巨量資料環境下之新聞主題暨輿情與股價關係之研究 - 政大學術集成
80
0
0
全文
(2) 誌謝 不同於其他人在完成論文後才開始著手誌謝,基於挑軟柿子的心態,這是我 論文最早開始進行的篇幅,卻花了好大一段時間才完成,看似可笑。或許是如陳 之藩先生所說,該感謝的人太多,但以一句謝天帶過又有點不好意思,那只好來 段長篇大論吧。 首先要感謝家人於論文期間的支持,忙碌中回家的次數漸漸減少,間隔也越 來越長,但電話另一端的支持與鼓勵卻是不中斷的,讓我在電話掛斷後更有動力 繼續論文進度。. 政 治 大 是能從老師那得到新的想法,每次都有新的見解與成長;也感謝劉文卿老師、李 立. 再來,感謝楊建民老師的指導,對學生而言老師就如同黃金屋般,討論時總. ‧ 國. 學. 有仁老師、季延平老師及邱光輝老師於論文提報及口試時的提點與建議,讓學生 於疏忽的部分能夠加以補強,更趨完善。. ‧. Lab 裡的小夥伴們也不能遺忘,感謝智勝、偉志、弘業、子洋、珀豪及柏辰. sit. y. Nat. 學長們的協助與經驗傳授,謝謝悅岑姊的照顧,還有一起奮鬥論文的函升,這段. al. er. io. 路程並不孤單,現在可以很高興的說我們完成論文任務了!智宏、早彬、佳芸、. v. n. 威宇及詮惟學弟妹的加入,替 Lab 注入了一股活潑的泉源,更像一個大家庭了,. Ch. 接下來的一年也好好加油喔。. engchi. i n U. 另外也要特別感謝幾位對我別具意義的人,於這段時間的包容與陪伴外,也 是我心靈傾訴的管道,只能說有你們的我真的很幸運。 最後,為期兩年的論文之旅看似結束了,從論文中我學到了追求真理的精神, 還有努力不懈的人生態度,對於未來的人生旅途,這並不是一個結束,而是迎接 之後一切事情的”網絡關鍵點”,但願日後能勇於面對一切挑戰,並記住這個當下 心懷熱情的自己,也與大家共勉之。 良杰 20140724 清晨於政治大學 i.
(3) 摘要 近年來科技、網路以及儲存媒介的發達,產生的資料量呈現爆炸性的成長, 也宣告了巨量資料時代的來臨。擁有巨量資料代表了不必再依靠傳統抽樣的方式 來蒐集資料,分析數據也不再有資料收集不足以致於無法代表母題的限制。突破 傳統的限制後,巨量資料的精隨在於如何從中找出有價值的資訊。 以擁有大量輿論和人際互動資訊的社群網站為例,就有相關學者研究其情緒 與股價具有正相關性,本研究也試著利用同樣具有巨量資料特性的網路新聞,抓 取中央新聞社 2013 年 7 月至 2014 年 5 月之經濟類新聞共計 30,879 篇,結合新. 政 治 大 網絡並且分析新聞的情緒和股價指數的關係。 立. 聞主題偵測與追蹤技術及情感分析,利用新聞事件相似的概念,透過連結匯聚成. ‧ 國. 學. 研究結果顯示,新聞事件間可以連結成一特定新聞主題,且能在龐大的網絡 中找出不同的新聞主題,並透過新聞主題之連結產生新聞主題脈絡。對此提供一. ‧. 種新的方式來迅速了解巨量新聞內容,也能有效的回溯新聞主題及新聞事件。. sit. y. Nat. 在新聞情緒和股價指數方面,研究發現新聞情緒影響了股價指數之波動,其. al. er. io. 相關係數達到 0.733562;且藉由情緒與心理線及買賣意願指標之比較,顯示新聞. n. 的情緒具有一定的程度能夠成為股價判斷之參考依據。. Ch. engchi. i n U. v. 關鍵字: 巨量資料、文字探勘、新聞主題偵測與追蹤、連結分析、情感分析. ii.
(4) Abstract In recent years, the technology, network, and storage media developed, the amount of generated data with the explosive growth, and also declared the new era of big data. Having big data let us no longer rely on the traditional sample ways to collect data, and no longer have the issue that could not represent the population which caused by the inadequate data collection. Once we break the limitations, the main spirit of big data is how to find out the valuable information in big data. For example, the social network sites (SNS) have a lot of public opinions and. 政 治 大 positive correlation with stock 立 prices. Therefore, the thesis tried to focus on the news interpersonal information, and scholars have founded that the emotions in SNS have a. ‧ 國. 學. which have the same characteristic of big data, using the web crawl to catch total of 30,879 economics news articles form the Central News Agency, furthermore, took the. ‧. “Topic Detection & Tracking” and “Sentiment Analysis” technology on these articles.. sit. y. Nat. Finally, based on the concept of the similarity between news articles, through the links. n. al. er. io. converging networks and analyze the relevant between news sentiment and stock prices.. i n U. v. The results shows that news events can be linked to specific news topics, identify. Ch. engchi. different news topics in a large network, and form the news topic context by linked news topics together. The thesis provides a new way to quickly understand the huge amount of news, and backtracking news topics and news event with effective. In the aspect of news sentiment and stock prices, the results shows that the news sentiments impact the fluctuations of stock prices, and the correlation coefficient is 0.733562. By comparing the emotion with psychological lines & trading willingness indicators, the emotion is better than the two indicators in the stock prices determination. Keywords: Big data, Text mining, News topic detection and tracking, Link analysis, Sentiment analysis. iii.
(5) 目錄. 誌謝................................................................................................................................. i 摘要................................................................................................................................ii Abstract ........................................................................................................................ iii 第一章 緒論................................................................................................................ 1 第一節 研究動機與目的.................................................................................... 1 第二章 文獻探討........................................................................................................ 3. 政 治 大. 第一節 巨量資料(Big Data)............................................................................... 3. 學. 2.1.2. 立. 巨量資料之定義與特性.................................................................... 3. ‧ 國. 2.1.1. 巨量資料之應用................................................................................ 4. 第二節 新聞主題偵測與追蹤(Topic Detection and Tracking, TDT)................ 6. ‧. 2.2.1. 新聞主題網絡.................................................................................... 7. y. Nat. sit. 第三節 情感分析................................................................................................ 9. 2.3.2. 情感詞典............................................................................................ 9. 2.3.3. 情感分析與股價間之關聯.............................................................. 11. n. al. er. 情感分析之定義................................................................................ 9. io. 2.3.1. Ch. engchi. i n U. v. 第四節 小結...................................................................................................... 12 第三章 研究方法與設計.......................................................................................... 13 第一節 資料蒐集.............................................................................................. 15 第二節 資料前處理.......................................................................................... 16 3.2.1 CKIP 斷詞 ....................................................................................... 16 3.2.2. 詞彙精簡.......................................................................................... 17. 3.2.3. 經濟詞彙判定.................................................................................. 17. 3.2.4. 特徵詞萃取...................................................................................... 18 iv.
(6) 向量空間模型.................................................................................. 19. 3.2.5. 第三節 新聞事件處理...................................................................................... 21 3.3.1. 新聞事件偵測與追蹤...................................................................... 21. 3.3.2. 新聞事件偵測與追蹤之參數設置.................................................. 21. 第四節 產生新聞主題網絡.............................................................................. 25 3.4.1. 新聞事件間關係計算...................................................................... 25. 第五節 新聞情緒計算...................................................................................... 26 3.5.1. 情感詞彙判定.................................................................................. 26. 3.5.2. 情感詞彙計算.................................................................................. 26. 3.5.4. 新聞情緒與股價指數之關係.......................................................... 29. 學. ‧ 國. 3.5.3. 政 治 大 新聞層面下的情緒.......................................................................... 27 立. 第四章 研究結果...................................................................................................... 31. 群集連結建立.................................................................................. 31. y. Nat. 4.1.1. ‧. 第一節 網絡式新聞主題.................................................................................. 31. 4.1.3. 新聞主題脈絡.................................................................................. 47. er. sit. 網絡關鍵點...................................................................................... 33. io. 4.1.2. al. n. 第二節. v i n 情緒與股價指數.................................................................................. 52 Ch engchi U. 4.2.1. 情緒與股價指數之關係.................................................................. 52. 4.2.2. 情緒與心理線之關係...................................................................... 55. 4.2.3. 情緒與買賣意願指標之關係.......................................................... 59. 第五章 研究結論與未來方向.................................................................................. 63 第一節 研究結論.............................................................................................. 63 第二節 未來方向.............................................................................................. 65 參考文獻...................................................................................................................... 67. v.
(7) 圖目錄. 圖 2-1 TDT 概念架構圖 ............................................................................................ 6 圖 2-2. 新聞主題事件軸架構圖 ................................................................................. 8. 圖 3-1. 研究架構圖 ................................................................................................... 14. 圖 3-2. 新聞資料庫其類別及資料數量 ................................................................... 15. 圖 3-3. 向量空間模型 ............................................................................................... 19. 圖 3-4. 詞彙-文件矩陣 .............................................................................................. 19. 圖 3-5. 平均群內相似度之變化量 ........................................................................... 24. 圖 3-6. 平均群間相似度之變化量 ........................................................................... 24. 圖 3-7. 新聞情緒值分布圖(新聞層面)..................................................................... 27. 圖 3-8. 一日情緒值數量分布圖(新聞層面)............................................................. 28. 圖 3-9. 每日平均情緒圖(新聞層面)......................................................................... 29. 立. 政 治 大. ‧. ‧ 國. 學. y. Nat. sit. 圖 3-10 台灣發行量加權股價指數 ........................................................................... 30. 圖 4-2. 關鍵點 124 .................................................................................................... 33. 圖 4-3. 關鍵點 149 .................................................................................................... 34. 圖 4-4. 關鍵點 190 .................................................................................................... 36. 圖 4-5. 關鍵點 255 .................................................................................................... 37. 圖 4-6. 關鍵點 303 .................................................................................................... 38. 圖 4-7. 關鍵點 308 .................................................................................................... 39. 圖 4-8. 關鍵點 324 .................................................................................................... 41. 圖 4-9. 關鍵點 366 .................................................................................................... 42. n. al. er. 群集連結之網絡 ........................................................................................... 32. io. 圖 4-1. Ch. engchi. i n U. v. 圖 4-10 關鍵點 412 .................................................................................................... 43 圖 4-11 關鍵點 465 .................................................................................................... 45 vi.
