行政院國家科學委員會專題研究計畫 成果報告
子計畫一:嵌入式即時作業系統核心程式之設計與實作
計畫類別: 整合型計畫 計畫編號: NSC91-2218-E-002-005- 執行期間: 91 年 08 月 01 日至 92 年 07 月 31 日 執行單位: 國立臺灣大學電機工程學系暨研究所 計畫主持人: 王勝德 計畫參與人員: 張致良、吳國賓、王暉文、謝榮明、樊乃維、陳宏明、黃乙丞 報告類型: 完整報告 處理方式: 本計畫可公開查詢中 華 民 國 92 年 10 月 31 日
i
行政院國家科學委員會補助專題研究計畫
成果報告
eHome: 電子家庭雛型之設計與實作
—子計畫一:嵌入式即
時作業系統核心程式之設計與實作(3/3)
計 畫 類 別 : □ 個 別 型 計 畫
5
整 合 型 計 畫
計畫編號:
91-2218-E-002-005
執行期間:
91年8月1日至92年7月31日
計畫主持人:
王勝德
計畫參與人員:張致良、
吳國賓、王暉文、謝榮明、樊乃維、陳宏明、
黃乙丞
成果報告類型(依經費核定清單規定繳交):□精簡報告
5
完整報告
本 成 果 報 告 包 括 以 下 應 繳 交 之 附 件 :
□
赴
國
外
出
差
或
研
習
心
得
報
告
一
份
□ 赴 大 陸 地 區 出 差 或 研 習 心 得 報 告 一 份
□ 出 席 國 際 學 術 會 議 心 得 報 告 及 發 表 之 報 告 各 一 份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、
列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
執行單位:國立台灣大學電機系
中 華 民 國 92 年 8 月 31 日
中文摘要
當今許多嵌入式系統皆用於可移動或攜帶方面的運用,電源管理方面的控制也已 普遍的存在於新一代的CPU當中。在本報告中將對嵌入式即時系統的電源管理技術 做一番討論。其中包含了動態電壓管理(DPM, Dynamic Power Management)與(DVS, Dynamic Voltage Scaling)這兩方面,並且在即時核心中運用動態電壓調節技術 (Dynamic Voltage Scaling)於RT-Linux 3.0並以康伯電腦的iPaq 3630做實驗的 平台,特別針對調節時期的電壓與頻率的轉換耗損方面的平衡,提出一個電源管 理導向(Power Aware)以Linux為基礎的嵌入式即時作業系統。
Abstract
Embedded systems have existed in many hand-held devices and the power-saving mechanism has been supported by many microprocessors. DVS (Dynamic Voltage Scaling) is a power-saving technique to calculate and adjust the voltage and frequency at run time, according to the workload requirement of OS. In this project, we developed DVS algorithm and implemented in RT-Linux 3.0 running on iPaq 3630. In this project, we addressed the issues and considered the management overhead of power transition, which has not been considered in the previous research. We proposed an algorithm that can reduce the power transition overhead up to 30% of the original one at most, and it will not damage the real time property. Finally, we implement the algorithm in the proposed Linux-based embedded operating systems.
Keywords: Embedded Systems, Linux, Power Management, Real Time System, Energy Consumption
目錄
中文摘要... 1 目錄... 3 1.1動機... 5 1.2CPU的省電模式 ... 6 1.3DVS技術 ... 7 1.3.1 Intra-Task DVS... 8 1.3.2 Inter-Task DVS... 9 1.3.2 Slack評估的方法... 9 1.4相關研究... 10 1.5問題描述... 10 1.6研究目的與方法... 11 1.7報告內容概述... 11第二章 關於DVS (DYNAMIC VOLTAGE SCALING) ... 13
2.1DVS電壓排程 ... 13 2.2即時系統的排程設計... 14 2.3靜態電壓排程... 14 2.4動態電壓排程... 16 2.4.1 空閒時間(slacks)... 16 2.5電壓調節點... 18 第三章 即時系統的工作模式 ... 20 3.1討論即時性模式... 20 3.2控制流程... 20 3.3週期性工作模式... 21 3.4耗電模型... 22
第四章 電壓排程的耗損 ... 23 4.1時間的耗損... 23 4.2能量耗損... 24 4.3電壓調整策略... 27 4.3.1 Miss-deadline ... 27 4.3.2 slacks和idle的利用與搜集... 31 4.3.3 演算法... 35 第五章 實驗... 36 5.1模擬平台的參數... 36 5.2測試樣本... 36 5.3模擬程式... 38 5.4模擬計劃... 40 第六章 分 析與討論... 42 第七章 結論... 48 參考文獻... 49 附錄 A 測試參數表... 53
第一章 緒論
1.1 動機
近些年來手持式或行動式的嵌入式系統設計面臨到許多系統本身資源分配相關方面的 問題。 其中這些裝置大都使用”電池”供給系統操作的電源,但是在使用上電池的蓄 電量往往供不應求。目前流行的這類裝置包括:無線通訊和影音方面的應用,都是具有 比過去傳統裝置更耗電的趨勢。因此,最近有些系統設計的研究論點是以電源管理為中 心取代了單純以CPU為中心的設計觀念也逐漸的增加[1]。 所以如何克服電源的瓶頸已 成為目前熱門的研究主題之一。此外,俗話說:無法開源,只得節流。省電與有效運用 能源的研究在各不同的領域中都有相當多的研究與討論。 事實上這也是手持式系統設 計裡最重要的考慮因素之一。 省電的設計不只能夠延長電池的使用時間,並且能夠降 低此類裝置的維修成本與延長裝置的使用壽命。因為低耗電意味著不需常常將系統做開 關機的動作、拆卸與更換電池或者需要常常充電,這樣一來當然就能減少人力物力的介 入維護,並且有些系統因低耗電所以較不會產生熱量,因此機構方面也可以採取較為簡 單的設計而且零件的壽命也會較長。如此一來整個系統的成本也可以下降。 從IC設計和作業系統等計算機科學方面已有許多低耗電或省電方面的研究[2,3]。 在 攜帶型電腦方面,各家軟硬體製造商都遵循相關的電源管理的規格,例如:(ACPI, Advanced Configuration and Power Interface)[4],它能夠讓作業系統控制若干不同 的工作模式或關閉系統的電源[5]以達到省電的目地。 此外,目前許多電源控制的研究 都在即時系統方面的應用,因為大多數有電源限制的應用都具有回應時間的要求限制。 例如:行動通訊和手持式的數位影音撥放裝備。然而過去都使用固定的電壓與頻率來設計系統,所以沒有辦法對相關的零件(尤其是 CPU)做電源的管理。近來因為半導體科技與電源設計技術的進步使得當系統運作時能夠 即時改變CPU的運作頻率和電源電壓。 所以動態電壓調節技術(DVS, Dynamic Voltage Scaling)是就因此而產生,DVS是將電壓降到一個適當的操作範圍並且能夠滿足相對的 工作表現,其所降低電壓所導至能夠節省能量的消耗為平方比。一般而言在即時系統 (Real-Time OS)中控制和選擇適當的操作頻率與電壓準位是由排程(scheduler)單元負
time or arrived time)與執行時間的限制或週期等資料計算出合適的操作參數,也就 是說針對目前的運算能力和預測未來所需的運算能力做一番調整。 圖 1.1 DVS 示意圖 基於前文所提到的資料,DVS技術已廣範的運用在許多的系統上。那麼,這項技術的使 用過去已有許多的研究,然而,卻少有關注於轉換過程的內涵。 這內涵包括了,計算 和處理DVS所產生的時間延遲和能量耗損。因此,本報告將針對硬即時系統(Hard Real Time)中的電壓排程對於這些耗損做深入的研究, 包含:系統運作時動態調節會損及即 時性的分析,還有這些耗損的原因有那些。 此外,在本文中將提出減少動態電壓調排 程時所產生的耗損且精確的模擬出此方法的成效。
1.2 CPU的省電模式
