國立臺中教育大學教育測驗統計研究所碩士論文
指導教授:郭伯臣 博士
應用可能值方法於大型測驗不同
年度間連結方法之效果探究
研究生:李德弘 撰
中
華
民
國
一
○
二
年
七
月
摘要
摘要
摘要
摘要
許多大型教育測驗提供的資料型態多為可能值,而次級資料分析者再利用其 資料進行統計分析。由於受測者與試題數量眾多,同時考量時間與受測者疲勞等 因素,因此在同一年度之間都採用等化的方式,將進行不同題本測驗的受測者成 就放至同一量尺上以利比較。而隨著教育政策的改變或是教學方式的改進,相同 年級與背景的受測者所擁有的能力便有所不同,因此不同年度間的測驗結果也不 能直接比較,因此年度間的成績是必須透過測驗連結的方式,才能進行分析比 較。然而不同大型測驗皆使用不同的連結方法,但未有相關文獻探討在使用可能 值方法時,各種連結方法之比較。因此本研究採用模擬資料探討不同的研究變項 (年度間差距、人數、向度數與題數)於不同的測驗連結方法下,使用可能值方 法對於回復新年度的群體參數估計之效果。本研究結果發現,在年度間能力沒有 差距時,同時校準法的效果最好,PISA 連結法跟固定試題參數法的效果較差。 當年度間能力差距增加時,同時估計法的效果隨之變差,而 TIMSS 連結法在年 度間有差距時表現最好。此外,人數的增加可以改善估計效果,但是 5600 人與 8400 人的結果差異不大。而增加題數可以降低估計誤差,但在向度內試題數皆相 同時,兩個向度與四個向度的估計成效沒有明顯差異。 關鍵字:可能值、測驗連結、大型測驗。Abstract
Population statistics is one of the main focuses of large-scale assessments such as means and standard deviations. Since the numbers of examinees and items are enormous, large-scale assessments use equating methods to make sure that every examinee takes different booklets are on the same scale. Therefore, examinees score can be compared even if they didn’t take the same test. The scores in different year can also be compared by linking procedure. The purpose of this study is to explore the performance of different manipulate factors based on linking methods used by large-scale assessments. The results show that concurrent method outperforms when recovers the population parameters under the assumption of no difference between two assessment years. TIMSS linking method is better than the others, when there are differents in population means, and concurrent method will reduce its accuracy. When the number of examinees is increasing, the bias will decresing, but difference between 5600 people and 8400 people is not obvious. Results also show that having longer test length can raise more accuracy, but with same test length, 2 dimensions and 4 dimensions have no obvious difference.
目次
目次
目次
目次
摘要 ... I ABSTRACT ... II 目次 ... III 表目錄 ... V 第一章 緒論 ... 1 第一節 研究動機 ... 1 第二節 名詞解釋 ... 3 第二章 文獻探討 ... 5 第一節 試題反應理論 ... 5 第二節 測驗等化 ... 6 第三節 可能值方法 ... 10 第四節 測驗連結 ... 13 第三章 研究方法 ... 17 第一節 研究流程 ... 17 第二節 模擬研究設計 ... 18 第三節 模擬實驗步驟 ... 24 第四節 研究工具 ... 25 第五節 評估準則 ... 25 第四章 研究結果 ... 27 第一節 探究比較各種連結方法 ... 27 第二節 在不同情境下,不同連結法估計效果之比較... 28 第五章 結論與建議 ... 55 第一節 結論 ... 55 第二節 未來研究建議 ... 56參考文獻 ... 57 中文部分 ... 57 英文部分 ... 58 附錄一 ... 61 附錄二 ... 67 附錄三 ... 73
表目錄
表目錄
表目錄
表目錄
表 表 表 表 2-1 TIMSS2007 年題本區塊設計表 ... 8 表 表 表 表 2-2 PISA2009 年題本區塊設計表 ... 9 表 表 表 表 3-1 研究共同變項設定 ... 19 表 表 表 表 3-2 TIMSS 2007 與歷年八年級數學成就量尺分數差異對照表 ... 19 表 表 表 表 3-2 兩個向度的 BIB 設計等化設定 ... 23 表 表 表 表 3-3 四個向度的 BIB 設計等化設定 ... 23 表 表 表 表 4-1 各種連結方法估計結果與前一年度之比較 ... 28圖目錄
圖目錄
圖目錄
圖目錄
圖 圖 圖 圖 2-1 TIMSS 及 NAEP 連結方法流程圖 ... 14 圖 圖 圖 圖 2-2 PISA 連結方法流程圖 ... 15 圖 圖 圖 圖 3-1 研究流程圖 ... 18 圖 圖 圖 圖 4-2-1 受測人數為 2100 時,群體能力平均之 RMSE ... 29 圖 圖 圖 圖 4-2-2 受測人數為 2100 時,群體能力標準差之 RMSE ... 30 圖 圖 圖 圖 4-2-3 受測人數為 5600 時,群體能力平均之 RMSE ... 32 圖 圖 圖 圖 4-2-4 受測人數為 5600 時,群體能力標準差之 RMSE ... 33 圖 圖 圖 圖 4-2-5 受測人數為 8400 時,群體能力平均之 RMSE ... 35 圖 圖 圖 圖 4-2-6 受測人數為 8400 時,群體能力標準差之 RMSE ... 36 圖 圖 圖 圖 4-2-7 年度間差距為 0 時,群體能力平均數之 RMSE ... 38 圖 圖 圖 圖 4-2-8 年度間差距為 0 時,群體能力標準差之 RMSE ... 39 圖 圖 圖 圖 4-2-9 年度間差距為 0.2 時,群體能力平均數之 RMSE ... 41 圖 圖 圖 圖 4-2-10 年度間差距為 0.2 時,群體能力標準差之 RMSE ... 42 圖 圖 圖 圖 4-2-11 年度間差距為 0.4 時,群體能力平均數之 RMSE ... 44 圖 圖 圖 圖 4-2-12 年度間差距為 0.4 時,群體能力標準差之 RMSE ... 45 圖 圖 圖 圖 4-2-13 年度間差距為 0 時,群體能力平均數之 RMSE ... 47 圖 圖 圖 圖 4-2-14 年度間差距為 0 時,群體能力標準差之 RMSE ... 48 圖 圖 圖 圖 4-2-15 年度間差距為 0.2 時,群體能力平均數之 RMSE ... 50 圖 圖 圖 圖 4-2-16 年度間差距為 0.2 時,群體能力標準差之 RMSE ... 51 圖 圖 圖 圖 4-2-17 年度間差距為 0.4 時,群體能力平均數之 RMSE ... 53 圖 圖 圖 圖 4-2-18 年度間差距為 0.4 時,群體能力標準差之 RMSE ... 53第一章
