國立交通大學
工業工程與管理學系
碩士論文
以組合派工法求解雙流線型工廠排程
A Combined Dispatching Criteria Approach to
Scheduling Dual Flow Shops
研 究 生:陳文旻
指導教授:巫木誠 博士
以組合派工法求解雙流線型工廠排程
A Combined Dispatching Criteria Approach to Scheduling
Dual Flow Shops
研究生:陳文旻
Student:Wen-Min Chen
指導教授:巫木誠 博士
Advisor:Dr. Muh-Cherng Wu
國 立 交 通 大 學
工業工程與管理學系
碩 士 論 文
A Thesis
Submitted to Department of Industrial Engineering and Management
College of Management
National Chiao Tung University
In Partial Fulfillment of the Requirements
For the Degree of Master of Science
In
Industrial Engineering
June 2009
Hsin-Chu, Taiwan, Republic of China
以組合派工法求解雙流線型工廠排程
研究生:陳文旻
指導教授:巫木誠 博士
國立交通大學工業工程與管理研究所
中文摘要
本論文主要研究一個允許跨廠製造之雙流線型工廠(Dual Flow Shop)排程問題。排程 目標為最小化寬裕度的變異係數。所謂的寬裕度,指的是交期與總加工時間之差距。此 排程問題包含兩項排程決策:加工途程( Route Assignment, 指派工件到各站)與工件排序 ( Job Sequencing )。本研究發展一套可同時求解加工途程與加工順序之基因演算法 (GA),而在加工順序方面更使用了多種派工法,讓基因演算法更具多樣性。這些派工法 包括單一啟發式演算法、組合派工法以及演化式之派工法則。針對這幾種演算法,本研 究皆透過實驗,進行數據間的比較。 實驗結果指出在各種情境下,上述三種方法中,並沒有一種派工法能顯著的贏過其 他績效。但是,在大部分的情境下,組合派工法皆能提供相對穩健與較佳之績效結果。 關鍵詞:排程、跨廠、雙流線型生產、組合派工法、基因演算法、交期
A Combined Dispatching Criteria Approach to Scheduling
Dual Flow Shops
Student:Wen-Min Chen
Advisor:Dr. Muh-Cherng
Wu
Department of Industrial Engineering and Management
National Chiao Tung University
Abstract
This research investigates a dual flow shop scheduling problem, which is in the context of allowing cross-shop processing. The scheduling objective is to minimize the coefficient of variation of slack time, in which the slack time of a job denotes the difference between its due date and total processing time. This scheduling problem involves two decisions: route assignment (assigning jobs to shops) and job sequencing. We developed a genetic algorithm (GA) for making the route assignment decision, which is further varied by including various kinds of dispatching algorithms. These dispatching algorithms include single heuristic rules, combined dispatching rules, and evolutionary approach. Numeric experiments for comparing these scheduling algorithms are carried out. Experiment results indicate that none of the GAs could outperform the others in all scenarios. Yet, the GA equipped with the combined dispatching rules is relatively more robust, performing quite well in most scenarios.
Keywords:scheduling; cross-plant; dual flow shop; combined dispatching criteria; genetic algorithm (GA); due date
誌 謝
本篇論文得以順利完成,首先我必須感謝我的指導教授巫木誠博士細心的指導,在 畢業口試前,經過了許多次的波折,有幾次都快讓我覺得無路可走時,老師卻都能為我 們找出一條可行之路,真的很感謝老師。此外,在口試期間,也承蒙許錫美教授、彭德 保教授、陳文智教授所提出的寶貴意見,讓本論文更趨於完善,僅此致謝。 在碩士班的兩年中也得到了許多人的幫助,像是碩二前的暑假,一起學習程式的 team-昭宏、慈盈、佳玟,以及教導我們程式撰寫的邱志文學長,由於我因為臨時的改題 目,比較晚加入學習,可是大家卻都盡力來幫我,讓我能跟上大家的進度,此外也很感 謝聰明的o1o-黃亮詮,有問題的時候他都能為我們解答。回想在碩士班中,巫老師齊下 的所有人,彼此互相打氣,一路走來有說不完的感謝。最後我還想感謝浩翰,在我心情 不好時,能給予我安慰,在我開心的時候能與我一起大笑,更能在我疑惑的時候,給予 我最佳的建議,謝謝你。 最後,謹以此論文獻給我最愛的家人,感謝他們能給予我最大的支持,讓我能盡自 己最大的努力來完成這份論文,謝謝大家。 陳文旻 于 新竹交大 2009’7’1目 錄
中文摘要... i Abstract ... ii 誌 謝 ...iii 圖目錄...viii 第一章 緒論 ... 1 1.1 研究動機 ... 1 1.2 研究議題 ... 1 1.3 研究方法 ... 3 1.4 論文組織 ... 5 第二章 文獻探討 ... 62.1 流線型生產排程( Flow Shop scheduling ) ... 6
2.1.1 Flexible Flow Shop 與 Dual Flow Shop 之比較 ... 8
2.2 多廠區相關文獻 ... 10 2.2.1 多廠區生產規劃 ... 10 2.2.2 水平式多廠區相關文獻 ... 11 2.2.3 不跨廠相關文獻 ... 12 2.2.4 跨廠相關文獻 ... 14 2.3 混合實驗設計 ... 17 2.4 基因演算法 ... 20 2.5 小結 ... 22 第三章 研究方法 ... 23 3.1 研究問題 ... 23 3.2 研究假設 ... 24
3.4 雙流線型工廠模式建構 ... 26 3.4.1 染色體設計 ... 27 3.4.2 染色體解讀 ... 28 3.4.3 加工途程 ... 29 3.4.4 加工順序 ... 34 3.4.5 適合度函數 ... 43 3.4.6 基因演算法求解流程 ... 49 3.5 小結 ... 51 第四章 實驗分析與比較 ... 53 4.1 實驗假設 ... 53 4.2 實驗目的與情境 ... 53 4.2.1 實驗目的 ... 53 4.2.2 實驗標竿 ... 54 4.2.3 實驗情境 ... 54 4.3 實驗分析與比較 ... 61 4.3.1 情境一 ... 61 4.3.2 情境二 ... 63 4.3.3 情境三 ... 65 4.3.4 情境四 ... 66 4.3.5 小結 ... 68 4.4 加工途程分析 ... 69 第五章 結論與未來建議 ... 73 5.1 結論 ... 73 5.2 未來建議 ... 74
表目錄
表 1. 1 跨廠範例 ...3
表 2. 1 Flexible Flow Shop 與 Dual Flow Shop 比較表 ...9
