行政院國家科學委員會補助專題研究計畫
成 果 報 告
□期中進度報告
分散式網路儲存系統安全傳輸問題的研究
Security issues of distributed networked storage systems
計畫類別:
個別型計畫 □整合型計畫
計畫編號:NSC 98-2221-E-009-068-MY3
執行期間: 98 年 8 月 1 日至 101 年 7 月 31 日
第三年度: 100 年 8 月 1 日至 101 年 7 月 31 日
計畫主持人:曾文貴 教授
計畫參與人員:林孝盈、官正傑、林輝讓、劉正偉、劉麗君
成果報告類型(依經費核定清單規定繳交):
精簡報告 ■完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
■出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、
列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
執行單位:國立交通大學 資訊工程系
中 華 民 國 101 年 10 月 28 日
2
中文摘要
本研究計畫將研究分散式網路儲存系統的安全
儲存機制。網路儲存系統提供使用者儲存資料在
網路上的儲存系統中,再透過網路進行資料存
取。目前的分散式網路儲存系統首要注重的是效
率,其次才是安全性,我們認為在資料隱私性上
還有許多改善的空間。
第一年度(98-99)我們發展了一個以隨機
線性編碼基礎的安全分散式網路儲存系統。在我
們的系統中,資料透過公開金鑰系統加密來達到
高度資料隱私性,隨機線性編碼方法則是提供了
儲存系統的容錯能力。整體系統的運作符合分散
式系統的環境特質,論文已在 IEEE TPDS (2010)
期刊發表。
第二年度(99-100)我們基於去年發展的
安全儲存系統,繼續提供多樣性的功能,例如,
如 何 將 安 全 儲 存 的 資 料 送 給 第 三 者
(forwarding),資料擁有者不需將儲存的資料取
回解密後再上傳,這樣可以減少大量的頻寬使
用。論文成果已經在 IEEE TPDS (2012)上發表。
第三年度(100-101),我們基於先前兩年
的成果,有一個安全強固且具有資料傳送給第三
者的分散式雲端儲存系統上,提出當系統的一些
伺服器出現錯誤時可以修復的機制,成果發表在
IEEE TrustCom-2011 會議上,完整論文也已投
稿到知名期刊。
關鍵詞: 分散式網路儲存系統,公開金鑰加密,
隨機容錯編碼,資料安全傳送,資料傳送。
英文摘要
In this project, we study security issues of
distributed
networked
storage
systems.
A
networked storage system enables users to store
data and to access data via Internet access.
Currently, distributed networked storage systems
are designed for efficiency and security is a second
issue. One of goals of this research is to improve
the data confidentiality in distributed networked
storage systems.
In the first year (2009-2010), we developed a
random linear code-based secure distributed
networked storage system. The system uses a
public key encryption scheme to provide high data
confidentiality and uses a random linear code to
achieve the data robustness. The data storing and
retrieval processes are fully distributed. The paper
has been published in IEEE TPDE.
In second year (2010-2011), we develop the
system such that it can support the functionality of
data forward. In this system, the data owner can
securely forward the stored data in the distributed
storage system to another user. The owner does
not need to retrieve the data back to process it for
forwarding to another user. The owner simply
sends a proxy re-encryption key to the storage
servers and the servers re-encrypt the data into a
ciphertext that can be decrypted by the target user.
This method reduces the bandwidth requirement
dramatically. We have finished a manuscript and
submitted it to an international journal.
In the third year (2011-2012), we continue to
research on distributed storage systems. Based on
the results of the previous two years, we consider
repair mechanisms for our robust and secure
storage system. We propose cooperative and
non-cooperative repair mechanisms. The results
have been published in the conference IEEE
TrustCom-2011. The complete paper is submitted
to a prestigious journal.
Keywords: Distributed networked storage system,
public key cryptosystem, random erasure code,
data forwarding, repair mechanism.
一. 計畫緣起及目的
由於高速網路與多樣隨身上網裝置的普及
化,許多服務都透過網路來傳遞。較為常見的有
網路信箱,搜尋引擎,網路聊天室,網路文件編
輯器等。這些透過網路提供的服務系統底層都使
用到了網路儲存系統的建構。我們考慮分散式網
路儲存系統這個基礎服務。
一個分散式網路儲存系統包含許多儲存伺
服器,彼此透過網路進行連結,其中並沒有一個
長駐的中央控制管理單位,這使得整體系統較為
彈性且不會在中央控制管理單位造成系統效能
瓶頸,但是相對地,管理效率就叫無法掌控。
將資料儲存在網路系統中首先會面臨的問
題是資料是否能夠正常取回,這點主要是透過容
錯機制來防止任何系統內部的意外錯誤,另外一
個新興的使用者疑慮是資料隱私性的問題,資料
存放在網路儲存系統之後是否會被惡意人士竊
取再利用,我們需要一個能夠同時處理系統容錯
與資料隱私性的雲端儲存系統。
最基本的容錯技術就是儲存副本,像是磁
碟陣列 RAID-1 或早期許多分散式儲存系統,都
使用副本技術。副本技術需要付出很大的儲存成
本。為了解決這個問題,Erasure codes 被提出
可以應用到容錯儲存上。
RAID-5 與 RAID-6 就應用了 Erasure codes
的技術, Lincoln erasure codes 是一個特殊
的 erasure codes 並被應用到儲存系統中以提
供容錯能力。其他種類的 Erasure Codes 還有很
多,例如 Low density parity checking codes
或者是 Evenodd codes 與 STAR codes,也都被
應用到儲存系統中來提供容錯能力。 Random
liner codes 可以容忍大量的儲存毀損且儲存成
本較副本技術低許多,但是需要使用較多的時間
進行編碼與解碼的運算。2006 年,Dimarks 與
Prabhakaran 等學者應用 random linear code
在分散式網路儲存環境中,以獲得具有容錯能力
但儲存空間成本較低的儲存系統,他們的結果亦
應用到無線感測網路系統中,可知在儲存空間成
本上是很有效率的。
想要保障使用者的資料不被第三者得知,
除了好的雲端管理與存取控管機制外,大概能做
的是把資料加密後再存入系統。加密可以由雲端
儲存系統來做,1993 年 Blaze 所提出的 CFS, 與
其衍生的 TCFS 與 NCryptfs,較為近期的系統則
有 OceanStore, Plutus, 與 Tahoe。然而我們想
要探討的資料隱私性,不僅是抵擋外來的攻擊,
更要預防雲端儲存中的惡意主機。對使用者來
說,全面相信雲端中的所有主機是較不實際的假
設,如果能夠達到在使用者不用信任這些主機的
情況下,仍能保障資料隱私性,這樣的保護機制
與儲存系統才能真正被使用者信任,進而使用。
我們結合了 random linear code 與公開金
鑰加密系統兩大工具,設計了一個安全的分散式
網路儲存系統。我們的分散式儲存系統同時具有
容錯能力與高度資料隱私性,除了儲存服務之
外,我們也新增了金鑰管理服務以降低使用者管
理金鑰上的風險。除此之外,我們還考慮如何有
效率的運用儲存的資料,雖然將資料加密儲存可
以提供好的安全保護,但是也限制了它們的使
用,大約是使用者將資料取回解密後處理,這樣
的動作需花費大量的網路頻寬,不方便且沒有效
4
率。如何提供有效率使用安全儲存資料的方法是
研究的重點。
當資料以分散式的方式儲存在儲存伺服器
時,可能損毀或遭到破壞,當這些錯誤發生時,
如何利用儲存在其他伺服器的資料將錯誤的伺