第一章
第一章
第一章 緒論
緒論
緒論
緒論
本研究主要探討大型測驗所使用之不同連結方法之差異,並透過模擬研究, 探討不同連結方法於不同情境設計,回復不同年度間的群體能力參數之成效。本 章將針對研究動機、研究目的與名詞解釋進行闡述。第一節
第一節
第一節
第一節 研究動機
研究動機
研究動機
研究動機
為了檢視學生的學習成就與變化趨勢,許多國家皆透過大型測驗建立學生學 習資料庫,以做為教學改進與制定政策的依據。國際上著名的「國際數學與科學 教 育 成 就 趨 勢 調 查 ( Trends in International Mathematics and Science Study,TIMSS)」、「國際學生評量(The Programme for International Student Assessment, PISA)」、「促進國際閱讀素養研究(Progress in International Reading Literacy Study, PIRLS)」,或是美國自行實施的「國家教育進展評量(National Assessment of Educational Progress, NAEP)」以及臺灣於 2006 年成立的「台灣學生學習成就評
量資料庫(Taiwan Assessment of Student Achievement, TASA)」,皆屬於紀錄追 蹤學生學習趨勢的大型測驗。
然而,為了研究學生學習成就的趨勢,了解不同年度間學生的學習成效。在 建置大型測驗資料庫的過程中,透過測驗連結的方法,能將不同年度之間的測驗 分數,放置於相同的量尺上再進行比較。譬如 TIMSS 與 NAEP 先使用同時估計 法估計學生能力參數,再利用線性轉換的原理回復新年度的群體參數(Allen,
Donoghue, & Schoeps, 2001 ; John, Michael, & Ina, 2008);PISA 則使用試題參數
等化法先估計新年度的試題參數,進而估計出群體的能力參數(OECD, 2009)。 由於大型測驗皆為固定實施,且兩次測驗之間的間隔較長,如 TIMSS 每 4 年實 施一次、PISA 每 3 年實施一次、NAEP 則是每 2 年實施一次;並且對於已經公佈 之試題參數是很難去修正的,因此新年度的估計量尺必須去配合舊年度的估計量 尺,如此一來,不同的連結方式就會造成不同的估計結果。而這些大型測驗在同 年度不同題本之間都使用同時估計法來做為水平等化的方法(Allen, Donoghue, &
Schoeps, 2001 ; John, Michael, & Ina, 2008),但是在不同年度間的連結時所使用
的連結方法又不盡相同(Foy, Galia, & Li, 2008;Qian, Isham, Worthington, & Liang,
2001;OECD, 2009)。因此,如何將兩個年度間的分數或是成就表現做適當的連 結便成為重要的議題,若是使用的方法不正確或是未能確切反映受測者的情況, 則連結後的結果很可能會與真實情況誤差過大。 目前國內測驗等化或是測驗連結的相關研究有關於不同 BIB 設計對測驗等 化的影響(曾玉琳、王暄博、郭伯臣、許天維, 2006),但是該研究是比較相同 年度中不同等化設計下,同時估計法或是分開估計法的優劣,並且所討論之結論 為個體能力的估計效果。而王敏嫻(2011)則是探討了使用可能值方法,對於在 單向度不同等化設計下,群體能力的回復效果,此研究著重於不同估計方法在相 同年度之能力估計成效。詹慧君(2011)對於不同年度間的單向度測驗連結方法 做比較,該研究使用期望後驗估計法去做參數的估計,著重於個體能力的估計。 大型測驗的測驗架構中,每一個科目下都包含著不同的內容領域,以 TIMSS 2007 八年級數學科為例,包含了數(number)、代數(algebra)、幾何(geometry)
以及資料與機率(data and chance)四個內容領域(Ruddock, O’Sullivan, Arora &
Erberber, 2008)。故僅以單一能力值描述整個群體便顯得有所不足,因此使用多
向度試題反應理論作為整體架構能夠得到更多的訊息。至於參數估計方面,相較 於傳統的點估計方法,如最大概似估計法、期望後驗估計法,可能值方法對於回 復群體參數有較好的回復性(von Davier, Gonzalez, & Mislevy, 2009;王敏嫻,
2011)。國際上的許多大型測驗亦以可能值方法作為群體特性之描述(Allen, Carlson, Johnson, & Mislevey, 2001;Foy, Galia, & Li, 2008;OECD, 2009)。
故本研究將在多向度試題反應理論的架構下,以可能值方法估計受試者能力 參數,以求配合大型測驗實際情況,探討不同情境設計下,各個大型測驗所使用 的連結方法之估計成效。
研究目的: 本研究欲探討不同連結方法於不同年度間回復群體參數之效果,包括同時估 計法、固定試題參數法、TIMSS 使用之連結方法以及 PISA 使用之連結方法。本 研究之變項包含:連結方法、向度個數、題本長度、兩年度受測者能力差距以及 受測者人數。根據上述,將研究目的條列如下: 壹、 探究比較各種連結方法。 貳、 在不同情境下,不同連結法估計效果之比較。 本研究依據上述研究目的,條列出待答問題如下: 1、群體年度間差異大小對於估計效果的影響。 2、人數多寡對於估計效果影響的程度。 3、各種連結方法的估計成效。
第二節
第二節
第二節
第二節 名詞解釋
名詞解釋
名詞解釋
名詞解釋
壹、測驗等化(equating) 在不完全相同但是測量相同特質的測驗題本中,利用數學方式將兩份測驗的 量尺轉換至相同的量尺,以利比較接受不同測驗的受測者的成績。本研究是指在 相同測驗年度中,使用 BIB 等化設計,將不同題本之間利用相同的試題區塊,將 所有的試題放至相同的量尺上。 貳、測驗連結(linking) 測驗連結為一個程序,能將一份測驗的分數轉換至另一份測驗的量尺上,使 其分數能夠直接互相比較。本研究是將新年度的分數轉換至舊年度的量尺,並探 討不同的測驗連結方法對於參數估計之影響。 參、評估指標 本研究使用真值與估計值的根均方差(RMSE)作為評估準則,如公式 1-12 1 ˆ ( ) ˆ ( , ) N k k k a a RMSE a a N = − =
∑
(公式 1-1) 其中k表示資料個數,k=1, 2, 3...,N ; 1 2 3 ( , , ,..., N) a= a a a a :表示真值; 1 2 3 ˆ ( ,ˆ ˆ ˆ, ,...,ˆN) a= a a a a :表示估計值。 當 RMSE 越小,表示估計值與真值之誤差越小,其估計效果越好。第二章
第二章
第二章
第二章 文獻探討
文獻探討
文獻探討
文獻探討
本研究是以多向度試題反應理論模式下以可能值方法進行能力估計,並探討 不同年度間於不同情境下,比較不同測驗連結方法對於回復群體能力參數之效 果,以下將針對:一、試題反應理論;二、可能值方法;三、測驗等化;三個部 分進行文獻的整理與探討。第一節
第一節
第一節
第一節 試題反應理論
試題反應理論
試題反應理論
試題反應理論
試題反應理論(item response theory, IRT)主要是以個別試題的觀點,來解 釋測驗分數的涵義。它認為學生在某一試題上的表現情形,與其背後的某種潛在 特質(或能力)之間具有某種關係存在,該關係可以透過一條連續性遞增的數學 函數來加以表示和詮釋,這個數學函數便稱作「試題特徵曲線」(item characteristic curve, ICC)。該數學函數的涵義是在表示學生的能力與其在該試題上做出正確反 應兩者之間的可能關係。(余民寧,2009)。 在二元計分的測驗中,受測者對於某題的作答反應機率函數可用下列數學公 式(Rasch, 1960 )表示 1 ( ) ( 1| , ) 1 exp[ ( )] i j ij j i j i P P X b b θ θ θ = = = + − − (公式 2-1-1) 其中Pi( )θj 為擁有能力值為θj的受測者 j在第i題答對的機率,bi為第i題的難 度參數。由於上述公式中對於試題的描述僅有bi一項,故此模式稱之為單參數對
