行政院國家科學委員會專題研究計畫 期中進度報告
子計畫四:DS-UWB 系統中通道等化與干擾抑制之設計與實現
(1/3)
計畫類別: 整合型計畫 計畫編號: NSC94-2219-E-110-002- 執行期間: 94 年 08 月 01 日至 95 年 07 月 31 日 執行單位: 國立中山大學通訊工程研究所 計畫主持人: 陳儒雅 計畫參與人員: 黃竹棋、郭哲酉 報告類型: 完整報告 報告附件: 出席國際會議研究心得報告及發表論文 處理方式: 本計畫可公開查詢中 華 民 國 95 年 5 月 30 日
行政院國家科學委員會補助專題研究計畫
成 果 報 告
■
期中進度報告
使用直接序列(DS)展頻技術之極寬頻無線通訊網路之研發—
子計畫四:DS-UWB 系統中通道等化與干擾抑制之設計與實現(1/3)
計畫類別: 個別型計畫
■整合型計畫
計畫編號:NSC 94-2219-E-110-002
執行期間:
94 年 08 月 1 日至 95 年 07 月 31 日
計畫主持人:陳儒雅
計畫參與人員:黃竹棋、郭哲酉
成果報告類型(依經費核定清單規定繳交): 精簡報告
■完整報告
本成果報告包括以下應繳交之附件:
赴國外出差或研習心得報告一份
赴大陸地區出差或研習心得報告一份
■出席國際學術會議心得報告及發表之論文各一份國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、列管
計畫及下列情形者外,得立即公開查詢
涉及專利或其他智慧財產權, 一年 二年後可公開查詢
執行單位:國立中山大學通訊工程研究所
中 華 民 國
95 年 05 月 30 日
摘 要
現今無線通訊蓬勃的發展,許多相關的系統與標準規格也應運而生。從早期的語音通 訊和低速率的資料傳輸,逐漸演變成多媒體通訊與高速率的資料傳輸,可以預期未來高資 料傳輸率的通訊系統,將會在生活中扮演很重要的角色。目前無線個人網路系統是涵蓋範 圍小,但是可以達到相當高傳輸速率的一種系統,其中常見採用極寬頻的技術來達到此目 的。極寬頻的最高傳輸速率可高於 1Gbps,這樣的傳輸速率可以滿足現今各式多媒體娛樂 的需求,也同時可以滿足電腦周邊傳輸速率的要求。 在本計畫中主要以IEEE 802.15.3a 的先前標準規格為藍本,針對極寬頻通訊系統的通 道環境與接收機做探討,同時以實現系統硬體為目標,其中會以直接序列展頻的系統為主。 本計畫的執行時間為三年,在本報告中呈現的是第一年的結果。其中我們主要先對直接序 列展頻極寬頻系統的架構與規格作一詳盡的探討,然後針對通道估計、通道等化、犁耙接 收機等機制的演算法詳加介紹,同時透過模擬方式討論其系統效能。另外我們也針對如何 尋找框架起始提出一盲蔽非同調的演算法。 關鍵詞: 極寬頻通訊、通道估計、犁耙接收機、等化器。目 錄
摘 要... i 目 錄... ii 圖索引... iv 表索引... vii 第一章 簡 介... 1 第二章 極寬頻系統基本架構與原理... 3 2.1 擾亂器... 4 2.2 前向錯誤更正編碼器... 6 2.3 穿孔... 7 2.4 交錯器... 8 2.5 預先附加前序(Preamble Prepend)... 9 2.5.1 擷取序列... 11 2.5.2 框架起始及資料欄位... 11 2.5.3 訓練序列... 11 2.5.4 實體層標頭... 11 2.5.5 充填位元... 13 2.5.6 尾端位元... 13 2.5.7 媒體接取層標頭... 13 2.5.8 標頭檢查序列... 13 2.6 資料傳輸速率... 14 第三章 通道估計... 16 3.1 通道模型... 16 3.1.1 路徑損耗模型... 16 3.1.2 多重路徑模型... 17 3.1.3 通道參數設定... 18 3.2 系統模型... 20 3.3 展頻碼特性分析... 21 3.4 訓練序列特性... 23 3.5 框架起始偵測... 26 3.6 通道估計... 28 第四章 犁耙接收機與等化器... 35 4.1 選擇性犁耙接收機... 35 4.2 等化器... 38 4.2.1 線性等化器特性分析... 394.2.2 非線性等化器特性分析... 47 4.2.3 線性與非線性等化器比較... 52 4.2.4 最小均方及遞迴最小平方演算法分析與比較... 53 第五章 模擬結果... 59 5.1 選擇性犁耙接收機對系統效能的影響... 59 5.2 最小均方線性等化器對系統效能的影響... 61 5.3 最小均方非線性決策回授等化器對系統效能的影響... 63 5.4 線性與非線性等化器對系統效能影響的比較... 65 5.5 最小均方及遞迴最小平方等化器對系統效能影響的比較... 68 第六章 結論... 71 參考文獻... 72
圖索引
圖2-1 實體層傳送機與接收機方塊圖 ... 3 圖2-2 實體層框架的格式化過程 ... 4 圖2-3 擾亂器架構 ... 5 圖2-4 K=6 的迴旋碼編碼器架構 ... 7 圖2-5 K=4 的迴旋碼編碼器架構 ... 7 圖2-6 穿孔的流程 ... 8 圖2-7 迴旋交錯器架構 ... 9 圖2-8 含前序的資料封包結構 ... 11 圖3-1 系統模型 ... 21 圖3-2 長度為 24 的展頻碼的週期性自相關函數 ... 23 圖3-3 長度為 24 的展頻碼的週期性交互相關函數 ... 24 圖3-4 2004 年七月版本的框架格式 ... 24 圖3-5 2005 年一月版本的框架格式 ... 24 圖3-6 高傳輸頻帶訓練序列的自相關函數 ... 25 圖3-7 低傳輸頻帶訓練序列的自相關函數 ... 26 圖3-8 硬式框架起始偵測性能比較 ... 27 圖3-9 軟式框架起始偵測性能比較 ... 27 圖3-10 在 CM1 中不同臨界值對框架起始偵測的性能影響... 28 圖3-11 時間同步方塊圖 ... 29 圖3-12 在 CM1 的通道下時間同步方塊圖的輸出波形,所抓到的資料起始點在 為第257 取樣時間... 29 圖3-13 相關法通道估計器 ... 30 圖3-14 通道為單一路徑時,通道估計器各分支的輸出 ... 32 圖3-15 通道為單一路徑時,所有通道估計器 4 個分支累加起來的輸出波形 .. 32 圖3-16 通道為單一路徑時,改變通道估計器累加的分支數量 ... 33 圖3-17 完美通道估計方塊圖 ... 33 圖3-18 完美通道估計與相關法通道估計路徑增益的強度比較 ... 34 圖3-19 完美通道估計與相關法通道估計路徑增益的相位比較 ... 34 圖4-1 犁耙接收機架構 ... 35 圖4-2 通道估計器所估計到之通道 ... 37 圖4-3 等化器分類圖 ... 38 圖4-4 線性濾波器架構 ... 39圖4-5 三個離散時間的通道模型 ... 41 圖4-6 通道 Ch4-5a 與三組不同的橫向式等化器權重摺積後的結果 ... 42 圖4-7 通道 Ch4-5a 在不同橫向式等化器的初始輸入值下的位元錯誤率性能 .. 43 圖4-8 通道 Ch4-5b 與三組不同的權重摺積後的結果 ... 44 圖4-9 通道 Ch4-5b 在不同等化器的初始輸入值下的位元錯誤率性能 ... 44 圖4-10 通道 Ch4-5c 與三組不同的權重摺積後的結果 ... 45 圖4-11 通道 Ch4-5c 在不同等化器的初始輸入值下的位元錯誤率性能... 45 圖4-12 在通道 Ch4-5a、b 及 c 中,有雜訊及無雜訊下訓練等化器權重的位元錯 誤率性能... 46 圖4-13 不同長度的等化器權重,在通道 Ch4-5a 中的位元錯誤率性能 ... 47 圖4-14 決策回授等化器架構 ... 48 圖4-15 通道 Ch4-5a 在不同決策回授等化器的初始輸入值下的位元錯誤率性能 ... 49 圖4-16 通道 Ch4-5b 在不同決策回授等化器的初始輸入值下的位元錯誤率性能 ... 50 圖4-17 通道 Ch4-5c 在不同決策回授等化器的初始輸入值下的位元錯誤率性能 ... 50 圖4-18 通道 Ch4-5a 在不同長度 N 的正向濾波器之等化器的位元錯誤率性能 51 圖4-19 通道 Ch4-5a 在不同長度 M 的回授濾波器之等化器的位元錯誤率性能52 圖4-20 在通道 Ch4-5a、b 及 c 中,線性及非線性等化器的位元錯誤率性能... 53 圖4-21 適應性濾波器架構 ... 53 圖4-22 LMS 及 RLS 線性等化器在通道 Ch4-5a 中的學習曲線... 57 圖4-23 LMS 及 RLS 線性等化器在通道 Ch4-5b 中的學習曲線... 58 圖4-24 LMS 及 RLS 線性等化器在通道 Ch4-5c 中的學習曲線... 58 圖5-1 選擇性犁耙接收機在 CM1 中的錯誤率性能... 59 圖5-2 選擇性犁耙接收機在 CM2 中的錯誤率性能... 60 圖5-3 選擇性犁耙接收機在 CM3 中的錯誤率性能... 60 圖5-4 選擇性犁耙接收機在 CM4 中的錯誤率性能... 61 圖5-5 採 1 個分支數之犁耙接收機與加上最小均方線性等化器後,在四種通道 模型中的錯誤率性能... 62 圖5-6 採 5 個分支數之犁耙接收機與加上最小均方線性等化器後,在四種通道 模型中的錯誤率性能... 62 圖5-7 採 10 個分支數之犁耙接收機與加上最小均方線性等化器後,在四種通道 模型中的錯誤率性能... 63 圖5-8 採 1 個分支數之犁耙接收機與加上最小均方決策回授等化器後,在四種 通道模型中的錯誤率性能... 64
