碩 士 論 文
電 控 工 程 研 究 所
國 立 交 通 大 學
用於低位元率輕量級視訊壓縮的
熵編碼模式切換技術
Study on Dual-mode Entropy Coding Selection for
Low Bit Rate Lightweight Video Compression
中 華 民 國 九 十 八 年 九 月
研究生:邱致瀚
用於低位元率輕量級視訊壓縮的
熵編碼模式切換技術
Study on Dual-mode Entropy Coding Selection for Low Bit
Rate Lightweight Video Compression
研究生:邱致瀚 Student:Zhi-Han Qiu
指導教授:董蘭榮 博士 Advisor:Lan-Rong Dung
國
立 交 通 大 學
電
控 工 程 研 究 所
碩
士 論 文
A ThesisSubmitted to Department of Electrical and Control Engineering College of Electrical Engineering and Computer Science
National Chaio-Tung University in Partial Fulfillment of the Requirements
for the Degree of Master in
Electrical and Control Engineering September 2009
Hsinchu, Taiwan, Republic of China
中 華 民 國 九 十 八 年 九 月
用於低位元率輕量級視訊壓縮的
熵編碼模式切換技術
研究生:邱致瀚
指 導 教 授 : 董 蘭 榮 博 士
國立交通大學
電控工程研究所
摘要
這篇論文的主要目標是為低位元率輕量級視訊壓縮設計一種熵編碼模式切 換演算法。在低位元率輕量級視訊壓縮中,熵編碼為系統中最花費時間的步驟。 而熵編碼採用 CABAC 平均約需要 CAVLC 1.5 倍的時間。所以我們發展熵編碼 模式切換演算法以達到有效切換模式的目的。我們利用熵編碼模式切換演算法計 算在使用位元率控制下,單張畫面使用兩種熵編碼模式會造成的畫質差。當 CABAC 能比 CAVLC 能有效提升畫面達 0.5dB 以上,才使用 CABAC 模式,反 之則使用 CAVLC 以節省時間。在演算法中,我們同時也為 CABAC 發展碼率預 估演算法而能用更快的速度取得 CABAC 的壓縮量。從模擬結果顯示能比只用 CAVLC 模式平均每張畫面能達到 0.7dB 的畫質提昇,而相對 CABAC 比 CAVLC 需要的時間,使用切換演算法平均能節省 40%的時間。Study on Dual-mode Entropy Coding Selection for Low
Bit Rate Lightweight Video Compression
Graduate Student: Zhi-Han Qiu Advisor: Dr. Lan-Rong Dung
Department of Electrical and Control Engineering National Chiao Tung University
Abstract
The objective of this thesis is to develop a dual-mode entropy coding selection algorithm for the low bit-rate lightweight video compression system. In applications of low bit-rate lightweight video compression system, entropy coding stage costs the most time and the time of CABAC is 1.5 times the time of CAVLC on the average. As a result, we develop a dual-mode entropy coding selection algorithm to choose the better mode for each frame encoded. Dual-mode entropy coding selection algorithm can be used to compute the PSNR difference of one frame which encoded by two kinds of entropy coding mode under rate control. When CABAC increases better PSNR value than CAVLC by 0.5 dB, the algorithm chooses CABAC mode to encode. When the value is below the threshold, the algorithm selects another mode. In our algorithm, we also present a CABAC rate estimation method to save computation complexity. Simulations shows that the proposed algorithm can produce better PSNR value by 0.7 dB than encoding by CAVLC only and save up to 40% additional simulation time than encoding by CABAC only.
誌 謝
這篇論文能夠完成,要謝謝許多照顧我以及幫助我的人。 首先謝謝我的指導教授,董蘭榮老師。在研究所的兩年中,董教授不厭其煩地為 我指點迷津,而也總能幫我考慮到許多原本沒想到的地方,讓我獲益良多。 另外,謝謝我的朋友們,能把我挫折時的沮喪換為歡笑,並且包容我的一切幼稚 以及任性。這幾年能夠跟你們相處在一起是我的幸運,除了謝謝之外,也希望我們能 夠一起成長。 同時,也感謝實驗室的學長─盟淳、穎毅、信丞、貫康、詠麟、嘉宏、博仁,在 求學和研究過程中給於指點及幫助,以及同學們─智聖、嘉鴻、昶翔,在課業與生活 上的互相扶持。另外要謝謝振揚同學於研究中的幫忙。 同時,謝謝我最親愛的家人,從我外出念書開始就不斷地關心和照顧我,給予我 沒有後顧之憂的生活,我能夠順利完成學業都要謝謝你們。最後也要謝謝我的女朋友 妙如,一路陪伴以來不斷的照顧和鼓勵,感謝妳。 這幾年謝謝你們了。 2009.9.22目
錄
中文摘要... i
英文摘要... ii
誌 謝... iii
目 錄... iv
圖 目 錄... vi
表目錄... viii
第一章 緒論... 1
1.1 研究動機與目的... 1
1.2 論文架構... 5
第二章 背景介紹與文獻回顧... 6
2.1 膠囊內視鏡取像格式... 6
2.2 H.264/MPEG-4 AVC畫面內估測的壓縮演算法 ... 7
2.2.1 畫面內估測 (Intra prediction) ... 7
2.2.2 整數轉換 (4×4 IntegerTransform)... 10
2.2.3 量化 (Quantization) ... 12
2.3 熵編碼... 14
2.3.1 內容適應性變動長度編碼法(CAVLC) ... 14
2.3.2 內容適應性二元算術編碼(CABAC) ... 17
2.3.2.1 二元轉換 ... 18
2.3.2.2 基於內容的機率模型選擇... 19
2.3.2.3 適應性二元算術編碼... 21
2.4 碼率預估 (rate estimation) 的文獻回顧 ... 26
2.5 位元率控制 (rate control)... 29
第三章 熵編碼模式切換演算法的設計 ... 30
3.1 畫面內估測模式的簡化... 30
3.1.1 DC模式 ... 31
3.1.2 重建G1 模式 ... 31
3.2 熵編碼模式切換演算法... 32
3.2.1 畫面編碼預算的計算... 36
3.2.2 QP的計算... 39
3.2.3 PNSR差值的計算... 41
3.2.4 模型係數更新... 42
3.2.5 線性模型的硬體實現分析... 43
3.3 熵編碼的碼率預估演算法... 46
3.3.1 CAVLC碼率預估演算法... 47
3.3.2 CABAC碼率預估演算法 ... 53
3.3.2.1 初步的CABAC碼率預估演算法 ... 53
3.3.2.2 改良的CABAC碼率預估演算法 ... 58
3.3.2.3 位元平行化碼率預估演算法... 61
3.3.2.4 level查表碼率預估演算法 ... 64
3.3.2.5 各種方法的優劣比較... 66
第四章 熵編碼模式切換演算法模擬結果 ... 71
4.1 演算法模擬結果... 71
4.2 硬體成本模擬結果... 74
第五章 結論... 75
參考文獻... 76
圖
目 錄
圖 1.1 delta-PSNR 圖 ... 2
圖 2.1 膠囊內視鏡畫面內估測壓縮演算法流程圖 ... 6
圖 2.2 相鄰像素值的關係圖... 8
圖 2.3 各種模式的猜測方向... 9
圖 2.4 CAVLC編碼 4×4 殘餘係數區塊的流程圖 ... 15
