行政院國家科學委員會專題研究計畫 期末報告
整合及開發人工智慧與語言科技以輔助跨語言資訊檢索與
語文教學活動 II
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 100-2221-E-004-014-
執 行 期 間 : 100 年 08 月 01 日至 102 年 05 月 31 日
執 行 單 位 : 國立政治大學資訊科學系
計 畫 主 持 人 : 劉昭麟
共 同 主 持 人 : 蔡介立、李佳穎、曾元顯
計畫參與人員: 碩士班研究生-兼任助理人員:蔡家琦
碩士班研究生-兼任助理人員:王瑞平
碩士班研究生-兼任助理人員:黃瑋杰
碩士班研究生-兼任助理人員:孫暐
報 告 附 件 : 出席國際會議研究心得報告及發表論文
公 開 資 訊 : 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢
中 華 民 國 102 年 06 月 30 日
中 文 摘 要 : 本年度的工作成果是以應用人工智慧與語言科技技術為中
心,應用的範圍在語言種類的維度方面包含中文與英文語
料;在語料種類的方面則中文一般語料、中文史料、中英文
平行語料、中文文史資料;在應用的內容方面包含了智慧型
教學系統領域中的中文語文教學、數位人文領域中的中文文
史資料研究,另外也包含了前一次的國科會計畫(2010-2011
年度)的成果發表的補助。
在研究計畫執行的時限方面,本研究計畫原本即依照進度規
劃進行。後來曾經所進行的延期,主要是因為下一期的國科
會研究計畫(2012-2013 年度)並沒有順利獲得通過,因此申
請延長這一次計畫執行期限,這樣可以把 2012 年 7 月時還剩
下的些許研究經費用來補助 2012 年 7 月之後一些必要的研究
活動,特別是補助學生參加國內外研討會與購買一些實驗室
基本用品。(2012-2013 年度)的研究計畫經申覆之後驚險獲
得補助。不過以下的成果列表,還是只列出原本計畫執行時
限中所發表的論文,並不包含 2012 年 8 月之後的成果。
本計畫最主要的成就是發表在 ACL 2012 和 ITS 2012 的工
作,這兩項工作都是這一研究計畫的重點:整合人工智慧與
語文處理技術來建構學習軟體。我們所完成的工作,不管是
從技術面與應用面,都獲得全世界各該領域最好的研討會的
接受與發表。ACL、ITS 分別是計算語言學、智慧型教學系統
領域中領導層級的國際學術會議。更加重要的是現在這一軟
體也在國內許多國小、家長、學生之間真實地使用。
本研究計畫在教學軟體之外,在中文文史資料分析、語言現
象的分析、專利文書中英文語料的機器翻譯等各方面的問題
都有所貢獻。我們與政治大學的文史學家合作,利用文字探
勘技術,進行數位人文領域的研究。與政大的語言學家合
作,分析英文語料中的一些語文現象。與台灣師範大學的資
訊科學專家合作,參加第九屆的 NTCIR 中的 PatentMT 的評
比。PatentMT 的主要工作是利用機器翻譯技術把中文的專利
文書翻譯成英文的版本。
此外,前一期國科會計畫(2010-2011)所完成的成果,因為
這一次計畫而能夠到 IEEE ICEBE 2011 國際學術研討會與
TAAI 2011 研討會去進行口頭報告,不僅僅分別獲得大會唯
一的最佳論文獎與論文佳作獎,後來更獲得世界知名科學雜
誌 NewScientist 的專文報導。
由於本研究計畫所合作、應用的種類很多,所以在這一摘要
中不能對個別研究工作的內容作深入的說明。從大原則來
說,我們須要了解、學習個應用領域的合作老師的需求,將
我們所熟知的人工智慧技術、語文處理技術應用在解決這一
些跨領域的研究議題上。在這過程中,有不少須要’客製
化’的工作要作。詳細的應用與工作內容請參考所發表的論
文。
在論文發表數目方面,自 2011 年 8 月至 2012 年 7 月之間,
這一研究計畫發表了 12 篇國際學術會議論文、7 篇國內學術
會議論文以及雜誌文章 1 篇。12 篇國際學術會議論文之中,
有 4 篇是常年在國內所舉辦的國際學術會議。基本數據的清
單請看下面列表,詳細資料則請看報告檔案。
國際會議論文的出處(括號中為篇數):ACL 2012 (1)、ITS
2012 (1)、GCCCE 2012 (1)、GURT 2012 (1)、PACLIC 2012
(2)、NTCIR-9 (1)、DADH 2011 (3)、TAAI 2011 (1)、IEEE
ICEBE 2011 (1)。國內會議論文的出處與篇數:第一屆電腦
輔助合作學習與人工智慧與教育研討會(3)、2011 年全國計
算機會議(2)、2011 年第十六屆人工智慧與應用研討會(1)、
2011 年第第廿三屆自然語言與語音處理研討會(1)。雜誌文
章的出處:能源報導,發行者為臺灣經濟研究院。
中文關鍵詞: 數位人文、中文史料分析、漢英專利文書機器翻譯、電腦輔
助語文學習、計算語言學
英 文 摘 要 : We applied techniques of artificial intelligence and
natural language processing to several application
domains in this project, including digital
humanities, intelligent tutoring systems,
computational linguistics, patent document machine
translations, and analysis of annual reports of USA
public corporations.
We cooperated with historians to analyze Chinese
historical documents that were published between 1830
and 1930. The text collection contains more than 120
million Chinese characters, and cover a wide range of
publications that are very useful for studying
Chinese history. We worked on the applicability of
Zipf’s Law in Chinese documents, the issue of
Chinese labors who worked in other countries, and how
the movement of constitutional monarchy during the
late Qing Dynasty in China. Results of this line of
work were published in DADH 2011.
We worked with psycholinguists to achieved a
practical computer assisted platform for preparing
games for learning Chinese characters. The platform
allows and assists teachers to prepare games via the
Internet, and the resulting games can be played by
students anywhere in the world instantly. The game
considers psycholinguistic factors in learning
Chinese characters, and proved to be very effective
in practice. Several elementary schools in Taiwan
adopted our game in their teaching activities, and
parents and students requested access to the game for
their own use at home. The results of this line of
work were published in ACL 2012 and ITS 2012.
We participated in the PatentMT task in NTCIR-9.
Participants of NTCIR-9 PatentMT task received 1
million sentence pairs of Chinese-English statements,
and they trained a translation model to convert
thousands of Chinese statements to English in the
test stage.
The analysis of annual reports (K10) of USA public
corporations was conducted in our NSC project in the
2010-2011 period. Due to the support of this extended
project, we were able to publish our results in IEEE
ICEBE 2011 and TAAI 2011. We are happy to record that
our work was highly appreciated in internationally
and domestically. We received the Best Paper Award in
IEEE ICEBE and the Merit Paper Award in TAAI 2011.
Our work was then reported in NewScientist, and the
student who worked with this project received a
thesis award from the Association for Computational
Linguistics and Chinese Language Processing.
