情 形。然而,實際所得結果並未發現清晰而 穩定的情緒狀態聚落(如圖1.3所示)。因 此,企圖先利用降低維度方法,然後再透 過分類器(classifier)找出各種情緒範圍的 做法,還需要進一步的調整與驗證。 圖1.3 情緒狀態的聚落分布情形。每一個資料點代 表參與者觀賞某一部情緒影片時的生理狀態。假 設圖中資料點的散布呈現清晰而穩定的聚落情 形,便可以再利用分類器加以畫分每一類情緒狀 態的所屬範圍。 綜合以上研究可知,不論是透過圖片 或影片所激發的情緒狀態,皆可由中樞神 經反應或周邊生理反應取得穩定指標。然 而,如果所得指標之強韌度(robustness)充 足,則當參與者的情緒狀態發生變化時, 亦應可即刻測得顯著的指標變化。 基於以上邏輯,我們依照Hajcak等人 [6]及Ochser等人[7]之研究設計,「利用參 與者的情緒評估(appraisal)做為改變其自 身情緒的主要操弄,藉以驗證所得生理指
標之強韌性」。本研究之刺激材料同樣為 IAPS情緒圖片,而且也分成正向和負向兩 大類。至於評估的操弄則分成三類,包 括:注視、增強,以及再評估。當參與者 被要求注視時,他只需要持續觀看圖片即 可;若參與者被要求進行增強時,他必須 藉由「想像與呈現圖片相關的內容」以增 強其情緒引發強度;至於若參與被要求進 行再評估時,則他必須藉由想像與圖片內 容有關事物,以減緩當下所引發的情緒強 度。譬如呈現傷殘圖片時,參與者可以想 像圖片中的血腥部份是電影特效或是蕃 茄醬,以達到再評估的效果。實驗結果發 現,當參與者被要求增強圖片所引發的情 緒時,腦波中與情緒相關的正向緩波在反 應強度上亦隨之增加,而且伴隨發生主觀 情緒反應同時受到增強的情況。此外,當 參與者在面對負向情緒並被要求降低其 情緒時,臉部皺眉肌的活動量隨之降低, 且其主觀情緒正負向程度亦隨之增加。 在另一個相關研究中,我們則進一步 的將情緒降低策略區分為:重新詮釋、第 三者角度與空想,並且以單純觀看作為控 制組。當參與者被告知利用重新詮釋的方 式降低情緒時,他必須對圖片的內容加以 重新解釋;當參與者被告知利用第三者角 度這種策略時,他則必須以更客觀的角度 面對圖片,藉由拉遠自身和圖片的距離藉 以降低情緒;當參與者被告知使用空想的 策略時,他必須在注視畫面時放空思緒藉 以降低情緒影響;至於當參與者被告知單 純觀看時,則他僅需自由地感受圖片內容 即可,無須進行其他額外處理。實驗結果 顯示,在觀看負向情緒圖片時,參與者因 採取降低情緒策略而使正向緩波的反應 強 度 顯 著 地 低 於 參 與 者 純 粹 觀 看 圖 片 時,且於主觀情緒經驗上亦反映情緒強度 的降低。若進一步探討不同情緒調控策略 的差異,則可發現空想策略的效用優於其 他兩者,而且不論是在正向緩波或參與者 主觀經驗上皆是如此。 綜合以上兩項相關研究結果可知, ERP中的正向緩波確實是可以穩定反映 參與者情緒狀態的良好指標。 1.2.2 注意力狀態生理與行為指標之探索 除了如何透過各種生理指標反映情 緒狀態之外,我們也很關心「如何透過各 種生理指標反映注意力狀態」這個議題。 這一部分的研究主要在找出能夠區 辨各種注意力狀態的生理與行為指標組 合,而注意力狀態則以注意程度(level of attention)的操弄為主。實驗作業採多重物 體追踪作業(multiple objects tracking)加以 修改而得,並且變化其作業難度以操弄注 意程度之高低。實驗時呈現8個連續運動 的實心白色圓形,包括4大圓、4小圓。在 運動過程中,不定時隨機選取其中2圓改 變顏色(變紅或變藍),而參與者必須報告 事先界定之目標事件其出現次數。所謂簡 單作業的目標事件類似特徵搜尋(feature search)作業,例如2變色圓皆變為紅色; 而困難作業所界定目標事件則類似連結 搜尋(conjunction search)作業,例如變色的 圓變為一紅一藍,而且紅色的必須是大 圓;至於控制作業則為觀看圓點運動,但 是不做任何反應;此外,在實驗開始前要 求參與者張開眼睛並安靜坐著,藉以記錄 基準線達五分鐘。根據注意力特徵整合論 (feature integration theory),困難作業較簡 單作業需要投入更多的注意力,控制作業 與 基 準 線 的 注 意 程 度 則 是 做 為 參 考 標 準。實驗過程中同時記錄各項生理指數, 包括32個通道的腦電波、心電圖、皮膚電 阻反應、眼動電位圖、呼吸及膚温。由於 三種作業呈現完全相同視覺刺激,而且目 標事件之出現機率亦控制為相同,因此可 單純反映注意程度所造成的影響。 在結果分析方面,採用多變量分析進 行統計考驗。主要結果(如表1.1所示)顯示 各種周邊神經系統指標之中,唯有指溫可 反映不同注意程度,高注意程度的指溫顯
著小於低注意程度。至於中樞神經系統指
標中,可歸納出兩點主要發現(如表1.2所
示):(1)Alpha, Beta, Theta波段的拓樸圖形 中,高注意程度的功率強度普遍高於低注 意程度,該結果與Fairclough, Venables,與 Tattersall(2005)[4]研究結果一致;(2)針對 Alpha波段,可發現高注意程度的功率強 度 普 遍 大 於 低 注 意 程 度 , 該 結 果 支 持 Klimesch, Sauseng 與 Hanslmayr(2007)[7] 對Alpha波段的認知功能所提出的「抑制 假設(inhibition-timing hypothesis)」。 表1.1 注意力狀態的周邊生理反應指標 基準線 控制 低注意 高注意 IBI 846.52 865.70 844.41 846.52 SDNN 61.49 58.36 58.15 54.53 HF 10.16 10.34 10.35 10.23 MF 11.92 12.10 11.80 11.93 LF 12.39 13.03 12.68 12.77 LH/HF 1.22 1.26 1.20 1.25 呼吸 15.22 16.78 17.60 17.48 眨眼 頻率 18.56 20.82 18.84 18.20 眨眼 時間 611.85 450.61 460.53 472.13 SCL 0.32 0.31 0.40 0.43 指溫 95.66 95.16 95.33 94.63 主觀 評量1 -- 13.48 50.60 77.73 主觀 評量2 -- 8.75 43.59 64.18 註:淺灰區域代表事後比較達顯著(p<0.05),深灰區域 表示趨近顯著水準(p<0.1)。各生理分數的單位如下,IBI (ms), SDNN (ms), HF, MF, LF (ln(ms2)), LH/HF (none),
