‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
國立政治大學英國語文學系碩士班碩士論文
國立政治大學英國語文學系碩士班碩士論文
國立政治大學英國語文學系碩士班碩士論文
國立政治大學英國語文學系碩士班碩士論文
指導教授
指導教授
指導教授
指導教授:
:
:張郇慧
:
張郇慧
張郇慧 博士
張郇慧
博士
博士
博士
Advisor: Dr. Claire H. H. Chang
普通單字在特殊文類的呈現
普通單字在特殊文類的呈現
普通單字在特殊文類的呈現
普通單字在特殊文類的呈現:
:
:
:
針對商業年報語言詞塊之語料庫研究
針對商業年報語言詞塊之語料庫研究
針對商業年報語言詞塊之語料庫研究
針對商業年報語言詞塊之語料庫研究
General Lexis in Specialized Genre:
A Corpus Study on Formulaic Language in Business Reports
研究生
研究生
研究生
研究生:
:
:陳俊宏
:
陳俊宏
陳俊宏 撰
陳俊宏
撰
撰
撰
Name:
:
:Chen, Chun-hung
:
中華民國
中華民國
中華民國
中華民國 102 年
年
年
年 1 月
月
月
月
January 2013
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
General Lexis in Specialized Genre:
A Corpus Study on Formulaic Language in Business Reports
A Master Thesis
Presented to
Department of English,
National Chengchi University
In Partial Fulfillment
of the Requirements for the Degree of
Master of Arts
by
Chen, Chun-hung
January 2013
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
AcknowledgementThis thesis is in fact a composition by many intellectual minds. This study was first motivated by the late Professor Cynthia Hsin-feng Wu [吳信鳳教授], who had suggested me to invest my study into the ESP field at the entrance interview of TESOL Program of Department of English of Chengchi University. My
competence of knowledge in TESOL and ESP was further broadened and deepened by Professor Leah C.Y. Yeh [葉潔宇教授] and Professor Yi-Ping Huang [黃怡萍教
授]; my performance in academic writing was enhanced by Professor Ming-chung Yu
[余明忠教授] and Professor Judy H. Y. Yu [尤雪瑛教授] with basics of thesis writing and advanced course on discourse organization, respectively. Many thanks to Professor Siaw-Fong Chung [鍾曉芳教授], who has filled me in with essence of corpus linguistics and statistics and equipped me with studied attitude and administrative skills on doing research. This piece of academic work is
accomplished with instruction of Professor Claire H. H. Chang’s [張郇慧教授], who provides me with the largest degree of freedom to have my enthusiasm and creativity fulfilled. Professor Chang always gives me advice on the level of logic of argument, without which this thesis would fail in maintaining coherence and consistency.
Thanks to professors who had commented on my thesis at proposal and final oral test. Comments from Professor Cheung, Hintat [張顯達教授], Professor
Yi-Ping Huang [黃怡萍教授], Professor Her, One-Soon [何萬順教授], and Professor Lin, Yowyu [林祐瑜教授] really help optimize this study from aspects of logic of argument, framing of research questions and hypotheses, implications on TESOL, and other technical issues.
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
Thanks to all faculty members of the Department of English, who have built a warm environment to make academic excellence realizable. And I would like to express my sincere gratitude to my classmates: Jonathan Wang, Rachel Tseng, Emily Hung, and Mandy Huang; they have sharpened my thoughts with their keen
observation and insightful opinions shared in class.
And lastly, I would like to dedicate this work to Lord Jesus Christ and my dear wife, who found my life with miracles and unfailing love.
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
Table of Contents CHAPTER 1 INTRODUCTION ... 1CHAPTER 2 LITERATURE REVIEW ... 5
2.1 COMMON WORDS IN ENGLISH FOR SPECIFIC PURPOSES ... 5
2.1.1 Common core hypothesis ... 6
2.1.2 Specifiable words in specific genres ... 8
2.1.3 Lexical patterns in different contexts ... 9
2.1.4 Tentative research question ...12
2.2 EXTRACTION OF WORDS ...12
2.2.1 Common words ...13
2.2.2 Tentative research question ...14
2.2.3 Specialized words ...15
2.2.4 Summary on methods for extracting words ...18
2.2.5 Operational definition of common words ...19
2.3 IDENTIFICATION OF FORMULAIC LANGUAGE ...20
2.3.1 Collocation ...21
2.3.2 Lexical bundles (N-Grams) ...24
2.3.3 Cumulative frequency ...26
2.4 INTEGRATING CORPUS RESEARCH WITH GENRE-BASED METHOD ...28
2.5 SUMMARY OF CHAPTER AND RESEARCH QUESTIONS ...31
CHAPTER 3 RESEARCH DESIGN ... 35
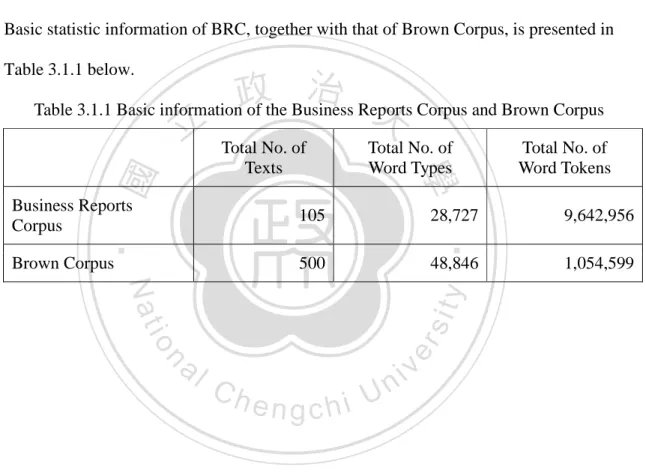
3.1 CREATING BUSINESS REPORTS CORPUS ...35
3.1.1 Source of data ...35
3.1.2 Corpus size ...36
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
3.2 EXTRACTING COMMON WORDS ... 46
3.2.1 Excluding technical words and compounds ... 46
3.2.2 Keyword, words with unusually frequency ... 46
3.2.3 Matching words in Senior High English Wordlist for Reference ... 47
3.2.4 Key-keyword, keywords sorted according to text coverage ... 48
