國
立
交
通
大
學
運 輸 科 技 與 管 理 學 系 碩 士 班
碩 士 論 文
旅次分配推估方法之研究
研 究 生:李亦晴
指導教授:卓訓榮 教授
中
華
民
國
九
十
八
年
七
月
旅次分配推估方法之研究
Estimation Of Trip Distribution
研究生:李亦晴 Student:Yi-cing Lee
指導教授:卓訓榮 Advisor:Hsun-Jung Cho
國立交通大學
運輸科技與管理研究所
碩士論文
A Thesis
Submitted to Institute of Transportation Technology and Management
College of Management
National Chiao Tung University
In
July 2009
旅次分佈推估方法之研究
研究生:李亦晴 指導教授:卓訓榮
國立交通大學
運輸科技與管理研究所
摘
摘
摘
摘 要
要
要
要
運輸規劃中,交通起迄流量是基本且重要的資料,傳統的調查方法大 多費時耗力且成本高,然而在交通流量大時,進行母體調查並不容易;本 研究目的在利用可獲得資料推估交通旅次起迄資料,交通量的產生源自於 運輸需求,然而,運輸需求是一種衍生需求,意即運輸並非旅行者真正目 的,旅行者是為達成某種社會經濟活動而產生對運輸的需求;在古典引力 模式中,僅探討可量測的變項,如:人口分佈、相異兩質點的距離,但是, 交通旅次產生的潛在需求是不易被量測的,更重要的是,這種不易被量測 的潛在需求正是交通量產生之泉源。本研究嘗試利用數學式來描述這些抽 像的變項,建構一個可推估旅次資料的引力模式。 本研究亦對以路段資訊反推高速公路起迄表之可行性進行研究探討, 構建以路段資訊推估高速公路旅次起迄分佈矩陣之模式,並以國道一號沿 線北自汐止、南至岡山的電子收站資料作模式驗證,以暸解模式之可行性, 希望藉此避免傳統調查方法之困難又可獲得可靠的高速公路車輛起迄 表。Estimation Of Trip Distribution
Student: Yi-cing Lee Advisor: Hsun-Jung Cho
National Chiao Tung University
Institute of Transportation Technology and Management
Abstract
In transportation planning, traffic flow of origin-destination is an vital and basic data. Traditional survey method expend a large number of labor power and material resources, the more important thing is that it's not easy to survey population while the traffic flow is large. The aim of this study is to modify the classical gravity model, and to use available data estimating origin-destination trip matrices. Traffic is based on transportation demand, however, transportation demand is a derived demand. It means that transportation is not the main purpose of traveler, the traveler requires transportation because of they want to achieve some economics activity. In classical gravity model ,it merely discuss the measurable variable, it doesn't care about the unmeasurable variable, like population , distance between origin and destination. But, the potential demand producted by transportation is uneasy to be measure, the more critical is that the potential demand it is a source of traffic. This study use mathematical-type to describe the abstract variables, and provide a model for estimating highway trip matrices. Another, this study develop a model for estimating based on link information as well. Finally, using available data to realize the feasibility of the model in this study.
誌謝
誌謝
誌謝
誌謝
感謝眾人的支持與協助,得以完成本文。首先,感謝恩師 卓訓榮教授, 在這兩年來亦步亦趨的指導與訓練,使得學生在研究上能夠有小小的成果; 並且在邏輯思考層面上,獲得此生受用不盡的概念。論文口試之際,感謝 韓復華教授與周幼珍教授,在百忙之中撥冗細審,並提供諸多建議與指教, 使本論文漸臻完備,在此表謝忱。 感謝實驗室的所有成員,謝謝昱光學長、健綸學長在研究以及人生觀上 面的指導與分享;謝謝黃恆學長、日錦學長、嘉駿學長在執行雷達計畫案 的協助與共患難;謝謝如君陪伴我研究所這兩年,以及一同前往北京當交 換學生互相扶持的日子,謝謝同學老總、猴給、建嘉在學業上給予我的支 援,以及生活上的協助,你們都是我研究生活上不可或缺的同伴;感謝學 弟志霖、學妹怡婷,因為有你們的加入,讓實驗室更顯活耀;感謝已畢業 的學長姐:宜珊、之音以及小捲,雖然只共處了一年,但因為你們的關心與 熱心,讓碩一甫進實驗室的我備感溫馨。 感謝在新竹的朋友,永泰、阿邦、冬瓜、阿振、筱雯,因為有你們,讓 我在新竹的日子能夠精采有趣,特別是永泰在研究程式上不厭其煩的講解, 因為你的協助與支持,使得我得以順利畢業。另外,還有我的高中同學們, 對初到新竹的我照顧有加,以及大學同學們,尤其是球,在閒暇之餘互相 關心、互吐苦水。 最後,感謝父母二十幾年來一路上無私的付出,因為你們的支持,不論 我何時能畢業,只為完成我去北京交換學生想法,得以無憂的學習與拓展 視野;因為你們的支持,而得以在無慮的情況下完成學業;因為你們的支 持,得以一路上選擇我自己想走的路,即便有時多轉了幾個彎兒,你們總 是說「沒關係!」,簡短的一句話,囊括無限的包容,這對我而言,絕對是 莫大的支持與動力,使我能繼續向前;還有哥哥的不具體卻是心中很踏實 的支持,使我得以完成學位。此時此刻的我,是滿足而開心的,謹以此文 獻給我的家人,因為你們對我的全力支持與付出而完成此文。衷心感謝! 李亦晴 謹誌 中華民國九十八年七月 于新竹
目錄
目錄
目錄
目錄