CPU的耗電管理主要是調整CPU的供給電壓和頻率。目前市面上一些新型的CPU大都具有 上述兩種省電的模式。即使有些CPU並不是為攜帶型產品所設計的也都會具備省電的功 能,只是節省的程度不一。因為目前有些桌上型的CPU運作時會產生非常驚人的熱量, 這些熱量容易導致電子元件壽命的縮短,因此能夠具備省電模式是解決的方法之一。 在頻率調整方面,當CPU沒事做或只有少許的工作量時,可以降低運作的頻率來節省耗 電。在這方面,近來的CPU具備許多的模式來達成這樣的效果。例如:Intel的Mobile Pentium Ⅲ具有7種模式:Normal, Stop Grant, Auto Halt, Quick Start,HALT/Grant Snoop, Sleep, Deep Sleep[6],其中Deep Sleep是最省電的模式,但是需要花費30us 才能回到正常的工作模式,若是從Auto Halt返回正常的工作模式則需要10 bus clock 才能完成。因此,這相關的時間消耗必須加以注意。此外,還有的省電措施包含內部功 能模組的選擇,此方式的作用為:將不需要使用的功能關閉以節省耗電量,例如:不需使用浮點運算時,可將FPU( Floating Point Unit)關閉不用或者是內含的周邊,像是串 列埠(serial port)關閉。
1.3 DVS技術
DVS (Dynamic Voltage Scaling)是指CPU可以依照其原設計的規格給予不同的工作電
壓,且改變工作電壓不需關閉電源重新啟動的一種技術,例如:Transmeta的CrusoeTM
CPU, AMD的Mobile K6和Athlon的CPU, Intel Xscale系列的RISC。
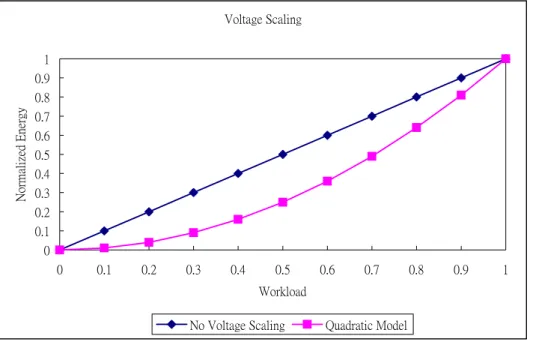
在降低電壓方面,CPU在較低的電壓底下工作可以節省電源和減少能量的消耗,一般而 言,CPU的耗電量與這個式子 V2 f 相對應的,V是工作電壓,f指頻率。 所以DVS是一種以CPU的耗電量與供給電壓間的關係是平方比為基礎的省電技[7],進一 步說明:CPU運作頻率的降低意味著CPU的電壓也可以跟著降低以節省耗電[8]。 以這種 情況來說電壓降低所導致執行時間的延長,大約是呈平方的反比。 其中有一方面需特 別注意;就是用來處理調節CPU速度時軟硬體所要付出的代價, 這代價包含了電源損耗 與時間的延遲。 有些DVS相關的研究對電壓調節時所需的代價是比較樂觀的[9]或忽略 不計。因此,在第四章中將詳細討論這方面的問題。 Voltage Scaling 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Workload N or m alized E ne rg y
No Voltage Scaling Quadratic Model
圖 1.2 Voltage Scaling
在Hard Real-Time系統使用DVS技術的電壓排程中,有兩種主要的方法:Intra-Task和 Inter-Task。
其中最主要的差別為:這兩種類的演算法所計算或預測出來的空閒時間(slack)是使用 在目前的Task還是下一個Task上。Inter-Task的電壓調節點是介於Task與Task之間,而 Intra-Task則是在Task內部置入調節點。因此,Inter-Task所產生的slack是給下一個 Task使用,而Intra-Task使用的Task則是用予目前的Task。
1.3.1 Intra-Task DVS
在即時系統中每個Task最差情況下的工作時間為WCET(Worst Case Execution Time)。 然 而在一個Task內可能有許多執行的分支與路徑,因為執行的路徑不同所以造成執行時間 的變化。所以當執行路徑不是WCEP(Worst Case Execution path)時工作將產生slack。 在 這 種 情 況 下 , Intra-DVS 為 利 用 slack 的 時 間 , 可 以 立 即進行調整以節省能量。 Intra-Task的演算法有下面兩種: 1. 路徑法 路徑法是依程式執行的路徑去決定工作電壓和執行頻率,若是執行的路徑與預先參考的 執行路徑不同時,則工作電壓和執行頻率將會被調整。所以如果新執行路徑的執行時間 多過於參考路徑,則工作電壓和執行頻率將會上升以保持工作的即時性。 換句話說, 如果新的路徑比參考路徑早完成的話,那麼CPU的工作電壓和執行頻率要下降以減少能 源的消耗。 2. 推測法 推測法為一開始執行就用低速然後視需要的時候再加速,比一開始用高速當slack發生 時再減速來得好。 一開始用低速執行,如果工作結束得比WCET早,如此將不需要用高 速去執行。 理論上,如果能夠推測Task的工作時間那麼就能夠計算出最佳化的排程。 此外,運用推測法CPU的速度將在既定的時間點提高工作電壓和執行頻率。因此推測法 有可能無法完全運用所有的slack,而路徑法則可以完全運用slack。
1.3.2 Inter-Task DVS
Inter-DVS是利用TASK與TASK之間的時間作工作電壓和執行頻率的調節,步驟為:(1)執 行。 (2)工作完成並計算下一個工作的執行時間。 (3)指定下一個工作的供應電壓。 (4) 執行下一個工作。大部份的Inter-DVS演算法在計算下一個工作的執行時間上有所不同 一般Inter-DVS包括二個方面:slack的評估和slack的分配。 Slack評估的目的是盡可能的將slack time找出來,而slack分配目的是將slack分散使 得工作的條件儘可能平均。Slack的來源有兩個:靜態的slack是指在WCET到時間限制間 那些額外的時間。而動態的slack將視工作在執行時所產生的空閒時間。1.3.2 Slack評估的方法
(1)靜態 靜態常數的評估法是用來計算最穩定工作速度的方法,保證工作排程的最小執 行速度。 (2)動態 三個常用的動態評估技術: ¾ 擴張法 即使所有的工作用最大常速度排程,因為真正的工作的執行時間 常常少於它們的WCET所以會有動態slack times。一個簡單的方法用來估 計動態slack time,就是用下一個工作的啟始時間。 ¾ 優先權利用法 這個方法的基本想法是,當高優先權工作在它的deadline 前完成那麼接下來低優先權的工作,能夠使用高優先權剩下來的slack time。相反的,也有可能是高優先權的工作去利用從低優先權工作的slack time。然而後者要精確地實作,需要大量的計算。 ¾ 經驗法 TASK的實際執行時間往往都不會到達最長執行時間。為提高預測 的準確率,可以使用過去執行過的經驗來提高slack的預測準確率。1.4 相關研究
在過去的研究中電壓調節點方面的研究大約分為兩類:一種為Intra-Task,另一種為 Interval Scheduling的方式。 Intra-Task的方法主要是利用編譯程式(Compiler)的幫 助,自動[10]或手動[11](由使用者指定)的方式加入電壓的調節點,主要是希望實際電 壓設定的曲線能夠符合應用軟體的確時需要,這種方法的好處是:電壓需求的曲線確時 能夠較接近最佳的狀況,因為,設計者可以依其特別的運作方式在程式內部較敏感的地 方加入調節點以修正電壓的曲線。 其缺點是,程式碼的增加。因為,每個點都要加入 相關的特徵值以修正用電的情況,那麼相關的資料和軟體都會增加程式碼。 其次,程 式內部執行的路徑(又可當作所需執行的程式碼)因為判斷式而有所不同,若在每一個 Base-Block都加入調節點。那麼程式的執行效率將會大大的降低。
Interval Scheduling方面,是介於Task Level和Intra-Task的方式,主要是OS透過一 個固定的Interval,搜集和設定目前的電源需求。 這個方法的優點是,它能夠提供比 Task Level更多的電壓調整點,因此能夠更加的接近實際電源曲線,且程式方面不需插 入額外的程式碼。因此易於使用。 其缺點是,此方法較適用於電壓與頻率的變化為線 性的改變。 但實際上目前的CPU都是非連續的電壓階層和頻率。因此,即使計算出結果, 但仍然不適用。此外,Interval scheduling的方式,其Task內相依的狀況無法確實的 被反應出來。 此外,上述兩種方法並未針對電壓調節點做深入的探討。 電壓調整點本身就會耗費能 源還有時間的延遲。 若太多的電壓調整點則會造成系統效率的降低與能量的耗損甚至 即時性的破壞。若是電壓調整點太少,則容易造成能量的浪費。 為此,本研究採用Inter-Task的電壓調整策略,並針對非連續電壓和頻率的CPU為平台, 在硬即時系統的架構下,求取電壓調整點與電源調整的平衡策略。以降低電壓調整點所 造成的能量和時間的耗損並且保持其電壓管理的特性與即時性質。
1.5 問題描述
若有一組Task,τi∈Task{1.. },1N ≤ ≤ ,Ci N i為τi需要執行的週期,Si為τi執行的速度單 位為Hz,Smax和Smin分別是最快和最慢的執行速度, i wcet T 為最長的執行時間, i ac T 是實際的 執行時間,Co是電壓調節點的耗損:那麼當無電壓調節耗損的狀況時,CPU的利用率U為: 1 ( / ) i N i i i wcet C S U T = =
∑