(8) 圖 4-12 網絡中各關鍵點及衛星點 ........................................................................... 46 圖 4-13 點 465 之網絡 ............................................................................................... 48 圖 4-14 點 412 之網絡 ............................................................................................... 49 圖 4-15 網絡中各關鍵點及衛星點 ........................................................................... 51 圖 4-16 情緒與發行量加權股價指數之走勢圖 ....................................................... 53 圖 4-17 情緒與股價減移動平均線之走勢圖 ........................................................... 55 圖 4-18 情緒與心理線之走勢圖 ............................................................................... 58 圖 4-19 情緒與買賣意願指標之走勢圖 ................................................................... 62. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. vii. i n U. v.
(9) 表目錄. 表 3-1. 平均群內相似度及平均群間相似度 ........................................................... 23. 表 4-1. 關鍵點 124 之連結內容摘要 ....................................................................... 34. 表 4-2. 關鍵點 149 之連結內容摘要 ....................................................................... 36. 表 4-3. 關鍵點 190 之連結內容摘要 ....................................................................... 37. 表 4-4. 關鍵點 255 之連結內容摘要 ....................................................................... 38. 表 4-5. 關鍵點 303 之連結內容摘要 ....................................................................... 39. 表 4-6. 關鍵點 308 之連結內容摘要 ....................................................................... 40. 表 4-7. 關鍵點 324 之連結內容摘要 ....................................................................... 42. 表 4-8. 關鍵點 366 之連結內容摘要 ....................................................................... 43. 表 4-9. 關鍵點 412 之連結內容摘要 ....................................................................... 44. 立. 政 治 大. ‧. ‧ 國. 學. 表 4-10 關鍵點 465 之連結內容摘要 ....................................................................... 45. y. Nat. sit. 表 4-11 關鍵點及出度 ............................................................................................... 48. n. al. er. io. 表 4-12 點 465 之關鍵點網絡 ................................................................................... 49. i n U. v. 表 4-13 點 412 之關鍵點網絡 ................................................................................... 50. Ch. engchi. 表 4-14 各關鍵點之新聞主題脈絡 ........................................................................... 51 表 4-15 情緒與股價指數之相關係數 ....................................................................... 52 表 4-16 情緒與股價減移動平均線之相關係數 ....................................................... 54 表 4-17 情緒及心理線與股價指數之相關係數 ....................................................... 56 表 4-18 情緒及心理線與股價減移動平均線之相關係數 ....................................... 57 表 4-19 情緒及買賣意願指標與股價指數之相關係數 ........................................... 59 表 4-20 情緒及買賣意願指標與股價減移動平均線之相關係數 ........................... 61. viii.
(10) 第一章. 緒論. 第一節 研究動機與目的 近年來科技、網路以及儲存媒介的發達,產生的資料量呈現爆炸性的成長, 巨量資料(Big Data)也隨著媒體、企業、學界等方的紛紛提及迅速竄紅,正式宣告 巨量資料時代的來臨。以往資料可能在有新聞事件時才被產生與收集,礙於技術 和成本,收集資料也只能藉由抽樣的方式獲得母體部分的資料,再利用樣本來推 測母體;相較於巨量資料,即時的資料隨時產生,幾乎可以直接分析母體而不必 再使用樣本來分析資料。根據研究機構 IDC 指出,2009 至 2020 年資料量將會有. 政 治 大. 44 倍的成長(Ballve, 2013),在這樣的巨量資料成長環境下,除了日後技術上於處. 立. 理或儲存須因應的問題外,對於涉及現實中各層面的巨量資料,能夠在巨量資料. ‧ 國. 學. 中找到有價值的問題,並給予解決也將是很重要的議題。. 巨量資料勢必對現有之資料分析方式產生衝擊,若將傳統之分群分類方法應. ‧. 用於巨量資料中,除了效率之議題外,分出巨量之群集也將於實用性上大大降低。. y. Nat. sit. 因此許多新的分析方式儼然而生,像是以網絡之概念來表達巨量資料,並透過網. n. al. er. io. 絡 之 方 式 來 進 行 分 群 (Handcock, Raftery, & Tantrum, 2007; Vu, Hunter, &. i n U. v. Schweinberger, 2013);甚至是利用網絡分析、連結分析技術,探討在網絡中重要. Ch. engchi. 之節點,成為另一種解析巨量資料之方式(Magnusson, 2012)。 社群網站具有大量輿論與人際互動資訊,會影響群眾行為。2013 年曾發生 駭客入侵 Associated Press 的 Twitter 專頁並發布假消息造成大眾恐慌,立即導 致道瓊工業指數下跌 0.9%(Vigna, 2013);英國的基金公司 Derwent Capital Markets 更藉由 Twitter 推文中的情緒來預測股價波動,最後擁有超過 1.5%的報酬率(許 凱玲, 2011) ,顯示在巨量資料下的資訊傳播,可以迅速的對大眾情緒造成影響, 而大眾情緒甚至與股價波動有相關性(Brown, 1999)。 而以投資的角度,若能利用資料即時了解大環境趨勢,將可大幅提升投資精 準度和報酬率,相較於過往投資人常以移動平均線、心理線、買賣意願指標等技 1.
(11) 術指標作為投資決策,然而有些技術指標需要長時間之數據來計算,屬於落後指 標,如此便不具備資訊的時效性,將無法靈活的對市場做瞭解及反應。若 Twitter 中的推文可以反映大眾情緒,而大眾情緒與股價波動具有關聯,改以同樣具備巨 量資料以及時效性的新聞來觀察,報導的文字或許能反映當下的輿情,萃取出的 輿情或許和股價也具有關聯性。 基於上述論點,本研究的目的可分為以下: (1) 針對巨量新聞資料,除了應用現有之新聞主題偵測與追蹤技術外,並佐 以網絡之概念進行分析,藉由網絡的方式連結新聞,建立能即時產生新. 政 治 大 (2) 藉由情感分析技術來量化新聞輿情,透過新聞資料的輿情找出蘊含的經 立 聞主題脈絡之系統,進而迅速瞭解當前大環境的狀況。. 的問題外,也能成為反映市場趨勢的新指標。. 學. ‧ 國. 濟趨勢,探討與股價的關聯性,藉由即時分析解決技術指標資訊時效性. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. 2. i n U. v.
(12) 第二章. 文獻探討. 第一節 巨量資料(Big Data) 近年來隨著科技進步,電腦分析運算的速度、儲存媒介的容量與性能均大幅 提升,以及行動裝置、社群網路、雲端服務的發展以及物聯網(Internet of Things, IOT)的崛起(Adler, 2013; Atzori, Iera, & Morabito, 2010),大量的資料迅速的產生、 互相傳送與儲存,資料量呈現爆炸性的成長。根據研究指出,在一分鐘內就有 10 萬則新的 Twitter 訊息、200 萬個 Google 搜尋結果以及 600 萬次的 Facebook 訊息 瀏覽,而每天約產生 2.5 EB (Exabytes,1*1018 )的資料(IBM; Intel)。隨著資料的巨. 政 治 大. 幅成長以及媒體期刊的提及,巨量資料(Big Data)這個名詞也逐漸為人所耳熟能. 立. 詳。. ‧ 國. 學 ‧. 2.1.1 巨量資料之定義與特性. y. Nat. 巨量資料可以視為一群資料集的集合,其資料集大小遠超出尋常電腦軟體所. er. io. sit. 能擷取、管理以及在允許時間內處理的量,通常一個資料集的大小可以達到數 PB(Petabytes, 1*1015 ) (Gold, 2012)。然而巨量資料並非只是一個名詞或是術語,. al. n. v i n 反而可以視為在大量資料上處理和應用的總稱。 有學者認為針對巨量資料需要應 Ch engchi U. 用新的處理方式才能達到更佳的決策和結果(Laney, 2001, 2012),並具有資料量 (Volume)、時效性(Velocity)、變化性(Variety)三大特性,後續又有相關報導提出巨 量資料除了這三大特性也必須兼具真實性(Veracity) (Normandeau, 2013),對於這 些特性說明如下:. (1)資料量:巨量資料源自各式各樣的媒介與平台,像是歷年來儲存的交易資 料、社群網站的評論與訊息以及物聯網中行動載體、感應元件資訊的收集等等構 成了龐大的資料量。網際網路和雲端服務的普及也造就了資料能夠大量且快速的. 3.
(13) 流通與儲存。. (2)時效性:對於巨量資料,傳統的儲存再分析的方式除了無法負荷如此龐大 的資料外,對於資料的處理也將耗費大量時間,一旦分析結果的時間過久,資訊 也將不具備價值。因此在巨量資料中,必須能夠對資料進行即時性的儲存、處理 與分析。. (3)變化性:巨量資料涵蓋了各種不同格式的資料,結構化資料如傳統資料庫. 政 治 大 件、電子郵件、音樂、影像等等。 立. 中的數值、交易紀錄;半結構化或非結構化資料如感測器產生的紀錄檔(Log)、文. ‧ 國. 學. (4)真實性:上述提到巨量資料源自於各種類型的資料蒐集而得,然而資料來. ‧. 源多元化時,資料必須有足夠的品質和正確性,才能做為日後分析決策的依據。. y. sit. io. n. al. er. 析的結果。. Nat. 舉例來說,像是於社交網站刻意散布假消息或是刻意抹黑的評價,都會影響到分. 2.1.2 巨量資料之應用. Ch. engchi. i n U. v. 巨量資料其中一個特性為包含大量且廣泛的資訊,也因為其特性所以影響的 領域很廣,凡舉經濟、科技、生技醫療、社群網路分析、趨勢偵測、電子商務甚 至是商業決策等等都在其應用範疇內(Cambria, Rajagopal, Olsher, & Das, 2013)。 然而巨量資料無疑也帶來一些挑戰,以技術面來說,面對無時無刻產生的資料, 除了儲存媒介容量的成長必須趕得上資料的產生速度外(Gantz & Reinsel, 2012), 對於資料的處理與分析技術也得因應即時的大量資料而有提升效率上的需求。 自 2003 年起,Google 陸續提出相關技術(Dean & Ghemawat, 2008; Ghemawat, Gobioff, & Leung, 2003; Melnik et al., 2010),Google File System 為一個分散式檔 4.
