Goal-Oriented SOM for Document Clustering
Student: Pei-Yuan Hsieh Advisor: Dr. Hao-Ren Ke, Dr. Wei-Pang Yang.
Institute of Computer and Information Science National Chiao Tung University
ABSTRACT
In this thesis, a Goal-Oriented Self-Organizing Map (GOSOM) is proposed to
cluster documents according to user’s goals. GOSOM is motivated by
Self-Organzing Map (SOM) model and allows the user to specify what kinds of
results should be clustered. The specified goals are analyzed by Latent Semactic
Analysis (LSA) to determine their relationships to input vectors. GOSOM properly
enhances the features of input vectors when caculating similarity in the clustering
process; in this manner, GOSOM is capable of guiding the clustering result toward
user’s goals. Additionally, a weighted majority voting algorithm is provided to label
the clustering result with respect to the specified goals. Furthermore, GOSOM
presents a user relevance feedback mechanism to improve the performance of
clustering. A system called Goal-Oriented Document Clustering system (GODOC) is
implemented to verify that GOSOM is superior to convensional SOM. Experiment
results show that GOSOM significantly improve 21.67% in accuracy, 28.47% in
recall.
Keywords: Self-Organizing Map, Latent Semantic Analysis, Document
目標導向之 SOM 應用於文件分群
研究生: 謝佩原 指導教授: 柯皓仁博士,楊維邦博士
國立交通大學資訊科學研究所
摘 要
在這篇論文中,我們提出一目標導向之 SOM (Goal-Oriented Self-Organizing Map, GOSOM) 來將文件依使用者的目標分群。GOSOM 是基於 Self-Organzing
Map (SOM) 加以改良,可讓使用者指定想要的分群結果種類。使用者指定的目
標是透過潛在語意分析 (Latent Semantic Analysis, LSA) 方法,來分析其與輸入 向量 (Input Vector) 的關係。GOSOM 適當地加強了輸入向量的特徵,以致於 在分群過程中計算相似度時,可將分群結果導向使用者想要的目標。此外,我 們也提出一個權重的多數決 (Weighted Majority Voting) 方法,將分群結果以使 用者的觀點作適當標記。最後,GOSOM 提供了一個使用者相關回饋 (User Relevance Feedback) 的機制,以改善分群的結果。我們實作了「目標導向文件
分 群 系 統 」 (Goal-Oriented Document Clustering system, GODOC) 來 驗 證 GOSOM 優於傳統的 SOM 模型。實驗結果證明,相較於傳統的 SOM,GOSOM
在準確率上 (Accuracy) 平均增加 21.67%、求全率則 (Recall) 增加 28.47%。
誌謝
本論文能夠順利完成,首先得感謝兩位指導教授,柯皓仁老師與楊維邦老 師。在他們的教導下,我得以學會獨立研究的精神與能力;也感謝他們不厭其 煩地點出我犯的錯誤,並予以細心指正。 謝謝交大資訊科學資料庫實驗室的學長姊、學弟妹和同學們,因為有你們 的集思廣義才讓我的碩士論文得以順利進行。尤其要感謝鄭培成學長、黃夙賢 學長、葉鎮源學長、林忠億學長,常撥空與我討論問題,助我解決諸多疑難雜 症。 最後,要感謝關心我的家人,一直在背後默默支持我,讓我能全心全意地 投入學業與研究中。也謝謝可愛的 eponie,總在我沮喪、情緒低落時,包容我 的壞脾氣。謹將此論文,獻給你們。 May, 2004目錄
英文摘要...I 中文摘要... II 誌謝... III 目錄...IV 圖目錄...V 表目錄...VI 方程式目錄... VII 第一章 簡介...1 第一節 文件分群系統...1 第二節 研究動機與目的...4 第三節 論文架構...5 第二章 文件分群相關研究工作...7第一節 Self-Organizing Map (SOM) ...8
第二節 使用者相關文件分群 (User-Involved Document Clustering)... 11
第三節 潛在語意分析 (Latent Semantic Analysis) ...13
第四節 SOM 在文件分群的應用...16
第三章 目標導向文件分群模型及系統實作...20
第一節 目標導向之 SOM (Goal-Oriented SOM, GOSOM) ...20
第二節 目標導向文件分群系統 (Goal-Oriented Document Clustering System, GODOC) ...31 第四章 實驗結果分析與評估...33 第一節 實驗資料及實驗設計...33 第二節 評估方法...35 第三節 實驗結果與討論...36 第五章 結論與未來研究方向...40 第一節 結論...40 第二節 未來研究方向...41 參考文獻...42
圖目錄
圖 1:相關研究發展...7
圖 2:SOM 的 Network Topology[Roussinov01] ...8
圖 3:範例文件列表...14
圖 4:Adaptive Search 流程示意[Roussinov01] ...18
圖 5:GOSOM 模型示意圖 ...21
圖 6:經 LSA 方法得到的詞–詞關係矩陣範例 ...24
圖 7:經 SOM 分群後的模型向量矩陣範例...26
圖 8:GODOC 流程圖 ...31
表目錄
表格 1:第一類實驗資料說明...34 表格 2:第二類實驗資料說明...34 表格 3:實驗 1 結果數據...37 表格 4:實驗 2 結果數據...37 表格 5:實驗 3 結果數據...38方程式目錄
方程式 1:以 Euclidean Distance 為相似度定義 9
方程式 2:Model Vector Update 10
方程式 3:hc( X),i,t 10 方程式 4:另一種hc( X),i,t定義法 10 方程式 5:以 Euclidean Distance 作為相似度定義 23 方程式 6:改良後的相似度定義 23 方程式 7:改良後的相似度公式中,詞的權重 23 方程式 8:每個詞在文件向量d 中的重要性 29 i 方程式 9:某詞與所有詞平均關係值 30 方程式 10:將詞與使用者目標usergoall關係值提高 30 方程式 11:原 Accuracy 計算公式[Liu02] 35 方程式 12:改良後 Accuracy 計算公式 35 方程式 13:Recall 公式 36
第一章 簡介
第一節 文件分群系統