從上式來看,U<1時,系統是可排程的且具電壓調整的可能,以節省耗電. U=1時,系統 的執行速度必需為Smax,無法省電. 當U>1時,Task將無法排程。 因此,當計入電壓調節耗損時仍然必需滿足以上條件。 1 ( / ) 1 i N o i i wcet C S U T = − ≥∑
因此,將產生兩個問題: ¾ 若把Co的執行耗損併入WCET內,可解決無法排程的問題,但是如此一來容易造成CPU 的閒置與浪費。因此,需要一個方法幫助設計者決定CPU的運算能力。 ¾ 因此,可否將電壓調節點從N個改為M個,0 M≤ ≤N。 (N-M)則是可減少轉換的耗 損,但不能破壞原來的即時性與省電的特性。 上述的問題可以經由排程的策略和耗電分析方面著手以符合實際應用上的需要。1.6 研究目的與方法
研究目的 瞭解動態電壓排程的電源及工作頻率改變時的時間延遲與能量耗損 從系統觀點提出改善的措施 研究方法 針對硬即時系統的電壓排程做為平台,採取電腦軟體模擬的方式進行。 模擬的重點在於即時性的比較與能量消耗的比較。 詳細的內容請參考第四章。1.7 報告內容概述
本章為緒論,主要提出研究的動機與初步的背景資料做一簡要的說明。 接著為討論調 節時期時間的延遲與能量的耗損;其原因皆為DVS而生,所以在第二章中則討論DVS相關 原因與過去的研究並區分為動態排程與靜態排程兩方面。 DVS與即時系統間的關係則在第三章中敘述。 第四章則是先將整個DVS排程時間與能量的關係建立其數學模型,然後 提出轉換與耗損之間平衡的公式與演算法以增加省電的機會且不會造成即時性的消失。 第五章主要是呈現實驗相關的工作,從實驗環境的建立,實驗參數,測試樣本,數據分 析與製圖。 第六章將討論本研究的重點與成果和未來的工作。接著,參考資料與附錄 將列印於後。
第二章
關於DVS (Dynamic Voltage Scaling)
2.1 DVS電壓排程
DVS的目地是將task在執行時的速度降低以至於CPU主電壓的降低而達到節省耗電量。 在 即時系統方面目前在DVS中被提出的方法是針對TASK在執行時間的限制下,尋求最小的 電源消耗。 目前有許多即時系統方面相關的排程理論[12,13]都是將CPU的執行速度當 作為常數, 因此,並不符合現在實際上的應用。 要將CPU執行的速度降低得要多方面的考慮。首先是靜態的DVS:是將一堆TASK以最長的 執行時間計算其所需最低的執行速度。關於DVS排程方面, 其中EDF (Earliest Deadline First)算是一種蠻簡單且排程效果 不錯的一種方法,有些較為複雜的方法是採用經驗法則,也就是說系統利用過去執行的 經驗做為下次決定執行參數的依據,這些經驗的取得可以由設計者介入調整或動態的經 由一套回授的機制將相關資料予以保留以供未來的執行週期運用。在相關的應用或研究 上,各家的結果若跟不使用DVS的排程系統比較下,大約能夠節省1.4%到90%的能量[14, 15,16,17,18,19,20]。
這一方面過去的研究中 Yao 等人[21]曾提出了靜態的離線(static off-line)的演算 法,其假設在獨立非週期的情況下,TASK滿足所有的時間限制,能夠獲得最低的電源消 耗量。 這演算法在n個TASK的時間複雜度為:O(nlog2n)。 與此相關的研究在[22]中提出了一種非週期性的在線(on line)排程方法,這種演算法 是計算全部TASK所需執行效率的總和,然後設定固定的執行速度給所有的TASK。然而, 此方法將不會影響到離線(off-line)排程的結果。 在論文[23]中則對非先佔式多工 (Non-preemptive)的能源排程做了討論。 論文[24]則討論有一堆週期性的工作並具有 相同的工作週期則CPU的電壓變化率則有其上限。因為作者提到,這類問題即使是線性 變化的還是難以控制,因此提出了方法來解決這個問題。關於上述靜態排程方法在一般 週期性的工作模式中其電緣消耗的特性有潛在的不同[25], Aydin等人[26]最近則說明 了靜態的動態電壓排程與回餽式的排程有著相同的問題。
2.2 即時系統的排程設計
設計即時系統時,基本上都考慮系統在最差的狀況下運作,但是系統實際運作時其運作 應處於較佳的狀況也就是說時間上或資源上都比最差期況下要寬裕。 因此,大多數的 研究專門使用最差狀況的執行時間(WCET, Worst-Case Execution Time)去保證系統執 行時的時間限制,所以可以從那些執行後所剩下時間或CPU的運算能力中獲得好處。事 實上,程式執行時它真實的執行時間有很大的變化;例如:在參考文獻[28]中提到,一般 的應用程式在最佳狀況和最差狀況下程式執行的效率可能差上10倍。 動態的監視和搜 集那些沒被用到的運算能力或執行效率就是在電源排程的研究中如何在有效的執行情 況下精確的獲得執行所需的時間,據此與WCET的狀況相比較以節省那些多餘的電源。 在 這方面的研究中,主要針對CPU的執行速度做動態的調整,調整的依據是參考過去執行 的情況,因此,系統得不斷的記錄運行的狀態。 但是這會有一個問題,因為它是參考 過去的執行狀況,也許用平均值的方法或其它估計的方式並無法依據真正的時間限制, 使得在某些情況下TASK所被負與的執行速度會過慢將導致即時性的破壞。
2.3 靜態電壓排程
靜態的電壓排程(Static voltage scheduling)又稱為離線電壓排程(Off-line Voltage
Scheduling),是指系統在離線的狀況下將利用Task τi在時間的限制下需執行最多的週 期藉以計算出CPU執行的速度,若所需週期為Ci則在Smax的執行速度下若是在時間限制內 就能夠執行完畢那麼τi就有可能因為降低執行的速度而節省電源並且能夠符合時間的 限制。 上述方法稱為”靜態電壓排程”並且強調它的”靜態”屬性,因為這種方法只有討論最 差情況(worst-case)的task參數。往往最差情況的參數是設計人員在設計時就予以規 劃,但缺乏實際執行時的參考資料可供電壓調節之用。
以下還是針對Task Level及System Level這兩種層次討論靜態電壓排程:
針對Task level的電源管理, Task τi它的時間限制(deadline)為Di,則τi在執行速度
設定為 i i i D C S = 時是能夠安全的被執行完畢,當然這裡必需考慮的是:若Si>Smax那麼Task τi將不可能在時間的限制內被執行完畢也就是無法排程。此外,若Si<Smin那麼CPU的速度
還是要被設定為Si=Smin因為,CPU的執行速度有其上下限,Smin為下限,因此必須額外考慮
臨界點的問題。
基於以上說明,單一的Task Level之電壓調整最好在程式開啟始的位置就利用相關的參 數將速度計算出來,使得往後在執行時就能節省電源。
System Level方面, 若有N個週期性的Task使用EDF的方式排程,若是其執行速度的設 定落在g(S)的函數圖型上,那麼所有task的時間限制都能滿足而且耗電量的總合也會是 最小的。如此一來,一堆週期性的task在CPU使用率U的狀況下,U必須小於等於1(大於1 將無法排程),則CPU的耗電量將是max{Smin,USmax}。
為了適當的表示出靜態電源管理的成果;在此,將gidle假設為0且g(S)=αS3(因為電壓與頻 率間存在對應的關係,為簡化計算過程所以假設V ≈S)。 若T1…TN工作週期的最小公倍 數 為 Tlcm 則 當 執 行 速 度 參 數 Smax=1 , Tlcm 這 段 週 期 的 能 量 消 耗 為
∑
= = N i lcm i lcm i i UT T T S C S g 1 max max) ( α 若執行速度設為USmax那麼,在Tlcm週期的能量消耗將為∑
= = N i lcm i lcm i i U T T T US C U g 1 3 max ) ( α 將低於Smax=1的時候,因為U2小於αUTlcm。
舉例來說,若U為0.5則靜態排程出來的結果將只有原消耗能量的25%。 這種最佳的狀況是因為我們可以給予一個固定的實際利用率給函數gi(S),但實際上不同 的Task被賦予不同的工作,因此有可能會使用不同的硬體或大小不同的記憶體甚至是不 同的存取模式。 因此,對每個不同的Task都會有不同的耗電率,所以gi()也會因應τi 而 有 所 不 同 。 這 不 同 的 耗 電 率 可 以 對 應 到 不 同 的 Task 或 在 一 Task 內 不 同 的 區 段 (Intra-Task)。 所以這裡就是要找到省電的最佳化: 1 min{N ( ) i } i i i i i C g S T S =
∑
如此:∑
= ≤ N i i i i S T C 1 1 max min S S S ≤ i ≤上述的式子是說明τi在執行時的速度為Si,那麼τi的執行時間為 i i S C ,所以Task執行的 時間將從 i i T C 到 i i i S T C 。 EDF排程只要是將每個Task的利用率累加,其結果小於等於1則不 會產生miss-deadline的情況。 在解決以上最佳化的問題之後(詳細的推導過程可以參考[29]),所得的相關參數,例如: 速度的參數。可以保存在Task的參數表內,當Task執行時再透過系統去設定相對的速 度。所以OS也要做點小改變,在做Context Switch時也要跟著改CPU的執行速度。 針對靜態電壓排程做點小的總結:在靜態排程中從系統的角度或單一Task的角度來看排 程方法和目標是相同的;都是只要考慮實際利用率和WCET的關係。若是考慮單一的Task 那麼問題是相當的單純,若是考慮若干Task那麼必需所有的Task一起考慮,否則有可能 會發生不能排程的現像,此時,以單一的Task而言未必是最佳的狀況,但為維持所有Task 的工作能夠準時完成所有的利用率必須合併計算。
