結合網域名稱與網路代理伺器進行資訊管制與分流之架構及
結合網域名稱與網路代理伺器進行資訊管制與分流之架構及
結合網域名稱與網路代理伺器進行資訊管制與分流之架構及
結合網域名稱與網路代理伺器進行資訊管制與分流之架構及
其實作
其實作
其實作
其實作
曾黎明
曾黎明
曾黎明
曾黎明,
, 郭廖軒
,
,
郭廖軒
郭廖軒
郭廖軒,
,
,
, 游象甫
游象甫,
游象甫
游象甫
,
,
, 劉之掦
劉之掦
劉之掦
劉之掦
國立中央大學
國立中央大學
國立中央大學
國立中央大學,
,
,
, 資訊工程研究所
資訊工程研究所
資訊工程研究所,
資訊工程研究所
,
, 分散式系統實驗室
,
分散式系統實驗室
分散式系統實驗室
分散式系統實驗室
國立中央大學
國立中央大學
國立中央大學
國立中央大學,
,
,
, 電子計算機中心
電子計算機中心
電子計算機中心
電子計算機中心
摘要
摘要
摘要
摘要
隨著 WWW 的普及,資訊的散佈非常迅 速,對知識的累積有很正面的幫助,然而 Web 上的各種資訊也衍生出負面的問題,就是越來越 多不當資訊充斥其間,例如色情圖片與粗暴文 字。本論文主要分析如何對以網站阻擋為主的不 當資訊防治,同時根據 TANet 現狀,提出多種 以網路代理伺服器利用網域名稱系統進行色情 資訊過濾的策略。這些方式對於代理伺服器不會 造成額外負擔,而佈置成本與效率上只需要一台 專用的網域名稱伺服器,有集中管理、維護容 易、使用單位容易加入之優點。為驗證策略的可 行性我們實作系統雛型,並安裝於桃園區域網路 中心,實驗結果顯示本系統可有效阻斷色情網站 的存取;同時由於效果顯著方式簡單,已有其他 地區學校加入並希望能引進利用。 關鍵字: 關鍵字: 關鍵字: 關鍵字:不當資訊攔阻,網域名稱伺服器,網路 代理伺服器
Abstra ct
With the popularity of WWW, fast information distribution greatly speed up the aggregation of knowledge. However, a variety of information on Web pages produces an unexpected problem-abusing information distribution, such as adult and violence. The article addresses how to find out adult contents on Internet and to avoid accessing them by a scalable simple approach. Considering the operation of TANet, we propose proxy-based approaches to filter abusing information. The approaches utilize existing domain name software as a special server. The cost is only a private domain name server and no extra load on the filtering system. Finally, we implemented a prototype to demonstrate our approaches. The system was installed at National Central University in Taoyuan to test its effect. The experiment shows that our system effectively blocks the retrieval to abusing information. Because of the great effect, many other institutions joint to our system and inform us to adopt the system.
Keywords: Abusing information filtering, domain
name system, proxy server
1
11
1 緒論
緒論
緒論
緒論