數模式(one-parameter logistic model, 1PL)又稱為 Rasch 模式。另外在二元計分 的測驗架構下還有二參數對數模式(two-parameter logistic model, 2PL)與三參數 對數模式(three-parameter logistic model, 3PL)。
本研究是採用多向度隨機係數模式(Multidimensional Random Coefficients
Wilson and Wang(1997)所提出的,該模式為 Rasch 模式的延伸,故每一題的
試題參數亦只有一個。MRCMLM 除了應用於二元計分,亦可以使用於部分給分 模式(partial credit model)跟評定量尺模式(rating scale model)。隨著模式中設 計矩陣(design matrix)與計分矩陣(scoring matrix)的設定,MRCMLM 也可以 描述題間多向度與題內多向度的作答反應(Kennedy,2005)。本研究所採用的是 二元計分且為題間多向度的架構,所以將針對多向度二元計分模式作介紹。 MRCMLM 的作答反應機率函數如下 exp[ '( )] ( ; | ) exp[ '( )] j j j z x B A P x z B A θ ξ ξ θ θ ξ =Ω − = −
∑
(公式 2-1-2) 其中x是受測者的作答反應組型,答對記為 1,答錯則記為 0,ξ 為整份測驗的 試題參數向量,θj 是第 j 個受測者相對於各向度間的能力向量,z 則是所有可 能作答反應組型。另外公式中的 A 稱為設計矩陣,B 稱為計分矩陣;計分矩陣是 表示題目與向度間的關係,而設計矩陣是表示題目與試題參數間的關係。由於本 研究是採用二元計分模式,故受測者的可能作答反應只有完全答對或是完全答錯 兩種結果,因此上述公式可以化簡為下列數學式 exp( ) ( 1; | ) exp( ) 1 j j j B A P x B A θ ξ ξ θ θ ξ − = = − + (公式 2-1-3) 因為本研究以二元計分多向度 IRT 為架構,故使用 MRCMLM 作為模擬作答 反應之機率模式。第二節
第二節
第二節
第二節 測驗等化
測驗等化
測驗等化
測驗等化
在實施大型測驗時,由於作答時間有限且題庫中試題數眾多,等化設計是一 種常見的測驗實施方式。通過等化設計,可以將每個試題都給予測驗,並且單一 受測者並不需要做完題庫中所有的試題。測驗等化設計有許多的方法,如定錨不等組設計(NEAT)與平衡不完全區塊設計(BIB)。目前國內有王暄博(2006) 針對大型測驗中 NEAT 與 BIB 等化法之比較,以及王敏嫻(2011)也以單向度試 題反應理論為基礎去探討在不同等化設計在水平等化中,可能值方法與其他估計 方法在回復個體以及群體能力參數的效果。本研究係參考 TIMSS 與 PISA 的等化 方式,由於這兩個測驗皆採用 BIB 設計作為其等化方式,故以下將針對 BIB 設計 與這兩個大型測驗的等化方式作介紹。
壹
壹
壹
壹、
、
、
、平衡不完
平衡不完
平衡不完
平衡不完全區塊設計
全區塊設計
全區塊設計
全區塊設計(
(
(
(balanced incomplete block design, BIB)
)
)
)
BIB 設計是將題庫中的題目分成若干個區塊,而區塊之間的試題並不重複, 而受試者僅需接受部分區塊的試題,而不同的受測者可能會接受到完全相同、部 分相同或是完全不同的區塊。最後再將所有受測者的作答反應資料堆疊後進行能 力與試題參數的估計(曾玉琳、王暄博、郭伯臣、許天維,2006)。由於 BIB 設 計是將試題區塊與題本的配置方式採用螺旋(spiral)排列的方式,此方式可使每 一個試題區塊的施測次數相同,也就是說題庫中所有的試題被挑出來接受測驗的 次數皆相同(van der Linden, Veldkamp & Carlson, 2004;Nemhauser & Wolsey,
1999)。此設計在沒有限制作答時間的條件下,必須符合下列條件: 1 , 1,..., t ib i X k b B = = =
∑
(公式 2-2-1) 1 , 1,..., B ib b X r i t = ≤ =∑
(公式 2-2-2) 1 , 1,..., B ijb b X λ i j t = ≥ ≤ =∑
(公式 2-2-3) 2 , 1,.... 1,..., ib jb ijb X +X ≥ z i< =j t b= B (公式 2-2-4) 其中: b 指題本代號 b=1,...,B; k 指每個題本所配置的區塊數; r 指試題區塊在所有題本中出現的次數;i 指題庫中個別區塊的代號 i=1,..., t ; j 指題庫中成對區塊中第二個區塊的代號 j=1,...,N ; λ指成對試題區塊出現在相同區塊位置的次數; ib x 指試題區塊與題本的配置組型,其中 xib∈{0,1} , =1,...,b B i=1,..., t ; ijb z 指成對試題區塊與題本的配置組型,其中zijb∈{0,1} , =1,...,b B i< =j 1,..., t ; 除此之外,BIB 設計必須符合三項基本限制: 1、每一個題本內的試題區塊數要相同; 2、2.試題區塊做結合以求出最小的題本數; 3、3.每一個試題區塊在所有題本中出現的次數要相同。 但是在實際設計的時候,也需考慮試題的內容、形式與作答時間(王暄博,2006)。
貳
貳
貳
貳、
、
、
、TIMSS 所使用的
所使用的
所使用的 BIB 等化設計
所使用的
等化設計
等化設計
等化設計
以 TIMSS 2007 為例,該次測驗一共有 14 個題本(Booklet),每個題本是由 四個區塊組合而成,分別為數學區塊(M01~M14)以及科學區塊(S01~S14)各 兩個區塊。每個試題區塊在題本中出現 2 次(, Christine, Alka, & Ebru, 2008)。 表 2-1 為 TIMSS 2007 年的 BIB 設計。 表 表 表 表 2-1 TIMSS2007 年題本區塊設計表 題本 編號 區塊 1 區塊 2 區塊 3 區塊 4 題本 編號 區塊 1 區塊 2 區塊 3 區塊 4 題本 1 M01 M02 S01 S02 題本 8 S08 S09 M08 M09 題本 2 S02 S03 M02 M03 題本 9 M09 M10 S09 S10 題本 3 M03 M04 S03 S04 題本 10 S10 S11 M10 M11 題本 4 S04 S05 M04 M05 題本 11 M11 M12 S11 S12 題本 5 M05 M06 S05 S06 題本 12 S12 S13 M12 M13 題本 6 S06 S07 M06 M07 題本 13 M13 M14 S13 S14 題本 7 M07 M08 S07 S08 題本 14 S14 S01 M14 M01參
參
參
參、
、
、
、PISA 所使用的
所使用的
所使用的
所使用的 BIB 等化設計
等化設計
等化設計
等化設計
相對於 PISA2006 的主軸為科學,2009 測驗的主軸是閱讀,因此閱讀的題目 數較多。PISA2009 將題本區分為兩大類型,分別是標準題本組(standard booklet
set)與較簡單題本組(easier booklet set),較簡單題本組是提供給在 PISA2006
中閱讀表現在 450 分以下以及在 2008 年預試時閱讀成績也是相同程度的新加入 國家。兩類題本皆由四個區塊組成,包含 7 個閱讀區塊(R1~R7)、3 個數學區 塊(M1~M3)以及 3 個科學區塊(S1~S3);其中 R3 與 R4 分別有標準難度 R3A 與 R4A 以及難度較低的 R3B 與 R4B。每一個試題區塊在一組題本組中出現的次 數都是四次;此外 PISA2009 亦準備了一份題數較少的測驗題本(UH Booklet) 給特殊需求的學生(OECD, 2009)。表 2-2 為 PISA2009 年的題本設計。 表 表 表 表 2-2 PISA2009 年題本區塊設計表(續下頁)
資料來源︰PISA2009 Technical Report(p.30) 題本 題本題本 題本 區塊區塊區塊 1 區塊 區塊區塊區塊區塊 2 區塊區塊 3 區塊區塊 區塊區塊區塊區塊 4 標準題本組標準題本組標準題本組標準題本組 較簡單題本組較簡單題本組較簡單題本組較簡單題本組 題本 1 M1 R1 R3A M3 Y 題本 2 R1 S1 R4A R7 Y 題本 3 S1 R3A M2 S3 Y 題本 4 R3A R4A S2 R2 Y 題本 5 R4A M2 R5 M1 Y 題本 6 R5 R6 R7 R3A Y 題本 7 R6 M3 S3 R4A Y 題本 8 R2 M1 S1 R6 Y Y 題本 9 M2 S2 R6 R1 Y Y 題本 10 S2 R5 M3 S1 Y Y 題本 11 M3 R7 R2 M2 Y Y