服器修護或對新加入的伺服器寫入一些資料,使
得整個系統還具有強固與安全的特性,是值得研
究的課題。
二. 研究成果
第一年度(2009-2010)
第一年度的研究成果為提出一個安全的分
散式網路儲存系統。我們的系統有三個角色,儲
存伺服器,金鑰管理伺服器與使用者。假定系統
有 n 個儲存伺服器,m 個金鑰管理伺服器,使用
者要儲存 k 筆資料。使用者的資料將被加密後存
入 系 統 , 系 統 會 透 過 分 散 式 容 錯 編 碼
(decentralized erasure coding) 將資料分散
儲存在 v 個儲存伺服器中,當使用者要將資料取
回時,系統中的金鑰管理伺服器會與 u 個儲存伺
服器聯絡取得資料並協助使用者進行解密運
算,使用者自己再進行解碼以拿到資料。在這期
間,由於儲存伺服器與金鑰伺服器都是獨立進行
編碼與協助解密的程序,所以不需要一個中央控
制單位的協助。
在功能性上,我們透過錯誤更正碼儲存來
因應系統中儲存伺服器可能意外地斷線或儲存
設備的毀損,使得系統在發生意外狀況時仍能夠
提供服務。在資料隱私性上,我們則是考慮一個
高度隱私性的要求,使用者的資料不僅僅是其他
系統中使用者無法接觸,負責提供服務的儲存伺
服器本身亦無法得知資料的內容。
研究成果的主要貢獻,從學術理論上來
看,我們提供了一個結合了容錯技術與公開金鑰
加密系統的密碼學工具,這個工具能夠在一個非
集中式的儲存系統環境中被使用,使得系統同時
具有資料可信賴與高度隱私性並且兼顧了分散
式的優點,另外針對系統中資料儲存的取回正確
率上,我們亦提供了一個完整的分析方式並建議
了一組通用的系統參數。
從儲存系統發展與應用上來看,我們強調
了資料隱私性在雲端儲存系統上的重要性與一
個強度上的分野,早期網路儲存系統的隱私性是
建立在完全信任儲存伺服器的假設下,僅對登入
的使用者進行身分認證,我們則是強調資料隱私
性的強度應該要能夠消除對儲存伺服器的信任
的假設條件。
在容錯能力上來說,我們的系統能夠容忍
(n-k)個儲存伺服器錯誤與(m-t)個金鑰管理伺
服器錯誤。只要有 k 個儲存伺服器與 t 個金鑰管
理伺服器仍正常運作,則使用者可以有很高的機
率將資料取回。
在資料隱私性方面,因為資料都是以加密
的型態被儲存,所以即使是所有的儲存伺服器都
被攻擊者控制,資料內容仍能保密。我們對於金
鑰管理伺服器則有較高的信任要求,我們假設這
些金鑰管理伺服器有較好的安全機制以保障使
用者的各個部分解密金鑰。
第二年度(2010-2011)
為了在分散式安全的儲存系統上達到具有 data
forwarding 的能力,我們提出了新的門檻式的
再 加 密 協 定 (threshold re-encryption
scheme),然後將整合到安全的儲存系統裡。結
合的系統具有安全、容錯、data forwarding 的
功能,這項工作的主要困難度在於如何在加密的
系統上同時做容錯計算與 data forwarding。
我們將伺服器分為儲存伺服器與金鑰伺服
器,其中金鑰伺服器位於私有雲中,我們將金鑰
分由金鑰伺服器持分,當使用者要取回資料時,
由金鑰伺服器向儲存伺服器要求資料做部分解
密,當使用者有足夠的解密資料就可以將真正的
資料計算出來。我們還改進了先前對儲存伺服器
數 n,分配的訊息數 v,文件的的分割數 k 等作
了更精確的計算,得到較好的 bounds.
詳細內容請見我們所附的論文。
第三年度(2011-2012)
我們基於先前兩年的成果,有一個安全強固且具
有資料傳送給第三者的分散式 雲端儲存系統
上,提出當系統的一些伺服器出現錯誤時可以修
復的機制。我們有兩種修復機制,第一種是新加
入的儲存伺服器間不相互傳遞訊息,第二種是新
加入的儲存伺服器間可以相互傳遞訊息。原先對
修復機制有一個最低下界值(lower bound),用
我們的方法可以得到在平均下,可以打破此下界
值,在絕大多數的情形下,加入的伺服器可以跟
少於 k 個原先存在的儲存伺服器溝通交換訊
息,而系統還是可以保持良好的強固性。
這部分的成果發表在 IEEE TrustCom-2011
會議上,完整論文也已投稿到知名期刊。
三. 計畫成果自評
整個三年計劃我們已經發表了以下的論
文:
1. Hsiao-Ying Lin, Wen-Guey Tzeng, Shiuan-Tzuo Shen and Bao-Shuh P. Lin. A Practical Smart Metering System Supporting Privacy Preserving Billing and Load Monitoring. In the10th International Conference on Applied
Cryptography and Network Security (ACNS 2012), June 2012.
2. Hsiao-Ying Lin, John Kubiatowicz and Wen-Guey Tzeng. A Secure Fine-Grained Access Control Mechanism for Networked Storage System. In the Sixth IEEE International Conference on Software Security and Reliability (IEEE SERE 2012), June 2012.
3. Hsiao-Ying Lin, Wen-Guey Tzeng. A Secure Erasure Code-based Cloud Storage System with Secure Data Forwarding, IEEE Transactions on Parallel and Distributed Systems 23(6). pp.995-1003, 2012.
4. Hsiao-Ying Lin, Wen-Guey Tzeng, Bao-Shuh Lin. A Decentralized Repair Mechanism for Decentralized Erasure Code based Storage Systems. In the 10th IEEE International Conference on Trust, Security and Privacy in Computing and Communications (IEEE TrustCom-2011), Nov, 2011.
5. Hsiao-Ying Lin, Wen-Guey Tzeng. A Secure Decentralized Erasure Code for Networked Storage Systems, IEEE Transactions on Parallel and Distributed Systems, 21(11), pp.1586-1596, 2010.
其中有兩篇高水準的期刊論文,另外一篇
正在投稿中,研究成果符合計劃的預期。
A Decentralized Repair Mechanism for
Decentralized Erasure Code based Storage Systems
Hsiao-Ying Lin∗, Wen-Guey Tzeng†, Bao-Shuh Lin∗
∗Intelligent Information and Communications Research Center,†Department of Computer Science
National Chiao Tung University Hsinchu, Taiwan
[email protected], [email protected], [email protected]
Abstract—Erasure code based distributed storage systems provide data robustness by storing encoded-fragments over servers. To maintain data robustness, a repair mechanism recovers a storage system from server failures by repairing encoded-fragments. For decentralized erasure code based stor-age systems, we propose a decentralized repair mechanism. Our mechanism has the following features. Firstly, an encoded-fragment is replenished by a combination of a number u of encoded-fragments that are randomly chosen. Secondly, the number u depends on the number of the available encoded-fragments and is independent of the pattern of missing encoded-fragments. Thirdly, multiple encoded-fragments are simultaneously replenished in parallel. We measure the com-munication cost in terms of the number u of required network connections for replenishing an encoded-fragment. We then conducted a numerical analysis by using traces of real systems. We find that our requirement on u is smaller than that from existing methods. Both theoretical and numerical results show that our decentralized repair mechanism outperforms existing ones in terms of the communication cost under the same consideration of efficiency cost for storage.