表 2. 2 水平式多廠區文獻 ...12 表 2. 3 跨廠文獻分析 ...15 表 3. 1 Stage 1 加工時間與累積加工時間表 ...32 表 3. 2 切割點於 J1、J4 中間 ...32 表 3. 3 切割點於 J3、J2 中間 ...32 表 3. 4 Stage 2 加工時間與累積加工時間表 ...33 表 3. 5 Stage 2 最佳切割點 ...33 表 3. 6 分廠結果 ...33 表 3. 7 8 個工件分廠資訊 ...38 表 3. 8 8 個工件加工時間與交期 ...38 表 3. 9 平均數與標準差的計算 ...39 表 3. 10 標準化後的數值 ...39 表 3. 11 實驗點 ...41 表 3. 12 加工優序計算 ...42 表 3. 13 Stage 1 首次派工情形 ...45 表 3. 14 Stage 1 後續派工情形 ...45 表 3.15 Stage 2 首次派工情形 ...46 表 3. 16 Stage 2 後續派工情形 ...48 表 3. 17 計算 CV ...48 表 4. 1 情境一工件加工時間與交期設計方法 ...55 表 4. 2 情境二工件加工時間與交期設計方法 ...56
表 4. 4 情境四工件加工時間與交期設計方法 ...60 表 4. 5 情境一之派工法績效值(CV)...62 表 4. 6 情境一之派工法改善率 ...62 表 4. 7 情境一之最佳組合權重 (a) 效率協調 (b) 效率不協調...62 表 4. 8 情境二之派工法績效值(CV)...63 表 4. 9 情境二之派工法改善率 ...64 表 4. 10 情境二之最佳組合權重 (a) 效率協調 (b) 效率不協調...64 表 4. 11 情境三之派工法績效值(CV)...65 表 4. 12 情境三之派工法改善率 ...65 表 4. 13 情境三之最佳組合權重 (a) 效率協調 (b) 效率不協調...66 表 4. 14 情境四之派工法績效值(CV)...67 表 4. 15 情境四之派工法改善率 ...67 表 4. 16 情境四之最佳組合權重 (a) 效率協調 (b) 效率不協調...67 表 4. 17 GA-Comb 在加工效率協調之情境 ...69 表 4. 18 GA-Comb 在加工效率不協調之情境 ...70 表 4. 19 GA-GA 在加工效率協調之情境...70 表 4. 20 GA-GA 在加工效率不協調之情境...70
圖目錄
圖 1.1 雙流線型工廠生產流程示意圖 ...2
圖 2. 1 Hybrid Flow Shop Environment...7
圖 2. 2 Dual Flow Shop 跨廠問題...8
圖 2. 3 Flexible Flow Shop 跨廠問題 ...8
圖 2. 4 實驗設計求解空間示意圖 (a)二因子(b)三因子...17
圖 2. 5 混合實驗求解空間示意圖 (a)二因子(b)三因子...17
圖 2. 6 單體實驗 (a)單體晶格設計(b)單體質心設計...18
圖 2. 7 擴充單體晶格設計 ...18
圖 2. 8 基因演算法的求解流程 ...20
圖 3. 1 雙流線型( Dual Flow Shop )工廠排程 ...23
圖 3. 2 染色體設計方式 ...27 圖 3. 3 染色體的兩種解讀 ...28 圖 3. 4 Stage 1 分廠示意圖 ...30 圖 3. 5 8 個 Job 的分廠示意圖...31 圖 3. 6 染色體三站加工途程示意圖 ...34 圖 3. 7 EDD 派工法說明案例...36 圖 3. 8 SPT 派工法說明案例...36 圖 3. 9 LSF 派工法說明案例...37
圖 3. 10 Augmented Simplex-Lattice Design...41
圖 3. 11 染色體解讀示意圖 ...42
圖 3. 12 線性順序交配(LOX)...50
圖 3. 13 SWAP 示意圖 ...50
第一章 緒論
1.1 研究動機
半導體業的蓬勃發展,生產技術快速進步的同時,業界面臨的是源源不絕的外部需 求,而當市場需求旺盛時,更會有需求大於供給的情況產生,此時,企業為了避免訂單 的流失,促使各公司紛紛透過水平上的擴廠、增加生產線等來擴充產能,以承接更大量 的訂單,也因此形成了多廠區的生產型態。 過去多廠區型態的生產排程模式,主要建立在單一廠區的生產方式上。多廠區中的 單廠個別生產規劃可分為兩階段,第一階段首先進行訂單指派的規劃,大多採全面性的 訂單管理,分配好各廠訂單種類後,再進行第二階段各廠獨自的產能規劃。此種生產方 式,無法同時考量多廠間的生產績效、產能利用等,因此當市場需求不確定下,造成臨 時訂單變動時,已排定的排程無法給予充裕的緩衝時間來因應訂單的調動,而工廠更無 法立即透過擴廠、增加生產線等,需要大量時間與金錢的方式來解決因訂單變動所產生 的產能不足問題。因此若繼續依照現有的排程方式進行單廠各別加工,可能造成訂單的 遲交,間接的影響到企業的聲譽。所以當多廠間的單廠排程無法滿足龐大而多變的市場 需求時,為了有效地利用生產設備、增加產能,又不增加額外的投資下,跨廠支援因此 而產生。 所謂的跨廠支援,即是生產方式與機台性質相近的工廠,當一廠產能不堪負荷,而 另一廠尚有剩餘產能時,彼此可以互相進行廠與廠之間的支援行為,即是將無法負荷的 工件轉由另一廠來進行生產,藉此不僅可滿足兩廠客戶需求,更可以充分的利用閒置產 能,換言之,就是為企業帶來更多可用的產能。所以本研究主要針對此類具有跨廠特性 的流線型生產排程問題進行規劃,為此型態的問題提出最佳排程建議。1.2 研究議題
如上節所述,客戶臨時的訂單需求變動,將會造成廠內已排定之排程的混亂,使得 其他工件也都接連著受到影響。所以如何能在短期提供臨時所需的產能,使得跨廠排程的研究逐漸變的重要。本研究針對此類排程問題,以雙廠流線型工廠為對象,提出一套 生產排程的方法,希望能為不同情境下的工廠,提出最有效的排程建議。 圖 1.1 雙流線型工廠生產流程示意圖 本論文所研究的排程問題為雙流線型工廠排程(圖 1.1),所謂的雙流線型工廠,指的 是兩個生產功能相近,且為流線型(Flow Shop)生產方式的廠,能夠透過彼此工件間的跨 廠加工,達到產能的互相協調。 由於實際工廠生產線極為複雜,本論文為了便於進行後續排程規劃的探討,故將其 簡化為兩廠(Plant A、Plant B)、三站的形式。針對 Plant A 與 Plant B 兩廠,決定出允許 工件跨廠的兩個跨廠點後,接著便可依照這兩點,將整條生產線劃分為前、中、後三段 製程,由圖1.1 來看,A1、B1 代表著前段製程,A2、B2 代表中段製程,而 A3、B3 代 表著後段製程。每段製程間的跨廠點,代表工件流經此處時,可以選擇是否進行跨廠加 工,也就是工件在此處是可被允許跨廠的位置。
針對兩廠或兩廠以上的生產規劃,將會面臨到兩項決策,分別為加工途程( Route Assignment )與加工順序( Job Sequencing )的決策。所謂的加工途程,指的是顧客下單
後,必須決定彼此的工件配置問題,哪些工件是要分給A 廠,哪些要分給 B 廠;而所
謂的加工順序,即是根據各廠所分配到的工件,進行廠內加工順序的配置。
在過去文獻中,多廠區生產規劃的文獻大多僅針對加工途程進行分析與研究,當工 件分配至各廠後,便以先進先出的方式進行工件的加工,對於加工順序之決策,並未多 做分析。部份的文獻,會針對這兩項決策進行兩階段性的排程,第一階段先透過計算各
一派工法進行單廠各自的生產排程規劃。但是,兩階段性的排程並無法同時考量同一個
績效指標,所以最終的績效結果或許並非能達到最佳。針對這個問題,劉謹銘於2009
年提出一套能夠同時考量多廠區加工途程與加工順序兩項決策的演算法,透過平衡各廠 產能與最早交期最先加工(Earliest Due Date;EDD)法則,運用基因演算法進行演化,以 求解雙流線型工廠的生產排程問題。
在過去多廠區生產排程文獻中,可以發現都是以單一派工法則來決定加工順序,但 是,Dabbas et al.(2003)與 Lin et al.(2005)在其研究中,都曾驗證過單一派工法則在某些 情境或是績效指標下,改善率是有限的。所以劉氏的雙流線型工廠排程中,並非皆能以 單一派工法來達到最佳績效。故本論文將針對此問題提出一套組合派工法,融合多種單 一派工法的優點,為各種生產情境給予最佳的派工建議。
1.3 研究方法