資料來源︰PISA2009 Technical Report(p.30) 為配合大型測驗之實際施測情境,本研究主要參考 TIMSS 2007 之 BIB 設 計,建立同年度之間 BIB 等化設計之題本,詳細設計變項於第三章討論。
第三節
第三節
第三節
第三節 可能值方法
可能值方法
可能值方法
可能值方法
可能值方法是以加入作答反應與背景變項的潛在迴歸模式,去計算每位受測 者能力的後驗分佈,再由該分佈中隨機抽取可能值作為該受測者的能力估計。其 原理如下:首先界定事前密度函數 (prior density fuction) fθ( ; )θ α 作為受測者母群能力
之分佈,實際應用上常假設受試者來自一個常態分佈的母群體,其平均數為µ, 標準差為σ ,如公式(2-3-1): 題本 題本題本 題本 區塊區塊區塊 1 區塊 區塊區塊區塊區塊 2 區塊區塊 3 區塊區塊 區塊區塊區塊區塊 4 標準題本組標準題本組標準題本組標準題本組 較簡單題本組較簡單題本組較簡單題本組較簡單題本組 題本 12 R7 S3 M1 S2 Y Y 題本 13 S3 R2 R1 R5 Y Y 題本 21 M1 R1 R3B M3 Y 題本 22 R1 S1 R4B R7 Y 題本 23 S1 R3B M2 S3 Y 題本 24 R3B R4B S2 R2 Y 題本 25 R4B M2 R5 M1 Y 題本 26 R5 R6 R7 R3B Y 題本 27 R6 M3 S3 R4B Y UH 題本 閱讀 數學/ 科學
1 2 2 2 2 2 ( ) ( ; ) ( ; , ) (2 ) exp 2 fθ θ α fθ θ µ σ πσ θ µ σ − − = = − (公式 2-3-1) 其中,θ 代表受試者能力值,α則為θ 分佈的參數集。公式(2-3-1)也常以下列 公式呈現: 2 , ~ (0, ) E E N θ µ= + σ (公式 2-3-2) 而 Adams, Wilson & Wu(1997)的作法,是以潛在迴歸模式 T
n Y β取代平均數µ,其 中Y 是由 u 個輔助變項(背景變項)所組成的向量,n Y 是固定且已知的條件變數,n 代表受測者 n 的輔助變項狀態之描述;β 是一個相對應的迴歸係數向量。則受測 者 n 的母群模式可表示如下: 2 , ~ (0, ) T n Yn E En n N θ = β + σ (公式 2-3-3) 利用迴歸模式Yn'β取代平均數µ,其中Y 為 u 的矩陣,n' β為迴歸係數,則受試 者的母群之能力分佈為一平均數為Yn'β,標準差為σ 之常態分配,可表示如公式 (2-3-4): 1 2 2 2 2 1 ( ; , , ) (2 ) exp ( ' ) '( ' ) 2 n n n n n n n f θ Y β σ πσ θ Y β θ Y β σ − = − − − (公式 2-3-4) 以公式(2-3-4)作為受試者母群體之先驗分佈,其邊際後驗機率可以被表示如公 式(2-3-5), 2 2 2 ( ; ) ( ; , , ) ( ; , , , ) ( ; , , , ) n n n n n n n n n x n n f x f Y h Y x f x W θ ξ θ θ β σ θ ξ β σ ξ β σ = (公式 2-3-5)
其中需要估計的值為β 、σ 和ξ 參數,其中 ξ為試題參數。 而多向度的母群能力分佈可表示為公式(2-3-6) 1 1 2 2 1 ( ; , ) (2 ) exp ( ) ( ) 2 d T n n n n f θ γ Σ = π − Σ− − θ γ− Σ− θ γ−
(公式 2-3-6) 其中 d 為向度數,γ 為迴歸係數矩陣,Σ是 d d× 的變異數共變數矩陣。而每個受 測者的能力後驗分佈如公式(2-3-7) ( ; | ) ( ; , ) ( ; , , | ) ( ; , , ) x n n n n n x n f x f h x f x θ θ θ ζ γ Σ = ζ θ ζ γ θ γΣ Σ
(公式 2-3-6) 大型測驗所主要關注的是群體之能力表現,根據研究指出,可能值方法在群 體能力參數的回復上比傳統的點估計方法有較佳的效果(Wu, 2005; von Davier,
Gonzalez,& Mislevy, 2009),原因在於可能值方法是從所估計能力值的後驗分佈
中隨機抽取受測者能力的可能值,並直接進行母群參數計算,而非先估計個體的 能力,再以其個體能力估計值來計算群體參數,因此可以使群體參數的估計更精 準,提供群體參數估計的一致性(Mislevy & Sheehan, 1989; Mislevy, Beaton,
Kaplan, & Sheehan, 1992)。此外,可能值方法將受測者的背景變項一併納入進行
估計,如此不僅能降低試題參數估計的誤差,也能提高能力估計的精準性(Mislevy,
1984; Mislevy & Sheehan, 1989)。目前國際上知名的大型測驗如 NAEP、TIMSS
及 PISA 等皆是使用可能值的型態提供給次級資料分析者受測者的成就資料(Lee,
Grigg & Dion, 2007; Foy, Galia, & Li, 2008;OECD, 2009)。基於上述理由,本
研究以可能值方法作回復群體參數,減少與大型測驗估計方式的差異性,再比較 各種連結方法之效果。
第四節
第四節
第四節
第四節 測驗
測驗
測驗
測驗連結
連結
連結
連結
由於大型測驗都是透過測驗連結的程序,將不同年度之間的參數轉化至同一 個量尺上做為比較。基本上而言,測驗銜接也算是等化的一種,只不過它所遭遇 的問題較為單純,所引發的學術爭議也較少(余民寧,2009)。本研究欲探討的 連結方法包括同時估計法(concurrent calibration method)、固定試題參數法(fixedb’s method)、TIMSS 使用之連結方法以及 PISA 使用之連結方法,以下將針對這 四種方法做介紹。
壹
壹
壹
壹、
、
、
、同時
同時
同時
同時校準
校準
校準
校準法
法
法
法
當兩份測驗有著相同的定錨試題時,由於作答反應資料會出現重疊的部分, 因此將新舊兩個年度的作答反應一併放入電腦中估計試題與能力參數。由於是同 時估計兩個年度,故所得到的參數將會在同一個量尺上,因此不需要再做線性轉 換。 貳 貳 貳 貳、、、固定、固定固定固定試題參數法試題參數法試題參數法試題參數法 亦可稱為 b 值固定法,此方法是先估計出舊年度測驗的試題參數,將定錨題 的參數固定後,再去對新年度測驗估計非定錨試題的試題參數以及能力參數,而 定錨題的試題參數便不再估計。固定試題參數法已經透過試題參數將新年度測驗 校準至舊年度的量尺,因此不需要再用到線性轉換的程序。 參 參 參 參、、、TIMSS 及、 及及及 NAEP 連結方法連結方法連結方法 連結方法 TIMSS 與 NAEP 所使用的連結方法皆相同,都是先使用同時估計法估計兩份 測驗的暫時量尺(provisional scale)。再利用公式 2-4-1 計算舊年度測驗的暫時 量尺與公告量尺(report scale)之間的線性轉換係數α、β。使用所得到的α、β 將新年度的暫時量尺以公式 2-4-1、2-4-2、2-4-3 做線性轉換,轉換後的量尺即為新年度測驗的公佈量尺(Foy, Galia, & Li, 2008;Qian, Isham, Worthington, & Liang, 2001)。 = A B θ αθ +β (公式 2-4-1) = A B b αb +β (公式 2-4-2) = / A B a a α (公式 2-4-3) 其中 θA與 θB 為兩組受測者的能力估計值,bA 與 bB是兩份測驗的試題難度估 計值,aA 與aB則是兩份測驗的試題鑑別度估計值。而α 、β即為兩份測驗的線 性轉換係數。TIMSS 與 NAEP 的連結方法流程如下圖 2-1 舊年度 作答反應 計算線性 轉換係數 新年度 作答反應 同時估計法