圖 2.5 CAVLC範例... 16
圖 2.6 CABAC編碼符號位元的流程圖... 17
圖 2.7 合併Unary code 和the kth order Exp-Golomb code 的虛擬碼... 19
圖 2.8 Range和Low 示意圖 ... 21
圖 2.9 適應性二元算術編碼 (encodeDecision) 流程圖 ... 22
圖 2.10 Renormalization流程圖... 23
圖 2.11 適應性二元算術編碼 (encodeBypass) 流程圖... 24
圖 2.12 適應性二元算術編碼二元算術編碼 (encodeTerminate) 流程圖 25
圖 3.1 bayer pattern影像的資料重排 ... 30
圖 3.2 兩種模式的R-D 曲線比較圖... 32
圖 3.3 熵編碼切換演算法的流程圖 ... 33
圖 3.4 group layer 流程圖 ... 34
圖 3.5 frame layer 流程圖 ... 35
圖 3.6 group layer 的設計 ... 37
圖 3.7 資料更新方式... 43
圖 3.8 R-QP model 記憶體... 44
圖 3.9 PSNR-QP table... 45
圖 3.10 CAVLC編碼率預測的R-QP關係圖 ... 52
圖 3.11 符號位元(bin)編碼時的資料傳遞... 54
圖 3.12 單符號位元(bin) 於適應性二元算術編碼時的資料傳遞 ... 55
圖 3.13 單符號位元(bin) 於適應性二元算術編碼的內外部資料傳遞 .... 56
圖 3.14 單符號位元(bin) 的碼率估測... 58
圖 3.15 改良的單符號位元(bin) 碼率估測... 60
圖 3.16 單符號位元(bin) 的平行化碼率估測... 63
圖 3.17 不同QP值壓縮下level的平均編碼量 ... 65
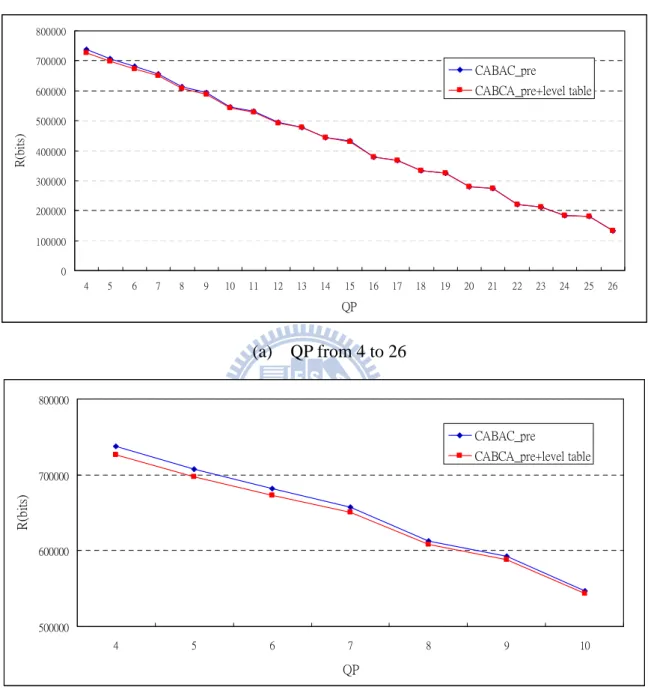
圖 3.18 CABAC編碼率預測的R-QP關係圖 ... 68
圖 3.19 CABAC_pre使用level table 所造成的誤差... 70
表目錄
表 1.1 內視鏡系統模擬時間比例表 ... 3
表 2.1 畫面內估測的模式... 8
表 2.2
QP和
Qstep對應表 ... 12
表 2.3 CAVLC所用的編碼符號和統計量 ... 15
表 2.4 編碼符號需要的參考統計量 ... 16
表 3.1 記憶體所造成的切換誤差率 ... 44
表 3.2 SATD分類區間數所造成的M值MSE ... 46
表 3.3 suffix_length 值為 0 到 4 對應的level編碼結果 ... 48
表 3.4 影響編碼長度的level門檻值... 48
表 3.5 對應suffix_length變動的level門檻值 ... 49
表 3.6 CAVLC碼率預估演算法模擬比較 ... 50
表 3.7
codIRangeLPS值對應的bits_length表格... 60
表 3.8 各種預設Range值的壓縮量模擬結果 ... 62
表 3.9 採用預設的Range值下的bit_length表 ... 64
表 3.10 level的平均預估編碼量... 66
表 3.11 CABAC碼率預估演算法模擬比較... 66
表 3.12 使用level table的模擬結果 ... 69
表 4.1 測試影像... 71
表 4.3 邏輯閘數統計... 74
第一章 緒論
1.1 研究動機與目的
在[1]中提到,視訊標準經過多年來的發展,一個基本的視訊壓縮系統會包含動態估 測、動態補償、訊號轉換、和熵編碼四個主要的部份。而這四個部分是由最原始的 differential pulse code modulation (DPCM) 編碼加上離散餘弦轉換(DCT)發展而來。 DPCM [2]、[3]是利用預測資料和原始資料的相關性去減少壓縮資料量,而相減完的殘 餘資料在經過 DCT [4]轉換到頻域以減少資料量,最後的熵編碼則是透過移除統計的相 關性來壓縮資料。而這種由預測和訊號轉換所組成的系統也被稱為混合視訊壓縮(hybrid video coding)[5]、[6]. 在 2003 年最新制定新一代的視訊標準 H.264/MPEG-4 AVC [7]、[8],和之前的 MPEG-4、H.263、MPEG-2 比較,H.264 可以達到 39%、49%、64%的碼率降低 [9],所 以 H.264 可以提供更高的編碼效能。 低位元率輕量化視訊壓縮為系統具有的傳輸頻寬很低,位元率可能只有 1~2M (bit/s),而系統本身為了滿足可攜性的功能,所以採用電池供電。為了讓電池可以儘可 能的長時間使用,所以整個壓縮系統不採用耗電的動態估測技術或模式選擇(mode decision)等技術。低位元率輕量化視訊壓縮最典型的例子為無線膠囊內視鏡系統[10]、 [11]、[12]、[13]、[14]、[15],後兩者為之前我們所開發的系統。系統壓縮影像尺寸為 512×512,而 frame rate 為 2 (frames/sec),當位元率為 2M (bits/s)時。因此視訊壓縮演算 法必須儘可能的減少功率消耗,但又必須儘可能提高影像畫質。
內容適應性二元算術編碼(CABAC)。根據 [16]、[17]的研究結果,在相同的畫質之下, CABAC 平均可以比 CAVLC 節省 9%~14%的壓縮資料量,但是因為兩種熵編碼性質上 的不同,即 CAVLC 為直接對整個符號編碼,而 CABAC 卻是以符號位元為單位進行編 碼,所以對於同樣的內容,CABAC 需要比較多的時間去編碼,根據我們的模擬,在壓 縮單張 d1 的畫面時,CABAC 平均要花 1.5 倍 CAVLC 的時間。 圖 1.1 delta-PSNR 圖 圖 1.1 為使用 football.yuv (D1,4:2:0)以 JM11.0[18] 實際壓縮的結果,橫軸為每秒的 位元率(bits/s),縱軸為熵編碼的 PSNR 差,為 CABAC 減去 CAVLC 的 PSNR 值差距。 從圖 1.1 來看,在固定 x 軸的值之下,對應到 y 軸的兩點,即為兩種模式在固定位元率 時的 PSNR 差距。但是在不同的位元率之下,兩者間的 PSNR 差會有所改變。在固定位 元率且兩者壓縮的 PSNR 差距小於 0.5dB 時,表示兩種方法此時並無差異,那當這種情 況發生時,我們應該要使用 CAVLC 來壓縮以節省壓縮時間。這代表我們可以設計出一 種機制去估計出當前壓縮畫面兩者的 PSNR 差,而根據這個 PSNR 差來切換熵編碼模式。
Part (%) Entropy coding 90.56 Q/IQ 3.44 DCT/IDCT 1.29 Intra prediction 4.57 Others 0.14 total 100 表 1.1 內視鏡系統模擬時間比例表 在我們之前設計的內視鏡系統中[15],熵編碼只使用 CAVLC 模式。從表 1.1 模擬時 間表可以看出熵編碼階段在整個系統中要消耗最多的執行時間,而 CABAC 消耗的時間 又比 CAVLC 更為增加。所以為了要在輕量化視訊壓縮系統中有效地利用 CABAC 來增 加畫質,所以要發展熵編碼模式切換演算法,為當前畫面選擇最有利的熵編碼模式。當 畫質可以明顯改善時,選擇 CABAC 模式,反之則使用 CAVLC 以減少熵編碼階段的時 間消耗。我們將先計算出固定頻寬下每張畫面的編碼預算,再利用熵編碼模式切換演算 法去選擇最有利的熵編碼模式。 在本文中,我們針對低位元率輕量化視訊壓縮設計了一種熵編碼模式切換演算法。 在系統前端的畫面內估測,我們保留之前改良的設計,只使用一種模式來估測。接下來, 利用演算法從系統位元率計算出每張畫面的編碼預算,從編碼預算利用 R-QP 模型和 PSNR-QP 模型去計算兩種熵編碼要符合編碼預算的量化值。從量化值導致的畫質差是 否有明顯改善在兩種熵編碼間選擇當下最有利的模式和對應的量畫值。為了避免硬體實 現時除法器的使用,所以在兩個模型的使用上,改用以查表的方法實現。為了讓在每張 畫面的壓縮時間在演算法執行時不會超過使用 CABAC 壓縮的時間,我們發展了
CABAC 碼率估測演算法去估計 CABAC 的壓縮量。CABAC 碼率估測演算法主要是利 用減少原始 CABAC 的執行步驟以加快速的猜測出壓縮量。在碼率估測演算法的發展 中,我們根據模擬結果發現碼率估測演算法的準確度會對模式造成影響,所以我們以誤 差值去選擇最後使用的方法。而最後我們的 CABAC 碼率估測演算法平均可以比 CABAC 減少約三分之二的執行時間又能準確提供切換訊息且以硬體實現時只需要些微 消耗。從模擬結果顯示,能比只用 CAVLC 模式壓縮平均每張畫面能達到 0.7dB 的畫質 提昇,而跟 CABAC 相比,使用切換演算法平均能節省 40%的多餘時間,且能同時達成 位元率的控制。
1.2 論文架構 第一章 緒論 包括整個論文的介紹和說明研究動機和方法 第二章 背景介紹與文獻回顧 對 H.264 的熵編碼演算法和位元率控制演算法有初步的介紹,最後再 探討碼率預測相關的論文 第三章 熵編碼模式切換演算法的設計 針對研究目的提出本論文的演算法,並逐節介紹演算法各步驟的設計過程。 針對兩種熵編碼的碼率預估進行各種方式的改善並模擬使用結果。 第四章 模擬結果與比較 分析熵編碼模式切換演算法的整體模擬結果和模擬以硬體實現的結果。 第五章 結論與未來展望 分析說明整體結果,並由訂出未來可進行的方向。