通道模型中的錯誤率性能... 64 圖5-10 採 10 個分支數之犁耙接收機與加上最小均方決策回授等化器後,在四 種通道模型中的錯誤率性能... 65 圖5-11 選擇性犁耙接收機分別加上最小均方線性等化器及決策回授等化器,在 CM1 中的錯誤率性能 ... 66 圖5-12 選擇性犁耙接收機分別加上最小均方線性等化器及決策回授等化器,在 CM2 中的錯誤率性能 ... 66 圖5-13 選擇性犁耙接收機分別加上最小均方線性等化器及決策回授等化器,在 CM3 中的錯誤率性能 ... 67 圖5-14 選擇性犁耙接收機分別加上最小均方線性等化器及決策回授等化器,在 CM4 中的錯誤率性能 ... 67 圖5-15 選擇性犁耙接收機分別加上最小均方及遞迴最小平方線性等化器,在 CM1 中的錯誤率性能 ... 69 圖5-16 選擇性犁耙接收機分別加上最小均方及遞迴最小平方線性等化器,在 CM2 中的錯誤率性能 ... 69 圖5-17 選擇性犁耙接收機分別加上最小均方及遞迴最小平方線性等化器,在 CM3 中的錯誤率性能 ... 70 圖5-18 選擇性犁耙接收機分別加上最小均方及遞迴最小平方線性等化器,在 CM4 中的錯誤率性能 ... 70
表索引
表2-1 擾亂器的種子辨識與數值 ... 6 表2-2 前向錯誤更正碼規格 ... 6 表2-3 不同型式的前序 ... 10 表2-4 三種不同長度前序的資料封包規格 ... 10 表2-5 框架起始規格 ... 12 表2-6 實體層標頭 ... 13 表2-7 低操作頻帶下可行的資料傳輸速率 ... 14 表2-8 高操作頻帶下可行的資料傳輸速率 ... 15 表3-1 鏈路餘裕分析表 ... 17 表3-2 多重路徑通道特性和相關的參數 ... 19 表3-3 Piconet 通道號碼、碼率、中心頻率與展頻碼組 ... 22 表3-4 長度為 24 與 12 的展頻碼 ... 22 表3-5 長度為 6 與小於 6 的展頻碼 ... 23 表4-1 線性橫向式架構等化器的模擬參數 ... 42 表4-2 決策回授架構等化器的模擬參數 ... 48第一章 簡 介
隨著科技的進步,資料傳遞量也隨之增大。目前網路環境正處於有線傳輸和無線傳輸 彼此互聯性不足的窘境,為了要達到有效率的高速無線傳輸,頻寬的需求也急遽增加。極 寬頻是一相當具潛力的技術,極寬頻利用在時域只持續幾百兆分之一秒的脈衝波造成高達 幾GHz 的頻帶寬,所以可傳輸之資料速率相對提高至數百 Mbps 以上。而其在傳輸通道中 的頻譜功率密度極低,所以能提供相當優越的保密性,並同時可適用於多用戶通訊環境。 而極寬頻不使用載波技術,僅使用脈衝信號,所以在電路設計上可省略射頻相關複雜的電 路,使得整體系統的電路複雜度、成本與體積均可大幅降低。同時其在頻譜上是將自身的 信號覆蓋在其他系統的信號上的頻帶上,使得頻帶資源能有效利用,並且兼具高傳輸率、 低耗電量、低成本等優點。 在1893 年,赫茲(Hertz)已經開始研究脈衝放電所產生電磁波的現象。直到 1962 年, 隨著 HP 取樣示波器及短脈衝產生器的問世,脈衝信號的研究因為有儀器可以測量才有更 進一步的發展。極寬頻剛開始稱為「無載波」無線電或脈衝(impulse)無線電,極寬頻過去 的用途主要是在軍事通訊及雷達上,近年來由於商用無線頻寬的需求提升,所以許多企業 希望將極寬頻的頻道使用能夠商用化。於是在2001 年十一月,IEEE 802.15.3a 小組成立, 並開始審核極寬頻相關技術,以促使極寬頻商用化標準的制訂。而在 2002 年二月,美國 聯邦通信委員會批准了極寬頻設備的合法使用,也明確認定了極寬頻商用化的可行性。美 國聯邦通訊委員會對極寬頻的使用規範,主要是限定在3.1 到 10.6 GHz 發送信號的功率頻 譜密度遮罩(spectrum mask)。 IEEE802.15.3a 工作小組先前審核極寬頻無線個人網路系統標準中,有兩大提案處於 競爭狀態,一個是以 Intel 為首所提出的多頻帶正交分頻多工(MB-OFDM),另一個是以 Motorola 為首所提出的直接序列分碼多重進接方案。在時域與頻域的轉換上,可明顯看出 直接序列分碼多重進接可有效率的利用最大頻寬來產生最短的脈衝,而且可有效率的降低 對其他家用無線傳輸的干擾,並可提供較有效率且準確的定位功能。而多頻帶正交分頻多工的優點在於可滿足不同國家對於頻段使用的彈性,且其成本較低。由於這兩個提案在表 決時,均沒有超過75%以上的支持率,彼此僵持不下的場景讓標準制訂的時程延宕。在今 年初工作小組終於做出解散的動作,也讓這兩種提案由各自支持的廠商進行產品化,由市 場來決定最後的系統。 在本報告中章節的安排如下:在第二章中針對極寬頻系統的基本架構與原理作介紹, 此部分主要是依循先前 IEEE802.15.3a 中的提案為藍本,我們也比較不同時間點提案內容 所做的修正。在第三章中先介紹極寬頻通訊的通道特性,同時分析系統中所使用的展頻碼 與訓練序列特性。接著我們提出一盲蔽非同調框架起始偵測(start frame detection)的演算 法,模擬分析其性能,我們也同時提出通道估計的演算法。在第四章中,我們介紹採用的 選擇性犁耙(rake)接收機與等化器之架構,探討線性與非線性等化器、不同的適應性演算 法,同時考量犁耙接收機與等化器結合對系統性能的影響。模擬結果與分析在第五章中有 詳細的敘述。最後第六章為整個報告的結論。
第二章 極寬頻系統基本架構與原理
本章將介紹極寬頻系統在實體層處理信號的流程[1]。極寬頻系統的傳送機與接收機中
的信號處理流程如圖 2-1 所示,在傳送端包含了擾亂器(scrambler)、正向錯誤更正編碼器
(forward error correct encoder, FEC encoder)、穿孔(puncture)、交錯器(interleaver)、前序插入 (preamble prepend)、符元調變以及脈衝塑形(pulse shaping)等。而接收端則是做與傳送端反 像的動作,包含了符元解調變、解交錯器、解穿孔、解碼、解擾亂等部分。
TX
Data
→ Scrambler
FEC
Encoder Puncture Interleave
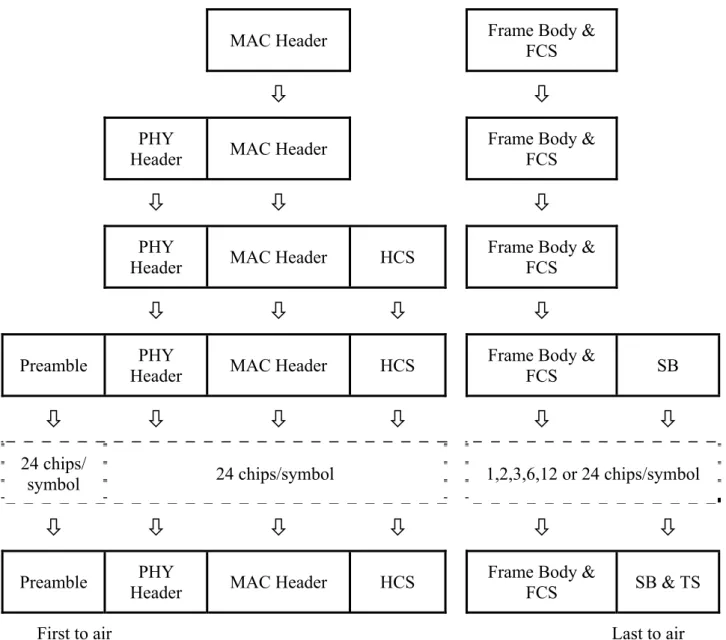
Preamble Prepend Symbol Mapper Pulse Shaper → RF RX Data ← De- scrambler FEC Decoder De- puncture De- interleave Polarity Detector RF Front End Physical Interface ← RF 圖2-1 實體層傳送機與接收機方塊圖 資料會依序從擾亂器作擾亂的動作後,經前向錯誤更正編碼器作編碼,接著作穿孔以提 高 編 碼 率(code rate), 然 後 經 過 交 錯 器 來 避 免 叢 集 錯 誤 (burst error) , 最 後 加 入 前 序 (preamble),之後便可以進行調變、脈波塑形後由射頻電路傳送出去。我們將針對圖 2-1 不
同方塊圖的基本原理在此章的各小節做簡單的介紹。圖 2-2 為實體層框架的格式化過程,
其中的標頭檢查序列(header check sequence,HCS)、尾端符號(tail symbol,TS)、塞入位元 (stuff bit,SB)會在 2.5 小節內介紹。
MAC Header Frame Body & FCS
Ø
Ø
PHY
Header MAC Header
Frame Body & FCS
Ø
Ø
Ø
PHY
Header MAC Header HCS
Frame Body & FCS
Ø
Ø
Ø
Ø
Preamble Header PHY MAC Header HCS Frame Body & FCS SB
Ø
Ø
Ø
Ø
Ø
Ø
24 chips/
symbol 24 chips/symbol 1,2,3,6,12 or 24 chips/symbol
Ø
Ø
Ø
Ø
Ø
Ø
Preamble Header PHY MAC Header HCS Frame Body & FCS SB & TS
First to air Last to air
圖2-2 實體層框架的格式化過程
2.1 擾亂器
使用擾亂器的目的是為了確保傳輸的位元數足以維持時序回復(clock recovery)。擾亂
器的架構如圖2-3 所示,其相當於一個偽亂數產生器(pseudo random generator)。利用偽亂
數產生器所產生的隨機亂數碼(PN code)與資料做模數二(modulo-2)的運算,如此便可達到 訊號擾亂的目的。
以下我們詳細敘述擾亂器的運作方式:在每個實體層框架的起始時,會先將位移暫存 器(shift register)的內容清除為 0,然後再將種子數值(seed value)存入暫存器中,接著就可以
運算。隨著時間的增加,後面的框架本體(frame body)也依序做同樣的處理。
在此要注意的是,只有MAC Header 和框架本體需經擾亂器處理;而實體層標頭則不
會經過擾亂器的處理。擾亂器的產生多項式(generator polynomial)為
g(D)=1+D +D14 15 (2.1)