(14) 案系統,使得資料能夠分散儲存在不同的儲存媒介中,並且分散儲存的資料也能 夠被存取;MapReduce 為一個演算法,藉由鍵值(Key & Value)對應的方式,能夠 在平行化及巨量資料的環境中快速存取資料;而 Dremel 提供了與資料庫的互動 性並改善以往資料庫存取的效能,於幾秒鐘內就可以處理數兆個資料查詢指令。 有了這些相關技術,巨量資料開始有了被分析的可能,然而除了技術層面, 巨量資料的實際應用也逐漸於現實世界中發生。美國總統歐巴馬(Obama)於 2012 年的總統競選中就利用巨量資料進行分析並擬定競選策略,找出競選資料中支持 者的關聯性與喜好,進而成功達成募款並預測選票的趨勢(Issenberg, 2013; Scherer,. 政 治 大 包裹資訊以及裝載在卡車上感應器的回傳資訊,優比速公司開發了一個稱為 立. 2012);優比速公司(UPS)也於企業營運上使用巨量資料,其中分析大量的顧客與. ORION (On-Road Integration Optimization and Navigation)的系統,藉由此系統可. ‧ 國. 學. 以分析出最佳的運輸路徑,一天可以減少約 3000 萬美元的營運支出(Davenport &. ‧. Dyché, 2013)。. y. Nat. 由以上例子可以得知,藉由巨量資料能促成更精確的分析、提供更可靠的決. er. io. sit. 策,進而可以提升工作效率、降低成本、減少風險並提供趨勢預測、決策支援等 相關應用,因此如何在巨量資料中創造新的價值來源並找出其蘊含的資訊是一個. n. al. 十分重要的議題。. Ch. engchi. 5. i n U. v.
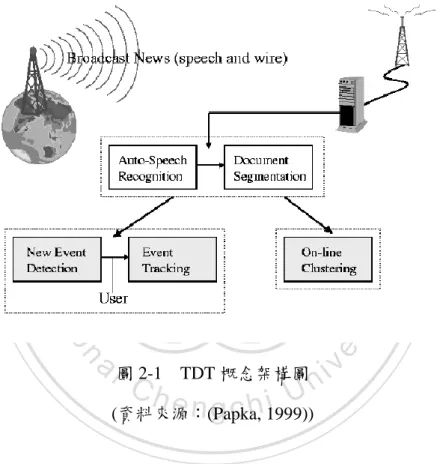
(15) 第二節 新聞主題偵測與追蹤(Topic Detection and Tracking, TDT) 「新聞主題偵測與追蹤(Topic Detection and Tracking, TDT)」之研究始於 1996 年,為美國國防部高等研究計畫局主導之計畫,該計畫最初目的在於利用自動化 技術,將許多具有關聯性的新聞廣播及電子化新聞找出或追蹤新聞事件(Allan, Papka, & Lavrenko, 1998)。其中 TDT 的架構圖如圖 2-1。. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. n. a l圖 2-1 TDT 概念架構圖 i v n Ch U engchi (資料來源:(Papka, 1999)). 起初的新聞主題偵測與追蹤主要分成三大問題,分別為(1)如何將一連串的 資料進行分割,並成為個別的新聞事件或故事;(2)針對某一新聞資料,判斷該新 聞是否為該新聞事件的第一則新聞;以及(3)給予某新聞事件下的數篇新聞,如何 利用這些新聞在接下來的新聞資料中找出接續的新聞。而在 2004 年,定義新聞 主題偵測與追蹤的計劃分成五個主要應用,應用如下(NIST, 2004):. (1) 故事分割:在連續性的新聞主題中,偵測其中的變化並切分成不同的故 6.
(16) 事。 (2) 新聞主題偵測:判斷新進的故事是否屬於既有的新聞事件群集或是為新 群集。 (3) 新聞主題追蹤:將新進的故事分類至相似的新聞事件群集中。 (4) 新故事偵測:偵測新進的故事是否為新聞主題下的第一個故事。 (5) 連結偵測:偵測故事彼此之間是否有主題性的相關聯。. 而所謂的新聞主題(News Topic)可以被定義為: 「新聞主題為一連串相關聯的. 政 治 大 Event)則可以被定義為: 「新聞事件為一事情發生在特定的時間以及地點。」 ,例 立. 新聞事件和活動所構成。」 ,例如「洪仲丘案」(Cieri et al., 2002);而新聞事件(News. 如「白衫軍運動」(Allan et al., 1998)。. ‧ 國. 學 ‧. 2.2.1 新聞主題網絡. sit. y. Nat. 目前已有很多新聞主題偵測與追蹤相關的研究,像是探討新聞間彼此的關聯、. al. er. io. 因果關係甚至以視覺化呈現(Ikeda, Fujiki, & Okumura, 2006; Uramoto & Takeda,. v. n. 1998),基於前述之基礎,有學者提出了建構出新聞主題事件軸的研究(Lin & Liang,. Ch. engchi. i n U. 2008),該研究利用網路爬蟲抓取新聞資料後,應用類神經網路(Neural network)中 的自我組織圖(Self-organizing map, SOM)來對新聞文章進行分類,研究中定義分 類至同一類別的的新聞文章即屬於同一個新聞事件。 後續針對各個歸類出的新聞事件進行餘弦相似度(Cosine Similarity)計算以 了解新聞事件間關係,並將相似度超過門檻值的新聞事件進行連結。建立起各個 新聞事件的連結後,再選定具有高文件頻率(Document frequency)的詞彙做為整個 新聞主題的關鍵字,並利用這些詞彙來計算出各個已連結新聞事件與新聞主題的 關聯度以及新聞事件間連線的權重,之後應用最大生成樹選取出高新聞主題關聯 度及高連線權重的事件,以呈現出新聞主題事件軸的脈絡。最後,再針對新聞主 7.
(17) 題事件軸脈絡下的各個新聞事件,進行新聞內容的摘要。其中新聞主題事件軸的 架構如圖 2-2。. 政 治 大. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. 圖 2-2. engchi. i n U. v. 新聞主題事件軸架構圖. (資料來源:(Lin & Liang, 2008)). 8.
(18) 第三節 情感分析 2.3.1 情感分析之定義 伴隨網際網路盛行以及 Web 2.0 時代的開始,論壇、部落格、微博、Twitter、 Facebook 等社群媒體逐漸興起,使用者的腳色由原本被動的接收資訊演變成資 訊的製造者,甚至開始與新聞、論壇、Wikipedia 內的內容進行互動(Gloor, Krauss, Nann, Fischbach, & Schoder, 2009),這樣的演變造成大量的資料產生,其中也包 含了許多個人的情緒和意見,我們可以藉由情感分析(Sentiment Analysis)技術於 資料中找出像是情緒上的喜怒哀樂或是意見上的褒貶,不必藉由人工的方式讀完. 政 治 大. 大量的資料,就可以快速瞭解大眾對物品的評價或是新聞事件的看法。. 立. 情感分析又稱之為意見探勘(Opinion Mining),基本上在業界較多人稱之為. ‧ 國. 學. 情感分析,而於學術界則是兩者都有學者在使用(Liu, 2012)。總體來說,情感分 析為結合自然語言處理、文字探勘以及資訊檢索等領域的研究(Cambria et al.,. ‧. 2013),目的在針對非結構化的資料像是新聞、評論、文章等,擷取其中的情緒、. y. Nat. n. al. er. io. sit. 評價與態度(Liu, Mobasher, & Nasraoui, 2011; Mishne, 2006)。. 2.3.2 情感詞典. Ch. engchi. i n U. v. 目前情感分析大多數應用於非結構化的文字處理,從文章的結構來看,主要 由句子和詞彙所構成,詞彙為構成字詞意義的最小單位,傳統的情感分析將帶有 情緒或是意見的詞彙區分成正負兩種極性,例如”自信”為帶有正向情緒的詞彙, 極性為正;”自卑”則是帶有反向情緒的詞彙,極性為負(Turney, 2002; Turney & Littman, 2003)。所以詞彙也是能表達情緒和意見的最小的單位,由此得知,在情 感分析中擁有情緒或是意見的詞彙為重要的分析依據(Liu, 2012)。 根據上述論點,針對文章進行情感分析前,要找出帶有情緒或是意見的詞彙, 通常使用的是關鍵字偵測法(Keyword-based Detection Methods),主要為利用已建. 9.
(19) 立的情感辭典與文章進行比對,若找到相符合的詞彙,則根據情感辭典給予該詞 彙符合的情感極性(孫瑛澤, 陳建良, 劉峻杰, 劉昭麟, & 蘇豐文, 2010)。使用關 鍵字偵測法時,情感分析的成效取決於情感辭典的完善程度,目前有三種建構情 感辭典的方法(Feldman, 2013),茲說明如下: (1) 手動方式建立:以人工去判斷該詞彙是否具有情緒或是意見成分,並且 手動判斷該詞彙之極性,準確度高但耗時費力。 (2) 詞典方式(Dictionary-based approaches)建立:事先建立一小部分具有情緒 的種子詞彙,再根據詞典(例如,WordNet)中種子詞彙的”同義詞”與”反義詞”進行. 政 治 大 義詞,則標記相反極性(Miller, Beckwith, Fellbaum, Gross, & Miller, 1990)。 立. 學習,若新進詞彙為種子詞彙的同義詞,則與種子詞彙標記的相同極性;若為反. (3) 語料庫方式(Corpus-based approaches)建立:藉由先建立一小部份具有情. ‧ 國. 學. 緒的種子詞彙,並利用連接詞的概念來判斷在語料庫中的詞彙是否為具有相同極. ‧. 性。例如”妹妹活潑又可愛”,"活潑”與”可愛”分別為形容詞,”又”為連接詞,假. io. er. 為正向情感的詞彙(Hatzivassiloglou & McKeown, 1997)。. sit. y. Nat. 設已知”活潑”為帶有正向情感的詞彙,藉由連接詞建立的關聯,即判斷”可愛”也. 針對情感詞典的建構,由於國外較早開始進行相關研究,外語詞彙部分較為. al. n. v i n 齊全,著名的有 GI(General Inquirer lexicon、MPQA subjectivity C h lexicon)、Sentiment engchi U lexicon、SentiWordNet 以及 Emotion lexicon 等情感詞典(Esuli & Sebastiani, 2006; Hu & Liu, 2004; Mohammad & Turney, 2010; Stone, Dunphy, Smith, & Ogilvie, 1968; Wilson, Wiebe, & Hoffmann, 2005),基於不同領域下相同詞彙可能會有情感的差 異,也有學者於財務領域方面建構專業詞彙的情感詞典(Loughran & McDonald, 2011)。至於中文情感詞典的部分,則有台灣大學自然語言處理實驗室所建立的 NTUSD 意見詞詞典以及知網的 HowNet-VSA 詞典(Ku, Lo, & Chen, 2007; Wu, CHARNG-RURNG TSAI, TZONG-HAN TSAIi, & YUNG-JEN HSU, 2013)。. 10.