TIMSS & NAEP 連結方法
暫時性量尺 舊年度測驗 暫時量尺 新年度測驗 暫時量尺 舊年度測驗 公佈量尺 轉換係數 α、β 線性 轉換 新年度公佈 能力量尺 圖 圖 圖 圖 2-1 TIMSS 及 NAEP 連結方法流程圖
肆 肆 肆 肆、、、PISA 連結方法、 連結方法連結方法連結方法 PISA 所使用的即是 b 值等化法;先單獨估計新年度測驗的試題參數,並抽 出定錨題的參數與舊年度測驗已公佈的定錨題試題參數計算其線性轉換係數,其 線性轉換公式為公式 2-4-2、2-4-3。再將新年度測驗所有的試題參數以剛得到的 轉換係數做線性轉換,得到新年度測驗的公佈試題參數,最後以公佈試題參數再 去估計受測者能力參數(OECD, 2009)。其流程如圖 2-2 暫時試數參數 新年度 作答反應 估計 試題參數
PISA 連結方法
抽出定錨題 試題參數 新年度 定錨題參數 舊年度 定錨題參數 轉換係數 α、β 計算線性 轉換係數 線性轉換 新年度公佈 試題參數 新年度公布 能力量尺 估計 能力參數 圖 圖圖 圖 2-2 PISA 連結方法流程圖第三章
第三章
第三章
第三章 研究方法
研究方法
研究方法
研究方法
本研究以 MRCMLM 之試題反應理論為基礎,使用模擬資料進行使用不同連 結方法對於可能值方法回復群體參數估計之影響,並比較在群體能力與前一年度 有不同差異時,各種連結方法對於回復新年度的群體參數之效果。本章節共分五 個部分:一、研究流程;二、模擬研究變項設計;三、模擬實驗步驟;四、研究 工具;五、評估準則。第一節
第一節
第一節
第一節 研究流程
研究流程
研究流程
研究流程
本 研 究 以 多 向 度 試 題 反 應 理 論 為 基 礎 , 討 論 多 向 度 隨 機 係 數 模 式 (MRCMLM)架構下,不同的測驗連結方法於兩年度間不同能力差距之估計效 果。研究流程條列如下,亦可參考圖 3-1: 一、文獻的蒐集與探討 本研究在確定研究主題後,先收集測驗等化、測驗連結以及可能值方法 的相關文獻。 二、研究變項設定 在參考各個相關文獻與技術報告,設定欲探討之人數、能力差距、試題 數與配合的向度數,並依照文獻建立 BIB 等化設計。 三、產生模擬資料 使用電腦程式依照不同變項建立兩個不同年度的受測者能力、背景變項 與試題難度,再依照 MRCMLM 產生作答反應,最後使用測驗軟體配合不同 連結方法回復新年度的群體參數。 四、比較不同連結方法之估計精準度 依據不同的情境比較各種連結法的估計效果,包含群體平均數以及群體 標準差,並與真值計算 RMSE。 五、撰寫研究結果圖 圖 圖 圖 3-1 研究流程圖
第二節
第二節
第二節
第二節 模擬研究
模擬研究
模擬研究
模擬研究設計
設計
設計
設計
本研究藉由模擬資料,欲探討不同連結方法於能力差距不同之效果,故本節 將針對模擬研究變項設定中之參數設定做說明。本研究的共同變項設定整理如表 3-1,並分別說明如下。表 表 表 表 3-1 研究共同變項設定 研究變項 變項設定 受測者能力分佈差距 0、0.2、0.4 測驗向度個數 2、4 每個向度試題長度 8、16 每個年度受測人數 2100 人、5600 人與 8400 人 同一年度間等化方法 BIB 設計 測驗連結方法 PISA 連結方法 固定試題參數法 TIMSS 及 NAEP 連結方法 同時校準法 每一情境模擬資料個數 50 壹 壹 壹 壹、、、受測者群體能力分、受測者群體能力分受測者群體能力分受測者群體能力分佈佈佈佈 本研究中受測者群體之能力分佈之設定係參考 de la Torre(2009)。依據不 同年度產生兩組受試者,受測者均具有兩組背景變項以及一個年度變項,其中背 景變項為連續變項並且與所產生能力值之間相關為 0.7 與 0.3;而年度變項則為離 散的數據,以 1 表示為新的年度,0 表示為舊的年度。而能力值依據多變量常態 分佈所產生,並將舊年度的能力平均設定為 0,新年度的能力平均則以 TIMSS
2007 國際數學報告(Mullis, Martin, & Foy, 2008)中,各個國家於 1999、2003 與 2007 之間八年級的量尺分數之差距作為進步之依據,詳細數據如表 3-2 所示。 表 表 表 表 3-2 TIMSS 2007 與歷年八年級數學成就量尺分數差異對照表(續下頁) 參與國家 2007 與 2003 量 尺分數差異 2007 與 1999 量 尺分數差異 2007 與 1995 量 尺分數差異 Chinese Taipei 13 13 Korea, Rep. of 8 10 17 Singapore -13 -12 -16
Hong Kong SAR -14 -10 4
參與國家 2007 與 2003 量 尺分數差異 2007 與 1999 量 尺分數差異 2007 與 1995 量 尺分數差異 Hungary -12 -15 -10 England 15 17 16 Russian Federation 4 -14 -12 United States 4 7 16 Lithuania 4 24 34 Czech Republic -16 -16 -42 Slovenia 9 7 Armenia 21 Australia -8 -13 Sweden -8 -48 Scotland -8 -6 Serbia 9 Italy -4 0 Malaysia -34 -45 Norway 8 -29 Cyprus 6 -11 -2 Bulgaria -13 -47 -63 Israel -32 -3 -12 Romania -14 -11 Lebanon 16 Thailand -26 Jordan 3 -1 Tunisia 10 -28 Indonesia -5 2
Iran, Islamic Rep. of -8 -19 -15
Bahrain -3
Egypt -16
Colombia 47
Palestinian Nat’l Auth. -23
Botswana -3
Ghana 34
*該年度空白者即為當年未參與
由表 3-2 可以得知,同一個國家在 TIMSS 2003 與 2007 之間的群體量尺分數 相差最多至 34 分,而 2007 與 1999 之間的差異最高為 47 分,由於 TIMSS 的量 尺分數為平均數 500、標準差 100 的量尺,故轉換為標準量尺後差距即為 0.34 與 0.47。因此設定兩年度之間的差距為 0、0.2 與 0.4 三種情境,其產生方式服從多 變量常態分佈所產生,如公式 3-1 所示。 0 ~ , 0 Y Y YY k MVN Y θθ θ θ θ + Σ Σ Σ Σ (公式 3-1) 其中θ為受測者的能力向量,Y為背景變項,k即為能力差距 0、0.2 與 0.4,Σθθ是 能力之間的相關,ΣθY是能力與背景變項之間的相關,ΣYY則為背景變項之間的相 關,本研究設定兩組背景變項之間互相獨立,故 1 0 0 1 YY Σ = 。以四向度且能力差 距為 0.2 為例,其舊年度的能力真值與背景變項來自 1 2 3 4 1 2 0 1 0.9 0.9 0.9 0.7 0.3 0 0.9 1 0.9 0.9 0.7 0.3 0 0.9 0.9 1 0.9 0.7 0.3 ~ , 0 0.9 0.9 0.9 1 0.7 0.3 0 0.7 0.7 0.7 0.7 1 0 0 0.3 0.3 0.3 0.3 0 1 MVN Y Y θ θ θ θ 而新年度的能力真值與背景變項則來自於 1 2 3 4 1 2 0.2 1 0.9 0.9 0.9 0.7 0.3 0.2 0.9 1 0.9 0.9 0.7 0.3 0.2 0.9 0.9 1 0.9 0.7 0.3 ~ , 0.2 0.9 0.9 0.9 1 0.7 0.3 0 0.7 0.7 0.7 0.7 1 0 0 0.3 0.3 0.3 0.3 0 1 MVN Y Y θ θ θ θ