Keywords-decentralized erasure codes; regenerating codes; network coding; distributed storage;
I. INTRODUCTION
Erasure code based distributed storage systems provide data robustness by storing encoded-fragments over servers. An (𝑛, 𝑘) erasure code encodes a message of 𝑘 symbols to a codeword of𝑛 symbols such that the message can be decoded from any𝑘 codeword symbols. The code tolerates
𝑛−𝑘 erasure errors. To store a message in an (𝑛, 𝑘)-erasure
code based distributed storage system with 𝑛 servers, the message is encoded into a codeword by the erasure code and each of its codeword symbols is stored in a different server. A server failure corresponds to an erasure error of the stored codeword symbol. As long as𝑘 servers are available, the message can be recovered. In this paper, we sometimes refer a codeword symbol as an encoded fragment and use them interchangeably.
A decentralized erasure code is an erasure code that inde-pendently computes each codeword symbol for a message. Thus, the encoding process for a message consists of 𝑛 parallel tasks of generating codeword symbols. Each server executes one task to compute a codeword symbol. This kind
of systems is suitable for decentralized environments, where no centralized authority coordinates the tasks, such as peer-to-peer and ad-hoc networks. Parallel computing also speeds up the storing process.
Maintenance of robustness in an erasure code based dis-tributed storage system requires to replenish codeword sym-bols when servers fail or leave the system. A straightforward solution is to compute the original message from available codeword symbols and then to regenerate missing codeword symbols from the message. This approach leads to higher communication and computation cost. Another approach is to generate codeword symbols by directly combining 𝑢 available ones. When a new server joins the system, it queries𝑢 available servers to generate a codeword symbol. The generated codeword symbol can be different from the missing one. But, the property that any𝑘 codeword symbols can recover the message remains.
In previous studies, efficiency is measured by the storage cost (the number of bits a server stores) and the repair bandwidth (the number of bits a new server received for replenishing a codeword symbol). However, in considering the communication cost, the cost of establishing network connections is significant. Establishing network connections between servers involves authentication and negotiation process. The entailed communication cost is significant, especially when𝑢 is large. For example, when 𝑢 = 𝑛 − 1, a new server needs to connect all available servers in the system. Thus, we measure the communication cost by the number 𝑢 of required network connections, as well as the repair bandwidth.
We study repair mechanisms for decentralized erasure code based storage systems. In a decentralized erasure code based storage system, we show that 𝑢 = 𝑘 is a sufficient condition for a repair mechanism. Specifically, we are inter-ested in finding out whether𝑢 can be smaller than 𝑘.
Contributions. We propose a decentralized repair
mecha-nism for decentralized erasure code based storage systems with the following features:
∙ A codeword symbol is replenished by a combination of a number 𝑢 of randomly chosen codeword symbols without recreating the original message.
2011 International Joint Conference of IEEE TrustCom-11/IEEE ICESS-11/FCST-11
978-0-7695-4600-1/11 $26.00 © 2011 IEEE DOI 10.1109/TrustCom.2011.79
∙ The number 𝑢 depends on the number of available codeword symbols and is independent of the pattern of missing codeword symbols.
∙ Multiple codeword symbols can be independently re-plenished.
We theoretically study the lower bound for𝑢. The bound depends on the number of available servers and the param-eter 𝑘. With a fixed 𝑘, the larger the number of available servers is, the smaller𝑢 can be. It shows flexibility between the parameter 𝑢 and the number of available servers. We then conducted a numerical analysis by using traces of real systems. Both theoretical and numerical results show that
𝑢 can be smaller than 𝑘. When 𝑢 < 𝑘, the average repair
bandwidth for a server failure is less than the size of the original message. From the aspect of information theory, it gives a light data confidentiality, which is independently interesting. When a new server joins the system and tries to recover a missing codeword symbol, some codeword sym-bols are sent to the new server from remaining servers. An eavesdropper may eavesdrop the transmitted codeword sym-bols and recover the original message. If𝑢 is smaller than
𝑘, the information in the eavesdropped codeword symbols is
not enough to compute the message. This confidentiality is light since increasing eavesdropped codeword symbols will eventually reveal the message. Thus, it is advised to encrypt communication channel between servers.
We compare our decentralized repair mechanism with other mechanisms in terms of communication cost and storage cost. The result shows that our decentralized repair mechanism outperforms existing ones in terms of the com-munication cost under the same consideration of efficiency cost for storage.
II. RELATEDWORK
We briefly review repair mechanisms of erasure code based distributed storage systems.
In erasure code based distributed storage systems, repair-ing codeword symbols is essential to maintain robustness against server failures. Since regenerating codeword sym-bols after reconstructing the message is costly in terms of communication and computation cost, a hybrid approach is proposed [1]. A storage server stores the message whereas other storage servers store encoded-fragments. When some servers fail, the storage server storing the message regen-erates missing encoded-fragments. The asymmetric storing structure complicates system management.
Dimakis et al. introduced regenerating codes [2]. The codes are to minimize storage cost and repair bandwidth. They showed that repair bandwidth can be decreased by letting a new server query more than 𝑘 servers. However, storage cost would slightly increase. The tradeoff between storage cost and repair bandwidth is described as a curve where two extreme points are highlighted. By the points, they proposed two repair mechanisms, minimum storage
regime and minimum bandwidth regime. In the minimum storage regime, a new server queries𝑘 +1 randomly chosen servers; in the minimum bandwidth regime, a new server queries𝑛 − 1 randomly chosen servers. By using the cut-set bound of network coding in an information flow graph, a repair mechanism corresponding to a point on the curve is proved that after a system is repaired, a user retrieves a mes-sage with probability1. More constructions and discussions of regenerating codes can be found in [3], [4].
Rashmi et al. [5] proposed exact regenerating codes, which exactly regenerate missing codeword symbols. Shah et al. [6] took the consideration that traffic conditions vary among different links. They proposed flexible regenerating codes, which allow a new server download different amounts of data from different servers. Alternative models of repair mechanisms [7], [8], [9] are proposed for different scenarios. Nevertheless, the family of regenerating codes handles only the case of one server failure. Once a server fails or leaves the system, the repair mechanism is immediately executed. This approach increases system load.
Hu et al. [10] proposed a mutually cooperative recovery mechanism to recover distributed storage systems from mul-tiple server failures. The mechanism has two communication phases. First, each new server queries all remaining servers. Second, each new server communicates with all other new servers. Thus, a new server totally queries 𝑛 − 1 servers. Recently, Oggier and Datta [11] proposed self-repairing ho-momorphic codes for repairing multiple server failures. Each new server queries a fixed number of servers to regenerate missing codeword symbols and the number can be less than
𝑘. However, a new server has to query a specific subset of
old servers to regenerate some codeword symbol. There is a mapping from a codeword symbol to specific subsets of old servers for regenerating the codeword symbol. Thus, self-repairing homomorphic codes need a central table for these mappings. The deterministic self-repairing homomorphic codes are not suitable for decentralized environments.
Dikaliotis et al. [12] studied the method of detecting faulty errors in distributed storage systems. Rashmi et al. [13] proposed a framework that integrates two erasure codes to obtain features from both codes. Pawar et al. [14] discussed data confidentiality issue when a repair mechanism is ex-ecuted. Papailiopoulos and Dimakis [15] gave a reduction between the problem of maximizing data confidentiality and the problem of minimizing repair bandwidth.
