斷裂時代中的量化研究:統計方法學 的興起與未來
邱皓政
國立中央大學企業管理學系
摘 要
量化研究方法是近幾個世紀以來的重要科學研究典範,過去許多有關研究方 法的爭議多與質化與量化的對比有關,但是近年來有關量化研究的議題卻多與 測量、分析與量化方法論本身的議題有關,本文列舉了古典測量理論與項目反 應理論、外顯變數模型與潛在變數模型、單層次模型分析與多層次模型分析、
明確測量與模糊測量、古典機率理論與貝氏理論等五個當代重要的量化方法理 論與技術,說明量化研究的發展現況,並檢視了台灣近二十年來(1986-2005 年)
博碩士論文應用這五種新量化技術的概況,發現結構方程模式(SEM)是近二 十年來發展最快速,應用最廣泛的統計方法學,並逐年快速增加中。本文同時 說明了統計方法學的精神與要義,並利用三個希臘字母α、β、γ對於量化研究未 來的發展與應用議題以隱喻的方式來加以說明。
關鍵字:統計方法學、項目反應理論、結構方程模式、階層線性模式、模糊統 計、貝氏統計
壹、緒論:新雙城記
英國文學家狄更斯(Charles Dickens; 1812-1870)在其以法國大革命為背景 所完成的名著《雙城記》(A Tale of Two Cities)中,以下列數語開場:
這是最好的時代,也是最壞的時代;
這是智慧的時代,也是愚蠢的時代;
這是篤信的時代,也是疑慮的時代;
這是光明的季節,也是黑暗的季節;
這是希望的春天,也是絕望的冬天;
我們什麼都有,也什麼都沒有;
我們全都會上天堂,也全都會下地獄。
以這些文學緘言對應到學術研究的當代發展,是一個非常貼切且令人深思 的對照。心理學的研究發現,未知的歷史與未知的未來,都同樣令處在當下的 人類感到焦慮而被迫採取行動,然而行動的結果,未必讓人類得到緊張的抒解,
除非人們能夠正確的找到問題的癥結加以解決,這就是一種創造者能夠「上天 堂」的智慧。當代的量化研究,也走到一個令人驚愕的新《斷層線上》(Living on the Fault Line)1,不論是結構方程模式(structural equation modeling, SEM)、階 層線性模式(hierarchical linear modeling, HLM)、潛在類別模式(latent class modeling, LCM)、項目反應理論(item response theory, IRT)、模糊統計(fuzzy statistics)、貝氏統計(Bayesian statistics),雖然無一是方法學或統計學上的新觀 念或新產物,但是對於社會科學的量化研究傳統卻都是一種斷裂式的發展
(disruptive innovation),更可能是一種典範的轉移。研究者會突然發現,過去 我們所賴以維繫的信念、成功的歷史與經驗、慣用的方法與策略,都面臨了挑 戰。事實上,有人仍篤信傳統,有人卻在邁進新時代之前遲疑、疑慮、觀望。
這果真是一個我們什麼都有,也卻是什麼都沒有的尷尬年代。
傳 統 以 來 , 量 化 研 究 ( quantitative research ) 的 主 要 對 比 是 質 化 研 究
(qualitative research),除了因為兩種取向所使用的符號系統不同之外,質化方
1 Jeoffrey Moore 所著,敘說網路科技對於企業經營的衝擊與因應的策略。台灣 由臉譜出版,陳正平翻譯。
式的科學想像與哲學基礎都與量化研究迥然不同,對於「真理」(truth)的定義 與信念也不相同,造成兩種取向的疏離、分裂,甚至於相互排斥。到了今天,
質與量的爭議似乎趨向平緩,甚至有越來越多的學者對於質量爭議所造成的內 在耗損提出批判與反思,例如 Hardy 與 Bryman(2004)指出,質與量的分裂讓 社會科學內部的派系林立情形惡化,學者們之間的交流與學習成長速度趨緩,
但是大家所面對的社會實體卻是同一個,目標也相同。不論是質或是量化研究,
在操作上都面臨資料整理與縮減(data reduction)、從事文獻對話、避免偏激或 事實的扭曲、事實的投影與再現的相同要求,而且都需要面對誤差(error)的問 題,尤其是當我們提出更複雜的問題時,誤差結構益趨複雜(Hardy & Bryman, 2004; Kirk & Miller, 1986; Mishler, 1979)。如果我們面對的挑戰都一樣,問題都 相似,只是達成目的方式與途徑不同,那麼爭議的意義在哪裡?