隨著網際網路的普及,越來越多的資訊以數位化的形式呈現在網路上。使 用者常會使用搜尋引擎 (例如:Google) 來搜尋想要的資訊,但是往往遇到許多 的問題。第一、一般搜尋引擎皆以關鍵字來當成搜尋的條件,但對於使用者而 言,大部分搜尋的目的只是存在一個概念,很難透過簡單的關鍵字去涵蓋想要 搜尋的目的。第二、越來越多的數位化資訊導致大量的查詢結果。使用者無法 從頭至尾瀏覽全部的搜尋結果,導致搜尋出來的結果無法提供有效的幫助。大 量的搜尋結果需要透過有效的方法,整理成使用者能夠接受的數量以及格式。 許多研究者提出將搜尋的結果分群成不同的概念,讓使用者根據所欲搜尋的目 的,選擇想要的概念。對於使用者來講,搜尋結果根據不同的概念來分群,可 以讓使用者對於想搜尋的文件有更完整的參考依據,並且透過分群縮小搜尋結 果的數量,幫助使用者瞭解哪些搜尋結果才符合使用者的目的。如果再加上回 饋式的查詢讓使用者修正查詢的條件,查詢的結果便能夠越來越正確地達到使 用者的目的。 文件由文字所組成,所以基本上文件分類的問題就是文字分類的問題。自 動決定文件所欲歸類的分類,稱之為文件分群 (Document Clustering)。文件分 群應用在訓練資料 (Training Data) 不足或者分類的目的不固定的時候,在分類 的時候無法透過訓練資料獲得分類的資訊,同時也要決定所欲歸類的分類。文 件分群的應用有許多,例如搜尋引擎,可以透過文件分群系統決定文件所屬的 分類;例如報社可以將編輯好的新聞透過文件分群主動分類;電子報提供的新 聞自動派送服務,也可透過文件分群系統將使用者有興趣的文章用電子郵件傳送給使用者;甚至網頁也可透過文件分群建立起階層性質的分類目錄方便使用 者根據分類來瀏覽網頁。 最傳統的文件分群方法,是利用一些分群規則,根據文件是否符合規則來 決定文件所屬分群。此種分群方法的優點是簡單而且分類有效率,但缺點是需 要大量的專家來編輯分群規則,而且對於新進的文件必須時常修改分群規則以 保持分群系統的正確性。於是有許多研究,希望能夠自動決定文件的分群,透 過自動學習的過程,將文件由關鍵字來表達,以關鍵字跟各種類別的關連程度 來決定文件所屬的分群。此時會面對兩個問題。一是有效的文件表示法,二是 如何將文件自動分群。 關於有效的文件表示法,一般最常採用的模型 (Model) 就是向量空間模型 (Vector Space Model) 。其主要精神在於,將欲自動分類的文件,以向量來表示,
而向量中不同的座標軸,代表不同的字詞,該座標軸的值,即為該字詞於該文 件中的權重。關於向量空間模型的研究很多,大略如下: 1.在向量空間模型中,以詞 (Term) 為文件的基本單位,因此,如何適當 斷詞切字是相當重要的。最直覺的方法就是採用字典檔 (Dictionary),將所 有的詞都建立在一個檔案中,然後用逐字比對的方式來斷詞。這個方法的 準確率相當高,但卻有個缺憾:當出現字典裡沒記載的詞時,斷詞就會斷 錯[Lin96]。 2.由於字詞的數目太多,因此必須選取重要且具有代表性的關鍵字來表達 文 件 , 以 簡 化 文 件 自 動 分 群 的 計 算 過 程 。 此 類 問 題 稱 之 為 維 度 縮 減 (Dimension Reduction),運用維度縮減的技術在某些情況下可以用 1/10 的關鍵字來代表文件,而不會降低文件表達的正確性[Sebastiani02]。
3.字詞在一文件中的權重,一般常定義為字詞於該文件中出現次數,稱作
Tf (Term Frequency);但也有考慮到,同一個字詞若在太多篇文件出現,反
而無法區別不同類型文件。因此有把字詞出現的文章篇數 (Document Frequency) 也加以考慮的 TFIDF 方法[Salton88]。
在如何將文件自動分群方面,類神經網路 (Neural Network) 是個被廣為使 用的方法。類神經網路為一個大型具有權重的網路,透過學習 (Learning) 的方 式來調整權重,然後利用學習過的網路來分群資料。一般的類神經網路,需要 額 外 的 訓 練 資 料 來 進 行 其 學 習 過 程 ; 但 採 用 非 監 督 式 學 習 (Unsupervised Learning) 的類神經網路便可以不需要訓練資料–它可以直接從欲分群的資料 中自我學習,對權重進行適當的調整[Haykin94]。 誠如文章一開始提到的,現今使用者需要一個文件自動分群的系統,來幫 助他們快速掌握文件的內容。但在全球資訊網蓬勃發展的今日,資訊爆炸讓使 用者對於搜尋文件的要求,從資訊的層次提升到知識的層次。使用者對於大量 資訊不再只有瀏覽的目的,而是要從大量的資訊歸納出知識以便後續學習與應 用。對於使用者來說,如果能夠根據需要的的主題,透過搜尋系統自動將搜尋 的結果分門別類呈現給使用者,將會大大減少使用者人工整理資料的時間。這 對於從事系統性的分析寫作:如學術研究、新聞報導、歷史事件分析…等等, 有相當大的幫助。舉例來說,若使用者希望蒐集關於「人工智慧」方面的資料, 首先,他會用關鍵字「人工智慧」,透過搜尋引擎找回可能相關的文件。接下來, 他發現找回來的文件實在太多,要分門別類整理過後,才容易使用。但是,使 用者因為應用上的需求,希望能依照「專家系統」、「資訊檢索」這兩個特定方 向來分群。除此之外,蒐集來的資料,可能還包含其他不相關的如「基因演算 法」、「模糊控制」...等等文件,使用者會希望將其他不相關的文件排除在分群 結果之外,或者分到”其他”的分群當中。由以上的應用得知,傳統的文件分群 演算法,著重在分群結果,卻忽略使用者有一定的分群目標,往往使得分群結
果不合乎使用者的需求,於是,如何讓使用者設定想要分群的方向,又能夠兼 顧文件自動分群的特性,便成為一個重要的研究議題。 然因使用者的搜尋條件不固定,每次不同的搜尋都要準備不同的訓練資 料;這對使用者而言,不但麻煩,而且也有實行上的困難。另外,訓練資料還 需事先判定答案,在資料量較大時,這亦成為另一難題。所以,在此採用不必 額外訓練的文件自動分群方法,較為恰當。 要達到不必額外訓練的文件自動分群,則必須採用非監督式學習的文件分 群演算法。Kohonen 在 1984 年提出的 Self-Organzing Map (SOM) [Kohonen84] 就是這類的演算法。它被大量運用在語音辨識 (Speech Recognition) 上。後來, Kohonen 在 1996 年進行了 WEBSOM [Honkela96]的研究計畫,將 SOM 運用在
新聞群組 (News Group) 文件的文件自動分群上。此後,關於運用 SOM 在文件 自動分群的研究,絡繹不絕[Roussinov01] [Guerrero Bote02]。隨著 SOM 的應用 日 漸 廣泛 ,各 種改 良的 版 本也 就應 運而 生。 如 DSOM [Su01] , GHSOM [Dittenbach02],TASOM [Shah-Hosseini03],ADSOM [Ressom03]…等等,都是
改良原本 SOM 演算法。但關於將 SOM 應用在依使用者需求分群這類的研究, 並不多見。例如前述,讓使用者設定分群方向,引導文件進行自動分群,就是 一個需求很高,具相當實用性的應用。因此,我們希望能藉由探討「如何以特 定目標引導 SOM 自動分群」這樣的研究,實際將 SOM 應用到一個目標導向文 件分群系統上,以滿足使用者進階的需求。
第二節 研究動機與目的
在 Kangas(1996)、Kohonen(1998)中可發現,SOM 分群的過程中,相似度 計算公式是主導因素之一。因此,我們認為若能使用潛在語意分析 (LSA), 導出所有詞之間的相互關係[Deerwester90],進而在分群過程中計算相似度時,依其與使用者目標相關程度予以加強或減弱,應有助於「引導 SOM 分 群過程,以符合使用者需求」此目的。同樣的,我們亦將此概念應用於提出 的群聚標記 (Cluster Labeling) 方法及使用者相關回饋機制 (User Relevance
1. 改良 SOM,使其具備目標導向分群的能力。
2. 提出一個配合使用者設定目標的群聚標記法,以利使用者辨別分群結
果。
3. 設計一個適合的使用者相關回饋機制,能有效改善前面兩個步驟的分
群結果,使其更符合使用者需求。
4. 實 作 目 標 導 向 文 件 分 群 系 統 (Goal-Oriented Document Clustering System, GODOC),其核心為本論文中改良過的 SOM 演算法
本 論 文 基 於 前 述 原 因 及 需 求 , 提 出 一 個 目 標 導 向 之 SOM 模 型 (Goal-Oriented SOM),並以其為核心實作 GODOC。GOSOM 基於 SOM,融
合 LSA 加以改良,使 SOM 具有目標導向分群的能力。此外,關於群聚標記, 我們提出一權重的多數決 (Weighted Majority Voting) 方法[Mavroudi02],可 以配合使用者設定的目標對群聚進行標記,以便於讓使用者更容易理解各個 群聚的內容。此外,我們提出了一個能配合 GOSOM 的使用者相關回饋機制, 以期讓文件分群的結果,更符合使用者的要求。
第三節 論文架構
本論文首先在第二章介紹目標導向文件分群的相關研究,包含傳統 SOM 演算法、LSA、使用者相關的文件分群法、以及將 SOM 應用於文件分群的研 究。接下來,在第三章詳述我們提出的 GOSOM 主要精神及各模組的功能。接 著,介紹以 GOSOM 為核心的 GODOC 系統架構及採用的技術;第四章是以此系統進行實驗,評估 GOSOM 的準確性及穩定程度,以證明 GOSOM 的可行性; 最後,在第五章總結本論文,並探討未來的研究發展方向。
第二章 文件分群相關研究工作
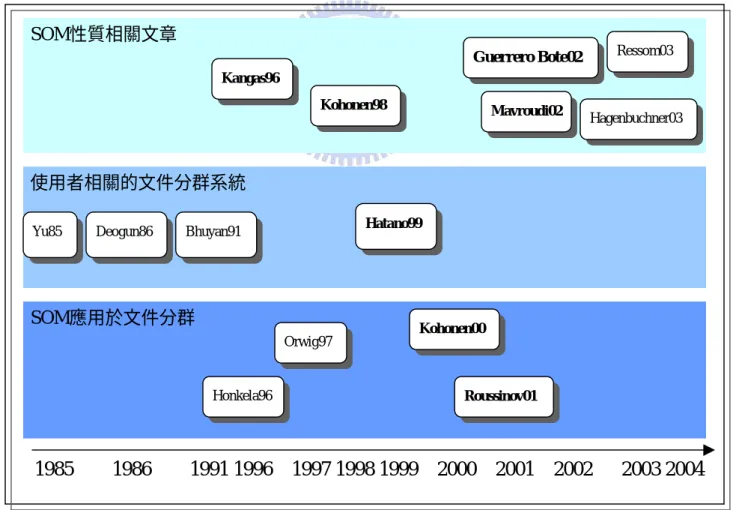
本章說明目標導向文件分群相關的研究工作。關於本論文提出的「目標導 向之 SOM」應用於文件分群上,相關研究工作主要分三方面:
SOM 性 質 探 討 : [Kangas96][Kohonen98][Guerrero Bote02][Mavroudi02] [Ressom03][Hagenbuchner03]