III. OURREPAIRMECHANISM
We firstly describe a decentralized erasure code based storage system as our system model and then introduce our repair mechanism. We show our bound on the parameter𝑢 for the repair mechanism.
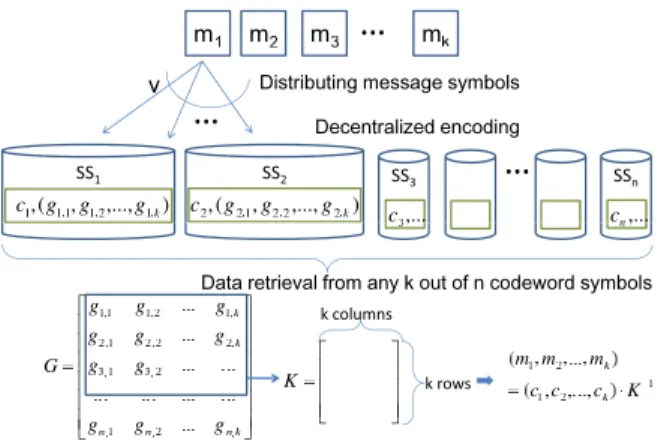
Figure 1. The model of decentralized erasure code based storage systems.
A. Decentralized Erasure Code based Storage System
Dimakis et al. [16] proposed a decentralized erasure code based storage system where the encoding process is ac-complished by decentralized servers in parallel. Afterward, for strengthening data confidentiality, Lin and Tzeng [17], [18] proposed secure decentralized erasure codes where data are encoded in an encrypted form. Illustrated in Fig. 1, a decentralized erasure code based storage systems is de-scribed as follows. There are 𝑛 servers, SS1,SS2, . . .,
SS𝑛, and a message is represented as a vector of symbols
𝑚1, 𝑚2, . . . , 𝑚𝑘 in some finite field. To store the message, each symbol is distributed to 𝑣 randomly chosen servers. A server SS𝑖 then picks a random coefficient 𝑔𝑖,𝑗 for a received message symbol 𝑚𝑗 and linearly combines all received message symbols as a codeword symbol𝑐𝑖. If𝑚𝑗 is not received,𝑔𝑖,𝑗 is set to0. Note that the combination is operated in the finite field. Globally, all chosen coefficients form a generator matrix 𝐺 = [𝑔𝑖,𝑗], 1 ≤ 𝑖 ≤ 𝑛, 1 ≤ 𝑗 ≤ 𝑘, which encodes the vector of 𝑘 message symbols to the vector of 𝑛 codeword symbols. To retrieve the message, a user queries 𝑘 randomly chosen servers to get 𝑘 codeword symbols, say 𝑐1, 𝑐2, . . . , 𝑐𝑘, and the corresponding coeffi-cients. The coefficients form a square matrix𝐾, which is a submatrix of𝐺. The user decodes the message by computing (𝑐1, 𝑐2, . . . , 𝑐𝑘) × 𝐾−1, where𝐾−1 is the inverse matrix of
𝐾. A successful data retrieval of the system is the event that 𝐾 is invertible. The probability of a successful data retrieval
is overwhelming when𝑣 is sufficiently large [16], [17], [18]. From the results in [16], the system parameters are suggested as follows in order to guarantee a high probability of a successful data retrieval. When 𝑛 = 𝑎𝑘, 𝑣 = 𝑏 ln 𝑘, and 𝑏 > 5𝑎 with constants 𝑎 and 𝑏, the probability of a successful data retrieval is at least1−𝑘/𝑝−𝑜(1), where 𝑝 is the prime order of the underlined group. Later in [18], these parameters are generalized for 𝑛 = 𝑎𝑘𝑐 and 𝑐 ≥ 1. When
𝑛 = 𝑎𝑘𝑐,𝑣 = 𝑏𝑘𝑐−1ln 𝑘, 𝑏 > 5𝑎, and 𝑐 ≥ 1 with constants
𝑎 and 𝑏, the probability of a successful data retrieval is at
Figure 2. Our repair model for decentralized erasure code based storage systems.
least1 − 𝑘/𝑝 − 𝑜(1).
B. Decentralized Repair Mechanism
Let messages be stored among𝑛 servers in a decentralized erasure code based storage system. After a period of time, some servers fail. Let the number of remaining servers be
𝛼𝑛, where 𝛼 < 1. By the results [16], [17], [18], any 𝑘
remaining servers can recover the message with probability 1 − 𝑘/𝑝 − 𝑜(1). To repair the system from (1 − 𝛼)𝑛 server failures, (1 − 𝛼)𝑛 new servers join the system. We shall call a remaining server as an old server and a newly joining one as a new server. A repair procedure is initiated by new servers (see Fig. 2). After executing the repair procedure, the storage system is recovered from server failures so that any 𝑘 servers, no matter new or old ones, shall recover the message with an overwhelming probability.
Repair procedure. New server SS𝑗performs the following steps:
1) Query 𝑢 randomly chosen old servers, SS𝑗1,
SS𝑗2, . . ., SS𝑗𝑢. A queried old server SS𝑗𝑖
re-turns the stored codeword symbol and coefficients (𝑐𝑗𝑖, 𝑔𝑗𝑖,1, 𝑔𝑗𝑖,2, . . . , 𝑔𝑗𝑖,𝑘).
2) Choose a random coefficient 𝑧𝑗𝑖 for a received
(𝑐𝑗𝑖, 𝑔𝑗𝑖,1, 𝑔𝑗𝑖,2, . . . , 𝑔𝑗𝑖,𝑘).
3) Encode all received data into a new codeword symbol and the corresponding coefficients (˜𝑐𝑗, ˜𝑔𝑗,1, ˜𝑔𝑗,2, . . . , ˜𝑔𝑗,𝑘): ˜𝑐𝑗= ∑ 1≤𝑖≤𝑢 𝑧𝑗𝑖𝑐𝑗𝑖, ˜𝑔𝑗,𝑠= ∑ 1≤𝑖≤𝑢 𝑧𝑗𝑖𝑔𝑗𝑖,𝑠, 1 ≤ 𝑠 ≤ 𝑘
4) Store the resulting(˜𝑐𝑗, ˜𝑔𝑗,1, ˜𝑔𝑗,2, . . . , ˜𝑔𝑗,𝑘).
By considering communication cost of establishing net-work connections between servers, we want a smaller𝑢. A larger 𝑢 means that the new server queries more codeword symbols from old servers. The combination of these queried codeword symbols contains more information about the mes-sage. Therefore, we need to carefully select𝑢. Apparently, if
𝑢 ≥ 𝑘, more than 𝑘 codeword symbols are queried and they
are sufficient to recover the message with an overwhelming probability. The combination of these codeword symbols in the new server, together with the codeword symbols from
other 𝑘 − 1 servers, should provide enough information to recover the message. On the other hand, if𝑢 < 𝑘, the queried codeword symbols are not sufficient to recover the message and their combination contains less information about the message. We are interested in finding out how smaller 𝑢 can be such that the combination of the queried codeword symbols still provides sufficient information, when together with other codeword symbols, to recover the message with an overwhelming probability.
C. Main Result
We assume that 𝑛 = 𝑎𝑘𝑐 and 𝛼𝑛 = 𝑘𝑑 for some constant 𝑎, 𝑐, 𝛼, and 𝑑, where 𝑐 ≥ 1, 𝛼 < 1, and 𝑑 > 1. This assumption can be generally applied to decentralized erasure code based storage systems. Our results are given in Theorem 1 and Theorem 2. Proofs are provided in subsequent subsections.
