1
以正規概念分析為基礎之本體論自動擴展機制
林群貿 李明哲 王宗一 國立成功大學工程科學系 [email protected]摘要
隨著數位學習領域的標準趨向統一化,大部 分的數位教材內容、學習元件(Learning Object) 皆是以 IEEE 所制定的「學習物件後設資料」 (learning objects metadata; LOM)來描述學習元 件。我們可以輕易的在網路上搜尋到許多符合國 際標準的學習元件,而這些學習元件可以一再的 被不同的教學者重組、再利用。然而,隨著科技 日新月異,在數位學習領域裡,新的學習概念也 逐漸增多。 因此本研究提出一個以正規概念分析為基礎 之本體論自動擴展機制,主要著重在分析 LOM (Learning Object Metadata)欄位的特性,再配合一 個經過改良的 TF-IDF(Term Frequency-Inverse Document Frequency)資料前處理方法-Location weight TF-IDF(LTF-IDF)所擷取出重要的關鍵 詞,接著藉由本研究提出的學習概念擷取機制, 判斷是否有新學習概念之形成,並配合領域專家 所建立的本體論(Ontology),將新學習元件概念 做新增的動作。 關鍵詞:本體論、數位學習、正規概念分析、 學習物件後設資料一、 緒論
近年來,由於電腦的普及與全球資訊網(WWW) 的蓬勃發展,所以越來越多的資訊都能夠經過上 網使用搜尋引擎而被大量被取得,然而這種資訊 的擴充速度將逐漸地失去掌控,導致資訊爆炸的 時代隨之來臨。然而,在教學方面,許多老師們 紛紛使用數位教材取代傳統的教學,因此在關於 數位學習(e-Learning)這方面的研究也越來越 被受到重視。 所以,如何有效地將網路上收集到的這些數 位教材加以處理分類過後,再將之轉變整合成一 個有系統的學習資料集是相當的重要的。所以也 開始有許多人對於學習資料做自動分類及學習 路徑建構等相關的研究。 然而隨著科技日新月異,在數位學習領域 裡,當要學習的課程越來越多,需要學習的概念 也逐漸增多,就需要更多的專家來制定這些學習 的課程概念,如何自動擷取課程的學習概念,成 為一門重要的課題,因此本論文提出一個以正規 概念分析為基礎之本體論自動擴展機制,來幫助 我們將網路上所收集的學習元件做學習概念自 動化的擷取及本體論的擴展。二、 相關研究
2.1 本體論基本定義
本體論(Ontology)源自哲學理論,其意義是 有系統的解釋存在的現象。主要探討存在現象的 一切現實事物的基本特徵。本體論定義了一個主 題領域的構成詞彙,包含詞彙間基本條件與關 係,以及延伸詞彙所定義的基本條件與關係的法 則。本體論是一種正規化的(formal)、明確的 (explicit)、概念化的(conceptualization)、分享的 (share)描述[2]。知識本體是一種明確的且概念化2 描述的邏輯理論[3] 當我們要使用本體論來描述某特定領域下 的 知 識 時 , 本 體 論 便 是 由 概 念 (Concept 或 Class)、屬性(Attribute、Property 或 Slot)、實例 (Instance)與關係(Relation)等元素所組合而成[4]。
2.2 關鍵字擷取
擷取文件重要資訊以進行文件自動分類或 文件管理之相關研究中,其中最具代表性之文件 特徵資訊為「文件關鍵字」;因此,過去諸多文 件自動分類研究乃以文件關鍵字為概念特徵。有 些關鍵字足以代表文件中重要概念;所以許多研 究者提出自動擷取文件關鍵字之方法,以擷取文 件中具代表性之關鍵字,利於文件後續之內容分 析。我們將關鍵字擷取方法區分為「文法剖析」、 「詞庫比對」與「統計分析」三種方法: (1) 文法剖析法 透過自然語言處理技術的文法剖析程式,剖 析出文件中的名詞片語,再運用一些自然語言處 理相關的方法與準則,過濾掉不適合的詞彙。其 結果幾乎也都是有意義的名詞片語,但大部份的 剖析程式,需要藉助已經建立的詞典或語料庫, 因此其缺點無法擷取所有關鍵字(因為受限於詞 庫規模)。除此之外,有些文法剖析法甚至只能 剖析合乎文法的完整文句,使得書目、標題等資 料裡的關鍵詞或特殊專有名詞,無法被擷取出 來。 (2) 詞庫比對法 關鍵字擷取技術中以「詞庫比對法」所擷取 之詞彙正確性最高,此乃因直接比對詞庫中之正 確詞彙,可保證所擷取之詞彙皆為正確合理之詞 彙;但其缺點為無法擷取所有關鍵字(因受限於 詞庫規模)。詞庫比對之前需先建立詞庫,關於 詞庫建立之相關研究,具有詞彙間關聯之詞庫, 利用詞庫中與輸入關鍵字高度相關之其他關鍵 字,查詢時能一併搜尋並回應相同概念資料。 (3) 統計分析法 透過對文件的分析,累積足夠的統計參數 後,再將統計參數符合某些條件的片語擷取出 來。最簡單的統計參數是計數詞彙發生的頻率, 即詞頻,將詞頻落在某一範圍的詞彙取出。由於 沒有用到詞庫或語料庫,會有擷取錯誤的情況發 生,得到無意義或不合法的詞彙。此外,統計參 數不足的關鍵詞無法被選到。然而其優點是較不 受語文國別與句型的限制,而且可以擷取出未曾 被詞庫、語料庫網羅的專業用語、新生詞彙與專 有名稱等片語。2.3