當社會科學研究者逐漸脫離對立,發展出相互尊重與包容的學術氛圍的同 時,量化研究本身又陷入了另一場傳統與現代的爭議之中。更由於身處於同一 種實證典範的思維與理論技術系統之下,這一次的爭議不但更直接的挑戰到量 化數據的統計原理(例如貝氏統計與傳統機率)、抽樣理論與方法(例如多層次 樣本結構問題)、測量基礎(例如古典測量理論與項目反應理論、模糊測量與明 確測量的對話)與分析模式(例如潛在變數模式的發展)等各個關鍵環節,議 題的對話更加尖銳。從另一個角度來看,也正因為斷裂式變革帶來的衝擊,使 得社會科學研究者能夠跳脫習以為常的工作模式,挑戰自己視為理所當然的觀 點,正視各種替代方案,擴展科學視野,這種在測量方法、分析技術與研究方 法學上的變革,毋寧是社會科學領域在量化取向的躍升進步的契機,如同雙城 記之緘言:這是光明的季節與希望的春天的前夕,但是,我們必須穿越這一切,
否則此刻研究者所面臨的黑暗季節將無限延伸,而非僅是絕望的冬天而已。
貳、當代量化研究中的張力
一、科學史觀下的量化研究
對於科學典範與其變動描述最傳神者,非科學哲學家孔恩(Thomas Kuhn)
莫屬。自從上個世紀初,以符號哲學與實證主義為核心的科學方法從自然科學 領域擴展到社會科學與行為科學領域,科學家們在重要的研究議題、科學論述 的常規程序與方法、科學問題解決的模式與評價判準等各面向逐漸獲得共識,
發展出一個龐大的科學社群,也使得以假設考驗與數量檢證為核心程序的量化
方法成為常態方法。以孔恩的語言來說,這個歷史時段中的強勢科學社群,其 所思、所言、所行,構成了一個常態科學中被共同遵守的典範(paradigm),在 著名的《科學革命的結構》(The Structure of Scientific Revolutions)一書2中,孔 恩指出科學發展的韻律就是科學典範興衰的循環。當一個典範成熟之時,典範 支持者所屬的科學社群主宰了科學的運作方式,同時也決定了知識的產出,但 是一旦渡過了常態的顛峰,典範科學無法解決的問題或內部矛盾逐漸增加,未 解的異例形成危機(scientific crisis),促成邊緣科學或新方法與新技術的興起與 競爭,當某一群人在某些有利的條件下逐漸獲得多數人的認同,形成新的共識 時,舊有典範於是逐漸衰亡,新典範取而代之,完成了一場寧靜的科學革命,
再次進入另一輪迴的常態科學。
從孔恩的科學史觀來看,量化方法足以被視為是一個常態科學,雖然異例 不斷,但是站在挑戰位置的質化方法在過去五十年來也未能搖撼量化方法的主 宰地位,這背後有兩個可能,第一,是真正的潛在新科學社群尚未形成,第二,
是孔恩的科學演化史觀有問題。
我們先從第二個可能來談。因為理論粒子物理上的突破而獲得 1979 年諾貝 爾 物 理 學 獎 與 1991 年 美國 國 家 科 學 獎 章 的 德 州 大學 教 授 溫 伯 格 ( Steven Weinberg),在他的一本近作《科學迎戰文化敵手》3(Facing Up: Science and Its Cultural Adversaries)中,以聳動的標題「迎戰」,來凸顯他的「科學知識是客觀 真理」觀點與一些哲學家、文化評論家、科學社會學家、女性主義者等反對有 所謂的客觀知識的科學「文化敵手」的碰撞,更重要的是他單挑了被這些文化 敵手奉為規臬的科學史學家孔恩,將其「科學革命」、「蓋士塔轉換」、「不可共 量」等核心概念加以剖析,指出其間盲點。例如溫伯格認為經過科學革命之後,
新社群並不會發生無法瞭解、或完全批判揚棄前科學的激烈對抗從而產生不可 共量問題,例如物理系的學生學習相對論之前,還是要從定型的牛頓力學開始。
溫伯格批評孔恩為了維護自己立場而提出一些不全然正確的論述。
溫伯格的一個重要理念,是認為科學知識具有普遍性與客觀性,當代的科 學家要了解前常態科學期的成熟理論並不困難,前期的觀點也不會全然消失或
2《科學革命的結構》被譽為二十世紀後半葉最有影響力的一本學術著作,首版 於 1962 年出版,1970 年加上後記(Postscript)後的第二版為最常被引用的版本,
1996 年出版第三版。
3 Steven Weinberg 所著,輯錄其 23 篇非專業性文章,由天下文化(2003)出版,
李國偉翻譯。
被遺棄。科學上的變革可以算是演化,但不能稱之為革命。科學思想與技術的 變革或許造成某些基本立場或重要概念的改變,也不必然全盤推翻科學家們評 估理論的方法與標準,也不影響前期理論發現的價值,他說「…假如理論奠基 於簡單普遍的原則上,又能以自然的方式好好解釋實驗的數據,那它就算是成 功的理論。」(p.194)…,他甚至說明了演化的內在張力,他說「當科學家達到 對自然的一種新理解時,他或她會經驗到強烈的快感。在長時間內這類經驗會 教導我們如何判斷,哪種類型的科學理論會產生讓我們瞭解自然的快感。」(p.
197)。
從溫伯格出發,我們要回到第一個可能的討論就相對簡單了。因為質性研 究的基本教義派就是溫格伯眼中的「文化敵手」之一。那些激進的質性研究者 站在啟蒙觀與後現代的思潮中,挑戰溫伯格所身處的常態科學陣營,但是並沒 有提出決定性的替代方案。就如同先前所說的,當代社會科學領域對於質量爭 議已經採取兼容並蓄的觀點,並接受各種方法都能為科學發現與人類知識的提 升有所助益(Babbie, 2002; Hardy & Bryman, 2004)。換言之,我們的「敵人」不 再是質性研究,那麼造成新一波科學演化或變革的主要因子會是什麼?
二、當代量化科學中的重要爭議
(一)古典測量與客觀測量
我們如果從量化研究最前端的測量出發,第一個發生在量化研究當中的重 要議題是古典測量理論(classical test theory, CTT)與項目反應理論(IRT)的爭 議。這兩種測量理論觀點的歧異,主要圍繞在客觀測量(objective measurement)
與線性關係(linear relationship)兩個核心議題上。前者牽涉到測量的行動本身 與測量結果的關係,後者則與潛在特質的計量模型有關。在此,我們並不想重 述 CTT 與 IRT 的對話細節,但是對於這兩個理論學派爭論的核心議題與造成的 影響卻感到興趣。
CTT 的主要焦點在於測量誤差的評估與控制,換言之,CTT 關心的是測量 信度,因此 CTT 的主要(甚至於唯一)假設是測驗分數(O)由真分數(T)與 誤差分數(E)所組成:
(O)bserved score = (T)rue score + (E)rror score (1)
透過對於誤差的估計(例如同一份工具進行兩次測量的分數變動、同一個 構念的兩題類似題目的得分差異),我們得以掌握真分數被測量到的程度。誤差 是具有獨立同質分佈(independently identically distributed, IID)的隨機變數,信 度的定義即是 1 減去誤差分數的變異佔總變異的比例:
2 2
1