2.4 動態電壓排程
動態電壓的排程主要是跟據Task實際執行的狀況加以加以統計,精準的計算出與WCET之 間的最大範圍,此範圍將是實際能夠加以省電的區域,因此,又比靜態的電壓排程更貼 近於實際耗電的曲線。為了簡化討論的過程,因此假設所有的Task耗電的因素都是相同 的,Ss是經過靜態電壓排程所給定的執行速度的參數。 當Task實際執行時間若在WCET的指定時間前完成,那麼這段剩餘的時間就稱為slack(沒 被用到的可執行時間),slack是會變動的,因為Task內部被執行的cycle數目有多有少, 因此,充份的利用這些slack再加以省電,更可彌補靜態排程的盲點。2.4.1 空閒時間(slacks)
有一種估計slack的方法是利用過去同一Task被執行後的情況下加以統計,換句話說, 就是從歷史中找答案。動態的調整電壓和執行時的頻率都會造成系統在時間上的延遲,所以若WCET的時間為 twc, 經 過 調 整 後 實 際 所 花 費 的 時 間 為 tac, 那 麼tac ≤twc 才 行 , 否 則 會 因 調 整 而
miss-deadline,然而slackearly=twc-tac,這slackearly就是實際上可以節省能量的時間長度。
此外,有另一種計算的方式是以執行的cycle數來做計算,假設對最多需要執行的cycle 為Cwc,實際執行cycle數的平均值為Cav。 Ss是由靜態排程所決定的執行速度。因此,twc 將會等於 wc s C S ,也就是說twc是Πwc個cycles在Ss的速度下執行所需的時間。換句話說, slack的時間為 wc ( ) ac ac wc wc ac s C D t D t D t t t S − − = − − − = − 就是指從目前的時間到deadline 以Ss的速度執行完Cwc個cycles後的slack(空閒時間)。 在指定的工作下,讓Task執行到WCET的狀況其實相當的罕見,有可能是不正常的情況發 生,一般而言,設計者在發展時已將各種可能都考慮進去了,因此,時間都會有所餘裕。 因此,也給了能夠充份利用這些slack的機會。 此外,程式執行的cycles不一定會每次 相同,所以透過執行時期的統計,就能夠依其平均值予以預測slack,做為指定下次速 度的依據。要預測下一次的執行過後的slackspeculate為: wc av speculate early s C C slack slack S − = + 這個預測成立的假設在於Task的執行cycles是較為平均的,因此,以實際執行的平均時 間來說,比利用WCET要精準得多。 經過Scheduler計算過後獲得一個預測的slack,就可以將slack加入可執行的時間裡 面。所以,若C為所需執行的cycle數,Ss是靜態排程所決定的速度,從上面所述已知執 行的時間為 s C S ,加上預測出來的slack,那麼下一次執行的速度為: next s C S C slack S = + Snext被計算出來的結果,可以說是完成工作的最低要求的速度。在實際執行的情況下所 花的時間為 next C S ,萬一最壞的狀況產生時,若真的使用Snext的話,那將會造成miss deadline,因此,在速度的計算上要做一些補救的措施;以執行的cycle而言為C,Cwc為 最多需執行的cycle數,那麼我起碼要有Cwc−C 的時間用最高執行速度來做補救。因此,
max wc ac next C C C D t S S − − − ≥ 所以總執行時間必需保留補救的時間: max next feasible wc ac C S S C C D t S ≥ = − − − 將上述兩個式子加以整理,獲得最大的slack為: max max ( wc ) ac s C C C slack slack D t S S − ≤ = − − − 調整執行速度的耗損 在上述排程的模型當中都忽略了調整執行速度的損耗,這損耗包含兩個部份:一是時間 的損耗,二是能量的損耗。 在這一個章節當中將研究耗損會花費多長的時間和多少的 能量,跟上述的模型間又有多少的影響。
2.5 電壓調節點
“電壓調節點”顧名思義就是指系統進行電源管理的時候,為改變CPU執行速度與轉換 電壓時的執行點,因此,它對電源管理會產生影響,所以是我們需要討論的對象之一。 “電壓調節點”基本上是由若干程式碼與各程式或Task執行時管理CPU速度或相關參數 的資料所構成。 “電壓調節點”的程式有部份存在於一般的應用程式中,一些存在系 統核心當中,無論調節的程式存在於系統的那部份,其功能主要是決定出CPU新的執行 速度後產生系統的呼叫,然後由核心內部執行CPU速度與電壓的變更工作。因此,從系 統層次規劃上”電源調節”的架構規化可以分為兩個層次: Task-Level: 其範圍僅是利用Task本身的資訊,例如:時間上的限制和所需執行的週期。 針對這些訊息決定CPU的執行速度。 在Task-Level內電壓調節的位置可以由 設計者在Task內部插入相關的函式或由編譯程式做相關的處理。 所以,設 計者或編譯程式可以在程式啟始的位置就執行電壓的調節。 System-Level: 其決定CPU執行速度的範圍是針對整個系統,系統將參考所有執行中Task 的相關參數以決定CPU的執行速度。 例如:系統可以在下一個Task開始執行 前就預先決定其執行的速度。為了決定執行的速度,電壓調節的程式必需瞭解Task的相關參數,在許多的研究中都將 此參數稱為task profile information,例如: 在時間和效率的限制下最差的執行情況 與平均的執行情況以及執行時期的資料,例如:使用CPU的時間或者程式提早被結束。 task profile information可以先被計算並加以儲存,但是執行時期的資料得在真正被 執行的時候才有辦法搜集得到而且也許需要OS或硬體上的幫忙,才能順利的搜集到。 不同執行速度管理的方法主要基於以下兩個主要觀念:第一,找出系統執行時有空閒的 地方,第二,如何充份運用這些空閒的地方來達成電源管理的目地。
第三章
即時系統的工作模式
3.1 討論即時性模式
大部份的即時系統討論時都用τi做表示,i代表有i個Task,這些Task有時執行時間的限 制Di,這是即時系統中最基本也是最重要的元素之一。若假設有一個Task在時間0的時候 開始執行,則Di可以被視為這個Task, τi在時間上的工作區間。 Ci是指τi需要多少的運算週期才能完成。為了便於數學模型的推導Ci是不會跟隨執行速 度或CPU架構,例如︰超純量或管線設計而改變。此外,也不討論記憶體存取時因CPU不 同的執行速度而產生的變化,在此要特別提出這一點,因為記憶體的存取會比在CPU內 部做存取更花費執行週期,在某些的CPU架構下,記憶體的存取的週期會因CPU速度的不 同而有不同,有時CPU的速度較快,所以必需耗費較多的週期等待記憶體的資料傳輸, CPU較慢時等待的週期可能變得少些,在這裡將這個問題都假設為最長週期,來保持Ci 的穩定性。 在此,我們將運用亂數產生若干Ci的值來做實驗。Ci的單位是週期若在單位時間內則為 赫茲(Hz)頻率. 目前的CPU執行的速度大都以百萬赫茲(MHz)為單位,為簡化計算與模 擬,時間將以微秒為對應(micro-second, μs) 。這樣使得計算的單位趨於一致。 在Task內部,會影響執行週期的長短主要在於控制流程方面的問題,控制流程則包含了: 迴圈(loop),判斷式(IF-THEN-ELSE)或副程式等等。以迴圈來說,又區分為固定迴圈 (For)和變動迴圈(條件迴圈),迴圈的次數會影響Ci被執行的總數。判斷式則要視其條件 和執行的分支來決定Ci的數量。副程式方面則是一種遞迴的想法,重複上述的說明.此 外,就是一些固定會被執行到的工作。以下將就控制流程和週期性的工作予以探討。3.2 控制流程
將Task Pi切為ni段, τi,(j),1<=j<=ni若某一段是迴圈,呼叫副程式或其它的分支,則 Pi的流程圖在圖(3.1),假設每一斷τi,(j) 都要執行Ci,(j)週期。 每一段都以一個方塊做 表示,每一段若是一個迴圈的話則用一個圓形和曲線表示,曲線上的數字為迴圈執行的次數。 區段流程圖是一個完整程式的小分支,可以用個端點記號來表示。程式執行的 方式必需遵循指定的方式由起點向終點執行。 在流程圖中的某一點j, ,( ) i j WC C 是指j這點所需執行的週期,那麼 ,( ),1 i j WC i C ≤ ≤ ,能夠j n 被遞迴計算為 ,( ) ,( ) ,( ) ( ) max{ } i j i k WC i j WC k B j C C C ∈ = + B(j)是指j段內的子區段。如果方塊1為程式Pi中第一個被執行的區段,則Ci=Ci,(1)帶表這一 段程式最大的執行週期。 雖然已知最差的執行情況下要在時間限制內完成是即時系統必需確保的問題,Pi的執行 還是比Ci小很多[28],這是因為所輸入的資料和系統架構(例如:快取記憶體的大小)所決 定。 實際的執行週期往往小於最差情況下的估計和程式內部執行路徑的不同所導致。 如果 ,( ) i j avg C 是指這段執行週期的平均值則它的數學式如下: ,( ) ,( ) ,( ) ( ) ( ) i j i j avg k i k k B j Avg C C Pb C ∈ = +