FCA 正規化概念分析
FCA 正規化概念分析(Formal Concept Analysis)是一種從資料集合(Data sets)中發現概 念結構(Conceptual structures)的資料分析理論, 在 1982 年由 Rudolf Wille 提出了這個方法之 後, FCA 目前己經快速的發展並應用到許多領 域如:醫學、心理學、音樂學、語言學、資料庫、 圖書館學、資訊科學、軟體工程、生態學及其它 領域。Priss(2003)指出「在資訊科學的領域中, FCA 也有許多的應用:FCA 運用在數學方格上 可以用來解釋分類系統。正式的分類系統可以根 據關係之間的一致性來分析。」
2.3.1 概念點陣(Concept Lattices)
概念點陣繪製出一個最上方之具體概念至 下方特殊概念排序的圖形,最上方的最大子概 念,稱為上確界 (Supremum);最下方的最小子 概念,稱為下確界(Infimum)。圖 1 是表 1 所呈現 出概念全文的概念點陣,全文中若有註記為 「X」,意味著與同一列的物件跟同一欄的 Slots 有關聯,其中上確界包含了屬性„Fish‟ 的所有物 件集合,向下移動得到一個較特殊概念—包含物 件集合{„Fred‟,„Bob‟, „Mel‟} 及屬性集合 {„Fish‟, „Chicken‟},呈現出較少的物件分配到 較多的屬性。進一步分析整個概念點陣,它提供 了更多隱藏在資料間概念的關聯 (Tam,2004)。3
表 1 概念本文
圖 1 概念點陣
三、 學習概念探勘機制
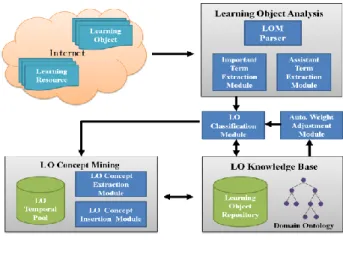
3.1 系統架構
LOM 剖析器(LOM Parser)
本模組主要的功能為用來剖析學習元件後 設資料(LOM),並分析欄位的特性,找出有助於 判斷分類的關鍵詞(Term)。
重要關鍵字擷取模組(Important Term Set
Extraction Module)
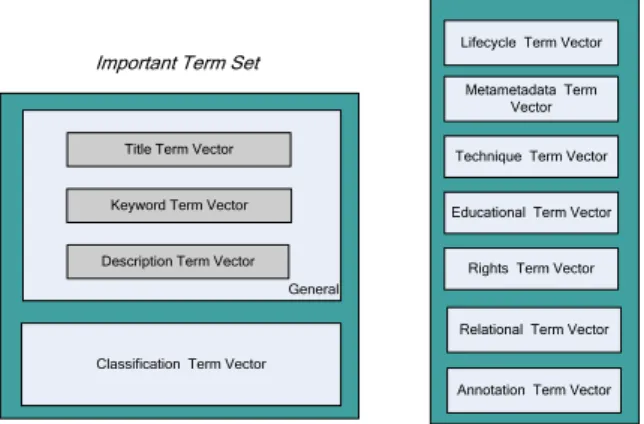
剖析學習元件後設資料後,經過斷字移除 (StopWords Remove)、Stemming Algorithm 處理 後,找出有助於判斷分類的關鍵詞(Term),建立 Important Term Set , 包 含 Title 、 keyword 、 Description 等 資 訊 , 其 中 Title 、 Keyword 、 Description 欄位隱含著許多有助於分類的關鍵 詞,因此我們從這些欄位中取出和 Ontology 有對
應的關鍵詞,並個別建立 Title Term Vector、 Keyword Term Vector、Description Term Weigh Vector。
Term
Title Term Vector
Frequency superclass subclass 1 1 Term Frequency superclass subclass 1 1
Keyword Term Vector
Term
Description Term Vector
Frequency object inherit 2 1 class 6 superclass 1 subclass 1
輔助關鍵字擷取模組(Assistant Term Set
Extraction Module)
除了擷取出 Important Term Set 外,我們會 在再從學習元件的 LOM 中找出有助於分類的欄 位,並建立 Assistant Term Set。我們將這些關鍵 詞存入 Assistant Term Set 作為輔助後續的分類判 斷。像是學習元件後設資料中的 technical 類別主 要是描述此學習元件的技術需求和特性,以一個 介紹 JAVA 程式語言的學習元件為例,在其 LOM 中的 technical 欄位,含有 J2SE Development Kit 5.0、Jbuilder…等關鍵詞,藉由這些資訊,我們 可以得知這個學習物件跟 Java 程式語言有一定 的關係。我們將這些關鍵詞存入 Assistant Term Set 作為輔助後續的分類判斷。