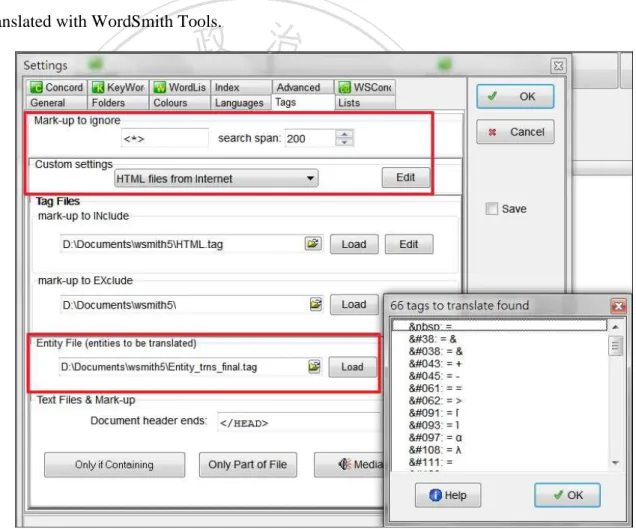
3.2.5 Procedure for extracting common words with WordSmith Tools ... 48
3.3 LOCATING FORMULAIC LANGUAGE FROM DIFFERENT GENRES ... 57
3.3.1 Selecting genres for comparing formulaic language ... 57
3.3.2 Syntagmatic variation and paradigmatic variation of formulaic language ... 59
3.3.3 Procedure for identifying formulaic language with AntConc ... 59
3.4 FLOWCHART OF RESEARCH DESIGN ... 66
CHAPTER 4 RESULTS AND DISCUSSION ... 67
4.1 EXTRACTED COMMON WORDS ... 67
4.2 LENGTH OF FORMULAIC LANGUAGE ACROSS GENRES ... 74
4.3 COMPOSITION OF FORMULAIC LANGUAGE ACROSS GENRES ... 77
4.4 SUMMARY OF CHAPTER... 89
CHAPTER 5 CONCLUSION ... 91
5.1 OVERVIEW OF RESEARCH QUESTIONS AND RESEARCH RESULTS ... 91
5.2 SIGNIFICANCE AND IMPLICATION ... 93
5.3 RESEARCH IN PROSPECT ... 94
REFERENCES ... 97
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
List of FiguresFigure 3.1.1 Downloading 20-F documents of queried company on SEC website ... 40
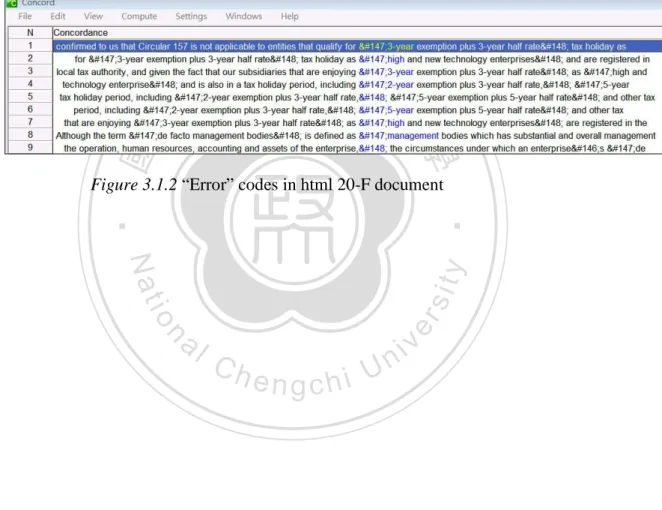
Figure 3.1.2 “Error” codes in html 20-F document ... 42
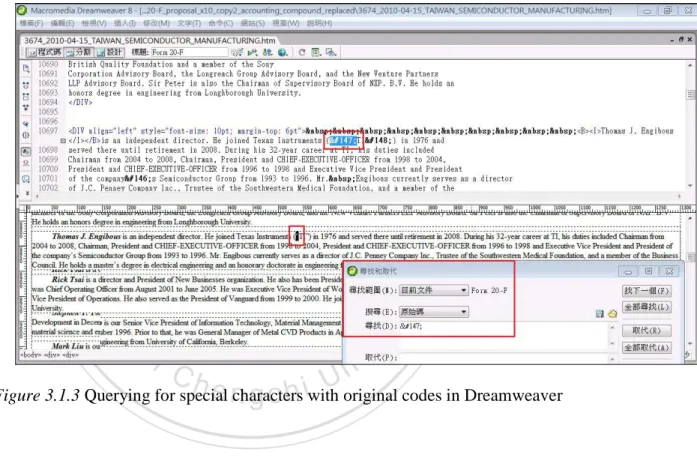
Figure 3.1.3 Querying for special characters with original codes in Dreamweaver ... 43
Figure 3.2.1 Adjusting setting for html brackets and special characters ... 49
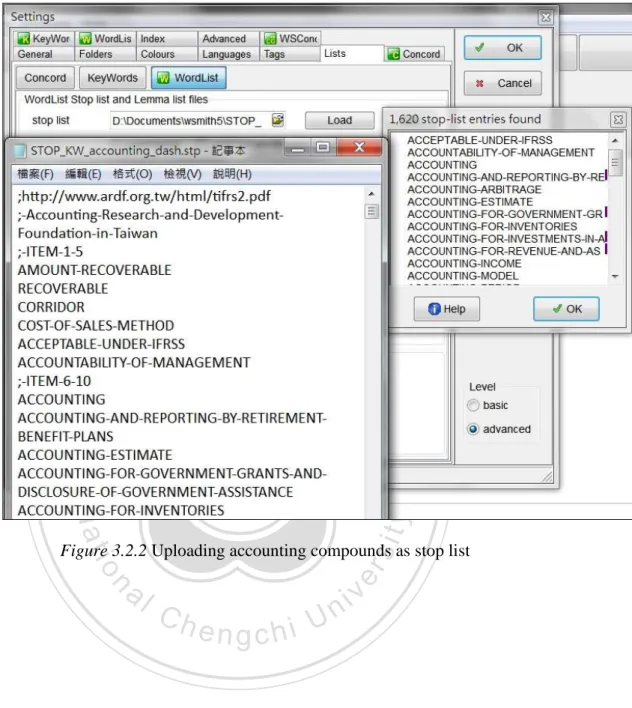
Figure 3.2.2 Uploading accounting compounds as stop list ... 51
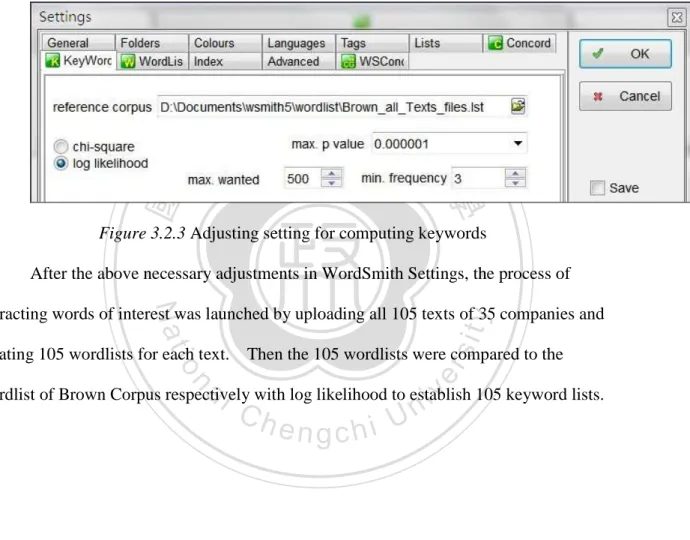
Figure 3.2.3 Adjusting setting for computing keywords ... 52
Figure 3.2.4 Key-keywords assorted based on degree of text coverage ... 53
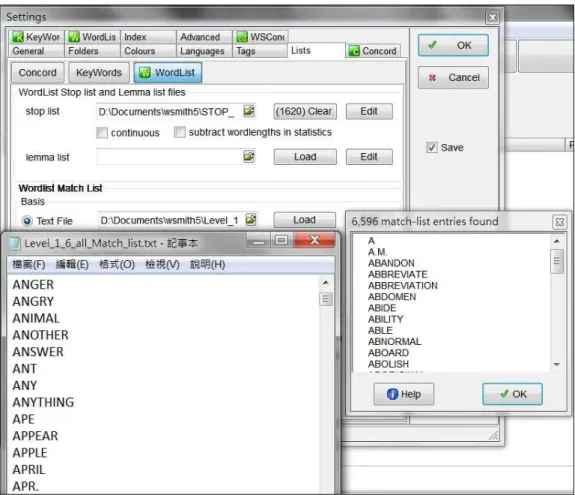
Figure 3.2.5 Adjusting setting for Match List with the Senior High English Wordlist for Reference ... 54
Figure 3.2.6 Immediate results of the matching process ... 55
Figure 3.2.7 Final results of the matching process ... 56
Figure 3.3.1 Querying for collocates of applicable in Business Reports Corpus with AntConc ... 61
Figure 3.3.2 Querying applicable together with a context word the ... 62
Figure 3.3.3 Results of querying for collocates of applicable with its context word the 63 Figure 3.3.4 Final results of finding collocates of applicable with the method of cumulative frequency ... 64
Figure 3.3.5 Concordance lines of applicable together with its extracted collocates ... 65
Figure 3.4.1 Flowchart of research design ... 66
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
List of TablesTable 3.1.1 Basic information of the Business Reports Corpus and Brown Corpus . 45 Table 3.3.1 Basic information of Business Reports Corpus and the two subdivisions
of Brown Corpus for investigation ... 58
Table 4.1.1 Distribution of extracted key-keywords in BRC ... 70
Table 4.1.2 Distribution of extracted key-keywords in SHEWR [高中英文參考詞彙 表] ... 71
Table 4.2.1 Length of formulaic sequences composed by annual ... 74
Table 4.2.2 Length of formulaic sequences composed by applicable ... 75
Table 4.2.3 Length of formulaic sequences composed by financial... 75
Table 4.2.4 Length of formulaic sequences composed by significant ... 75
Table 4.3.1 Composition of formulaic language composed by annual ... 77
Table 4.3.2 Composition of formulaic language composed by applicable ... 82
Table 4.3.3 Composition of formulaic language composed by financial ... 84
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
摘要 摘要 摘要 摘要 對專業英語教學而言,如何擇取語言教學內容,是一項相當重要的工作。 學界一般建議專業英語教學教師,以與專業科目教師協同合作的方式,來共同協 商出語言教學內容。但此協同方式的運作,往往受限於教學資源及教師之間對何 謂知識的認知差距,常常窒礙難行。本研究即著力於探討語料庫方法運用在擇取 專業英語教學內容的實際操作,期盼能提供一套有效的解決方案。 本研究將研究內容鎖定在普通單字及普通單字所組成的語言詞塊,並特別 將研究範圍著重於商業文類。為了使本研究順利進行,作者應用語料庫相關知 識,建立了一個商業年報語料庫。在擷取普通單字及語言詞塊時,也嚴謹運用了 相關的語料庫技術,如單字顯著程度、單字涵蓋範圍、及累積詞頻法等等。此研 究找出了數量適中的普通單字,能利於在授課時間有限的專業英語教學,進行課 程規劃。本研究也證實了普通單字,會因為所處的文類不同,而組成不同的語言 詞塊。 本論文的研究結果及研究流程,展示了以語料庫方法擷取專業英語教學的 語學內容,效率良好,結果明確。同時本研究的研究結果,也將語言的慣性組成 模式,顯明出來。最後,本研究的研究結果所顯示的普通單字,乃是專業英文與 一般英文共享重疊的單字,可視之為一般英語教學銜接至專業英語教學的重要教 學內容。由於研究過程採用了高中英語參考詞彙表,本研究之結果特別適用於台 灣的英語教學情境,尤其對大學商學院之英語教學,更是貼切實用。 關鍵字 關鍵字 關鍵字 關鍵字:::專業英語教學、單字表、高中英文參考詞彙表、商業英文、語料: 庫、文類分析、詞塊‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
AbstractThis study aims to apply corpus method on filtering out language content for ESP course. Following Dudley-Evans and St John’s (1998) idea of real content, this thesis focuses on locating general lexis from different genres.
For this study, general lexis is viewed as common words and formulaic language composed with common words. In this project, common words are