本論文的最主要是為了解決一個雙流線型工廠排程問題,在具有相似生產線的兩個 廠,且彼此有跨廠的合作關係時,可以透過本研究決定出兩廠間的工件配置與加工順序。 論文依照多廠區的兩項決策分兩部份做介紹,首先是決定工件的加工途程,此部份 在本研究是依據兩廠產能負荷程度進行分廠,決定工件在各廠、各站的加工位置,換言 之,就是決定兩廠的跨廠行為。舉例來說,如表1.1 所示,J1~J8 代表的是工件 1 到工 件8,它們放置的位置,代表在兩廠的加工位置,所以由此表可以發現,工件 2 在第一 站位於B 廠加工,第二站換到 A 廠,第三站又回到 B 廠加工,也就是說工件 2 在 A、B 兩廠中具有跨廠行為產生。 表 1. 1 跨廠範例 第一站 第二站 第三站 A 廠 J1,J3,J5,J4 J1,J2,J3,J5,J4 J1,J3,J5,J4 B 廠 J2,J6,J7,J8 J6,J7,J8 J2,J6,J7,J8第二部份要接著決定工件的加工順序,本研究採用組合派工法來進行求解,其主要 作法是先使用混合實驗(Mixture Designs)和反應曲面(Response Surface Method)最佳化來 求得不同派工法權重的想法,接著再將多個派工法依據個別權重進行線性組合。組合派 工法的貢獻就是他會針對不同的情境給予派工方式的建議。假設某個情境下,若運用單 一法則EDD 進行派工會讓績效最佳,則透過組合派工法所求得的權重值便會使 EDD 之 權重最高,反之,若某情境是適合使用最短加工時間最先加工(SPT)法則,則會使 SPT 所占的權重值最高。 所以,本研究的主要貢獻便是針對不同的生產情境,能夠同時給予最適當的跨廠與 派工建議,讓最終績效指標最佳化。 在績效指標的決定方面,本研究採用變異係數(CV;CV=標準差/平均數)作為最終的 目標式。會採用變異係數作為目標式的原因,是由於本研究的排程屬於工廠生產前的預 排排程,當企業接獲訂單之後,便會開始預排每個工件的開始加工時間。為了能讓工件 臨時變動時,能有足夠的緩衝時間來因應,不必因為產能不足而重排程,所以在進行工 件預排時,會希望達到以下兩個目的: 1. 每個工件都具有足夠緩衝時間。 2. 滿足客戶訂單交期。 為了避免臨時訂單變動造成原排程的變更與額外的損失,規劃結果希望能使變動的 工件,具有足夠的緩衝時間,也就是完工時間與交期間的寬裕度能最大化,使得訂單被 要求提前出貨時,也能保有足夠的時間可以運用,達到第一項目的。但是實際情況下, 我們並無法得知哪個工件將會被提前出貨,因此本研究為了兼顧到所有的可能性,希望 能讓所有工件的寬裕度差異最小,所以我們可以透過最小化寬裕度的標準差來達到這個 目的。 但在這樣的指標下產生一個限制,就是所有工件必須都要在交期內完工,因為標準 差小只能讓每個值都很接近,並無法保證不延誤交期。而實際工廠中,也不能完全保證
因此,為了同時達到最小化標準差與最大化平均數兩項指標,本研究使用變異係數 作為最終的績效指標。後續將針對各種情境,只要透過本研究的雙流線型工廠排程模 型,便可以決定是否進行跨廠,以及應該使用的派工法則為何。
1.4 論文組織
本論文內容共含五章。第一章敘述研究動機、研究問題與研究方法介紹。第二章為 相關文獻介紹,首先探討與雙流線型工廠有關之生產型態,並進行多廠文獻之比較、混 合實驗與求解工具基因演算法之介紹。第三章針對本研究的兩項決策,進行問題分析與 定義,說明如何決定工件加工途程,以及組合派工法方法介紹。第四章為實例驗證。第 五章提出未來可延伸之研究方向。第二章 文獻探討
本章將介紹與本研究相關之文獻,首先針對流線型(Flow Shop)生產方式做分析,接 著介紹與本論文較為接近的多廠文獻與組合派工相關文獻,最後再簡略的介紹一下本研 究所使用之基因演算法相關內容。
2.1 流線型生產排程( Flow Shop scheduling )
本論文研究的是雙流線型( Dual Flow Shop)生產排程,Flow Shop的問題在過去幾十 年以前就已經被廣泛的研究,依照Allahverdi et al. (1999)的說法,Flow Shop首先被 Johnson (1954)所研究,他針對兩部機台,目標式為最小化Makespan來進行求解,後續 就越來越多人針對Flow Shop等議題進行不同的研究。
在2008年Allahverdi et al.對於Flow Shop的解釋為,假設總共有m個站,每個站擁有 一部或多部機台,則工件皆必須依照相同的加工順序於m個站中進行生產,即稱為Flow Shop生產方式。並將過去的Flow Shop文獻分為四種類型,分別是Flow Shop、No-Wait Flow Shop、Flexible (Hybrid) Flow Shop、Assembly Flow Shop。
在這四種類型中,本研究的Dual Flow Shop似乎與其中的Flexible (Hybrid) Flow Shop 極為相似,所以為了驗證兩者的異同處,在後續將為兩者作一個簡單的分析與比較。
1. Flow Shop
Flow Shop指的是一個工作站中僅含有一部機台,且所有的工件會依照相同的順序
在各站進行加工。在過去,這種問題在所有的流程是生產排程中最常被拿來做研究。
2. No-Wait Flow Shop
No-Wait Flow Shop 指的是當前一個作業完成之後,下一個作業會立刻開始,中間 沒有等候時間,此排程問題最早由 Adiri 和 Pohoryles 在 1982 年提出(Adiri and
3. Flexible (hybrid) Flow Shop
Flexible (Hybrid) Flow Shop意指至少有一站的機台超過一部。假設生產線共有u站, 至少一站擁有m個平行機台,所有工件會依照相同的順序進行加工,每個工件最多僅能 被一台機台所製造,每個機台最多也只能加工一個工件。在流線型的複雜度方面,Linn and Zhang (1999)更進一步將製造複雜性分成三類:(1) 兩站HFS、(2) 三站HFS、(3) k 站(k>3)HFS。這三者中唯一的差異就是在解決每站兩機台的流程問題時,求解時間非常 大(Johnson, 1954);而機台增加到三台時,此問題就成了NP-hard的問題(Garey and Johnson, 1979)。
圖 2. 1 Hybrid Flow Shop Environment
4. Assembly Flow Shop
Assembly Flow Shop 意指每個工件若必須進行 m-1 次特定的加工,第一站中每個工 件會被指派到事先決定好的機台進行加工,接著在第二站進行裝配。舉例來說,假設在 一個只有兩站n 個工件的 Assembly Flow Shop 排程問題中,每個工件必須進行 k+1 次的
作業,此時也將有k+1 個不同的機台來進行這些不同的作業,每個機台一次只能加工一
個工件,針對每個工件,前k 個作業會在第一站的平行機台中進行處理,而最後一項作
業會再第二站進行加工;第一站中的前k 項作業會被指派到不同的機台進行加工,而在
第二站的最後一項作業將在第一站所有k 個作業都完工之後才會開始進行,這兩站的裝
2.1.1 Flexible Flow Shop 與 Dual Flow Shop 之比較
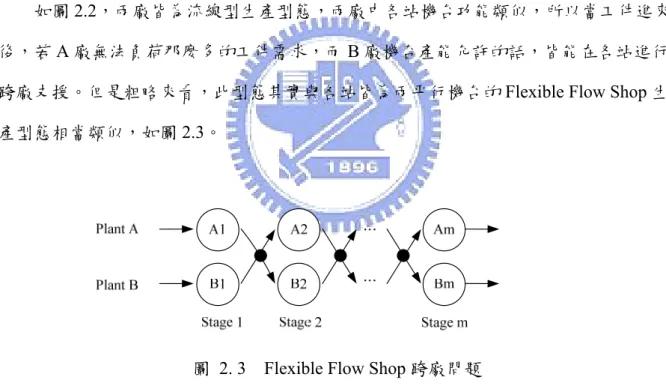
Dual Flow Shop 所探討跨廠問題,過去對於此問題的研究並不多,而本論文所研究 的型態如下:
圖 2. 2 Dual Flow Shop 跨廠問題
如圖2.2,兩廠皆為流線型生產型態,兩廠中各站機台功能類似,所以當工件進來
後,若A 廠無法負荷那麼多的工件需求,而 B 廠機台產能允許的話,皆能在各站進行
跨廠支援。但是粗略來看,此型態其實與各站皆為兩平行機台的Flexible Flow Shop 生 產型態相當類似,如圖2.3。
圖 2. 3 Flexible Flow Shop 跨廠問題
Flexible Flow Shop 生產型態中,每站的兩個機台其功能也相類似,工件進來後,假 若兩機台皆空閒時,便可以任選一機台進行加工。若粗略來看,兩者生產型態是相當類 似的,此時便會令人產生疑惑,如果可以將Dual Flow Shop 的問題看作 Flexible Flow Shop 的問題,那本論文是否沒有研究的意義,為了分清楚兩者間的差異,以下將針對
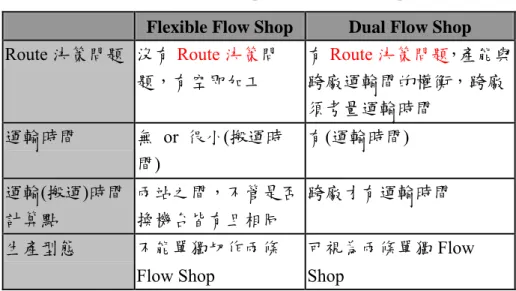
表2. 1 Flexible Flow Shop 與 Dual Flow Shop 比較表 Flexible Flow Shop Dual Flow Shop Route 決策問題 沒有Route 決策問 題,有空即加工 有Route 決策問題,產能與 跨廠運輸間的權衡,跨廠 須考量運輸時間 運輸時間 無 or 很小(搬運時 間) 有(運輸時間) 運輸(搬運)時間 計算點 兩站之間,不管是否 換機台皆有且相同 跨廠才有運輸時間 生產型態 不能單獨切作兩條 Flow Shop 可視為兩條單獨Flow Shop
表2.1 將兩者之間的差異做個比較,Flexible Flow Shop 與 Dual Flow Shop 第一項不
同為Route 的決策問題,指的是工件由本站換到下一站加工時,是否必須事先決定工件
的流向,也就是決定工件的加工途程位置。由Flexible Flow Shop 的模型中可以發現, 當工件在第一站的任何機台加工後,到了第二站進行加工時,選擇機台的依據不會受第
一站加工位置的影響,例如第一站在圖2.3 上方的機台加工,而第二站則是看哪個機台
有空就在哪個機台加工;但Dual Flow Shop 就不同了,當第一站在圖 2.2 中的 A 廠進行 加工後,要到第二站時,主要是先在同一廠做,當產能不足而另一廠有多餘產能時才會 進行跨廠加工,所以本研究的跨廠排程會考量前一廠的加工位置,並不是哪個機台有空 就能在那加工。