Technique Term Vector Title Term Vector
Keyword Term Vector
Description Term Vector General
Relational Term Vector Lifecycle Term Vector
Metametadata Term Vector
Educational Term Vector
Rights Term Vector
Annotation Term Vector Classification Term Vector
Important Term Set
Assistant Term Set
4
圖 3 系統架構
學習元件分類模組( LO Classification
Module)
根據 Important Term Set、Assistant Term Set 所提供的關鍵詞(Term)與本體論的資訊,將學習 元件做概念分數(TCS, Total Concept Score)的計 算,並制定兩個 TCS 門檻值 λ1(下界)與 λ2(上 界),利用 λ1 與 λ2 來過濾出與本 ontology 有些 許程度相關的學習元件,以便作新學習元件概念 之擷取,至於兩個 TCS 門檻值 λ1 與 λ2 值的制 定,將在實驗設計與結果分析,會有詳細的介紹。 自 動 化 權 重 調 整 模 組 (Automatic Weight adjustment Module) 本模組隱含機器學習(Machine Learning)的 概念,主要是分析 Ontology 中每個類別(Concept) 裡已 分類 學 習 元 件是 因為 哪幾 個類 別 關 鍵詞 (Concept Term)的對應(match)而分類至此類別, 並自動將這些類別關鍵詞的權重提高,以表示這 些類別關鍵詞對此類別的重要度。
學習概念擷取模組(LO Concept Extraction
Module)
剖析學習元件的 Important Term Set,並分析 Title 、Keyword、Description 這三個欄位的特 性,因為這三個欄位與學習元件內容有較高的相 關性。找出這三個欄位中有描述學習元件概念的 關鍵詞(Term),將這些關鍵詞(Term)計算其出現 的詞頻,並利用一個以 TF-IDF 為基礎的 LTF-IDF 方法,找出那些在學習元件中足以被視為概念的 重要關鍵字,進而擷取出學習概念。
學習概念新增模組(LO Concept Insertion
Module)
擷取出的學習概念,先定義學習概念的關鍵 詞集合,並利用 Jaccard co-efficient 相似度計算 學習概念與領域知識本體(ontology)中每個概念 之相似度,找出與學習概念關係最接近的概念, 再利用 FCA(Formal Concept Analysis)分析學習 概念與領域知識本體(ontology)的階層關係,並將 學習概念新增到適合的概念下。
領域本體論(Domain Ontology)
由領域專家所建立,用來輔助學習元件的分 類,例如 Java Learning Object Ontology[5]、ACM
Computing Classification Ontology[6]。
3.2 學習元件分類模組
本模組會利用重要關鍵字和輔助關鍵字擷 取 模 組 所 收 集 到 的 Important Term Set 和 Assistant Term Set,去計算學習元件與 ontology 的概念分數(TCS, Total Concept Score)。我們會去 制定兩個 TCS 門檻值 λ1(下界)與 λ2(上界),利用 λ1 與 λ2 來過濾出與可能含有新學習概念的學習 元件,以便作新學習概念之擷取。設定好λ1 與 λ2 的值,我們可以將 TCS 與 λ1、λ2 的關係分成以 下三種情況討論: Case 1. 學習元件之 TCS 小於 λ1,表示此學 習元件與本 ontology 無關,則不做任何處 理。 Case 2. 若欲過濾的學習元件之 TCS 大於 λ1,但小於 λ2,表示此學習元件與本 ontology 有 些 許 程 度 的 相 關 且 可 能 含 有 新 學 習 概 念,這種情況也是本論文所要研究的重點。 Case 3. 若欲過濾的學習元件之 TCS 大於 λ2,表示此學習元件與本 ontology 有高度的 相關,則直接進行分類。