英文關鍵詞: Digital Humanities, Text Mining in Chinese Historical
Documents, Chinese-English Patent Document Machine
Translation, Intelligent Tutoring Systems for
Learning Chinese, Computational Linguistics
行政院國家科學委員會補助專題研究計畫
□期中進度報告
■期末報告
整合及開發人工智慧與語言科技以輔助跨語言資訊檢索與語文教學
活動
計畫類別:
■
個別型計畫 □整合型計畫
計畫編號:
NSC-100-2221-E-004-014-
執行期間:100 年 8 月 1 日至 102 年 5 月 31 日
執行機構及系所:國立政治大學資訊科學系
計畫主持人:劉昭麟
共同主持人:李佳穎、蔡介立、曾元顯
計畫參與人員:黃瑋杰、蔡家琦、王瑞平、孫暐
本計畫除繳交成果報告外,另含下列出國報告,共 _壹_ 份:
□移地研究心得報告
■
出席國際學術會議心得報告
□國際合作研究計畫國外研究報告
處理方式:除列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年
■
二年後可公開查詢
中 華 民 國 102 年 6 月 30 日
本年度的工作成果是以應用人工智慧與語言科技技術為中心,應用的範圍在語言種類的維
度方面包含中文與英文語料;在語料種類的方面則中文一般語料、中文史料、中英文平行
語料、中文文史資料;在應用的內容方面包含了智慧型教學系統領域中的中文語文教學、
數位人文領域中的中文文史資料研究,另外也包含了前一次的國科會計畫
(2010-2011 年度)
的成果發表的補助。
在研究計畫執行的時限方面,本研究計畫原本即依照進度規劃進行。後來曾經所進行的延
期,主要是因為下一期的國科會研究計畫
(2012-2013 年度)並沒有順利獲得通過,因此申請
延長這一次計畫執行期限,這樣可以把
2012 年 7 月時還剩下的些許研究經費用來補助 2012
年
7 月之後一些必要的研究活動,特別是補助學生參加國內研討會與購買一些實驗室基本
用品。
(2012-2013 年度)的研究計畫經申覆之後驚險獲得補助。因此以下的成果列表,還是
只列出原本計畫執行時限中所發表的論文,而不包含
2012 年 8 月之後的成果。
本計畫最主要的成就式發表在
ACL 2012 和 ITS 2012 的工作,這兩項工作都是這一研究計畫
的重點:整合人工智慧與語文處理技術來建構漢字學習軟體。我們所完成的工作,不管是
從技術面與應用面,都獲得全世界各該領域最好的研討會的接受與發表。
ACL、ITS 分別是
計算語言學、智慧型教學系統領域中領導層級的國際學術會議。
本研究計畫在教學軟體之外,在中文文史資料分析、語言現象的分析、專利文書中英文語
料的機器翻譯等各方面的問題都有所貢獻。我們與政治大學的文史學家合作,利用文字探
勘技術,進行數位人文領域的研究。與政大的語言學家合作,分析英文語料中的一些語文
現象。與台灣師範大學的資訊科學專家合作,參加第九屆的
NTCIR 中的 PatentMT 的評比。
PatentMT 的主要工作是利用機器翻譯技術把中文的專利文書翻譯成英文的版本。
此外,前一期國科會計畫(
2010-2011)所完成的成果,因為這一次計畫而能夠到 IEEE ICEBE
2011 國際學術研討會與 TAAI 2011 研討會去進行口頭報告,不僅僅分別獲得大會唯一的最佳
論文獎與論文佳作獎,後來更獲得世界知名科學雜誌
NewScientist 的專文報導。參與研究工
作的研究生,後來也獲得了中華民國計算語言學會的碩士論文佳作獎。
在數位人文的研究方面,我們與政治大學的文史學家合作,分析了政治大學所特有的「中
國近現代思想與文學史」專業數據庫中的資料。這一資料庫收錄了西元
1830 到 1930 年許
多中國的出版品,主要是與思想史相關的論述。文件內容已經在過去的研究計畫中全部數
位化,包含了一億兩千萬個字。我們在這一期研究計畫中,分析了
Zipf’s 原則在中文古文資
料的適用性、分析了清末時期對於中國華工、華人、華商的態度、分析了清末政府對於君
主立憲制度的各項討論與推展。這一部分的研究工作發表於台灣大學數位典藏研究中心所
主辦的
The Third International Conference of Digital Archives and Digital Humanities 研討會。
我們與中央研究院語言學研究所的心理語言學家李佳穎博士合作,開發一個有心理與認之
理論基礎的漢字學習遊戲平台。這一個平台讓老師可以透過網路編輯遊戲內容,編輯所得
的遊戲可以立即上線讓學生遊玩。以比較技術的角度看,這一個平台包含了
authoring tools
和
gaming component。Authoring tools 的建構利用到我們自己所開發的自然語言處理技術。
Gaming component 的部分,則是經過真實的學生的試用和評測。這一遊戲現在也廣受許多
國小和家長的青睞,是一個實際運作中的遊戲平台。這一部分的工作,也被在
ACL 和 ITS 兩
個重量級的國際學術研討會接受發表,可以說是學術與實務兼顧的成功工作。
我們也與台灣師範大學資工系的曾元顯老師一起參加
NTCIR-9 的 PatentMT 的工作。PatentMT
活動提供一百萬漢英專利文書的句對給參與者,參與團隊利用這一批語料訓練機器翻譯模
型,然後藉此在測試階段翻譯測試的中文句子。我們在這一項活動中表現並不突出,不過
參與的研究生第一次有機會接觸到百萬句對的大量資料,在處理大量資料方面獲得不少的
經驗。
由於本研究計畫所合作、應用的種類很多,所以在這一摘要中不能對個別研究工作的內容
作深入的說明。從大原則來說,我們須要了解、學習個應用領域的合作老師的需求,將我
們所熟知的人工智慧技術、語文處理技術應用在解決這一些跨領域的研究議題上。在這過
程中,有不少須要
”客製化”的工作要作。詳細的應用與工作內容請參考所發表的論文。
在論文發表數目方面,自
2011 年 8 月至 2012 年 7 月之間,這一研究計畫發表了 12 篇國際
學術會議論文、
7 篇國內學術會議論文以及雜誌文章 1 篇。12 篇國際學術會議論文之中,
有
4 篇是常年在國內所舉辦的國際學術會議。以下是所發表的論文的基本數據。
國際會議
1. ACL 2012 一篇 (50th Annual Meeting of the Association for Computational Linguistics)
2. ITS 2012 一篇 (11th International Conference on Intelligent Tutoring Systems)
3. GCCCE 2012 一篇 (16th Global Chinese Conference on Computers in Education)
4. GURT 2012 一篇 (Georgetown University Round Table on Languages and Linguistics)
5. PACLIC 2012 兩篇 (25th Pacific Asia Conference on Language, Information and
Computation)
6. NTCIR 2011 一篇 (9th NTCIR Workshop Meeting on Evaluation of Information Access
Technologies)
7. DADH 2011 三篇 (3rd International Conference of Digital Archives and Digital Humanities)
8. TAAI 2011 一篇 (2011 Conference on Technologies and Applications of Artificial Intelligence)
9. IEEE ICEBE 2011 一篇 (2011 IEEE International Conference on e-Business Engineering)
國內會議
10. 第一屆電腦輔助合作學習與人工智慧與教育研討會 3 篇
11. 2011 年全國計算機會議 2 篇
12. 2011 年第十六屆人工智慧與應用研討會 1 篇
13. 2011 年第第廿三屆自然語言與語音處理研討會 1 篇
雜誌文章
14. 能源報導(發行者為臺灣經濟研究院)
附件論文
1. Wei-Jie Huang(黃瑋杰), Chia-Ru Chou(周家如), Yu-Lin Tzeng(曾郁琳), Chia-Ying Lee(李佳穎),
and Chao-Lin Liu. Applications of GPC rules and character structures in games for learning
Chinese characters, Proceedings of the Fiftieth Annual Meeting of the Association for
Computational Linguistics (ACL'12), system demonstrations, 1 ‒6. Seogwipo, Jeju, South Korea,
8-14 July 2012.