Theorem 1 shows that in a decentralized erasure code based storage system with 𝑛 servers, our repair mechanism with𝑢 = 𝑘 recovers the system from (1−𝛼)𝑛 server failures.
Theorem 1. Let 𝑛 = 𝑎𝑘𝑐 for some constants 𝑎 and 𝑐, where 𝑐 ≥ 1. Let the number 𝛼𝑛 of old servers be 𝑘𝑑, where 𝛼 < 1 and 𝑑 > 1. Let the system be repaired by our repair mechanism with 𝑢 = 𝑘. Consider the event of a successful data retrieval that 𝑘 randomly chosen servers from new and old servers recover a message. The probability of a successful retrieval is at least 1 −2𝑘𝑝 − 𝑜(1).
Theorem 2 shows the bound on𝑢 for our repair mecha-nism. The bound reveals the opportunities for 𝑢 < 𝑘.
Theorem 2. Let𝑛 = 𝑎𝑘𝑐 and 𝛼𝑛 = 𝑘𝑑 for some constants 𝑎, 𝑐, 𝛼, and 𝑑, where 𝑐 ≥ 1, 𝛼 < 1, and 𝑑 > 1. Let the parameter 𝑢 be set such that
𝑢 ≥ min{𝑘, max{(𝑑 − 1) ln 𝑘2𝑘 , ( 𝑘 (𝑑 − 1) ln 𝑘+ 𝑑 𝑑 − 1 ) }} After the system is repaired by our repair mechanism, the probability of a successful retrieval is at least1−2𝑘𝑝 −𝑜(1).
Corollary 1. When 𝑑 > ln 𝑘𝑘 , it is sufficient to have 𝑢 ≥
min{𝑘, 𝑘
(𝑑−1) ln 𝑘+ 𝑑−1𝑑 }. When 𝑑 ≤ ln 𝑘𝑘 , it is sufficient to have𝑢 ≥ min{𝑘,(𝑑−1) ln 𝑘2𝑘 }.
Proof: When 𝑑 > ln 𝑘𝑘 , we have (𝑑−1) ln 𝑘2𝑘 < ( 𝑘 (𝑑−1) ln 𝑘+𝑑−1𝑑 ) . When 𝑑 ≤ ln 𝑘𝑘 , we have (𝑑−1) ln 𝑘2𝑘 ≥ ( 𝑘 (𝑑−1) ln 𝑘+𝑑−1𝑑 ) .
From Theorem 2, with a fixed 𝑑, 𝑢 can be less than 𝑘 when𝑘 is sufficiently large. Similarly, with a fixed 𝑘, 𝑢 can be less than 𝑘 when 𝑑 is sufficiently large. It implies that when available servers are abundant, a new server can query fewer servers for replenishing a codeword symbol.
Figure 3. The random bipartite graph𝔾 of the repair mechanism. D. Proof of Theorem 1
LetE0 be the event that 𝑘 servers randomly chosen from 𝛼𝑛 old servers recover a message. Our assumption on 𝛼𝑛
old servers is thatPr[E0] ≥ 1−𝑘/𝑝−𝑜(1). Let 𝑛1and𝑛2be the numbers of queried old servers and queried new servers, respectively. Thus,𝑛1+ 𝑛2= 𝑘. Let the event E1 be that𝑘
servers randomly chosen from old and new servers recover a message. Our goal is to show thatPr[E1] ≥ 1 − 2𝑘/𝑝 − 𝑜(1). We divide the event E1 into subevents as shown in
Equation (1).
Pr[E1] = Pr[E1∣𝑛1= 𝑘] Pr[𝑛1= 𝑘]
+ Pr[E1∣𝑛1< 𝑘] Pr[𝑛1< 𝑘] (1)
When𝑛1= 𝑘, we directly obtain:
Pr[E1∣𝑛1= 𝑘] = Pr[E0] ≥ 1 − 𝑘/𝑝 − 𝑜(1) > 1 − 2𝑘/𝑝 − 𝑜(1)
When𝑛1< 𝑘, we model the repair mechanism as a random
bipartite graph𝔾 and analyze the random graph.
Illustrated in Fig. 3, the random bipartite graph is 𝔾 = (𝑉1, 𝑉2, 𝐸), where 𝑉1and𝑉2are vertex sets with∣𝑉1∣ = 𝛼𝑛
and ∣𝑉2∣ = (1 − 𝛼)𝑛 and 𝐸 is the edge set. Each vertex 𝑣𝑖 in 𝑉1 represents an old server SS𝑖 and each vertex 𝑣𝑗 in
𝑉2 represents a new server SS𝑗. There is an edge (𝑣𝑖, 𝑣𝑗) between vertices 𝑣𝑖 ∈ 𝑉1 and 𝑣𝑗 ∈ 𝑉2 if and only if the
new serverSS𝑗 queries the old serverSS𝑖. Note that a new server queries𝑘 old servers. A set 𝑆 of 𝑘 servers represents a set of servers chosen for data retrieval. The set𝑆 consists of two subsets𝑆1 and 𝑆2 of vertices in 𝔾, where 𝑆1⊆ 𝑉1
with ∣𝑆1∣ = 𝑛1 and 𝑆2 ⊆ 𝑉2 with ∣𝑆2∣ = 𝑛2. Event E2 is
that there is a maximal matching from 𝑆2 to𝑉1∖ 𝑆1. We divide the event E1conditioned on𝑛1< 𝑘 into subevents as
shown in Equation (2), where ¯E2 is the complement event
of E2.
Pr[E1∣𝑛1< 𝑘] Pr[𝑛1< 𝑘]
= Pr[E1∣E2∧ (𝑛1< 𝑘)] Pr[E2∣𝑛1< 𝑘] Pr[𝑛1< 𝑘]
+ Pr[E1∣¯E2∧ (𝑛1< 𝑘)] Pr[¯E2∣𝑛1< 𝑘] Pr[𝑛1< 𝑘] (2)
We need Lemma 1 and Lemma 3 to formulate relations between events E1 and E2 to complete this proof.
Lemma 1. Pr[E1∣E2∧ (𝑛1< 𝑘)] ≥ 1 − 2𝑘/𝑝 − 𝑜(1)
When E2 happens, there is a maximal matching from 𝑆2
to𝑉1∖ 𝑆1. That is, a subset 𝑆2′ ⊆ 𝑁(𝑆2) ∖ 𝑆1 exists with ∣𝑆′
2∣ = 𝑛2
Let𝐾 be the 𝑘 × 𝑘 matrix formed by coefficients from queried servers in𝑆1∪𝑆2. When𝐾 is invertible, E1happens.