5
首先我們先定義學習元件分類演算法所使 用到的相關名詞:
(1)Important Term & Concept Term
在 Important Term Set 中的關鍵詞(Term)皆 稱為 Important Term,而在 Ontology 中每個類別 (Concept)皆有一組關鍵詞用來代表此類別,我們 稱此組關鍵詞為類別關鍵詞(Concept Term)。 (2)BCS(Basic Concept Score)
對一個類別而言,只要 Important Term Set 中有 任 一 個關 鍵詞 對應 (match) 到 類 別的 類 別關鍵 詞,我們稱此類別為 Basic Concept,而此類別與 Important Term Set 的對應總分,稱為 BCS。主要 是計算一個學習元件後設資料與 Basic Concept 的對應程度,對應分數越高的 Basic Concept 表 示此類別越有可能成為這個學習元件的所屬分 類,算分的依據是考量每個對應關鍵詞(Match Term)在學習元件後設資料的重要度(LOM Term Weight)和對應關鍵詞在類別的重要度(Concept Term Weight)。
n j i j i TW KW DW CW CTW BCS 1(公式 1)
LOM Term Weight:
表示對應關鍵詞在此學習元件後設資 料的重要度(權重)。ㄧ個關鍵詞對於學習元 件的重要度取決於這個關鍵詞是從學習元 件後設資料中的哪個欄位擷取出來和關鍵 詞在學習元件後設資料的出現頻率而決定 的。例如一個關鍵詞是從學習元件後設資料 的Title欄位中擷取出來的,那麼它的重要度 就比一個關鍵詞從Description欄位中擷取出 來的重要度還高。我們針對學習元件後設資 料中不同的欄位保留不同的參數,以調整權 重。 Vector Term Title in Frequency Term TW Vector Term Keyword in Frequency Term KW Vector Term n Descriptio in Frequency Term DW Vector Term tion Classifica in Frequency Term CW
Concept Term Weight( i
j CTW ): Ontology中,每一個類別皆有一組類別關 鍵 詞 (Concept Terms) 用 來 代 表 此 類 別 , i j CTW 表示第i個類別的第j個類別關鍵詞的 權重。 i j CTW 越高表示此關鍵詞對類別的重 要度越高,也越能代表這個類別。
n x CT CT CT i x i j i j MatchFre MatchFre MTF 1 (公式 2) i j CT MatchFre :表示 Ontology 中,第 i個類別(Concept)的 Matched Frequency Array 中第 j 欄位的內含值。即求出被 分類至這個類別底下的學習元件有多 少個和第 j 個類別關鍵詞對應。
n x CTi x MatchFre 1 :加總 i 類別裡所有類別 關鍵詞的 Matched Frequency。 Inverse Concept Frequency:一個類別關鍵詞 屬於越多的類別,表示這個類別關鍵詞較不 具代表性,它的 ICF 值較低。相反的,當一 個類別關鍵詞屬於較少的類別時,表示這個 類別較具代表性,對於所屬的類別,重要度 越高。 i j CT have that concepts of # ontology in concepts of # log i j CT ICF (公式 3) #of conceptsin ontology : 表 示 Ontology 中的類別個數 i j CT have that concepts of # :表示有
6 多少個類別包含 i j CT i j W :表示類別關鍵詞 j 在類別 i 的權重。當 MTF 越高且 ICF 越高,則權重越高。 i j i j i j MTFCT ICFCT W (公式 4)
Concept Term Weight i
j CTW :表示正規化後 的類別關鍵詞權重,將權重值限定在 0~1 之 間
n x CT CT CT CT i x i x i j i j i j ICF MTF ICF MTF CTW 1 2 (公式 5) Java_Course …… Encapsulation Relationships_among_En capsulated_Components ClassInterface Package Inheritance Polymorphism