2. Chien-Liang Chen(陳建良), Chao-Lin Liu, Yuan-Chen Chang(張元晨), and Hsiangping Tsai(蔡
湘萍
). Exploring the relationships between annual earnings and subjective expressions in US
financial statements, Proceedings of the IEEE International Conference on e-Business
國科會補助專題研究計畫出席國際學術會議心得報告
日期: 102 年 6 月 30 日
2012 年的 Association for Computational Linguistics 國際學術研討會是第五十屆,在韓國濟州
島舉辦。幾年前,我國也曾爭取主辦這一次的會議,最後與韓國進行二選一的競爭,可惜
功敗垂成。
ACL 2012 年在七月八日到十四日舉行。
ACL 這樣一個有悠久歷史的國際學術研討會,許多架構是眾所皆知的。從 2008 年至今,也
是我們實驗室第三次能夠在
ACL 報告研究成果。除了學習更多先進的學術進展之外,過去
幾次所得的觀察與體驗已經大同小異。
ACL 是一個完整的國際學術研討會,有會前的 tutorial、
會議前後的專題工作坊
(workshops)、系統展示、包含長篇論文和短篇論文的主會議。
計畫編號
NSC-100-2221-E-004-014-
計畫名稱
整合及開發人工智慧與語言科技以輔助跨語言資訊檢索與語
文教學活動
出國人員
姓名
劉昭麟、
黃瑋杰
服務機構
及職稱
國立政治大學資訊科學系
教授與研究生
會議時間
101 年 7 月 8 日至
101 年 7 月 14 日
會議地點 韓國濟州島
會議名稱
(中文)
(英文) The Fiftieth Annual Meeting of Association for
Computational Linguistics
發表題目
(中文)
(英文) Applications of GPC rules and character structures in
games for learning Chinese characters
就如過去一樣,由我國學者所發表的論文,並不容易在
ACL 發表。今年比較特別的是包含
清華大學和政治大學有數個系統展示的作品。
對政大的實驗室來說,今年比較特別的是,負責報告的人不再是計畫主持人。經由政大資
訊科學系自籌經費的補助,我們能夠補助研究生來參與這一個盛會。可惜即使參與
ACL 報
告成果,並且獲得很好評分
(展件編號為一號)的作品,政大的研究生仍然沒有能夠獲得國科
會的補助。
研究生來參與
ACL,當然是要盡量參與所有學術活動,所以讓研究生參與了會前的 tutorial。
ACL 的 tutorial 仍然具有相當深度,對於政大的研究生來說是有挑戰性的。
在聆聽
ACL 的專題演講和論文發表之後,其實心得也是類似的。我們要多加油,否則與國
際間最頂尖的學術團隊的距離,只會愈來愈遠。或許這是中研院或者國內最頂尖大學的任
務。在政治大學我們努力培有有潛力的學生,將來加入中研院或者更好的大學的團隊,來
參與我國在自然語言處理方面的前緣研發團隊。
本次會議的論文集已經公佈在網路上,網址是
http://aclweb.org/anthology/P/P12/
。
本次參與會議所發表的論文附在隨後頁面。
Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, pages 1–6, Jeju, Republic of Korea, 8-14 July 2012. c 2012 Association for Computational Linguistics
Applications of GPC Rules and Character Structures in Games for
Learning Chinese Characters
§Wei-Jie Huang ↑Chia-Ru Chou ↕Yu-Lin Tzeng ‡Chia-Ying Lee †Chao-Lin Liu †§National Chengchi University, Taiwan ‡↑↕Academia Sinica, Taiwan
†
[email protected], ‡[email protected]
Abstract
We demonstrate applications of psycholin-guistic and sublexical information for learn-ing Chinese characters. The knowledge about the grapheme-phoneme conversion (GPC) rules of languages has been shown to be highly correlated to the ability of reading alphabetic languages and Chinese. We build and will demo a game platform for strengthening the association of phonologi-cal components in Chinese characters with the pronunciations of the characters. Results of a preliminary evaluation of our games indicated significant improvement in learn-ers’ response times in Chinese naming tasks. In addition, we construct a Web-based open system for teachers to prepare their own games to best meet their teaching goals. Techniques for decomposing Chinese characters and for comparing the similarity between Chinese characters were employed to recommend lists of Chinese characters for authoring the games. Evaluation of the authoring environment with 20 subjects showed that our system made the authoring of games more effective and efficient.
1 Introduction
Learning to read and write Chinese characters is a challenging task for learners of Chinese. To read everyday news articles, one needs to learn thou-sands of Chinese characters. The official agents in Taiwan and China, respectively, chose 5401 and 3755 characters as important basic characters in national standards. Consequently, the general pub-lic has gained the impression that it is not easy to read Chinese articles, because each of these thou-sands of characters is written in different ways.
Teachers adopt various strategies to help learn-ers to memorize Chinese charactlearn-ers. An instructor at the University of Michigan made up stories based on decomposed characters to help students remember their formations (Tao, 2007). Some take linguistics-based approaches. Pictogram is a major formation of Chinese characters, and radicals carry
partial semantic information about Chinese charac-ters. Hence, one may use radicals as hints to link the meanings and writings of Chinese characters. For instance, “河”(he2, river) [Note: Chinese char-acters will be followed by their pronunciations, denoted in Hanyu pinyin, and, when necessary, an English translation.], “海”(hai3, sea), and “洋”(yang2, ocean) are related to huge water sys-tems, so they share the semantic radical, 氵, which is a pictogram for “water” in Chinese. Applying the concepts of pictograms, researchers designed games, e.g., (Lan et al., 2009) and animations, e.g., (Lu, 2011) for learning Chinese characters.
The aforementioned approaches and designs mainly employ visual stimuli in activities. We re-port exploration of using the combination of audio and visual stimuli. In addition to pictograms, more than 80% of Chinese characters are
phono-semantic characters (PSCs, henceforth) (Ho and
Bryant, 1997). A PSC consists of a phonological
component (PC, henceforth) and a semantic
com-ponent. Typically, the semantic components are the radicals of PSCs. For instance, “讀”(du2), “瀆”(du2), “犢” (du2), “牘”(du2) contain different radicals, but they share the same phonological components, “賣”(mai4), on their right sides. Due to the shared PC, these four characters are pro-nounced in exactly the same way. If a learner can learn and apply this rule, one may guess and read “黷”(du2) correctly easily.
In the above example, “賣” is a normal Chinese character, but not all Chinese PCs are standalone characters. The characters “檢”(jian3), “撿” (jian3), and “儉”(jian3) share their PCs on their right sides, but that PC is not a standalone Chinese character. In addition, when a PC is a standalone character, it might not indicate its own or similar pronunciation when it serves as a PC in the hosting character, e.g., “賣” and “讀” are pronounced as /mai4/ and /du2/, respectively. In contrast, the pro-nunciations of “匋”, “淘”, “陶”, and “啕” are /tao2/.
Pronunciations of specific substrings in words of alphabetic languages are governed by grapheme-phoneme conversion (GPC) rules, though not all languages have very strict GPC rules. The GPC rules in English are not as strict as those in Finish 1
(Ziegler and Goswami, 2005), for instance. The substring “ean” are pronounced consistently in “bean”, “clean”, and “dean,” but the substring “ch” does not have a consistent pronunciation in “school”, “chase”, and “machine.” PCs in Chinese do not follow strict GPC rules either, but they re-main to be good agents for learning to read.