中文摘 中文摘 中文摘 中文摘要要要要 ... ii 英文摘要 英文摘要 英文摘要 英文摘要 ... iii 誌謝 誌謝 誌謝 誌謝 ...iv 表目錄 表目錄 表目錄 表目錄 ... viii 圖目錄 圖目錄 圖目錄 圖目錄 ... ix 第一章 第一章 第一章 第一章 緒論緒論緒論緒論 ... 1 1.1 研究動機 ... 1 1.2 研究目的 ... 2 1.3 研究方法及流程 ... 3 第二章 第二章 第二章 第二章 文獻回顧文獻回顧文獻回顧文獻回顧 ... 4 2.1 傳統車輛起迄調查方法之回顧 ... 4 2.2 車輛起迄推估模式 ... 6 2.2.1 極大熵模式 ... 6 2.2.2 引力模式 ... 7 2.2.3 干預機會模式 ... 10 2.2.4 引力-機會模式 ... 10 2.2.5 最大概似法 ... 11 2.2.6 最小平方法 ... 11 2.3 不完整資料之種類與處理 ... 13 2.4 統計上處理不完整資料的方法 ... 14 第三章 第三章 第三章 第三章 模式的建構模式的建構模式的建構模式的建構 ... 18 3.1 古典引力模式 ... 18 3.2 廣義引力模式 ... 20 3.2.1 空間分隔的量測 ... 20 3.2.2 阻抗函數 ... 22 3.2.3 定義引力模式 ... 22 3.2.4 模式的原則 ... 233.3 本研究模式 ... 27 3.3.1 模式建構的原則 ... 27 3.3.2 模式建構的基本假設 ... 28 3.3.3 模式的特性 ... 29 3.3.4 模式推導 ... 32 3.3.4.1 模式(一)推導 ... 33 3.3.4.2 模式(二)推導 ... 34 第四章 第四章 第四章 第四章 抽樣分析與資料整理抽樣分析與資料整理抽樣分析與資料整理... 38抽樣分析與資料整理 4.1 抽樣方法 ... 38 4.1.1 系統抽樣 ... 38 4.2 檢定方法 ... 40 4.3 資料蒐集 ... 41 4.2.1 資料整理 ... 42 4.2.2 抽樣比例與母體型態分析 ... 44 第五章 第五章 第五章 第五章 模式推估與驗證模式推估與驗證模式推估與驗證 ... 47模式推估與驗證 5.1 樣本與母體型態分析 ... 47 5.2 起迄資料推估流程 ... 48 5.3 模式優劣程度指標 ... 49 5.4 模式推估與優劣程度測試 ... 50 5.4.1 古典引力模式推估 ... 50 5.4.2 模式(一) ... 51 5.4.3 模式(二) ... 52 5.4.4 小抽樣比例樣本推估 ... 54 5.4.5 小結 ... 56 第六章 第六章 第六章 第六章 不完整資料插補不完整資料插補不完整資料插補 ... 58不完整資料插補 6.1 引力模式插補不完整資料 ... 58 6.2不完整資料插補流程 ... 59 6.3不完整資料處理 ... 60
第七章 第七章 第七章 第七章 結論與建議結論與建議結論與建議 ... 61結論與建議 7.1 結論... 61 7.2 建議... 62 參考文獻 參考文獻 參考文獻 參考文獻 ... 63 附錄 附錄 附錄 附錄、、、、一一一一 ... 65
表目錄
表目錄
表目錄
表目錄
表 3-1 旅次起迄分佈矩陣表... 24 表 4-2 車種代碼 ... 42 表 4-4 方向 ... 42 表 4-5 國道一號 交通車輛起迄表 ... 44 表 4-6 每 2 輛車抽取第一輛車的起迄表 ... 45 表 4-7 每 10 輛車抽取第一輛車的起迄表 ... 45 表 4-8 每 20 輛車抽取第一輛車的起迄表 ... 46 表 4-9 每 30 輛車抽取第一輛車的起迄表 ... 46 表 5-1 模式間推估程度比較... 56 表 5-2 模式間小抽樣比例樣本推估程度比較 ... 57圖目錄
圖目錄
圖目錄
圖目錄
圖 1-1 研究方法及流程... 3 圖 2.1 都市區域圖 ... 14 圖 3-1 子群體示意圖... 27 圖 4-1 原始資料型態... 41 圖 4-2 時間遞移抽樣 28 小時 ... 43 圖 5-1 起迄資料推估流程圖 ... 48 圖 5-3 模式(一)母體與推估起迄資料比較圖 ... 51 圖 5-4 模式(二)母體與推估起迄資料比較圖 ... 53 圖 5-5 古典引力:以抽樣比例小樣本推估資料與母體資料比較圖 ... 54 圖 5-6 模式(一):以抽樣比例小樣本推估資料與母體資料比較圖 ... 55 圖 6-1 不完整資料插補流程圖 ... 59 圖附-1 站 1 至站 2 間的路段流量 ... 65 圖附-2 站 2 至站 3 間的路段流量 ... 65 圖附-3 站 3 至站 4 間的路段流量 ... 66第一章
第一章
第一章
第一章 緒論
緒論
緒論
緒論
1.1 研究動機
研究動機
研究動機
研究動機
高速公路車輛起迄表的資訊,傳統上有:路邊訪問、車輛牌照登錄、 郵卡問卷、電話訪問、錄影或照相偵測、車輛標記、車輛追蹤、匝道收費、 人口普查等等方法取得。但這些方法之資料收集過程各有其困難,資料的 精確度也不同,更重要者是這些調查方法之功能亦不相同,為了達到某些 特定目的,使得很多調查方法都有其侷限無法達成該目的。除了傳統調查 方法之外,在某些較易取得的資訊下,是否有新的方法可以避免傳統調查 之困難又可求得高速公路車輛起迄表?而這些方法之可行性且其限制又 如何呢?期望構建一可推估高速公路旅次起迄分佈矩陣之模式,並以本研 究調查之資料進行測試,以暸解模式之可行性,希望藉此避免傳統調查方 法之困難又可求得高速公路車輛起迄表。 。本研究首先針對傳統各起迄調查方法進行理論分析,亦即就高速公 路之起迄特性,探討應該採用何種調查較佳及面臨的問題為何?其次就較 適合高速公路起迄調查之車輛牌照登錄法中的攝影、錄音及人工抄錄三種 方式進行實作分析,透過實際調查一方面將三種調查方式(攝影、錄音、 人工抄錄)所遭遇到的困難及問題列出,另一方面也就高速公路匝道形式 及匝道交通量等不同狀況,應該採用哪一種調查方式較佳作成建議,以供 未來應用之參考。另外,本研究亦對以路段資訊反推高速公路起迄表之可 行性進行研究探討,構建以路段資訊推估高速公路旅次起迄分佈矩陣之模 式,並以本研究調查之資料進行測試,以暸解模式之可行性,希望藉此避 免傳統調查方法之困難又可求得高速公路車輛起迄表。(民 84,卓訓榮等)1.2 研究目的
研究目的
研究目的
研究目的
高速公路車輛起迄表是高速公路規劃、設計的主要參考依據,分別探 討高速公路之各項資訊所推估起迄表模式,並以國道一號沿線北自汐止、 南至岡山的電子收站資料作模式驗證,以探討其可行性;期望在資源有限 的情況下,提出經濟且可靠的模式供高速公路車輛起迄推估,以及,以引 力模式進行資料插補處理。1.3 研究方法及流程
研究方法及流程
研究方法及流程
研究方法及流程
研究方法及流程
研究方法及流程
研究方法及流程
研究方法及流程
圖 1-1 研究方法及流程 [資料來源:本研究整理] 研究問題界定 確立研究目的 文獻資料蒐集 起迄推估方法分析 研究範圍規劃 高速公路資訊蒐集與處理 抽樣設計與分析 模式建構 模式驗證與分析 結論與建議 模式修正與參數校估 模式修正與參數校估第二章
第二章
第二章
第二章 文獻回顧
文獻回顧
文獻回顧
文獻回顧
2.1 傳統車輛起迄調查方法之回顧
傳統車輛起迄調查方法之回顧
傳統車輛起迄調查方法之回顧
傳統車輛起迄調查方法之回顧