(20) 2.3.3 情感分析與股價間之關聯 早在 2003 年,世新大學開始針對台灣股市的投資者進行普查,藉由衡量投 資人的主觀情緒,編制出台灣股票投資人情緒指數,並且探討情緒指數與股價指 數的相關性,研究指出兩者具有正相關(相關係數 0.57),一旦情緒上楊,股價指 數也會跟著上揚(郭敏華, 2009)。其他學者也針對融資比率、放空比率、基金折價 比率、市場成交量等情緒代理變數結合成間接情緒指標(Indirect Sentiment Index), 進而探討與股市市場的報酬程度(Huang, 2013)。 上述研究指出情緒與經濟市場具備了一定程度的關聯性,藉此在情感分析的. 政 治 大 探討情緒是否為造成影響的因素或是用於趨勢上的預測並提供決策用途(Liu, 立 部分,除了瞭解大眾的情緒與意見外,也可以其他專業領域進行關聯性的研究,. ‧ 國. 學. 2012),相關研究像是藉由 Twitter 中發言的情緒推斷股市的趨勢(Bollen, Mao, & Zeng, 2011)、針對金融評論的情緒預測未來經濟走勢(Devitt & Ahmad, 2007)、分. ‧. 析投資人於微網誌中的情緒與股價的關聯性(Bar-Haim, Dinur, Feldman, Fresko, &. sit. y. Nat. Goldstein, 2011; Feldman, Rosenfeld, Bar-Haim, & Fresko, 2011)甚至新聞中的輿情. n. al. er. io. 也被應用於交易策略上(Zhang & Skiena, 2010)。. Ch. engchi. 11. i n U. v.
(21) 第四節 小結 基於上述的文獻探討,本研究打算分析同樣具備巨量特性的新聞文章,結合 新聞主題偵測與追蹤技術以及情感分析,將新聞依時間與相似度進行歸類,並參 考新聞主題事件軸之研究,針對巨量新聞資料建立新聞主題網絡,進而能夠快速 瞭解新聞內容、迅速瞭解新聞發展脈絡。 而相關研究指出情緒與股市指數有正相關之關係,本研究也打算探討新聞所 內涵的情緒是否和經濟指標有相關聯。若具有關聯,透過即時分析情緒使之成為 具備時效性上且能反映市場趨勢的指標,更能成為新的風向球。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 12. i n U. v.
(22) 第三章. 研究方法與設計. 本研究將蒐集而得的大量新聞資料,利用新聞事件偵測與追蹤技術及 k-NN 演算法,將新聞歸類至相關聯的新聞事件,再計算出新聞事件間彼此的關係,建 構出呈現新聞事件連結之新聞主題網絡。最後結合情感分析技術,將新聞進行情 緒運算,在龐大的新聞資料中,能夠快速得知大環境下的新聞情緒並與股價指數 做比較。 整體研究架構如圖 3-1,主要分成五大部分:「資料蒐集」、「資料前處理」、 「新聞事件處理」 、 「產生新聞主題網絡」及「新聞情緒計算」 ,將於後依序介紹。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 13. i n U. v.
(23) (一)資料蒐集. (二)資料前處理 CKIP 斷詞. 新聞文件 詞彙精簡/ 經濟詞彙處理. CNA (網路爬蟲). 特徵值萃取 新聞資料庫. 向量空間模型. 立. 政 治 大. (三)新聞事件處理. ‧ 國. 學. 新聞事件偵測與追蹤. k-NN Algorithm. ‧. n. Ch. engchi. y. sit. io. al. 新聞事件間關係計算. er. Nat. (四)產生新聞主題網絡. i n U. v. (五)新聞情緒計算 情感詞彙判定 情感詞彙計算 新聞層面下的情緒 新聞情緒與股價指數之關係 圖 3-1. 研究架構圖. (資料來源:本研究). 14.
(24) 第一節 資料蒐集 本研究之新聞資料源自中央通訊社網站(http://www.cna.com.tw/),並利用 JSoup 網路爬蟲技術抓取網頁內容,分析該新聞網站的網頁原始碼架構後,抓取 特定 HTML 標籤內的內容,即可取得該篇網頁的新聞本文。另外,因為要針對 新聞做時間上的分析,該新聞上線的時間也是本研究的蒐集目標,其他可供為後 續處理的資料像是新聞標題、作者以及該新聞在中央通訊社網站的預設類別也一 併擷取。 本研究蒐集了 2013 年 7 月至 2014 年 5 月的新聞作為研究資料,經濟類別共. 政 治 大 一類別的新聞進行分析就可直接使用。 立. 計 30,879 篇。除此之外,也分別將其他類別的新聞進行擷取,倘若日後需要對專. ‧ 國. 學. 接著將取得的新聞本文資料連同時間及其餘屬性資料儲存進資料庫中,以供 後續流程處理。如圖 3-2。. ‧. n. er. io. sit. y. Nat. al. 圖 3-2. Ch. engchi. i n U. v. 新聞資料庫其類別及資料數量 (資料來源:本研究). 15.
(25) 第二節 資料前處理 新聞資料為一連串的文字屬於非結構化的資料,資料沒有固定的結構性,因 此在對新聞資料進行偵測與追蹤前,必須先針對抓取的資料做轉換前處理,以量 化的方式來呈現該篇新聞資料,以利後續針對新聞資料進行處理。. 3.2.1 CKIP 斷詞 本研究利用中央研究院的中文詞知識庫小組(Chinese Knowledge Information Processing Group, CKIP)開發的中文斷詞服務系統來處理資料。首先將個別抓取. 政 治 大. 到的新聞資料傳至斷詞系統中,待系統處理完畢後,回傳結果會將新聞資料切割. 立. 成為個別的詞(term)並搭配詞性(part of speech, POS)表示,以下為 CKIP 系統斷詞. ‧ 國. 學. 的前後對照範例: 斷詞前:. ‧. n. al. er. io. sit. y. Nat. 數位影像品牌 Canon 宣布,其 EOS 系列單眼相機全球累計產量在 2 月初已 突破 7000 萬台,預估適用於 EOS 系列數位單眼相機的 EF 鏡頭,可望在 2014 年產量突破 1 億大關。 斷詞後:. Ch. engchi. i n U. v. 數位(A) 影像(N) 品牌(N) Canon(FW) 宣布(Vt) ,(COMMACATEGORY) 其(DET) EOS(FW) 系列(N) 單眼(A) 相機(N) 全球(N) 累計(Vt) 產量(N) 在 (P) 2 月 (N) 初 (POST) 已 (ADV) 突 破 (Vt) 7000 萬 (DET) 台 (M) , (COMMACATEGORY) 預估(Vt) 適用(Vt) 於(P) EOS(FW) 系列(N) 數位 (A) 單眼(A) 相機(N) 的(T) EF(FW) 鏡頭(N) ,(COMMACATEGORY) 可 望 (Vt) 在 (P) 2014 年 (N) 產 量 (N) 突 破 (Vt) 1 億 (DET) 大 關 (N) 。 (PERIODCATEGORY). 16.
(26) 3.2.2 詞彙精簡 本研究蒐集數個月的新聞文章就將近約 3 萬多篇,斷詞後的詞彙數量預計將 會非常龐大,然後有些詞彙對於該文章的內容較無代表性,為避免日後進行新聞 事件處理及情緒運算時過多不必要的資料影響效率及正確性,利用 CKIP 處理過 的資料皆具有詞性標記的特性,在處理時一併刪除不必要的屬性。然而文章中名 詞具備實體識別(Named entity recognition, NER)之特性,可以代表相關之人事時 地物(古倫維, 2000);而動詞可以藉由動作或是面部表情來表示情緒,副詞可以修 飾情緒,具有反映強落程度之特性。故本研究僅保留名詞(N)、名物化動詞(Nv)、. 政 治 大. 副詞(Adv)、及物動詞(Vt)以及不及物動詞(Vi)這五種詞性之詞彙,並刪除中文停 止字,以簡化資料量。. 立. ‧ 國. 學. 3.2.3 經濟詞彙判定. ‧. CKIP 對於擁有較多專有名詞的經濟新聞可能會產生分詞結果不理想的情況. y. Nat. sit. 發生。舉例來說,景氣領先指標為景氣指標其中的一個因子,對於判斷未來景氣. n. al. er. io. 具有一定的參考性,但經由 CKIP 系統處理的結果將會分成”景氣”、”領先”以及”. i n U. v. 指標”三個詞,反而喪失了該詞彙原有的意義,對於之後的新聞文章分群及情緒. Ch. engchi. 計算也將因為分詞處理的結果不佳,導致後續研究有誤差甚至是錯誤。 本研究由收集網路既有之相關經濟詞彙(http://www.quote123.com/aspnet/usm kt/edu/glossary/glossary.aspx)以及股價指數詞彙(http://www.cybertranslator.idv.tw/c omeco_stockindex.htm),並以人工方式過濾 CKIP 已可自行斷詞之 2 至 3 字的短 詞後,進行統整建立出本研究之經濟詞庫,再將該經濟詞庫與斷詞結果做比對, 如果在連續的斷詞結果中與經濟詞庫的詞彙符合,則將該連續斷詞結果進行合併, 成為新的詞彙並更新斷詞結果,使經濟詞彙能夠正確的被判斷出來。. 17.