Despite the differences among phoneme systems and among the degrees of strictness of the GPC rules in different languages, ample psycholinguis-tic evidences have shown that phonological aware-ness is a crucial factor in predicting students’ read-ing ability, e.g., (Siok and Fletcher, 2001). Moreo-ver, the ability to detect and apply phonological consistency in GPCs, including the roles of PCs in PSCs in Chinese, plays an instrumental role in learners’ competence in reading Chinese. Phono-logical consistency is an important concept for learners of various alphabetic languages (Jared et al., 1990; Ziegler and Goswami, 2005) and of Chi-nese, e.g., (Lee et al., 2005), and is important for both young readers (Ho and Bryant, 1997; Lee, 2009) and adult readers (Lin and Collins, 2012).
This demonstration is unique on two aspects: (1) students play games that are designed to strengthen the association between Chinese PCs and the pro-nunciations of hosting characters and (2) teachers compile the games with tools that are supported by sublexical information in Chinese. The games aim at implicitly informing players of the Chinese GPC rules, mimicking the process of how infants would apply statistical learning (Saffran et al., 1996). We evaluated the effectiveness of the game platform with 116 students between grade 1 and grade 6 in Taiwan, and found that the students made progress in the Chinese naming tasks.
As we will show, it is not trivial to author games for learning a GPC rule to meet individualized teaching goals. For this reason, techniques reported in a previous ACL conference for decomposing and comparing Chinese characters were employed to assist the preparation of games (Liu et al., 2011). Results of our evaluation showed that the author-ing tool facilitates the authorauthor-ing process, improv-ing both efficiency and effectiveness.
We describe the learning games in Section 2, and report the evaluation results of the games in Section 3. The authoring tool is presented in Sec-tion 4, and its evaluaSec-tion is discussed in SecSec-tion 5. We provide some concluding remarks in Section 6.
2 The Learning Games
A game platform should include several functional
components such as the manage-ment of players’ accounts and the maintenance of players’ learning profiles. Yet, due to the page limits, we focus on the parts that are
most relevant to the demonstration.
Figure 1 shows a screenshot when a player is playing the game. This is a game of
“whac-a-mole” style. The target PC appears in the upper
middle of the window (“里”(li3) in this example), and a character and an accompanying monster (one at a time) will pop up randomly from any of the six holes on the ground. The player will hear the pro-nunciation of the character (i.e., “裡”(li3)), such that the player receives both audio and visual stim-uli during a game. Players’ task is to hit the mon-sters for the characters that contain the shown PC. The box at the upper left corner shows the current credit (i.e., 3120) of the player. The player’s credit will be increased or decreased if s/he hits a correct or an incorrect character, respectively. If the player does not hit, the credit will remain the same. Play-ers are ranked, in the Hall of Fame, according to their total credits to provide an incentive for them to play the game after school.
In Figure 1, the player has to hit the monster be-fore the monster disappears to get the credit. If the player does not act in time, the credit will not change.
On ordinary computers, the player manipulates the mouse to hit the monster. On multi-touch tablet computers, the play can just touch the monsters with fingers. Both systems will be demoed.
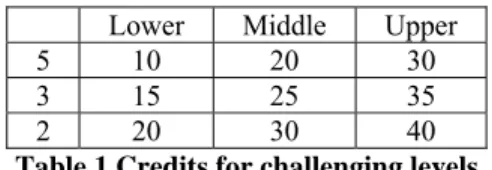
2.1 Challenging Levels
At the time of logging into the game, players can choose two parameters: (1) class level: lower class (i.e., grades 1 and 2), middle class (i.e., grades 3 and 4), or upper class (i.e., grades 5 and 6) and (2) speed level: the duration between the monsters’ popping up and going down. The characters for lower, middle, and upper classes vary in terms of frequency and complexity of the characters. A stu-dent can choose the upper class only if s/he is in the upper class or if s/he has gathered sufficient credits. There are three different speeds for the monsters to appear and hide: 2, 3, and 5 seconds. Choosing different combinations of these two
pa-Figure 1. The learning game
rameters affect how the credits are added or de-ducted when the players hit the monsters correctly or incorrectly, respectively. Table 1 shows the in-crements of credits for different settings. The num-bers on the leftmost column are speed levels. 2.2 Feedback Information
After finishing a game, the player receives feed-back about the correct and in-correct actions that were taken during the game. Figure 2 shows such an example.
The feedback informs the players what characters were correctly hit (“埋”(mai2), “理”(li3), “裡”(li3), and “鯉”(li3)), incorrectly hit (“婷”(ting2) and “袖”(show4)), and should have been hit (“狸”(li2)). When the player moves mouse over these characters, a sample Chinese word that shows how the character is used in daily lives will show up in a vertical box near the middle (i.e., “裡面”(li3 mian4)).
The main purpose of providing the feedback in-formation is to allow players a chance to reflect on what s/he had done during the game, thereby strengthening the learning effects.
On the upper right hand side of Figure 2 are four tabs for more functions. Clicking on the top tab (繼續玩) will take the player to the next game. In the next game, the focus will switch to a different PC. The selection of the next PC is random in the current system, but we plan to make the switching from a game to another adaptive to the students’ performance in future systems. Clicking on the second tab (看排行) will see the player list in the Hall of Fame, clicking on the third tab (返回主選單) will return to the main menu, and clicking on the fourth (加分題) will lead to games for extra credits. We have extended our games to lead students to learning Chinese words from char-acters, and details will be illustrated during the demo.
2.3 Behind the Scene
The data structure of a game is simple. When com-piling a game, a teacher selects the PC for the game, and prepares six characters that contain the
PC (to be referred as an In-list henceforth) and
four characters as distracter characters that do not
contain the PC (to be referred as an Out-list
hence-forth). The simplest internal form of a game looks like {target PC= “里”, In-list= “裡理鯉浬哩鋰”, Out-list= “塊鰓嘿鉀” }. We can convert this ture into a game easily. Through this simple struc-ture, teachers choose the PCs to teach with charac-ter combinations of different challenging levels.
During the process of playing, our system ran-domly selects one character from the list of 10 characters. In a game, 10 characters will be pre-sented to the player.
3 Preliminary Evaluation and Analysis
The game platform was evaluated with 116 stu-dents, and was found to shorten students’ response times in Chinese naming tasks.
3.1 Procedure and Participants
The evaluation was conducted at an elementary school in Taipei, Taiwan, during the winter break between late January and the end of February 2011. The lunar new year of 2011 happened to be within this period.
Students were divided into an experimental group and a control group. We taught students of the experimental group and showed them how to play the games in class hours before the break be-gan. The experimental group had one month of time to play the games, but there were no rules asking the participants how much time they must spend on the games. Instead, they were told that they would be rewarded if they were ranked high in the Hall of Fame. Table 2 shows the numbers of participants and their actual class levels.
As we explained in Section 2.1, a player could choose the class level before the game begins. Hence, for example, it is possible for a lower class player to play the games designed for middle or even upper class levels to increase their credits faster. However, if the player is not competent, the credits may be deducted faster as well. In the eval-uation, 20 PCs were used in the games for each class level in Table 1.
Pretests and posttests were administered with the standardized (1) Chinese Character Recognition
Figure 2. Feedback information
Lower Middle Upper
Experimental 11 23 24
Control 11 23 24
Table 2. Number of participants Lower Middle Upper
5 10 20 30 3 15 25 35 2 20 30 40 Table 1.Credits for challenging levels
Test (CCRT) and (2) Rapid Automatized Naming Task (RAN). In CCRT, participants needed to write the pronunciations in Jhuyin, which is a pho-netic system used in Taiwan, for 200 Chinese characters. The number of correctly written Jhuyins for the characters was recorded. In RAN, participants read 20 Chinese characters as fast as they could, and their speeds and accuracies were recorded.