O T
rxx
(2)
一旦測量的信度達到一定的理想程度,測驗分數即被視為可以代表個體能 力的真實分數,進而進行測驗分數的意義的檢驗(效度衡鑑),或是進行實務上 的應用(例如成就評量或人事決策)。
IRT 對於 CTT 的基本定義所做出的致命一擊,是對於測量得到的數據無法 客觀反應特質的內容,而是工具依賴的結果的質疑。例如甲乙兩人在 IQ 測驗得 分 100 分與 80 分,其中的 100、80,以及相減後的 20,都僅是測驗工具上的一 種數量現象,沒有客觀與等距的意義。而由於是非等距測量,對於誤差是 IID 分 配的假設即不存在。為了解決非等距問題,IRT 利用勝敗比(Odds)的計算來獲 得客觀測量分數,以及以 ICC(item characteristic curve)來建立受測者能力特質 的分佈狀況。例如對於一個二元計分的題目,答對記為 1,答錯記為 0,所有受 測者的答題狀況可以換算成答對機率 P1 與答錯機率 P0,兩者的比值即為 Odds。
若有兩位能力分別為θ1與θ2的學生,在同樣一個難度(δ)的題目上作答情形分 別是 Odds1 與 Odds2,兩者比值如下:
Odds ratio
2 1 2
1 2 1
/ /
Odds
Odds (3)
如果求出的比值為 2,即表示第一位的能力是第二位的兩倍,若比值為.5,
表示第二位的能力是第一位的兩倍,此時得到的量尺即為比率量尺。將公式 3 取對數後得到 θ1-θ2,為兩人能力差距的邏輯(logit)單位,此一數值與測驗本 身及題目特性無關,符合心理特質的強度為等距的假設,可進行加減乘除的運 算。進一步的,由於測量尺度為等距邏輯單位,因此所有受測者在特定題目的 得分可以描繪成一個服從羅吉斯分配的肩形項目特徵曲線,說明該題的難度、
鑑別度、與猜測度,如圖 1 所示:
圖 1 三個不同難度測驗題目的項目特徵曲線
在傳統的測量理論下,測驗題目的難度、鑑別度、信度都是樣本依賴(sample dependent)的統計量,亦即同一個題目的計量特性會隨著樣本的特性而改變,
不符合科學客觀原則。相對之下,ICC 各參數不會隨著樣本特性的不同而改變,
具有項目參數不變性(invariance of item parameters)之優勢。
IRT 的出現可追溯至 1930 年代(例如 Richardson, 1936)甚至更早,發展至 今可以說是當代心理計量領域獨領風騷的重要學理觀點。到了電腦出現後的 80、90 年代更是迅速蓬勃發展。根據余民寧(1991)的說法,「…這兩派理論目 前並行流通於測驗學界,但試題反應理論卻有後來居上,逐漸凌駕古典測驗理 論之上,甚至進而取而代之之勢…」,但是余文中亦曾提及「…古典測驗理論雖 然不夠嚴謹,但理論淺顯易懂,便於在實際測驗情境(尤其是小規模資料)實 施;當代測驗理論雖然嚴謹,但理論艱深難懂,僅適用於大樣本測驗資料的分 析」。另一方面,IRT 的應用亦有其所植基的基本假設基礎,例如測驗題目都在 測量單向度(unidimension)特質,且每個題目具有局部獨立(local independence)
的特徵,亦即項目間無相關,某一個題目不能為另一個題目提供線索。這些假 設的滿足也造成 IRT 取向的普及上的限制。
基本上,IRT 對於社會科學研究的意義,不僅在於他可以解決傳統測驗發展 的瓶頸,提出創新的作法(例如以題目訊息量來反應測量的信度,提出非常模 參照的測驗模式、直接的測驗等化與比較、提升電腦適性測驗應用價值等),更 重要的是在於 IRT 提供了社會科學與自然科學一樣能夠進行客觀測量的實證研
究的基礎,得以鉅細靡遺的檢驗心理測量所存在的測量偏誤(test bias),並進一 步的能夠與當代重要的分析技術(例如 SEM、HLM)相結合,未來的發展可期。
(參見王文中, 2004, 2006; 余民寧, 1991; Hambleton & Swaminathan, 1985;
Hambleton, Swaminathan, & Rogers, 1991; Hulin, Drasgow, & Parsons, 1983; Lord, 1980)。
(二)外顯變數與潛在變數
如果說 IRT 是心理計量領域的獨門暗器的話,那麼潛在變數模型(latent variable modeling, LVM)(余民寧,2006; Benlter, 1980; Bollon, 1989; Loehlin, 2004)則是橫掃社會科學各領域的重裝武器。如果 Spearnman 能夠看到一百年 後他所提出的因素分析的基本概念被如此發揚光大,對於當代社會科學研究影 響如此之深的話,他一定心滿意足、了無遺憾。在民國七十年代中期的一場學 術會議中,剛進入研究所就讀的我,親見一位學者慷慨激昂的大肆抨擊因素分 析的使用過於氾濫,結果二十年過後,問題不但沒有稍解,因素分析的延伸模 型:結構方程模式(structural equation modeling, SEM)更是野火燎原、一發不 可收拾,在一些重要期刊上,有接近三成的論文都與因素分析有關(Fabrigar, Wegener, MacCallum, & Strahan, 1999),本文檢視台灣博碩士論文當中 SEM 的普 及率為各種新量化方法之冠,可見其在社會科學研究中的重要性。
潛在變數(latent variable)可以說是二十世紀計量心理學家最重要的發明之 一。學過統計的朋友都知道,統計教科書的第一章一定會介紹四個重要名詞:
名義、順序、等距與比率尺度(Stevens, 1946),利用這些尺度所測量到的變數 是統計分析的基本材料,但是這些測量的概念與測量結果無法解決社會科學的 一個大難題,亦即有許多人類的行為特質、心理屬性或社會現象沒辦法直接觀 察,例如智力、創造力、憂鬱這些被稱為構念(construct)的抽象概念,不像傳 統測量程序能夠對於所關心的現象(例如身高、股價、投票率)可直接加以測 量, 得 到 的變 數 稱 為外 顯 變數 ( manifest variables) 或觀 察 變 數(observed variables),相對之下,用於反應構念強度與內涵者稱為潛在變數。潛在變數必 須經過操作型定義,將潛在變數與構念的現象加以連結,並藉由統計程序來 加以估計,得到的潛在變數得以用來反應構念的強度(Nunnally & Bernstein,
1994)。
在各種統計方法中,最具代表性的潛在變數模型為因素分析模型。因素分 析(factor analysis)作為潛在變數模型最早獲得發展的一種技術,被形容為一種
「將變項的複雜性加以簡化的最有效的工具」(one of the most powerful methods
yet for reducing variable complexity to greater simplicity)(Kerlinger, 1979, p.