Respiration (number per minute), 眨眼頻率 (number per minute), 眨眼時間 (number per minute), SCL (μS), 指 溫(°F)。 除此之外,即便Fairclough等人[4]發 現HRV、呼吸與眨眼等指標可反映不同心 智負荷(mental load)的程度,但本研究並 未 發 現 任 何 顯 著 差 異 。 該 現 象 仍 與 Fairclough與Houston(2004)[3]研究一致, 他們採用注意力之Stroop作業探討其生理 機制,亦沒有發現HRV指標受不同注意力 情 況 影 響 。 本 研 究 與 Fairclough 與 Houston[3]皆簡化實驗的刺激與流程,並 盡可能控制知覺因素或心智負荷因素為 一致,企圖僅誘發出高低注意程度。因 此,本研究推測HRV可能與心智負荷或其 他知覺因素有關,但與注意力程度的關連 性較低。 總結而言,本研究控制不同注意程度 的 知 覺 因 素 完 全 一 致 後 , 發 現 指 溫 、 Alpha、Beta與Theta波段可反映不同注意 程度。至於HRV或其他周邊神經生理指標 所反映的心智成分,仍有待未來研究加以 分析探討。 表 1.2 注意力狀態的中樞神經反應 基準線 控制 低注意 高注意 α β θ γ δ 註:紅色代表高功率強度,藍色代表低功率強度。 1.3 系統實作 基於上述基礎研究成果,我們具體實 現了使用者情緒與注意力偵測系統之原 型。然而,由於以上基礎研究主要聚焦於 對 中 樞 神 經 反 應 與 周 邊 生 理 指 標 的 探 討,譬如腦波、心跳、呼吸、膚電和膚溫 等,由使用者所展現出來的其他外顯行為 與物理訊息,譬如聲音、臉部表情、手勢 和身體姿態等,同樣有助於判斷個體的情 緒與注意力狀態,因此在我們具體實現的
各種原型中,這些資訊來源也將一併被納 入考量與實作。 以下將分別針對這個系統原型的聲 音偵測、臉部表情偵測、生理訊號偵測, 以及空間位置與姿態偵測等各個部分加 以描述。 1.3.1 SEAD聲音偵測模組 在SEAD 的聲音偵測模組部份,我們 首先開發了階層式的語音、人聲非語音及 其他環境雜訊之分類演算法,辨識準確率 超過90%。然後再加上人聲非語音部份做 更細部的探討,包含笑聲、噴嚏聲、鼾聲、 尖叫聲等(如圖 1.4 所示)。 圖 1.4 SEAD 階層式音訊分類機制 由於加入更多種類的音訊,使我們必 須 重 新 評 估 特 徵 選 取 的 項 目(feature selection)。為了有效掌握各維度特徵對辨 識準確率之影響程度,我們採Multivariate
Adaptive Regression Splines (MARS) 與 support vector machine 進行交叉驗證,將 特徵的重要性加以排序。實驗結果顯示, 當選取所有類別特徵進行辨識時,準確率 約在 80-85%之間。只選擇排名前三重要 特徵進行辨識時,準確率僅有些微的降低 (78%)。因此,在計算資源有限的狀況下, 可考慮簡化處理程序而不致過度影響分 類的結果。 1.3.2 SEAD臉部表情偵測模組 對於 SEAD 臉部表情偵測模組的描 述,主要又可分成人臉偵測與表情識別兩 大部分。在人臉偵測部分我們開發了能夠 偵測各種角度(含正面、左右側與俯視)的 人臉快速演算法(Robust Multipose Face Detection Using Directional Edge Maps) (如圖 1.5 所示),此方法的計算速度優於 Viola 與 Jones 所提出的演算法,並且能夠 同時處理多重角度的影像資訊,而其中使 用的Directional Edge Maps (DEM)概念, 與modified Adaboost 程序,更可輕易修 改並且套用至其他物件偵測應用,如人員 計數、車牌辨識等。 圖 1.5 SEAD 四軌同步即時人臉偵測系統 關於表情識別部份,我們使用 local- appearance-based 方法來判別基本情緒中 的部份類別。原有作法使用的是靜態影 像,因此效果未達預期目標。但是如果加 上appearance-based 方法,則由於對五官 定位並未特別要求,所以容易受到人臉角
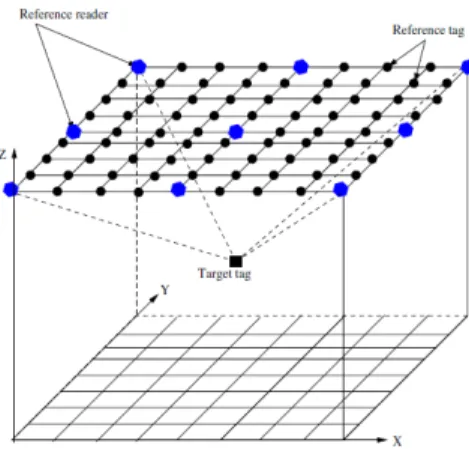
度影響。因此我們結合 model-based 方法 來補強,對特定五官更精確的定位,以改 善辨識準確度。在另一方面,我們也結合 了動態資訊,利用區域的變化量與方向等 資訊,開發出另一套表情識別系統。 1.3.3 SEAD生理訊號偵測模組 在生理訊號的偵測與傳輸方面,由於 我們使用的感測器Biofeedback 2000 x-pert 系統為藍芽傳輸介面,而藍芽介面有其傳 輸範圍與穿透力的限制,因此為了達到讓 使用者可以隨意行動於智慧生活空間的 目的,我們考慮加入了一個 PDA(模組整 體架構如圖1.6 所示)。這個 PDA 本身具 有藍芽與Wi-Fi 的傳輸介面,因此由 PDA 扮演媒介資料傳輸的角色。換言之,PDA 的藍芽端負責與感測器溝通,而Wi-Fi 端 則負責與伺服器溝通。此外,PDA 也可 以用來進行一些簡單的訊號處理工作,譬 如由伺服器指定參數,在未達條件之前, 不將感測器所得資料回傳伺服器。在這個 系統架構中,伺服器位居主導地位。它可 以決定是否透過 PDA 代為收集生理資 訊,或者藉由藍芽介面與生理感測器直接 聯繫。此外,伺服器在接收生理資訊之 後,更可以進一步決定要採用哪些演算法 或與其他伺服器連結(譬如前述聲音與臉 部表情偵測模組)來判斷使用者的情緒與 注意力狀態。 圖 1.6 SEAD 生理訊號偵測模組 1.3.4 SEAD空間位置與姿態偵測模組 除了上述各種透過音訊、視訊與基礎 生理訊號所建置完成的各種偵測模組之 外,我們也利用了active RFID 技術來達 到兩項附加的目的,包括(1)偵測使用者的 空間位置,以利提供個人化的數位服務。 譬如當使用者由客廳移動到臥室時,可以 主動開啟臥室的電視並且切換到使用者 剛才所觀看的頻道;(2)偵測使用者的手勢 或身體姿態,藉以輔助判斷其情緒或注意 力狀態。換言之,我們透過 active RFID 技術建置了空間位置與身體姿態的偵測 模組。 在這個模組中,我們利用四台 RFID 讀取器(reader)及數個參照標籤(reference tag)來實作出立體空間中的人體位置與姿 勢變化。我們採用Wang, Wu 與 Tzeng 所