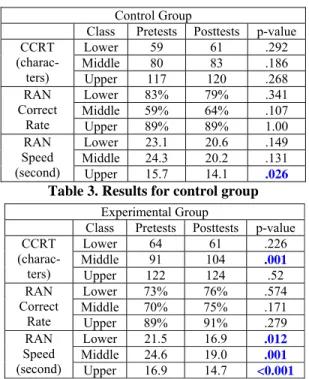
3.2 Results and Analysis
Table 3 shows the statistics for the control group. After the one month evaluation period, the perfor-mance of the control group did not change signifi-cantly, except participants in the upper class. This subgroup improved their speeds in RAN. (Statisti-cally significant numbers are highlighted.)
Table 4 shows the statistics for the experimental group. After the evaluation period, the speeds in RAN of all class levels improved significantly.
The correct rates in RAN of the control group did not improve or fall, though not statistically sig-nificant. In contrast, the correct rates in RAN of the experimental group improved, but the im-provement was not statistically significant either.
The statistics for the CCRT tests were not statis-tically significant. The only exception is that the middle class in the experimental group achieved better CCRT results. We were disappointed in the falling of the performance in CCRT of the lower class, though the change was not significant. The
lower class students were very young, so we con-jectured that it was harder for them to remember the writing of Jhuyin symbols after the winter break. Hence, after the evaluation, we strengthened the feedback by adding Jhuyin information. In Fig-ure 2, the Jhuyin information is now added beside the sample Chinese words, i.e., “裡面” (li3 mian4).
4 An Open Authoring Tool for the Games
Our game platform has attracted the attention of teachers of several elementary schools. To meet the teaching goals of teacher in different areas, we have to allow the teachers to compile their own games for their needs.
The data structure for a game, as we explained
in Section 2.3, is not complex. A teacher needs to
determine the PC to be taught first, then s/he must choose an In-list and an Out-list. In the current im-plementation, we choose to have six characters in the In-list and four characters in the Out-list. We allow repeated characters when the qualified char-acters are not enough.
This authoring process is far less trivial as it might seem to be. In a previous evaluation, even native speakers of Chinese found it challenging to list many qualified characters out of the sky. Be-cause PCs are not radicals, ordinary dictionaries would not help very much. For instance, “埋” (mai2), “狸”(li2), “裡”(li3), and “鯉”(li3) belong to different radicals and have different pronuncia-tions, so there is no simple way to find them at just one place.
Identifying characters for the In-list of a PC is not easy, and finding the characters for the Out-list is even more challenging. In Figure 1, “里” (li3) is the PC to teach in the game. Without considering the characters in In-list for the game, we might believe that “甲” (jia3) and “呈” (cheng2) look equally similar to “里”, so both are good distract-ers. If, assuming that “理”(li3) is in the In-list, “玾” (jia3) will be a better distracter than “埕” (cheng2) for the Out-list, because “玾” and “理” are more similar in appearance. By contrast, if we have “裡” in the In-list, we may prefer to having “程” (cheng2) than having “玾” in the Out-list.
Namely, given a PC to teach and a selected In-list, the “quality” of the Out-list is dependent on the characters in In-list. Out-lists of high quality influence the challenging levels of the games, and will become a crucial ingredient when we make the games adaptive to players’ competence.
4.1 PC Selection
Control Group
Class Pretests Posttests p-value
CCRT (charac-ters) Lower 59 61 .292 Middle 80 83 .186 Upper 117 120 .268 RAN Correct Rate Lower 83% 79% .341 Middle 59% 64% .107 Upper 89% 89% 1.00 RAN Speed (second) Lower 23.1 20.6 .149 Middle 24.3 20.2 .131 Upper 15.7 14.1 .026
Table 3. Results for control group Experimental Group
Class Pretests Posttests p-value
CCRT (charac-ters) Lower 64 61 .226 Middle 91 104 .001 Upper 122 124 .52 RAN Correct Rate Lower 73% 76% .574 Middle 70% 75% .171 Upper 89% 91% .279 RAN Speed (second) Lower 21.5 16.9 .012 Middle 24.6 19.0 .001 Upper 16.9 14.7 <0.001 Table 4. Results for experimental group
In a realistic teaching situation, a teacher will be teaching new characters and would like to provide students games that are related to the structures of the new characters. Hence, it is most convenient for the teachers that our tool decomposes a given character and recommends the PC in the character. For instance, given “理”, we show the teacher that we could compile a game for “里”. This is achiev-able using the techniques that we illustrate in the next subsection.
4.2 Character Recommendation
Given a selected PC, a teacher has to prepare the In-list and Out-list for the game. Extending the techniques we reported in (Liu et al., 2011), we decompose every Chinese character into a se-quence of detailed Cangjie codes, which allows us to infer the PC contained in a character and to infer the similarity between two Chinese characters.
For instance, the internal codes for “里”, “理”, “裡”, and “玾” are, respectively, “WG”, “MGWG”, “LWG”, and “MGWL”. The English letters denote the basic elements of Chinese char-acters. For instance, “WG” stands for “田土”, which are the upper and the lower parts of “里”, “WL” stands for “田中”, which could be used to rebuild “甲” in a sense. By comparing the internal codes of Chinese characters, it is possible to find that (1) “理” and “裡” include “里” and that (2) “理” and “玾” are visually similar based on the overlapping codes.
For the example problem that we showed in Figures 1 and 2, we may apply an extended proce-dure of (Liu et al., 2011) to find an In-list for “里”: “鋰裡浬狸埋理娌哩俚”. This list includes more characters than most native speakers can produce for “里” within a short period. Similar to what we reported previously, it is not easy to find a perfect list of characters. More specifically, it was relative-ly easy to achieve high recall rates, but the preci-sion rates varied among different PCs. However, with a good scoring function to rank the characters, it is not hard to achieve quality recommendations by placing the characters that actually contain the target PCs on top of the recommendation.
Given that “里” is the target PC and the above In-list, we can recommend characters that look like the correct characters, e.g., “鈿鉀鍾” for “鋰”, “裸袖嘿” for “裡”, “湮湩渭" for “浬”, “狎猥狠狙” for “狸” , and “黑墨" for “里”.
We employed similar techniques to recommend characters for In-lists and Out-lists. The database that contains information about the decomposed
Chinese charac-ters was the same, but we utilized different object functions in selecting and ranking the characters. We considered all elements in a character to rec-ommend
charac-ters for In-lists, but focused on the inclusion of target PCs in the decomposed characters to ommend characters for Out-lists. Again our rec-ommendations for the Out-lists were not perfect, and different ranking functions affect the perceived usefulness of the authoring tools.
Figure 3 shows the step to choose characters in the Out-list for characters in the In-list. In this ex-ample, six characters for the In-list for the PC “ ” had been chosen, and were listed near the top: “搖遙謠瑤鷂搖”. Teachers can find characters that are similar to these six correct characters in separate pull-down lists. The screenshot shows the operation to choose a character that is similar to “遙” (yao2) from the pull-down list. The selected character would be added into the Out-list.
4.3 Game Management
We allow teachers to apply for accounts and pre-pare the games based on their own teaching goals. However, we cannot describe this management subsystem for page limits.
5 Evaluation of the Authoring Tool
We evaluated how well our tools can help teachers with 20 native speakers.
5.1 Participants and Procedure
We recruited 20 native speakers of Chinese: nine of them are undergraduates, and the rest are gradu-ate students. Eight are studying some engineering fields, and the rest are in liberal arts or business.
The subjects were equally split into two groups. The control group used only paper and pens to au-thor the games, and the experimental group would use our authoring tools. We informed and showed the experimental group how to use our tool, and members of the experimental group must follow an illustration to create a sample game before the evaluation began.