第二項與第三項與運輸(搬運)時間有關,過去的研究中 Flexible Flow Shop 兩站之間 大都沒有所謂的運輸時間(或稱搬運時間),只有部分文獻有討論到兩站之間的搬運時 間,而且是廠內間站與站的搬運,只要工件從本站到下一站都需要設定搬運時間,若假 設搬運時間相同時,則在進行跨機台的決策時,便不需要將搬運時間考量進去;至於 Dual Flow Shop,本論文設定跨廠皆須運輸時間,且運輸時間是比照真實世界來設定,
假設兩個可以互相進行支援的廠,一座在桃園,另一座在新竹,運輸時間相較於Flexible
Flow Shop 的搬運時間是多上許多。雖然 Dual Flow Shop 單廠站與站間的工件轉移雖然 也是會有搬運時間存在,但是相較於廠際間的運輸時間,搬運時間是相當小的,所以
Dual Flow Shop 才會延伸出跨廠的決策問題。由此來看,Flexible Flow Shop 與 Dual Flow Shop 間的運輸(搬運)時間除了差在時間長短以外,Flexible Flow Shop 主要是站與站之間 就必須搬運時間,而Dual Flow Shop 原則上是跨廠工件才會有運輸時間,所以兩者是相 當不同的。
第四項不同在於生產型態的不同,Flexible Flow Shop 不能單獨拆作兩條 Flow Shop 來看,因為工件選擇在站中哪個機台加工是依照誰先有空先加工;Dual Flow Shop 若不 進行跨廠,其實是可以視為兩條單獨的Flow Shop。
以上這四點是Flexible Flow Shop 與 Dual Flow Shop 間基本的不同點,除了上述原 因以外,本研究之所以會想針對Dual Flow Shop 進行延伸,更為實際的原因是為了能夠 透過跨廠加工,藉此以最少金錢、最少時間來提供兩廠最大的產能。所以其實兩者的差 異是很大的,因此本論文將針對較少人所研究的跨廠支援進行探討,並建構一套生產排 程模式,為企業提供最佳的排程建議。
2.2 多廠區相關文獻
目前針對多廠區的文獻很多,為了繼續做深入的研究,所以首先必須先瞭解何謂多 廠區,而它又分做哪些種類,本節將針對多廠區作一個詳細的介紹。2.2.1 多廠區生產規劃
一般而言,所謂的多廠區,在目前看來有兩種不同的多廠型態。有些學者將其定位 在供應鏈中,廠間如供應鏈般的前後關係,透過上下游多個廠進行整合與排程關係,生 產功能則有上下游不同的差異,其為垂直式多廠概念( Frederix, 1996;Timpe et al., 2000);而部份學者則將其解釋為一個公司同時擁有多個相類似的生產工廠,但廠間有 地理位置或組織差異,其為橫向多廠概念(Chen et al., 1999;Sauer et al., 1998)。本文所 建構的多廠區型態屬於後者水平式多廠區型態。針對水平式的多廠區相關文獻定義有許多,但大體上的觀念是相同的。Caroloin (1995)將多廠區定義為在同一企業下的兩個廠對於某產品之某段製程具有相同或互補的 製程能力,產品的製造流程可以使用不同廠區內的資源。而在Thierry et al.(1995)中,也 將多廠區定義為當一個公司的生產設施分佈於不同的地理位置,即稱其具有多廠特性。 Vercellis (1999)也提到,將訂單需求分配至不同區域生產,以每個具有相同生產特性之 工廠共同完成訂單需求。也就是將散佈在各地功能類似的工廠視為多廠規劃的主體,是 屬於橫向的多廠關係。 一般來說,具多廠生產之製造廠區,工廠大多坐落在不同地區,生產規劃的方式亦 由單廠擴充至多廠的型態相對衍生出複雜的生產規劃,在Sauer et al.(1998)研究中也指 出,將產品分配至不同廠進行加工時,會產生複雜的交互依賴關係,因此在考量多廠區 生產型態時,與單廠區相比,其實是複雜許多的。
2.2.2 水平式多廠區相關文獻
水平式多廠區可以分做兩種,分別為跨廠與不跨廠。所謂的跨廠,是廠與廠之間在 一開始決定好要加工的工件途程後,後續工件在各自廠內加工時若遇到產能不足或其他 限制,而另一廠能夠支援時,便可進行工件跨廠的動作;而所謂的不跨廠,即是廠與廠 之間在一開始決定好要加工的工件途程後,便各自進行單廠工件排序,其中不管是否有 產能閒置或產能不足等其他限制,都不互相進行工件跨廠的動作,有些文獻甚至只作工 件途程上的分配。依照上面的論述,本研究又可以將跨廠與不跨廠分作兩步驟,工件途 程( Route Assignment )、工件排序( Job Sequencing ),表 2.2 將水平式跨廠與不跨廠相關 文獻進行分類:表2. 2 水平式多廠區文獻 不跨廠 跨廠 Route Assignment Thierry et al. (1995) 陳建銘 (2003) Sambasivan et al. (2005) 張美滿 (2002) Toba (2005) Wu and Chang (2007) Wu et al.(2008) Route Assignment + Job Sequencing Sauer et al. (1998) Vercellis (1999) Sauer et al. (2000) 郭乃蓁 (2000) Guinet (2001) Chen et al. (2005) 劉謹銘 (2009) 本研究 表2.2 將多廠區文獻依照跨廠與不跨廠分作左右兩區塊文獻,依照只作加工途程
( Route Assignment )決策與加工途程( Route Assignment )、加工順序( Job Assignment )皆 有考量,將文獻再分為上下兩個區塊。也就是說,左上角是僅考量加工途程之不跨廠文 獻,反之,右下角區塊的文獻則是加工途程與加工順序兩項決策皆有考量的跨廠文獻。 以下將在2.2.3 節針對不跨廠文獻、2.2.4 節針對跨廠文獻做簡單介紹
2.2.3 不跨廠相關文獻
1. 僅討論工件途程之不跨廠文獻: Thierry et al. (1995) 將多廠定義為”當一個公司的生產設備位於不同的地理位置即 為多廠生產”,指出多廠區問題主要決定產品在不同產區間的生產以及不同時段間的運 送問題。將限制滿足問題(Constraint Satisfaction Problem)領域的滿足限制方法,應用 於多廠規劃之線性規劃模式的求解,並同時考慮到有些生產單位在切換生產產品時需要 較長設置時間的特性。限制滿足問題的求解法是藉由限制來一步步縮小求解空間,等到 無法再縮小時,就利用各種啟發式方法來快速找到好的解。此研究有考慮到當某些生產單位在切換生產產品時需要較長設置時間的特性,所以各生產單位在規劃時的時間區間 大小不同。
Sambasivan et al. (2002) 提出一啟發式法則運用 Lagrangean 來解決多廠多階的廠內 運送( inter-plant transfers )問題。 陳建銘(2003) 針對擁有多製造廠區的企業面臨緊急訂單時,迅速判斷利潤最大的緊 急訂單承接組合,方法分兩階段,第一階段規劃方法為典型的背包問題( Knapsack Problem)原則,考量企業獲利目標,求得緊急訂單利潤最大承接評估模式,第二階段以 各廠區內一般訂單、第一階段所求出的解,以線性規劃模式求出總成本最小化的跨廠區 產能規劃。 2. 分階段討論工件途程與工件排序之不跨廠文獻: Sauer et al. (1998)使用模糊理論的概念來處理傳統上會用固定值代替或是忽略不記 的一些不確定因素如產能和運輸時間等。在Sauer et al. (1998)的研究中,將多廠區生產 系統的排程問題分為全域( global )排程、區域( local )排程與運輸排程。全域層次的主要 任務是產生每個位置( location )中需要被製造的中間產品( intermediate product )之需求 量,在不影響其他廠區的同時,提供足夠的彈性使得區域排程(指的是單一位置)能夠反 應區域性的干擾事件,他藉由加入緩衝時間的啟發式法則及模糊技術來最佳化機器群組 的平均負荷。 Sauer et al. (2000)則是進一步的將各廠間的運輸排程問題納入多廠規劃的求解中, 藉由將運輸排程問題轉換成類似於生產排程的問題,之後和其餘各廠一起規劃求解,並 認為多廠規劃的目的在於產生一組穩健的排程,也就是此排程要使各單廠的排程人員有 足夠的彈性去處理各自的變異,並且不會影響到其他工廠。
Vercellis (1999) 考量生產規劃中的主生產排程( master production planning, MPS )以 及產能配置( capacity allocation )問題求解每一廠區具相同生產流程之多廠間生產問題。
將需求量分配至不同區域生產,利用LP 方式解決具相同生產流程之多廠區生產規劃問