使用者相關的文件分群系統:[Yu85][Deogun86][Bhuyan91] [Hatano99] SOM 應用於文件分群:[Honkela96] [Orwig97] [Kohonen00] [Roussinov01]
圖 1 依年份及技術整理了相關研究的發展,而粗體的部分是本論文主要參 考的研究。
1985 1986 1991 1996 1997 1998 1999 2000 2001 2002 2003 2004 Hatano99
Yu85 Deogun86 Bhuyan91 使用者相關的文件分群系統
Mavroudi02
Hagenbuchner03
Guerrero Bote02 Ressom03
Kohonen98 Kangas96 SOM性質相關文章 Honkela96 Orwig97 Roussinov01 Kohonen00 SOM應用於文件分群 圖 1:相關研究發展
由於我們的「目標導向文件分群系統」核心 — GOSOM,是以 SOM 為基 礎改良,所以,首先在第一節介紹傳統 SOM 演算法,藉以瞭解其性質。而「目 標導向文件分群系統」是以使用者的興趣為目標,所以在第二節,會介紹與使 用者相關的文件分群系統。接下來,因為我們的系統用了 LSA,以連結使用者 目標及其他詞間的相關程度,所以在第三節中,我們會簡單介紹 LSA,並以一 實例說明。最後,在第四節中,會提到兩個將 SOM 應用於文件分群的系統 — WEBSOM 及 Adaptive Search,以瞭解將 SOM 應用於文件分群系統的各種議題。
第一節 Self-Organizing Map (SOM)
SOM 是種非監督式學習 (Unsupervised Learning) 的類神經網路模型,由
Kohonen 於 1984 提出。與監督式學習 (Supervised Learning) 的類神經網路模型
不同的是,SOM 不需額外的訓練資料。SOM 將多維空間的資料對應到二維的 平面上,並且在二維的平面上維持多維空間中空間距離的關係。亦即,在多維 空間上相近的資料,在二維空間上會被群聚在相近的點上,進而達成分群的目 的。圖 2 是其網路拓樸 (Network Topology) 示意圖。SOM 應用在文件分群上 主要分成幾個步驟:
K 個輸出點 (Output Node)
Kohonen’s Layer
N 個輸入點 (Input Node) 圖 2:SOM 的 Network Topology[Roussinov01]
1. 初始化輸入點 (Input Node):
套用向量空間模型 (Vector Space Model) 將每筆文件量化,使其成為一
個座落在關鍵字空間中的向量。而每個向量,就代表一個輸入點,稱為 輸入向量 (Input Vector)。 2. 建立及初始化輸出點 (Output Node): 通常輸出點是以一個矩形平面排列,所以,需設定矩形長寬以決定輸出 點總個數。而每個輸出點都有一個模型向量 (Model Vector),此向量的 維度需與輸入向量的維度相同,此向量可視為輸入向量所在空間中的一 點,其起始值可用亂數決定。 3. 進行學習 (Learning) 過程: 以下所描述的,為一次完整循環 (Iteration) 的過程,要反覆進行數次, 直到整個 SOM 收斂,或者超過某一循環次數門檻限制才停止。 一個循環要依序用所有輸入向量對所有輸出點模型向量做調整,調整過 程如下: A. 選擇勝利點 (Winner Node):計算輸入向量 跟所有輸出點模型 向量的距離,模型向量與輸入向量 最近的輸出點為勝利點。最 常被使用的距離計算公式如方程式 1。其中, m 代表在第 t 次調整模型向量時,某一輸出點 i 的模型向量。 X X ) (t i
∑
2 ) ) ) ( ( -) ( ( )) ( , ( j i j j i t Dim Dim t Similarity X m = X m 方程式 1:以 Euclidean Distance 為相似度定義 B. 調整模型向量:根據 0 方程式 2 來調整模型向量的值:)) ( -( ) ( ) 1 (t i t hc( ),i,t i t i m X m m + = + X ×
0 方程式 2:Model Vector Update
0 方程式 2 中,h 控制了分群過程中模型向量學習速度的快 慢及影響鄰近區域點 (Neighborhood Node) 的能力。 一般 的定義如方程式 3 所示,為第 個輸出點在第 t 次調整模型向量 時,將輸入向量 的勝利點 帶入後,所得的函數值。其中 r 、 分別為勝利點及第i個輸出點在矩形平面的座標向量。 t i c( X),, X t i c h( X),, i ) (x c c i r − − = ) ( 2 exp ) ( 2 2 , ), ( t t h c i t i c
α
σ
r r X 方程式 3:hc( X),i,t 在方程式 3 中,α(t)介在 0~1 之間,是個單調遞減 (Monotonically Decreasing) 的函數,它影響了學習速度的快慢。σ(t)亦為一單調 遞減的函數,它牽涉到勝利點影響鄰近區域點的能力。經此調整 後,所有的模型向量,都會有不同程度向輸入向量 移動的趨 勢。但在不同的應用中, 有較為簡易的定義法,例如方程 式 4: X t i c h( X),,
−
<
=
otherwise
R
if
t
α
h
c i t c i,
0
),
(
, ), (r
r
X 方程式 4:另一種hc( X),i,t定義法 在方程式 4 裡,只有與距離勝利點距離在範圍 R 內的鄰近區域 點,才會被調整值。4. 指定群聚: 在學習過程完成後,每個輸出點的模型向量,就是分群的依據。方法如 下:計算每個輸入向量與所有輸出點模型向量的距離,把該輸入向量指 派給距離最近的輸出點。將所有代表文件的輸入向量指派完後,即可得 到一個依照文件相似度分群的 2D 地圖。 5. 標記 (Label) 群聚區域: 由於輸出點的模型向量是分群的依據,因此可做為群聚標記時的參考。 而 Roussinov (2001)提到一種適合文件分群工作的群聚標記法如下:從每 個輸出點的模型向量中,選出一個值最大的座標軸相對應的關鍵字,來 代表該點。若相鄰的輸出點擁有一樣的關鍵字,則合併為同一個群聚。
第二節 使用者相關文件分群 (User-Involved Document Clustering)
一般的自動分群過程,其目的是針對某種群聚內部結構的測量 (Internal Measure),找出最佳化的解,諸如在一個群聚內的相似度測量…等等[Kim00]。 其中,使用者的想法並沒有被考慮在內。但從實際應用的角度而言,使用者的 想法是很重要的。Yu (1985)提出了以使用者意見為主的分群法 — Adaptive Document Clustering。其主要過程如下[Yu85]: 步驟 1: 1. 若所有文件為 ,則將每個文件 指定到一個在一維實數線 上的位置 ,1 N R R R1, 2,..., i X i R
(
-∞ ,∞)
≤ i≤ N 2. 給定一個查詢 (Query) A. 用之前儲存(或預先設定)的群聚,作為回應。B. 請使用者勾選跟查詢相關 (Relevant) 的文件。 C. 更動文件在實數線上的位置,使得在步驟 B 中使用者勾選的、與 此查詢相關的文章,在實數線上的位置互相靠近;不相關的文章 中,隨機選出文件,使其遠離其重心。 3. 重複步驟 2 數次。 步驟 2:經過數次查詢後,依據下列方法決定群聚: 在實數線上以遞減方向,確認文件。設d為兩個相鄰文件在步驟 1 開始前 的平均距離。若經步驟 1 之後,兩相鄰文件的距離小於d ,則將此兩個 文件歸到同一個群聚中。否則,就歸到不同的群聚。 3 / 這 種 依 據 使 用 者 意 見 分 群 的 相 關 研 究 , 被 稱 為 使 用 者 導 向 分 群 法 (User-Oriented Clustering) [Raghavan87a][Raghavan87b][Bhuyan89]。此類分群演
算法的主要精神,是以使用者所提供的正/負面答案,逐步對分群結果進行調 整,形成最後答案[Bhuyan91]。而 Hatano (1999)提出了基於 SOM 的互動式分類 (Interactive Classification) , 他 提 供 給 使 用 者 五 個 回 饋 式 運 算 (Feedback
Operation),讓使用者與 SOM 達成互動。其五個運算如下: 擴大 (Enlarge):使用者若對某個詞進行「擴大」運算,系統會針對文 件的特徵向量 (Feature Vector) 作適當調整,使得歸類為該詞的群聚 數盡量增多。 刪除 (Delete):使用者若針對某個詞進行「刪除」運算,則系統會將 含該關鍵字的文章,排除在分群過程之外。 合併 (Merge):使用者可針對數個詞進行「合併」運算,指定其成為 另一個新詞。系統將把文件的特徵向量中,此數個詞的頻率相加,視 為指定的新詞頻率。
注意 (Notice):使用者可對所有文件進行「注意」運算,系統會針對 所有的索引詞 (Index Term) 做 Tf-IDf 的計算,取分數高的前 m 個。