180),Nunnally 與 Bernstein(1994)直言因素分析是心理構念測量的核心。
Guiford 在一甲子之前,就已經認為因素分析所能夠幫助研究者所提出因素效度
(factorial validity)證據,是心理構念研究的重要方法學突破。他篤定的說,構 念是否存在,一切都看因素(…the answer then should be in terms of factors)
(Guiford, 1946, p. 428)。Borsboom, Mellenbergh,& Heerden(2004)抱持著本 體論的觀點(ontology),認為構念雖隱含在可觀察的事物背後,但我們所測 量到的相關(ij),事實上是由於一個真實存在的構念直接影響的結果,如 果把構念的影響力以因素負荷量(以 λ係數表示)來表示,我們所觀察到的 外顯變數的相關係數(ij)可被兩個λ係數的乘積所取代:
j i
ij
(4)
此時我們可以宣稱外顯變數之間的關係被「構念」所解釋,當構念存在 於模型中時,外顯變數之間即不再具有關連,達成所謂的局部獨立性(local independence)。若以路徑概念圖來表示,潛在變數與外顯變數的關係可由圖二 來表示。
圖 2 基本的潛在變數模型(CFA)圖示
圖 2 呈現了帶有三個外顯變數與一個潛在變數的因素分析模型。模型中, 即為潛在變數,以橢圓表示。作為 X1到 X3三個外顯變數的共同影響源(common source),可以完全解釋外顯變數之間的相關,使得三個變數之間形成沒有關連 的局部獨立,各外顯變數被潛在變數解釋的程度以λ11、λ21、λ31表示,因素負荷 量係數的平方表示外顯變數被潛在變數解釋的程度,亦即項目信度(item reliability),無法被解釋的部分(1-信度)就是測量誤差,為圖三當中的 δ1、δ2
X1
X2
X3
1
λ11
λ21
λ31
δ1
δ2
δ3
與δ3。整個模型可以下列迴歸方程式來表示:
x
x (5)
傳統上,研究者在進行因素分析之前,並未對因素結構有任何預期與立 場,而藉由統計數據來研判因素結構,帶有濃厚的嘗試錯誤的意味,因此稱為 探索性因素分析(exploratory factor analysis; EFA)。然而,有時研究者在研究之 初既已提出某種特定結構關係的假設,例如某一個概念的測量問卷是由數個不 同子量表所組成,此時因素分析可以被用來確認資料的模式是否即為研究者所 預期的形式,稱為驗證性因素分析(confirmatory factor analysis; CFA)(Anderson
& Rubin, 1956; Jöreskog, 1967)。CFA 使用的範圍相當廣泛,大大超越了傳統 EFA 用來簡化數據或抽取因素的單純目的,CFA 可以用來檢驗抽象概念或潛 在變項的存在與否,評估測驗工具的項目效度與信效度,並且檢驗特定理論 假設下的因素結構。然而,雖然 CFA 可以說是因素分析技術的一大進展,但 是 EFA 與 CFA 意兩者的目的不同,使用的時機也不一樣。從研究的立場來 看,CFA 並不足以完全取代 EFA,兩者反而具有相輔相成的功效(Coste, Bouee, Ecosse, & Pouchot, 2005; Thompson, 2004)。到了七十年代,隨著電腦的普及,
因素分析的便利性大為提高,同時在 Jöreskog 等人的努力下,因素分析模式與 社會科學的另一個重要分析技術:路徑分析(path analysis)相結合,促成了結 構方程模式的發展與風行。
圖 3 典型的 SEM 模型與參數圖示 X1
X2
X3
1
Y1 Y2
Y3
η1
Y4 Y5 Y6
η2 γ21
γ11
β21
1
2
一個典型的 SEM 模型,包含了測量模型(measurement model)與結構模 型(structure model)兩部分,前者用來定義潛在變數(亦即 CFA),後者用來探 討潛在變數間的影響與相互的作用(亦即路徑分析),如果我們今天有三個潛在 變數,每一個潛在變數可以利用前面圖二的概念來加以定義,那麼我們即可以 進一步以單箭頭來說明三個潛在變數的影響關係,如圖 3 所示。其中1、η1、η2
代表三個潛在變數,η1、η2作為被解釋的依變數,為潛在的內衍變項(endogenous variables);1作為解釋他人的自變數,為潛在的外衍變項(exogenous variables), 潛在內衍變項無法被解釋的部分稱為干擾項(disturbance),以表示,在潛在變 數之間的關係可以用下列迴歸方程式來表示,即為 SEM 的結構模型:
(6)
將測量模型的方程式(公式 5)與結構模型方程式(公式 6)加以整合來求 取最佳聯立解,即是結構方程模式分析(Jöreskog & Sörbom, 2004)4。到了今 天,可以用來估計結構方程模型的統計軟體越來越多(例如 LISREL、AMOS、
MPLUS、EQS、PLS、SAS 等),也擁有專屬的期刊、龐大的學術社群,以及不 計其數的相關論文的發表,堪稱當代最具常態科學的一的學術社群5。究其根本,
都回歸 Spearman 當初所關心的問題:為什麼智力測驗的測量分數之間會有高相 關?是不是有一個智力的心理構念在背後?