1.路邊訪問調查法 此法通常於規劃研究區之週界進行,在道路與週界相交之處設置調查 站,由交通警察協助攔截通過之車輛,對其起迄點、目的等特性進行調查。 將調查結果予以分析處理,資料分析時再以放大系數進行調整,即可獲得 旅次分佈矩陣,但此法不適用於公速公路。 2.車輛牌照登錄法 此法於車輛可能通過之地點設置調查站,將通過各調查站之車輛牌照 號碼以人工、錄音或攝影方式登錄後,再將各站資料利用電腦進行比對, 以得到旅次分佈矩陣。 該方法進行時不會干擾交通情況是其優點,但仍有一些缺點存在,如: (1) 車速高與車流量大時,錄音與人工抄錄調查員難以正確讀取及記 錄牌照號碼,造成日後電腦作業上比對困難或產生錯誤。 (2) 當一車輛之車號無法被尋獲配對時,將造成兩個以上之車號孤立 或重覆車號,增加不準確率。 (3) 當以攝影方式進行時則成本太高且拍攝亦受到天候影響而無法拍 錄,且當攝影人員疏失時,將造成某些路口或匝道之車輛牌照全 部無法辨識,則造成調查之全部資料無法運用。 3.郵卡問卷法 此法即是於主要車輛經過地點,攔截車輛發給駕駛人已附回郵之調 查卡,由駕駛人填妥,寄回研究單位,進行資料分析。該問卷不當場回收 以免造成交通延誤,但也因此造成問卷回收率不高,無法反映實際情形。 4.電話訪問法 以研究區內之住戶為對象,透過電話號碼抽樣進行,以電話訪問的方 式調查其前一日之旅次資料。此法節省人力是其優點,其缺點為: (1)僅包含家旅次,不包括非家旅次。 (2)調查之資料並無區外至區外通過性旅次。5.車輛標記法 於調查站設立標誌指示駕駛人打開車燈,再於車流可能轉向之地點記 錄打開車燈之車輛數以得到其轉至特定方向之車流。缺點在於駕駛人之配 合度影響整個調查結果。 6.車輛追蹤法 以雇用車輛追蹤紀錄之方式進行研究區內的起迄點調查,但此方法實 施困難且成本亦高。 7.匝道收費站法 收費公路之收費方式若為入匝道取票,出匝道付費者可直接統計其回 收收票票證,以得車輛起迄點資料,此法在台灣之高速公路並不適用。 8.人口普查法 利用人口普查之時機,同時附帶調查交通特性,以獲得旅次起迄點之 資料,此法若問卷詳細將可得到最精確的靜態資料作為基年資料之用。缺 點是: (1)調查成本太高。 (2)調查時間間隔太長,在快速成長地區較不適用。
2.2 車輛起迄推估模式
車輛起迄推估模式
車輛起迄推估模式
車輛起迄推估模式
由於傳統起迄資料蒐集耗費能力物力及時間,因此,近年來,Ortuzar 和 Willumsen(2001)、Roy 和 Thill(2004)以及 Cascetta 等人(2007),致力 於利用簡易獲得的資訊、低成本、低人力的方式來推估旅次起迄方法。
Wilson(1967)、Jayet(1990)將傳統的絕對空間距離概念轉換成人口遷移阻力,
距離可作為具體測量中介機會。
常見的推估模型如:極大熵法(Entropy maximization)、引力模式(Gravity
model) 、 干 預 機 會 模 式 (Intervening opportunities) 、 引 力 - 機 會 模 式 (Gravity-opportunity model)以及最大概似法(Maximum likelihood)。以下茲
作介紹:
2.2.1 極大熵模式
Clausuis 的經驗準則-熱力學第二定律,極大熵的觀念是引用熱力 學的觀念,將氣體分子結構中的分佈及穩定狀態,比擬為人在社會中 的行為狀態,在各種限制件下找出最可能的系統狀態。該定律說明當 一個熱力學系統達到最後熱平衡狀態時,該系統的熵會達到最大值; 進一步的研究指出當系統的熵最大時,其自由能將成為最小。極大熵 法是由 Wilson(1970)提出,主要改進了引力模式後得出;引力模式廣 為運輸規劃者所使用,極大熵法亦受學者重視,兩者都需滿足旅次總 產生數。在此一特性的影響下人們慣性的傾向於將熵視為類似能量的 巨觀物理量;引力模式和極大熵法主要有別於,前者提出主要是物理 觀念,後者是基於統計分析觀點,因此後者較具有推理之基礎。 將極大熵原理用來確定交通量分佈的基本想法,是把交通網路看 作一個基本對稱系統,利用交通生成量及其分佈,定義系統狀態的概 率分佈及對應於分佈的熵,然後在關於該系統狀態的約束條件下,求 使熵最大的那個分佈,即所推估的交通量分佈。其模型如下:概率分佈Tij 定義的熵為
∑∑
− = = i j ij ij ij i j s P P P H( , , 1,2,..., ) ln (2-1) 必須滿足為 i i ij O T =∑
(2-2) j j ij D T =∑
(2-3) 利用最大熵原理,令 T T P T D b T O a ij ij j j i i = , = , = 可知 1 = =∑
∑
j j i i b a (2-4) j i ij i j ij a P b P =∑
=∑
, (2-5) C T C i j ij ij =∑∑
(2-6) 在(2-1)(2-2)(2-3)限制式下求(2-1)極大值得 ) ( ij j i ij KO D f C T = (2-7)2.2.2 引力模式
引力模式早期是類比牛頓的萬有引力定律(式 2.1.1), 2 ij j i ij d m m F =γ (2-8) 表示兩質量mi和mj在距離dij時萬有引力為Fij;γ
為常數 而導出引力模式,Reilly(1931)將此概念應用到都市系統分析,其基本 公式如下:2 ij j i ij C D O k T = (2-9) 其中 為常數 旅行成本 點吸引的交通量 表示 點產生的交通量 表示 的交通起迄量 至 由 : : k C j D i O j i T ij j i ij : : : 由於在交通流量起迄表中必須滿足以下限制式: i i ij O T =
∑
j j ij D T =∑
故引力模式修正為以下一般式 Tij = AiBjOiDjf(Cij) (2-10) 其中 1 1 − − = =∑
∑
i ij i i j j ij j j i C f O A B C f D B A ) ( ) ( 以上兩式能滿足(2-2)(2-3),以遞迴方式求解。 後來威爾生(Wilson, 1967)發現,引力模型可用最大熵法(entropy maximizing)導出,使得此模型更具推理基礎,且改稱此種模型為空間交互作用模型(spatial interaction model)。目前在規劃上引用最廣泛之都 市空間模型者為勞利模型(lowry model)。推導引力模式以最大熵法之 前,先介紹總成本限制式 C C T i j ij ij =
∑∑
(2-11)推導過程如下: 目標為極大化起迄矩陣
{ }
Tij 的熵分配{ }
=∏
ij ij ij T T T W ! ! ) ( 為總起迄量 T 故可能產生的情況是w,且其數量超過 ij T w = ∑W({ }
Tij ) 限制式為 i i ij O T =∑
j j ij D T =∑
C C T i j ij ij =∑∑
以 Lagrangian multiplier 求解: N N N N tirling W W C T C T D T O W j i i j ij ij j i ij j j i j ij i i − ≈ − + − + − + =∑
∑
∑
∑
∑∑
ln ! ln ln ) ( ) ( ) ( ln 近似 有效率,故利用 比 因求解 為 S s multiplier Lagrangian , ,λ β λ β λ λ L 則 N N N ln ! ln = ∂ ∂ 故 ij j i C ij ij j i ij ij j i ij ij e T C T C T T β λ λ β λ λ β λ λ − − − = − − − = = − − − − = ∂ ∂ ln ln 0 L 令 故 Tij = AiBjOiDjf(Cij) 各符號如前文所示,其中 f(Cij)為阻抗函數。將引力模式發揚光大者為勞利模式(Lowry model),但最初的勞利 模型是一種潛能模型,用來處理人口的分佈。在這個模式內,配置任 何一區的人口數量,取決於該區內各項分區潛能之總和。然而,加林 (Garin,1966)加以修改,對相互作用所使用的度量則以引力模式為基礎, 發展至今;Casey(1955)、Huff(1964)等人將他運用在起迄資訊推估。
2.2.3 干預機會模式
干預機會模式(Intervening opportunities)是假設一個旅行者滿足下 一個旅行的機會是受到前一次旅行的影響。Stouffer(1940、1960)原始 的干預機會模式是藉由 Wilson(1967、1970)極大熵模式推演而來,並 且假定旅次與空間累積機率為線性關係(Oppengeim, 1980),數學模式 如下:[
LVj LVj]
i i ij kO e e T = − −1 − − (2-12) 其中ki為校正因子,Vj−1是前一區到 j-1 區的累積機率,(2-12)必須 滿足限制式 i j ij O T =∑
(2-13)[
]