Guinet (2001)認為多廠生產規劃的目的在於找出「誰該生產」與「什麼時候產品和 工件必須生產」這兩個問題的答案,提出以二階( two-level )式生產管理手法管理多廠生 產系統,指出多廠規劃問題可以被建構成受限於變動和固定成本的流動問題(flow problem),或者是以提早和延遲總和最小化為目標的非相關平行機台排程問題。而其 在考量產能限制和機台設置特性,以及生產、設置和運輸等成本最小化的情形下,提出 了一個「主要-對偶線性規劃法」來求解多廠規劃問題。 郭乃蓁 (2000)提出晶圓製造廠多廠間的訂單抵換機制,期使晶圓製造業者在面臨顧 客提出的插換單要求時,能依據各廠之生產特性及產能,作最合適的調度,基於平衡負 荷的理念,以關鍵資源為監控重點,首先透過「產能推估模組」,依據既定的排程資訊 與插入訂單的交期,進行其達交性的粗估。其次,在訂單分派模組中的篩選階段,挑選 出最適抵換方案,期能維持系統績效。最後,在抵換推估模組中,依據各廠訂單異動的 結果,進行重排程及異動之績效評估。
2.2.4 跨廠相關文獻
因為本論文主要研究跨廠排程,所以本節將針對表2.2 中跨廠文獻,作更進一步的 比較,如表2.3。表2. 3 跨廠文獻分析 張美滿 (2002) Toba (2005) Wu and Chang ( 2007) Wu et al. ( 2008) 劉謹銘(2009) 當機情境 不考慮當機 不考慮當機 過去當機資料 推估 平均當機率 不當機 決策 三階段規劃 模式 (Route ) 動態、即時 跨廠規劃 (Route) 每週定期「跨廠 產能交易」 (Route) 跨廠區「途 程規劃」 (Route) 跨廠區「排程規 劃」(Route & Sequencing) 派工法則 -- -- -- -- EDD 跨廠方式 瓶頸站產能 負荷程度 動態進行 產能交易 1 切點,切點 未定 2 切點,切點已 定
目標 Total Cost Cycle time Throughput Throughput Slack(寬裕度) 生產型態 Job shop &
Flow Shop Reentrant Job Shop Reentrant Job Shop Reentrant
Job Shop Flow Shop
1. 僅討論工件途程之跨廠文獻: 張美滿(2002) 針對多廠區規劃問題,在廠與廠間歷史銷售量及既有的資源設備下, 建立三階段規劃模式,以生產總成本最小為目標。第一階段業務依歷史銷售量統一接 單,管理人員以機器產能限制,並考量生產成本、製造成本、延遲成本、外包成本等成 本因子之總成本最小下,求出各廠區所需生產的最佳訂單數量。第二階段求出各廠區各 工作站的產能負荷量與瓶頸工作站。第三階段針對瓶頸工作站加以平衡,取得工作站跨 廠生產量、外包量與產能利用率,之後便依據最佳跨廠產能結果安排生產細部規劃與排 程規劃。此論文考量各廠區產能限制與各廠區不同的生產成本;外包成本等,非常符合 各企業規劃現況,但並未考量緊急訂單。 Toba (2005) 提出一項負荷平衡法來平衡在多個半導體晶圓廠中所有產品的加工作 業。對於半導體多廠區生產規劃分析研究中,以動態、即時作跨廠途程規劃,將作業 (operation)分成多個作業集合,每個「作業集合」完工之後,需即時決定下一個「作業 集合」的生產工廠,目標是最小化cycle time。後續藉由模擬實驗來驗證此方法比普通 的方法更能改善多個具有獨自製造能力的晶圓廠中的負荷。其能有效的減少在每個廠中 每個加工步驟的等候時間及前置時間。
Wu and Chang (2007) 對於晶圓廠之短期產能交易決策模式分析研究中,利用單項/ 多項做短期產能交易決策,每週按「原訂生產計畫」與「現在機台狀況」,來預估各廠 區每一工作站的下週產能利用率。當各廠產能利用率失衡時,低利用率之工作站將販賣 產能給他廠高利用率工作站,此研究之決策為決定每週最佳的產能交易組合,以最大化 兩廠長期利潤總和為目標。 Wu and Chen (2008) 對於半導體雙廠區產能相互支援的途程規劃分析研究中,提出 兩項決策,決定跨廠位置與每個產品的途程比例,運用現性規劃求解跨廠切點,然後再 運用基因演算法求解途程比例。此研究透過途程的可切割性作跨廠生產規劃決策,充份 利用機台產能,在目標CT 下最大化整體產出。 2. 同時討論工件途程與工件排序之跨廠文獻: 劉謹銘(2009) 針對跨廠提出一套方法,此研究認為過去並未有人同時討論過工件途 程與工件排序這兩項決策,所以運用基因演算法提出新的基因表達法來同時求取工件的 此兩項資訊。在加工途程決策方面,以兩廠負荷時間差距最小化作為分廠點;在加工順 序決策方面,以最早交期最先加工(EDD)的單一派工法則來進行工件排序。為了因應多 變的市場需求,希望排程能具充分的穩定性,選擇最小化變異係數(CV)為其績效指標。
由表2.2 及表 2.3 中得知,張美滿(2002)、Toba (2005)、Wu and Chang (2007)、Wu and Chen (2008)此四篇文獻都只作了工件途程( Route Assignment )的分配,而劉謹銘(2009) 才有同時對工件途程與工件排序作相關的研究,但是,劉氏的文獻中,僅針對單一派工 法則來進行工件排序,而Dabbas et al.(2003)與 Lin et al.(2005)在其研究中,都曾驗證過 單一派工法則在某些情境或是績效指標下,改善率是有限的。所以本論文後續將針對此 模型,提出一套組合派工法,讓不同情境或績效指標下,都能以此方法求得最適宜的派 工法則
2.3 混合實驗設計
混合實驗設計首先由Scheffe 於 1958 年提出,他認為所謂混合實驗,指的是在一個 實驗中,若實驗的品質特性(反應變數)與各成分(因子)間含量的比例有關,則此實驗稱 為混合實驗。並定義實驗設計中各因子佔總成份比例必須為0 到 1 之間,而且所有因子 比例加總必須為1。假設獨立變數Xi為混合實驗中之成份,則Xi有下列特性: 1 ~ 1 1 0 1 = = ≤ ≤∑
= p i i i X p i X (2.1) 由於混合實驗中具有 1 1 =∑
= p i i X 的限制式,導致實驗可行解區域將減少而造成與一般 實驗設計有所差異。在過去二因子及三因子實驗設計中,解空間的範圍如圖2.4 所示, 分別為一個二維平面與立方體;但若加上混合實驗的 1 1 =∑
= p i i X 限制,其解空間便降低一 維,如圖2.5 所示為一條線與一個三角形的範圍。 (a) (b) 圖 2. 4 實驗設計求解空間示意圖 (a)二因子(b)三因子 (a) (b) 圖 2. 5 混合實驗求解空間示意圖 (a)二因子(b)三因子混合實驗設計一般若無成分比例限制時會使用單體實驗設計。所謂成分比例無限制 的單體實驗,指的是組成品質特性(反應變數)的各成分(因子)並沒有上下限的限制,或
是成份皆落於某個區域,可以透過轉換將其值轉換成0 到 1 之間。若該實驗的成份之比
例介於0 至 1 之間時,可使所有成份比例於可行解範圍內呈現規則形狀,在此情況下,
便能透過單體實驗來進行規劃。一般的單體實驗方法,包括單體晶格設計(simplex lattice design)與單體質心設計(simplex centroid design),單體晶格設計是將各實驗點均勻的分佈 在實驗可行區域內,而單體質心設計則是在單體晶格設計的實驗點中,在增加一個中心 點作為實驗點(圖 2.6)。 (a) 單體晶格設計 (b) 單體質心設計 圖 2. 6 單體實驗 (a)單體晶格設計(b)單體質心設計 但基於實驗點過少可能造成的實驗誤差,所以由單體晶格延伸出擴充單體晶格設計 (Augmented Simplex-Lattice Design)(如圖 2.7),由單體晶格可行域中,進行端點與中間點 的連線來增加實驗點。
進行實驗設計後,通常會以反應曲面法(Response Surface Method)來尋找最佳配方, 最佳化過程如下: (1) 依據實驗設計的實驗點進行實驗。 (2) 由實驗設計的結果建構出反應曲面方程式。 (2) 檢定此反應曲面方程式的正確性與解釋程度。 (3) 依據績效導向,由方程式中找出最佳配方。 通過這四個步驟可以確保適配出來的模型符合實際資料,且能由此模型得到最佳配 方。其中反應曲面模型之定義如下:
∑ ∑∑
∑∑
∑
< < < = + + + + = k j i k j i ijk q j i j i ij q i i ix β xx β xx x L β β η 1 0 (2.2) 由於混合模型與反應曲面模型中所使用之多項式是不相同的,要讓混合實驗使用, 需要將反應曲面模型之多項式中的截距項皆化簡為0。所以通常會使用以下幾個模型: 線性(Linear) 模型:∑
= = q i i ix 1 β η (2.3) 二次項(Quadratic) 模型:∑∑
∑
< = + = q j i j i ij q i i ix β xx β η 1 (2.4) 完全立方(Full Cubic) 模型:∑ ∑∑
∑∑
∑∑
∑
< < < < = + − + + = k j i k j i ijk q j i j i j i ij q j i j i ij q i i ix β xx δ xx x x β xx x β η ( ) 1 (2.5) 特殊立方(Special Cubic) 模型:∑ ∑∑
∑∑
∑