這個多項式能產生一組最大長度序列(maximal length sequence),而且這個多項式是一個質 數多項式(primitive polynomial)。利用這個產生多項式所產生的隨機二位元串列可表示為 14 15 n n n x =x − ⊕x − (2.2) 其中⊕代表模數二的加法。而起始序列(initialization sequence)定義為 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [ i i i i i i i i i i i i i i i ] init n n n n n n n n n n n n n n n x = x − x − x − x − x − x − x − x − x − x − x − x − x − x − x − (2.3) 在此 i n k x − 代表了第k個時間延遲位元的起始輸出值。經過擾亂之後的資料位元s 可表示為 n n n n s = ⊕b x (2.4) 其中b 代表尚未經過擾亂的位元資料。接收端的解擾亂器(de-scrambler)使用的起始序列是n 由資料封包中實體層標頭內所含的種子識別(seed identifier)所決定,和發射端擾亂器的起始 序列是一樣的。 圖2-3 擾亂器架構 表 2-1 中所列出為擾亂器所使用的四組種子數值。種子識別會放在資料封包中的實 體層標頭內,每組種子識別對應一組15 位元的種子數值。而實體層剛開始傳送時的種子識 別會設定為 00,每次實體層送出資料封包後,種子識別便會以二位元翻轉計數器(2-bit rollover counter)的方式逐次進位。而種子數值的狀態(state)彼此都會相距 8192 個狀態,這 已經是這階數的產生多項式的最大相距狀態。這個距離也相當於傳送一個1024 個八位元組 框架的分隔長度。 D D D … D D
Seed Identifier Seed Value 0,0 1111 1111 1111 111 0,1 0111 0000 1111 111 1,0 0111 1111 0000 000 1,1 0111 1000 0000 111 表2-1 擾亂器的種子辨識與數值
2.2 前向錯誤更正編碼器
資料經擾亂器打亂後,接著會作前向錯誤更正編碼。傳輸端會使用迴旋編碼器 (convolutional encoder)來對資料編碼,使得接收端能利用解碼器來對因通道雜訊、衰褪或 失真所造成的錯誤進行更正。而迴旋編碼器有兩個重要的定義,分別是編碼率和限制長度 (constraint length)。前向錯誤更正編碼器的規格如表 2-2 所示,其中碼率為 3/4 的錯誤更正 碼是藉由碼率 1/2 錯誤更正碼經過穿孔而得,在 UWB 的元件上面會註明能支援的前向錯 誤更正編碼率。Code Type Constraint Length & Generator Polynomials
Possible Rates
Implementation Requirements Convolutional Constraint length K=6,
Generating polynomial (65, 57)
Rate ½ or ¾ Mandatory for Tx: Rate ½ & ¾ Mandatory for Rx: Rate ½ Optional for Rx: Rate ¾ Convolutional Constraint length K=4,
Generating polynomial (15,17)
Rate ½ or ¾ Mandatory for Tx: Rate ½ & ¾ Optional for Rx: Rate ½ & ¾
表2-2 前向錯誤更正碼規格
圖2-4 K=6 的迴旋碼編碼器架構 圖2-5 K=4 的迴旋碼編碼器架構
2.3 穿孔
資料經前向錯誤更正編碼後,接下來做穿孔的處理。穿孔是在傳輸端打掉一些已編碼 資料位元以提升碼率,然後當接收端收到時,迴旋解碼器會將原本被打掉位元的位置填入 零,接著用Viterbi 演算法進行解碼。圖 2-6 是以將碼率為 1/2 的編碼資料提高到碼率為 3/4 的穿孔流程。Punctured coding (r=3/4) Source Data x0 x1 x2 x3 x4 x5 x6 x7 x8 Ø a0 a1 a3 a4 a6 a7 Encoded Data b0 b2 b3 b5 b6 b8 Stolen bit Ø Bit Stolen Data a1 b0 a1 b2 a3 b3 a4 b5 a6 b6 a7 b8 (Tx/Rx data) Ø Bit inserted a0 a1 0 a3 a4 0 a6 a7 0 0 Inserted dummy 0 bit data b0 0 b2 b3 0 b5 b6 0 b8 Ø Decoded data y0 y1 y2 y3 y4 y5 y6 y7 y8 圖2-6 穿孔的流程
2.4 交錯器
由於迴旋解碼器無法對抗叢集錯誤,因此資料必須使用交錯器來將叢集錯誤打散。在 IEEE 802.15.3a 中建議使用迴旋交錯器(convolutional interleaver)而不是區塊交錯器(block interleaver)是因為迴旋交錯器所需的時間延遲較低,記憶體需求也較低。圖 2-7 為迴旋交錯器的架構,將已編碼的資料以序列的方式移入N 個位移暫存器(除了第零個暫存器沒有任
何記憶空間外,其他相鄰的暫存器各差 J 個位元的記憶體,且由上往下遞增)。每當新的
零個暫存器然後重新開始。解交錯器的工作方式則正好相反,也就是說第一個暫存器的延 遲是(N-1)J,而最後一個暫存器的延遲為零,其餘程序和交錯器相同。交錯器和解交錯器 的輸出和輸入的換相器必須同步。在IEEE 802.15.3a 中,交錯器的 J=7 而 N=10。但在某些 情形下,例如傳送的資料框架很短時,傳送端則不使用交錯器,這資訊會在實體層標頭內 註明。 J 2J (N-2)J (N-1)J Encoded
bits Interleavedbits
圖2-7 迴旋交錯器架構
2.5 預先附加前序(Preamble Prepend)
資料經擾亂器、前向錯誤更正編碼、打孔及交錯器後,接著會加入一串前序(preamble)。 而依照不同的資料傳輸率,前序會有三種不同的長度,這三種前序只有資料欄位長度(field durations)不同,其他結構都完全一樣。這三種前序的設定方式分別為: 額定前序(Nominal preamble):適用於額定的資料傳輸率及通道。 長前序(Long preamble):適用於較低的資料傳輸率及較差的通道。 短前序(Short preamble):適用於較高的資料傳輸率及較好的通道。表2-3 則為這三種不同長度前序的描述表。當前序型態描述符號(preamble type descriptor)
以八位元組(octet)為表示時,前六位元設定為零。表 2-4 為這三種不同長度前序的資料封包 規格。
Preamble Type b1-b0
Medium (default) 00
Short 10
Long 11
表2-3 不同型式的前序
Nominal Preamble Long Preamble Short Preamble Acquisition sequence 512 x 24 chips 1024 x 24 chips 256 x 24 chips
SFD 32 x 24 chips 32 x 24 chips 32 x 24 chips
Data Field 24 x 24 chips 24 x 24 chips 24 x 24 chips
Training Sequence 6144 chips 6144 chips 6144 chips
PHY Header 16 bits 16 bits 16 bits
MAC Header TBD TBD TBD
HCS 16 bits 16 bits 16 bits
表2-4 三種不同長度前序的資料封包規格
圖 2-8 為含前序的資料封包結構,首先傳輸端的媒體接取層標頭會先選一組 piconet
擷取碼(piconet acquisition code, PAC),然後設定對應的載波頻率偏移。接著發射端使用亂
數碼來對PAC 碼進行調變來得到擷取序列(acquisition sequence),其中擷取序列的功用包括
自動增益控制(automatic gain control, AGC)和鎖定時脈信號頻率。接著加入框架起始(SFD, start frame delimiter),其功用是用來告知接收端下一個傳送欄位將是資料欄位。而資料欄位 則是用來告知接收端的決定迴授等化器(decision feedback equalizer, DFE)訓練序列(training sequence)的傳輸率。然候是加入訓練序列(training sequence)來對決定迴授等化器進行訓
frames)。 Acquisition sequence 9μs SFD (32 bit) Data Field (24 bit) Training (various lengths)
PHY Header MAC Header Data
圖2-8 含前序的資料封包結構 接下來幾個小節將詳加介紹圖 2-8 資料封包中的組成份子,包括構成了前序的擷取序 列、框架起始、資料欄位以及訓練序列,另外還將介紹圖 2-2 中所列的實體層標頭、充填 位元、尾端符號、媒體接取層標頭以及標頭檢查序列。
2.5.1 擷取序列