extracted from a homemade Business Reports Corpus (BRC) with reference to Senior High English Wordlist for Reference (SHEWR) [高中英文參考詞彙表] and
Chinese–English Translation of Important Accounting Terms [重要會計用語中英對
照] in Taiwan, also with notions of corpus linguistics including keyness and text
coverage. Then with number of extracted common words being compared to the total amount of SHEWR, practicality of SHEWR applied in business genre is measured and a subset word bank of SHEWR is identified to link instruction of English of General Purpose to that of English of Specific Purposes in the context of Taiwan.
Secondly, formulaic language is regarded as multi-word units composed with previously extracted common words. Instead of Mutual Information, t-score, or lexical bundles, Danielsson’s (2007) method of cumulative frequency is adopted to locate formulaic language. Cross-genre analyses on formulaic language identified from BRC, Subdivision A of Brown Corpus (texts of reportage) and Subdivision H of Brown Corpus (official documents) are conducted to verify whether composition of formulaic language is correlated with types of genre, which may affect description of phraseology as well as practice of the English teaching method Lexical Approach (Lewis, 2000).
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
This thesis has successfully demonstrated that the corpus method is a handy and efficient approach for ESP practitioners to sort out language content for
instruction. One by-product of this study is that the difficulty level (as designated in SHEWR) of extracted common words is attached to allow further investigation together with data of text coverage and overall frequency.
Keywords: Corpus, English for Specific Purposes (ESP), English for Business
Purpose (EBP), formulaic language, keyness, phraseology, real content, syntagmatic variation, paradigmatic variation, wordlist, genre analyses
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
Chapter 1 IntroductionThe teaching of English for Specific Purposes (ESP) has been generally regarded as an identifiable activity in English Language Teaching (ELT). The distinctness of ESP could be attributed to the consensus that ESP teachers are required to bring about practical outcomes for learners with specific professional backgrounds in limited course time (Dudley-Evans & St John, 1998, p. 1). Most ESP teachers, assumedly equipped with training in teaching General Purpose English (GPE), are thus positioned in difficult situations, where they do not possess the subject knowledge in fields which their students specialize in (Wu & Badger, 2009). This knowledge gap not only intrinsically changes the status of ESP practitioners from “primary knower” to “language consultant” in the perspective of language teaching methodology, but also implies that practitioners need assistance in designing courses under such circumstance (Dudley-Evans & St John, 1998, pp. 13-16). Arranging language content, a central process in course design and material management, is of primary concern for ESP practitioners (Hyland, 2002, pp. 393-394).
To deal with actual content with limited subject knowledge, we can consult Dudley-Evans and St John’s (1998) classification of carrier content and real content (p. 11). Carrier content refers to language items that carry context related to a specific subject; for example, the word germinate in a course on life cycle of a plant. In
comparison, real content denotes language that performs certain communicative function in the context. For example, the bolded preposition as and morphemes s in the sentence
As the plant germinates, the seed swells are language of describing process, which is the
real focus of this biology course. It is also noted that real content does not entail technical knowledge as carrier content does (Dudley-Evans & St John, 1998, p. 11).
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
Furthermore, we can observe that the real content comes as multiple lexical units formed with relatively general lexeme1 like the preposition as and the morphemes s. For ESP
practitioners, real content is the real focus for instruction (Dudley-Evans & St John, 1998, pp. 11, 16) and it is an issue of practicality as for how to sort out real content from ESP materials with efficiency. To resolve this issue, collaboration2 between ESP
practitioners and subject teachers has been proposed as an ideal and feasible solution for content management as well as course development (Dudley-Evans & St John, 1998, pp. 15-16).