貳 貳 貳 貳、、、測驗向度個數與試題長度、測驗向度個數與試題長度測驗向度個數與試題長度測驗向度個數與試題長度 本研究架構於多向度試題反應理論,因此將每個模擬題本分為 2 向度與 4 向 度兩種情況;並且每個向度分別施測 8 題或是 16 題兩種情況,因此單一年度的 受測者測驗總題數會有 16(2 個向度各 8 題)題、32(4 個向度各 8 題與 2 個向 度各 16 題)題與 64(4 個向度各 16 題)四種情況。 參 參 參 參、、、人數設定、人數設定人數設定人數設定 根據 PISA2009 技術報告指出,參與該年度測驗的國家人數扣除列支敦斯登 (Liechtenstein)約 300 人,其他參與國家至少皆有 2700 人以上(OECD,2012)。 而臺灣該年度則有 5581 人參加數學測驗,並考慮到 TASA 四年級數學科在 2006 年施測樣本數為 8083 人(國家教育研究院籌備處,2009)、2007 年施測樣本數為 8200 人(國家教育研究院籌備處,2009),施測人數皆有 8000 人以上。故為了配 合本研究的等化設計,使得 7 個題本受測人數皆相同,因此設定每一年度的受測 者人數分別為 2100 人、5600 人以及 8400 人,即每個題本施測人數為 300 人、800 人與 1200 人。 肆 肆 肆 肆、、、等化設計、等化設計等化設計等化設計 兩個向度的 BIB 設計如表 3-2,當實驗設計為一個向度測驗 8 題時,每個試 題區塊有 4 題試題,每個向度則有 7 個試題區塊(A1~A7、B1~B7),如此可 以組出 7 個題本(題本 1~題本 7),而每一個題本包含 4 個試題區塊共 16 題試 題。當實驗設計為一個向度測驗 16 題時,依照上述的方式設定,但每個區塊內 的試題數則更改為 8 題,此情境下每個題本包含 4 個試題區塊共 32 題試題。
表 表 表 表 3-2 兩個向度的 BIB 設計等化設定 題本 向度 1 向度 2 區塊 1 區塊 2 區塊 1 區塊 2 題本 1 A1 A2 B1 B2 題本 2 A2 A3 B2 B3 題本 3 A3 A4 B3 B4 題本 4 A4 A5 B4 B5 題本 5 A5 A6 B5 B6 題本 6 A6 A7 B6 B7 題本 7 A7 A1 B7 B1 四個向度的 BIB 設計如表 3-3,當實驗設計為一個向度測驗 8 題時,每個試 題區塊有 4 題試題,每個向度則有 7 個試題區塊(A1~A7、B1~B7、C1~C7、 D1~D7),如此可以組出 7 個題本(題本 1~題本 7),而每一個題本包含 4 個 試題區塊共 32 題試題。當實驗設計為一個向度測驗 16 題時,依照上述的方式設 定,但每個區塊內的試題數則更改為 8 題,此情境下每個題本包含 4 個試題區塊 共 64 題試題。 表 表 表 表 3-3 四個向度的 BIB 設計等化設定 題本 向度 1 向度 2 向度 3 向度 4 區塊 1 區塊 2 區塊 1 區塊 2 區塊 1 區塊 2 區塊 1 區塊 2 題本 1 A1 A2 B1 B2 C1 C2 D1 D2 題本 2 A2 A3 B2 B3 C2 C3 D2 D3 題本 3 A3 A4 B3 B4 C3 C4 D3 D4 題本 4 A4 A5 B4 B5 C4 C5 D4 D5 題本 5 A5 A6 B5 B6 C5 C6 D5 D6 題本 6 A6 A7 B6 B7 C6 C7 D6 D7 題本 7 A7 A1 B7 B1 C7 C1 D7 D1
伍 伍 伍
伍、、、測驗連結方法、測驗連結方法測驗連結方法測驗連結方法
本研究探討不同的測驗連結方法對於群體參數的估計效果,連結方法分為
PISA 連結方法(b 值等化法)、固定試題參數法(b 值固定法)、TIMSS 及 NAEP
連結方法與同時校準法。 陸 陸 陸 陸、、、試題難度、試題難度試題難度試題難度數分數分數分數分佈佈佈佈 試題難度參數設定為截尾常態分佈,每一個向度的試題參數分開產生,平均 數皆為 0,標準差為 1,並將範圍界定於−3 ~ 3。
第三節
第三節
第三節
第三節 模擬實驗步驟
模擬實驗步驟
模擬實驗步驟
模擬實驗步驟
本研究之模擬實驗步驟如下: (一)模擬試題難度參數服從常態截尾分佈,並且建立題庫共 392 題,從題庫中 挑選試題組成題本,並且符合舊年度與新年度之全部向度平均難度皆為 0; (二)模擬兩年度之受測者能力真值與背景變項服從標準多變量常態分佈,並假 設向度間能力相關約為 0.9,而背景變項與能力相關分別為 0.7 與 0.3; (三)使用 IRT 單參數 MRCMLM 模式計算受測者正確作答機率,並根據其機率 產生作答反應; (四)根據其作答反應透過 ACER ConQuest 2.0 軟體並使用可能值方法進行參 數估計;(五)依據 PISA 連結方法、固定試題參數法、TIMSS 及 NAEP 連結方法以及 同時校準法將新年度的能力參數做線性轉換並計算群體參數;
(六)將步驟(五)所估計之新年度能力參數與新年度能力真值做比較;
第四節
第四節
第四節
第四節 研究工具
研究工具
研究工具
研究工具
本研究使用的工具有 MATLAB 軟體與 ACER ConQuest 2.0 軟體,分別敘述 如下。
1、MATLAB
本研究使用 MATLAB 程式產生受測者的能力、背景變項與年級變項以及試 題難度,進而模擬受測者作答反應,並且計算群體參數的估計誤差。
2、ACER ConQuest 2.0
ACER ConQuest 2.0 為可應用於單向度、多向度 IRT 模式之軟體。本研究使 用 ACER ConQuest 2.0 進行能力與試題參數的估計,利用可能值方法回復群體能 力參數。
第五節
第五節
第五節
第五節 評估準則
評估準則
評估準則
評估準則
本研究中不同連結方法之比較,是將原始模擬產生的受測者群體能力參數視 為真值,並計算不同模擬情境下,使用不同連結方法之群體能力參數估計值,且 模擬 50 次後計算其根均方差(RMSE)以了解不同研究設計下,各種連結方式對 於回復新年度群體能力參數之效果;RMSE 之結果越小,表示該情境的估計誤差 就越小,該連結方法就有較好的估計結果。 本研究中群體參數分別探討新年度群體能力的平均值與標準差兩個部分,受 測者群體能力參數平均值的 RMSE 如公式 3-2,受測者群體能力參數標準差的 RMSE 如公式 3-3。 50 2 1 ˆ ( ) ˆ ( , ) 50 k k k RMSE µ µ µ µ = − =∑
(公式 3-2) 50 2 1 ˆ ( ) ˆ ( , ) 50 k k k RMSE σ σ σ σ = − =∑
(公式 3-3)其中k表示每一個模擬資料集個數,k=1, 2, 3,..., 50 1 2 3 ( , , ,..., k) µ= µ µ µ µ :在第k個模擬資料集之群體能力平均真值 1 2 3 ˆ ( ,ˆ ˆ ,ˆ ,..., ˆk) µ= µ µ µ µ :在第k個模擬資料集之群體能力平均估計值 1 2 3 ( , , ,..., k) σ = σ σ σ σ :在第k個模擬資料集之群體能力標準差真值 1 2 3 ˆ (ˆ , ˆ , ˆ ,..., ˆk) σ = σ σ σ σ :在第k個模擬資料集之群體能力標準差估計值
第四章
第四章
第四章
第四章 研究結果
研究結果
研究結果
研究結果
本章將呈現各種連結方法優劣之探討以及電腦模擬的結果,以下分別說明第 一節「探究比較各種連結方法」與第二節「在不同情境下,不同連結法估計效果 之比較」。第一節
第一節
第一節
第一節 探究比較各種連結
探究比較各種連結
探究比較各種連結
探究比較各種連結方法
方法
方法
方法
壹
壹
壹
壹、
、
、
、同時校準法
同時校準法
同時校準法
同時校準法
同時估計法需要一次處理大量的資料,因此估計時間便會增加,但也因為資 料量較大,理論上所回復之參數也會較為準確。由於該方法的估計結果是將兩年 度同時放至新的量尺上,因此第二年度的估計結果無法與第一年度的公佈結果直 接做比較。 貳 貳 貳 貳、、、固定、固定固定固定試題參數法試題參數法試題參數法試題參數法 固定試題參數法的定錨題試題參數並不會改變,也就是說第二年度的定錨題 參數將不會修正。而由於是使用相同的量尺,因此所估計出新的試題參數與受測 者能力參數不需要經過任何線性轉換,便可以直接與第一年度的結果比較。 參 參 參 參、、、TIMSS 及、 及及及 NAEP 連結方法連結方法連結方法 連結方法 由於此方法先使用同時估計,因此它亦有估計時間較長之缺點,除此之外, 第二年度的試題參數也必須另外使用線性轉換做調整。 肆 肆 肆 肆、、、PISA 連結方法、 連結方法連結方法連結方法 此連結法跟 TIMSS 及 NAEP 連結方法相比,其優點是先估計出第二年度的 試題參數,經由線性轉換的程序將試題參數轉換至第一年的量尺上,因此第二年 度的公佈試題參數就已經確定,不需額外的線性轉換程序。 根據以上結論,將各種連結方法對於能力參數、試題參數是否能與第一年度 公布量尺直接做比較以及其線性轉換之基礎整理如表 4-1表 表 表 表 4-1 各種連結方法估計結果與前一年度之比較 連結方法 能力參數 試題參數 線性轉換基礎 同時估計法 不能直接比較 不能直接比較 無線性轉換 固定試題參數法 可直接比較 可直接比較 無線性轉換 TIMSS 及 NAEP 連結方法 可直接比較 需做線性轉換 轉換能力參數量尺 PISA 連結方法 可直接比較 可直接比較 轉換試題參數量尺