隨著網際網路的普及,其已成為現今很 重 要的傳播媒介之一,使用者可輕易從網站得到各 種資訊。由於架設網站(WWW server)的技術相 當簡單,稍具電腦知識的人均可建構自己的專屬 網站,再加上許多入口網站提供免費或非常便宜 的磁碟空間供使用者放置個人網頁,因此網際網 路充滿各種資訊。 WWW 使得資訊的散佈非常迅速,對知識 的累積有很正面的幫助,然而 Web 上的各種資 訊也衍生出一些負面的問題,例如有人利用網頁 教導如何自殺或製造爆裂物用於恐怖活動,同時 也有 團體 利用 網路 宣傳種 族歧 視或法西斯主 義,而報上也常刊登利用網路販賣管制藥品的新 聞,這些資訊的散佈很明顯的造成一些社會問 題。然而對 TANet 而言最需要立刻管制的不當 資訊是色情,色情資訊和上述提及的不當資訊相 比,色情資訊多半以圖片或影片形式存在,色情 小說的用字也簡單露骨,直接刺激感觀,挑動人 性原始的慾望;相對於其他不當資訊,其圖片文 字大都沒有這樣的效果。由於 TANet 上的使用 者除了成年的研究生及大專學生外,還包括未成 年的高中、國中及小學生,其判斷力尚未成熟, 容易對所接觸的色情資訊加以模仿,造成嚴重的 社會問題。 圖 圖圖 圖 1 1 1 客戶端使用代理伺服器存取網頁1 客戶端使用代理伺服器存取網頁客戶端使用代理伺服器存取網頁 客戶端使用代理伺服器存取網頁 本論文目的在於分析如何對以色情為主的
不當資訊進行攔截。圖 1 是網頁存取的過程,可 用來說明可能的網頁檢查策略。當使用者利用瀏 覽器觀看網頁時必須輸入網站名稱,可能是 IP, 但大多使用網域名稱(domain name)。若使用者 有設定網路代理伺服器(proxy server),則瀏覽器 將網址送給代理伺服器,由其將網址送給網域名 稱伺服器(domain name server),解析成 IP;若 使用者不使用代理伺服器,則瀏覽器會將網址送 給網域名稱伺服器以解析出對應 IP。接著根據 IP,瀏覽器或代理伺服器便連接對應的網站,以 HTTP (HyperText Transfer Protocol)下載網頁。 由以上網頁存取的過程,可能的網頁攔阻地點為 使用者端電腦或瀏覽器、網路代理伺服器、網域 名稱伺服器或網站。而過濾 Web 資訊的策略,大 致上可分為 URL-based 與 Content-based 兩種, URL-based 主 要 讓 使 用 者 不 能 存 取 受 限 制 的 URL,而 Content-based 主要過濾網頁內容,如 文字或圖片。 本論文主要貢獻在於提出一個可擴充大小 (scalable)的網頁過濾架構與分流管制機制,適 用於 TANet 環境-以網路代理伺服器瀏覽網 頁,當代理伺服器向網域名稱伺服器查詢網域名 稱時,若網域名稱伺服器發現其為色情網站時, 會傳回一特定網域名稱,將使用者導向警告或分 流網站,阻止或以密碼機制計次限制其瀏覽。此 架構具有以下優點:管理集中,維護容易;不需 於瀏覽器、代理伺服器或路由器費時費力過濾網 頁;低建置成本;可輕易擴充,提供攔截站專業 進行網頁分級,而非完全攔阻。目前本架構已完 成雛型,並順利運作於桃園區網的全部網路代理 伺服器。 本論文其餘內容如下,第二節介紹現有過濾 產品的作法及相關論文研究;第三節說明系統的 架構與設計;第四節為實作與測試,展示本系統 在中央大學桃園區網中心代理伺服器上實作的 成果;最後是結論及未來展望。
2
2
2
2 相關研究
相關研究
相關研究
相關研究
應用於色情網頁阻擋的的技術可分為不當 網站 阻擋 (Bad site blocking) 及網頁 內容 過濾 (Content filtering)。
2.1
2.1
2.1
2.1 不當網站阻擋
不當網站阻擋
不當網站阻擋
不當網站阻擋
利用此技術來防制不當資訊是最簡單也是 最直接的方法。目前有許多軟體[4][5]即是使用 此類方式以防止不想被使用者接觸之資料。以色 情的資訊來說,此方法即是運用長期收集色情網 站位址作為防治基礎,對使用者的網路服務應求 進行位址比對,若是不當資訊網站位址,則會阻 擋連線。 不當網址黑名單可由下列方式可產生:
人工瀏覽網站內容
透過瀏覽網站內容,以判斷這個網站是否 含有有害內容;不過由於網站增加的速度非常 快,要將所有網站都分類完成幾乎不可能。目前 有一些組織推動一些分級的標準,並請志工來幫 忙 分 類 , 常 見 的 分 級 標 準 有 :PICS、 NetShepherd、RSACi、Safe Surf等;此方式是先 定義網路文件之檢索方式及文件標籤分級之語 法,進而在網頁上標上分級的標籤,使得網頁可 以透過此方式加以過濾、篩選,進而限制使用者 濫用有害資訊的傳佈。此外,過濾軟體都會提供 使用者申報不當網站的介面。利用程式分析內容
首先透過類似搜尋引擎的 crawler 去蒐集 網站列表,然後程式分析每個網站的內容,分析 的方法有很多種,主要是利用文字或是圖片亦或 是影像的比對,來判斷是否含有有害的資訊。 根據統計全世界色情網站總數約有二十三 萬個,網際網路中的色情網站每日以三百至五百 個以上的數量成長,因此使用黑名單的問題在 於: l 更新黑名單不容易 l 無法即時分析與阻擋 黑名單可以使用 hostname 或 URL 的形 式,也就是說阻擋某些不當資訊,可以阻擋整個 網站或者是網站裡的某幾個網頁;URL 的主要 好 處 攔 阻 問 題 網 頁 的 精 準 度 高 , 例 如 像 www.geocities.com裡面可能是某些免費網頁空 間含有色情內容,但是 URL 的 filtering,要建的 列表會變得相當大,增加系統過濾時的負擔;而 利用 hostname 過濾最大的好處是系統負擔低, 但精準度就會下降。2.2