< < < = + + = k j i k j i ijk q j i j i ij q i i ix β xx β xx x β η 1 (2.6) 本研究使用三種派工法則(成分)來進行混合實驗,混合實驗的實驗點採用擴充單體 晶格設計的十個實驗點,透過反應曲面最佳化來求取每個派工法的最佳權重值,這部份 將在第三章研究方法中,做更詳細的介紹。2.4 基因演算法
基因演算法(Genetic Algorithm;GA)為 Holland 於 1975 年所提出的一種隨機多點 平行式全區域搜尋法則。是基於「物競天擇」及「遺傳法則」的概念,所謂的「物競天 擇」是指Gas 會在尋優過程中去蕪存菁,踢除較差的成員,保留較優良的成員。而「物 競天擇」的操作方式則是模仿遺傳學複製、交配及突變等三大法則,故稱之。 基因演算法其搜尋過程在一個特定的基因編碼(Gene encoding)的規則下,以特定 的演算法或隨機產生起始的族群(Population),再依據定義的目標函數(Objective function)計算個體的適應值(Fitness),個體的適應值愈高代表適應能力愈強,其衍生 為子代的機率愈大。經過多代繁衍所得的最高適應值之染色體即為最佳解。常見的運算 子即為之前提到的複製(Reproduction)、交配(Crossover)及突變(Mutation)三種, 每個運算子重覆循環執行,如此一代一代進化過程中,保存最好的染色體,直到系統達 到預定的演化次數或所設定的誤差容許度內為止。整個基因演算法的解題流程如圖2.8 所示。 圖 2. 8 基因演算法的求解流程
以下為基因演算法各名詞之介紹: 染色體與基因 在執行基因演算法前,必須透過編碼的程序,將決策變數轉成可以代表可行解的字 串,此字串稱為染色體,在其中的每個字元稱為基因,一般是以一個基因代表一個決策 變數,基因值即代表決策變數值。 族群 在基因演算法的過程中可以同時存在多個染色體,數個染色體形成的群體稱為族 群。 適合度函數 評估所有染色體在族群中之表現好壞,表現好的染色體即表示適應力較佳,因此存 活機率也較高,反之較差的染色體適應力較差,因此存活機率也較低。 在求解過程中,必須將染色體的表現轉換成適合度函數值,在望大的情境中,會將染色 體的目標值當成其適合度函數;在望小的情境中,因為染色體的目標值越小適應函數值 越高,通常以染色體目標值的倒數或是取族群中最大目標值減去該染色體目標值當作適 合度函數;若為望目的情境,染色體的目標值越接近設定的目標值適合度函數值越高, 故先求算染色體目標值與設定值之差距,再用望小問題方法來求其適合度函數。最後選 取族群中適合度函數值最高的染色體當做下一代。 選擇策略 針對交配池中的所有染色體,依據其適應函數值來選擇下一代。選擇的方式目前有 很多種:俄羅斯輪盤法(Roulette wheel selection)、競賽法(Tournament selection)。
所謂的俄羅斯輪盤法,意思是說每個染色體將被選中來進行繁衍後代之機率,為該 染色體之適合度值佔族群每一染色體之適合度值總和的比例。這方法的缺點為適合度函 數值較好的染色體容易支配整個族群的染色體的選擇,容易過早陷入局部最佳解。 競賽法是隨機選取兩個或以上的染色體,在望小的問題中,選擇最小適合度函數值 的染色體,這個方法可以避免過早陷入局部最佳解。 交配
交配是兩個被隨機選取的染色體彼此交換其內部的基因,藉由這個方法試圖找到較 好的染色體,一般排程的交配有單點交配(one-point crossover)、線性順序交配(LOX: linear Order Crossover Operator)、部分相應交配(PMX: Partially matched crossover
Operator)、 NABEL Operator 等 突變
突變通常會配合交配一同使用,避免基因演算法陷入局部最佳化 (local optimum)。 一般常用的突變有 Swap (交換)、Inverse (反轉)及 Insert (插入)(Wang and Zheng, 2003)。 至於基因演算法在本論文中的各步驟流程以及相關之參數設定(如族群大小、突變 率、交配率以及終止條件),將於第三章中詳細描述。
2.5 小結
過去多廠文獻中,大多文獻都是研究不跨廠的居多,而且大部分都只做工件途程的 研究,所以本研究主要的特色除了針對極少人探討的跨廠問題進行研究外,還同時討論 了工件途程與工件排序問題,後續更運用權重來組合不同派工法,找出各種情境下最適 合的派工法則。接下來的章節將針對本研究所使用的求解方法做詳細的介紹。第三章 研究方法
本章主要在說明如何運用基因演算法與組合派工法,求解雙流線型工廠排程模式, 並針對本研究的兩項決策,進行相關的參數設定。首先進行問題的描述與假設,其次介 紹如何決定工件的加工途程與加工順序,以及適合度函數,最後介紹基因演算法的所有 流程。3.1 研究問題
如前所述,本論文所研究的問題為雙流線型工廠排程(圖 3.1),所謂的雙流線型工 廠,指的是兩個生產功能相近,且為流線型(Flow Shop)生產方式的廠,能夠透過彼此工 件間的跨廠加工,達到產能的互相協調。為了便於進行排程規劃的探討,故將其簡化如 下: z 兩廠,各有三個 Stage。 z 各個 Stage 機台功能相似。 z 以實際工廠生產線可進行跨廠的位置進行切割,切出三部份。 z 兩廠皆為 Flow Shop 生產方式。 z 每個 Stage 都可做互相支援。 A1 A2 A3 Plant A Plant B B1 B2 B3Stage 1 Stage 2 Stage 3
跨廠點 跨廠點
雙流線型工廠排程面臨的排程問題有兩點,第一點為客戶下單後,中央必須決定兩 廠訂單配置問題;第二點為決定廠際間與各廠工件排序問題。透過本論文整體排程規劃 後,希望能藉此解決客戶臨時訂單變動問題。 在績效指標的決定方面,第一章已經說明過,本研究將採用變異係數(CV;CV=標 準差/平均數)作為最終的目標式,藉此達到兩個目的:(1) 每個工件都具有足夠緩衝時 間;(2) 滿足客戶訂單交期。為了達到第兩個目的,必須使寬裕度的標準差很小、平均 數很大,這樣才能滿足每個工件都具有足夠緩衝時間的目的,而且工件也能不延誤交 期。因此,透過最小化寬裕度的變異係數(CV),來同時達到最小化標準差與最大化平均 數兩項指標。
3.2 研究假設
本研究對於跨廠的情境可以分作三部份,分別為Route、Machine、Job,以下將針 對各項進行情境的定義與假設。 1. Route z 共有 A、B 兩廠 z 廠間可作跨廠支援加工,跨廠運輸時間需考慮且固定 z 每個 Job 都須經三道加工流程(Flow Shop)2. Machine z 各廠各 Stage 各有一機台 z 機台不停機不當機 z 無 setup time 3. Job z 訂單即為工單 z 工廠起始階段沒有 WIP (空廠)
z Job 批量不可切割 z 一有跨廠 Job 即進行跨廠(不集批運送) 本論文為雙流線型工廠排程所以一開始在Route 的假設中,便將模型定義為兩間工 廠,而且廠與廠之間彼此可以進行不定期的跨廠支援,為了將跨廠模式加以簡化,本論 文設定工廠起始階段沒有WIP (空廠),以實際工廠生產線可進行跨廠的位置進行切割, 切出三部份,所以最後僅針對前段製程(第一站)、中段製程(第二站)與後段製程(第三 站),分成縮簡的三個站來研究,每站都僅有一部加工機台,因為屬於流線型生產模式, 每個工件也都必須經過三道加工流程(Flow Shop)。 針對跨廠部分的設定,因為要與單廠平行機台有所差異,又希望能更貼近事實,所 以在進行跨廠時,需考慮跨廠時間,而且不管是在哪站進行跨廠,其跨廠時間都會是一 樣的,當一有要跨廠的工件時,即進行跨廠(不集批運送)。 對於機台的設定,由於本研究屬於預排排程,所以就不去考量機台停機、當機問題, 而且不考慮設置時間(setup time);至於工件的設定,每個工件都具有各自的交期日,可 以是相同的,也可以是不同,而且工件是不可切割的。 針對以上機台與工件的假設下,將在後續說明如何建構一個同時考量加工途程與加 工順序,以解決多廠區複雜的排程問題。
3.3 問題複雜度
如同先前一直提及的,本論文屬於多廠排程問題,所以須進行兩項決策的求解:加 工途程( Route Assignment )、加工順序( Job Sequencing )。要透過整數規劃求解上述兩項決策時,必須同時考量加工途程與加工順序來進行模 式的建構,而本研究必須再加上交期的限制,在進行整數規劃時,須考量到時間點的安 排,所以複雜度非常高,求解是很困難的。以加工途程來看,其求解空間的算法為 m n F × , F 代表工廠數,m代表站別,n代表工件數,以本研究來看為兩廠、三站形式,當有40 個待加工工件時,其加工途程的求解空間便為23×40這麼多的可能。而在實際業界裡,工
件一定不只有40 個,站別也一定會超出三站,每個工件都按照這樣的方式來計算加工 途程的話,結果會是相當驚人的,後續就更不用提還要再加上加工順序的所有的排列結 果。