第二章 背景介紹與文獻回顧
在本章的內容之中,將以無線膠囊內視鏡中演算法的技術作為輕量化視訊壓縮的流 程基礎來進行說明,圖 2.1 為整個輕量化視訊壓縮演算法的架構圖。從 2.1 節開始,將 從影像格式 bayer pattern 開始,逐步介紹這個系統中各個部份用到的技術。在第 2.3 節 裡面,將詳細介紹兩種熵編碼演算法。在 2.4 節中將介紹碼率預估演算法的文獻回顧。 第 2.5 節將簡述系統中利用的位元率控制演算法。 4x4 Integer Transform Rate Control bit stream Intra Prediction (DC mode) Quantize Entropy Coding Image Capture 圖 2.1 輕量化視訊壓縮演算法流程圖2.1 膠囊內視鏡取像格式
膠囊內視鏡的影像捕捉方式是透過單片色彩濾鏡的旋轉在 CMOS 感應器上的每個 像素點紀錄不同顏色的值。紀錄的排列方式如圖 2.1 中,左上角的彩圖所示。即取像畫 面上,G 平面的取樣像素資料會呈現對角線的排列,而在不同的列中,在分別對 R 平 面和 B 平面取樣。因為人類視覺系統對 G plane 的變化較為敏銳,且 G plane 的能量 在自然界中所佔的比例也比其他的兩個顏色較高,所以 RGB 三者取樣的資料量比為 1:2:1。在我們的演算法中,對於影像感應器(image sensor)捕捉的 raw image 不先經過解馬 賽克(Demosaicking)的運算做像素三原色補色,也不將補色後的彩色像素做色彩空間轉 換(Color-Space Transform)。即不把彩色像素 R、G、B 三原色轉換成 Y、Cb、Cr,而是 直接進行壓縮,這樣可以減少執行色彩空間轉換的功率消耗。
2.2 H.264/MPEG-4 AVC 畫面內估測的壓縮演算法
接下來的幾個部份所用到的基本方法都是參考於 H.264/MPEG-4 AVC[8]中使用的技 技術。在標準中,基本的畫面估測方式有兩種:分別為畫面內估測(intra prediction),和畫 面間估測(inter prediction),為了延長電池使用時間,所以整個壓縮流程不採用會消耗功 率很大的畫面間估測而只使用畫面內估測。 2.2.1 畫面內估測 (Intra prediction) 畫面內估測的原理主要是利用當前編碼區塊周圍的資訊去建立一個預測區塊,然後 只壓縮兩者的差值。當預測區塊的值越接近編碼區塊時,兩者相減所得的殘餘資料量會 越低,而壓縮率會越高。H.264 的基本編碼單位區塊為巨方塊( macroblock : MB),在 4:2:0 取樣格式下的話,一個巨方塊由 1 個 16×16 的亮度區塊和 2 個 8×8 的彩度區塊所組成。 而亮度區塊和彩度區塊可以切割成的最小尺寸為 4×4。在膠囊內視鏡系統中,因為色彩 空間不是使用 YUV,而是使用 bayer pattern,所以我們的最小編碼區塊的尺寸就直接設 為 4×4 以方便壓縮,而這樣也省去要壓縮巨方塊檔頭的資料量。在建立預測區塊的內容 時,主要是利用已經編碼過,然後再重建完的相鄰編碼區塊的內容去猜測。這裡的相鄰 區塊是該編碼區塊上方、右上方和左方的編碼區塊,因為編碼順序的關係,所以這三個 單位的像素內容在要壓縮當前區塊時已經是重建過後的資訊,即解碼端對應的資料。猜 測的方式是利用上方、右上方和左方編碼內容去重建一個預測區塊。圖 2.2 為[1]中所提到相鄰像素值的關係圖,圖中的 a 到 p 為要猜測的像素值位置,而 A 到 L 則是相鄰的 編碼區塊已知像素值位置。 圖 2.2 相鄰像素值的關係圖 節錄自[1] 在標準中,針對不同的編碼單位尺寸有不同的猜測方式可供選擇。對一個 16×16 巨 方塊有 4 種模式可供選擇,而 4×4 編碼單位有 9 種方式可供選擇,這 9 種方式列於表 2.1 中,而圖 2.3 為[1]中各模式對應的猜測方向。 表 2.1 畫面內估測的模式 節錄自[1]
2.2.2 整數轉換 (4×4 IntegerTransform)
因為傳統壓縮標準中的離散餘弦轉換(discrete cosine transform,簡稱為 DCT)會帶 來硬體上實現的麻煩,所以在 H.264 中,為了簡化複雜度,提出了整數轉換。整數轉換 是近似的 4×4 離散餘弦轉換,最大的優點是可以把傳統的浮點運算改成只需要加法和移 位的運算。下面的推導過程參考於[19]。 傳統 DCT 公式以矩陣形式表示: (2.1) ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − = = c a b a b a c a b a c a c a b a c b b c a a a a b c c b a a a a X AXA Y T 這裡的 a,b,c 分別為: ) 8 3 cos( 2 1 ), 8 cos( 2 1 , 2 1 π π = = = b c a 為了簡化運算,將矩陣乘法中重複的項提到外面。 所以可以將(2.1 式)改寫成以(2.2 式)表示: (2.2) ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⊗ ⎟ ⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎜ ⎜ ⎜ ⎝ ⎛ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − − = ⊗ = 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 b ab b ab ab a ab a b ab b ab ab a ab a d d d d d d d d X E ) (CXC Y T 這裡的 a,b,d 分別為,c 值和前頁相同: b c d b a= = ), = 8 cos( 2 1 , 2 1 π
近似離散餘弦轉換的整數轉換則寫成為: (2.3) ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⊗ ⎟ ⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎜ ⎜ ⎜ ⎝ ⎛ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − = 4 / 2 / 4 / 2 / 2 / 2 / 4 / 2 / 4 / 2 / 2 / 2 / 1 1 2 1 2 1 1 1 2 1 1 1 1 1 2 1 1 2 2 1 1 1 1 1 2 1 1 2 1 1 1 1 2 2 2 2 2 2 2 2 b ab b ab ab a ab a b ab b ab ab a ab a X Y 反整數轉換則寫成為: (2.4) ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − ⎟ ⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎜ ⎜ ⎜ ⎝ ⎛ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⊗ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − = 5 . 0 1 1 5 . 0 1 1 1 1 1 5 . 0 5 . 0 1 1 1 1 1 5 . 0 1 1 1 1 1 5 . 0 1 1 1 5 . 0 1 5 . 0 1 1 1 2 2 2 2 2 2 2 2 b ab b ab ab a ab a b ab b ab ab a ab a X Y 這裡的 a,b,d 則分別為: 2 1 , 5 2 , 2 1 = = = b d a
2.2.3 量化 (Quantization) 在整個壓縮編碼的流程之中,經過畫面內估測後的殘餘值資料經過整數轉換之後, 會在經過量化這一個步驟,才把資料傳給熵編碼端。量化步驟在整個壓縮中所扮演的角 色是利用量化值去調整壓縮的品質。當使用較大的量化值,會讓殘餘值的資料變的較 少,可以讓壓縮率上升,但因為資料表示位數減少的關係而有較大的失真,這會導致影 格解壓縮回來之後的品質下降,反之亦然。 在 H.264 的標準中,定義了 52 個量化值,如表 2.2 中所示,每個量化值 QP 都可以 對應到一個真實的量化參數Qstep。當 QP 相差 6,則Qstep值為兩倍的增減。 QP 0 1 2 3 4 5 6 7 8 9 10 11 12 step Q 0.625 0.6875 0.8125 0.875 1 1.125 1.25 1.375 1.625 1.75 2 2.25 2.5 QP 13 14 15 16 17 18 19 20 21 22 23 24 25 step Q 2.75 3.25 3.5 4 4.5 5 5.5 6.5 7 8 9 10 11 QP 26 27 28 29 30 31 32 33 34 35 36 37 38 step Q 13 14 16 18 20 22 26 28 32 36 40 44 52 QP 39 40 41 42 43 44 45 46 47 48 49 50 51 step Q 56 64 72 80 88 104 112 128 144 160 176 208 224 表 2.2 QP和 Qstep對應表