Every subject must author 5 games, each for a
Figure 3. Selecting a character for an Out-list
different PC. A game needed 6 characters in the In-list and 4 characters in the Out-In-list. Every evalua-tor had up to 15 minutes to finish all tasks.
The games authored by the evaluators were judged by psycholinguists who have experience in teaching. The highest possible scores for the In-list and the Out-list were both 30 for a game.
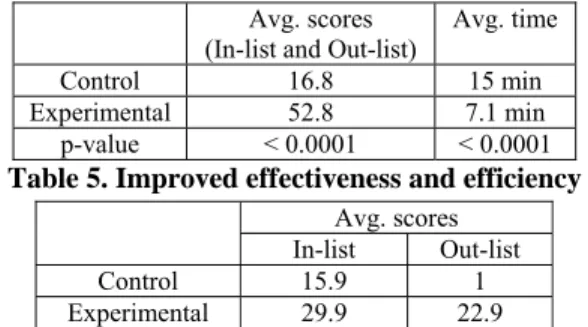
5.2 Gains in Efficiency and Effectiveness
Table 5 shows the results of the evaluation. The experimental group outperformed the control group in both the quality of the games and in the time spent on the authoring task. The differences are clearly statistically significant.
Table 6 shows the scores for the In-list and Out-list achieved by the control and the experimental groups. Using the authoring tools helped the evalu-ators to achieved significantly higher scores for the Out-list. Indeed, it is not easy to find characters that (1) are similar to the characters in the In-list and (2) cannot contain the target PC.
Due to the page limits, we could not present the complete authoring system, but hope to have the chance to show it during the demonstration.
6 Concluding Remarks
We reported a game for strengthening the associa-tion of the phonetic components and the pronun-ciations of Chinese characters. Experimental re-sults indicated that playing the games helped stu-dents shorten the response times in naming tasks. To make our platform more useable, we built an authoring tool so that teachers could prepare games that meet specific teaching goals. Evaluation of the tool with college and graduate students showed that our system offered an efficient and effective environment for this authoring task.
Currently, players of our games still have to choose challenge levels. In the near future, we wish to make the game adaptive to players’ compe-tence by adopting more advanced techniques, in-cluding the introduction of “consistency values”
(Jared et al., 1990). Evidence shows that foreign students did not take advantage of the GPC rules in Chinese to learn Chinese characters (Shen, 2005). Hence, it should be interesting to evaluate our sys-tem with foreign students to see whether our ap-proach remains effective.
Acknowledgement
We thank the partial support of NSC-100-2221-E-004-014 and NSC-98-2517-S-004-001-MY3 projects of the Nation-al Science Council, Taiwan. We appreciate reviewers’ invaluable comments, which we will respond in an ex-tended version of this paper.
References
C. S.-H. Ho and P. Bryant. 1997. Phonological skills are im-portant in learning to read Chinese, Developmental
Psy-chology, 33(6), 946–951.
D. Jared, K. McRae, and M. S. Seidenberg. 1990. The basis of consistency effects in word naming, J. of Memory &
Lan-guage, 29(6), 687–715.
Y.-J. Lan, Y.-T. Sung, C.-Y. Wu, R.-L. Wang, and K.-E. Chang. 2009. A cognitive interactive approach to Chinese characters learning: System design and development, Proc.
of the Int’l Conf. on Edutainment, 559–564.
C.-Y. Lee. 2009. The cognitive and neural basis for learning to reading Chinese, J. of Basic Education, 18(2), 63–85. C.-Y. Lee, J.-L. Tsai, E. C.-I Su, O. J.-L. Tzeng, and D.-L.
Hung. 2005. Consistency, regularity, and frequency effects in naming Chinese characters, Language and Linguistics, 6(1), 75–107.
C.-H. Lin and P. Collins. 2012. The effects of L1 and ortho-graphic regularity and consistency in naming Chinese char-acters. Reading and Writing.
C.-L. Liu, M.-H. Lai, K.-W. Tien, Y.-H. Chuang, S.-H. Wu, and C.-Y. Lee. 2011. Visually and phonologically similar characters in incorrect Chinese words: Analyses, identifica-tion, and applications, ACM Trans. on Asian Language
In-formation Processing, 10(2), 10:1–39.
M.-T. P. Lu. 2011. The Effect of Instructional Embodiment
Designs on Chinese Language Learning: The Use of Em-bodied Animation for Beginning Learners of Chinese Characters, Ph.D. Diss., Columbia University, USA.
J. R. Saffran, R. N. Aslin, and E. L. Newport. 1996. Statistical learning by 8-month-old infants, Science, 274(5294), 1926–1928.
H. H. Shen. 2005. An investigation of Chinese-character learning strategies among non-native speakers of Chinese,
System, 33, 49–68.
W.T. Siok and P. Fletcher. 2001. The role of phonological awareness and visual-orthographic skills in Chinese read-ing acquisition, Developmental Psychology, 37(6), 886– 899.
H. Tao. 2007. Stories for 130 Chinese characters, textbook used at the University of Michigan, USA.
J. C. Ziegler and U. Goswami. 2005. Reading acquisition, developmental dyslexia, and skilled reading across lan-guages: A psycholinguistic grain size theory, Psychological
Bulletin, 131(1), 3–29.
Avg. scores
(In-list and Out-list) Avg. time
Control 16.8 15 min
Experimental 52.8 7.1 min
p-value < 0.0001 < 0.0001 Table 5. Improved effectiveness and efficiency
Avg. scores
In-list Out-list Control 15.9 1 Experimental 29.9 22.9 Table 6. Detailed scores for the average scores
Exploring the Relationships between Annual Earnings and Subjective Expressions
in US Financial Statements
Chien-Liang Chen Chao-Lin Liu Yuan-Chen Chang Hsiang-Ping Tsai
Dept. of Computer Science Dept. of Computer Science Dept. of Finance Dept. of Finance National Chengchi University National Chengchi University National Chengchi University Yuan Ze University
Taipei, Taiwan Taipei, Taiwan Taipei, Taiwan Taoyuan, Taiwan
[email protected] [email protected] [email protected] [email protected]
Abstract—Subjective assertions in financial statements
influence the judgments of market participants when they assess the value and profitability of the reporting corporations. Hence, the managements of corporations may attempt to conceal the negative and to accentuate the positive with "prudent" wording. To excavate this accounting phenomenon hidden behind financial statements, we designed an artificial intelligence based strategy to investigate the linkage between financial status measured by annual earnings and subjective multi-word expressions (MWEs). We applied the conditional random field (CRF) models to identify opinion patterns in the form of MWEs, and our approach outperformed previous
work employing unigram models. Moreover, our novel
algorithms take the lead to discover the evidences that support the common belief that there are inconsistencies between the implications of the written statements and the reality indicated by the figures in the financial statements. Unexpected negative earnings are often accompanied by ambiguous and mild statements and sometimes by promises of glorious future.
Keywords-Natural language processing, opinion mining, financial text mining, sentiment analysis, information extraction
I. INTRODUCTION
In recent years, researchers have implemented quantitative methods to investigate the relationships between financial performance and the textual content of the press. Loughran and McDonald developed positive and negative single-word lists, that better reflected the tone of U.S. financial statements (10-K filings), and they examined the linkage between textual statements and financial figures [15]. Antweiler and Frank studied the influence of the discussions on Internet message boards about 45 companies, which list in the Dow Jones Industrial Average, and their stock prices. They concluded that stock messages could help predict market volatility but not stock returns [1]. Li relied on the information in the texts of annual financial statements to examine the implications of risk sentiment of corporation's 10-K filings for stock returns and future earnings. Li found that risk sentiment is negatively correlated with future earnings and future stock returns [13]. Tetlock et al. used negative words contained in the financial press about the S&P 500 to show that the negative words are useful predicators for both earnings and returns [27].