Let𝐾1be the𝑘 × 𝑘 matrix formed by coefficients from the
servers in𝑆1∪ 𝑆2′. Since𝑆1∪ 𝑆2′ is a subset of𝑘 vertices in 𝑉1,𝐾1is invertible with probability at least1 − 𝑘/𝑝 − 𝑜(1). Since the subgraph induced by 𝑆2 and 𝑆′2 has a perfect
matching, 𝐾 has full rank if 𝐾1 has full rank. Moreover,
each row in𝐾 can be expressed as a linear combination of rows in𝐾1. Thus,𝐾 can be expressed as 𝑇 × 𝐾1 for some
𝑘×𝑘 matrix 𝑇 . Entries of 𝑇 are randomly and independently
determined by new servers. To have 𝐾 invertible, 𝐾1 and 𝑇 must be invertible. When 𝐾1 is invertible,𝑇 is invertible
with probability at least1 − 𝑘/𝑝 according to the Schwartz-Zippel Theorem. Thus, we have
Pr[E1∣E2∧ (𝑛1< 𝑘)]
= Pr[𝐾 is invertible∣E2∧ (𝑛1< 𝑘)]
≥ Pr[𝐾1 is invertible∧ 𝑇 is invertible∣E2∧ (𝑛1< 𝑘)] ≥ (1 − 𝑘/𝑝 − 𝑜(1)) × (1 − 𝑘/𝑝)
≥ 1 − 2𝑘/𝑝 − 𝑜(1)
Lemma 2. (Hall’s Theorem) If and only of for any subset
𝐵 ⊆ 𝑆2, the number of neighbors of 𝐵 in 𝑉1∖ 𝑆1 is no less than the size of 𝐵, i.e., ∣𝑁(𝐵) ∖ 𝑆1∣ ≥ ∣𝐵∣, where 𝑁(𝐵) ⊆ 𝑉1 is the set of neighbors of 𝐵, there exists a maximal matching from𝑆2to𝑉1∖ 𝑆1.
Lemma 3. Pr[E2∣𝑛1< 𝑘] = 1
Proof: When 𝑢 = 𝑘, each vertex 𝑣 in 𝑆2 has 𝑘 neighbors in𝑉1. For all possible𝐵, where 1 ≤ ∣𝐵∣ ≤ 𝑛2,
∣𝑁(𝐵) ∖ 𝑆1∣ ≥ 𝑘 − 𝑛1= 𝑛2≥ ∣𝐵∣.
Hence, Pr[E2∣𝑛1< 𝑘] = 1.
From Equation (1), Lemma 1, and Lemma 3, we have
Pr[E1] = Pr[E1∣𝑛1= 𝑘] Pr[𝑛1= 𝑘] + Pr[E1∣𝑛1< 𝑘] Pr[𝑛1< 𝑘] ≥ Pr[E1∣𝑛1= 𝑘] Pr[𝑛1= 𝑘]
+ Pr[E1∣E2∧ (𝑛1< 𝑘)] Pr[E2∣𝑛1< 𝑘] Pr[𝑛1< 𝑘] ≥ (1 − 𝑘/𝑝 − 𝑜(1)) Pr[𝑛1= 𝑘]
+ (1 − 2𝑘/𝑝 − 𝑜(1)) Pr[𝑛1< 𝑘] ≥ 1 − 2𝑘/𝑝 − 𝑜(1)
It concludes this proof.
E. Proof of Theorem 2
The proof of Theorem 2 is similar to the proof of Theorem 1 except for the analysis of the random graph. To ease the analysis, the original repair procedure is modified to that a new server randomly queries an old server 𝑢
times with replacement. Thus, a new server may query less than 𝑢 distinct old servers. The modification leads to a different random graph. The probability of a maximum matching from 𝑆2 to 𝑉1∖ 𝑆1 in the new random graph is
smaller than that in the original random graph. Hence the probability in the original random graph is underestimated. Let𝔾′= (𝑉1, 𝑉2, 𝐸′) be the random bipartite graph, where ∣𝑉1∣ = 𝛼𝑛, ∣𝑉2∣ = (1 − 𝛼)𝑛, and 𝐸′ is the edge set. Let
event E’2 is that there is a maximal matching from 𝑆2 to 𝑉1∖𝑆1. Again, we need Lemma 1 and Lemma 4 for relations between events E1 and E’2to complete this proof.
Lemma 4. Pr[E′2∣𝑛1< 𝑘] ≥ 1 − 𝑜(1)
Proof: We use Lemma 2 (Hall’s theorem) and Lemma 5
to bound the probability Pr[E′2∣𝑛1 < 𝑘]. Lemma 5 is a
bound for𝐶𝑦𝑥(Due to limited space, the proof for Lemma 5 is omitted): Lemma 5. 𝐶𝑦𝑥≤ ( 𝑥(𝑥−𝑦+1) 𝑦 )𝑦 2
When there exists a subset𝐵 ⊆ 𝑆2where∣𝑁(𝐵) ∖ 𝑆1∣ < ∣𝐵∣, no maximal matching from 𝑆2 to 𝑉1 ∖ 𝑆1 exists.
We consider every possible subset 𝐵 and overestimate the probability of the complement event of E’2 by a union
bound.
Pr[∃𝐵 ⊆ 𝑆2, ∣𝑁(𝐵) ∖ 𝑆1∣ < ∣𝐵∣] ≤ 2𝑘⋅ max
𝐵⊆𝑆2{Pr [∣𝑁(𝐵) ∖ 𝑆1∣ < ∣𝐵∣]}
Let ∣𝐵∣ = 𝑡, where 1 ≤ 𝑡 ≤ 𝑛2. The event that some
subset 𝐵 exists for ∣𝑁(𝐵) ∖ 𝑆1∣ < ∣𝐵∣ is equivalent to the
event that some subset 𝐴 exists where 𝐴 ⊆ 𝑉1∖ 𝑆1,∣𝐴∣ ≤ 𝑡 − 1, and 𝐴 ∪ 𝑆1⊇ 𝑁(𝐵) Pr [∣𝑁(𝐵) ∖ 𝑆1∣ ≤ ∣𝐵∣] = Pr[∃𝐴, ∣𝐴∣ ≤ 𝑡 − 1, 𝐴 ∪ 𝑆1⊇ 𝑁(𝐵)] ≤ 𝐶𝛼𝑛−𝑛1 𝑡−1 ( 𝑘 − 1 𝛼𝑛 )𝑡𝑢 (Lemma 5) ≤ (2(𝛼𝑛 − 𝑛 1)(𝛼𝑛 − 𝑛1− 𝑡 + 2) 𝑡 )𝑡−1 2 ( 𝑘 𝛼𝑛 )𝑡𝑢 Since we want Pr[∃𝐵 ⊆ 𝑆2, ∣𝑁(𝐵) ∖ 𝑆1∣ < ∣𝐵∣] < 𝑒−𝑘, it is sufficient to have: ( 2(𝛼𝑛 − 𝑛1)(𝛼𝑛 − 𝑛1− 𝑡 + 2) 𝑡 )𝑡−1 2 ( 𝑘 𝛼𝑛 )𝑡𝑢 < 𝑒−2𝑘 (3) Now we substitute 𝛼𝑛 = 𝑘𝑑 in Equation (3) and overesti-mate the left hand side:
( 2𝑘2𝑑 𝑡 )𝑡−1 2 𝑘(1−𝑑)𝑡𝑢< 𝑒−2𝑘 (4) We take nature logarithm on both sides of Equation (4) and
obtain the bound on𝑢:
𝑢 > (𝑡 − 1)(ln 2 + 2𝑑 ln 𝑘 − ln 𝑡) + 4𝑘2(𝑑 − 1)𝑡 ln 𝑘
When𝑡 = 1, the bound becomes(𝑑−1) ln 𝑘2𝑘 . When2 ≤ 𝑡 ≤ 𝑘, it is sufficient to have𝑢 > 𝑑−1𝑑 +(𝑑−1) ln 𝑘𝑘 . Combining the result from Theorem 1, we obtain the requirement on𝑢:
𝑢 ≥ min{𝑘, max{(𝑑 − 1) ln 𝑘2𝑘 , ( 𝑘 (𝑑 − 1) ln 𝑘 + 𝑑 𝑑 − 1 ) }}.