接下來,將文件的特徵向量,轉換成以此m 個索引詞表示。 分析 (Analysis):使用者可對所有文件進行「分析」運算,系統會在 決定文件的特徵向量時,排除使用者不熟悉的索引詞。 與前述的使用者導向分群法的主要精神相似,此系統也運用回饋式的方 法,讓使用者表達意見[Hatano99]。本論文提出的目標導向文件分群概念,修 正 Hatano (1999)的方法,讓使用者在分群前,即可用自己的興趣為目標,主動 地在分群過程中引導系統,使系統產生符合使用者觀點的分群結果,而不必等 到初次分群完成,才使用回饋式的方法,讓使用者逐步修正分群結果。
第三節 潛在語意分析 (Latent Semantic Analysis)
2.2.1 LSA 簡介
潛在語意分析 (Latent Semantic Analysis, LSA) 是種對於字與字之間,基於 在文件中被使用的關係,以統計方法來做分析、做為大量文件輔助訓練資料的 方法。主要的精神是基於在文件中,字詞的共同出現與否,來作為其字義上相 似程度的判斷。它可以適當地表現人類知識的推演建立過程。LSA 有兩大步 驟:奇異值分解 (Singular Value Decomposition, SVD) 和維度約化 (Dimension Reduction)。SVD 是一種數學矩陣的分解技術,能將文件所隱含的知識抽象轉 換到語意空間中,而維度約化能萃取文件知識在語意空間中的較重要的部分, 使 LSA 能更精確地推演出文件所隱含的的知識。若將 LSA 應用到文件索引 (Document Indexing) , 則 能 發 現 文 件 間 或 字 詞 間 深 層 的 相 似 關 係 [Deerwester90]。 2.1.3 LSA 的實例說明 [Landauer98]
以下,舉在 Landauer (1998)中,所提到的一個簡單例子,來說明 LSA 的流 程。在這個例子中,文字的內容是給定九篇技術文件的標題,有五篇是人機互 動 (Human Computer Interaction, HCI) 的相關文件,分別稱為 c1、c2、c3、c3、 c4、c5。其他 4 篇則是關於數學圖形理論 (Mathematical Graph Theory) 的相關
文件,分別稱做 m1、m2、m3、m4。圖 3 是這些文件標題的列表。
Example of text data: Titles of Some Technical Memos
c1: Human machine interface for ABC computer applications c2: A survey of user opinion of computer system response time c3: The EPS user interface management system
c4: System and human system engineering testing of EPS
c5: Relation of user perceivedresponse time to error measurement m1: The generation of random, binary, orderedtrees
m2: The intersectiongraphof paths in trees
m3: Graph minors IV: Widths of trees and well-quasi-ordering M4: Graph minors: A survey
圖 3:範例文件列表 首先,從這些標題中,挑選出現 2 次以上的詞 (圖 3 中斜體部分),共有 12 個。然後根據這些詞跟文件標題,建構一個詞-文字內容 (Word-by-Context) 的矩陣 。在 中,列的部分,是代表各個不同的詞;行的部分,是代表各篇 不同的文件標題;值是該詞在某篇文件標題中出現的次數。 X X X = 1 1 1 0 0 0 0 0 0 g ra p h 0 1 1 1 0 0 0 0 0 tre e s 1 0 0 0 0 0 0 1 0 su rv e y 0 0 0 0 0 1 1 0 0 E P S 0 0 0 0 1 0 0 1 0 tim e 0 0 0 0 1 0 0 1 0 re sp o n se 0 0 0 0 0 2 1 1 0 sy ste m 0 0 0 0 1 0 1 1 0 u se r 0 0 0 0 0 0 0 1 1 c o m p u te r 0 0 0 0 0 0 1 0 1 in te rfa c e 0 0 0 0 0 1 0 0 1 h u m a n m 4 m 3 m 2 m 1 c 5 c 4 c 3 c 2 c 1
而矩陣X 在經過 SVD 分解之後,可分解成W、 、S P 三個矩陣的連乘。 T − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − = 18 . 0 68 . 0 34 . 0 28 . 0 30 . 0 01 . 0 14 . 0 45 . 0 03 . 0 23 . 0 68 . 0 16 . 0 11 . 0 07 . 0 00 . 0 22 . 0 62 . 0 04 . 0 23 . 0 25 . 0 29 . 0 39 . 0 59 . 0 03 . 0 23 . 0 49 . 0 01 . 0 58 . 0 04 . 0 47 . 0 08 . 0 54 . 0 03 . 0 18 . 0 27 . 0 21 . 0 17 . 0 02 . 0 03 . 0 27 . 0 11 . 0 19 . 0 33 . 0 14 . 0 30 . 0 05 . 0 02 . 0 28 . 0 17 . 0 08 . 0 07 . 0 43 . 0 11 . 0 27 . 0 05 . 0 02 . 0 28 . 0 17 . 0 08 . 0 07 . 0 43 . 0 11 . 0 27 . 0 27 . 0 03 . 0 17 . 0 21 . 0 16 . 0 33 . 0 36 . 0 17 . 0 64 . 0 01 . 0 00 . 0 00 . 0 38 . 0 33 . 0 10 . 0 34 . 0 06 . 0 40 . 0 49 . 0 06 . 0 30 . 0 25 . 0 11 . 0 59 . 0 16 . 0 04 . 0 24 . 0 11 . 0 01 . 0 07 . 0 50 . 0 28 . 0 55 . 0 14 . 0 07 . 0 20 . 0 41 . 0 06 . 0 52 . 0 34 . 0 11 . 0 41 . 0 29 . 0 11 . 0 22 . 0 W = 36 . 0 0 0 0 0 0 0 0 0 0 56 . 0 0 0 0 0 0 0 0 0 0 85 . 0 0 0 0 0 0 0 0 0 0 31 . 1 0 0 0 0 0 0 0 0 0 50 . 1 0 0 0 0 0 0 0 0 0 64 . 1 0 0 0 0 0 0 0 0 0 35 . 2 0 0 0 0 0 0 0 0 0 54 . 2 0 0 0 0 0 0 0 0 0 34 . 3 S − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − = 45 . 0 52 . 0 02 . 0 62 . 0 26 . 0 08 . 0 02 . 0 24 . 0 06 . 0 07 . 0 45 . 0 76 . 0 45 . 0 06 . 0 02 . 0 01 . 0 05 . 0 01 . 0 04 . 0 25 . 0 15 . 0 34 . 0 67 . 0 26 . 0 24 . 0 43 . 0 18 . 0 36 . 0 00 . 0 21 . 0 30 . 0 03 . 0 37 . 0 72 . 0 26 . 0 08 . 0 60 . 0 15 . 0 35 . 0 39 . 0 33 . 0 21 . 0 38 . 0 21 . 0 05 . 0 03 . 0 01 . 0 02 . 0 02 . 0 15 . 0 27 . 0 04 . 0 03 . 0 95 . 0 08 . 0 25 . 0 19 . 0 10 . 0 51 . 0 57 . 0 21 . 0 50 . 0 11 . 0 53 . 0 62 . 0 44 . 0 19 . 0 11 . 0 23 . 0 13 . 0 17 . 0 06 . 0 08 . 0 02 . 0 01 . 0 00 . 0 28 . 0 54 . 0 46 . 0 61 . 0 20 . 0 T P