此類求解空間大且複雜,無法用整數貴化模型求解之問題,過去的文獻將其定義為 NP-hard 的問題 (Garey and Johnson, 1979),若要藉由整數規劃模型來求取最佳解,其解 題所花費的時間,可不是一天兩天就可以完成的。然而,對於業界而言,時間就是金錢, 若要為了求得最佳解而花費個一兩個月來進行解題,當你求出解時,工件也全都超過原 本答應給客戶的交期了。所以為了能以最快的速度進行求解,又希望所求的解不至於太 差,大家開始退而求其次,交由一些演算法來解決。過去有許多篇文獻都在針對此類 NP-hard 的問題提出不同的演算法,或是將不同的演算法套用在不同的問題中求解。本 研究也不例外,後續的解題將運用Holland (1975)所提出的基因演算法,來進行本研究 的求解,並運用組合派工法進行加工順序的排列,希望能以最快的速度來求出最佳近似 解。
3.4 雙流線型工廠模式建構
本節分為四個部份來介紹雙流線型工廠模式的建構流程:(1)染色體設計;(2)染色 體解讀;(3)適合度函數;(4)基因演算法求解流程。 在第一部份將針對基因演算法中的染色體進行介紹,第二部份說明本章的重點—加 工途程與加工順序在染色體中如何被解讀;第三部份針對基因演算法中的適合度函數做 介紹;最後第四部份說明基因演算法求解流程與相關設定。 以下針對上述三個部份,進行相關符號的設定: i :工件代號, i = 1, 2,…,n s:加工順序,s=1, 2,…,o j :Stage 代號, j =1, 2,…,mf j s i P,, , :工件 i 在工廠 f 、Stage j ,加工順序s的製造時間 f j s i ST,, , :工件 i 在工廠 f 、Stage j ,加工順序s的開始生產時間 f j s i CT,, , :工件 i 在工廠 f 、Stage j ,加工順序s的完工時間 TS:運輸時間 i d :工件 i 的 Due Date s σ :寬裕度的標準差 s X :寬裕度的平均數 CV :寬裕度的變異係數, s s X CV = σ
3.4.1 染色體設計
本節介紹基因演算法中用來進行演化的染色體設計方式,所謂的染色體 (chromosomes),指的是在執行基因演算法前,必須透過編碼的程序,將決策變數轉成可 以代表可行解的字串,而此字串稱為染色體。 在本研究中,染色體就代表著一組待加工的工件,如圖3.2,為染色體表達方式, 其排列的方式便是工件加工時的順序。染色體中的基因格便代表著一個工件,彼此的順 序不固定,染色體的長度由工件數量來決定,數量越多染色體越長。舉例來說,第一個 基因格編號為J5 便代表著工件 5。J5 J3 J7 J1 J6 J4 J8 J2
染色體
圖 3. 2 染色體設計方式後續進行基因演算法的時候,只要透過這條染色體的演化,運用下一節的解讀方 式,便能同時代表工件加工途程與加工順序的意義。
3.4.2 染色體解讀
在過去研究中,染色體只要透過不同的解讀方式便可以呈現不同的意義,而在本論 文中,透過不同解讀方式可以同時呈現本研究的兩個決策方向:加工途程與加工順序。 圖3.3代表的是染色體的兩種解讀方式,本研究的貢獻之一就是只要透過一條染色體,就 能同時針對加工途程(Route Assignment)與加工順序(Job Sequencing)做解讀。圖 3. 3 染色體的兩種解讀 在加工途程的部份,使用平衡兩廠加工時間負荷的方式進行分廠,而且同時針對跨 廠與不跨廠進行求解,最後將結果最好的作為最後的加工途程方式,所以這樣的加工途 程解讀下,可以為工廠提出最佳的跨廠建議,如果跨廠績效值較佳,便選擇跨廠;反之, 便選擇不跨廠。 在加工順序方面,使用組合派工法,將多種不同的單一派工法進行組合,透過混合 實驗與反應曲面最佳化找出最適合的權重值,而此權重值便反映了應該使用何種派工 法。當權重值偏向單一派工法,則建議加工順序方面使用單一派工法來進行排程;若偏 向多種單一法則的組合權重,則建議使用組合過後的新權重。由此,只要不管是任何工 件組合,組合派工法都可以給予最佳的派工方式建議。
3.4.3 加工途程
所謂的加工途程,指的是每個工件在進行加工時所會經過的路徑。在本研究中,因 為涉及跨廠觀念,而且每一廠都是Flow Shop 的生產方式,所以可以使用另一種觀點來 進行說明:所謂的加工途程,指的就是決定工件在每一站的加工位置,也就是決定每一 站中,工件的分廠位置。 工件分廠的方式,主要依循一個觀念「分廠後兩廠各自的總負荷時間能最接近」, 兩個能互相進行跨廠支援的廠,如果隨意的進行分廠,可能會造成某一廠負荷過重,當 負荷過重時可以透過跨廠將工件交由他廠來做,但是因為工件的跨廠必須考量運輸時 間,可能造成最後完工產品交期的延誤,喪失訂單的可能。因此工件分廠的方式是必須 被慎重考量的,本研究希望讓工件分完廠後,兩廠的負荷量能夠相同,所以將平衡負荷 量的方式作為分廠的準則。在決定機台負荷量時,本論文認為所謂負荷量也可以視為機 台運作的程度,當一台機台一天工作24 小時才能如期完工,相較於另一台一天只運作 20 小時便可完工,兩者相比,可以明顯看出前一部機台負荷量較大,所以本研究將負荷 量以兩廠各站之機台的加工時間多寡來替代。因此,本研究針對工件分廠模式可以建構 如下: Stage 1: Min P P for i n k o s s i k s s i 1~ 1 1 1 2 , 1 , , 1 1 , 1 , , −∑
=∑
− = = (3.1) Stage 2: Min P P P P for i n k o s s i k o s s i k s s i k s s i 1~ 2 1 2 1 1 ,,2,2 1 ,,1,2 1 ,,2,1 1 ,,1,1 = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ +∑
∑
∑
∑
− = − = = = (3.2) Stage m: n i for P P P P P P Min m m k o s m s i k o s s i k o s s i k s m s i k s s i k s s i ~ 1 1 ,, ,2 1 ,,2,2 1 ,,1,2 1 ,, ,1 1 ,,2,1 1 ,,1,1 2 1 2 1 = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + + + − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + + +∑
∑
∑
∑
∑
∑
− = − = − = = = = L L (3.3)在進行分廠之前,會先將所有的工件 i 都以隨機的方式重排,重排的目的是為了讓 後續的分廠能嘗試多種不同的組合,而這部份由3.3 節可得知其組合很多,所以本研究 將採用基因演算法來進行此部分的排列。 工件在重排過後便可進到分廠的部份,方程式(3.1)到(3.3)各自呈現 Stage 1 到 Stage m 的分廠模式,在方程式中,Pi,s,j,f 表示工件 i 在工廠 f 第 j 部機台,加工順序s的製造 時間,所以
∑
= 1 1 1 , 1 , , k s s i P 代表的是由隨機排列的工件組合中,在工廠A、Stage 1 中的加工時 間累積至第k1個工件( k1個隨機排列的工件 ),如圖 3.4 中的前半段,中間那條序為染 色體,也就是待加工的工件序,J3 即為工件編號 3;而∑
− = 1 1 2 , 1 , , k o s s i P 即代表在工廠B、Stage 1 中的加工時間,由圖3.4 中的切點開始算起,累積至第 o-k1個工件。由於本論文分廠所 依循的觀念是「分廠後兩廠各自的總負荷時間能最接近」,為了讓分廠後兩廠的負荷時 間差不多,所以在(3.1)式中,便將兩廠的總加工時間進行相減,並取最小值,因為只希 望最小化兩廠總加工時間的差距,不管相減之後的正負值,所以便將此差距取絕對值, 再進行最小化的動作。由圖3.4 來看即工件由左側(A 廠)開始累加加工時間,並隨時與 右側(B 廠)相比較,找到兩者差距最小的點即為 Stage 1 的切點(k1)。 圖 3. 4 Stage 1 分廠示意圖由上述觀點,透過(3.1)式便可求出所有工件在 Stage 1 的分廠情形,也就是能夠求 出k1之值,因為希望能以全廠的觀點來進行分廠考量,所以做完Stage 1 的分廠之後, 接著可以進行Stage 2 求解(3.2)式中的 k2值,求解時會將Stage 1 的加工時間再拿來與 Stage 2 相加總,然後才能進行 k2的求取,一階一階的算出每一Stage 的分廠位置,等到 加總至Stage j,便完成了兩廠每一 Stage 的分廠。如(3.3)式子前半段括號中的
∑
∑
∑
= = = + + + km s m s i k s s i k s s i P P P 1 1 , , , 1 1 , 2 , , 1 1 , 1 , , 2 1 L ,此式即為整個A 廠在 Stage j 中的總加工時間,而後 半段括號中的∑
∑
∑
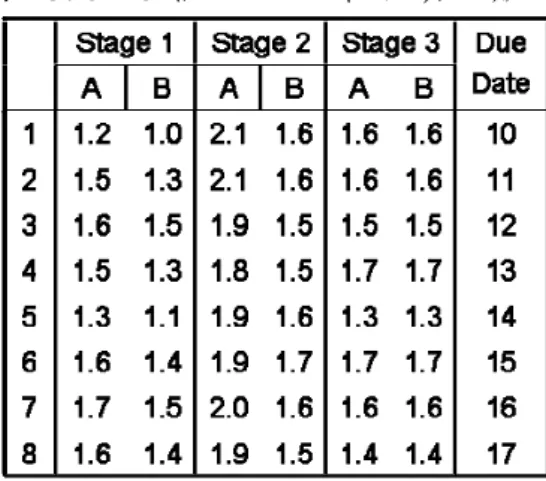