1 1− − − = LVn i e k n 為總區域數, 以 Vj代替一般的 Dj,意即吸引到 j 區的交通量相當於遷移到 j 區 的真實機會(Stouffer,1940、1960)。2.2.4 引力-機會模式
引力-機會模式(Gravity-opportunity model)是以干預機會代替成本 的引力模式型態,將成本改寫為(Wills,1986、Roy,1933、Almeida and Goncalves,2001) ,其基本公式如下:Cij =Vj(i) (2-14) 雙限制式的引力-機會模式為 ) exp( j(i) j i j i ij ab O D V T = −β (2-15) 1 − − =
∑
j i j j j i b D V a exp( β ( )) 1 − − =∑
i i j i i j aO V b exp( β ())其中a 和i bj利用最大概似法則校估而來,(Goncalves and Ulyssea
Neto,1993);可獲得其結果類比於引力模型,(Evans,1971), a 和i bj為校 正因子以確保流量限制式守恆。
2.2.5 最大概似法
由英國統計學家費雪(R.A Fisher,1912)提出,最大概似法假設旅次分佈 為 Poisson 分配,且已知路網中的路段旅次交通量,並以概似值來從中判 斷最佳的 OD 矩陣。其模式一般形式為: Max∏
− − ij t ij ij ij ij ij ij t T T ! ) )( exp( ρ ρ s.t. 判斷準則為概似值越大時,該推估 OD 矩陣也越佳。2.2.6 最小平方法
此法係利用先期起迄分佈矩陣及路段交通量來推估起迄分佈矩陣,且 假設推估值與調查值具有不偏性,模式能提供估計的信賴區間,以供對於 估計準確性的一個參考,但推估結果的正確與否與先期起迄分佈矩陣相關 甚大。其模式一般型式為:PT f t s f f W f f T T Z T T Min T T = − − + − − − − 1 1 . . ) ( ) ( ) ( ) ( 其中 的協方差矩陣 的協方差矩陣 比例 起迄點使用特定路段的 估計的路段流量 觀察的路段流量 估計的旅次分佈矩陣 先期的旅次分佈矩陣 f W T P f f T T : : : : : : Z :
2.3 不完整資料之種類與處理
不完整資料之種類與處理
不完整資料之種類與處理
不完整資料之種類與處理
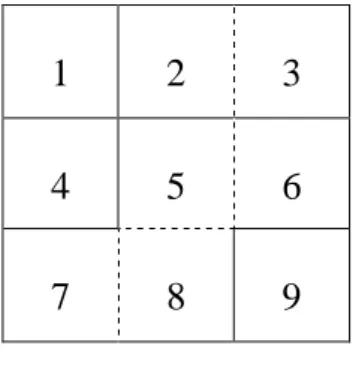
在一般調查中,資料不完整的種類有二: (1)某一抽樣單位(Sample unit) 所有資料均未收集,此稱為 unit nonresponse;(2)某一種抽樣單位對某些問 項不與回答而造成 item nonresponse。對於兩種不完整資料的處理通常是對 於抽樣單位再度調查或以某種適合的方法代入缺失值(missing values)。缺 失值可分為很多不同類型,不同型式的缺失值其處理方式不同,因此須先 將旅次起迄分佈矩陣所產生的不完整資料予以分類,並根據分類原則定義 本研究之問題範圍。本研究將旅次起迄分佈矩陣所產生不完整資料處理的 情形分為以下四點: (1) 在每一高速公路匝道進出口採取車輛牌照登錄法,再進行車牌 之比對,即可得到一組旅次起迄分佈矩陣。 (2) 當我們針對都是區域進行家庭訪問等之抽樣調查,因為分區多, 加上人力、財力不足,各區域選取的樣本很少,以致調查之結 果可能沒有顯示出某些起迄分佈的旅次量,使得這些區域的旅 次量因此被忽略,而產生不完整資料。 (3) 調查之初,由於某一區域尚未開發而沒有旅次產生,經一段時 間後,我們可以成長因素法則來求算未來地區旅次,但對於原 本尚未開發區域則未加考慮,對於未來旅次量的估計會有偏差, 便可能會有不完整資料產生。 (4) 圖 2.1 表示將都市劃分為九個區域(1-9),為節省調查費用,執行 調查時僅對 1,2,4,5,7 的區域進行家庭訪問調查,及對河川(圖中 以虛線表示),實施周界調查。因此。我們之旅次分佈矩陣中將 得不到 3-->6,8-->9,9-->3,…,此亦屬不完整資料。1 2 3
4 5 6
7 8 9
圖 2.1 都市區域圖
(資料來源:Day & Hawkins,1979)
上述四種不完整資料其產生的原因皆異,後三種產生不完整資料的原 因並非完全是因為實際旅次量少而造成;然而,第一種則純粹是因為實際 的旅次量少,經抽樣使得微小的旅次量消失,或是,抽樣比例小造成不完 整資料。本研究將針對第一種不完整資料型態的問題進行研究。
2.4 統計上處理不完整資料的方法
統計上處理不完整資料的方法
統計上處理不完整資料的方法
統計上處理不完整資料的方法
交通上處理不完整資料的方法多以交通上現有估計起迄分佈矩陣之 模式為主,其缺點為它使用了目前尚未成熟的模式,或成熟的模式尚沒有 適用於國內的參數值(指模式中所需的參數值),因此本研究嘗試避開既有 的模式,尋找統計上處理不完整模式的方法,分析各方法使用的限制與適 用性。 進行隨機抽樣或系統抽樣而產生不完整資料時,在統計上的處理方式, 大致包含下列三種(Aiffi and Elashodd,1966):(1) 完整資料法(compelete-case analysis) 將所有有缺失值的資料剔除後,只分析完整的資料,其優點 為簡單且能不經調整就適用於既有的統計軟體,缺點則為失去了 部分資訊(loss of information),使分析結果有偏差,尤其在有許多 缺 失 值 的 情 況 。 其 相 關 研 究 包 含 Keleinbaum,Margensten and Kupper(1981)及 Dixon(1983)等。
(2) 可用資料法(available-case analysis)
相對於只取完整資料法,可用資料法則只剔除缺失值分析所
有 可 用 資 料 , 但 也 使 得 分 析 變 得 複 雜 。 其 相 關 研 究 包 含
Dixon(1983)、Kim and Curry(1977)、Haitovsky(1968)、Azen and Van Guilder(1981)等。 (3) 插補法(fill-in method) 對每一缺失值代入適當的值,使現有資料成為完整資料,然 後再用完整資料分析法進行分析。 上述三種方法中,前二種處理不完整資料的方式較為簡單, 將不完整資料剔除即可,但旅次起迄分佈矩陣不似一般問卷調查, 可將部份資料剔除再進行研究。它賴於起迄分佈表中每一起迄對 之值皆存在,才得以成為一完整的旅次起迄分佈矩陣,進而再以 此資料進行運輸規劃的研究。因此,我們必須採用插補法,將缺 失值代入一適當的值,再用完整資料分析。下面僅就與本研究方 法相關之插補法做較詳細的介紹。 在統計上,研究插補法的文獻很多,在其插補的分類方式亦隨分類
精細度之不同,而有不同的分類方式,本研究擬以 Little and Rubin(1987) 的分類原則簡介如下:
(1) 平均插補(Means imputation (filled in))
本方法是將觀察到的值與缺失值問題給予適當的權重,再將其值 平均;亦或以尚存在完整值之平均值將缺失值補足。如 Buck’s
Method (Buck,1960)。
(2) 現期資料插補(Hot deck imputation)
首先觀察資料之分佈型態,對於其型態有所了解,再根據此分佈 型 態 對 缺 失 值 部 分 給 予 一 適 當 的 經 驗 值 。 相 關 文 獻 包 含
et.al.(1986)
(3) 替代插補(Subtitution imputation)
觀察變數間的相關性,對於高度相關的變數,其間之部分變數若 存在著不完整資料,則可以其相關變數(完整資料)之值推導出缺失 值的部分。
(4) 前期資料插補(Cold deck imputation)
本法純粹是以前期之資料作為根據,再以適當的插入。 (5) 迴歸插補(Regression imputation) 根據完整資料求取足以代表資料型態的迴歸線,再將缺失值之 x 值代入所得到之回歸線,即可求出我們所須之yˆ。Buck’s Method (Buck,1960)、Yate’s Method(1933)、Bartlett(1937)皆是這方面的研 究。