當初 Spearman 對於因素分析的興趣來自於他對於智力(IQ)測量的好奇,
由於智力是一個強度的概念,因此因素分析一向把潛在變數以連續變數視之,
後來的學者把潛在變數擴展到類別形式,進行潛在類別分析(latent class analysis, LCA )( McCutcheon, 1987 ), 用 以 探 討 類 別 外 顯 變 數 ( categorical manifest variables)背後的類別潛在變數(categorical latent variables),稱為潛在類別模 式(LCM)(Lazarsfeld & Henry, 1968),也是一種用以探討潛在變數的模型化 分析技術。
4這些符號系統是由最早出現的 LISREL 軟體所定義,該軟體可至Scientific Software International,Inc.的網頁http://www.lisrel.com或http://www.ssicentral.com獲得試用版軟 體。
5台灣有關 SEM 的討論,最早是林清山教授(1984)在測驗年刊發表的《線性結構關 係(LISREL)電腦程式的理論與應用》一文,近年來在社會與行為科學的應用領域,
許多博碩士論文與實證研究已經採用 SEM 技術,教學上,已經許多學校開授 SEM 課 程,並有專書出版(如侯傑泰、溫忠麟、成子娟,2003; 余民寧,2006;李茂能,2006;
邱皓政,2003;吳明隆,2006;黃芳銘,2002)。
以圖 3 為例,如果把圖中的各外顯變數與潛在變數視為類別變數時,即成 為潛在類別模型。因素分析是以潛在變數來解釋外顯變數之間的線性相關(linear relationship),達到局部獨立性;LCA 的目的即在於以最少的潛在類別數目來解 釋外顯變數之間的關連,來達到局部獨立性。先前我們已經介紹過的 IRT 模型 也是一種針對類別變數進行的潛在變數模型,因此 LCA 模型的提出,意味著類 別變數與連續變數均可以整合在同一個潛在模型當中,LCM 的提出替 IRT 與 SEM 兩種潛在變數模型提供了一個最佳的溝通互補的平台與橋樑,隨著分析 軟體(例如 MPLUS 與 LatentGold)的成熟,LCA、SEM、IRT 三者的整合發 展將是潛在變數模型下一波的重要議題(參見 Muthén & Muthén, 2004)。
(三)個體分析與整體分析
如果說「構念」是重視人類個別差異的心理學家一生揮之不去的夢魘,那 麼「脈絡」(context)就是重視社會結構與社會影響力的社會科學家心中永遠的 痛。傳統以來,社會科學的量化研究對於個體的關心多於整體與結構,個體雖 然是基本的研究單位,但是個體卻身存於系統、結構或脈絡之中。當研究者忽 略了總體,以個別觀察值為單位所進行的個體主義式研究(individualism)時,
研究者的眼界無疑受到根本的約束,而這個約束,慢慢被多層次研究(multilevel research)或脈絡分析(contextual analysis)這種整體主義式研究(holism)所打 開(Courgeau,2003)。
量化研究對於脈絡的分析,主要建築在社會科學常見的多層次資料結構之 上。多層次資料(multilevel data)是指研究樣本具有階層性(hierarchical)或叢 集(clustered)的特徵,使得研究者所測量到的觀察值具有特殊的相依/隸屬/配 對關係,造成樣本獨立性假設的違反與統計檢定的失效。常見的例子為家庭研 究的子女夫妻嵌套(nested)在家庭之中,各家庭又嵌套在縣市地域之中;學生 嵌套在班級之中,班級嵌套在學校之中;員工嵌套在部門之中,部門嵌套在組 織之中;團隊成員嵌套在各團體中;縱貫研究的個體重複觀察嵌套在個體之中。
在多層次資料結構中,最底層是由最小的分析單位所組成(例如個別的學 生),稱為個體層次(micro level)。越高階的層次則分析單位越大,稱為總體層 次(macro level),例如學生為第一層(個體層次),其所屬的「班級」屬於第二 層(總體層次),班級所屬的「學校」屬於第三層(亦為總體層次)。依變數(或 稱為效標變數或準則變數)是個體層次的觀察值,對於依變數進行解釋的預測 變數(稱為解釋變數或自變數)可以存在於個體層次,也可以存在於總體層次,
或同時存在兩個層次,用以探討不同層次解釋變數對於依變數的影響。當個體
層次解釋變數透過組內聚合(aggregate)程序形成高階解釋變數時,特別稱為脈 絡變數(contextual variables)(Duncan, Curzort, & Duncan, 1966),例如學生 IQ 對於學業成績的影響,學生 IQ 雖作為個體層次解釋變數,但可聚合成為班級 IQ
(亦即求取全班學生 IQ 的平均數),此時的平均 IQ 作為脈絡變數,係以「班級」
為測量與分析單位。如果還有學校的區分,班級層次的脈絡變數可以再聚合成 更高階的校級層次 IQ。
圖 4 二階層模型的階層結構變數型態與關係
以學業成就研究為例,若研究者關心師生 IQ 對於學生學習成就的影響時,
如果資料結構為多位學生嵌套在一個老師之中,「師生 IQ」一詞就涉及了不同層 次不同分析單位的三種變數,此一二階層的模型架構與變數關係如圖 4 所示。
個體層次的學生 IQ 是學生學習成就的低階解釋變數(對於依變項的影響,以 A 實線箭頭表示),老師的 IQ 則是高階層解釋變數(對於依變項的影響,以 B 實 線箭頭表示),同一個班級的學生同屬一組,因此總體層次自然存在一個類似於 類別變數的效果形成班級差異,造成各組之間平均數與係數的變動,是為組間 效果。同一個班級的學生 IQ 可以聚合成高階的脈絡變數(全班平均 IQ),表示 該班的 IQ 優劣。脈絡變數與嵌套的低階解釋變數為同一個變數(學生 IQ),但 是分析單位不同。脈絡變數對於依變項的影響即為脈絡效果(當低階解釋變數 獲得控制的情況下,脈絡變數對於依變項的影響,以實線箭頭 C 表示)。各變數 的關係可以下列三式來表示。
學生個人 IQ
導師 IQ
學習成就 全班平均 IQ
Level 1: 學生 Level 2: 班級
脈絡變數 高階解釋變數
低階解釋變數 依變數
組間差異
C A
B
個體層次 總體層次