Although studies on collaborative teaching report successful outcomes (Dudley-Evans, 2001), some researchers have expressed qualified agreement on the efficiency of collaboration. Belcher (2006) has indicated that modest resources provided by institutions and reluctance of teachers to cooperate with each other can obstruct collaboration (p. 140). The reluctance, according to Barron (2003), can be attributed to the inherent and incompatible diversity of collaborators’ respective
1
According to Crystal’s (2003) definition, lexemes refer to minimal distinctive units for discerning meanings. Either occurring as grammatical variants such as –s, -ing, and –ed in walks, walking, and walked, or appearing as multiple lexical units to express complete meanings, like kick the bucket (= “die”), lexemes differ from words in that the term word treats language items based on orthography, not semantic unit (pp. 265-266).
2 Collaboration, when viewed in the aspect of the degree of relative involvement between language teachers and subject teachers, is further categorized into co-operation, collaboration, and team-teaching (Dudley-Evans, 2001, pp. 226-228; Dudley-Evans & St John, 1998, pp. 42-47). The process of collaboration, according to Barron (2003), is suggested to be administered under the methodology of
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
philosophy of knowledge from different fields (p. 297). Motivated by these difficulties in collaborative teaching between ESP practitioners and subject teachers, this thesis considers the feasibility of another solution that can manage ESP content with minimum human interference. Corpus research, famed for its objective and automatic approach to text analysis, is thus put under contemplation to locate real content from ESP texts. The present thesis aims to prove that application of corpus method, in addition to
collaboration, is an effective and practical approach to identify content that doesn’t involve subject knowledge for ESP practitioners.
Having observed that real content involves multiple lexical units composed by general lexis3, the next chapter will narrow down the scope of research focus to the level
of word to review how words, specifically common ones4, are conceptualized in the ESP
field and from the perspective of corpus linguistics. Based on understanding of nature of words, the rest of Chapter 2 continues by introducing corpus techniques to extract words of interest as well as multiple lexical units. Chapter 2 ends with proposing research questions which are framed for achieving the objective of this project. Chapter 3 gives report on methodology along with its induced research design that encompasses the process of creating a corpus for exploration, extracting common words of interest, and identifying multiple lexical units. Chapter 4 demonstrates results on both extracted words and identified multiple lexical units, which in turn signify the efficacy of corpus approach to locate real content for ESP instruction. Finally, Chapter 5 concludes the
3
The term lexis is used as an umbrella term to refer to the vocabulary of a language (Crystal, 2003, p. 268). In the present thesis, lexis includes morphemes, words, and multiple lexical units. Lexis differs from lexeme in that the former does not considers the semantic aspect but the latter does.
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
present study with implication of research results on ESP pedagogy; other issues for prospect research will also be addressed.
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
Chapter 2 Literature Review
In Introduction, it is mentioned that real content, the real focus of ESP courses, can be regarded as multiple lexical units composed with general lexemes that do not possess technical meanings of a specific subject. To make identifying real content a feasible task, this chapter discusses the issue of general lexis in ESP and the phenomenon of multiple lexical units by reference to related researches in the ESP field and those in corpus linguistics, respectively.
2.1 Common words in English for Specific Purposes
One principal issue in ESP is to account the specificity of any given types of ESP5
to distinguish themselves from General Purpose English (GPE). Account of specificity has been given from a number of different perspectives, including language content, communication skills, and needs analysis (Dudley-Evans & St John, 1998), of which language content concerns most for this thesis. The following sections introduce specificity of language content from three different but interwoven prospects towards conceptualizing ESP: (a) Corder’s (1973, cited in Bloor & Bloor, 1986, pp. 16-21)
common core hypothesis, which assumes the existence of a basic core in ESP content; (b) Basturkmen’s (2006) interpretation of the notion of specificity, in which specifiable
5 Traditionally, ESP has been segmented into two main areas: English for Academic Purposes (EAP) and English for Occupational Purposes (EOP) (Dudley-Evans & St John, 1998, pp. 5-6). Subordinate categorization goes on to generate seemingly endless acronyms, e.g., English for Academic Legal Purposes (EALP), English for Academic Business Purposes (EABP), English for Academic Medical Purposes (EAMP), and so forth (Belcher, 2006, p. 134). For the following literature review, this thesis will touch on English for Academic Purposes (EAP) and English for Business Purposes (EBP) by referring them with the same acronym ESP, since classification of types of ESP is not the major concern for this study.
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
language items occur in specific genres (pp. 26-28); and (c) Sinclair’s idiom principle (1991, pp. 110-112), which promotes a praseological view in describing language (Hunston, 2002, pp. 137-157).
2.1.1 Common core hypothesis. Common core hypothesis (Corder 1973, cited
in Bloor & Bloor, 1986, pp. 16-21), a widely-accepted perspective on specificity of ESP language, posits that there is a basic set of vocabulary and structures shared among language varieties, and this basic core is to be prioritized in syllabus. Common core hypothesis is composed of two constructs: common core and common core plus.
Common core represents high-frequency words and sentence structures that are
all-purpose in any situation, whereas language items fall outside the common core are regarded as common core plus, which gives specific-purpose meanings in target
disciplines or occupations. For applied linguists who adopt this hypothesis, the common core is a construct that can be realized as a specific set of lexis and grammatical
constructions; this set is supposed to be basics for language learning, upon with
purpose-specific language can be added in syllabus in sequence. This belief is shown in Coxhead and Nation’s (2001) argument advocating application of their categorization of academic vocabulary: “When learners have mastered control of the 2,000 words of general usefulness in English, it is wise to direct vocabulary learning to more specialized areas depending on the aims of the learners” (pp. 252-253).
Common core hypothesis can be observed in a number of lexical researches. For example, Coxhead’s (2000) Academic Word List (AWL) was compiled by excluding words in West’s (1953, cited in Coxhead, 2000) General Service List (GSL) from a
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
representative of the common core for exclusion, and the remaining words, filtered with corpus linguistic procedure to be identified as academic vocabulary, were implicitly regarded as the common core plus. In addition to academic purposes (Coxhead, 2000; Coxhead & Nation, 2001), this thread of research can also be seen in many studies for compiling wordlists in other specialized domains, such as business (Chujo & Genung, 2004), engineering (Ward, 2009a), medical academics (Baker, 1988; Wang, Liang, & Ge, 2008), and so forth.
However, common core hypothesis receives some criticism regarding validity of the common core. Bloor and Bloor (1986) doubts that the common core pre-exists independently from any language varieties6 (pp. 18-20). They argue that, in language
teaching, any language items must be presented “within the context of some variety” and it is inevitable to “present the basic elements in some kind of linguistic context” (Bloor & Bloor, 1986, p. 18). In other words, the common core does not exist in vacuum a priori, but has existence a posteriori since the common core is derived from linguistic contexts. Bloor and Bloor (1986) emphasize the importance of context, as they affirm:
A language learner is as likely to acquire “the language” from one variety as from another, but the use of language, being geared to situation and participants, is learned in appropriate contexts. This view supports a theory of language use and the basis of language acquisition theory. (p. 28)
Bloor and Bloor’s criticism on common core hypothesis is accepted by Flowerdew and Peacock (2001), who add that common core hypothesis neglects the
6 Bloor and Bloor (1986) use the terms varieties and registers nearly synonymously, both of which refer to language in use (pp. 20-21).