(6) 隨機回歸插補(Stochastic regression imputation)
對於我們所得到之迴歸線y=a+bx+ε,假設ε為 normal 或 binary,
在本假設的基礎上建構處理不完整資料的模式。Herzog and Rubin
(1983)研究過這方面的問題。
(7) 組合插補(Composite method)
本方法是將前述之方法加以組合來處理不完整資料。如以 Hot
deck+regression 這方面的問題於 Schieber(1978)中有詳細的討論。
(8) 多重插補(Multiple imputation method)
本方法是從已觀察得到的資料型態中,抽取多個樣本值,再將每一樣 本值與其他觀察到得值做不同的組合,尋找一較適當的樣本值做為缺失值 的插補。其缺點在於抽取的樣本值並不知為何種分配型態,也就是說,原 始資料的型態與條件機率的型態(抽取之樣本值)可能並不相同;另外,此 種方法須將各種樣本值與母體作不同的組合,一旦缺失值增加時,每一格
子點與其他格子點的組合更是繁多,使得資料處理的過程繁雜,是本方法 的缺失。 統計上對於不完整資料的問題有多方面的討論,其方法中,大多需 要資料的規律性,抑或需要較多額外的資料,當若干資料無法重新調查取 得或沒有規律的存在時,很多方法將無法使用,因此本研究希望提出以較 少的資料(即現有的資料)即可處理不完整資料的方法。對於 Little and Rubin(1987)之分類本研究再以其使用的工具予以分類,並說明應用於本研 究之問題時可能遭遇的問題與限制所在。
第三
第三
第三
第三章
章
章
章 模式的建構
模式的建構
模式的建構
模式的建構
本研究所建構推估高速公路車輛起迄表的方法是以引力模式為基 礎,並將此法加以改善,使其更適用於抽樣產生之車輛旅次起迄調查 資料;並嘗試以引力模式作不完整資料插補。因此,以下將先詳盡的 介紹引力模式,再根據不足之處予以改善,最後,在第五章以實際的 例子來比較傳統引力模式與本研究所提出方法的優劣所在。3.1 古典引力模式
古典引力模式
古典引力模式
古典引力模式
引力模式早期是類比牛頓的萬有引力定律,該模式至今已有悠久 的歷史,除了科學領域,目前已廣泛運用於各社會學領域。起初,觀 察到人類的遷移行為可類比於牛頓的萬有引力定律,並將人類的行為 以數學式表示: (Young,1924) 2 D kF M = / (3-1) 其中 k 為常數,M 是遷移的人口數,F 是區域吸引強度,D 是距離。 隨後,Reilly(1931)將引力模式應用在零售市場,描述消費者選擇 店 家 的 行 為 ; Stewert(1941) 提 出 人 口 統 計 引 力 模 式 (demographic gravitation),假定人口中心 i 及 j 具有交互作用 Tij,定義為人口質量 Pi 和 Pj的乘積,除以 i 和 j 距離平方,即 2 − = i j( ij) ij GPP d T G:人口統計引力常數,(3-2) Stewart(1948、1950)、Dodd(1950)再予以權重(weights)關係,數學 式如下: 2 − = ( i i)( j j)( ij) ij G wP w P d T (3-3) 利用權重來表示人口質量的「異質性」;並以能量(demographic energy)來代替力量(demographic force)。Huff(1963)在零售模型中,藉由消費者的集合探討選擇購物區位, 假設 Pij為消費者自區位 i 至 j 的機率,tij為 i 到 j 的旅行時間,−λ為引 力指數,Wj表示迄點 j 的相關引力,Huff 模型如下:
∑
− − = j ij j ij j ij t W t W P λ λ (3-4)在 Huff 模型中,主要是移除了 Newtonian model 的嚴格限制:
(1) 在兩個獨立個體中,需要處理的是旅行時間而非距離。 (2) 允許引力參數(λ)從觀察值校估而來,而非直接指派為(-2)次方。 此外,關於原始的引力模式,未考慮到其他地區競爭的吸引,因 此容易高估地區內之間的引力,修正後之引力模式可描述如下,在兩 個或更多地區之間的相互作用量與分區大小(或吸引力)成正比,而就分 區間之距離及參與競爭分區之間之相對吸引力成反比,並在模型中加 入一校正因子以代表其他分區的競爭力,修正後的模型如下:
∑
− − = j b ij j b ij j i ij d P d P P T (3-5) 其中 Tij 表 i 區到 j 區的旅次,若 1 − − =∑
j b ij j i Pd A 令 , 上式將改寫為 b ij j i i ij PAPd T = − , b ij j iPd A j i區到 區的或然率為 − 意即 。3.2 廣義
廣義
廣義
廣義引力
引力
引力
引力模式
模式
模式
模式
本研究目的在利用可獲得資料推估交通旅次起迄資料,交通量的 產生源自於運輸需求,然而,運輸需求是一種衍生需求,意即運輸並 非旅行者真正目的,旅行者是為達成某種社會經濟活動而產生對運輸 的需求;在古典引力模式中,僅探討可量測的變項,如:人口分佈、相 異兩質點的距離,但是,交通旅次產生的潛在需求是不易被量測的, 更重要的是,這種不易被量測的潛在需求正是交通量產生之泉源。以 下,我們嘗試利用數學式來描述這些抽像的變項:3.2.1 空間分隔的量測
Ashish Sen 和 Tony E. Smith(1995)假定:在相異兩質點當中,隱含
數個空間分隔(spatial separation ),在行為者(actors)和機會(opportunity) 中產生交互中作,這些交互作用受到個別行為者(如:通勤者、購物者) 和機會(如:工作、商店各種經濟活動) 的影響,在不同情況下,便產生 相異的空間分隔。我們試圖了解行為者和機會所形成的空間分隔對交 互作用的影響是吸引力或是排斥力,因此具體化上述變項;假定已知 交互作用中,每個行為者集合 A,α∈A,機會集合 B,β∈B,存在有 限相關的分隔屬性(separation attributes)集合k∈K,介於 A 和 B 之間, 空間分隔可表示為有限集合{ck :k∈K},存在分隔量(separation profile) } : ) , ( { ) , ( c k K cα β = k α β ∈ ,以c(α,β)來具體化表示對交互作用的影響所 需的成本;進而以空間總合假設表達如下: 假設一組行為者形式{αi :i∈I}和一組機會形式{βj: j∈J},分隔向 量 為 c = {c(αi,βj):i∈I, j∈ J} , 介 於 行 為 者 αi 和 機 會 βj , N n J j I i jn in : },{ : }, ,..., {α ∈ β ∈ =1 ,觀察的交互作用(observed interactions) ) , ( i j N α β ,作用頻次(interaction frequency) N(αi,βj)/N,以及估計介於 i
α 和βj的機率為Pc(αi,βj)。以下為 Ashish Sen 和 Tony E. Smith(1995)
一般性: R1.(恆正性) C c∈ ∀ ,∀s∈S,型態機率Pc(s)恆正。 R2.(對稱性) 給定∀c∈C,和一對s',s∈S ,若s',s的相異僅有排序上的不同,則 ) ' ( ) (s P s Pc = c 。 R3.(連續性) 給定∀s∈S, ∀c∈C,和∀ε >0,必定∃δ >0,使得在所有在c'∈C, δ < −c' c 時,|Pc(s)−Pc(s')|<ε 恆成立。
Ashish Sen 和 Tony E. Smith(1995) 更 進 一 步 定 義 空 間 作 用 過 程 (Spatial interaction process)如下:
定義 3. 1 空間作用過程(Spatial interaction process)
在 S 中的機率函數集合,P =
{
Pc :c∈C}
,是為空間作用過程,若且3.2.2 阻抗函數
阻抗函數(deterrence function)是測度行為者針對變動區位 i 和區位 j 距離的意願,阻抗函數有多種型態,以下介紹最常見:
(1)冪次阻抗函數(Power deterrence function)
( )
−θ = ij ij c F( ) c (3-6) (2) 指數阻抗函數(Exponential deterrence function)] c exp[- ij ij c F( )= θ (3-7)
其中θ可解釋為成本敏感度參數(cost sensitivity parameter),
Kulldorf(1955)研究首度發現指數型態的阻抗函數比冪次型態更加配適
諸如遷移旅次這類型的資料;這種根據經驗所獲得的結果,在 Morrill 和 Pitts(1967)的實驗中獲得驗證。
3.2.3 定義引力模式
Ashish Sen 和 Tony E. Smith(1995)將引力模式的定義如下:
定義 3.2: (一般引力模式) } : {Pc c∈C = Ρ 被稱為引力模式,若且為若,∀c∈C,∃Ac,Bc,Fc >0, 使得所有起迄對,ij∈I×J ) ( ) ( ) ( ) ( ij c c c ij c N A i B j F c E = (3-8) 定義 3.3: (指數型態引力模式) } : {Pc c∈C = Ρ 被稱為指數型引力模式,若且為若,∀c∈C,∃Ac,Bc >0 和存在成本敏感度向量 K c ∈R θ ,使得所有起迄對,ij∈I×J ] c exp[- ij t c c c ij c N A i B j E ( )= ( ) ( ) θ (3-9)
3.2.4 模式的原則
已知行為者總和 A,機會總和 B,分隔測度(separation measures),
} :
{ck k∈K ,定義空間總合組合(spatial aggregation scheme)具有一對有
限分割的{αi :i∈I}和{βj : j∈J},總合函數{Φk:k∈K},指派到每對 Ai 和 Bj,則分隔量表示為 cij =(cijk :i∈I,j∈J),並以數學式表示: c c Ai Bj k K k k k ij =Φ [ (α,β):α∈ ,β∈ ] , ∈ (3-10) 則定義 k ij c 的集合分隔量 c (c :k K) k ij ij = ∈ (3-11) 表示每對((αi,βj):i∈I, j∈J)的成本總和,進而的,將所有對發生 的成本總合分隔結構(separation configuration)表示如下: ) : (c ij I J c= ij ∈ × (3-12) 旅次調查之目的在了解由某一區 i 到另一區 j 的交通量,調查之後 通常將資料表示成二向列聯表的形式(two-way contingency table)。首先 介紹各符號的意義: 區吸引的旅次量。 區產生的旅次量。 旅次需求量的總和。 的旅次需求量。 至迄點 路網中起點 : : : : j D i O T j i T j i ij 在交通上,一個 IXJ 的二向列聯資料型態如下:
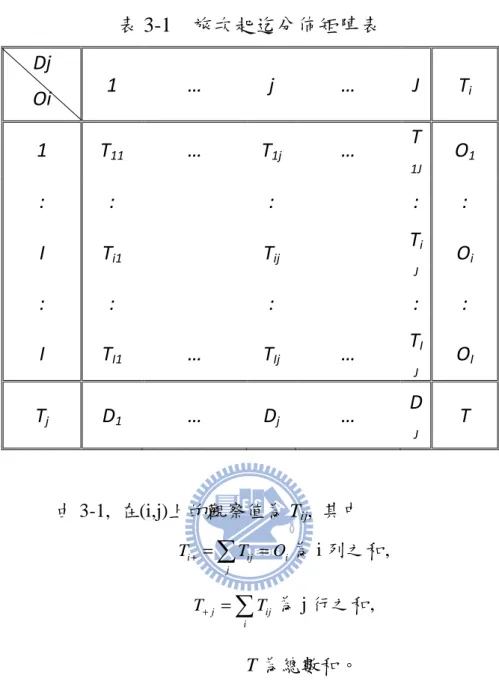
表 3-1 旅次起迄分佈矩陣表
Dj
Oi
1
…
j
…
J
T
i1
T
11…
T
1j…
T
1JO
1:
:
:
:
:
I
T
i1T
ijT
i JO
i:
:
:
:
:
I
T
I1…
T
Ij…
T
I JO
IT
jD
1…
D
j…
D
JT
由 3-1, 在(i,j)上的觀察值為 Tij, 其中 i ij i j T+ =∑
T =O 為 i 列之和,∑
= + i ij j T T 為 j 行之和, T 為總數和。Wilson( 1967)發現,引力模型可用最大熵法(entropy maximizing)
導出,使得此模型更具推理基礎,且改稱此種模型為空間交互作用 模型(spatial interaction model)。
給定: i j ij O T =
∑
(3-13) j i ij D T =∑
(3-14) 利用觀察值 Oi、Dj的資訊來估計參數 A(i)、B(j)和θ,以模式] c exp[- ij ij A i B j T = ( ) ( ) θ (3-15) 推估旅次Tij。 推估的方法為根據限制式,極大化起迄矩陣{Tij}的熵分配,根 據限制式多寡,Wilson 將它分類為以下四種引力模式: (1) Unconstrained Tij = AiOif(cij) (3-16) (2) Production-constrained Tij = AiOif(cij) (3-17) 1 − =
∑
j ij i f c A ( ) 其中 。 (3) Attraction-constrained Tij = BjDjf(cij) (3-18) 1 − =∑
i ij j f c B ( ) 其中 (4) Doubly-constrained Tij = AiBjOiDjf(cij) (3-19) 1 − =∑
j ij j j i B D f c A ( ) 其中 (3-20) 1 以迭代方式求得 − =∑
i ij i i j AO f c B ( ) (3-21)式(3-19)可改寫為Oi分派的雙限制式引力模式:
∑
= j ij j j ij j j i ij c f D B c f D B O T ) ( ) ( 式(3-19)可改寫為Dj分派的雙限制式引力模式:∑
= i ij i i ij i i j ij c f O A c f O A D T ) ( ) (3.3 本研究模式
根據以上所述, 為 Dj,意即將迄點的吸引量視為行為者欲達成的機會 在整個起迄資料的關係 量 Dj,簡言之,在 量正可以類比 j 區所提供的經濟活動 因上述關係,所以 正更加配適於交通起迄資料的推估 假設以及性質:3.3.1 模式建構的
給定起點群體( population), B,其中 attribute) k∈K,則測度分離 Ai為 A 的子群體 起點集合(origin set)(spatial aggregation scheme) A 和 B 的有限分割
模式
,我們將 I 視為 Oi,即行為者為起點的 將迄點的吸引量視為行為者欲達成的機會;再仔細探討 在整個起迄資料的關係,j 區位提供的經濟活動多寡,關係著 在 i 點有行為者欲到 j 點進行經濟活動, 區所提供的經濟活動。 所以讓筆者感興趣於進階探討引力模式是否能經修 正更加配適於交通起迄資料的推估。以下是關於引力模式的建構原則模式建構的原則
(origin population ),A 和迄點群體(destination
其中,存在一個相關的有限分隔屬性集合
則測度分離(separation measures)集合為
{
圖 3-1 子群體示意圖
[資料來源:本研究整理]
的子群體,Bj為 B 的子群體,如上圖 3-1 所示,
(origin set) I,迄點集合(destination set) J,定義空間總合系統 (spatial aggregation scheme)為包含
的有限分割 } : {Ai i∈I {Bj : j∈J} 為起點的產生量;J 視 再仔細探討 Dj 關係著 j 的吸引 ,而 Dj的交通 讓筆者感興趣於進階探討引力模式是否能經修 以下是關於引力模式的建構原則、 destination 存在一個相關的有限分隔屬性集合(separation
{
ck :k∈K}