再經過維度約化,取新維度為 2,亦即保留矩陣 中最高的兩個數值,其餘的 數值均設為 0,相當於只取三個矩陣W、 、 S S P 的前 2 列,其餘值設為 0,分 別得到W'、S'、P' 。由此,我們可得到一重建矩陣T '=W X ' 'S P' 。 T X 62 . 0 71 . 0 50 . 0 22 . 0 15 . 0 21 . 0 10 . 0 25 . 0 04 . 0 minors 85 . 0 98 . 0 69 . 0 31 . 0 20 . 0 30 . 0 15 . 0 34 . 0 06 . 0 graph 66 . 0 77 . 0 55 . 0 24 . 0 14 . 0 27 . 0 14 . 0 23 . 0 06 . 0 trees 42 . 0 44 . 0 31 . 0 14 . 0 27 . 0 21 . 0 23 . 0 53 . 0 10 . 0 survey 11 . 0 20 . 0 14 . 0 07 . 0 24 . 0 63 . 0 51 . 0 55 . 0 22 . 0 EPS 22 . 0 19 . 0 13 . 0 06 . 0 28 . 0 42 . 0 38 . 0 58 . 1 16 . 0 time 22 . 0 19 . 0 13 . 0 06 . 0 28 . 0 42 . 0 38 . 0 58 . 0 16 . 0 response 05 . 0 21 . 0 15 . 0 07 . 0 56 . 0 27 . 1 05 . 1 23 . 1 45 . 0 system 19 . 0 12 . 0 08 . 0 03 . 0 39 . 0 70 . 0 61 . 0 84 . 0 26 . 0 user 12 . 0 09 . 0 06 . 0 02 . 0 24 . 0 41 . 0 36 . 0 51 . 0 15 . 0 computer 04 . 0 10 . 0 07 . 0 03 . 0 16 . 0 40 . 0 33 . 0 37 . 0 14 . 0 interface 09 . 0 16 . 0 12 . 0 05 . 0 18 . 0 47 . 0 38 . 0 40 . 0 16 . 0 human m4 m3 m2 m1 c5 c4 c3 c2 c1 ' − − − − − − − − − − − − − − − − − − − − − − − − − = 而觀察 '與 後我們可發現,原本”trees”這個詞彙,在 中的 m4 並沒有出 現,所以值為 0。但因為 m4 的標題中出現了”graph”、 ”minor”這兩個與”tree” 相關的詞,所以在經過重建的矩陣 '中,”trees”在 m4 的值被修改成 0.66。另 外,”survey”這個詞彙原本在 m4 的值是 1,但在經過重建的矩陣 中,其值被 降為 0.42,恰準確地反映了”survey”這個詞對於 m4 這個領域 — ”Mathematical Graph Theory”的文件標題來說,並不重要。由此可知,LSA 的確能萃取出文件 知識在語意空間中較重要的部分,進而估量每個詞彙對不同文字內容的重要性。 X X X X ' X
第四節 SOM 在文件分群的應用
2.3.1 WEBSOM 系列 赫 爾 辛 基 大 學 (Helsinki University) 開 發 了 一 個 文 件 分 群 系 統 WEBSOM,及其改良版本 WEBSOM2。這個系統主要是用來幫助使用者在極大量的文件中,快速而有效地找出想要的資料。主要概念是,將文件依據其相 似度來分群,以減少使用者搜尋的時間。系統是基於 SOM 演算法來實作的, SOM 中所需的輸入向量則是以文件本身的詞彙統計資料來表示。整個系統主要
提供二種功能:
內容強調的搜尋 (Content Addressable Search):
使用者用系統提供的介面,來描述他們想要文件的概念。系統會將此 概念模擬成一短文,然後將此短文位於 SOM 結果地圖 (Result Map) 的位置標出。而此位置周圍的文件就是使用者可能要找的文件了。 關鍵字搜尋 (Keyword Search): 在系統將所有文件做完分群、產生地圖之後,會以適當方法選出代表 地圖上各個群聚的關鍵字。若使用者特別對某關鍵字文件有興趣,則 可選擇關鍵字搜尋。系統會將符合查詢關鍵字的區域標示出來,讓使 用者可快速瀏覽這些文件。 這個系統遇到的主要問題是,如何在有限資源及時間內,將極大量的文件 依相似度分群。因此,主要探討的問題就是如何加快 SOM 的速度。在文件的 前處理 (Preprocessing) 上,Kaski (1997)提出了用隨機對映 (Random Mapping) 的方法來解決關鍵字過多的問題。在 SOM 演算法上,Kohonen (2000)提出了下 面幾點改進: 在代表文件的輸入向量中,會有許多維度的值為 0。這可以用來加速 文件相似度的計算,以應用於 SOM 中所有用到計算文件相似度處。 建構一個規模 (Size) 較小的 SOM 來進行計算,再把結果當成之後完 整、大規模的 SOM 的起始值依據,以增進大規模 SOM 收斂的速度。
在 SOM 分群的過程進行中,可採用許多逼近法來加速找尋勝利點, 又保持相當的準確性。如何有效的平行化處理 (Parallelized) 也被提出 [Kohonen00]。 2.3.2 適應式搜尋 (Adaptive Search) Roussinov (2001)提到:傳統的關鍵字搜尋並不是一個好方法,因為使用者 可能對他所要搜尋的主題並不完全瞭解,以致於無法給定精確的搜尋關鍵字。 而 Cutting (1992)提出一個新方法:先把文件分群,再從各個分群文件挑出關鍵 字,描述該文件群,讓使用者方便點選某群文件,再繼續進行分群、讓使用者 點選的工作,直到使用者滿意為止。但是,這種結合分群的瀏覽式搜尋,花的 時間比傳統關鍵字搜尋還多,而且找到的文章,相關性反而比較低。因此, Roussinov (2001)提出一種新方法,名為 ”Adaptive Search”,主要概念是:在搜
尋引擎跟使用者之間,多加一個中間層 (Layer)。其流程如圖 4,主要步驟為: 1. 使用者先透過中間層對傳統關鍵字搜尋引擎下關鍵字搜尋。 2. 中間層把搜尋引擎傳回來的文件用 SOM 分成幾個較小的群聚,且將 每個群聚做適當的標記,呈現給使用者。 Information Need Web Pages Feedback form feedback Commercial Search Engine Adaptive Search User Query
3. 使用者透過中間層的”feedback form”做使用者相關回饋,指出哪幾群 是符合使用者興趣的。另外,使用者也可以再補上有興趣的關鍵字。
4. 中間層根據使用者的 feedback,再形成更精準的查詢字串,向搜尋引
擎發出查詢。之後就重複(2)~(4)的步驟,直到找出使用者滿意的文件 為止[Roussinov01]。
第三章 目標導向文件分群模型及系統實作
本論文提出一個目標導向之 SOM (Goal-Oriented Self-Organizing Map, GOSOM) 模型。GOSOM 基於傳統 SOM,並結合了潛在語意分析 (Latent
Semantic Analysis, LSA),達成以使用者興趣,引導文件分群過程的功能,使之
更符合使用者的需求。在群聚標記方面,為了讓使用者更易瞭解分群結果,我 們提出一權重的多數決 (Weighted Majority Voting) 方法。此外,我們針對此模 型特性,提出了使用者相關回饋 (User Relevance Feedback) 方法,並將 GOSOM 實作在目標導向文件分群系統 (Goal-Oriented Document Clustering System, GODOC)。 首先,在本章的第一節,先描述 GOSOM 的架構,再逐一介紹模型中各元 件的細節。在談到 GOSOM 時,共有三個重點。一、介紹 SOM 在文件分群上 的傳統作法及 GOSOM 如何改良;二、解釋權重的多數決群聚標記法;三、說 明使用者相關回饋的方法。在本章的第二節,會介紹 GODOC 的流程,並分別 介紹各元件。
第一節 目標導向之 SOM (Goal-Oriented SOM, GOSOM)
由第二章的介紹中可知,傳統 SOM 主要是藉由輸入點一次次對輸出點的 模型向量做調整,使得輸出點逐漸形成相似的群聚,最後才將每個輸入點,依 其跟所有輸出點模型向量的相似度大小,來指定其分群結果,因此,輸出點的 模型向量,具有代表分配到該輸出點內所有輸入點特徵的功能。由此可知: 若要達成「依使用者興趣為目標,引導分群過程」的目的,可從「依 使用者興趣來定義相似度」著手。因為在 SOM 中,輸出點群聚形成 的過程,正是依據相似度大小來決定的。相似度越大,越容易形成群
聚。所以,若採用具某特性的相似度函式,則分群過程就會被此特性 影響。 分群的解釋方法,必須要跟模型向量的內容有相當程度關係,因為這 代表了 SOM 的分群結果。 GOSOM 就是基於這兩個基本精神,融入目標導向分群的概念,所提出的 模型。圖 5 是 GOSOM 模型示意圖,其流程如下: (2) Specified goals (3) (2) Term Weighting Term Weighting Term Weighting Term Relationship Matrix Relevance Feedback LSA Clustering Labeling
SOM with modified Similarity Function
(4) Result (5) Pick up Positive Answer
GOSOM (6) Enhanced Weighting