前序的架構中第一塊資料就是擷取序列,其主要功用是設定增益(gains)及時脈同步 (clock synchronization)。擷取序列是由一串亂數碼所組成,此序列為階層式(hierarchical)序 列,具有平坦的頻譜特性,使接收端更容易達到同步,對不同的piconet 通道提供好的區隔。2.5.2 框架起始及資料欄位
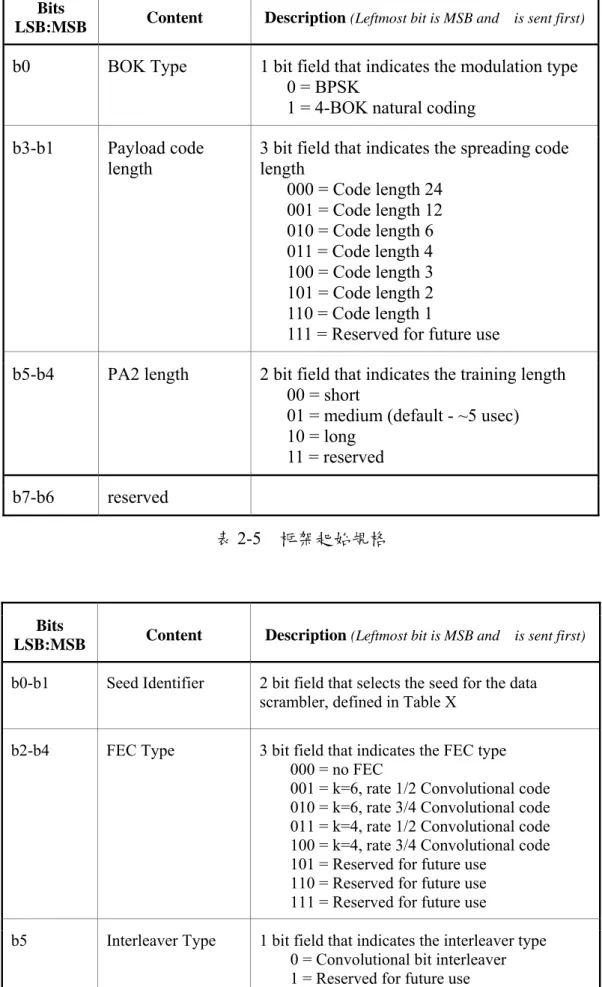
框架起始由32 位元的二位元碼所組成,其定義實體層標頭的框架時序。框架起始的後 面則是資料欄位。其規格列於表2-5 中。2.5.3 訓練序列
為了使每個傳送封包能達到足夠的隨機化,每一資料封包中用來調變PAC 的訓練序列 也都不同,傳送端使用亂數產生器來達到這個目的。而訓練序列的長度是6144 位元,其位 元長度與資料傳輸率有關。2.5.4 實體層標頭
實體層標頭是由三個8 位元組所組成,其包含了資料框架的資訊。實體層各欄位的內 容列於表2-6。傳送順序是由 b0 依序到 b23。Bits
LSB:MSB Content Description (Leftmost bit is MSB and is sent first)
b0 BOK Type 1 bit field that indicates the modulation type 0 = BPSK
1 = 4-BOK natural coding
b3-b1 Payload code
length
3 bit field that indicates the spreading code length 000 = Code length 24 001 = Code length 12 010 = Code length 6 011 = Code length 4 100 = Code length 3 101 = Code length 2 110 = Code length 1
111 = Reserved for future use
b5-b4 PA2 length 2 bit field that indicates the training length 00 = short
01 = medium (default - ~5 usec) 10 = long
11 = reserved b7-b6 reserved
表2-5 框架起始規格
Bits
LSB:MSB Content Description (Leftmost bit is MSB and is sent first)
b0-b1 Seed Identifier 2 bit field that selects the seed for the data
scrambler, defined in Table X
b2-b4 FEC Type 3 bit field that indicates the FEC type
000 = no FEC
001 = k=6, rate 1/2 Convolutional code 010 = k=6, rate 3/4 Convolutional code 011 = k=4, rate 1/2 Convolutional code 100 = k=4, rate 3/4 Convolutional code 101 = Reserved for future use
110 = Reserved for future use 111 = Reserved for future use
b5 Interleaver Type 1 bit field that indicates the interleaver type
0 = Convolutional bit interleaver 1 = Reserved for future use
b6 4-BOK code type 0 = 4-BOK natural coding 1 = 4-BOK Gray coding b7 Reserved
b8-b23 Frame Body Length A 16 bit field that contains the length of the frame
body, including FCS, in octets, MSB is b11, LSB is b23, e.g. 4 octets of data, is encoded as
0000000000100. A zero length frame body is encoded as 000000000000. Note that there is no FCS for a zero length frame body.
表2-6 實體層標頭
2.5.5 充填位元
使用4-BOK 來調變時,若是媒體接取層協定資料單元(MAC Protocol Data Unit, MPDU)
的總長度不是偶數,在調變之前必須將一個充填位元接在MPDU 之後,其值可以是一或是
零,在接收端接收到時會自動去除。在計算 MPDU 長度時,標頭檢查序列(Header check
sequence, HCS)和框架檢查序列(Frame check sequence, FCS)並不會計算在內。
2.5.6 尾端位元
資料在經過擾亂器輸出後,會在媒體接取層框架本體之後加入尾端位元,也就是框架 檢查序列或充填位元之後。目的是在資料傳送結束後,將迴旋編碼器中的位移暫存器清空 成為零。舉例來說,對於K=4 的編碼器,媒體接取層框架後面需要加入三個尾端位元;對 於K=6 的編碼器,媒體接取層框架後面則需要加入五個尾端位元。2.5.7 媒體接取層標頭
媒體接取層標頭是依照IEEE Std 802.15.3-2003 所制定,並無任何改變。2.5.8 標頭檢查序列
標頭檢查序列的計算包含了實體層和媒體接取層標頭的總和。標頭檢查序列包含了16位元的循環冗員檢查(Cyclic Redundancy Check, CRC)接在媒體接取層標頭之後,其主要是 用來結合實體層和媒體接取層標頭。標頭檢查序列的多項式如下:
16 12 5
這個循環冗員檢查和IEEE Std 802.11b-1999 所制定的完全相同。
2.6
資料傳輸速率
表 2-7 列出在低操作頻帶下所有可行的資料傳輸率,這些都是經過前向錯誤更正編碼
後的資料傳輸速率。表2-8 則列出在高操作頻帶下所有可行的資料傳輸速率。
Data Rate FEC Rate BPSK Code Length 4-BOK Code Length Symbol Rate
28 Mbps ½ L=24 - Fchip/L 55 Mbps ½ L=12 - Fchip/L 110 Mbps ½ L=6 L=12 Fchip/L 110 Mbps 1 L=12 L=24 Fchip/L 220 Mbps ½ L=3 L=6 Fchip/L 220 Mbps 1 L=6 L=12 Fchip/L 330 Mbps ½ L=2 L=4 Fchip/L 440 Mbps 1 L=3 L=6 Fchip/L 500 Mbps ¾ L=2 L=4 Fchip/L 660 Mbps 1 L=2 L=4 Fchip/L 660 Mbps ½ L=1 L=2 Fchip/L 1000 Mbps ¾ L=1 L=2 Fchip/L 1320 Mbps 1 L=1 L=2 Fchip/L 表2-7 低操作頻帶下可行的資料傳輸速率
Data Rate FEC Rate BPSK Code Length 4-BOK Code Length Symbol Rate 55 Mbps ½ L=24 - Fchip/L 110 Mbps ½ L=12 - Fchip/L 110 Mbps 1 L=24 - Fchip/L 220 Mbps ½ L=6 L=12 Fchip/L 220 Mbps 1 L=12 - Fchip/L 330 Mbps ½ L=4 L=8 Fchip/L 440 Mbps ½ L=3 L=6 Fchip/L 440 Mbps 1 L=6 L=12 Fchip/L 500 Mbps ¾ L=4 L=8 Fchip/L 660 Mbps 1 L=4 L=8 Fchip/L 660 Mbps ½ L=2 L=4 Fchip/L 1000 Mbps ¾ L=2 L=4 Fchip/L 1320 Mbps 1 L=2 L=4 Fchip/L 1320 Mbps ½ L=1 L=2 Fchip/L 2000 Mbps ¾ L=1 L=2 Fchip/L 表2-8 高操作頻帶下可行的資料傳輸速率
第三章 通道估計
本章節首先敘述 IEEE 802.15.3a 中所提出的通道模型[2],接著討論在 IEEE802.15.3a
規格中展頻碼、訓練序列的特性以及接收端的通道估計與框架起始偵測。
3.1 通道模型
為了用來設計、測試與驗證IEEE 802.15.3a 實體層,IEEE 802.15.3a 工作小組提出極寬
頻通道模型,其中包含了路徑損耗模型和多重路徑模型。
3.1.1 路徑損耗模型
為了公平地比較不同的實體層提案並確定最後制定的標準有足夠的性能表現,所以 IEEE 802.15.3a 的工作小組提出路徑損耗模型供大家使用。首先利用自由空間路徑損耗模 型來測試所得出的鏈路餘裕(link margin)是否足以對抗路徑損耗、實作損失(implementation losses)、波形失真(waveform distortion)及不完美的多重路徑能量收集(imperfect multipath energy capture)等損耗,然後採用福利司傳導公式(Friis transmission formula)來計算整體的路