整個量化的步驟可以如(2.5 式)所示: (2.5) ) / ( ij step ij round X Q Y = 其中,Xij為經過整數轉換後在矩陣中的係數,Qstep為前頁所提到的量化參數,而 ij Y 為量化後經四捨五入的係數。
2.3
熵編碼
熵編碼的功用主要是去除編碼符號間的重複性,按照符號出現的機率,用預先設計 好的碼字去置換符號,而碼字的長度會和符號的出現機率成反比,以達成壓縮的功能。 在本節中,將詳述兩種熵編碼的演算法,而在 2.3.3 小節中將介紹關於兩種熵編碼的碼 率預估演算法。 2.3.1 內容適應性變動長度編碼法(CAVLC) CAVLC 的設計原理和視訊壓縮標準 MPEG-2、MPEG-4 所用的熵編碼是類似的 [20]。在轉換步驟中,不論採用的是離散餘弦轉換或是整數轉換,經過量化後的 4×4 的 殘餘值區塊之中,其係數值會出現一種特別的分布,即非零整數值會分布在區塊的左上 角,而左上角在物理意義上代表低頻的部份,相對的,區塊的高頻部份,即右下角的部 份,係數值的絕對值通常是比較小的,或是值都為零。 CAVLC 的壓縮原理是將一個 4×4 的殘餘值區塊以反向的之字型(zigzag)順序掃出, 將 16 個元素排成一維向量(1×16)。而這個向量可以用一些預先設計好的統計量來描述, 因為在解碼端可以利用這些統計量的值還原成原本的殘餘值區塊。這些統計量即為 CAVLC 定義的編碼符號。對於編碼符號,CAVLC 會根據相鄰區塊的統計值分布,適應 性地去選擇編碼表格來壓縮。在一個 4×4 的殘餘值區塊之中,CAVLC 需要的統計量和對應的編碼符號為: 編碼符號 統計量 coeff_token 非零係數的個數、連續 1 的個數 trailing_ones_sign_flag 連續 1 的正負號 level 非零係數的絕對值和正負號 total_zeros 非零係數間所夾的零的個數 (第一個非零係數和 最後一個非零係數之間) run_before 兩個非零係數間所夾的零的個數 表 2.3 CAVLC 所用的編碼符號和統計量 而它們的編碼順序則如下面圖 2.4 所示: 圖 2.4 CAVLC 編碼 4×4 殘餘係數區塊的流程圖
每一個編碼符號都有自己的編碼表格。在編碼每個符號時,除了要具備前面所列表 2.3 的統計量之外,在適應性地調整編碼表格時所用的參考統計量亦不同,如下面表 2.4 所示。也就是在編碼時,除了該編碼符號的值之外,其它同一個係數區塊內的編碼符號 值也會參考到,而也有可能要參考不同係數區塊內的編碼符號。 編碼符號 參考統計量 coeff_token MB 類型,上方和左方係數區塊的 非零係數的個數 level 同一矩陣編碼過的最大係數絕對值 total_zeros 非零係數的個數 run_before 剩下的係數間零的個數 表 2.4 編碼符號需要的參考統計量 CAVLC 編碼範例[1]: 圖 2.5 上面方格中為一個 4×4 殘餘係數區塊原始內容,經過反向之字形掃描的向量列在 下面,而 Bitstream 為壓縮結果。 圖 2.5 CAVLC範例 節錄自[1]
2.3.2 內容適應性二元算術編碼(CABAC)
下圖 2.6 是[17]中所提到的 CABAC 編碼流程圖,CABAC 在編碼的步驟上可以分為
三個步驟。這三個步驟分別為二元轉換、機率模型選擇、和最後由虛線所框起來的二元
算術編碼
。
CABAC 和 CAVLC 一個不同的地方是 CABAC 除了會去編碼量化過的 4×4殘餘係數區塊之外,也會對一些檔頭資料進行編碼,像是 MB 類型,移動向量,參考影 格等等。在本節中將詳細介紹 CABAC 的三個步驟。在我們的系統中,因為檔頭資料統 一使用 Exp-Golomb Coding 編碼,所以在這裡會著重在殘餘係數區塊的編碼。
CABAC 把基本的編碼符號稱為符號元素(syntax element,在圖 2.6 中簡稱為 s.e)。符 號元素在資料結構上可能是一個位元或是一個整數。經過二元化之後,符號元素將被轉 換成一個符號位元序列(bin string),該序列由符號位元所組成,而位元值為 0 或 1。 CABAC 編碼的方式則是以符號位元(bin)為單位進行編碼,每一個符號位元會有一個預 設的機率模型可以使用,符號位元在經過編碼後,會根據實際編碼的值去更新機率模型 的值。而機率模型預測的結果越準確,CABAC 就可以得到更高的壓縮效率。
圖 2.6 CABAC編碼符號位元的流程圖 節錄自[17]
2.3.2.1 二元轉換 因為符號元素在資料結構上可能是一個位元或是一個整數。所以並不是所有的符號 元素都要經過二元轉換。要做二元轉換的原因是因為 CABAC 對壓縮連續出現的相同 0 或 1 可以較佔優勢,所以當符號元素以原本的二進位表示時,其二元出現的機率較難以 預測時,即會進行二元轉換以轉換成適當的符號位元序列以方便機率模型預測,而會進 行二元轉換的符號元素在標準中是規定好的。 二元轉換的方式是將符號元素的值以另外一種二元的編碼來表示。編碼的內容皆為 0 和 1 的序列。而編碼的方式有下列六種。 Unary code 當符號元素的值為 n 時,所對應的 unary code 為由 n 個`1'和 1 個`0'所組成。
Truncated unary code
truncated unary code 轉換的規則和 unary code 很像。但是額外加了一個門檻值 x 當符號元素的值 n 小於 x,所對應的 truncated unary code 為由 n 個`1'和 1 個`0'所 組成。而當 n 大於或等於 x 時,則所對應的 truncated unary code 為由 x 個`1'所組成。
Fixed-length code
The kth order Exp-Golomb code
the kth order Exp-Golomb code 編碼方式見下面圖 2.7 [17]。
圖 2.7 合併Unary code 和the kth order Exp-Golomb code 的虛擬碼 [17]
Table mapping code
採用直接查表的方式轉換。 合併使用 一個符號元素中,分段使用上面兩種轉換方式。
2.3.2.2 基於內容的機率模型選擇
符號位元(bin)在編碼的時候,是由該位元採用的二元算術編碼方式來決定是否會使
用機率模型。在圖 2.6 中,當二元算術編碼的方式是採用 regular coding engine 時,才會 去為這個位元選擇機率模型。而採用 bypass coding engine 時,則不選擇機率模型。因 為 bypass coding engine 是用來編碼當符號位元序列(bin string)中,1 或 0 出現的機率接 近的情況,所以就直接以出現機率 0.5 猜測,而不使用機率模型。
預測機率模型表裡面存放的值為機率狀態(pstate)和符號位元的較高機率出現值 (valMPS,以下簡稱 MPS)。pstate 代表這個符號位元會出現 MPS 的機率,而 MPS 的內 容為 0 或 1,代表兩者中哪者出現的機率高。不同的符號位元可能會對應到相同的機率 模型位置,而該位置在標準中以機率狀態索引(ctxidx)表示。 在使用 CABAC 時,機率模型表的使用週期為 slice 定義的大小。在我們的設計中, 則是以一張畫面為使用週期。在每個使用週期一開始,必須以畫面的 QP 值和畫面型態 去重設機率模型表中存放的值。 在基於內容的機率模型選擇步驟中,對應一個進來的符號位元,必須根據它所屬的 符號元素去選擇 ctxidx 的計算公式。 例如:要編碼 coded_block_flag 的公式為(2.6 式) [8]: (定義:一個 4×4 殘餘係數區塊是否所有的元素皆為零) (2.6) ctxIdxInc et ctxCatOffs et ctxidxOffs ctxidx= + + 在這裡,ctxidxOffset 為 coded_block_flag 這個符號元素在機率模型表中起始的位 置,而 ctxIdxInc 為這個符號位元在符號位元序列中的位置對應值或是要參考係數區塊 的值去做調整,ctxCatOffset 則代表係數區塊類型的權重,如亮度區塊和彩度區塊所對 應的值即不同。 在下一個步驟的時候,會因為符號位元實際值和 MPS 的相同與否,去決定 pstate 的 增減與否,而改變後 pstate 和 MPS 必須再記錄回機率模型表之中,以達到隨內容更新的 作用。
2.3.2.3 適應性二元算術編碼
二元算術編碼可以算是一種簡化的算術編碼。算術編碼在運作上必須先知道每個符 號的出現機率,而符號的出現機率可以對應到一個範圍。在編碼時,會一直遞迴地去更 新範圍,而這個範圍即是代表符號組合出現的機率。二元算術編碼是因為要編碼的符號 元素只有 0 和 1,所以整個更新的步驟可以大為簡化,因為更新的過程就是在原來的過 程中產生兩個新的範圍。在二元算術編碼中,也因為只會產生兩個新範圍,所以編碼的 方式就可以大為簡化,而不用像原始的算術編碼在記錄代表機率的範圍時,需要使用很 多位元數。 在標準中所規定的二元算術編碼,基本原理和上述的相同。下面的圖 2.8 可以代表 二元算術編碼每次在編碼時如何更新範圍。圖 2.8 中的 Range 和 Low 代表要壓縮一個 符號位元所需要的數值。Range 代表這個符號位元所在的區域,而 Low 所代表的則是整 個範圍的下界,所以 Range 和 Low 的總和即為整個區域的上界。CABAC 使用的編碼範 圍大小為[0~1023]。在前文所提到該符號位元對應的 pstate 和 MPS 即可以計算出這個符 號位元代表 MPS 和 LPS 的範圍,分別為 和 。LPS 指的是出現機率較小的 0 或 1,相對於 LPS 而言。 MPS R RLPS 圖 2.8 Range 和 Low 示意圖