When𝑢 meets this requirement, Pr[E′2∣𝑛1< 𝑘] ≥ 1−𝑒−𝑘=
1 − 𝑜(1).
From Equation (1), Lemma 1, and Lemma 4, we have Pr[E1]
= Pr[E1∣𝑛1= 𝑘] Pr[𝑛1= 𝑘] + Pr[E1∣𝑛1< 𝑘] Pr[𝑛1< 𝑘] ≥ Pr[E1∣𝑛1= 𝑘] Pr[𝑛1= 𝑘]
+ Pr[E1∣E′2∧ (𝑛1< 𝑘)] Pr[E′2∣𝑛1< 𝑘] Pr[𝑛1< 𝑘] ≥ 1 − 2𝑘/𝑝 − 𝑜(1)
It concludes this proof.
IV. NUMERICALANALYSIS ANDPARAMETERIZED
COMPARISON
We conducted a numerical analysis by using traces of sev-eral real systems. We also compare our decentralized repair mechanism with other robustness management mechanisms.
A. Numerical Analysis
We introduce two key parameters from real systems. One is the number 𝑛 of servers. The other is the fraction 𝑓 of failed servers per day. From traces of real systems, the number of servers varies as well as the fraction𝑓 over time. We bring the average values into our repair mechanism in the theoretical setting.
Traces. We quote statistics from [2] by Dimakis et al.
The statistics summarized parameters from traces of 4 real systems: desktop PCs within Microsoft Corporation [19], Gnutella peers [20], Skype superpeers [21], and the Plan-etLab. The average number 𝑛 of servers and the average fraction𝑓 of failed servers per day are shown in Table I.
The parameter𝑢 represents the communication cost and
only depends on𝑘 and 𝑑. We are interested in the value of 𝑢 with different system scales 𝑛 and different numbers 𝑘𝑑 of available servers. In a lazy strategy for repairing a system, the number 𝑘𝑑 determines a threshold value that triggers execution of a repair procedure. From Theorem 2 and Corollary 1, we illustrate the numerical results in Table II. With a fixed𝑘, when 𝑑 gets larger, 𝑢 can be smaller. With a fixed 𝑑, when 𝑘 gets larger, 𝑢 is much smaller than 𝑘. It shows that when remaining servers are abundant, the robustness maintaining cost is lower. More importantly, the number of servers queried by a new server can be smaller
than𝑘. For example, when 𝑘 = 8 and 𝑛 = 4096 servers are available,𝑢 can be set to only 3.
Survival duration. Since our repair mechanism recovers
the storage system from multiple server failures, a strategy for periodical repairing is supported. We are interested in the duration time that a storage system can stand against server failures without any repairing. That is, the system still have sufficient servers to perform the repair procedure when needed. This period of time is called survival duration. We consider various 𝛼𝑛 remaining servers. We bring the fraction𝑓 of failed servers per day into the scenario. With a fixed𝑓, the system losses 𝑛𝑓 servers per day if no repair procedure is performed. The survival duration in days is estimated as⌊(𝑛 − 𝛼𝑛)/⌈𝑛𝑓⌉⌋. When 𝑛 ≫ 𝛼𝑛, the survival duration is close to1/𝑓. We choose 𝑢 as small as possible under the limitation that𝛼𝑛 < 𝑛. The numerical results are given in Table III. For example, in the case of PlanetLab, the system has303 servers and 0.017% of servers fail per day on average. When 𝑘 = 4, we set 𝑢 = 3, which is the smallest one with𝛼𝑛 < 𝑛 (see Table II). The threshold value of available servers is 16. Thus, the system stands against server failures for 47 days. After the 47th day, the system would not have sufficient servers for the repair procedure to work.
B. Parameterized Comparison
As introduced in Section II, some repair mechanisms can be applied to decentralized erasure code based storage sys-tems. From the family of regenerating codes [2], we choose two mechanisms, the minimum bandwidth regime (MBR) and the minimum storage regime (MSR). The two mecha-nisms result in two extreme points on the trade off curve. MBR minimizes the repair bandwidth and MSR minimizes the storage cost. We also compare our mechanism with the mutual cooperative recovery (MCR) mechanism [10] and self-repair homomorphic codes (SRHC) [11] since they both consider multiple server failures.
Let 𝑙 be the size of a message in bits. We compare our mechanism with them in the following items: 1)the number 𝑢 of required connections per server failure, 2)the number of repaired server failures, 3)required bandwidth for replenishing a codeword symbol in bits, 4)storage cost per server in bits, and 5) method type. The 5th item is an indicator of whether the mechanism is suitable in a decentralized environment. When the repair procedure is independent of missing codeword symbols, we call such mechanism ”symmetric”. In other words, an asymmetric repair mechanism uses different steps for different pat-terns of missing codeword symbols. For example, SRHC is asymmetric since it regenerates a codeword symbol from a specific set of survival codeword symbols. The comparison is summarized in Table IV.
Regenerating codes show that repair bandwidth can be less than the size 𝑙 of the message when a new server
Trace Microsoft PCs Gnutella Skype PlanetLab
𝑛: average number of nodes 41970 1846 710 303
𝑓: fraction of failed node per day 0.038 0.3 0.12 0.017
Table I
STATISTICS OF SYSTEM TRACES[2].
𝑘 = 4
𝑑
2 3 4 5 6𝑢
3 3 3 3 2𝑘
𝑑 16 64 256 1024 4096𝑘 = 8
𝑑
2 3 4 5𝑢
6 4 3 3𝑘
𝑑 64 512 4096 32768𝑘 = 16
𝑑
2 3 4 5𝑢
8 5 4 3𝑘
𝑑 256 4096 65536 1048576 Table IINUMERICAL ANALYSIS FOR THE NUMBER𝑢FOR DIFFERENT𝑘AND𝛼𝑛.
Trace Microsoft Gnutella Skype PlanetLab
𝑛
41970 1846 710 303𝑓
0.038 0.3 0.12 0.017𝑘
4 8 4 8 4 8 4 8𝑢
3 3 3 4 3 4 3 6𝛼𝑛
16 4096 16 512 16 512 16 64Survival duration (days) 26 23 3 3 8 2 47 39
Table III
NUMERICAL ANALYSIS FOR SURVIVAL DURATION IN DAYS.
𝑢
server failures bandwidth storage type MBR [2]𝑛 − 1
single (2𝑛−𝑘−1)𝑘(2𝑛−2)𝑙 (2𝑛−𝑘−1)𝑘(2𝑛−2)𝑙 symmetricMSR [2]
𝑘 + 1
single (𝑛−𝑘)𝑘(𝑛−1)𝑙 𝑘𝑙 symmetricMCR [10]
𝑛 − 1
multiple (𝑛−𝑘)𝑘(𝑛−1)𝑙 𝑘𝑙 symmetricSRHC [11]
< 𝑘
multiple 𝑢𝑙𝑘 𝑘𝑙 asymmetricOur work
< 𝑘
multiple 𝑢𝑙𝑘 𝑘𝑙 symmetricTable IV
COMPARISON OVER REPAIR MECHANISMS.
queries more than𝑘 servers. However, they only tolerate one server failure. MCR tolerates multiple server failures, but the number of required connections for repairing a failure is
𝑛 − 1. In other words, a new server has to communicate
with all other servers in the storage system. SRHC is a novel way to recover the system from multiple server failures with 𝑢 < 𝑘. But, SRHC is not suitable for distributed or decentralized environment because it is asymmetric.