; ,i∈I,j∈J , 定義空間總合系統具有總合函數 } : {Φk k∈K (3-22) 指派到每對 Ai和 Bj,則分隔量為 } , , : {c i I j J k K cij = ijk ∈ ∈ ∈ (3-23) 並以數學式表示: K k B A c cijk =Φk[ k(α,β):α∈ i,β ∈ j] , ∈ (3-24) 上述,表示每對{(αi,βj):i∈I,j∈J}的分隔集合,ck(α,β)表示介於 β α, 的 k 類分隔屬性。 進而的,將所有對發生的分隔總合分隔結構(separation configuration)表示如下: } : {c ij I J c= ij ∈ × (3-25) 再者,R 表示實數,R+表示非負整數,若在 K 的非負分隔測度表為 K+,則可能的分隔向量, V,寫為卡氏積(cartesian product)型態 + + − + × = K K K R R V ( ) ( ) (3-26) 進階的,假設相關的結構類別(configuration class),C } , : {c c V ij I J V C ij J I = ∈ ∈ × = × ij∈I×J (3-27) 並定義所有作用型態集合(出象空間,outcome space) 為 S 。
3.3.2 模式建構的基本假設
假設一: 假設所有子群體足夠大,以確保介於 Ai和 Bj的作用所產生的 機率為正,即∀s∈S,∀c∈C,Pc(s)>0。假設二: 假設所有α ∈Ai對於某一個β所產生的分隔一致,且所有 j B ∈ β 對於某一個α亦所產生的分隔一致。 假設三: 假設∀s∈S,∀c∈C,使得Pc(s)為一連續型函數。
3.3.3 模式的特性
本模式的一般性: 恆正性: 根據假設一,可得到機率恆正的性質;相對於到本研究的行為意義 為在交通起迄資訊上結構性不為零的資料,必有起迄事件的發生, 與實際情況一致,符合上述 R1.恆正性。 對稱性: 根據假設二,可得到符合 R2.對稱性的性質,了解到起迄產生的機 率與時間為獨立,可以在下文經過完整定義後得到證明。 連續性: 根據假設一,解釋機率模型為一平滑曲線,使得針對模式作參數校 估時,進行分割求解,仍能得到一個理想的解,亦符合上述 R3.連續 性。根據 Sen & Smith(1955)所定義的空間作用過程,因為本模式滿足
R1、R2、R3,故機率函數集合
P =
{
Pc :c∈C}
為了分析空間作用過程,P =
{
Pc :c∈C}
在Ω空間中的量測特性,指定 一數值函數 X 在Ω上,在作用型態,w,上可能發生的數值x,使得 x w X( )< ;令S(x)={
s∈S : X(s)≤ x}
,則機率表示為∑
∈ = ≤ S s c c X x P s P( ) ( ) (3-28) 關聯的平均值(或是期望值)為∑
∈ = S s c c X X s P s E ( ) ( ) ( ) (3-29) 對本研究而言,給定一個起迄對(origin-destination pair),其相對應作 用(ij-interactions)得作用旅次為Tij(s),對於一個非負整數,nij,其機率 為∑
∈ = = = S s c ij ij c ij c n P T n P s P( ) ( ) ( ) (3-30) 則作用旅次為∑
∑
= = ∈ nij ij c ij S s c ij ij c T T s P s n P n E ( ) ( ) ( ) ( ) (3-31) 總旅次記為 T s T s T J I ij ij = =∑
× ∈ ) ( ) ( (3-32) 若兩個作用型態,s和s 的各別作用僅有發生順序上的差別, ' ∀s,s'∈S, 則 ) ' ( ) ( ) ' ( ) ( s P s P J I ij s T s T c c ij ij = ⇒ × ∈ = (3-33) 故符合 R2.的對稱性。 若Pc(ij)記為在ij ∈I× J(= S1)的型態機率(pattern probability),則∑
× ∈ = J I ij c c S P ij P( 1) ( ) (3-34)定義 3.4: (廣義一般型態引力模式) P = {Pc :c∈C}被稱為引力模式,若且為若,∀c∈C,∃Ac,Bc,Fc >0, 使得起迄對(i,j),∀ij∈I×J , ) c ( 2 1 c c c ij ij c T W iW j A i B j F E ( )= ( ) ( ) δ( ) γ( ) (3-35) 其中W1(i),W2(j)為校正因子,δ,γ 為模式參數。 定義 3.5: (廣義指數型態引力模式) P ={Pc :c∈C} 被 稱 為 指 數 型 引 力 模 式 , 若 且 為 若 , 0 > ∃ ∈ ∀c C, Ac,Bc ,且存在成本敏感度向量, K c∈R θ ,使得所有起迄對 J I ij j i, ),∀ ∈ × ( , ] c exp[-2 1 ij t c c c ij c T W iW j A i B j E ( )= ( ) ( ) δ( ) γ( ) θ (3-36) 其中W1(i),W2(j)為校正因子,δ,γ 為模式參數。 對於觀察該模式的行為意義而言,了解每個交互作用旅次對整個交通 起迄資料的影響,因此,以機率型式表達,更具有重要的意義,作用 機率(interaction probability)定義為
∑
∑
× ∈ × ∈ = = J I gh gh c c c ij c c c J I gh gh c ij c c c F j B i A c F j B i A T E T E ij p ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( (3-37) 定義 3.3.3 的廣義指數型態引力模式寫為∑
∑
× ∈ × ∈ = = J I gh ij t c c c ij t c c c J I gh gh c ij c c j B i A j W i W j B i A j W i W T E T E ij p ] c exp[-] c exp[-2 1 2 1 θ θ γ δ γ δ ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( (3-38) 根據定義 3.3.3 的廣義指數型態引力模式,當 1 0 1 1:W1(i)= ,且δ = ,γ = case ,則 ] c exp[-2 ij t c c ij c T W j B j E ( )= ( ) ( ) θ 機率型態改寫為∑
∑
× ∈ × ∈ = = J I gh ij t c c ij t c c J I gh gh c ij c c h B h W j B j W T E T E ij p ] c exp[-] c exp[-2 2 θ θ ) ( ) ( ) ( ) ( ) ( ) ( ) ( 則各起迄對(i,j),∀ij∈I×J,旅次Tij為 Tij = Ac(i)pc(ij)∑
∑
∈ ∈ = = J h ij t c c ij t c c c J h gh c ij c c h B h W j B j W i A T E T E i A ] c exp[-] c 2 2 θ θ ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ([
ij]
t c c c i B j A j W i W exp- c = 1( ) 2( ) ( ) ( ) θ (3-39)即為 3.2.4 節中,Wilson 所定義 Doubly constrained 的Oi分派引力模
式; 0 1 1 2:W2(j)= ,且δ = ,γ = case ,則 ] c exp[-1 ij t c c ij c T W i A i E ( )= ( ) ( ) θ 機率型態改寫為
∑
∑
∈ × ∈ = = I g ij t c c ij t c c J I gh gh c ij c c i A i W i A i W T E T E ij p ] c exp[-] c exp[-1 1 θ θ ) ( ) ( ) ( ) ( ) ( ) ( ) ( 則各起迄對(i,j),∀ij∈I×J,旅次Tij為 ) ( ) (j p ij B Tij = c c∑