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
semantic aspect of language. They state the fact that meanings of one identical item may vary according to contexts and thus meanings cannot be divorced from context7.
As Flowerdew and Peacock (2001) affirm: “[M]eaning is determined by context, if meaning is to be incorporated into the common core hypothesis, it is not possible to escape from the notion of specific varieties” (p. 17).
On common core hypothesis, the above criticisms can be synthesized as that the common core is an a posteriori construct that can only be derived from specific language uses. In my view, although the common core seems a theoretical construct, the
hypothesis is necessary for syllabus design in that management of materials requires systematically arranging language content, and using form of language (lexical units and grammatical structures) as criteria to grade contents is the most objective and replicable method for pedagogical practice. Thus the present thesis supports an adapted version of common core hypothesis, in which the existence of common core is not an assumption but a set of language items derived empirically from specific contexts.
At this point, we are drawn to a further discussion about forms of language and context where language items occur, which will be taken up by the next section.
2.1.2 Specifiable words in specific genres. To conceptualize forms of
language and context of language in a framework for English for Specific Purposes (ESP), Basturkmen (2006) presents the concept of specificity on two different layers of notions (pp. 12-13, pp. 26-28). In Basturkmen’s framework, specificity of ESP language is
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
dealt with by categorizing ESP content as language uses and language systems.
Language uses refer to units of language use, such as speech acts and genres, which is specific in target disciplines and workplace. On the other hand, language systems refer
to sentence-level features such as certain forms or patterns that occur in specific situation. Language features that occur in one specific environment are not exclusive to those in other contexts, and are therefore considered as specifiable elements in ESP language. In other words, one kind of language system appears in multiple language uses.
With Basturkmen’s ESP framework, since genres are relatively easy to be recognized or predetermined, the focus of this literature review is to be confined to sentence-level language features to proceed to our study on common words in ESP.
2.1.3 Lexical patterns in different contexts. When language is put under
scrutiny at the sentence level, conventional grammar theorists mostly adhere to dichotomy of vocabulary and syntax, which treats words and grammar structures separately. This traditional approach to meaning interpretation assumes that lexis and syntax operate at different level of language; that is, a sequence of linguistic elements are segmented and can be presented in a tree structure and nodes in the tree are points open to lexical choices, which is termed by Sinclair (1991) as open-choice principle for describing organization of language.
Nevertheless, Sinclair (1991) doubts whether this “slot-and filler” model is the primary one for language organization and description (p. 114). According to Sinclair (1991), the open-choice principle loses validity in describing frequently co-occurring multi-words (e.g., of course, hard evidence, set eyes on, etc.) and lexical choices along language sequences are in fact restrained by semantic environment and discourse
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
organization in speech acts or genres with specific social functions (pp. 110-112). This feature of unrandomness is termed as idiom principle by Sinclair (1991), who maintains that it should be the primary model that dominates language phenomenon (pp. 110, 114); where one sequence opens to variation, the open-choice principle comes into play as the complement rule to govern lexical choices. These two principles together adequately describe the phenomenon of multi-words that vary with different degree of fixedness (Sinclair, 1991, p. 114).
Sinclairs’s argument and other studies in the field of lexical research have challenged the traditional vocabulary-grammar dichotomy and lead to a phraseological view toward language (Schulze & Römer, 2008). Phraseology refers to that vocabulary behaves in preferred sequences that may assign specific meanings (Hunston, 2002, p. 137). Research on phraseology can be seen from lots of lexical studies focusing on collocation (Durrant, 2009), lexical bundles (N-Grams) (Hyland, 2008; Jablonkai, 2010; Römer, 2008), pattern grammar (Charles, 2006; Groom, 2005; Hunston & Francis, 1998), semantic sequences (Hunston, 2008), and so forth, all of which can be covered under the over-arching term formulaic language (Schmitt, 2010). The view of phraseology has laid a firm base for the lexical approach to English Language Teaching (ELT) (Lewis, 2000, pp. 147-148).
The phenomenon of phraseology can be demonstrated by the word maintain. According to Hunston (2002), maintain patterns in three different ways to express dissimilar meanings—“maintain something,” “maintain that something is true,” and “maintain something at a level” (p. 139); these phraseologies unambiguously express
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
essential for frequent words, which behave in rather fixed phrases (Hunston, 2002, p. 102); hence phraseologies of frequent words are significant teaching points in language instruction (Hunston, 2002, p. 139).
Researchers have indicated that phraseologies of words are closely related to disciplines and genres. Durrant (2009), in his study on compiling a collocation list for students in academic context, has indicated that lexical knowledge required for learners in Arts and Humanities are strikingly different from that for those in the domains of Natural Science and Social Science. Charles (2006), with her comparison of reporting clauses (that-clause complement) in two corpora of Politics/International Relations and Material Science, has found that language of Materials Science features in the use of the pattern find/show/observe that. In addition to cross-disciplinary observation, Groom (2005) has added another aspect on genre comparison (research articles and book reviews) on exploring the two patterns it v-link ADJ that- and it v-link ADJ to-inf, and has reported quantitative difference in distribution across the involved two genres and two disciplines (History and Literary Criticism). Disciplinary variation of lexical bundles has also been observed by Hyland (2008), who has analyzed frequencies of 4-word bundles in four disciplines: Biology, Electrical Engineering, Applied Linguistics, and Business Studies.
The above studies signify the role of contexts for variance of language patterns. They also echo Basturkmen’s ESP framework (Section 2.1.2), in which language items are specifiable in specific genres. Moreover, taking common core hypothesis, genres, and phraseology all together on board, it invites an interesting inquiry for variation of formulaic language composed by common words across genres.
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
2.1.4 Tentative research question. To conclude, conceptualization of common
words in ESP must be based on specific language use. And since that words pattern in relation to context, it awaits our further exploration on phraseology of common words across genres. Here one research question is tentatively proposed:
How formulaic language, composed with identical common words, vary across genres?
This question indirectly relates to the purpose of the present thesis. This study aims to prove that corpus method can provide ESP practitioners assistance to identify real content for language instruction; if the proposed research question can be responded with definite result, this study in itself would serve as a demonstration for the application of corpus in arranging ESP materials. Moreover, the proposed question directly relates to real content of ESP, which refers to multiple lexical units composed with general vocabulary (see Introduction). Therefore, research results obtained for the research question would simply be real content of ESP.
The following sections continue the discussion about common words and phraseology from one another perspective: methodology for extracting common words and for identifying formulaic language.
2.2 Extraction of words
Before touching on methods for extracting common words from texts, we have to discuss how to define common words. The idea of common words, or general
vocabulary, is necessitated by pedagogical need to creating reading materials or setting vocabulary goal for language learners. Common words are generally accounted for in a
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
higher-frequency vocabulary necessary to achieve a basic functionality with a language” (p. 75). The concepts of frequency and functionality of words will be surveyed by reviewing three studies on creating word lists.
2.2.1 Common words. One well-known venture for compiling common words is
West’s (1953, cited in Schmitt, 2010, p. 75) General Service List (GSL), which contains about 2,000 words that can function as basic words for illustrating more advanced vocabulary for language learners. With this pedagogical purpose, words in GSL were selected by considering word frequency, word-building capacity, and types of genre, and so forth. Colloquial, slang words, and technical words for specialized fields were excluded. GSL has been a prestigious groundwork for subsequent lexical researches. For example, GSL has been employed to compile the Academic Word List (AWL) (Coxhead, 2000) and has also been applied as yardstick to measure learners’ vocabulary knowledge (Ward, 2009b).