這裡的RLPS可以由公式(2.7)所得到, PLPS紀錄的值即為 LPS 會發生的機率。RMPS亦然。
LPS LPS R P
R = × (2.7)
但是為了實現不使用乘法的演算法,所以 pstate 中紀錄的是預先定義好的機率狀態 值。在 CABAC 中,利用 pstate 和 Range 就可以查表得到現在的RLPS。而RMPS則是用
Range 減去RLPS就能計算出。二元算術編碼有三種運作方式,當符號元素中 MPS 和 LPS
兩者的出現機率相差較大時,則採用 encodeDecision 的方式,而當出現機率接近的時候 則使用 encodebBypass 的方式。下圖(2.8)和圖(2.9)是定義在[8]中,二元算術編碼使用 encodeDecision 方式的流程圖。另兩種列於後頁。
圖 2.10 Renormalization流程圖 節錄自[8] 在圖 2.9 中,第一個方塊即代表RLPS的查表過程。在計算出RLPS和RMPS後,就可以 根據現在要壓縮的符號位元和機率模型中紀錄的 MPS 是否相同來進行編碼。當兩者相 同的情況發生時,也就是猜對的情況,則新的範圍會被RMPS取代,反之猜錯則由RLPS取 代。而新的 Low 也必須一起更新。而圖 2.10 則是代表在圖 2.9 中 Renormalize 區塊的流 程圖。 為了讓在壓縮每一個符號位元時,所用的 Range 和 Low 都能在保持在定義好的區 間中,所以在圖 2.9 中,上半段的步驟已經按照更新了 Range 和 Low,且必須讓新的 Range 和 Low 回到合理的範圍。Range 合理的範圍為[256~512],而 Low 則是[0~1023]。 在圖 2.10 中,會先判斷 Range 是否大於 256,小於 256 時,就會進行 Renormalize 的步 驟,而這也是 CABAC 輸出位元的機制。當整個編碼範圍確保完全落於上半區間時,即
Range 小於 256,而 low 大於 512 時,即會輸出 1,反之則輸出 0。當上下區間都有接觸 到時,則讓未來輸出位元長度(bitsoutstanding)加 1。 接下來介紹剩下的兩種運作方式,當符號元素中 MPS 和 LPS 兩者的出現機率相差 較小時,即兩者的機率都接近 0.5 時,則採用 encodeBypass 的方式。當符號位元採用 encodeBypass 的方式編碼,則不需要選擇機率表格,而當定義的 CABAC 編碼範圍要結 束時,則採用 encodeTermination 的方式。下面的圖 2.11 和圖 2.12 為 encodeBypass 的流 程圖和 encodeTermination 的流程圖。兩者進行的流程和圖 2.9 類似。 圖 2.11 適應性二元算術編碼 (encodeBypass) 流程圖 節錄自[8]
2.4 碼率預估 (rate estimation) 的文獻回顧
在我們設計的演算法中,因為要同時在壓縮的步驟中使用 CABAC 和 CAVLC,但 是又只需要知道壓縮完的資料量就可以更新模型,所以我們可以選擇在壓縮一張畫面時 只真正執行其中一個,而另外一個熵編碼就採用碼率預估的方式取得壓縮完的資料量以 減少計算時間上的消耗。另外,因為猜測的準確度會影響到切換模式,所以在我們的設 計上,也必須同時兼顧猜測的準確性。 在[21]、[22]、[23]這三篇論文中,都有提到要怎麼去猜測一個殘餘係數區塊經過熵 編碼後的資料量。[21]是針對 CAVLC 的資料量猜測,而[22]和[23]則是針對 CABAC 的 資料量猜測。這三篇提出壓縮資料量猜測的原因都是為了去減少執行 rate distortion optimization (RDO)的時間。RDO 執行的方式如下:在 H.264 中,因為一個 MB 定義了 16 種的變動尺寸大小區塊切割模式,而要選擇最佳的模式,根據 Lagrange optimization theory ,必須利用每一種切割模式會產生的誤差和實際編碼量去計算代價函數(cost function)的值,而以模式能有最小的代價函數為所選定的模式。但是為了求出實際編碼 量,殘餘係數區塊必須經過所有的編碼步驟,這樣會太消耗時間,所以在熵編碼的步驟 上,就有一些研究提出了關於壓縮資料量的猜測方法。 在[21]中,預估殘餘係數區塊經過 CAVLC 壓縮後資料量的方法,也是要先求得在 CAVLC 執行時需要的編碼符號。在利用[21]所提出的(2.8 式)去計算殘餘係數區塊壓縮 後的資料量。在(2.8 式)裡,R 為預估的資料量, 為區塊中的非零係數個數, 為最 1 c T Tz 後一個非零係數前的零的個數, 為所有非零係數值的絕對值總和,而 為非零係 數出現的順序,從低頻往高頻的方向排,從 開始。 l SAT fk∑
=+
+
+
=
Tc k k l z cT
SAT
f
T
R
13
.
0
(2.8) 這個方法等於是將編碼表格中的編碼資料長度和統計量的關係簡化成函數。雖然可 以表達出兩個不同矩陣壓縮完的資料量變化,但是這個方法在預估不是用查表編碼的編 碼符號上,如 Level,會有比較大的預估誤差,而 Run_zero 的部份用固定權重係數 0.3 在某些情況下也會有預估誤差。 在[22]中所提出的猜測方法是利用原始的熵定義。上一節中,我們列出了用 CABAC 編碼一個 4×4 係數矩陣所需要的編碼符號。而[22]所提出的方法是:在編碼單位都經過二 元化之後,會變成符號位元序列。對同一個編碼符號所產生的序列而言,去統計出每個 序列中出現的 0 和 1 分別的個數,就可以計算 0 和 1 在這個序列中發生的機率,再利用 (2.9 式) 和(2.10 式)算出兩者等效的編碼位元數,最後再利用(2.11 式)就能計算這個位元 序列的編碼量。每個編碼符號都按照這個方式計算就可以預估整個殘餘係數區塊資料 量。在(2.9~2.11 式中),R 為預估的資料量, 為位元序列編碼「1」的編碼代價,而 為編碼「0」的代價。 zero B one B ) 5 . 0 ln( / ln log2 zero zerozero P P B =− = (2.9) ) 5 . 0 ln( / ) 1 ln( zero one P B = − (2.10) one one zero zero N B N B R= × + × (2.11) 在[23]中所提出的方法,同樣需要對應的編碼符號。和[22]不同的是,[23]的方法對 應 不 同 的 編 碼 符 號 必 須 使 用 不 同 的 預 估 公 式 。 對 significant_coeff_flag 和 last_significant_coeff_flag 這 兩 個 編 碼 符 號 來 說 , 使 用 (2.12 式 ) , 而 對
coeff_abs_level_minus1 來說,則使用(2.13 式)。編碼符號的定義請參閱[8]。(2.13 式)的 使用會根據預先定義好的門檻值,而門檻值由(2.14 式)和(2.15 式)決定。在[22]和[23]中, 對於 coeff_block_flag 都是直接用一個數字猜測,因為它的資料長度只有 1 位。而 coeff_sign_flag 則不需要猜測,因為壓縮完的資料等於原本的資料量。 (2.12) 5 . 1 , 1 _map = z× z + sm× s z = sm = s C N C N C C R
∑
= =total coeff i i L Est R _ 1 ) ( (2.13) ⎩ ⎨ ⎧ ≤ = otherwise T L if L avg L L Est ) ( ) ( (2.14) ⎩ ⎨ ⎧ > = otherwise QP T 15 8 5 (2.15)2.5 位元率控制 (rate control)
在一個壓縮的系統中,因為進入熵編碼端的資料流量是固定的,但是壓縮所產生的 輸出資料量卻會隨著畫面的內容而變。為了不讓輸出的資料量長度造成緩衝器資料超過 範圍或是沒有資料被讀取,必須使用位元率控制來讓編碼完的位元率達到我們所要求的 值。下面將介紹所使用的位元率控制演算法[24]。 在[24]中提出了配合 H.264 技術的位元率控制演算法,位元率控制的最小單元稱為 basic unit。basic unit 由任意個 MB 所組成。在我們的設計中,basic unit 將設定為整個畫 面。位元率控制演算法的完整步驟如下:
1. 使用 fluid traffic model 和 linear tracking theory [25]去計算當前面的編碼預算。先利用 系統每秒輸出的位元率和畫面數去計算整個畫面群組(GOP)擁有的預算。然後在壓縮 每一張畫面後,計算出目標的緩衝器佔有率。利用這兩項值去計算當前畫面的編碼 預算。
2. 如果設定 basic unit 小於整個畫面的話,把剩餘的預算平均分配給目前畫面中剩 下的 basic unit。
3. 利用前一個畫面中,相同位置 basic unit 的平均絕對值誤差總和(MAD),去猜測 目前 basic unit 的 MAD
4. 使用quadratic R-D model [26]、[27]去計算出壓縮這個basic unit需要的 QP