(27) 3.2.4 特徵詞萃取 在本章節一開始有提到,新聞文章為一連串的文字,屬於非結構化的資料, 為了能進行後續的新聞偵測與追蹤以及應用分類分群的技術,必須擷取出能夠代 表各篇新聞文章的特徵,相關學者研究指出,文章中的詞彙若具備高的 TFIDF 值, 則該詞彙對該篇文章就具有較高的代表性(Salton & Buckley, 1988),故本研究使 用 TFIDF 作為新聞文件的特徵值。 TFIDF 為詞頻(Term Frequency, TF)與逆文件頻率(Inverse Document Frequency, IDF)的乘積,其中 TF 代表一個詞彙在該篇文件出現的次數,而 IDF 則是當一個. 政 治 大. 詞彙同時出現於太多文件時,對該篇文章的重要性則相對降低的所進行的修正,. 立. 𝑡𝑓𝑖,𝑗 =. 學. 𝑛𝑖,𝑗. (公式 1). ∑ 𝑛𝑖,𝑗 |𝑁|. (公式 2). 𝑖. er. io. sit. y. Nat. 𝑖𝑑𝑓𝑖 = log 𝑑𝑓. ‧. ‧ 國. TF 和 IDF 的公式分別如下:. 其中𝑛𝑖,𝑗 是詞彙 i 在文件 j 中出現的次數,而∑ 𝑛𝑖,𝑗 為文件 j 中所有詞彙出現的. al. n. v i n 次數總和,而|𝑁|為文件集中全部的文件數,𝑑𝑓 為詞彙 i 出現在整個文件及的文 Ch e n g c h 𝑖i U 件數。最後𝑡𝑓𝑖𝑑𝑓𝑖,𝑗 即為𝑡𝑓𝑖,𝑗 和𝑖𝑑𝑓𝑖 的乘積。. 然而文件長度可能會影響詞彙出現的次數,為了避免不同文件長度的影響 , 針對 TFIDF 作正規化處理(Popescu, 2001),正規化公式如下:. Weight =. 𝑡𝑓𝑖𝑑𝑓𝑖,𝑗 √∑(𝑡𝑓𝑖𝑑𝑓𝑖,𝑗 ). 18. 2. (公式 3).
(28) 3.2.5 向量空間模型 為了使文件能夠互相進行相似度計算,本研究採用向量空間模型(Salton, Wong, & Yang, 1975),將每份文件轉化成為向量來表示,向量的組成則為該文件 各 詞 彙 的 權 重 值 。 舉 例 來 說 , 每 份 文 件 就 可 透 過 此 方 式 來 表 示 , Doci = (W1 , W2 , W3 , … . , Wn )。如圖 3-3 所示。. 政 治 大. 立. ‧. ‧ 國. 學. 圖 3-3. 向量空間模型. y. sit. io. er. Nat. (資料來源:(Salton et al., 1975)). 最後可以將每份文件向量組合成一個矩陣,即為詞彙-文件矩陣(Term-. n. al. Ch. Document Matrix),如圖 3-4。. 圖 3-4. engchi. i n U. 詞彙-文件矩陣. 19. v.
(29) (資料來源:(Salton & McGill, 1983)). 藉由詞彙-文件矩陣可以計算出文章間的相似程度,在這裡採用的是餘弦相 似度計算,藉由計算兩文件向量間的夾角來代表兩文件於空間中的距離。根據餘 弦函數之特性,角度越小其值越大,相似度也就越高。而餘弦相似度公式如下:. cos 𝜃 =. ∑ 𝐴𝑖 ∗𝐵𝑖 √∑(𝐴𝑖 )2 ∗√∑(𝐵𝑖 )2. (公式 4). 政 治 大. 其中 A 與 B 代表兩向量文件,而𝐴𝑖 與𝐵𝑖 則代表 A 與 B 文件中某一向量維度 之數值。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 20. i n U. v.
(30) 第三節 新聞事件處理 3.3.1 新聞事件偵測與追蹤 本研究參考新聞事件偵測與追蹤的方法來處理新聞事件(Yang et al., 1999), 首先進行新聞事件偵測時須先將各新聞群以向量表示,方法為計算出各個已存在 新聞事件中的群集質心。接下來當一個新聞文件新增時,先進行新聞事件偵測來 判斷是否為新的新聞事件。在這裡應用門檻值(Threshold)的概念,若偵測分數大 於門檻值則不為已存在的新聞事件,並將新進文件歸類至新的群集中;若偵測分 數小於門檻值則接續應用新聞事件追蹤,並應用 k-NN 分類的方式將該新聞文件. 政 治 大. 歸類至現有的新聞事件。而偵測分數的計算如下方公式:. 學. ‧ 國. 立. 𝑘. score(x) = 1 − 𝑚𝑎𝑥𝑐𝑚 ∈𝑤𝑖𝑛𝑑𝑜𝑤 {(1 − 𝑚)𝑠𝑖𝑚(𝑥⃗, ⃗⃗⃗⃗⃗⃗⃗)} 𝑐𝑚𝑖 𝑖. (公式 5). ‧. y. Nat. 在公式中,𝑥⃗為新進入的文件,⃗⃗⃗⃗⃗⃗⃗為新進文件鄰近時間內第 𝑐𝑚𝑖 i 個文件的質心,. er. io. sit. 𝑠𝑖𝑚(𝑥⃗, ⃗⃗⃗⃗⃗⃗⃗)即為新進文件與質心的相似度。此公式加入了時間衰退的概念,其中 𝑐𝑚𝑖 m 為鄰近時間內所含的文件數,k 為文件群集中文件 x 發生的時間至最新文件的. n. al. Ch. 時間區間中所包含的文件數。. engchi. i n U. v. 根據(Yang, Ault, Pierce, & Lattimer, 2000; Yang et al., 1999; 戴尚學, 2003)的 研究指出此新聞事件偵測之門檻值通常為 0.15 至 0.23 之間,故本研究採平均值, 設定新聞事件偵測之門檻值為 0.19;而根據(Chen, Chen, Sun, & Chen, 2003)之研 究,新聞事件之週期通常為 7 天,故 m 值為 7 天新聞區間內所包含的文件數量。. 3.3.2 新聞事件偵測與追蹤之參數設置 為往後之實驗能取得較佳之結果,本研究先利用少量之新聞資料進行多次的 新聞事件偵測與追蹤,進而調整出較佳的參數。資料方面則採用 2013 年 7 月至 21.
(31) 2013 年 10 月之新聞做為測試研究資料,經濟類別共計 7057 篇。 於新聞事件偵測之參數設定方面,原則上延續先前學者之研究,新聞事件偵 測門檻值設定為 0.19,而偵測分數公式中的 m 值則設定為 7 天內新聞數。 於新聞事件追蹤之參數設定方面,本研究嘗試以 K 值為 3、5,新聞事件追 蹤門檻值為 0.01、0.02、0.03…至 0.1 之組合進行重複測試,並利用平均群內相 似度及平均群間相似度作為衡量指標,判斷出最佳之參數組合。 平均群內相似度之公式如下:. ∑𝐶𝑘. ∑𝑑 ∈𝐶 ∑𝑑 ∈𝐶 𝑠𝑖𝑚(𝑑𝑖 ,𝑑𝑗 ) 𝑖 𝑘 𝑗 𝑘. 𝑁𝑘. 1 𝑁𝑘 ×(𝑁𝑘 −1)× 2. 𝑁. 立. × 政 治 大. ∑𝑐 ∈𝐶 ∑𝑐 ∈𝐶 𝑠𝑖𝑚(𝑐𝑖 ,𝑐𝑗 ) 𝑖 𝑗 1 2. 𝐶×(𝐶−1)×. Nat. er. io. sit. y. (公式 7). ‧. ‧ 國. 學. 平均群間相似度之公式如下:. (公式 6). 於公式 6 中,N 代表文件總數量,𝑁𝑘 為群𝐶𝑘 之文件總數量,𝑠𝑖𝑚(𝑑𝑖 , 𝑑𝑗 )則代. al. n. v i n 表在𝐶𝑘 中之文件 i 及文件 j 之相似度;於公式 7 中 C 代表了群集總數量,而 Ch engchi U. 𝑠𝑖𝑚(𝑐𝑖 , 𝑐𝑗 )則代表了 i 群及 j 群兩群集之質心相似度。而不同 K 值與新聞事件追. 蹤門檻值之平均群內相似度及平均群間相似度如下表 3-1。. K值. 3. 門檻值. 平均群內相似度. 平均群間相似度. 0.01. 0.081748536. 0.091681382. 0.02. 0.12891513. 0.051400679. 0.03. 0.140052288. 0.039726055. 0.04. 0.178041327. 0.030818848. 0.05. 0.192276527. 0.026859892. 0.06. 0.209906813. 0.023318979. 0.07. 0.22342914. 0.021786781. 22.
(32) 5. 0.08. 0.242126439. 0.021144883. 0.09. 0.243777809. 0.019962172. 0.1. 0.256878286. 0.018644142. 0.01. 0.109433465. 0.082568527. 0.02. 0.129264322. 0.054433971. 0.03. 0.141010668. 0.034630331. 0.04. 0.174811071. 0.027642149. 0.05. 0.19952154. 0.02563959. 0.06. 0.208188448. 0.02302509. 0.07. 0.223985687. 0.021105652. 0.08. 0.247103336. 0.02017266. 0.09. 0.245328047. 0.019242309. 0.1 表 3-1. 立. 0.258428524 治 0.018075193 政 大 平均群內相似度及平均群間相似度 (資料來源:本研究). ‧ 國. 學. 觀察上表 3-1,由於提升門檻值時,平均群內相似度會相對增加,平均群間. ‧. 相似度會相對減少,會有較好之分群品質但也會提升總分群數,因此必須取得門. y. Nat. sit. 檻值與分群數之平衡。. n. al. er. io. 故本研究透過比較變化量之方式來決定參數組合,觀察於何門檻值時,平均. i n U. v. 群內相似度會相對增加幅度最大,而平均群間相似度會相對減少幅度最大。平均. Ch. engchi. 群內相似度與平均群間相似度兩者之變化量,如下圖 3-5、圖 3-6。. 平均群內相似度之變化量 K=3. K=5. 變化量. 0.04 0.03 0.02 0.01 0 -0.01. 0.01. 0.02. 0.03. 0.04. 0.05. 0.06. 事件追蹤門檻值 23. 0.07. 0.08. 0.09. 0.1.