提供RFID-Based 3-D Positioning Schemes 做法。這種作法是在天花板或地板上佈置 參照標籤網格,並且將要定位的追蹤標籤 (tracking tag)隨意放置在六面體內,而四 個角落則放置讀取器,而且每台讀取器都 會收集所有標籤的訊號強度。將追蹤標籤 的訊號強度與參照標籤的訊號強度加以 比較,即可估算出追蹤標籤與每個讀取器 之間的距離,最後再利用三角定位法算出 追蹤標籤的座標(如圖 1.7)。
根據我們的實作結果,如果在一個長 240 公分、寬 180 公分的空地上,每隔 60 公分擺放一個參照標籤,使其構成 5X4 的棋盤方格,則我們所得到的空間定位結 果其誤差值將在 30 公分以內。換句話 說,這種利用active RFID 所得到的空間 定位技術,不但可以用來標記使用者的所 在位置,而且可以用來判斷使用者較大的 肢體動作、手勢與身體姿勢。但是如果要 用在判斷使用者較為細緻的手勢,譬如比 出勝利的 V 字型動作,則需要更細緻的 RFID 網格方可實現。 1.4 成果檢討 本子計畫之主要目的在於透過各項 基礎心理學研究,提供建置SEAD 系統原 型時之理論參考與實證依據。我們所得到 的基礎研究結論如下: 情緒的周邊生理指標包括:(1)心跳速 率增加反映負向情緒、(2)皺眉肌電位 增加反映負向情緒、(3)微笑肌電位增 加反映正向情緒,以及(4)皮膚電阻降 低反映情緒強度增強,但無關情緒的正 負向。 情緒的中樞生理指標,主要為 ERP 中 的正向緩波可以反映情緒的強度。 情緒的中樞神經反應併同周邊生理反 應,可以透過線性轉換而得到具有代表 性的少數維度,並且可能利用分類器找 出情緒類別。 注意力的周邊生理指標主要為膚溫,亦 即當注意力越集中、膚溫越低。 注意力的中樞生理指標主要為 Alpha 波段強度,亦即當注意程度越高、Alpha 波強度越強。 此外,我們在這個子計畫中也透過對 音訊、視訊、基礎訊號以及RFID 訊號的 處理,建置完成包含下列模組的SEAD 系 統原型: 聲音偵測模組。 臉部表情偵測模組。 生理訊號偵測模組。 空間位置與身體姿態偵測模組。 總評而言,本子計畫已經完成大部分 預期目標,但仍列舉以下幾項議題或思考 方向,作為未來延續本研究之參考: 在基礎研究上應加強關於音調、語意、 表情、手勢、身體姿態等,與情緒狀態 之間的關聯性探討。在心理學領域,這 一方面的研究成果較為豐碩,而且較為 成熟。此外,在基礎研究上宜開發關於 音調、表情、身體姿態等,與注意力狀 態之間的關聯性探索。在心理學領域, 這一方面的研究成果較為罕見,值得創 新研究。 現行的生理分析方法可能具有即時性 (real-time)方面的限制。譬如 ERP 的分 析乃是集合多次同樣嘗試後所得之平 均結果,而頻譜分析則需要收集固定時 間的生理資訊方可做出分析,因此從取 得生理資訊到做出結論之間有固定的 時間差。未來應考量實際應用時的即時 性需求,改以其他更為瞬時(transient) 而強韌(robust)的分析方法來建構生理 指標。 系統原型中各模組之間的統整性宜再 提高,然而囿限總計劃執行期程之時間 限制,唯有等待延續性計畫獲得支持通 過方可使系統原型的建置更加完滿。 子計畫二 智慧型閱讀增進系統(SRF) 2.1 主要目的 SRF 乃為本研究計畫中,針對三大智 慧生活空間之一─書房的實地應用。該項 子計畫之主要目的,在於當使用者置身於 書房內進行學習時(而且主要是透過電腦
所進行的學習),如何主動偵測其情緒與 認知狀態,並且適時地提供適切的服務。 關於 SRF 的基礎研究與系統實作, 我們著重於眼動(eye-movement)、閱讀與 音樂三者之間的關係。我們所探討的基礎 議題包括「閱讀材料的基本屬性對眼動型 態的影響」,以及「由音樂所引發的情緒 對閱讀的影響」等。簡單地說,在 SRF 的構想中,我們可以透過眼動型態來反映 使用者的認知與情緒狀態,然後藉由提供 適當的音樂片段作為調節情緒的手段,以 利達成增進使用者學習效果的目的。因 此,在 SRF 的系統原型中,我們實作了 兩套模組,包括基於眼動型態的「理解程 度偵測模組」,以及基於眼動型態的「情 緒音樂推薦模組」。 2.2 基礎研究 2.2.1 閱讀材料屬性與眼動型態 過去的文獻指出,無論是中文或英文 的閱讀歷程,許多物理變項(typographic variables),例如字體樣式(font type)、字體 大小(character size)、字距(character space) 及行距(line space)等,都會影響人們的閱 讀歷程。另外也有實驗發現,不同的字體 樣式(如明體與隸體)、字體大小(10 與 14),也會影響參與者的閱讀速度及理解 程度,而且參與者對不同的字體樣式與字 體大小也有不同的喜好。當然,不同的字 體樣式其可讀性也會有所不同,譬如明體 相較於其他字體容易閱讀。然而,以往探 討物理變項影響閱讀歷程的研究,大都只 以整體閱讀時間(overall reading time)以及 理解分數(comprehension score)做為依變 項,無法更進一步解釋為何這些變項會造 成整體閱讀時間以及理解程度上差異的 內在歷程。