(1) (1) Model VectorMatrix User Document Vectors 圖 5:GOSOM 模型示意圖 1. 將文件經處理過所形成的文件向量,輸入到 LSA 及搭配改良相似度定 義的 SOM 中。 2. 運用 LSA,可產生詞-詞的關係矩陣,再以使用者輸入的分群目標配合 此矩陣,可將使用者分群目標代表的概念擴展到其他詞,可對所有詞 產生適當的權重。
3. 將傳統 SOM 配合改良過的相似度定義,及步驟 2 所得的詞權重,可產 生代表初步分群結果的模型向量矩陣。 4. 以步驟 2 所得的詞權重,配合本論文提出的群聚標記法,可為步驟 3 的模型向量矩陣作適當標記,產生分群結果,呈現給使用者。 5. 使用者可針對分群結果,勾選分群正確的文件,做使用者相關回饋。 6. 系統根據使用者的意見,對步驟 2 所得的詞權重作調整,再次進行分 群。 在接下來的小節內,會分別介紹 GOSOM 的四個元件:LSA、改良的相似度定 義、群聚標記、以及使用者相關回饋。 3.1.1 LSA 我們實作了一個能執行 LSA 方法的元件。在 LSA 中最主要的矩陣運算技 術,就是 SVD 分解。我們採用http://math.nist.gov/javanumerics/jama/[NIST]上 的 Jama-1.0.1 套件來實作,而其他的矩陣運算應用,也是基於此套件延伸發展 而來。 3.1.2 改良的相似度定義 在傳統應用 SOM 於文件分群的系統裡,大部分是採用向量模型空間,所 有文件都以詞為特徵,將文件化為實數的特徵向量來描述。而本研究欲達成之 目的,是要依「使用者目標」分群;也就是說,分群過程中,相似與否要從「使 用者目標」的觀點來決定。在此,「使用者目標」不是一個詞,而是一個概念 (比 如說:「使用者目標」可能為「捷運偷拍」這種模糊的概念)。因此,為了將「概 念」這種特色引入,我們使用 LSA 方法,深層分析文件中詞與詞的關係,可得 一詞–詞關係矩陣,藉此找出與「使用者目標」較相關的詞。如此,我們便可 用「依與使用者目標相關的詞分群」這種方法,在向量空間模型中達成「依使
用者目標分群」的目的。參考之前的文獻,SOM 最常將相似度定義成 Euclidean Distance (方程式 5)[Kohonen98]。
∑
2 ) ) ) ( ( -) ( ( )) ( , ( i i i Dim t Dim t Similarity X m = X m 方程式 5:以 Euclidean Distance 作為相似度定義 而這樣的相似度定義,無法強調特定目標,如:使用者的興趣或喜好。我 們認為,與使用者目標較相關的詞,在相似度計算中,應為其主要因素。因此, 我們提出了一個改良後的相似度定義如方程式 6:∑
2 ) ) ) ( ( -) ( ( )) ( , ( ' i i i i Dim Dim t W t Similarity X m = X m 方程式 6:改良後的相似度定義 在輸入向量 與m 兩個向量相減時,於每個不同字詞對應的座標軸i, 乘上反映其重要程度的權重 (Weight) W ,將較重要的詞,乘以較大的權重; 較不重要的詞,乘以較小的權重。如此在計算相似度時,會強調在較重要詞上 的差異,而相對忽略其他不重要的詞。接著,我們將W 定義如方程式 7: X (t) i i )) , ( max ( j j i F i usergoal W = R 方程式 7:改良後的相似度公式中,詞的權重 在此,usergoal 代表第使用者 j 個使用者目標。R是透過 LSA 方法得到的 詞–詞關係矩陣,R 表示第 i 個詞與跟第 j 個詞的相關程度 – 其值介在-1~1 之間[Deerwester90]。 是一個映射方程式,將 的值域對映到 0~1,定義為 j , (i j) ( F R( ji, )) R( ji, ) 0 )) , ( 1 )) , ( − ( ( ) 1 ( 1 ) , ( ) , ( − = F F R R − − − j i j i R R j i j i 。經整理,得 2 1 ) , ( + = i j F(R(i, j)) R 。 舉例來說,若透過 LSA 得到的矩陣如: − − − − − − − − − − − − − − − − − − − − − − − − − − − − = 1 85 . 0 9 . 0 9 . 0 2 . 0 5 . 0 2 . 0 7 85 . 0 1 7 . 0 8 . 0 7 . 0 9 . 0 4 . 0 6 9 . 0 7 . 0 1 8 . 0 4 . 0 75 . 0 1 . 0 5 9 . 0 8 . 0 8 . 0 1 4 . 0 1 . 0 3 . 0 4 2 . 0 7 . 0 4 . 0 4 . 0 1 3 . 0 1 . 0 3 5 . 0 9 . 0 75 . 0 1 . 0 3 . 0 1 6 . 0 2 2 . 0 4 . 0 1 . 0 3 . 0 1 . 0 6 . 0 1 1 7 6 5 4 3 2 1 Term Term Term Term Term Term Term Term Term Term Term Term Term Term R 圖 6:經 LSA 方法得到的詞–詞關係矩陣範例 而使用者的分群目標為 Term 2、4、7 三類(亦即 usergoal 、 、usergoal ),我們若欲決定W ,則套用方程式 7 後,計算如下:由R中可得,Term 1 這個詞與三者關係程度為[0.6,0.3,0.2]。 因此, ,W 。 2 1 =Term 1 4 2 Term usergoal = , ( maxR i 7 3 =Term 6 . 0 )= j 1 = usergoal F(0.6)=0.8 3.1.3 群聚標記 (Cluster Labeling) 在 SOM 分群過程結束後,每個輸出點會有一個模型向量,其維度與輸入點同。 而輸出點的模型向量,代表分配到該輸出點內,所有輸入點的特徵 (Feature)。 所以,若要對一個輸出點做標記,以代表分配到此輸出點的輸入點(也就是文 件),一定要參考模型向量。而將這些輸出點分群結果作適當標記 (Labeling), 有助於讓使用者瞭解該群聚文件的特性。
3.1.3.1 權重的多數決 (Weightd Majority Voting)
根據 Roussinov (2001) 所提出的適應式搜尋 (Adaptive Search) 系統中,是根據 每個輸出點的模型向量,選出其中值最高的座標軸,將其對應的字詞,當作該 輸出點代表的群聚之標記。本論文提出一融合多數決 (Majority Voting) 精神
1. 首先,定義與第 i 個詞的最相關的使用者目標為:
)
l
(i,usergoa
)
TermGoal(i
R
j j usergoalmax
arg
=
R是透過 LSA 方法得到的詞–詞關係矩陣。 2. 延續 3.1.2.中改良相似度定義時的計算公式,設第 i 個詞的權重為: )) , ( max ( j j i F i usergoal W = R 3. 接著,定義第 j 個使用者目標,在輸出點(p, q)上,對於第 i 個詞的分數:
≠
=
else
i
usergoal
TermGoal
if
usergoal
i
Score
q p j i j,
)
(
,
0
)
,
(
,m
) ( ,q i p m 表示在輸出點(p, q)的模型向量m中,第 i 個詞對應的座標軸值。 4. 有了 後,我們便可定義第 j 個使用者目標在輸出點 中的總分為: ) , (i usergoalj Score ) , (p q =∑
× i i j j Score i usergoal W usergoal SumofGoal( ) ( , ) 5. 最後,依據各個使用者的目標總分來決定輸出點(p, q)的標記:
Label
p,qarg
usergoalmax
SumofGoal
(
usergoal
j)
j=
舉例來說,套用「權重的多數決」決定輸出點(1,1)的步驟如下:
若輸出點的規模為 3×3,輸入向量維度及輸出點的模型向量維度皆為
得到的詞–詞關係矩陣如圖 6、 2 1 ) , ( )) , ( (R i j = R i j + 8.2 1.1 4.3 3.5 5.9 1.3 7.6 6.5 9.8 7.1 6.1 5.1 4.4 4.5 5.0 6.2 7.1 3.5 2.2 2.1 1.1 F 、M為 SOM 分 群後所得的模型向量矩陣,內容如圖 7:
[
= 9.6 5.5 6.7 3.7 3.9 2.2 2.5 5.5 2.1 7.3 5.6 2.1 4.7 5.8 5.1 9.1 8.7 4.9 4.2 3.5 3.8 4.1 8.1 6.7 3.8 3.6 4.3 2.5 8.7 4.5 3.2 5.5 5.6 4.3 1.1 9.1 5.5 4.5 7.1 6.9 5.1 1.3 M 圖 7:經 SOM 分群後的模型向量矩陣範例 決定與第 i 個詞的最相關的使用者目標:]
3 2 1 2 3 1 1 usergoalusergoal
)
7
(
usergoal
)
6
(
usergoal
)
5
(
usergoal
)
4
(
usergoal
)
3
(
usergoal
)
2
(
usergoal
2
.
0
3
.
0
6
.