(33) 圖 3-5. 平均群內相似度之變化量 (資料來源:本研究). 平均群間相似度之變化量. 變化量. K=3 0.045 0.04 0.035 0.03 0.025 0.02 0.015 0.01 0.005 0 0.02. 0.03. 立. 圖 3-6. 政 治 大 0.04. 0.05. 0.06. 0.07. 0.08. 0.09. 0.1. 事件追蹤門檻值. 學. 平均群間相似度之變化量 (資料來源:本研究). ‧. ‧ 國. 0.01. K=5. sit. y. Nat. 觀察圖 3-5,當門檻值為 0.04 時,平均群內相似度之增加幅度最大;而觀察. al. er. io. 圖 3-6,可以發現門檻值從 0.02 至 0.04 時,其平均群間相似度之減少幅度相對其. v. n. 他門檻值為大,觀察到這裡可以將門檻值之範圍縮減至 0.02~0.04。然而在比較 3. Ch. engchi. i n U. 者分群品質之情況下,0.04 之分群品質會比 0.02 及 0.03 良好,故本研究選擇 0.04 作為新聞事件追蹤之門檻值;接著參考 K=3 及 K=5 時,分群門檻值為 0.04 之平 均群內相似度及平均群間相似度,發現在平均群內相似度差異不大之情況下, K=5 之平均群間相似度明顯低於 K=3 之平均群間相似度,顯示 K=5 為較佳選擇。 總結以上,本研究決定採取新聞事件偵測與追蹤之參數為:. 新聞事件偵測門檻值為 0.19、K 值為 5、新聞事件追蹤門檻值為 0.04. 24.
(34) 第四節 產生新聞主題網絡 3.4.1 新聞事件間關係計算 本研究接下來參考(Uramoto & Takeda, 1998)運用權重的概念將新聞事件間 的關係呈現,利用此公式可以衡量各新聞事件下詞彙的權重,公式如下:. 𝐶𝜀𝑗 (𝑡𝑒𝑟𝑚𝑖 ). 𝜀. weight(𝑡𝑒𝑟𝑚𝑖 𝑗 ) = 𝜀𝑗. 𝑔𝑡𝑒𝑟𝑚 = { 𝑖. 其中𝐶𝜀𝑗. ∑𝑣𝑒𝑐𝑡𝑜𝑟 𝐶𝜀 (𝑡𝑒𝑟𝑚) 𝑗. × log 𝑁. 𝜀. 𝑘 𝑘 (𝑡𝑒𝑟𝑚𝑖 ). 𝑗 × 𝑔𝑡𝑒𝑟𝑚 𝑖. (公式 8). 1.5 , 𝑡𝑒𝑟𝑚𝑖 𝑑𝑜𝑛`𝑡 𝑎𝑝𝑝𝑒𝑎𝑟 𝑖𝑛 𝑡ℎ𝑒 𝑝𝑟𝑒𝑣𝑖𝑜𝑢𝑠 𝑘 𝑒𝑣𝑒𝑛𝑡𝑠 , 𝑎𝑛𝑑 𝑡𝑒𝑟𝑚𝑖 with high DF. 1 , 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒. 政 治 大 (𝑡𝑒𝑟𝑚 )代表在新聞事件𝜀 中𝑡𝑒𝑟𝑚 出現的次數;∑ 立 𝑖. 𝑖. 𝑗. 𝑣𝑒𝑐𝑡𝑜𝑟 𝐶𝜀𝑗. (𝑡𝑒𝑟𝑚)為. ‧ 國. 學. 此新聞事件𝜀𝑗 下的總詞彙數;𝑁𝑘 (𝑡𝑒𝑟𝑚𝑖 )代表發生在此新聞事件𝜀𝑗 之前的 K 個新 𝜀. 𝑗 聞事件中包含𝑡𝑒𝑟𝑚𝑖 的新聞事件數;𝑔𝑡𝑒𝑟𝑚 為針對此詞彙是否有出現在𝜀𝑗 之前的 K 𝑖. ‧. 個新聞事件中而做的修正權重,因為對此新聞事件𝜀𝑗,越多詞彙沒有在先前 K 個. y. Nat. sit. 新聞事件中出現,則此新聞事件𝜀𝑗 可能包含先前 K 個新聞事件沒有提及的資訊,. n. al. er. io. 因此有越多差異字存在,代表此新聞事件𝜀𝑗 越難和之前的 K 個新聞事件有相關. i n U. v. 聯,而此新聞事件越有可能成為一特定新聞事件串的起頭。. Ch. engchi. 本研究挑選各新聞事件中前十高文件頻率的詞彙,建立起各新聞事件中每個 詞彙的權重後,再利用先前向量空間模型的概念,建立起新聞事件與詞彙的矩陣, 便可進行新聞事件間的相似度計算。新聞事件間的連結建立則是根據彼此間的相 似度,如超過門檻值則建構出新聞事件間的連線。而研究指出,最佳的 K 值為 3,新聞事件相似度門檻值為 0.04302(Lin & Liang, 2008; 胡家瑜, 2009)。. 25.
(35) 第五節 新聞情緒計算 3.5.1 情感詞彙判定 此部分將對文章中的詞彙進行判斷,判斷該詞彙是否具有情感成分,並將 此字詞標記為情感詞彙,以利後續進行新聞輿情的研究。本研究採用國立台灣 大學意見詞詞典(NTUSD),將分詞後的結果與意見詞詞典進行比對,若有相符 合的詞彙,便進行情感詞彙及極性(polarity)的標記。 考量到情感詞彙之前的修飾詞可能會影響情感詞彙的極性,例如樂觀與不 樂觀,雖然在意見詞典庫中樂觀所代表的極性為正向,但加入”不”這個修飾詞. 政 治 大. 後,便會改變該字詞的極性。本研究參考(李啟菁, 2010)建立的否定字詞庫,於. 立. 情感詞彙判定時一起加入判斷,做法為當找出情感詞彙時,往前尋找該情感詞. ‧ 國. 學. 彙的前一個詞彙是否與否定字詞庫中的詞彙有相符合,若符合則將目前情感詞 彙的極性反向標記;反之,不符合則維持目前情感詞彙的極性。. ‧ y. Nat. er. io. sit. 3.5.2 情感詞彙計算. 本研究預計將蒐集而得的新聞,依時間排列而呈現出長時間下新聞的情緒變. al. n. v i n 化,在此之前,必須針對單篇新聞的內涵情緒做計算,本研究參考先前學者針對 Ch engchi U 微博文章的情感計算(婁鑫坡, 2012),其計算公式如下:. Sentiment Score(𝑑𝑜𝑐𝑗 ) = ∑𝑡𝑖 ∈𝑠𝑡 𝑝𝑜𝑙𝑎𝑟𝑖𝑡𝑦(𝑡𝑖 ) ∗ 𝑡𝑖 𝑝𝑜𝑙𝑎𝑟𝑖𝑡𝑦(𝑡𝑖 ) = {. (公式 9). +1 , sentimental polarity is positve. −1 , sentimental polarity is negative.. 其中𝑑𝑜𝑐𝑗 代表新聞文章,而𝑠𝑡代表該新聞文件中具備情緒及極性標記的情緒 詞彙集合,𝑝𝑜𝑙𝑎𝑟𝑖𝑡𝑦(𝑡𝑖 )代表該情緒詞彙的正負極性,若情緒為正向值為+1,反之 則為-1。而𝑡𝑖 代表了該情緒詞彙的情緒分數,在這裡並不探討每個詞彙的情緒強 26.
(36) io. sit. y. ‧. ‧ 國. 學. Nat. n. 2013-07-13 06:50:12 2013-07-13 08:31:13 2013-07-13 09:00:13 2013-07-13 09:11:13 2013-07-13 09:41:14 2013-07-13 10:38:14 2013-07-13 10:48:15 2013-07-13 12:04:16 2013-07-13 12:31:17 2013-07-13 12:45:17 2013-07-13 14:30:18 2013-07-13 15:14:19 2013-07-13 16:01:20 2013-07-13 18:13:22 2013-07-13 19:15:23 2013-07-13 19:43:24 2013-07-13 22:09:26 2013-07-14 10:07:30 2013-07-14 10:16:30 2013-07-14 10:33:31 2013-07-14 11:02:31 2013-07-14 11:31:32 2013-07-14 14:32:36 2013-07-14 14:55:36 2013-07-14 15:22:36 2013-07-14 17:23:38 2013-07-14 18:29:39 2013-07-14 21:26:41 2013-07-14 21:35:41. 14 12 10 8 6 4 2 0 -2 -4 -6. 立. 圖 3-7. al. (資料來源:本研究). v i n 新聞情緒值分布圖(新聞層面) C hengchi U er. 新聞情緒. 弱程度,故假設每個具有情緒的詞彙其詞彙情緒值均為 1。最後將該新聞文件中. 所有詞彙情緒值做加總,即可得到該篇新聞的情緒分數。. 3.5.3 新聞層面下的情緒 計算出所有蒐集而得的新聞文章情緒後,以下擷取七月中某兩日的新聞,簡. 略示意其情緒之分布狀況,如圖 3-7。. 新聞情緒值分布圖(新聞層面) 每篇新聞情緒值. 政 治 大. 圖 3-7 為新聞情緒之分布圖,橫軸為新聞文章發佈的時間,縱軸代表該篇文. 章的情緒值,兩日內共有 57 篇文章的情緒值,因新聞文章在抓取時即依時間順. 序依序抓取,故圖 3-5 之情緒呈現也具備依時間排列之特性。. 然而本研究於三個月內蒐集而得的文章即達 7057 篇,考量到過多資料時圖. 表上呈現的資訊反而更為雜亂,並且暫時不考慮情緒極端值的情況下,一日內各. 篇文章情緒差異程度可能很小,光以各篇文章間的情緒分布可能無法有效的判斷. 出情緒趨勢與波動,故本研究將新聞情緒的呈現從”篇”改以”日”為單位,其做法. 27.