而有許多眼動研究指出,藉由 觀察眼睛移動的位置以及凝視時間的長 短,可幫助我們得到更多有關閱讀歷程的 訊息,因此在本研究中,我們加入了眼動 指標,以便進一步了解這些物理變項對於 閱讀歷程的影響。 本研究操弄不同的字體樣式(楷體與 明體)、字體大小(24 與 32 像素(pixel))及 字元間距(1/4 與 1/8 字體寬度),檢視其對 閱讀歷程之影響。實驗設計為參與者內設 計;實驗材料採中研院詞庫小組語料庫內 八篇文章,每篇文章字數介於 1866-2358 字,皆為敘述文,其難易程度與情緒性經 前測評定顯示無差異存在。我們所採用的 眼球運動指標包括:(1)凝視點數(fixation number),落在字體定義範圍內的視為有 效凝視點;(2)平均凝視時間(mean fixation duration),將所有有效凝視點的凝視時間 平均;(3)平均掃視長度,(mean saccade length),將所有有效的掃視長度平均,以 及(4)回視率(regression rate),在閱讀文章 時往回掃視的頻率。此外,我們也同時紀 錄整體閱讀時間、理解分數以及主觀偏好 (preference)。 研究結果顯示,隨著字體變大,凝視 次數會增加,掃視長度變長,但凝視時間 卻隨著變短,且回視頻率也隨著增加。當 字距變大時,凝視次數會增加,掃視長度 變長,但凝視時間卻隨著變短,且回視頻 率無明顯增加的情況。在字體樣式方面, 楷體的凝視時間比明體長,且在整體閱讀 時間與字距有交互作用產生,當字距較大 時,楷體的閱讀時間比明體長,但是當字 距較小時,楷體和明體的閱讀時間沒有差 異。然而,在參與者主觀評量對這些格式 的喜好程度與難易程度時,當字體越大, 參與者認為楷體比明體易閱讀也較令人 喜歡,但當字體變小時,卻認為明體比楷 體易閱讀,喜好程度也隨之增高。雖然在 上述指標中,顯示字體樣式、字體大小以 及字距有不同的效果,但是參與者在理解 問題的答對率上卻無明顯差異。 總結而言,在有相同閱讀理解程度的 情況下,明體的呈現方式較楷體更有效 率,尤其在呈現字距較大的情況下。
2.2.2 音樂引發之情緒與眼動型態 由於 SRF 是以眼動型態作為反映使 用者認知與情緒狀態的指標,並且以推薦 適切的音樂作為主要的服務項目,因此在 基礎研究上必須進一步驗證音樂所引發 的情緒對參與者的影響,而且是透過使用 者的眼動型態來反映這些影響。對此,我 們進行了兩項實驗,分別探討當參與者閱 讀中性或帶有情緒性的文章時,音樂所引 發的情緒對眼動型態的影響。
根據 Huber, Beckmann 與 Herrmann (2004)的假設,在正向情緒下,當個體進 行知識擷取時會對整個架構進行理解;相 反的,在負向情緒下,個體反而會傾向於 注意特殊細節或局部資訊。因此,本研究 第一個部分即在於驗證「由音樂所引發的 情緒,是否確實對參與者產生影響,而反 映於其注意力焦點與眼動型態?」實驗結 果顯示,聆聽不同音樂所引發的情緒並不 會影響參與者閱讀普通記敘文的歷程。換 言之,聆聽不同情緒性音樂的參與者在眼 動軌跡上並沒有顯著差異。然而,這樣的 結果也可能肇因於藉由音樂所引發的情 緒,尚未達到足夠的激起程度,因此無法 產生顯著的閱讀行為差異。 除了上述單純探討音樂所引發的情 緒,對原本處於中性狀態的參與者所產生 的影響之外,其所閱讀文章內涵與聆聽音 樂情緒之間的一致性,則是本研究第二部 分所要探討的主題。Bower (1981)指出, 如果個體當下的情緒與所接收資訊的情 緒內涵一致時,會產生情緒一致性效果 (mood congruency effect)。譬如開心的個 體接受或處理開心的訊息時,會因為訊息 與當下情緒是一致的,因此增強個體訊息 處理的效率。相反地,當開心的個體在處 理難過的訊息時,反而降低其處理效率。 本研究即在操弄音樂所引發情緒的正負 向,以及閱讀材料的情緒正負向兩者間之 一致性,檢視其對閱讀眼動型態的影響。 實驗結果發現,文章與音樂之間的確有互 相交互作用。聆聽快樂音樂的參與者,比 起讀難過的文章,他們在閱讀快樂的文章 時會花更多的時間。但是聆聽難過音樂的 參與者,在閱讀快樂或難過的文章上卻沒 有任何顯著差異。然而,上述音樂與文章 一致性的影響,只有當參與者必須詳讀文 章細節(而非擷取文章大意)時,才會發揮 作用。 2.3 系統實作 目前實作完成的SRF系統原型有兩 個模組,包括基於眼動型態的「理解程度 偵測模組」,以及基於眼動型態的「情緒 音樂推薦模組」。前者的主要目的在於透 過使用者的眼動型態,主動辨識其對文章 內容的理解程度,而無須透過後續閱讀測 驗等作法,即可得知使用者的學習成效, 據以調整學習材料的進度、難度等。至於 後者的主要目的則,在於透過使用者的眼 動型態,推薦其聆聽合適的音樂以達到調 節情緒的目的。 2.3.1 SRF理解程度偵測模組 多年以來,關於眼動軌跡和閱讀認知 歷程的研究都在探討字詞與眼動行為的 關係,或是分析整篇文章的統計結果,鮮 少從資料探勘(data mining)的角度切入。 本研究希望發展出一套系統,採用適合的 演算法來分析眼動資料,最終可應用於輔 助閱讀。這個系統能經由學習來針對不同 使用者的閱讀歷程,作出即時分析與判 斷,然後用來幫助閱讀能力不佳的個體, 找出他們的閱讀習慣跟一般人的差別,並 告知他們在閱讀文章時可以採用什麼樣 的方式增進對文章的理解。 眼動資料的處理與分析可分成三個 階段:(1)原始眼動資料前處理,本研究以 凝視與掃視兩種眼動行為作為主要分析 目標。凝視和掃視的眼動行為依照等量法