第三章 熵編碼模式切換演算法的設計
在本章中,我們將介紹熵編碼模式切換演算法。為了使用一個完整的輕量級視訊 壓縮系統進行演算法的模擬,前端的畫面內估測,轉換和量化等步驟將使用[15]的系統 設計。在 3.1 節將簡述之前研究在畫面內估測的改良。3.2 節將介紹合併位元率控制之 後的熵編碼模式切換演算法。3.3 節為碼率預估演算法的深入分析。
3.1 畫面內估測模式的簡化
在
[15]的研究之中,我們已經提出了一個輕量級視訊壓縮系統編碼器。為了節省功 率的消耗,所以我們選擇只採用畫面內估測的方式,而完全不使用畫面間偵測。在我們 的系統中,最小的編碼單位為 4×4 的殘餘係數區塊。但是因為 bayer pattern 格式包含四 個間隔的資料要分別做壓縮,所以每次從記憶體中讀取的大小為 8×8 的區塊,而讀取出 來的資料要再重新整理成四個不同顏色的平面,如圖 3.1 所示。而 G1 平面和 G2 平面 因為資料的相關性很高,所以在分析的過程中,兩者的表現也很接近。 圖 3.1 bayer pattern 影像的資料重排3.1.1 DC 模式
如 2.2.1 節所提到的,對於 4×4 的殘餘係數區塊,畫面內估測有 9 種模式可以使用。 在[15]的研究中,我們先證明了在打開 RDO 之後,使用所有尺寸的畫面內估測和只使 用 4×4 的 9 種模式,在我們使用的輸出位元率下,兩者的表現是很接近的。而只使用 8×8 的模式反而相差的比較遠,所以先拿掉 8×8 的模式,以節省功率消耗。接下來,再使用 4×4 的 9 種模式和只用 4×4 的 DC 模式做比較。DC 模式是利用相鄰區塊的值取平均後 所得的值去建立預測區塊,如圖 2.3 的 mode 2 所示。而這個區塊的特性是每一個元素 都是計算出的平均值。在經過分析後發現到在三個顏色平面的模擬中,兩者的 PSNR 差 距在使用的位元率下都小於 0.3 dB,因此我們只用 DC 模式來執行畫面內估測。
3.1.2 重建 G1 模式
同樣在[15]的研究之中,我們也提出重建 G1 模式。這個模式建立的原理是利用 G1 平面和 G2 平面兩者資料的相關性很高。在圖 3.1 中,右上方的 G1 區塊經過整個編 碼流程之後,會計算出一個新的重建區塊給下一個要編碼的 G1 區塊去當作預測參考。 而這個重建區塊和左下方的 G2 區塊資料關聯性很高,所以用這個重建區塊去當作 G2 區塊的預測矩陣應該可以猜的更準,也就是讓殘餘資料量變的更低,同時 G2 區塊可以 節省下重建的步驟。圖 3.2 為在[15]中分析 G2 區塊使用 DC 模式和使用重建 G1 模式的 R-D 曲線比較圖。在 PSNR 值為 40dB 時,兩者的差距大約 0.6dB。
圖 3.2 兩種模式的R-D 曲線比較圖 節錄自[15]
3.2 熵編碼模式切換演算法
在本節中,我們會提出一個切換熵編碼模式的演算法。這個方法將利用 2.5 節中所
提到的位元率控制演算法計算需要的資訊。在壓縮每一張畫面之前,先計算出當前畫面 的編碼預算,再利用 rate-QP model(R-Q model) 去計算出要符合畫面預算需要的 QP 值, 而對兩種不同的熵編碼模式則會各算出自己對應的 QP 值,在將兩者 QP 值的差異對應 到 PSNR-Q model 上,計算出用兩種模式壓縮對畫質的影響。在根據畫質差是否有超過 預設值而在兩者間切換。我們選定去判斷切換的預設值為 0.5dB。下面圖 3.3 代表我們 在影像中執行熵編碼模式切換演算法的步驟
圖 3.3 熵編碼切換演算法的流程圖
在[24]的位元率控制演算法中,如果選擇一張畫面為基本單位(basic unit),那整個 控制流程會分成兩個層面進行控制。這兩個層面分別為 GOP 層控制和 frame 層控制, 我們為了保留使用 GOP 層控制的優點,和減少碼率預估的時間消耗,所以將 N 張畫面 組成一個 group。我們預設的 N 值為 4,以方便於硬體實現時執行除法運算。
整個演算法最外圍以 group 為單位執行。而在每個 group 中,才針對每張畫面進行 模式切換,所以同一個 group 中的畫面不一定會使用同一個熵編碼模式。在圖 3.3 中, 一開始執行的 initialize model 步驟是為了計算 R-Q model 和 PSNR-Q model 的係數初始 值並設定。而因為 initialize model 步驟在整個編碼流程中只會執行一次且為了在編碼第 一個 group 時就可以切換模式,所以實際上這個步驟將預先執行好,而不會放在系統 中。圖 3.4 和 圖 3.5 兩個流程圖則分別代表在圖 3.3 中的 group layer 和 frame layer 步驟。 在接下來的小節中,將依序對流程圖中的每個步驟進行介紹。
3.2.1 畫面編碼預算的計算 在[24]所用的 GOP 層控制中,在每個 GOP 前兩張壓縮的畫面,不會為畫面計算編 碼預算,而是第三張畫面後才開始計算。GOP 層控制主要的目的為: (1) 根據一個 GOP 中包含的畫面張數,利用每張畫面可以用的編碼量來為整個 GOP 設定壓縮量預算。(2) 當編碼畫面屬於另一個 GOP 時,前一個 GOP 如果有多餘的預算編碼量或是多用了預算 編碼量,可以把這個量傳遞給下一個 GOP,以符合位元率控制。(3)為了讓輸出位元率 在控制時,值不會太過劇烈變動,前一個 GOP 每張 P 畫面所用的 QP 值會被記錄下來, 最後算出的平均單張畫面 QP 值會成為下個 GOP 前兩張畫面的初始 QP 值。 在我們的演算法中,因為沒有使用畫面間估測,因此所有的畫面都屬於 I frame。所 以在我們的設計中,就沒有 GOP 的區別。但是為了保持上面所列出的三項優點,所以 我們利用 GOP 的觀念將 N 張畫面組成一個 group。除了第一個 group 使用預設的 QP 當 作初始值,之後其他的 group 則同樣採用上述的方法傳遞資料,如圖 3.4 所示。這樣設 計可以讓後面的 group 可以利用前面留下來的多餘預算或是在這個 group 必須降低預 算。上述的方法簡化後的公式如(3.1 式)和(3.2 式)所示。 ) ( ) 1 ( ) ( i group group r i group N R F n u R + = × + (3.1) group i i group N I QP sum QP (+1) = ( ( )) (3.2)
在(3.1 式)和(3.2 式)中,下標的 group(i+1) 表示影片中預編碼的第 i+1 個 group,所
以 代表第(i+1)個 group 在這個 group 開始編碼時的預算編碼量, 為上一
個 group 經過編碼後剩下的預算編碼量。 為輸出頻寬,單位為 bits/s。 為每秒壓 ) 1 (i+ group R Rgroup(i) ) (n u Fr
縮的畫面張數,單位為 frames/s。而 為定義一個 group 內的畫面數。 為第
(i+1)個 group 的初始 QP,這個 group 的第一個畫面將使用 QP 進行量化。 為
第 i 個 group 內每張畫面所用的 QP 值總和。 group N QPgroup(i+1) )) ( (QP Ii sum
在圖 3.5 中,frame layer 第一個步驟就是要去判斷現在要編碼的畫面是否為該 group
中的第一張畫面,如果是的話,就直接用 去壓縮,而此時不進行熵編碼模式切 換的選擇。在第一張畫面中要同時執行 CAVLC 的編碼和 CABAC 的碼率猜測。這是為 了避免前一個 group 如果都選擇了相同的熵編碼模式,則另一個模式的 R-Q model 將失 去更新的機會,而這也會讓模型和實際值的誤差隨著沒被挑選中而越大。所以為了在每 一個 group 中,兩種熵編碼模式都至少能更新一次模型,所以要在第一張畫面得出兩種 熵編碼的碼率以對兩種模式的 R-Q model 進行更新。但是實際上只需要執行一種熵編 碼,所以我們選擇執行 CAVLC 的編碼和 CABAC 的碼率猜測,因為這種組合的模擬時 間會小於 CABAC 的編碼和 CAVLC 的碼率猜測。當畫面不為 group 中的第一張時,則 要進行熵編碼模式切換的選擇,而此時必須計算出當前畫面的編碼預算,group 的設計 如圖 3.6 所示,在 group 中的第一張畫面要執行兩種熵編碼模式,而後面的畫面則只需 要執行選擇的熵編碼模式。 ) 1 (i+ group QP 圖 3.6 group layer 的設計
在計算畫面的編碼預算時,我們利用[24]中演算法的第一個步驟。這個步驟在執行 上要先使用預先設定好的虛擬緩衝器。接下來,再定義兩個描述緩衝器內資料狀態的變 數: target buffer level(Tbl)和 actual buffer occupancy( ),兩個值的單位皆為 bits。Tbl代