Our mechanism outperforms existing ones in terms of the communication cost under the same consideration of efficiency cost for storage. A new server queries less than
𝑘 servers and the required bandwidth is less than 𝑙. At the
same time, the storage cost is as less as the cost of the MSR. Moreover, our repair mechanism recovers a decentralized erasure code based storage system from multiple server failures.
The sacrifice is the probability of a successful data re-trieval. The probabilities of a successful data retrieval in MBR, MSR, and MCR are all 1’s. Since SRHC exactly
regenerates missing codeword symbols, the probability is 1 as well. While our mechanism has lower communica-tion cost, the probability of a successful data retrieval is 1 − 2𝑘/𝑝 − 𝑜(1). However, by choosing a sufficient large 𝑝, the probability1 − 2𝑘/𝑝 − 𝑜(1) is overwhelming. Moreover, the probability can be dramatically increased by letting a user query more than𝑘 servers for data retrieval.
V. CONCLUSION ANDFUTUREWORK
We consider the measurement of communication cost in terms of the number 𝑢 of connections that a new server has to establish. Our repair mechanism provides flexible adjustment between𝑢 and the number of remaining servers. More importantly, our results confirm that to repair a server failure, a new server can query less than𝑘 servers.
Our repair mechanism symmetrically repairs multiple server failures of decentralized erasure code based storage systems. Thus, a lazy repair strategy or a periodical repair strategy can be taken upon our repair mechanism. It is
compatible with most decentralized erasure code based stor-age systems without any change in encoding and decoding methods. Both theoretical and numerical results show that our decentralized repair mechanism is efficient and practical. In our repair mechanism, new servers do not commu-nicate with each other during the repair procedure. In some practical cases, they can exchange information for repairing. Intuitively, mutual communications among new servers can further decrease the number 𝑢. Exploring the quantity of possible improvement is our work in progress. Statistical simulation results are also required to demonstrate the practicality of our repair mechanism.
ACKNOWLEDGMENT
The research was supported in part by projects ICTL-100-Q707, ATU-100-W958, NSC 98-2221-E-009-068-MY3, NSC 100-2218-E-009-003-, and NSC 100-2218-E-009-006-.
REFERENCES
[1] Rodrigo Rodrigues and Barbara Liskov. High availability in dhts: Erasure coding vs. replication. In Proceedings of the
4th International Workshop on Peer-to-Peer Systems - IPTPS 2005, 2005.
[2] Alexandros G. Dimakis, Brighten Godfrey, Martin J. Wain-wright, and Kannan Ramchandran. Network coding for distributed storage systems. In Proceedings of the 26th IEEE
International Conference on Computer Communications – INFOCOM 2007, pages 2000–2008. IEEE, 2007.
[3] Y. Wu, A. G. Dimakis, and K. Ranchandran. Deterministic regenerating codes for distributed storage systems. In
Pro-ceedings of the 45th annual Allerton conference on Commu-nication, control, and computing, Allerton’07, pages 1243–
1249. IEEE Press, 2007.
[4] Alexandros G. Dimakis, Brighten Godfrey, Yunnan Wu, Martin J. Wainwright, and Kannan Ramchandran. Network coding for distributed storage systems. IEEE Transactions on
Information Theory, 56(9):4539–4551, 2010.
[5] K. V. Rashmi, Nihar B. Shah, P. Vijay Kumar, and Kannan Ramchandran. Explicit construction of optimal exact regen-erating codes for distributed storage. In Proceedings of the
47th annual Allerton conference on Communication, control, and computing, Allerton’09, pages 1243–1249. IEEE Press,
2009.
[6] Nihar B. Shah, K. V. Rashmi, and P. Vijay Kumar. A flexibile class of regenerating codes for distributed storage. In Proceedings of IEEE symposium on Information Theory
2010, pages 1943–1947. IEEE Press, 2010.
[7] Soroush Akhlaghi, Abbas Kiani, and Mohammad Reza Ghanavati. A fundamental trade-off between the download cost and repair bandwidth in distributed storage systems. In
Proceedings of IEEE International Symposium on Network Coding 2010 – NetCod, pages 1–6, 2010.
[8] Salim El Rouayheb and Kannan Ramchandran. Fractional repetition codes for repair in distributed storage systems. In Proceedings of the 48th annual Allerton conference on
Communication, control, and computing, Allerton’10. IEEE
Press, 2010.
[9] Alessandro Duminuco and Ernst W. Biersack. Hierarchical codes: A flexible trade-off for erasure codes in peer-to-peer storage systems. Peer-to-Peer Networking and Applications, 3(1):52–66, 2010.
[10] Yuchong Hu, Yinlong Xu, Xiaozhao Wang, Cheng Zhan, and Pei Li. Cooperative recovery of distributed storage systems from multiple losses with network coding. Selected Areas in
Communications, IEEE Journal on, 28(2):268–276, 2010.
[11] Frederique Oggier and Anwitaman Datta. Self-repairing homomorphic codes for distributed storage systems. In
Proceedings of the 30th IEEE international conference on Computer communications 2011. IEEE Press, 2011.
[12] Theodoros K. Dikaliotis, Alexandros G. Dimakis, and Tracey Ho. Security in distributed storage systems by communicating a logarithmic number of bits. In Proceedings of IEEE
symposium on information theory 2010. IEEE Press, 2010.
[13] K. V. Rashmi, Nihar B. Shah, and P. Vijay Jumar. Enabling node repair in any erasure code for distributed storage, 2011. [14] Sameer Pawar, Salim El Rouayheb, and Kannan Ramchan-dran. On secure distributed data storage under repair dy-namics. Technical Report UCB/EECS-2010-18, University of California Berkeley, EECS, 2010.
[15] Dimitris S. Papailiopoulos and Alexandros G. Dimakis. Dis-tributed storage codes meet multiple-access wiretap channels. In Proceedings of the 48th Annual Allerton Conference on
Communication, Control, and Computing, Allerton’10, pages
1420–1427, 2010.
[16] Alexandros G. Dimakis, Vinod Prabhakaran, and Kannan Ramchandran. Decentralized erasure codes for distributed networked storage. IEEE/ACM Transactions on Networking, 14:2809–2816, 2006.
[17] Hsiao-Ying Lin and Wen-Guey Tzeng. A secure decentralized erasure code for distributed network storage. IEEE
trans-actions on Parallel and Distributed Systems, 21:1586–1594,
2010.
[18] Hsiao-Ying Lin and Wen-Guey Tzeng. A secure erasure code based cloud storage system with secure data forwarding. manuscript.
[19] William J. Bolosky, John R. Douceur, David Ely, and Marvin Theimer. Feasibility of a serverless distributed file system de-ployed on an existing set of desktop pcs. ACM SIGMETRICS
Performance Evaluation Review, 28:34–43, 2000.
[20] Stefan Saroiu, P. Krishna Gummadi, and Steven D. Gribble. A measurement study of peer-to-peer file sharing systems. In
Proceedings of Multimedia Computing and Networking, 2002.
[21] Saikat Guha, Neil Daswani, and Ravi Jain. An experimental study of the skype peer-to-peer voip system. In Proceedings
of the 5th International Workshop on Peer-to-Peer Systems,