Functionality of GSL can be evaluated by measuring the proportion of GSL words in texts of different genres or disciplines. According to Coxhead’s review (Coxhead, 2000, pp. 213-214), words in GSL cover up to more than 75% of fiction, non-fiction, and academic texts; the high percentage demonstrates the practicality of GSL.
An equivalent work of General Service List (GSL) in East Asia is Jeng and his colleagues’ Senior High English Wordlist for Reference8 [高中英文參考詞彙表] (Jeng,
Chang, Cheng, & Gu [鄭恆雄、張郇慧、程玉秀與顧英秀], 2002). The creation of this
8 The compilation of Senior High English Wordlist for Reference is partly activated by its 1998 version, created by Chang and his colleagues [張武昌等] (1998, cited in Jeng, Chang, Cheng, & Gu [鄭恆雄、張郇
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
word list is motivated by need for reference word list that helps delimit the amount of vocabulary required for senior high school students in Taiwan to take the College Entrance Examination. Senior High English Wordlist for Reference is graded into six levels, each with 1,080 words to aggregate 6,480 words in total, which were extracted from a collection of texts from 21 kinds of source covering from textbooks from Taiwan and the U.S. and ready-made wordlists from Mainland China, Japan, and
English-speaking countries like Canada and the British. Its major principle to enlist words is based on a specified threshold of word frequency. For example, words enlisted from Level 1 to Level 4 were determined by a threshold of 5 occurrences in the collection of texts. Socio-cultural factors, grammatical categories, word families, and so forth, were considered in creating and displaying Senior High English Wordlist for Reference. This word list is anticipated to serve as a primary benchmark for vocabulary learning in the pedagogical context of Taiwan.
As for functionality of Senior High English Wordlist for Reference (hereafter SHEWR), there seem scant studies on measuring proportion of SHEWR words in specific genres and disciplines. The present thesis thus sets one of its research aims as to evaluate the functionality of SHEWR in specific context.
2.2.2 Tentative research question. Here one tentative research question is
proposed:
To what extent do SHEWR [高中英文參考詞彙表] words occur in texts of specific genre?
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
Dudley-Evans and St John’s (1998, pp. 11, 16) argument that it is the real content, language that doesn’t involve technical knowledge, should be the focus of ESP practitioners’ instruction (see Introduction of this thesis). And more importantly, by investigating functionality of SHEWR against an ESP background, we have a chance to survey whether the common-word list brings benefits to English teaching of one specific occupation or context and to signify the usefulness of SHEWR for ESP pedagogy in Taiwan. Section 2.4 will address which kind of genre is to be put under exploration; the following section continues the discussion on word extraction with wordlist made for specific purpose.
2.2.3 Specialized words. The idea of functionality in making common word lists
can also be observed in the process of creating other word lists for specific purpose. The well-known Academic Word List (AWL) (Coxhead, 2000), possessing some important notions on functionality underlying its delicate compiling procedure, will be attended below as an exemplar for specialized wordlists.
The AWL contains 570 word families (all derivatives closely related to one stem is counted as one word family) selected from a 3.5-million-word collection of written academic texts covering 28 subjects from 4 disciplines, and this word list was compiled by
(a) excluding word families listed in West’s (1953) General Service List (GSL), and (b) including any word family members with a minimum occurrence of 15 times in the
28 subjects and 10 times in each of the 4 disciplines, and
(c) including any word family members with a minimum occurrence of 100 times in the established Academic Corpus.
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
There are four fundamental notions underlying the creation process of AWL: i) seeing members of the same word family as one word, ii) text coverage, iii) frequency, and iv) excluding GSL to identify AWL. Each of these four notions is worthy of further discussion.
The first notion underlying AWL is that, words in AWL are presented in the form of word family. For instance, the word indicate is treated as one single entry, leaving aside its derivatives (indication, indicative, indicator) and all inflections (indicated,
indicates, indicating, indications, indicators) (Coxhead, 2000, p. 218). The reason for
Coxhead to count closely morphologically related words as one single unit for wordlist inclusion is based on psycholinguistic researches, which maintain that derivatives and inflections of one stem are easily accessed and hence might be stored as one component in the mental lexicon.
However, from the perspective of genre analyses, different members of the same word family may possess distinctive connotation in specific genre. For example, in exploration on a collection of cancer research articles, Gledhill (1995, as cited in Hunston, 2002, p. 201) has pointed out that choices between is and was reflect specific philosophy of the discipline under study. Therefore, it is a subjective decision as whether to present morphologically related words in one single entry or to display them as separate entries. For the present thesis with its attempt to describe common words in patterns (Section 2.1.4), it is more appropriate to present words in their different forms separately to allow subsequent identification of formulaic language composed by common words.
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
considered subjects (minimum set as 15 occurrences) and disciplines (minimum set as 10 occurrences). Generally the composition of a corpus is designed according to
predetermined purpose by deliberately balancing proportion of texts of various types (Hunston, 2002, pp. 28-30). By observing word coverage among all texts within a corpus, one can ensure that selected words occur across contexts and do not bias for
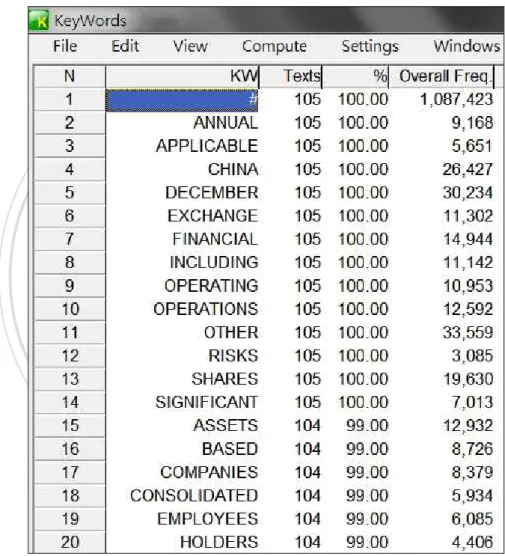
certain types of texts. This notion of word coverage has been applied in corpus software. For example, Wordsmith Tools (Scott, 1997, 2011b) possesses the “Key-Keywords”
function to compute words with information of their degree of coverage among texts. The notion of word coverage will be applied in this thesis to extract common words of interest.
The third notion involved in creating AWL is frequency of word occurrences. Similar to GSL and Senior High English Wordlist for Reference mentioned above, AWL has utilized frequency as threshold for word selection (threshold set as a minimum of 100 occurrences). The idea of frequency presumes that one word with higher frequency in a corpus signifies its greater probability of occurrence in real language use, which therefore implies its pedagogical importance (Hunston, 2002, p. 194). Nevertheless, discerning significance of words based solely on raw frequency often results in grammatical words such as prepositions of, to, in, and so forth, because they come with relatively higher occurrence compared to content words (Hunston, 2002, pp. 3-5).