表的是位元率控制預期達到的緩衝器佔有率,而 則是實際上緩衝器的佔有率。在編碼 完 GOP 中第一個 P 畫面的時候,Tbl會被重設為 ,這時 的值代表前兩張畫面在緩 衝器內的佔有量。接下來在編碼每一張 P 畫面之後,Tbl會每張逐次的減少,以回到 0 的值,這代表希望在編碼完這個 GOP 之後,緩衝器可以將資料清空。在我們的設計中, 同樣也以這兩個變數來描述編碼資料在虛擬緩衝器中的狀態。 c B c B c B Bc 因為我們使用 group 的設計,所以在編碼完第一張畫面後,就可以重設預期的緩衝 器佔有率 。再利用修改後的(3.3 式)、(3.4 式)、(3.5 式)就可以計算出當前畫面的編碼 預算。(3.3 式)是利用緩衝器佔有率去估算編碼預算 Tbl ) ( ~ i n f ,而(3.4 式)是利用整個 group 所具有的編碼預算平均分配給剩下的畫面去估算單張畫面的編碼預算 。3.5 式則是 以前兩式的加權平均作為計算出的編碼預算。 ) ( ˆ i n f )) ( ) ( ( 5 . 0 ) ( ) ( ~ 1 1 − − − − = c i i r i B n Tbl n F n u n f (3.3) N n R n f i group i ) ( ) ( ˆ = (3.4) ) ( ˆ 5 . 0 ) ( ~ 5 . 0 ) (n f n f n f = + (3.5) 上面三個公式中,n 代表目前要編碼的畫面。 和 為上一張畫面編碼 過的在虛擬緩衝器中的佔有率。 為上一張畫面編碼過剩下的 group 編碼預算。 為 group 中剩下的未編碼畫面數,包括當前要編碼這一張。 ) (ni−1 Tbl Bc(ni−1) ) ( i−1 group n R N
3.2.2 QP 的計算
在利用位元率控制演算法計算出當前畫面的編碼預算後,接下來,必須去計算這個
編碼預算在兩種熵編碼模式的等效 QP,如圖 3.5 所示。而要計算出兩種熵編碼模式的 QP,必須使用 R-Q model。R-Q model 是描述壓縮演算法在選擇不同的 QP 去壓縮時所 對應的編碼量的關係。
在[24]中所使用的 quadratic R-D model 在 R-Q domain 上可以表示為(3.6 式)。在(3.6 式)中,R 代表編碼後的資料量,而 a 和 b 為二次模型的兩個係數。而以(3.7 式)則可以 從單張畫面的編碼預算 R 得出 QP。 2 QP b QP a R= + (3.6) R bR a a QP 2 4 2 + ± = (3.7) 但是考慮(3.6 式)和(3.7 式)計算時和硬體實現上的複雜度,且二次曲線模型在以線 性迴歸的方式更新模型係數時,需要比較多的計算量,而且針對兩種熵編碼模式都必須 分別計算模型係數,所以在此功率的消耗必須倍增。而且在[28]、[29]中,都有提出使 用線性模型去取代二次曲線模型的想法。而在[28]中,更提出在線性模型中,使用 domain 會比 domian 更為準確,所以我們打算使用 step Q QP R−Qstep線性模型去計算。 step Q R− 線性模型如(3.8 式)所示。 b Q a R step + = (3.8)
所以從單張畫面的編碼預算得出 的方式如(3.9 式)所示。而兩種熵編碼模式將各自 由自己的 model 計算 。 step Q step Q R− Qstep b R a Qstep − = (3.9) 在 2.2.3 節中,已經介紹過 QP 和 的關係。從(3.9 式)得出的 可以直接以表 2.2 換算等效的 QP 值。QP 代表量化表的順序,從 0 開始到 51 結束,總共 52 個值,每 個值對應一個 ,也就是實際上的量化數,兩者間可以互換。從表 2.2 中可以看到, 當 QP 小於 4 時, 將小於 1,而 等於 1 時的壓縮量,已經近乎於無損壓縮的資 料量,為了讓壓縮後的資料量不在上昇而增加功率消耗,而且此時與 PSNR 值的關係 變成難以用線性模型描述,所以我們在使用上,不會用到 QP 小於 4 的四個值,所以有 效的 QP 個數為 48。實際上在計算時,都是用 去計算,不過因為 的值為非線性 變化,而 QP 值為線性變化,所以在描述內容和顯示結果時,都是用 QP 值表示所用的 值。 step Q Qstep step Q step Q Qstep step Q Qstep step Q 我們定義在線性模型上以 QP 值 52 對應的資料量為 ,而 QP 值 4 對應的資料 量為 。 和 是用來處理當編碼預算不在這兩個值之間時,即當編碼預算大於 max R min R Rmax Rmin max R 或小於Rmin,則所得出的 QP 值分別為 52 或 4。
3.2.3 PNSR 差值的計算 在我們的切換演算法中,定義兩種熵編碼模式壓縮完的PNSR 要相差 0.5dB 以上才 會進行模式的切換。在圖 3.5 中,PD 代表兩者壓縮後的 PNSR 差值。在前兩小節中, 我們利用位元率控制演算法根據輸出頻寬計算出單張畫面編碼預算,然後再用R−Qstep 線性模型算出需要的 QP 值,而兩種熵編碼會根據自己的線性模型計算出對應的 而這個 QP 值剛好可以拿來計算兩者壓縮後的 PNSR 差值。 QP 值。 在壓縮演算法中,QP 值會設計成和壓縮完的 PNSR 值成線性關係[30],所以我們 同樣只要用一個簡單的線性模型來描述,如(3.10 式)所示。而對同一張畫面來說,當使 用的 QP 值固定,不管熵編碼使用的模式為何,都不會影響到壓縮後的 PNSR 值。所以 在切換演算法中,只需要使用一個 PNSR-QP 模型。 d QP c PSNR= × + (3.10) 當兩種熵編碼算出的 QP 值分別為 和 ,則兩者的差值可以(3.11 式)表示。 於 ,只 bac QP QPvlc 從(3.11 式)可以得知當兩者 QP 值相差大 1 時 要當 a 值大於 0.5 時,即代表 PNSR 差值大於 0.5 dB。 ) (QPbac QPvlc c PD= × − (3.11)
因為 CABAC 的壓縮表現比 CAVLC 優異,所以 CABAC 的 R-D 曲線會在 CAVLC 的上方,即使用固定 QP 值壓縮,畫面熵編碼模式採用 CABAC,壓縮後的 PNSR 值會 大於等於 CAVLC 的 PNSR 值。所以(3.11 式)是用QPbac−QPvlc表示兩者的 QP 差值。在
我們演算法的設計中,會在 initialize model 步驟中預設一個初始的熵編碼模式,因為 group 中的第一張畫面不做編碼模式切換,所以在第一個 group 的第一張畫面,即使用 預設的熵編碼模式編碼。而之後除了每個 group 的第一張畫面,則都會進行編碼模式切 換。當 PNSR 差值大於 0.5dB,表示 CABAC 在當前頻寬下,壓縮的畫質可以顯著提昇; 而當 PNSR 差值小於 0.5 dB,為了節省時間,則將編碼模式保持在 CAVLC。 3.2.4 模型係數更新 圖3.5 的流程中,在壓縮完每一張畫面後,要對三個線性模型進行係數更新。分別 為兩種熵編碼分別的R−Qstep模型和共同使用的PSNR−QP模型。更新的方式是將過程 中記錄的固定筆的資料 迴歸去計算模型係 PSNR−QP模型(3.10 式)為 例,係數 a,b 更新的公式如(3.12 式)、(3.13 式)所示。P 為每張畫面壓縮時的i PSNR 值, 而QP 為量化使用的i QP 值,n 則為記錄的資料個數。 用線性 數[31],以
∑
∑
∑
∑ ∑
− − = n QP QP n QP P QP P c i i i i i i 2 2 ( ) (3.12) P aQ P QP a P n d = 1(∑
i −∑
i)= − (3.13) 錄資料更新的方式則像是 FIFO 緩衝器的運作,如圖 3.7 所示。 記圖 3.7 資料更新方式 以 模型為例,假設我們的系統存 n 筆資料,對熵編碼模式的線性模型來說, 每一筆資料代表畫面序列實際壓縮後的(R, )資料。在 initialize model 步驟中,即會 把 n 筆資料放滿,而同時也計算出初始模型係數值。在壓縮的過程中,當壓縮完一張畫 面後,新的(R, )資料會存放在第一個位置,而第 n 個位置的資料會被第 n-1 個位置 的資料覆蓋,所以第 n 筆的資料等於被拋棄。在資料更新完畢之後,即利用被記錄的這 n 筆資料去計算模型係數。我們預設的 n 為 8,為 2 倍 group 內包含的畫面張數。 step Q R− step Q step Q 3.2.5 線性模型的硬體實現分析 在前三小節中,我們在利用(3.9 式)計算 QP 和(3.12 式)更新係數時,都會需要浮點 數的除法器,為了減低演算法以硬體實現的成本,所以我們使用查表的方式來取代除法 的運算。在R−Qstep模型的計算上,我們使用 R-QP model 記憶體來取代,如圖 3.8 所示。 兩種熵編碼都需要自己的 R-QP model 記憶體。以一種熵編碼來說明,我們的記憶 體的位址為 52,代表 52 種 QP 值的變化,不過實際上只使用 48 種 QP 值。而每個位址 會紀錄 N 筆的 R 值,N 為同一個 QP 值之下要紀錄的資料數,而 R 為畫面以該 QP 值實 際壓縮的資料量。
圖 3.8 R-QP model 記憶體 所以這個記憶體的使用方式為,在演算法實際執行前,我們先收集畫面在48 種 QP 值壓縮下的 R 值以當作記憶體的預設值。而每次壓縮完,則將壓縮量 R 儲存到對應的 QP 位址,儲存的方式和圖 3.7 的方式相同,所以只會儲存最近的 N 筆資料。每次儲存 完之後,會針對每個 QP 值內儲存的資料取平均。平均完的資料則用來為編碼預算選擇 要使用的 QP 值。和 3.2.2 節相同,我們同樣要先計算畫面的編碼預算,在將編碼預算 和平均後的 52 個資料做比較,以相差最少者對應的位址為選定的 QP 值,而兩種熵編 碼同樣都以這個方法得出對應的 QP 值。 1 2 3 13.34% 10.58% 18.88% 表 3.1 記憶體所造成的切換誤差率 表3.1 為使用 R-QP model 記憶體進行切換和實際以(3.9 式)計算兩者的模式切換誤 差,可以發現在 3 個測試影像中所造成的平均誤差約 14%,從第四章的模擬結果來看, 這個模式切換誤差是可以接受的,因為對整體的結果沒有造成很大的影響,而且可以省 去使用浮點數除法器。當記憶體的 N 取 4,而畫面壓縮最大資料量為 1M (bits/frame)時, 需要的記憶體大小為 2×48×4×20,約為 0.94 KB。但是因為在位元率控制中,畫面編碼 預算的變動量約為±50%之間,所以以頻寬 250k bits/frame 為例,需要的記憶體大小為