∑
⋅ 其中Pbk是執行時從j段到k段的機率,所以若j段內只有一條路到B(j)那麼它的機率為: ( ) 1 k k B j Pb ∈ =∑
3.3 週期性工作模式
即時系統大都是做一些週期性的工作,因此,假設是N個週期性的Task被EDF方式排程, 若有一個工作我們定為τi則它的工作週期的時間我們用Ti表示,在此將對執行時的週期 做一個假設,假設τi開始執行的時間就落在週期開始的地方, τi結束的地方就是週期 結束的地方。在此先提到一種frame-based system,這是一種特殊週期的即時系統,就 是以frame為單位,一直重覆的執行著;Frame是由一堆Task所組成,因此,在同一個Frame 內的Task都具有相同的工作週期和相同的啟動時間,我們用T表示。這樣的系統安排通 常是運用在研究方面,因為如此的安排比一般的即時系統更為方便進行改善和證明。 有一組Task,{τ1,...,τN},令∑
= = N i i i T C U 1 表示這組Task在最高的執行速度下則CPU使用率 的總合為1,所以U必需被考慮的就是在系統中一定要保留下來的CPU使用率,那麼就能夠得知若U ≤ ,1Ti =Di且使用EDF方式排程,則在任何情況下,每一個Task都能被滿足其 時間的限制[29]。
3.4 耗電模型
具電壓調節功能的CPU其電源消量與執行速度之間的關係為平方比。電壓為平方項,執 行速度則為線性變化[14]。所以DVS之所以能夠省電就是因為CPU或其它主要的元件能夠 改變工作電壓和操作頻率。所以在執行速度為S,其電源消耗的函數為g(S)。 這個g(S) 的函數圖型為二次多項式的曲線[14]。若τi在t1和t2的時間內由CPU執行,那麼在CPU速 度S維持不變也就是把S當常數的情形下,t1與t2間所消耗的能量為∫
2 1 )) ( ( t t g S t dt也等於g(S)(t2-t1).另一方面,若CPU的速度可以從Smax:最快的執行速度,最耗電的狀況;Smin最慢的執行速度
與最不耗電之間做線性的變化,還有Sidle指CPU處於idle的狀態下其耗電會比Smin小,但會
比g(0)大,g(0)<Sidel <Smin。速度的管理最主要的是從導出耗電量的曲線函數g(S)中 找出結果,在此特別假設τi被分配到ti的時間執行,因為τi需要Ci個執行週期,這些週 期又使用了ti的時間,所以CPU的速度為 i i i C S t = 。 因為,耗電函數是曲線函數g則為: ( )i i ( ) ( )(i ) g S t ≤s S x g S t′ + ′′ −x X 代 表 CPU 速 度 不 同 時 執 行 時 間 , S' 與 S'' 是 兩 種 不 同 的 速 度( 'S ≠S'') , 所 以 (i ) i S x S t′ + ′′ −x =C 代表在ti的時間內使用不同的執行速度,比上固定執行速度下所能節 省的電源。值得注意的是:前面的狀況是單一Task且執行時間與時間限制相同(ti=Di), 若是不只一個Task的情況下速度分配的情況可能無法符合每一個Task的時間限制。
第四章
電壓排程的耗損
“電壓排程”望文生義就是以使用電壓的高低做為排程的依據,然而電壓轉換時會產生 能量的耗損與時間的延遲。 圖 4.1 Task 時序圖 如圖4.1所示,過去的討論大都基於左邊的方法,雖然合理但卻不切實際,上圖右邊是 較趨向實際的情況。 在Task轉換的過程中若是需要調整電壓或頻率,那麼在時間軸上 兩Task間是不連續的,這就是本研究中所指出的耗損。 那麼,既然耗損存在,是否有方法能夠減少這方面的耗損或是降低這耗損對系統的影響? 答案是肯定的。因此,本研究將解決以下的問題: 在能量的耗損上:減少電壓調整所發生的次數,但是不能損及原來省電方面的架構。在 時間的延遲上不能損及即時系統的時間限制。 調整執行速度的耗損,在上述排程的模型當中都忽略了調整執行速度的損耗,這損耗包 含兩個部份:一是時間的損耗,二是能量的損耗。 在這一個章節當中將研究耗損會花費 多長的時間和多少的能量,跟上述的模型間又有多少的影響。4.1 時間的耗損
直覺上時間的耗損主要分為兩個方面:軟體方面 耗於計算出新的合理速度 硬體方面 耗於電路本身的延遲,DC-to-DC的轉換延遲與時脈產生器所產生的延遲 因為在即時系統中,保持工作的即時性是最重要的。因此,任何會影響即時性的因素都 必須被謹慎的考慮。 當考慮改變CPU的電壓或執行速度時,Ci和Cavg_i,都必需將這些耗損的時間加進來,以 Intel SA1110的CPU[30]改變執行的速度將耗費200us[31],在59Mhz的工作頻率下,大 約需要11000個週期,在最高速221.2Mhz時約需45400個週期。 此外,改變電壓則需更 長的時間,因為可變式的電壓源大都由DC-to-DC的轉換器供應,這轉換器無法立刻的針 對所需的電壓做出立即的反應,通常需要一小段的時間,對於人類而言,轉換的時間是 微不足道的,但是在即時系統中,這轉換的時間是無法被忽略的。而且,轉換過程中CPU 通常無法執行指令,怕會有不穩態產生。 因此,有時得視需要插入一些延遲或無動作 的指令。 以Intel SA1110為例,改變電壓將耗費250us的時間, lpARM CPU[32] (低電 壓ARM8架構的CPU)從10Mhz的工作頻率升至100Mhz需15us。 另外的例子則為:全美達 (Transmeta) TM5400是特別依DVS[33]所設計的CPU,它是以每階33MHZ的頻率調整,每 一階的時間是相同的,因此,調整時需視情況累加其轉換時間,另外有些CPU在改變操 作電壓和操作頻率的同時能夠執行指令[32,14],但是在轉換的時間內頻率是變動的在 這轉換的週期內需要特別注意,以免有錯誤發生。 為使模型趨於單純,因此,本文將 以轉換週期時無法執行指令為討論的前題。 如此,以SA1110為例:改變頻率的損耗時間為200us,改變頻率為250us,這些時間 與執行速度無關是固定的。所以以Fo代表改變頻率的耗損,Vo代表改變電壓的耗損,因 此,以時間而言slack必需大於(Fo+Vo)才值得轉換,此外,必需具備下列條件並令Co為軟 體的耗損才能符合即時系統的需要: 1 ( ( )) o o o current C C D F V S + ≤ − + ⋅
4.2 能量耗損
藉由上述的模型推導,以下將開始推導能對應的能量耗損: 由VLSI相關的文獻中指出,降低電壓後意味著能量的下降,因此運作的頻率因應能量的 改變,因此必需與以降低。 可由下列式子表示:2 ( ) d L t V g C V V = −
上述式子為單一個gate的延遲性與電壓的關係。CL為負載電容(load capacitance),V
為工作電壓,Vt為工作電壓的下限。 另外,由於操作頻率與電壓基本上也呈一個對應的關係[34],所以能量也與頻率成平方 比(E∝ f2),因此跟據g d的公式,頻率應該如下面式子: 2 ( t) k V V f V − = k為電路常數[35]。 能量與頻率的關係則為: 2 2 ( ( ) ) 2 2 t t V f f f E V k k k ∝ + + + 因此,若是較複雜的電路由n個gate所構成,那麼在Vw的電壓下的延遲則為: 2 2 1
(
)
1(
)
S U M i i n n L w w g d L i w t i w tC
V
V
D
g
C
V
V
V
V
= =⋅
=
=
=
−
−
∑
∑
SUM L C 為負載電容的總合。 此時它的功率消耗為: 2 SUM w L wP
=
C
⋅ ⋅
f V
f為工作頻率。由此式可看出,功率的耗損是與電壓呈二次比與頻率為一次比,因此, 降低電壓比降低頻率要能夠節省更多的能源。若此,CPU每次執行一個指令就需要經過n 個gate,那麼所花費的功率也就為Pw。 因此就產生了一個功率的函數P,由功率函數計算消耗能量有以下的關係:∫
=
2 1)
(
T TP
t
dt
E
T1,T2為時間區間。 t∈{ ... },0T T1 2 < < 則上述則可計算出TT1 T2 1到T2間的能量。 所以將上述時間與頻率的參數代入如下:2 1
(
)
i(
)
i T d i i i T aC
C
E
P
d t
P
d t
S
S
=
∫
=
∫
則為一個Task執行指定工作時所需的能量,ai是Task的arrived time, di為deadline,
S為操作頻率。 軟體耗損的能量則為:若處理DVS程式為Cso個cycles,那麼軟體的耗損為: 0
(
)
so C so S soC
E
P
dt
S
=
∫
硬體的耗損可分為調整頻率和調整電壓,時間分別為Fto及Vto: 頻率調整的能量為: 0(
)
to F F toE
=
∫
P F dt
電壓調整的能量為: 0( )
to V V toE
=
∫
P V dt
那麼,完整的Task所需的能量如下: i T i so F VE
=
E
+
E
+
E
+
E
執行的時間為: i i so total to to i iC
C
T
F
V
S
S
=
+
+
+
且必需 i itotal deadline current
T
≤
T
−
T
否則會無法排程
此時,Taski的slacki為:
(
)
i i
i deadline current total
0
(
)
slacki i i T slack slackE
=
∫