(37) 為將一天內的每篇文章情緒值以投影(project)的方式投影至縱軸,假設該天共有 20 則新聞文章,則將該 20 則新聞文章的情緒值對縱軸做投影,即可得到該天情 緒值的數量分布圖,如圖 3-8。. 一日情緒值數量分布圖(新聞層面). 政 治 大. 立 -1. 0. 1. 2. 3. 5. 新聞情緒. 7. 12. ‧. 一日情緒值數量分布圖(新聞層面). Nat. y. 圖 3-8. io. n. al. sit. (資料來源:本研究). er. -3. 分布曲線. 學. 5 4.5 4 3.5 3 2.5 2 1.5 1 0.5 0. ‧ 國. 情緒次數. 次數. i n U. v. 藉由圖 3-8 的情緒值數量分布,可以得知該日情緒的分布狀況,也可得知該. Ch. engchi. 日情緒的平均值、標準差、最大值以及最小值,本研究利用平均值作為當日情緒 的代表值,而標準差、最大值以及最小值則可作為當日新聞情緒分布情況,並藉 由這些數值瞭解當日新聞情緒是否有特別的變化,例如有極端情緒值發生,最大 或最小值可作為後續資料判讀的參考。後續對每日的新聞進行相同步驟,得出每 日的平均情緒值後,就可以得出以”日”為單位的新聞情緒分布,並以此情緒分布 代表總體之新聞情緒。下圖簡略呈現七月份的每日平均情緒值,如圖 3-9。. 28.
(38) 每日平均情緒圖(新聞層面) 平均情緒值 7 6 4. 3 2 1 0 -1 -2. -3. 2013/7/1 2013/7/2 2013/7/3 2013/7/4 2013/7/5 2013/7/6 2013/7/7 2013/7/8 2013/7/9 2013/7/10 2013/7/11 2013/7/12 2013/7/13 2013/7/14 2013/7/15 2013/7/16 2013/7/17 2013/7/18 2013/7/19 2013/7/20 2013/7/21 2013/7/22 2013/7/23 2013/7/24 2013/7/25 2013/7/26 2013/7/27 2013/7/28 2013/7/29 2013/7/30 2013/7/31. 日平均情緒值. 5. 圖 3-9. 立. 政 治 大. 每日平均情緒圖(新聞層面) (資料來源:本研究). ‧ 國. 學. 藉由圖 3-9 的每日平均情緒可以看出日與日間情緒的差異,情緒走勢是否持. ‧. 續上升或是下降,亦或是發生轉向的情形。. n. er. io. al. sit. y. Nat. 3.5.4 新聞情緒與股價指數之關係. i n U. v. 將每天之經濟新聞進行情緒計算後,股價指數方面則採用台灣證券交易所編. Ch. engchi. 製之發行量加權股價指數,並以收盤指數進行與新聞情緒做比較。股價指數資料 則擷取自 Yahoo Finance 之歷史股價資訊(代碼:^TWII),為期與新聞同期,同樣 為 2013 年 7 月至 2014 年 5 月。Yahoo Finance 之台灣發行量加權股價指數資訊 如下圖 3-10。. 29.
(39) 立. 政 治 大. (資料來源:Yahoo Finance). 學. ‧ 國. 圖 3-10 台灣發行量加權股價指數. ‧. Nat. n. al. r=. er. io. sit. coefficient)來測量兩變數關係之強弱,其計算公式如下:. y. 兩者之關聯性計算部分,本研究採用皮爾森相關係數(Pearson correlation. ∑𝑛 ̅) 𝑖=1(𝑥𝑖 −𝑥̅ )(𝑦𝑖 −𝑦. Ch. engchi. i v(公式 10) n U. 𝑛 2 √[∑𝑛 ̅)2 ] 𝑖=1(𝑥𝑖 −𝑥̅ ) ][∑𝑖=1(𝑦𝑖 −𝑦. 其中𝑥𝑖 為第 i 個 x 的數值,𝑦𝑖 為第 i 個 y 的數值,𝑥̅ 為 x 的平均數,𝑦̅為的平 均數,計算出的 r 會介於-1 至 1 間,並以|𝑟|之值代表兩變數關係,傳統上當|𝑟| ≤ 0.3為低度相關,0.3 < |𝑟| < 0.6為中度相關,而|𝑟| ≥ 0.6時為高度相關。. 30.
(40) 第四章. 研究結果. 第一節 網絡式新聞主題 本研究蒐集之新聞區間為 2013 年七月至 2014 年五月,蒐集共計 30,879 篇 經濟新聞,應用 3.3 節之新聞事件偵測與追蹤方式,在新聞事件偵測門檻值為 0.19、K 等於 5 及新聞事件追蹤門檻值等於 0.04 之參數下,共計分出 603 群。然 而就實際觀察分群之結果,發現有大量之群集僅有數篇新聞,較難觀察出其群集 之基本概念;藉此,本研究採用平均值之概念,將群內新聞數大於平均群新聞數 之群集作為有效群集,而群內新聞小於平均群新聞數之群集則捨去。經分析而得,. 政 治 大. 平均群新聞數為 51.2,而群內新聞數大於 51.2 之群集共有 155 群,155 群之總新. 立. 聞數為 24,152 篇,約占 80%之新聞量。. ‧ 國. 學. 在 155 群有效群集中,也觀察到群集間具有相似的內容,其內容似乎具有相 互連結之特性,本研究預計藉由連結各新聞事件進而建構出新聞主題性之概念。. ‧ y. Nat. er. io. sit. 4.1.1 群集連結建立. 本研究根據 3.4.2 小節之方式計算出各有效群集間之相似程度,建構連線之. al. n. v i n 門檻值則設為平均群間相似度C0.02764,一但相似度大於平均群間相似度則建立 hengchi U. 起群集間之連線。待群集連結計算完成後,利用圖形化程式描繪出各群集間相連 線之網絡,如下圖 4-1. 31.
(41) 政 治 大. 立. ‧. 群集連結之網絡. Nat. y. ‧ 國. 學. 圖 4-1. n. er. io. al. sit. (資料來源:本研究). i n U. v. 觀察圖 4-1 群集連結之網絡圖,線條代表群集間互有關聯,且連線具有方向. Ch. engchi. 性,因分群採用新聞事件偵測與追蹤之方法,群集的產生具有先後順序,群集之 數字越大者也代表其越晚發生,而被指向之群集將會比來源之群集晚發生;連線 之粗細則代表群集間之相似程度,線條越粗相似程度就越高。從連線可看出各群 集因彼此間關係進而相互連結且匯集,而連線越密集處更可能因為匯集了許多群 集而蘊含出新聞主題之概念。. 32.
(42) 4.1.2 網絡關鍵點 在網絡中連線越密集處之群集越具有其重要性,在網絡不複雜之情況下,我 們可以用觀察之方式找出網絡關鍵點。然而在此複雜之網絡中,觀察之方式顯然 不切實際且有失偏頗,為此本研究採用連結分析之方式,藉由計算其中各節點之 Eigenvector Centrality 與 Page Rank 之數值,分別取其數值前 30 之節點再互相取 交集,進而得出在網絡中之關鍵點。 取得網絡中的關鍵點後,本研究接著觀察關鍵點與其衛星點之內容,探討是 否能夠藉由關鍵點以及連結其衛星點群集,萃取出網絡中相似之群集,並藉此概. 政 治 大. 念達成在巨量資料中產生新聞主題之目標,以下簡略呈現 10 個網絡中之關鍵點:. 立. ‧. ‧ 國. 學. (1) 關鍵點 124:. n. er. io. sit. y. Nat. al. Ch. engchi. 圖 4-2. i n U. v. 關鍵點 124. (資料來源:本研究). 新聞主題: 核能議題 群集編號. 新聞數量. 群集內容摘要. 10. 56. 颱風、停電 33.
(43) 14. 55. 工程會. 46. 98. 再生能源. 84. 168. 核四議題、公投. 124. 58. 原能會、福島核電廠. 144. 102. 電價、用電. 177. 98. 核四、台電 表 4-1. 關鍵點 124 之連結內容摘要. (資料來源:本研究). (2) 關鍵點 149:. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 圖 4-3. i n U. v. 關鍵點 149. (資料來源:本研究). 新聞主題: 產業新聞 群集編號. 新聞數量. 群集內容摘要 34.
(44) 3. 139. 大立光新聞. 6. 263. 鴻海新聞. 8. 347. 手機、平板新聞. 9. 268. 台灣 GDP、PMI. 12. 292. 面板商新聞. 21. 191. 美債、各國債卷. 24. 388. HTC 新聞. 45. 147. 聯發科新聞. 64. 82. 83. 154. 94. 276. 華碩新聞. 137. DRAM 新聞. 108. 金控業新聞. 130. 矽品、日月光新聞. 359. 台灣公司 EPS、股利. ‧ 國. 112. 199. 63. 233. 131. 台灣公司營收新聞、業績. 236. 75. 台灣出口新聞. 249. 120. 太陽能新聞. 320. 64. 業界營收新聞. 321. 57. 業界營收新聞. 326. 68. 雲端新聞. 366. 123. 晶片廠新聞. 412. 94. 台灣公司營收新聞、業績. v. 巴西經濟新聞. n. al. er. sit. y. 156. io. 149. Nat. 145. ‧. 120. 學. 104. 立. 政 治電路板廠新聞 大 台積電、電子股. Ch. i n U. e n g c h i 聯電新聞. 35.
(45) 表 4-2. 關鍵點 149 之連結內容摘要. (資料來源:本研究). (3) 關鍵點 190:. 立. 政 治 大 關鍵點 190. ‧. ‧ 國. 學. 圖 4-4. (資料來源:本研究). n. al. er. io. sit. y. Nat. 新聞主題: 兩岸經貿. v. 群集編號. 新聞數量. 4. 279. 11. 254. 人民幣、台幣、定存. 48. 213. 自由經濟示範區. 62. 88. 台商新聞. 85. 168. 金管會、第三方支付. 113. 217. 兩岸金融、人民幣 TRF、TMU 業務. 135. 67. 服貿協議、陸資來台. 180. 171. 金融業新聞. 190. 72. 上海自貿區. Ch. 群集內容摘要. i n U. e n g c服貿協議相關新聞 hi. 36.
(46) 217. 51. 兩岸電子商務、第三方支付. 220. 88. 亞洲經濟新聞、WEF. 303. 211. 台星經貿協議 表 4-3. 關鍵點 190 之連結內容摘要. (資料來源:本研究). (4) 關鍵點 255:. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. C圖h4-5 關鍵點 255 U n i engchi. v. (資料來源:本研究). 新聞主題: 房地產 群集編號. 新聞數量. 群集內容摘要. 9. 268. GDP、PMI、經濟成長新聞. 28. 62. 房仲、奢侈稅、囤房新聞. 50. 83. 實價登錄、房價. 79. 238. 美國經濟成長新聞、房屋、建商 37.