第二節
第二節
第二節
第二節 在不同情境下
在不同情境下
在不同情境下
在不同情境下,
,
,
,不同連結法估計效果之比較
不同連結法估計效果之比較
不同連結法估計效果之比較
不同連結法估計效果之比較
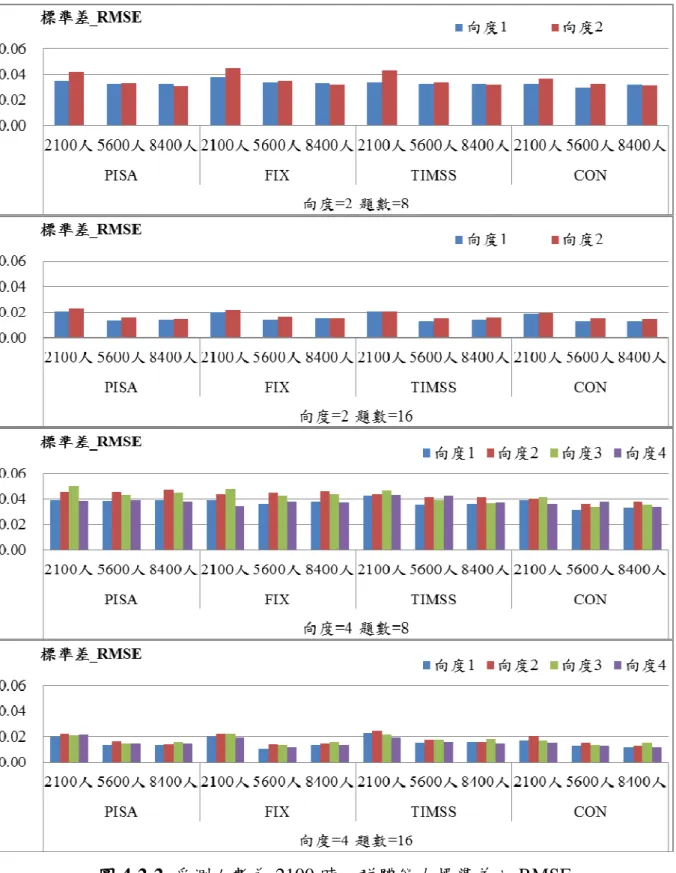
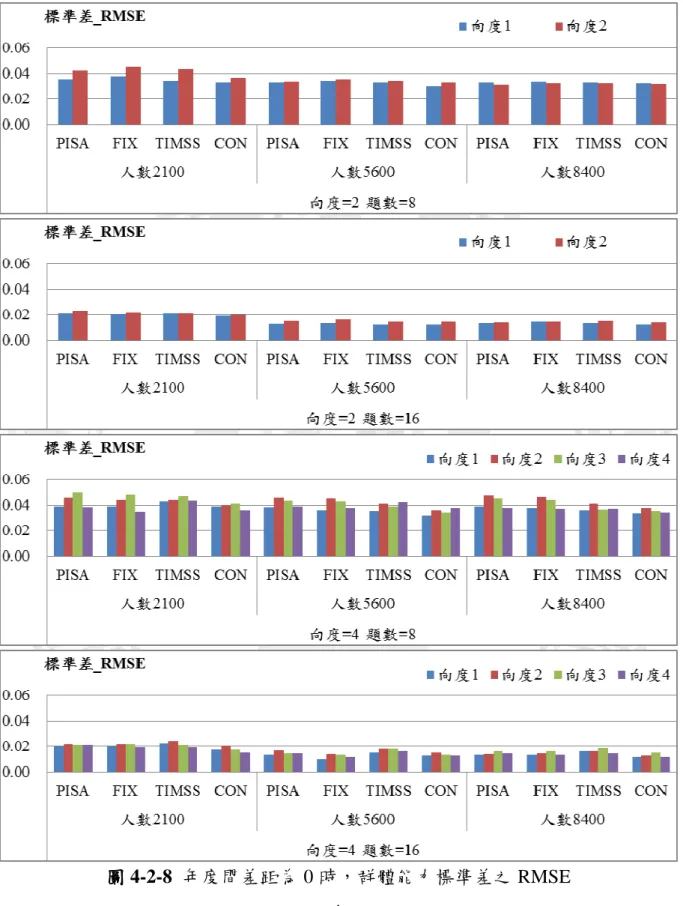
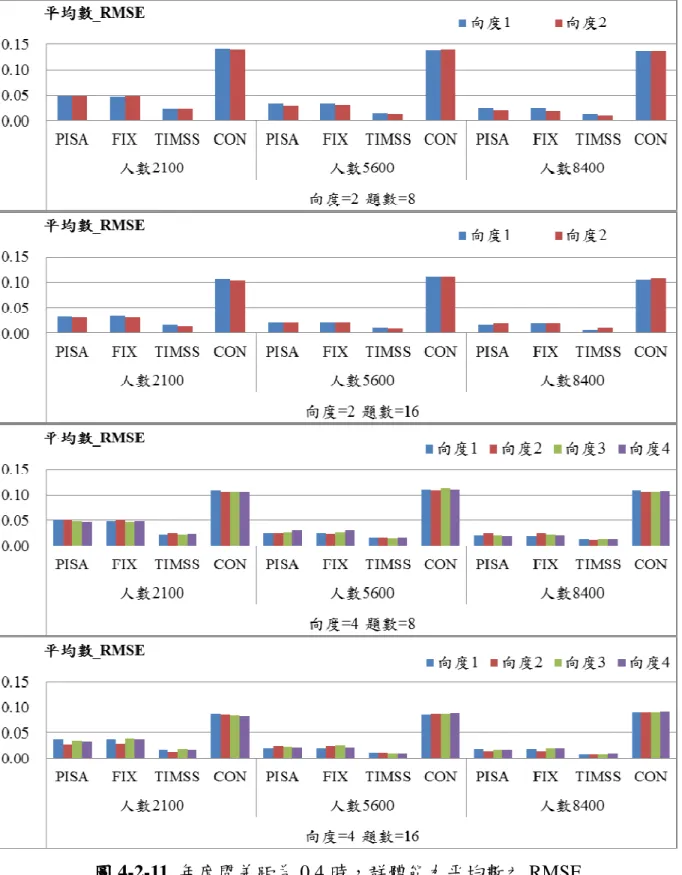
本節將各種情境下的估計效果分成三種類型,分別依照年度間能力差距、受 測人數與不同連結方法去探討對於估計精準度之影響。為了閱讀方便,將以 CON 表示同時校準法、FIX 表示固定試題參數法、PISA 表示 PISA 連結方法、TIMSS 則代表 TIMSS 及 NAEP 的連結方法。 壹 壹 壹 壹、、、探討年度間能力差距、探討年度間能力差距探討年度間能力差距探討年度間能力差距,,,對於估計精準度之影響,對於估計精準度之影響對於估計精準度之影響對於估計精準度之影響 本研究模擬兩年度之間能力參數差距為 0、0.2、0.4 三種情境,探討當年度 間差距不同時,對於不同連結方法的估計之影響,並比較不同向度與試題長度、 人數的設計下,不同連結方法之效果,詳細研究數據將於附錄一中呈現。 一 一 一 一、、、、當當當受測者人數為當受測者人數為受測者人數為受測者人數為 2100 之情境之情境之情境之情境 當受測者人數為 2100 人時,群體能力平均 RMSE 如圖 4-2-1 所示,而群體 標準差之 RMSE 則如圖 4-2-2 所示,研究結果顯示: 1、除了 CON 以外,另外三種連結法平均數的 RMSE 並不會隨著年度間能 力差異的增加而增加。 2、CON 對於平均數的估計會隨著年度間能力差距而改變,當差異達到 0.4 時,其估計誤差最大。 3、年度間的能力差異對於估計群體的標準差並沒有明顯的影響,差距為 0、 0.2 以及 0.4 時的標準差估計相近。4、在向度數相同時,題數 16 題的估計結果與 8 題的相比,其 RMSE 皆降 低,平均數較不明顯,但是標準差則有明顯的差異。此結果與王暄博 (2006),王敏嫻、曾筱倩、郭伯臣、吳慧珉(2010)的研究結果相同。 圖 圖 圖 圖 4-2-1 受測人數為 2100 時,群體能力平均之 RMSE
圖 圖 圖
二 二 二 二、、、、當受測者人數為當受測者人數為當受測者人數為 5600 之情境當受測者人數為 之情境之情境之情境 當受測者人數為 5600 人時,群體能力平均 RMSE 如圖 4-2-3 所示,而群體 標準差之 RMSE 則如圖 4-2-4 所示,研究結果顯示: 1、跟人數為 2100 人時有相同的結果,除了 CON 以外,另外三種連結法平 均數的 RMSE 並不會隨著年度間能力差異的增加而增加。 2、CON 對於平均數的估計會隨著年度間能力差距而改變,當差異達到 0.4 時,其估計誤差最大。
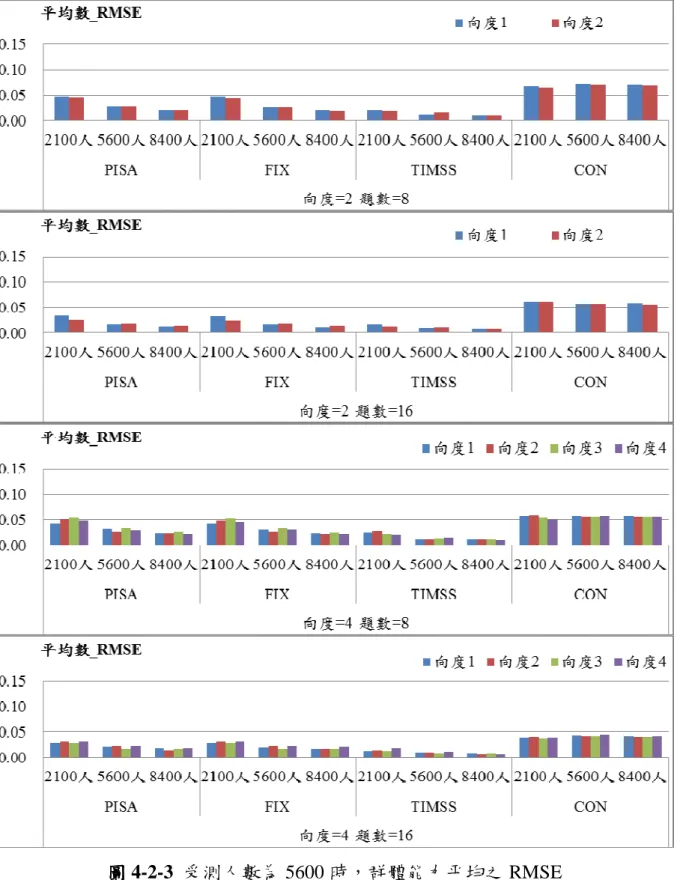
3、PISA、FIX 跟 CON 三種方法標準差的 RMSE 並沒有隨著能力的差距而
有明顯的差異,但是 TIMSS 標準差隨著能力差距的增加,其 RMSE 則有 些微的提高。 4、與人數為 2100 人時的結果相同,當向度數相同時,試題數較多的估計結 果其 RMSE 皆降低,平均數較不明顯,但是標準差則有明顯的差異。 5、在總題數 32 題的情境之下,向度數為 4,單一向度試題數為 8 的標準差 表現一致性的比向度數為 2,單一向度試題數為 16 的標準差表現要差。
圖 圖 圖
圖 圖 圖
三 三 三 三、、、、當受測者人數為當受測者人數為當受測者人數為 8400 之情境當受測者人數為 之情境之情境之情境 當受測者人數為 8400 人時,群體能力平均 RMSE 如圖 4-2-4 所示,而群體 標準差之 RMSE 則如圖 4-2-5 所示,研究結果顯示: 1、平均數的估計跟人數為 2100 人與 5600 人時有相同的結果,除了 CON 以 外,另外三種連結法平均數的 RMSE 並不會隨著年度間能力差異的增加 而增加。 2、CON 對於平均數的估計會隨著年度間能力差距而改變,當差異達到 0.4 時,其估計誤差最大。 3、TIMSS 在差異增加時,其標準差的 RMSE 會有些微的上升。 4、與人數為 2100 跟 8400 人時的結果相似,在向度數相同的情境下,試題 數較多的估計結果其 RMSE 皆降低,平均數部分都已經很低,所以沒有 明顯差異,但是標準差則有明顯的差異。 四 四 四 四、、、、小結小結小結 小結 不論人數多寡,CON 都會隨著年度間的差距增加而 RMSE 提高,這有可能 是在估計的時候,估計程式會主動將兩個年度看成一個較大的群體,並且以兩個 群體能力的平均值當作預估的平均值。也就是說對於能力較低的舊年度會高估, 而能力較高的新年度會低估,以求整體達到一個接近常態分佈而非雙峰分佈的效 果。因此,當新年度的能力平均越高時,其估計值與真值的差距便越大,RMSE 就越高。而 TIMSS 經過線性轉換的程序就可以避免這個情況的發生,因為計算 了舊年度的公佈量尺與暫時量尺的線性轉換係數,並應用於新年度的公佈量尺與 暫時量尺上。至於 PISA 與 FIX 並沒有將兩個年度的資料一起估計,故不會產生 這樣的疑慮。
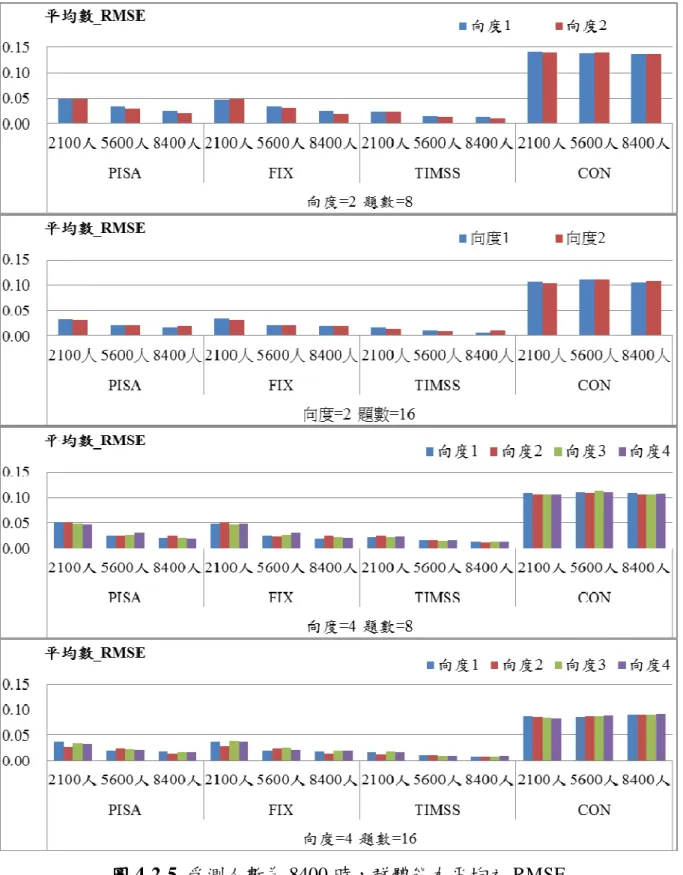
圖 圖 圖
圖 圖 圖
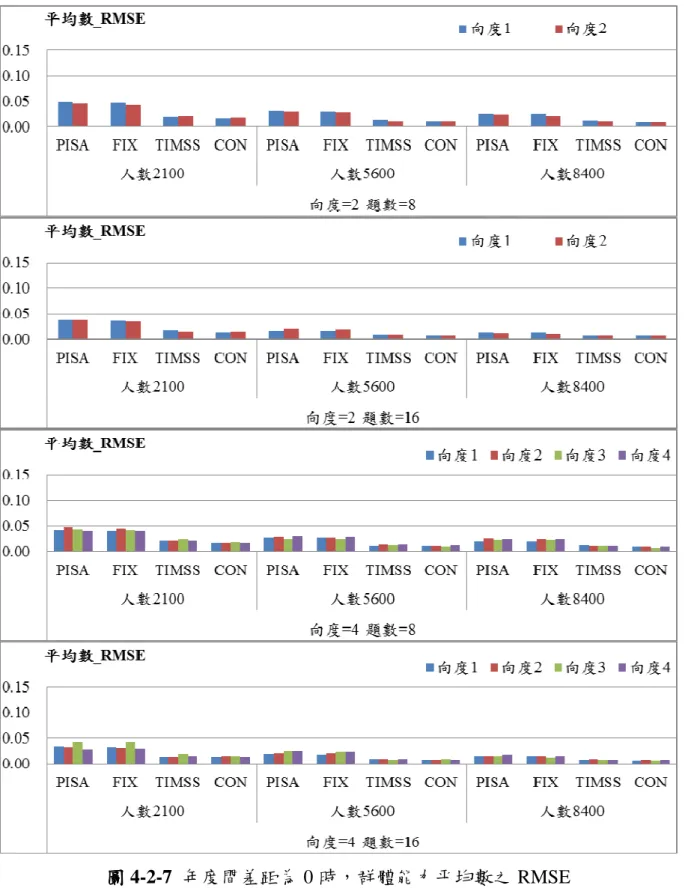
貳 貳 貳 貳、、、探討受測人數、探討受測人數探討受測人數探討受測人數,,,,對於估計精準度之影響對於估計精準度之影響對於估計精準度之影響 對於估計精準度之影響 本研究模擬受測人數分別為 2100、5600 及 8400 三種情境,並比較不同向度 與試題長度、年度間能力差距的設計下,不同連結方法之效果,詳細研究結果將 於附錄二中呈現,本節圖中橫軸分別為四種連結方法以及受測人數,縱軸為 RMSE。 一 一 一 一、、、、當當當兩年度間能力差距為當兩年度間能力差距為兩年度間能力差距為兩年度間能力差距為 0 之情境之情境之情境之情境 年度間差距為 0 之群體能力平均 RMSE 如圖 4-2-1、群體能力標準差 RMSE 如圖 4-2-2,得以下結論: 1、當兩個年度差距為 0 時,隨著人數的增加,而平均數之 RMSE 都會降低。 2、人數為 5600 人與 8400 人之間平均數的差距跟 2100 人與 5600 人之間平 均數的差距要來的小。 3、隨著人數的增加,標準差 RMSE 都會降低。 4、跟平均數不同的是,人數為 5600 人與 8400 人之間標準差的差距比較不 明顯。 5、針對題數與向度數的變化,其結果與前一節的結果相似,試題數由 8 題 增為 16 題時,平均數的 RMSE 降低的並不明顯,但是標準差都有明顯 的減少。這部分與相關研究所得到的結論相同(葉昶成、郭秀芬、郭伯 臣、曾筱倩, 2011;詹慧君, 2011),提高試題數有助於增加測驗估計的 精準度。
圖 圖 圖
圖 圖 圖
圖 4-2-8 年度間差距為 0 時,群體能力標準差之 RMSE
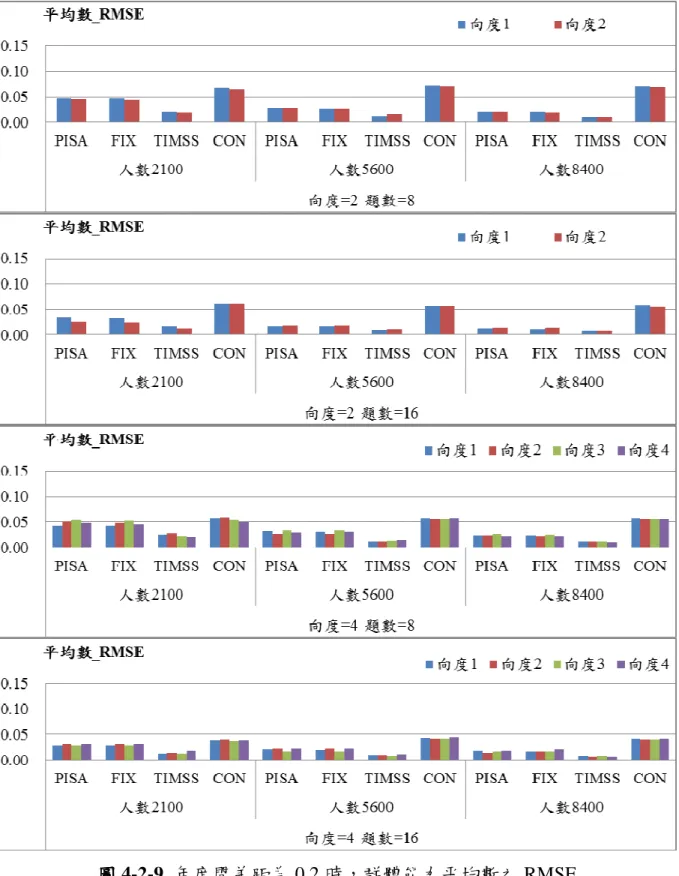
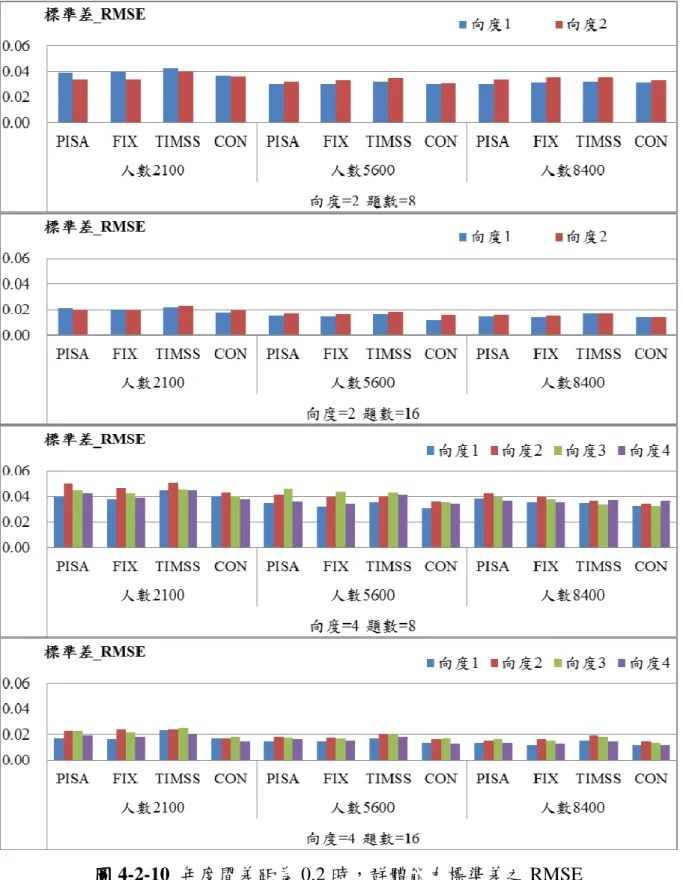