P T
dt
,4.3 電壓調整策略
過去的電壓調整策略,大都是依CPU和Workload的使用率直接來做調整並沒有考慮耗損 時,那麼很容易造成無法排程或miss-deadline。 使用即時系統的目的還是在利用和確保”即時”的工作性質,因此任何排程策略的產生 首先必需確保Miss-deadline不會產生。因此,本研究提出結合電壓調整之耗損的排程 策略將從即時性質開始討論。4.3.1 Miss-deadline
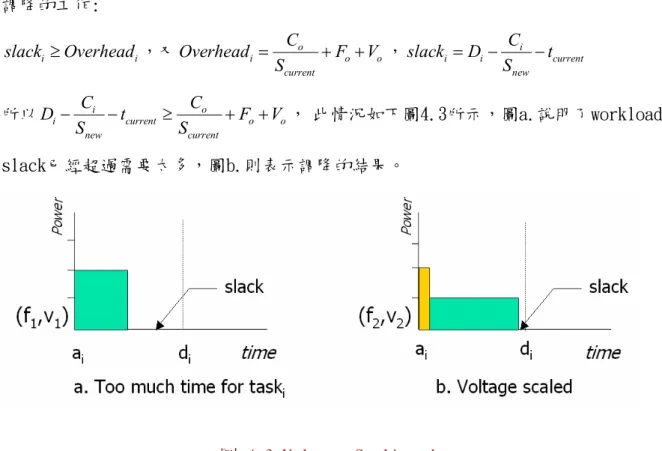
Miss-deadline的原因主要是沒有足夠的時間處理調整時的耗損,因此Task在面臨調整 時需要將調整的時間計算進去,但是如此一來,似乎只要將WCET的時間加上轉換的時間 就萬無一失了?但是,增加WCET將意味著需要更高階的CPU才能保證這所有的工作都能準 時完成,然而CPU效能的提升意味著CPU實際的利用率可能會降低,如此的考慮方法太過 於消極。因此,在本研究中提出有效的策略來保證即時性質,並且比將調整的延遲加入 WCET內要能夠減少為做電壓調整所發生的耗損。 圖 4.2 Voltage scaling up 計算 i current i i current C S D t α = ⋅ − , ai ≤tcurrent 若αi>1,則需做升頻與升壓的動作。因此需重新計算升頻與升壓的時間延遲的結果是否 仍然滿足工作的執行所需:( ) ( ) i o new i i o o current C C S D F V t α = + ⋅ − + − , Snew≤Smax 如果αi>1,則無法排序,若是αi ≤ 則可以繼續執行,基本上scheduler必須提供足夠的1 運算能力以確保即時系統的運行。 相反的,若是現在的運算能力足以應付現行的工作所需。那麼在降壓降頻後新的操作頻 率仍然需要足夠應付工作所需否則將得不償失。因此,下列式子必須成立,才需做實際 調降的工作: i i slack ≥Overhead ,又 o i o o current C Overhead F V S = + + , i i i current new C slack D t S = − − 所以 i o i current o o new current C C D t F V S S − − ≥ + + , 此情況如下圖4.3所示,圖a.說明了workload和 slack已經超過需要太多,圖b.則表示調降的結果。
圖 4.3 Voltage Scaling down
此外,還有若干的狀況需要進一步考慮調降的工作。 若是調降後會產生miss-deadline 則無法執行scaling down的動作,圖4.4說明了這樣的情況。
圖 4.4 Voltage scaling down but miss deadline. 上述說明了slack必需足夠才能做電壓的調整。此外,考慮一種排程的狀況,若Task的 workload小於轉換的耗損,那麼不斷的做轉換將導致更多的損耗。 證明如下: 假設有N個Task{1..N},Task{1,3,5,…,N}的WCET使用的工作電壓為v1, Task{2,4, 6,8…,N-1}的WCET使用v2且Di−1 = ,暫不考慮idle的情況。ai 令 i ac i T <Overhead, 1 2 2 1, v v 80% V >V S =S ⋅ 則使用本研究所提的演算法和直接使用DVS的差 別如下: 1 2 2 2 DVS overhead N N E = E + E + ⋅N E 1 1 1 2 / 2 1 1 1 ( i ( ) i ( ) ) ( ) i i N D D N i i i a a i v v i C C E P dt P dt P Overhead S S + + + = = =
∑
∫
+∫
+∑
2: 1 1: 0.8, 2: 1 1: 0.64 V V = ∴E E = Q 2 82 100 DVS overhead N E = ⋅ E + ⋅N E _ 2 DVS O E = ⋅N E , 根據上述的轉換策略所決定的演算法此類Job將不會做電壓調整。 因此,當原式所定義: 2 overhead V E >E 所以, Edvs >Edvs o_圖 4.5 工作量小於電壓調節的耗損. 藉由圖4.5 (a)說明了,電壓的調節必須視其工作量的大小做判斷,也就是投資報酬率 的觀念。在這樣的定義當中暫時忽略miss-deadline的情況發生,單就能量的損耗而言 做計算,換言之;若是調降後所節省下來的能量小於電壓調節時的能量消耗,尤其工作 量又小於電壓調節時的損耗,那麼反而會導致額外的浪費。 此外,在圖4.ZZ的(b)及(c) 又導出miss-deadline的狀況其中若 2 2 max, v max V =V S =S 則會發生miss-deadline,當然這 樣的假設過於極端,然而確可借此突顯出電壓調節造成延遲的重要性。誠如前文所撰, 將電壓調節的延遲時間加入WCET內就不會產生miss-deadline了,當然,這是解決的方 法之一,可是WCET的增加勢必造成為處理所有極端的情況下必須採用更高階的CPU,如 此一來對系統設計是不利的且因CPU運算能力的升級,有可能會更耗電。 因此,為 deadline的控制並充份利用slack和idle的時間做電壓調整的動作。將擬定另外的策略。 基本上,Scheduler若計算出現行的運算量是CPU目前的運算能力無法負擔的,那麼將無 條件加以調整提昇電壓和頻率。 以符合需要且確保工作的即時性。但是,操作電壓和 頻率的下降則有較多的考慮,例如:若是工作量在較低的頻率下雖可運算結束,但是加 上電壓調節的時間延遲,則有可能會超過其限制的時間這麼做將得不償失,沒有必要。 此時,slack將會產生,可以將slack搜集起來並視情況再利用。 圖 4.6 說明著這樣的關係:
圖 4.6 保持原來的操作參數 因此,下面將針對一些task排列的狀況,來增加slack和idle的重新利用。
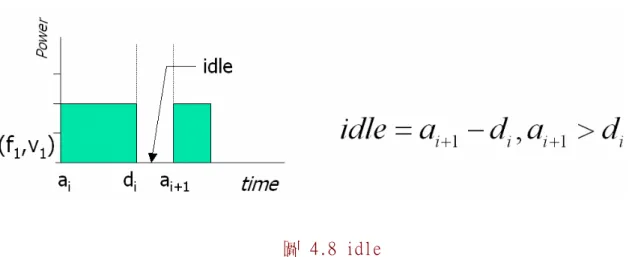
4.3.2 slacks和idle的利用與搜集
首先對slack的定義再說明:slack是指task實際完成的時間到WCET之間的時間。 而idle則是兩task之間的空閒時間。 在某些情況下slack也可以視作idle。 下面以數學式與圖型說明: 圖 4.7 slack上圖為突顯slack與idle的時間在觀念上的不同,因此taski與taski+1之間是緊緊相連
的,假設taski的deadline與taski+1的arrive time是相同的。 然而slack會依task執行
的狀況而有所不同,在第三章中已討論過它的機率模型,在此將不再贅述。 此外在Inter-Task的演算法中,slack的再利用基本上是給下個task使用的,因此,意 味著若要執行下一個Task將會有調節的機會。所以,需要調節與否將視所剩餘的時間是 否足夠轉換的耗損所需。 至於idle方面,可由圖 4.8做清楚的認知與定義。 Idle是指OS目前並沒有任何task在 執行,CPU是處於閒置的狀態。
圖 4.8 idle 圖 4.8 的idle為兩個task在時間上並沒有任何的重疊,這段沒有工作的時間就是idle time,目前較常見的CPU幾乎都有專門提供idle的工作模式,idle的工作模式下,CPU是 處於較省電的狀態。 因此,能夠獲得較長的idle模式也是電源管理的重點之一。而Idle 與slack不同,idle發生時當然可以利用idle的時間將電壓和操作頻率降到最低。但是 在下一個task來到之後將再需要一次的調節,所以在idle時間做調整將需要兩次調節的 時間。 其次,slack和idle也有混合的情況出現。 圖 4.9 Idle 與 slack 的混合狀態 圖4.9 是一種混合的狀態,結合著slack與真正的idle時間而成。 有了上述這三種空閒 的情況。因此,電壓調整的策略可以充份的利用這些空閒的時間做調整且降低或不會對 工作造成即時性的危害。 首先,只有slack的情況,由於slack的發生和時間的長度是具機率性質。因此,運用方 面先視它的長度及下一task的工作需要做調整。所以,有下面幾種情況: slack>overhead,且下一工作的需求是升壓與升頻。那麼scheduler可以將CPU進入idle
slack>overhead,且下一工作的需求是降壓與降頻。那麼scheduler可以將先降壓降頻 然後再進入idle模式,如圖4.10(b)所示。 圖 4.10 利用 slack 做升降壓 slack<overhead, 且下一工作為升壓與升頻。 那麼scheduler將立刻升壓升頻。 slack<overhead, 且下一工作為降壓與降頻。 那麼還要計算調節佔用多少的工作時間, 並且如果仍需降頻則立刻降頻,若是無法降頻則使用原來的狀態進入idle模式。此外, 若下一個task的WCET小於overhead那麼也將保持原來的狀態。以免得不嘗失。 Idle時間方面,若task queue內已有task待處理,基本上考慮的方式與slack是一樣的 考慮方式。 若是task queue內沒有task在等待處理那麼只能直接進入idle模式,然後 視需要再加以調整。 圖 4.11 運用 idle 與 slack 做調整