Level 1: Yij 0j 1jXij ij (7) Level 2: 0j 00 01Zju0j (8)
j j
j 10 11Z u1
1
(9)
若 X 與 Z 為不同的變數,則 Z 稱為高階解釋變數。若Zj Xj,則 Z 稱 為脈絡變數。公式 7 代表第一層的迴歸模式,也就是個體層次解釋變項與被解 釋變項的關係,而公式 8、9 代表第二層的迴歸模式,0j與1j表示高階迴歸
分析的誤差項,誤差分配均需滿足以 0 為平均數、以00與11為變異數的聯合 常態分配假設。高階迴歸是對低階迴歸分析的參數變化進行解釋(也就是影響 學業成績的個體因素的強弱或差異),而非對依變項(學習成就)本身的解釋。
若將三個公式整合,得到整合方程式(或混合模型,mixed model),其表示如下:
Mixed: Yij 0010Xij 01Zj 11ZjXij u0j u1jXij ij (10)
公式 10 中,迴歸係數00為第二層對於第一層截距進行解釋的截距,01為
第二層變數對於第一層截距進行解釋的斜率,在混合模型中代表的就是總體層 次解釋變項對個體層次依變項的影響;10為第二層對於第一層斜率進行解釋的 截距,也就是個體層次解釋變項對第一層依變項的影響,11為第二層變數對於 第一層斜率進行解釋的斜率,即為跨層級交互作用效果(cross-level interaction)。 總體層次解釋變數反應了環境或背景的特徵,對個體的影響是一種脈絡效果
(contextual effects)(邱皓政、溫福星,2007; Courgeau,2003; Snijder & Bosker, 1999)。脈絡分析的最大價值在於生態謬誤(ecological fallacy)(Robinson, 1950;
Snijders & Bosker, 1999)的避免。
基本上,多層次分析技術是延伸自線性迴歸的概念,將代表各階層的多組 迴歸方程式組合成混合模型,再以多元迴歸原理進行參數估計,稱為多層次線 性模式(Multilevel Linear Modeling; MLM)(Tabachnick & Fidell, 2006; Curran, 2003; Snijders & Bosker, 1999)。經過了諸多學者的努力探究,近年來多層次資料 的分析在原理與技術上都已有非常成熟的發展(參考溫福星,2006;張雷、雷 靂、郭伯良,2003; Ferron, Dailey, & Yi, 2002; Ferron, Hess, Hogarty, Dedrick, Kromrey, Lang, & Niles, 2004; Raudenbush & Bryk, 2002)6。
6台灣對於多層次模型的應用尚處於起步的階段,溫福星(2006)所著的《階層
值得注意的是,傳統的 MLM 模型並沒有納入潛在構念的概念,在目前廣為 流行的 HLM 軟體(Raudenbush, Bryk, Cheong, & Congdon, 2004)雖然可以處理 因素的萃取,但是仍是受到諸多的限制(Tabachnick & Fidell,2006)。近年來多 層次分析技術的主要焦點議題之一,就是以 SEM 來處理多層次資料,進行多層 次結構方程模式(Multilevel SEM; MSEM)(Heck, 2001; Jedidi & Ansari, 2001;
Goldstein, 2003; Goldstein & Browne, 2001; Goldstein & McDonald, 2003; Hox, 2002; Jöreskog & Sörbom, 2004; Rabe-Hesketh, Skrondal, & Zheng, 2007),是 SEM 與 MLM 兩大技術典範整合應用的前夕。
(四)明確測度與模糊測度
在社會科學領域,測量理論與分析技術的另一個突破是源自於工程領域中 的模糊控制理論。在本卷的另一篇論文中,林原宏教授回顧了模糊理論在社會 科學界的發展與現況後,樂觀的指出模糊量化方法在社會科學資料分析上具有 高度應用價值,主要原因之一是人類思考與決策歷程具有模糊的特性,採用模 糊方法不但不會「越看越模糊」,而可以提供研究者更貼近人類行為現象的本 質。其次是模糊資料的分析模式大多不需要資料分配假設,可以得到更具有強 韌、穩健特性(robust)的量化發現。
基本上,模糊理論從數學的模糊集合(fuzzy set)的觀點出發,採取有別於 傳統機率論以或然率(probability)來表示事件出現的先驗機率,改以可能性
(possibility)來說明事件在發生後的不確定性,進而配合不同的測量需要或分 析議題而發展出獨特的模糊分析方法。換言之,將模糊理論的觀點應用在社會 科學的測量與分析上,可能涉及模糊理論的不同部分的應用,在社會科學應用 仍處於起步的狀態,仍有相當值得探討的空間(劉湘川,2007; Nguyen & Wu, 2006)。林原宏(2007)將模糊理論在社會科學領域的應用,區分成樣本的分群
(集群分析)、態度與意見調查分析(模糊測量)、模糊量化參數估計、評鑑的 應用、決策與判斷等幾個不同面向。
傳統測量是採古典集合的統計觀點,例如測量題目的不同選項、變數的不 同數值是若 P 則非 Q 的完全互斥事件,從集合論的觀點來看,事件的發生情形 是一種明確集合(crisp set),例如不是男、就是女; 不是喜歡,就是不喜歡。傳
線性模式》是台灣第一本有關 HLM 的專門著作,香港則有張雷、雷靂、郭伯良
(2002)的專書。邱皓政(2006)翻譯了 Kraft 與 de Leeuw(1998)的多層次模 型導論一書。在余民寧(2006)、陳正昌、程炳林、陳新豐、劉子鍵(2006)的 著作中則有專章討論。
統的李克特五點量表(Likert scale)要求受測者圈選 1 到 5 點量尺當中的一個,
來反應個人的想法或感受,也是一種明確集合的觀念。在自然科學中,研究者 所觀測的對象多為客觀的實體,因此多能符合明確集合的基本要求。但是在社 會科學研究中,研究對象多為「人」,而人的思維與感受卻帶有大量的波動與不 明確特性。因此以明確集合來進行測量與量化模型的建立多有不妥之處。
舉一個實例來說,如果詢問同學畢業旅行的最佳地點,可能的選項包括 1.