{ class , final , super , subclass , superclass } Object
……
Overloading Overriding Subclass and Superclass
MatchFre 1 1 2 3 3 Weigth 0.14 0.15 0.41 0.625 0.625 圖 4 概念權重計算範例 我們以圖為例,superclass 這個關鍵詞的 CTW 的計算方式如以以下過程所示: 3 . 0 10 3 1
n x CT CT CT i x i j i j MatchFre MatchFre MTF 2.23 1 170 log CT have that concepts of # ontology in concepts of # log i j i j CT ICF 1.069 0.625 23 . 2 3 . 0 1 2
n x CT CT CT CT i x i x i j i j i j ICF TF ICF TF CTW 因此我們可以得知,superclass 這個關鍵詞的 CTW 為 0.625。(3)Assistant Term Match Score
與BCS的算法相同,ATMS計算出Assistant Term Set與類別的命中分數
n j i j i CTW ATW ATMS 1 (公式6) Vector Term Assistant in Frequency Term ATW(4)Candidate Concept Score i i i ATMS BCS CCS (公式7)
(5)Normalized Candidate Concept Score
將Candidate Concept Score正規化,使分數介於 0~1之間(n表示候選類別的個數),具有有降階的 作用。
n j j i i CCS CCS NCCS 1 2 ) ( (公式8)(6)Hierarchical Impact Score
類 別 和 類 別 在 Ontology 上 若 在 相 同 的 Hierarchical Path上,表示這兩個類別具有一定程 度的關係,我們給予互相的影響分數。其中m表 示候選類別中,有m個候選類別與第i個類別,在 相同的Hierarchical Path上。
m k k i i h o p s o f n u mb er NCCS NCCS HIS 1 k to i fro m (公式9)(7)Total Concept Score
求出每個候選類別的總分,TCS最高的即為學習 元件的所屬類別
7 i i i HIS NCCS TCS (公式 10) (8)將 TCS 與 λ1 和 λ2 兩個門檻值做比較,會有 以下三種情況 (i). 將所有候選 Concept 的 TCS 由高至低排 序,找出 TCS 分數最高的 Concept 作為目 標 Concept,若 TCS 分數高於 λ2,則將學 習元件放入此 Concept。 (ii). 若 TCS 分數最高的 Concept 之 TCS 分數與 介於 λ1 和 λ2 之間,則將學習元件放入學 習元件暫存庫中暫存,由概念擷取模組做 學習概念的擷取。 (iii). 若TCS分數最高的Concept之TCS分數小 於λ1,表示此學習元件與本ontology無關, 則不做任何處理。
3.3 概念擷取模組
本 模 組 會 先 取 出 學 習 元 件 後 設 資 料 的 Important Term Set , 包 含 Title 、 keyword 、 Description 等 資 訊 , 接 著 將 學 習 元 件 利 用 LTF-IDF 方法(一個改良的 TFIDF 方法),擷取出 重要的關鍵詞。相關研究證實出現於文件中前段 與後段之文句,因具有描述主題與總結主題之詞 彙,故此兩部分之詞彙其重要性較高。根據一個 詞(term)出現的位置,可以去判斷詞的重要程度 [7]。所以本研究根據詞的位置,給予詞不同的權 重 , 並 結 合 了 TF-IDF 方 法 , 產 生 了 一 個 LTF-IDF(Location weight TF-IDF),希望可以提高 擷取關鍵詞的精確度。 