(47) 74. 136. 房市、房價. 113. 217. 金管會. 180. 171. 金融業、各大金控新聞. 210. 151. 日股、亞股. 250. 62. 國外房價、房貸. 255. 110. 財務部長、房價、打房 表 4-4. 關鍵點 255 之連結內容摘要. (資料來源:本研究). (5) 關鍵點 303:. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 圖 4-6. i n U. v. 關鍵點 303. (資料來源:本研究). 新聞主題:貿易協定 群集編號. 新聞數量. 群集內容摘要. 4. 279. 服貿新聞. 62. 141. 台商新聞. 73. 85. 台灣出口貿易新聞 38.
(48) 125. 106. 歐盟、台歐經貿. 153. 243. 韓國 FTA. 176. 66. 台星經貿. 190. 72. 上海自貿區、金管會、大陸設分行. 217. 51. 兩岸電子商務、第三方支付. 220. 88. WEF、亞太經濟新聞. 236. 75. 台灣出口貿易新聞. 303. 221. 台星經貿、跨太平洋夥伴協定(TPP). 427. 201. 立. 表 4-5. 治 政 服貿新聞、太陽花學運 大 關鍵點 303 之連結內容摘要. ‧ 國. 學. (資料來源:本研究). ‧. (6) 關鍵點 308:. n. er. io. sit. y. Nat. al. Ch. engchi. 圖 4-7. i n U. 關鍵點 308. (資料來源:本研究). 39. v.
(49) 新聞主題:國際財經新聞 群集編號. 新聞數量. 群集內容摘要. 17. 179. 央行、通貨膨脹. 30. 93. 台灣景氣、失業率. 40. 78. 英國經濟新聞. 79. 238. 美國經濟、房屋、房價. 91. 158. 黃金價格. 95. 302. 日本經濟、安倍經濟學. 102. 144. 103. 396. 143. 399. 歐元新聞. 66. 新加坡經濟新聞. 151. 日股、亞股. 88. 亞洲經濟新聞、WEF. 90. 美國經濟、聯準會、QE 新聞. ‧ 國 67. 345. 100. 465. 52. y. sit. al. v. 外商新聞. n. 324. er. io. 308. Nat. 220. ‧. 210. 立. 學. 176. 美國經濟、QE 新聞 政 治 大 美股. Ch. i n U. e n g c h i葉倫、QE 日幣新聞、通貨膨脹. 表 4-6. 關鍵點 308 之連結內容摘要. (資料來源:本研究). 40.
(50) (7) 關鍵點 324:. 圖 4-8. 學. ‧ 國. 立. 政 治 大 關鍵點 324. (資料來源:本研究). y. ‧. Nat. sit. 新聞主題:國際財經新聞. 91. 158. 102. 144. 103. 396. 美股. 176. 66. 新加坡經濟新聞. 210. 151. 日股、亞股. 259. 96. 國際油價. 263. 102. LED 產業新聞. 308. 90. 美國經濟、聯準會、QE 新聞. 324. 67. 外商新聞. n. al. 群集內容摘要. er. 新聞數量. io. 群集編號. Ch. i n U. v. 黃金價格. e n g c美國經濟、QE hi 新聞. 41.
(51) 465. 日幣新聞、通貨膨脹. 52 表 4-7. 關鍵點 324 之連結內容摘要. (資料來源:本研究). (8) 關鍵點 366:. 立. 政 治 大. ‧. ‧ 國. 學 y. 關鍵點 366. (資料來源:本研究). n. al. er. io. sit. Nat. 圖 4-9. i Ch 新聞主題: 產業新聞U n engchi. v. 群集編號. 新聞數量. 群集內容摘要. 3. 139. 大立光新聞. 12. 292. 面板商新聞. 45. 147. 聯發科新聞. 64. 82. 電路板廠新聞. 104. 137. DRAM 新聞. 149. 359. 台灣公司 EPS、股利. 199. 63. 聯電新聞 42.
(52) 233. 131. 台灣公司營收新聞、業績. 249. 120. 太陽能新聞. 366. 123. 晶片廠新聞. 412. 94. 台灣公司營收新聞、業績 表 4-8. 關鍵點 366 之連結內容摘要. (資料來源:本研究). (9) 關鍵點 412:. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. i n U. engchi. v. 圖 4-10 關鍵點 412 (資料來源:本研究). 新聞主題: 產業新聞 群集編號. 新聞數量. 群集內容摘要. 6. 263. 鴻海新聞. 12. 292. 面板商新聞. 15. 104. 製造業、外銷訂單 43.
(53) 24. 388. HTC 新聞. 45. 147. 聯發科新聞. 64. 82. 電路板廠新聞. 94. 276. 華碩新聞. 104. 137. DRAM 新聞. 120. 108. 金控業新聞. 145. 130. 矽品、日月光新聞. 149. 359. 台灣公司 EPS、股利. 199. 63. 233. 131. 236. 75. 台灣出口貿易新聞. 154. 仁寶、華寶. 120. 太陽能新聞. 123. 晶片廠新聞. 94. 台灣公司營收新聞、業績. al. n. 表 4-9. er. sit. y. ‧ 國. io. 412. Nat. 366. ‧. 249. 立. 學. 240. 政 治 聯電新聞 大 台灣公司營收新聞、業績. v. 關鍵點 412 之連結內容摘要. i n C(資料來源:本研究) hengchi U. (10) 關鍵點 465:. 44.
(54) 圖 4-11 關鍵點 465 (資料來源:本研究). 新聞主題:國際財經新聞 群集編號. 新聞數量. 群集內容摘要. 17. 179. 央行、通貨膨脹. 40. 78. 英國經濟新聞. 91. 158. 黃金價格. 95. 302. 日本經濟、安倍經濟學. 102. 144. 103. 396. 澳洲、日澳協議. 399. 歐元新聞. 74. 央行、QE 退場 日股、亞股. 324. 67. 384. 53. 465. 52. al. 美國、聯準會、QE 新聞. n. 90. er. io. 308. sit. 151. y. Nat. 210. ‧ 國. 185. 144. ‧. 143. 美股. 學. 137. 立. 政 治美國、QE 大 新聞. Ch. engchi. i n U. v. 外商新聞. 菲律賓經濟新聞. 日幣新聞、通貨膨脹 表 4-10 關鍵點 465 之連結內容摘要 (資料來源:本研究). 觀察上述列舉之 10 點關鍵點之連結內容,可以發現建立連線關係的各群集 間的確具有相關聯的新聞內容,並可根據關鍵點及其衛星點歸納出明確之新聞主 題概念。而下圖 4-12 為各關鍵點及衛星點在網絡中的分布情形。. 45.
(55) 立. 政 治 大. sit er. io. (資料來源:本研究). y. ‧. ‧ 國. 學. Nat. 圖 4-12 網絡中各關鍵點及衛星點. al. n. v i n 觀察上圖 4-12,各關鍵點以大圓圈表示 ,而關鍵點之衛星點則以小圓圈表示, Ch engchi U. 並以顏色區別各關鍵點及其衛星點。在上色之後可以明顯看出群集間匯集之情形, 並可發現關鍵點間其實也相互具有連線,在先前 10 點的關鍵點內容分析中,也 發現幾個關鍵點具有相似之新聞主題,似乎新聞主題間也具有相互連結之特性。 本研究認為,利用網絡之特性,除了可以將各群集匯集出新聞主題之概念, 藉由關鍵點代表新聞主題;而匯集出的各個新聞主題也可以藉由網絡之方式將相 似或是發生於前後不同時間點的新聞主題連結,進而產生新聞主題之脈絡。. 46.
(56) 4.1.3 新聞主題脈絡 接續上一小節之論點,本研究將探討網絡中各新聞主題之相互連結,是否能 夠形成新聞主題之脈絡或是將網絡分成特定幾個新聞主題。然而新聞主題的形成 是藉由找出網絡中的關鍵點而得,所以本研究也將從關鍵點的角度來找出新聞主 題之脈絡。 在先前也有提到,網絡中群集的連結是具有方向性的,連結的源頭為較早發 生之群集,而連結中箭頭指向的群集為後續產生之群集。根據這樣的連結方式, 匯集而得的網絡其最終端之節點將不會有任何從自身延伸而出的連結,也就是出. 政 治 大 端節點,再以最終端節點追溯其與先前節點之連線(即最終端節點之進度),進而 立. 度(Out-Degree)為 0。故本研究打算結合關鍵點及出度判斷新聞主題脈絡之最終. 關鍵點. 528. 0. 236. y. 465. 0. 235. sit. Nat. 出度. io. a l0. n. 427. 出度 5 0. er. 關鍵點. ‧. ‧ 國. 學. 得到此節點之新聞主題脈絡。下表 4-11 呈現網絡中各關鍵點以及其出度。. Ch. i n U 233. engchi. v. 6. 220. 4. 1. 217. 2. 337. 0. 190. 3. 326. 0. 177. 0. 324. 1. 156. 7. 308. 3. 149. 10. 303. 1. 143. 4. 255. 0. 124. 2. 250. 1. 95. 9. 412. 0. 366. 47.
數據
相關文件
摘要: 本文第一作者係台灣工業與應用數學會 (TWSIAM) 副理事長, 從事工程數 學教育二十餘年, 發現工程師不甚了解張量, 數學家不熟悉莫耳 (Mohr) 圓,
就學與就業之職能 治療暨實習、職業 輔導評量學暨實 習、職業復健暨實 習、職能評估與職 業復健暨實習、職 業輔導評量專題研 究、職業輔導評量
Additional Key Words and Phrases: Topic Hierarchy Generation, Text Segment, Hierarchical Clustering, Partitioning, Search-Result Snippet, Text Data
電機工程學系暨研究所( EE ) 光電工程學研究所(GIPO) 電信工程學研究所(GICE) 電子工程學研究所(GIEE) 資訊工程學系暨研究所(CS IE )
In our AI term project, all chosen machine learning tools will be use to diagnose cancer Wisconsin dataset.. To be consistent with the literature [1, 2] we removed the 16
對照加拿大學人麥基概括的東南亞大都市地區 Desakota 區的特徵,中國 20
資料探勘 ( Data Mining )
根據研究背景與動機的說明,本研究主要是探討 Facebook