∑
∈ ∈ = = I g ij t c c ij t c c c I g gh c ij c c i A i W i A i W j B T E T E j B ] c exp[-] c exp[-1 1 θ θ ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ([
ij]
t c c c i B j A j W i W exp- c = 1( ) 2( ) ( ) ( ) θ (3-40)即為 3.2.4 節中,Wilson 所定義 Doubly constrained 的Dj分派引力模式。
3.3.4 模式推導
收費站交通量,根據所得的資訊及限制式,利用極大熵法來推導上述所 定義的廣義指數型態引力模式。同時,由 3.2.2 的抗阻函數得到,指數 型態的抗阻函數針對起迄類型的資料具有較佳的配適能力,故本模式選 抗阻函數為指數型態。 模式推導,主要在推導在相關假設、限制式之下,校正因子所隱含 的變數,以利在第五章模式驗證時,將模式作實際應用。
3.3.4.1 模式(一)推導
以下為模式推導: 根據定義 3.5 以及 Wilson 所提出的雙限制式引力模式 ] c exp[-) ( ) ( ) ( ) ( ) ( ij 1 2 c c c ij c T W iW j A i B j E = δ γ θ 則 且 當 W1(i)=1 δ =0, ] c exp[-) ( ) ( ) ( ij 2 c c ij c T W j B j E = γ θ (3-41) 機率型態改寫為∑
∑
∈ × ∈ = = I g ij c c ij c c J I gh gh c ij c c j B j W j B j W T E T E ij p ] c exp[-) ( ) ( ] c exp[-) ( ) ( ) ( ) ( ) ( 2 2 θ θ γ γ 則各起迄對(i,j),∀ij∈I×J,旅次Tij為 ) ( ) (i p ij A Tij = c c∑
∑
∈ ∈ = = I g ij c c ij c c c I g gh c ij c c j B j W j B j W i A T E T E i A ] c exp[-) ( ) ( ] c exp[-) ( ) ( ) ( ) ( ) ( ) ( 2 2 θ θ γ γ 1 2 ' 1( ) ( ) ( )exp[- c ] − ∈ =∑
I g ij c c j B j W i W γ θ 令 ] c exp[-) ( ) ( ) ( Tij =W1'(i)W2 j Ac i Bcr j θc ij 則 根據限制式,因此1 ' 1 2 ' 1 2 2 ' 1 ] c exp[-) ( ) ( ) ( ) ( ) ( ] c exp[-) ( ) ( ) ( ) ( ] c exp[-) ( ) ( ) ( − = ⇒ = ⇒ = =
∑
∑
∑
∑
i ij c c r c c c i ij c c r c c i ij c c c i ij i (i)A W j B j B j W j B i (i)A W j B j W j B j B i A j (i)W W T θ θ θ 模式(一): 引力模式 ] c exp[-) ( ) ( ) ( 2 ' 1 c ij r c c ij W (i)W j A i B j T = θ 其中 1 2 ' 1() ( ) ( )exp[- c ] − ∈ =∑
I g ij c c j B j W i W γ θ 1 ' 1 2( ) ( ) ( ) ( )exp[- c ] − =∑
i ij c c r c c j B j W(i)A i B j W θ 模式(一)為指數型引力模式。 由於交通量的產生,源自於運輸需求,而運輸需求是一種衍生性需求, 而兩起迄點之間的經濟活動方才是交通量產生的泉源;因此,模式(一) 的意義在於給予O、i Dj一組敏感度參數δ,γ ,使之彌補古典引力模式所 無法解釋的母體實際現象。3.3.4.2 模式(二)推導
已知當求解最佳化問題時,給予的限制式越多,越能解出符合所 求的最佳解;在本研究中,所謂的最佳解,即是校估出一組最佳參數 的引力模式,再利用樣本資料推估母體。 因此,在模式(二)中,希望加入一組路段限制式,使之推估出的參 數,更能解釋母體現象;以下是關於線性路網(高速公路主線上收費 站)路段資訊: (附錄、一) s T f k i j ij k = −∑
2∑ ∑
∑
∑
+ + + = n n n m m m T T s , 1 1, 其中 線性路網路段流量 : f 將 doubly-constrained 加上路段限制式 s T f k i j ij k = −∑
2∑ ∑
∑
∑
+ + + = n n n m m m T T s , 1 1, 其中 推導過程如下: 目標式:極大化起迄矩陣{ }
Tij 的熵分配{ }
=∏
ij ij ij T T T W ! ! ) ( 為總起迄量 T 故可能產生的情況是w,且其數量超過 ij T{ }
) ( Tij W w= ∑ 限制式: ) (i A T c j ij =∑
) (j B T c i ij =∑
C C T i j ij ij =∑∑
s T f k i j ij k = −∑
2∑ ∑
以 Lagrangian multiplier 求解目標式: ) 2 ( ) ( ) ) ( ( ) ) ( ( ln s T f C T C T j B T i A W k i j ij k i j ij ij j i ij c j i j ij c i − − + − + − + − + =∑
∑∑
∑∑
∑
∑
∑
∑
γ β λ λ L∑
∑
+ + + = n n n m m m T T s , 1 1,N N N N tirling W W j i − ≈ ln ! ln ln , 近似 有效率,故利用 比 因求解 為 S s multiplier Lagrangian , ,λ β γ λ 則 N N N ln ! ln = ∂ ∂ 故 γ β λ λ γ β λ λ γ β λ λ 2 2 0 2 − − − − = − − − − = = − − − − − = ∂ ∂ ij j i C ij ij j i ij ij j i ij ij e T C T C T T ln ln L 令 42) -(3 1 2 1 2 − − − − − − − − ⋅ = = = =
![表 4-2 車種代碼 代碼 車種 31 小客車 32 小貨車 41 大客車 42 大貨車 5 聯結車 0 其他 [資料來源:本研究整理] 表 4-4 方向 代號 方向 N 北上 S 南下 E 東 W 西 [資料來源:本研究整理] 由於本研究著重在交通車輛起迄資料推估,且車輛起迄表不分車 種,故忽略車種。 4.2.1 資料整理 本研究資料為民國 96 年 7 月](https://thumb-ap.123doks.com/thumbv2/9libinfo/8516122.186166/52.892.318.574.89.738/小客車小貨車大客車大貨車聯結車由於本在交通車輛起本研究為民國.webp)
![圖 5-4 模式(二)母體與推估起迄資料比較圖 [資料來源:本研究整理] 模式指標: 23899 ∑ − == ij ijijTTERRˆ 模式檢定: H 0 :母體資料與推估資料型態相同 H 1 :母體資料與推估資料型態不盡相同 α = 0.05 檢定統計量 D α / 2 = 0.076162 臨界值 = 0.2137 接受虛無假設,即母體資料與推估資料型態相同。 0 500 1000 1500 200](https://thumb-ap.123doks.com/thumbv2/9libinfo/8516122.186166/63.892.84.837.115.524/ˆH母體資料與推估資料型態相H母體與推臨界值虛無假設即母.webp)