LTF-IDF(Location weight TF-IDF)計算公式,如公式 11 所示: (公式 11) 如式子(3-11)中 為計算詞彙 的權重,其 中 為詞彙 在文件 d 中所出現的位置 加權詞頻, 計算方式如公式 12 所示: (公式12) 如公式12中 為詞彙 在文件d中第一段 落所出現的頻率, 為詞彙 在文件d中 最後一段落所出現的頻率, 為詞彙 在 文件d中所出現的頻率,公式11中 如公式 12: (公式13) 如公式13中|D|為所有文件的總篇數, 為 有出現詞彙 的文件篇數。 學習概念擷取流程 : 1. 當學習元件暫存庫裡,學習元件的數量累 積至一定數量時,分析每篇學習元件的 LOM(Learning Object Metadata)。 2. 擷取 LOM 裡的 Important Term,並計算Important Term 裡 每 個 字 詞 (Term) 的 LTF-IDF 分數,並將每篇 LTF-IDF 分數最 高的關鍵字列出來。 3. 若有兩篇以上的學習元件之 LTF-IDF 分 數最高的關鍵字,為同一字的話,將具有 相同關鍵字的學習元件,視為一候選概念 的集合。 4. 當候選概念(Candidate Concepts)集合中, 學習元件數量累積超過一定數量時,則將 候選概念視為正式概念。 5. 定義正式概念的概念關鍵字集合,再將正 式概念送到學習概念儲存庫裡,由概念新 增模組做概念新增的動作。
8 圖 4 概念擷取流程圖
3.4 概念新增模組
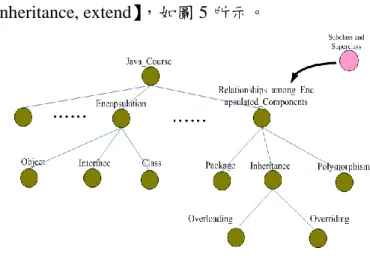
當我們擷取出一個正式概念後,必須找出本 體論中與此正式概念關係最接近的概念,因此如 何尋找出最接近的概念變成一門重要的課題。所 以本論文提出了利用 Jaccard co-efficient 相似度 計算公式,去計算概念之間的相似度。Jaccard 係 數是在衡量資料交集(Transaction Data Set)時最 為廣泛使用的相似度量測標準,計算本體論中的 每個概念與此正式概念的相似度,再將這些和正 式 概 念 關 係 相 近 的 概 念 與 正 式 概 念 , 利 用 FCA(Formal Concept Analysis)建構出概念點陣 (Concept Lattices),判斷正式概念與本體論的階 層關係,並將此正式概念新增至本體論中。 Jaccard co-efficient 相似度計算公式: (公式14) 如式子(3-14),若有 X、Y 兩個集合,X={a} Y={a ,b} ,則 X 與 Y 之相似度為 1/2。 我們將定義後的 New Concept 的關鍵字集 合,與 JLOO 裡的每個概念之關鍵字集合做 Jaccard co-efficient 相似度的計算。 我們以一個 實例來說明: 假 設 有 一 正 式 概 念 叫 Superclass and subclass , 欲 新增 至 JLOO , 其 關 鍵 字 集合為【 subclass, superclass, super, final, class,
Inheritance, extend】,如圖 5 所示。
圖 5 新增正式概念之示意圖
我們將 superclass and subclass 其關鍵字集合 與 JLOO 裡的其他概念的關鍵字集合,做 Jaccard co-efficient 相似度的計算,結果如表 2 所示。 表 2 概念間相似度與關鍵字集合 概念名稱 相似度 關鍵字集合 inheritance 0.285 inheritance, extend overriding 0.25 overriding, inheritance, extend overload 0.25 overload, inheritance, extend constructors 0.125 constructor , class abstract_class 0.125 abstract , class class 0.111 class, instance, encapsulation
9