(Quantile)分類,把眼動資料中數字資料進 行編碼,將原始眼動資料分別轉換成凝視 和掃視兩種眼動序列。(2)序列的分析,找 出重複出現機率較高的字串。(3)建立高出 現 率 的 字 串 和 閱 讀 理 解 程 度 之 間 的 關 連,並分析出可以判斷理解程度的眼動軌 跡規則。 本研究的實驗程序是讓參與者閱讀8 篇難度不一的文章,閱讀結束後會有閱讀 測 驗 來 評 量 參 與 者 對 於 文 章 的 理 解 程 度,並且要求參與者評估自己對文章的理 解程度。舉其中一位參與者A的結果為 例,他對第三篇測驗文章的理解程度偏 低,而第七篇的理解評量皆為滿分。以下 則是A在兩篇文章中的掃視距離與凝視時 間的直方分佈圖(如圖2.1所示)。由圖可 知,A在完全理解的文章中,整體的凝視 時間都偏短,集中在200毫秒以下;理解 不足的文章中則是略為拉長。而且在充分 理解的情況下,正向掃視的距離比較長, 回視次數比較少;而理解不足的情形下則 反之。 圖 2.1 眼動與閱讀理解程度之關係 接著,我們找出4個跟A的理解程度有 高度相關的字串。以下是這4個字串在8 篇文章中出現的次數統計(如表2.1): 其中,字串S1,S2,S1,S1,R,S1是最後系 統判斷A的理解程度的主要規則。如果這 個字串沒有出現在文章中,理解分數會被 歸到4分滿分,表示完全理解;如果是出 現1次以上,歸類為2分,表示對該文章理 解不完全。上面的結果顯示8篇文章中有5 篇的理解判斷的分類正確,其他3篇有2 篇分類結果與原始結果相差1分。系統學 習結果尚可接受,但是仍有進步空間。在 後續研究與實作中,預期將調整字串搜尋 的演算法,將字串在文章中的出現次數提 升,藉以凸顯重要字串在文章中的出現機 率,期使分類結果更加精準。 表 2.1 眼動與閱讀理解程度結果舉例 重要 字串 S1,S2,S1 S1,R,S1 F3,F3,F4 F3,F4,F3 F2,F2,F5 F4,F2,F2 F1,F1,F1 F5,F2,F3 分 數 文章1 0 1 0 1 4 文章2 0 0 1 1 4 文章3 2 1 0 0 2 文章4 0 0 0 1 3 文章5 0 1 2 0 4 文章6 1 0 0 0 1 文章7 0 0 0 0 4 文章8 0 0 0 0 1 2.3.2 SRF情緒音樂推薦模組 這個模組的主要目的是希望發展出 一套搜尋引擎,透過使用者在閱讀時的眼 動軌跡的輔助,自動判斷使用者有興趣的 關鍵字,然後自動替使用者進行搜尋與推 薦,譬如提供適合的音樂以調節情緒。本 研究的特色在於,我們不用一般分析眼動 時關心每個AOI(area of interest)上的眼動 資料,而是將眼動資料以時間序列的方式 進行分析,並且用資料探勘找出眼動序列 中代表感興趣的眼動軌跡。 大多數的搜尋引擎需要透過使用者 輸入關鍵字來進行查詢,或是透過使用者 的具體回饋來增進搜尋成效。然而,現在 許多要求回饋的方式經常造成使用者不 小的負擔,或是難以完全表達使用者真正 的興趣,因此我們希望利用使用者在閱讀 時的眼動軌跡序列,來對使用者有興趣的
關鍵字進行判斷。 首先,我們設計一個實驗收集眼動的 資料。實驗開始時會先讓參與者閱讀一則 提示語,讓他知道實驗的方式與流程。接 著讓參與者閱讀4至8篇文章,並且在閱讀 完後讓他回答對文章感興趣的程度,以及 對文章感興趣的關鍵字。接著分析眼動的 資料。我們採用的眼動特徵為凝視持續時 間以及掃視位移長度,這也是一般最常用 於眼動分析的特徵。 由於我們希望判別眼動特徵所代表 的意涵,而不只是單純分析其所顯示的數 值 , 所 以 想 要 透 過 編 碼(encoding) 的 方 式,去除眼動特徵中較不具意義的差別, 將可能是表示相同意涵的眼動特徵以相 同的符號表示。在下圖2.2中,A及B分別 為凝視持續時間以及掃視位移長度的統 計圖表,縱軸為資料個數,橫軸為距離平 均數幾個標準差。由下圖可以看出兩種資 料的分佈情況都相當集中,因此只用數值 分群是不適當的。於是,我們改為採用 「C(I)=int(X* tanh((I-Avg)/Dev))」的函數 進行編碼,因為tanh有在越接近0成長幅度 越快的特色。而輸入數值所得到的C(I)值 相同以相同的符號表示,其中Avg為數值 的平均數,Dev為數值的標準差。 (A) (B) 圖 2.2 眼動資料示意圖 最後希望找出有哪些眼動片段經常 在使用者閱讀感興趣的文章時出現,也就 是找出眼動軌跡中的重複片段。現階段我 們設定編碼的X=3的條件下,找出出現在 90%的使用者感興趣的閱讀軌跡中,容許 三個錯誤的眼動重複片段,並且去除經常 出現在使用者不感興趣的閱讀軌跡中的 眼動片段。 目前找出一些重複出現的凝視時間 的片段,然而卻發現眼動片段出現的位置 與參與者有興趣的文字的位置不一致。我 們 判 斷 可 能 的 原 因 是 編 碼 的 結 果 不 夠 好。另外,也發現片段有時有來回重複閱 讀或是跳行的閱讀的情況,因此可能需要 將掃視跟閱讀方向的資訊結合在一起進 行疵料探勘,希望找出比較好的結果。 綜合來說,目前以眼動型態輔助搜尋 與推薦的模組已經具體成型。然而,因為 透過資料探勘方法所建構的學習模型需 要更多的訓練與驗證資料,而且有若干參 數需要調整,因此有待後續研究持續進行 調校。然而,偵測眼動軌跡是一種非侵入 式的測量方法,可以在不打斷使用者正常 閱讀的情況下,蒐集到使用者所提供的回 饋,因此十分值得繼續鑽研、改進。 2.4 成果檢討 簡單地說,SRF是將主動計算與情意 計算應用在閱讀空間(即書房)的子系統。 然而,SRF系統原型卻有別於前述SEAD 的建置策略,試圖利用眼動型態與資料探 勘方式,有效偵測使用者的認知與情緒狀 態,而且目前也已經獲得確實可行的系統 雛型。我們在這個子計畫中所獲得的基礎 研究結論主要包括: 閱讀材料的物理屬性可能會影響閱讀 者的主觀偏好與閱讀時間,但是在客觀 測量的理解程度上則無差異。至於如果 當字體較大時,建議使用明體以取得較 高的閱讀效率與使用者偏好;字體較小 時則以採用楷體為宜。 當閱讀者一面聆聽音樂、一面閱讀中性 文章時,音樂所引發的情緒對眼動型態 並無顯著影響;當閱讀者一面聆聽音 樂,一面閱讀帶有正負向情緒的文章