0
max
arg
)
(
max
arg
)
1
(
j=
=
=
=
=
=
=
=
=
TermGoal
TermGoal
TermGoal
TermGoal
TermGoal
TermGoal
i,usergoal
TermGoal
j usergoal jR
計算第 i 個詞的權重:
[
]
1 1 . 0 125 . 0 1 4 . 0 1 8 . 0 ) 6 . 0 ( ) 2 . 0 3 . 0 6 . 0 max ( )) ( max ( 7 6 5 4 3 2 1 = = = = = = = = = = W W W W W W F F i,usergoal F W j j j R 計算三個使用者分群目標,在輸出點(1,1)上,對於第 i 個詞的分數: Score =0 Score 0 ) , 7 ( 0 ) , 6 ( 5 . 4 ) , 5 ( 0 ) , 4 ( ) , 3 ( 1 . 5 ) , 2 ( 3 . 1 ) , 1 ( 1 1 1 1 1 1 1 = = = = = = usergoal Score usergoal Score usergoal Score usergoal Score usergoal usergoal Score usergoal Score 0 ) , 7 ( 5 . 5 ) , 6 ( 0 ) , 5 ( 1 . 7 ) , 4 ( 0 ) , 3 ( 0 ) , 2 ( 0 ) , 1 ( 2 2 2 2 2 2 2 = = = = = = = usergoal Score usergoal Score usergoal Score usergoal Score usergoal usergoal Score usergoal Score 1 . 9 ) , 7 ( 0 ) , 6 ( 0 ) , 5 ( 0 ) , 4 ( 9 . 6 ) , 3 ( 0 ) , 2 ( 0 ) , 1 ( 3 3 3 3 3 3 3 = = = = = = = usergoal Score usergoal Score usergoal Score usergoal Score usergoal Score usergoal Score usergoal Score 計算三個使用者分群目標的總分如下: 7025 . 6 125 . 0 5 . 4 1 1 . 5 8 . 0 3 . 1 ) (usergoal1 = × + × + × = SumofGoal 65 . 7 1 . 0 5 . 5 1 1 . 7 ) (usergoal2 = × + × = SumofGoal 86 . 11 1 . 1 . 9 4 . 0 9 . 6 ) (usergoal3 = × + × = SumofGoal 最後,依據各個使用者的目標總分決定標記: 3 1 ,1 arg max [6.7025,7.65,11.86] usergoal Label j usergoal = = ) 1 , 1 結果,輸出點( 的標記為第三個使用者分群目標。 3.1.3.2 其他類 (Unrelated)
在前面我們提到用「權重的多數決」方式來決定一個群聚的標記。此方法 是考慮到「相對多數」的概念。但在真實應用中,還要考慮到「絕對多數」的 問題。例如:欲分群的文件,是從搜尋引擎中得到,其中可能有些不屬於使用 者指定的任一目標。若使用前述的「權重的多數決」,將會錯將這些文件,歸到 其中某目標裡。為了解決這個問題,我們採用一個「總分門檻」方法,敘述如 下: 從 LSA 方法獲得的詞–詞關係矩陣為 ,R 表示第 i 個詞與跟第 j 個詞的相關程度。 R ( ji, ) ) (ε F 是一個映射方程式,定義為: 2 1 ) (ε =ε + F 。 1. 將所有分群目標與所有詞的關係程度取平均值
ε
=∑
∑
i j j i i j (, ) 1 1 R , i 、 j 分別為所有詞的個數,及使用者分群目標個數。 2. 設一總分門檻α (α= 2 1 , 3 1 , ..等等)。在「權重的多數決」的步驟 3 中, 若沒有任一分群目標總分 ≥ × ×∑
i q p i F(ε) m , () α ,則將此輸出點標記 為「其他」類,而非統計總分最高的分群目標。m 表示在輸出點 的模型向量 中,第 i 個詞對應的座標軸值。 ) ( ,q i p ) , (p q m 3. 舉例說明: 延續前一個例子,R如圖 6、M如圖 7。決定輸出點(1,3)的步驟如下: 三個使用者目標的累計總分 依 序 分 別 為 : 3.8675、4.12、5.88。 ) (usergoalj SumofGoal 設總分門檻值為α=0.5。經由上述「總分門檻」方法計算得ε=-0.057, 檢查發現: 3.8675 < 4.12 < 5.88 < 0.5×F(−0.057)×( 1.1 + 2.1 + 2.2 + 3.5 + 7.1 + 6.2 + 5.0 ) = 0.5×0.4715×27.2 = 6.4124則表示此輸出點與三個分群目標都不太相關,應標記成「其他」類比 較適合。
3.1.4 使用者相關回饋 (User Relevance Feedback)
本論文在 3.1.2 提出的改良相似度定義,是以詞權重為基礎。因此,若能 正確地找出接近使用者觀點的詞權重值,有助於改善分群結果。在一般檢索系 統 (Retrieval System) 的使用者相關回饋策略裡,認為使用者勾選的正面答案 中,其向量的主要特徵較為重要,因此,會在計算時將這些特徵加強。所以, 基於此一精神,我們提出了依照使用者勾選的正面答案調整詞權重的使用者相 關回饋法。其演算法敘述如下: 定義:n 為使用者勾選系統分群正確文件的篇數、 為使用者相關回饋的次數、f t 為輸入向量的維度、d 為代表使用者勾選系統分群正確的第 i 篇文件的文件向 量、 為使用者勾選第 i 篇文件的系統標記、R 為term 跟 在詞–詞關係矩陣中的值、 i ) (di k
Label (termj,termk) j
term β 為使用者相關回饋的衰退率、γ 為詞調整的 擴充程度,0≤β,γ ≤1。 步驟: 1. 計算每個詞在 d 中的重要性如方程式 8: i a a i a i
term
term
W
importance
(
d
,
)
=
d
(
)
×
方程式 8:每個詞在文件向量di中的重要性 di(terma)表term 在 d 中的值、W 定義如方程式 7。 a i a 2. 將所有詞根據方程式 8 算出重要性,依序由高到低排列, 取γ ×t 個 詞。3. 對每個在步驟 2 中被挑中的termj,計算出此詞與所有詞平均關係值如 方 程 式 9 。 然 後 對 所 有 的 詞 進 行 測 試 調 整 : 若 ,則將term 與 所代表使用者目 標usergoal 的關係值如方程式 10 提高。 ) ( ) ,
(termk termj ≥ Avg termj
R l k Label d( i)
∑
= = t k k j j t term term term Avg 1 ) , ( ) ( R 方程式 9:某詞與所有詞平均關係值 f old old new i k Label term , ( )) [ ( 1)] (1 ) ( d =R + R − − ×β × −β R 方程式 10:將詞與使用者目標usergoall關係值提高 4. 對其他被勾選的文件重複進行步驟 1、2、3。 舉某一篇使用者勾選分群正確的文件 d 做說明: i γ ×t =3、β =0.1、 =1、f Label d( i)=Term2、R如圖 6。 設依步驟 1、2 計算重要性後,依高低順序排列為:Term3、Term5、 Term6、Term1、Term4、Term7、Term2。則應取前 3 個詞:Term3、 Term5、Term6 進行測試調整。 以 Term3 為例:先計算門檻 0.157 7 ) , ( ) ( 7 1 3 3 =∑
=− = k k term term term Avg R 237 . 0 ) 1 . 0 1 ( 1 . 0 7 . 0 744 . 0 ) 1 . 0 1 ( 1 . 0 6 1 1 − = − × × = − × × 。 再對所有詞進行測試,只有 Term1、Term3 通過,因此對二者與使用 者目標 Term2 的關係值進行如下調整: 3 . 0 ) , ( . 1 6 . 0 ) , ( 2 3 2 1 + − = + = new new term term term term R R第二節 目標導向文件分群系統 (Goal-Oriented Document
Clustering System, GODOC)
在參考了 Kohonen (1998) WEBSOM 及 Hotano (1999)後,本論文提出一套 GODOC,其核心為 3.1 所提出的 GOSOM,希望將傳統應用 SOM 於文件分群
的方式,加以改進,融入目標導向以及使用者相關回饋的概念,以期文件分群 準確度更加提升,更符合使用者需求。圖 8 是 GODOC 的流程圖。處理的步驟 如下: GODOC 3 3 2 4 1 2 1 Result User Feedback User Feedback 4 Result Specified Goals Specified Goals Document Vectors Document Preprocessing GOSOM User Interface Matched Documents User 圖 8:GODOC流程圖 1. 將欲分群的文件及分群目標,輸入到 GODOC 中。 2. 文件經過處理後,轉化成文件向量,跟使用者的分群目標一起輸入 GOSOM。 3. 系統將 GOSOM 的分群結果透過使用者介面,呈現給使用者 4. 使用者透過使用者介面,勾選分群正確的文件做使用者回饋,讓系統 再次進行分群。 接下來會介紹各元件:包括了文件前處理,及使用者介面。GOSOM 則在 本章第一節已介紹過。
3.2.1 文件前處理 (Document Preprocessing)
GODOC 的文件事先處理含兩部分:斷詞切字與去除停用字 (Stop Word)。
在文件分群的研究領域裡,斷詞切字本身就是一個重要的研究項目。本論文在 斷詞切字這方面係採用「字典檔比對法」,以http://www.mandarintools.com上的 中文斷詞切字工具為基礎,加以改寫。而去除停用字部分,一樣係採用「字典 檔比對法」處理。 3.2.2 使用者介面 (User Interface) 使用者介面的部分,如圖 9 所示,是採用 html 的介面,網頁伺服器採
用 Caucho 公司所出版的 Resin。GOSOM 係利用 JAVA 程式語言來發展。一個 格子就是 SOM 的一個輸出點,也就是一個群聚。每個群聚會有一個標記,代 表這個群聚內的文件,都被標記成該類文件,不同的顏色代表不同的標記。 .