The problem of high-frequency of grammatical words can be resolved by utilizing the notion of unusual frequency. Unusual frequency refers to outstandingness of words, or keyness of words in the software Wordsmith Tools (Scott, 1997, 2011b), which is measured by comparing word frequencies between two corpora. With corpus software,
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
degree of outstandingness of word is computed by comparing their frequencies in one corpus to those in another reference corpus with statistic measures such as chi-squared or loglikelihood. The same notion of unusual frequency will be employed by the present thesis to locate common words in order to avoid the problem of high-frequency words.
Lastly, in the process of creating AWL, words in General Service List (GSL) were assumed to represent general vocabulary and were excluded to narrow down the scope of candidate words pertinent to academic usage. This procedure indicates that in lexical research, general words and specialized ones are regarded to be mutually defined; in any collection of texts, specialized words can be specified by excluding general ones, and vice versa. For the present study, common words that do not involve technical meanings are to be extracted by excluding specialized words from target corpus.
In addition to corpus techniques for extracting specialized words, as those in creating AWL mentioned above, using a technical dictionary has been proved a reliable method for identifying specialized words. Chung and Nation (2004), in their study on comparing efficacy of four different approaches to identify specialized words in anatomy text, indicate that using a technical dictionary can have an accurate rate about 80%, which is comparable to that with corpus method. For the present study, which has previously acknowledged that general words and technical ones are mutually defined, it will adopt a specialized wordlist made by professionals in the field to identify common words.
2.2.4 Summary on methods for extracting words. Section 2.2.1 and Section
2.2.3 have studied on methods for extracting words of interest to synthesize working definition for common words. With our review on West’s GSL (1953, cited in Schmitt,
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
have concluded that the degree of functionality of wordlist can be evaluated by measuring the portion those words bear in any discipline or genre; and SHEWR, a
common word list geared to needs of English learners in Taiwan, requires to be evaluated with a similar method. Also, the detailed survey on Coxhead’s (2000) AWL has
amalgamated some practical notions and corpus techniques for word extraction. These notions and corpus techniques will contribute to give operational definition of common words in the present thesis, as will be illustrated below.
2.2.5 Operational definition of common words. For the present thesis, the
abovementioned notions involved in compiling AWL on extracting words of interest will be applied to yield common words of pedagogical value for English learners in Taiwan. To put it specifically, common words in this study will be extracted by
(a) excluding words that possess specialized meanings in the target corpus, and (b) selecting words of significant outstandingness by comparing them to their
equivalents in a reference corpus, and
(c) matching previously resulted words to those in the Senior High English Wordlist for Reference (SHEWR) [高中英文參考詞彙表] (Jeng, et al. [鄭恆雄等], 2002), and (d) sorting previously resulted words according to degree of coverage in the target
corpus.
Among the above steps, it is anticipated that Step (c) will create pedagogical value for English learners in Taiwan by bridging the gap between ESP and public education, since the resulted words are going to be evaluated with their proportion in specific genre and used for locating formulaic language across genres. For this thesis,
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
the series of procedure serve as the operational definition of common words of interest. Application of this definition will be reported in Chapter 3.
To recap, Section 2.2 has reviewed West’s General Service List (GSL), Jeng and his colleagues’ [鄭恆雄等] Senior High English Wordlist for Reference (SHEWR) [高中
英文參考詞彙表] and Coxhead’s Academic Word List (AWL) to gain insights regarding
compiling word lists for either general or specific purposes. Pedagogical purpose of expected wordlist affects subjective decisions on which kind of corpus and ready-made wordlist to be adopted. With corpus methods, words can be extracted by objective computation considering word coverage, simple/unusual frequency, and techniques of matching or exclusion. For the present thesis, with one of its aims to identify formulaic language composed by common words, the issue of utilizing which kind of corpus and wordlist will be discussed in Section 2.4. Prior to Section 2.4, the following section will investigate a rather difficult topic in corpus linguistics: methods for identifying formulaic language.
2.3 Identification of formulaic language
As been mentioned in section 2.1.3, corpus linguists have noted the phenomena that language items tend to occur in patterns that cannot be explained with
vocabulary-grammar dichotomy, which leads to the phraseological view toward language organization and description. Under the overarching term formulaic language,
phraseology has been approached from various perspectives including collocation, lexical bundles (N-grams), pattern grammar, and so forth. These various descriptions signify the complexity of formulaic language, on which formulaic language is defined by Wray
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
[A] sequence, continuous or discontinuous, of words or other elements, which is, or appears to be, prefabricated: that is, stored and retrieved whole from memory at the time of use, rather than being subject to generation or analysis by the language grammar.
The latter half of Wray’s definition focuses on the view of phycholinguistics. Here we center on the first line of Wray’s definition: formulaic language can be continuous or discontinuous sequence of words.
Take the sequence a(n) ____ ago for illustration (Schmitt, 2010, p. 132). This string of formulaic language is composed with continuous lexical items, along which the underlined slot is open to temporal lexemes, such as hour, year or very long time, making this string discontinuous at the slot. It is this feature of internal lexical variation that imposes difficulty on identification of formulaic language (Schmitt, 2010, p. 120). Difficulties about identifying formulaic language will be explored further by examining collocation and lexical bundles, with which corpus method for locating formulaic language with lexical variation is to be discussed.
2.3.1 Collocation. Collocation refers to the language phenomenon that two words
co-occur with biased tendency, which can be measured with corpus statistics (Hunston, 2002, p. 68). Tendency of any two words to co-occur can be gauged via two
conceptually-different approaches: One measures the strength of association of the two words with mutual information (MI) and the other considers the probability of
co-occurrence of them with asymptotic hypothesis test (Schmitt, 2010, p. 124; Clear, 1993, pp. 279-282), both of which are discussed below.
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
Mutual information (MI) denotes the strength of co-occurrence of two words by comparing “the actual co-occurrence of the two items with their expected co-occurrence” (Hunston, 2002, p. 71). The actual co-occurrence of the two words is the observed occurrences appeared in a pre-determined span within which one of the two items is set as the node word; the expected co-occurrence refers to expected instances of the two words in the target corpus as a whole within the same width of span. MI is computed by dividing the Observed (O) with the Expected (E), and converting the resulted ratio to a base-2 logarithm, as demonstrated by the formula below:
E O
MI =log2 (Schmitt, 2010, p. 130)
Conventionally, a MI-score above 3 can be regarded as a significant value for identifying collocation (Hunston, 2002, p. 71). For example, to find co-occurring words of the word gaze in the Bank of English (Hunston, 2002, pp. 69-71), gaze is queried as
the node word with span of node set as 4:4; that is, four words to the left of the node word and four words to the right. Results show that the collocate (co-occurring word of the queried word) of gaze with highest MI-score (12.1) is the word Angelopoulos, which
is the name of the director of the film Ulysses Gaze. The high score of MI of gaze and Angelopoulos is motivated by the strong relation between the film and the director.
Another approach to identify collocation considers probability of co-occurrence of any two words by testing hypothesis. Statistic measures (t-score, z-score, chi-squared, and log-likelihood) are applicable to hypothesis tests, in which the null hypothesis is designated as that “words appear together no more frequently than we would expect by
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
and the result is divided by the standard deviation (Hunston, 2002, p. 70), as demonstrated below: O E O score t− = − (Schmitt, 2010, p. 126)
Normally, a t-score above 2 is taken to be significant (Hunston, 2002, p. 72). Take the same example of gaze in the Bank of English, the collocate with the highest t-score (25.2) is his, with which we can claim with certainty that gaze lexically prefers
his.