− = − = − = + + + o km s m s i k o s s i k o s s i P P P 1 2 , , , 1 2 , 2 , , 1 2 , 1 , , 2 1 L 為整個B 廠的總加工時間,兩者相減取 最小值,便能讓兩廠負荷時間最為接近。 本研究在基因演算法中,會分兩支線同時求解跨廠與不跨廠的分廠模式,針對跨廠 的部份,採取上述分廠方式;不跨廠,則三站皆採用第一站的分廠方式,由於透過上述 方程式來進行跨廠求解,可能會遇到三站切點相同的情形,此時便會將其列為不跨廠的 解。由此,本研究便可以同時計算跨廠與不跨廠之績效,再透過基因演算法篩選出最佳 的結果,作為工廠加工途程之建議。 加工途程案例說明 圖3.5 以八個工件、三個 Stage 的例子來做說明,工件 J1 至 J8 做隨機排列後,希望 由此來決定三個Stage 的分廠情形: 圖 3. 5 8 個 Job 的分廠示意圖作法:表3.1 為工件 1 至 8 隨機排列後 Stage 1 的加工時間與累積加工時間表,表 中第一列為工件序,第二列與第五列為工件各自在A 廠與 B 廠 Stage 1 中的加工時間, 也就是方程式中的Pi,s,j,f,第三列與第四列為A 廠與 B 廠的累積加工時間,即為方程式
∑
= 1 1 1 , 1 , , k s s i P ,第三列由左邊開始累計,第四列由右邊開始累計。此表的目的是為了找到一 個最好的切點,能夠讓A 廠(第三列)與 B 廠(第四列)所累計的加工時間最為接近,也就 是希望達到(3.1)式中的結果。 表 3. 1 Stage 1 加工時間與累積加工時間表 Job 1 4 8 3 2 7 6 5 Fab A 1.2 1.5 1.6 1.6 1.5 1.7 1.6 1.3 累積A 1.2 2.7 4.3 5.9 7.4 9.1 10.7 12 累積B 10.5 9.5 8.2 6.8 5.3 4 2.5 1.1 Fab B 1 1.3 1.4 1.5 1.3 1.5 1.4 1.1 表 3. 2 切割點於 J1、J4 中間 Job 1 4 8 3 2 7 6 5 Fab A 1.2 1.5 1.6 1.6 1.5 1.7 1.6 1.3 累積A 1.2 2.7 4.3 5.9 7.4 9.1 10.7 12 累積B 10.5 9.5 8.2 6.8 5.3 4 2.5 1.1 Fab B 1 1.3 1.4 1.5 1.3 1.5 1.4 1.1 表 3. 3 切割點於 J3、J2 中間 Job 1 4 8 3 2 7 6 5 Fab A 1.2 1.5 1.6 1.6 1.5 1.7 1.6 1.3 累積A 1.2 2.7 4.3 5.9 7.4 9.1 10.7 12 累積B 10.5 9.5 8.2 6.8 5.3 4 2.5 1.1 Fab B 1 1.3 1.4 1.5 1.3 1.5 1.4 1.1 表3.2 首先測試切於 J1 與 J4 間兩廠之差距,發現 A 廠累計值為 1.2,而 B 廠累計 值為9.5,所以此切點讓兩廠 Stage 1 加工時間差了 9.5-1.2 = 8.3;繼續嘗試下個切點,直到表3.3 切於 J3 與 J2 之間時,發現 A 廠累計為 5.9,B 廠累計為 5.3,兩者差距為 5.9-5.3 = 0.6,是所有切點中差距最小的,所以便選擇此點作為 Stage 1 的分廠點。 找完Stage 1 的切點後,再來就是依照同樣的步驟去找出 Stage 2 的分割點,表 3.4 為Stage 2 相關資訊,因為要尋找能使整廠加工時間差距最小的切點,所以第二站在考 量累積加工時間時要將第一站的累積時間也考量進來,如表3.4 第三列,A 廠的 J1 累積 加工時間為Stage 1 中 A 廠最佳切點的累積時間 5.9,加上 Stage 2 在 A 廠的加工時間 2.1,所以第三列的第一格為 5.9+2.1 = 8,其他的欄位都與 Stage 1 作法相同,由方程式 (2)可以求出兩廠在 Stage 2 的最佳分廠點在 J8 與 J3 之間(表 3.5),經由此步驟計算下去 便可將三個Stage 的分廠點都求出,表 3.6 即為三個 Stage 分廠結果。而圖 3.3 為染色體 三站加工途程示意圖。 表 3. 4 Stage 2 加工時間與累積加工時間表 Job 1 4 8 3 2 7 6 5 Fab A 2.1 1.8 1.9 1.9 2.1 2 1.9 1.9 累積A 8 9.8 11.7 13.6 15.7 17.2 19.6 21.5 累積B 17.9 16.3 14.8 13.3 11.8 10.2 8.6 6.9 Fab B 1.6 1.5 1.5 1.5 1.6 1.6 1.7 1.6 表 3. 5 Stage 2 最佳切割點 Job 1 4 8 3 2 7 6 5 Fab A 2.1 1.8 1.9 1.9 2.1 2 1.9 1.9 累積A 8 9.8 11.7 13.6 15.7 17.2 19.6 21.5 累積B 17.9 16.3 14.8 13.3 11.8 10.2 8.6 6.9 Fab B 1.6 1.5 1.5 1.5 1.6 1.6 1.7 1.6 表 3. 6 分廠結果 Stage 1 Stage 2 Stage 3 A 廠 1,4,8,3 1,4,8 1,4,8,3 B 廠 2,7,6,5 3,2,7,6,5 2,7,8,3
圖 3. 6 染色體三站加工途程示意圖
3.4.4 加工順序
所謂的加工途程,指的是工件進到各站時的先後加工順序。在本節將針對本研究的 重點—組合派工法,進行詳細的介紹。 一、組合派工法之定義 組合派工法指的是將多種不同的派工法則 (如 EDD、SPT、Slack Time…等) 依某種 方法進行組合,藉此整合成一項新的派工準則。而整合後的派工準則,其特性是可以包 含所有單一的派工法或是重新創造出一項新的規則。 本論文的績效指標為最小化寬裕度的變異係數(CV),將針對這點選定與績效指標有 關的三種派工準則來進行組合,藉此分析兩廠應該如何來訂定彼此間的生產排程,為了 將三項決策準則整合成單一準則,必須分別對此三項決策準則給予一個權重值,而不同 的權重組合將導致不同的CV 值,因此本章擬找出三項決策準則的最佳權重組合(optimal weighting portfolio),期能最小化所有工件間績效值。 後續更藉由此研究來指出績效指標好壞會受到許多因素的影響,單單僅用一項派工 準則來進行排程的規劃,並不夠具有說服力。為加強驗證這一點,本研究後續將針對單 一派工法則與組合派工法則兩種模式進行不同情境的實驗比較,藉此強調組合派工法相 較於單一準則所能適用的情境更廣,並且對於排程而言,能夠最小化CV 的績效值。二、組合派工法研究架構 組合派工法的主要架構分作三個部份:(1) 單一派工準則的選定;(2) 數值轉換;(3) 設計實驗尋找最佳權重組合。找出最佳權重組合之後,便可將所選定的派工準則依照此 權重來組合成一個新的派工準則,接著便可以將此新的派工準則運用在跨廠排程工件排 序的部份,強化本研究之績效。 以下將針對上述三點,做更詳細的介紹。 (1) 派工準則的選定 進行派工準則的選定,其所憑藉的依據是此派工準則對於績效指標是否會有所影 響,如果會造成影響,則應該選取,如果不會造成影響,那麼此派工準則便沒有被選取 的必要。 所以在本研究下,績效指標為寬裕度的CV 值, s s X CV = σ ,寬裕度 = 完工時間-交 期。會影響此績效值的派工法則很多,本研究找出三種差異度很大的派工法則來進行組 合派工法的分析與研究:
1. Earliest Due Date (EDD)
Due Date 越早的工件,讓他能越先被加工。換句話說就是緊急的先做,所以具 有較早交期的工件,也能較早完工。 舉例來說,圖3.4 代表的是三個工件(J1、J2、J3)的相關資訊,上方為工件交期, 下方為加工時間。依照EDD 法則來排,排法為 J1ÆJ2ÆJ3,績效指標 69 . 0 67 . 1 16 . 1 1= = CV ;若不按交期長短排列,例如J3ÆJ2ÆJ1,則 3.38 33 . 1 51 . 4 3 = = CV , 按照EDD 排列的績效值較佳。由此可以發現 EDD 派工法則對於績效指標 CV 是會 有影響的。
圖 3. 7 EDD 派工法說明案例
2. Shortest Processing Time (SPT)
加工時間越短的工件越先加工。此派工法則讓加工時間短的先做,所帶來 的好處是能讓後面的工件不必在其後方等候太久,節省Queuing time,較不會延誤 到後方工件的完工時間,平均數變大。如圖3.5,最短加工時間之工件為 J1,所以 J1ÆJ2ÆJ3,績效為 0.93 33 . 4 04 . 4 1= = CV ;反之,績效為 1.25 67 . 1 08 . 2 3 = = CV ,按照SPT 排列的績效值較佳。由此可以發現SPT 派工法則對於績效指標 CV 也是會有影響的。 圖 3. 8 SPT 派工法說明案例 本研究所選用的SPT 並非如過去所使用的當站加工時間最小最先做,而是採用 第一站加工時間最小的最先加工。原因是因為原本的SPT 是屬於動態的,每一站要 進新工件加工時都會判斷一次工件在當站的加工時間長短,而本論文屬於預排排 程,要事先決定好所有工件的順序,所以無法每站都去重排一次,所以本研究便選