2×10×4×20,約 0.2 KB。 而在 PSNR-QP 模型的計算上,我們使用 PSNR-QP table 來取代,如圖 3.9 所示。 當要判斷 PD 有沒有大於 0.5 時,其實不需要把c的值很準確的算出來,而是只要知道c 的值乘上多大的整數可以大於 0.5 即可,我們將這個整數定為 M,利用(3.14 式)可以計 算 M 值,所以模式切換的判斷變成如(3.15 式)所示。 ) / 5 . 0 ( c ceil M = (3.14) (3.15) CAVLC else CABAC ) -QP (QP if M bac vlc = = ≤ mode mode 圖 3.9 PSNR-QP table
PSNR-QP table 的建立,是將圖片以預測後的 SATD 值去分類圖片。將 SATD 值分 成數個區間,而同一個區間內的圖片則使用相同的 PSNR-QP table。PSNR-QP table 在每 個區間中要為 52 個 QP 值建立預先計算好的 M 值。在這裡,M 的紀錄大小為 0~4。0 代表此處的等效 PSNR 已經大於 50 dB 以上,不進行模式的切換,而 M 值出現 4 以上 的機率很低,所以 4 以上的情況都化簡以 4 表示。PSNR-QP table 的使用方式為利用畫
面實際壓縮時的 SATD 值去選擇對應的表格,在用兩種熵編碼對應的值去選擇 M 值, 當選擇出的 M 不同時,以較小值為主,這樣做的理由是 M 值出現較小值的機率會比較 大值高。 4 8 16 32 64 128 SATD 0.1301 0.1271 0.1169 0.1141 0.103 0.104 表 3.2 SATD 分類區間數所造成的 M 值 MSE
表 3.2 為測試影像在不同 SATD 分類區間數下所造成的 M 值 MSE 變化。MSE 值的 計算為同一 SATD 分類下單一畫面的 M 值和整個區間的平均值計算的結果。我們最後 選擇的分類數為 16,因為分類數 8 到 16 是 MSE 減少最大的地方,而雖然分類數越大 可以造成 MSE 值的下降,但是分類數越大將直接導致表格變大,且 MSE 值的下降趨勢 漸趨於飽和。同樣在位元率控制中,QP 值的變動最大約為±10,所以實際的表格大小約 為 16×20×3,約為 1Kb。
3.3 熵編碼的碼率預估演算法
在這節中,將介紹我們設計的兩種熵編碼位元率預估演算法。在每一小節的最後面 將列出各種方法的預估 QP 誤差值和各種方法的速度。速度方面希望能盡量減少 CAVLC 的編碼和 CABAC 的碼率猜測兩者執行時間總合和 CABAC 執行編碼時間的比值,以真 實達到節省時間的效果。我們在兩種熵編碼所用的碼率預估演算法基本上也是要先去統 計出必要的編碼符號,再利用編碼符號實際上的值去換算出預估的壓縮位元率。3.3.1 CAVLC 碼率預估演算法
在第 2.3.1 節中,已經介紹過 CAVLC 編碼需要的統計量。這些統計量中,除了編碼 符號 level 之外,所有其他的編碼符號在壓縮時的編碼內容都可以透過查表而得。因此, 除了 level 之外,所有其他的編碼符號在我們的猜測方法中,也都是透過查表的方式去 得到編碼長度。而所有的表格,則依然參考[8]裡面所定義的表格。這樣做的好處是,在 之前的設計中[15],CAVLC 查表的部份原本就有紀錄編碼長度,所以如果這個碼率預估 演算法要以硬體實現,不會有任何額外的硬體消耗。 而 level 的部份,我們必須從實際壓縮殘餘係數區塊得到 level 的值,去計算出實際 的編碼長度為何。下面的表 3.1 是利用測試平台 jm11.0[18]實際編碼 level 的結果。使用 的 level 編碼參數 suffix_length 值為 0 到 3,而 suffix_length 值的整個範圍為 0 到 6。
Level suffix_length : 0 1 1 -1 01 2 001 -2 0001 3 00001 -3 000001 … … -7 00000000000001 ±8 ~±15 000000000000001xxxx ≧ ±16 0000000000000001xxxxxxxxxxxx Level suffix_length : 1 1 10 -1 11 2 010 -2 011 3 0010 -3 0011 … … 14 000000000000010 -14 000000000000011 15 0000000000000010 -15 0000000000000011 > ±15 0000000000000001xxxxxxxxxxxx
Level suffix_length : 2 1 100 -1 101 2 110 -2 111 3 0100 -3 0101 … … 29 00000000000000100 -29 00000000000000101 30 00000000000000110 -30 00000000000000111 > ±30 0000000000000001xxxxxxxxxxxx Level suffix_length : 3 1 1000 -1 1001 2 1010 -2 1011 3 1100 -3 1101 … … 59 000000000000001100 -59 000000000000001101 60 000000000000001110 -60 000000000000001111 > ±60 0000000000000001xxxxxxxxxxxx 表 3.3 suffix_length 值為 0 到 4 對應的 level 編碼結果 從四個表格中可看到,除了 suffix_length 值等於 0 的情況之外,其他三個表格皆會 在當 level 值大於某個門檻值之後,編碼長度即固定為 28,即表格中呈現灰色的部份。 而在小於門檻值時,則編碼長度會和 level 絕對值呈正比。而 suffix_length 值等於 0 時, 則具有兩個門檻值。表 3.4 列出不同 suffix_length 值之下,影響編碼值長度變動或固定 的 level 門檻值,意即當 level 小於門檻值時,編碼長度屬於變動值。 suffix_length level 門檻值 0 8 1 15 2 30 3 60 4 120 5 240 6 480 表 3.4 影響編碼長度的 level 門檻值
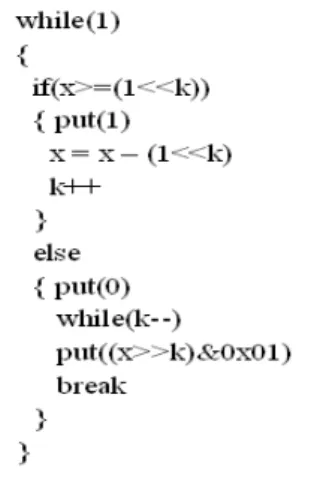
![圖 2.9 適應性二元算術編碼 (encodeDecision) 流程圖 節錄自[8]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8612096.190793/32.892.210.798.511.1043/圖29適應性二元算術編碼encodeDecision流程圖節錄自8.webp)
![圖 2.10 Renormalization流程圖 節錄自[8] 在圖 2.9 中,第一個方塊即代表 R LPS 的查表過程。在計算出 R LPS 和 R MPS 後,就可以 根據現在要壓縮的符號位元和機率模型中紀錄的 MPS 是否相同來進行編碼。當兩者相 同的情況發生時,也就是猜對的情況,則新的範圍會被 R MPS 取代,反之猜錯則由 R LPS 取 代。而新的 Low 也必須一起更新。而圖 2.10 則是代表在圖 2.9 中 Renormalize 區塊的流 程圖。 為了](https://thumb-ap.123doks.com/thumbv2/9libinfo/8612096.190793/33.892.185.806.109.670/節錄自相同來進行編情況發生時也就是猜對情況範圍須一起更新為了.webp)
![圖 3.2 兩種模式的R-D 曲線比較圖 節錄自[15]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8612096.190793/42.892.189.733.130.723/圖32兩種模式的RD曲線比較圖節錄自15.webp)



![圖 3.18 CABAC 編碼率預測的 R-QP 關係圖 0 2000004000006000008000001000000 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 QPR(bits) CABAC CABCA_preCABAC_pp[22][23] (a) QP from 4 to 27 020000400006000080000 100000120000140000 28 29 30 31 32 33](https://thumb-ap.123doks.com/thumbv2/9libinfo/8612096.190793/78.892.135.804.164.480/圖CABAC編碼率預測的關係252627QPRbitsCABACCABCApreCABACpp2223aQPfrom4to26.webp)