徑損耗。表 3-1 中列出計算鏈路餘裕所需考慮的參數。為了比較性能的方便性,只有以黃
底特別標示的參數是各實體層提案可自行定義的,其他參數則必須相同。
Parameter Value Value
Throughput (Rb) > 110 Mbps > 200 Mbps
Average Tx power (PT) dBm dBm
Tx antenna gain (GT) 0 dBi 0 dBi
max min '
f f
fc = : geometric center frequency of
waveform ( fmin and fmax are the -10 dB edges of
the waveform spectrum)
Hz Hz
Path loss at 1 meter ( 20log (4 '/ )
10 1 f c L = π c ) 8 10 3× = c m/s dB dB
Path loss at d m (L2 =20log10(d)) 20 dB at d=10 meters
12 dB at d=4 meters
Rx power (PR =PT +GT +GR −L1 −L2 (dB)) dBm dBm
Average noise power per bit (N =−174+10*log10(Rb))
dBm dBm
Rx Noise Figure (NF) 7 dB 7 dB
Average noise power per bit (PN = N+NF) dBm dBm
Minimum Eb/No (S) dB dB
Implementation Loss1 (I) dB dB
Link Margin (M =PR −PN −S−I) dB dB Proposed Min. Rx Sensitivity Level2 dBm dBm
表3-1 鏈路餘裕分析表 其中實作損耗是指濾波器失真、相位雜訊及頻率誤差等損耗因子的整體損耗。而最小 敏感度(sensitivity)的定義是指接收端在白色高斯雜訊通道下接收ㄧ個符元所需的最小平均 能量,其中是有把編碼率及信號調變效應考慮進去。
3.1.2 多重路徑模型
UWB 通道模型的是根據多次實際通道量測值來對 Saleh-Valenzuela 通道模型做修正後 而得。在量測中發現觀測值比較符合對數常態分布,所以建議此模型的多重路徑增益強度 採用對數常態分布而不是一般常見的瑞雷分布(Rayleigh distribution)。在此也假設叢集 (cluster)和叢集中的分支線(ray)有獨立的衰褪,因此多重路徑模型可表示成下列的離散時間 脈衝響應∑∑
= = − − = L l K k i l k i l i l k i i t X t T h 0 0 , , ) ( ) ( α δ τ (3.1) 其中{ i l k , α }代表多重路徑增益係數,{ i l T }代表第 l 個叢集的延遲時間,{τ }代表對應於第k ,il l 個叢集中第 k 個分支線的延遲時間,{X }代表對數常態遮蔽效應(log-normal shadowing),i 而 i 代表第 i 個實現(realization)。而本模型所定義參數如下: Tl =第 l 個叢集中第一條路徑的到達時間; τk,l =對應於第 l 個叢集到達時間 Tl的第 k 條分支線到達時間;Λ =叢集到達率(arrival rate); λ =分支線到達率,也就是每個叢集中的路徑到達率。 所以根據定義,我們可以知道τ0,l =0。而叢集到達時間及分支線到達時間的機率分布如下
(
)
(
)
(
)
(
)
1 1 , ( 1), , ( 1), exp , 0 exp , 0 l l l l k l k l k l k l p T T T T l p τ τ λ λ τ τ k − − − − ⎡ ⎤ = Λ ⎣−Λ − ⎦ > ⎡ ⎤ = ⎣− − ⎦ > (3.2) 多重路徑增益係數可表示為 l k l l k l k, p ,ξ β , α = (3.3) , 1 2 ( ) / 20 2 2 , , 1 2 , 20log10( ) Normal( , ) , or 10 k l n n l k l k l l k l μ ξ β ∝ μ σ +σ ξ β = + + (3.4) 其中 Normal(0, 2) 1 1 ∝ σ n 和 Normal(0, 2) 2 2 ∝ σ n ,且二者獨立,所以對(3.4)做平方期望值推得 , 2 / / , 0 l k l T l k l E⎡⎢ξ β ⎤ = Ω⎥ e− Γe−τ γ ⎣ ⎦ (3.5) 其中Ω 是第一個叢集中第一條分支線的平均能量,0 pk,l是因反射所造成的信號反轉效應, 可為+1 或−1。而μ k,l 的值為 20 ) 10 ln( ) ( ) 10 ln( / 10 / 10 ) ln( 10 2 2 2 1 , 0 , σ σ γ τ μ = Ω − l Γ− kl − + l k T (3.6) 其中ξl代表第 l 個叢集的衰減,βk ,l代表第 l 個叢集中的第 k 條分支線的衰減。此模型並不 是複數模型而是實數模型。 最後,由於所有多重路徑能量的對數常態遮蔽效應是由X 所表示,所以對於每個實i 現{ i l k , α }都會正規化至單位能量。其中遮蔽效應的機率分佈表示為 2 10 20log ( )Xi ∝Normal(0,σx) (3.7)3.1.3 通道參數設定
根據前ㄧ小節的敘述,通道模型需要六個關鍵參數來定義,分別是:Λ =叢集到達率; λ =分支線到達率,亦即在每個叢集中的路徑到達率; Γ =叢集衰退因子(decay factor); γ =分支線衰退因子; 1 σ =叢集的對數常態衰減項的標準差(dB); 2 σ = 分支線的對數常態衰減項的標準差(dB); x σ =對所有多重路徑實現的對數常態遮蔽項的標準差(dB)。 表3-2 列出一些經由量測所得的初始模型參數。 Target Channel Characteristics5 CM 11 CM 22 CM 33 CM 44
Mean excess delay (nsec) (τm) 5.05 10.38 14.18
RMS delay (nsec) (τrms) 5.28 8.03 14.28 25 NP10dB 35 NP (85%) 24 36.1 61.54 Model Parameters Λ (1/nsec) 0.0233 0.4 0.0667 0.0667 λ (1/nsec) 2.5 0.5 2.1 2.1 Γ 7.1 5.5 14.00 24.00 γ 4.3 6.7 7.9 12 1 σ (dB) 3.3941 3.3941 3.3941 3.3941 2 σ (dB) 3.3941 3.3941 3.3941 3.3941 x σ (dB) 3 3 3 3 Model Characteristics5
Mean excess delay (nsec) (τm) 4.9 9.4 13.8 26.8
RMS delay (nsec) (τrms) 5 8 14 26
NP10dB 13.3 18.2 25.3 41.4
NP (85%) 21.4 37.2 62.7 122.8
Channel energy mean (dB) -0.5 0.1 0.2 0.1
Channel energy std (dB) 2.9 3.3 3.4 3.2
表3-2 多重路徑通道特性和相關的參數
以下為對於表3-2 中特別標明數字的地方做說明:
2. 此模型是根據非直視路徑(Non Line of Sight,NLOS) (0-4m)的通道量測結果 所定。 3. 此模型是根據非直視路徑 (4-10m)的通道量測結果所定。 4. 模型是代表極端的非直視路徑多重路徑通道,特別設計來滿足 25 nsec 的均 方根延遲擴散(RMS delay spread)。 5. 這些特性是在取樣時間為 167 psec 之下所得。
3.2 系統模型
極寬頻直接序列分碼多工進接系統模型如圖3-1 所示。輸入的二位元資料經二位元相 位鍵移(BPSK)調變後,乘上一展頻碼作展頻,接著經過脈波塑形(pulse shaping),其中使用 的脈波塑形為平方根升餘弦(square root raise cosine,SRRC)。接著乘上載波,經過多重路 徑通道,到達接收端後解載波經過匹配濾波器。接著做通道估計,得到多重路徑通道中每 個路徑的時間延遲與路徑增益,再經過犁耙接收機以收集到最大的信號能量,再利用等化 器降低前後訊號所產生的符際干擾。最後經解二位元相位鍵移調變解回二位元資料。考慮 一 DS-UWB 的訊號模型,欲傳送的二位元資料經 BPSK 數位調變後形成一組序列 0 1 { , , ,d d dN},其中dn =d n( )
為+1 或−1,而n=0,1, ,N為時間標示。接著做直接序列展 頻乘上展頻序列,展頻序列描述如下( )
23 0 2 ( c ) j j c t jT p t p rect T = − =∑
(3.8) 其中p 為展頻碼,j ( ) c t rect T 為寬度T 、高度為 1 的方波。經直接序列展頻後的得到的訊號c 如下( )
(
)
0 N n b n s t d p t kT = =∑