圖4.11 (a)說明了idle或 slack時間不足時會佔用到task的執行時間。 圖4.11(b)則說 明了slack和idle的運用。 基於上述的情況可知,動態排程和靜態排程最大的不同就是對予slack的預測,在本報 告中提出一個方法,其方法的基本概念是從「應用導向」來增加slack預測的正確性。 「應用導向」是指應用程式在執行時,基本上都有一定的脈絡可循。例如:一個MP3的撥 放程式其動作大體上為讀取MP3檔案內容、解碼、撥放等一直重覆的動作。 因此,在動態排程時最主要的一個限制就是下一個工作不知何時會產生。因此,如果能 夠知道下一個工作或完整的工作串列,那麼處理動態排程將跟靜態排程一樣的準確。 在本報告中以雙向指標的資料結構利用context switch時將指標分別指向其上下TASK, 以建立上下游的關係,如此一來當下一回合又進入此TASK時,將能夠知道下一個工作的 參數,以增加slack預測的準確性。
4.3.3 演算法
P o w erT ran sitio n A w areS ch ed u ler(T ask Q u eu e T ) = w o rk lo ad b y cu rren t o p erate sp eed
if > 1 th en
id le_ tim e= arriv e_ tim e-cu rren t_ tim e
if id le_ tim e o verh ead th en // u se id le_ tim e fo r p o w er tran sitio n
α α
≥
id le_ tim e= id le_ tim e-o verh ead
= re-calcu late w o rk lo ad w ith h ig h er o p erate sp eed if > 1
set_ id le(id le_ ti
th en fail(u n ab le to sch ed u le)
m )e // en ter id le state an d w ak eu p w h en id α
α
le_ tim e reach ed else
= re-calcu late w o rk w ith n ew sp eed an d p artial o r fu ll o vrh ead if > 1 th en fail(u n ab le to sch ed u le) vo ltag e_ scale_ u p ( ) freq _ scale_ u p ( ) en d if els α α α α e if alp h a < 1 th en
id le_ tim e= arriv e_ tim e-cu rren t_ tim e if (d ead lin e-arrive tim e) o verh ead th en
if id le_ tim e> 0 th en set_ id le(id le_ tim e) an d k eep cu rren t o p erate sp eed en d if
if id le_ tim
≤
e o verh ead th en
= re-calcu ate w o rk lo ad w ith lo w er o p erate sp eed if > 1 th en k eep cu rren t o p erate sp eed
else freq _ scale_ d o w n ( ) vo ltag e_ scale_ d o w n ( ) α α α α ≥
id le_ tim e= id le_ tim e-o verh ead en d if
else
= re-calcu ate w o rk lo ad w ith lo w er o p erate sp eed an d p artial o r fu ll o verh ead set_ id le(i if > 1 th en k ee d le p c _ tim e u rr ) en t o α α p erate sp eed
else freq _ scale_ d o w n ( ) vo ltag e_ scale_ d o w n ( ) en d if en d if end if p erfo rm (task ) end . α α
第五章
實驗
本研究使用軟體模擬驗證,軟體模擬的環境參數主要分為兩方面,第一,為平台的參數。 第二則為測試樣本。 因為軟體模擬就是為了縮短裡論與實際方面的距離,若沒有採用 較實際的工作參數。那麼,所獲得的資料將降低其參考的價值。 同樣的,測試樣本的 涵蓋面需要儘可能的廣泛,才能得到較為完整的結果。5.1 模擬平台的參數
為驗證本報告在第四章所提的方法將採用軟體模擬。模擬參數的樣本來自於Intel公司 所出品的SA1110的CPU的32位元整合型CPU,本程式所取的參數表如表5.1,其中CPU的核 心電壓為1.47V至2.10V,外部I/O的電壓為3.3V,操作頻率分為12階,範圍由 59MHZ~221.2MHZ。* 擷自 SA1110 Developer’s Manual, Oct 2001
表5.1 SA1110參數表
為方便計算,模擬程式內的時間刻度為1μs,如此一來可以將頻率與時間的關係簡化。
5.2 測試樣本
struct TASK {
pID : unsigned long; // Task ID aTIME : unsigned long; // arrived TIME dTIME : unsigned long; // deadline
real_cycles : unsigned long; // Workload by cycles
max_cycles : unsigned long; // Worst Case Execution cycles min_cycles : unsigned long; // Best Case Execution cycles uplink[5] : struct TASK; // Tasks UpLink
downlink[5] : struct TASK; // Tasks downLink }
此外,為了自動產生一些特別規格的Task Set,所以程式內部也具備了產生Task Set的 功能,以減少輸入的時間提升模擬的效率。 以下,是相關輸入的參數:
struct _TASK_SET_{
N : unsigned long; // Number of Tasks Period : unsigned long; // Range of period aTIME : unsigned long; // arrive time dTIME : unsigned long; // deadline
cycles : unsigned long; // Workload by cycles }
這Task Set的產生程式只是產生Task,並不會依不同特性的排程演算法做排列,因此, 若選用EDF排程,則需另外依deadline做排序,若RMS則需要利用period做排序。
因此,只需要將Task的規格寫成一文字檔, 輸入之後將自動產生具相關規格和特性的 Task Set。
下面的列表是本研究的工作樣本。所產生不同的CPU Utilization的資料將置於附錄A。
Utilization WCET Execution Time Cycles Period
450 45 9954 450 2250 168.75 62213 2250 0.25 3375 253.125 93319 3375 2250 281.25 62213 2250 0.50 3375 421.875 93319 3375
900 225 49770 900 450 168.75 37328 450 2250 168.75 62213 2250 0.75 3375 1012.5 93319 3375 450 112.5 24885 450 2250 1125 62213 2250 1.00 3375 843.75 93319 3375
表5.2 Task Sets parameters
Utilization的值為,所有Task Set的執行時間與WCET比率的總合,雖然在設計樣本的 同時就需要考慮,但在程式內部仍然有檢查的機置來避免這種沒有辦法排程的情況產 生。
5.3 模擬程式
模擬程式主要分成三個部份:
Slack Estimation : slack預測的機置,此機置可以與各種不同的排程演算法互相搭配。 以取得slack的長短做有效的運用。
Return of Investment Control : 過濾掉投資報酬率較差的轉換。 例如:slack不夠長 的,Task執行時間太短的Task。都不應轉換以免因轉換而造成更大的耗損。
Power Control : 電壓和頻率控制的機制,此為配合第四章的轉換策略。
執行部份 : 因為所需執行的週期是虛擬的,所以主要是用來計算消耗的能量和時間, 此外,利用參數設定程式週期的Low Bound,以亂數產生出介於Low Bound到WCET間需要 執行的週期數,以產生不同的slack。
能量與時間週期控制單元 : 用以記錄耗費的能量與經過時間,並加以記錄且將結果轉 換為Excel檔案格式,以方便分析與統計。
5.4 模擬計劃
模擬的情況和條件以off-line為主,首先必須設定對照組,本研究的對照組如下: 1. No DVS