時,則會顯現情緒一致性效果,亦即當 個體閱讀快樂的文章而聆聽快樂的音 樂時,他會花費較多的時間注意文章細 節。至於在閱讀難過的文章時,音樂的 影響則無顯著差異。 此外,SRF的系統原型迄今則已經完 成下列兩項功能模組的試作,包括: 基於眼動型態偵測理解程度模組。 基於眼動型態推薦情緒音樂模組。 然而,由於眼動型態的基礎研究與實 際應用在資料分析上具有較高的技術門 檻與複雜性,因此以下提供幾項重點供後 續研究參考: 基礎研究與應用實作的分析方法的搭 配性宜再提高。譬如現有幾項基礎研究 成果均以特定時段內的眼動參數平均 值或標準差作為指標,而實作時則是以 時間序列方式進行資料探勘,兩者在基 本邏輯上確實有所差異。然而,為了解 決前述於 SEAD 檢討中所提到的即時 性問題,應以時間序列分析方法為較佳 考量。 基礎研究方面宜再增加關於使用者於 居家學習環境中所面臨之情境、困難, 以及需求的探討與驗證,期能於實作中 提供更多為使用者所需的適切服務。譬 如既有基礎研究僅探討參與者對閱讀 材料的理解程度,但是參與者的注意力 分配也不失為一個重要的學習課題。因 此在後續研究中值得加以深入探討。 系統原型的實作可加入其他生理指標 或行為指標,作為判斷使用者情緒與認 知狀態的依據。譬如 Picard 等人曾經 利用座椅上的壓力板來偵測學童的學 習挫折,並且試圖在學童產生學習障礙 時提供調整學習材料的難度,或是重新 複習舊有材料等各種作法。SRF 既有實 作僅著重於眼動型態,將來可以增加考 慮聲音、臉部表情、身體姿態與各種中 樞及周邊生理指標等。 利用音樂作為學習效果的調節手段,確 實為具體可行的做法之一。但是甚麼樣 的音樂會引發甚麼樣的情緒,似乎具有 相當顯著的個人差異。因此,未來仍應 繼續秉持利用資料探勘或其他機器學 習(machine learning)方法來提供個人 化服務的基本精神。然而,誠如前述 Picard 等人對於輔助學習的作法,SRF 的後續研究可以增加考慮其他調節情 緒或輔助學習的手段,譬如配合降低材 料難度、複習舊有材料,以及適時建議 使用者進行適度的休息等。 子計畫三 智慧型電視管理系統(STVM) 3.1 主要目的 近年來隨著數位電視的誕生,互動電 視(interactive TV)的觀念在未來將逐漸取 代傳統的收視概念與習慣,使觀賞電視節 目的活動由現有的單向訊息傳遞模式,轉 變為雙向的溝通與互動。基於情意計算與 主動計算等兩大主軸,本子計畫期望能夠 創新發展出具有以下兩大類功能的未來 智慧型互動電視管理系統:(1)工具性功能 (instrumental function),舉凡與電視系統 操作有關的功能都屬於這種類別,譬如頻 道轉換、調節音量、自動開/關機及重播、 自動錄影與使用者介面設計等;以及(2) 心理性功能(psychological function),其他 能提升或豐富收視者個人經驗的功能都 屬於這個類別,譬如個人化偏好紀錄與節 目推薦、播放調節情緒音樂或圖片、擬人 化智慧型互動對象(virtual agent),以及許 多貼心小提醒等。因此,簡單地說,STVM 就是情意計算與主動計算在休閒空間中 (即客廳)的具體應用。 不論是在探討工具性服務或心理性 服務這兩類不同的主題時,本子計畫的基 礎研究都可以分成三個步驟:(1)首先蒐集 使用者在看電視的情境中所產生的各種 需求;(2)接著針對各種需求提供可行的服
務,並且試作各種可能設計,然後依照實 驗法邏輯判斷各種設計的優劣;(3)最後, 透過使用者對STVM原型的試用,驗證並 調整各種功能的實際效能。因此,以下關 於基礎研究與系統原型的描述,都將以 「工具性服務」和「心理性服務」作為區 分段落的依據。 3.2 基礎研究 3.2.1 工具性服務的基礎研究 使用者需求分析研究。在著手設計各 種工具性服務之前,我們必須先了解使用 者的需求。透過對文獻的回顧與整理,我 們發現對於電視觀眾直接與電視機的互 動,以及對電視機操控方式的需求等相關 議題的探討,其實相當鮮少。因此,我們 進行一個焦點團體(focus group)研究,以 搜集初步的資料,作為後續實驗研究的依 據。在我們的焦點團體研究中,分三個年 齡層(12至22,23至45,45以上)共徵得 55位受試者,其中包括26位男性與29位女 性,每一年齡層的受試者分為兩組,共得 六組。進行的程序分為三個階段,首先讓 團體成員彼此介紹認識,閒談個人日常看 電視的狀況等,以提升團體討論的氣氛。 第二階段引導成員討論現有電視所提供 的功能中,何者是有用的、重要的,而何 者是有待改進或有新的可能發展方向。第 三階段則透過設計未來電視之遙控器的 作業,據以討論未來電視應有的功能,以 及可能發展出那些新的功能或更好的功 能。結果發現,大部分的參與者建議宜著 重兩方面的電視操控功能,包括音量調整 功能及頻道選取功能。 音量調節功能研究。根據上述焦點團 體研究結果,我們首先設計出五種新式的 音量調節功能:(1)線性(linear)模式:視前 後兩個頻道之間的音量差異,將其畫分為 數個間距,每次的調整幅度為上升或下降 一個間距、(2)遞減(degression)模式:在一 個時間區段內,隨著音量按鍵次數增加, 調整幅度為先大後小的遞減方式、(3)頻率 依賴(frequency-dependent)模式:依按鍵之 頻率決定調整幅度,頻率愈高則調整幅度 越大、(4)傳統(traditional)模式:每次的調 整幅度為上升或下降一單位,以及(5)半自 動(semi-automatic)模式:按下特定功能鍵 即自動調整為預設的偏好音量,之後可用 傳統模式加以微調。然後,我們利用實驗 來驗證這五種模式的實際效能。主要結果 包括:(1)傳統調整模式的確與其他四種調 整模式有相當大的差異,其所需的調整時 間較久,點擊次數也較多;(2)相較之下, 半自動模式的操作時間較短,點擊次數也 較少,是較有效的調整模式。 頻道選取功能研究。除了上述音量調 節功能之外,如何創新選台的方式,也是 在焦點團體研究中,被參與者特別提出的 另一項具體需求。因此,我們仿照網頁瀏 覽器的上一頁、下一頁功能,設計出新式 的頻道切換模式,稱之為前N台(Prior-N) 切換。在Prior-N模式中,系統會自動地將 前幾個觀看過的頻道記錄在Prior-N選單 中。使用者可以藉由按下遙控器的特定按 鍵,呼叫出 Prior-N選單(如圖3.1所示)。 圖 3.1 Prior-N 介面設計 選單將出現在螢幕右方,而使用者可 藉由點選選單中代表各頻道的圖示,切換 至某一頻道(如圖3-2所示)。我們利用這個 邏輯設計出可能呈現下列三種提示線索 之 一 的Prior-N 選 單 : (1) 頻 道 編 號