由 表 2,我們可以得知,在 JLOO 中與 superclass and subclass 關係比較接近的概念,以 及與 superclass and subclass 的相似度,並利用這 些概念的關鍵字集合,如表 2,當作 FCA(Formal Concept Analysis) 中 建 構 概 念 本 文 (Concept Context)的屬性,如圖 6,進而建構出概念點陣 (Concept Lattice) ,如圖 7,可以得知 superclass and subclas 這個概念應該新增至 inheritance 此概 念下。 圖 6 概念本文(Concept Context) 圖 7 概念點陣(Concept Lattice) 如何將正式概念新增回本體論: 1. 將定義後的 New Concept 的關鍵字集合, 與 JLOO 裡的每個概念之關鍵字集合做 Jaccard co-efficient 相似度的計算。 2. 利用 Jaccard co-efficient 相似度,挑選出 與正式概念關係接近的概念。 3. 將這些概念的關鍵字集合,與正式概念的 關鍵字集合當作每個概念的屬性,並建立 出概念本文。 4. 利用概念本文建構出 概念點陣(Concept Lattices),分析正式概念與本體論之間的 階層關係。 5. 將正式概念新增到適當的本體論概念下。 圖 8 新增正式概念流程圖
四、 實驗設計與結果分析
實驗一:制定出兩個 TCS 門檻值 λ1(下界)與 λ2(上 界)的值。 (1). 收集與 Java 課程無關的學習元件 120 篇 (2). 收集與 Java 課程相關的學習元件 120 篇 (3). 收集與 Java 課程相關但學習概念並不存在 JLOO 裡的學習元件 120 篇。 利用(1)和(2),與 Java 程式設計課程相關和無關 的學習元件各 120 篇,分別計算出其 TCS(Total Concept Score)平均值,如表 3 所示: 表 3 TCS 平均值 由以上表格得知, λ1 與λ2 的值應介於 0.27 和 1.27 之間。分別利用(1)~(3)這些學習元件分別 來測詴λ1 的過濾準確率 P(λ1) 、 λ2 的過濾 準確率 P(λ2)、(λ1、λ2)區間的過濾準確率 P (λ 1、λ2),進而求出整體過濾準確率,公式如下 所示 :10 如圖 8 實驗結果,λ1 與 λ2 區間大小的選擇, 區間太大會有誤判的情況,區間太小會造成準確 率太低的情況,根據本研究實驗測詴,λ1 與 λ2 區間為 0.6 會有較好的成效,如圖 4-3 所示,當 λ1=0.4 而 λ2=1.0 時,過濾準確率為 72%,所以(λ1 , λ2)=(0.4 , 1.0),較為恰當。 圖 8 實驗一結果 實驗二:本研究方法(LTF-IDF)與其他關鍵字擷 取方法(TF-IDF)之評比
使用 Java Learning Object Ontology (JLOO) [10]中所提供的 100 份 Java 學習元件,共包含 了 10 個學習概念,每個概念各 10 份學習元件。 當作實驗的輸入目標資料。接著使用 LTF-IDF 以及 TF-IDF 這兩種關鍵字擷取方法,分別計算 它們所產生的最重要的關鍵字,與經過領域專家 定義的正確關鍵字做比對,是否正確。 而這些正確的關鍵字集合,是經由專家用人 工的方法從 JLOO 的 100 份 Java 學習元件所 挑出的具課程代表性的關鍵字,並且再使用資料 挖掘中很常被使用的準確率(Precision)來加以觀 察。準確率表示所輸出的資料集合中,正確資料 的比例是多少。準確率 (Precision)計算公式如 下: Precision = (公式15) 如圖 9 所示,若僅使用 TF-IDF 的方法來尋 找關鍵字的話,將會使得所得的準確率較低,由 於這些重要的關鍵字大多是出現在文章的前後 段落部分,因此本研究方法提出了 LTF-IDF 方法 來尋找關鍵字,去加重前後段落關鍵字的權重, 使它的準確率能有效的提升。 表 3 TF-IDF 與 LTF-IDF 方法擷取概念之比較 圖 9 LTF-IDF 與 TF-IDF 擷取概念精確度之比較 實驗三: 本研究方法與其他的文件分類方法成果 之比較。
11
將 本 研 究 方 法 (Automatic Ontology Expansion Mechanism),分別對 VSM (以向量空 間模型為基礎之分類方法)、Latifur R. Khan [8] 所提出的音樂物件的分類方法以及陳偉洲[1]所 提出的以 Java Learning Object Ontology 為基礎 的學習元件分類法(OALOC) 做一個比較。其 中,OALOC 與 Latifur 皆是以一個已知架構為基 礎的分類方法,而本研究以及 VSM 則是僅根據 對學習元件本身內容的分析而求得想要的結果。 如圖10所示,是本研究方法與其他的文件分 類方法所做的一個比較表,隨著學習概念的數量 增加,本研究方法在分類準確度有逐漸的提升, 主要的原因是本研究所提出的機制會自動產生 一個概念類別,相較於其他的方法,本研究的分 類準確度較高。 圖 10 分類準確率
五、結論與未來展望