出國一週、2.環島一周、3.台灣外島、4.露營烤肉加轟趴,明確集合的作法是以 單選題形式要求同學從四個中選擇一個最偏好的方式,此時「比較想要出國」
的某生的測量結果是 1、0、0、0。相對的,模糊集合的作法則是考慮了隸屬度
(membership),亦即每一個選擇你有多麼喜歡,要求列出喜歡程度,此時某生 的回答可能是 70%、20%、10%、0%,結果仍是「比較想要出國」。林原宏(2007)
的例子則說明了「老人」一詞的模糊集合定義與年齡變數的關係(不同年齡的 人的「老人」隸屬度不同)。一旦以數學方式完成了模糊集合的定義後,兩個或 更多集合元素的相似程度(或傳統統計上的相關概念)即可以利用模糊關係矩 陣(fuzzy relation matrix)來進行估計,得到類似性與相關性的估計結果。
與 IRT 相同之處,模糊測量對於古典測量理論的質疑仍是「等距測量」的 假定。林原宏(2002)指出,一般心理測驗當中的題目量尺(例如 Likert 量尺)
只能說是順序測量,但普遍被社會科學研究者視為等距量尺,過度簡化了人類 感受的複雜性與不確定性,因此建議應以模糊數(fuzzy number)來代替傳統量 尺的測量方式。
台灣學術領域有關模糊理論的應用,集中於工程領域,社會科學領域的應 用可以追溯到劉湘川與簡茂發(1992)在測驗年刊的論文,本卷當中,林原宏 教授(2007)提出了極具參考價值的文獻整理論文,北京大學程乾生教授與吳 伯林教授(2007)從數學原理與實際應用的角度說明,劉湘川教授(2007)則 完成了模糊測度重要數學程序的推導,在模糊方法學的發展上注入一股新的力 量7。
(五)古典機率與貝氏統計
在數學裡給定某個數是 2, 它就一直是 2。但在機率裡,某事件的機率有可
7 吳伯林(2005)所著之《模糊統計導論》為台灣第一本有關模糊統計的專門著 作,林原宏(2006)將James J. Buckley的《模糊統計》予以翻譯,兩書皆由五南 圖書公司出版。
能因情況而變。例如在馬路上遇到一個人,在隨機的情況下,是男與是女的機 率各為 0.5,但如果是走在女生宿舍的走廊上的話,機率就變成 1.0 了(因為宿 舍裡不會有男生)。當我們在進行一個研究或實驗之前,即獲得某些資訊時,對 於我們所觀測到的機率就會隨之改變,這就是貝氏機率的觀念。以正式的數學 來定義,若 A 與 B 為樣本空間 Ω中的二事件, 且P(B)>0,那麼在給定 B 的發 生機率的條件下,A 事件的條件機率, 以P A|B 定義如下:
( ) )| (
B P
B A B P
A
P (11)
若令P(AB)P(A)P(B|A),則上式則為:
( ) )| ( )
| (
B P
A B P A B P
A
P (12)
公式 12 稱為貝氏定理(Bayes’rule)。P(A|B)為事件 B 發生的前提下,事件 A 發生的機率,亦即 A 事件的條件機率,也稱為事後機率(posterior probability),
)
| (B A
P 為樣本機率(sample probability),P( A)為事前機率(prior probability)。 在貝氏的觀點下,樣本資料與參數(例如迴歸係數、變異數等)都是未知 的隨機變數(Cox & Hinkley, 1974; Lee, 1989; Gelman et al., 1995),貝氏的觀點 將先驗機率或特定訊息(例如專家知識)連同樣本資料一起用來估計參數分配,
一旦後驗分配被決定之後,即可利用傳統的機率原則進行統計決策或應用,例 如參數機率超過某一個閾值即被視為一特定情況。
傳統統計方法(又稱為頻次統計學,frequentist statistics)與貝氏統計最大的 不同是對於機率的看法,頻次統計學者眼中的機率是特定事件(A)在一個固定 的樣本空間反覆出現的頻率,即先前公式中的 P(A)。貝氏統計學者眼中的機率 則是基於科學知識所建構 出的一種模型(a model of scientific knowledge)
(Austin, et al, 2002),機率的計算帶有主觀或可操弄的元素,允許研究者對於參 數的出現形式進行特殊的定義並納入估計。在進行統計推論時,頻次學者先提 出一組統計假設,再從樣本計算出觀察機率(後驗機率)即俗稱的 p 值,如果 p 值非常極端,小於某一顯著水準(例如 5%),即宣稱推翻虛無假設,接受對立 假設,此一過程可以說是一種演繹(deductive)的結果(Freedman, 1996; Davidoff,
1999; Goodman, 1999)。相較之下,貝氏方法則是一種歸納(inductive)的策略,
藉由觀察到的資訊來評估特定假設的可能性,藉以進行後驗機率的計算。
另一方面,貝氏方法亦可以像傳統樣本統計量的區間估計,對於所關心的 特定參數計算可靠區間(credible interval),95%的可靠區間意味著有 95%的機率 可以正確估計到母體的參數。由於貝氏定理結合了事前機率與事後機率,因為 可以導入先前的經驗(事前機率),比起傳統機率理論只由樣本統計量推導出事 後機率更有效率。另一方面,繁瑣耗時的演算藉由馬可夫鏈蒙地卡羅法(Markov Chain Monte Carlo; MCMC)(Gilks et al., 1996)與電腦科技,可以大幅提昇貝氏 估計的效率,預測的品質較傳統頻次統計更為理想,因此近年來貝氏方法在醫 學、財務、資管、工程等領域發展非常快速(Goodman, 1999; Lilford & Braunholtz, 1996)。
在社會與行為科學領域,貝氏的應用雖然仍不多見,但是已經可以看到一 些實際的應用,例如 French 與 Smith(1997)證明了人類的判斷歷程並不完全符 合傳統固定機率的推導模式,而帶有特殊的主觀影響。Austin、Brunner, & Hux
(2002)以 Bayeswatch 一詞,認為貝氏統計在臨床研究具有重要價值。最近的 一篇文章中,Norris(2006)將貝氏方法應用到語言認知決策歷程的研究,用以 解釋文字的頻率為何會影響字詞辨識,認為視覺文字辨識歷程是一種理想的貝 氏決策結果。
圖 5 單徑型貝氏網路之圖示
在財務、工程、資訊管理領域的貝氏應用,多結合模擬與資料庫分析,以 貝氏網路(Bayesian network)來進行預測。貝氏網路是將貝氏定理與類圖理論
(graphoid theory)相結合,利用非循環性的圖形(directed acyclic graph)見構 成一個貝氏網路(如圖 5),藉以進行預測。圖五中的圓圈是節點(node),亦即 隨機變數,因此網路中有 A 到 F 六個隨機變數。各節點的關係由單箭頭,亦即
A
B D E
C F