(number)、(2)頻道標誌(Logo)、及(3)節目 的代表性畫面,並且透過心理實驗法檢驗 這三種模式的效能與可用性。 實驗結果顯示:(1)就使用比例而言, 在提示頻道標誌的情況下,其使用比例高 於的隨機使用的比例且達顯著,顯示此一 設計相較於另外兩種傳統的切換模式,使 用者有較高的使用意願。但是另外兩種提 示資訊則未能引起參與者產生較高的使 用意願;(2)在操作時間上,使用頻道編號 作為提示線索時,使用者操作時間最短, 而使用節目代表畫面作為提示線索時,操 作時間最長,則顯示在實際操作上,以頻 道編號情況有最佳的效率;(3)從主觀評量 問卷的反應可知,使用者認為Prior-N模式 的設計新奇、聰明、有幫助,而且認為未 來電視應該具有這項功能,而其本身也願 意使用此一功能。 3.2.2 心理性服務的基礎研究 使用者偏好的生理指標。個人化的節 目推薦功能,是許多現有互動電視系統的 主要訴求之一。然而,若要達到妥善推薦 的目的,即需要從使用者身上蒐集到某些 有用的資訊。譬如以TiVo為例,它的遙控 器上即有兩個不同按鈕,可供使用者在觀 賞完特定節目後,按下按鈕表示是否喜歡 這個節目,藉以作為日後推薦相關類型節 目的主要依據。但是我們希望能在不干擾 使用者的情況下,達到蒐集資訊的目的, 因此希望透過各種生理及行為反應,找出 能夠分辨參與者個人偏好的具體指標。 我們設計了一個實驗,要求參與者觀 看若干電視節目並且評定其喜好程度。同 時,我們也記錄了參與者的各種中樞神經 與周邊生理反應,包括腦波、心跳、呼吸、 膚溫和膚電等。參與者必須先依序瀏覽6 個事先錄製的電視節目各2分鐘。然後, 他可以依照自己的喜好在這6個電視節目 之間自由觀看20分鐘。最後,參與者再依 序觀看6個相同節目但不同片段的內容各 2分鐘,並且評估他們對這些節目的主觀 偏好分數。由於這個研究的主要目的是在 於能夠找出確實反映主觀偏好的生理指 標,因此我們嘗試利用多元回歸模型探討 不同生理指標對偏好評量的預測力。研究 結果主要發現:(1)眾多周邊生理指標中只 有呼吸可以顯著預測主觀偏好的分數,而 且兩者具有正相關;(2)腦波資料則顯示 FC6的Delta頻段(負相關)、FC1的Gamma 頻段(負相關)以及TP1的Gamma頻段(正 相關)可以顯著預測主觀偏好的分數。整 體而言,以上述四個指標預測使用者對電 視節目的偏好程度,其預測力可以達到 22.4%。 虛擬互動對象的情緒表達能力。為了 讓STVM能夠順利發揮心理性功能,我們 除了必須使系統能夠主動偵測到使用者 的各種注意力與情緒狀態之外,STVM與 使用者互動的媒介也將扮演著極為重要 的角色。以擬人化(譬如畫面中出現虛擬 寵物)和非擬人化(譬如對話框模式)的比 較為例,前者應能大幅提升調節使用者情 緒的功能。因此,本子計畫同時著手探討 虛擬互動對象(即virtual agent)如何透過肢 體動作表達各種情緒的相關議題。 我們將虛擬對象從動畫的繪製到實 際表達出情緒的整個歷程,切分為三個層 次,包括:(1)動畫參數層次,亦即實際產 生各種動作變化的參數設定,譬如位移、 速度、加速度等;(2)風格參數層次,亦即 Laban的動作分析研究中,用來表達各種 動作變化的參數值高低。包括了平滑度 (jerky-smooth)、僵硬度(stiff-loose)、速度 (fast-slow)、擴張度(expanded-contracted) 和力道(soft-hard)(如圖3.2所示),以及(3) 情緒參數層次,亦即各種基本情緒類型, 包括生氣、害怕、高興、悲傷等。 接著,我們利用兩項實驗研究,分別 探討動畫參數層次到風格參數層次的對 應性,以及風格參數層次到情緒參數層次 的對應性。前者在檢驗動畫角色是否能有
效地展現出各種動作風格,而後者則旨在 掌握動畫角色是否能有效地表達各種情 緒。
(A) loose (B) stiff 圖 3.2 風格參數示意圖(以僵硬度為例) 實驗結果顯示,除了力道(soft-hard) 這項風格參數之外,其餘四項風格參數的 表現均能被參與者正確地辨識出來。至於 各種風格參數與情緒參數之間的對應,我 們則可以透過實驗結果找出下列關係:(1) 要表達憤怒時,虛擬角色的肢體擴張性應 增加;(2)要表達恐懼時,虛擬角色應該顯 得動作僵硬、緩慢,而且身體稍微蜷曲; (3)要表達愉快時,虛擬角色則反而要讓動 作變得放鬆、節奏加快,而且讓身體呈現 較為開放的姿態;(4)至於要表達悲傷時, 虛 擬 角 色 的 風 格 參 數 設 定 與 恐 懼 時 相 仿,但是動作要更為鬆弛,而且也更為緩 慢。 3.3 系統實作 為了方便進行STVM的基礎研究與 原型建置,我們首先採用Windows Media Center作為開發環境,設計出一個互動電 視的實驗平台,稱為SimTV。SimTV可以 模擬第四台有線電視的環境,在實驗中提 供多個頻道供使用者觀賞。運用此一實驗 平台,實驗設計者可以根據不同的實驗需 求,很輕易的控制節目頻道的內容及排程 順序,也可以加入特定的電視功能,觀察 使用者的行為及反應。 SimTV的程式邏輯部分,採用C#搭配 MCE SDK來撰寫,但是在電視操作介面 上則是採用MCML(Media Center Markup Language)語言來設計。此外,本研究以 SQL Server 2005設計了一套SimTV的資 料庫,包括節目資料、排程資料以及使用 者資料等,以因應實驗所需的節目安排。 下圖3.3為SimTV平台之概觀。 圖 3.3 實驗平台 SimTV 架構概觀 3.3.1 STVM 工具性服務模組 基於SimTV這個實驗平台與前述相 關基礎研究所得結果,我們同樣利用MCE 為底層,搭配C#和MCML撰寫出STVM的 系統原型(如圖3.4所示)。 圖3.4 STVM系統原型架構 搭配使用SEAD系統中的人臉辨識模 組,我們的STVM原型已經可以實作出下 列幾項工具性服務功能:
新式音量調節功能。包括線性模式、遞 增模式、頻率依賴模式、半自動模式, 以及傳統模式等各種選擇。 新式頻道選取功能。包括傳統上下鍵選 台模式、傳統數字鍵選台模式,以及 Prior-N選台模式等各種選擇。 自動開機/關機功能。亦即當使用者出 現時,自動開啟電視電源並且登入;當 使用者離開時,自動關閉電視電源並且 紀錄收視歷程。 自動暫停/播放功能。亦即若使用者短 暫離開,則自動暫停節目播放,俟使用 者返回後再自動恢復播放。若為線上節 目則利用自動錄影功能,輔助達到上述 目的。 3.3.2 STVM 心理性服務模組 此外,在STVM的系統原型中,我們 也實作了下列幾項心理性服務功能: 貼心提醒功能。譬如當偵測到使用者頭 部歪斜時,會提醒他保持良好的坐姿; 或 者 當 偵 測 到 使 用 者 收 視 時 間 過 長 時,則建議他進行適度的休息。 節目推薦系統功能。譬如當使用者剛登 入系統時,會主動詢問是否需要推薦節 目;或者當偵測到使用者頻繁轉台時, 表示他可能感到無聊而主動詢問是否 需要推薦節目。 3.4 成果檢討 總體來說,STVM是一個整合性與完 成度都比較高的子計畫。而且不論是在使 用者需求的探討、將心理學原理原則運用 於系統原型設計,以及設計成果的成效驗 證等各方面,STVM都能做到符合以使用 者為中心設計(user-centered design)的基 本精神。然而,我們仍然列舉以下幾項重 點供後續研究參考: 個人化推薦系統模組尚未實作完成,而 這項功能正是決定STVM實際效能的 主要原因之一。因此,不論是在推薦系 統的使用者介面設計,抑或推薦系統的 實質內涵(包括個人偏好指標的建立, 以及推薦系統的邏輯與演算法等),都 值得繼續進行更深入的研究與實作。 以動畫角色呈現的使用者介面尚未實 作完成,目前仍然僅限於以對話框式的 使用者介面呈現各種功能選單。不過, 若要達到這個目的,則涉及影像繪製與 疊合(overlay)的問題,而可能需要突破 MCE平台的限制,以其他環境開發新 的STVM原型。 對於使用者在休閒環境中所從事的活 動,可以擴充到看電視、打電動、聽音 樂和上網等各種行為。換言之,STVM 所提供的播放、錄製與推薦等功能,可 以突破線上電視或預錄節目的限制,將 線上或個人蒐藏的音樂、短片,以及各 種電視遊樂器電玩(如Wii, XBOX等)和 線上遊戲等,全數納入考慮。 未來電視數位化之後,將會伴隨電視節 目內容的播放,傳送更多有關節目屬性 的附屬資訊(meta data),因此在構思可 能的工具性與心理性服務時,可以將這 項轉變列入考量。譬如可以利用節目本 身 的 附 屬 資 訊 來 做 個 人 化 推 薦 的 依 據,或者利用廣告片段的附屬資訊來自 動刪除或跳過廣告等。未來互動電視的 可能發展,相信和數位化之後的附屬資 訊有極大關聯。 子計畫四 智慧型睡眠輔助系統( SSS) 4.1 主要目的 這個子計劃的主要目的在於建立一 個睡眠協助系統,透過非接觸式的方式偵 測睡前及早晨的警醒狀態(arousal),以及 睡眠的品質,進而控制睡眠外在環境,以 促進入睡及提昇早晨的警覺狀態。換句話
說,SSS的建置將為使用者帶來高品質的 睡眠,以及早晨起床後更清醒的身體與心 理狀態。 為了達到上述目的,我們搭配進行幾 項基礎研究,以作為設計SSS系統原型時 的實證參考。這些研究議題包括「音樂對 晚間睡眠的影響」,以及「音樂對晨起清 醒程度的影響」等。 4.2 基礎研究 4.2.1 音樂對於晚間睡眠品質的影響 為了突顯音樂對於晚間睡眠品質可 能產生的調節效果,我們特別利用加法作 業、聽覺心算測驗(Paced Auditory Serial Addition Test;PASAT)以及抽象推理測驗 來誘發參與者在睡前產生壓力。然後,播 放快、慢兩種節奏的音樂供參與者聆聽 (控制組則無音樂播放),試圖藉由測量其 睡眠中的腦波、肌電、膚電與膚溫等各種 生理反應,探討音樂節奏對調節睡眠品質 的影響。 研究結果顯示,入睡所需時間(sleep onset latency, SOL)與壓力操弄後的高頻 與低頻HRV的比率(LF/HF,代表交感與副 交感神經系統的平衡)成正相關(r=.486, p=.016),顯示交感神經活動愈活躍,SOL 時間愈長。另外,在腦波的部份,SOL與 壓力操弄前的beta1%呈負相關(r=-.532*, sig.=.013),並與嘗試入睡時Beta2減少的 量呈負相關(r=-.440, sig.=.046),顯示基準 現beta1低者以及嘗試入睡時Beta2減少越 少者,入睡所需時間愈長。HRV及腦波的 Beta波可能作為預測入睡狀況的指標。 在給予認知壓力下,參與者主觀的焦 慮程度有顯著的上升(F=7.467, P=.013), LF/HF也有顯著上升(F=4.779, P=.040)。然 而,在給予不同的音樂的狀況下,三組間 並無顯著差異,當以HF作為依變項,發 現以實驗操弄前後差異值作為依變項,組 間差異未達顯著(F=.823, P=.453),顯示副 交感神經系統對於壓力的反應在三種音 樂操弄之下無明顯差異。而LF/HF在組間 改 變 量 之 差 異 接 近 顯 著 (F=3.041, P=.069)。交感神經活動在無音樂與慢板音 樂均緩慢上升,快板音樂組有較大的上升 趨勢。在腦波的頻譜分析方面,僅有Delta 波 在 操 弄 前 後 有 顯 著 改 變(F = 19.69, p< .05),然而不同音樂組之間差異亦未達 顯著。 在睡眠變項方面,入睡所需時間及睡 眠效率在三組之間皆沒有顯著差異,但就 其平均值來看,快、慢節奏的音樂皆有使 SOL增高以及睡眠效率變差的傾向(見下 表4.1)。 表4.1 音樂類型與入睡 Sleep onset latency Sleep efficiency 無音樂 Mean ±SD 6.89 ± 2.87 72.63 ± 23.99 慢板音樂 Mean ±SD 16.69 ± 19.29 59.55 ± 26.18 快板音樂 Mean ±SD 16.50 ± 17.27 51.57 ±31.87 F 1.334 1.260 整體來說,研究結果顯示睡前HRV與 腦波的測量可能可以作為預測之後睡眠 狀況的指標,且可以反應出壓力影響所產 生的變化。然而,預期中慢節奏的音樂可 以促進睡眠的假設,並沒有得到驗證。 4.2.2 音樂對於晨起清醒程度的影響 除了探討音樂節奏對夜間睡眠品質 的影響,本研究也想了解音樂節奏對參與 者晨起清醒後的警覺程度有何影響。因 此,根據過去睡眠怠惰(sleep inertia)的相 關研究,我們在參與者醒來後以每10分鐘