− (3.9) 在此我們選取Tb=24T 為一位元時間,c Tc= 0.7616 nsec為一碼時間。DS-UWB通道模型係採為5~26毫微秒(nsec)。通道的數學模型可表示成 1 0 ( ) I i ( i) i h t hδ t τ − = =
∑
− (3.10) 其中 I 為多重路徑的數量,h 為第i i 個路徑增益,τi為第 i 個路徑的延遲時間。 圖3-1 系統模型3.3 展頻碼特性分析
在IEEE802.15.3a 中定義了十二個 piconet,如表 3-3 所示。其中有六個在低頻段(號 碼1 至 6,碼率為 1300 MHz 到 1365 Mhz,中心頻率由 3900 MHz 到 4095 MHz),另外六 個在高頻段(號碼7 至 12,碼率為 2600 MHz 到 2730 Mhz,中心頻率由 7800 MHz 到 8190 MHz),其中piconet 通道 1 至通道 4 是在系統中必須強制設計的,而其他的 piconet 通道則 是選擇性設計的。每個piconet 所使用的碼率都不相同,中心頻率是碼率的三倍。其中展頻 碼組共有六組,低頻段與高頻段共用這六組展頻碼。Piconet Channel Chip Rate Center Frequency Spreading Code Set 1 1313 MHz 3939 MHz 1 2 1326 MHz 3978 MHz 2 3 1339 MHz 4017 MHz 3 4 1352 MHz 4056 MHz 4 5 1300 MHz 3900 MHz 5 6 1365 MHz 4095 MHz 6 7 2626 MHz 7878 MHz 1 8 2652 MHz 7956 MHz 2 9 2678 MHz 8034 MHz 3 10 2704 MHz 8112 MHz 4 11 2600 MHz 7800 MHz 5 12 2730 MHz 8190 MHz 6 表3-3 Piconet 通道號碼、碼率、中心頻率與展頻碼組 在表3-4 與表 3-5 中將使用 BPSK 調變的展頻碼組列出,展頻碼的長度可分為 24、12、 6、4、3、2、1 七種,在長度 24 與 12 中的展頻碼是採用三位階的形式(即碼值有 1,-1, 0 三種),其主要用意在於產生低交互相關的展頻碼組。以長度為 24 的展頻碼來看,在同 一碼組中,0 位階的碼片數目都為 2,而在長度為 12 的展頻碼中,0 位階的碼片數目為 1。 在長度為6 與小於 6 的展頻碼組中,展頻碼的形式皆為 1,0,0,…,表示這些碼組僅利用縮小 信號傳送時間的方式來達到展頻,而不額外利用展頻碼的交互相關與自相關特性,其作用 可視為脈衝無線電的一種。 Code Set
Number L=24 Codes L=12 Codes
1 -1, 0, 1, -1, -1, -1, 1, 1, 0, 1, 1, 1, 1, -1, 1, -1, 1, 1, 1, -1, 1, -1, -1, 1 0, -1,-1,-1, 1, 1, 1,-1, 1, 1,-1, 1 2 -1, -1, -1, -1, 1, -1, 1, -1, 1, -1, -1, 1, -1, 1, 1, -1, -1, 1, 1, 0, -1, 0, 1, 1 -1, 1,-1,-1, 1,-1,-1,-1, 1, 1, 1, 0 3 -1, 1, -1, -1, 1, -1, -1, 1, -1 , 0 -1, 0, -1, -1, 1, 1, 1, -1, 1, 1, 1, -1, -1, -1 0, -1, 1,-1,-1, 1,-1,-1,-1, 1, 1, 1 4 0, -1, -1, -1, -1, -1, -1, 1, 1, 0, -1, 1, 1, -1, 1, -1, -1, 1, 1, -1, 1, -1, 1, -1 -1,-1,-1, 1, 1, 1,-1, 1, 1,-1, 1, 0 5 -1, 1, -1, 1, 1, -1, 1, 0, 1, 1, 1, -1, -1, 1, 1, -1, 1, 1, 1, -1, -1, -1, 0, -1 -1,-1,-1, 1, 1, 1,-1, 1, 1,-1, 1, 0 6 0, -1, -1, 0, 1, -1, -1, 1, -1, -1, 1, 1, 1, 1, -1, -1, 1, -1, 1, -1, 1, 1, 1, 1 0, -1,-1,-1, 1, 1, 1,-1, 1, 1,-1, 1 表3-4 長度為 24 與 12 的展頻碼
Code Set
Numbers L=6 Codes L=4 Codes L=3 Codes L=2 Codes L=1 Code
1 through 6 1,0,0,0,0,0 1,0,0,0 1,0,0 1,0 1 表3-5 長度為 6 與小於 6 的展頻碼 圖3-2 是長度為 24 展頻碼的週期性自相關函數圖,總共有六種不同的顏色,分別代表 不同的碼組。當時間差為0 時自相關函數值為 1,其他當時間差不為 0 時,自相關函數值 大多介於0.2 到-0.2 之間,單由自相關函數來看,其特性並不是很好。圖 3-3 是長度為 24 展頻碼不同碼組的交互相關函數圖,其分佈範圍約在 0.3 到-0.3 之間,部分則高達 0.5 或 -0.5,以一般展頻碼的特性而言,這樣的交互相關函數值是比較大的,但因為不同 piconet 的碼率皆有相對位移,所以整體交互相關值還會下降。
3.4 訓練序列特性
關於DS-UWB 規格的框架格式,在 2004 年七月的版本與 2005 年一月的版本有些微改 變。圖3-4 是 2004 年七月的版本,而圖 3-5 是 2005 年一月的版本。 圖3-2 長度為 24 的展頻碼的週期性自相關函數圖3-3 長度為 24 的展頻碼的週期性交互相關函數 Acquisition Sequence 8 μs TBD TBD μs Training Sequence 4 μs SFD
1 μs HeaderPHY HeaderMAC Data
圖3-4 2004 年七月版本的框架格式 Acquisition Sequence 9 μs SFD (32 bit) Data Field (24 bit) Training (various lengths) PHY
Header HeaderMAC Data
圖3-5 2005 年一月版本的框架格式 在新版中,獲取序列的長度由時間8微秒增加到9微秒,原先框架起始序列(SFD, star frame delimiter)也由訓練序列後提前到獲取序列後,同時其長度由1微秒縮減至0.6微秒左 右。同時訓練序列的長度不再固定為4微秒,而是總共6144碼片的長度會根據碼率與展頻增 益而變動。在2004年七月版本中的訓練序列定義了兩個,分別是對高傳輸頻帶與低傳輸頻 帶的中長度訓練序列,其他長訓練序列與短訓練序列則未定義。高傳輸頻帶的中長度訓練 序列定義為 JNJNB5ANB6APAPCPANASASCNJNASK9B5K6B5K5D5D5B9ANASJPJNK5MNCPATB5 CSJPMTK9MSJTCTASD9ASCTATASCSANCSASJSJSB5ANB6JPAPD6B5ATASCPMNCS
NMNMPJSANCSN5JSK6JTJPMPJNJSASCNN5DAASB9K5MSD5B7291AT2W67PGC9Q1F NKPHH9R64FGJZRK9TYMS2KEWFCMRY31Q8NQZ8J5YNYTTS00Y87NKWHKV8J4YN PJRS2GEWQMJRSJGARPMKGHRRA84GKT1Z3J50,其表示方式是以32為基底。另外低傳 輸頻帶的中長度訓練序列定義為 JNJNB5ANB6APAPCPANASASCNNASK9B5K6B5K5D5D5B9ANASJPJNK5MNCPATB5C SJPMTK9MSJTCTASD9ASCTATASCSANCSASJSJSB5ANB6JPN5DAASB9K5MSCNDE6 AT3469RKWAVXM9JFEZ8CDS0D6BAV8CCS05E9ASRWR914A1BR。高傳輸頻帶的訓練 序列包含了1725個位元,而低傳輸頻帶的訓練序列則包含了865個位元。零與一的數目相當 接近,但是零的數目略多於一的數目。在圖3-6與圖3-7中分別呈現高傳輸頻帶與低傳輸頻 帶訓練序列的自相關特性,兩者皆有非常接近脈衝的特性。利用此訓練序列可以訓練通道 估計器估計通道脈衝響應以供等化器使用。 圖3-6 高傳輸頻帶訓練序列的自相關函數
圖3-7 低傳輸頻帶訓練序列的自相關函數
3.5 框架起始偵測
框架起始序列為一 32 位元的偽亂碼資訊,在接收機中必須將此序列的起始時間偵測 出,因為如果判斷錯誤,在後面的資料場(data field)的資訊將無法正確解讀,後續的資料解 調也無法進行。框架起始偵測器我們採用相關器法來完成,而其可分成兩種,一為硬式決 策,另一為軟式決策。所謂硬式決策就是將框架起始序列位元資料判斷成一或零後再送入 相關器中,而軟式決策則是不先將資料判斷成一或零及直接送入相關器中。圖3-8 與圖 3-9 分別比較硬式與軟式框架起始偵測在不同通道下的性能,軟式決策法明顯優於硬式決策 法。圖3-10 則以 CM1 為例,觀察不同臨界值對框架起始偵測的性能影響,以 19 為決策臨 界值可以得到適當的性能表現,在其他通道中,臨界值也是採用19 會有較佳的表現。0 5 10 15 20 25 0.0 0.2 0.4 0.6 0.8 1.0 S F D detec ti on probabi lity E b/No (dB) hard CM1 CM2 CM3 CM4 圖3-8 硬式框架起始偵測性能比較 0 5 10 15 20 25 0.0 0.2 0.4 0.6 0.8 1.0 S F D de te ct io n pro bab ility E b/No (dB) soft CM1 CM2 CM3 CM4 圖3-9 軟式框架起始偵測性能比較