Some researchers in opinion mining have employed different machine learning techniques. Pang et al. utilized the concept of naive Bayes, maximum entropy classification, and support vector machines to classify the sentiment of movie reviews at the document level [19]. Weibie et al. classified subjective sentences based on syntactic features such as the syntactic categories of the constituents [28]. Kim and Hovy used syntactic features to identify the opinion holders in the MPQA
corpus by a ranking algorithm that considered maximum entropy [11]. Choi et al. adopted a hybrid approach that combined CRF and the AutoSlog information extraction learning algorithm to identify sources of opinions in the MPQA corpus [4].
Unlike traditional models that considered individual words (unigrams) and "bag of words" [17], we attempt to automatically extract MWEs which could capture the subjective evaluations of the financial status of the corporation more precisely. Opinion patterns include opinion holders and subjective multi-word expressions (MWEs). For instance, the opinion patterns in the sentence "The Company believes the profits could be adversely affected" include opinion holder "The Company" and two subjective expressions: "believe" and "could be adversely affected".
Our leading contribution is to link positive and negative financial status with subjective multi-word expressions and to propound that the managements of the companies have an incentive to hide negative information but to promote positive information. First, we propose a computational procedure to model the text in financial statements which uses conditional random field models to identify opinion patterns. Second, we trained and tested the models with the annotated MPQA corpus [18] to tune and evaluate the CRF models. Third, we employed the best-performing CRF model that we found from a sequence of experiments to extract subjective opinion patterns in U.S. financial statements. Fourth, we employed multinomial logistic regression to verify whether the opinion patterns were indicative of the earnings of the corporations, and also designed a discriminative strategy to quantify the linkages between annual earnings and the use of subjective MWEs. Finally, using the algorithmically-identified MWEs, we examined whether companies indeed expressed different strengths of positivity and negativity for different earning outcomes, and we found that the companies inclined to use weaker expressions when mentioning negative results.
II. FINANCIAL DATA AND CORPORA
The financial statements used in this work are U.S. SEC 10-K filings of public companies downloaded from the EDGAR database [6]. We also used annual quantitative information about the companies from the Compustat database [23]. Opinion patterns were extracted from the financial statements of 324 U.S. companies for the years between 1996 and 2007, and we merged two different data sources (EDGAR and Compustat) by matching company names and dates (The matching table is provided by Sufi [25]). After eliminating the data with missing values, the number of data items was reduced from 2102 to 1421 to produce what may be describe as a "small dataset". In robustness test, we expanded our sample size from 1421 to 22780 which sample included reports of 6534 U.S. companies
ranging from the year 1996 to 2007, and the data with missing values also be dropped.
The task of the identification of opinion patterns was conducted at the sentence level by using the MPQA corpus [18]. We used the corpus to train the opinion patterns identification model and selected tagging labels which included five different aspects of labels "agent", "expressive-subjectivity", "objective speech event", "direct-subjective" and "target". The IOB format is employed (Ramshaw and Marcus [21]). In Table 1 "according to" is tagged as "B-objective speech event" and "I-objective speech event" in sequence, where "B" stands for the first word of a phrase and "I" stands for the internal word of a phrase. The single word "believe" is both the first and the internal word of a segment, and would be tagged as "B-direct-subjective".
III. OPINION PATTERN IDENTIFICATION:CRFMODELS
This section explains how we attained our linguistic features and built the opinion patterns identifications with linear chain CRF models. The CRF models would be evaluated by the MPQA corpus in section V and also would be applied to the extraction of subjective expressions in the financial statement. A. CRF models and feature sets
The identification of opinion patterns is viewed as a sequential tagging problem which necessitates the incorporation of morphological, orthographical, predicate-argument structure, syntactic and simple semantic features to train the linear-chain conditional random field (refer to Lafferty et al. [12] for use of the linear-chain CRF model). The task of the processing of the feature values of the linguistic features was completed using the Stanford NLP toolkits [24], ASSERT semantic role labeler [3] [20] and CGI Shallow parser [10] for linguistic features. B. Morphological and orthographical features
Original token (f1): we separated the words in a sentence by both the white space and punctuation and also kept the original form without further processing. Lemmatization (f2): the tokens above may contain many syntactic derivations and pragmatic variations since the different parts of speech of the words derived from the same lemma word are semantically equivalent, and the lemma word usage can reduce the complexity of feature spaces. Initial words, words all in capitals or with first character capitalized (f3): in English, abbreviations of words or words all in capitals are probably all or part of the name of specific entities. Word with alphabetic letters and numbers mixed (f4): it is observed that some organizations tend to have a name with alphabets and numbers mixed for ease in memorized (e.g., the U.S. company “3M”). Punctuation (f5): the punctuation in sentences functions best in marking boundaries of semantic units that separate different phrases or clauses.
C. Predicate-argument structure features
The predicate-argument structure (PAS) has been successfully implemented in labeling semantic roles. The PAS
is a structure that captures the events of interest and the participant entities involved in events that correspond to predicate and arguments, respectively. Generally speaking, the predicate is usually a verb that conveys the type of event. Position of predicate (f6): arguments are usually near the predicate, especially agent and patient (subject and object of verb). Before or after predicate (f7): the arguments before or after the predicate perform different types of semantic roles. For example, in the sentence “Peter chases John”, since the predicate is “chases” and two arguments, Peter (arg0) and John (arg1), correspond to agent (Subject) and patient (object), respectively, it can be concluded the relative position of the arguments from the predicate has an influence on the semantic roles while the syntactic categories are the same. Voice (f8): whether the predicate is active or passive voice that can affect the type of arguments. In the sentence “John is chased by Peter” the predicate changes the voice, and the tense of verb is modified and both sequences of arguments are changed. Considering relative position from predicate and voice makes the resolution of the opinion holders more feasible.