Both abovementioned approaches to identify collocation are objective and reliable because conceptions of statistics are applied. However, employment of statistics might make identifying collocation an unnecessary heavy task. Danielsson (2003), critiquing on Church and Hanks’ (1989, as cited in Danielsson, 2003, p. 112) advocating the use of t-score to discern strong support as a more common collocation than powerful support, indicates that the same conclusion would be reached by simply observing raw frequency of collocation, since that strong support occurred 175 times and powerful support occurred only twice in their collection of texts. Applying raw frequency to identify collocation would turn our attention to lexical bundles
(N-Grams), which will be introduced in the next section.
To consider identification of collocation together with one of the objectives of the present thesis, locating formulaic language formed with common words, those methods for identifying collocation are obviously incapable of picking out multi-word expression such as a(n) ____ ago mentioned previously. Moreover, variation within formulaic language is beyond the scope of a collocation list, unless collocates are to be observed from concordance lines (Hunston, 2002, p. 77).
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
In summary, the identification of collocation, when viewed under corpus linguistic methodology to identify formulaic language, is restricted on locating multi-word expressions as well as lexical variables. Over-reliance of statistics on collocation identification might also be a potential defect in locating formulaic language.
The problem of identifying multi-word units and avoidance of use of statistics can be dealt with if formulaic language is regarded as lexical bundles, which will be
discussed in the next section.
2.3.2 Lexical bundles (N-Grams). In the previous section, we have discussed
corpus statistics for identifying collocation. In addition to collocation, there is another type of formulaic language called lexical bundles, which refers to words that co-occur continuously within a predetermined length of a word string with high raw frequency (Biber et al. 1999, as cited in Biber, 2009, p. 282). The conventional method to locate lexical bundles with corpus software is to set length of word sequence as 3-word, 4-word, or 5-word, and word bundles can be sorted out based on simple frequency. Lexical bundles are also called N-Grams because they come with fixed string of N length (Schmitt, 2010, p. 123).
Research on lexical bundles brings benefits to ESP course. For example, Jablonkai (2010) has conducted a study on English documents of the European Union (EU) and collected 4-word lexical bundles of different discourse functions, which can serve as language focus for ESP writing instruction. For instance, it is necessary to is used to claim importance of a following proposition; as set out in clarifies topic of
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
According to Jablonkai, a large portion of EU texts consist of lexical bundles, which therefore should be explicitly taught in class on English for EU purposes.
Although the process of identifying lexical bundles seems a reliable procedure, in which all words in an identified bundle are sorted out based on simple frequency, this approach is not without problem. As previously shown, lexical bundles tend to be composed with prepositions (e.g., as, to, in), and prepositions often position at the boundary of identified bundles. Sometimes there comes with multi-words that are difficult to interpret, such as in so for as or to in Article #9, which are also listed in
Jablonkia’s (2010) results. This phenomenon is largely due to the fact that in English, prepositions are words that have relatively higher frequency than other words do (see Hunston, 2002, pp. 69-70), and prepositions’ high frequency make themselves the regular members of lexical bundles. High frequency of prepositions also causes identified lexical bundles to have prepositions as boundary words, as simple frequency is used in the identification process.
One more drawback of lexical bundles is that they do not allow variable items to be observed along the located word string. Identified lexical bundles are composed of continuous sequence of words, such as it is necessary to (Jablonkai, 2010, p. 262), with which we are not able to inquiry whether the sequence opens to variation, such as it is
vital to.
The abovementioned demerits of lexical bundles, as well as those in collocation, are sought to be avoided by continuing discussion on other available method for locating formulaic language in the next section.
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
2.3.3 Cumulative frequency10. To better the process and results of locating
multi-word sequence, Danielsson (2007) proposes an alternative11 that can solve the
above problems in the identification of collocation and lexical bundles.
Instead of presetting length of sequences as in identifying lexical bundles, Danielsson (2007) sets off locating multi-words by seeking the most frequent
co-occurring word (F1) of any target node item (N) within a span of 9 words (i.e., four words in two respective sides of the queried word). Once F1 is recognized, F1 and N are then used together in the subsequent step with the same 9-word-span to proceed the search for the next most frequent word (F2). The same procedure is repeated until the frequency of newly found co-occurring word fall to below 5. For example, Danielsson (2007) launched a query with the word jam, and ended it up in a small number of concordance embedded with a definite multi-word sequence stuck in a traffic jam.
There is one central point that is worth noting in Danielsson’s method. In identifying collocates (high-correlated words) of the target item, Danielsson (2007) has left aside conventional statistics computation such as Mutual Information or t-score based on the reason that these statistics are largely derived from the assumption of random distribution; the assumption doesn’t hold true in language since language is an obviously non-random system (p. 18). Therefore, the notion of simple frequency is adopted in
10 The term cumulative frequency comes from Hunston’s (2008) discussion on the role of frequency in locating semantic sequences.
11
The software ConcGram (Greaves, 2005) has been developed for locating multi-words with variation of constituents identified without querying a target word in advance (Cheng, Greaves, & Warren, 2006). Since
‧
國
立
政 治 大
學
‧
N
a
tio
na
l C
h engchi U
ni
ve
rs
it
y
Danielsson’s method, in which the most frequent co-occurring words observed cumulatively are taken as collocates of the queried word.
Another advantage of Danielsson’s method is that syntagmatic and paradigmatic variations of multi-word sequence are allowed to be recognized or testified.
Syntagmatic variation refers to that each word in a sequence is open to other modifying items inserted in between. For example, an intuitive guess at syntagmatic variation of Danielsson’s result stuck in a traffic jam had been stuck in a hellish traffic jam; however, the guess is not verified with observation on all extracted concordance lines. The other kind of variation, paradigmatic variation, refers to that one word in a sequence may be substituted with other words at the same slot. This variation can be checked by testing each word in a string to see if there are slots open to variations. For instance, the position of stuck in the sequence stuck in a traffic jam was checked by observing items ahead of the sequence in a traffic jam, and results showed that sitting, waiting, caught, were interchangeable with stuck. Based on the above findings, Danielsson (2007) affirms that this test for paradigmatic variation is valuable for discovering a set of lexis whose meanings denote certain associations that is only interpretable along with the specified word string.
One other vantage of Danielsson’s (2007) method is that, in my view, the length of any identified formulaic language can be measured with number of extracted
collocates. This measure would gauge formulaic language with quantitative data and give information that cannot be provided with those methods for identifying collocation and lexical bundles (Section 2.3.1 & 2.3.2).
![Figure 3.1.1 displays result of a sample query for Taiwan Semiconductor Manufacturing Corporation (TSMC) [台灣積體電路有限公司]: the SIC (Standard Industrial Classification) code is shown and all available 20-F documents are chronically listed](https://thumb-ap.123doks.com/thumbv2/9libinfo/8329453.175410/58.892.160.824.497.848/Figure11queryforManufacturing台灣積體電路有限公司StandardIndustrialClassificationcodeisshownandallavailable2Fdocumentsarechronically.webp)
![Figure 3.2.6 demonstrates result of the matching action. There were 733 words in the key-keywords list that match SHEWR [高中英文參考詞彙表]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8329453.175410/73.892.237.742.285.838/Figure36demonstratesresultofthematchingactionTherewere733wordsinthekeykeywordslistthatmatchSHEWR高中英文參考詞彙.webp)