2.2
2.2
2.2 內容過濾
內容過濾
內容過濾
內容過濾
此方式主要是對網頁的內容進行過濾,以 達到防治有害資訊內容的效果。對於其他傳播方 式,如 email、newsgroups,此方法依然可以防 治。
影像處理
以偵測色情圖片為例,目前已有許多研究 [8][9]、技術[1]及產品[2][3][6]可以有效的過 濾出色情圖片,主要都是利用影像處理的技術, 例如:利用統計學上的影像分析原理,將影像與 資料庫做比對以偵測出皮膚,再根據皮膚的分部區域及大小,或者是人體的特徵,來判別影像是 否為色情圖片。
文字檢索
文字檢索的方法不外乎固定網址與關鍵字 的搜尋,不過利用關鍵字的比對常容易出錯,例 如”his recipes for cooking a chicken breast”含有 『breast』字眼,但這句話卻只是要煮雞胸肉, 再平常也不過,所以可能需要一些語意的分析[7] 來解決問題。
2.3
2.3
2.3
2.3 攔截點的配置
攔截點的配置
攔截點的配置
攔截點的配置
不當網頁的攔截點可以在使用者端電腦或 瀏覽器、網路代理伺服器、網域名稱伺服器或網 站。若在使用者端電腦攔截,現有許多產品多是 以 browser plug-in 的形式,主要是利用黑名單的 阻擋,並可利用網路更新黑名單;除此也可利用 content filter 來實作。若在網路代理伺服器,則 可使用黑名單或內容過濾的方法,本方式可以自 行產生黑名單。同時網站端也可過濾色情資訊, 例如 kimo,可能的過濾方式有人工瀏覽或程式 分析。至於網域名稱的攔截配置,於第三節詳 述。
3
3
3
3 系統架構與設計
系統架構與設計
系統架構與設計
系統架構與設計
本節提出兩種基於網域名稱伺服器及網路 代理伺服器的色情網頁攔阻策略,並且討論黑名 單的更新。
3.1Host filtering by DNS & Authentication Gateway
我們首先介紹一個 Host Filtering 架構如圖 2,假設有一張正確的色情網址列表,列表的內 容為色情網站的域名;將此列表建入 private local root DNS 的 zone file 中,每一筆色情網址是一個 A record 指到特定 Authentication Server 的 IP。 先不考慮使用者會以 IP 來透過 proxy 存取網 頁,從過濾端來看,只要將 proxy 的 DNS Server 設為 private local root DNS,接著當使用者存取 某網頁時,proxy 會去指定的 DNS 查詢此網頁主 機的 IP,如果此主機是受限制的網站且存在於 色情網址列表中,proxy 會查到 Authentication Gateway 的 IP,並將網頁的 request 導向到此 Authentication Gateway,使用者必須經過一道認 證 手續 並 且 替 換 新 的 Gateway 位置當 proxy server,以改變使用的途徑,才可存取網站。 由於假設多數的使用者是透過 proxy server 連外 ,因 此遇 到特 殊的網 站被 阻擋而轉向時 Gateway 的 web 網頁介面提供警示及身份辨 識,通過密碼之後,再將使用者的 proxy 轉向到 Gateway,才能到真正的網站。 Gateway 對外的介面是使用外部 ISP 的 IP 位址,以確保來回封包的分流,並且將取得的資 訊暫存在 Authentication Gateway 中的 cache 以供 再利用節省頻寬。 更換 proxy server 之目的在於提供分流, 同時避免將封包資訊暫存於防治用 proxy server 的 cache 當中。 圖 圖 圖 圖 2222. Host filtering by DNS
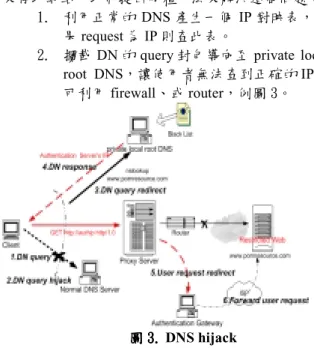
這樣的架構只需要增加一台擁有色情網站黑名 單的 DNS server,而不需要安裝任何的軟體在 proxy 上,系統不需要額外的資源來過濾色情網址,因為 proxy 原本就需要將 domain name 反查成 IP;進而達 到防堵與效能兼具。主要優點: 1. 管理集中,維護容易 2. 系統消耗資源低,跟沒有使用 filtering 軟體 前效率相同 3. 建置成本低 但本架構有一個主要的困難,如果使用者利用 IP 而不是 hostname 來瀏覽網站,就無法攔阻,首先 考慮使用者利用 IP 存取網頁的機會,在不刻意逃避 防堵軟體的話,一般來說 web 使用者較不常利用 IP 來存取網站。我們提出兩種方法來解決這個問題: 1. 利用正常的 DNS 產生一個 IP 對映表,如 果 request 為 IP 則查此表。
2. 攔截 DN 的 query 封包導向至 private local root DNS,讓使用者無法查到正確的 IP, 可利用 firewall、或 router,例圖 3。
圖 圖圖
圖 3.3.3. DNS hijack3.