D. Syntactic features
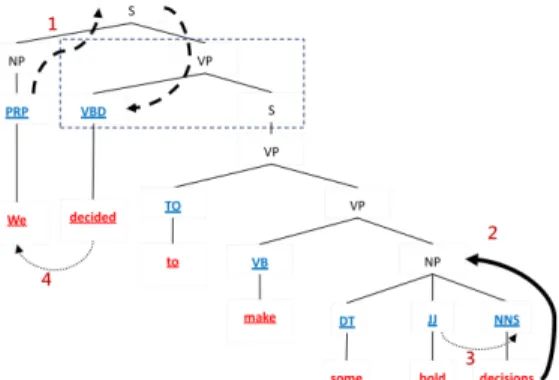
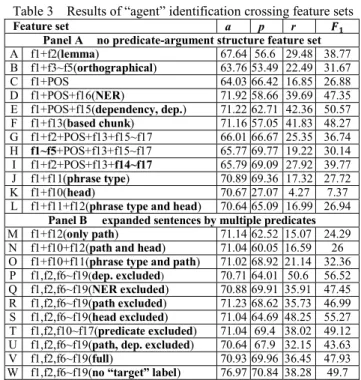
Sub-categorization of predicate (f9): the feature is the verb phrase sub-structure that expresses the VP sub-parse tree structure where predicate located. The Dash frame in Figure 1 indicates that the sub-categorization of “decided” is “VPÎVBD-S”. The function of the feature is to analysis the phrase or the clause that follows predicate, and it increases the ability in discriminating between arguments. Head word and its POS (f10): the features are the syntactic head of the phrase and the syntactic category of the head. Different heads in a noun phrase can be used to express different semantic roles. If the head word is “he” or “Bill” rather than “computer”, then the probability that the noun phrase is the opinion holder increases. The Collins’ head word algorithm is adopted for head word recognition [5]. We also included the head word and head word’s POS of the parent node and grandparent node for considering the contextual syntactic features in the linear data. Syntactic category of phrase (phrase type, f11): different semantic roles tend to be realized by different syntactic categories. The opinion holders are usually the noun phrases and sometimes prepositional phrases, and subjective expressions tend to be verb phrases. The syntactic categories of the word or the phrase are not pure linear data which has been expressed in tree structure, i.e., the phrase type of the word “decisions” in Figure 1 is NNS while the phrase type of “some bold decisions” is NP. We traced only three syntactic categories of non-terminal nodes upward from the parent of the leaf nodes if the head word
Table 1 A sample sentence and annotations of the MPQA According to Datanalisis' November poll, 57.4 percent of those polled
feel as bad or worse than in the past. MPQA annotation labels Opinion
holder 1 According to: objective speech event. Datanalisis' November poll: agent; Opinion
holder 2
57.4 percent of those polled: agent; feel: direct-subjective;
of parent phrase is such leaf node. For example in Figure 1, because the head word of the NP “some bold decisions” is “decisions” and the head of the VP “make some bold decisions” is “make”, the noun “decisions” would be the phrase type only NNS and NP without VP. In contrast, the verb “make” contains VB, VP and VP in sequence. Syntactic path and partial path (f12): the path helps predict the semantic labels. The syntactic path feature describes the syntactic relation from constituent to the predicate in the sentence with the syntactic categories of the node which is passed through. In Figure 1, the path from “We” to “decides” can be represented as either “PRP↑NP↑S↓VP↓VBD” or “NP↑S↓VP↓VBD” depending on whether the syntactic type is PRP or NP of word “We”. The partial path is the part of the syntactic path which contains the lowest common ancestor of the constituent and predicate (e.g., the lowest common ancestor is S in the sentence, so the partial path can be reduced to “PRP↑NP↑S”).
Based chunk (f13): the based chunk feature is a partial parsing structure. We represent the based chunk in IOB format which makes the segmentation of phrase boundary more precise. Subordinate noun clause followed verb and noun phrase before verb phrase (f14): since our phrase type feature is only three levels of syntactic category from the parents of parse tree leaf nodes, the macro syntactic structure information may be omitted if the parse tree is constructed deeply. In sentence “The management believed that …,” the subordinate noun clause following the verb “believed” is usually embedded with subjective expressions. We used the Stanford tregex toolkit to extract such patterns from the parse tree [24]. Syntactic dependency (f15): the feature is to capture the grammatical relation that includes three types of grammar dependency “subject relationship”, “modifying relationship” and “direct-object relationship”. The Subject relationship includes the “nominal subject” and the “passive nominal subject”, which correspond to the noun that is the syntactic subject of the active and passive clause; the modifying relationship consists of adjectival modifier or adverbial modifier, which can be any an adjectival (adverb) word that modifies the meaning of the noun (verb or adjective). The direct-object relationship indicates the noun that is the direct object of the verb. We utilized the Stanford dependency parser to get the dependency parse tree for the dependency features [24]. The opinion holders, opinion words in subjective expressions and opinion targets are correlated with the subject, modifying and direct-object relationship individually. In Figure 1, the label of the phrase “to make some bold decisions” is “expressive-subjectivity”, and we can observe that the opinion word in the phrase is “bold” with an adjective POS that modifies the noun “decisions”. Since the word “we” is the subject of verb “decides”, the identification of the relationship of the subject with the verb can be used to predict the opinion holders.
E. Simple semantic features
Named entity recognition (NER, f16): when utilizing the syntactic features, it is hard to distinguish the entity name from the other noun phrases. The NER can better identify the name of a person, who may be the opinion holder or the opinion target. Stanford NER [24] was employed to label the name of persons, organizations and locations. Subjective word and its polarity (f17): the subjective words which appear in sentences can help not only judging whether the sentence is an opinion sentence but also detect the opinion words in the labels
“expressive-subjectivity” and “direct-subjective”. The subjective words can be classified by two aspects which are the strengths of the subjectivity and the polarity. According to different levels of subjectivity, the strength can be either one of objective, weak subjectivity or strong subjectivity. Moreover, the weak and strong subjectivity can be further divided into positive, negative or neutral. The subjective word dictionary was manually collected by Wiebe [29]. Verb-clusters of predicate (f18): verbs with similar semantic meanings might appear together in the same document. In order to arrange the semantically-related verbs into one group, we use verb clusters to avoid the occurrence of the presence of rare verbs which would deteriorate the model performance. The ASSERT toolkit adopts a probabilistic co-occurrence model to cluster the co-occurrence of a verb into 64 clusters. The frame of the predicate in FrameNet (f19): We used the FrameNet [7] to query the name of the frame which a particular predicate belonged.
IV. LINKAGES BETWEEN EARNINGS AND SUBJECTIVE MWES
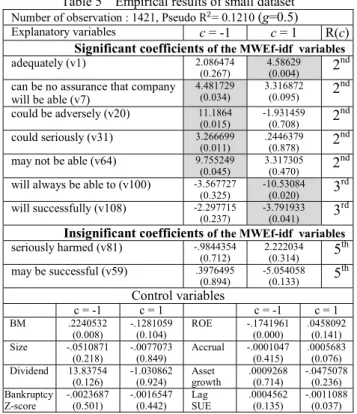
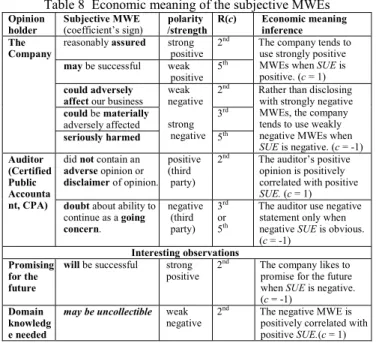
We aim to investigate whether the subjective MWEs in the U.S. financial statements reflected the trend of firm’s earnings. We used multinomial logistic regression (Stata [26]) to explain the relationship between annual earnings and subjective MWEs and to infer its economic meaning.
A. Dependent variable: standardized unexpected earnings Our main concern in regard to the financial status of the company is each firm’s standardized unexpected earnings (SUE) which capture the trend of the firm’s earnings (following Li [13] and Tetlock et al. [27]). The SUE is viewed as the dependent variable of our research. The SUE for each firm in year t is calculated as,
(1) (2) Where is the earnings of the firm in year t, and the mean and volatility of unexpected earnings (UE) are equal to the mean ( ) and standard deviation ( ) of the unexpected earnings of each firm within a period of 12 years unexpected earnings. We transformed the SUE into three categories (Y) which are positive (1), no changed (0) and negative (-1), and the criteria is described as,
1, if
1, if
0, otherwise.
(3) Where is a constant that we set to 0.5. The reason for transforming the Y from a numeric dependent variable into a categorical variable is to avoid any minor changes in SUE disturbing the empirical results.
B. Explanatory variables: MWEf-idf and control variables The main explanatory variables in this study, an information retrieval weighting schema, was employed to quantify the MWEs. Moreover, other factors that have been traditionally considered as correlated with earnings are employed as control variables1. Further, the frequency of the occurrence of the
1
The control variables were the financial factors that relate with the SUE. The control variables include lag SUE (SUE of the previous year), BM ratio (natural log of dividing book value by market value), ROE (return on equity), accruals (earnings minus operating cash flow), size (natural log of market value), Dividend (cash dividend divided by book value) and Bankruptcy Score (Z-score) [23].