2. Statically-Scaled EDF 3. Look-Ahead DVS
4. Statically-Scaled EDF + Our proposed scheme 5. Look-Ahead DVS + Our proposed scheme
模擬的目地:
1. 比較各種演算法在相同的Task Set的Power Transition個數 2. 比較能量消耗的情形 3. 比較即時性質 環境設定: 1. Power Transition個數 輸入一數量的Task,在不同的CPU Utilization下,範圍從10%至100%間取得轉 換個數的數據。 如此,可以計算出能量與時間耗損的純量也可看出轉換耗損佔 用所用資源的比率 2. 能量消耗 給予四組不同的slack比率(0%,25%,50%,75%)並在不同的CPU利用率下10%~100% 藉以模擬各種不同情況的能量消耗。 3. 比較即時性 當Power transition對於Task的比率增加時,系統的效率會變差,一但系統的 效率不好將損及即時性質。因此將Task所對Power transition的比率從0.25一 直提到30倍,也就是說Task所佔的時間是Power Transition的30倍至0.25倍, 如此可以看出系統的耗電情況和所佔用的時間。
42
第六章
分 析與討論
依據模擬計劃的說明,針對Power Transition個數的情況如下:
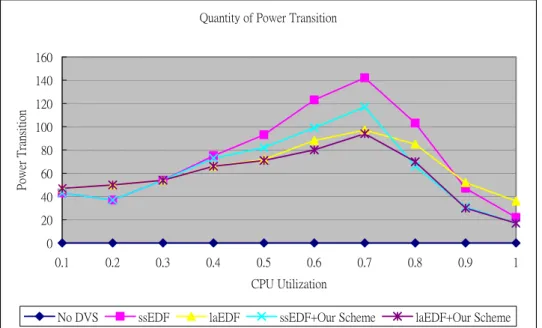
圖 6.1 Quantity of Power Transition
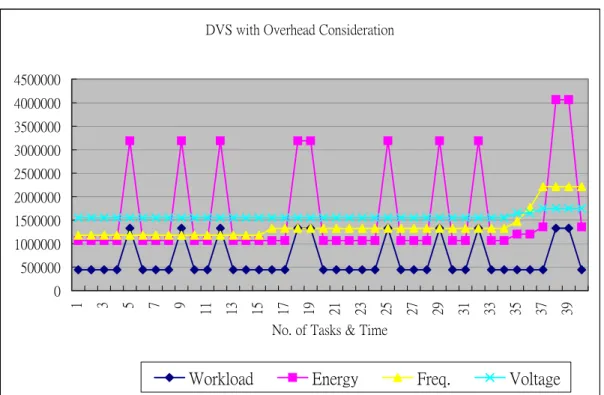
圖6.1呈現了Power Transition分佈的狀況,其高峰部份大約是在CPU利用率的60%~80% 之間,這樣的趨勢說明了Power Transition的轉換耗損在使用率大約70%左右達到最高 峰,在圖的兩側CPU是處於較低工作量或高工作量反而是比較穩定的。 在本圖所示在一 般的狀態下本研究所提出的方法可以降低轉換次數約30%左右。 因此,意味著在轉換上 的耗損也能夠減少30%。 除此之外,實際工作的過程請參考下面圖6.2工作圖,這是未經過本報告所提方法調整 的,在80%的CPU使用率下,40個Task的執行情況共發生11次的調整。 圖6.BB為經過本 研究調整的情況,只發生兩次的調整。 但是消耗能量的總合並沒有增加。雖然有時需 要使用較高的電壓來唯持即時性,但是因減少花費於轉換的耗損,所以整體的能量消耗 反而比較低。
Quantity of Power Transition
0 20 40 60 80 100 120 140 160 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 CPU Utilization Po wer T ra ns itio n
No DVS ssEDF laEDF ssEDF+Our Scheme laEDF+Our Scheme
DVS with NO overhead consideration
3500000 4000000
圖 6.2 ssEDF
圖 6.3 ssEDF + Our Scheme
在能量比較方面,底下圖6.4到圖6.7為不同的工作量下的能源消耗的比較,CPU Utilization是指每個工作量的upper bound,也就是說每個Task只執行CPU Utilization 的所對應的週期數,其餘的就是slack。 例如:某個TASK的執行時間為10秒,若其Deadline 為100秒,則CPU例用率為0.1,若是TASK實際執行時間為2.5秒,則其佔原WCET的25%。 其
DVS with Overhead Consideration
0 500000 1000000 1500000 2000000 2500000 3000000 3500000 4000000 4500000 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
No. of Tasks & Time
25% WCET 0 10000 20000 30000 40000 50000 60000 70000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 CPU Utilization E ner gy Cons umption
NO DVS ssEDF laEDF ssEDF+Our Scheme laEDF+Our Scheme
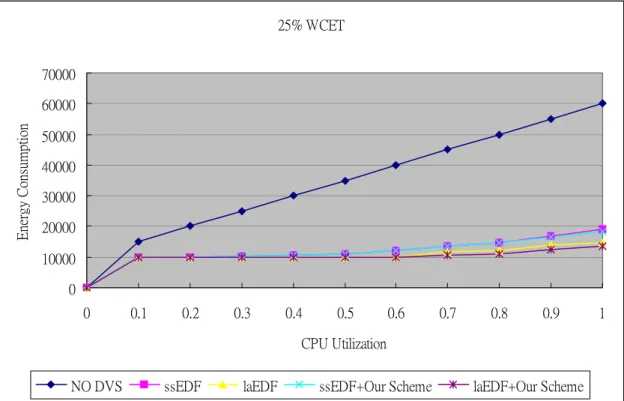
圖 6.4 Energy Consumption of 25% WCET
以圖6.4的情況來分析,實際的CPU利用率還不是很高。因此,CPU一直處於較低速的狀 態就運行就足夠應付工作所需。所以轉換的機會較少;CPU一直是處於較穩定的情況所以 與原來的的演算法差距不會太大。大約是2%~至5%。
圖6.5的情況來說,轉換的機會較多,因此具有比較多的能量差別,尤其是ssEDF演算法 大約有17%的差別且總耗損能量有2%左又的差距。
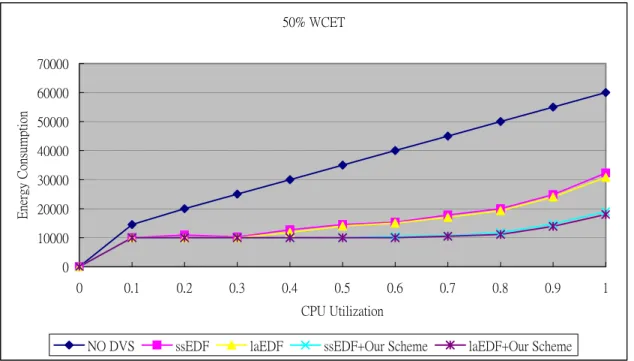
50% WCET 0 10000 20000 30000 40000 50000 60000 70000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 CPU Utilization Ener gy Consumpt io n
NO DVS ssEDF laEDF ssEDF+Our Scheme laEDF+Our Scheme
圖 6.5 Energy Consumption of 50% WCET
圖6.6 是75% WCET的情況,這種情況下調整的機會最頻繁。因此,在這種狀況來說總耗 電量與調節上的耗損差距最大。 75% WCET 0 10000 20000 30000 40000 50000 60000 70000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 CPU Utilization Ener gy Consumpt io n
NO DVS ssEDF laEDF ssEDF+Our Scheme laEDF+Our Scheme
圖 6.6 Energy Consumption of 75% WCET
圖6.7 所表示的情況則本方法就比較糟了,其原因為:雖然轉換調整的機會變少了,但 是為保持即時性,所以CPU將被要求較高的運算能力。因此,整體的能量消耗就稍稍多 了些。
100% WCET 0 10000 20000 30000 40000 50000 60000 70000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 CPU Utilization E ner gy Cons umption
NO DVS ssEDF laEDF ssEDF+Our Scheme laEDF+Our Scheme
圖 6.7 Energy Consumption of 100% WCET
最後在即時性值方面,若CPU利用率接近1,且Overhead的時間大過於Task的可執行時間 時Miss-Deadline的情況會越嚴重,且造成OS的效率不佳。 圖6.8為執行200個Task,且 CPU利用率為75%,可以看出Overhead比例對Task的影響。
Ratio of Miss-Deadline 0 10 20 30 40 50 60 70 30 25 20 15 10 5 4 3 2 1 0.5 0.25 Workload/Overhead Q uantity of M is s-D eadline
No DVS ssEDF laEDF ssEDF+Our Scheme laEDF+Our Scheme
第七章
結論
在本研究中專注於一個一直被忽略的問題,而Power Transition Overhead就是一個典 型的例子。
在本研究中使用SA1110的電源參數,探討在轉換的過程中所造成時間的延遲和能量的耗 損,透過數學模型與電子電路的物理性質已證明了這種現像的存在,在文中提出了一個 演算法主要包含三個部份:Slack Estimation, Return of Investment與Power Control, 能夠有效的降低許多不必要的轉換,在大多數的場合裡以整體的耗電量而言也有節省的 趨 勢 。 此 外 , 對 即 時 性 也 有 較 佳 的 保 障 。 針 對 減 少 的 耗 損 而 言 , 以 一 般 的 Statically-Schedule EDF的演算法做比較有30%的減少,與較佳且先進的Look-Ahead EDF演算法做比較,使用本文的前後也有2%到5%的降低。 雖然在CPU接近滿載(超過90%) 時的耗電量會稍微高一點,但在即時系統中,應該還是符合絕大多數的工作範圍。 因此,這項議題將來深入研究將有一個主要的方面,就是slack estimation,如果能夠 增進slack預測的可靠度,那麼將可以加以利用,使得能夠更貼近系統實際的能量需要 以求取最佳的利用率,降低耗電量。