0 5 10 15 20 25 0.0 0.2 0.4 0.6 0.8 1.0 S F D det ec ti on p robabilit y E b/No (dB) CM1 threshold 15 17 19 21 23 25 27 29 31 max 圖3-10 在 CM1 中不同臨界值對框架起始偵測的性能影響
3.6 通道估計
由於訓練序列經脈波塑形、多重路徑通道與匹配濾波器的影響,接收到的訊號的起始 點已不再是一開始訓練序列的起始點,故需作時間同步來尋找正確起始點。在本報告中, 時間同步係採用相關法(correlation)完成,其方塊圖如圖 3-11 所示。接收到的信號經解載波 與匹配濾波器後,與一段經展頻後的訓練序列做相關運算後,因為經展頻後的訓練序列的 自相關函數(autocorrelation function)具有近似於脈衝的形式,因此輸出可以視為ㄧ週期性的 脈衝串經過合成的通道(脈波塑形、多重路徑通道與匹配濾波器的合成效果)後的值。再取 經相關器後的 I 軸與 Q 軸訊號c (t) 與I c (t) 平方後相加,取出最大合成波形的振幅所對應Q 時間點,此即為多重路徑通道中的最大增益路徑所對應的資料的起始點。圖3-11 時間同步方塊圖
圖 3-11 中的 ( )r t 是經過通道後的接收訊號, ( )s t 是一串經展頻後的訓練序列,虛線所
框的部份為相關器。圖3-12 為對標準規格的 CM1 通道做時間同步,由圖可知取樣時間索
引(sampling time index)為 257 時有最大信號能量,以其為訓練序列的起始點,可得到多重 路徑通道的最大增益路徑的時間延遲。 0 500 1000 1500 2000 2500 0 2 4 6 8 10 12 14 16 18 20
22 Output signal of synchronization block diagram in CM1
Time(sample) Po w er 257 Maximum 圖3-12 在 CM1 的通道下時間同步方塊圖的輸出波形,所抓到的資料起始點在為第 257 取樣時間
在取得時間同步後,接著將同一接收到的訊號r t
( )
拿來做通道估計,通道估計係採用 相關法完成,其方塊圖如圖3-13。在不考慮雜訊的狀況下,接收到的信號與展頻碼做相關 運算後會產生一週期性的脈衝串,主要是因為展頻碼的自相關函數具有近似脈衝的形式。 首先假設訓練序列為已知,為了要得到通道脈衝響應,我們將週期性的脈衝串每間隔固定 一位元時間就乘上其相對應的位元值後,再進行累加,此動作是確保在時間點mT 上b m個 脈衝都是正向累加。而在其他時間點nT ,且 nb ≠ 時,這m m個脈衝的值為隨機產生的正一 或負一,因此m個脈衝相加時,會有正負相消的情況產生。且若m趨近於無窮大時,脈衝 值為正一或負一的機率會趨近於1 2,因此在m個脈衝中正一與負一的個數會接近各半, 因此m個脈衝相加後的結果會趨近於零。在此我們將此種現象稱為資料調和。因此除了mTb 時間點上的脈衝外,其他的脈衝則會因為資料調和的關係而平均掉,所以就可得到估計的 通道響應值。 圖3-13 相關法通道估計器 圖 3-13 中所接收到的訊號r t( ) ( ) ( )
=s t ∗h t ,其中s t( )
為經直接序列展頻後得到的資 料,h t( )
為脈波塑形、多重路徑通道與匹配濾波器所形成的合成通道。考慮經相關器後輸 出的訊號如下( )
(
) ( )
(
) ( )
( )
(
) ( )
( )
(
) ( )
0 0 0 0 0 0 1 1 1 b b b T b N T n b n b N T n b n b N n p b n v r t p t dt T d p t nT h p t dt T d p t nT p t dt h T d R nT h τ τ τ τ τ τ τ τ = = = = + × ⎡ ⎤ = ⎢ − + ∗ ⎥× ⎣ ⎦ ⎡ ⎤ = ⎢ − + ⎥∗ ⎣ ⎦ = − ∗∫
∑
∫
∑
∫
∑
(3.11) 其中v( )
τ 為經相關器後的輸出,Rp( )
τ 為展頻序列的自相關函數。接著訊號v( )
τ 經各個延 遲,乘上各個已知的資料{ , , , }d d0 1 dn ,n=0,1, ,m,m N,然後把所有分支的輸出經 累加器(accumulator)加起來,將時間點為mT 以後的波形,視為估計到的通道b ˆh t 。為方便( )
數學分析,在此簡化成只使用4 個分支,即m=3。數學分析如下 當 m = 3 時(
)
( )
( )
(
)
(
)
(
)
(
)
( )
(
)
(
)
(
)
(
)
-0 3 0 3 1 3 2 3 3 3 4 2 0 2 1 2 2 2 3 -- - 2 - 3 - 4 - - 2 - 3 - 4 m b m k k p p b p b p b p b p b p b p b p b v t kT d h t d d R t d d R t T d d R t T d d R t T d d R t T h t d d R t T d d R t T d d R t T d d R t T = × ⎡ ⎤ = ∗⎣ + + + + + ⎦ ⎡ ⎤ + ∗⎣ + + + + ⎦∑
iii iii( )
(
)
(
)
(
)
( )
(
)
(
)
1 0 1 1 1 2 0 0 0 1 - 2 - 3 - 4 - 3 - 4 p b p b p b p b p b h t d d R t T d d R t T d d R t T h t d d R t T d d R t T ⎡ ⎤ + ∗⎣ + + + ⎦ ⎡ ⎤ + ∗⎣ + + ⎦ iii iii 令( )
(
)
( )
0 0 1 ˆ -1 N m k k n p b n k h t d d R t nT h t m = = + ⎡ ⎤ = ⎢ ⎥∗ + ⎣∑∑
⎦ (3.12) 其 中 d 為 已 知 訊 號 , 用 來 確 保 各 個 分 支 所 輸 出 的 波 形 在 時 間 點 為n mT 時 為 正 值 ,b {0,1, , } k = m 。接著考慮通道為理想的單一路徑,即令h t( )=δ( )t ,而m=3,如圖 3-14 所示,可看到圖中(a)為第一個分支的輸出訊號,其時間點為 3T 時的脈衝為正值,圖中(b)b 為第二個分支的輸出訊號,其時間點為3T 時的脈衝為正值,以此類推,如圖中框起來的部b 分所示。接著將這幾個分支的訊號相加起來,將會得到如圖3-15 近似於脈衝的波形。在此 注意到的是,圖3-15 為時間點為 3T 以後的波形,即圖 3-14 中取樣時間 1152 前的脈衝串b 皆被捨棄。接著討論改變分支的數量時會產生的效應,如圖3-16,根據先前提到的資料調 和的現象,當分支數量為 m 時,在時間點為nT ,且 nb ≠ 時,此時間點上的 m 個脈衝會m正負相消,且當分支數量 m 越大,正負一的個數會更接近,因此脈衝相消後會趨近於零, 最後便能使得整個波型越趨近於一理想脈衝;但由於系統標準規格上的訓練序列長度有 限,因此必須在序列長度與效能之間取得平衡點。 0 500 1000 1500 2000 2500 3000 3500 4000 -4 -2 0 2 4 A m pl itud e
Output signals of different branch of channel estimator in single path channel
0 500 1000 1500 2000 2500 3000 3500 4000 -4 -2 0 2 4 0 500 1000 1500 2000 2500 3000 3500 4000 -4 -2 0 2 4 0 500 1000 1500 2000 2500 3000 3500 4000 -4 -2 0 2 4 Time(sample) A m pl itud e A m pl itud e A m pl itude (a) (b) (c) (d) 圖3-14 通道為單一路徑時,通道估計器各分支的輸出 0 500 1000 1500 2000 2500 3000 3500 4000 -4 -3 -2 -1 0 1 2 3
4 Estimated channel for 4 accumulations in single path channel
Time(sample) A m plit ud e
0 2000 4000 6000 8000 10000 12000 -3.5 0 3.5 0 2000 4000 6000 8000 10000 12000 -3.5 0 3.5 0 2000 4000 6000 8000 10000 12000 -3.5 0 3.5 Time(sample) Am pl itu de Am pl itu de A m plit ud e m=16 m=128 m=1024
Estimated channels for m accumulations in single path channel