二 二 二 二、、、、當兩年度間能力差距為當兩年度間能力差距為當兩年度間能力差距為 0.2 之情境當兩年度間能力差距為 之情境之情境 之情境 年度間差距為 0.2 之群體能力平均 RMSE 如圖 4-2-3、群體能力標準差 RMSE 如圖 4-2-4,得以下結論: 1、PISA、FIX 與 TIMSS 這三種連結方法,皆隨著人數的增加,而平均數之 RMSE 都降低。 2、CON 連結法對於人數的改變沒有差異,並不會隨著人數增加而提高平均 數估計效果。 3、CON 除外,人數為 5600 人與 8400 人之間平均數的差距跟 2100 人與 5600 人之間平均數的差距要來的小。 4、人數為 2100 人時,估計效果最差,人數為 5600 人與 8400 人之間標準差 RMSE 並沒有差別。 5、與能力差距為 0 的時候結果一樣,增加相同向度的試題題數,有助於提 高整體估計精準度,平均數較不明顯,可是標準差的 RMSE 降低許多。
圖 圖 圖
圖 圖 圖
三 三 三 三、、、、當兩年度間能力差距為當兩年度間能力差距為當兩年度間能力差距為 0.4 之情境當兩年度間能力差距為 之情境之情境 之情境 年度間差距為 0.4 之群體能力平均 RMSE 如圖 4-2-5、群體能力標準差 RMSE 如圖 4-2-6,得以下結論: 1、平均數估計與兩年度間能力差距為 0.2 時有著相同的結果,就是 PISA、 FIX 與 TIMSS 這三種連結方法,皆隨著人數的增加,而平均數 RMSE 都
降低。 2、CON 連結法對於人數的改變沒有差異,平均數估計並不會隨著人數增加 而提高估計效果。 3、CON 除外,人數為 5600 人與 8400 人之間平均數 RMSE 的差距跟 2100 人與 5600 人之間平均數 RMSE 的差距要來的小。 4、人數為 2100 人時,標準差估計效果最差,人數為 5600 人與 8400 人之間 標準差 RMSE 則沒有差別。 5、與之前的結果相同,增加試題數可以降低標準差的 RMSE,平均數的 RMSE 降低程度也較明顯。 四 四 四 四、、、、小結小結小結 小結 在能力差距為 0 的情況下,人數增加皆有助於降低平均數的 RMSE,當人數 達到 5600 人就已經有不錯的結果,增加至 8400 人所降低的 RMSE 已經沒有明顯 的差異。當能力差距不為 0 時,除了 CON 以外的三種方式也是有一樣的結果, 而人數增加並沒有對 CON 有所幫助。
圖 圖圖
圖 圖 圖
參 參 參
參、、、不同測驗連結方法估計結果、不同測驗連結方法估計結果不同測驗連結方法估計結果不同測驗連結方法估計結果
本研究探討了不同連結方法之效果,分別為同時估計法(CON)、固定試題 參數法(FIX)、TIMSS 使用之連結方法(TIMSS)以及 PISA 使用之連結方法 (PISA)。四種連結方法,並比較在不同能力差距、不同受測人數與不同向度與 試題長度的設計下,不同連結方法之效果,詳細研究數據將於附錄三中呈現。 一 一 一 一、、、、 當當當年度間能力差距為當年度間能力差距為年度間能力差距為年度間能力差距為 0 之情境之情境之情境 之情境 年度間差距為 0 之群體能力平均 RMSE 如圖 4-3-1、群體能力標準差 RMSE 如圖 4-3-2,得以下結論: 1、不論當人數為 2100、5600 或是 8400 人時,CON 的平均數估計效果最好, TIMSS 次之,PISA 與 FIX 最差。這個結果與詹慧君(2011)的研究結
果相同,都是 TIMSS 的估計效果優於 PISA 跟 FIX。
2、當人數為 8400 人時且單一向度試題數為 16 題時,不論是 2 個向度或是 4 個向度,四種連結方法的平均數估計效果皆差不多。 3、四種方法的標準差估計效果差異不大,CON 稍微好一些,但是差異不明 顯。 4、向度數與試題數的部分跟前面的結論一樣,在同一項度內有相同試題數 的情況下,向度數為 2 或是 4,對於估計效果並沒有差異;但是在相同 的向度下增加試題題數,平均數的 RMSE 會稍微降低,而標準差則是明 顯改善。
圖 圖 圖
圖 圖 圖
二 二 二 二、、、、 當年度間能力差距為當年度間能力差距為當年度間能力差距為 0.2 之情境當年度間能力差距為 之情境之情境之情境 年度間差距為 0 之群體能力平均 RMSE 如圖 4-3-3、群體能力標準差 RMSE 如圖 4-3-4,得以下結論: 1、不論當人數為 2100、5600 或是 8400 人時,TIMSS 的平均數估計效果最 好,CON 最差。 2、四種方法的標準差估計效果都差不多,但是 TIMSS 連結法的標準差 RMSE 都較其他三種方法略高。 3、除了 CON,試題數由 8 題增加至 16 題,對於平均數的估計有改善,相 較於能力差異為 0 時 RMSE 降低幅度較明顯。而標準差的 RMSE 依然是 有明顯的下降。 4、同樣在總題數 32 題的情境下,2 個向度各 16 題的 RMSE 皆小於 4 個向 度各 8 題,平均數降低的程度與標準差相比較不明顯。
圖 圖 圖
圖 圖 圖
三 三 三 三、、、、 當年度間能力差距為當年度間能力差距為當年度間能力差距為 0.4 之情境當年度間能力差距為 之情境之情境之情境 年度間差距為 0 之群體能力平均 RMSE 如圖 4-3-3、群體能力標準差 RMSE 如圖 4-3-4,得以下結論: 1、不論當人數為 2100、5600 或是 8400 人時,TIMSS 的平均數估計效果最 好,CON 最差。 2、在相同的向度數以及試題數下,CON 的平均數估計誤差明顯高於其他三 種方法。 3、四種方法的標準差估計效果都差不多,但是 TIMSS 連結法的標準差 RMSE 都較其他三種方法略高,尤其是人數為 5600 人與 8400 人的情境 下。 4、與能力差異為 0.2 時的結果相同,除了 CON 以外,當試題數由 8 題增加 至 16 題,對於平均數的估計有些微改善,而標準差的 RMSE 依然是有 明顯的下降。 5、同樣在總題數 32 題的情境下,2 個向度各 16 題的 RMSE 皆小於 4 個向 度各 8 題的 RMSE,平均數降低的程度與標準差相比較不明顯。 四 四 四 四、、、、 小結小結小結 小結 PISA、FIX 跟 TIMSS 的連結法皆會隨著人數增加、題數增加而提高估計精 準度,增加向度數則無法改善估計精準度。而 CON 在能力差距不為 0 的時候, 其平均數 RMSE 皆高於其他三種連結方法,並且不會隨著人數增加而改善估計精 準度。此外,TIMSS 的標準差在能力差距較大時,其標準差 RMSE 則會比其他 三種方式略高。
圖 圖 圖
圖 圖 圖
第五章
第五章
第五章
第五章 結論與建議
結論與建議
結論與建議
結論與建議
第一節
第一節
第一節
第一節 結論
結論
結論
結論
本研究使用模擬資料探討不同連結方法對於回復群體參數之效果,針對群體 能力參數的平均與標準差,比較不同連結方式的估計效果,並探討在不同連結方 法下,當群體能力有差異時對於回復新年度群體參數之效果。經由模擬結果分別 針對受測人數、群體差異大小、連結方法得到以下結論: 壹 壹 壹 壹、、、 群體差異大小、群體差異大小群體差異大小群體差異大小 年度間的差異大小,對於估計誤差有影響,當差距增加時,估計誤差 也隨著加大,平均數的部分 CON 的連結法最為明顯,其他三種則是沒有明 顯的差異。而標準差的部分雖然會隨著年級間的差距增加而有些為提升, 但是其差異不明顯。 貳 貳 貳 貳、、、 受測人數、受測人數受測人數受測人數 受測人數的增加對於回復群體平均數有影響,提高受測人數有助於增 加估計精準度,尤其是當人數由 2100 人提高到 5600 人時,但是若將人數 提高至 8400 人,其 RMSE 降低的部分就比較不明顯。而標準差則是在 2100 人時表現最差,5600 人與 8400 人則無明顯的差異,不一定哪一種人數較 好。 參 參 參 參、、、 連結、連結連結連結方法方法方法方法 同時估計法在能力差距為 0 的時候表現最好,但是隨著能力差距的增 加,其估計誤差亦隨著加大,並且遠高於其他三種的連結方法。當能力差 距不為 0 時,群體平均數則是 TIMSS 的表現最好,但是 TIMSS 的標準差 則是稍微高於其他的連結方法。PISA 跟 FIX 在向度數、題數、人數以及群 體差異均相同的情況下,兩者的表現差異不大。 綜合以上所述,在實際情況下實施兩年度間的測驗連結,由於其群體間的差 異是未知的,因此不適合使用同時估計法作為其連結方法;而施測人數不宜太少,根據本研究的結果當受測人數有 5600 人時即有良好估計效果。而相同的總 題數 32 題的情況下,2 個向度各 16 題的估計效果比 4 個向度各 8 題的估計效果 要好。因此如果欲提升估計精準度,試題設計的部分可以以增加同一向度的試題 的題數,但是增加向度數則沒有幫助。