3.2 Two level hybrid filtering architecture
在 2.1 節曾經討論過色情網站增加的速度太 快,加上某些色情網站為了躲避 filter 軟體,會不定 時的換 IP,或者 hostname;所以需要一個即時過濾 的機制,這是一般用黑名單阻擋的過濾軟體辦不到 的。此外,有些網站例如www.geocities.com,可能只 是某些網站內容有問題,所以還必須經過內容過濾 的步驟,對網頁內容做即時的阻擋。 即時的分 析需要透過 content-base 的過濾方 法,但最大的缺點就是增加過濾主機的 overhead,並 使得回應時間增加,針對這樣的問題,我們在這裡 提 出 一 個 兩 層 式 的 filtering 架 構 , 結 合 了 content-based 的過濾方法,但也兼顧到了效能上的問 題。 如圖 4 所示,前端的 HTTP redirector 是利用 3.1 節 所 提 到 的 架 構 , 基 本 原 理 仍 是 將 特 定 的 hostname,透過改變 DNS 的回應,將使用者的 request 導向到特定的機器上,在這裡我們將後端作了一些 變化,首先是將 Authentication Server 置放在一台具 content filtering 功能的 server 上,另外後端置放數台 的 proxy server,這些 proxy server 跟正常的 proxy server 沒有什麼不同,工作就是將使用者的要求轉 送。當使用者瀏覽某網頁時,先將 http 的要求送給 了前端的 redirector,接著 redirector 去詢問 private local root DNS 此網頁的主機是否在黑名單中,如果 不在的話,這個要求就轉送給其他正常的 proxy 去處 理,如果在黑名單中的話,則轉送到具有 content filtering 功能的 server 上,進行網頁內容的過濾。 這改善了只有單純 hostname filtering 無法達到 的即時過濾功能,另外也解決了 content-based 軟體 所造成系統的 overhead,因為兩層式的架構分散了系 統的負擔,有問題的 URL 才會經過 content filtering 的 server,這樣也大大減少了平均使用者回應時間。
圖 圖 圖
圖 4.4.4. Two level hybrid filtering architecture4.
3
33
3.3
.3
.3
.3 色情網址黑名單之更新
色情網址黑名單之更新
色情網址黑名單之更新
色情網址黑名單之更新
Access log mining
如圖 4 中,log analyzer 是用來 offline 分析正常 proxy 中 user 的 access log,根據一些 pattern 判斷使 用者是否瀏覽不正當網站,並將此網站加入黑名 單。此外可以利用關連性的連接分析,我們可以分 析使用者存取的網站內容是否有與黑名單網址連 結。
監聽封包
由於 private local root DNS 上之黑名單不可能 包含所有的域名,所以當一個查詢在本地端的 zone file 無法找到結果時,private local root DNS 便會將 該查詢轉向其上層的域名伺服器,如圖 5。此時, private local root DNS 所有對外的域名查詢即代表著 不在本地 zone File 內的域名,這些域名可能是正常 的域名( 非色情網站 ),也有可能是色情網站的域 名但是卻不在我們的黑名單中,經由監聽這些對外 查詢的流量,我們可以過濾出可疑的域名( 例如: 域
名中含有 xxx, sex, adult 等 ),再對這些可疑域名做 進一步確認,如為色情網站,即將其寫入 private local root DNS 的黑名單中。 圖 圖圖 圖 5.5.5.5. 監聽監聽監聽監聽 DNS 封包,增加可疑域名於黑名單封包,增加可疑域名於黑名單封包,增加可疑域名於黑名單封包,增加可疑域名於黑名單
4
4
4
4 系統實作與測試
系統實作與測試
系統實作與測試
系統實作與測試
目前我們已實作 3.1 節中的雛型,並將之應用 於 TANET 桃園縣區域網路中心中央大學所管理的代 理 伺 服 器 (proxy.tyrc.edu.tw, proxy1.tyrc.edu.tw, cache.tyrc.edu.tw),每部伺服器平均每天接受五百萬 次存取以上。private local root DNS server,電腦配備 Pentium III 800 、 512MB RAM , DNS 主 要 是 用 bind-8.2.5 架設,另外利用了 TCPDUMP 3.7 去擷取對 外的 DNS 封包,如 3.3 節所示,可以攔截到不在名 單內的 hostname。如圖 6 所示,private local root DNS 中的 root.zone 裡面有很多筆 A record 是將色情網站 的 domain name 指 到 教 育 部 校 安 中 心 的 IP(140.111.1.67,圖 7)。所以只要有人連黑名單的網 站,就會被導到校安中心;而不在黑名單上的網站, 只要 domain name 裡面含有 sex 或 xxx 等字眼一樣也 會加到 zone file 中,而被導向到其他的網頁。 圖 圖 圖 圖 6.6.6.6. root.zone 中色情網站為中色情網站為中色情網站為 A record 指向中色情網站為 指向指向 140.111.1.67指向 由於原本代理伺服器的機制也是需要將使用者 request 的網站 domain name,轉換成 IP,所以這個系 統完全不增加舊有代理伺服器系統的負擔;而 private local root DNS,幾十萬筆的 zone file 記錄仍在 DNS