圖3-16 通道為單一路徑時,改變通道估計器累加的分支數量 在此設定一對照組,我們考慮一輸入訊號為一脈衝δ( )t ,經同樣的方塊後,如圖3-17 所示。由於輸入訊號為δ( )t ,所以圖3-17 中的r t
( )
=δ( ) ( )
t ∗h t =h t( )為完美的合成通道響 應,在此稱之為完美通道(perfect channel)估計。比較完美通道與前述所提出的相關法通道 估計器所估計出的通道,圖 3-18 為其路徑增益強度的比較圖,圖 3-19 為路徑增益相位的 比較圖,在此我們所用的多重路徑通道為標準規格上的CM1 通道。可發覺在第 14 碼時間 之前的大小和相位都很接近,即CM1 通道的主要影響部份都估計的很接近。 圖3-17 完美通道估計方塊圖0 2 4 6 8 10 12 14 16 18 20 22 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Perfect channel Estimated channel Time (chip) Estimated channels in CM1 M agn itude 圖3-18 完美通道估計與相關法通道估計路徑增益的強度比較 0 2 4 6 8 10 12 14 16 18 20 22 -4 -3 -2 -1 0 1 2 3 4 Perfect channel Estimated channel Time (chip) P hase Estimated channels in CM1 圖3-19 完美通道估計與相關法通道估計路徑增益的相位比較 最後注意到的是,時間同步是必須先執行的,否則如果直接用相關法去估計脈波塑 型、多重路徑通道與匹配濾波器所形成的合成通道,將無法精確取出多重路徑通道的最大
第四章 犁耙接收機與等化器
在多重路徑的通道環境下,傳送信號的能量會分散在不同的路徑中,因此需要利用多 重路徑合成的方式,將信號能量收集起來,以提高信號解調的性能。而最常看到的多重路 徑信號能量收集器為犁耙接收機[3],其中使用了最大比例結合(Maximum Ratio Combining, MRC)的技術。 使用犁耙接收機已能相當程度的提高信號解調的性能,但若考慮如何更進一步改善接 收機的效能,在此考慮在犁耙接收機之後加上等化器,再觀察其改善系統效能之能力。而 在等化器的部份會再針對使用線性或非線性的形式,或是不同演算法的等化器做進一步的 分析與討論。
4.1 選擇性犁耙接收機
圖4-1 犁耙接收機架構選擇性犁耙接收機(selection rake receiver)其架構如圖 4-1 所示,接收信號會經過不同分 支(finger)後再結合起來,每個分支的架構相似,需將原先展頻時所用的同一組展頻碼作不
同程度的延遲
( )
τi ,然後乘上適當的權重(weighting),最後再乘上信號,做解展頻的動作, 而權重的選取通常讓結合後的信號雜訊比為最大。其中不同程度的延遲與權重是藉由通道 估計器估算後得到。 而選擇性犁耙接收機中每個分支的延遲是由多重路徑的時間延遲所決定,權重則為多 重路徑的路徑增益取共軛,可得到 ˆ i j i i i A∗=a e−θ =h∗ (4.1) 因此接收信號進入某個分支後,若原本受到路徑增益 hi的影響,此時再乘上此分支的權重 Ai*,則 ˆ i i i i h ×A∗ = ×h h∗ (4.2) 若假設通道估計器所計算出的通道為完美通道,可得到 2 i i i i i h ×A∗ = ×h h∗ = h (4.3) 因此在此分支上乘上適當的權重可將多重路徑的相位消除掉,以收集到此多重路徑上最大 的信號能量。如果將所有多重路徑全部納入犁耙接收機考量,則所有分支所蒐集到的總信 號能量為 1 2 1 1 I i i h − = =∑
(4.4) 因此考慮所有分支的犁耙接收機能將所有信號能量收集起來,可利用最大的信號雜訊功率 比而得到最好的信號解調性能。 經由通道估計器估算後,可得到通道的每個多重路徑的路徑增益及其時間延遲,但由 於考量的系統中一個碼時間有 16 次的過度取樣(oversample),因此所估計到極寬頻通道的 多重路徑可能多達上千個,如果將這些多重路徑全部納入犁耙接收機量,會造成系統複雜 度過高,所以不可能以上述的所有分支的方式設計犁耙接收機,因此我們會以能量最大的 多重路徑為基準,而得到以碼時間為單位的估計通道,如圖4-2 所示:圖4-2 通道估計器所估計到之通道 而估計到的通道,其多重路徑的數目仍多達上百個,因此我們會再以能量最大的數個多重 路徑中選擇適當的路徑數目,以降低整體系統複雜度。 接著計算出選擇性犁耙接收機輸出的結果 U:
(
)
(
) ( )
(
)
(
)
(
)
( )
(
)
1 0 0 1 -1 0 0 0 0 1 1 1 0 0 0 0 0 0 Re ( ) Re Re Re b b b b L T j j j L T I n i b i j j j n i L I T L T i j n i b j j j j i n j U r t p t h dt d h p t nT n t p t h dt h h d p t nT p t dt h n t p t dt τ τ τ τ τ τ − ∗ = − ∞ ∗ = = = − − ∞ − ∗ ∗ = = = = ⎡ ⎡ ⎤ ⎤ = ⎢ ⎣ − ⎦ ⎥ ⎣ ⎦ ⎡ ⎡⎡ ⎤ ⎤ ⎤ = ⎢ ⎢⎢ − − + ⎥ − ⎥ ⎥ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦ ⎡ ⎤ ⎡ ⎤ = ⎢ − − − ⎥+ ⎢ − ⎣ ⎦ ⎣∑∫
∑
∫
∑ ∑
∑∑ ∑
∫
∑
∫
(
)
( )
(
)
( )
(
)
1 1 1 0 0 0 0 0 1 2 1 1 0 0 0 0 0 Re Re Re b L I L T i j n b p b i j j j j i n j L L I j n b p b i j n b p b i j j n j i n i j h h d T R nT h n t p t dt h d T R nT h h d T R nT N Y I N τ τ τ τ τ − − ∞ − ∗ ∗ = = = = − ∞ − − ∞ ∗ = = = = = ≠ ⎥ ⎦ ⎡ ⎤ ⎡ ⎤ = ⎢ + − ⎥+ ⎢ − ⎥ ⎣ ⎦ ⎣ ⎦ ⎡ ⎤ ⎢ ⎥ ′ = ⎢ + + − ⎥+ ⎢ ⎥ ⎣ ⎦ ′ ′ = + +∑∑ ∑
∑∫
∑
∑
∑∑ ∑
(4.5) 其中( )
1 2 0 0 Re L j n b p b j n Y h d T R nT − ∞ = = ⎧ ⎫ = ⎨ ⎬ ⎩∑
∑
⎭ (4.6)(
)
1 1 0 0 0 Re L I i j n b p b i j j i n i j I h h d T R nT τ τ − − ∞ ∗ = = = ≠ ⎧ ⎫ ⎪ ⎪ ′ = ⎨ + − ⎬ ⎪ ⎪ ⎩ ⎭∑∑ ∑
(4.7)( )
(
)
1 0 0 Re L Tb j j j N h n t p t τ dt − ∗ = ⎧ ⎫ ′ = ⎨ − ⎬ ⎩∑∫
⎭ (4.8) 在(4.5)式中,L 為犁耙接收機分支的數目,p t( τj)hj ∗ − 為第 j 個分支中經過延遲再乘上權重 的展頻碼。根據展頻碼的自相關函數Rp( )
t 的特性,在整數倍位元時間取樣時,自相關函 數會有最大值1,而在非整數倍位元時間取樣時自相關函數值會介於 0.2 到−0.2 之間。Y 為 每個分支解出的信號的總和。 I ′ 為多重路徑所造成的符號間干擾,由於 I ′ 中展頻碼自相關 函數的取樣時間為非整數倍位元時間,因此有效的壓抑符號間干擾的成分。N′為雜訊經過 犁耙接收機後的成分,在此仍將之視為一雜訊項。4.2 等化器
等化器其實就是一濾波器[4],若在我們考慮的系統中,從傳送端的展頻的方塊開始到 犁耙接收機為止,將其視為一等效通道,則之後的等化器主要作用就是要將此等效通道的 效應消除掉。而根據不同的形式、架構、或演算法,可分類出各種不同的等化器如圖4-3:等化器主要分成線性及非線性兩種形式,而每一種形式中還可以分為橫向(transversal)及梯 形(lattice)等不同的架構,在每個不同的架構下還可搭配各種不同的演算法來使用,且不同 的形式、架構和不同演算法的等化器都各存在其不同的特性。在接下來的章節裡將針對線 性及非線性兩種形式和最小均方(least mean square, LMS)及遞迴式最小平方(recursive least square, RLS)演算法之等化器的各種特性作分析與討論。
4.2.1 線性等化器特性分析
在此我們考慮一種橫向式架構的線性等化器,又稱為是tapped-delay line 的架構,此等 化器的架構如圖4-4 所示: 圖4-4 線性濾波器架構 其中u n( )
為犁耙接收機輸出的信號,我們可以將其視為原傳送信號經過一個等效通道 後的結果,將u n( )
經過不同的延遲之後再乘上適當的權重(w ),最後再全部相加後,成為i 等化器的輸出y n( )
。線性等化器主要目的即為消除此等效通道的效應,以還原回原傳送信 號。 假設等效通道為h n′( )
,且此通道長度為 I,則其 Z 轉換函數為H′( )
z ;且假設我們已 找到一組適當的權重w n( )
,此組權重長度為 M,則其 Z 轉換函數為W z( )
;最後此等化器 輸出為y n( )
,其Z 轉換函數為Y z( )
。若原傳送訊號為d n( )
,其 Z 轉換函數為D z( )
,根據上述條件,則u n