由 於 電 腦 的 普 及 與 全 球 資 訊 網 的 蓬 勃 發 展,使用者經由網路來搜尋自己有興趣的課題, 而達成學習的目的,已經是現今最常見的趨勢之 一。雖然使用網路搜尋適合的教材片段、學習元 件,來取代傳統的獨立製作教材方式,可以節省 人力和成本的花費。然而,由於這些網路上的素 材通常都是分散且組織零散的,難以達到再利用 的目的。 而且,面對這些豐富、大量的學習元件,教 學者卻必須以人工的方式定義學習元件的主題 概念,非常浪費人力與成本。因此,本論文提出 一個以正規概念分析為基礎之本體論自動擴展 機制,藉由 LTF-IDF 找出那些能夠代表學習元 件的主要關鍵字,當做學習概念,再使用 Jaccard co-efficient 相似度計算公式來計算學習概念與 本體論概念之間的關聯程度,之後再將學習概念 新增利用本研究所提出的機制,的確能有效的擷 取出學習概念,並能找出與學習概念關係相近的 概念,自動地擴展本體論。將有助於使用者,管 理及學習所需要的知識。 根據實驗後的結果發現,本研究所提出的學 習概念擷取機制,雖然能夠有效的擷取出學習概 念,但對於學習概念新增回本體論方面上,在本 體論中『概念階層』的判斷,也還有進步的空間。 而且當人為建構本體論的時候,會依據個人主觀 的因素來作建構,因此每個人建構出來的本體論 都不太一樣,在建立『概念階層』的時候,我們 無法明確的得知新的『概念』是不是就是最底層 的『概念』,以後會不會有新的『概念』衍生出 來。 所以在建立『概念階層』的時候,不論是 利用手動或是自動的方式,都很難做到完全的正 確。 除此之外,由於本研究是屬於比較一般化的 方法,前處理的部份也僅用了以統計為基礎的方 法計算出重要的學習元件關鍵字,所以在關鍵字 萃取方面的準確率無法盡善盡美。 在未來的研究中,如果能再加上自然語言處 理對關鍵字之間的關聯性加以分析,以及能夠分 辨出學習元件關鍵字之間的相異領域的方法,相 信能夠得到更佳的結果。12
六、致謝
本研究承蒙國科會計畫 NSC95-2221-E-006-158-MY3經費部分補助,特 此感謝。參考文獻
[1] 陳偉洲, "基於本體論之學習元件自動分類演 算法",成功大學工程科學研究所, 2006.[2] R. Neches, R. Fikes, T. Finin, T. Gruber, R.
Patil, T. Senator, and W. R. Swartout, "ENABLING TECHNOLOGY FOR
[3] F. Sebastiani, “Machine Learning in Automated
Text Categorization”, ACM Computing Surveys, Vol.34, No.1, March 2002, pp.1-47.
[4] N.F.Noy and D.L.Mcguinness, ”Ontology
Development 101: A Guide to Creating Your First Ontology,” Stanford Knowledge System Laboratory Technical Report KSL-01-05 and Stanford Medical Informatics Technical Report SMI-2001-0880,Mar.2001.
[5] M. C. Lee, D. Y. Ye, and T. I. Wang, ”Java
Learning Object Ontology”, The 5th IEEE International Conference on Advanced Learning Technologies, pp.538-542, July 2005,
Kaohsiung, Taiwan.
[6] The ACM Computing Classification System
[1998Version],
http://www1.acm.org/class/1998/.
[7] F. Chen and K. Han and G. Chen, ”An Approach
to Sentence-Selection-Based Text
Summarization” , Oct. 2002
[8] Khan, L., "Ontology-based Information
Selection," Ph.D. Dissertation, Department of Computer Science, University of Southern California, 2000.
.