鍊結(chain)來連結。上層的節點稱為根節點(root node),表示所有的資訊未 蒐集前的事前機率,最下層的機率代表某一現象的發生情形,稱為證據節點
(evidence node)。由於各節點僅以單一見頭符號鍊結,因此是一個單徑型網路
(single connected network)。整個網路的機率可以下面的貝氏機率式來反應:
)
| ( )
| ( ) ,
| ( ) ,
| ( )
| ( ) ( ) , , , , ,
(A BC D E F P A P B AP C AB P D B E P E AP F D
P (13)
以 D 為例,B 與 E 均為 D 的母節點(parent node),亦即造成 D 的原因
(cause),D 就是結果(outcome)。在 D 未知的情況下,B 與 E 互相獨立,但是 如果 D 為已知時,則 B 與 E 稱為相依。對於 D 節點,可以計算出前導機率(head of D)與結果機率(tail of D),其中e
A,B,E
,e
C,F ,貝氏網路主 要即是在進行π與 λ的估計。)
| ( )
(D P D e
(D)P(e|D) (14)
與貝氏網路具有類似的預測功能的模型還包括決策樹(decision tree)與類 神經網路(neural network),在電腦運算功能大幅提昇的推波助瀾下,這些方法 都有長足的發展,尤其是作為人工智慧(actifact intelligence)發展學習網路或預 測系統的重要算則與分析技術。其中決策樹是一連串決策點的連結而成的決策 網路,用以進行決策分析,包括建立決策樹(訓練資料來建立)、修剪決策樹、
產生學習規則等三個主要步驟(Quinlan, 1986, 1993)。另一方面,類神經網路則 是從腦與神經系統的類比獲得啟發的一種資訊處理技術,具有平行運算與高嘗 試錯誤容忍率的學習特性,近年來則廣泛被應用在資訊與工程科技的探勘、診 斷與預測研究中(Rumelhart & Mcclelland, 1986)。
三、台灣學術領域應用的現況
近年來,台灣高等教育的發展極為迅速,除了公私立大學的擴充,技職體 系亦朝大學化的方向發展,到了 95 學年度(2006),台灣地區總計有 163 所大 專院校(大學 94 所、獨立學院 53 所、專科 16 所),研究所數目為 2832,學系 數為 4666,專任教師 48255 人(男性 32630 人,女性 15625 人)。高等教育的擴 充一方面提高大學與研究所的入學率,同時也擴大了學術研究人才的規模。其
中最明顯的變化是博碩士畢業人數的增加,在 76 學年度(1987)時,碩士畢業 人數僅有 4483 人,90 學年度(2001)增加到 25900 人,94 學年度(2005)則 為 45736 人,增加超過 10 倍。博士畢業人數也從 76 學年度(1987)的 297 人,
逐年增加到 94 學年度(2005)的 2614 人(教育部教育統計資料,2006)。當博 碩士畢業生人數以倍數增加的同時,我們可以推估每年涉入論文指導的指導教 授以及論文口試委員的人數將相當可觀,為了使這些研究生能夠順利完成論 文,所開授的方法學課程數量龐大。因此,要瞭解各種新興技術在台灣學術領 域的應用情形,最直接的一個管道是檢視台灣博碩士論文當中使用各種技術的 情 形 , 另 一 方 面 , 由 於 國 家 圖 書 館 所 建 制 的 博 碩 士 論 文 資 訊 網
(http://etds.ncl.edu.tw/theabs/index.jsp)功能完善,因此利用該系統分別針對五 種量化方法在過去二十年間(1986 至 2005)的應用狀況進行檢索。檢索時,各 種方法所使用的關鍵字如下:
1. IRT:試題反應理論、項目反應理論、Item Response Theory、Item Character Curve
2. SEM:結構方程模式、結構方程模型、驗證性因素分析、Structural Equation Modeling、LISREL
3. MLM:階層線性模式、階層線性模型、Hierarchical Linear Modeling、Multilevel Modeling
4. Fuzzy:模糊集合、模糊統計、模糊數學、模糊測度、Fuzzy set、Fuzzy Statistics 5. Bayesian:貝氏統計、貝氏方法、貝氏網路、貝氏定理、Bayesian、Bayes’rule
剔除無關的論文之後,五種方法得到的論文篇數分別為 IRT(533)、SEM
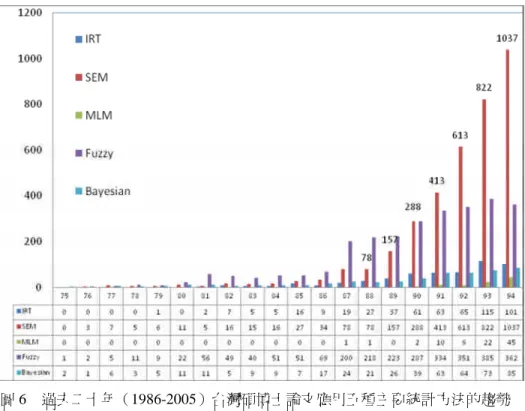
(3631)、MLM(90)、Fuzzy(2726)、Bayesian(481),共 7461 筆資料有效資 料。其中以 SEM 的應用篇數最多,其次是 Fuzzy 方法。而 SEM 的應用在 2000 年之後呈現逐年快速增加的趨勢,顯示台灣近年來使用 SEM 於博碩士論文的情 況相當可觀,並且持續增加中,相對之下,有關模糊方法的應用數量雖多,但 是卻有趨於平緩的趨勢。至於多層次模型分析的使用最少,只有 90 篇,但是卻 集中於近兩年:2004 年有 22 篇、2005 年則有 45 篇,顯示 MLM 的應用在台灣 屬於起步的階段。貝氏統計的應用則在過去四年間呈現高峰,但是並沒有增加 的趨勢(如圖 6 所示)。
圖 6 過去二十年(1986-2005)台灣碩博士論文應用五種主要統計方法的趨勢
值得注意的是,雖然模糊統計與貝氏統計的應用數量不少,但是如果就不 同的學門來看,這兩種方法應用在社會科學的比例並不高,各學門的分類結果 如表 1。其中模糊統計的應用在工程學門最多,共有 1344 筆,幾佔模糊方法的 2726 篇中的一半,其次是商業管理類的 398 篇,可見得在工程學門大量使用模 糊控制理論。貝氏方法應用在商業及管理的 190 最多,數學及電算電機學門的 136 篇居次,工程 90 篇第三,顯示貝氏方法應用在社會科學當中的管理商業類 科具有相當之潛力。
雖然貝氏統計與模糊統計應用在商業管理類科的篇數很多,但是商業管理 類科則以 SEM 的應用最為普遍,共有 2015 篇,同時在 90 學年度之後,每年的 篇數逐年增加,分別為 135、210、355、482、565,顯示在商學領域,SEM 是 非常重要的一個量化方法。SEM 不但應用在商業管理學門,在教育學門的應用 也很高,共有 420 篇,也呈現逐年遞增的現象。有趣的是,在 SEM 發源地的心 理學門,SEM 的應用情形卻相對冷清,在以經濟、社會與心理學門的合併歸類 下,只有 142 篇 SEM 的應用,心理學門在其他四類方法的使用也很少,顯示台 灣心理學門對於這些進階量化方法的使用情形並不普遍。