系統可允許負擔的大小中,以本系統為例目前 DNS 中有 56721 筆色情網站的資料。與其他同類型的 URL filter 軟體相比,最大的優點就是:集中管理維護容 易、系統負擔低、建置成本低。 圖 圖圖 圖 7. 7. 7. 7. 140.111.1.67 教育部校安中心教育部校安中心教育部校安中心教育部校安中心網頁網頁網頁網頁
5
5
5
5 結論
結論
結論
結論
網路的普及對社會產生相當大的衝擊,其影響 層面愈來愈廣,然而面對諸多經由網路散佈的不當 資訊,提出防制機制是不容忽視的課題。本論文主 要分析如何對以色情為主的不當資訊進行攔截;同 時根據 TANet 現狀,提出多種以網路代理伺服器利 用網域名稱系統進行色情資訊過濾的策略及網站訪 問、分流的方法。這些方式對於網路代理伺服器不 會造成額外的負擔,而建置成本只需要多一台網域 名稱伺服器,且集中管理維護容易。為驗證策略的 可行性我們實作系統雛型,並安裝於桃園區域網路 中心,實驗結果顯示本系統可有效阻斷色情網站的 存取;同時由於效果顯著,已有其他學校單位希望 能引進採用。
誌謝
誌謝
誌謝
誌謝
This research was supported by the Communications Software Technology project of Institute for Information Industry and sponsored by MOEA, R.O.C. The authors would also like to thank the National Science Council of the Republic of China for fanatically supporting this research under Contract No. NSC-91-2213-E008-016.
參考文獻
參考文獻
參考文獻
參考文獻
[1] http://dir.salon.com/sex/world/2000/06/19/nasa/in dex.html
[2] Dr. Pornographic Image GateLocker
[3] IMira Screening,
http://www.ulead.com.tw/es/imscreening/runme.h tm
[4] Microsystems Software, “CyberPatrol”, http://www.microsys.com/cyber/default.htm [5] Solid Oak Software, “CyberSitter”,
http://www.solidoak.com/cybersit.htm [6] PORNsweeper, http://www.mimesweeper.com/products/msw/por nsweeper/ [7] I. Anagnostopoulos, G. Kouzas, C. Anagnostopoulos, D. Vergados, I. Papaleonidopoulos, A. Generalis, V. Loumos and E. Kayafas, “Automatic web site classification in a large repository under information filtering and retrieval techniques,” Electrotechnical Conference, pp.279 -283, 2002.
[8] Feng Jiao, Wen Gao, Lijuan Duan and Guoqin Cui, “Detecting adult image using multiple features,” Proceedings of International Conferences on Info-tech and Info-net, Volume: 3, 2001.
[9] D. Smith, R. Harvey, Yi Chan and Bangham J.A., “Classifying Web pages by content,” IEE European Workshop on Distributed Imaging, 1999.
[10] 林承宇, ”網際網路上「有害資訊內容」之探 討─以我國法律管制可行性為中心,” 國立政 治大學廣電研究所, 民 89。