第四章 實驗結果分析與評估
第一節 實驗資料及實驗設計
由於系統是為了「以使用者興趣為目標,進行目標導向的分群」這樣的目 而設計,因此我們希望能測試出在「目標導向」這種概念下,系統的效能表現。 所以我們便以文件內容中的文字主要特性,假設為分群目標,以此進行測試。 實驗資料的來源為網路新聞文件,共分兩類。第一類實驗資料共有兩組, 大部分是聯合知識庫 (http://udndata.com/library) 中五大報的新聞;另有少部分 透 過 入 口 網 站 PChome (http://www.pchome.com.tw) 及 搜 尋 引 擎 Google(http://www.google.com)找到的新聞文件。第二類全部都是和 Yahoo 奇摩合作的 中央社 (http://tw.news.yahoo.com/polity/cna/) 提供的網路新聞。 在第一類的文件中,文件都有兩個主題,一個是同組內所有文件共有的「中 心主題」,另一個是跟「中心主題」相關的「特性主題」。舉例來說:有兩篇文 件都跟「洩密」有關係,其中一篇是關於「花蓮選舉洩密案」,另一篇是跟「陳 水扁飛彈洩密案」有關,則因此對這兩篇文件可設定共通的中心主題是「洩密」, 而二者分別的「特性主題」則為「選舉」、「飛彈」。在第一類實驗中,我們把「特 性主題」當成使用者感興趣的主旨,設定為分群目標,以此進行分群實驗。本 類實驗文件中,「特性主題」較為明確,是某事件的專有名詞,文件數量較少。 兩組文件的內容特性如下表: 第一組資料集 第二組資料集 時間 2002/01/01~2004/02/13 2001/01/01~2004/02/13 中心主題 洩密 偷拍 總篇數 100 100
特性主題(分群目標)數 3 2 特性主題(分群目標)篇數 「選舉洩密」:26 「國安密帳洩密」:27 「飛彈洩密」:27 「其他」:20 「捷運偷拍」:40 「璩美鳳偷拍」:40 「其他」:20 文件長度 大部分約 1000 字內 大部分約 1000 字內 表格 1:第一類實驗資料說明 第二類的實驗文件特性,與前一類不同,只設定有一個較為模糊的「特性 主題」。在前述中提到,本類的實驗文件皆為中央社的網路新聞。我們就以原網 站上,將新聞略分成十大類的類別為主題,當成「分群目標」。本類的文件較第 一類文件不同處為:文件長度較長、其分群目標較為模糊無特定之專有名詞。 其內容特性如下表: 第一組資料集 時間 2003/11/11~2003/11/30 中心主題 無 總篇數 200 特性主題(分群目標)數 3 特性主題(分群目標)篇數 「健康類新聞」:55 「財經類新聞」:55 「政治類新聞」:55 「其他類」:35 文件長度 大部分約 1000 字~1500 字 表格 2:第二類實驗資料說明
在實驗設計方面,總共有三個實驗。第一個實驗是使用第一類實驗文件, 目的在證明本系統的效能改善。第二個實驗則使用第二類實驗文件,目的在證 明,雖然文件數變多,分類目標較為模糊,但系統的效能仍能穩定地維持一定 水準。第三個實驗則混合使用第一、二類實驗文章,希望測出我們的使用者回 饋在不同資料下的反應。
第二節 評估方法
本論文所提出的演算法,主要的目的是希望能「依照使用者的興趣為目標」 來引導分群,傳統分群系統的評估法,如 intra-cluster, inter-cluster…等等並不符 合我們的目的。因此參考 Slonim (2000)、Liu (2002),透過改良監督式文件分類 系統中的(Supervised Text Classfifcation)準確度 ( Accuracy ) 來做評估。原公 式如方程式 11:N
Ans
Accuracy
N i i i∑
1)
,
(
==
α
δ
方程式 11:原Accuracy計算公式[Liu02]當x=y時,δ(x,y)=1,否則δ(x,y)=0;而 是系統給第i篇文件的標記、Ans
是第i篇文件的人工答案標記。但考慮到我們系統額外加入「其他」這類標記, 所以將原公式改良如方程式 12。其中,當 x≠「其他」、y≠「其他」,且 x=y 時, ' i α i δ (x,y)=1,否則 'δ (x,y)=0;而 是系統給第i篇文件的標記, 是 i α Ansi other 1 =
∑
δ
, Ans
)
Accuracy
N i i i(
'
N-Sum
α
=
方程式 12:改良後Accuracy計算公式第 i 篇文件的人工答案標記,Sumother是被系統標記為「其他」的文件篇數。 為避免標記時,「其他」類過多,造成 Accuracy 很高,但實際系統效能不 好的誤判情形,我們還加入了資訊檢索系統的評估法,來評估實驗文件中,各 類文件的求全率 (Recall),其公式如方程式 13: A A A Ans α Class call( )= Re 方程式 13:Recall公式
其中, α 是系統將文件標記為「A 類」的總篇數、A Ans 是人工答案中「AA
類」標記的總篇數。當「其他」類過多時,將會反映在 Recall 的數值上 (Recall 會很低)。因此,要同時對此兩項評估指標做觀察,才能得知系統的實際效能表 現。
第三節 實驗結果與討論
4.2.1 實驗一 此實驗目的在於比較 GOSOM 依使用者特定的觀點分群的效能,藉由 Accuracy 跟 Recall 來估計其效能。在斷詞切字的部分,我們將在整個資料集 (Data Set) 中,只出現 1 次 (Tf=1) 的詞去掉,不予使用。表格 3 是其實驗結 果。 從實驗結果中我們可以發現,隨著不同的實驗資料,Accuracy 跟 Recall 的 值會跟著相對變動。針對特定概念的引導分群,在 Accuracy 上,GOSOM 平均 將 SOM 改善 24.6%;在 Recall 方面則改善 24.25%。第一類實驗資料 1 第一類實驗資料 2
Method SOM GOSOM SOM GOSOM
Size 6*6 6*6 6*6 6*6 Accuracy 0.44 0.56 0.59 0.72 Recall 0.548 0.693 0.737 0.9 表格 3:實驗1結果數據 4.2.2 實驗二 此實驗目的在於希望證明雖然文件數變多,分群目標較為模糊,但系統的 效能仍能穩定地維持一定水準,依使用者喜好,將關於某一主題的文字內容, 依使用者特定的觀點分群,並藉由 Accuracy 跟 Recall 來估計其效能。表格 4 是其實驗結果。 從實驗數據中,我們可以發現,與分類目標數同為 3 的第一類實驗資料相 比,雖然在 Accuracy 方面改善效果下降至 18.75%,但在 Recall 方面的改善卻 上升至 32.7%。因此,我們認為 GOSOM 對於 SOM 的改善效果尚稱穩定。 第二類實驗資料 1
Method SOM GOSOM
Size 6*6 6*6 Accuracy 0.48 0.57 Recall 0.424 0.563 表格 4:實驗2結果數據 4.2.3 實驗三 此實驗目的在於測試我們提出的使用者相關回饋策略,是否能進一步改善 GOSOM 效能。若可,則表示策略成功。此外,由於我們的使用者相關回饋機 制是調整詞權重,所以實驗結果亦可證明透過其他方法,只要能提升詞權重的
品質,GOSOM 的效能表現會更好。與前兩個實驗相同,我們透過 Accuracy 跟 Recall 來估計其效能。表格 5 是其實驗結果。 第一類實驗資料 1 第一類實驗資料 2 第二類實驗資料 1 使用者回饋前後 回饋前 回饋後 回饋前 回饋後 回饋前 回饋後 使用者勾選出的正 確答案比例 0 0.1 0 0.15 0 0.15 Accuracy 0.56 0.61 0.72 0.78 0.57 0.525 Recall 0.693 0.751 0.9 0.975 0.563 0.527 表格 5:實驗3結果數據 在第一類實驗資料中,我們的使用者相關回饋機制在 Acuuracy 及 Recall 的兩項測量上,效能都有提升 — 第一組資料 Acuuracy 較回饋前改善 8.9%, Recall 改善 8.3%;第二組資料 Acuuracy 較回饋前改善 8.3%,Recall 改善 8.3%。
這表示了透過使用者相關回饋來調整詞權重,的確可以在提升 GOSOM 的效 能。但在第二類的實驗資料中,Recall 及 Accuracy 都變差,這表示若策略失敗, 無法將真正重要的特徵反映於詞權重,GOSOM 的效能便會下降。至於在第一 類實驗資料中,改善效果會明顯比第二類來的好,其主要原因是由於我們在 3.1.4 提出的策略中,步驟 3 會依詞–詞關係矩陣,將原本使用者勾選文件中的 主要特徵加以延伸,找出其他相關的詞,加強其詞權重,所以步驟 3 對於詞– 詞關係矩陣的品質反應較為靈敏。而第二類實驗資料的使用者目標較為模糊, 所以經由 LSA 方法找出的詞–詞關係矩陣,較無法有效凸顯重要的詞。因此, 在詞–詞關係矩陣品質較不好的情形下,步驟 3 的延伸動作效果便減弱,而容 易對詞權重做不適當的調整。 4.2.3 綜合討論 綜合前面三個小節的實驗,我們可以發現,GOSOM 的效能表現關鍵,在 於詞權重是否能適度加強,而這跟詞–詞關係矩陣有直接的關係。在本論文提
出應用 LSA 方法的架構下,使用者目標若為較清晰的概念,GOSOM 的分群結 果會較好。因此,若未來能找到比 LSA 更有效的方法,能將使用者目標所代表 的概念,擴展到其他詞上,將能使 GOSOM 更具實用性。 關於使用者相關回饋:要根據使用者的意見,對分群系統作有效而顯著的 改進並不容易。本論文提出的使用者相關回饋機制,受詞–詞關係矩陣影響太 大,因此即便使用者正確地表達了意見,系統也不一定能有顯著改善。如何參 考類似 LVQ[Kohonen98]的演算法,找到在 SOM 中可做使用者相關回饋機制的 切入點,從而提出有效的回饋法,是個可嘗試的方向。在圖形檢索 (Image Retrieval) 方面,有人提出將輸入資料的特徵分開,套用多個 SOM,來落實使 用者相關回饋機制,亦或是個可行的方法。但如何應用在本系統中,仍待研究 [Laaksonen01]。